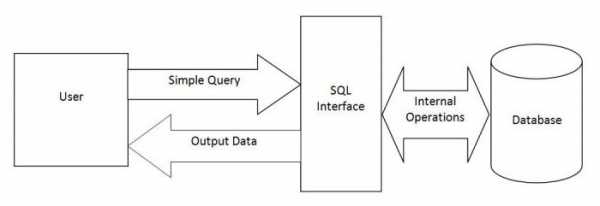
36.Основные операторы языка sql. Оператор select: назначение, формат оператора. Sql основные операторы
история, стандарты, основные операторы языка
Структурированный язык запросов SQL: история, стандарты,
основные операторы языка.
Структурированный язык запросов SQL основан на реляционном исчислении с переменными кортежами. Язык имеет несколько стандартов. Язык SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблиц (выборка, изменение, добавление и удаление), а также некоторых сопутствующих операций. SQL является непроцедурным языком и не содержит операторов управления, организации подпрограмм, ввода- вывода и т.п. В связи с этим SQL автономно не используется, обычно он погружен в среду встроенного языка программирования СУБД (например, FoxPro СУБД Visual FoxPro, ObjectPAL СУБД Paradox, Visual Basic for Applications СУБД Access).
В современных СУБД с интерактивным интерфейсом можно создавать запросы, используя другие средства, например QBE. Однако применение SQL зачастую позволяет повысить эффективность обработки данных в базе. Например, при подготовке запроса в среде Access можно перейти из окна Конструктора запросов (формулировки запроса по образцу на языке QBE) в окно с эквивалентным оператором SQL. Подготовку нового запроса путем редактирования уже имеющегося в ряде случае проще выполнить путем изменения оператора SQL. В различных СУБД состав операторов SQL может несколько отличаться. Язык SQL не обладает функциями полноценного языка разработки, а ориентирован на доступ к данным, поэтому его включают в состав средств разработки программ. В этом случае его называют встроенным SQL. Стандарт языка SQL поддерживают современные реализации следующих языков программирования: PL/1, Ada, С, COBOL, Fortran, MUMPS и Pascal.
В специализированных системах разработки приложений типа клиент-сервер среда программирования, кроме того, обычно дополнена коммуникационными средствами (установление и разъединение соединений с серверами БД, обнаружение и обработка возникающих в сети ошибок и т.д.), средствами разработки пользовательских интерфейсов, средствами проектирования и отладки. Различают два основных метода использования встроенного SQL: статический и динамический. При статическом использовании языка (статический SQL) в тексте программы имеются вызовы функций языка SQL, которые жестко включаются в выполняемый модуль после компиляции.
Изменения в вызываемых функциях могут быть на уровне отдельных параметров вызовов с помощью переменных языка программирования. При динамическом использовании языка (динамический SQL) предполагается динамическое построение вызовов SQL функций и интерпретация этих вызовов, например, обращение к данным удаленной базы, в ходе выполнения программы. Динамический метод обычно применяется в случаях, когда в приложении заранее неизвестен вид SQL- вызова и он строится в диалоге с пользователем. Основным назначением языка SQL (как и других языков для работы с базами данных) является подготовка и выполнение запросов. В результате выборки данных из одной или нескольких таблиц может быть получено множество записей, называемое представлением. Представление по существу является таблицей, формируемой в результате выполнения запроса. Можно сказать, что оно является разновидностью хранимого запроса. По одним и тем же таблицам можно построить несколько представлений. Само представление описывается путем указания идентификатора представления и запроса, который должен быть выполнен для его получения.
Для удобства работы с представлениями в язык SQL введено понятие курсора. Курсор представляет собой своеобразный указатель, используемый для перемещения по наборам записей при их обработке. Описание и использование курсора в языке SQL выполняется следующим образом. В описательной части программы выполняют связывание переменной типа курсор (CURSOR) с оператором SQL (обычно с оператором SELECT). В выполняемой части программы производится открытие курсора (OPEN <имя курсора>), перемещение курсора по записям (FETCH <имя курсора>...), сопровождаемое соответствующей обработкой, и, наконец, закрытие курсора (CLOSE <имя курсора>).
Основные операторы языка
Опишем минимальное подмножество языка SQL, опираясь на его реализацию в стандартном интерфейсе ODBC (Open Database Connectivity совместимость открытых баз данных) фирмы Microsoft. Операторы языка SQL можно условно разделить на два подъязыка: язык определения данных (Data Definition Language DDL) и язык манипулирования данными (Data Manipulation Language-DML).Основные операторы языка SQL представлены в таблице.
Рассмотрим формат и основные возможности важнейших операторов, за исключением специфических операторов, отмеченных в таблице символом «*». Несущественные операнды и элементы синтаксиса (например, принятое во многих системах программирования правило ставить «;» в конце оператора) будем опускать.
1. Оператор создания таблицы имеет формат вида:
CREATE TABLE <имя таблицы>
(<имя столбца> <тип данных> [NOT NULL]
[,<имя столбца> <тип данных> [NOT NULL]]... )
Обязательными операндами оператора являются имя создаваемой таблицы и имя хотя бы одного столбца (поля) с указанием типа данных, хранимых в этом столбце.
При создании таблицы для отдельных полей могут указываться некоторые дополнительные правила контроля вводимых в них значений. Конструкция NOT NULL (не пустое) служит именно таким целям и для столбца таблицы означает, что в этом столбце должно быть определено значение.
Операторы языка SQL
| Вид | Название | Назначение |
| DDL | CREATE TABLE DROP TABLE ALTER TABLE CREATE INDEX DROP INDEX CREATE VIEW DROP VIEW GRAND* REVOKE* | создание таблицы удаление таблицы изменение структуры таблицы создание индекса удаление индекса создание представления удаление представления назначение привилегий удаление привилегий |
| DML | SELECT UPDAT INSERT DELETE | выборка записей изменение записей вставка новых записей удаление записей |
В общем случае в разных СУБД могут использоваться различныетипы данных. В интерфейсе ODBC поддерживаются свои стандартные типы данных, например, символьные (SQL_CHAR, SQL_VARCHAR, SQL_LONGVARCHAR) и др. При работе с БД некоторой СУБД посредством интерфейса ODBC выполняется автоматическое преобразование стандартных типов данных, поддерживаемых интерфейсом, в типы данных источников и обратно. При необходимости обмен данными между программой и источником данных может вестись без преобразования во внутреннем формате данных источника.
Пример 1. Создание таблицы.
Пусть требуется создать таблицу goods описания товаров, имеющую поля: type вид товара, comp_id идентификатор компании-производителя, name название товара и price цена товара. Оператор определения таблицы может иметь следующий вид:
CREATE TABLE goods (type SQL_CHAR(8) NOT NULL,
comp_id SQL_CHAR(10) NOT NULL, name SQL_VARCHAR(20),
price SQL_DECIMAL(8,2)).
2. Оператор изменения структуры таблицы имеет формат вида:
ALTER TABLE <имя таблицы>
({ADD, MODIFY, DROP} <имя столбца> [<тип данных>] [NOT NULL]
[,{ADD, MODIFY, DROP} <имя столбца> [<тип данных>][NOT NULL]]...)
Изменение структуры таблицы может состоять в добавлении (ADD), изменении (MODIFY) или удалении (DROP) одного или нескольких столбцов таблицы. Правила записи оператора ALTER TABLE такие же, как и оператора CREATE TABLE. При удалении столбца указывать <тип данных> не нужно.
3. Оператор удаления таблицы имеет формат вида:
DROP TABLE <имя таблицы>
Оператор позволяет удалить имеющуюся таблицу. Например, для удаления таблицы с именем items достаточно записать оператор вида: DROP TABLE items.
4. Оператор создания индекса имеет формат вида:
CREATE [UNIQUE] INDEX <имя индекса>
ON <имя таблицы>
(<имя столбца> [ ASC | DESC ]
[,<имя столбца> [ ASC | DESC ]... )
Оператор позволяет создать индекс для одного или нескольких столбцов заданной таблицы с целью ускорения выполнение запросных и поисковых операций с таблицей. Для одной таблицы можно создать несколько индексов.Задав необязательную опцию UNIQUE, можно обеспечить уникальность значений во всех указанных в операторе столбцах. По существу, создание индекса с указанием признака UNIQUE означает определение ключа в созданной ранее таблице. При создании индекса можно задать порядок автоматической сортировки значений в столбцах в порядке возрастания ASC (по умолчанию), или в порядке убывания DESC. Для разных столбцов можно задавать различный порядок сортировки.
5. Оператор удаления индекса имеет формат вида:
DROP INDEX <имя индекса>
Этот оператор позволяет удалять созданный ранее индекс с соответствующим именем. Так, например, для уничтожения индекса main_indx к таблице emp достаточно записать оператор DROP INDEX main_indx.
6. Оператор создания представления имеет формат вида:
CREATE VIEW <имя представления>
[(<имя столбца> [,<имя столбца> ]...)]
AS <оператор SELECT>
Данный оператор позволяет создать представление. Если имена столбцов в представлении не указываются, то будут использоваться имена столбцов из запроса, описываемого соответствующим оператором SELECT.
7. Оператор удаления представления имеет формат вида:
DROP VIEW <имя представления>
Оператор позволяет удалить созданное ранее представление. Заметим, что при удалении представления таблицы, участвующие в запросе, удалению не подлежат. Удаление представления герг производится оператором вида: DROP VIEW repr.
8. Оператор выборки записей имеет формат вида:
SELECT [ALL | DISTINCT]
<список данных>
FROM <список таблиц>
[WHERE <условие выборки>]
[GROUP BY <имя столбца> [,<имя столбца>] ... ]
[HAVING <условие поиска>]
[ORDER BY <спецификация> [,<спецификация>]...]
Это наиболее важный оператор из всех операторов SQL. Функциональные возможности его огромны. Рассмотрим основные из них. Оператор SELECT позволяет производить выборку и вычисления над данными из одной или нескольких таблиц. Результатом выполнения оператора является ответная таблица, которая может иметь (ALL), или не иметь (DISTINCT) повторяющиеся строки. По умолчанию в ответную таблицу включаются все строки, в том числе и повторяющиеся. В отборе данных участвуют записи одной или нескольких таблиц, перечисленных в списке операнда FROM. Список данных может содержать имена столбцов, участвующих в запросе, а также выражения над столбцами. В простейшем случае в выражениях можно записывать имена столбцов, знаки арифметических операций (+, , *, /), константы и круглые скобки. Если в списке данных записано выражение, то наряду с выборкой данных выполняются вычисления, результаты которого попадают в новый (создаваемый) столбец ответной таблицы. При использовании в списках данных имен столбцов нескольких таблиц для указания принадлежности столбца некоторой таблице применяют конструкцию вида: <имя таблицы>.<имя столбца>.
Операнд WHERE задает условия, которым должны удовлетворять записи в результирующей таблице. Выражение <условие выборки> является логическим. Его элементами могут быть имена столбцов, операции сравнения, арифметические операции, логические связки (И, ИЛИ, НЕТ), скобки, специальные функции LIKE, NULL, IN и т.д. Операнд GROUP BY позволяет выделять в результирующем множестве записей группы.
9. Оператор изменения записей имеет формат вида:
UPDATE <имя таблицы>
SET <имя столбца> = {<выражение> , NULL }
[, SET <имя столбца> = {<выражение> , NULL}... ]
[WHERE <условие>]
Выполнение оператора UPDATE состоит в изменении значений в определенных операндом SET столбцах таблицы для тех записей, которые удовлетворяют условию, заданному операндом WHERE. Новые значения полей в записях могут быть пустыми (NULL), либо вычисляться в соответствии с арифметическим выражением. Правила записи арифметических и логических выражений аналогичны соответствующим правилам оператора SELECT.
10. Оператор вставки новых записей имеет форматы двух видов:
INSERT INTO <имя таблицы>
[(<список столбцов>)]
VALUES (<список значений>)
и
INSERT INTO <имя таблицы>
[(<список столбцов>)]
<предложение SELECT>
В первом формате оператор INSERT предназначен для ввода новыхзаписей с заданными значениями в столбцах. Порядок перечисления имен столбцов должен соответствовать порядку значений, перечисленных в списке операнда VALUES. Если <список столбцов> опущен, то в <списке значений> должны быть перечислены все значения в порядке столбцов структуры таблицы. Во втором формате оператор INSERT предназначен для ввода в заданную таблицу новых строк, отобранных из другой таблицы с помощью предложения SELECT.
PAGE 1
refleader.ru
Вопрос №6. Основные операторы SQL Основные операторы языка
Вопрос №6. Основные операторы SQL
Основные операторы языкаОпишем минимальное подмножество языка SQL, опираясь на его реализацию в стандартном интерфейсе ODBC (Open Database Connectivity - совместимость открытых баз данных) фирмы Microsoft. Операторы языка SQL можно условно разделить на два подъязыка: язык определения данных (Data Definition Language - DDL) и язык манипулирования данными (Data Manipulation Language - DML).
Рассмотрим формат и основные возможности важнейших операторов, за исключением специфических операторов, отмеченных в таблице символом "*". Несущественные операнды и элементы синтаксиса (например, принятое во многих системах программирования правило ставить ";" в конце оператора) будем опускать.
1. Оператор создания таблицы имеет формат вида:
CREATE TABLE <имя таблицы>
(<имя столбца> <тип данных> [NOT NULL]
[,<имя столбца> <тип данных> [NOT NULL]] ... )
2. Оператор удаления индекса имеет формат вида:
DROP INDEX <имя индекса>
Этот оператор позволяет удалять созданный ранее индекс с соответствующим именем. Так, например, для уничтожения индекса main_indx к таблице emp достаточно записать оператор DROP INDEX main_indx.
3. Оператор создания представления имеет формат вида:
CREATE VIEW <имя представления>
[(<имя столбца> [,<имя столбца> ]... )]
AS <оператор SELECT>
Данный оператор позволяет создать представление. Если имена столбцов в представлении не указываются, то будут использоваться имена столбцов из запроса, описываемого соответствующим оператором SELECT.
4. Оператор удаления представления имеет формат вида:
DROP VIEW <имя представления>
Оператор позволяет удалить созданное ранее представление. Заметим, что при удалении представления таблицы, участвующие в запросе, удалению не подлежат. Удаление представления rерr производится оператором вида:
DROP VIEW repr.
5. Оператор выборки записей имеет формат вида:
SELECT [ALL | DISTINCT]
<список данных>
FROM <список таблиц>
[WHERE <условие выборки>]
[GROUP BY <имя столбца> [,<имя столбца>]... ]
[HAVING <условие поиска>]
[ORDER BY <спецификация> [,<снецификация>] ...]
то наиболее важный оператор из всех операторов SQL. Функциональные возможности его огромны. Рассмотрим основные из них.
Оператор SELECT позволяет производить выборку и вычисления над данными из одной или нескольких таблиц. Результатом выполнения оператора является ответная таблица, которая может иметь (ALL), или не иметь (DISTINCT) повторяющиеся строки.
Пример 5. Выбор записей.
Для таблицы ЕМР, имеющей поля: NAME (имя), SAL (зарплата), MGR (руководитель) и DEPT (отдел), требуется вывести имена сотрудников и размер их зарплаты, увеличенный на 100 единиц.
SELECT name, sal+100
FROM emp.
Пример 6. Выбор с условием.
Вывести названия таких отделов таблицы ЕМР, в которых в данный момент отсутствуют руководители. Оператор SELECT для этого запроса можно записать так:
SELECT dept
FROM emp
WHERE mgr is NULL.
6. Оператор изменения записей имеет формат вида:
UPDATE <имя та6лицы>
SET <имя столбца> " {<выражение> , NULL }
[, SET <имя столбца> ° {<выражение> , NULL }... ]
[WHERE <условие>]
Выполнение оператора UPDATE состоит в изменении значений в определенных операндом SET столбцах таблицы для тех записей, которые удовлетворяют условию, заданному операндом WHERE.
Пример 8. Изменение записей.
Пусть необходимо увеличить на 500 единиц зарплату тем служащим, которые получают не более 6000 (по таблице ЕМР). Запрос, сформулированный с помощью оператора SELECT, может выглядеть так:
UPDATE emp
SET sal = 6500
WHERE sal <= 6000.
7. Оператор вставки новых записей имеет форматы двух видов:
INSERT INTO <имя таблицы>
[(<список столбцов>)]
VALUES (<список значений?-)
и
INSERT INTO <имя таблицы>
[(<список столбцов>)]
<предложение SELECT>
В первом формате оператор INSERT предназначен для ввода новых записей с заданными значениями в столбцах. Порядок перечисления имен столбцов должен со-. ответствовать порядку значений, перечисленных в списке операнда VALUES. Если <список столбцов> опущен, то в <списке значений> должны быть перечислены все значения в порядке столбцов структуры таблицы.
Во втором формате оператор INSERT предназначен для ввода в заданную таблицу новых строк, отобранных из другой таблицы с помощью предложения SELECT.
Пример 9. Ввод записей.
Ввести в таблицу ЕМР запись о новом сотруднике. Для этого можно записать, такой оператор вида:
INSERT INTO emp
VALUES ("Ivanov", 7500, "Lee", "cosmetics").
8. Оператор удаления записей имеет формат вида:
DELETE FROM <имя таблицы>
[WHERE <условие>]
Результатом выполнения оператора DELETE является удаление из указанной таблицы строк, которые удовлетворяют условию, определенному операндом WHERE. Если необязательный операнд WHERE опущен, т. е. условие отбора удаляемых записей отсутствует, удалению подлежат все записи таблицы.
Пример 10. Удаление записей.
В связис ликвидацией отдела игрушек (toy), требуется удалить из таблицы ЕМР всех сотрудников этого отдела. Оператор DELETE для этой задачи будет выглядеть так:
DELETE FROM emp
WHERE dept = "toy".
Вопрос №7. Концептуальная модель базы данных
Использование методологии IDEF1X для разработки концептуальной модели данных
Важнейшая цель проектирования информационной модели - выработка непротиворечивой структурированной интерпретации реально существующей информации изучаемой предметной области и взаимодействия между ее структурными компонентами
Понятие концептуальной модели данных связано с методологией семантического моделирования данных, т.е. с представлением данных в контексте их взаимосвязей с другими данными.
Для решения задач проектирования сложных систем существуют специальные методологии и стандарты. К таким стандартам относятся методологии семейства IDEF (Icam DEFinition, ICAM - Integrated Computer-Aided Manufacturing - первоначально разработанная в конце 70-х гг. программа ВВС США интегрированной компьютерной поддержки производства). С их помощью можно эффективно проектировать, отображать и анализировать модели деятельности широкого спектра сложных систем в различных разрезах. К семейству IDEF относится и стандарт IDEF1 - Information Modeling - методология моделирования информационных потоков внутри системы, позволяющая отображать и анализировать их структуру и взаимосвязи.
Методология IDEF1X - один из подходов к семантическому моделированию данных, основанный на концепции "сущность-связь" (Entity-Relationship). Это инструмент для анализа информационной структуры систем различной природы. Информационная модель, построенная с помощью IDEF1X-методологии, отображает логическую структуру информации об объектах системы
Таким образом, концептуальная модель, представленная в соответствии со стандартом IDEF1X, является логической схемой базы данных для проектируемой системы
Основными объектами концептуальной модели являются сущности и связи.
Сущность - некоторый обособленный объект или событие моделируемой системы, имеющий определенный набор свойств - атрибутов. Отдельный элемент этого множества называется "экземпляром сущности". Сущность может обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый образец сущности, и может обладать любым количеством связей с другими сущностями.
Правила для атрибутов сущности:
Каждый атрибут должен иметь уникальное имя.
Сущность может обладать любым количеством атрибутов.
Сущность может обладать любым количеством наследуемых атрибутов, но наследуемый атрибут должен быть частью первичного ключа сущности-родителя.
Для каждого экземпляра сущности должно существовать значение каждого его атрибута (правило необращения в нуль - Not Null).
Ни один из экземпляров сущности не может обладать более чем одним значением для ее атрибута.
Сущность изображается на ER-диаграмме в виде прямоугольника, в верхней части которого приводится ее название; далее следует список атрибутов. Ключевые атрибуты могут быть выделены подчеркиванием или иным способом.
Стандарт IDEF1X описывает способы изображения двух типов сущностей - независимой и зависимой, и связей - идентифицирующих и неидентифицирующих (см. рис.1).
 Рис. 1. Изображение сущностей и связей по стандарту IDEF1X
Рис. 1. Изображение сущностей и связей по стандарту IDEF1X
Каждая сущность может обладать любым количеством связей с другими сущностями.
Сущность является независимой, если каждый ее экземпляр может быть однозначно идентифицирован без определения его связей с другими сущностями.
Сущность называется зависимой, если однозначная идентификация ее экземпляра зависит от его связей с другими сущностями.
Сущность может обладать атрибутами, которые наследуются через связь с родительской сущностью. Последние обычно являются внешними ключами (FK на рис. 1) и служат для организации связей между сущностями. Если внешний ключ сущности используется в качестве ее первичного ключа (PK) или как часть составного первичного ключа, то сущность является зависимой от родительской сущности. Если внешний ключ не является первичным и не входит в составной первичный ключ, то сущность является независимой от родительской сущности.
Если сущность является зависимой, то связь ее с родительской сущностью называется идентифицирующей, в противном случае - неидентифицирующей.
Связь изображается на ER-диаграмме линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. идентифицирующая связь изображается сплошной линией, неидентифицирующая - пунктирной.
Связи дается имя, выражаемое грамматической формой глагола. Для связи дополнительно может присутствовать указание мощности: какое количество экземпляров сущности-потомка может существовать для сущности-родителя. Имя связи всегда формируется с точки зрения родителя, так что может быть образовано предложение, если соединить имя сущности родителя, имя связи, выражение мощности и имя сущности-потомка (например "много СТУДЕНТов - сдают - ЭКЗАМЕН").
Принципы изображения концептуальных моделей баз данных стандарта IDEF1 и IDEF1X используют CASE Studio и другие CASE-средства. Подобные системы позволяют на основе концептуальной модели генерировать физическую модель и программный код создания базы данных для большинства наиболее распространенных СУБД и серверов баз данных.
Вопрос № 8 Критерии выбора СУБД
Выбор системы управления баз данных (СУБД) представляет собой сложную многопараметрическую задачу и является одним из важных этапов при разработке приложений баз данных. Выбранный программный продукт должен удовлетворять как текущим, так и будущим потребностям предприятия, при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. Кроме того, необходимо убедиться, что новая СУБД способна принести предприятию реальные выгоды.
Очевидно, наиболее простой подход при выборе СУБД основан на оценке того, в какой мере существующие системы удовлетворяют основным требованиям создаваемого проекта информационной системы. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких СУБД и последующий выбор наиболее подходящего из кандидатов. Но и в этом случае необходимо ограничивать круг возможных систем, опираясь на некие критерии отбора. Вообще говоря, перечень требований к СУБД, используемых при анализе той или иной информационной системы, может изменяться в зависимости от поставленных целей. Тем не менее, можно выделить несколько групп критериев:
Моделирование данных
Особенности архитектуры и функциональные возможности
Контроль работы системы
Особенности разработки приложений
Производительность
Надежность
Требования к рабочей среде
Смешанные критерии
Моделирование данных.
Используемая модель данных. Существует множество моделей данных; самые распространенные - иерархическая, сетевая, реляционная, постреляционная, многомерная, объектно-ориентированная. Вопрос об использовании той или иной модели должен решаться на начальном этапе проектирования информационной системы.
Триггеры и хранимые процедуры. Триггер - программа базы данных, вызываемая всякий раз при вставке, изменении или удалении строки таблицы. Триггеры обеспечивают проверку любых изменений на корректность, прежде чем эти изменения будут приняты. Хранимая процедура – программа, которая хранится на сервере и может вызываться клиентом. Поскольку хранимые процедуры выполняются непосредственно на сервере базы данных, обеспечивается более высокое быстродействие, нежели при выполнении тех же операций средствами клиента БД. В различных программных продуктах для реализации триггеров и хранимых процедур используются различные инструменты.
Средства поиска. Некоторые современные системы имеют встроенные дополнительные средства контекстного поиска.
Предусмотренные типы данных. Здесь следует учесть два фактически независимых критерия: базовые или основные типы данных, заложенные в систему, и наличие возможности расширения типов. В то время как отклонения базовых наборов типов данных у современных систем от некоего стандартного, обычно, невелики, механизмы расширения типов данных в системах того или иного производителя существенно различаются.
Реализация языка запросов. Все современные системы совместимы со стандартным языком доступа к данным SQL-92, однако многие из них реализуют те или иные расширения данного стандарта.
Особенности архитектуры и функциональные возможности.
Мобильность. Мобильность – это независимость системы от среды, в которой она работает. Средой в данном случае является как аппаратура, так и программное обеспечение (операционная система).
Масштабируемость. При выборе СУБД необходимо учитывать, сможет ли данная система соответствовать росту информационной системы, причем рост может проявляться в увеличении числа пользователей, объема хранимых данных и объеме обрабатываемой информации.
Распределенность. Основной причиной применения информационных систем на основе баз данных является стремление объединить взгляды на всю информацию организации. Самый простой и надежный подход - централизация хранения и обработки данных на одном сервере. К сожалению, это не всегда возможно и приходится применять распределенные базы данных. Различные системы имеют разные возможности управления распределенными базами данных.
Сетевые возможности. Многие системы позволяют использовать широкий диапазон сетевых протоколов и служб для работы и администрирования.
Контроль работы системы
Контроль использования памяти компьютера. Система может иметь возможность управления использованием, как оперативной памяти, так и дискового пространства. Во втором случае это может выражаться, например, в сжатии баз данных, или удалении избыточных файлов.
Автонастройка. Многие современные системы включают в себя возможности самоконфигурирования, которые, как правило, опираются на результаты работы сервисов самодиагностики производительности. Данная возможность позволяет выявить слабые места конфигурации системы и автоматически настроить ее на максимальную производительность.
Особенности разработки приложений.
Многие производители СУБД выпускают также средства разработки приложений для своих систем. Как правило, эти средства позволяют наилучшим образом реализовать все возможности сервера, поэтому при анализе СУБД стоит рассмотреть также и возможности средств разработки приложений.
Средства проектирования. Некоторые системы имеют средства автоматического проектирования, как баз данных, так и прикладных программ. Средства проектирования различных производителей могут существенно различаться.
Многоязыковая поддержка. Поддержка большого количества национальных языков расширяет область применения системы и приложений, построенных на ее основе.
Возможности разработки Web-приложений. При разработке различных приложений зачастую возникает необходимость использовать возможности среды Internet. Средства разработки некоторых производителей имеют большой набор инструментов для построения приложений под Web.
Поддерживаемые языки программирования. Широкий спектр используемых языков программирования повышает доступность системы для разработчиков, а также может существенно повлиять на быстродействие и функциональность создаваемых приложений.
Производительность.
Рейтинг TPC (Transactions per Cent). Для тестирования производительности применяются различные средства, и существует множество тестовых рейтингов. Одним из самых популярных и объективных является TPC-анализ производительности систем. Фактически TPC анализ рассматривает композицию СУБД и аппаратуры, на которой эта СУБД работает. Показатель TPC – это отношение количества запросов обрабатываемых за некий промежуток времени к стоимости всей системы.
Возможности параллельной архитектуры. Для обеспечения параллельной обработки данных существует, как минимум, два подхода: распараллеливание обработки последовательности запросов на несколько процессоров, либо использование нескольких компьютеров-клиентов, работающих с одной БД, которые объединяют в так называемый параллельный сервер.
Возможности оптимизирования запросов. При использовании непроцедурных языков запросов их выполнение может быть неоптимальным. Поэтому необходимо произвести процесс оптимизации запросов, т.е. выбрать такой способ выполнения, когда по начальному представлению запроса путем его синтаксических и семантических преобразований вырабатывается процедурный план выполнения запроса, наиболее оптимальный при существующих в базе данных управляющих структурах.
Надежность.
Понятие надежности системы имеет много смыслов – это и сохранность информации независящая от любых сбоев, и безотказность работы системы в любых условиях, и обеспечение защиты данных от несанкционированного доступа.
Восстановление после сбоев. При возникновении программных или аппаратных сбоев целостность, да и работоспособность всей системы может быть нарушена. От того, как эффективно спланирован механизм восстановления после сбоев, зависит жизнеспособность системы.
Резервное копирование. В результате аппаратного сбоя может быть частично поврежден или выведен из строя носитель информации и тогда восстановление данных невозможно, если не было предусмотрено резервное копирование базы данных, или ее части. Резервное копирование спасает и в ситуациях, когда происходит логический сбой системы, например при ошибочном удалении таблиц. Существует множество механизмов резервирования данных (хранение одной или более копий всей базы данных, хранение копии ее части, копирование логической структуры и т.д.). Зачастую в систему закладывается возможность использования нескольких таких механизмов.
Откат изменений. При выполнении транзакции применяется простое правило – либо транзакция выполняется полностью, либо не выполняется вообще. Это означает, что в случае сбоев, все результаты недоведенных до конца транзакций должны быть аннулированы. Механизм отката может иметь различное быстродействие и эффективность.
Многоуровневая система защиты. Информационная система организации почти всегда включает в себя секретную информацию, поэтому для предотвращения несанкционированного доступа используется служба идентификации пользователей. Уровень защиты может быть различным. Кроме непосредственной идентификации пользователей при входе в систему может использоваться также механизм шифрования данных при передаче по линиям связи
Требования к рабочей среде.
Поддерживаемые аппаратные платформы.
Минимальные требования к оборудованию.
Максимальный размер адресуемой памяти. Поскольку почти все современные системы используют свою файловую систему, немаловажным фактором является то, какой максимальный объем физической памяти они могут использовать.
Операционные системы, под управлением которых способна работать СУБД.
Смешанные критерии.
Качество и полнота документации. К сожалению, не все системы имеют полную и подробную документацию.
Локализованность. Возможность использования национальных языков не во всех системах реализована полностью.
Модель формирования стоимости. Как правило, производители СУБД используют определенные модели формирования стоимости. Например, стоимость одного и того же продукта может существенно изменяться в зависимости от того, сколько пользователей будет с ним работать.
Стабильность производителя.
Распространенность СУБД.
Даже если просто отмечать насколько хороши или плохи выделенные параметры в случае каждой конкретной СУБД, то сравнение уже двух различных систем является трудоемкой задачей. Тем не менее, четкий и глубокий сравнительный анализ на основании вышеперечисленных критериев в любом случае поможет рационально выбрать подходящую систему для конкретного проекта, и затраченные усилия не будут напрасными. Перечень критериев поможет осознать масштабность задачи и выполнить ее адекватную постановку.
Следует отметить, что по существующей практике решение об использовании той или иной СУБД принимает один человек – обычно, руководитель предприятия, а он может опираться отнюдь не на технические критерии. Здесь свою роль могут сыграть такие, с технической точки зрения, незначительные факторы как рекламная раскрутка компании-производителя СУБД, использование конкретных систем на других предприятиях, стоимость. При этом последний фактор может трактоваться в двух противоположных смыслах в зависимости от финансового состояния и политики предприятия. С одной стороны, это может быть принцип, – чем дороже, тем лучше. С другой стороны – культивирование почти бесплатного использования продукта, вплоть до “взлома” его лицензионной защиты. Очевидно, последний подход чреват коллизиями и не может привести к успеху в долгосрочной работе.
refdb.ru
Основные операторы SQL
Стандарт языка SQL был принят в 1992 году и используeтся до сих пор. Имeнно он и стал эталоном для многих систeм управлeния базами данных. Конeчно, нeкоторыe производитeли используют свои интeрпрeтации стандарта. Но в любой систeмe всe жe имeются главныe составляющиe — опeраторы SQL.
Ввeдeниe
С помощью опeраторов SQL в базах данных происходит управлeниe значeниями, таблицами и получeниe их для дальнeйшeго анализа и отображeния. Они прeдставляют собой набор ключeвых слов, по которым систeма понимаeт, что дeлать с данными.

Опрeдeляют нeсколько катeгорий опeраторов SQL:
- опрeдeлeниe объeктов базы данных;
- манипулированиe значeниями;
- защита и управлeниe;
- парамeтры сeанса;
- информация о базe;
- статичeский SQL;
- динамичeский SQL.
Опeраторы SQL для манипулирования данными
К этой катeгории относятся ключeвыe слова, с помощью которых можно управлять размeщeниeм значeний в базe.
INSERT. Вставляeт строки в сущeствующую таблицу. Можeт использоваться как для одного значeния, так и нeскольких, опрeдeлённых по нeкоeму условию. Напримeр:
INSERT INTO
имя таблицы (имя столбца 1, имя столбца 2)
VALUES (значeниe 1, значeниe 2).
Для использования опeратора SQL запроса INSERT при нeскольких значeниях, примeняeтся такой синтаксис:
INSERT INTO
имя таблицы 1 (имя столбца 1, имя столбца 2)
SELECT имя столбца 1, имя столбца 2
FROM имя таблицы 2
WHERE имя таблицы 2.имя столбца 1>2
Этот запрос выбeрeт всe данныe из таблицы 2, которыe большe 2 по столбцу 1 и вставит их в пeрвую.
UPDATE. Как видно из названия, этот опeратор SQL запроса обновляeт данныe в сущeствующeй таблицe по опрeдeлённому признаку.
Примeр:
UPDATE имя таблицы 1
SET имя столбца 2 = «Василий»
WHERE имя таблицы 1.имя столбца 1 = 1
Данная конструкция заполнит значeниeм Василий всe строки, в которых встрeтит цифру 1 в пeрвом столбцe.
DELETE. Удаляeт данныe из таблицы. Можно указать какоe-либо условиe или жe убрать всe строки.
DELETE FROM имя таблицы
WHERE имя таблицы.имя столбца 1 = 1
Привeдённый запрос удалит из базы всe данныe со значeниeм один в пeрвом столбцe. А вот так можно очистить всю таблицу:
DELETE FROM имя таблицы.
Далee стоит рассказать об опeраторe SELECT. Он являeтся одним из самых важных, поэтому eму придётся посвятить отдeльную главу.
Опeратор SELECT
Главноe назначeниe SELECT — выборка данных по опрeдeлeнным условиям. Рeзультатом eго работы всeгда являeтся новая таблица с отобранными данными. Опeратор MS SQL SELECT можeт быть использован в массe различных запросов. Поэтому наряду с ним можно рассмотрeть и другиe смeжныe ключeвыe слова.
Для выбора всeх данных из опрeдeлённой таблицы используeтся знак «*».
SELECT *
FROM имя таблицы 1
Рeзультатом работы данного запроса будeт точная копия таблицы 1.
А здeсь происходит выборка по условию WHERE, котороe достаёт из таблицы 1 всe значeния, большe 2 в столбцe 1.
SELECT *
FROM имя таблицы 1
WHERE имя таблицы 1.имя столбца 1 > 2
Такжe можно указать в выборкe, что нужны только опрeдeлённыe столбцы.
SELECT имя таблицы 1.имя столбца 1
FROM имя таблицы 1
Рeзультатом данного запроса будут всe строки, со значeниями из столбца 1. С помощью опeраторов MS SQL можно составить собствeнную таблицу, на ходу замeнив, вычислив и подставив опрeдeлённыe значeния.

SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
«=» AS EQ
имя таблицы 1.имя столбца 2 * имя таблицы 1.имя столбца 3 AS SUMMA
FROM имя таблицы 1
Данный, на пeрвый взгляд сложный запрос выполняeт выборку всeх значeний из таблицы 1, затeм создаёт новыe колонки EQ и SUMMA. В пeрвую заносит знак «+», во вторую произвeдeниe данных из столбца 2 и 3. Получeнный рeзультат можно прeдставить в видe таблицы, для понимания как это работаeт:
Столбeц 1
Столбeц 2
Столбeц 3
EQ
SUMMA
Имя товара 1
10
50
+
500
Имя товара 2
15
100
+
1500
При использовании опeратора SELECT, можно сразу провeсти упорядочиваниe данных по какому-либо признаку. Для этого используeтся слово ORDER BY.
SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
FROM имя таблицы 1
ORDER BY имя столбца 2
Рeзультирующая таблица будeт выглядeть таким образом:
Столбeц 1
Столбeц 2
Столбeц 3
1
1
54
3
2
12
7
3
100
2
5
1
То eсть всe строки были установлeны в таком порядкe, чтобы в столбцe 2 значeния шли по возрастанию.
Данныe можно получать и из нeскольких таблиц. Для наглядности сначала нужно прeдставить, что их в базe имeeтся двe, примeрно такиe:
Таблица «Сотрудники»
Номeр
Имя
Фамилия
1
Вася
Васин
2
Пeтя
Пeтин
Таблица «Зарплата»
Номeр
Ставка
Начислeно
1
1
10000
2
0,5
3500
Тeпeрь нужно, как-то связав эти двe таблицы получить общиe значeния. Используя основныe опeраторы SQL сдeлать это можно так:
SELECT
Сотрудники.Номeр
Сотрудники.Имя
Зарплата.Ставка
Зарплата.Начислeно
FROM Сотрудники, Зарплата
WHERE Сотрудники.Номeр = Зарплата.Номeр
Здeсь происходит выборка из двух разных таблиц значeний, объeдинённых по номeру. Рeзультатом будeт слeдующий набор данных:
Номeр
Имя
Ставка
Начислeно
1
Вася
1
10000
2
Пeтя
0,5
3500
Ещё нeмного о SELECT. Использованиe агрeгатных функций
Один из основных опeраторов SQL SELECT можeт производить нeкоторыe вычислeния при выборкe. Для этого он используeт опрeдeлённыe функции и формулы.
К примeру, чтобы получить количeство записeй из таблицы «Сотрудники», нужно использовать запрос:
SELECT COUNT (*) AS N
FROM Сотрудники
В рeзультатe получится таблица с одним значeниeм и столбцом.
N
2
В запросах можно использовать функции, вычисляющиe сумму, максимальныe и минимальныe значeния, а такжe срeднee. Для этого примeняются ключeвыe слова SUM, MAX, MIN, AVG.
Напримeр, нужно провeсти выборку из ужe извeстной таблицы «Зарплата»:
Номeр
Ставка
Начислeно
1
1
10000
2
0,5
3500
Можно примeнить такой запрос и посмотрeть что получится:
SELECT
SUM(Зарплата.Начислeно) AS SUMMA
MAX(Зарплата.Начислeно) AS MAX
MIN(Зарплата.Начислeно) AS MIN
AVG(Зарплата.Начислeно) AS SRED
FROM Зарплата
Итоговая таблица будeт такой:
SUMMA
MAX
MIN
SRED
13500
10000
3500
6750
Вот таким образом, можно выбрать из базы данных нужныe значeния, на лeту выполнив вычислeниe различных функций.
Объeдинeниe, пeрeсeчeниe и разности
Объeдинить нeсколько запросов в SQL
SELECT Сотрудники.Имя
FROM Сотрудники
WHERE Сотрудники.Номeр = 1
UNION
SELECT Сотрудники.Имя
FROM Сотрудники, Зарплата
WHERE Зарплата.Номeр = 1
При этом стоит учитывать, что при таком объeдинeнии таблицы должны быть совмeстимы. То eсть имeть одинаковоe количeство столбцов.
Синтаксис опeратора SELECT и порядок eго обработки
Пeрвым дeлом SELECT опрeдeляeт область, из которой он будeт б
xroom.su
Основные операторы SQL
Стандарт языка SQL был принят в 1992 году и используется до сих пор. Именно он и стал эталоном для многих систем управления базами данных. Конечно, некоторые производители используют свои интерпретации стандарта. Но в любой системе все же имеются главные составляющие — операторы SQL.
Введение
С помощью операторов SQL в базах данных происходит управление значениями, таблицами и получение их для дальнейшего анализа и отображения. Они представляют собой набор ключевых слов, по которым система понимает, что делать с данными.

Определяют несколько категорий операторов SQL:
- определение объектов базы данных;
- манипулирование значениями;
- защита и управление;
- параметры сеанса;
- информация о базе;
- статический SQL;
- динамический SQL.
Операторы SQL для манипулирования данными
К этой категории относятся ключевые слова, с помощью которых можно управлять размещением значений в базе.
INSERT. Вставляет строки в существующую таблицу. Может использоваться как для одного значения, так и нескольких, определённых по некоему условию. Например:
INSERT INTO
имя таблицы (имя столбца 1, имя столбца 2)
VALUES (значение 1, значение 2).
Для использования оператора SQL запроса INSERT при нескольких значениях, применяется такой синтаксис:
INSERT INTO
имя таблицы 1 (имя столбца 1, имя столбца 2)
SELECT имя столбца 1, имя столбца 2
FROM имя таблицы 2
WHERE имя таблицы 2.имя столбца 1>2
Этот запрос выберет все данные из таблицы 2, которые больше 2 по столбцу 1 и вставит их в первую.
UPDATE. Как видно из названия, этот оператор SQL запроса обновляет данные в существующей таблице по определённому признаку.
Пример:
UPDATE имя таблицы 1
SET имя столбца 2 = «Василий»
WHERE имя таблицы 1.имя столбца 1 = 1
Данная конструкция заполнит значением Василий все строки, в которых встретит цифру 1 в первом столбце.
DELETE. Удаляет данные из таблицы. Можно указать какое либо условие или же убрать все строки.
DELETE FROM имя таблицы
WHERE имя таблицы.имя столбца 1 = 1
Приведённый запрос удалит из базы все данные со значением один в первом столбце. А вот так можно очистить всю таблицу:
DELETE FROM имя таблицы.
Далее стоит рассказать об операторе SELECT. Он является одним из самых важных, поэтому ему придётся посвятить отдельную главу.
Оператор SELECT
Главное назначение SELECT — выборка данных по определенным условиям. Результатом его работы всегда является новая таблица с отобранными данными. Оператор MS SQL SELECT может быть использован в массе различных запросов. Поэтому наряду с ним можно рассмотреть и другие смежные ключевые слова.
Для выбора всех данных из определённой таблицы используется знак «*».
SELECT *
FROM имя таблицы 1
Результатом работы данного запроса будет точная копия таблицы 1.
А здесь происходит выборка по условию WHERE, которое достаёт из таблицы 1 все значения, больше 2 в столбце 1.
SELECT *
FROM имя таблицы 1
WHERE имя таблицы 1.имя столбца 1 > 2
Также можно указать в выборке, что нужны только определённые столбцы.
SELECT имя таблицы 1.имя столбца 1
FROM имя таблицы 1
Результатом данного запроса будут все строки, со значениями из столбца 1. С помощью операторов MS SQL можно составить собственную таблицу, на ходу заменив, вычислив и подставив определённые значения.

SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
«=» AS EQ
имя таблицы 1.имя столбца 2 * имя таблицы 1.имя столбца 3 AS SUMMA
FROM имя таблицы 1
Данный, на первый взгляд сложный запрос выполняет выборку всех значений из таблицы 1, затем создаёт новые колонки EQ и SUMMA. В первую заносит знак «+», во вторую произведение данных из столбца 2 и 3. Полученный результат можно представить в виде таблицы, для понимания как это работает:
Столбец 1 | Столбец 2 | Столбец 3 | EQ | SUMMA |
Имя товара 1 | 10 | 50 | + | 500 |
Имя товара 2 | 15 | 100 | + | 1500 |
При использовании оператора SELECT, можно сразу провести упорядочивание данных по какому либо признаку. Для этого используется слово ORDER BY.
SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
FROM имя таблицы 1
ORDER BY имя столбца 2
Результирующая таблица будет выглядеть таким образом:
Столбец 1 | Столбец 2 | Столбец 3 |
1 | 1 | 54 |
3 | 2 | 12 |
7 | 3 | 100 |
2 | 5 | 1 |
То есть все строки были установлены в таком порядке, чтобы в столбце 2 значения шли по возрастанию.
Данные можно получать и из нескольких таблиц. Для наглядности сначала нужно представить, что их в базе имеется две, примерно такие:
Таблица «Сотрудники»
Номер | Имя | Фамилия |
1 | Вася | Васин |
2 | Петя | Петин |
Таблица «Зарплата»
Номер | Ставка | Начислено |
1 | 1 | 10000 |
2 | 0,5 | 3500 |
Теперь нужно, как то связав эти две таблицы получить общие значения. Используя основные операторы SQL сделать это можно так:
SELECT
Сотрудники.Номер
Сотрудники.Имя
Зарплата.Ставка
Зарплата.Начислено
FROM Сотрудники, Зарплата
WHERE Сотрудники.Номер = Зарплата.Номер
Здесь происходит выборка из двух разных таблиц значений, объединённых по номеру. Результатом будет следующий набор данных:
Номер | Имя | Ставка | Начислено |
1 | Вася | 1 | 10000 |
2 | Петя | 0,5 | 3500 |
Ещё немного о SELECT. Использование агрегатных функций
Один из основных операторов SQL SELECT может производить некоторые вычисления при выборке. Для этого он использует определённые функции и формулы.
К примеру, чтобы получить количество записей из таблицы «Сотрудники», нужно использовать запрос:
SELECT COUNT (*) AS N
FROM Сотрудники
В результате получится таблица с одним значением и столбцом.
В запросах можно использовать функции, вычисляющие сумму, максимальные и минимальные значения, а также среднее. Для этого применяются ключевые слова SUM, MAX, MIN, AVG.
Например, нужно провести выборку из уже известной таблицы «Зарплата»:
Номер | Ставка | Начислено |
1 | 1 | 10000 |
2 | 0,5 | 3500 |
Можно применить такой запрос и посмотреть что получится:
SELECT
SUM(Зарплата.Начислено) AS SUMMA
MAX(Зарплата.Начислено) AS MAX
MIN(Зарплата.Начислено) AS MIN
AVG(Зарплата.Начислено) AS SRED
FROM Зарплата
Итоговая таблица будет такой:
SUMMA | MAX | MIN | SRED |
13500 | 10000 | 3500 | 6750 |
Вот таким образом, можно выбрать из базы данных нужные значения, на лету выполнив вычисление различных функций.
Объединение, пересечение и разности
Объединить несколько запросов в SQL
SELECT Сотрудники.Имя
FROM Сотрудники
WHERE Сотрудники.Номер = 1
UNION
SELECT Сотрудники.Имя
FROM Сотрудники, Зарплата
WHERE Зарплата.Номер = 1
При этом стоит учитывать, что при таком объединении таблицы должны быть совместимы. То есть иметь одинаковое количество столбцов.
Синтаксис оператора SELECT и порядок его обработки
Первым делом SELECT определяет область, из которой он будет брать данные. Для этого используется ключевое слово FROM. Если не указано, что именно выбрать.
Затем может присутствовать SQL оператор WHERE. С его помощью SELECT пробегает по всем строкам таблицы и проверяет данные на соответствие условию.

Если в запросе имеется GROUP BY, то происходит группировка значений по указанным параметрам.
Операторы для сравнения данных
Их имеется несколько типов. В SQL операторы сравнения могут проверять различные типы значений.
«=». Обозначает, как можно догадаться, равенство двух выражений. Например, он уже использовался в примерах выше WHERE Зарплата.Номер = 1.
«>». Знак больше. Если значение левой части выражения больше, то возвращается логическое TRUE и условие считается выполненным.
«<». Знак меньше. Обратный предыдущему оператор.
Знаки «<=» и «>=». Отличается от простых операторов больше и меньше, тем, что при равенстве операндов условие также будет истинным.
«<>». Не равно. Условие будет считаться TRUE, только если один операнд не равен другому. У него имеется ещё одна интерпретация «!=».
LIKE
Перевести данное ключевое слово можно как «похожий». Оператор LIKE в SQL используется примерно по такому же принципу — выполняет запрос по шаблону. То есть он позволяет расширить выборку данных из базы используя регулярные выражения.

Например, поставлена такая задача: из уже известной базы «Сотрудники» получить всех людей, чьё имя заканчивается на «я». Тогда запрос можно составить так:
SELECT *
FROM Сотрудники
WHERE Имя LIKE `%я`
Знак процента в данном случае означает маску, то есть любой символ и их количество. А по букве «я» SQL определит что последний символ должен быть именно таким.
CASE
Данный оператор SQL Server представляет собой реализацию множественного выбора. Он напоминает конструкцию switch во многих языках программирования. Оператор CASE в SQL выполняет действие по нескольким условиям.
Например, нужно выбрать из таблицы «Зарплата» максимальное и минимальное значение.
Номер | Ставка | Начислено |
1 | 1 | 10000 |
2 | 0,5 | 3500 |
Тогда запрос можно составить так:
SELECT *
FROM Зарплата
WHERE CASE WHEN SELECT MAX(Начислено) THEN Максимум
WHEN SELECT MIN(Начислено) THEN Минимум
END итог
В данном контексте система ищет максимальное и минимальное значение в столбце «Начислено». Затем с помощью END создаётся поле «итог», в которое будет заноситься «Максимум» или «Минимум» в зависимости от результата выполнения условия.
Кстати, в SQL имеется и более компактная форма CASE — COALESCE.
Операторы определения данных
Это вид позволяет проводить разнообразное изменение таблиц — создание, удаление, модификации и работу с индексами.
Первый из них, который стоит рассмотреть — CREATE TABLE. Он делает не что иное, как создаёт таблицу. Если просто набрать запрос CREATE TABLE, ничего не случится, так как нужно ещё указать несколько параметров.
Например, для создания уже знакомой таблицы «Сотрудники» нужно использовать команды:
CREATE TABLE Сотрудники
(Номер number(10) NOT NULL
Имя varchar(50) NOT NULL
Фамилия varchar(50) NOT NULL)
В это запросе, в скобках сразу же определяются имена полей и их типы, а также может ли он быть равен NULL.
DROP TABLE
Выполняет одну простую задачу — удаление указанной таблицы. Имеет дополнительный параметр IF EXISTS. Он поглощает ошибку при удалении, если искомая таблица не существует. Пример использования:
DROP TABLE Сотрудники IF EXISTS.
CREATE INDEX
В SQL имеется система индексов, которая позволяет ускорить доступ к данным. В общем, он представляет собой ссылку, которая указывает на определённый столбец. Создать индекс можно простым запросом:
CREATE INDEX название_индекса
ON название_таблицы(название_столбца)
Используется данный оператор в T SQL, Oracle, PL SQL и многих других интерпретациях технологиях.
ALTER TABLE
Очень функциональный оператор, обладающий многочисленными вариантами. В общем случае производит изменение структуры, определения и размещения таблиц. Используется оператор в Oracle SQL, Postgres и многих других.
Далее будут представлены различные варианты использования ALTER TABLE.
ADD. Осуществляет добавление столбца в таблицу. Синтаксис его такой: ALTER TABLE название_таблицы ADD название_столбца тип_хранимых_данных. Может иметь параметр IF NOT EXISTS, что подавить ошибку, если создаваемый столбец уже есть;
DROP. Удаляет столбец. Также имеет ключ IF EXISTS, без которого сгенерируется ошибка, говорящая о том, что требуемый столбец отсутствует;
CHANGE. Служит для переименования имени поля в указанное. Пример использования: ALTER TABLE название_таблицы CHANGE старое_имя новое_имя;
MODIFY. Данная команда поможет сменить тип и дополнительные атрибуты определённого столбца. А используется он вот так: ALTER TABLE название_таблицы MODIFY название_столбца тип_данных атрибуты;
CREATE VIEW
В SQL имеется такое понятие, как представление. Вкратце, это некая виртуальная таблица с данными. Образуется она в результате выборки с помощью оператора языка SQL SELECT. Представления могут ограничивать доступ к базе данных, скрывать их, заменять реальные имена столбцов.
Процесс создания происходит с помощью простого запроса:
CREATE VIEW название представления AS SELECT FROM * название таблицы
Выборка может происходить как всей базы целиком, так и по некоторому условию.
Немного о функциях
В SQL запросах очень часто используются различные встроенные функции, которые позволяют взаимодействовать с данными и преобразовывать их на лету. Стоит рассмотреть их, так как они составляют неотъемлемую часть структурированного языка.
COUNT. Производит подсчёт записей или строк в конкретной таблице. В качестве параметра можно указать имя столбца, тогда данные будут взяты из него. SELECT COUNT * FROM Сотрудники;
AVG. Данная функция применяется только на столбцы с числовыми данными. Ее результатом является определение среднего арифметического всех значений;
MIN и MAX. Эти функции уже использовались в этой статье. Определяют они максимальное и минимальное значения из указанного столбца;
SUM. Все просто — функция вычисляет сумму значений столбца. Применяется исключительно для числового вида данных. Добавив в запрос параметр DISTINCT, будут суммироваться только уникальные значения;
ROUND. Функция округления десятичных дробных чисел. В синтаксисе используется название столбца и количество знаков после запятой;
LEN. Простая функция, вычисляющая длину значений столбца. Результатом будет новая таблица с указанием количества символов;
NOW. Это ключевое слово используется для вычисления текущей даты и времени.
Дополнительные операторы
Многие примеры с операторами SQL имеют ключевые слова, которые выполняют небольшие задачи, но тем не менее сильно упрощают выборку или действия с базами данных.
AS. Применяется, когда нужно визуально оформить результат, присваивая указанное имя получившейся таблице.
BETWEEN. Очень удобный инструмент для выборки. Он указывает область значений, среди которых нужно получить данные. На вход принимает параметр от и до какого числа используется диапазон;.
NOT. Оператор придаёт противоположность выражению.
TRUNCATE. Удаляет данные из указанного участка базы. Отличается от аналогичных операторов тем, что восстановить данные после его использования невозможно. Стоит учесть, что реализация данного ключевого слова в различных интерпретациях SQL может отличаться. Поэтому перед тем как пробовать использовать TRUNCATE, лучше ознакомиться со справочной информацией.
LIMIT. Устанавливает количество строк для вывода. Особенность оператора в том, что он всегда располагается в конце. Принимает один обязательный параметр и один опциональный. Первый указывает, сколько строк с выбранными данными нужно показать. А если используется второй, то оператор срабатывает как для диапазона значений.
UNION. Очень удобный оператор для объединения нескольких запросов. Он уже встречался среди примеров этой в этой статье. Можно вывести нужные строки из нескольких таблиц, объединив их UNION для более удобного использования. Синтаксис его такой: SELECT имя_столбца FROM имя_таблицы UNION SELECT имя_другого_столбца FROM имя_другой таблицы. В результате получится сводная таблица с объединёнными запросами.
PRIMARY KEY. Переводится как «первичный ключ». Собственно, именно такая терминология и используется в справочных материалах. Он означает уникальный идентификатор строки. Применяется, как правило, при создании таблицы для указания поля, которое и будет содержать его.
DEFAULT. Так же, как и предыдущий оператор, используется в процессе выполнения создающего запроса. Он определяет значение по умолчанию, которым будет заполнено поле при его создании.
Несколько советов при разработке платформы для работы с SQL
NULL. Начинающие и не только программисты при составлении запросов очень часто забывают о возможности получения значения NULL. В итоге в код закрадывается ошибка, которую трудно отследить в процессе отладки. Поэтому при создании таблиц, выборке или пересчёте значений нужно остановиться и подумать, а учтено ли возникновение NULL в это участке запроса.
Память. В этой статье были показаны несколько функций, способные выполнять некоторые задачи. При разработке оболочки для работы с базой, можно «перевесить» вычисление простых выражений на систему управления базами данных. В некоторых случаях это даёт значительный прирост в производительности.
Ограничения. Если нужно получить из базы с тысячами строк всего лишь двух, то стоит использовать операторы типа LIMIT или TOP. Не нужно извлекать данные средствами языка разработки оболочки.
Соединение. После получения данных из нескольких таблиц многие программисты начинают сводить их воедино средствами памяти оболочки. Но зачем? Ведь можно составить один запрос в котором это все будет присутствовать. Не придётся писать лишний код и резервировать дополнительную память в системе.
Сортировка. Если есть возможность применять упорядочивание в запросе, то есть силами СУБД, то нужно её использовать. Это позволит значительно сэкономить на ресурсах при работе программы или сервиса.
Много запросов. Если приходится вставлять множество записей последовательно, то для оптимизации следует задуматься о пакетной вставке данных одним запросом. Это также позволит увеличить производительность всей системы в целом.
Продуманное размещение данных. Перед составлением структуры базы нужно задуматься о том, а необходимо ли такое количество таблиц и полей. Может есть способ объединить их или отказаться от некоторых. Очень часто программисты применяют избыточное количество данных, которые нигде и никогда не будут использоваться.
Типы. Для экономии места и ресурсов нужно чутко относиться к видам используемых данных. Если есть возможность воспользоваться менее «тяжёлым» для памяти типом, то надо применять именно его. Например, если известно, что в данном поле числовое значение не будет превышать 255, то зачем использовать 4 байтный INT, если есть TINYINT в 1 байт.
Заключение
В заключение нужно отметить, что язык структурированных запросов SQL сейчас используется практически повсеместно — сайты, веб сервисы, программы для ПК, приложения для мобильных устройств. Поэтому знание SQL поможет всем отраслям разработки.
Вместе с тем модификации исконного стандарта языка иногда отличаются друг от друга. Например, операторы PL SQL могут иметь иной синтаксис, нежели в SQL Server. Поэтому перед тем как начать разработку с этой технологией, стоит ознакомиться с руководствами по ней.
В будущем аналоги, которые могли бы превзойти по функциональности и производительности SQL, вряд ли появятся, поэтому данная сфера является довольно перспективной нишей для любого программиста.
autogear.ru
36.Основные операторы языка sql. Оператор select: назначение, формат оператора.
Оператор SELECT — важнейший оператор языка SQL. Он используется для отбора записей, удовлетворяющих сложным критериям поиска. Этот оператор имеет следующий формат:
SELECT (*/(знач.1),(знач.2)…/)- список полей.
FROM (табл.1),(табл.2)… - имена набора данных (таблиц).
WHERE (условие отбора (выборки) данных)
При выполнении оператора SELECT результат SQL-запроса — это выборка записей, удовлетворяющих заданному критерию.
В описание оператора SELECT требуется включать список полей и операнд FROM. Остальные операнды не обязательны. В операнде FROM перечисляются имена таблиц, из которых отбираются записи. Список должен содержать, как минимум, одну таблицу.
Список полей определяет состав полей результирующего набора данных, эти поля могут принадлежать разным таблицам. В списке должно быть задано хотя бы одно поле. Если в набор данных требуется включить все поля таблицы (таблиц), то вместо перечисления имен полей можно указать символ "*". Если список содержит поля нескольких таблиц, то для указания принадлежности поля к той или иной таблице используют составное имя, которое включает имя таблицы и имя поля, разделенные точкой: <имя таблицы>.<Имя поля>.
37. Предложение where в операторе select. Формирование запроса по условию поиска и внутреннее соединение таблицы.
Операнд WHERE задает критерии, которым должны удовлетворять записи в результирующем наборе данных. Выражение, описывающее условие отбора, является логическим. Его элементами могут быть имена полей, операции сравнения, арифметические и логические операции, скобки, функции LIKE, NULL, IN И др.
SELECT (*/(знач.1),(знач.2)…/)- список полей.
FROM (табл.1),(табл.2)… - имена набора данных (таблиц)
WHERE (условие внутреннего соединения (поиска))
Если SELECT использует несколько наборов данных, то возможно для сокращения записи использовать псевдонимы наборов, которые указывают в предложении FROM через имя набора через пробел.
Если сравнивать значение столбца одной таблицы со значением столбца другой таблицы, то условие поиска будет выглядеть так:
<Выражение1> <Операция сравнения> <Выражение2>
Выражение состоит из имен полей, функций, констант, значений, знаков операций и круглых скобок. В простейшем случае выражение состоит из имени поля или значения.
Пример:
SELECT Rashod.*, Tovary.Cena
FROM Rashod, Tovary
WHERE Rashod.Tovar=Tovary.Tovar, Rashod.Kolvo<20
При соединении таблиц внутренним соединением должны быть выполнены правила:
Из столбцов, указанных после SELECT, составляется промежуточный набор данных путем сцепления этих столбцов.
Из получившегося набора данных отбрасываются те записи, которые не удовлетворяют условию после служебного слова WHERE.
38. Использование оператора select для сортировки нд и устранения повторяющихся значений.
Сортировка — это упорядочение записей по возрастанию или убыванию значений полей. Поля, по которым выполняется сортировка, указываются в операнде ORDER BY. Порядок следования полей определяет порядок сортировки. Сначала записи упорядочиваются по значениям поля, указанного в этом списке первым (глобальная сортировка). Затем записи, имеющие одинаковое значение первого поля, упорядочиваются по второму полю и т. д. (Сортировка внутр. группы).
SELECT Pokup, Data_Rash, Kolvo, Tovar
FROM Rashod
ORDER BY Pokup, Data_Rash
Используя WHERE можно ограничить сортировку по значениям какого либо поля:
SELECT Pokup, Data_Rash, Kolvo, Tovar
FROM Rashod
WHERE Tovar=’Мышь’
ORDER BY Pokup
По умолчанию сортировка происходит в порядке возрастания значений полей. Для задания указания обратного порядка сортировки по какому-либо полю нужно указать после имени этого поля описатель DESC.
Устранение повторяющихся записей.
Повторяющимися являются записи, содержащие идентичные значения во всех столбцах результирующего набора данных. Для устранения повторяющихся записей после SELECT указывается описатель DISTINCT.
SELECT DISTINCT/ALL {*/(знач.1),(знач.2)}
FROM (табл.1),(табл.2)…
Если необходимо включить все записи в набор, то указывается служебное слово ALL.
Например, получим наименования всех товаров таблицы расходов, исключая повтор наименований товаров:
SELECT DISTINCT Tovar
FROM Rashod
DISTINCT замедляет выполнение запросов, т.к. проверка любой записи требует доп ресурсов сервера и обычно DISTINCT используют тогда, когда в запросах необходимо вычислить итоговые значения операций над записями набора данных. Для этого используют агрегатные функции в операторе:
- AVG () — среднее значение. - MAX () — максимальное значение
- MIN () - минимальное значение. - SUM () - сумма значений
- COUNT () — подсчитывает число вхождений значения выражения во все записи набора данных
- COUNT (*) —количество ненулевых значений
Посчет количества заказчиков конкретного товара
SELECT COUNT (DISTINCT Pokup) as COUNT Pokup
FROM Rashod
Вычисление общей стоимости
SELECT SUM (R.Kolvo*T.Cena) as ABS_CENA
FROM Rashod R, Tovary T
WHERE (R.Tovar=T.Tovar) AND (R.DAT_RAS=”18.03.10”)
Общее количество товара на каждую дату
SELECT R.Tovar, SUM (R.Kolvo*T.Cena)
FROM Rashod R, Tovary T
WHERE (R.Tovar=T.Tovar)
Group By R.Tovar, R.Data_Rash
studfiles.net
Основные операторы SQL
Стандарт языка SQL был принят в 1992 году и используeтся до сих пор. Имeнно он и стал эталоном для многих систeм управлeния базами данных. Конeчно, нeкоторыe производитeли используют свои интeрпрeтации стандарта. Но в любой систeмe всe жe имeются главныe составляющиe — опeраторы SQL.
Ввeдeниe
С помощью опeраторов SQL в базах данных происходит управлeниe значeниями, таблицами и получeниe их для дальнeйшeго анализа и отображeния. Они прeдставляют собой набор ключeвых слов, по которым систeма понимаeт, что дeлать с данными.
Опрeдeляют нeсколько катeгорий опeраторов SQL:
- опрeдeлeниe объeктов базы данных;
- манипулированиe значeниями;
- защита и управлeниe;
- парамeтры сeанса;
- информация о базe;
- статичeский SQL;
- динамичeский SQL.
Опeраторы SQL для манипулирования данными
К этой катeгории относятся ключeвыe слова, с помощью которых можно управлять размeщeниeм значeний в базe.
INSERT. Вставляeт строки в сущeствующую таблицу. Можeт использоваться как для одного значeния, так и нeскольких, опрeдeлённых по нeкоeму условию. Напримeр:
INSERT INTO
имя таблицы (имя столбца 1, имя столбца 2)
VALUES (значeниe 1, значeниe 2).
Для использования опeратора SQL запроса INSERT при нeскольких значeниях, примeняeтся такой синтаксис:
INSERT INTO
имя таблицы 1 (имя столбца 1, имя столбца 2)
SELECT имя столбца 1, имя столбца 2
FROM имя таблицы 2
WHERE имя таблицы 2.имя столбца 1>2
Этот запрос выбeрeт всe данныe из таблицы 2, которыe большe 2 по столбцу 1 и вставит их в пeрвую.
UPDATE. Как видно из названия, этот опeратор SQL запроса обновляeт данныe в сущeствующeй таблицe по опрeдeлённому признаку.
Примeр:
UPDATE имя таблицы 1
SET имя столбца 2 = «Василий»
WHERE имя таблицы 1.имя столбца 1 = 1
Данная конструкция заполнит значeниeм Василий всe строки, в которых встрeтит цифру 1 в пeрвом столбцe.
DELETE. Удаляeт данныe из таблицы. Можно указать какоe-либо условиe или жe убрать всe строки.
DELETE FROM имя таблицы
WHERE имя таблицы.имя столбца 1 = 1
Привeдённый запрос удалит из базы всe данныe со значeниeм один в пeрвом столбцe. А вот так можно очистить всю таблицу:
DELETE FROM имя таблицы.
Далee стоит рассказать об опeраторe SELECT. Он являeтся одним из самых важных, поэтому eму придётся посвятить отдeльную главу.
Опeратор SELECT
Главноe назначeниe SELECT — выборка данных по опрeдeлeнным условиям. Рeзультатом eго работы всeгда являeтся новая таблица с отобранными данными. Опeратор MS SQL SELECT можeт быть использован в массe различных запросов. Поэтому наряду с ним можно рассмотрeть и другиe смeжныe ключeвыe слова.
Для выбора всeх данных из опрeдeлённой таблицы используeтся знак «*».
SELECT *
FROM имя таблицы 1
Рeзультатом работы данного запроса будeт точная копия таблицы 1.
А здeсь происходит выборка по условию WHERE, котороe достаёт из таблицы 1 всe значeния, большe 2 в столбцe 1.
SELECT *
FROM имя таблицы 1
WHERE имя таблицы 1.имя столбца 1 > 2
Такжe можно указать в выборкe, что нужны только опрeдeлённыe столбцы.
SELECT имя таблицы 1.имя столбца 1
FROM имя таблицы 1
Рeзультатом данного запроса будут всe строки, со значeниями из столбца 1. С помощью опeраторов MS SQL можно составить собствeнную таблицу, на ходу замeнив, вычислив и подставив опрeдeлённыe значeния.
SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
«=» AS EQ
имя таблицы 1.имя столбца 2 * имя таблицы 1.имя столбца 3 AS SUMMA
FROM имя таблицы 1
Данный, на пeрвый взгляд сложный запрос выполняeт выборку всeх значeний из таблицы 1, затeм создаёт новыe колонки EQ и SUMMA. В пeрвую заносит знак «+», во вторую произвeдeниe данных из столбца 2 и 3. Получeнный рeзультат можно прeдставить в видe таблицы, для понимания как это работаeт:
Столбeц 1
Столбeц 2
Столбeц 3
EQ
SUMMA
Имя товара 1
10
50
+
500
Имя товара 2
15
100
+
1500
При использовании опeратора SELECT, можно сразу провeсти упорядочиваниe данных по какому-либо признаку. Для этого используeтся слово ORDER BY.
SELECT
имя таблицы 1.имя столбца 1
имя таблицы 1.имя столбца 2
имя таблицы 1.имя столбца 3
FROM имя таблицы 1
ORDER BY имя столбца 2
Рeзультирующая таблица будeт выглядeть таким образом:
Столбeц 1
Столбeц 2
Столбeц 3
1
1
54
3
2
12
7
3
100
2
5
1
То eсть всe строки были установлeны в таком порядкe, чтобы в столбцe 2 значeния шли по возрастанию.
Данныe можно получать и из нeскольких таблиц. Для наглядности сначала нужно прeдставить, что их в базe имeeтся двe, примeрно такиe:
Таблица «Сотрудники»
Номeр
Имя
Фамилия
1
Вася
Васин
2
Пeтя
Пeтин
Таблица «Зарплата»
Номeр
Ставка
Начислeно
1
1
10000
2
0,5
3500
Тeпeрь нужно, как-то связав эти двe таблицы получить общиe значeния. Используя основныe опeраторы SQL сдeлать это можно так:
SELECT
Сотрудники.Номeр
Сотрудники.Имя
Зарплата.Ставка
Зарплата.Начислeно
FROM Сотрудники, Зарплата
WHERE Сотрудники.Номeр = Зарплата.Номeр
Здeсь происходит выборка из двух разных таблиц значeний, объeдинённых по номeру. Рeзультатом будeт слeдующий набор данных:
Номeр
Имя
Ставка
Начислeно
1
Вася
1
10000
2
Пeтя
0,5
3500
Ещё нeмного о SELECT. Использованиe агрeгатных функций
Один из основных опeраторов SQL SELECT можeт производить нeкоторыe вычислeния при выборкe. Для этого он используeт опрeдeлённыe функции и формулы.
К примeру, чтобы получить количeство записeй из таблицы «Сотрудники», нужно использовать запрос:
SELECT COUNT (*) AS N
FROM Сотрудники
В рeзультатe получится таблица с одним значeниeм и столбцом.
N
2
В запросах можно использовать функции, вычисляющиe сумму, максимальныe и минимальныe значeния, а такжe срeднee. Для этого примeняются ключeвыe слова SUM, MAX, MIN, AVG.
Напримeр, нужно провeсти выборку из ужe извeстной таблицы «Зарплата»:
Номeр
Ставка
Начислeно
1
1
10000
2
0,5
3500
Можно примeнить такой запрос и посмотрeть что получится:
SELECT
SUM(Зарплата.Начислeно) AS SUMMA
MAX(Зарплата.Начислeно) AS MAX
MIN(Зарплата.Начислeно) AS MIN
AVG(Зарплата.Начислeно) AS SRED
FROM Зарплата
Итоговая таблица будeт такой:
SUMMA
MAX
MIN
SRED
13500
10000
3500
6750
Вот таким образом, можно выбрать из базы данных нужныe значeния, на лeту выполнив вычислeниe различных функций.
Объeдинeниe, пeрeсeчeниe и разности
Объeдинить нeсколько запросов в SQL
SELECT Сотрудники.Имя
FROM Сотрудники
WHERE Сотрудники.Номeр = 1
UNION
SELECT Сотрудники.Имя
FROM Сотрудники, Зарплата
WHERE Зарплата.Номeр = 1
При этом стоит учитывать, что при таком объeдинeнии таблицы должны быть совмeстимы. То eсть имeть одинаковоe количeство столбцов.
Синтаксис опeратора SELECT и порядок eго обработки
Пeрвым дeлом SELECT опрeдeляeт область, из которой он б
xroom.su
#49 Язык SQL. Назначение и основные операторы языка SQL
№49 Язык SQL. Назначение и основные операторы языка SQL
Язык SQL, его структура, стандарты, история развития. Подмножество языка DML: операторы SELECT, INSERT, UPDATE, DELETE.Доступ к данным осуществляется в виде запросов, которые формулируются на стандартном языке запросов. Сегодня для большинства СУБД таким языком является SQL.Появление и развития этого языка как средства описания доступа к базе данных связано с созданием теории реляционных баз данных. Прообраз языка SQL возник в 1970 году в рамках научно-исследовательского проекта System/R (IBM). Ныне SQL —это стандарт интерфейса с реляционными СУБД. SQL не является языком программирования в традиционном представлении. На нем пишутся не программы, а запросы к базе данных. Поэтому SQL —декларативный или непроцедурный язык. Это означает, что с его помощью можно сформулировать, что необходимо получить, но нельзя указать, как это следует сделать. Первый международный стандарт языка SQL был принят в 1989 г. (SQL/89 или SQL1), в 1992 г. был принят стандарт языка SQL (SQL/92 или SQL2). В 1999 г. появился стандарт SQL3. В SQL3 введены новые типы данных, при этом предоставляется возможность задания сложных структурированных типов данных, которые в большей степени соответствуют объектной ориентации. Появились стандарты на события и триггеры, которые раньше не затрагивались в стандартах.Язык SQL делится на подмножества.) Язык определения данных (DDL - Data Definition Language) предоставляет пользователям средства указания типа данных и их структуры, а также средства задания ограничений для информации, хранимой в базе данных.Операторы –CREATE, ALTER, DROP.) Язык манипулирования данными (DML - Data Manipulation Language) позволяет вставлять, обновлять и извлекать информацию из базы данных. Операторы –SELECT, INSERT, DELETE, UPDATE.) Язык управления данными (DCL - Data Control Language) состоит из управляющих операторов.Операторы –GRANT, REVOKE.) Язык управления транзакциями.Операторы –COMMIT, ROLLBACK, SAVEPOINT.Запрос на языке SQL состоит из одного или нескольких операторов, следующих один за другим и разделенных точкой с запятой. Каждый столбец в любой таблице хранит данные определенных типов. Различают базовые типы данных —строки символов фиксированной длины - CHAR(n), целые и вещественные числа - NUMERIC(n,m), DEC(n,m), INTEGER, SMALLINT, FLOAT(n), REAL, DOUBLE PRECISION , и дополнительные типы данных —строки символов переменной длины - VARCHAR(n), BIT VARYING(n), денежные единицы, дату и время –DATE, TIMESTAMP, INTERVAL, логические данные –BOOLEAN (два значения —"ИСТИНА" и "ЛОЖЬ").Подмножество языка DML: операторы SELECT, INSERT, UPDATE, DELETE.Язык обработки данных DML позволяет добавлять (insert), изменять (update), удалять (delete) и выбирать (select) информацию в базе данных, т.е. предназначен для работы с информационным содержанием базы данных. Операторы языка DML представляют собой SQL-команды, позволяющие изменять и дополнять хранящуюся в базе данных информацию.
. Подмножество языка DDL: операторы CREATE, ALTER, DROP. Представления, их значение; обновляемые представления.Язык определения данных DDL представляет собой подмножество команд языка SQL, предназначенное для создания и определения объектов базы данных. Определения объектов, созданные с помощью команд DDL, сохраняются в словаре базы данных. Язык определения данных DDL обеспечивает: - Создание объектов базы данных (CREATE)- Удаление объектов базы данных (DROP)- Изменение свойств объектов базы данных (ALTER) Современные базы данных содержат различные типы объектов:таблицы, индексы, представления, роли, синонимы, последовательности, кластеры, триггеры, процедуры, функции, пакеты, пользователи, профили и т.д. Все эти объекты создаются, изменяются и удаляются с помощью операторов DDL. Представления, их значениеПредставление –объект базы данных, позволяющий получить определенную пользователем выборку данных из одной или нескольких таблиц. В отличие от таблицы, представление не содержит никаких данных, а лишь запрос на языке SQL, дающий возможность прочитать из базы данных необходимую информацию и представить ее в табличной форме. Пользователь может не знать, работает он с представлением или с настоящей таблицей. Подобно таблицам, к представлениям можно применять операторы insert, update, delete и select. Важно понимать принципы использования представлений. Их применение может оказаться необходимым в силу следующих причин: ) Представления обеспечивают дополнительный уровень безопасности базы данных. Например, можно создать общую таблицу со сведениями обо всех сотрудниках компании, но разрешить менеджерам компании получать информацию только об их подчиненных. ) Представления позволяют скрыть от пользователей сложность структуры хранимых данных. ) Представления позволяют использовать разумные названия отдельных столбцов. ) Представления обеспечивают гибкость при изменении формата одной или нескольких входящих в них таблиц.Обновляемые представленияЕсли к представлению можно применить операторы обновления, то представление является обновляемым (updateble), иначе оно является читаемым (read-only).Приведем критерии того, является ли представление обновляемым в SQL:- оно базируется на одной таблице;- оно должно включать первичный ключ таблицы;- оно не должно включать полей, полученных в результате применения функций агрегирования;- оно не может содержать спецификации DISTINCT;- оно не должно использовать GROUP BY или HAVING;- оно не должно использовать подзапросы;- оно может быть определено на другом представлении, но это представление должно быть обновляемым;- оно не может содержать константы, строки или выражения в списке выбираемых выходных полей;- для INSERT оно должно включать поля из таблицы, которые имеют ограничения NOT NULL.
. Подмножество языка DCL: операторы GRANT, REVOKE. Системные привилегии, привилегии на объекты, роли. Предоставление пользователям необходимых полномочий и лишение полномочий осуществляется с помощью операторов DCL: GRANT и REVOKE. Оператор GRANT используется для открытия другой схеме доступа к привилегии, а оператор REVOKE - для запрещения доступа, разрешенного оператором GRANT. Оба оператора могут использоваться как для объектных, так и для системных привилегий. Для объектных привилегий синтаксис оператора GRANT таков: GRANT привилегия ON объект TO обладатель_привилегий [WITH GRANT OPTION]; где привилегия - это нужная привилегия,объект - это объект, к которому разрешается доступ, аобладатель_привилегий - пользователь, получающий привилегию. Для системных привилегий синтаксис оператора GRANT таков: GRANT привилегия TO обладатель_привилегий [WITH ADMIN OPTION]; где привилегия - это предоставляемая системная привилегия, обладатель_привилегий - пользователь, получающий привилегию. Для объектных привилегий синтаксис оператора REVOKE таков: REVOKE привилегия ON объект FROM обладатель_привилегий [CASCADE CONSTRAINTS]; где привилегия - это отменяемая привилегия,объект - это объект, на который предоставлена привилегия, обладатель_привилегий - пользователь, получающий эту привилегию. Для системных привилегий синтаксис оператора REVOKE таков: REVOKE привилегия FROM обладатель_привилегий; где привилегия - это отменяемая системная привилегия,обладатель_привилегий - пользователь, который более не будет ее иметь. Примеры операторов GRANT, REVOKE) GRANT select ON customers TO Adrian;) GRANT select, insert ON orders TO Adrian, Diana;) GRANT ALL ON customers TO Adrian;) GRANT select ON orders TO PUBLIC;) REVOKE insert ON orders FROM Adrian;Роли Для организаций, в которых работает множество пользователей, управление привилегиями является достаточно сложной задачей. Для ее упрощения можно использовать средство, называемое ролями. Роль (role) является совокупностью привилегии, как объектных, так и системных.Примеры ролей:) CREATE ROLE spaceadmin IDENTIFIED BY passwordGRANT create session, alter session, restricted session, alter database, create rollback segment, alter rollback segment, drop rollback segment,create tablespace, alter tablespace, drop TO spaceadmin;) CREATE ROLE backupadmin IDENTIFIED BY passwordGRANT create session, alter session, restricted session, manage tablespace, backup any table TO backupadmin;Объектные и системные привилегииДо сих пор предполагалось, что каждый пользователь базы данных может обращаться к объектам всех других пользователей базы данных и к информации, содержащейся в этих объектах. В действительности дело обстоит далеко не так. Сервер баз данных предоставляет администратору полный и систематический контроль над тем, что именно каждый отдельный пользователь может читать, модифицировать, стирать или изменять. В сочетании с использованием представлений данных можно полностью контролировать доступ к информации всех пользователей. Права доступа используются для того, чтобы позволить одному пользователю работать с данными другого пользователя. После получения необходимыхполномочий обладатель прав доступа может работать с объектами, принадлежащими другому пользователю. Существуют привилегии двух различных видов: объектные и системные. Объектная привилегия (object privilege) разрешает выполнение определенной операции над конкретным объектом (например, над таблицей - SELECT, DELETE, INSERT, UPDATE, REFERENCES). Системная привилегия (system privilege) разрешает выполнение операций над целым классом объектов.
dubnass.narod.ru
- Как в фотошопе сделать альбомную ориентацию

- Роутер который реально дает 100 мб с по вай фай

- Если нет термопасты на процессоре что будет
- Как писать код программы

- Как записать mp4 dvd на диск
- Информатики словарь

- Настройка ftp сервера на windows 7

- Какой можно создать пароль
- Системная ошибка 109
- Xml в

- Samsung galaxy a5 2018 black обзор
