Sql execute описание: EXECUTE (Transact-SQL) — SQL Server
Содержание
Передача параметров в динамический запрос в T-SQL / Хабр
Я не раз сталкивался с необходимостью построения динамического запроса и здесь есть ряд подводных камней о которых я расскажу ниже. Пример динамического запроса:
declare @sql varchar(100) = 'select 1+1' execute( @sql)
1. Запуск строки через Execute создает отдельный блок кода, в котором текущие переменные будут не видны, но видны все временные таблицы.
2. Обратите внимание на передачу переменных со значением NULL. Любое слияние с NULL в результате даст NULL, следовательно, вместо запроса, вы можете получить пустую строку.
declare @i int declare @sql varchar(100) = 'select ' + cstr(@i) execute( @sql ) -- Ошибка
3. Передачу дат и времени. Даты лучше передавать в формате ГГГГММДД. При передаче параметров со временем следует обратить внимание на потерю точности. Для сохранения точности значения лучше передавать через временную таблицу.
4. Передача параметров с плавающей десятичной точкой имеет те же проблемы, что и передача времени внутрь построенного запроса.
5. Строковые значения – потенциально опасный код. Для начала внутри строки все одинарные кавычки должны быть продублированы. Сама строка заключена в одинарные кавычки.
Пример ошибочного кода:
Declare @str varchar(100) = 'Number ''1'' ' Declare @sql varchar(1000) = 'select String = '+ IsNull( '''' + @str + '''', 'null' ) Execute( @sql ) -- запуск кода выдаст ошибку
Правильный код:
Declare @str varchar(100) = 'Number ''1'' ' Declare @sql varchar(1000) = 'select String = '+ IsNull( '''' + replace( @str, '''', '''''') + '''', 'null' ) Execute( @sql )
6. Подстановка списков в секцию IN. Основная опасность – пустой список. В этом случае секция будет иметь вид типа ‘поле IN ()’, что при компиляции вызовет ошибку. Как метод борьбы: в начало списка всегда включать NULL или заменить пустую строку на NULL.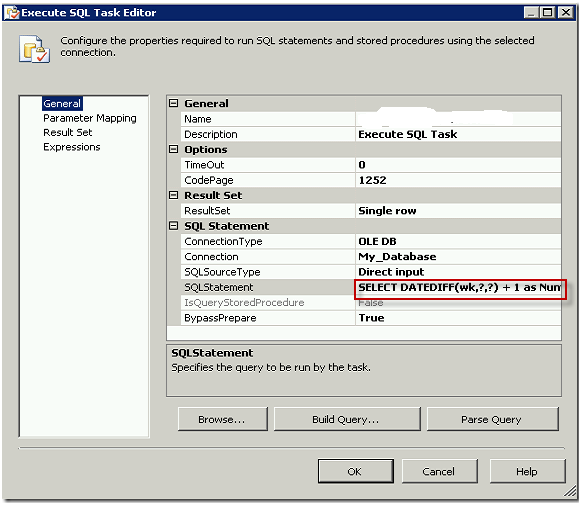 NULL можно сравнивать с любым типом данных. Сравнение с NULL всегда дает отрицательный результат, но при этом список гарантированно не пустой.
NULL можно сравнивать с любым типом данных. Сравнение с NULL всегда дает отрицательный результат, но при этом список гарантированно не пустой.
Declare @list varchar(100) = ''
iif @list = '' set @list = 'null'
Declare @sql varchar(1000) = 'select number from documents where id in ('+@list+') '
Execute( @sql )
Вот пример безопасной передачи сложных параметров через временную таблицу:
if OBJECT_ID('tempdb..#params') is not null drop table #params
create table #params ( v1 int, v2 datetime, v3 varchar(100) )
insert #params values ( 1, getdate(), 'Строка ''1''')
declare @sql varchar(1000) = '
declare @v1 int, @v2 datetime, @v3 varchar(100)
select @v1 = v1 , @v2 = v2, @v3 = v3 from #params
select @v1, @v2, @v3
'
execute(@sql)
drop table #params
Ну и на закуску маленькие хитрости:
Передаваемые параметры лучше вначале объявить через переменные, инициализировать эти переменные и уже эти переменные использовать в ходе вычислений. В этом случае повышается читаемость текста запроса и отлаживать его легче.
В этом случае повышается читаемость текста запроса и отлаживать его легче.
Если обходится без переменных, то можно использовать следующий метод:
set @sql = 'select <VAR1> + <VAR2>' set @sql = replace(@sql, '<VAR1>', '1') set @sql = replace(@sql, '<VAR2>', '2') execute( @sql )
Кроме вышеперечисленных особенностей есть еще пару способов передачи параметров:
1. Использовать sp_executesql (как правильно мне подсказали в комментариях)
2. Обернуть запрос во временную хранимую процедуру и запускать ее. При большом количестве запусков этот способ даже эффективнее.
declare @sql varchar(200) = ' create procedure #test ( @p1 int, @p2 int) as select @p1 + @p2' execute( @sql ) exec #test 1, 2 exec #test 3,4 drop procedure #test
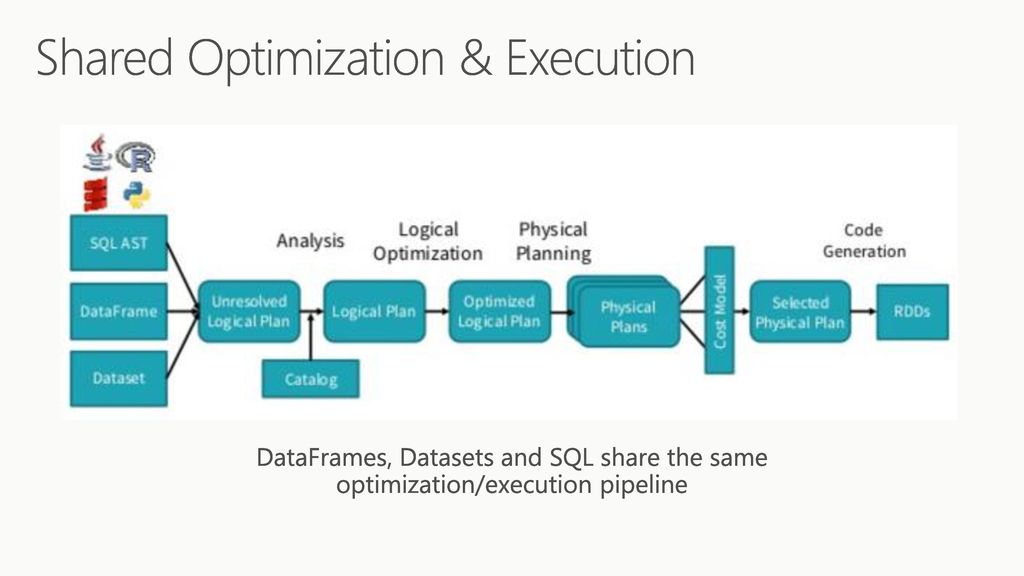
Dynamic T-SQL и как он может быть полезен / Хабр
В наших проектах нам приходится решать различные задачи. Для решения некоторых из них мы используем dynamic T-Sql (далее по тексту dynamic sql).
Для чего нужен dynamic sql? Каждый решает для себя. В одном из проектов с помощью dynamic sql мы решили задачи построения динамичных отчетов, в других — миграцию данных. Также dynamic sql незаменим в случаях, когда требуется создать/изменить/получить данные или объекты, но значения/названия приходят в качестве параметров. Да, это может показаться абсурдом, но есть и такие задачи.
Дальше мы покажем несколько примеров, как это можно реализовать с помощью dynamic sql.
Выполнить динамическую команду можно несколькими способами:
- С использование ключевого слова
EXEC/EXECUTE; - C использование хранимой процедуры
sp_executesql
Данные способы отличаются между собой кардинально. На небольшом примере мы постараемся пояснить, чем они отличаются.
Пример кода с EXEC/EXECUTE
DECLARE @sql varchar(1000)
DECLARE @columnList varchar(75)
DECLARE @city varchar(75)
SET @columnList = 'CustomerID, ContactName, City'
SET @city = 'London'
SELECT @sql = ' SELECT CustomerID, ContactName, City ' +
' FROM dbo. customers WHERE 1 = 1 '
SELECT @sql = @sql + ' AND City LIKE ''' + @city + ''''
EXEC (@sql)
customers WHERE 1 = 1 '
SELECT @sql = @sql + ' AND City LIKE ''' + @city + ''''
EXEC (@sql)
 customers WHERE 1 = 1 '
SELECT @sql = @sql + ' AND City LIKE ''' + @city + ''''
EXEC (@sql)
customers WHERE 1 = 1 '
SELECT @sql = @sql + ' AND City LIKE ''' + @city + ''''
EXEC (@sql)
Как видно из запроса выше, мы формируем динамическую команду. Если выполнить select @sql, то результат будет следующий:
SELECT CustomerID, ContactName, City FROM customers WHERE City = 'London'
Что же тут плохого? — Запрос отработает, и все будут довольны. Но все же, есть несколько причин, почему так делать не стоит:
- При написании команды очень легко ошибиться с количеством «’», т.к. необходимо указывать дополнительные «’», чтобы передать текстовое значение в запрос.
- При таком запросе возможны Sql инъекции (SQL Injection). Например, стоит задать значение для
@cityвроде такогоset @city = '''DROP TABLE customers--'''
— и результат будет печальный, т.к. операция
selectвыполнится успешно, как и операцияDROP TABLE customers. - Возможна ситуация, когда у вас будет несколько переменных, содержащих коды ваших команд. Что-то типа такой
EXEC(@sql1 + @sql2 + @sql3).
Какие трудности могут возникнуть тут?
Нужно помнить, что каждая команда отработает отдельно, хотя на первый взгляд, может показаться, что будет выполнена операция конкатенации(@sql1 + @sql2 + @sql3), а затем выполнится общая команда. Также нужно помнить, что накладывается общее ограничение на параметр команды EXEC в 4000 символов. - Происходит неявное приведение типов, т.к. параметры передаются в виде строки.

Что изменится при использовании sp_executesql? – Разработчику проще писать код и его отлаживать, т.к. код будет написан практически как обычный Sql запрос.
Пример кода с sp_executesql
DECLARE @sqlCommand varchar (1000) DECLARE @columnList varchar (75) DECLARE @city varchar (75) SET @city = 'London' SET @sqlCommand = 'SELECT CustomerID, ContactName, City FROM customers WHERE City = @city' EXECUTE sp_executesql @sqlCommand, N'@city nvarchar(75)', @city = @city
Что же изменилось?
- В отличие от
EXECUTEпри использованииsp_executesql, не нужно никакое приведение типов, если мы используем типизированные параметрыsp_executesql. - Это решает проблему с дополнительными «’».
- Решается проблема безопасности — Sql инъекции (SQL Injection).
Для обоих подходов планы запросов кэшируются, но они отличаются. Эти отличия приведены на рисунке 1 и рисунке 2.
Получение плана запроса
SELECT q.TEXT,cp.usecounts,cp.objtype,p.*, q.*, cp.plan_handle FROM sys.dm_exec_cached_plans cp CROSS apply sys.dm_exec_query_plan(cp.plan_handle) p CROSS apply sys.dm_exec_sql_text(cp.plan_handle) AS q WHERE q.TEXT NOT LIKE '%sys.dm_exec_cached_plans %' and cp.cacheobjtype = 'Compiled Plan' AND q.TEXT LIKE '%customers%'
План запрос при использование Exec
План запроса при использовании sp_executesql
Также одно из преимуществ использования sp_executesql – это возможность возвращать значение через OUT параметр.
Далее приведем пример, как мы решили одну из проблем в проекте с использованием dynamic sql.
Допустим, у нас есть товар (да неважно, собственно, что это: товар, анкета на должность, персональная анкета). Смысл в том, что каждый объект имеет свой набор свойств (атрибутов), который его характеризует, а их может быть разное количество, и они будут разного типа. Как хранить в БД – это проблема архитектуры.
Для клиента нужен был отчет, который из себя представлял n строк на m столбцов. Где m и был наш набор атрибутов. Отчет собирался по группе объектов или для какого-то объекта из группы. Но смысл остается все тот же: каждый отчет содержит разное количество столбцов для каждой группы объектов.
Поскольку изначально существовала связь между объектами, то решение проблемы выбрали без изменения архитектуры БД. На наш взгляд, решений данной проблемы может быть несколько:
- Использовать систему отчетности, например, MS Sql Reporting Service. Создать матричный отчет, а в качестве запроса у нас будет «простой»
Select. Почему мы так не сделали? В проекте не так много было отчетов, чтобы внедрять туда SSRS. - Использовать тот же «простой»
selectи на серверной стороне уже создавать DataSet необходимой «формы». Да, так задача была решена изначально, когда данных о товарах было очень мало. Как только данных стало достаточно много, то время сбора отчета стало выходит за установленный timeout. - Использовать
Pivotв sql. Да, отличное решение, когда вы знаете, что у вас только эти атрибуты, и новых не будет. А что делать, когда количество атрибутов часто меняется. И опять же, для каждой группы объектов у нас свой набор атрибутов, мы снова вернемся к созданию процедуры для каждой группы объектов. Не очень удобное решение, не правда ли? - А если использовать Pivot, но добавить туда немного dynamic sql? – Да, это решение, которое имеет право на жизнь. Его мы и опишем, как пример использования dynamic sql…
 Почему мы так не сделали? В проекте не так много было отчетов, чтобы внедрять туда SSRS.
Почему мы так не сделали? В проекте не так много было отчетов, чтобы внедрять туда SSRS.
Ссылка на скрипты для создания таблиц и запроса.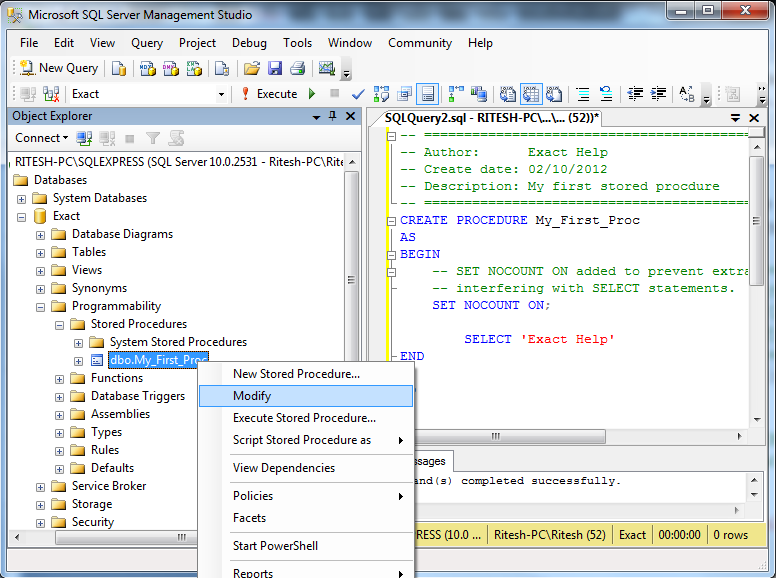
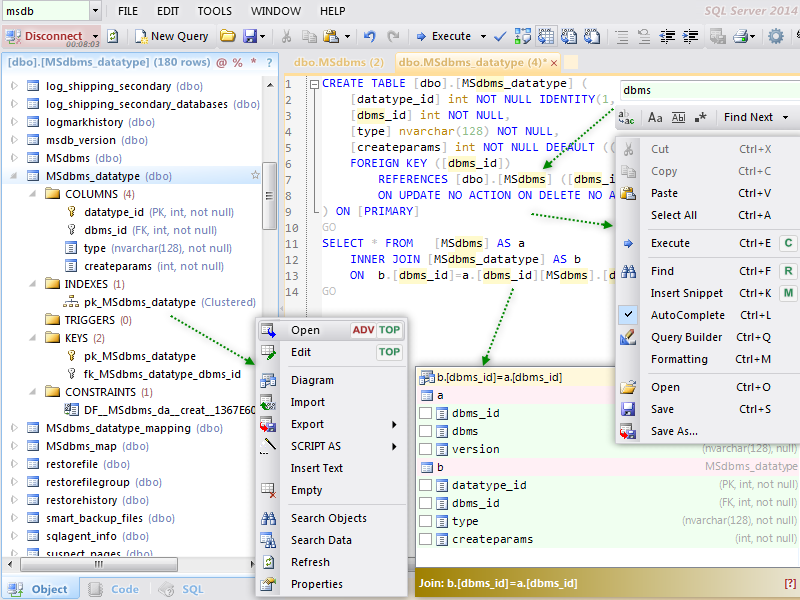
В основе отчета будет лежать обычный запрос:
Основной код для отчета
SELECT p.Id as ProductID, p.Name as [Наименование], pcp.Name as PropertiesName, vpp.Value as Value FROM dbo.Products p INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id and vpp.PropertiesCategoryOfProductsId = pcp.Id where p.CategoryOfProductsId = @CategoryOfProductsId
Код запроса для построения отчета
SELECT p.Id as ProductID, p.Name as [Наименование], pcp.Name as PropertiesName, vpp.Value as Value FROM dbo.Products p INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id and vpp.PropertiesCategoryOfProductsId = pcp.Id where p.CategoryOfProductsId = @CategoryOfProductsId Код запроса для построения отчета declare @CategoryOfProductsId int = 1 declare @PivotColumnHeaders nvarchar(max)= REVERSE(STUFF(REVERSE((select '[' + Name + ']' + ',' as 'data()' from dbo.
 PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
if(@PivotColumnHeaders>'')
declare @PivotTableSQL nvarchar(max)
BEGIN
SET @PivotTableSQL = N'
SELECT *
from (SELECT p.Id as ProductID,
p.Name as [Наименование],
pcp.Name as PropertiesName,
vpp.Value as Value
FROM dbo.Products p
INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId
INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id
and vpp.PropertiesCategoryOfProductsId = pcp.Id
where p.CategoryOfProductsId = @CategoryOfProductsId
) as Pivot_Data
PIVOT (
MIN(Value)
FOR PropertiesName IN (
' + @PivotColumnHeaders + '
)
) AS PivotTable
'
EXECUTE sp_executesql @PivotTableSQL, N'@CategoryOfProductsId int', @CategoryOfProductsId = @CategoryOfProductsId;
END
PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
if(@PivotColumnHeaders>'')
declare @PivotTableSQL nvarchar(max)
BEGIN
SET @PivotTableSQL = N'
SELECT *
from (SELECT p.Id as ProductID,
p.Name as [Наименование],
pcp.Name as PropertiesName,
vpp.Value as Value
FROM dbo.Products p
INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId
INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id
and vpp.PropertiesCategoryOfProductsId = pcp.Id
where p.CategoryOfProductsId = @CategoryOfProductsId
) as Pivot_Data
PIVOT (
MIN(Value)
FOR PropertiesName IN (
' + @PivotColumnHeaders + '
)
) AS PivotTable
'
EXECUTE sp_executesql @PivotTableSQL, N'@CategoryOfProductsId int', @CategoryOfProductsId = @CategoryOfProductsId;
END
Давайте рассмотрим, что же мы тут написали:
- Инициализируем переменную со значением нашей категории товаров —
declare @CategoryOfProductsId int = 1 - Далее нам нужно получить список колонок для нашей категории товаров, но при этом они должны быть заключены в “[]” скобки и перечислены через “,” как этого требует синтаксис функции
Pivot—Получение списка колонок для категории товаров
declare @PivotColumnHeaders nvarchar(max)= REVERSE(STUFF(REVERSE((select '[' + Name + ']' + ',' as 'data()' from dbo.
PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
Ну а дальше все просто: при выполнении кода список колонок для функцииPivotбудет подставлен из@PivotColumnHeaders
Если выполнитьselect @PivotTableSQL, то мы получим тот запрос, который без использования dynamic sql нам бы пришлось писать вручную.Результатом выполнения данного запроса будет отчет такого вида:
В заключение стоит еще раз отметить используя dynamic sql, мы можем решать на первый взгляд нетривиальные задачи тривиальными способами. Для этого порой требуется посмотреть на проблему с другой стороны.
 PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
| опции | отображение строки в строки | Дополнительные параметры. Значение по умолчанию — пустая карта ( {} ).
|
 Значение по умолчанию – 9.0031 ложь . Поддерживаемые значения:
Значение по умолчанию – 9.0031 ложь . Поддерживаемые значения: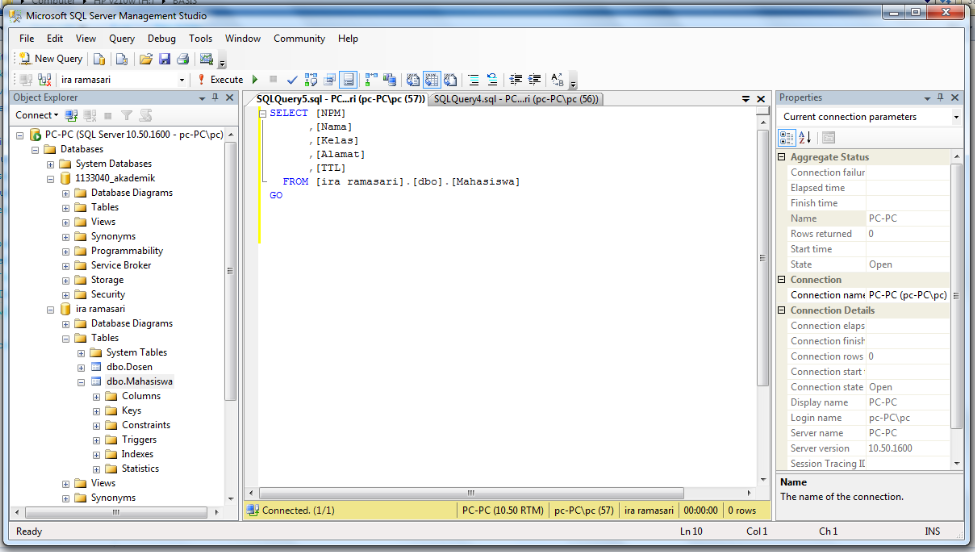 Поддерживаемые значения:
Поддерживаемые значения:
 Значение по умолчанию – 9.0031 верно . Поддерживаемые значения:
Значение по умолчанию – 9.0031 верно . Поддерживаемые значения: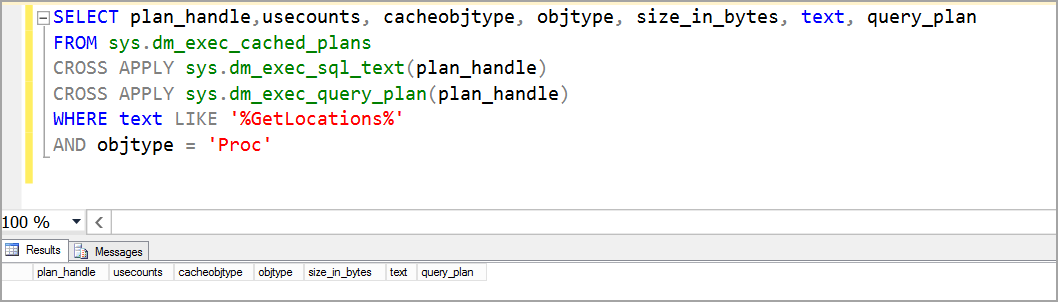 Значение по умолчанию — 9.0031 верно . Поддерживаемые значения:
Значение по умолчанию — 9.0031 верно . Поддерживаемые значения: Поддерживаемые значения:
Поддерживаемые значения:Соединитель SQL Databricks для Python
Соединитель SQL Databricks для Python — это библиотека Python, которая позволяет использовать код Python для выполнения команд SQL в кластерах Databricks и хранилищах SQL Databricks. Соединитель Databricks SQL для Python проще в настройке и использовании, чем аналогичные библиотеки Python, такие как pyodbc. Эта библиотека соответствует PEP 249 — Спецификация API базы данных Python v2.0.
Требования
Начало работы
Соберите следующую информацию о кластере или хранилище SQL, которое вы хотите использовать:
Имя узла сервера кластера. Вы можете получить это из значения Server Hostname на вкладке Advanced Options > JDBC/ODBC для вашего кластера.
HTTP-путь кластера. Вы можете получить это из значения HTTP Path на вкладке Advanced Options > JDBC/ODBC для вашего кластера.
Маркер личного доступа Databricks для рабочей области.
Примечание
Из соображений безопасности не следует жестко закодировать эту информацию в коде. Вместо этого вы должны получить эту информацию из безопасного места. Например, в примерах кода далее в этой статье используются переменные среды.
Имя хоста сервера хранилища SQL. Вы можете получить это из значения Server Hostname на вкладке «Сведения о соединении» для вашего хранилища SQL.
Путь HTTP к хранилищу SQL. Вы можете получить это из значения HTTP Path на вкладке «Сведения о соединении» для вашего хранилища SQL.
Маркер личного доступа Databricks для рабочей области.
Примечание
Из соображений безопасности не следует жестко закодировать эту информацию в коде. Вместо этого вы должны получить эту информацию из безопасного места. Например, в примерах кода далее в этой статье используются переменные среды.
Установите библиотеку Databricks SQL Connector для Python на компьютере для разработки, запустив
pip install databricks-sql-connector.

Примеры
В следующих примерах кода показано, как использовать соединитель Databricks SQL для Python для запроса и вставки данных, запроса метаданных, управления курсорами и подключениями и настройки ведения журнала.
Этот пример кода извлекает их server_hostname , http_path и значения переменной подключения access_token из следующих переменных среды:
DATABRICKS_SERVER_HOSTNAME, что представляет значение Server Hostname из требований.DATABRICKS_HTTP_PATH, который представляет значение HTTP-пути из требований.DATABRICKS_TOKEN, который представляет ваш маркер доступа из требований.
Можно использовать другие подходы к получению этих значений переменных подключения. Использование переменных окружения — это лишь один из многих подходов.
Использование переменных окружения — это лишь один из многих подходов.
Данные запроса
Вставить данные
Запрос метаданных
Управление курсорами и соединениями
Настройка ведения журнала
Данные запроса
В следующем примере кода показано, как вызвать соединитель SQL Databricks для Python, чтобы выполнить базовую команду SQL в кластере или хранилище SQL. Эта команда возвращает первые две строки из бриллиантов табл.
Таблица алмазов включена в наборы данных Sample. Эта таблица также представлена в Учебном пособии: Запрос данных с помощью записных книжек.
из блоков данных импортировать sql
импорт ОС
с sql.connect(server_hostname = os.getenv("DATABRICKS_SERVER_HOSTNAME"),
http_path = os.getenv("DATABRICKS_HTTP_PATH"),
access_token = os.getenv("DATABRICKS_TOKEN")) как соединение:
с connection. cursor() в качестве курсора:
cursor.execute("SELECT * FROM default.diamonds LIMIT 2")
результат = курсор.fetchall()
для строки в результате:
печать (строка)
 cursor() в качестве курсора:
cursor.execute("SELECT * FROM default.diamonds LIMIT 2")
результат = курсор.fetchall()
для строки в результате:
печать (строка)
cursor() в качестве курсора:
cursor.execute("SELECT * FROM default.diamonds LIMIT 2")
результат = курсор.fetchall()
для строки в результате:
печать (строка)
Вставка данных
В следующем примере показано, как вставлять небольшие объемы данных (тысячи строк):
из блоков данных import sql
импорт ОС
с sql.connect(server_hostname = os.getenv("DATABRICKS_SERVER_HOSTNAME"),
http_path = os.getenv("DATABRICKS_HTTP_PATH"),
access_token = os.getenv("DATABRICKS_TOKEN")) как соединение:
с connection.cursor() в качестве курсора:
cursor.execute("СОЗДАТЬ ТАБЛИЦУ, ЕСЛИ НЕ СУЩЕСТВУЕТ квадратов (x int, x_squared int)")
квадраты = [(i, i * i) для i в диапазоне (100)]
values = ",".join([f"({x}, {y})" для (x, y) в квадратах])
cursor.execute(f"ВСТАВИТЬ В квадраты ЗНАЧЕНИЯ {значения}")
cursor.execute («ВЫБЕРИТЕ * ИЗ ПРЕДЕЛА квадратов 10»)
результат = курсор.fetchall()
для строки в результате:
печать (строка)
Для больших объемов данных следует сначала загрузить данные в облачное хранилище, а затем выполнить команду КОПИРОВАТЬ В.
Запрос метаданных
Существуют специальные методы для получения метаданных. В следующем примере извлекаются метаданные о столбцах в образце таблицы:
из databricks import sql
импорт ОС
с sql.connect(server_hostname = os.getenv("DATABRICKS_SERVER_HOSTNAME"),
http_path = os.getenv("DATABRICKS_HTTP_PATH"),
access_token = os.getenv("DATABRICKS_TOKEN")) как соединение:
с connection.cursor() в качестве курсора:
cursor.columns (имя_схемы = "по умолчанию", имя_таблицы = "квадраты")
печать (курсор. fetchall ())
Управление курсорами и соединениями
Рекомендуется закрыть все соединения и курсоры, с которыми было покончено. Это освобождает ресурсы в кластерах Databricks и хранилищах SQL Databricks.
Вы можете использовать диспетчер контекста ( с синтаксисом , который использовался в предыдущих примерах) для управления ресурсами или явным образом вызывать close :
из блоков данных import sql импорт ОС соединение = sql.
 connect(server_hostname = os.getenv("DATABRICKS_SERVER_HOSTNAME"),
http_path = os.getenv("DATABRICKS_HTTP_PATH"),
access_token = os.getenv("DATABRICKS_TOKEN"))
курсор = соединение.курсор()
курсор.выполнить("ВЫБЕРИТЕ * из диапазона(10)")
печать (курсор. fetchall ())
курсор.закрыть()
соединение.закрыть()
connect(server_hostname = os.getenv("DATABRICKS_SERVER_HOSTNAME"),
http_path = os.getenv("DATABRICKS_HTTP_PATH"),
access_token = os.getenv("DATABRICKS_TOKEN"))
курсор = соединение.курсор()
курсор.выполнить("ВЫБЕРИТЕ * из диапазона(10)")
печать (курсор. fetchall ())
курсор.закрыть()
соединение.закрыть()
Справочник API
Пакет
Модуль
Методы
способ подключения
Классы
СоединениеклассМетоды
закрытьметодкурсорметод
КурсорклассАтрибуты
размер массиваатрибутописаниеатрибут
Методы
отменаметодзакрытьметодвыполнитьметодметод выполнениякаталогиметодсхемыметодтаблицыметодстолбцыметодfetchallметодfetchmanyметодfetchoneметодfetchall_arrowметодfetchmany_arrowметод
РядклассМетоды
метод asDict
Преобразование типов
Package
databricks-sql-connector
Использование: pip install databricks-sql-connector
См. также databricks-sql-connector в индексе пакетов Python (PyPI).
также databricks-sql-connector в индексе пакетов Python (PyPI).
Модуль
databricks.sql
Использование: из databricks import sql
Методы
подключить метод создать соединение с базой данных
as.
Возвращает объект Connection.
Параметры |
|---|
server_hostname Тип: Имя хоста сервера для кластера или хранилища SQL. Этот параметр является обязательным. Пример: |
http_path Тип: Путь HTTP к кластеру или хранилищу SQL. Этот параметр является обязательным. Пример: |
access_token Тип: Ваш персональный токен доступа Databricks для рабочей области кластера или хранилища SQL. Этот параметр является обязательным. Пример: |
конфигурация_сессии Тип: Словарь параметров конфигурации сеанса Spark. По умолчанию Этот параметр является необязательным. Пример: |
http_headers Тип: Дополнительные пары (ключ, значение) для установки в заголовках HTTP при каждом запросе RPC к клиенту Этот параметр является необязательным. Начиная с версии 2.0 |
каталог Тип: Исходный каталог для подключения. Этот параметр является необязательным. Начиная с версии 2.0 |
схема Тип: Исходная схема для подключения. Этот параметр является необязательным. Начиная с версии 2.0 |

Классы
Соединение класс
Представляет соединение с базой данных.
Methods
close method
Закрывает соединение с базой данных и освобождает все связанные ресурсы на сервере. Любые дополнительные вызовы этого соединения вызовут ошибку 9.0370 .
Нет параметров.
Нет возвращаемого значения.
курсор метод
Возвращает механизм, позволяющий просматривать записи в базе данных.
Нет параметров.
Возвращает объект Cursor.
Курсор класс
Атрибуты
размер массива атрибут
Используется с методом fetchmany, указывает размер внутреннего буфера, который также является тем, сколько строк фактически извлекается с сервера за раз.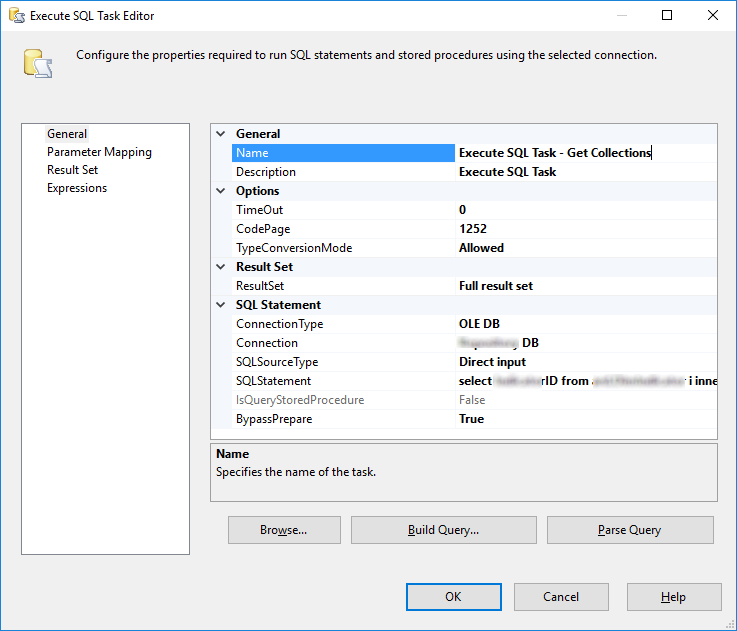 Значение по умолчанию – 9.0369 10000 . Для узких результатов (результатов, в которых каждая строка не содержит много данных) следует увеличить это значение для повышения производительности.
Значение по умолчанию – 9.0369 10000 . Для узких результатов (результатов, в которых каждая строка не содержит много данных) следует увеличить это значение для повышения производительности.
Доступ для чтения и записи.
описание атрибут
Содержит список Python из кортежей объектов. Каждый из этих объектов кортежа содержит 7 значений, причем первые 2 элемента каждого объекта кортежа содержат информацию, описывающую один столбец результатов следующим образом:
имя: Имя столбца.type_code: Строка, представляющая тип столбца. Например, целочисленный столбец будет иметь код типаint.
Остальные 5 элементов каждого 7-элементного кортежа объекта не реализованы, и их значения не определены. Обычно они возвращаются в виде 4 значений None , за которыми следует одно значение True .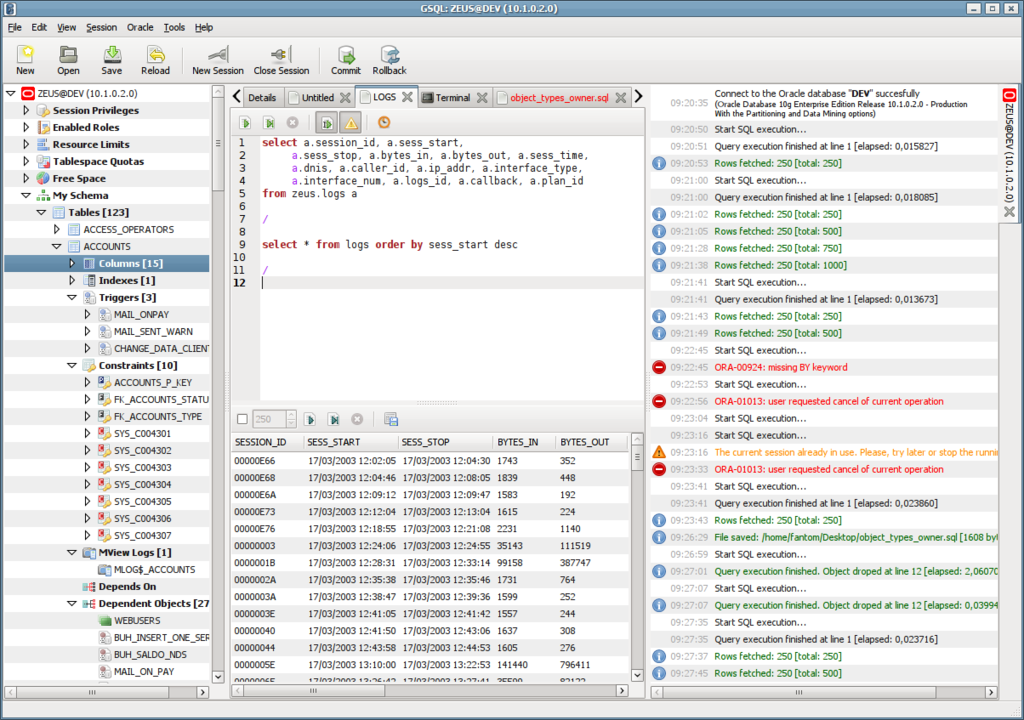
Доступ только для чтения.
Методы
Отменить метод
Прерывает выполнение любого запроса к базе данных или команды, запущенной курсором. Чтобы освободить связанные ресурсы на сервере, вызовите метод close после вызова метода cancel .
Нет параметров.
Нет возвращаемого значения.
метод close
Закрывает курсор и освобождает связанные ресурсы на сервере. Закрытие уже закрытого курсора может вызвать ошибку.
Нет параметров.
Нет возвращаемого значения.
выполнить метод
Подготавливает и затем выполняет запрос к базе данных или команду.
Нет возвращаемого значения.
Параметры |
|---|
операция Тип: Запрос или команда для подготовки и выполнения. Этот параметр является обязательным. Пример без курсор.выполнить( 'ВЫБЕРИТЕ * ИЗ default.diamonds, ГДЕ вырезать = "Идеальный" ПРЕДЕЛ 2' ) Пример с параметрами курсор.выполнить(
'SELECT * FROM default.diamonds WHERE cut=%(cut_type)s LIMIT 2',
{ 'cut_type': 'Идеально' }
)
|
параметры Тип: словарь Последовательность параметров для использования с операцией Этот параметр является необязательным. По умолчанию |

метод executemany
Подготавливает и затем выполняет запрос к базе данных или команду, используя все последовательности параметров в аргументе seq_of_parameters . Сохраняется только окончательный набор результатов.
Нет возвращаемого значения.
Параметры |
|---|
операция Тип: Запрос или команда для подготовки и выполнения. Этот параметр является обязательным. |
seq_of_parameters Тип: Последовательность множества наборов значений параметров для использования с Этот параметр является обязательным. |
каталоги метод
Выполнить запрос метаданных о каталогах. Фактические результаты должны быть получены с помощью fetchmany или fetchall .
Важные поля в результирующем наборе включают:
Нет параметров.
Нет возвращаемого значения.
Начиная с версии 1.0
схемы метод
Выполнить запрос метаданных о схемах. Фактические результаты должны быть получены с помощью fetchmany или fetchall .
Важные поля в наборе результатов включают:
Нет возвращаемого значения.
Начиная с версии 1.0
Параметры |
|---|
имя_каталога Тип: Имя каталога для получения информации. Этот параметр является необязательным. |
имя_схемы Тип: Имя схемы, о которой требуется получить информацию. Этот параметр является необязательным. |
таблицы метод
Выполнение запроса метаданных о таблицах и представлениях. Фактические результаты должны быть получены с помощью fetchmany или fetchall .
Важные поля в наборе результатов включают:
Имя поля:
ТАБЛИЦА_CAT. Тип: стр. Каталог, которому принадлежит таблица.Имя поля:
TABLE_SCHEM. Тип:стр. Схема, которой принадлежит таблица.Имя поля:
ИМЯ_ТАБЛИЦЫ. Тип:стр. Имя таблицы.Имя поля:
TABLE_TYPE. Тип:стр. Тип отношения, напримерVIEWилиTABLE(применяется к Databricks Runtime 10.2 и выше, а также к Databricks SQL; предыдущие версии Databricks Runtime возвращают пустую строку).
 Тип:
Тип: Нет возвращаемого значения.
Начиная с версии 1.0
Параметры |
|---|
имя_каталога Тип: Имя каталога для получения информации. Этот параметр является необязательным. |
имя_схемы Тип: Имя схемы, о которой требуется получить информацию. Этот параметр является необязательным. |
имя_таблицы Тип: Имя таблицы для получения информации. Этот параметр является необязательным. |
типы_таблиц Тип: Список типов таблиц для соответствия, например Этот параметр является необязательным. |

столбцы метод
Выполнение запроса метаданных о столбцах. Фактические результаты должны быть получены с помощью fetchmany или fetchall .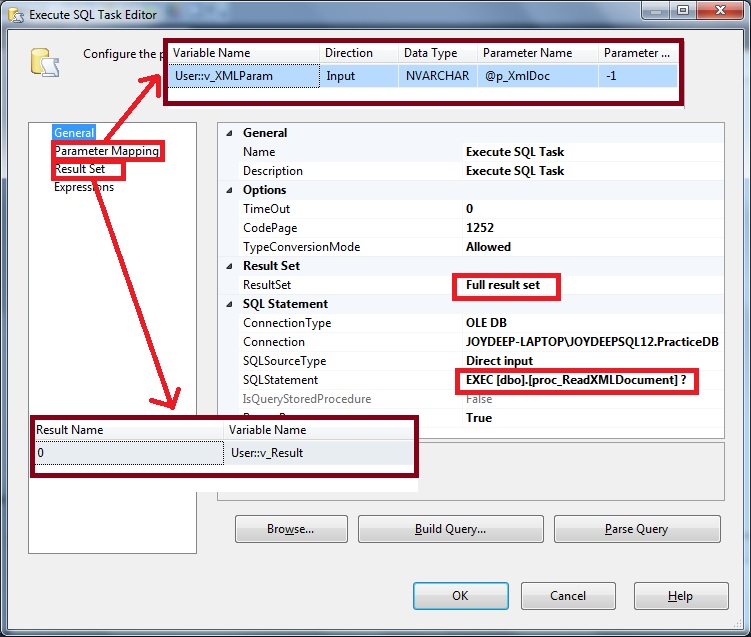
Важные поля в наборе результатов включают:
Имя поля:
TABLE_CAT. Тип:стр. Каталог, которому принадлежит столбец.Имя поля:
TABLE_SCHEM. Тип:стр. Схема, которой принадлежит столбец.Имя поля:
ИМЯ_ТАБЛИЦЫ. Тип:стр. Имя таблицы, которой принадлежит столбец.Имя поля:
COLUMN_NAME. Тип:стр. Имя столбца.
Нет возвращаемого значения.
Начиная с версии 1.0
Параметры |
|---|
имя_каталога Тип: Имя каталога для получения информации. Этот параметр является необязательным. |
имя_схемы Тип: Имя схемы, о которой требуется получить информацию. Этот параметр является необязательным. |
имя_таблицы Тип: Имя таблицы для получения информации. Этот параметр является необязательным. |
имя_столбца Тип: Имя столбца, о котором требуется получить информацию. Этот параметр является необязательным. |
метод fetchall
Получает все (или все оставшиеся) строки запроса.
Нет параметров.
Возвращает все (или все оставшиеся) строки запроса в виде списка Python из Строка объектов.
Выдает ошибку , если предыдущий вызов метода execute не вернул никаких данных или вызов execute еще не был выполнен.
fetchmany method
Получает следующие строки запроса.
Возвращает до размера (или атрибут arraysize, если размер не указан) следующих строк запроса в виде списка Python из объектов Row .
Если их меньше размер 9Осталось выборки 0370 строк, будут возвращены все оставшиеся строки.
Выдает ошибку , если предыдущий вызов метода execute не вернул никаких данных или вызов execute еще не был выполнен.
Параметры |
|---|
размер Тип: Количество следующих строк для получения. Этот параметр является необязательным. Если не указано, значение Пример: |
fetchone method
Получает следующую строку набора данных.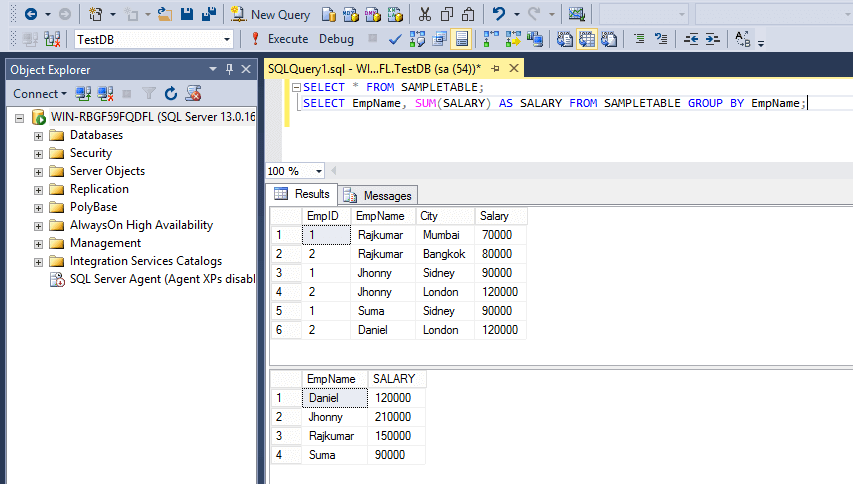
Нет параметров.
Возвращает следующую строку набора данных в виде единой последовательности в виде объекта Python tuple или возвращает None , если доступных данных больше нет.
Выдает ошибку , если предыдущий вызов метода execute не вернул никаких данных или не выполнить вызов еще не был сделан.
fetchall_arrow method
Получает все (или все оставшиеся) строки запроса в виде объекта PyArrow Table .
Запросы, возвращающие очень большие объемы данных, должны использовать fetchmany_arrow , чтобы уменьшить потребление памяти.
Нет параметров.
Возвращает все (или все оставшиеся) строки запроса в виде таблицы PyArrow.
Выдает ошибку , если предыдущий вызов метода execute не вернул никаких данных или не выполнить вызов еще не был сделан.
Начиная с версии 2.0
fetchmany_arrow method
Получает следующие строки запроса в виде объекта PyArrow Table .
Возвращает до аргумента размера (или атрибута arraysize, если размер не указан) следующих строк запроса в виде объекта Python PyArrow Table .
Выдает ошибку , если предыдущий вызов метода execute не вернул никаких данных или не выполнить вызов еще не был сделан.
Начиная с версии 2.0
Параметры |
|---|
размер Тип: Количество следующих строк для получения. Этот параметр является необязательным. Если не указано, значение Пример: |
Строка class
Класс row представляет собой кортежеподобную структуру данных, представляющую отдельную строку результата.
Если строка содержит столбец с именем "my_column" , вы можете получить доступ к полю "my_column" строки через
row. . Вы также можете использовать числовые индексы для доступа к полям, например, 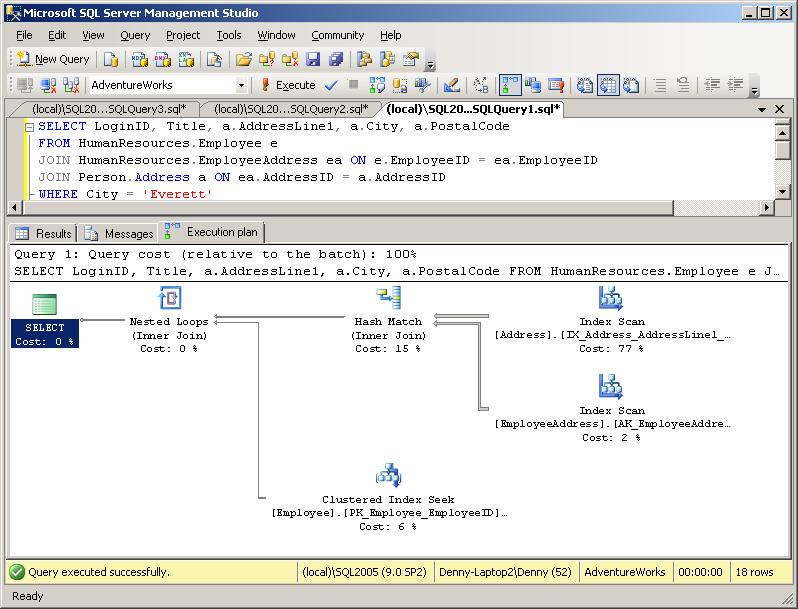 my_column
my_column row[0] .
Если имя столбца не разрешено в качестве имени метода атрибута (например, оно начинается с цифры),
то вы можете получить доступ к полю как строка["1_my_column"] .
Начиная с версии 1.0
Методы
Метод asDict
Возвращает словарное представление строки, которая индексируется именами полей. Если есть повторяющиеся имена полей,
одно из повторяющихся полей (но только одно) будет возвращено в словарь. Какое повторяющееся поле возвращается, не определено.
Нет параметров.
Возвращает dict полей.
Преобразование типов
В следующей таблице типы данных Apache Spark SQL сопоставляются с их эквивалентами типов данных Python.
Тип данных Apache Spark SQL | Тип данных Python |
|---|---|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
 ndarray
ndarray  дата-время
дата-время Поиск и устранение неисправностей
tokenAuthWrapperInvalidAccessToken: недопустимый токен доступа сообщение
Проблема : при запуске кода вы видите сообщение, подобное Ошибка во время запроса к серверу: tokenAuthWrapperInvalidAccessToken: недопустимый токен доступа .
Возможная причина : значение, переданное в access_token , не является допустимым токеном личного доступа к Databricks.
Рекомендуемое исправление : убедитесь, что значение передано в access_token правильный и попробуйте еще раз.
gaierror(8, 'имя узла или имя сервера предоставлено или неизвестно') сообщение
Проблема : при запуске кода вы видите сообщение, похожее на Ошибка во время запроса к серверу: gaierror(8, ' имя узла или имя сервера не указано или неизвестно') .
Возможная причина : Значение, переданное в server_hostname , не является правильным именем хоста.
Рекомендуемое исправление : Убедитесь, что значение передано на server_hostname верно и повторите попытку.
Дополнительные сведения о поиске имени хоста сервера см. в разделе Получение сведений о соединении.
IpAclError сообщение
Проблема : при запуске кода вы видите сообщение Ошибка во время запроса к серверу: IpAclValidation при попытке использовать
разъем на ноутбуке Databricks.
Возможная причина : Возможно, для рабочей области Databricks включен список разрешенных IP-адресов. С разрешенным списком IP-адресов, соединений
из кластеров Spark обратно в плоскость управления по умолчанию не разрешены.
Рекомендуемое исправление : Попросите администратора добавить подсеть уровня данных в список разрешенных IP-адресов.