Масштабирование базы данных через шардирование и партиционирование. Шаржирование базы данных
Шардирование баз данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. БауманаПоследнее изменение этой страницы: 17:11, 9 июня 2017.
Шардирование (горизонтальное партиционирование) — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т. д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
- На нескольких серверах создается одна и та же таблица (только структура, без данных).
- В приложении выбирается условие, по которому будет определяться нужное соединение (например, четные на один сервер, а нечетные — на другой).
- Перед каждым обращением к таблице происходит выбор нужного соединения.
Критерий шардинга — какой-то параметр, который позволит определять, на каком именно сервере лежат те или иные данные.
- ID поля таблицы
- Хеш-таблица с соответствиями «пользователь=сервер» (Тогда, при определении сервера, нужно будет выбрать сервер из этой таблицы. В этом случае узкое место — это большая таблица соответсвия, которую нужно хранить в одном месте.)
- Определять имя сервера с помощью числового (буквенного) преобразования. (Например, можно вычислять номер сервера, как остаток от деления на определенное число (количество серверов, между которыми Вы делите таблицу). В этом случае узкое место — это проблема добавления новых серверов — Вам придется делать перераспределение данных между новым количеством серверов.)
Подход с применением шардирования баз данных
Если возникает вопрос о разнесении одной таблицы по нескольким базам данных, то в первую очередь необходимо переосмыслить структуру самой таблицы. И надо понимать, что предусмотреть возможность использования шардирования надо заранее, иначе придется переписывать много кода. Второй момент. Начинать все же лучше с одной базы данных, а затем при повышении нагрузки заниматься дихотомией - разделением нагруженной базы данных по-палам. В идеале, после деления, нагрузка должна будет разделиться поровну, но если так не получиться, то не переживайте - более нагруженную базу всегда можно поделить еще раз.
Деление баз должно происходить на основании некого хеша полученного от некого поля. При таком делении все записи касающиеся одного конкретного пользователя всегда будут в одной таблице. В принципе такое деление можно производить условно до бесконечность - ограничением будет лишь длина хеша.
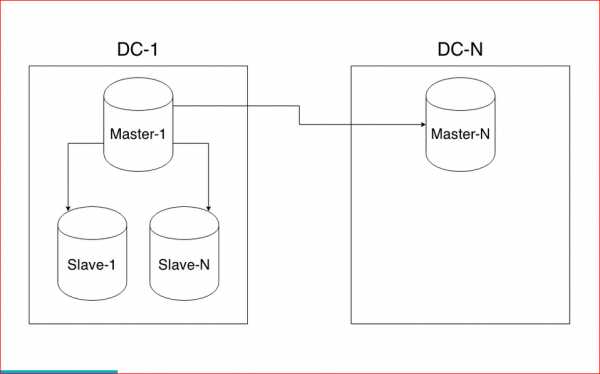
Шардинг и репликация
Репликация
- Многие приложения только читают данные (Правда многие из этих чтений идут из memcache или другого кэша)
- Используем слейвы для выполнения чтений
- Репликация асинхронна (Нужно аккуратно чтобы не читать старые данные; Слейвы могут быть на разных позициях)
- Не помогает масштабировать запись (Слейвы обычно могут выдерживать меньше записей чем мастер так как выполняют записи в один поток)
- Кэши слейвов обычно очень дублированы
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Шардинг
- Когда функциональное разбиение и репликация не помогают
- Разбиваем данные на маленькие кусочки и храним на многих серверах
- “Единственное” решение для крупного масштаба
- Нужно аккуратное планирование
- Может быть не просто реализовать (Особенно если это не предусмотрено дизайном)
- Как разбивать данные очень критичный вопрос (Часто бывает надо несколько копий данных с разным разбиением)
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
SQL Azure Federations
Если приложение использует базы данных MS SQL, возникает несколько вопросов. Конечно первое что приходит в голову — организовать кластер из виртуальных машин SQL Server. Решение достаточно простое и хорошо всем знакомое. А что делать, если приложение использует базу данных как сервис (SaaS)? Что если мы не хотим заниматься настройкой кластера SQL Server? Конечно же, если мы говорим о Windows Azure, то в качестве SQL базы данных будет использоваться SQL Azure. Эта база данных поддерживает технологию горизонтального масштабирования (шардинг) называемую SQL Azure Federations. Принцип ее работы очень простой: логически независимые друг от друга строки одной таблицы хранятся в разных базах данных.
Ограничения SQL Azure
Что это дает: во-первых, изоляцию данных друг от друга. Данные одного аккаунта никак не связаны с данными другого. Соответственно, применением технологии шардинга мы можем реализовать не только горизонтальное масштабирование базы данных, но и multi-tenant сценарий.
Увеличивается скорость выборки данных из базы, поскольку сам размер хранящихся в конкретном шарде данных на порядок меньше, чем суммарный объем базы. Однако, в любой технологии есть свои недостатки. Шардинг не исключение. Если вспомнить, архитектуру SQL Azure, то как известно сервис не поддерживает выборку данных из нескольких баз данных одновременно. То есть одна база данных — одно соединение. И шарды — не исключение. То есть, если допустим простейший запрос на возврат количества клиентов в базе данных необходимо выполнить на каждом шарде отдельно.
Исходный запрос:
SELECT Count(*) FROM AccountПример запроса для конкретного шарда:
USE FEDERATION Accounts(AccountId = 4) WITH RESET, FILTERING = OFF GO SELECT Count(*) FROM AccountЛогику же суммирования значений, возвращаемых этим запросом необходимо размещать в приложении. То есть в результате использования федераций часть кода «уйдет» в приложение, поскольку на уровне базы данных некоторые возможности обычного SQL Server ограничены.
Конечно SQL Azure Federations не является панацеей и можно реализовать свой принцип горизонтального масштабирования баз данных. Допустим multi-tenant подход — тоже своего рода горизонтальное масштабирование базы данных. Поскольку данные одного пользователя отделены не только «логически» от данных другого пользователя, но и «физически». Если необходимо добавить нового пользователя — мы конфигурируем для него отдельную базу данных. Вопрос в том, что в логике приложения должен быть механизм «роутинга». То есть приложение должно знать с какой базой данных оно в данный момент работает.
Сама задумка компании Microsoft хорошая. Было бы неплохо получить инструмент позволяющий легко масштабировать базу данных. Однако как правило, перед принятием окончательного решения перейти к использованию SQL Azure Federations, необходимо тщательно провести анализ существующей базы данных, либо продумать до мельчайших деталей архитектуру базы данных, которую будет использовать приложение, а также саму логику приложения по работе с этой базой.
Серверы баз данных, поддерживающие шардирование:
MongoDB поддерживает шардирование с версии 1.6.
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis база данных с поддержкой шардирования на стороне клиента.
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга[1], Facebook[2] и Twitter[3] применяют шардирование поверх MySQL и т. д.
Ссылки
Масштабирование базы данных через шардирование и партиционирование / Блог компании Конференции Олега Бунина (Онтико) / Хабр

Денис Иванов (2ГИС)
Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.Немного расскажу о себе — я работаю в команде WebAPI в компании 2GIS, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка — 25 млн. активных пользователей в месяц, и в среднем нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем — это большое количество данных. Когда вы разрабатываете тот или иной проект, у вас в любой момент времени может случиться так, что данных становится очень много. Если бизнес работает, он приносит деньги. Соответственно, данных больше, денег больше, и с этими данными что-то нужно делать, потому что эти запросы очень долго начинают выполняться, и у нас сервер начинает не вывозить. Одно из решений, что с этими данными делать — это масштабирование базы данных. Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад "Как устроена MySQL репликация" Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?
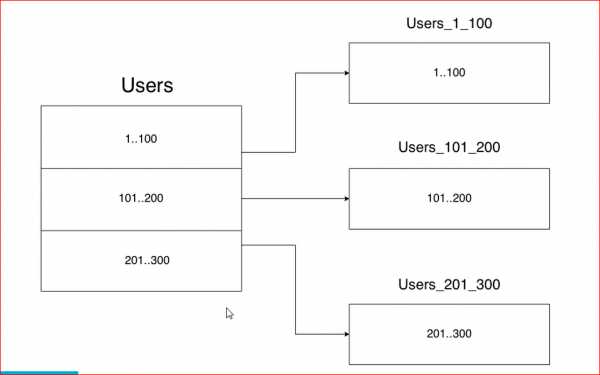
У нас есть большая таблица, например, с пользователями — у нас очень много пользователей. Партицирование — это когда мы одну большую таблицу разделяем на много маленьких по какому-либо принципу. С горизонтальным шардингом все примерно так же, но при этом у нас таблички лежат в разных базах на других инстансах.

Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а. Давайте рассмотрим простую табличку, наверняка, практически в 99% проектов такая табличка есть — это новости.

У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок — совершенно стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
Всего нужно будет сделать 2 действия над табличкой — это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей. Наследованная таблица будет иметь все колонки родителя — той базовой таблицы, которую мы указали, а также она может иметь свои колонки, которые мы дополнительно туда добавим. Она будет полноценной таблицей, но унаследованной от родителя, и там не будет ограничений, индексов и триггеров от родителя — это очень важно. Если вы на базовой таблице насоздаете индексы и унаследуете ее, то в унаследованной таблице индексов, ограничений и триггеров не будет.
2-ое действие, которое нужно сделать — это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.

В данном случае признак — это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу. Какие типы проверок бывают для партицированных таблиц?

Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений — это вхождение в список, например, у нас может быть 3 автора новости именно в этой партиции, и бывает диапазон значений — это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.

И так просто его сделать можно. Но нельзя. Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое. Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую — между 200 и 300. В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет. Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во вторую больше 200, но не 200, и меньше либо равно 300.
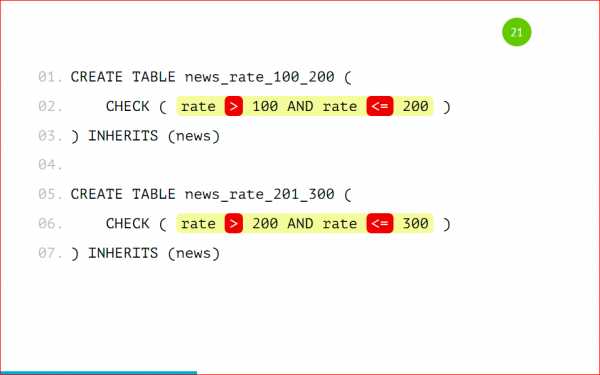
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую — с рейтингом 100.
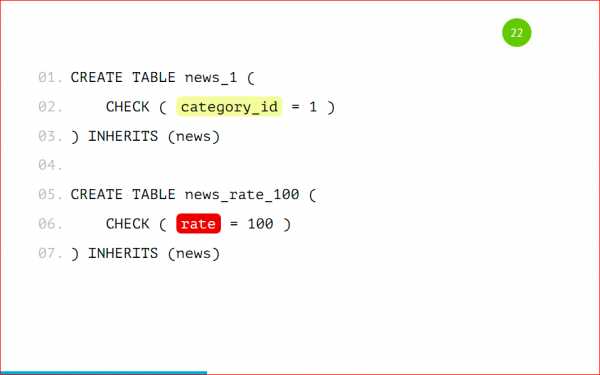
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись. Партицировать стоит по одному признаку, по какому-то одному полю — это очень важно. Давайте рассмотрим нашу партицию целиком:
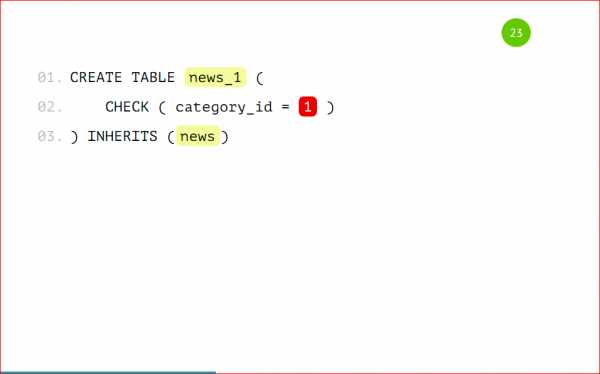
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта таблица будет унаследована от базовой таблицы news — все очень просто.

Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1 попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это правило создается на базовой таблице.

Таким образом мы заводим нужное нам количество партиций. Для примера я буду использовать 2 партиции, чтобы было проще. Т.е. у нас все одинаково, кроме наименований этой таблицы и условия, по которому данные будут туда попадать. Мы также заводим соответствующие правила по шаблону на каждую из таблиц.

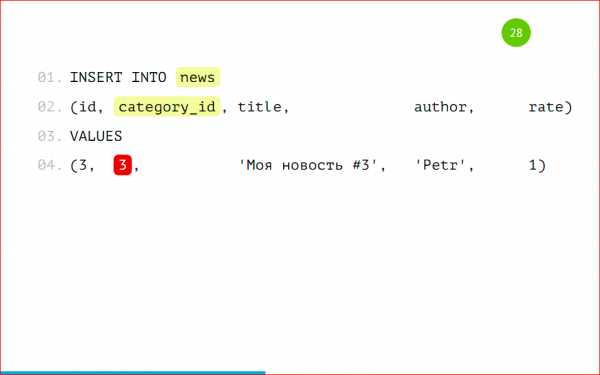
Давайте рассмотрим пример вставки данных:

Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже вставить данные с category_id=3.
Вот мы выбираем данные, у нас они все есть:

Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
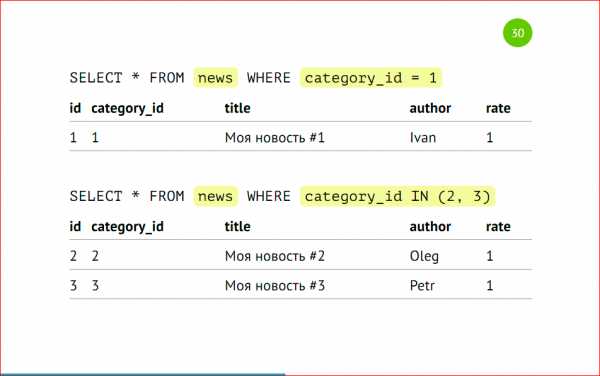
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.

Мы можем выбирать данные напрямую из партиций — это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у нас нет 3-ей партиции, а данные попадут в основную таблицу.
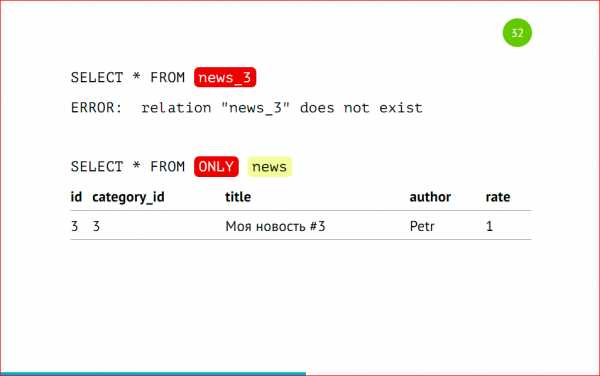
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.

Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму партицию.

Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя вставлять» — это тоже очень удобно — мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не так, мы на уровне базы все это отловим.

Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной партиции. Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.

Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это выглядит со стороны explain’а:
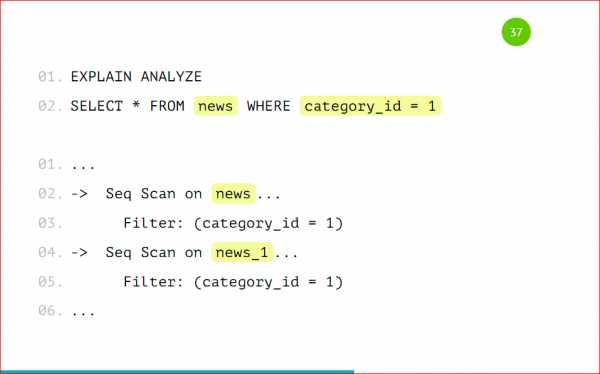
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает оптимизатор — это правильно, и так действительно быстрее.
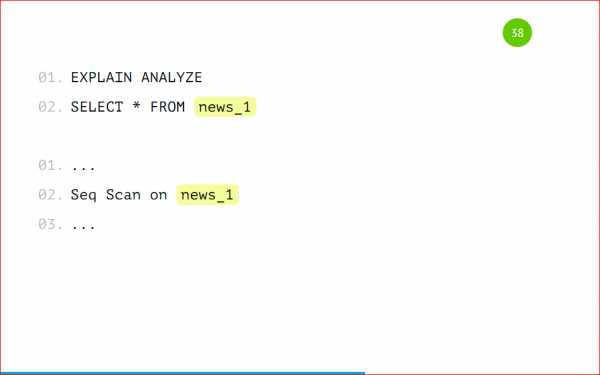
Мы можем посмотреть, как будет выглядеть explain на самой партиции.
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного. Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы

Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension'ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.

Как же нам запартицировать ее? А просто вот так:
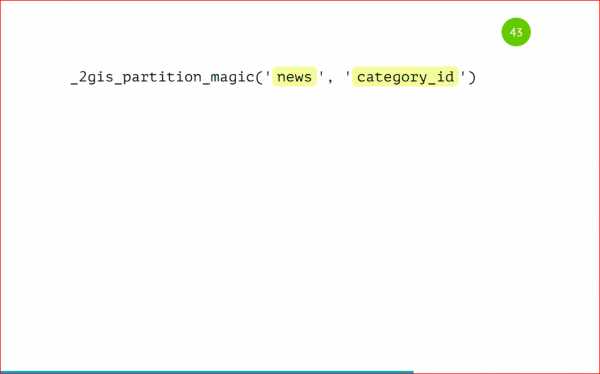
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.

После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.

Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает. Какие мы получаем за счет этого преимущества:
- при вставке мы автоматически создаем партицию, если ее еще нет;
- поддерживаем актуальную структуру, можем управлять просто базовой таблицей, навешивая на нее индексы, проверки, триггеры, добавлять колонки, и они автоматически будут попадать во все партиции после вызова этой процедуры еще раз.
Перейдем ко второй части доклада — это горизонтальный шардинг. Напомню, что горизонтальный шардинг — это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами — news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы будем работать:

Та же самая таблица:

Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать — это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
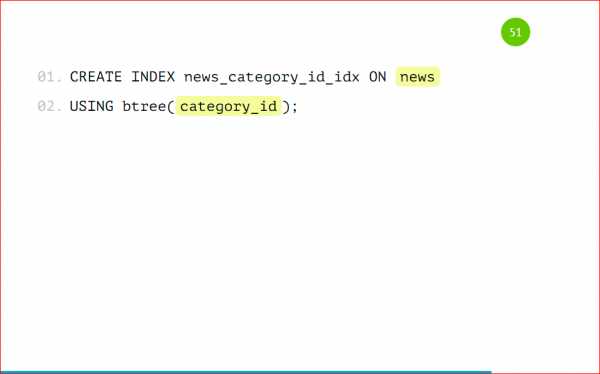
Несмотря на то, что у нас стоит check — проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
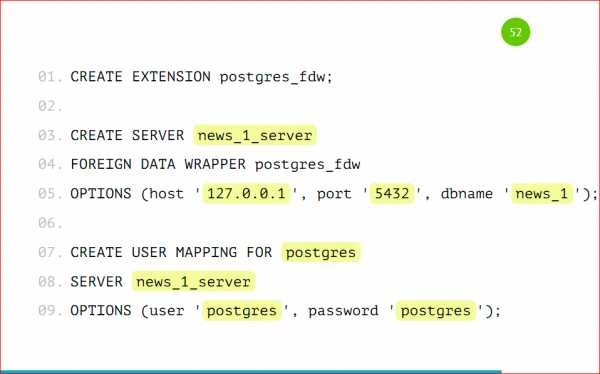
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как foreign data wrapper.
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный) и базу, которую мы завели.
Далее мы создаем маппинг для пользователя — по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет указать, чтобы все работало.
Далее мы заводим табличку на основном сервере:

Это будет табличка с такой же структурой, но единственное, что будет отличаться — это префикс того, что это будет foreign table, т.е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту — это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем сервер, добавляем маппинг, создаем таблицу. Все, что осталось — это завести нашу основную таблицу.

Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее — никаких переписываний, ничего в приложении не делать.
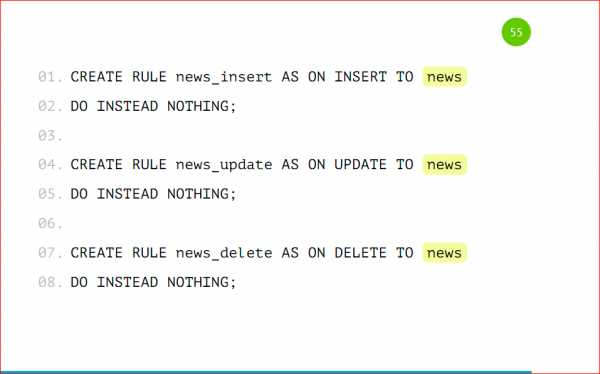
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т.е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.

Т.е. единственное отличие — это в category_id мы будем указывать имя таблицы. Также посмотрим на вставку данных.

Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т.е. у нас указано, что мы ничего не будем делать, если не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные, если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные

Обратите внимание на сортировку идентификаторов — у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет — посылает запросы на удаленные машины, собирает эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую обращаемся в шард.
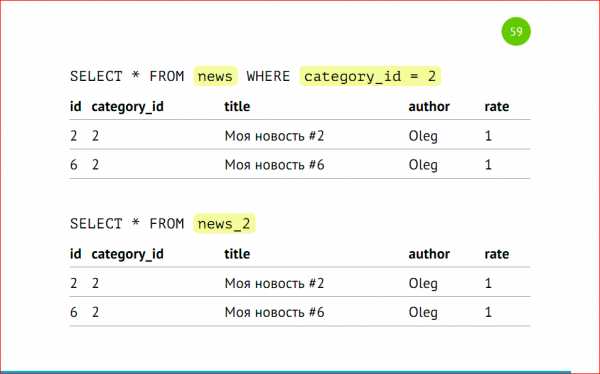
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.

У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan — это удаленный скан, который выполняется на другом сервере.

Партицирование — это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию, готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у нас объем данных в таблице сокращается, т.к. это разные таблицы.
Шардинг — лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем просто бесконечное количество серверов добавлять, и все будет замечательно работать.
Контакты
Блог компании 2ГИСhabr.com
Шардирование - это... Что такое Шардирование?
| Возможно, эта статья содержит оригинальное исследование. Добавьте ссылки на источники, в противном случае она может быть выставлена на удаление.Дополнительные сведения могут быть на странице обсуждения. |
Шардирование это горизонтальное партиционирование баз данных в компьютерном кластере.
Архитектура базы данных
Горизонтальное партиционирование — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т. д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Серверы баз данных, поддерживающие шардирование
MongoDB
MongoDB поддерживает шардирование с версии 1.6.
Plugin for Grails
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis
Redis база данных с поддержкой шардирования на стороне клиента.
SQL Azure
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга[1], Facebook[2] и Twitter[3] применяют шардирование поверх MySQL и т. д.
Примечания
dic.academic.ru
Шардинг, перебалансировка и распределенные транзакции в реляционных базах данных
При разработке нового проекта в качестве основной СУБД нередко выбираются реляционные базы данных, такие, как PostgreSQL или MySQL. В этом действительно есть смысл. Первое время у проекта мало пользователей, и потому все данные помещаются в один сервер. При этом проект активно развивается. Нельзя заранее сказать, какой функционал в нем станет основным, а какой будет выкинут. Есть много историй о том, как мобильный дейтинг в итоге превращался в криптомессанджер, и подобного рода. РСУБД удобны на ранних этапах, потому что они универсальны. Так, PostgreSQL из коробки имеет встроенный полнотекстовый поиск, умеет эффективно работать с геоданными, а также подходит для хранения очередей и рассылки уведомлений. По мере развития проекта и роста нагрузки часть данных может быть перенесена в специализированные NoSQL решения. Также нагрузку можно распределить, поделив базу на несколько совершенно не связанных между собой баз, а также при помощи потоковой репликации. Но что делать в случае, если все это не помогло? В этом посте я постараюсь ответить на данный вопрос.
Примечание: Хочу поблагодарить gridem, sum3rman и gliush за активное участие в обсуждении поднятых в данном посте вопросов. Многие из озвученных ниже идей были позаимствованы у этих ребят.
Декомпозиция проблемы
Задачу построения горизонтально масштабируемого РСУБД-кластера можно разделить на следующие сравнительно независимые задачи:
- Автофейловер. С ростом числа машин в системе встает проблема автоматической обработки падения этих машин. В рамках сего поста автофейловер не рассматривается, так как ему был посвящен отдельный пост Stolon: создаем кластер PostgreSQL с автофейловером. Далее эта задача считается решенной. Предполагается, что все кусочки данных (vbucket’ы) хранятся на репликасетах с автофейловером (кластерах Stolon’а). Термин репликасет позаимствован у MongoDB.
- Шардинг, или распределение данных по репликасетам.
- Перебалансировка, или перемещение данных между репликасетами.
- Решардинг. Под решардингом далее понимается изменение схемы шардирования или ее параметров. Например, изменения числа частей, на которые нарезаются данные. Важно подчеркнуть, что это совершенно отдельная от перебалансировки задача и их не следует путать. Данная терминология (перебалансировка, решардинг, и что это не одно и то же) позаимствована из документации множества таких NoSQL решений, как Cassandra, CouchDB, Couchbase и Riak.
- Распределенные транзакции. Поскольку данные распределяются по нескольким репликасетам, возникает проблема выполнения транзакций между репликасетами.
- Автоматизация. Переизобретать все описанное выше в каждом новом проекте трудоемко и непрактично. Поэтому возникает закономерное желание как-то решить эту проблему один-единственный раз и потом повторно использовать это решение. Увы, как будет показано ниже, очень сложно представить себе универсальное решение, которое подходило бы всем. Поэтому в рамках данной заметки вопрос автоматизации не рассматривается.
Попробуем рассмотреть озвученные проблемы по отдельности.
Шардинг
Существует много схем шардирования. С довольно полным списком можно ознакомиться, например, здесь. Насколько мне известно, наиболее практичной и часто используемой схемой (в частности, она используется в Riak и Couchbase) является следующая.
Каждая единица данных относится к определенной «виртуальной корзине», или vbucket. Число vbucket определяется заранее, берется достаточно большим и обычно является степенью двойки. В Couchbase, например, по умолчанию существует 1024 vbucket’а. Для определения, к какому vbucket относится единица данных, выбирается некий ключ, однозначно определяющий единицу данных, и используется формула типа:
vbucket_num = hash(key) % 1024
Couchbase, например, является KV-хранилищем. Поэтому совершенно логично единицей данных в нем является пара ключ-значение, а ключом, определяющим единицу данных, является, собственно, строковый ключ. Но единица данных может быть и более крупной. Например, если мы пишем социальную сеть, то можем создать 1024 баз данных с одинаковой схемой, а в качестве ключа использовать идентификатор пользователя. Самое главное здесь, чтобы данные, попадающие в разные vbucket’ы, были как можно менее связанными друг с другом, а в идеале — вообще никак не связанными.
Описанным выше способом мы получаем отображение (ключ → номер vbucket). Однако это отображение не дает нам ответа на вопрос, где физически следует искать данные, то есть, к какому репликасету они относятся. Для этого используется так называемый словарь, отображающий номер vbucket’а в конкретный репликасет. Поскольку выше было сказано, что задачу автоматического фейловера мы решаем при помощи Stolon, а ему для работы нужен Consul, который, помимо прочего, является KV-хранилищем, вполне логично хранить словарь в Consul. Например, словарем может быть документ вида:
{ "format_version": 1, "vbuckets": [ "cluster1", "cluster2", ... "clusterN" ]}
Здесь format_version нужен на случай изменения формата словаря в будущем. Также нам нужна версия (ревизия) словаря, увеличивающаяся при каждом обновлении словаря. Выше она не приведена, так как в Consul это есть из коробки для всех данных и называется ModifyIndex. Наконец, в массиве vbuckets по i-му индексу хранится имя кластера Stolon, соответствующего i-му vbucket. В случае, если в настоящее время происходит перебалансировка (см далее), вместо одного имени кластера хранится пара ["clusterFrom","clusterTo"] — откуда и куда сейчас переносятся данные.
Вы спросите, зачем так сложно? Во-первых, эта схема очень гибкая. Например, на ранних этапах развития проекта мы можем использовать один репликасет, хранящий все 1024 vbucket’а. В будущем мы можем использовать до 1024-х репликасетов. Если каждый репликасет будет хранить 1 Тб данных (далеко не предел по сегодняшним меркам), это обеспечит хранение петабайта данных во всем кластере. Во-вторых, при добавлении новых репликасетов не возникает необходимости перемещать вообще все данные туда-сюда, как это происходит, например, при использовании формулы hash(key) % num_replicasets. Наконец, мощности машин в кластере могут различаться. Эта схема позволяет распределить данные по ним неравномерно, в соответствии с мощностями.
Перебалансировка
Что делать в случае, если мы хотим переместить vbucket с одного репликасета на другой?
Начнем со словаря. Каким образом он будет изменяться при перебалансировке, было описано выше. Но перед началом переноса vbucket’ов важно убедиться, что все клиенты увидели новый словарь, в котором отражен процесс переноса. Каким образом это можно сделать? Простейшее решение заключается в том, что для каждой версии словаря раз в определенный интервал времени T (скажем, 15 секунд) клиенты пишут в Consul «словарь такой-то версии последний раз использовался тогда-то». Само собой разумеется, предполагается, что время между клиентами более-менее синхронизировано с помощью ntpd. Если словарь никем не используется уже T*2 времени, можно смело полагать, что все клиенты увидели новую версию словаря. Сами клиенты могут запрашивать последнюю версию словаря просто время от времени, или же воспользоваться механизмом Consul подписки на изменения данных.
Итак, все клиенты знают о начале перебалансировки. Далее возможны варианты.
- Только чтение. Проще всего запретить изменение переносимых данных. Клиенты могут читать с clusterFrom, но не могут ничего записывать. Для многих проектов такое решение вполне подходит. Например, для переноса можно выбрать время, когда системой пользуется меньше всего людей (4 часа ночи) и тем немногим, что попытаются что-то записать, честно сказать, что у проекта сейчас maintenance. Если vbucket’ы достаточно маленькие, перенос все равно займет лишь несколько минут, после чего пользователь сможет повторить запрос.
- Все данные неизменяемые. На первый взгляд это кажется странным, но многим реальным проектам (социальные сети, почта, IM, и прочее) на самом деле не очень-то нужны изменяемые данные. Все данные можно представить в виде лога событий. Новые данные добавляются с помощью обычного insert. В тех редких случаях, когда нужно что-то изменить, update делается через вставку новой версии данных, а delete — через вставку специальной метки, что данные больше не существуют. При таком подходе при переносе данных можно писать в clusterTo, а читать из clusterFrom и clusterTo. У этого подхода есть и ряд других преимуществ — простота синхронизации мобильных клиентов, версионность всех данных (важно в финансах), предсказуемая производительность (не нужен autovacuum), и прочие.
- Логическая репликация между clusterFrom и clusterTo. Ждем полной синхронизации, работая только с clusterFrom. Затем переключаемся на clusterTo и работаем только с ним. Это наиболее универсальное решение, но есть нюансы. Например, в случае с PostgreSQL логическая репликация — это очень болезненная тема. Наиболее многообещающим решением здесь является pglogical, но у него есть ряд существенных ограничений. Кроме того, последний раз, когда я пробовал pglogical, мне попросту не удалось заставить его работать. Вероятно, вам придется написать свою собственную логическую репликацию. Но это сложно и затратно по времени, так как следует корректно обрабатывать несколько транзакций, выполняющихся параллельно, откаты транзакций, и прочее в таком духе.
- Смешанный подход, то есть, использование (1), (2) или (3) на выбор администратора, запустившего перенос. Или же использование разных подходов для разных данных в базе.
Дополнение: Вместо pglogical вы, вероятно, захотите использовать логическую репликацию, которая начиная с PostgreSQL 10 теперь есть из коробки.
В случаях (1) и (2) данные можно переносить обычным pg_dump или воспользоваться COPY:
-- экспорт таблицыCOPY tname TO PROGRAM 'gzip > /tmp/data.gz';-- экспорт данных по запросуCOPY (SELECT * FROM tname WHERE ...) TO PROGRAM 'gzip > /tmp/data.gz';-- импорт данныхCOPY tname FROM PROGRAM 'zcat /tmp/data.gz';
Следует также отметить, что вместо логической репликации можно использовать обычную потоковую. Для этого нужно, чтобы каждый vbucket жил на отдельном инстансе СУБД. В частности, PostgreSQL позволяет легко запускать много инстансов на одной физической машине безо всякой виртуализации. В этом случае вы, вероятно, захотите выбрать несколько меньшее число vbuckets, чем предложенные ранее 1024. Еще, как альтернативный вариант, можно реплицировать вообще все данные, а потом удалять лишние. Но это дорого и будет работать только при введении в строй совершенного нового репликасета.
На мой взгляд, наиболее правдоподобным и универсальным вариантом на сегодняшний день является использование потоковой репликации с удалением лишних данных по окончании репликации по сценарию (3). Это работает только при добавлении совершенно нового, пустого репликасета. В случае, если данные нужно слить с нескольких репликасетов в один, следует использовать pg_dump по сценарию (1).
Решардинг
Напомню, что решардингом, в отличие от перебалансировки, называется изменение числа vbucket’ов или же полное изменение схемы шардирования. Последнее по моим представлениям является очень сложной задачей, делается крайне редко, и исключительно в случае, если весь шардинг реализован непосредственно в самом приложении, а не на стороне СУБД или какого-то middleware перед ним. Здесь очень многое зависит от конкретной ситуации, поэтому далее мы будем говорить о решардинге только в контексте изменения числа vbucket’ов.
Простейший подход к решардингу — это не поддерживать его и просто заранее выбирать достаточно большее количество vbucket’ов :)
Если же решардинг все-таки требуется поддерживать, многое зависит от того, что было выбрано за единицу данных (см параграф про шардинг). Допустим, ей является строка в таблице. Тогда мы можем очень просто удвоить количество vbucket’ов. Вспомним формулу:
// былоvbucket_num = hash(key) % 1024 [ = hash(key) & 0x3FF ]// сталоvbucket_num = hash(key) % 2048 [ = hash(key) & 0x7FF ]
После удвоения числа vbucket’ов половина ключей будут соответствовать все тому же номеру бакета, от 0 до 1023. Еще половина ключей будет перенесена в бакеты с 1024 по 2047. Притом ключ, ранее принадлежавший бакету 0, попадет в бакет 1024, ранее принадлежавший бакету 1 — в бакет 1025, и так далее (у номера бакета появится дополнительный старший бит, равный единице). Это означает, что если мы возьмем текущий словарь, и модифицируем его так:
// оператор ++ означает операцию append, присоединение массива с концаdict.vbuckets = dict.vbuckets ++ dict.vbuckets
… то все ключи автоматически окажутся на нужных репликасетах без какого-либо переноса. Теперь, когда число vbucket’ов удвоилось, бакеты можно переносить с репликасета на репликасет, как обычно. Уменьшение числа vbucket’ов происходит аналогично в обратном порядке — сначала серия переносов, затем обновление словаря. Как и в случае с перебалансировкой, следует проверять, что все клиенты увидели новую версию словаря.
Если единицами данных являются базы данных с одинаковой схемой, все несколько сложнее. В этом случае не очень понятно, как можно быстро и правильно для общего случая разделить каждую базу на две. Похоже, лучшее, что можно сделать при такой схемы шардирования, вместо использования формулы hash(key) % 1024 просто сообщать пользователю количество vbucket’ов. В этом случае определение номера бакета по ключу, а также перенос данных в случае решардинга перекладываются на приложение. Зато число бакетов может в любой момент быть увеличено на произвольное число просто путем создания пустых бакетов. Или уменьшено путем удаления лишних бакетов, в предположении, что пользователь заблаговременно перенес из них все данные.
Распределенные транзакции
Поскольку бакеты могут быть логически связанными и храниться на разных репликасетах, иногда приходится делать транзакции между репликасетами. При правильно выбранной схеме шардирования распределенные транзакции должны выполняться редко, поскольку они всегда недешевы. Если в вашем проекте распределенные транзакции не нужно делать никогда, вам сильно повезло.
Как всегда, в зависимости от ситуации задачу можно решить разными способами. Допустим, вы решили воспользоваться описанной выше идеей с неизменяемыми данными, и каждый пользователь в вашем проекте читает данные только из своего бакета. В этом случае «транзакцию» между бакетами А и Б можно выполнить по предельно простому алгоритму:
- Создайте объект «транзакция», хранящий все, что вы хотите записать в бакеты А и Б.
- Произведите запись в бакет А. Запись должна производиться в одну локальную транзакцию, а у записанных объектов должна быть метка, к какой транзакции они относятся. Если объекты с соответствующей меткой уже записаны, ничего не делать.
- Аналогичным образом произведите запись в бакет Б.
- Удалите объект «транзакция»;
Шаги (2) и (3) могут выполняться параллельно. Если выполнение кода прервется на шаге (2), (3) или (4), «транзакцию» всегда можно будет докатить (специально предусмотренным для этого процессом). Это возможно по той причине, что операции (2) и (3) идемпотентны — их повторное выполнение приводит к тому же результату. При этом, поскольку пользователь читает данные только из своего бакета, с его точки зрения данные всегда консистентны.
Само собой разумеется, это не настоящие транзакции, но для многих проектов их будет более, чем достаточно. При определенных условиях этот подход можно применить даже в случае, если данные в бакетах изменяемые.
Описание более универсального подхода можно найти в блоге Дениса Рысцова. Также этот прием описан как минимум в документации к MongoDB и блоге CockroachDB. В общих чертах алгоритм примерно такой:
- Создайте объект «транзакция» с состоянием committed = false, aborted = false.
- При обращении к объектам в вашей базе данных на чтение и на запись указывайте в них ссылку на транзакцию. При обращении на запись в специальное поле допишите, каким станет объект в случае, если транзакция завершится успешно (локальные изменения). Если у объекта уже есть метка, и соответствующая транзакция:
- … закоммичена, примените локальные изменения объекта и запишите свою метку.
- … отменена, очистите локальные изменения и запишите свою метку.
- … все еще выполняется, значит произошел конфликт. Вы можете подождать, отменить свою транзакцию, или отменить чужую транзакцию. Примите во внимание, что процесс, выполнявший другую транзакцию, мог уже умереть. Так что, как минимум при определенных условиях вы должны отменять ту, другую транзакцию (например, если она начала выполнение достаточно давно). Иначе затронутые ею объекты останутся заблокированы навсегда.
- Если транзакция все еще не прибита другими процессами, измените ее состояние на committed = true. Это ключевой момент алгоритма. Так как этот шаг выполняется атомарно, и все транзакции знают, как трактовать локальные изменения, у транзакции нет никаких промежуточных состояний. В любой момент времени она либо применена, либо нет.
- Почистите за собой — примените локальные изменения ко всем затронутым объектам, затем удалите объект «транзакция». Этот шаг не обязателен в смысле корректности алгоритма. Он просто освобождает место на диске от данных, которые стали ненужны.
Важно! Приведенное описание предполагает, что каждая операция чтения или записи выполняется в отдельной транзакции при уровне изоляции serializable. Или, в более общем случае, если СУБД не поддерживает транзакций, в одну CAS-операцию. Однако выполнение нескольких операций в одной транзакции не влияет на корректность алгоритма.
Этот алгоритм довольно неприятно применять по той причине, что абсолютно все транзакции, включая локальные, должны понимать, как трактовать локальные изменения. Разумеется, при условии, что вы хотите получить snapshot isolation. При определенных условиях вас может устроить и более слабый уровень изоляции. Примите также во внимание, что snapshot isolation — это не serializable. При нем возможна аномалия write skew. Впрочем, для многих приложений может быть вполне достаточно и snapshot isolation. В частности, это самый высокий уровень изоляции, поддерживаемый в Oracle.
Хочу еще раз подчеркнуть важность проставления метки транзакции на шаге (2) не только при записи, но и при чтении. Если этого не делать, другая транзакция может изменить объект, который вы читаете, и при повторном его прочтении вы увидите что-то другое. Если вы точно знаете, что не станете ничего писать в него, то можете просто закэшировать объект в памяти. Все это, конечно же, написано в предположении, что вы желаете получить snapshot isolation. Возможно, вы готовы мириться с аномалиями, получая в обмен скорость и/или простоту кода.
Заключение
Горизонтальное масштабирование РСУБД — задача решаемая. Несмотря на сложность некоторых описанных выше моментов, это ничто по сравнению со сложностями, которые вас ждут при использовании в проекте исключительно NoSQL решений. В частности, для обеспечения какой-либо консистентности придется делать распределенные транзакции, как было описано выше, практически на все.
Как вы могли убедиться, тут довольно сложно представить универсальное решение, подходящее абсолютно всем и всегда. И это мы еще упустили из виду, например, такие важные вопросы, как репликация между несколькими ДЦ и снятие консистентных бэкапов с множества репликасетов! Именно ввиду существования огромного количества возможных решений мы не рассматривали вопрос автоматизации всего описанного выше.
Надеюсь, что вы нашли представленный выше материал интересным. Как обычно, если у вас есть вопросы или дополнения, не стесняйтесь оставлять их в комментариях!
Метки: СУБД.
eax.me
Горизонтальное масштабирование базы данных реального проекта с помощью SQL Azure Federations / Блог компании EPAM / Хабр
Шардинг
Вопрос масштабирования приложений в облаке возникает очень часто. Сама концепция облачных технологий подразумевает масштабирование приложений по запросу. Любой уважающий себя облачный провайдер поддерживает соответствующие функции.Зачем вообще нужно горизонтальное масштабирование? Когда возникает вопрос повышения производительности приложения, то есть несколько вариантов. Как известно можно купить новое «железо» для сервера, добавить количество оперативной памяти и т. д. Этот принцип называется вертикальным масштабированием. Однако этот способ может быть достаточно дорогим, долгим, да и имеет предел. Можно конечно купить топовое железо, однако оно может не потянуть все требования вашего приложения.
Второй способ, называемый горизонтальным масштабированием, предполагает расширение вычислительных ресурсов доступных приложению за счет увеличения количества серверов или инстансов приложения, в случае PaaS, на которых размещено ваше приложение. То есть если раньше ваше приложение было расположено на одном сервере, и в какой-то момент оно перестало «вытягивать» нагрузку, можно просто купить второй точно такой же сервер. Поставить на него ваше приложение и таким образом часть запросов к приложению будет идти на первый сервер, часть — на второй.
Этот принцип и положен в горизонтальное масштабирование приложений размещенных в «облаке», только вместо реальных физических серверов и у нас есть понятие виртуальная машина. Когда экземпляра одной виртуальной машины недостаточно вашему приложению — вы можете увеличить его, таким образом распределив нагрузку между несколькими виртуальными машинами.
Если рассматривать возможности облачной платформы от Microsoft, то они достаточно широкие. Есть auto-scaling, scaling по запросу, причем все это доступно как с помощью UI, так и с помощью SDK, REST API и PowerShell.
Однако если с масштабированием приложения (PaaS) или виртуальных машин (IaaS) все достаточно просто, указываете сколько инстансов вам необходимо, столько и будет, то в случае если ваше приложение использует базы данных MS SQL, возникает несколько вопросов. Конечно первое что приходит в голову — организовать кластер из виртуальных машин SQL Server. Решение достаточно простое и хорошо всем знакомое. А что делать, если приложение использует базу данных как сервис (SaaS)? Что если мы не хотим заниматьсянастройкой кластера SQL Server?
Конечно же, если мы говорим о Windows Azure, то в качестве SQL базы данных будет использоваться SQL Azure. Эта база данных поддерживает технологию горизонтального масштабирования (шардинг) называемую SQL Azure Federations. Принцип ее работы очень простой: логически независимые друг от друга строки одной таблицы хранятся в разных базах данных. Самый простой пример:
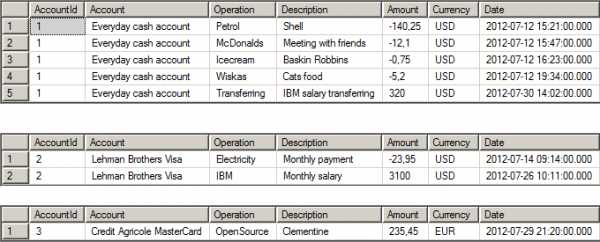
Это одна и та же таблица, данные которой хранятся в разных экземплярах базы данных (шардах). То есть данные аккаунта с идентификатором 1 хранятся в первой базе данных, с идентификатором 2 — во второй и т. д.
Ограничения SQL Azure
Итак, что же это нам дает? Во-первых изоляцию данных друг от друга. Данные одного аккаунта никак не связаны с данными другого. Соответственно, применением технологии шардинга мы можем реализовать не только горизонтальное масштабирование базы данных, но и multi-tenant сценарий.Увеличивается скорость выборки данных из базы, поскольку сам размер хранящихся в конкретном шарде данных на порядок меньше, чем суммарный объем базы.
Однако, в любой технологии есть свои недостатки. Шардинг не исключение. Давайте подумаем, какие же недостатки могут встретиться при использовании технологии шардинга на примере базы данных, описанной выше?
Если вспомнить, архитектуру SQL Azure, то как известно сервис не поддерживает выборку данных из нескольких баз данных одновременно. То есть одна база данных — одно соединение. И шарды — не исключение. То есть, если допустим пройстейший запрос на возврат количества клиентов в базе данных необходимо выполнить на каждом шарде отдельно.
Исходный запрос:SELECT Count(*) FROM Account
Пример запроса для конкретного шарда:USE FEDERATION Accounts(AccountId = 4) WITH RESET, FILTERING = OFFGOSELECT Count(*) FROM Account
Логику же суммирования значений, возвращаемых этим запросом необходимо размещать в приложении. То есть в результате использования федераций часть кода «уйдет» в приложение, поскольку на уровне базы данных некоторые возможности обычного SQL Server ограничены.
Предисловие
Конечно SQL Azure Federations не является панацеей и вы можете реализовать свой принцип горизонтального масштабирования баз данных. Допустим multi-tenant подход — тоже своего рода горизонтальное масштабирование базы данных. Поскольку данные одного пользователя отделены не только «логически» от данных другого пользователя, но и «физически».Если необходимо добавить нового пользователя — мы конфигурируем для него отдельную базу данных. Вопрос в том, что в логике приложения должен быть механизм «роутинга». То есть приложение должно знать с какой базой данных оно в данный момент работает.
Но вернемся к SQL Azure Federations… Сама задумка компании Microsoft достойна всяческих похвал. Было бы неплохо получить инструмент позволяющий легко мастабировать базу данных. А еще бы сделать auto-scaling, на основе результатов определенных запросов (ну это уже фантастика)…
Однако как правило, перед принятием окончательного решения перейти к использованию SQL Azure Federations, необходимо тщательно провести анализ существующей базы данных (а как правило переносятся уже существующие базы), либо продумать до мельчайших деталей архитектуру базы данных, которую будет использовать приложение, а также саму логику приложения по работе с этой базой.
С теорией вроде разобрались. Однако как правило на практике встречается достаточно большое количество граблей, на которые можно наступить. Поэтому вместо того, чтобы показывать как можно легко начать использовать SQL Azure Federations с нуля, мы попробуем мигрировать существующую базу данных SQL Azure на использование федераций. Рассмотрим шаги, которые нужно сделать DBA, а также проблемы с которыми можно столкнуться на этапе миграции.
В общем не переключайтесь! Всем хорошего начала рабочей недели!
habr.com
Масштабирование баз данных — партиционирование, репликация и шардинг
Масштабирование SQL и NoSQL
Описанные ниже схемы масштабирования применимы как для реляционных баз данных, тах и для NoSQL-хранилищ. Разумеется, что у всех баз данных и хранилищ есть своя специфика, поэтому мы рассмотрим только основные направления и в детали реализации вдаваться не будем.
Партиционирование (partitioning)
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. Для правильного конфигурирования параметров партиционирования необходимо, чтобы в каждом потоке было примерно одинаковое количество записей.
Например, на новостных сайтах имеет смысл партиционировать записи по дате публикации, так как свежие новости на несколько порядков более востребованы и чаще требуется работа именно с ними, а не со всех архивом за годы существования новостного ресурса.
Репликация (replication)
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Например, создание нескольких дополнительных slave-серверов позволяет снять с основного сервера нагрузку и повысить общую производительность системы, а также можно организовать слэйвы под конкретные ресурсоёмкие задачи и таким образом, например, упростить составление серьёзных аналитических отчётов — используемый для этих целей slave может быть нагружен на 100%, но на работу других пользователей приложения это не повлияет.
Шардинг (sharding)
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Например, в системах типа социальных сетей ключом для шардинга может быть ID пользователя, таким образом все данные пользователя будут храниться и обрабатываться на одном сервере, а не собираться по частям с нескольких.
web-creator.ru
HighLoad Junior Блог
Денис Иванов (2ГИС)
Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.
Немного расскажу о себе – я работаю в компании WebAPI в 2GIS-е, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка – 25 млн. активных пользователей в месяц, и в среднем нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем – это большое количество данных. Когда вы разрабатываете тот или иной проект, у вас в любой момент времени может случиться так, что данных становится очень много. Если бизнес работает, он приносит деньги. Соответственно, данных больше, денег больше, и с этими данными что-то нужно делать, потому что эти запросы очень долго начинают выполняться, и у нас сервер начинает не вывозить. Одно из решений, что с этими данными делать – это масштабирование базы данных.
Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад "Как устроена MySQL репликация" Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?
У нас есть большая таблица, например, с пользователями – у нас очень много пользователей. Партицирование – это когда мы одну большую таблицу разделяем на много маленьких по какому-либо принципу.
С горизонтальным шардингом все примерно так же, но при этом у нас таблички лежат в разных базах на других инстансах.
Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а.
Давайте рассмотрим простую табличку, наверняка, практически в 99% проектов такая табличка есть – это новости.
У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок – совершенно стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
Всего нужно будет сделать 2 действия над табличкой – это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей. Наследованная таблица будет иметь все колонки родителя – той базовой таблицы, которую мы указали, а также она может иметь свои колонки, которые мы дополнительно туда добавим. Она будет полноценной таблицей, но унаследованной от родителя, и там не будет ограничений, индексов и триггеров от родителя – это очень важно. Если вы на базовой таблице насоздаете индексы и унаследуете ее, то в унаследованной таблице индексов, ограничений и триггеров не будет.
2-ое действие, которое нужно сделать – это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.
В данном случае признак – это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу.
Какие типы проверок бывают для партицированных таблиц?
Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений – это вхождение в список, например, у нас может быть 3 автора новости именно в этой партиции, и бывает диапазон значений – это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.
И так просто его сделать можно. Но нельзя.
Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое.
Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую – между 200 и 300.
В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет.
Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во вторую больше 200, но не 200, и меньше либо равно 300.
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую – с рейтингом 100.
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись. Партицировать стоит по одному признаку, по какому-то одному полю – это очень важно.
Давайте рассмотрим нашу партицию целиком:
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта таблица будет унаследована от базовой таблицы news – все очень просто.
Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1 попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это правило создается на базовой таблице.
Таким образом мы заводим нужное нам количество партиций.
Для примера я буду использовать 2 партиции, чтобы было проще. Т.е. у нас все одинаково, кроме наименований этой таблицы и условия, по которому данные будут туда попадать. Мы также заводим соответствующие правила по шаблону на каждую из таблиц.
Давайте рассмотрим пример вставки данных:
Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже вставить данные с category_id=3.
Вот мы выбираем данные, у нас они все есть.
Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.
Мы можем выбирать данные напрямую из партиций – это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у нас нет 3-ей партиции, а данные попадут в основную таблицу.
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.
Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму партицию.
Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя вставлять» – это тоже очень удобно – мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не так, мы на уровне базы все это отловим.
Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной партиции. Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.
Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это выглядит со стороны explain’а:
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает оптимизатор – это правильно, и так действительно быстрее.
Мы можем посмотреть, как будет выглядеть explain на самой партиции.
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного.
Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы.
Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension'ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.
Как же нам запартицировать ее? А просто вот так:
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.
После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.
Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает.
Какие мы получаем за счет этого преимущества:
· при вставке мы автоматически создаем партицию, если ее еще нет;
· поддерживаем актуальную структуру, можем управлять просто базовой таблицей, навешивая на нее индексы, проверки, триггеры, добавлять колонки, и они автоматически будут попадать во все партиции после вызова этой процедуры еще раз.
Мы получаем действительно большое преимущество в этом. Вот ссылочка: https://github.com/2gis/partition_magic.
На этом первая часть доклада закончена. Мы научились партицировать данные. Напомню, что партицирование применяется на одном инстансе – это тот же самый инстанс базы, где у вас лежала бы большая толстая таблица, но мы ее раздробили на мелкие части. Мы можем совершенно не менять наше приложение – оно точно так же будет работать с основной таблицей – вставляем туда данные, редактируем, удаляем. Так же все работает, но работает быстрее. Приблизительно, в среднем, в 3-4 раза быстрее.
Перейдем ко второй части доклада – это горизонтальный шардинг.
Напомню, что горизонтальный шардинг – это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами – news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы будем работать:
Та же самая таблица:
Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать – это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
Несмотря на то, что у нас стоит check – проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как foreign data wrapper.
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный) и базу, которую мы завели.
Далее мы создаем маппинг для пользователя – по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет указать, чтобы все работало.
Далее мы заводим табличку на основном сервере
Это будет табличка с такой же структурой, но единственное, что будет отличаться – это префикс того, что это будет foreign table, т.е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту – это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем сервер, добавляем маппинг, создаем таблицу. Все, что осталось – это завести нашу основную таблицу.
Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее – никаких переписываний, ничего в приложении не делать.
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т.е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.
Т.е. единственное отличие – это в category_id мы будем указывать имя таблицы.
Также посмотрим на вставку данных.
Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т.е. у нас указано, что мы ничего не будем делать, если не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные, если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные.
Обратите внимание на сортировку идентификаторов – у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет – посылает запросы на удаленные машины, собирает эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую обращаемся в шард.
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.
У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan – это удаленный скан, который выполняется на другом сервере.
Партицирование – это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию, готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у нас объем данных в таблице сокращается, т.к. это разные таблицы.
Шардинг – лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем просто бесконечное количество серверов добавлять, и все будет замечательно работать.
Вконтакте
Google+
← Производительность запросов в PostgreSQL – шаг за шагом Sharding – patterns and antipatterns →highload.guide
- Изменить пароль пользователя postgresql

- Как скрыть

- Что такое движок виртуализации

- Utorrent это

- С какого года одноклассники

- Как на компе сделать скрин экрана
- Какой язык программирования выбрать новичку

- Чистка от рекламы

- Powershell работа с файлами

- Центр обновлений в windows 10
- На компьютере не показывает картинки