Select ms sql: SELECT (Transact-SQL) — SQL Server
Содержание
sql server — Как выглядит конструкция IF…THEN в SQL SELECT?
Вопрос задан
Изменён
7 лет 1 месяц назад
Просмотрен
7k раза
Как мне выполнить IF…THEN в операторе SQL SELECT?
Например:
SELECT IF(Obsolete = 'N' OR InStock = 'Y' ? 1 : 0) AS Saleable, * FROM Product
Перевод вопроса How to perform an IF…THEN in an SQL SELECT? @Eric Labashosky
- sql-server
1
Оператор CASE является ближайшим аналогом IF в SQL и поддерживается во всех версиях SQL Server.
SELECT CAST(
CASE
WHEN Obsolete = 'N' or InStock = 'Y'
THEN 1
ELSE 0
END AS bit) as Saleable, *
FROM Product
Единственный случай, когда нужно использовать именно CAST — если вам нужен результат в виде булевого значения; если вас устроит тип int, решение следующее:
SELECT CASE
WHEN Obsolete = 'N' or InStock = 'Y'
THEN 1
ELSE 0
END as Saleable, *
FROM Product
Оператор CASE можно внедрить в другой оператор CASE и даже включить в агрегированный объект.
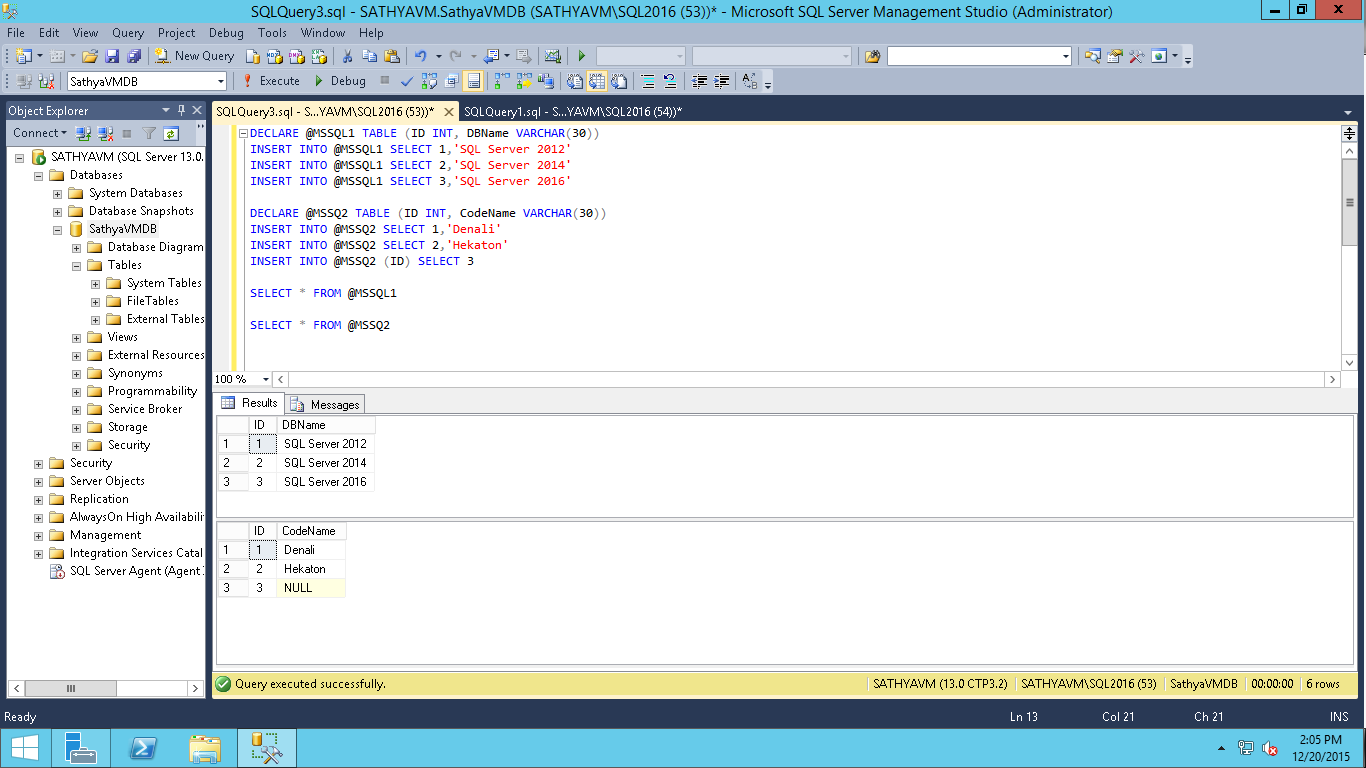
SQL Server Denali (SQL Server 2012) добавляет оператор IIF, также присутствующий в access: (замечено Martin Smith)
SELECT IIF(Obsolete = 'N' or InStock = 'Y', 1, 0) as Selable, * from Product
Перевод ответа How to perform an IF…THEN in an SQL SELECT? @Darrel Miller.
0
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
mysql — SQL SELECT Сумма строк
Вопрос задан
Изменён
8 лет 1 месяц назад
Просмотрен
6k раз
Вывести список проектов с указанием сумм, выплачиваемых их участникам (зарплаты и надбавки).
SELECT PROJECT.Project, SUM(Salary), SUM(Bonus)
FROM PROJECT
INNER JOIN PROJECT_EMP ON PROJECT_EMP.ID_Project=PROJECT.ID_Project
INNER JOIN EMP ON PROJECT_EMP.ID_Emp=EMP.ID_Emp
LEFT JOIN BONUS ON BONUS.ID_Emp=EMP.ID_Emp
GROUP BY PROJECT.Project
Но нужно, чтобы вместо двух последних столбиков был один с их суммой
- mysql
- sql
- sql-server
1
SELECT PROJECT.Project, SUM(Salary) + ISNULL( SUM(Bonus), 0) FROM PROJECT INNER JOIN PROJECT_EMP ON PROJECT_EMP.ID_Project=PROJECT.ID_Project INNER JOIN EMP ON PROJECT_EMP.ID_Emp=EMP.ID_Emp LEFT JOIN BONUS ON BONUS.ID_Emp=EMP.ID_Emp GROUP BY PROJECT.Project
 Project, SUM(Salary) + ISNULL( SUM(Bonus), 0)
FROM PROJECT
INNER JOIN PROJECT_EMP ON PROJECT_EMP.ID_Project=PROJECT.ID_Project
INNER JOIN EMP ON PROJECT_EMP.ID_Emp=EMP.ID_Emp
LEFT JOIN BONUS ON BONUS.ID_Emp=EMP.ID_Emp
GROUP BY PROJECT.Project
Project, SUM(Salary) + ISNULL( SUM(Bonus), 0)
FROM PROJECT
INNER JOIN PROJECT_EMP ON PROJECT_EMP.ID_Project=PROJECT.ID_Project
INNER JOIN EMP ON PROJECT_EMP.ID_Emp=EMP.ID_Emp
LEFT JOIN BONUS ON BONUS.ID_Emp=EMP.ID_Emp
GROUP BY PROJECT.Project
используйте SUM(Salary) + SUM(Bonus)
1
Осталось только добавить ‘+‘ и название поля Sum для наглядности
SELECT PROJECT.Project, SUM(Salary) **+** SUM(Bonus) **AS Sum**
FROM PROJECT
INNER JOIN PROJECT_EMP ON PROJECT_EMP.ID_Project=PROJECT.ID_Project
INNER JOIN EMP ON PROJECT_EMP.ID_Emp=EMP.ID_Emp
LEFT JOIN BONUS ON BONUS.ID_Emp=EMP.ID_Emp
GROUP BY PROJECT.Project
2
SUM(salary) + IFNULL(SUM(bonus), 0)
Если сумма SUM(salary) тоже может приобретать значение NULL, то и её аналогично обернуть в вызов IFNULL(). Это в MySQL, в MS SQL же аналогом этой функции является
Это в MySQL, в MS SQL же аналогом этой функции является ISNULL().
3
В MS SQL надо SUM(ISNULL(Salary, 0)) + SUM(ISNULL(Bonus, 0)).
Вообще, если поле может содержать NULL, то в агрегатных функциях нужно внутри функции проврять на NULL.
Если прменять как ISNULL(SUM(Bonus), 0), то можно получить неверный результат в следующем случае: если только в некоторых строках группируемых данных в поле Bonus есть NULL, а у остальных реальное значение, то эти значения не будут учитываться
(к примеру по проекту А:
* Сотрудник1 — Бонус=10
* Сотрудник2 — Бонус=5
* Сотрудник3 — Бонус=NULL.
При ISNULL(SUM(Bonus), 0) результат будет 0,
При SUM(ISNULL(Bonus, 0)) результат будет 15)
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
ИМЕЕТ (Transact-SQL) — SQL Server
Редактировать
Твиттер
Фейсбук
Электронная почта
- Статья
Применяется к: SQL Server База данных SQL Azure Azure SQL Управляемый экземпляр Azure Synapse Analytics Analytics Platform System (PDW) Конечная точка SQL в Microsoft Fabric Warehouse в Microsoft Fabric
Задает условие поиска для группы или агрегата. HAVING можно использовать только с оператором SELECT. HAVING обычно используется с предложением GROUP BY. Когда GROUP BY не используется, существует неявная единая агрегированная группа.
Соглашения о синтаксисе Transact-SQL
Синтаксис
[ HAVING <условие поиска> ]
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
документацию по предыдущим версиям.
Аргументы
<условие_поиска>
Задает один или несколько предикатов для групп и/или агрегатов. Дополнительные сведения об условиях поиска и предикатах см. в разделе Условия поиска (Transact-SQL).
Типы данных text , image и ntext нельзя использовать в предложении HAVING.
Примеры
В следующем примере используется простое предложение HAVING , извлекающее общее количество для каждого SalesOrderID из Таблица SalesOrderDetail , превышающая $100000,00 .
ИСПОЛЬЗОВАТЬ AdventureWorks2012 ; ИДТИ ВЫБЕРИТЕ SalesOrderID, SUM (LineTotal) AS SubTotal ОТ Sales.SalesOrderDetail СГРУППИРОВАТЬ ПО SalesOrderID СУММА (LineTotal)> 100000,00 ЗАКАЗАТЬ ПО SalesOrderID ;
Примеры: Azure Synapse Analytics and Analytics Platform System (PDW)
В следующем примере используется предложение HAVING для получения общего SalesAmount , превышающего 9. 0047 80000 для каждого
0047 80000 для каждого OrderDateKey из таблицы FactInternetSales .
-- Использует AdventureWorks ВЫБЕРИТЕ OrderDateKey, SUM (SalesAmount) AS TotalSales ОТ FactInternetSales СГРУППИРОВАТЬ ПО OrderDateKey СУММА(SalesAmount) > 80000 ЗАКАЗАТЬ ПО OrderDateKey;
См. также
СГРУППИРОВАТЬ ПО (Transact-SQL)
ГДЕ (Transact-SQL)
SQL Server SELECT Примеры
Автор: Koen Verbeeck |
Обновлено: 12 апреля 2021 г. |
Комментарии | Связанный: Подробнее > TSQL
Проблема
При сохранении данных в разных таблицах базы данных SQL в какой-то момент времени вы
захочет получить некоторые из этих данных. Здесь оператор SELECT для
Появляется язык SQL. Этот учебник научит вас, как использовать SELECT для чтения, агрегирования
и сортировать данные из одной или нескольких таблиц базы данных.
Решение
Все запросы в этом руководстве по SQL написаны на
Образец базы данных Adventure Works. Вы можете установить его на свой компьютер, чтобы вы могли
Вы можете установить его на свой компьютер, чтобы вы могли
выполнить запросы самостоятельно, чтобы увидеть результаты. Вы также можете взять примеры запросов
и замените имена таблиц и имена столбцов именами из вашей собственной базы данных.
Поскольку для чтения данных мы будем использовать только оператор SQL SELECT,
риск изменения или удаления данных. В примерах в этом совете используется AdventureWorks2017.
база данных.
Примеры операторов SQL SELECT
В самой простой форме предложение SELECT имеет следующий синтаксис SQL для
База данных Microsoft SQL Server:
ВЫБЕРИТЕ * ИЗ <ИмяТаблицы>;
Этот SQL-запрос выберет все столбцы и все строки из таблицы. Например:
ВЫБЕРИТЕ * ОТ [Человека].[Человека];
Этот запрос выбирает все данные из таблицы Person в схеме Person.
Если нам нужно только подмножество столбцов, мы можем явно перечислить каждый столбец
разделенные запятой, вместо использования символа звездочки, который включает все
столбцы.
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека];
Синтаксис для сортировки результатов
Иногда требуется отобразить строки в порядке, отличном от порядка SQL.
Сервер возвращает результаты. Вы можете сделать это с помощью
ПОРЯДОК SQL
пункт ПО.
ВЫБЕРИТЕ столбец1, столбец2, столбец3, … ОТ <имя таблицы> ORDER BY columnX ASC | DESC
Вы можете сортировать по одному или нескольким столбцам, и вы можете выбрать сортировку по возрастанию
(ASC) или по убыванию (DESC). Вернем строки с восходящей датой изменения:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] ASC;
По возрастанию используется по умолчанию, поэтому вам не нужно явно указывать ASC.
Теперь с датой изменения по убыванию:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] DESC;
Вы можете сортировать по нескольким столбцам, поэтому давайте сортировать по убыванию даты изменения
сначала, затем по возрастанию имени.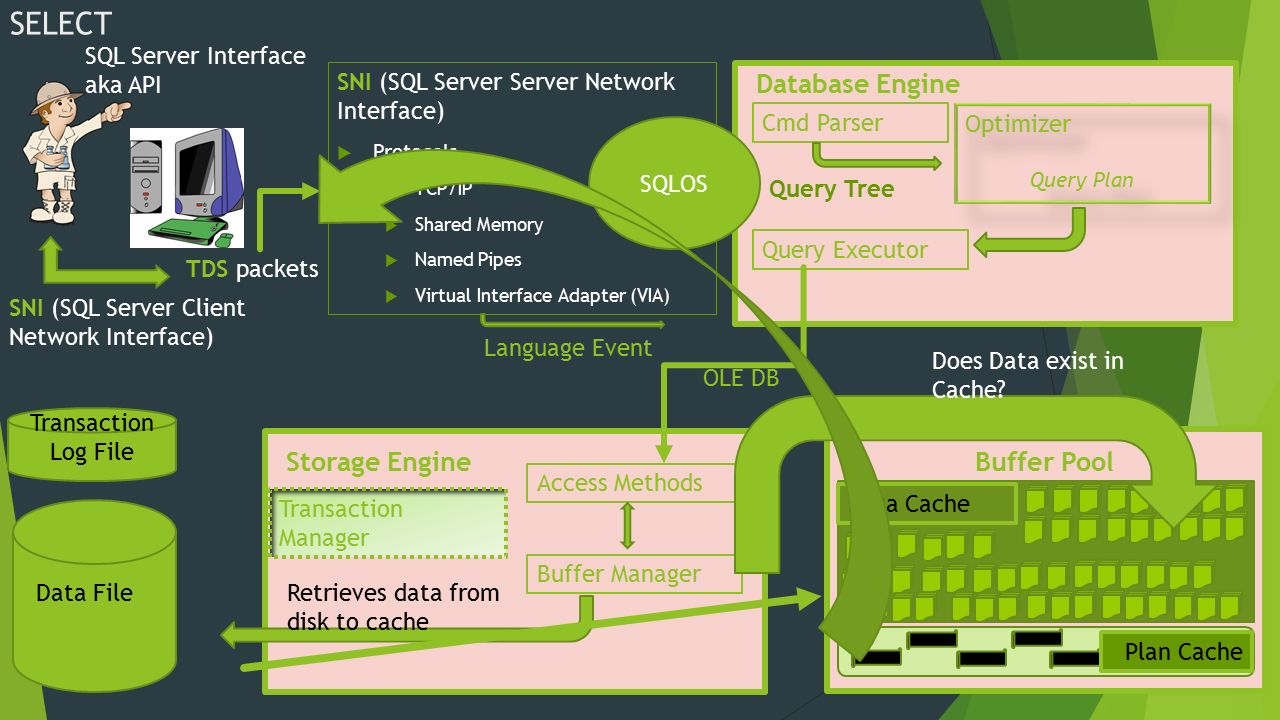
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ORDER BY [ModifiedDate] DESC, Имя;
Например, вы можете увидеть, как третья и четвертая строки результирующего набора (Carla
и Маргарет) поменялись местами.
Фильтрация данных из таблицы
Иногда вам может понадобиться ограничить количество строк, возвращаемых
запрос, особенно если у вас есть таблица с большим количеством строк. Если вы
просто интересно взглянуть на данные, вы можете использовать
ТОР пункт. Например, это вернет первые 10 строк таблицы:
ВЫБЕРИТЕ ВЕРХ(10)
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека];
Вместо числа можно также использовать процент. Этот запрос возвращает
количество строк, равное (или почти равное) 15% от общего количества строк:
ВЫБЕРИТЕ ВЕРХНИЙ(15) ПРОЦЕНТ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека]. [Человека];
 [Человека];
[Человека];
В случае с этой таблицей (всего 19 972 строки) запрос возвращает 2 996
ряды.
Если вы хотите отфильтровать строки по условию,
Можно использовать предложение WHERE. Обычно он имеет следующую структуру:
ВЫБЕРИТЕ столбец1, столбец2, … ОТ <имя_таблицы> ГДЕ <логическое выражение>;
Каждая строка, в которой выражение возвращает значение true, возвращается запросом. Следующее
запрос возвращает всех лиц с именем «Роб».
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб';
В следующем примере три запроса возвращают строки, в которых значение BusinessEntityID равно, меньше
или больше 130.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] = 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека]. [Человека]
ГДЕ [BusinessEntityID] < 130;
 [Человека]
ГДЕ [BusinessEntityID] < 130;
[Человека]
ГДЕ [BusinessEntityID] < 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] > 130;
Вы можете использовать различные функции и операторы, такие как
НРАВИТСЯ оператор для
более продвинутый поиск строк. В этом примере мы ищем всех людей, у которых
имя начинается с «Роб».
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%';
Дополнительные примеры LIKE см. в совете
Синтаксис SQL Server LIKE с подстановочными знаками. Пример с использованием
Функция ГОД:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ ГОД([Дата изменения]) = 2011;
Теперь возвращаются только строки, в которых строка была изменена в 2011 году:
Вы можете использовать логические операторы И, ИЛИ и НЕ для объединения различных логических
выражения друг с другом. Следующий запрос выбирает все строки, в которых имя
Следующий запрос выбирает все строки, в которых имя
равно «Роб», а измененная дата была в 2011 году:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
И ГОД([Дата изменения]) = 2011;
Мы получим совершенно другой набор результатов, если заменим И на ИЛИ. Теперь все ряды
возвращаются, если имя равно Rob или где строка была изменена в
2011.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
ИЛИ ГОД([ModifiedDate]) = 2011;
Группировка данных из таблицы SQL Server
Если вы не хотите возвращать отдельные строки сведений из таблицы, а хотите
сводные результаты, вы можете использовать
Предложение GROUP BY. Запрос имеет следующий формат:
.
ВЫБЕРИТЕ столбец 1, столбец 2, <функция агрегации> (столбец 3) ОТ <имя_таблицы> СГРУППИРОВАТЬ ПО столбцу1, столбцу2
В SQL Server существует множество различных функций агрегирования, таких как SUM, AVG,
МИН, МАКС и так далее. Вы можете найти список
Вы можете найти список
здесь. Если вы используете только агрегации, вам не нужно использовать GROUP BY.
пункт. Например, мы можем вернуть количество строк в таблице с помощью
Функция СЧЁТ:
ВЫБРАТЬ СЧЕТЧИК(1) КАК RowCnt ОТ [Человека].[Человека];
Новое имя – RowCnt – было присвоено результату с помощью AS
ключевое слово. Это также называется «назначением псевдонима». Добавляя ГРУППУ
BY по имени и предложению WHERE (см. предыдущий раздел), мы можем посчитать
сколько раз имя начинается с «Роб».
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя];
Каждый столбец, который не используется внутри функции агрегирования и не
константа, должна быть помещена в предложение GROUP BY. Например, если мы добавим Фамилия
на SELECT, но не на GROUP BY, мы получаем ошибку:
Фильтрация сводных результатов
Используя предложение WHERE, вы можете отфильтровать отдельные строки.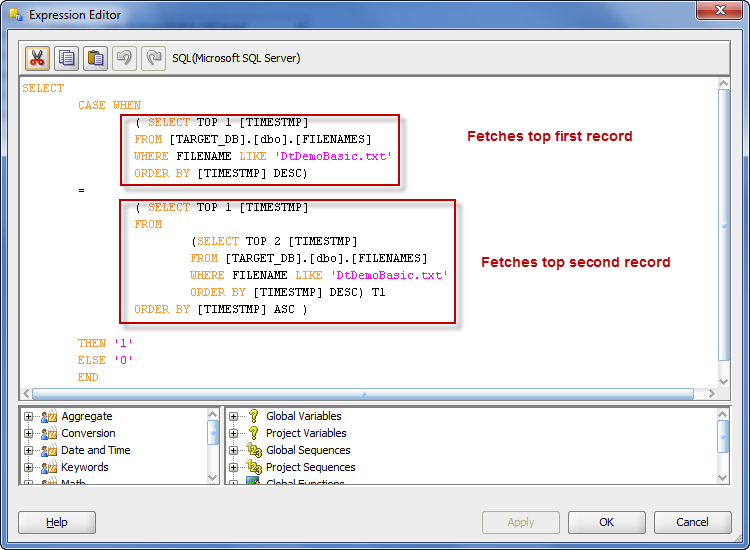 Но что, если вы хотите
Но что, если вы хотите
фильтровать результат агрегированной функции? Это невозможно в ГДЕ
предложение, так как эти результаты не существуют в исходной таблице. Мы можем сделать это
с
предложение HAVING. Используя предыдущий пример, мы хотим вернуть только имена —
начиная с «Роб» — где количество строк не менее 20.
запрос становится:
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя]
ИМЕЕТ СЧЁТ(1) >= 20;
Выбор данных из нескольких таблиц SQL Server
Часто вам не нужны данные из одной таблицы, но вам нужно
комбинировать разные таблицы, чтобы получить желаемый результат. В SQL вы делаете это, «присоединяясь»
столы. Вы берете одну таблицу и определяете, какие столбцы должны совпадать со столбцами
другого стола. Они разные
типы соединения в SQL:
- INNER JOIN — возвращаются только строки, совпадающие между обеими таблицами.
- LEFT OUTER JOIN – возвращаются все строки из первой таблицы вместе
с любыми соответствующими строками из второй таблицы. Также есть ПРАВОЕ СОЕДИНЕНИЕ,
что меняет отношения. - FULL OUTER JOIN — возвращает все строки из обеих таблиц. Если есть
нет соответствия, отсутствующая сторона будет иметь значения NULL вместо фактических значений столбца. - CROSS JOIN – это декартово произведение всех строк обеих таблиц.
Нет соответствия. Если у вас есть 100 строк в первой таблице и 10 в
во втором набор результатов будет содержать 100 * 10 = 1000 строк. Этот тип соединения
следует использовать с осторожностью, поскольку потенциально он может возвращать много строк. Мы
не будем обсуждать это дальше в этом совете.
 Также есть ПРАВОЕ СОЕДИНЕНИЕ,
Также есть ПРАВОЕ СОЕДИНЕНИЕ,Сообщение в блоге
Наглядное объяснение соединений SQL иллюстрирует каждый тип соединения диаграммой Венна.
Давайте проиллюстрируем каждый тип соединения на примере запроса.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Следующий запрос использует INNER JOIN для возврата всех строк и всех столбцов таблицы.
таблицы Person и таблицы Employee, но только если они имеют совпадающие идентификаторы BusinessEntityID.
Другими словами, запрос возвращает людей, которые являются сотрудниками AdventureWorks.
ВЫБЕРИТЕ * ОТ [Человека].[Человека] INNER JOIN [HumanResources].[Employee] ON [Employee].[BusinessEntityID] = [Person].[BusinessEntityID];
Если вы не хотите вводить имена таблиц каждый раз, когда ссылаетесь на столбец,
вы также можете использовать псевдонимы. Здесь таблица Person имеет псевдоним «p».
и таблица «Сотрудник» с «e».
ВЫБЕРИТЕ * ОТ [Человек].[Человек] p INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Если между таблицами есть столбцы с одинаковыми именами, необходимо добавить префикс
их с именем таблицы или с соответствующим псевдонимом. В следующем запросе мы
вернуть BusinessEntityID обеих таблиц, поэтому они должны иметь префикс.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources]. [Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
 [Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Рекомендуется добавлять ко всем столбцам в операторе SELECT префикс
псевдоним таблицы, так как он покажет, из какой таблицы взят каждый столбец. Этот
позволяет избежать путаницы со стороны людей, читающих ваш запрос, особенно если они не
знаком со структурой базы данных.
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Когда мы меняем тип соединения на LEFT OUTER JOIN, все строки из таблицы Person
будет возвращен. Неважно, есть ли совпадение с Сотрудником
стол. Если есть совпадение, будет возвращено значение столбца HireDate.
Если нет, вместо этого будет возвращен NULL.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
LEFT OUTER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
В результирующем наборе видно, что HireDate не возвращается для
лица, не являющиеся работниками:
RIGHT OUTER JOIN использует точно такой же принцип, но возвращает все строки из
вторая таблица и только совпадающие результаты из первой таблицы. Обычно это не
Обычно это не
часто используется, так как LEFT OUTER JOIN легче читать.
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Чтобы проиллюстрировать концепцию FULL OUTER JOIN, мы используем JobCandidate
также стол. Эта таблица содержит 13 строк. Только 2 из этих 13 кандидатов на самом деле
были приняты на работу, и у них BusinessEntityID не равен NULL.
В следующем запросе мы сначала объединяем Person и Employee вместе, чтобы
найти всех сотрудников. Затем мы используем FULL OUTER JOIN, чтобы получить всех кандидатов на работу.
также в наборе результатов запроса.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,j.[BusinessEntityID]
,e.[Дата найма]
,j.[JobCandidateID]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON p.[BusinessEntityID] = e.[BusinessEntityID]
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ [HumanResources].[JobCandidate] j ON e.[BusinessEntityID] = j.[BusinessEntityID];
290 сотрудников и 13 кандидатов на работу. Принято на работу двух кандидатов,
Принято на работу двух кандидатов,
так они тоже наемные работники. Это означает, что общая сумма возвращенных строк
должно быть 301 (290 + 13 – 2).
Первые строки — это сотрудники, которых невозможно найти в таблице JobCandidate.
Столбец JobCandidateID имеет значение NULL.
В конце набора результатов добавляются кандидаты на работу:
На красной площади у нас 11 кандидатов на работу, которые не были приняты на работу. Все
столбцы равны NULL, за исключением столбца JobCandidateID. В зеленом квадрате имеем
пример кандидата на работу, который был принят на работу. Все столбцы имеют значения в этом
случай.
Наконечник
Пример присоединения к SQL Server немного подробнее рассказывает о различных присоединениях.
типы.
Заключение
Давайте объединим все предыдущие разделы в один запрос. Этот
запрос возвращает количество всех сотрудников, имя которых начинается с «Роб»,
отсортированы по этому счету по возрастанию.
ВЫБЕРИТЕ
стр. [Имя]
,COUNT(1) КАК RowCnt
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID]
ГДЕ p.[FirstName] LIKE 'Rob%'
СГРУППИРОВАТЬ ПО [p].[Имя]
ЗАКАЗАТЬ ПО [RowCnt] ASC;
 [Имя]
,COUNT(1) КАК RowCnt
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID]
ГДЕ p.[FirstName] LIKE 'Rob%'
СГРУППИРОВАТЬ ПО [p].[Имя]
ЗАКАЗАТЬ ПО [RowCnt] ASC;
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID]
ГДЕ p.[FirstName] LIKE 'Rob%'
СГРУППИРОВАТЬ ПО [p].[Имя]
ЗАКАЗАТЬ ПО [RowCnt] ASC;
Как видно из запроса, вы также можете сортировать по псевдонимам (в данном примере RowCnt) и
не только на реальных физических столбцах из таблицы.
Следующие шаги
- В этом совете мы только слегка коснулись того, что делает оператор SELECT.
сможет сделать. Вот еще несколько сложных конструкций:- Объединение наборов результатов с UNION (ALL):
UNION против UNION ALL в SQL Server
- Использование подзапросов -
Пример подзапроса SQL Server — и связанные подзапросы:
Некоррелированный и коррелированный подзапрос SQL Server.
- Создание коррелированных запросов или использование табличных функций с ПРИМЕНЕНИЕМ:
SQL Server ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ и ВНЕШНЕЕ ПРИМЕНЕНИЕ
- Более продвинутая группировка с использованием
НАБОРЫ КУБ, РОЛЛАП и ГРУППИРОВКА.
- Объединение наборов результатов с UNION (ALL):
