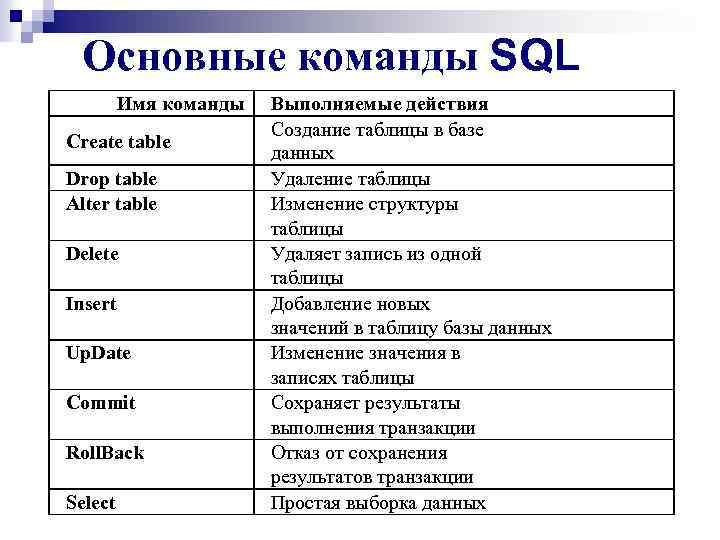
Sql для чайников запросы: Урок 1. Первые SQL запросы
Содержание
Архитектура обработки SQL запросов в Microsoft SQL Server | Info-Comp.ru
Приветствую Вас на сайте Info-Comp.ru! Сегодня мы с Вами разберем внутреннюю архитектуру обработки SQL запросов в Microsoft SQL Server.
Дело в том, что между тем моментом, когда мы нажали кнопку «Выполнить», т.е. послали SQL запрос, и моментом, когда мы увидели запрашиваемые данные, внутри SQL Server выполняется огромная, многоэтапная работа, о которой полезно знать всем разработчикам и администраторам Microsoft SQL Server.
Заметка! Что нужно знать и уметь разработчику T-SQL.
Иными словами, сегодня мы поговорим о том, что именно происходит, так сказать, за «кулисами» в том момент, когда мы посылаем запрос на SQL Server.
Содержание
- Введение в архитектуру обработки запросов в SQL Server
- Relational Engine
- Query Parsing
- Parsing
- Algebrizer
- Query Optimization
- Simplification
- Trivial Plan Optimization
- Full Optimization: Search 0
- Full Optimization: Search 1
- Full Optimization: Search 2
- Query Execution
- Выводы (общая схема)
Введение в архитектуру обработки запросов в SQL Server
Многие начинающие разработчики думают, что, когда мы запускаем SQL запрос на выполнение, Microsoft SQL Server просто парсит текст запроса и сразу возвращает нам данные. Однако это не так.
Однако это не так.
SQL Server перед тем, как вернуть нам результат, т.е. данные, выполняет достаточно много сложных различных операций, иными словами, данные нам возвращаются только после работы сложного внутреннего механизма, о котором мы сейчас и поговорим, т.е. о том, что на самом деле происходит с момента, когда мы нажали кнопку «Выполнить» и послали SQL запрос, до того, когда мы увидели запрашиваемые данные.
Итак, внутри SQL Server работает сложный механизм, работу которого обеспечивают несколько специально созданных так называемых «движков», каждый из которых отвечает за определенный участок работы.
За обработку SQL запросов в Microsoft SQL Server отвечает движок, который называется – Relational Engine.
Заметка! Обзор инструментов для работы с Microsoft SQL Server.
Relational Engine
Relational Engine – это компонент Microsoft SQL Server, который отвечает за обработку SQL запросов.

На входе данный движок принимает текст SQL запроса, а на выходе отдает данные, которые мы запрашивали с помощью этого SQL запроса.
Relational Engine включает несколько этапов обработки SQL запроса. Можно выделить 3 основных, глобальных этапа:
- Query Parsing
- Query Optimization
- Query Execution
Обязательно стоит отметить, что каждый из этих этапов включает несколько дополнительных этапов, иными словами, на каждом этапе запускается несколько процессов, отвечающих за ту или иную обработку SQL запроса.
Давайте чуть более подробно поговорим о каждом этапе обработки SQL запроса компонентом Relational Engine, таким образом, Вы будете понимать, какие процессы запускаются, когда мы выполняем SQL запрос в Microsoft SQL Server.
Query Parsing
Parsing
На данном этапе выполняются следующие действия:
- Чтение и разбор текста запроса
- Генерирование хэша по тексту запроса
- Проверка кэша планов, т.
 е. поиск подходящего плана в кэше. Иными словами, если для данного текста запроса ранее уже был сформирован план выполнения, то необязательно выполнять все последующие действия, так как можно взять план из кэша
е. поиск подходящего плана в кэше. Иными словами, если для данного текста запроса ранее уже был сформирован план выполнения, то необязательно выполнять все последующие действия, так как можно взять план из кэша - Синтаксический анализ
- Построение дерева логических операторов
 е. поиск подходящего плана в кэше. Иными словами, если для данного текста запроса ранее уже был сформирован план выполнения, то необязательно выполнять все последующие действия, так как можно взять план из кэша
е. поиск подходящего плана в кэше. Иными словами, если для данного текста запроса ранее уже был сформирован план выполнения, то необязательно выполнять все последующие действия, так как можно взять план из кэшаЗаметка! Назначение хранимых процедур в языке T-SQL.
Algebrizer
На данном этапе происходит так называемый Binding – это проверка на существования объектов базы данных, столбцов в таблицах, которые указаны в запросе, а также сопоставление каждого объекта дерева с реальным объектом системного каталога.
Результатом этапа Query Parsing является Query Tree (дерево запроса, т.е. дерево логических шагов, необходимых для преобразования исходных данных в формат, требуемый результирующему набору).
Query Optimization
Query Optimization – это как раз тот самый, всем известный «Оптимизатор запросов», основной функцией которого является построение плана выполнения запроса.

План выполнения запроса – это набор конкретных действий, выполнение которых приведет SQL запрос к итоговому результату.
Иными словами, план выполнения запроса – это то, как именно будет выполняться пользовательский запрос, т.е. как именно будет осуществляться доступ к исходным данных, в каком порядке, какие конкретные методы будут использоваться для извлечения данных из каждой таблицы, какие конкретные методы будут использованы для вычислений, фильтрации, статистической обработки и сортировки данных.
А все дело в том, что SQL Server может выполнить запрос и получить одни и те же данные разными способами, т.е. набор физических операций в различных условиях будет отличаться.
Таким образом, работа оптимизатора заключается как раз в создании оптимального плана выполнения запроса, при котором результат возвращается быстрее всего и задействовано меньше всего ресурсов.
Заметка! Более подробно о плане выполнения запроса в Microsoft SQL Server мы поговорили в отдельном материале.
 План выполнения запроса в Microsoft SQL Server.
План выполнения запроса в Microsoft SQL Server.Данный этап, т.е. процесс оптимизации запроса, включает несколько фаз, в частности:
- Simplification
- Trivial Plan Optimization
- Full Optimization
- Search 0
- Search 1
- Search 2
Simplification
На данном этапе происходит упрощение дерева запроса, например:
- удаление ненужных соединений
- разворачивание подзапросов в соединения (если это возможно)
- условия фильтрации могут быть перемещены в начало дерева запроса, чтобы отфильтровать данные как можно раньше
Trivial Plan Optimization
Это этап поиска тривиального плана, т.е. если запрос может быть решен единственным способом, то значит, запрос удовлетворяет условию тривиального плана и никакие правила оптимизации применять не стоит.
Full Optimization: Search 0
На этом этапе оптимизатор ищет хороший план за минимальное время. Но данный этап может быть пропущен, и оптимизатор сразу может перейти к следующему этапу, если запрос не удовлетворяет определенным условиям.
Full Optimization: Search 1
На данном этапе используются дополнительные правила преобразования и некоторые возможные перестановки вариантов соединения данных. Если после генерации плана на этой стадии, план все еще недостаточно хорош, то данная стадия повторяется с целью поиска параллельного плана. После чего два плана сравниваются, и для оценки выбирается лучший из них. Если этот лучший план все еще не проходит внутренние пороги оптимизатора, то управление переходит к следующей фазе.
Full Optimization: Search 2
Это самый последний этап оптимизации, на котором в любом случае будет найден тот или иной план выполнения запроса.
На этапе Query Optimization перед тем, как передать найденный, т.е. итоговый план запроса на выполнение, этот план помещается в кэш планов, для случаев, если этот же запрос в ближайшее время будет использован повторно.
Заметка! Статистика в Microsoft SQL Server – что это такое и для чего она нужна.
Query Execution
Результатом предыдущего этапа является план выполнения запроса, т.е. на входе в данный этап мы имеем готовый план выполнения, который необходимо реализовать.
Query Execution предназначен как раз для этого, т.е. на данном этапе реализуется план выполнения запроса.
Выглядит это примерно следующим образом, в ходе выполнения плана и обработки конкретных шагов Query Execution запрашивает у подсистемы хранилища (Storage Engine) данные из базовых таблиц, которые требуются для формирования результирующего набора данных.
Затем он преобразует эти данные в формат результирующего набора данных и возвращает этот набор клиенту.
Все действия, связанные с блокировками, с записями в файл данных и журнал транзакций, выполняются на стороне подсистемы хранилища, т.е. в Storage Engine.
Выводы (общая схема)
Таким образом, мы понимаем, что начиная с момента, когда SQL запрос поступил на сервер, внутри Microsoft SQL Server запускается сложный механизм, который обрабатывает этот SQL запрос.
Иными словами, между тем моментом, когда мы послали SQL запрос на сервер и моментом, когда мы увидели запрашиваемые данные, будет выполнена огромная работа.
Чтобы подытожить все вышесказанное, давайте посмотрим на схему, на которой изображено верхнеуровневое представление всего процесса обработки SQL запроса в Microsoft SQL Server.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Лучшие вопросы средней сложности по SQL на собеседовании аналитика данных
Автор оригинала: Zachary Thomas
Первые 70% курса по SQL кажутся довольно простыми. Сложности начинаются на остальных 30%.
С 2015 по 2019 годы я прошёл четыре цикла собеседований на должность аналитика данных и специалиста по анализу данных в более чем десятке компаний. После очередного неудачного интервью в 2017 году — когда я запутался в сложных вопросах по SQL — я начал составлять задачник с вопросами по SQL средней и высокой сложности, чтобы лучше готовиться к собеседованиям. Этот справочник очень пригодился в последнем цикле собеседований 2019 года. За последний год я поделился этим руководством с парой друзей, а благодаря дополнительному свободному времени из-за пандемии отшлифовал его — и составил этот документ.
После очередного неудачного интервью в 2017 году — когда я запутался в сложных вопросах по SQL — я начал составлять задачник с вопросами по SQL средней и высокой сложности, чтобы лучше готовиться к собеседованиям. Этот справочник очень пригодился в последнем цикле собеседований 2019 года. За последний год я поделился этим руководством с парой друзей, а благодаря дополнительному свободному времени из-за пандемии отшлифовал его — и составил этот документ.
Есть множество отличных руководств по SQL для начинающих. Мои любимые — это интерактивные курсы Codecademy по SQL и Select Star SQL от Цзы Чон Као. Но в реальности первые 70% из курса SQL довольно просты, а настоящие сложности начинаются в остальных 30%, которые не освещаются в руководствах для начинающих. Так вот, на собеседованиях для аналитиков данных и специалистов по анализу данных в технологических компаниях часто задают вопросы именно по этим 30%.
Удивительно, но я не нашёл исчерпывающего источника по таким вопросам среднего уровня сложности, поэтому составил данное руководство.
Оно полезно для собеседований, но заодно повысит вашу эффективность на текущем и будущих местах работы. Лично я считаю, что некоторые упомянутые шаблоны SQL полезны и для ETL-систем, на которых работают инструменты отчётности и функции анализа данных для выявления тенденций.
Содержание
- Сделанные допущения и как использовать руководство
- Советы по решению сложных задач на собеседованиях по SQL
- Задачи на самообъединения
- № 1. Процентное изменение месяц к месяцу
- № 2. Маркировка древовидной структуры
- № 3. Удержание пользователей в месяц (несколько частей)
- Часть 1
- Часть 2
- Часть 3
- № 4. Нарастающий итог
- № 5. Скользящее среднее
- № 6. Несколько условий соединения
- Задачи на оконные функции
- № 1. Найти идентификатор с максимальным значением
- № 2. Среднее значение и ранжирование с оконной функцией (несколько частей)
- Часть 1
- Часть 2
- Другие задачи средней и высокой сложности
- № 1. Гистограммы
- № 2. Перекрёстное соединение (несколько частей)
- Часть 1
- Часть 2
- № 3. Продвинутые расчёты
- № 1.
 Гистограммы
ГистограммыНужно понимать, что на собеседованиях дата-аналитиков и специалистов по анализу данных задают вопросы не только по SQL. Другие общие темы включают обсуждение прошлых проектов, A/B-тестирование, разработку метрик и открытые аналитические проблемы. Примерно три года назад на Quora публиковались советы по собеседованию на должность аналитика продукта (product analyst) в Facebook. Там эта тема обсуждается более подробно. Тем не менее, если улучшение знаний по SQL поможет вам на собеседовании, то это руководство вполне стоит потраченного времени.
В будущем я могу перенести код из этого руководства на сайт вроде Select Star SQL, чтобы было проще писать инструкции SQL — и видеть результат выполнения кода в реальном времени. Как вариант — добавить вопросы как проблемы на платформу для подготовки к собеседованиям LeetCode. Пока же я просто хотел опубликовать этот документ, чтобы люди могли прямо сейчас ознакомиться с этой информацией.
Сделанные допущения и как использовать руководство
Предположения о знании языка SQL: Предполагается, что у вас есть рабочие знания SQL. Вероятно, вы часто используете его на работе, но хотите отточить навыки в таких темах, как самообъединения и оконные функции.
Как использовать данное руководство: Поскольку на собеседовании часто используется доска или виртуальный блокнот (без компиляции кода), то рекомендую взять карандаш и бумагу — и записать решения для каждой проблемы, а после завершения сравнить свои записи с ответами. Или отработайте свои ответы вместе с другом, который выступит в качестве интервьюера!
- Небольшие синтаксические ошибки не имеют большого значения во время собеседования с доской или блокнотом. Но они могут отвлекать интервьюера, поэтому в идеале старайтесь уменьшить их количество, чтобы сконцентрировать всё внимание на логике.
- Приведённые ответы не обязательно единственный способ решить каждую задачу. Не стесняйтесь писать комментарии с дополнительными решениями, которые можно добавить в это руководство!
 Не стесняйтесь писать комментарии с дополнительными решениями, которые можно добавить в это руководство!
Не стесняйтесь писать комментарии с дополнительными решениями, которые можно добавить в это руководство!Советы по решению сложных задач на собеседованиях по SQL
Сначала стандартные советы для всех собеседований по программированию…
- Внимательно выслушайте описание проблемы, повторите всю суть проблемы интервьюеру
- Сформулируйте пограничный случай, чтобы продемонстрировать, что вы действительно понимаете проблему (т. е. строку, которая не будет включена в итоговый запрос SQL, который вы собираетесь написать)
- (Если проблема связана с самообъединением) для своей же пользы нарисуйте, как будет выглядеть самообъединение — обычно это минимум три столбца: нужный столбец из основной таблицы, столбец для объединения из основной таблицы и столбец для объединения из вторичной таблицы
- Или, когда вы лучше освоите задачи самообъединения, можете объяснить этот шаг устно
- Начните писать SQL, пусть с ошибками, вместо попыток полностью понять проблему. Формулируйте свои предположения по ходу дела, чтобы ваш интервьюер мог вас поправить.
 Формулируйте свои предположения по ходу дела, чтобы ваш интервьюер мог вас поправить.
Формулируйте свои предположения по ходу дела, чтобы ваш интервьюер мог вас поправить.Благодарности и дополнительные ресурсы
Некоторые из перечисленных здесь проблем адаптированы из старых записей в блоге Periscope (в основном написанных Шоном Куком около 2014 года, хотя его авторство, видимо, убрали из материалов после слияния SiSense с Periscope), а также из обсуждений на StackOverflow. В случае необходимости, источники отмечены в начале каждого вопроса.
На Select Star SQL тоже хорошая подборка задачек, дополняющих проблемы из этого документа.
Пожалуйста, обратите внимание, что эти вопросы не являются буквальными копиями вопросов с моих собственных собеседований, и они не использовались в компаниях, в которых я работал или работаю.
Задачи на самообъединение
№ 1. Процентное изменение месяц к месяцу
Контекст: часто полезно знать, как изменяется ключевая метрика, например, месячная аудитория активных пользователей, от месяца к месяцу.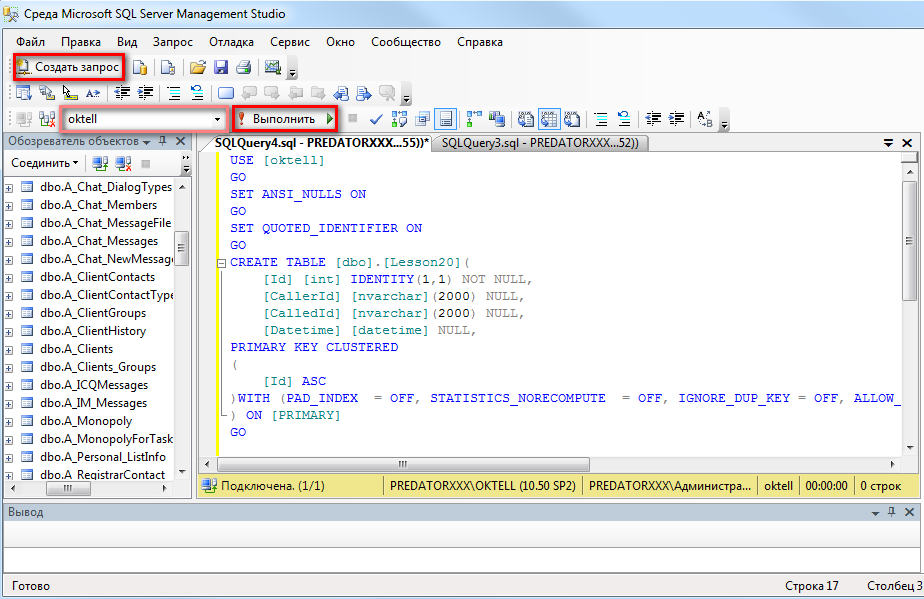 Допустим у нас есть таблица
Допустим у нас есть таблица logins в таком виде:
| user_id | date | |---------|------------| | 1 | 2018-07-01 | | 234 | 2018-07-02 | | 3 | 2018-07-02 | | 1 | 2018-07-02 | | ... | ... | | 234 | 2018-10-04 |
Задача: найти ежемесячное процентное изменение месячной аудитории активных пользователей (MAU).
Решение:
(Это решение, как и другие блоки кода в этом документе, содержит комментарии об элементах синтаксисе SQL, которые могут отличаться между разными вариантами SQL, и прочие заметки)
WITH mau AS
(
SELECT
/*
* Обычно интервьюер позволяет вам написать псевдокод для
* функций даты, т. е. НЕ будет проверять, как вы их помните.
* Просто объясните на доске, что делает функция
*
* В Postgres доступна DATE_TRUNC(), но аналогичный результат
* могут дать другие функции даты SQL или их комбинации
* См. https://www.postgresql. org/docs/9.0/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC
*/
DATE_TRUNC('month', date) month_timestamp,
COUNT(DISTINCT user_id) mau
FROM
logins
GROUP BY
DATE_TRUNC('month', date)
)
SELECT
/*
* В эту инструкцию SELECT не нужно буквально включать предыдущий месяц.
*
* Но как упоминалось в разделе с советами выше, может быть полезно
* хотя бы набросать самообъединения, чтобы не запутаться, какая
* таблица представляет прошлый месяц к текущему и т.д.
*/
a.month_timestamp previous_month,
a.mau previous_mau,
b.month_timestamp current_month,
b.mau current_mau,
ROUND(100.0*(b.mau - a.mau)/a.mau,2) AS percent_change
FROM
mau a
JOIN
/*
* Как вариант `ON b.month_timestamp = a.month_timestamp + interval '1 month'`
*/
mau b ON a.month_timestamp = b.month_timestamp - interval '1 month'  org/docs/9.0/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC
*/
DATE_TRUNC('month', date) month_timestamp,
COUNT(DISTINCT user_id) mau
FROM
logins
GROUP BY
DATE_TRUNC('month', date)
)
SELECT
/*
* В эту инструкцию SELECT не нужно буквально включать предыдущий месяц.
*
* Но как упоминалось в разделе с советами выше, может быть полезно
* хотя бы набросать самообъединения, чтобы не запутаться, какая
* таблица представляет прошлый месяц к текущему и т.д.
*/
a.month_timestamp previous_month,
a.mau previous_mau,
b.month_timestamp current_month,
b.mau current_mau,
ROUND(100.0*(b.mau - a.mau)/a.mau,2) AS percent_change
FROM
mau a
JOIN
/*
* Как вариант `ON b.month_timestamp = a.month_timestamp + interval '1 month'`
*/
mau b ON a.month_timestamp = b.month_timestamp - interval '1 month'
org/docs/9.0/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC
*/
DATE_TRUNC('month', date) month_timestamp,
COUNT(DISTINCT user_id) mau
FROM
logins
GROUP BY
DATE_TRUNC('month', date)
)
SELECT
/*
* В эту инструкцию SELECT не нужно буквально включать предыдущий месяц.
*
* Но как упоминалось в разделе с советами выше, может быть полезно
* хотя бы набросать самообъединения, чтобы не запутаться, какая
* таблица представляет прошлый месяц к текущему и т.д.
*/
a.month_timestamp previous_month,
a.mau previous_mau,
b.month_timestamp current_month,
b.mau current_mau,
ROUND(100.0*(b.mau - a.mau)/a.mau,2) AS percent_change
FROM
mau a
JOIN
/*
* Как вариант `ON b.month_timestamp = a.month_timestamp + interval '1 month'`
*/
mau b ON a.month_timestamp = b.month_timestamp - interval '1 month' № 2. Маркировка древовидной структуры
Контекст: предположим, у вас есть таблица tree с двумя столбцами: в первом указаны узлы, а во втором — родительские узлы.
node parent 1 2 2 5 3 5 4 3 5 NULL
Задача: написать SQL таким образом, чтобы мы обозначили каждый узел как внутренний (inner), корневой (root) или конечный узел/лист (leaf), так что для вышеперечисленных значений получится следующее:
node label 1 Leaf 2 Inner 3 Inner 4 Leaf 5 Root
(Примечание: более подробно о терминологии древовидной структуры данных можно почитать здесь. Однако для решения этой проблемы она не нужна!)
Решение:
Благодарность: это более обобщённое решение предложил Фабиан Хофман 2 мая 2020 года. Спасибо, Фабиан!
WITH join_table AS
(
SELECT
cur.node,
cur.parent,
COUNT(next.node) AS num_children
FROM
tree cur
LEFT JOIN
tree next ON (next.parent = cur.node)
GROUP BY
cur.node,
cur.parent
)
SELECT
node,
CASE
WHEN parent IS NULL THEN "Root"
WHEN num_children = 0 THEN "Leaf"
ELSE "Inner"
END AS label
FROM
join_table Альтернативное решение, без явных соединений:
Благодарность: Уильям Чарджин 2 мая 2020 года обратил внимание на необходимость условия WHERE parent IS NOT NULL, чтобы это решение возвращало Leaf вместо NULL. Спасибо, Уильям!
Спасибо, Уильям!
SELECT
node,
CASE
WHEN parent IS NULL THEN 'Root'
WHEN node NOT IN
(SELECT parent FROM tree WHERE parent IS NOT NULL) THEN 'Leaf'
WHEN node IN (SELECT parent FROM tree) AND parent IS NOT NULL THEN 'Inner'
END AS label
from
tree№ 3. Удержание пользователей в месяц (несколько частей)
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Использование самообъединений для расчёта показателей удержания, оттока и реактивации».
Часть 1
Контекст: допустим, у нас есть статистика по авторизации пользователей на сайте в таблице logins:
| user_id | date | |---------|------------| | 1 | 2018-07-01 | | 234 | 2018-07-02 | | 3 | 2018-07-02 | | 1 | 2018-07-02 | | ... | ... | | 234 | 2018-10-04 |
Задача: написать запрос, который получает количество удержанных пользователей в месяц.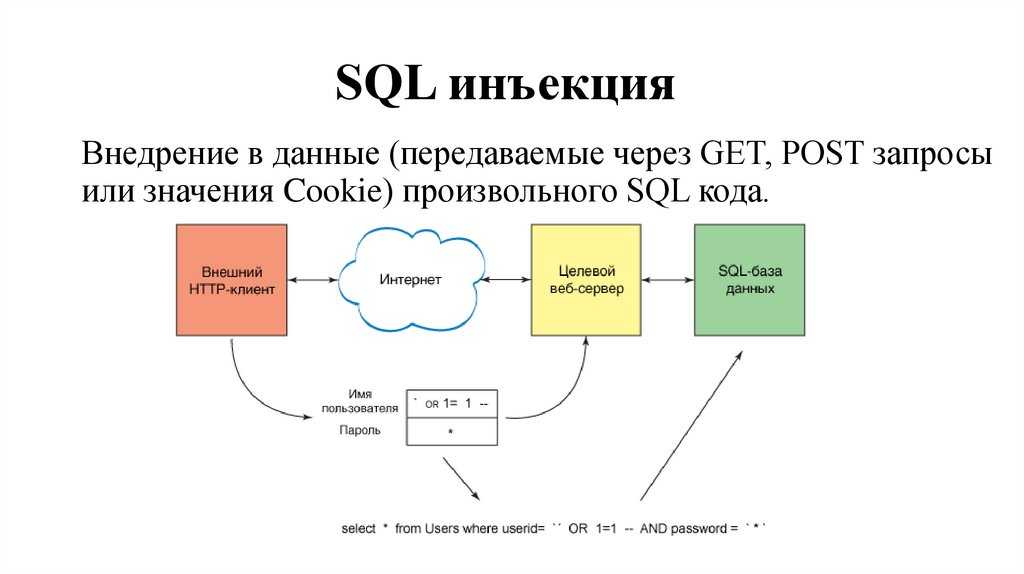 В нашем случае данный параметр определяется как количество пользователей, которые авторизовались в системе и в этом, и в предыдущем месяце.
В нашем случае данный параметр определяется как количество пользователей, которые авторизовались в системе и в этом, и в предыдущем месяце.
Решение:
SELECT
DATE_TRUNC('month', a.date) month_timestamp,
COUNT(DISTINCT a.user_id) retained_users
FROM
logins a
JOIN
logins b ON a.user_id = b.user_id
AND DATE_TRUNC('month', a.date) = DATE_TRUNC('month', b.date) +
interval '1 month'
GROUP BY
date_trunc('month', a.date)Благодарность:
Том Моэртел указал на то, что предварительная дедубликация user_id перед самообъединением делает решение более эффективным, и предложил код ниже. Спасибо, Том!
Альтернативное решение:
WITH DistinctMonthlyUsers AS (
/*
* Для каждого месяца определяем *набор* пользователей, которые
* выполнили авторизацию
*/
SELECT DISTINCT
DATE_TRUNC('MONTH', a.date) AS month_timestamp,
user_id
FROM logins
)
SELECT
CurrentMonth. month_timestamp month_timestamp,
COUNT(PriorMonth.user_id) AS retained_user_count
FROM
DistinctMonthlyUsers AS CurrentMonth
LEFT JOIN
DistinctMonthlyUsers AS PriorMonth
ON
CurrentMonth.month_timestamp = PriorMonth.month_timestamp + INTERVAL '1 MONTH'
AND
CurrentMonth.user_id = PriorMonth.user_id month_timestamp month_timestamp,
COUNT(PriorMonth.user_id) AS retained_user_count
FROM
DistinctMonthlyUsers AS CurrentMonth
LEFT JOIN
DistinctMonthlyUsers AS PriorMonth
ON
CurrentMonth.month_timestamp = PriorMonth.month_timestamp + INTERVAL '1 MONTH'
AND
CurrentMonth.user_id = PriorMonth.user_id
month_timestamp month_timestamp,
COUNT(PriorMonth.user_id) AS retained_user_count
FROM
DistinctMonthlyUsers AS CurrentMonth
LEFT JOIN
DistinctMonthlyUsers AS PriorMonth
ON
CurrentMonth.month_timestamp = PriorMonth.month_timestamp + INTERVAL '1 MONTH'
AND
CurrentMonth.user_id = PriorMonth.user_idЧасть 2
Задача: теперь возьмём предыдущую задачу по вычислению количества удержанных пользователей в месяц — и перевернём её с ног на голову. Напишем запрос для подсчёта пользователей, которые не вернулись на сайт в этом месяце. То есть «потерянных» пользователей.
Решение:
SELECT
DATE_TRUNC('month', a.date) month_timestamp,
COUNT(DISTINCT b.user_id) churned_users
FROM
logins a
FULL OUTER JOIN
logins b ON a.user_id = b.user_id
AND DATE_TRUNC('month', a.date) = DATE_TRUNC('month', b.date) +
interval '1 month'
WHERE
a.user_id IS NULL
GROUP BY
DATE_TRUNC('month', a. date) date)
date)Обратите внимание, что эту проблему можно решить также с помощью соединений LEFT или RIGHT.
Часть 3
Примечание: вероятно, это более сложная задача, чем вам предложат на реальном собеседовании. Воспринимайте её скорее как головоломку — или можете пропустить и перейти к следующей задаче.
Контекст: итак, мы хорошо справились с двумя предыдущими проблемами. По условиям новой задачи теперь у нас появилась таблица потерянных пользователей user_churns. Если пользователь была активен в прошлом месяце, но затем не активен в этом, то он вносится в таблицу за этот месяц. Вот как выглядит user_churns:
| user_id | month_date | |---------|------------| | 1 | 2018-05-01 | | 234 | 2018-05-01 | | 3 | 2018-05-01 | | 12 | 2018-05-01 | | ... | ... | | 234 | 2018-10-01 |
Задача: теперь вы хотите провести когортный анализ, то есть анализ совокупности активных пользователей, которые были реактивированы в прошлом.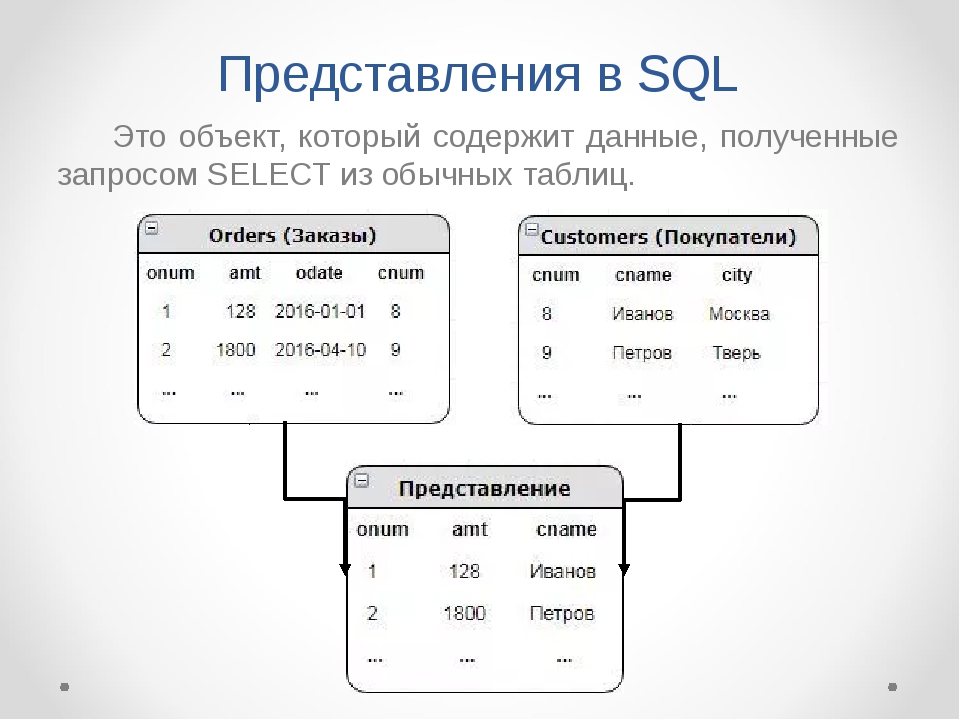 Создайте таблицу с такими пользователями. Для создания когорты можете использовать таблицы
Создайте таблицу с такими пользователями. Для создания когорты можете использовать таблицы user_churns и logins. В Postgres текущая временная метка доступна через current_timestamp.
Решение:
WITH user_login_data AS
(
SELECT
DATE_TRUNC('month', a.date) month_timestamp,
a.user_id,
/*
* По крайней мере, в тех вариантах SQL, что я использовал,
* не нужно включать в инструкцию SELECT колонки из HAVING.
* Я здесь выписал их для большей ясности.
*/
MAX(b.month_date) as most_recent_churn,
MAX(DATE_TRUNC('month', c.date)) as most_recent_active
FROM
logins a
JOIN
user_churns b
ON a.user_id = b.user_id AND DATE_TRUNC('month', a.date) > b.month_date
JOIN
logins c
ON a.user_id = c.user_id
AND
DATE_TRUNC('month', a.date) > DATE_TRUNC('month', c. date)
WHERE
DATE_TRUNC('month', a.date) = DATE_TRUNC('month', current_timestamp)
GROUP BY
DATE_TRUNC('month', a.date),
a.user_id
HAVING
most_recent_churn > most_recent_active date)
WHERE
DATE_TRUNC('month', a.date) = DATE_TRUNC('month', current_timestamp)
GROUP BY
DATE_TRUNC('month', a.date),
a.user_id
HAVING
most_recent_churn > most_recent_active
date)
WHERE
DATE_TRUNC('month', a.date) = DATE_TRUNC('month', current_timestamp)
GROUP BY
DATE_TRUNC('month', a.date),
a.user_id
HAVING
most_recent_churn > most_recent_active№ 4. Нарастающий итог
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Моделирование денежных потоков в SQL».
Контекст: допустим, у нас есть таблица transactions в таком виде:
| date | cash_flow | |------------|-----------| | 2018-01-01 | -1000 | | 2018-01-02 | -100 | | 2018-01-03 | 50 | | ... | ... |
Где cash_flow — это выручка минус затраты за каждый день.
Задача: написать запрос, чтобы получить нарастающий итог для денежного потока каждый день таким образом, чтобы в конечном итоге получилась таблица в такой форме:
| date | cumulative_cf | |------------|---------------| | 2018-01-01 | -1000 | | 2018-01-02 | -1100 | | 2018-01-03 | -1050 | | .
 .. | ... |
.. | ... |Решение:
SELECT
a.date date,
SUM(b.cash_flow) as cumulative_cf
FROM
transactions a
JOIN b
transactions b ON a.date >= b.date
GROUP BY
a.date
ORDER BY
date ASCАльтернативное решение с использованием оконной функции (более эффективное!):
SELECT
date,
SUM(cash_flow) OVER (ORDER BY date ASC) as cumulative_cf
FROM
transactions
ORDER BY
date ASC№ 5. Скользящее среднее
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Скользящие средние в MySQL и SQL Server».
Примечание: скользящее среднее можно вычислить разными способами. Здесь мы используем предыдущее среднее значение. Таким образом, метрика для седьмого дня месяца будет средним значением предыдущих шести дней и его самого.
Контекст: допустим, у нас есть таблица signups в таком виде:
| date | sign_ups | |------------|----------| | 2018-01-01 | 10 | | 2018-01-02 | 20 | | 2018-01-03 | 50 | | .
 .. | ... |
| 2018-10-01 | 35 |
.. | ... |
| 2018-10-01 | 35 |Задача: написать запрос, чтобы получить 7-дневное скользящее среднее ежедневных регистраций.
Решение:
SELECT a.date, AVG(b.sign_ups) average_sign_ups FROM signups a JOIN signups b ON a.date <= b.date + interval '6 days' AND a.date >= b.date GROUP BY a.date
№ 6. Несколько условий соединения
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Анализ вашей электронной почты с помощью SQL».
Контекст: скажем, наша таблица emails содержит электронные письма, отправленные с адреса [email protected] и полученные на него:
| id | subject | from | to | timestamp | |----|----------|--------------|--------------|---------------------| | 1 | Yosemite | [email protected] | [email protected] | 2018-01-02 12:45:03 | | 2 | Big Sur | [email protected] | [email protected] | 2018-01-02 16:30:01 | | 3 | Yosemite | thomas@g.
 com |
com | Задача:написать запрос, чтобы получить время отклика на каждое письмо (id), отправленное на [email protected]. Не включать письма на другие адреса. Предположим, что у каждого треда уникальная тема. Имейте в виду, что в треде может быть несколько писем туда и обратно между [email protected] и другими адресатами.
Решение:
SELECT
a.id,
MIN(b.timestamp) - a.timestamp as time_to_respond
FROM
emails a
JOIN
emails b
ON
b.subject = a.subject
AND
a.to = b.from
AND
a.from = b.to
AND
a.timestamp < b. timestamp
WHERE
a.to = '[email protected]'
GROUP BY
a.id  timestamp
WHERE
a.to = '
timestamp
WHERE
a.to = 'Задачи на оконные функции
№ 1. Найти идентификатор с максимальным значением
Контекст: Допустим, у нас есть таблица salaries с данными об отделах и зарплате сотрудников в следующем формате:
depname | empno | salary | -----------+-------+--------+ develop | 11 | 5200 | develop | 7 | 4200 | develop | 9 | 4500 | develop | 8 | 6000 | develop | 10 | 5200 | personnel | 5 | 3500 | personnel | 2 | 3900 | sales | 3 | 4800 | sales | 1 | 5000 | sales | 4 | 4800 |
Задача: написать запрос, чтобы получить empno с самой высокой зарплатой. Убедитесь, что ваше решение обрабатывает случаи одинаковых зарплатами!
Решение:
WITH max_salary AS (
SELECT
MAX(salary) max_salary
FROM
salaries
)
SELECT
s. empno
FROM
salaries s
JOIN
max_salary ms ON s.salary = ms.max_salary empno
FROM
salaries s
JOIN
max_salary ms ON s.salary = ms.max_salary
empno
FROM
salaries s
JOIN
max_salary ms ON s.salary = ms.max_salaryАльтернативное решение с использованием RANK():
WITH sal_rank AS
(SELECT
empno,
RANK() OVER(ORDER BY salary DESC) rnk
FROM
salaries)
SELECT
empno
FROM
sal_rank
WHERE
rnk = 1;№ 2. Среднее значение и ранжирование с оконной функцией (несколько частей)
Часть 1
Контекст: допустим, у нас есть таблица salaries в таком формате:
depname | empno | salary | -----------+-------+--------+ develop | 11 | 5200 | develop | 7 | 4200 | develop | 9 | 4500 | develop | 8 | 6000 | develop | 10 | 5200 | personnel | 5 | 3500 | personnel | 2 | 3900 | sales | 3 | 4800 | sales | 1 | 5000 | sales | 4 | 4800 |
Задача: написать запрос, который возвращает ту же таблицу, но с новым столбцом, в котором указана средняя зарплата по департаменту. Мы бы ожидали таблицу в таком виде:
Мы бы ожидали таблицу в таком виде:
depname | empno | salary | avg_salary | -----------+-------+--------+------------+ develop | 11 | 5200 | 5020 | develop | 7 | 4200 | 5020 | develop | 9 | 4500 | 5020 | develop | 8 | 6000 | 5020 | develop | 10 | 5200 | 5020 | personnel | 5 | 3500 | 3700 | personnel | 2 | 3900 | 3700 | sales | 3 | 4800 | 4867 | sales | 1 | 5000 | 4867 | sales | 4 | 4800 | 4867 |
Решение:
SELECT
*,
/*
* AVG() is a Postgres command, but other SQL flavors like BigQuery use
* AVERAGE()
*/
ROUND(AVG(salary),0) OVER (PARTITION BY depname) avg_salary
FROM
salariesЧасть 2
Задача: напишите запрос, который добавляет столбец с позицией каждого сотрудника в табели на основе его зарплаты в своём отделе, где сотрудник с самой высокой зарплатой получает позицию 1. Мы бы ожидали таблицу в таком виде:
Мы бы ожидали таблицу в таком виде:
depname | empno | salary | salary_rank | -----------+-------+--------+-------------+ develop | 11 | 5200 | 2 | develop | 7 | 4200 | 5 | develop | 9 | 4500 | 4 | develop | 8 | 6000 | 1 | develop | 10 | 5200 | 2 | personnel | 5 | 3500 | 2 | personnel | 2 | 3900 | 1 | sales | 3 | 4800 | 2 | sales | 1 | 5000 | 1 | sales | 4 | 4800 | 2 |
Решение:
SELECT
*,
RANK() OVER(PARTITION BY depname ORDER BY salary DESC) salary_rank
FROM
salaries Другие задачи средней и высокой сложности
№ 1. Гистограммы
Контекст: Допустим, у нас есть таблица sessions, где каждая строка представляет собой сеанс потоковой передачи видео с длиной в секундах:
| session_id | length_seconds | |------------|----------------| | 1 | 23 | | 2 | 453 | | 3 | 27 | | .
 . | .. |
. | .. |Задача: написать запрос, чтобы подсчитать количество сеансов, которые попадают промежутки по пять секунд, т. е. для приведённого выше фрагмента результат будет примерно такой:
| bucket | count | |---------|-------| | 20-25 | 2 | | 450-455 | 1 |
Максимальная оценка засчитывается за надлежащие метки строк («5-10» и т. д.)
Решение:
WITH bin_label AS
(SELECT
session_id,
FLOOR(length_seconds/5) as bin_label
FROM
sessions
)
SELECT
CONCATENTATE(STR(bin_label*5), '-', STR(bin_label*5+5)) bucket,
COUNT(DISTINCT session_id) count
GROUP BY
bin_label
ORDER BY
bin_label ASC № 2. Перекрёстное соединение (несколько частей)
Часть 1
Контекст: допустим, у нас есть таблица state_streams, где в каждой строке указано название штата и общее количество часов потоковой передачи с видеохостинга:
| state | total_streams | |-------|---------------| | NC | 34569 | | SC | 33999 | | CA | 98324 | | MA | 19345 | | .
 . | .. |
. | .. |(На самом деле в агрегированных таблицах такого типа обычно есть ещё столбец даты, но для этой задачи мы его исключим)
Задача: написать запрос, чтобы получить пары штатов с общим количеством потоков в пределах тысячи друг от друга. Для приведённого выше фрагмента мы хотели бы увидеть что-то вроде:
| state_a | state_b | |---------|---------| | NC | SC | | SC | NC |
Решение:
SELECT
a.state as state_a,
b.state as state_b
FROM
state_streams a
CROSS JOIN
state_streams b
WHERE
ABS(a.total_streams - b.total_streams) < 1000
AND
a.state <> b.state Для информации, перекрёстные соединения также можно писать без явного указания соединения:
SELECT
a.state as state_a,
b.state as state_b
FROM
state_streams a, state_streams b
WHERE
ABS(a.total_streams - b.total_streams) < 1000
AND
a.state <> b. state Часть 2
Примечание: этот скорее бонусный вопрос, чем реально важный шаблон SQL. Можете его пропустить!
Задача: как можно изменить SQL из предыдущего решения, чтобы удалить дубликаты? Например, на примере той же таблицы, чтобы пара NC и SC появилась только один раз, а не два.
Решение:
SELECT
a.state as state_a,
b.state as state_b
FROM
state_streams a, state_streams b
WHERE
ABS(a.total_streams - b.total_streams) < 1000
AND
a.state > b.state № 3. Продвинутые расчёты
Благодарность: эта задача адаптирована из обсуждения по вопросу, который я задал на StackOverflow (мой ник zthomas.nc).
Примечание: вероятно, это более сложная задача, чем вам предложат на реальном собеседовании. Воспринимайте её скорее как головоломку — или можете пропустить её!
Контекст: допустим, у нас есть таблица table такого вида, где одному и тому же пользователю user могут соответствовать разные значения класса class:
| user | class | |------|-------| | 1 | a | | 1 | b | | 1 | b | | 2 | b | | 3 | a |
Задача: предположим, что существует только два возможных значения для класса.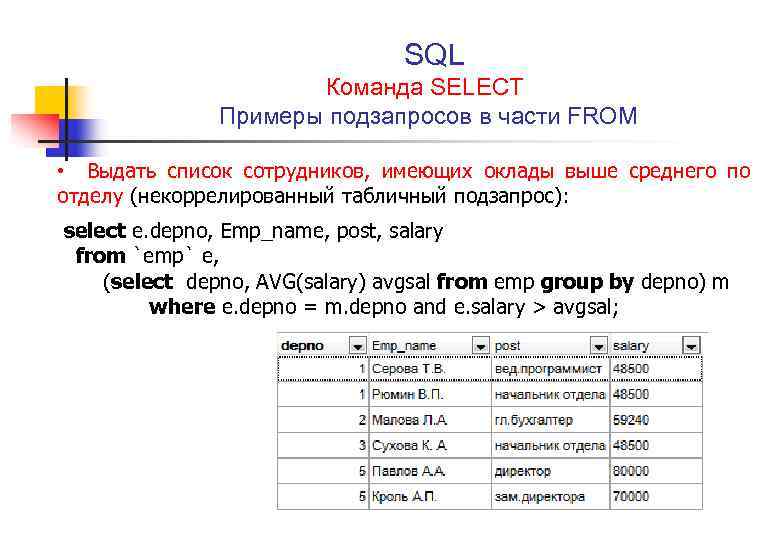 Напишите запрос для подсчёта количества пользователей в каждом классе. При этом пользователи с обеими метками
Напишите запрос для подсчёта количества пользователей в каждом классе. При этом пользователи с обеими метками a и b должны относиться к классу b.
Для нашего образца получится такой результат:
| class | count | |-------|-------| | a | 1 | | b | 2 |
Решение:
WITH usr_b_sum AS
(
SELECT
user,
SUM(CASE WHEN class = 'b' THEN 1 ELSE 0 END) num_b
FROM
table
GROUP BY
user
),
usr_class_label AS
(
SELECT
user,
CASE WHEN num_b > 0 THEN 'b' ELSE 'a' END class
FROM
usr_b_sum
)
SELECT
class,
COUNT(DISTINCT user) count
FROM
usr_class_label
GROUP BY
class
ORDER BY
class ASCАльтернативное решение использует инструкции SELECT в операторах SELECT и UNION:
SELECT
"a" class,
COUNT(DISTINCT user_id) -
(SELECT COUNT(DISTINCT user_id) FROM table WHERE class = 'b') count
UNION
SELECT
"b" class,
(SELECT COUNT(DISTINCT user_id) FROM table WHERE class = 'b') count Изучение SQL: что нужно знать о SQL перед началом работы в 2022 году
Изучение SQL: что необходимо знать о SQL перед началом работы в 2022 году | Учебный курс по программированию в Беркли
Это правда жизни: если вы хотите зарабатывать на жизнь программистом, вам нужно уметь обращаться с базой данных. Разработчики никогда не смогли бы создавать или поддерживать функциональные веб-сайты, программное обеспечение или программы, если бы у них не было хорошо отточенных навыков сбора, управления и анализа данных.
Разработчики никогда не смогли бы создавать или поддерживать функциональные веб-сайты, программное обеспечение или программы, если бы у них не было хорошо отточенных навыков сбора, управления и анализа данных.
Но прежде чем программисты смогут использовать данные , они должны знать, как получить к ним доступ. SQL, или язык структурированных запросов, — это базовый инструмент, который позволяет программистам делать именно это. В этой статье мы рассмотрим основы этого основного языка запросов и ответим на следующие вопросы:
- Что такое SQL?
- Зачем изучать SQL?
- Для чего используется SQL?
- Сколько времени нужно, чтобы изучить SQL?
- Как выучить SQL с нуля?
- Какие профессии требуют знания SQL?
- Чему еще я должен научиться, чтобы дополнить свои навыки SQL?
Начнем.
Что такое SQL?
SQL (произносится как «sequel» и «S-Q-L» в отрасли взаимозаменяемо) — это язык запросов, который позволяет программистам находить, изменять или иным образом манипулировать информацией в реляционных базах данных. Полезность SQL и простой для изучения синтаксис уже давно закрепили за ним статус стандартного языка для внутренних разработчиков и специалистов по данным. Язык запросов также можно использовать в тандеме с языками сценариев, такими как PHP, для создания динамических веб-страниц.
Полезность SQL и простой для изучения синтаксис уже давно закрепили за ним статус стандартного языка для внутренних разработчиков и специалистов по данным. Язык запросов также можно использовать в тандеме с языками сценариев, такими как PHP, для создания динамических веб-страниц.
Зачем изучать SQL?
Если вы делаете карьеру, которая хотя бы косвенно связана с манипулированием или анализом данных (например, внутреннее программирование, наука о данных, кибербезопасность и т. д.), вам необходимо изучить SQL. Как упоминалось ранее, SQL — это стандартный язык запросов , используемый для взаимодействия с реляционными базами данных. Если у вас нет этого фундаментального навыка, вам будет сложно выполнять свои повседневные обязанности или даже найти работодателя, готового нанять вас.
В конце концов, знание того, как работать с данными, не является обязательным на современном рынке труда. Компании во всех отраслях все больше полагаются на информацию, которую дает анализ данных; согласно недавнему отчету Technavio, ожидается, что рынок больших данных вырастет на 142,5 миллиарда долларов в период с 2020 по 2024 год. Знание SQL может иметь решающее значение для получения работы вашей мечты или ее потери.
Навыки, описанные в этих руководствах:
- Базы данных
- Команды и функции
- Операторы
- Подзапрос и СОЕДИНЕНИЕ
- Отзыв заявлений
- Строки и таблицы
Для чего используется SQL?
С 1980-х годов SQL является стандартом Американского национального института стандартов (ANSI) и Международной организации по стандартизации (ISO) для создания, управления и манипулирования реляционными базами данных. Используя SQL, разработчики могут выполнять широкий спектр задач. К ним относятся, но не ограничиваются:
- Создание базы данных
- Вставка новых данных в существующую базу данных
- Изменение данных
- Получение данных
- Удаление данных
- Создание или удаление новых таблиц
- Установка прав доступа
- Создание представления, функции и хранимых процедур
Стоит отметить, что SQL является стандартом только для управления реляционными базами данных .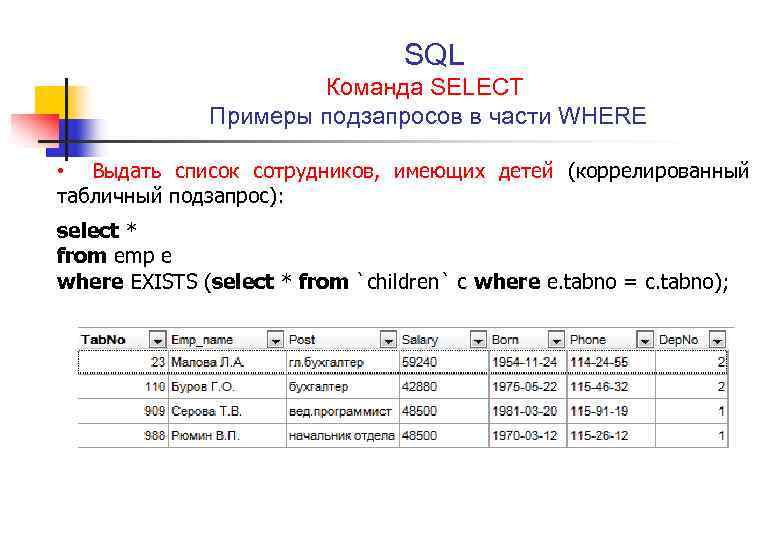 Реляционные базы данных организуют информацию в таблицы, которые связаны в соответствии с их общими («связанными») данными. Эта структура позволяет пользователям лучше понять, как связаны точки данных, и дает им возможность находить информацию и создавать новые таблицы с помощью одного запроса.
Реляционные базы данных организуют информацию в таблицы, которые связаны в соответствии с их общими («связанными») данными. Эта структура позволяет пользователям лучше понять, как связаны точки данных, и дает им возможность находить информацию и создавать новые таблицы с помощью одного запроса.
Нереляционные (NoSQL) базы данных, в отличие от , не хранят данные в строках и столбцах. Таким образом, для этих баз данных обычно требуются другие языки запросов (например, Cassandra CQL или Cosmos DB), хотя стоит отметить, что большинство из них на самом деле являются вариантами SQL.
Какие профессии требуют знания SQL?
Если вы заинтересованы в изучении SQL, велики шансы, что вы, вероятно, имеете в виду карьеру, но нет причин ограничивать себя! Знание вариантов может помочь вам расширить свой кругозор и определить путь карьеры, который соответствует вашим навыкам и интересам. Ниже мы перечислили несколько карьерных путей, требующих знания SQL.
Разработчик программного обеспечения
Как следует из названия, разработчики программного обеспечения — это программисты, занимающиеся проектированием, разработкой и внедрением программного обеспечения. Эти специалисты работают над автоматизацией различных функций и созданием блок-схем для обеспечения бесперебойной и эффективной работы. Разработчики программного обеспечения также используют базы данных для хранения пользовательской информации и управления ею, поэтому владение SQL имеет решающее значение.
Эти специалисты работают над автоматизацией различных функций и созданием блок-схем для обеспечения бесперебойной и эффективной работы. Разработчики программного обеспечения также используют базы данных для хранения пользовательской информации и управления ею, поэтому владение SQL имеет решающее значение.
Разработчик баз данных
Разработчики баз данных несут ответственность за то, чтобы системы управления базами данных (СУБД) могли эффективно обрабатывать огромные объемы данных. Из-за характера работы разработчики баз данных часто работают вместе с разработчиками программного обеспечения. В их обязанности входит, помимо прочего, проектирование и разработка эффективных и функциональных баз данных, обновление существующих баз данных и управление ими, а также выявление и устранение проблем с базами данных по мере их возникновения.
Аналитик данных
Доступ, анализ и очистка данных являются основными обязанностями аналитика данных.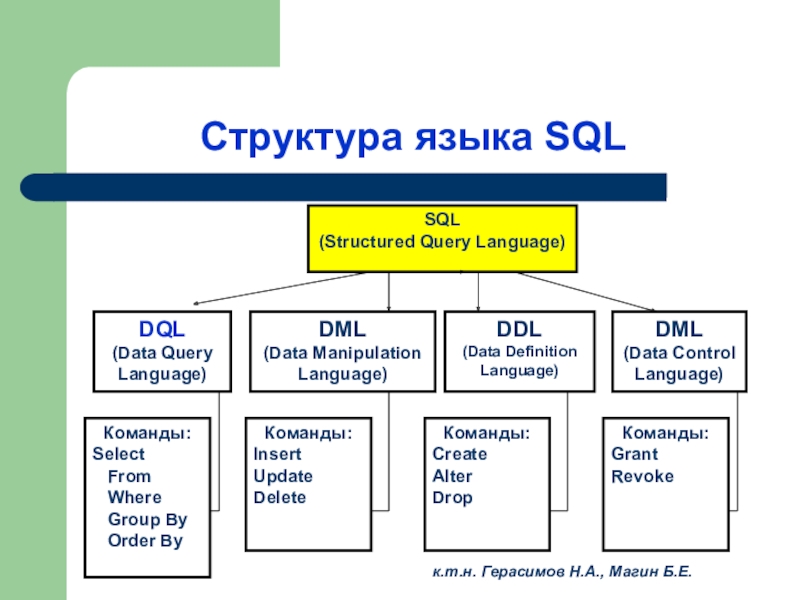 Эти люди помогают предприятиям и другим организациям выявлять шаблоны и модели в массивных наборах данных. Аналитики данных должны хорошо разбираться в программировании, статистике и, конечно же, в SQL.
Эти люди помогают предприятиям и другим организациям выявлять шаблоны и модели в массивных наборах данных. Аналитики данных должны хорошо разбираться в программировании, статистике и, конечно же, в SQL.
Специалист по обработке и анализу данных
Несмотря на то, что должностные инструкции специалистов по данным частично совпадают с должностными инструкциями аналитиков данных, эти две профессии различаются. Специалисты по данным лучше разбираются в анализе данных, программировании и статистике, чем аналитики; эти профессионалы несут ответственность за получение стратегически ценных идей и выводов из шаблонов данных.
Специалист по обеспечению качества (QA)
Специалисты по обеспечению качества несут ответственность за выявление и устранение недостатков кода до того, как программный продукт выйдет на рынок, а также за обеспечение соответствия всех операций установленным стандартам и рекомендациям. Специалисты по обеспечению качества также предотвращают, решают и смягчают такие проблемы, как сбои веб-сайтов, программные вирусы и непредвиденные ошибки. Эти специалисты часто сотрудничают с разработчиками для продвижения функциональности веб-сайта или программы.
Эти специалисты часто сотрудничают с разработчиками для продвижения функциональности веб-сайта или программы.
Сколько времени нужно для изучения SQL?
Поскольку SQL является относительно простым языком, учащиеся могут ознакомиться с его основами в течение двух-трех недель. Тем не менее, если вы планируете использовать навыки SQL на работе, вам, вероятно, потребуется более высокий уровень беглости.
Насколько быстро вы достигнете мастерства, зависит от вашего метода обучения. Если вы попытаетесь выучить SQL самостоятельно, процесс может занять около шести месяцев — дольше, если вы не практикуете SQL регулярно. Однако вы можете ускорить этот процесс, посетив интенсивную формализованную программу обучения, например, учебный курс по программированию. Если вы зарегистрируетесь в одном из них, вы можете рассчитывать на то, что освоите SQL всего за три месяца.
Введение в SQL — как выучить SQL с нуля
Понимание SQL может дать вам неоценимое преимущество как техническому специалисту. Даже если у вас нет опыта веб-разработки или разработки программного обеспечения, вы можете начать изучать SQL самостоятельно и начать работать над овладением языком. Если вы планируете работать с базами данных в любом качестве или хотите расширить свой профессиональный кругозор, изучение SQL может быть чрезвычайно продуктивным, если не необходимым.
Даже если у вас нет опыта веб-разработки или разработки программного обеспечения, вы можете начать изучать SQL самостоятельно и начать работать над овладением языком. Если вы планируете работать с базами данных в любом качестве или хотите расширить свой профессиональный кругозор, изучение SQL может быть чрезвычайно продуктивным, если не необходимым.
Ниже мы привели разбивку того, что вам нужно знать до и во время изучения SQL.
Что нужно знать перед началом работы
Прежде чем приступить к изучению SQL, необходимо знать несколько моментов о языке, его возможностях и ограничениях.
Практические приложения SQL
Конкретные приложения SQL могут различаться в зависимости от ролей и отраслей, но в целом язык запросов используется для управления базами данных. Ученые и аналитики данных обычно используют SQL для загрузки, запроса и иной организации данных в таблицы. Инженеры данных могут использовать SQL для назначения разрешений на данные среди членов компании. Большинство веб-сайтов используют базы данных для хранения пользовательских данных, и многие разработчики используют SQL для взаимодействия с собираемой ими информацией.
Большинство веб-сайтов используют базы данных для хранения пользовательских данных, и многие разработчики используют SQL для взаимодействия с собираемой ими информацией.
Не прекращайте учиться после того, как освоите SQL
SQL — один из самых популярных языков программирования, используемых сегодня. Однако, как мы упоминали ранее, для управления базами данных используется только , а не . Учитывая растущую потребность в масштабируемых нереляционных базах данных, начинающие программисты и специалисты по данным могут захотеть дополнить свои знания SQL, изучив один или несколько языков запросов NoSQL.
Начните с основ
Вы бы дали тому, кто учится читать древнеанглийский сборник пьес Шекспира? Ответ очевиден — ведь когда мы начинаем учиться, мы начинаем с основ.
То же самое относится и к SQL. Сосредоточившись на основах, вы сможете легче адаптировать свое образование и подготовиться к более сложной работе с базами данных в будущем.
Хотите знать, как это выглядит на практике? Как правило, новички в SQL должны сосредоточиться на изучении того, как использовать серверов баз данных — программы, облегчающие управление базами данных, а также стандартные команды, используемые при навигации по базам данных. Другие базовые понятия включают синтаксис SQL, запросы, модификаторы и вычисления.
Давайте подробнее рассмотрим несколько кратких руководств по SQL.
Синтаксис
Синтаксис относится к правилам, которые определяют комбинации символов в языке. Для SQL синтаксис немного различается между базами данных с одной и несколькими таблицами. Вам нужно будет понять синтаксис предложений и операций, таких как те, которые мы перечислили ниже. Имейте в виду, что синтаксис может различаться в зависимости от базы данных, количества таблиц и того, являются ли таблицы секционированными!
UPDATE
Это предложение можно использовать для присвоения имен таблицам и настройки столбцов для включения новых значений. В базах данных с несколькими таблицами предложение UPDATE будет обновлять все строки, которые соответствуют определенным условиям один раз, даже если условия выполняются несколько раз в одной строке.
В базах данных с несколькими таблицами предложение UPDATE будет обновлять все строки, которые соответствуют определенным условиям один раз, даже если условия выполняются несколько раз в одной строке.
SET
Кодировщики могут использовать предложение SET для определения столбцов, которые они хотят обновить, а также значений, которые они хотят ввести.
ПО УМОЛЧАНИЮ
Применение предложения DEFAULT позволяет пользователям сбросить столбцы до их начальных значений.
WHERE
Предложение WHERE используется для указания того, какие строки пользователь хочет обновить; отказ от использования этого предложения приведет к обновлению каждой строки.
ORDER BY
Кодировщики могут использовать предложение ORDER BY для определения порядка просмотра строк данных. Это предложение нельзя использовать с несколькими таблицами.
ПРЕДЕЛ
Использование предложения LIMIT позволит кодировщикам ограничить количество строк, обновляемых с помощью данной команды. Это предложение нельзя использовать с несколькими таблицами.
Это предложение нельзя использовать с несколькими таблицами.
Это всего лишь несколько начальных примеров предложений и синтаксиса, которые вам необходимо изучить, прежде чем вы освоите SQL.
Манипулирование данными
Помимо извлечения и анализа данных, SQL позволяет пользователям манипулировать информацией в базе данных. Как правило, манипулирование данными относится к вставке, обновлению или удалению данных. Вы можете использовать SQL для корректировки информации, представленной в базе данных, чтобы она была более точной и актуальной. Команды для этого относительно просты (например, «ОБНОВЛЕНИЕ» и «УДАЛЕНИЕ»), что делает процесс изменения существующих данных относительно простым и понятным.
Написание запросов
Запросы имеют решающее значение, поскольку они позволяют кодировщикам получать доступ, управлять или организовывать данные в базе данных. «Запрос» и «команда» в этом отношении часто взаимозаменяемы. При написании SQL-запросов необходимо убедиться, что вы используете правильное форматирование и язык, чтобы гарантировать точные результаты. Например, если вы хотите создать новую таблицу в базе данных, вы должны отформатировать ее следующим образом:
При написании SQL-запросов необходимо убедиться, что вы используете правильное форматирование и язык, чтобы гарантировать точные результаты. Например, если вы хотите создать новую таблицу в базе данных, вы должны отформатировать ее следующим образом:
Работая над освоением SQL, вы познакомитесь со спецификациями, необходимыми для написания запросов. Мастерство естественно придет с учебой и практикой!
Агрегированные функции
С помощью агрегатных функций кодировщики могут собирать данные из нескольких источников и суммировать их для анализа данных. Ниже мы включили несколько основных функций SQL, которые пользователи могут использовать при агрегировании данных.
SQL COUNT
Использование COUNT подсчитает, сколько строк данных содержится в таблице.
SQL SUM
Эта функция предоставляет кодировщикам сумму всех данных в выбранном ими столбце.
SQL AVG
Программисты могут использовать SELECT AVG для вычисления среднего значения данных в указанном столбце.
SQL MAX
Это простая команда, используемая для поиска максимального значения, доступного в заданном наборе данных.
SQL MIN
Как и MAX, MIN — это простая команда, которая помогает пользователям определить минимальное значение, присутствующее в заданном наборе данных.
Все эти функции, кроме SQL COUNT, игнорируют значения NULL.
Соединение таблиц
Пользователи SQL могут применять JOINS для объединения данных из двух или более таблиц, определяя их общие значения. Существует пять основных типов соединений, все из которых перечислены ниже.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Этот тип соединения возвращает строки, если он идентифицирует совпадения в обеих таблицах.
LEFT JOIN
Это возвращает все строки из левой таблицы независимо от того, есть ли совпадения в правой.
ПРАВОЕ СОЕДИНЕНИЕ
ПРАВОЕ СОЕДИНЕНИЕ противоположно левому; он возвращает все строки из правой таблицы независимо от того, есть ли совпадения в левой.
ПОЛНОЕ СОЕДИНЕНИЕ
ПОЛНОЕ СОЕДИНЕНИЕ возвращает строки, если оно идентифицирует совпадение в одной из таблиц.
SELF JOIN
SELF JOIN рассматривает одну таблицу как две, соединяя ее с самой собой.
Нужна ли мне сертификация SQL? Как я могу получить один?
Строго говоря, формальная сертификация SQL не требуется. В большинстве случаев будет достаточно возможности продемонстрировать свои навыки на собеседовании по программированию или портфолио. Тем не менее, вы можете и должны получить сертификат SQL, если хотите предоставить конкретные доказательства своих навыков потенциальным работодателям и повысить свои шансы на трудоустройство.
Важно отметить, что стандартная сертификация SQL отсутствует; многие учетные данные, которые вы можете получить, зависят от поставщика или роли. Например, вы можете пройти сертификацию по SQL для T-SQL (которую используют Microsoft и Sybase) или для администрирования данных, разработки баз данных или архитектуры баз данных.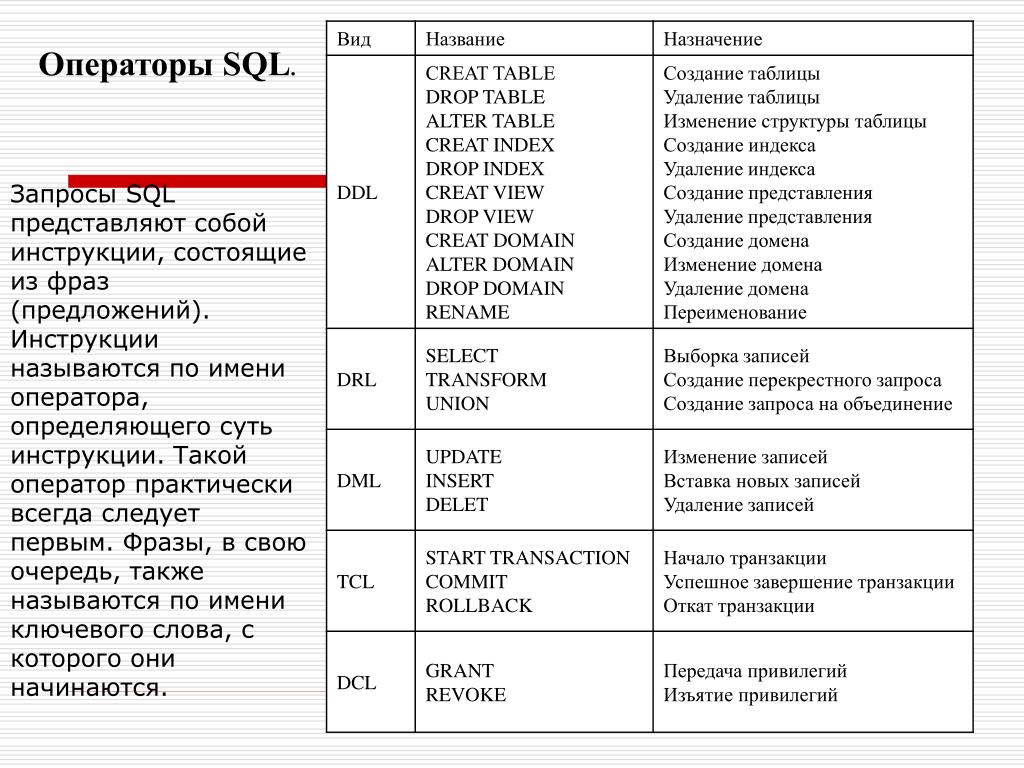 В этом контексте получение сертификата связано не столько с SQL или программированием SQL, сколько с демонстрацией того, что вы владеете конкретными программами или вариантами на основе SQL.
В этом контексте получение сертификата связано не столько с SQL или программированием SQL, сколько с демонстрацией того, что вы владеете конкретными программами или вариантами на основе SQL.
Как получить сертификат SQL
Несмотря на то, что вы можете освоить SQL на учебных курсах по программированию, такие программы обычно не предлагают сертификацию. Лучше всего будет получить базовое понимание SQL через буткемп или самостоятельные курсы, а затем подготовиться к одному из экзаменов, указанных ниже.
- Сертификация MySQL — MySQL
- Oracle Database SQL Certified Associate — Oracle University
- Сертификация PostgreSQL — Корпоративная БД
Чему еще я должен научиться, чтобы дополнить свои навыки SQL?
Изучение SQL будет лишь частью вашего развития и образования, поскольку роли, требующие знания SQL, также потребуют других навыков кодирования. Ниже мы перечислили несколько основных навыков, которые должны стать основой для вашего набора инструментов программирования.
Python
Python — это интуитивно понятный язык сценариев с открытым исходным кодом, используемый для создания веб-приложений и контента. Как язык с открытым исходным кодом, Python бесплатен и легко доступен; он также был разработан для совместимости с различными системами, включая виртуальные машины Mac, Windows, Unix и Java.
JavaScript
По состоянию на 2020 год JavaScript был самым востребованным языком программирования среди менеджеров по найму. Он часто используется в интерфейсной веб-разработке для создания динамических, отзывчивых элементов, таких как кнопки, формы и базовая анимация.
Node.js
Node.js — это среда выполнения с открытым исходным кодом — инфраструктура, облегчающая выполнение программ или приложений в режиме реального времени — которая позволяет программистам использовать JavaScript в программировании на стороне сервера. Node.js позволяет разработчикам писать полнофункциональные серверные приложения с доступом к операционной и файловой системам компьютера.
HTML
Язык гипертекстовой разметки, или HTML, является обязательным для тех, кто интересуется интерфейсной веб-разработкой. Кодировщики используют HTML для определения структуры и дизайна каждой веб-страницы на сайте в целом.
CSS
Каскадные стили листов, или CSS, используются вместе с HTML для форматирования макета и внешнего вида веб-страниц. Разработчики могут использовать CSS для единообразного определения шрифта, цветовой схемы, размера таблицы и других элементов дизайна на веб-сайте.
Django
Django, как и Node.js, — это бесплатная платформа с открытым исходным кодом, предназначенная для поддержки и ускорения проектов программирования на одном языке — в случае Django, Python. Django помогает веб-разработчикам быстро создавать безопасные веб-сайты; структура была разработана для поощрения использования повторно используемого кода и ограничения ненужного дублирования.
Bootstrap
Bootstrap — это интерфейсный фреймворк и набор инструментов для проектирования, разработанный, чтобы помочь программистам быстро создавать веб-страницы и приложения. На нем размещены различные инструменты HTML, CSS и JavaScript, которые могут поддержать усилия программиста и минимизировать время, необходимое для создания элементов с нуля.
На нем размещены различные инструменты HTML, CSS и JavaScript, которые могут поддержать усилия программиста и минимизировать время, необходимое для создания элементов с нуля.
Веб-разработка
Если вы хотите проникнуть в технический сектор, но не совсем уверены, чем хотите заниматься, вам следует подумать об изучении веб-разработки полного стека. Разработчики с полным стеком — это универсальные, гибкие профессионалы, которые владеют серверными базами данных и логикой, которые обеспечивают веб-сайтам их функциональность, а также внешний дизайн. Их разнообразные наборы навыков обеспечивают им ступеньку почти к любой технически подкованной карьере, которую вы только можете назвать, от анализа данных до информационной безопасности.
Если вы заинтересованы в изучении SQL — или каких-либо фундаментальных навыков кодирования или обработки данных — вы можете подумать о регистрации в учебном лагере Berkeley Coding Boot Camp или Berkeley Data Analytics Boot Camp. Эти интенсивные программы могут дать вам основные навыки и практический опыт, необходимые для получения работы начального уровня в выбранной вами области технологий. У вас есть сила воли и средства для построения карьеры; теперь вам нужно только начать.
Эти интенсивные программы могут дать вам основные навыки и практический опыт, необходимые для получения работы начального уровня в выбранной вами области технологий. У вас есть сила воли и средства для построения карьеры; теперь вам нужно только начать.
Для получения дополнительной информации о предложениях Berkeley Boot Camps, пожалуйста, свяжитесь с нами .
Навигация по статьям SQL
От базовых знаний к более продвинутым методам кодирования SQL.
Готовы узнать больше о Berkeley Coding Boot Camp в Сан-Франциско ? Свяжитесь с консультантом по приему по телефону (510) 306-1218.
Делиться своими данными с третьими лицами для персонализированной рекламы
Делиться своими данными с третьими лицами для персонализированной рекламы
Мы делимся информацией с деловыми партнерами для предоставления персонализированной онлайн-рекламы. В соответствии с Калифорнийским законом о конфиденциальности потребителей («CCPA») обмен некоторыми данными может в широком смысле рассматриваться как «продажа» информации. За исключением этого типа обмена, мы не продаем вашу информацию. Вы можете отказаться от этих «продаж» в соответствии с CCPA. Ваш выбор сохраняется в этом браузере на этом устройстве. Если вы очистите файлы cookie браузера, вам нужно будет снова отказаться от «продаж».
В соответствии с Калифорнийским законом о конфиденциальности потребителей («CCPA») обмен некоторыми данными может в широком смысле рассматриваться как «продажа» информации. За исключением этого типа обмена, мы не продаем вашу информацию. Вы можете отказаться от этих «продаж» в соответствии с CCPA. Ваш выбор сохраняется в этом браузере на этом устройстве. Если вы очистите файлы cookie браузера, вам нужно будет снова отказаться от «продаж».
Чтобы узнать больше об использовании ваших личных данных компанией 2U, ознакомьтесь с нашей Политикой конфиденциальности.
Изучение SQL: Учебник по SQL для начинающих
КОДИРОВАНИЕ
PRO
СКИДКА 36%
Попробуйте SQL на практике с Programiz PRO
Получите скидку сейчас
Указатель страниц
- Введение
- SQL ВЫБРАТЬ (I)
- SQL ВЫБРАТЬ (II)
- SQL СОЕДИНЕНИЕ
- База данных SQL
- Вставка и удаление SQL
- Ограничения SQL
- Дополнительные темы SQL
- О SQL
- Зачем изучать SQL?
- Как выучить SQL?
Введение
- Введение в SQL
SQL SELECT (I)
- SQL SELECT и SELECT WHERE
- SQL И, ИЛИ и НЕ
- SQL ВЫБЕРИТЕ ОТЛИЧНЫЙ
- SQL ВЫБРАТЬ КАК
- SQL LIMIT, TOP и FETCH FIRST
- Оператор SQL IN
- SQL МЕЖДУ оператором
- SQL IS NULL, а НЕ NULL
- SQL МИН() и МАКС()
- СЧЕТЧИК SQL()
- SQL SUM() и AVG()
SQL SELECT (II)
- SQL ORDER BY
- SQL ГРУППА ПО
- SQL КАК
- Подстановочные знаки SQL
- ОБЪЕДИНЕНИЕ SQL
- Подзапрос SQL
- SQL ЛЮБОЙ и ВСЕ
- СЛУЧАЙ SQL
- SQL ИМЕЕТ
- SQL СУЩЕСТВУЕТ
SQL СОЕДИНЯЕТ
- SQL СОЕДИНЯЕТ
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ SQL
- SQL ЛЕВОЕ СОЕДИНЕНИЕ
- SQL ПРАВОЕ СОЕДИНЕНИЕ
- SQL ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
База данных SQL и таблица
- Создание базы данных SQL
- Создание таблицы SQL
- База данных SQL Drop
- Таблица удаления SQL
- Изменить таблицу SQL
- База данных резервного копирования SQL
Вставка, обновление и удаление SQL
- Вставка SQL в
- Обновление SQL
- Выбор SQL в
- Выбор SQL для вставки
- SQL Удалить и усечь строки
Ограничения SQL
- Ограничения SQL
- Ограничение SQL Not Null
- Уникальные ограничения SQL
- Первичный ключ SQL
- Внешний ключ SQL
- Проверка SQL
- SQL по умолчанию
- Создание индекса SQL
Дополнительные темы SQL
- Типы данных SQL
- Дата и время SQL
- Операторы SQL
- Комментарии SQL
- Представления SQL
- Хранимые процедуры SQL
- SQL-инъекция
Что такое SQL?
SQL — это стандартизированный язык программирования, который используется для взаимодействия с системами баз данных.
SQL используется для
- создания баз данных
- создавать таблицы в базе данных
- прочитать данные из таблицы
- вставить данные в таблицу
- обновить данные в таблице
- удалить данные из таблицы
- удалить таблицы базы данных
- удалить базы данных
- предоставлять и отзывать разрешения
- резервное копирование и восстановление баз данных
- и многие другие операции с базой данных
Зачем изучать SQL?
- SQL используется для связи с популярными системами реляционных баз данных. Он используется в таких системах данных, как MySQL, PostgreSQL, Oracle и многих других.
- Знание SQL предпочтительно на таких ответственных работах, как инженер-программист , бизнес-аналитик , специалист по данным и т. д.
Как выучить SQL?
- Учебник по SQL от Programiz — Мы предоставляем пошаговые руководства вместе с предложениями, операторами, функциями и примерами.
