Автоматизированное восстановление баз данных MS SQL из бэкапов08.12.2016 19:18. Sql восстановление базы из бэкапа
Создание резервной копии и восстановление базы данных MySQL с помощью mysqldump
В данной статье рассмотрим несколько практических примеров резервирования восстановления баз с помощью mysqldump. Утилита mysqldump – это эффективный инструмент для создания резервной копии базы данных MySQL. Он позволяет создать *.sql файл с совокупностью (дампом) всех таблиц и данных основной базы данных (источника).
С целью резервирования баз данных MyISAM, лучше использовать инструмент mysqlhotcopy, который мы обязательно опишем в следующих статьях, так как с ними он работает быстрее и эффективнее.
С помощью mysqldump, можно как создавать резервную копию локальных баз данных, так и восстанавливать их на удалённых базах данных. В данной статье рассмотрим несколько практических примеров резервирования восстановления баз с помощью mysqldump.
Базовыми командами для создания резервной копии и восстановления базы данных MySQL с помощью mysqldump есть:
-
Создание резервной копии:
# mysqldump –u[пользователь] –p[пароль_пользователя] [имя_базы] [название_файла_резервной_копии_базы].sql
Например:
# mysqldump -uroot -pqwerty my_db my_db-dump1.sql
-
Восстановление резервной копии:
# mysql -u[пользователь] -p[пароль_пользователя] [имя_базы] [название_файла_резервной_копии_базы].sql
Например:
# mysql -uroot -pqwerty my_db my_db-dump1.sql
В данных командах:
-u – параметр, который указывает логин, с помощью которого в данном случае осуществляется подключение к базе данных;
-p – параметр, который указывает пароль пользователя данного логина. Если после данного параметра не указать пароль, то после запуска команды его необходимо будет ввести дополнительно;
[имя_базы] – имя базы данных, резервную копию которой необходимо создать;
[название_файла_резервной_копии_базы].sql – пользователь может указать любое удобное название файла резервной копии базы данных. Если указать название файла как в предоставленном примере, то резервная копия базы будет создана в папке из которой запускалась команда, а именно: C:\Program Files\MySQL\MySQL Server 5.7\bin
Чтобы сохранить резервную копию базы в другой папке, перед названием файла резервной копии базы в команде, необходимо указать путь к такой папке. В таком случае команды создания и восстановления резервной копии базы будут выглядеть следующим образом:
# mysqldump -uroot -pqwerty my_db C:\Users\Valery\Documents\MySQL_Backup\my_db-dump1.sql # mysql -uroot -pqwerty my_db C:\Users\Valery\Documents\MySQL_Backup\my_db-dump1.sql
Далее рассмотрим разные варианты создания и восстановления резервной копии базы данных MySQL.
Как создать резервную копию базы данных MySQL
Чтобы создать резервную копию одной базы данных достаточно использовать стандартную команду, которая описана выше:
# mysqldump –u[пользователь] –p[пароль_пользователя] [имя_базы] [название_файла_резервной_копии_базы].sql
Например:
# mysqldump -uroot -pqwerty my_db > my_db-dump1.sql
Резервная копия нескольких баз данных
Прежде чем создавать резервную копию нескольких баз данных одновременно, идентифицируйте наличие баз данных.
Для этого введите команду show databases (в Workbench)
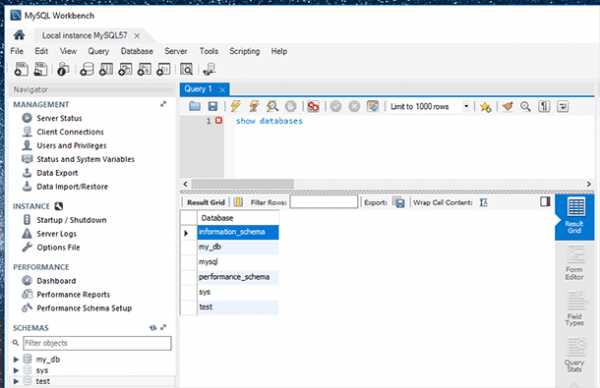
или # mysqlshow –uroot -p (в консоли).
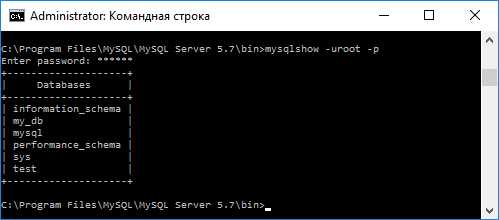
Если необходимо одновременно создать резервную копию нескольких баз данных (например, my_db и test), то для этого необходимо выполнить такую команду:
# mysqldump -uroot -pqwerty –databases my_db test my_db_test_backup.sql
Резервная копия всех баз данных
Если есть необходимость создать бэкап всех баз данных вашего профайла MySQL, то это можно сделать с помощью параметра –all-databases.
# mysqldump -uroot -pqwerty –all-databases all-databases_backup.sql
Резервная копия отдельной таблицы
Также можно создать резервную копию отдельной таблицы базы данных. В случае, если необходимо создать копию таблицы wp_commentmeta из базы данных my_db, то команда будет выглядеть следующим образом:
# mysqldump -uroot -p my_db wp_commentmeta table_ my_db-wp_commentmeta.sql
Примечание. Чтобы просмотреть список таблиц базы, введите команду: #mysqlshow –uroot –p my_db
Как восстановить базу данных MySQL из резервной копии
Восстановить базу данных MySQL из резервной копии, созданной любым из выше описанных способов можно одним стандартным способом, который описан в начале статьи.
hetmanrecovery.com
Как восстановить базу данных MySQL из бэкапа
1. Зайдите в панель Plesk, используя предоставленные Вам учетные данные. Для этого перейдите по ссылке вида https://доменное_имя_или_ip-адрес_сервера:8443/ (обратите внимание, что используется протокол HTTPS и порт 8443), введите имя пользователя и пароль, нажмите "Войти":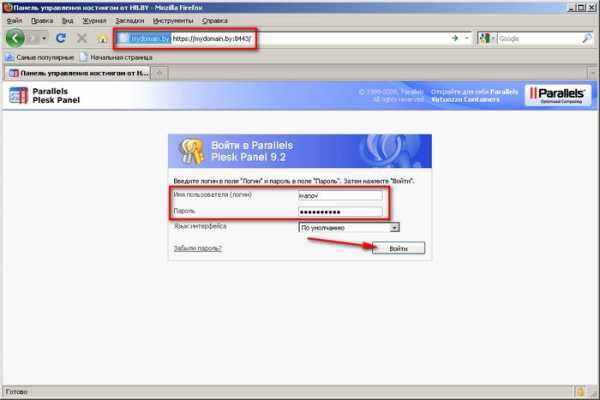 2. После успешного входа выберите «Домены» и перейдите к станице управления доменами:
2. После успешного входа выберите «Домены» и перейдите к станице управления доменами: 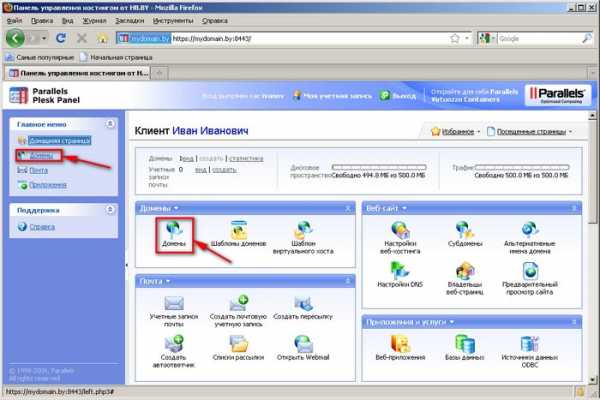
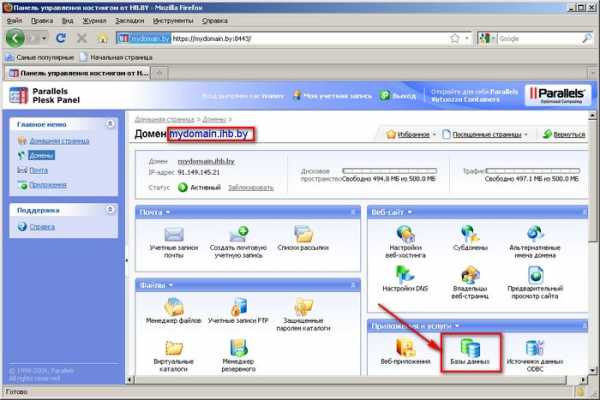 4. Откроется окно управления базами данных. В списке баз данных должна отображаться база данных, которая была создана на шаге 5 инструкции Как создать базу данных в Plesk
4. Откроется окно управления базами данных. В списке баз данных должна отображаться база данных, которая была создана на шаге 5 инструкции Как создать базу данных в Plesk 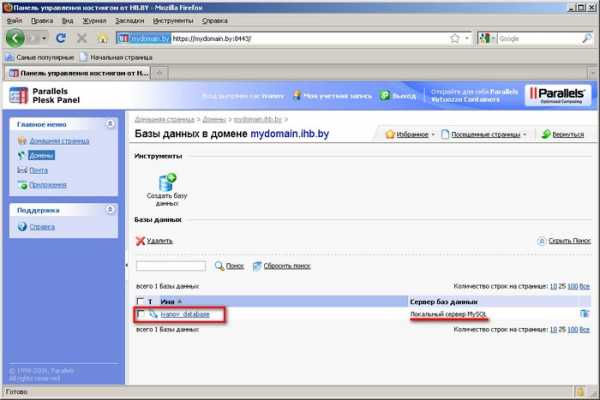 5. Напротив базы данных, которую предполагается восстановить из бэкапа, нажмите на кнопку «Управление базой данных посредством phpMyAdmin»:
5. Напротив базы данных, которую предполагается восстановить из бэкапа, нажмите на кнопку «Управление базой данных посредством phpMyAdmin»: 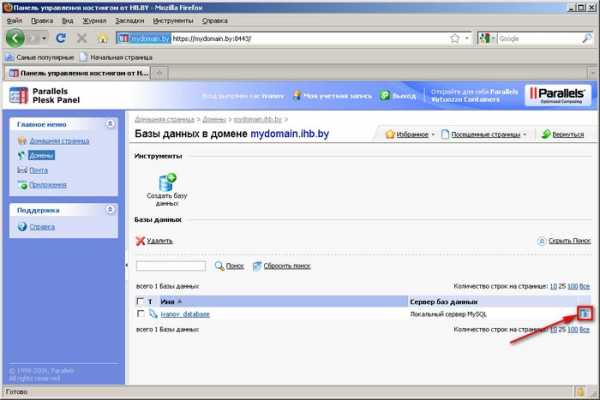 6. Откроется окно phpMyAdmin:
6. Откроется окно phpMyAdmin: 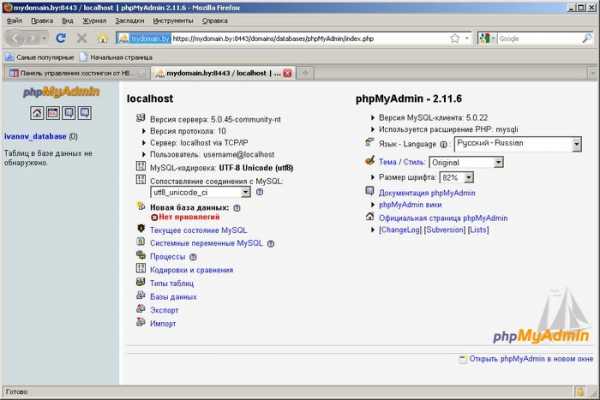 7. Нажмите «Импорт»:
7. Нажмите «Импорт»: 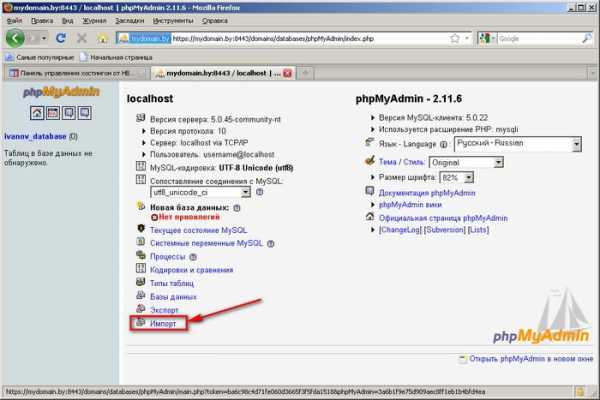 8. Откроется окно для восстановления базы данных MySQL из бэкапа. Выберите файл бэкапа (файл должен представлять собой набор инструкций SQL). Определите остальные параметры, например, кодировку в которой сохранен файл бэкапа. Нажмите кнопку «OK».
8. Откроется окно для восстановления базы данных MySQL из бэкапа. Выберите файл бэкапа (файл должен представлять собой набор инструкций SQL). Определите остальные параметры, например, кодировку в которой сохранен файл бэкапа. Нажмите кнопку «OK». 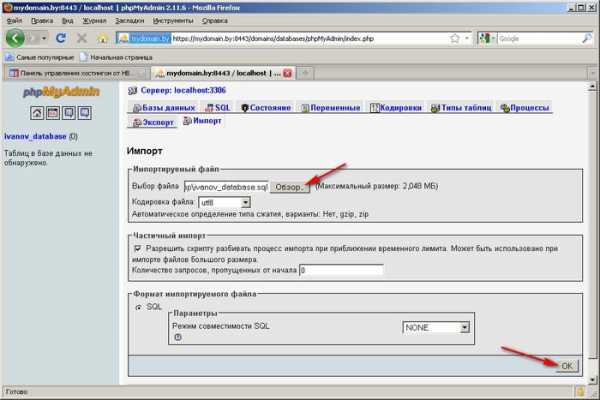 9. В случае, если бэкап был восстановлен успешно, Вы увидите сообщение о том, что импорт данных успешно завершен, а слева появятся импортированные таблицы:
9. В случае, если бэкап был восстановлен успешно, Вы увидите сообщение о том, что импорт данных успешно завершен, а слева появятся импортированные таблицы: 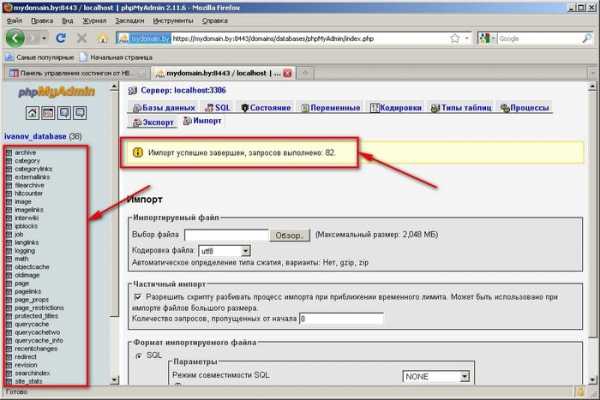
hb.by
Автоматизированное восстановление баз данных MS SQL из бэкапов
В этой статье я хотел бы рассказать о том, как с помощью утилиты Quick Maintenance & Backup for MS SQL настроить автоматическое восстановление баз данных из бэкапов на тестовом экземпляре SQL Server в сети. При этом создавать бэкапы будет штатный План обслуживания. Потребность в автоматизированном восстановлении может возникнуть в следующих случаях:
В сети можно найти примеры скриптов позволяющие в той или иной мере автоматизировать эти задачи. Но большинство решений требуют хорошего понимания T-SQL, предметной области и скорее всего потребуют изменения ваших Планов обслуживания. Я покажу как это сделать за 15-20 минут с помощью утилиты Quick Maintenance & Backup for MS SQL (QMB). Мы задействуем механизм XML планов восстановления — это XML файл с последовательностью бэкапов, который умеет создавать утилита. По информации в XML файле программа получит последовательность бэкапов, сформирует T-SQL скрипт для восстановления и запустит его на выполнение. Подробнее об этой возможности можно почитать здесь.
Подробнее о других возможностях утилиты читайте на официальном сайте, а также в этой статье.
ЗадачаИтак, допустим имеется рабочий SQL Server (Srv01) на котором развернуты несколько баз данных с Полной моделью восстановления. На сервере создан План обслуживания с произвольной стратегией резервного копирования. В моем случае это:
Полный бэкап – каждую неделю 24.00 в воскресенье Разностный бэкап – каждую ночь в 24.00 кроме воскресеньяБэкап лога – каждый день с 9.00 до 23.59 через каждые 1 часБэкапы создаются в папке F:MS SQLBackup. При этом для каждой базы агент SQL Server создает отдельные подпапки.
Задача: каждый день в 23:00 на резервном SQL Server (London) выполнять восстановление баз данных на последнее возможное состояние из бэкапов созданных на Srv01. Оба сервера находятся в единой локальной сети. После восстановления каждой базы данных необходимо проверить её целостность (DBCC CHECKDB). Таким образом, каждый вечер кроме воскресенья, будет выполняться восстановление из Полного бэкапа, разностного и журналов транзакций, созданных в течении дня. В понедельник восстановление будет проводится из Полного бэкапа и журналов транзакций, созданных в течении понедельника. Если по каким-то причинам восстановление не выполнится администратору должно прийти email-уведомление.
Понятно, что для того чтобы тестовый SQL Server (London) смог выполнить восстановление он должен иметь доступ к файлам бэкапов. Тут возможны два варианта:
По причине дополнительной надежности и простоты настройки мы реализуем второй вариант, т.е. утилита будет дополнительно копировать файлы в сетевую папку.
Общий порядок действийИтак, нам потребуется проделать следующие шаги:
- Создание XML плана восстановления на сетевом диске
- Восстановление по XML плану с сетевого диска
- Сценарий, на рабочем сервере Srv01, выполняющий создание XML плана восстановления в общей папке с копированием в неё файлов бэкапов. Старт каждый 1 час.
- Сценарий, на тестовом сервере London, выполняющий восстановление по XML плану из бэкапов, размещенных в общей папке. Старт каждый день в 23.00.
Ниже рассмотрим каждый шаг подробнее.
Установка QMB
Утилиту можно скачать тут. Пробный период — 30 дней.
Я поставил утилиту на тестовом сервере London. В общем случае программу можно установить на любом компьютере, работающем круглосуточно т.е. установка именно на SQL Server не обязательна. При установке программы оставляем все параметры по умолчанию. Инсталлятор установит службу QmbService и клиента.
Регистрация SQL Server и настройка уведомлений
При первом старте программы откроется мастер. Перейдем на следующий шаг и установим галку «Включить email-оповещения» и введем адрес электронной почты для получения уведомлений.
Для отправки уведомлений рекомендуется настраивать собственную учетную запись SMTP, но для простоты мы будем использовать встроенную. Далее введем имя SQL Server и учетную запись для подключения к SQL Server. Необходимо указать учетную запись имеющую привилегии sysadmin (по умолчанию sa).
На следующем шаге программа отобразит версию сервера, лицензию и признак сжатия резервных копий. Все параметры оставляем по умолчанию и нажимаем кнопку «Вперед».
В следующем окне можно настроить слежение за свободным местом на дисках. Если в этом нет необходимости, то снимите все чекбоксы с дисков.
Жмем кнопку «Вперед».
Нам не требуется обслуживать базы данных поэтому на последней странице мы выберем «Создать пустой автономный сценарий». Затем снимем галку «Создать автономный сценарий для обслуживания системных баз данных» и нажмем кнопку «Завершить».
Программа зарегистрирует SQL Server и откроет форму нового пустого сценария.
Создание XML-плана восстановления Любые задачи в программе исполняются в рамках сценариев. В окне нового автономного сценария ведем его имя Создание XML плана восстановления.
Добавим в сценарий задачу, которая будет создавать XML файл плана восстановления. Нажмем кнопку «Добавить». Откроется форма выбора задачи. Кликнем кнопку «Добавить новую задачу». Откроется форма новой задачи.
На форме нужно:
Примечание: Для сети без домена имя пользователя необходимо указывать в формате: КомпьютерПользователь
После выполнения всех действий, форма задачи будет выглядеть как на рисунке ниже.
Обратите внимание на признак «Копировать недостающие файлы архивных копий в общую папку». Благодаря этой опции программа автоматически скопирует недостающие файлы бэкапов с локального диска SQL Server в сетевую папку. При этом, путь к файлу источнику программа определит самостоятельно по информации о созданных резервных копиях, которую SQL Server хранит в системной базе msdb.
Нажмем кнопку Принять и выберем созданную задачу в сценарий. На форме сценария установим флаг «Запуск сценария по расписанию» и укажем расписание: Каждый день, через 1 час начиная с 9:30 до 22:30. Напомню, что План обслуживания создает бэкап лога каждый час с 9:00 до 23:59. Таким образом QMB будет обновлять XML план восстановления со сдвигом в 30 минут (9:30, 10:30, 11:30 и т.д). Нужно отметить, что если бы бэкапы создавались Политикой обслуживания QMB, то XML файл плана восстановления обновлялся бы автоматически.
Сценарий должен выглядеть как на рисунке ниже.
Теперь проверим сценарий. Для этого нажмем кнопку «Выполнить». Если все настроено верно, то в сетевую папку будут скопированы файлы резервных копий и создан файл RestorationPlan.xml. Если в ходе работы программа не найдет нужных файлов резервных копий, то задача завершится ошибкой. Таким образом мы заранее узнаем о потенциальных проблемах. Например, довольно часто, администраторы для передачи базы данных создают её полный бэкап (без параметра COPY_ONLY), а после передачи сразу удаляют его чтобы он не занимал место. Однако при этом рвется цепочка резервных копий и восстановление на актуальный момент времени становится невозможно. Программа выявит эту проблему ещё на этапе создания XML плана восстановления.
Сохраним сценарий. Теперь QMB через каждый час будет пересоздавать XML файл плана восстановления и копировать новые файлы бэкапов, которые создает штатный агент SQL Server.Нужно отметить, что задача по созданию XML плана копирует файлы, необходимые только для восстановления на последний возможный момент времени. При этом файлы копируются без папок т.е. все файлы будут размещены в указанной сетевой папке. В программе существует возможность настроить копирование подпапок, а даже удаление устаревших файлов в сетевой папке. Это можно сделать через пользовательскую задачу, содержащую CMD скрипт или используя Политику обслуживания QMB.
Восстановление на тестовом сервереВосстановление по XML плану выполняется аналогично, с помощью специальной задачи, размещенной в сценарии. Однако восстановление должно выполняться на тестовом SQL Server (London), поэтому этот сервер тоже необходимо зарегистрировать в программе. Для этого в древовидном списке слева нажмем кнопку «Зарегистрировать сервер». Процедура регистрации сервера полностью аналогична описанной ранее.
После регистрации сервера откроется окно автономного сценария. Введем наименование Восстановление по XML плану с Srv01 и укажем его расписание: Каждый день в 23:00.
Теперь из формы сценария добавим новую задачу, аналогично тому как мы создавали задачу для создания XML плана. Однако, теперь в поле тип укажем Восстановление по XML плану, выберем ранее созданное подключение к сетевой папке и укажем имя XML файла. Переключатель База источник определяет какие именно базы данных XML плана восстановления необходимо восстанавливать.
База данных в которую будет выполнено восстановление определяется одноименным переключателем. В нашем случае я буду восстанавливать в одноименные базы данных. Это значит, что на SQL Server будут созданы/перезаписаны базы данных имеющие аналогичные имена (в моем случае это три базы: Account2013, Account2014, Account2015). Таким образом эти базы будут актуализироваться до последнего состояния.
Режим Восстанавливать во временную базу данных следует выбирать, если восстановление выполняется с целью проверки файлов резервных копий и процедуры восстановления. В этом режиме QMB создаст временную базу с наименованием qmbTempRestoreDb[Случайный индекс], которая будет удалена после восстановления и проверки её целостности.
Сохраняем задачу и выбираем её в нашем сценарии.
Чтобы убедиться, что восстановление пройдет успешно выполним сценарий в ручном режиме. Программа последовательно восстановит каждую базу данных и выполнит тестирование её целостности. В зависимости от размеров баз данных процедура может занимать значительное время.
Сохраним сценарий. Теперь каждый день в 23:00 программа будет автоматически восстанавливать базы данных и в случае сбоя отправлять уведомления на Email.
Кроме этого, используя XML файл плана восстановления, администратор с помощью программы может вручную, в несколько кликов, восстанавливать базы данных на других SQL Server.
С удовольствием отвечу на ваши вопросы в комментариях или по электронной почте support@qmbsql.ruСпасибо за внимание!Источник
www.marketopic.ru
Автоматизированное восстановление баз данных MS SQL из бэкапов
 В этой статье я хотел бы рассказать о том, как с помощью утилиты Quick Maintenance & Backup for MS SQL настроить автоматическое восстановление баз данных из бэкапов на тестовом экземпляре SQL Server в сети. При этом создавать бэкапы будет штатный План обслуживания. Потребность в автоматизированном восстановлении может возникнуть в следующих случаях:
В этой статье я хотел бы рассказать о том, как с помощью утилиты Quick Maintenance & Backup for MS SQL настроить автоматическое восстановление баз данных из бэкапов на тестовом экземпляре SQL Server в сети. При этом создавать бэкапы будет штатный План обслуживания. Потребность в автоматизированном восстановлении может возникнуть в следующих случаях: - Если требуется регулярно актуализировать базы данных на тестовых серверах.
- Если требуется периодически проверять через восстановление созданные бэкапы: полный, разностный и журналы транзакций.
Подробнее о других возможностях утилиты читайте на официальном сайте, а также в этой статье.
Задача
Итак, допустим имеется рабочий SQL Server (Srv01) на котором развернуты несколько баз данных с Полной моделью восстановления. На сервере создан План обслуживания с произвольной стратегией резервного копирования. В моем случае это: Полный бэкап — каждую неделю 24.00 в воскресенье Разностный бэкап — каждую ночь в 24.00 кроме воскресенья Бэкап лога — каждый день с 9.00 до 23.59 через каждые 1 час Бэкапы создаются в папке F:\MS SQL\Backup. При этом для каждой базы агент SQL Server создает отдельные подпапки.Задача: каждый день в 23:00 на резервном SQL Server (London) выполнять восстановление баз данных на последнее возможное состояние из бэкапов созданных на Srv01. Оба сервера находятся в единой локальной сети. После восстановления каждой базы данных необходимо проверить её целостность (DBCC CHECKDB). Таким образом, каждый вечер кроме воскресенья, будет выполняться восстановление из Полного бэкапа, разностного и журналов транзакций, созданных в течении дня. В понедельник восстановление будет проводится из Полного бэкапа и журналов транзакций, созданных в течении понедельника. Если по каким-то причинам восстановление не выполнится администратору должно прийти email-уведомление.
Понятно, что для того чтобы тестовый SQL Server (London) смог выполнить восстановление он должен иметь доступ к файлам бэкапов. Тут возможны два варианта:
- Расшарить папку F:\MS SQL\Backup на Srv01 так чтобы она была доступна на London.
- С помощью QMB копировать бэкапы в общую сетевую папку, которая доступна на London.
Общий порядок действий
Итак, нам потребуется проделать следующие шаги:- Настроить общую сетевую папку
- Установить утилиту QMB
- Настроить уведомления и зарегистрировать в программе два SQL Server: Srv01 и London.
- Создать в программе две новых задачи:
- Создание XML плана восстановления на сетевом диске
- Восстановление по XML плану с сетевого диска
- Создать в программе два сценария:
- Сценарий, на рабочем сервере Srv01, выполняющий создание XML плана восстановления в общей папке с копированием в неё файлов бэкапов. Старт каждый 1 час.
- Сценарий, на тестовом сервере London, выполняющий восстановление по XML плану из бэкапов, размещенных в общей папке. Старт каждый день в 23.00.
Установка QMB
Утилиту можно скачать тут. Пробный период — 30 дней.
Я поставил утилиту на тестовом сервере London. В общем случае программу можно установить на любом компьютере, работающем круглосуточно т.е. установка именно на SQL Server не обязательна. При установке программы оставляем все параметры по умолчанию. Инсталлятор установит службу QmbService и клиента.
Регистрация SQL Server и настройка уведомлений
При первом старте программы откроется мастер. Перейдем на следующий шаг и установим галку «Включить email-оповещения» и введем адрес электронной почты для получения уведомлений.
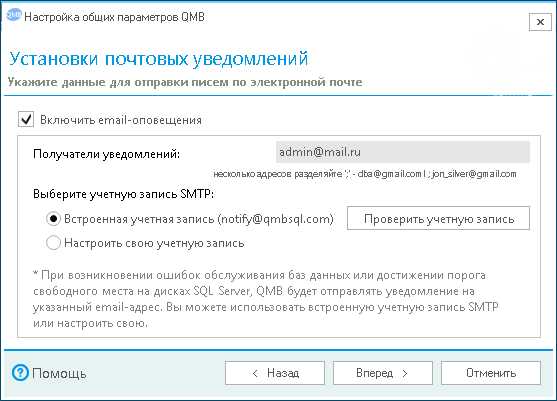 Для отправки уведомлений рекомендуется настраивать собственную учетную запись SMTP, но для простоты мы будем использовать встроенную. Далее введем имя SQL Server и учетную запись для подключения к SQL Server. Необходимо указать учетную запись имеющую привилегии sysadmin (по умолчанию sa).
Для отправки уведомлений рекомендуется настраивать собственную учетную запись SMTP, но для простоты мы будем использовать встроенную. Далее введем имя SQL Server и учетную запись для подключения к SQL Server. Необходимо указать учетную запись имеющую привилегии sysadmin (по умолчанию sa).На следующем шаге программа отобразит версию сервера, лицензию и признак сжатия резервных копий. Все параметры оставляем по умолчанию и нажимаем кнопку «Вперед».
В следующем окне можно настроить слежение за свободным местом на дисках. Если в этом нет необходимости, то снимите все чекбоксы с дисков.
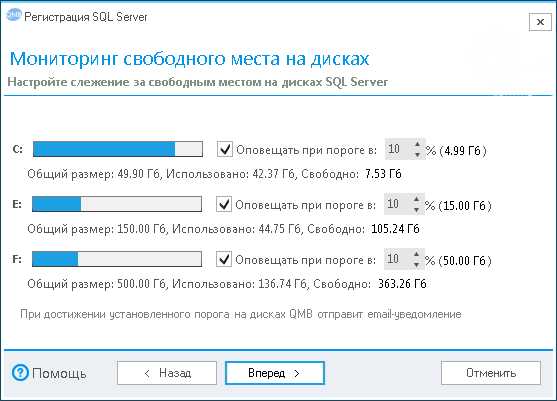 Жмем кнопку «Вперед».
Жмем кнопку «Вперед». Нам не требуется обслуживать базы данных поэтому на последней странице мы выберем «Создать пустой автономный сценарий». Затем снимем галку «Создать автономный сценарий для обслуживания системных баз данных» и нажмем кнопку «Завершить».
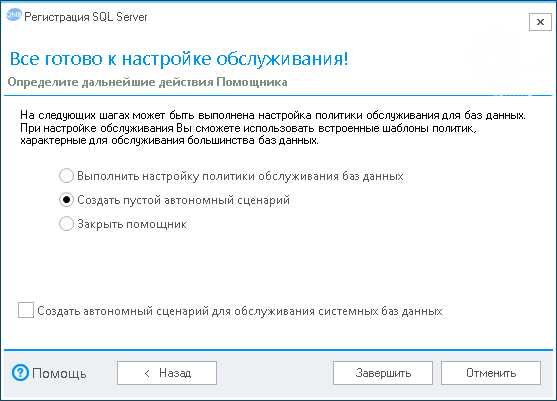 Программа зарегистрирует SQL Server и откроет форму нового пустого сценария.
Программа зарегистрирует SQL Server и откроет форму нового пустого сценария.Создание XML-плана восстановления
Любые задачи в программе исполняются в рамках сценариев. В окне нового автономного сценария ведем его имя Создание XML плана восстановления.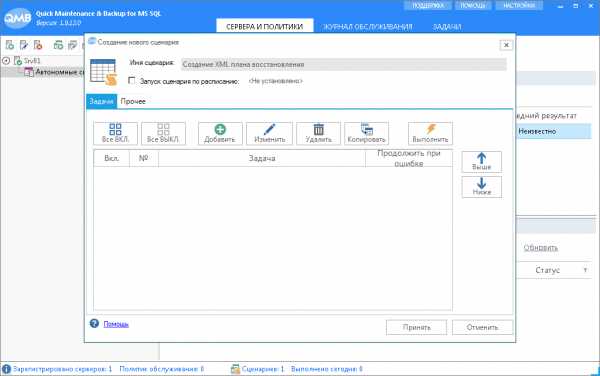 Добавим в сценарий задачу, которая будет создавать XML файл плана восстановления. Нажмем кнопку «Добавить». Откроется форма выбора задачи. Кликнем кнопку «Добавить новую задачу». Откроется форма новой задачи.
Добавим в сценарий задачу, которая будет создавать XML файл плана восстановления. Нажмем кнопку «Добавить». Откроется форма выбора задачи. Кликнем кнопку «Добавить новую задачу». Откроется форма новой задачи. 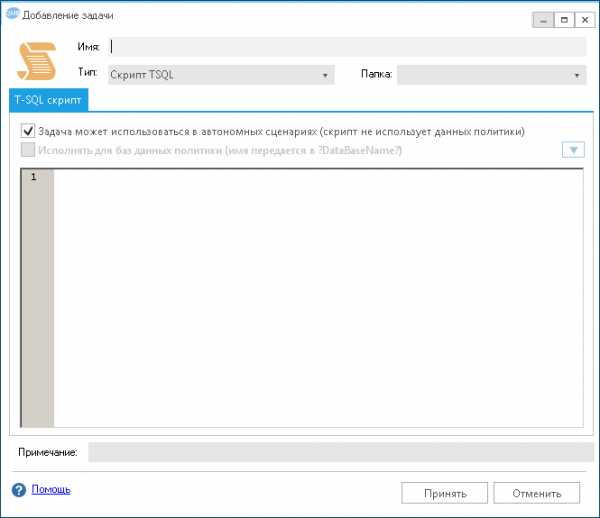 На форме нужно:
На форме нужно: - Изменить тип задачи на «Создание XML плана восстановления»
- Создать новое подключение к общей папке. В моем случае это папка \\Server\Backup на файловом сервере.
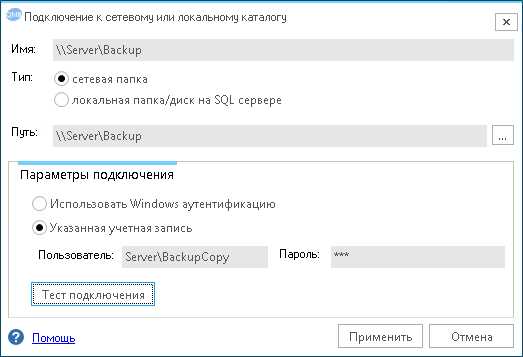 Примечание: Для сети без домена имя пользователя необходимо указывать в формате: Компьютер\Пользователь
Примечание: Для сети без домена имя пользователя необходимо указывать в формате: Компьютер\Пользователь - Выбрать базы данных которые войдут в XML план восстановления. В моем случае это три базы — Account2013, Account2014, Account2015.
- Указать имя задачи — Создание XML плана для Account2013, Account2014, Account2015.
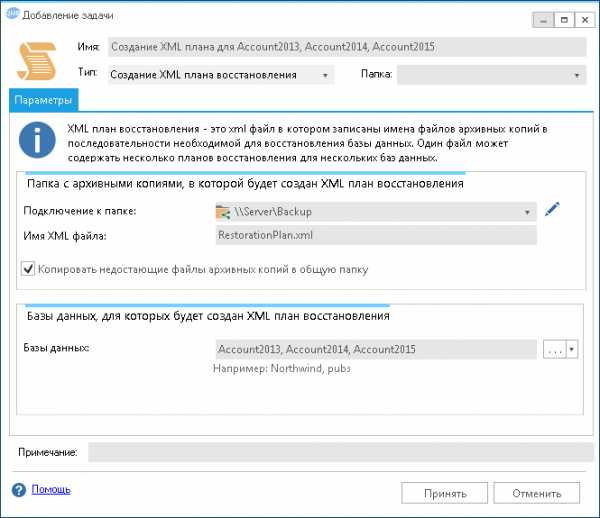 Обратите внимание на признак «Копировать недостающие файлы архивных копий в общую папку». Благодаря этой опции программа автоматически скопирует недостающие файлы бэкапов с локального диска SQL Server в сетевую папку. При этом, путь к файлу источнику программа определит самостоятельно по информации о созданных резервных копиях, которую SQL Server хранит в системной базе msdb.
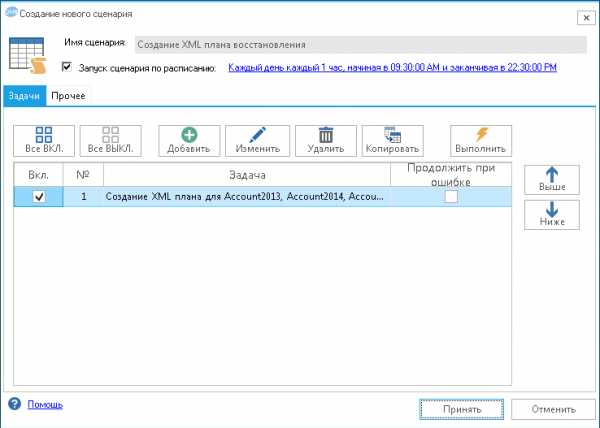
Обратите внимание на признак «Копировать недостающие файлы архивных копий в общую папку». Благодаря этой опции программа автоматически скопирует недостающие файлы бэкапов с локального диска SQL Server в сетевую папку. При этом, путь к файлу источнику программа определит самостоятельно по информации о созданных резервных копиях, которую SQL Server хранит в системной базе msdb.Нажмем кнопку Принять и выберем созданную задачу в сценарий. На форме сценария установим флаг «Запуск сценария по расписанию» и укажем расписание: Каждый день, через 1 час начиная с 9:30 до 22:30. Напомню, что План обслуживания создает бэкап лога каждый час с 9:00 до 23:59. Таким образом QMB будет обновлять XML план восстановления со сдвигом в 30 минут (9:30, 10:30, 11:30 и т.д). Нужно отметить, что если бы бэкапы создавались Политикой обслуживания QMB, то XML файл плана восстановления обновлялся бы автоматически.
Сценарий должен выглядеть как на рисунке ниже.
 Теперь проверим сценарий. Для этого нажмем кнопку «Выполнить». Если все настроено верно, то в сетевую папку будут скопированы файлы резервных копий и создан файл RestorationPlan.xml. Если в ходе работы программа не найдет нужных файлов резервных копий, то задача завершится ошибкой. Таким образом мы заранее узнаем о потенциальных проблемах. Например, довольно часто, администраторы для передачи базы данных создают её полный бэкап (без параметра COPY_ONLY), а после передачи сразу удаляют его чтобы он не занимал место. Однако при этом рвется цепочка резервных копий и восстановление на актуальный момент времени становится невозможно. Программа выявит эту проблему ещё на этапе создания XML плана восстановления.
Теперь проверим сценарий. Для этого нажмем кнопку «Выполнить». Если все настроено верно, то в сетевую папку будут скопированы файлы резервных копий и создан файл RestorationPlan.xml. Если в ходе работы программа не найдет нужных файлов резервных копий, то задача завершится ошибкой. Таким образом мы заранее узнаем о потенциальных проблемах. Например, довольно часто, администраторы для передачи базы данных создают её полный бэкап (без параметра COPY_ONLY), а после передачи сразу удаляют его чтобы он не занимал место. Однако при этом рвется цепочка резервных копий и восстановление на актуальный момент времени становится невозможно. Программа выявит эту проблему ещё на этапе создания XML плана восстановления. 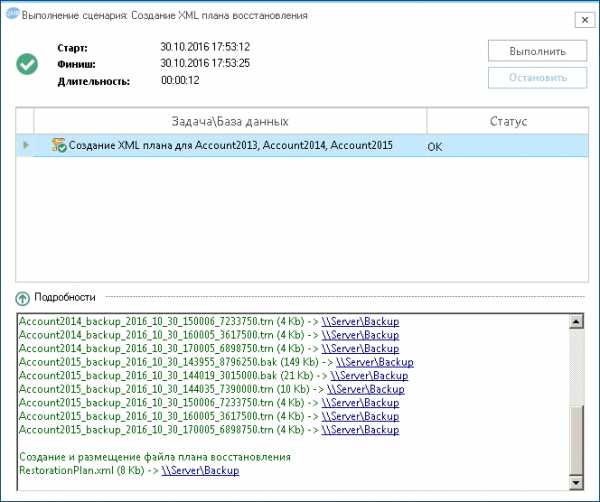 Сохраним сценарий. Теперь QMB через каждый час будет пересоздавать XML файл плана восстановления и копировать новые файлы бэкапов, которые создает штатный агент SQL Server. Нужно отметить, что задача по созданию XML плана копирует файлы, необходимые только для восстановления на последний возможный момент времени. При этом файлы копируются без папок т.е. все файлы будут размещены в указанной сетевой папке. В программе существует возможность настроить копирование подпапок, а даже удаление устаревших файлов в сетевой папке. Это можно сделать через пользовательскую задачу, содержащую CMD скрипт или используя Политику обслуживания QMB.
Сохраним сценарий. Теперь QMB через каждый час будет пересоздавать XML файл плана восстановления и копировать новые файлы бэкапов, которые создает штатный агент SQL Server. Нужно отметить, что задача по созданию XML плана копирует файлы, необходимые только для восстановления на последний возможный момент времени. При этом файлы копируются без папок т.е. все файлы будут размещены в указанной сетевой папке. В программе существует возможность настроить копирование подпапок, а даже удаление устаревших файлов в сетевой папке. Это можно сделать через пользовательскую задачу, содержащую CMD скрипт или используя Политику обслуживания QMB.Восстановление на тестовом сервере
Восстановление по XML плану выполняется аналогично, с помощью специальной задачи, размещенной в сценарии. Однако восстановление должно выполняться на тестовом SQL Server (London), поэтому этот сервер тоже необходимо зарегистрировать в программе. Для этого в древовидном списке слева нажмем кнопку «Зарегистрировать сервер». Процедура регистрации сервера полностью аналогична описанной ранее.После регистрации сервера откроется окно автономного сценария. Введем наименование Восстановление по XML плану с Srv01 и укажем его расписание: Каждый день в 23:00.
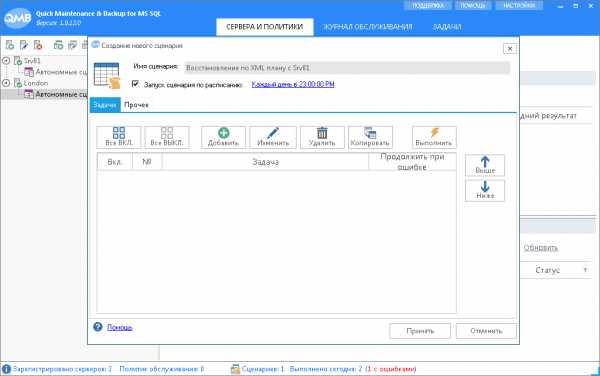 Теперь из формы сценария добавим новую задачу, аналогично тому как мы создавали задачу для создания XML плана. Однако, теперь в поле тип укажем Восстановление по XML плану, выберем ранее созданное подключение к сетевой папке и укажем имя XML файла. Переключатель База источник определяет какие именно базы данных XML плана восстановления необходимо восстанавливать.
Теперь из формы сценария добавим новую задачу, аналогично тому как мы создавали задачу для создания XML плана. Однако, теперь в поле тип укажем Восстановление по XML плану, выберем ранее созданное подключение к сетевой папке и укажем имя XML файла. Переключатель База источник определяет какие именно базы данных XML плана восстановления необходимо восстанавливать.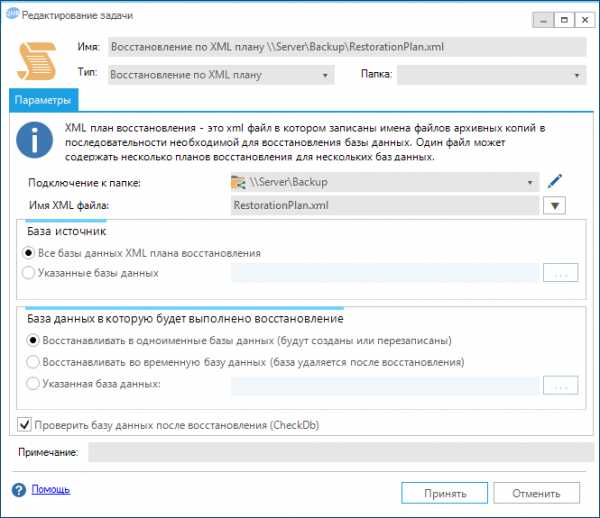 База данных в которую будет выполнено восстановление определяется одноименным переключателем. В нашем случае я буду восстанавливать в одноименные базы данных. Это значит, что на SQL Server будут созданы/перезаписаны базы данных имеющие аналогичные имена (в моем случае это три базы: Account2013, Account2014, Account2015). Таким образом эти базы будут актуализироваться до последнего состояния.
База данных в которую будет выполнено восстановление определяется одноименным переключателем. В нашем случае я буду восстанавливать в одноименные базы данных. Это значит, что на SQL Server будут созданы/перезаписаны базы данных имеющие аналогичные имена (в моем случае это три базы: Account2013, Account2014, Account2015). Таким образом эти базы будут актуализироваться до последнего состояния. Режим Восстанавливать во временную базу данных следует выбирать, если восстановление выполняется с целью проверки файлов резервных копий и процедуры восстановления. В этом режиме QMB создаст временную базу с наименованием qmbTempRestoreDb[Случайный индекс], которая будет удалена после восстановления и проверки её целостности.
Сохраняем задачу и выбираем её в нашем сценарии.
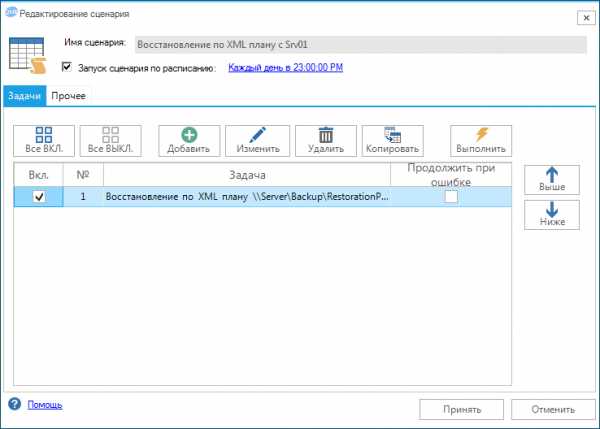 Чтобы убедиться, что восстановление пройдет успешно выполним сценарий в ручном режиме. Программа последовательно восстановит каждую базу данных и выполнит тестирование её целостности. В зависимости от размеров баз данных процедура может занимать значительное время.
Чтобы убедиться, что восстановление пройдет успешно выполним сценарий в ручном режиме. Программа последовательно восстановит каждую базу данных и выполнит тестирование её целостности. В зависимости от размеров баз данных процедура может занимать значительное время. 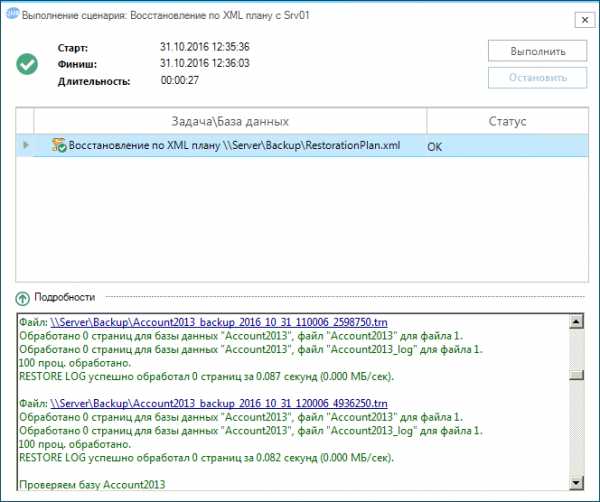 Сохраним сценарий. Теперь каждый день в 23:00 программа будет автоматически восстанавливать базы данных и в случае сбоя отправлять уведомления на Email.
Сохраним сценарий. Теперь каждый день в 23:00 программа будет автоматически восстанавливать базы данных и в случае сбоя отправлять уведомления на Email.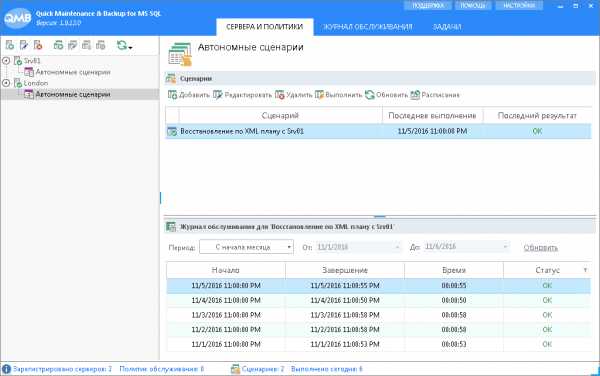 Кроме этого, используя XML файл плана восстановления, администратор с помощью программы может вручную, в несколько кликов, восстанавливать базы данных на других SQL Server.
Кроме этого, используя XML файл плана восстановления, администратор с помощью программы может вручную, в несколько кликов, восстанавливать базы данных на других SQL Server. С удовольствием отвечу на ваши вопросы в комментариях или по электронной почте support@qmbsql.ru Спасибо за внимание!
pcnews.ru
Прерывание восстановления базы из бэкапа
| "Nested Loop (cost=1074.01..1151.83 rows=1 width=40) (actual time=15.955..52.837 rows=13 loops=1)"" Output: ab.application_id, ab.book_id, ab.sale_price, ab.sale_price_wd, ab.purchase_price, ((((10000 - ecd.extra_discount))::bigint * b.base_price) / 10000), ((((10000 - ecd1.extra_discount))::bigint * b.base_price) / 10000), COALESCE(av.purchase_price_a (...)"" Buffers: shared hit=10718"" -> Nested Loop (cost=1073.87..1151.65 rows=1 width=52) (actual time=15.939..52.771 rows=13 loops=1)"" Output: ab.application_id, ab.book_id, ab.sale_price, ab.sale_price_wd, ab.purchase_price, b.base_price, b.publisher_id, ecd.extra_discount, ecd.publisher_id, ecd1.extra_discount, ecd1.publisher_id, av.purchase_price_average"" Join Filter: (ab.book_id = b.book_id)"" Rows Removed by Join Filter: 327600"" Buffers: shared hit=10692"" -> Nested Loop (cost=0.57..55.37 rows=52 width=32) (actual time=0.262..10.927 rows=25201 loops=1)"" Output: a.application_id, ecd.extra_discount, ecd.publisher_id, b.base_price, b.book_id, b.publisher_id, ecd1.extra_discount, ecd1.publisher_id"" Buffers: shared hit=6140"" -> Nested Loop (cost=0.29..49.36 rows=1 width=20) (actual time=0.253..0.665 rows=58 loops=1)"" Output: a.application_id, ecd.extra_discount, ecd.publisher_id, ecd1.extra_discount, ecd1.publisher_id"" Join Filter: (ecd.publisher_id = ecd1.publisher_id)"" Rows Removed by Join Filter: 3306"" Buffers: shared hit=29"" -> Nested Loop (cost=0.29..29.48 rows=9 width=12) (actual time=0.191..0.220 rows=58 loops=1)"" Output: a.application_id, ecd.extra_discount, ecd.publisher_id"" Join Filter: (a.homedep_id = ecd.target_department_id)"" Rows Removed by Join Filter: 1682"" Buffers: shared hit=16"" -> Index Scan using applications_idx_application_id on public.applications a (cost=0.29..8.29 rows=1 width=8) (actual time=0.009..0.010 rows=1 loops=1)"" Output: a.application_id, a.application_status, a.homedep_id, a.customer_id, a.manager_id, a.creation_date, a.delivery_date, a.discount_percent, a.absolute_cost, a.comments, a.application_priority, a.activation_date, a.appli (...)"" Index Cond: (a.application_id = 46071)"" Buffers: shared hit=3"" -> Seq Scan on public.mv_extra_charge_for_all_departments ecd (cost=0.00..14.82 rows=1820 width=12) (actual time=0.003..0.093 rows=1740 loops=1)"" Output: ecd.target_department_id, ecd.publisher_id, ecd.discount, ecd.extra_charge, ecd.ecdep_id, ecd.extra_discount, ecd.disdep_id"" Buffers: shared hit=13"" -> Materialize (cost=0.00..19.42 rows=9 width=8) (actual time=0.001..0.004 rows=58 loops=58)"" Output: ecd1.extra_discount, ecd1.publisher_id"" Buffers: shared hit=13"" -> Seq Scan on public.mv_extra_charge_for_all_departments ecd1 (cost=0.00..19.37 rows=9 width=8) (actual time=0.056..0.123 rows=58 loops=1)"" Output: ecd1.extra_discount, ecd1.publisher_id"" Filter: (ecd1.target_department_id = 1)"" Rows Removed by Filter: 1682"" Buffers: shared hit=13"" -> Index Scan using books_idx_publisher_id on public.books b (cost=0.29..5.56 rows=451 width=12) (actual time=0.004..0.106 rows=435 loops=58)"" Output: b.book_id, b.publisher_id, b.article, b.book_name, b.book_name_original, b.edition, b.edition_year, b.base_price, b.not_published, b.is_manual, b.manual_id, b.weight, b.units_in_box, b.create_date, b.bit_flags, b.rating, b.book_ (...)"" Index Cond: (b.publisher_id = ecd.publisher_id)"" Buffers: shared hit=6111"" -> Materialize (cost=1073.30..1094.11 rows=7 width=28) (actual time=0.000..0.001 rows=13 loops=25201)"" Output: ab.application_id, ab.book_id, ab.sale_price, ab.sale_price_wd, ab.purchase_price, av.purchase_price_average"" Buffers: shared hit=4552"" -> Merge Left Join (cost=1073.30..1094.08 rows=7 width=28) (actual time=7.850..7.862 rows=13 loops=1)"" Output: ab.application_id, ab.book_id, ab.sale_price, ab.sale_price_wd, ab.purchase_price, av.purchase_price_average"" Merge Cond: (ab.book_id = av.book_id)"" Buffers: shared hit=4552"" -> Index Scan using application_books_idx_application_id_book_id on public.application_books ab (cost=0.42..21.13 rows=7 width=20) (actual time=0.005..0.012 rows=13 loops=1)"" Output: ab.application_id, ab.book_id, ab.base_price, ab.sale_price, ab.paid_count, ab.free_count, ab.purchase_price, ab.purchase_price_date, ab.sale_price_wd, ab.log_create_date, ab.log_create_manager, ab.log_update_date, ab.log_ (...)"" Index Cond: (ab.application_id = 46071)"" Buffers: shared hit=11"" -> Sort (cost=1072.88..1072.90 rows=11 width=12) (actual time=7.841..7.842 rows=9 loops=1)"" Output: av.purchase_price_average, av.book_id"" Sort Key: av.book_id"" Sort Method: quicksort Memory: 25kB"" Buffers: shared hit=4541"" -> Subquery Scan on av (cost=1072.64..1072.69 rows=11 width=12) (actual time=7.831..7.833 rows=9 loops=1)"" Output: av.purchase_price_average, av.book_id"" Buffers: shared hit=4541"" -> HashAggregate (cost=1072.64..1072.67 rows=11 width=8) (actual time=7.830..7.831 rows=9 loops=1)"" Output: book_instances.book_id, (sum(book_instances.purchase_price) / count(*))"" Buffers: shared hit=4541"" -> Nested Loop (cost=17.63..1072.55 rows=11 width=8) (actual time=0.677..7.791 rows=161 loops=1)"" Output: book_instances.book_id, book_instances.purchase_price"" Buffers: shared hit=4541"" -> HashAggregate (cost=12.34..12.34 rows=1 width=4) (actual time=0.018..0.022 rows=13 loops=1)"" Output: application_books.book_id"" Buffers: shared hit=11"" -> Index Scan using application_books_idx_application_id on public.application_books (cost=0.42..12.32 rows=7 width=4) (actual time=0.005..0.012 rows=13 loops=1)"" Output: application_books.application_id, application_books.book_id, application_books.base_price, application_books.sale_price, application_books.paid_count, application_books.free_count, application (...)"" Index Cond: (application_books.application_id = 46071)"" Buffers: shared hit=11"" -> Bitmap Heap Scan on public.book_instances (cost=5.29..1060.20 rows=11 width=8) (actual time=0.459..0.593 rows=12 loops=13)"" Output: book_instances.book_instance_id, book_instances.book_id, book_instances.invoice_id, book_instances.storage_id, book_instances.book_status, book_instances.application_id, book_instances.purchase_pric (...)"" Recheck Cond: (book_instances.book_id = application_books.book_id)"" Filter: (book_instances.book_status = 100)"" Rows Removed by Filter: 2481"" Buffers: shared hit=4530"" -> Bitmap Index Scan on book_instances_idx_book_id (cost=0.00..5.29 rows=288 width=0) (actual time=0.134..0.134 rows=2494 loops=13)"" Index Cond: (book_instances.book_id = application_books.book_id)"" Buffers: shared hit=129"" -> Index Only Scan using publishers_idx_publisher_id on public.publishers p (cost=0.14..0.15 rows=1 width=4) (actual time=0.002..0.002 rows=1 loops=13)"" Output: p.publisher_id"" Index Cond: (p.publisher_id = b.publisher_id)"" Heap Fetches: 13"" Buffers: shared hit=26""Total runtime: 53.005 ms" |
forundex.ru
Восстановление SQL БД из бэкапа — NIKOLA.MOSCOW
Могу ли я развернуть бэкап на версии SQL Server, отличной от той, на которой был сделан бэкап? Какие проблемы могут возникнуть?
Вы можете восстановить бэкап на другой версии SQL Server, но только в том случае, если версия SQL Server, на которой вы разворачиваете бэкап, более новая чем та, на которой вы его сделали. Другими словами, вы можете развернуть бэкап, сделанный SQL Server 2000 на SQL Server 2005, SQL Server 2005 на SQL Server 2008 R2 или с SQL Server 2008 на SQL Server 2012, но никогда не сможете сделать этого в обратном направлении. Каждая версия SQL Server вносит свои изменения в базу данных и файлы, хранящие её. Компания Microsoft не будет «возвращаться в прошлое» и переписывать предыдущие версии SQL Server для поддержки этих изменений. Если же вам действительно нужно перейти на более старую версию SQL Server, вам нужно будет заскриптовать схему и сами данные (например, вот статья, посвящённая подобному переходу)
Для того, чтобы определить на какой версии SQL Server был создан бэкап, нужно посмотреть заголовок файла бэкапа:
RESTORE HEADERONLY FROM DISK = 'd:\bu\mm.bak';В результате вы увидите Major, Minor и Build-версии того экземпляра SQL Server, на котором был сделан бэкап (как показано на скриншоте снизу). Это позволит вам определить подходящую версию SQL Server для восстановления этого бэкапа.
При восстановлении БД на более новую версию SQL Server, может оказаться, что в ней присутствует что-то несовместимое с этой версией SQL Server. Наиболее безопасным подходом к переходу на новую версию SQL Server будет запуск Microsoft Upgrade Advisor (бесплатная утилита доступная для каждой версии SQL Server) на базе, которую требуется переносить, убедиться, что она готова, а затем сделать бэкап и восстановить её на новом экземпляре (но только в этом порядке, а не сначала попытаться перенести бэкап, а затем запустить помощника).
После восстановления, БД будет находиться в режиме совместимости с той версией SQL Server’а, с которой осуществлялся переход. Это означает, что ей будет доступен только тот функционал, который поддерживался версией SQL Server, на которой создавался бэкап. Для того, чтобы получить все преимущества новой версии SQL Server, нужно изменить уровень совместимости базы данных. Это можно сделать с помощью GUI, а можно скриптом:
ALTER DATABASE MyDB SET COMPATIBILITY_LEVEL = 110;Различные числа обозначают различные версии SQL Server: 90 для SQL Server 2005, 100 для SQL Server 2008 и 2008 R2 и 110 для SQL Server 2012 (более подробно о версиях SQL Server можно прочитать здесь — прим. переводчика).
Стоит добавить, что не все «переходы» возможны. SQL Server позволят «прыгнуть вперёд» только на две версии. Например, вы не можете развернуть бэкап, сделанный SQL Server 2000, на SQL Server 2012. Сначала вам нужно будет развернуть его на SQL Server 2008, установить соответствующий уровень совместимости, создать новый бэкап, а его, затем, развернуть на SQL Server 2012.
Могу ли я использовать операцию восстановления для создания копии базы даных? Что может пойти не так?
Да, вы можете это сделать. Если вы разворачиваете бэкап на другом сервере, то нужно убедиться в том, что на новом сервере у вас присутствуют те же самые логические диски, что и на «старом» сервере, либо вручную прописать правильные пути для файлов базы данных, используя опцию WITH MOVE команды RESTORE DATABASE:
RESTORE DATABASE NewDBName FROM DISK = 'c:\bu\mm.bak' WITH MOVE 'OldDB' TO 'c:\data\new_mm.mdf', MOVE 'OldDB_Log' TO 'c:\data\new_mm_log.ldf';У файлов баз данных есть как логические имена, так и физические имена файлов. Вам нужно всего лишь прописать все логические имена файлов и определить для каждого из них новое физическое размещение.
Основными проблемами, с которыми вы можете столкнуться, являются ошибки связанные с нехваткой свободного места на дисках, на которые вы восстанавливаете базу данных, либо вы можете забыть указать новое имя для базы данных и SQL Server будет пытаться восстановить базу данных поверх существующей БД.
Когда вы восстанавливаете БД на новом сервере, вы можете столкнуться с проблемой «Orphaned Users» (пользователей, утративших связь с учётной записью, согласно переводу на msdn – прим. переводчика), если пользователь базы данных связан с учётной записью, не представленной на новом сервере. Вам нужно будет исправить эту ошибку.
Можно ли присоединять как базу данных файл MDF, если у меня нет файла журнала транзакций?
Единственный вариант, когда это допустимо – если журнал транзакций был утерян уже после того как работа базы данных была корректно завершена. В любом случае – это не очень хорошая идея. При присоединении БД, файл журнала транзакций, так же как и файл данных, нужен для проведения процесса восстановления БД (здесь под восстановлением БД понимается не операция RESTORE DATABASE, а recovery – процесс, происходящий при каждом запуске SQL Server, при котором SQL Server «проходит» по журналу транзакций и приводит файлы данных в согласованное состояние – прим. переводчика). Тем не менее, в некоторых случаях возможно присоединение файла данных без файла журнала транзакций, но эта возможность предназначена только для тех случаев, когда файл журнала транзакций был повреждён или потерян в результате проблем с оборудованием и при отсутствии резервных копий. Конечно, база данных не может существовать без журнала транзакций, и при присоединении БД без файла журнала транзакций, SQL Server просто пересоздаст его.
Присоединение файла данных без файла журнала транзакций разрушает цепочку журналов и, в добавок, может оказаться, что в БД нарушена транзакционная или структурная целостность (в зависимости от состояния БД на момент «потери» журнала транзакций). Операция присоединения такой БД может завершаться ошибкой вне зависимости от того, какие бы действия не предпринимались.
Копирование файлов данных и файлов журнала транзакций допустимо только после выполнения операции отсоединения (detach), либо после того как процесс SQL Server был корректно завершён – это обеспечит корректное завершение всех транзакций. Копирование/перемещение файлов баз данных на другой сервер является более быстрым способом переноса БД на другой сервер, чем создание/разворачивание резервной копии, но не так безопасно (в том случае, если вы перемещаете непосредственно файлы БД, не имея копий). Так же, нужно помнить о том, что вы можете выполнить присоединение БД только на такой же или более новой версии SQL Server.
Моя БД лежит на SAN. Я слышал, что бэкапов SAN достаточно. Это правда?
Это может быть правдой. Главное чтобы ваша SAN (СХД, Сеть/Система Хранения Данных – прим. переводчика) поддерживала транзакции SQL Server. Если это так, тогда она будет знать о том, что в БД существуют транзакции и наличие этих транзакций может означать, что данные в файлах данных, могут быть не полными, поскольку процесс записи данных, изменённых в этих транзакциях, на жёсткий диск, может быть не завершён на момент создания резервной копии. Те бэкапы, которые делает сам SQL Server, естественно, учитывают эти моменты.
EMC Data Domain, например – это комбинация ПО и SAN, обеспечивающая поддержку транзакций, как и продукция других вендоров, но вам всё равно нужно проверить документацию вашего SAN. Обратите внимание на наличие фраз вроде «transaction consistency», или «transaction aware», или чего-то подобного. Если вы их не нашли, то я бы посоветовал вам проверить восстановление БД прежде чем вы решите, что бэкапов SAN вам достаточно для выполнения всех ваших требований к резервным копиям. Впрочем, даже после того, как вы убедились, что бэкапы SAN выполняются корректно, это вовсе не означает, что «родные» бэкапы SQL Server вам больше не нужны. Если вам нужна возможность восстановления вашей БД на момент времени, например, вам всё равно придётся делать бэкапы журнала транзакций средствами SQL Server.
Обычно, при создании бэкапа, SAN с поддержкой SQL Server, использует VDI-интерфейс SQL Server и «замораживает» БД на время создания резервной копии. Если вы запустите механизм создания такого бэкапа и посмотрите в журнал ошибок SQL Server, там вы увидите сообщения о том, что операции IO были заморожены.
Если вы полагаетесь на резервные копии создаваемые SAN, вам всё равно нужно проводить проверки целостности БД либо на «живых» БД, либо на копиях, восстановленных с бэкапа SAN. В противном случае, вы можете долгое время создавать бэкапы повреждённой БД и даже не знать об этом.
Почему я не могу использовать в качестве бэкапов копии файлов данных, созданных Windows? Мне не нужна возможность восстановления на произвольный момент времени.
SQL Server не является обычным десктопным приложением. Он управляет своими файлами таким образом, чтобы обеспечить выполнение всех свойств ACID (Atomic, Consistency, Isolated, Durable – чуть более подробно— прим. переводчика). Вкратце, чтобы обеспечить успешное завершение транзакций, SQL Server старается никому не давать доступ к своим файлам и сам модифицирует их так, как ему нужно.
Если вы просто скопируете файл данных, игнорируя блокировки и транзакции, которые могут выполняться в данный момент, это означает, что когда вы попробуете присоединить этот файл позже, он будет в несогласованном состоянии, что приведёт к ошибкам.
Только в том случае, когда база данных совершенно не изменяется, вы сможете скопировать файл и присоединить его позже. Если же существует хотя бы минимальная вероятность того, что в момент копирования файла была открыта хотя бы одна транзакция, скорее всего, вы получите неудачную резервную копию. Единственный безопасный способ копирования файлов данных и журналов транзакций для использования их в качестве бэкапов – это перевод БД в режим offline перед копированием.
Намного безопаснее и проще использовать встроенный механизм SQL Serverдля создания бэкапов. Такой бэкап будет являться полной копией вашей БД, и все свойства ACID будут выполнены.
У меня очень маленькая БД. Почему я не могу просто «выгрузить» каждую таблицу на диск для создания резервной копии?
Вы можете использовать что-нибудь вроде SQLCMD и выгрузить таблицы в простой текстовый файл, но потом, вместо того, чтобы просто одной командой восстановить БД, вам придётся выполнить целый ряд команд. Во-первых, вам нужно будет создать пустую БД. Затем, вам нужно будет создать и загрузить из файла каждую таблицу. Если какая-нибудь таблица содержит столбец IDENTITY, вам нужно будет выполнять SET IDENTITY_INSERT на каждой из этих таблиц. Так же, вам придётся тщательно определять порядок, в котором вы будете загружать данные в таблицы, чтобы обеспечивать целостность.
Плюс, учитывайте, что все ваши таблицы выгружены на диск в разное время, так что если данные как-то изменялись во время выгрузки, после восстановления вы не получите БД в целостном состоянии и вам придётся вручную искать ошибки и исправлять их.
Конечно, вы вправе поступать таким образом. С другой стороны, вы можете просто выполнить команду BACKUP DATABASE, а потом, когда понадобится, восстановить этот бэкап.
Зачем платить деньги за утилиты, делающие бэкапы, если SQL Server сам умеет это делать?
Существует три основные причины для использования сторонних программ, создающих бэкапы: руководство, автоматизация и функциональность. Если вы начинающий администратор баз данных или вообще не администратор баз данных, но вынуждены обслуживать СУБД как дополнение к своей основной работе, вы можете и не знать о том как, где и почему нужно настраивать бэкапы в SQL Server. Хорошая утилита (вроде SQL Backup Pro) может предоставить вам как раз такой тип руководства, который вам нужен для того, чтобы обеспечить сохранность ваших БД с помощью резервных копий.
Бэкапы, создаваемые самим SQL Server, работают отлично, но вам нужно проделать немало работы для того, чтобы их настроить и ещё больше для того, чтобы их автоматизировать. Хорошая сторонняя утилита сделает процесс автоматизации очень простым. Более того, с её помощью вы сможете автоматизировать другие процессы связанные с бэкапами, такие как зеркалирование/доставка журналов и проверка целостности бэкапа.
Наконец, хотя бэкапы SQL Server и делают то что вам надо, они, возможно, делают это не самым лучшим образом. Например, некоторые утилиты более эффективно сжимают резервные копии, сохраняя таким образом больше дискового пространства и сокращая время создания резервной копии. Так же, они добавляют функциональность – такую как шифрование файла резервной копии (что-то подобное возможно встроенными средствами SQL Server только в том случае, если сама БД зашифрована).
Если бэкап лежит на сетевой шаре, может ли кто-то прочитать его?
До тех пор пока вы не зашифровали непосредственно сам файл резервной копии – да – это самый обычный файл. Если кто-то получит доступ к этой шаре, то он сможет его прочитать любым текстовым редактором, либо просто скопировать и запустить восстановление из него на другом экземпляре SQL Server.
Более того, из бэкапа можно достать схему БД или данные, даже не восстанавливая его. Если у вас есть утилита SQL Data Compare, то она, запущенная с ключом /Export сможет вытащить все данные из бэкапа в CSV-формате, сравнивая этот бэкап с пустой БД и не спрашивая никакого пароля. Так же, та же самая SQL Data Compare сможет создать для вас скрипт создающий схему БД.
Для того чтобы предотвратить несанкционированный доступ к бэкапу, вам придётся сделать несколько вещей. Во-первых, убедиться, что шара, на которой хранятся бэкапы, доступна ограниченному кругу лиц. Во-вторых, вы должны хранить только те бэкапы, которые вам действительно нужны. Наконец, если вы используете сторонние утилиты для создания резервных копий (типа SQL Backup Pro), вы можете зашифровать бэкап, так что если кто-то и получит доступ непосредственно к файлу, то прочитать оттуда ничего не сможет.
Без сторонних утилит, вы сможете этого добиться, используя Transparent Data Encryption (TDE).
Для обеспечения наилучшего уровня безопасности, вам нужно выполнять все вышеперечисленные действия.
А кто-нибудь может изменить содержимое резервной копии?
Возможности изменять содержимое файла резервной копии не предусмотрено. Поскольку бэкап это постраничная копия базы данных (в том виде в котором она существовала на момент создания бэкапа), восстановленная копия этой БД будет находиться в абсолютно том же состоянии, в котором оригинал был на момент создания бэкапа.Когда SQL Server считывает каждую страницу, в ходе восстановления БД, он высчитывает её контрольную сумму, зависящую от её содержания, и сравнивает с тем значением, которое было прочитано с оригинальной страницы в момент создания бэкапа (подразумевается, что вы использовали параметр WITH CHECKSUM при создании резервной копии). Если кто-либо производил изменения в файле резервной копии, эти значения не совпадут и SQL Server отметит такую страницу как повреждённую.
Существует ли какой-либо флаг, установив который при создании бэкапа, я могу быть уверен, что всегда смогу из него восстановиться?
Если под таким флагом вы подразумеваете, что ваш процесс создания резервной копии включает в себя выполнение операции RESTORE VERIFYONLY после создания бэкапа, то нет, вы не можете быть уверены в том, что сможете восстановить БД из этого бэкапа. RESTORE VERIFYONLY может выполнять набор из двух проверок.
Во-первых, она проверяет заголовок бэкапа, чтобы убедиться, что в нём нет ошибок. Если заголовок повреждён, то вы не сможете восстановить БД из этого бэкапа.
RESTORE VERIFYONLY FROM DISK= '<Backup_location>'Вторая проверка возможно только в том случае, если вы запускали процедуру создания резервной копии с параметром WITH CHECKSUM. Это означает, что в ходе создания резервной копии, SQL Server пересчитывает и сверяет контрольные суммы для всех прочитанных страниц. Если он наткнётся на страницу, для которой эти суммы не сойдутся, операция создания резервной копии завершится с ошибкой. Если проверка завершается успешно, BACKUP WITH CHECKSUM вычислит и запишет контрольную сумму созданной копии.
Соответственно, RESTORE VERIFYONLY может использоваться для пересчёта контрольной суммы и проверки того, что за время хранения резервная копия не была повреждена
RESTORE VERIFYONLY FROM DISK= '<Backup_location>' WITH CHECKSUMПроблемы могут возникнуть в двух местах. Во первых, проверка заголовка в ходе выполнения VERIFYONLY не проверяет всё что может повлиять на процесс восстановления. Это означает, что RESTORE VERIFYONLY может завершиться без ошибок, но БД всё равно не сможет быть восстановлена из «проверенной» копии.
Во-вторых, CHECKSUM не может обнаружить повреждения, произошедшие в памяти. Если страница данных была обновлена, находясь в памяти и затем произошло её повреждение прежде чем она была записана на диск (и, соответственно, в бэкап), тогда вычисление контрольной суммы не покажет никакой ошибки, а просто подтвердит, что в бэкап была записана та же страница, что и содержалась в БД в момент создания бэкапа. Т.е. если страница уже была повреждена в момент создания бэкапа, ошибка не может быть найдена с помощью контрольной суммы и восстановление из этого бэкапа может завершиться ошибкой.
Единственный способ узнать наверняка, что из бэкапа можно восстановиться и полученная БД не повреждена – это восстановить его и, желательно, запустить проверку целостности БД на восстановленной копии.
Не содержит ли бэкап что-нибудь кроме данных? Может ли кто-нибудь прочесть пароли из него?
Бэкап содержит не только данные. Он содержит всю структуру базы данных. Она включается в себя все данные, процедуры, представления, функции и весь остальной код. Также, он содержит все настройки БД. Наконец, он содержит всю информацию о пользователях БД. Для обычной БД, каждый пользователь БД связан с учётной записью SQL Server. Пароли таких пользователей хранятся вместе с учётной записью, так что этих паролей в бэкапе не будет.
Однако, в автономных базах данных (contained databases — прим. переводчика) существует понятие USER WITH PASSWORD, поскольку сама идея автономных баз данных предполагает минимальную связь такой базы с сервером. В этом случае, пароль будет находиться в бэкапе, что может привести к попыткам достать его оттуда. Пароли хранятся не открытым текстом, они хэшируются, точно так же как пароли учётных записей (которые хранятся в системной базе данных master и, естественно, попадают в её бэкап).
Microsoft предлагает несколько best practices по безопасности автономных баз данных.
Зачем в бэкапе индексы, статистика и остальные штуки, которые легко пересоздать? Это же просто потеря времени?
А по-моему, потеря времени – это попытки разделить вещи таким образом и делать резервную копию только одной части. Во-первых, как это сделать? Например, как забэкапить данные, не делая, при этом, бэкапа кластерных индексов? Это невозможно, поскольку листовой уровень кластерного индекса – это страницы данных. Т.е., можно сказать, что кластерные индексы – это сами таблицы, поэтому кластерные индексы должны быть включены в бэкап. Конечно, возможно выделить некластерные индексы в отдельную файловую группу и не делать её бэкап, но потом, после восстановления того бэкапа, что у нас есть, нам всё равно нужно будет возвращать эту файловую группу к жизни и перестраивать все индексы. Так чего мы добьёмся?
Со статистикой так же возникнут проблемы. SQL Server бэкапит статистику вместе с базой данных (и она занимает очень мало места, поскольку, гистограмма, называющаяся статистикой, строится всего лишь по 200 строкам) и восстанавливает её вместе с БД. Однако, если после восстановления мы начнём пересоздавать индексы, поскольку не делали их резервной копии, нам придётся пересоздавать и статистику. Это так же потребует дополнительного времени, а база данных, тем временем, будет оставаться недоступной.
В конце концов, я бы поспорил с формулировкой «легко пересоздать», поскольку в экстренном случае, весь этот процесс может оказаться очень запутанным, что неизбежно приведёт к тому, что люди, работающие с этой базой данных, не смогут получить к ней доступ намного большее время, чем в случае простого восстановления из бэкапа.
Сама идея создания резервной копии заключается в том, чтобы можно было восстановить базу данных как можно более быстро и эффективно. Чем сложнее процесс восстановления, тем менее эффективна резервная копия. Да, для хранения индексов, пользователей, хранимых процедур и всего прочего, требуется дополнительное пространство, но увеличение скорости восстановления за счёт того, что всё лежит в одном месте, стоит этого дополнительного пространства.
ОМГ! Я только что удалил таблицу! Я знаю, что это есть в журнале транзакций. Как мне её вернуть?
После того как транзакция была зафиксирована, SQL Server не сможет её откатить. Операции DELETE И TRUNCATE удаляют данные совершенно разными способами. Операция DELETE удаляет данные с помощью транзакций, удаляющих каждую строку. Операция TRUNCATE просто отмечает странницы данных, на которых лежали удаляемые данные, как не использующиеся. Но последствия ни одной из этих операций не могут быть устранены вручную при просмотре журнала транзакций. Вместо этого, вам нужно выполнить процесс, называющийся восстановлением на момент времени. Вы должны немедленно сделать бэкап журнала транзакций вашей БД для того, чтобы сохранить все изменения сделанные до того момента, как вы случайно удалили нужные данные из таблицы. Затем, вам нужно выполнить шаги, описанные в главе 6 этой книги для восстановления на момент времени (в MSDN тоже всё есть – прим. переводчика).
Другой вариант – использование сторонних утилит, типа SQL Backup Pro, которые могут выполнять восстановление отдельных объектов БД в режиме online из имеющихся резервных копий.
А если я просто хочу создать с помощью бэкапа скрипт для построения БД, без восстановления непосредственно бэкапа…?
Стандартных средств для создания такого скрипта в SQL Server не предусмотрено. Однако, утилиты, типа SQL Compare, могут сформировать его. Он легко создаётся с помощью GUI, но так же это возможно с использованием PowerShell:
& 'C:\Program Files (x86)\Red Gate\SQL Compare 8\SQLCompare.exe' /Backup1:C:\MyBackups\MyBackupFile.bak /MakeScripts:"C:\MyScripts\MyBackupScript"
Так же, вы можете обратить внимание на SQL Virtual Restore. Эта утилита позволяет вам примонтировать бэкап к вашему SQL Server так, как будто бы вы запускали процесс восстановления из этого бэкапа, но не требует использования всего того места, которое было бы необходимым при восстановлени. Примонтированный таким образом бэкап выглядит как самая обычная база данных и вы можете заскриптовать её любым удобным вам образом.
nikola.moscow
- Настройка телеграмма
- Знание пк что такое пк

- Агп разъем

- Какой должен быть компьютер для игр

- Сами ремонтируем компьютер

- Выделить весь текст в word сочетание клавиш

- Сети для чайников
- Партионка ру

- Как очистить память на компьютере
- Komp uroki ru

- Как поменять язык в командной строке