Динамический запрос PIVOT SQL Server? Sql pivot пример
Динамический PIVOT в Microsoft SQL Server
--Создаем тестовую таблицу
CREATE TABLE Table1
(
[Customer] VARCHAR(10),
[MONTH] INT,
[YEAR] INT,
[COUNT] INT
)
GO
--вставляем данные в таблицу
INSERT INTO Table1([Customer],[MONTH],[YEAR],[COUNT])
VALUES ('A',9,2011,1),
('A',9,2011,8),
('A',9,2012,1),
('B',9,2011,3),
('B',10,2012,2),
('B',10,2012,2)
GO
--создаем переменную для хранения строки с заголовками столбцов
DECLARE @columns VARCHAR(8000)
SELECT @columns = COALESCE(@columns + ',[' + CAST([YEAR] AS VARCHAR) + ']', '[' + CAST([YEAR] AS VARCHAR)+ ']')
FROM Table1
GROUP BY [YEAR]
DECLARE @query NVARCHAR(4000)
--динамически конструируем текст запроса
SET @query = 'select * from (select
[customer],[Year],[Count] from Table1
)AS SourceTable
Pivot(sum([count]) for [Year] IN (' + @columns + ')) AS PVT;'
--выполнение запроса с помощью хранимой процедуры
EXECUTE SP_EXECUTESQL @query
Данный код создает таблицу Table1, соответствующую исходной таблице на рисунке. Затем
переменной @COLUMNS присваивается строка с годами через запятую, которые считываются запросом, с применением функции COALESCE. После этого можно сконструировать запрос, создающий сводную таблицу. Данный запрос в виде строки сохраняется в переменной @query и выполняется посредством хранимой процедуры sp_executesql. Результат выполнения запроса:
kirillov-blog.blogspot.com
sql - Динамический запрос PIVOT SQL Server?
Я знаю, что этот вопрос старше, но я смотрел через ответы и думал, что я могу расширить "динамическую" часть проблемы и, возможно, помочь кому-то выйти.
В первую очередь я построил это решение для решения проблемы, с которой несколько сотрудников столкнулись с непостоянными и большими наборами данных, которые нужно быстро поворачивать.
Это решение требует создания хранимой процедуры, поэтому, если это неясно, для ваших нужд, пожалуйста, прекратите читать сейчас.
Эта процедура будет принимать ключевые переменные сводной инструкции для динамического создания сводных операторов для разных таблиц, имен столбцов и агрегатов. Столбец Static используется как столбец/идентификатор группы для сводной таблицы (это может быть удалено из кода, если это не необходимо, но довольно часто используется в сводных операторах и было необходимо для решения исходной проблемы), столбец столбца - это то, где конечные имена столбцов будут генерироваться, а столбец значений - это то, к чему будет применяться совокупность. Параметр Table - это имя таблицы, включая схему (schema.tablename), эта часть кода может использовать некоторую любовь, потому что она не такая чистая, как мне бы хотелось. Это работало для меня, потому что мое использование не было публично, и SQL-инъекция не вызывала беспокойства. Параметр Aggregate примет любой стандартный sql-агрегат "AVG", "SUM", "MAX" и т.д. Код также по умолчанию имеет значение MAX как совокупность, это необязательно, но аудитория, изначально построенная для не понимающих опорных точек, и, как правило, используя max как совокупность.
Давайте начнем с кода для создания хранимой процедуры. Этот код должен работать во всех версиях SSMS 2005 и выше, но я не тестировал его в 2005 или 2016 году, но я не понимаю, почему это не сработает.
create PROCEDURE [dbo].[USP_DYNAMIC_PIVOT] ( @STATIC_COLUMN VARCHAR(255), @PIVOT_COLUMN VARCHAR(255), @VALUE_COLUMN VARCHAR(255), @TABLE VARCHAR(255), @AGGREGATE VARCHAR(20) = null ) AS BEGIN SET NOCOUNT ON; declare @AVAIABLE_TO_PIVOT NVARCHAR(MAX), @SQLSTRING NVARCHAR(MAX), @PIVOT_SQL_STRING NVARCHAR(MAX), @TEMPVARCOLUMNS NVARCHAR(MAX), @TABLESQL NVARCHAR(MAX) if isnull(@AGGREGATE,'') = '' begin SET @AGGREGATE = 'MAX' end SET @PIVOT_SQL_STRING = 'SELECT top 1 STUFF((SELECT distinct '', '' + CAST(''[''+CONVERT(VARCHAR,'+ @PIVOT_COLUMN+')+'']'' AS VARCHAR(50)) [text()] FROM '+@TABLE+' WHERE ISNULL('+@PIVOT_COLUMN+','''') <> '''' FOR XML PATH(''''), TYPE) .value(''.'',''NVARCHAR(MAX)''),1,2,'' '') as PIVOT_VALUES from '+@TABLE+' ma ORDER BY ' + @PIVOT_COLUMN + '' declare @TAB AS TABLE(COL NVARCHAR(MAX) ) INSERT INTO @TAB EXEC SP_EXECUTESQL @PIVOT_SQL_STRING, @AVAIABLE_TO_PIVOT SET @AVAIABLE_TO_PIVOT = (SELECT * FROM @TAB) SET @TEMPVARCOLUMNS = (SELECT replace(@AVAIABLE_TO_PIVOT,',',' nvarchar(255) null,') + ' nvarchar(255) null') SET @SQLSTRING = 'DECLARE @RETURN_TABLE TABLE ('+@STATIC_COLUMN+' NVARCHAR(255) NULL,'+@TEMPVARCOLUMNS+') INSERT INTO @RETURN_TABLE('+@STATIC_COLUMN+','+@AVAIABLE_TO_PIVOT+') select * from ( SELECT ' + @STATIC_COLUMN + ' , ' + @PIVOT_COLUMN + ', ' + @VALUE_COLUMN + ' FROM '+@TABLE+' ) a PIVOT ( '+@AGGREGATE+'('+@VALUE_COLUMN+') FOR '+@PIVOT_COLUMN+' IN ('+@AVAIABLE_TO_PIVOT+') ) piv SELECT * FROM @RETURN_TABLE' EXEC SP_EXECUTESQL @SQLSTRING ENDВ следующих примерах показаны различные инструкции выполнения, показывающие различные агрегаты в качестве простого примера. Я не хотел менять столбцы статические, столбцы и значения, чтобы упростить пример. Вы должны просто скопировать и вставить код, чтобы начать с ним общаться
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','sum' exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','max' exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','avg' exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','min' 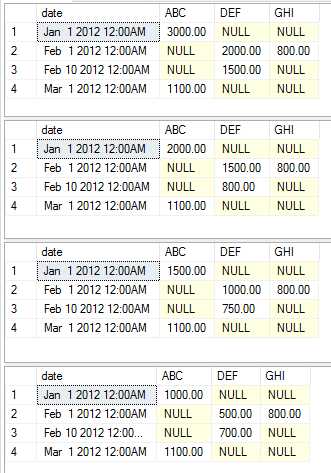
qaru.site
ФОРС. Интернет-журнал, № 2
(Pivot and Unpivot, by Arup Nanda )
Аруп Нанда, Член-директор коллегии Oracle ACE
Источник: сайт корпорации Oracle, серия статей «Oracle Database 11g: The Top New Features for DBAs and Developers» («Oracle Database 11g: Новые возможности для администраторов и разработчиков»), статья 16 http://www.oracle.com/technetwork/articles/sql/11g-pivot-097235.html
Представление информации в виде сводного кросс-табличного отчета, полученного из любой реляционной таблицы с использованием простого SQL-запроса, и сохранение данных из кросс-развернутой таблицы в реляционной таблице.
Поворот(Pivot)
Как известно, реляционные таблицы обычно представляются в матричном виде, то есть, они состоят из пар — столбец-значение. Рассмотрим, например, таблицу CUSTOMERS.
SQL> desc customers Name Null? Type ---------------------- ----- --------------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)Когда из этой таблицы делается выборка:
select cust_id, state_code, times_purchased from customers order by cust_id; выход таков CUST_ID STATE_CODE TIMES_PURCHASED ------- ---------- --------------- 1 CT 1 2 NY 10 3 NJ 2 4 NY 4 ... и так далее ...Заметим, что данные представлены в виде строк значений: для каждого клиента строка называет его домашний штат и количество заказов, сделанных им в магазине. Всякий раз, когда клиент делает следующий заказ, столбец times_purchased обновляется.
Теперь рассмотрим случай, когда надо получить отчет о частоте заказов по каждому штату, то есть, сколько клиентов в конкретном штате сделали один, два, три заказа и т.д. На стандартном языке SQL это могло бы выглядеть следующем образом:
Это та информация, которая вам нужна, только ее несколько неудобно читать. Лучше было бы представить эти же самые данные в виде кросс-табличного отчета, в котором следовало бы вертикально расположить частоту покупок, а коды штатов — горизонтально, как в сводной таблице:
Times_purchased CT NY NJ ... и так далее ... 1 0 1 0 ... 2 23 119 37 ... 3 17 45 1 ... ... и так далее. ...До Oracle Database11 вы сделали бы это посредством некоей сортировки функции декодирования для каждого значения и записали бы каждое неповторяющееся значение отдельным столбцом. Однако, такой способ неочевиден.
К счастью, сейчас имеется отличная новая возможность – PIVOT (ПОВОРОТ) для представления любого запроса в кросс-табличном формате, используя новый оператор, соответственно названный pivot . Теперь, когда в запросе написано:
select * from ( select times_purchased, state_code from customers t ) pivot ( count(state_code) for state_code in ('NY','CT','NJ','FL','MO') ) order by times_purchased / результат будет таким TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO' --------------- ---------- ------- ------ ---- ------ 0 16601 90 0 0 0 1 33048 165 0 0 0 2 33151 179 0 0 0 3 32978 173 0 0 0 4 33109 173 0 1 0 ... и так далее ...Это показывает возможности оператора pivot. Коды штатов (state_codes) показываются в строке заголовка, а не в столбце. Иллюстративно обычный табулированный формат выглядит так:
Рис. 1. Обычное табулированное представление.
В кросс-табличном отчете вы хотите переместить столбец «Times Purchased» в строку заголовка, как показано на рис. 2. Столбец становится строкой, как если бы столбец был повернут на 90 градусов против часовой стрелки, чтобы стать строкой заголовка. Это фигуративное вращение (figurative rotation) должно иметь поворотную точку (pivot point), и в нашем случае точкой поворота служит выражение count(stat_code).
Рис.2. Транспонированное представление
Это выражение должно быть задано в синтаксисе запроса:
... pivot ( count(state_code) for state_code in ('NY','CT','NJ','FL','MO') ) ...Вторая строка "for state_code ...," ограничивает запрос только указанными значениями. Эта строка необходима, поэтому, к сожалению, нужно заранее знать возможные значения. Это ограничение смягчается в XML-формате запроса, описанном далее в этой статье.
Обратите внимание на строку заголовка в отчете:
TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO' --------------- --------- ---------- ---------- -------- ----------Фразой FOR можно указывать алиасы для значений, которые станут заголовками столбцов.
Разворот (Unpivot)
Если для материи существует антиматерия, то и для транспонирования ( pivot) должно существовать обратное транспонирование ("unpivot"), не так ли?
Действительно, существует естественная необходимость в обратной к pivot операции, так сказать, в обратном транспонировании. Предположим, что есть сводная таблица, которая отображает кросс-табличный отчет следующим образом:
| Purchase Frequency | New York | Connecticut | New Jersey | Florida | Missouri |
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
| ... | . |
Теперь надо загрузить данные в реляционную таблицу CUSTOMERS:
SQL> desc customers Name Null? Type --------------------- -------- --------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)Данные из сводной таблицы должны быть переведены в реляционный формат и после этого сохранены. Конечно, вы могли бы написать сложный скрипт для SQL*Loader или SQL-скрипт, использующий функцию DECODE для загрузки данных в таблицу CUSTOMERS. Или же можно воспользоваться обратным повороту (pivot) действием — UNPIVOT – и разбить столбцы, чтобы они стали строками, как это возможно сделать в Oracle Database 11g.
Это проще продемонстрировать на примере. Создадим для начала кросс-таблицу, используя оператор pivot:
1 create table cust_matrix 2 as 3 select * from ( 4 select times_purchased as "Puchase Frequency", state_code 5 from customers t 6 ) 7 pivot 8 ( 9 count(state_code) 10 for state_code in ('NY' as "New York",'CT' "Conn",'NJ' "New Jersey",'FL' "Florida", 'MO' as "Missouri") 11 ) 12* order by 1 Проверим, как данные сохранены в таблице: SQL> select * from cust_matrix 2 / Puchase Frequency New York Conn New Jersey Florida Missouri ----------------- ---------- ------- ---------- ------- --------- 1 33048 165 0 0 0 2 33151 179 0 0 0 3 32978 173 0 0 0 4 33109 173 0 1 0 .. и так далее. ...В сводной таблице данные сохраняются следующим образом: каждый штат — это столбец в таблице ("New York", "Conn" и так далее).
SQL> desc cust_matrix Name Null? Type -------------------------- -------- --------------------------- Puchase Frequency NUMBER(3) New York NUMBER Conn NUMBER New Jersey NUMBER Florida NUMBER Missouri NUMBERВам необходимо разбить таблицу так, чтобы строки содержали только сокращения штатов и число заказов в этом штате. Это можно сделать с помощью оператора unpivot, как показано ниже:
select * from cust_matrix unpivot ( state_counts for state_code in ("New York","Conn","New Jersey","Florida","Missouri") ) order by "Puchase Frequency", state_code / Выход таков: Puchase Frequency STATE_CODE STATE_COUNTS ----------------- ---------- ------------ 1 Conn 165 1 Florida 0 1 Missouri 0 1 New Jersey 0 1 New York 33048 2 Conn 179 2 Florida 0 2 Missouri 0 ... и так далее ...Отметим, что каждое имя столбца стало значением в столбце STATE_CODE. Как Oracle узнал, что state_column — заголовок столбца? Он узнал это из следующего выражения в запросе:
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")Здесь вы определили, что значения "New York", "Conn" и т.д. — это значения нового столбца, называемого state_code, который вы хотите свернуть обратно (unpivoted). Посмотрим на фрагмент исходных данных:
Purchase Frequency New York Conn New Jersey Florida Missouri ----------------- ---------- ---------- ---------- ---------- --------- 1 33048 165 0 0 0Коль скоро имя столбца "New York" неожиданно стало значением в строке, где показать значение 33048, к какому столбцу его отнести? Ответ на этот вопрос находится в приведенном выше запросе прямо в выражении for в операторе unpivot. Как вы определите state_counts, таким и будет имя вновь создаваемого столбца в результирующем выводе.
Действие unpivot можно рассматривать как противоположное действию pivot, но не надо полагать, что одно из них может обратить то, что сделает другое. Например, в предыдущем примере вы создали таблицу CUST_MATRIX, использовав оператор pivot над таблицей CUSTOMERS. Затем был применен оператор unpivot к таблице CUST_MATRIX, но вы не получили в точности исходную таблицу CUSTOMERS. Вместо этого кросс-табличный отчет показал другой способ загрузки в реляционную таблицу. Таким образом, unpivot не отменяет действия, сделанные pivot, факт который нужно самым тщательным образом учитывать прежде, чем удалять (dropping) исходную таблицу после создания повернутой (pivoted) таблицы.
Некоторые очень интересные случаи использования unpivot, подобно рассмотренному ранее примеру, выходят за грани обычной обработки данных. Член-директор Oracle ACE Лукас Джеллема (Lucas Jellema) из компании Amis Technologies в заметке «Flexible Row Generator with Oracle 11g Unpivot Operator» показал, как генерировать строки специфичных данных для тестирования [От редакции FORS Magazine: перевод этой заметки приводится ниже в качестве приложения к данной статье]. В данной статье я буду использовать незначительно измененную форму его кода для генерации гласных английского алфавита:
select value from ( ( select 'a' v1, 'e' v2, 'i' v3, 'o' v4, 'u' v5 from dual ) unpivot ( value for value_type in (v1,v2,v3,v4,v5) ) ) / Выход таков: V - a e i o uЭта модель может быть расширена для создания генератора строк любого типа. Скажем спасибо Лукасу, показавшему нам этот остроумный прием.
XML Type
В предыдущем примере нужно было определить правильные коды штатов state_codes:
for state_code in ('NY','CT','NJ','FL','MO')Это требование предполагает, что вы знаете, какие значения присутствуют в столбце state_column. А как построить запрос, если не известно, какие значения допустимы?
К счастью, существует другая форма операции pivot — XML, которая позволяет создавать повернутый отчет в XML-формате, когда можно определить специальный оператор ANY, вместо литеральных значений. Вот пример:
select * from ( select times_purchased as "Purchase Frequency", state_code from customers t ) pivot xml ( count(state_code) for state_code in (any) ) order by 1 /Результат выводится как CLOB, поэтому прежде чем выполнять запрос, надо удостовериться, что параметр LONGSIZE устанавливает достаточное значение.
SQL> set long 99999Существуют два четких различия (помечены жирным шрифтом) этого запроса по сравнению с исходной операцией pivot. Во-первых, вы пишете pivot xml вместо просто pivot. Это создает вывод в формате XML. Во-вторых, выражение for содержит for state_code in (any) вместо длинного списка значений. XML позволяет использовать ключевое слово ANY, и вам не нужно вводить значения strong>state_code. Вот выход:
Purchase Frequency STATE_CODE_XML ------------------ -------------------------------------------------- 1 <PivotSet><item><column name = "STATE_CODE">CT</co lumn><column name = "COUNT(STATE_CODE)">165</colum n></item><item><column name = "STATE_CODE">NY</col umn><column name = "COUNT(STATE_CODE)">33048</colu mn></item></PivotSet> 2 <PivotSet><item><column name = "STATE_CODE">CT</co lumn><column name = "COUNT(STATE_CODE)">179</colum n></item><item><column name = "STATE_CODE">NY</col umn><column name = "COUNT(STATE_CODE)">33151</colu mn></item></PivotSet> ... и так далееКак можно видеть, тип столбца STATE_CODE_XML — действительно XMLTYPE, а <PivotSet> — корневой элемент (root element). Каждое значение представлено парами элементов «имя–значение». Вы можете использовать этот выход в любом XML-парсере для создания более наглядного выхода.
В дополнение к выражению ANY можно написать подзапрос. Предположим, существует список предпочтительных штатов, и вы хотите выбрать строки только для них. Вы сохранили коды предпочитаемых штатов в новой таблице, названной preferred_states:
SQL> create table preferred_states 2 ( 3 state_code varchar2(2) 4 ) 5 / Table created. SQL> insert into preferred_states values ('FL') 2> / 1 row created. SQL> commit; Commit complete. Теперь операция pivot выглядит следующим образом: select * from ( select times_purchased as "Puchase Frequency", state_code from customers t ) pivot xml ( count(state_code) for state_code in (select state_code from preferred_states) ) order by 1 /В подзапросе фразы for может быть все, что вы захотите. Например, если надо выбрать все записи, без ограничительных условий на предпочтительные штаты, во фразе for можно использовать следующую конструкцию:
for state_code in (select distinct state_code from customers)Подзапрос должен возвращать неповторяющиеся значения, иначе запрос будет ошибочным. Именно поэтому в запросе был использован оператор DISTINCT .
Заключение
Оператор Pivot добавляет очень важную и полезную функциональность в язык SQL. Вместо создания замысловатого непрозрачного кода с большим количеством функций-декодеров (decode functions), можно использовать функцию pivot для создания кросс-табличного представления любой реляционной таблицы. Точно так же можно преобразовать кросс-табличное представление в обычную реляционную таблицу, используя операцию unpivot. Выход pivot может быть как текстовым, так и в XML-формате. В последнем случае не нужно определять область значений, к которым применяется этот оператор.
=======*******=======
За более подробной информацией об операторах pivot и unpivot следует обратиться к документу Oracle Database 11g SQL Language Reference
=======*******=======
Приложение
Лукас Джеллема
Универсальный генератор строк для оператора Unpivot в Oracle11g
(Flexible Row Generator with Oracle 11g Unpivot Operator, by Lucas Jellema)
Источник: сайт AMIS Technology (http://technology.amis.nl/), http://technology.amis.nl/2007/10/05/flexible-row-generator-with-oracle-11g-unpivot-operator/">
Генератор строк — очень полезный механизм для многих (полу-) продвинутых SQL-запросов. В предыдущих статьях мы обсудили различные методы генерации строк. Тому примерами являются оператор CUBE, табличные функции (Table Functions) и фраза «Connect By Level < #» количества подходящих записей, не говоря уже о старом добром UNION ALL с многократным «select from dual». Эти приемы разнятся по гибкости и компактности. CUBE и Connect By обеспечивают легкую генерацию большого количества строк как с незначительным, так и сложным управлением значениями в таких строках, в то время как UNION ALL сложен и громоздок, даже при том, что он предоставляет большие возможности управления точными значениями.
Оператор Unpivot в Oracle11g предоставляет нам новый способ сгенерировать строки с великолепными возможностями управления над значениями в строках и более компактный и изящный синтаксис, чем альтернатива UNION ALL.
Давайте рассмотрим простой пример.
Предположим, что нам нужен набор строк с определенными значениями, возможно, для использования в качестве встроенного представления внутри нашего сложного запроса или в качестве автономного представления. В этом примере я взял шесть довольно бесполезных величин, но он излагает концепцию, что значение имеет.
Единственным select-предложением выборки из DUAL, а не шестью запросами из DUAL, которые по UNION ALL [соединяются] вместе, мы выбираем шесть требуемых значений, как из индивидуальных столбцов – от a до f. Оператор UNPIVOT, который мы затем применяем к этому результату, берет единственную строку с шестью столбцами и превращает ее в шесть строк с двумя столбцами, один из которых содержит имя исходного столбца исходной строки, а другой — значение в том исходном столбце:
select * from ( ( select ‘value1′ a , ‘value27′ b , ‘value534′ c , ‘value912′ d , ‘value1005′ e , ‘value2165′ f from dual ) unpivot > ( value for value_type in ( a,b,c,d,e, f) ) ) /Результат этого запроса таков: :
V VALUE - ——— A value1 B value27 C value534 D value912 E value1005 F value2165 6 rows selected.Замечание:
в ситуациях, где требуется прямая генерация большого количества строк, прием strong>«CONNECT BY» все еще будет превалирующим. Например, чтобы сгенерировать алфавит, следует использовать предложение типа:
1 select chr(rownum+64) letter 2 from (select level 3 from dual 4 connect 5 by level<27 6* )Однако, чтобы сгенерировать поднабор, скажем, все гласные из алфавита, подход с применением оператора strong>UNPIVOT может оказаться полезным.
select vowel from ( ( select ‘a’ v1 , ‘e’ v2 , ‘i’ v3 , ‘o’ v4 , ‘u’ v5 from dual ) unpivot ( vowel for dummy in ( v1,v2,v3,v4,v5) ) ) /www.fors.ru