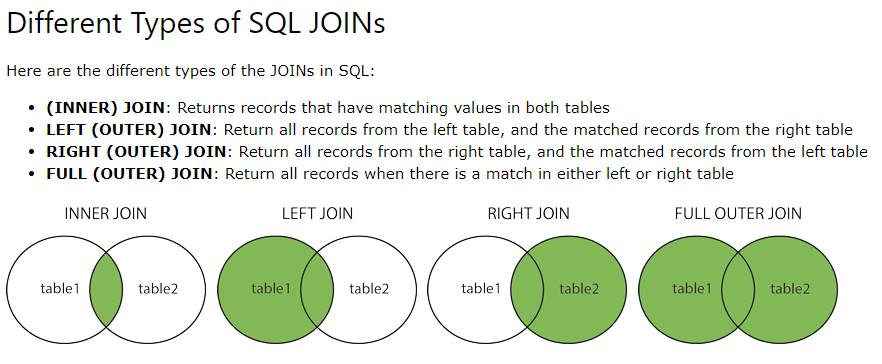
Sql inner join примеры: Оператор SQL INNER JOIN: синтаксис, примеры
Содержание
Как соединить две таблицы в PySpark с помощью JOIN
Иногда приходится работать с несколькими связанными таблицами сразу, причем требуется их каким-то образом соединять. В этом случае вам поможет операция JOIN в PySpark. Сегодня расскажем о INNER, LEFT, RIGHT и FULL JOIN, а также об особенности его применения.
Две таблицы
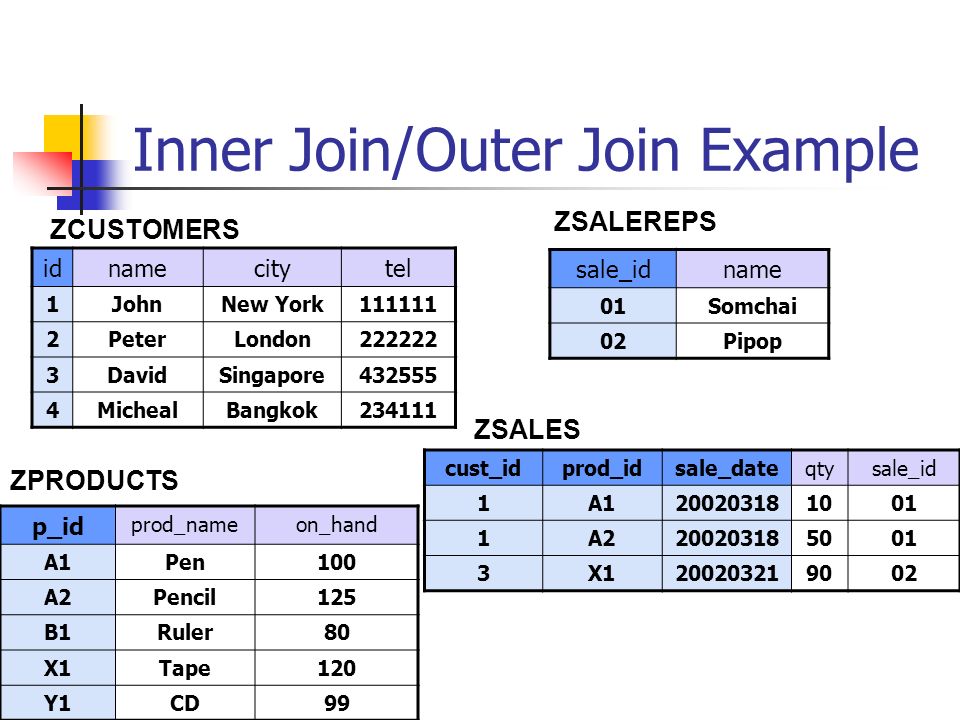
Допустим, имеется две таблицы. Первая таблицы с сотрудниками:
emp_data = [
(1, "Alexander", 2, 3500),
(2, "Roman", 1, 4500),
(3, "Tom", 1, 5500),
(4, "Alex", 3, 3000),
(5, "Arthur", 4, 4250),
(6, "Anna", 4, 3520),
(7, "Svetlana", 2, 3000),
(8, "Oleg", 5, 3200),
(9, "Felix", 1, 5500),
(10, "Olga", 5, 4970),
(11, "Anna", 4, 6320),
(12, "Tom", 3, 3500),
(13, "Felix", 4, 3520),
(14, "John", 2, 3500),
(15, "Finn", 5, 5570),
(16, "Polly", 3, 3800),
]
emp_schema = ["emp_id", "emp_name", "dept_id", "salary"]
emp = spark. createDataFrame(emp_data, emp_schema)
createDataFrame(emp_data, emp_schema)
 createDataFrame(emp_data, emp_schema)
createDataFrame(emp_data, emp_schema)
Вторая таблица с отделами:
dept_data = [
(1, "IT"),
(2, "Admin"),
(3, "HR"),
(4, "Finance"),
(6, "Marketing"),
]
dept_schema = ["dept_id", "dept_name"]
dept = spark.createDataFrame(dept_data, dept_schema)
Если мы еще раз взглянем на них. Ольга, Олег и Финн находятся в отделе под номером 5. Так вот во второй таблице нет отдела с таким номером. Но в ней есть отдел под номером 6, в который никто из сотрудников не входит. Эти знания нам пригодятся для изучения JOIN.
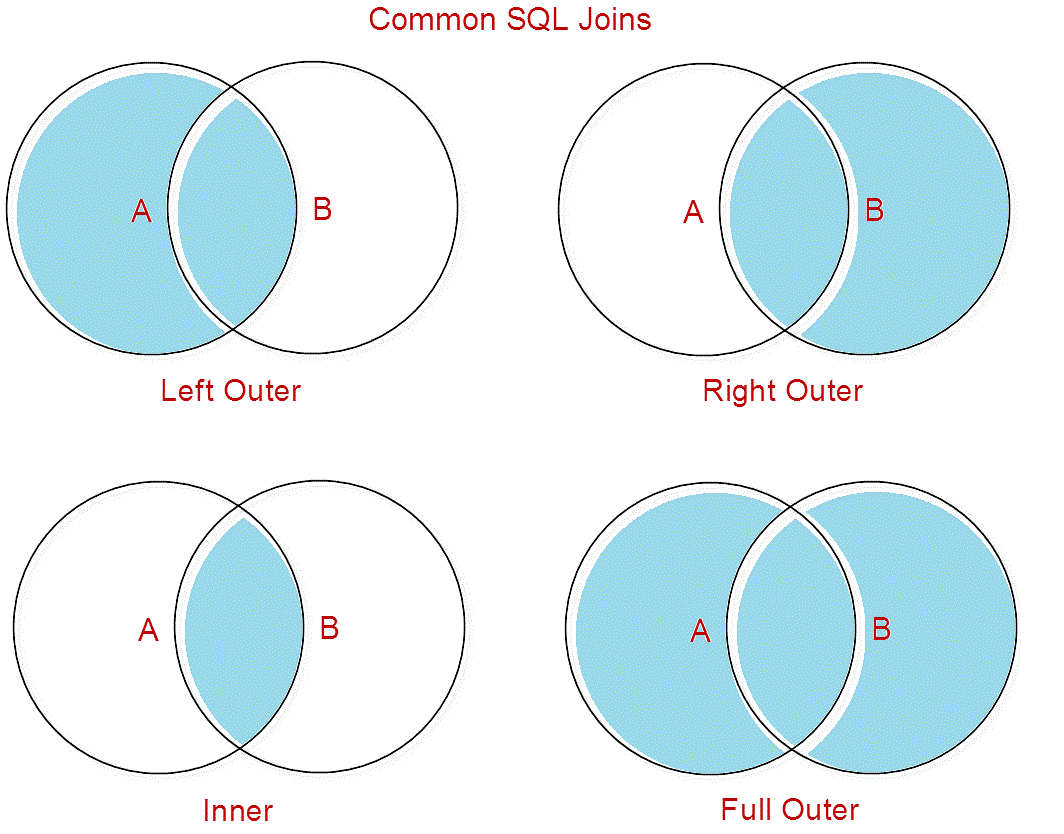
Синтаксис JOIN в PySpark
JOIN необходим для соединения нескольких таблиц. Есть следующие типы JOIN’ов:
INNER JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
В классическом SQL внутренние соединения строится из предложений FROM или WHERE. Внешние и перекрестные соединения строятся только из
Внешние и перекрестные соединения строятся только из FROM. Например, вот так выглядит внутреннее соединение в SQL:
SELECT e.emp_name, d.dept_name FROM employee e JOIN department d ON e.dept_id == d.dept_id
В PySpark соединения строятся из метода join, где первым параметром передается таблица для соединения, вторым — то самое условие ON, третьим — тип соединения (по умолчанию inner) [1].
INNER JOIN
Допустим нам нужно определить название отделов, в которые входят сотрудники. Как видим, в первой таблице даны только их номера. INNER JOIN выбирает записи из обеих таблиц только в том случае, если существует точные совпадения между ними. Так, например, 3 сотрудника состоят в неизвестном отделе, поскольку совпадений между ними и второй таблицей нет, то они не будут выбраны.
Итак, INNER JOIN в PySpark будет выглядеть одним из следующих образов:
# Некоторые способы вызова join.
 1-й -- самый явный
emp.join(dept, emp.dept_id == dept.dept_id, "inner")
emp.join(dept, emp.dept_id == dept.dept_id)
emp.join(dept, "dept_id")
"""
+-------+------+---------+------+---------+
|dept_id|emp_id| emp_name|salary|dept_name|
+-------+------+---------+------+---------+
| 1| 2| Roman| 4500| IT|
| 1| 3| Tom| 5500| IT|
| 1| 9| Felix| 5500| IT|
| 3| 4| Alex| 3000| HR|
| 3| 12| Tom| 3500| HR|
| 3| 16| Polly| 3800| HR|
| 2| 1|Alexander| 3500| Admin|
| 2| 7| Svetlana| 3000| Admin|
| 2| 14| John| 3500| Admin|
| 4| 5| Arthur| 4250| Finance|
| 4| 6| Anna| 3520| Finance|
| 4| 11| Anna| 6320| Finance|
| 4| 13| Felix| 3520| Finance|
+-------+------+---------+------+---------+
"""
1-й -- самый явный
emp.join(dept, emp.dept_id == dept.dept_id, "inner")
emp.join(dept, emp.dept_id == dept.dept_id)
emp.join(dept, "dept_id")
"""
+-------+------+---------+------+---------+
|dept_id|emp_id| emp_name|salary|dept_name|
+-------+------+---------+------+---------+
| 1| 2| Roman| 4500| IT|
| 1| 3| Tom| 5500| IT|
| 1| 9| Felix| 5500| IT|
| 3| 4| Alex| 3000| HR|
| 3| 12| Tom| 3500| HR|
| 3| 16| Polly| 3800| HR|
| 2| 1|Alexander| 3500| Admin|
| 2| 7| Svetlana| 3000| Admin|
| 2| 14| John| 3500| Admin|
| 4| 5| Arthur| 4250| Finance|
| 4| 6| Anna| 3520| Finance|
| 4| 11| Anna| 6320| Finance|
| 4| 13| Felix| 3520| Finance|
+-------+------+---------+------+---------+
"""
Как видим, три сотрудника из 5-го неизвестного отдела не были включены в результирующую таблицу.
LEFT JOIN в PySpark
При использовании LEFT JOIN выбираются записи, которые соответствуют второй таблице. Если совпадений нет, то возвращается null. Иными словами, таблица слева будет все записи.
Пример кода PySpark, который демонстрирует работу LEFT JOIN:
emp.join(dept, "dept_id", "left") """ +-------+------+---------+------+---------+ |dept_id|emp_id| emp_name|salary|dept_name| +-------+------+---------+------+---------+ | 5| 8| Oleg| 3200| null| | 5| 10| Olga| 4970| null| | 5| 15| Finn| 5570| null| | 1| 2| Roman| 4500| IT| | 1| 3| Tom| 5500| IT| | 1| 9| Felix| 5500| IT| | 3| 4| Alex| 3000| HR| | 3| 12| Tom| 3500| HR| | 3| 16| Polly| 3800| HR| | 2| 1|Alexander| 3500| Admin| | 2| 7| Svetlana| 3000| Admin| | 2| 14| John| 3500| Admin| | 4| 5| Arthur| 4250| Finance| | 4| 6| Anna| 3520| Finance| | 4| 11| Anna| 6320| Finance| | 4| 13| Felix| 3520| Finance| +-------+------+---------+------+---------+ """
Мы можем выбрать только нужные нам столбцы:
emp.
 join(dept, emp.dept_id == dept.dept_id, "left") \
.select("emp_name", "dept_name")
"""
+---------+---------+
| emp_name|dept_name|
+---------+---------+
| Oleg| null|
| Olga| null|
| Finn| null|
| Roman| IT|
| Tom| IT|
| Felix| IT|
| Alex| HR|
| Tom| HR|
| Polly| HR|
|Alexander| Admin|
| Svetlana| Admin|
| John| Admin|
| Arthur| Finance|
| Anna| Finance|
| Anna| Finance|
| Felix| Finance|
+---------+---------+
"""
join(dept, emp.dept_id == dept.dept_id, "left") \
.select("emp_name", "dept_name")
"""
+---------+---------+
| emp_name|dept_name|
+---------+---------+
| Oleg| null|
| Olga| null|
| Finn| null|
| Roman| IT|
| Tom| IT|
| Felix| IT|
| Alex| HR|
| Tom| HR|
| Polly| HR|
|Alexander| Admin|
| Svetlana| Admin|
| John| Admin|
| Arthur| Finance|
| Anna| Finance|
| Anna| Finance|
| Felix| Finance|
+---------+---------+
"""
Левое соединение можно рассматривать как: INNER JOIN + записи из левой таблицы.
RIGHT JOIN в PySpark
Следующий тип соединения — RIGHT JOIN. Очевидно, что он противоположный левому соединению. Правое соединение выбирает записи, которые совпадают с первой таблицей.
Пример RIGHT JOIN в PySpark:
emp.
 join(dept, emp.dept_id == dept.dept_id, "left")
"""
+------+---------+-------+------+-------+---------+
|emp_id| emp_name|dept_id|salary|dept_id|dept_name|
+------+---------+-------+------+-------+---------+
| null| null| null| null| 6|Marketing|
| 2| Roman| 1| 4500| 1| IT|
| 3| Tom| 1| 5500| 1| IT|
| 9| Felix| 1| 5500| 1| IT|
| 4| Alex| 3| 3000| 3| HR|
| 12| Tom| 3| 3500| 3| HR|
| 16| Polly| 3| 3800| 3| HR|
| 1|Alexander| 2| 3500| 2| Admin|
| 7| Svetlana| 2| 3000| 2| Admin|
| 14| John| 2| 3500| 2| Admin|
| 5| Arthur| 4| 4250| 4| Finance|
| 6| Anna| 4| 3520| 4| Finance|
| 11| Anna| 4| 6320| 4| Finance|
| 13| Felix| 4| 3520| 4| Finance|
+------+---------+-------+------+-------+---------+
"""
join(dept, emp.dept_id == dept.dept_id, "left")
"""
+------+---------+-------+------+-------+---------+
|emp_id| emp_name|dept_id|salary|dept_id|dept_name|
+------+---------+-------+------+-------+---------+
| null| null| null| null| 6|Marketing|
| 2| Roman| 1| 4500| 1| IT|
| 3| Tom| 1| 5500| 1| IT|
| 9| Felix| 1| 5500| 1| IT|
| 4| Alex| 3| 3000| 3| HR|
| 12| Tom| 3| 3500| 3| HR|
| 16| Polly| 3| 3800| 3| HR|
| 1|Alexander| 2| 3500| 2| Admin|
| 7| Svetlana| 2| 3000| 2| Admin|
| 14| John| 2| 3500| 2| Admin|
| 5| Arthur| 4| 4250| 4| Finance|
| 6| Anna| 4| 3520| 4| Finance|
| 11| Anna| 4| 6320| 4| Finance|
| 13| Felix| 4| 3520| 4| Finance|
+------+---------+-------+------+-------+---------+
"""
Здесь мы видим, что к отделу маркетинга никто не относится, поэтому он заполняется null-ами.
Если мы поменяем местами таблицы и используем левое соединение, то получим тот же результат:
dept.join(emp, "dept_id", "left")
FULL JOIN
FULL JOIN — это комбинация из левого и правого соединения. Иными словами, выдаст null для недостающих записей слева и справа.
Пример RIGHT JOIN в PySpark:
emp.join(dept, "dept_id", "full") """ +-------+------+---------+------+---------+ |dept_id|emp_id| emp_name|salary|dept_name| +-------+------+---------+------+---------+ | 6| null| null| null|Marketing| | 5| 8| Oleg| 3200| null| | 5| 10| Olga| 4970| null| | 5| 15| Finn| 5570| null| | 1| 2| Roman| 4500| IT| | 1| 3| Tom| 5500| IT| | 1| 9| Felix| 5500| IT| | 3| 4| Alex| 3000| HR| | 3| 12| Tom| 3500| HR| | 3| 16| Polly| 3800| HR| | 2| 1|Alexander| 3500| Admin| | 2| 7| Svetlana| 3000| Admin| | 2| 14| John| 3500| Admin| | 4| 5| Arthur| 4250| Finance| | 4| 6| Anna| 3520| Finance| | 4| 11| Anna| 6320| Finance| | 4| 13| Felix| 3520| Finance| +-------+------+---------+------+---------+ """
Помимо классических PySpark поддерживает еще разные типы соединений, с которыми можете ознакомиться в документации [1]. Также отметим, что результат операции соединения легко понять, однако то, что стоит “под капотом” уже другое дело. Если вы применяли соединения в своих запросов, то заметили, что даже для маленьких таблиц она выполняется не быстро. Это связано с перетасовкой (shuffle). Дело в том, что в одном исполнителе могут не оказаться совпадающих записей, поэтому запуститься перетасовка. Последующая операция преобразования также потребует совершить эту перетасовку. В этом случае мы можем разве что уменьшить их количество. Как это сделать рассказывали в отдельной статье, также используйте бакетирование.
Также отметим, что результат операции соединения легко понять, однако то, что стоит “под капотом” уже другое дело. Если вы применяли соединения в своих запросов, то заметили, что даже для маленьких таблиц она выполняется не быстро. Это связано с перетасовкой (shuffle). Дело в том, что в одном исполнителе могут не оказаться совпадающих записей, поэтому запуститься перетасовка. Последующая операция преобразования также потребует совершить эту перетасовку. В этом случае мы можем разве что уменьшить их количество. Как это сделать рассказывали в отдельной статье, также используйте бакетирование.
Core Spark — основы для разработчиков
А о том, как использовать соединение таблиц наиболее оптимальным способом вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
Записаться на курс
Смотреть раcписание
Источники
- join docs
14) SQL-соединения (примеры) — CoderLessons.
 com
com
Что такое Join в СУБД?
Объединение в СУБД – это бинарная операция, которая позволяет объединить продукт объединения и выбор в одном выражении. Цель создания условия соединения состоит в том, что оно помогает объединить данные из двух или более таблиц СУБД. Таблицы в СУБД связаны с использованием первичного ключа и внешних ключей.
В этом уроке по СУБД вы узнаете:
- Типы Присоединения
- Внутреннее соединение
- Тета Присоединиться
- EQUI присоединиться:
- Естественное соединение (⋈)
- Внешнее соединение
- Левое внешнее соединение (A B)
- Правое внешнее соединение (A B)
- Полное внешнее соединение (A B)
Типы Присоединения
В СУБД в основном есть два типа соединений:
- Внутренние объединения: Theta, Natural, EQUI
- Внешнее соединение: слева, справа, полностью
Давайте посмотрим на них подробно:
Внутреннее соединение
INNER JOIN используется для возврата строк из обеих таблиц, которые удовлетворяют данному условию. Это наиболее широко используемая операция соединения и может рассматриваться как тип соединения по умолчанию
Это наиболее широко используемая операция соединения и может рассматриваться как тип соединения по умолчанию
Внутреннее соединение или equijoin – это соединение на основе компаратора, которое использует сравнения равенства в предикате соединения. Однако, если вы используете другие операторы сравнения, такие как «>», это нельзя назвать equijoin.
Inner Join далее делится на три подтипа:
- Тета присоединиться
- Естественное соединение
- EQUI присоединиться
Тета Присоединиться
THETA JOIN позволяет объединять две таблицы на основе условия, представленного theta. Тета объединяет работу для всех операторов сравнения. Обозначается символом θ . Общий случай операции JOIN называется тэта-соединением.
Синтаксис:
A ⋈θ B
Тета-соединение может использовать любые условия в критериях выбора.
Рассмотрим следующие таблицы.
| Таблица А | Таблица Б | |||
| колонка 1 | колонка 2 | колонка 1 | колонка 2 | |
| 1 | 1 | 1 | 1 | |
| 1 | 2 | 1 | 3 | |
Например:
A ⋈ A.
 column 2 > B.column 2 (B)
column 2 > B.column 2 (B)| A ⋈ A.column 2> B.column 2 (B) | |
| колонка 1 | колонка 2 |
| 1 | 2 |
EQUI Присоединиться
EQUI JOIN выполняется, когда соединение Theta использует только условие эквивалентности. Объединение EQUI является наиболее сложной операцией, которую можно эффективно реализовать в СУБД, и одной из причин, по которой СУБД имеют существенные проблемы с производительностью.
Например:
A ⋈ A.column 2 = B.column 2 (B)
| A ⋈ A.column 2 = B.column 2 (B) | |
| колонка 1 | колонка 2 |
| 1 | 1 |
Естественное соединение (⋈)
NATURAL JOIN не использует ни один из операторов сравнения.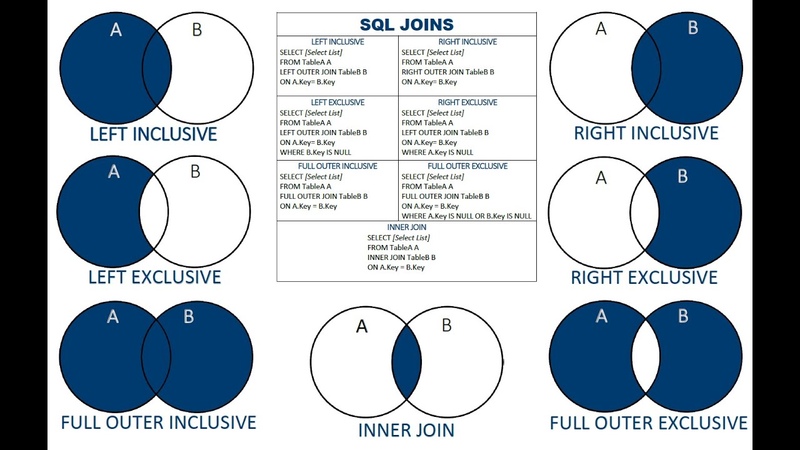 В этом типе объединения атрибуты должны иметь одинаковые имя и домен. В Natural Join должен быть хотя бы один общий атрибут между двумя отношениями.
В этом типе объединения атрибуты должны иметь одинаковые имя и домен. В Natural Join должен быть хотя бы один общий атрибут между двумя отношениями.
Он выполняет выборку, формируя равенство для тех атрибутов, которые появляются в обоих отношениях, и удаляет дубликаты атрибутов.
Пример:
Рассмотрим следующие две таблицы
| С | |
| Num | Квадрат |
| 2 | 4 |
| 3 | 9 |
| D | |
| Num | куб |
| 2 | 8 |
| 3 | 18 |
C ⋈ D
| C ⋈ D | ||
| Num | Квадрат | куб |
| 2 | 4 | 8 |
| 3 | 9 | 18 |
Внешнее соединение
OUTER JOIN не требуется каждая запись в два объединении таблиц , чтобы иметь соответствующую запись. При таком типе соединения таблица сохраняет каждую запись, даже если не существует другой подходящей записи.
При таком типе соединения таблица сохраняет каждую запись, даже если не существует другой подходящей записи.
Три типа внешних соединений:
- Левое внешнее соединение
- Правое внешнее соединение
- Полное внешнее соединение
Левое внешнее соединение (A B)
LEFT JOIN возвращает все строки из таблицы слева, даже если в таблице справа не найдено подходящих строк. Если в таблице справа не найдено ни одной подходящей записи, возвращается NULL.
Рассмотрим следующие 2 таблицы
| A | |
| Num | Квадрат |
| 2 | 4 |
| 3 | 9 |
| 4 | 16 |
| В | |
| Num | куб |
| 2 | 8 |
| 3 | 18 |
| 5 | 75 |
A B
| A ⋈ B | ||
| Num | Квадрат | куб |
| 2 | 4 | 8 |
| 3 | 9 | 18 |
| 4 | 16 | – |
Правое внешнее соединение (A B)
RIGHT JOIN возвращает все столбцы из таблицы справа, даже если в таблице слева не найдено подходящих строк. Если в таблице слева не найдено совпадений, возвращается NULL. ПРАВИЛЬНОЕ внешнее СОЕДИНЕНИЕ – противоположность ЛЕВОГО СОЕДИНЕНИЯ
Если в таблице слева не найдено совпадений, возвращается NULL. ПРАВИЛЬНОЕ внешнее СОЕДИНЕНИЕ – противоположность ЛЕВОГО СОЕДИНЕНИЯ
В нашем примере давайте предположим, что вам нужно получить имена участников и фильмы, взятые ими напрокат. Теперь у нас есть новый участник, который еще не арендовал ни одного фильма.
A B
| A ⋈ B | ||
| Num | куб | Квадрат |
| 2 | 8 | 4 |
| 3 | 18 | 9 |
| 5 | 75 | – |
Полное внешнее соединение (A B)
В FULL OUTER JOIN все кортежи из обоих отношений включаются в результат независимо от условия соответствия.
Пример:
A B
| A ⋈ B | ||
| Num | Квадрат | куб |
| 2 | 4 | 8 |
| 3 | 9 | 18 |
| 4 | 16 | – |
| 5 | – | 75 |
Резюме:
- В СУБД есть в основном два типа соединений 1) Внутреннее соединение 2) Внешнее соединение
- Внутреннее соединение является широко используемой операцией соединения и может рассматриваться как тип соединения по умолчанию.
- Внутреннее соединение подразделяется на три подтипа: 1) тета-соединение 2) естественное соединение 3) EQUI соединение
- Theta Join позволяет объединить две таблицы на основе условия, представленного theta
- Когда тэта-соединение использует только условие эквивалентности, оно становится равным соединению.
- При естественном объединении не используются операторы сравнения.
- Внешнее соединение не требует, чтобы каждая запись в двух таблицах соединения имела соответствующую запись.
- Наружное соединение далее подразделяется на три подтипа: 1) левое внешнее соединение 2) правое внешнее соединение 3) полное внешнее соединение
- Функция LEFT Outer Join возвращает все строки из таблицы слева, даже если в таблице справа не найдено соответствующих строк.
- RIGHT Outer Join возвращает все столбцы из таблицы справа, даже если в таблице слева не найдено подходящих строк.
- При полном внешнем объединении все кортежи из обоих отношений включаются в результат независимо от условия соответствия.


Начало работы с SQL INNER JOIN
Автор: Джим Эванс |
Обновлено: 2021-06-02 |
Комментарии (1) | Связанный: Подробнее > JOIN Tables
Проблема
SQL Server — это реляционная база данных, в которой таблицы спроектированы таким образом, чтобы
у них обычно есть первичный ключ, а отношения между таблицами устанавливаются путем определения
внешний ключ в других связанных таблицах. Например, таблица Vendor будет иметь
первичный ключ или уникальный идентификатор, назначенный каждой записи поставщика в таблице. А
связанная таблица, такая как таблица заказов на покупку, будет иметь ссылку на поставщика
записи, включив уникальный идентификатор, связанный с поставщиком, в качестве внешнего ключа.
При написании кода T-SQL, как вы соединяете такие таблицы, чтобы возвращать комбинированные данные?
Результаты?
Решение
Для объединения таблиц в T-SQL используется один из нескольких операторов соединения. В этом
Совет, мы сосредоточимся на самом основном типе соединения, ВНУТРЕННЕМ СОЕДИНЕНИИ. Другое присоединиться
Другое присоединиться
условия
включают LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN и SELF
ПРИСОЕДИНИТЬСЯ. Эти
можно прочитать в других ссылках на советы далее в этой статье. В этой статье
Я буду использовать примеры из базы данных Microsoft Sample.
ПриключенияВоркс.
Что такое ВНУТРЕННЕЕ СОЕДИНЕНИЕ
В T-SQL соединение — это термин, используемый для объединения записей из 2 или более таблиц.
что является эквивалентным соединением.
INNER JOIN — это базовая стандартная форма соединения. Объединение таблиц выполняется в
предложение FROM оператора T-SQL с использованием ключевого слова INNER JOIN
или ПРИСОЕДИНЯЙТЕСЬ. В этом совете я буду использовать полностью написанные ключевые слова INNER JOIN, чтобы четко
отличается от других типов соединения.
Когда использовать ВНУТРЕННЕЕ СОЕДИНЕНИЕ
INNER JOIN используется, когда вы хотите соединить записи из таблиц, и вы только
хотите вернуть строки с соответствующими записями. В нашем первом примере мы покажем
использование предложения INNER JOIN для возврата записей от поставщиков, у которых есть заказы на покупку.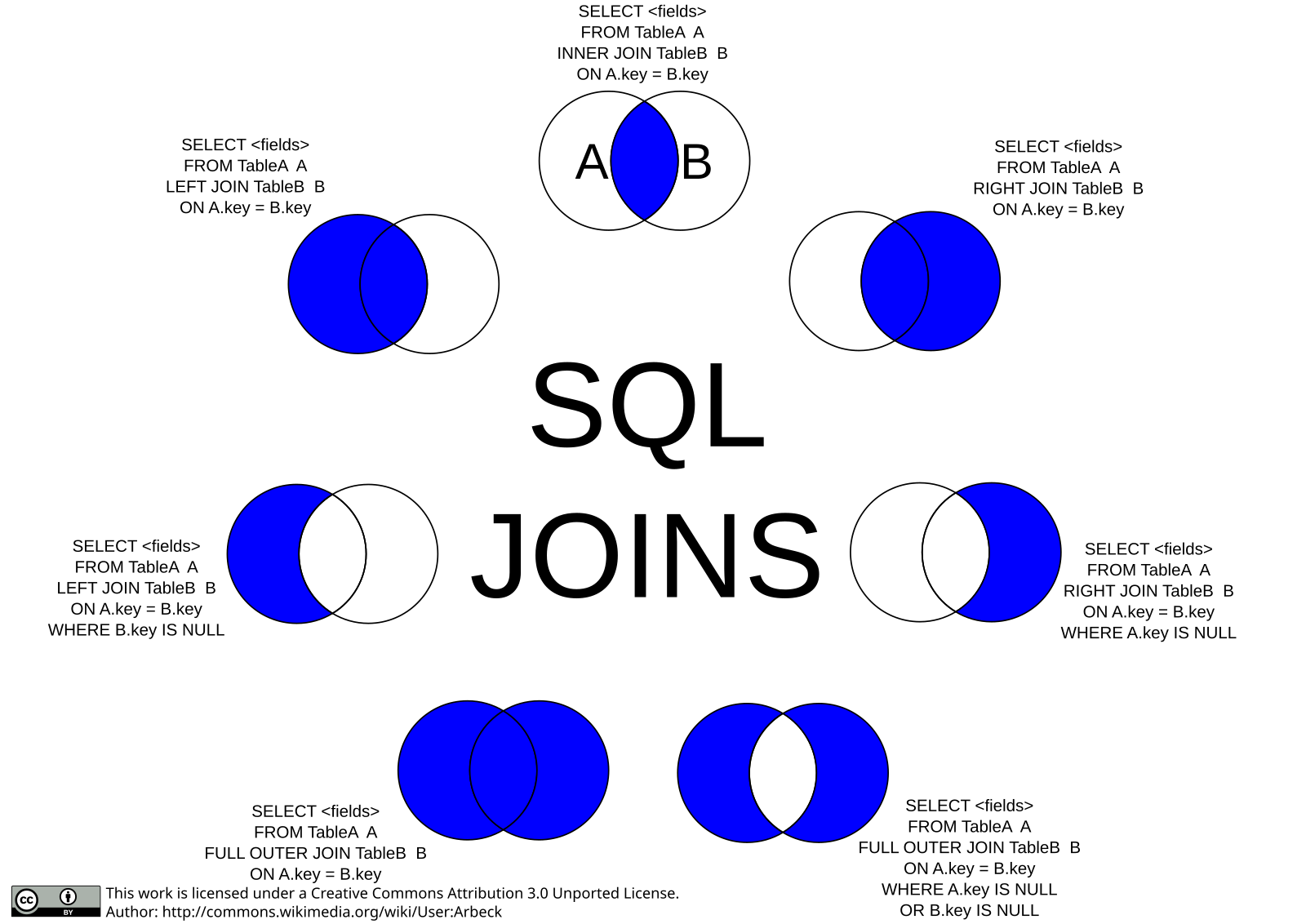
Любые поставщики, у которых нет заказов на покупку, не будут возвращены.
SQL INNER JOIN Пример 1 — поставщик к PurchaseOrderHeader
В этом примере мы вернем все записи PurchaseOrderHeader с соответствующими строками для
каждый поставщик с
ВЫБЕРИТЕ заявление. Первичным ключом таблицы Vendor (левая таблица) является BusinessEntityId, и он
ссылки на поле VendorID в таблице PurchaseOrderheader (правая таблица). Мы будем использовать
Синтаксис INNER JOIN и ON, указывающий имена столбцов из каждой таблицы, к которой мы присоединяемся.
Обратите внимание, что я использую псевдонимы таблиц в качестве ярлыка для обозначения того, в какой таблице находится каждый столбец.
выбор исходит от (v для поставщика и po для PurchaseOrderHeader).
Вот синтаксис JOIN в следующем запросе:
--Пример 1: Заказы на покупку по поставщику ВЫБИРАТЬ v.BusinessEntityID, v.Номер счета, v.Имя, po.PurchaseOrderID, po.VendorID, po.OrderDate, po.SubTotal, po.
 TaxAmt,
по.Фрейт,
po.TotalDue
ОТ [Закупки].[Поставщик] как v
INNER JOIN [Purchasing].[PurchaseOrderHeader] as po ON po.VendorID = v.BusinessEntityID
ЗАКАЗАТЬ ПО po.OrderDate, v.BusinessEntityID;
ИДТИ
TaxAmt,
по.Фрейт,
po.TotalDue
ОТ [Закупки].[Поставщик] как v
INNER JOIN [Purchasing].[PurchaseOrderHeader] as po ON po.VendorID = v.BusinessEntityID
ЗАКАЗАТЬ ПО po.OrderDate, v.BusinessEntityID;
ИДТИ
Пример 1 Результаты
Обратите внимание, что v.BusinessEntityId и po.VendorID, к которым мы присоединились, имеют
одинаковые значения в результатах. Показан частичный набор результатов.
SQL INNER JOIN Пример 2 — поставщик для заказа на поставку с деталями заказа
В следующем примере я создам первый запрос и, используя INNER JOIN,
добавьте дополнительные таблицы, чтобы перейти к строкам сведений о заказе и показать связанный с ним продукт
с каждой строкой сведений о заказе. На диаграмме ниже показаны 4 стола, за которыми я буду
присоединение с INNER JOIN.
В этом примере я показываю четыре таблицы, объединенные с помощью ВНУТРЕННЕГО СОЕДИНЕНИЯ.
--Пример 2: Заказы на покупку с подробной информацией по поставщику ВЫБИРАТЬ po.
 VendorID,
v.Номер счета,
v.Имя,
po.PurchaseOrderID,
pod.ProductID,
п.номер продукта,
р.Имя,
pod.OrderQty,
pod.UnitPrice,
pod.LineTotal
ОТ [Закупки].[Поставщик] как v
INNER JOIN [Purchasing].[PurchaseOrderHeader] as po ON po.VendorID = v.BusinessEntityID
INNER JOIN [Purchasing].[PurchaseOrderDetail] как pod ON pod.PurchaseOrderID = po.PurchaseOrderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [Производство].[Продукт] as p ON p.ProductID = pod.ProductID
ЗАКАЗ ПО pod.PurchaseOrderID, pod.ProductID;
ИДТИ
VendorID,
v.Номер счета,
v.Имя,
po.PurchaseOrderID,
pod.ProductID,
п.номер продукта,
р.Имя,
pod.OrderQty,
pod.UnitPrice,
pod.LineTotal
ОТ [Закупки].[Поставщик] как v
INNER JOIN [Purchasing].[PurchaseOrderHeader] as po ON po.VendorID = v.BusinessEntityID
INNER JOIN [Purchasing].[PurchaseOrderDetail] как pod ON pod.PurchaseOrderID = po.PurchaseOrderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [Производство].[Продукт] as p ON p.ProductID = pod.ProductID
ЗАКАЗ ПО pod.PurchaseOrderID, pod.ProductID;
ИДТИ
Пример 2 Результаты
Ввод результатов 4 соединенных таблиц с INNER JOIN на Vendor Aurora
Bike Center, идентификатор заказа на поставку 8 содержит 5 деталей строки заказа, показывающих некоторые очень
дорогие продукты для стопорных шайб. Показан частичный набор результатов.
Следующие шаги
Эти примеры INNER JOIN типичны для T-SQL, которые можно использовать для моделирования таблиц.
объединяйте запросы, соответствующие потребностям вашей базы данных. Ниже приведены ссылки на др.
Ниже приведены ссылки на др.
Руководства по SQL, в которых больше рассказывается о других типах соединений T-SQL.
- Все
Руководства по SQL JOIN на MSSQLTips.com - Узнать больше о
SQL Server T-SQL
- Подробнее о СОЕДИНЕНИЯХ:
Примеры SQL LEFT JOIN
- Читать о
Выбор данных из нескольких таблиц SQL Server
- Узнать о
ВНУТРЕННИЕ СОЕДИНЕНИЯ SSQL Server с предложением WHERE и логикой ORDER BY
Об авторе
Джим Эванс в настоящее время является ИТ-менеджером Crowe, который более 20 лет руководил группами администраторов баз данных, разработчиков, специалистов по бизнес-аналитике и управлению данными.
Посмотреть все мои советы
Последнее обновление статьи: 2021-06-02
SQLite INNER JOIN с примерами
Резюме : в этом руководстве показано, как использовать предложение внутреннего соединения SQLite для запроса данных из нескольких таблиц.
Введение в предложение внутреннего соединения SQLite
В реляционных базах данных данные часто распределяются по многим связанным таблицам. Таблица связана с другой таблицей с помощью внешних ключей.
Таблица связана с другой таблицей с помощью внешних ключей.
Чтобы запросить данные из нескольких таблиц, используйте ВНУТРЕННЕЕ СОЕДИНЕНИЕ . Предложение INNER JOIN объединяет столбцы из связанных таблиц.
Предположим, у вас есть две таблицы: A и B.
A содержит столбцы a1, a2 и f. B имеет столбцы b1, b2 и f. Таблица A связывается с таблицей B с помощью столбца внешнего ключа с именем f.
Ниже показан синтаксис предложения внутреннего соединения:
SELECT a1, a2, b1, b2 ИЗ ВНУТРЕННЕЕ СОЕДИНЕНИЕ B на B.f = A.f; Язык кода: SQL (язык структурированных запросов) (sql)
Для каждой строки в таблице A предложение INNER JOIN сравнивает значение столбца f со значением столбца f в таблице B. Если значение столбца f в таблице A равно значению столбца f в таблице B, он объединяет данные из столбцов a1, a2, b1, b2 и включает эту строку в результирующий набор.
Другими словами, предложение INNER JOIN возвращает строки из таблицы A, которым соответствует строка в таблице B.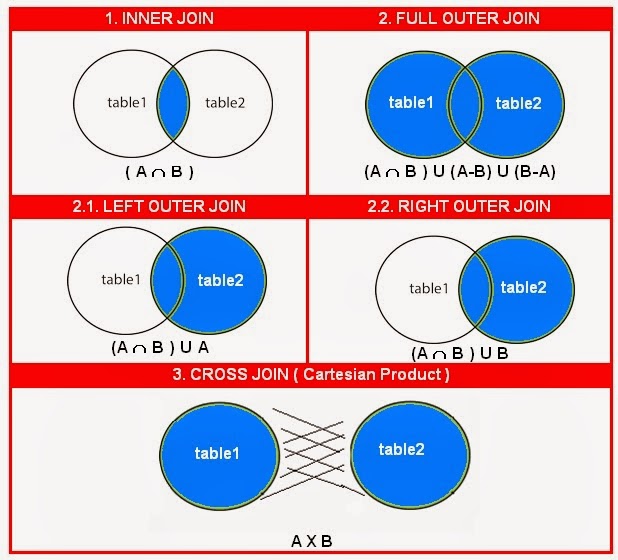
Эта логика применяется, если вы объединяете более 2 таблиц.
См. следующий пример.
В результирующий набор включаются только строки в таблице A: (a1,1), (a3,3) с соответствующими строками в таблице B (b1,1), (b2,3).
На следующей диаграмме показано предложение INNER JOIN :
SQLite
INNER JOIN примеры
. Таблица треков связана с таблицей альбомов через AlbumId столбец.
В таблице track столбец AlbumId является внешним ключом. А в таблице альбомов AlbumId является первичным ключом.
Чтобы запросить данные из таблиц дорожек и альбомов , используйте следующую инструкцию:
SELECT идентификатор, имя, заголовок ОТ треки ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid; Язык кода: SQL (язык структурированных запросов) (sql)
Попробуйте
Для каждой строки в таблице tracks SQLite использует значение в столбце Albumid таблицы Tracks для сравнения со значением в Albumid таблицы Albums . Если SQLite находит совпадение, он объединяет данные строк в обеих таблицах в результирующем наборе.
Если SQLite находит совпадение, он объединяет данные строк в обеих таблицах в результирующем наборе.
Вы можете включить столбцы AlbumId из обеих таблиц в окончательный набор результатов, чтобы увидеть эффект.
ВЫБОР
идентификатор,
имя,
треки.albumid как Album_id_tracks,
альбомы.albumid КАК альбом_id_albums,
заголовок
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid; Язык кода: SQL (язык структурированных запросов) (sql) Попробуйте
Внутреннее соединение SQLite — пример 3 таблиц
См. следующие таблицы: треков альбомов и исполнителей 9 0003
Одна дорожка принадлежит один альбом и один альбом имеют много треков. Таблица треков связана с таблицей альбомов через столбец альбомов .
Один альбом принадлежит одному исполнителю, и у одного исполнителя один или несколько альбомов.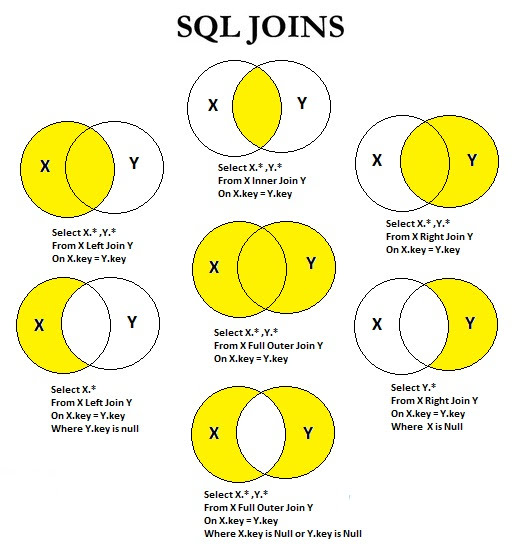
альбомов таблица ссылается на таблицу исполнителей через столбец artistid .
Для запроса данных из этих таблиц необходимо использовать два внутренних предложения соединения в операторе SELECT следующим образом:
SELECT
идентификатор,
треки.название как трек,
альбомы.название КАК альбом,
artist.name КАК исполнитель
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ исполнителей ON artists.artistid = Albums.artistid; Язык кода: SQL (язык структурированных запросов) (sql) Попробуйте
Вы можете использовать предложение WHERE для получения треков и альбомов исполнителя с идентификатором 10 в виде следующего оператора:
SELECT
идентификатор,
tracks.name AS Трек,
альбомы.название КАК Альбом,
Artists.name AS Художник
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ исполнителей ON Artists.
