Связать таблицы sql server: Создание связей по внешнему ключу — SQL Server
Содержание
Связи между таблицами базы данных / Хабр
1. Введение
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.

- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.

2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
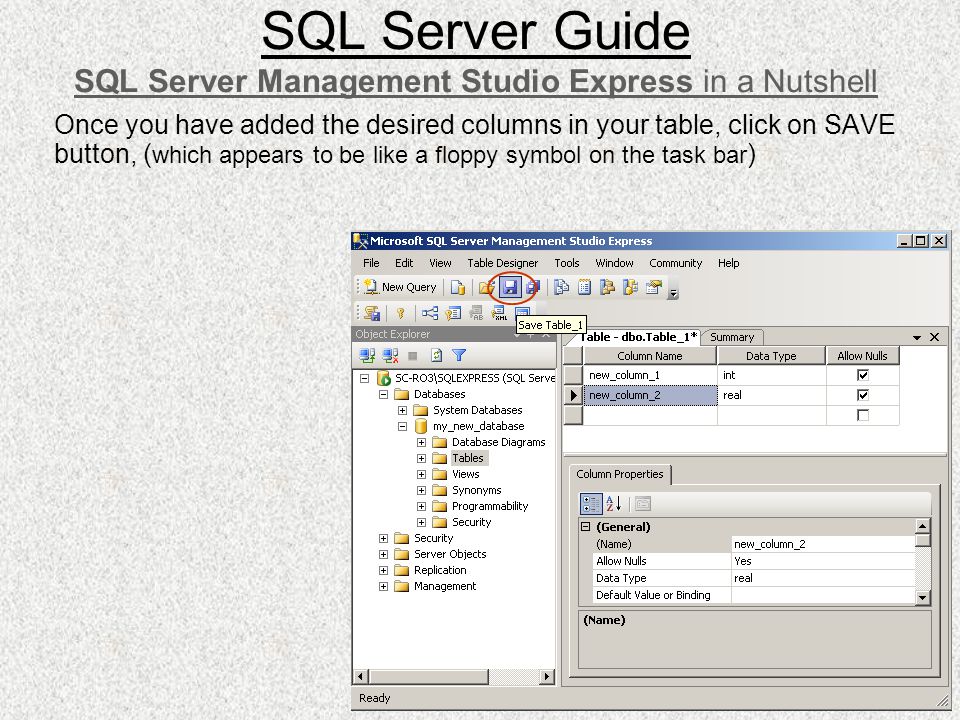
Рассмотрим подробно каждый из них.
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
Работников представляет таблица «Employee» (id, имя, возраст), должности представляет таблица «Position» (id и название должности). Как видно, обе эти таблицы связаны между собой по правилу многие ко многим: каждому работнику соответствует одна и больше должностей (многие должности), каждой должности соответствует один и больше работников (многие работники).
4.1. Как построить такие таблицы?
Мы уже имеем две таблицы, описывающие работника и профессию. Теперь нам нужно установить между ними связь многие ко многим. Для реализации такой связи нам нужен некий посредник между таблицами «Employee» и «Position». В нашем случае это будет некая таблица «EmployeesPositions» (работники и должности). Эта таблица-посредник связывает между собой работника и должность следующим образом:
| EmployeeId | PositionId |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 3 |
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
 При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
4.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee ( EmployeeId int primary key, EmployeeName nvarchar(128) not null, EmployeeAge int not null ) -- Заполним таблицу Employee данными. insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (1, N'John Smith', 22) insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (2, N'Hilary White', 22) insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (3, N'Emily Brown', 22) create table dbo.Position ( PositionId int primary key, PositionName nvarchar(64) not null ) -- Заполним таблицу Position данными.
 insert into dbo.Position(PositionId, PositionName) values(1, N'IT-director')
insert into dbo.Position(PositionId, PositionName) values(2, N'Programmer')
insert into dbo.Position(PositionId, PositionName) values(3, N'Engineer')
-- Заполним таблицу EmployeesPositions данными.
create table dbo.EmployeesPositions
(
PositionId int foreign key references dbo.Position(PositionId),
EmployeeId int foreign key references dbo.Employee(EmployeeId),
primary key(PositionId, EmployeeId)
)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 1)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 2)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (2, 3)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (3, 3)
insert into dbo.Position(PositionId, PositionName) values(1, N'IT-director')
insert into dbo.Position(PositionId, PositionName) values(2, N'Programmer')
insert into dbo.Position(PositionId, PositionName) values(3, N'Engineer')
-- Заполним таблицу EmployeesPositions данными.
create table dbo.EmployeesPositions
(
PositionId int foreign key references dbo.Position(PositionId),
EmployeeId int foreign key references dbo.Employee(EmployeeId),
primary key(PositionId, EmployeeId)
)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 1)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 2)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (2, 3)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (3, 3)Объяснения
С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.
 3. Вывод
3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
Пользователей будет представлять некая таблица «Person» (id, имя, фамилия, возраст), номера телефонов будет представлять таблица «Phone». Она будет выглядеть так:
| PhoneId | PersonId | PhoneNumber |
|---|---|---|
| 1 | 5 | 11 091-10 |
| 2 | 5 | 19 124-66 |
| 3 | 17 | 21 972-02 |
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка
. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
Но в нашем случае мы не можем сказать, что каждому телефону принадлежат несколько пользователей — номеру телефона может принадлежать только один пользователь.
Теперь прочтите еще раз заметку в конце пункта 5.1. — она станет для вас более понятной.
5.3. Реализация
Диаграмма
Код на T-SQL
create table dbo.Person ( PersonId int primary key, FirstName nvarchar(64) not null, LastName nvarchar(64) not null, PersonAge int not null ) insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (5, N'John', N'Doe', 25) insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (17, N'Izabella', N'MacMillan', 19) create table dbo.
 Phone
(
PhoneId int primary key,
PersonId int foreign key references dbo.Person(PersonId),
PhoneNumber varchar(64) not null
)
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (1, 5, '11 091-10')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (2, 5, '19 124-66')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (3, 17, '21 972-02')
Phone
(
PhoneId int primary key,
PersonId int foreign key references dbo.Person(PersonId),
PhoneNumber varchar(64) not null
)
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (1, 5, '11 091-10')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (2, 5, '19 124-66')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (3, 17, '21 972-02')
Объяснения
Наша таблица Phone хранит всего один внешний ключ. Он ссылается на некого пользователя (на строку из таблицы Person). Таким образом, мы как бы говорим: «этот пользователь является владельцем данного телефона». Другими словами, телефон знает id своего владельца.
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
| DisabledPersonId | EmployeeId |
|---|---|
| 1 | 159 |
| 2 | 722 |
| 3 | 937 |
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать
Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать
только
уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee ( EmployeeId int primary key, EmployeeName nvarchar(128) not null, EmployeeAge int not null ) insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (159, N'John Smith', 22) insert into dbo.
 Employee(EmployeeId, EmployeeName, EmployeeAge) values (722, N'Hilary White', 29)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (937, N'Emily Brown', 19)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (100, N'Frederic Miller', 16)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (99, N'Henry Lorens', 20)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (189, N'Bob Red', 25)
create table dbo.DisabledEmployee
(
DisabledPersonId int primary key,
EmployeeId int unique foreign key references dbo.Employee(EmployeeId)
)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (1, 159)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (2, 722)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (3, 937)
Employee(EmployeeId, EmployeeName, EmployeeAge) values (722, N'Hilary White', 29)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (937, N'Emily Brown', 19)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (100, N'Frederic Miller', 16)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (99, N'Henry Lorens', 20)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (189, N'Bob Red', 25)
create table dbo.DisabledEmployee
(
DisabledPersonId int primary key,
EmployeeId int unique foreign key references dbo.Employee(EmployeeId)
)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (1, 159)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (2, 722)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (3, 937)Объяснения
Таблица DisabledEmployee имеет атрибут EmployeeId, что является внешним ключом. Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
Одну и ту же связь можно рассматривать как обязательную и как необязательную. Рассмотрим вот такой пример:
Рассмотрим вот такой пример:
У одной биологической матери может быть много детей. У ребенка есть только одна биологическая мать.
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
Одну и ту же связь можно рассматривать как обязательную и как необязательную:
У одного человека может быть только один загранпаспорт.
 У одного загранпаспорта есть только один владелец.
У одного загранпаспорта есть только один владелец.А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
Любая связь многие ко многим является необязательной. Например:
Человек может инвестировать в акции разных компаний (многих). Инвесторами какой-то компании являются определенные люди (многие).
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
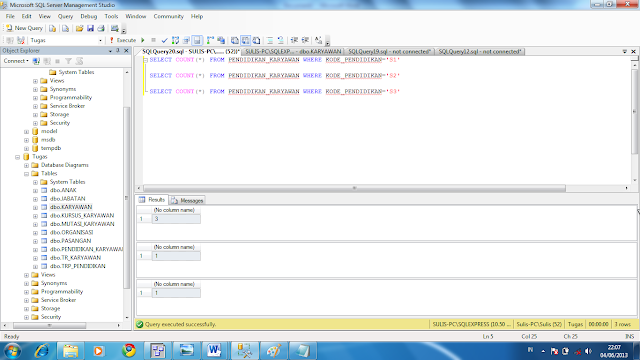
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
Одной персоне принадлежит много телефонов.
- Возле таблицы Person находится золотой ключик. Он обозначает слово «один».
- Возле таблицы Phone находится знак бесконечности. Он обозначает слово «многие».
9. Итоги
- Связи бывают:
- Многие ко многим.
- Один ко многим.
1) с обязательной связью;
2) с необязательной связью. - Один к одному.
1) с обязательной связью;
2) с необязательной связью.
- Связи организовываются с помощью внешних ключей.
- Foreign key (внешний ключ) — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
10. Задачи
Для лучшего усвоения материала предлагаю вам решить следующие задачи:
- Описать таблицу фильм: id, название, длительность, режиссер, жанр фильма. Обратите внимание на то, что у фильма может быть более одного жанра, а к одному жанру может относится более, чем один фильм.
- Описать таблицу песня: id, название, длительность, певец. При этом у песни может быть более одного певца, а певец мог записать более одной песни.
- Реализовать таблицу машина: модель, производитель, цвет, цена
- Описать отдельную таблицу производитель: id, название, рейтинг.
- Описать отдельную таблицу цвета: id, название.
У одной машины может быть только один производитель, а у производителя — много машин. У одной машины может быть много цветов, а у одного цвета может быть много машин. - Добавить в БД из пункта 6.2. таблицу военно-обязанных по типу того, как мы описали отдельную таблицу DisabledEmployee.
 Обратите внимание на то, что у фильма может быть более одного жанра, а к одному жанру может относится более, чем один фильм.
Обратите внимание на то, что у фильма может быть более одного жанра, а к одному жанру может относится более, чем один фильм.
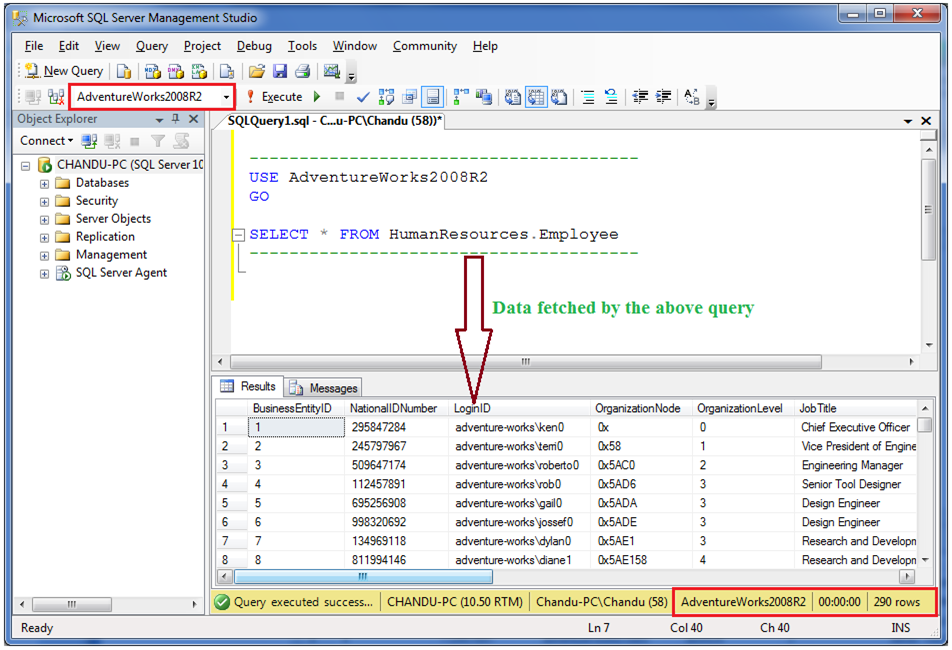
2.8. Связанные таблицы — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
На данный момент мы писали достаточно простые запросы, потому что использовали только одну таблицу. Но мы же создали в прошлой главе 4-е таблицы, и хотелось бы научиться связывать их в одно целое. Я бы не стал усложнять базу данных, создавая справочники, если бы связь не была возможной.
Но мы же создали в прошлой главе 4-е таблицы, и хотелось бы научиться связывать их в одно целое. Я бы не стал усложнять базу данных, создавая справочники, если бы связь не была возможной.
Давайте попробуем связать две таблицы на примере должностей. В таблице Peoples у нас есть поле «idPosition». В этом поле содержится идентификатор (первичный ключ) строки, с которой связана запись со строкой из таблицы «tbPosition». Следующий пример показывает, как можно связать эти таблицы:
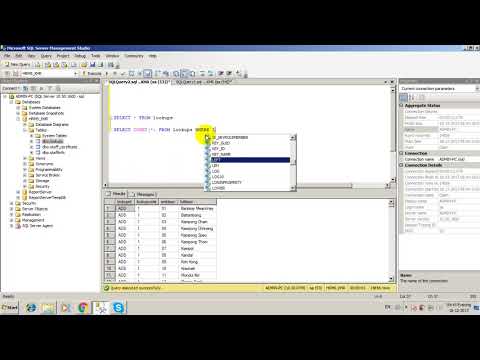
SELECT * FROM tbPeoples, tbPosition WHERE tbPeoples.idPosition=tbPosition.idPosition
Первая строка, как всегда говорит, что надо вывести все поля (SELECT *). Вторая строка говорит, из каких таблиц надо получать данные (FROM tbPeoples, tbPosition). На этот раз у нас здесь указано сразу две таблицы – работники и должности. Третья строка показывает связь:
tbPeoples.idPosition=tbPosition.idPosition
Для того, чтобы указать к какой таблице относиться поле «idPosition» (поле с таким именем есть в обеих таблицах, которые мы используем) мы записываем полное имя поля как ИмяБазы. ИмяПоля. Если имя поля уникально для обеих таблиц (как «vcFamil», которое есть только в таблице tbPeolpes), то можно имя таблицы опускать. Именно поэтому мы раньше опускали имя таблицы, когда использовали поля в секции SELECT и WHERE, ведь мы работали только с одной таблицей, и никаких конфликтов не могло быть. Как только мы указали две таблицы в секции FROM, сразу возникает вероятность встретиться с конфликтами имен полей.
ИмяПоля. Если имя поля уникально для обеих таблиц (как «vcFamil», которое есть только в таблице tbPeolpes), то можно имя таблицы опускать. Именно поэтому мы раньше опускали имя таблицы, когда использовали поля в секции SELECT и WHERE, ведь мы работали только с одной таблицей, и никаких конфликтов не могло быть. Как только мы указали две таблицы в секции FROM, сразу возникает вероятность встретиться с конфликтами имен полей.
Итак, в секции WHERE мы указываем, что поле «idPosition» из таблицы tbPeoples равно полю «idPosition» из таблицы tbPosition.
Связь необходима. Если ее не указать, то результат будет совершенно другим. Посмотрим, что произойдет, если не указывать связь, а просто выбрать данные из двух таблиц:
SELECT * FROM tbPeoples, tbPosition
Результат выполнения этого запроса показан на рисунке 2.4. На рисунке я немного изменил результат, чтобы поле «idPosition» из таблицы tbPeoples находилось рядом с одноименным полем (с которым происходит связь) из таблицы tbPosition. Выделенный фрагмент содержит поля, которые принадлежат таблице должностей.
Выделенный фрагмент содержит поля, которые принадлежат таблице должностей.
Теперь посмотрим на строку Иванова. Обратите внимание, что их много. Иванов связался со всеми существующими должностями. Потом идут строки Петрова, который так же связался со всеми возможными должностями. Таким образом, количество строк в результате равно количеству строк из первой таблицы умноженное на количество строк из второй таблицы. Такое объединение называется ортогональным или декартовым.
Теперь посмотрим, что означает связь:
tbPeoples.idPosition=tbPosition.idPosition
Будем смотреть на эту команду не как на связь, а на как простое ограничение WHERE, которое говорит, что в результате поле «idPosition» в обоих, таблицах должны быть равны. Посмотрите на результат работы запроса без связи. Где значения этих полей равны? Для Иванова это та строка, где связь произошла с должностью генерального директора. Для Петрова это связь с коммерческим директором и т.д. Таким образом, все лишние записи отбрасываются, и мы получаем в результате только те строки, которые связаны по правильному ключу.
Почему база данных сама не указывает связь? Просто среди таблиц может быть несколько ключей, в том числе, две таблицы могут связываться разными способами и сервер просто не может знать, какая именно связь нам нужна в данный момент. Например, исходя из практики, фамилия, имя, отчество и дата рождения образуют уникальное сочетание. Вы можете попытаться связать две таблицы по этим данным, не обращая внимания на внешние ключи, чтобы определить для себя какие-то дополнительные сведения.
При написании связи нам пришлось писать полные имена таблиц. Чтобы этого не приходилось делать, в запросе можно создавать псевдонимы. Псевдонимы создаются в секции FROM, ставятся через пробел после имени таблицы, и действуют только внутри этого запроса:
SELECT * FROM tbPeoples pl, tbPosition ps WHERE pl.idPosition=ps.idPosition
В данном запросе у нас используется две таблицы и для каждой из них указывается псевдоним. Для таблицы tbPeoples это псевдоним pl, а для таблицы tbPosition это ps. В качестве псевдонима может выступать любое имя из любого количества букв. Я чаще всего использую первую букву, если она не будет конфликтовать с другими именами. В данном случае имена двух таблиц начинается с буквы p, вот и приходиться использовать две буквы.
В качестве псевдонима может выступать любое имя из любого количества букв. Я чаще всего использую первую букву, если она не будет конфликтовать с другими именами. В данном случае имена двух таблиц начинается с буквы p, вот и приходиться использовать две буквы.
В секции WHERE теперь не надо писать полное имя таблицы. Достаточно только указывать псевдоним:
pl.idPosition=ps.idPosition
Удобство от использования псевдонимов очень хорошо заметно, когда вы будете связывать несколько таблиц. Давайте посмотрим, как связывать три таблицы:
SELECT * FROM tbPeoples pl, tbPosition ps, tbPhoneNumbers pn WHERE pl.idPosition=ps.idPosition AND pl.idPeoples=pn.idPeoples
В секции FROM перечислены уже три таблицы, а в секции WHERE наведены две связи. Таблица tbPeoples связана с таблицей должностей, а вторая связь связывает таблицу tbPeoples c таблицей телефонов.
У нас в таблице работников 19 записей, а в таблице телефонов 18 строк.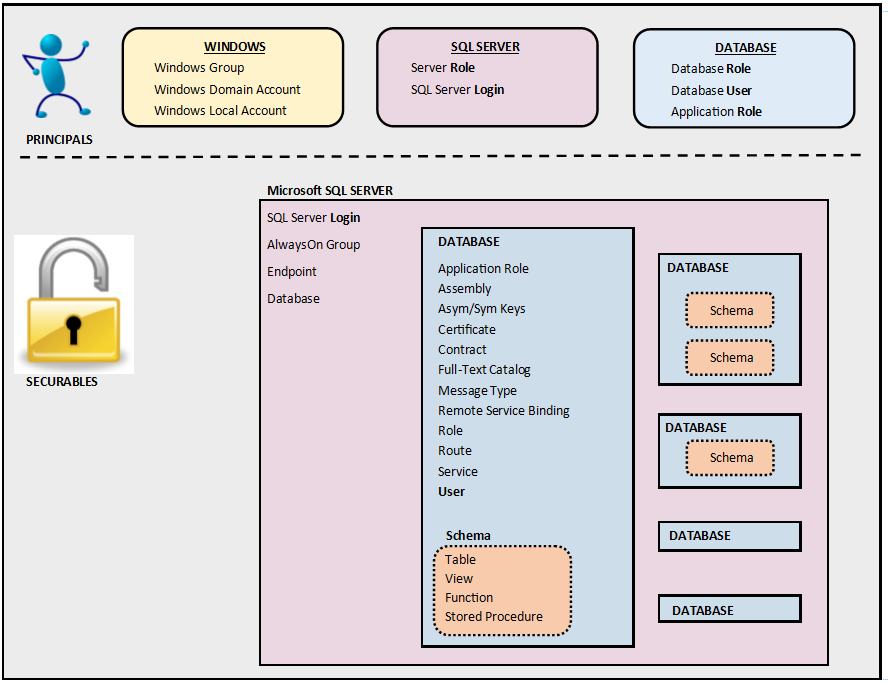 Проанализируйте результат и вы увидите, что некоторые работники имеют по несколько номеров телефонов. Например, строка Иванова встречается 3 раза, но с разными номерами. Те работники, которые не имеют телефонов, в результат не попали. Почему? Просто нет связи, а значит условие pl.idPeoples=pn.idPeoples не срабатывает.
Проанализируйте результат и вы увидите, что некоторые работники имеют по несколько номеров телефонов. Например, строка Иванова встречается 3 раза, но с разными номерами. Те работники, которые не имеют телефонов, в результат не попали. Почему? Просто нет связи, а значит условие pl.idPeoples=pn.idPeoples не срабатывает.
Использование жесткого объединение с помощью знака равенства называют внутренним объединением. Чтобы увидеть записи, которые не связаны, нужно использовать внешнее объединение, которое бывает левым или правым.
Как же тогда увидеть всех работников, и при этом наладить связь? Для этого используются левые объединения:
SELECT * FROM tbPeoples pl, tbPosition ps, tbPhoneNumbers pn WHERE pl.idPosition=ps.idPosition AND pl.idPeoples*=pn.idPeoples
Самое интересное кроется как раз в последнем условии:
pl.idPeoples*=pn.idPeoples
Обратите внимание, что слева от знака равно стоит знак умножения или проще – звездочка. Это значит, что из таблицы работников (tbPeoples, которая находиться со стороны звездочки) нужно взять все строки, а если есть связь с таблицей, указанной справа, то отобразить ее.
Это значит, что из таблицы работников (tbPeoples, которая находиться со стороны звездочки) нужно взять все строки, а если есть связь с таблицей, указанной справа, то отобразить ее.
Выполните этот запрос, и вы увидите всех работников. У тех, у кого нет номера телефона, поля из таблицы tbPhoneNumbers будут содержать нулевые значения NULL.
Использование знака * для не жесткого объединения описано в стандарте SQL, но я говорил, что не все базы данных поддерживают этот стандарт полностью. Например, MS Access позволяет создавать левые объединения, но здесь это делается совершенно по-другому. Мы рассмотрим этот метод в главе 2.8.
Когда мы связываем таблицы жестко с помощью знака равно, такое объединение называют внутренним. Когда мы используем не жесткое объединение со звездочкой, то оно бывает правым или левым. Чтобы вам проще было понять, где какое направление – посмотрите на звездочку. Мы ее поставили слева, значит, объединение было левым. Если бы звездочка была справа от знака равенства, то объединение стало бы правым.
Чтобы получить правое объединение, достаточно поменять поля местами:
SELECT * FROM tbPeoples pl, tbPosition ps, tbPhoneNumbers pn WHERE pl.idPosition=ps.idPosition AND pn.idPeoples=*pl.idPeoples
Вот теперь знак звездочки находиться справа. Как видите, разница в них небольшая, но она значительна при использовании объединения таблиц по методу MS.
Псевдонимы можно использовать в любой секции, даже в секции SELECT:
SELECT pl.vcFamil, pl.vcName, pl.vcSurname, ps.vcPositionName, pn.vcPhoneNumber FROM tbPeoples pl, tbPosition ps, tbPhoneNumbers pn WHERE pl.idPosition=ps.idPosition AND pl.idPeoples*=pn.idPeoples
Если быть более точным, то бывают случаи, когда использовать псевдонимы необходимо. Если есть имя поля, которое присутствует одновременно в обеих таблицах, то для его объявления в секции SELECT необходимо явно указать таблицу. Например, попробуйте добавить в список SELECT поле «idPeoples», без указания имени таблицы или псевдонима. В ответ на этот запрос, сервер выдаст ошибку: Ambiguous column name ‘idPeoples’ (двусмысленное имя колонки «idPeoples»). Сервер не знает, значение колонки «idPeoples», из какой таблицы нужно вернуть пользователю. Это вы знаете, что благодаря сравнению pl.idPeoples*=pn.idPeoples в результате все равно обе колонки будут содержать одно и то же значение, но сервер на это не надеется и даже не пытается понять, а просто выдает ошибку о двусмысленности.
В ответ на этот запрос, сервер выдаст ошибку: Ambiguous column name ‘idPeoples’ (двусмысленное имя колонки «idPeoples»). Сервер не знает, значение колонки «idPeoples», из какой таблицы нужно вернуть пользователю. Это вы знаете, что благодаря сравнению pl.idPeoples*=pn.idPeoples в результате все равно обе колонки будут содержать одно и то же значение, но сервер на это не надеется и даже не пытается понять, а просто выдает ошибку о двусмысленности.
При использовании связанных таблиц очень часто бывает необходимость выбрать одну таблицу полностью, а остальные могут выбираться частично. Например, давайте выберем из таблицы «tbPeoples» только ФИО, а из таблиц должностей и телефонов все поля:
SELECT vcFamil, vcName, vcSurname, ps.*, pn.* FROM tbPeoples pl, tbPosition ps, tbPhoneNumbers pn WHERE pl.idPosition=ps.idPosition AND pl.idPeoples*=pn.idPeoples
Обратите внимание, что поля, которые нам нужны из таблицы tbPeoples — перечисляются, а чтобы не перечислять все поля остальных таблиц, мы просто пишем ps.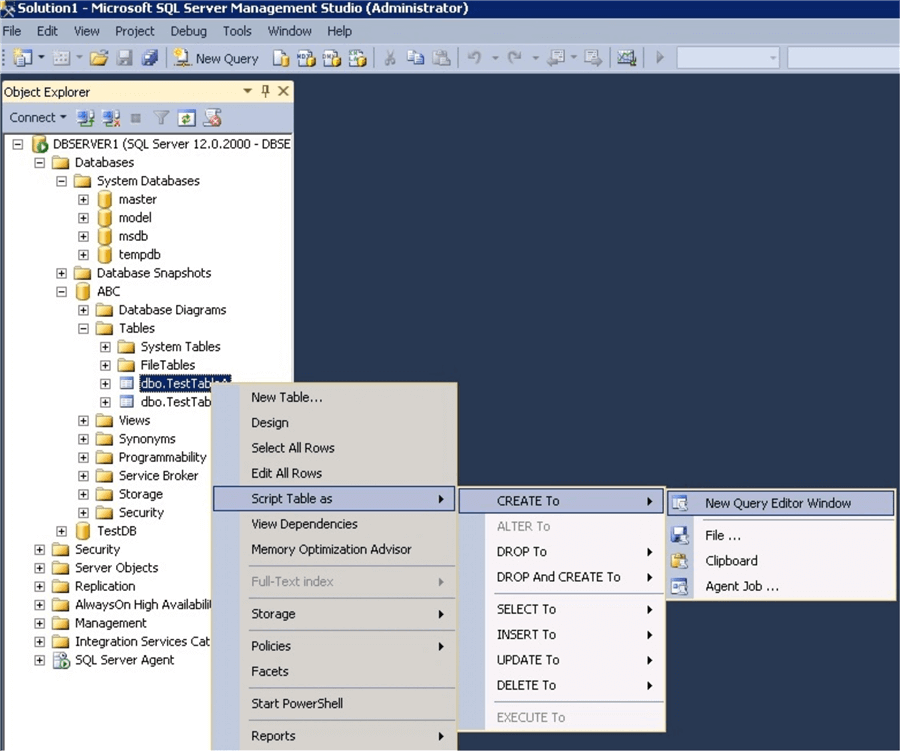 * или pn.*. То есть знак звездочки, означающий вывод всех полей относится не ко всем таблицам, а только к перечисленным.
* или pn.*. То есть знак звездочки, означающий вывод всех полей относится не ко всем таблицам, а только к перечисленным.
В главе 1.2.6 мы рассматривали пример создания таблицы, в которой внешний ключ был связан с первичным ключом той же самой таблицы. В нашей тестовой базе данных такой таблицей является tbPosition, где хранятся должности работников. В этой таблице поле «idParentPosition» связано с первичным ключом «idPosition» этой же таблицы и предназначено для указания названия должности, которая является главной. Таким образом, можно построить дерево главный-подчиненный.
Давайте попробуем вывести табличку из двух полей, где первое поле будет отображать название должности, а второе – главную должность. Вот как это будет выглядеть в виде SQL запроса:
SELECT p1.vcPositionName AS 'Должность',
p2.vcPositionName AS 'Главная должность'
FROM tbPosition p1, tbPosition p2
WHERE p1.idParentPosition*=p2.idPosition
Прежде чем мы разберем этот запрос, давайте посмотрим на результат его работы:
ДОЛЖНОСТЬ ГЛАВНАЯ ДОЛЖНОСТЬ Генеральный директор NULL Коммерческий директор Генеральный директор Директор по общим вопросам Генеральный директор Начальник отдела снабжения Коммерческий директор Начальник отдела сбыта Коммерческий директор Начальник отдела кадров Директор по общим вопросам ОТиЗ Директор по общим вопросам Бухгалтерия Коммерческий директор Менеджер по снабжению Начальник отдела снабжения Менеджер по продажам Начальник отдела сбыта
Первая строка соответствует должности генерального директора.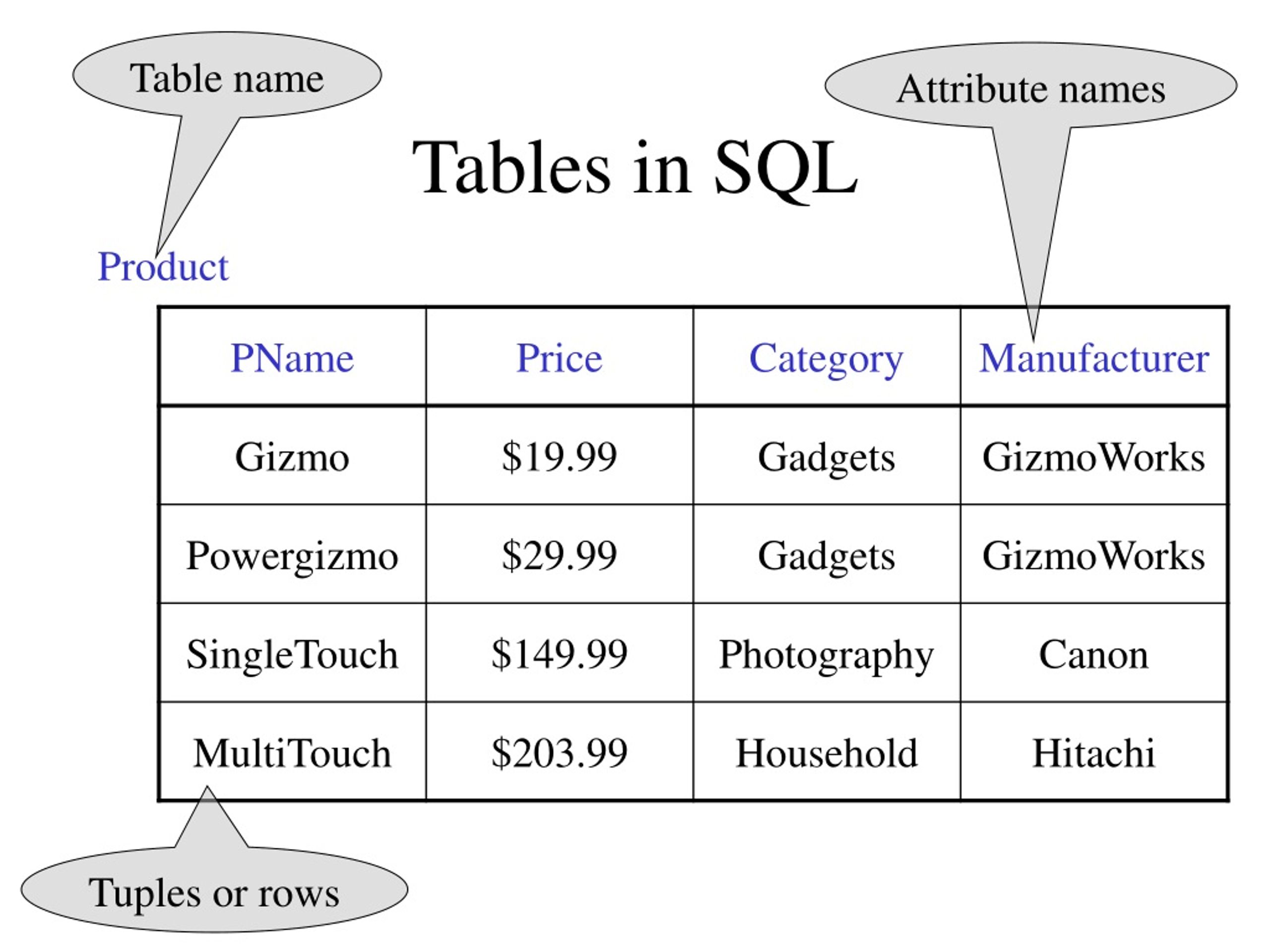 Это самый главный человек в компании, поэтому для нее во второй колонке указан NULL, т.е. главной должности нет.
Это самый главный человек в компании, поэтому для нее во второй колонке указан NULL, т.е. главной должности нет.
Следующая строка в первой колонке содержит должность коммерческого директора. Вполне логично, что она подчиняется генеральному директору, что и отображено во второй колонке результата.
Теперь посмотрим на SQL запрос, с помощью которого мы получили эти данные. Для начала посмотрим на секцию FROM, где дважды указана одна и та же таблица «tbPosition», но с разными псевдонимами p1 и p2. В секции WHERE мы наводим связь между псевдонимами одной и той же таблицы:
p1.idParentPosition*=p2.idPosition
Таким образом, через псевдонимы мы указали связь внутри одной и той же таблицы. В секции SELECT мы отображаем имя должности из первого псевдонима и имя из второго.
Теперь посмотрите на следующий запрос:
SELECT p1.vcPositionName AS 'Должность', p2.vcPositionName AS 'Главная должность', p3.vcPositionName AS 'Главная для главной' FROM tbPosition p1, tbPosition p2, tbPosition p3 WHERE p1.
 idParentPosition=p2.idPosition
AND p2.idParentPosition*=p3.idPosition
idParentPosition=p2.idPosition
AND p2.idParentPosition*=p3.idPosition
Здесь мы дважды использовали связь таблицы саму на себя. Результат работы этого запроса:
Должность Главная должность Главная для главной Коммерческий директор Генеральный директор NULL Директор по общим вопросам Генеральный директор NULL Начальник отдела снабжения Коммерческий директор ГенеральныйДиректор Начальник отдела сбыта Коммерческий директор ГенеральныйДиректор
Давайте теперь напишем запрос, который отобразит все записи из всех связанных таблиц нашей тестовой базы данных. А таблиц у нас всего 4, но в нашей секции FROM будет пять таблиц, потому что дважды будет ссылка на таблицу должностей, чтобы отобразить должность текущего работника и должность начальника:
SELECT pl.vcFamil, pl.vcName, pl.vcSurname, dDateBirthDay, p1.vcPositionName AS 'Должность', p2.vcPositionName AS 'Начальник', pn.
 vcPhoneNumber, pt.vcTypeName
FROM tbPeoples pl, tbPosition p1, tbPosition p2,
tbPhoneNumbers pn, tbPhoneType pt
WHERE pl.idPosition=p1.idPosition
AND p1.idParentPosition*=p2.idPosition
AND pn.idPeoples=pl.idPeoples
AND pt.idPhoneType=pn.idPhoneType
vcPhoneNumber, pt.vcTypeName
FROM tbPeoples pl, tbPosition p1, tbPosition p2,
tbPhoneNumbers pn, tbPhoneType pt
WHERE pl.idPosition=p1.idPosition
AND p1.idParentPosition*=p2.idPosition
AND pn.idPeoples=pl.idPeoples
AND pt.idPhoneType=pn.idPhoneType
Попробуйте разобраться в этом запросе. Если вы поймете его, то можно считать, что тема связанных таблиц усвоена удачно.
Объединение по стандарту SQL, который мы рассматривали в главе 2.7, описывает условие связи в секции WHERE. В MS зачем-то связи перенесли в секцию FROM. На мой взгляд, это как минимум не удобно для создания и для чтения связей. Стандартный вариант намного проще и удобнее. И все же, метод MS мы рассмотрим, ведь только с его помощью в MS Access можно создать левое или правое объединение, и этот же метод поддерживается в MS SQL Server.
Ортогональное объединение по методу MS, т.е. без указания связи:
SELECT * FROM tbPeoples CROSS JOIN tbPosition
Внутреннее объединение (эквивалентно знаку равенства) по методу MS описывается следующим образом:
SELECT *
FROM tbPeoples pl INNER JOIN tbPosition ps
ON pl. idPosition=ps.idPosition
 idPosition=ps.idPosition
idPosition=ps.idPosition
Как видите, для этого метода не нужна секция WHERE, но зато намного больше всего нужно писать. Вначале мы описываем, что нам нужно внутреннее объединение (INNER JOIN). Слева и справа от этого оператора указываются таблицы, которые нужно связать. После этого ставиться ключевое слово ON, и только теперь наводим связь между полями связанных таблиц. Таким образом, этот запрос эквивалентен следующему:
SELECT * FROM tbPeoples pl, tbPosition ps WHERE pl.idPosition=ps.idPosition
Самая большая путаница начинается, когда нужно объединить три таблицы в одно целое. Посмотрите на следующий запрос:
SELECT *
FROM tbPeoples pl LEFT OUTER JOIN tbPhoneNumbers pn
ON pl.idPeoples=pn.idPeoples
INNER JOIN tbPosition ps
ON pl.idPosition=ps.idPosition
Сначала объединяются таблицы tbPeoples и tbPhoneNumbers через внешнее левое объединение (LEFT OUTER JOIN). Затем указывается связь между этими таблицами. А вот теперь результат объединение, связываем внутренним объединением (INNER JOIN) с таблицей tbPosition. Внимательно осмотрите запрос, чтобы понять его формат, и что в нем происходит.
А вот теперь результат объединение, связываем внутренним объединением (INNER JOIN) с таблицей tbPosition. Внимательно осмотрите запрос, чтобы понять его формат, и что в нем происходит.
Чтобы получить правое объединение, необходимо просто поменять перечисление таблиц местами:
SELECT *
FROM tbPhoneNumbers pn RIGHT OUTER JOIN tbPeoples pl
ON pl.idPeoples=pn.idPeoples
INNER JOIN tbPosition ps
ON pl.idPosition=ps.idPosition
Меняется местами перечисление таблиц, а вот порядок указания связанных полей не имеет особого значения и здесь ничего не меняется.
Если честно, то мне не очень нравиться объединение по методу Microsoft. Какое-то оно неудобное и громоздкое. Даже не знаю, зачем его придумали, когда в стандарте есть все то же самое, только намного проще и нагляднее.
sp_addlinkedserver (Transact-SQL) — SQL Server
- Статья
- 12 минут на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
Управляемый экземпляр Azure SQL
Создает связанный сервер. Связанный сервер обеспечивает доступ к распределенным гетерогенным запросам к источникам данных OLE DB. После создания связанного сервера с помощью sp_addlinkedserver , к этому серверу можно выполнять распределенные запросы. Если связанный сервер определен как экземпляр SQL Server, можно выполнять удаленные хранимые процедуры.
Соглашения о синтаксисе Transact-SQL
Синтаксис
sp_addlinkedserver [ @server= ] 'сервер' [ , [ @srvproduct= ] 'product_name' ]
[ , [ @provider= ] 'имя_поставщика' ]
[ , [ @datasrc= ] 'источник_данных' ]
[ , [ @location= ] 'местоположение' ]
[ , [ @provstr= ] 'provider_string' ]
[ , [ @catalog= ] 'каталог' ]
Аргументы
[ @server = ]
‘сервер’
Имя создаваемого связанного сервера. Аргумент server равен sysname , без значения по умолчанию.
Аргумент server равен sysname , без значения по умолчанию.
[ @srvproduct = ]
‘product_name’
Имя продукта источника данных OLE DB для добавления в качестве связанного сервера. Значение product_name равно nvarchar(128) со значением по умолчанию NULL. Если значение равно SQL Server , provider_name , источник_данных , местоположение , провайдер_строка и каталог указывать не нужно.
[ @provider = ]
‘provider_name’
Уникальный программный идентификатор (PROGID) поставщика OLE DB, который соответствует этому источнику данных. Имя поставщика должно быть уникальным для указанного поставщика OLE DB, установленного на текущем компьютере. Значение provider_name равно nvarchar(128) .
- До SQL Server 2022 (16.x), если
@providerопущен, используется SQLNCLI. Использование SQLNCLI перенаправит SQL Server на последнюю версию поставщика OLE DB собственного клиента SQL Server. Ожидается, что поставщик OLE DB будет зарегистрирован с указанным PROGID в реестре. Вместо SQLNCLI рекомендуется MSOLEDBSQL. - Начиная с SQL Server 2022 (16.x), необходимо указать имя поставщика. Рекомендуется MSOLEDBSQL.
 Использование SQLNCLI перенаправит SQL Server на последнюю версию поставщика OLE DB собственного клиента SQL Server. Ожидается, что поставщик OLE DB будет зарегистрирован с указанным PROGID в реестре. Вместо SQLNCLI рекомендуется MSOLEDBSQL.
Использование SQLNCLI перенаправит SQL Server на последнюю версию поставщика OLE DB собственного клиента SQL Server. Ожидается, что поставщик OLE DB будет зарегистрирован с указанным PROGID в реестре. Вместо SQLNCLI рекомендуется MSOLEDBSQL.Важно
Собственный клиент SQL Server (часто сокращенно SNAC) был удален из SQL Server 2022 (16.x) и SQL Server Management Studio 19 (SSMS). Как поставщик OLE DB для собственного клиента SQL Server (SQLNCLI или SQLNCLI11), так и устаревший поставщик Microsoft OLE DB для SQL Server (SQLOLEDB) не рекомендуются для новой разработки. Переход на новый драйвер Microsoft OLE DB (MSOLEDBSQL) для SQL Server в будущем.
[ @datasrc = ]
‘data_source’
Имя источника данных, интерпретируемое поставщиком OLE DB. Значение источник_данных — это nvarchar( 4000 ) . data_source передается как свойство DBPROP_INIT_DATASOURCE для инициализации поставщика OLE DB.
data_source передается как свойство DBPROP_INIT_DATASOURCE для инициализации поставщика OLE DB.
[ @location = ]
‘location’
Расположение базы данных, интерпретируемое поставщиком OLE DB. Значение location равно nvarchar( 4000 ) со значением по умолчанию NULL. Аргумент расположение передается как свойство DBPROP_INIT_LOCATION для инициализации поставщика OLE DB.
[ @provstr = ]
‘provider_string’
Строка подключения поставщика OLE DB, определяющая уникальный источник данных. Значение provider_string равно nvarchar( 4000 ) со значением по умолчанию NULL. Аргумент provstr либо передается в IDataInitialize, либо задается как свойство DBPROP_INIT_PROVIDERSTRING для инициализации поставщика OLE DB.
Когда связанный сервер создается для поставщика OLE DB собственного клиента SQL Server, экземпляр можно указать с помощью ключевого слова SERVER как SERVER=имя_сервера\\имя_экземпляра , чтобы указать конкретный экземпляр SQL Server.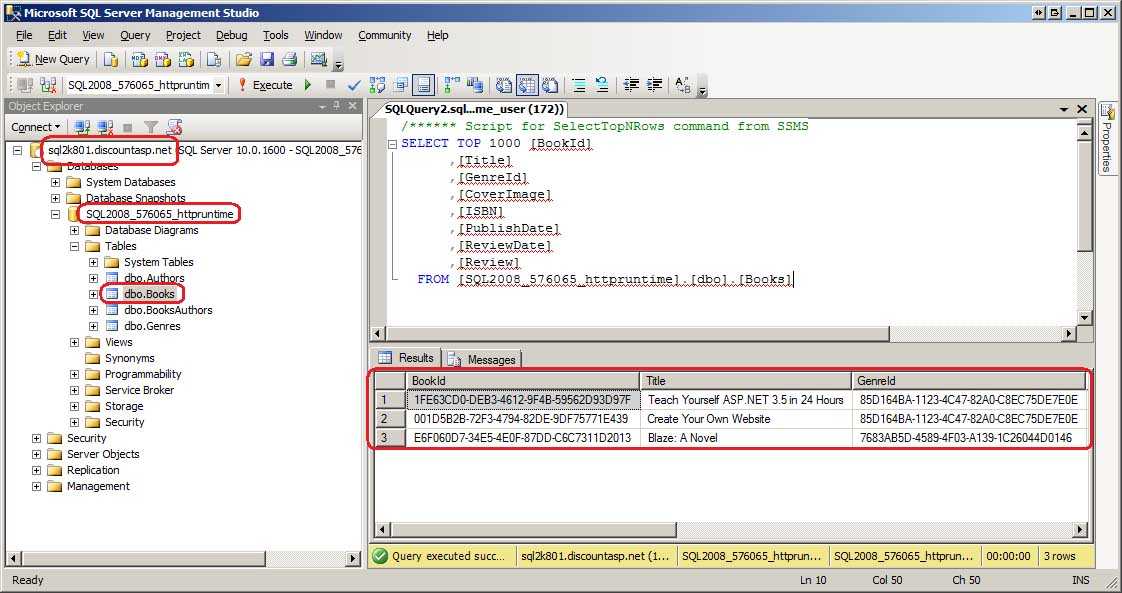 имя сервера — это имя компьютера, на котором работает SQL Server, а имя экземпляра — это имя конкретного экземпляра SQL Server, к которому будет подключен пользователь.
имя сервера — это имя компьютера, на котором работает SQL Server, а имя экземпляра — это имя конкретного экземпляра SQL Server, к которому будет подключен пользователь.
Примечание
Для доступа к зеркальной базе данных строка подключения должна содержать имя базы данных. Это имя необходимо для разрешения попыток аварийного переключения поставщиком доступа к данным. База данных может быть указана в @provstr или @catalog параметр. При необходимости строка подключения также может содержать имя партнера по отработке отказа.
[ @catalog = ]
‘каталог’
Каталог, который будет использоваться при подключении к поставщику OLE DB. Значение catalog равно sysname , значение по умолчанию равно NULL. Аргумент каталог передается как свойство DBPROP_INIT_CATALOG для инициализации поставщика OLE DB. Когда связанный сервер определен для экземпляра SQL Server, каталог ссылается на базу данных по умолчанию, с которой связан связанный сервер.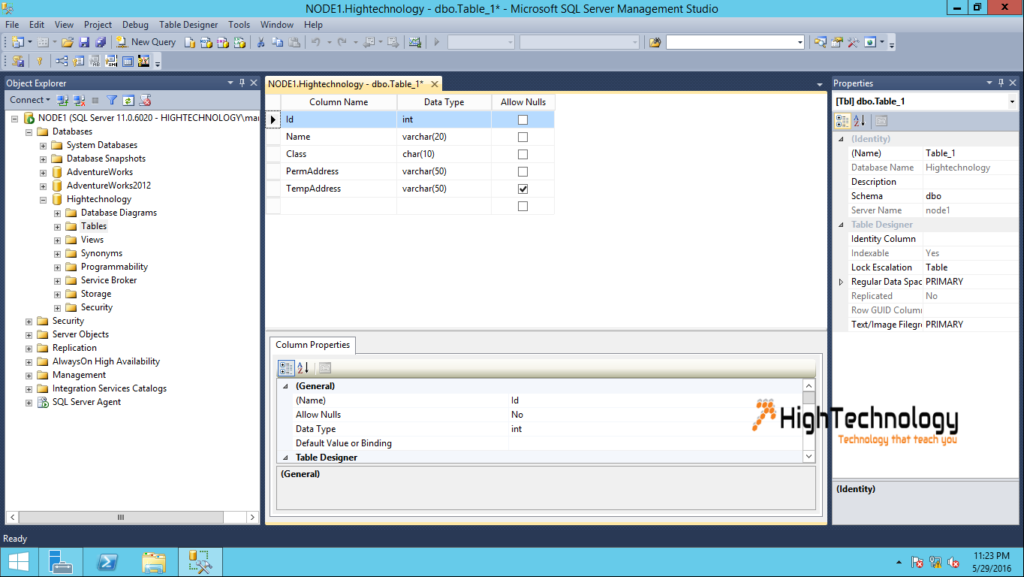
Значения кодов возврата
0 (успех) или 1 (неудача)
Наборы результатов
Нет.
В следующей таблице показаны способы настройки связанного сервера для источников данных, к которым можно получить доступ через OLE DB. Связанный сервер можно настроить несколькими способами для определенного источника данных; может быть более одной строки для типа источника данных. В этой таблице также показаны значения параметра sp_addlinkedserver , которые следует использовать для настройки связанного сервера.
| Удаленный источник данных OLE DB | Поставщик OLE DB | имя_продукта | имя_провайдера | источник_данных | местоположение | провайдер_строка | каталог |
|---|---|---|---|---|---|---|---|
| SQL Server | Поставщик OLE DB для собственного клиента Microsoft SQL Server | SQL Server 1 (по умолчанию) | |||||
| SQL Server | Поставщик OLE DB для собственного клиента Microsoft SQL Server | SQLNCLI | Сетевое имя SQL Server (для экземпляра по умолчанию) | Имя базы данных (необязательно) | |||
| SQL Server | Поставщик OLE DB для собственного клиента Microsoft SQL Server | SQLNCLI | имя сервера \ имя экземпляра (для конкретного экземпляра) | Имя базы данных (необязательно) | |||
| Oracle, версия 8 и выше | Поставщик Oracle для OLE DB | Любой | ОраОЛЕДБ.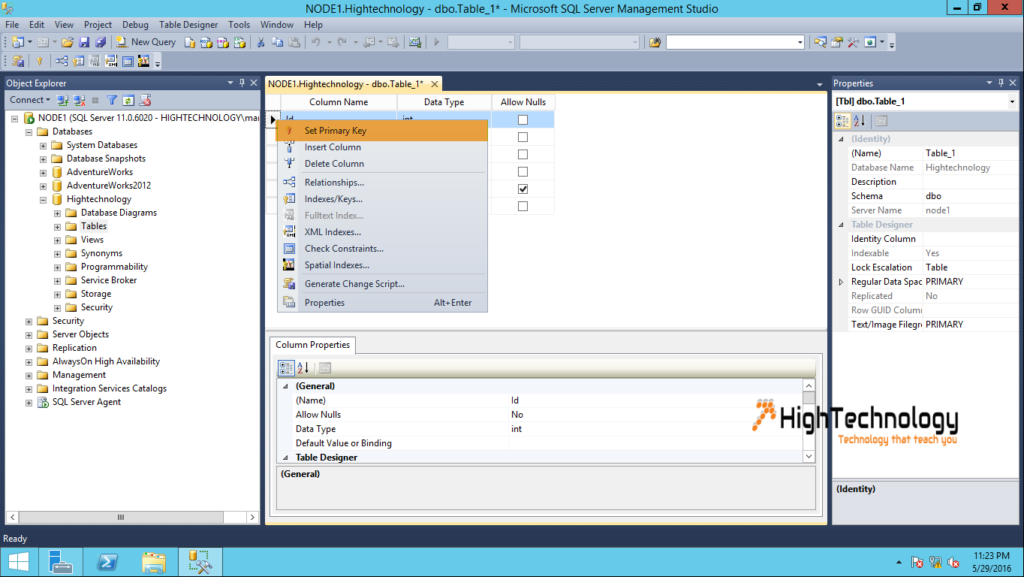 Оракул Оракул | Псевдоним для базы данных Oracle | |||
| Доступ/Жиклер | Поставщик Microsoft OLE DB для Jet | Любой | Microsoft.Jet.OLEDB.4.0 | Полный путь к файлу базы данных Jet | |||
| Источник данных ODBC | Поставщик Microsoft OLE DB для ODBC | Любой | MSDASQL | Системный DSN источника данных ODBC | |||
| Источник данных ODBC | Поставщик Microsoft OLE DB для ODBC | Любой | MSDASQL | Строка подключения ODBC | |||
| Файловая система | Поставщик Microsoft OLE DB для службы индексирования | Любой | MSIDXS | Имя каталога службы индексирования | |||
| Электронная таблица Microsoft Excel | Поставщик Microsoft OLE DB для Jet | Любой | Microsoft. Jet.OLEDB.4.0 Jet.OLEDB.4.0 | Полный путь к файлу Excel | Excel 5.0 | ||
| База данных IBM DB2 | Поставщик Microsoft OLE DB для DB2 | Любой | ДБ2ОЛЕДБ | См. документацию поставщика Microsoft OLE DB для DB2. | Имя каталога базы данных DB2 |
1 При таком способе настройки связанного сервера имя связанного сервера должно совпадать с сетевым именем удаленного экземпляра SQL Server. Используйте data_source , чтобы указать сервер.
2 «Любое» указывает, что название продукта может быть любым.
Поставщик OLE DB для собственного клиента Microsoft SQL Server — это поставщик, который используется с SQL Server, если имя поставщика не указано или если в качестве имени продукта указан SQL Server. Даже если вы укажете старое имя поставщика, SQLOLEDB, оно будет изменено на SQLNCLI при сохранении в каталоге.
Параметры data_source , location , provider_string и catalog определяют базу данных или базы данных, на которые указывает связанный сервер. Если какой-либо из этих параметров имеет значение NULL, соответствующее свойство инициализации OLE DB не устанавливается.
В кластерной среде при указании имен файлов, указывающих на источники данных OLE DB, используйте универсальное имя соглашения об именах (UNC) или общий диск для указания местоположения.
Хранимая процедура sp_addlinkedserver не может быть выполнена в пользовательской транзакции.
Important
Управляемый экземпляр SQL Azure в настоящее время поддерживает только SQL Server, базу данных SQL и другие управляемые экземпляры SQL в качестве удаленных источников данных.
Важно
Когда связанный сервер создается с помощью sp_addlinkedserver , для всех локальных входов добавляется самосопоставление по умолчанию. Для поставщиков, не являющихся поставщиками SQL Server, входы с проверкой подлинности SQL Server могут получить доступ к поставщику под учетной записью службы SQL Server. Администраторам следует рассмотреть возможность использования
Для поставщиков, не являющихся поставщиками SQL Server, входы с проверкой подлинности SQL Server могут получить доступ к поставщику под учетной записью службы SQL Server. Администраторам следует рассмотреть возможность использования sp_droplinkedsrvlogin для удаления глобального сопоставления.
Разрешения
Оператор sp_addlinkedserver требует ИЗМЕНИТЬ ЛЮБОЙ СВЯЗАННЫЙ СЕРВЕР разрешение. (Диалоговое окно SQL Server Management Studio New Linked Server реализовано таким образом, что требуется членство в фиксированной роли сервера sysadmin .)
Примеры
A. Используйте поставщик Microsoft SQL Server OLE DB
Следующие пример создает связанный сервер с именем SEATTLESales . Имя продукта — SQL Server , и имя поставщика не используется.
мастер ЕГЭ; ИДТИ EXEC sp_addlinkedserver N'СИЭТЛСалес', N'SQL-сервер'; ИДТИ
В следующем примере создается связанный сервер S1_instance1 на экземпляре SQL Server с помощью драйвера OLE DB для SQL Server.
EXEC sp_addlinkedserver @сервер=N'S1_instance1', @srvproduct=N'', @provider=N'MSOLEDBSQL', @datasrc=N'S1\экземпляр1';
В следующем примере создается связанный сервер S1_instance1 на экземпляре SQL Server с помощью поставщика OLE DB собственного клиента SQL Server.
Важно
Поставщик OLE DB для собственного клиента SQL Server (SQLNCLI) остается устаревшим, и его не рекомендуется использовать для новых разработок. Вместо этого используйте новый драйвер Microsoft OLE DB для SQL Server (MSOLEDBSQL), который будет обновлен с учетом самых последних функций сервера.
EXEC sp_addlinkedserver @сервер=N'S1_instance1', @srvproduct=N'', @provider=N'SQLNCLI', @datasrc=N'S1\экземпляр1';
B. Используйте Microsoft OLE DB Provider для Microsoft Access
Поставщик Microsoft.Jet.OLEDB.4.0 подключается к базам данных Microsoft Access, использующим формат 2002-2003. В следующем примере создается связанный сервер с именем SEATTLE Mktg .
Примечание
В этом примере предполагается, что и Microsoft Access, и образец базы данных Northwind установлены и что база данных Northwind находится в папке C:\Msoffice\Access\Samples на том же сервере, что и экземпляр SQL Server.
EXEC sp_addlinkedserver @сервер = N'SEATTLE Mktg', @provider = N'Microsoft.Jet.OLEDB.4.0', @srvproduct = N'OLE DB Provider для Jet', @datasrc = N'C:\MSOffice\Access\Samples\Northwind.mdb'; ИДТИ
C. Используйте Microsoft OLE DB Provider для ODBC с параметром data_source
В следующем примере создается связанный сервер с именем SEATTLE Payroll , который использует Microsoft OLE DB Provider для ODBC ( MSDASQL ) и параметр data_source .
Примечание
Прежде чем использовать связанный сервер, указанное имя источника данных ODBC должно быть определено как системный DSN на сервере.
EXEC sp_addlinkedserver @server = N'SEATTLE Payroll', @srvproduct = Н'', @provider = N'MSDASQL', @datasrc = N'LocalServer'; ИДТИ
D.
 Используйте Microsoft OLE DB Provider для электронной таблицы Excel
Используйте Microsoft OLE DB Provider для электронной таблицы Excel
Чтобы создать определение связанного сервера с помощью Microsoft OLE DB Provider для Jet для доступа к электронной таблице Excel в формате 1997–2003 гг., сначала создайте именованный диапазон в Excel, указав столбцы и строки рабочего листа Excel для выбора. Затем на имя диапазона можно ссылаться как на имя таблицы в распределенном запросе.
EXEC sp_addlinkedserver «ExcelSource», «Джет 4.0», «Майкрософт.Jet.OLEDB.4.0», 'c:\MyData\DistExcl.xls', НОЛЬ, «Эксель 5.0»; ИДТИ
Чтобы получить доступ к данным из электронной таблицы Excel, свяжите диапазон ячеек с именем. Следующий запрос можно использовать для доступа к указанному именованному диапазону SalesData в виде таблицы с помощью ранее настроенного связанного сервера.
ВЫБЕРИТЕ * ИЗ ExcelSource...SalesData; ИДТИ
Если SQL Server работает под учетной записью домена, имеющей доступ к удаленному общему ресурсу, вместо сопоставленного диска можно использовать путь UNC.
EXEC sp_addlinkedserver «ExcelShare», «Джет 4.0», «Майкрософт.Jet.OLEDB.4.0», '\\MyServer\MyShare\Spreadsheets\DistExcl.xls', НОЛЬ, «Эксель 5.0»;
E. Используйте Microsoft OLE DB Provider для Jet для доступа к текстовому файлу
В следующем примере создается связанный сервер для прямого доступа к текстовым файлам без связывания файлов в виде таблиц в файле Access .mdb. Поставщик — Microsoft.Jet.OLEDB.4.0 , а строка поставщика — Text .
Источником данных является полный путь к каталогу, содержащему текстовые файлы. Файл schema.ini, описывающий структуру текстовых файлов, должен находиться в том же каталоге, что и текстовые файлы. Дополнительные сведения о том, как создать файл schema.ini, см. в документации по ядру СУБД Jet.
Сначала создайте связанный сервер.
EXEC sp_addlinkedserver txtsrv, N'Jet 4.0', N'Microsoft.Jet.OLEDB.4.0', N'c:\data\distqry', НОЛЬ, N'Текст';
Настройте сопоставления входа.
EXEC sp_addlinkedsrvlogin txtsrv, FALSE, Admin, NULL;
Список таблиц на связанном сервере.
EXEC sp_tables_ex txtsrv;
Запросите одну из таблиц, в данном случае file1#txt , используя имя, состоящее из четырех частей.
ВЫБРАТЬ * ИЗ txtsrv...[file1#txt];
F. Использование поставщика Microsoft OLE DB для DB2
В следующем примере создается связанный сервер с именем DB2 , который использует поставщик Microsoft OLE DB для DB2 .
EXEC sp_addlinkedserver
@сервер=N'DB2',
@srvproduct=N'Microsoft OLE DB Provider для DB2',
@каталог=N'DB2',
@provider=N'DB2OLEDB',
@provstr=N'Исходный каталог=PUBS;
Источник данных=DB2;
HostCCSID=1252;
Сетевой адрес=XYZ;
Сетевой порт=50000;
Коллекция пакетов=admin;
Схема по умолчанию=admin;';
G. Добавьте базу данных SQL Azure в качестве связанного сервера для использования с распределенными запросами в облачных и локальных базах данных
Вы можете добавить базу данных SQL Azure в качестве связанного сервера, а затем использовать ее с распределенными запросами, которые охватывают локальные помещения и облачные базы данных. Это компонент для гибридных решений баз данных, охватывающих локальные корпоративные сети и облако Azure.
Это компонент для гибридных решений баз данных, охватывающих локальные корпоративные сети и облако Azure.
Коробочный продукт SQL Server содержит функцию распределенных запросов, которая позволяет создавать запросы для объединения данных из локальных источников данных и данных из удаленных источников (включая данные из источников данных, отличных от SQL Server), определенных как связанные серверы. Каждая база данных SQL Azure (кроме базы данных 9 логического сервера)0019 master database) можно добавить как отдельный связанный сервер, а затем использовать непосредственно в ваших приложениях базы данных, как и любую другую базу данных.
Преимущества использования Базы данных SQL Azure включают управляемость, высокую доступность, масштабируемость, работу со знакомой моделью разработки и реляционной моделью данных. Требования вашего приложения базы данных определяют, как оно будет использовать базу данных SQL Azure в облаке. Вы можете сразу переместить все свои данные в базу данных SQL Azure или постепенно перемещать некоторые данные, сохраняя при этом оставшиеся данные локально. Для такого гибридного приложения базы данных базу данных SQL Azure теперь можно добавить в качестве связанных серверов, а приложение базы данных может выполнять распределенные запросы для объединения данных из базы данных SQL Azure и локальных источников данных.
Для такого гибридного приложения базы данных базу данных SQL Azure теперь можно добавить в качестве связанных серверов, а приложение базы данных может выполнять распределенные запросы для объединения данных из базы данных SQL Azure и локальных источников данных.
Вот простой пример, объясняющий, как подключиться к базе данных SQL Azure с помощью распределенных запросов.
Сначала добавьте одну базу данных SQL Azure в качестве связанного сервера, используя собственный клиент SQL Server.
EXEC sp_addlinkedserver @server='LinkedServerName', @srvproduct='', @provider='sqlncli', @datasrc='ServerName.database.windows.net', @местоположение='', @provstr='', @catalog='ИмяБД';
Добавьте учетные данные и параметры на этот связанный сервер.
EXEC sp_addlinkedsrvlogin @rmtsrvname = 'LinkedServerName', @useself = «ложь», @rmtuser = 'Имя пользователя', @rmtpassword = 'мой пароль'; EXEC sp_serveroption 'LinkedServerName', 'rpc out', true;
Теперь используйте связанный сервер для выполнения запросов с использованием имен из четырех частей, даже для создания новой таблицы и вставки данных.
EXEC («СОЗДАТЬ ТАБЛИЦУ SchemaName.TableName (col1 int not null CONSTRAINT PK_col1 PRIMARY KEY CLUSTERED (col1))») в LinkedServerName;
EXEC ('INSERT INTO SchemaName.TableName VALUES(1),(2),(3)') at LinkedServerName;
Запросите данные, используя имена, состоящие из четырех частей:
SELECT * FROM LinkedServerName.DatabaseName.SchemaName.TableName;
Чтобы создать связанный сервер с управляемой проверкой подлинности, выполните следующий T-SQL. Метод проверки подлинности использует ActiveDirectoryMSI в параметре @provstr . Рассмотрите возможность использования @locallogin = NULL , чтобы разрешить все локальные входы в систему.
EXEC master.dbo.sp_addlinkedserver @сервер = N'MyLinkedServer', @srvproduct = Н'', @provider = N'MSOLEDBSQL', @provstr = N'Server=mi.35e5bd1a0e9b.database.windows.net,1433;Authentication=ActiveDirectoryMSI;'; EXEC master.dbo.sp_addlinkedsrvлогин @rmtsrvname = N'MyLinkedServer', @useself = N'False', @locallogin = N'user1@domain1.
 com';
com';
Если управляемое удостоверение Azure SQL Managed Instance (ранее называвшееся управляемым удостоверением службы) добавляется в качестве входа в удаленный управляемый экземпляр, то проверка подлинности управляемого удостоверения возможна со связанным сервером, созданным, как в предыдущем примере. Поддерживаются как назначенные системой, так и назначенные пользователем управляемые удостоверения.
Если установлено основное удостоверение, оно будет использоваться, в противном случае будет использоваться назначенное системой управляемое удостоверение. Если управляемое удостоверение создается повторно с тем же именем, вход в систему на удаленном экземпляре также необходимо создать повторно, поскольку новый идентификатор приложения управляемого удостоверения и SID субъекта-службы управляемого экземпляра больше не совпадают. Чтобы убедиться, что эти два значения совпадают, преобразуйте SID в идентификатор приложения с помощью следующего запроса.
SELECT convert(uniqueidentifier, sid) как AADApplicationID ОТ sys.
 server_principals
ГДЕ name = '<имя_управляемого_экземпляра>';
server_principals
ГДЕ name = '<имя_управляемого_экземпляра>';
Чтобы создать связанный сервер со сквозной аутентификацией, выполните следующий T-SQL.
EXEC master.dbo.sp_addlinkedserver @сервер = N'MyLinkedServer', @srvproduct = Н'', @provider = N'MSOLEDBSQL', @datasrc = N'mi.35e5bd1a0e9b.database.windows.net,1433';
При сквозной аутентификации контекст безопасности локального входа переносится на удаленный экземпляр.
Для сквозной проверки подлинности необходимо, чтобы субъект AAD был добавлен в качестве входа как в локальный, так и в удаленный Управляемый экземпляр Azure SQL. Оба управляемых экземпляра должны входить в группу доверия серверов. Когда требования выполнены, пользователь может войти в локальный экземпляр и запросить удаленный экземпляр через объект связанного сервера.
См. также
- Распределенные хранимые процедуры запросов (Transact-SQL)
- sp_addlinkedsrvlogin (Transact-SQL)
- sp_addserver (транзакт-SQL)
- sp_dropserver (Transact-SQL)
- sp_serveroption (Transact-SQL)
- sp_setnetname (Transact-SQL)
- Системные хранимые процедуры (Transact-SQL)
- Системные таблицы (Transact-SQL)
SQL СОЕДИНЕНИЕ двух и более ТАБЛИЦ в MySQL с использованием запроса на выборку
906:20
Связывание таблиц является очень распространенным требованием в SQL. Различные типы данных
Различные типы данных
могут храниться в разных таблицах и в зависимости от требований таблицы могут быть
связаны друг с другом, и записи могут отображаться очень интерактивным образом.
Мы можем связать более одной таблицы, чтобы получить записи в разных комбинациях в соответствии с требованиями. Хранение данных одной области в одной таблице и связывание их друг с другом с помощью ключевого поля — лучший способ проектирования таблиц, чем создание одной таблицы с большим количеством полей. Например, в базе данных учащихся вы можете хранить контактные данные учащихся в одной таблице, а отчет об успеваемости — в другой. Вы можете связать эти две таблицы, используя один уникальный идентификационный номер учащегося ( ID ).
Возьмем один пример связи таблиц, рассматривая продукт и клиента
отношение. У нас есть таблица продуктов, в которой все записи продуктов
хранится. Точно так же у нас будет таблица клиентов, в которой хранятся записи о клиентах.
хранится. Ежедневные продажи ведут учет всех продаж.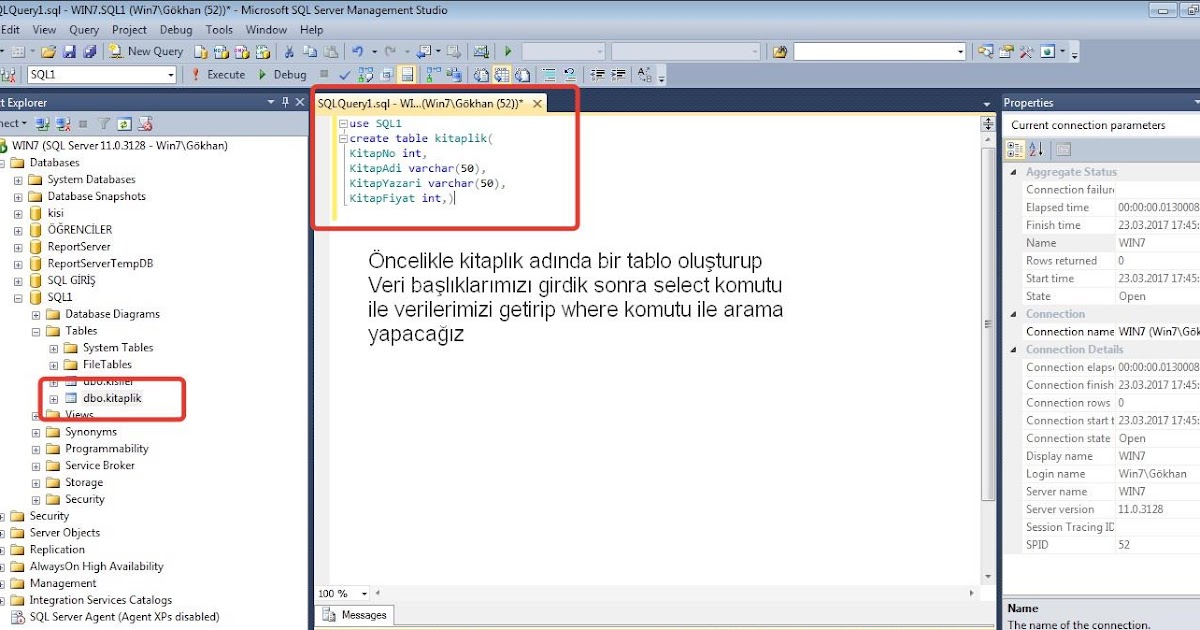 Эта таблица продаж будет
Эта таблица продаж будет
вести учет того, какой продукт кто приобрел. Таким образом, ссылка должна быть сделана из
Таблица продаж в таблицу продуктов и таблицу клиентов.
Это наш клиентский стол
| customer_id | имя | адрес | электронная почта |
| 1 | Роборт Джон | 123 Авеню, WS | [email protected] |
| 2 | Елена Хик | 567 авеню | [email protected] |
| 3 | Греческий Тор | 987 улица | [email protected] |
| 4 | Марр Бэтсон | жениться@sitename.com | |
| 5 | Дон Рафель | 456 Рафель | [email protected] |
Ниже приведена таблица продуктов.
Таблица продаж здесь ниже.
| sales_id | product_id | customer_id | date_of_sale | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 1 | 2 | 2004-11-12 00:00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | 2 | 1 | . Связанный учебник Левое соединение MySQL ВНУТРЕННЕЕ соединение MySQL Союз MySQL Из этих трех таблиц узнаем информацию о продажах, связав ВЫБЕРИТЕ product_name, customer.name, date_of_sale ОТ продаж, продукта, клиента ГДЕ product.product_id = sales.product_id И customer.customer_id >= sales.customer_id LIMIT 0, 30 Приведенная выше команда SQL связывает три таблицы и отображает требуемый результат.
Таким образом, мы можем связать три таблицы и получить содержательный отчет. USING LEFT , RIGHT, INNER объединение таблицНам может быть интересно узнать, какие продукты не проданы или кто клиенты, которые не купили. ←ЛЕВОЕ СОЕДИНЕНИЕ (основной запрос) ПРАВОЕ ПРИСОЕДИНЕНИЕ Внутреннее соединение КРЕСТ Присоединяйтесь Объединение SQL LEFT JOIN с использованием нескольких таблиц → Упражнение на LEFT JOIN с использованием таблиц продуктов и продаж → Эта статья написана командой plus2net.com . plus2net.com ▼ Объединение таблиц в запросе
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Мы будем использовать команду WHERE sql для связи разных таблиц. Здесь
Мы будем использовать команду WHERE sql для связи разных таблиц. Здесь 906:20
906:20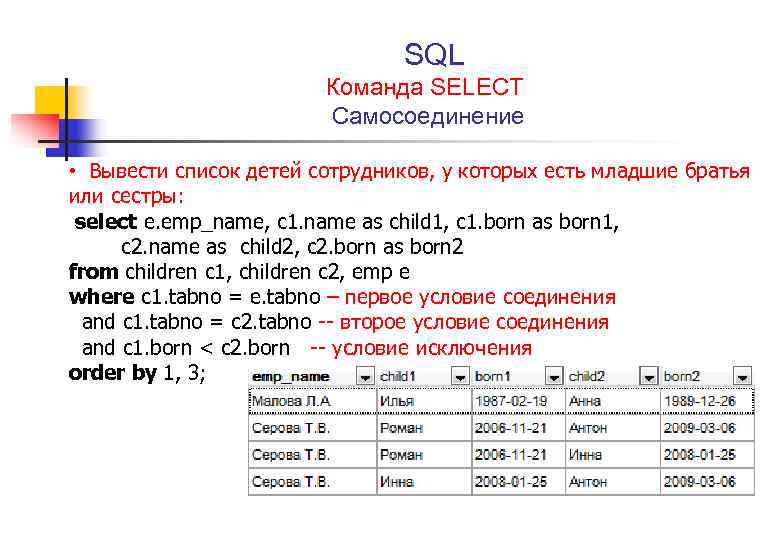 .. мой ксам. продолжайте эту работу!!!!
.. мой ксам. продолжайте эту работу!!!! .
.
 .. actually i am new to mysql
.. actually i am new to mysql .. синтаксическая ошибка, неожиданное ‘product_name’ (T_STRING) в C:xampphtdocsregmultiple.php в строке 28
.. синтаксическая ошибка, неожиданное ‘product_name’ (T_STRING) в C:xampphtdocsregmultiple.php в строке 28