Сравнение пустой строки с нулевым значением - SQL Server. Сравнение строк sql
string - Сравнение строк SQL, большее и меньшее, чем операторы
Операторы сравнения (включая < и >) работают со строковыми значениями, а также с номерами.
Для MySQL
"По умолчанию сравнения строк не чувствительны к регистру и используют текущий набор символов. По умолчанию используется latin1 (cp1252 западноевропейский), что также хорошо подходит для английского языка.
Сравнение строк будет чувствительным к регистру, если сопоставление строк в сопоставлении строк чувствительно к регистру, то есть имя набора символов заканчивается на _cs, а не _ci. Нет смысла повторять всю информацию, которая доступна в Справочном руководстве MySQL здесь.
Справочник операторов сравнения MySQL: http://dev.mysql.com/doc/refman/5.5/en/comparison-operators.html
Дополнительная информация о MySQL-символах/коллаборациях: http://dev.mysql.com/doc/refman/5.5/en/charset.html
Чтобы ответить на заданные вами вопросы:
A: Да, как в MySQL, так и в SQL Server
Q: и как он действует?
A: Оператор сравнения возвращает логическое значение: TRUE, FALSE или NULL.
Q: строка, меньшая, чем другая, предшествует в порядке словаря? Например, мяч меньше, чем вода?
A: Да, потому что 'b' приходит перед 'w' в сортировке characteset, выражение
'ball' < 'water'вернет TRUE. (Это зависит от набора символов и от сортировки.
Q:, и это сравнение чувствительно к регистру?
A: Независимо от того, зависит ли конкретное сравнение с регистром или нет, зависит от сервера базы данных; по умолчанию оба SQL Server и MySQL нечувствительны к регистру.
В MySQL можно выполнить сравнения строк, указав сопоставление наборов символов, чувствительность к регистру (имя набора символов будет заканчиваться на _cs, а не _ci)
Q: Например, BALL < вода, характер верхнего регистра влияет на эти сравнения?
A: По умолчанию в SQL Server и MySQL выражение
'ball' < 'water'вернет TRUE.
sql - Сравнение пустой строки с нулевым значением - SQL Server
Мне нужно сравнить два столбца и нажимать на проблемы при сравнении NULL с пустой строкой. Проще говоря, это то, на что я смотрю.
DECLARE @EmptyString VARCHAR(20) = '', -- Could have valid VARCHAR data, empty string, or NULL @Null VARCHAR(20) = Null; -- Could have valid VARCHAR data, empty string, or NULL SELECT CASE WHEN @EmptyString != @Null THEN 'Pass' ELSE 'Fail' END AS EmptyStringVsNullВ этом случае, поскольку все мы знаем, что пустая строка и значение столбца null различаются, я надеюсь, что результат вернется как "Pass", но это не так.
От Martin asnwer здесь он объясняет, что сравнение, подобное этому, приводит к UNKNOWN, а не TRUE или FALSE, что разъясняет причину Я вижу эти результаты, но мне нужно найти решение этого. Я знаю, что вокруг этого должен быть простой способ, который мне не хватает...
Я знаю, что есть несколько встроенных функций, таких как ISNULL() и NULLIF(), однако я не знаю, могут ли они помочь в этой ситуации...
ISNULL()
Если мы используем функцию ISNULL() для установки пустых значений в пустую строку, то сравнение не будет работать как пустая строка, равно пустой строке, например
Это также возвращает "FAIL", поэтому это не выход. Я всегда мог использовать ISNULL, чтобы преобразовать это в другую строку, но это все еще не подходит, поскольку пустая строка может иметь другое значение, которое случайно может соответствовать тому, что мы решили преобразовать в значение null.
NULLIF()
DECLARE @EmptyString VARCHAR(20) = '', @Null VARCHAR(20) = Null; SELECT CASE WHEN NULLIF(@EmptyString, '') != NULLIF(@Null, '') THEN 'Pass' ELSE 'Fail' END AS EmptyStringVsNullЕсли мы используем функцию NULLIF() для преобразования пустых строк в нуль, наше сравнение по-прежнему не возвращает true. Это связано с тем, что, как объяснено в связанном сообщении, сравнение нулевых значений приводит к UNKNOWN.
С простым примером SQL выше, как я могу проверить, что значение NULL не равно пустой строке?
sql - Сравнение строк в SQL Server 2008
<= работает отлично. Проблема, с которой вы сталкиваетесь, заключается в том, что вы ожидаете, что числовая сортировка будет отсутствовать. Это не работает без специальной обработки.
Сортировка строк
a1 - строки a10 сортируются в следующем порядке:
a1 a10 a2 a3 a4 ...Это связано с тем, что и a1, и a10 начинаются с "a1".
Поскольку они являются строками, числовые значения не имеют значения. Посмотрите, что произойдет, если подставить a- z для 0- 9:
ab aba ac ad aeТеперь вы видите, почему вы получаете результаты? В словаре aba приходит до ac, а a10 - до a2.
Чтобы решить вашу проблему, лучше всего разделить столбец на два: один char и один на номер. Некоторые неприятные выражения могут получить правильный порядок сортировки для вас, но это гораздо худшее решение, если у вас нет абсолютно никакого выбора.
Вот один из способов. Возможно, это не подходит или может быть более эффективным способом, но я не знаю, как все ваши данные.
SELECT FROM Table WHERE Col LIKE 'a%' AND Substring(Col, Convert(int, PatIndex('%[^a-z]%', Col + '0'), 1000)) <= 10Если альфа-часть - это всегда один символ, вы можете сделать это проще. Если числа могут иметь буквы после них, тогда требуется больше поворота.
Вы также можете попробовать производную таблицу, которая разбивает столбец на отдельные альфа-и числовые части, а затем помещает условия во внешний запрос.
Сверка
Помните, что каждая строка и столбец char -based имеет параметр сортировки, который определяет, какие буквы сортируются вместе (в основном для случая и акцентов), и это может изменить результаты операции неравенства.
SELECT * FROM Table WHERE Value <= 'abc' SELECT CASE WHEN Value <= 'abc' COLLATE Latin1_General_CS_AS_KS_WS THEN 1 ELSE 0 END FROM TableСравнение, которое я использовал там, чувствительно к регистру, чувствительность к акценту.
Вы можете увидеть все доступные вам сопоставления:
SELECT * FROM ::fn_helpcollations()qaru.site
Сравнение строк SQL, большее и меньшее, чем операторы MS SQL Server
Операторы сравнения (включая < и > ) «работают» со строковыми значениями, а также с числами.
Для MySQL
«По умолчанию сравнения строк не чувствительны к регистру и используют текущий набор символов. По умолчанию используется latin1 (cp1252 западноевропейский), который также хорошо подходит для английского языка».
Сравнение строк будет чувствительным к регистру, когда сопоставление строк в сопоставлении строк чувствительно к регистру, т.е. имя набора символов заканчивается на _cs а не на _ci . Нет смысла повторять всю информацию, которая доступна в Справочном руководстве MySQL здесь.
Справочник операторов сопоставления MySQL: http://dev.mysql.com/doc/refman/5.5/en/comparison-operators.html
Дополнительная информация о MySQL-символах / коллаборациях: http://dev.mysql.com/doc/refman/5.5/en/charset.html
Чтобы ответить на конкретные вопросы, которые вы задали:
Q: Это возможный способ сравнения строк в SQL?
A: Да, как в MySQL, так и в SQL Server
Q: и как он действует?
A: Оператор сравнения возвращает логическое значение: TRUE, FALSE или NULL.
Q: строка меньше, чем предыдущая в словаре? Например, мяч меньше, чем вода?
A: Да, поскольку «b» предшествует «w» в сортировке characteset, выражение
'ball' < 'water'вернет TRUE. (Это зависит от набора символов и от сортировки .
Q: и это сравнение чувствительно к регистру?
О: Является ли конкретное сравнение чувствительным к регистру или не зависит от сервера базы данных; по умолчанию оба SQL Server и MySQL нечувствительны к регистру.
В MySQL можно выполнить сравнения строк, указав сопоставление наборов символов, чувствительность к регистру (имя набора символов будет заканчиваться на _cs, а не на _ci)
Q: Например, BALL <water, символ верхнего регистра влияет на это сравнение?
A: По умолчанию, как в SQL Server, так и в MySQL, выражение
'BALL' < 'water'вернет TRUE.
В Microsoft SQL Server сопоставление определяет правила словаря для сравнения и сортировки символьных данных в отношении:
- чувствительность корпуса
- чувствительность к акценту
- ширина чувствительности
- чувствительность к кане
SQL Server также включает двоичные сопоставления, где сравнение и сортировка выполняется с помощью двоичной кодовой точки, а не словарных правил. Однажды вы можете выбирать из множества сортировок в соответствии с желаемой чувствительностью. Сортировка по умолчанию, выбранная для латинских языковых локалей во время установки SQL, нечувствительна к регистру и чувствительна к акценту.
Коллизия указана в экземпляре (во время установки), базе данных и уровне столбца. Сопоставление экземпляров определяет сортировку объектов уровня экземпляра, таких как логины и имена баз данных, а также идентификаторы переменных, меток GOTO и временных таблиц. Сопоставление базы данных (аналогично сопоставлению экземпляров по умолчанию) определяет сортировку идентификаторов базы данных, таких как имена таблиц и столбцов, а также литералы. Сопоставление столбцов (аналогично настройке базы данных по умолчанию) определяет сортировку этого столбца.
Несомненно, можно сравнить строки, используя '<', '>', '<>', LIKE, BETWEEN и т. Д.
sqlserver.bilee.com
Сравнение строк SQL с использованием IF MS SQL Server
Промежуточные пробелы игнорируются.
Если вы хотите действительно проверить, совпадают ли они, что-то вроде этого:
DECLARE @foo nvarchar(50) = 'foo' DECLARE @foo2 nvarchar(50) = 'foo ' -- trailing space IF @foo = @foo2 AND DATALENGTH(@foo) = DATALENGTH(@foo2) --LEN ignores trailing spaces SELECT 'true' ELSE SELECT 'false'Почему ваш пример верен:
http://www.timvw.be/2013/04/27/the-curious-case-of-trailing-spaces-in-sql/
Согласно http://www.andrew.cmu.edu/user/shadow/sql/sql1992.txt :
3) The comparison of two character strings is determined as fol- lows: a) If the length in characters of X is not equal to the length in characters of Y, then the shorter string is effectively replaced, for the purposes of comparison, with a copy of itself that has been extended to the length of the longer string by concatenation on the right of one or more pad char- acters, where the pad character is chosen based on CS. If CS has the NO PAD attribute, then the pad character is an implementation-dependent character different from any char- acter in the character set of X and Y that collates less than any string under CS. Otherwise, the pad character is a . b) The result of the comparison of X and Y is given by the col- lating sequence CS. c) Depending on the collating sequence, two strings may com- pare as equal even if they are of different lengths or con- tain different sequences of characters. When the operations MAX, MIN, DISTINCT, references to a grouping column, and the UNION, EXCEPT, and INTERSECT operators refer to character strings, the specific value selected by these operations from a set of such equal values is implementation-dependent.Я думаю, это связано с тем, что база данных обрезает конечные пробелы, но не ведущие пробелы.
Некоторая документация для поддержки этого предположения.
SQL Server следует спецификации ANSI / ISO SQL-92 (раздел 8.2, Общие правила № 3) о том, как сравнивать строки с пробелами. Стандарт ANSI требует заполнения для символьных строк, используемых в сравнении, чтобы их длины совпадали перед их сравнением. Заполнение напрямую влияет на семантику предикатов предложения WHERE и HAVING и других сравнений строк Transact-SQL. Например, Transact-SQL считает, что строки abc и abc эквивалентны для большинства операций сравнения.
sqlserver.bilee.com
- Где находится батарейка в компьютере

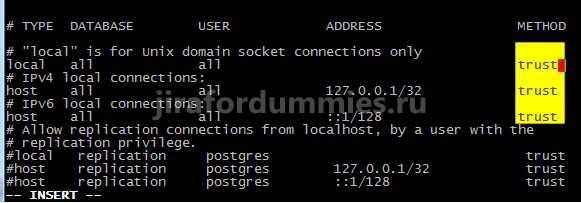
- Postgresql centos 7
- Расскажите как вы работаете за компьютером

- Как в firefox отключить аппаратное ускорение в

- Curl как установить на windows

- Отключить windows 10

- Icq номера

- Какие программы пк бывают

- Как вызывается контекстно зависимое меню
- Файл папка документ приложение
- Ip route параметры
