Xml path: Examples: Using PATH Mode — SQL Server
Содержание
XPATH + XML = быстрая обработка / Хабр
При выполнении запросов язык XPath оперирует такими сущностями как узлы. Узлы бывают нескольких видов: element (узел-элемент), attribute (узел-атрибут), text (узел-текст), namespace (узел-пространство имён), processing-instruction (узел-исполняемая инструкция), comment (узел-комментарий), document (узел-документ).
Рассмотрим, как в XPATH задаётся последовательность узлов, направления выборки и выбирать узлы с конкретными значениями.
Для осуществления выборки узлов в основном используется 6 основных типов конструкций:
Так же при выборе узлов имеется возможность использовать wildcard маски, когда нам неизвестно, какой вид должен принимать узел.
В языке XPATH для выборки относительно текущего узла используются специальные конструкции под названием оси.
Правило выборки может быть как абсолютным (//input[@placeholder=”Логин” – выборка начиная с корневого узла], так и относительным (*@class=”okved-table__code” – выборка относительно текущего узла).
Построение правила выборки на каждом шаге выборки осуществляется относительно текущего узла и учитывает:
- Название оси, относительно которой следует производить выборку
- Условие выборки узла по имени или по положению
- Ноль или более предикатов
В общем случае синтаксис одного шага выборки имеет вид:
axisname::nodetest[predicate]
Для выборки конкретных узлов по некоторым условиям, параметрам или позиции используют такое инструментально средство как предикаты. Условие предиката ставится в квадратных скобках. Примеры:
Помимо приведенных конструкций языка XPATH, он также содержит поддерживает ряд операторов (+, -, *, div, mod, =, !=, and, or и т.д.), а также более 200 встроенных функций.
Приведем такой практический пример. Нам необходимо выгрузить информацию о периодах определенного списка людей. Для этого воспользуемся сервисом notariat.ru.
Импортируем зависимости.
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup from multiprocessing import Pool from retry import retry import itertools, time, pprint, os, re, traceback, sys, datetime import pandas as pd, numpy as np, multiprocessing as mp
 webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from multiprocessing import Pool
from retry import retry
import itertools, time, pprint, os, re, traceback, sys, datetime
import pandas as pd, numpy as np, multiprocessing as mp
webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from multiprocessing import Pool
from retry import retry
import itertools, time, pprint, os, re, traceback, sys, datetime
import pandas as pd, numpy as np, multiprocessing as mp
Загружаем данные по людям:
df_people = pd.read_excel('people.xlsx')
Извлекаем информацию из страниц с информацией о людях.
def find_persons(driver, name, birth_date):
base_url = 'https://notariat.ru/ru-ru/help/probate-cases/'
# Обновление страницы поиска людей
driver.get(base_url)
# Поиск поля ввода имени и отправка значения
driver.find_element_by_xpath('//input[@name="name"]').send_keys(name)
# Поиск выпадающего списка для указания дня рождения
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div/a'). click()
# Выбор дня рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div//li[@data-option-array-index={}]'.format(birth_date.day)).click()
# Поиск выпадающего списка для указания дня месяца
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div/a').click()
# Выбор месяца рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div//li[@data-option-array-index={}]'.format(birth_date.month)).click()
# Ввод года рождения в виде строки
driver.find_element_by_xpath('//input[@placeholder="Год"]').send_keys(str(birth_date.year))
# Инициализация поиска
driver.find_element_by_xpath('//*[contains(., "Искать дело")]').click()
# Ожидание до 20 секунд до появления списка людей, данный список находится в контейнере с классом «probate-cases__result-list»
WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By. CLASS_NAME, "probate-cases__result-list")))
time.sleep(2)
# Ищем общее количество страниц с результатами
max_pages = 1
pages_counters = driver.find_elements_by_xpath('//a[@class="pagination__item-content"]')
if pages_counters:
max_pages = int(pages_counters[-1].text)
data = []
def parse_page_data():
# Извлекаем ссылки на все строки с данными по людям внутри нумерованного списка
lines = driver.find_elements_by_xpath('//ol[@class="probate-cases__result-list"]/li')
for line in lines:
name = ' '.join(map(lambda el: el[0].upper() + el[1:].lower(), line.find_element_by_xpath('.//h5').text.split()))
death_date = datetime.datetime.strptime(line.find_element_by_xpath('.//p').text.split(':')[-1].strip(), '%d.%m.%Y')
data.append((name, birth_date, death_date))
# Если всего одна страница с результатами
if max_pages == 1:
parse_page_data() # то парсим то что есть и на этом заканчиваем
else:
for page_num in range(1, max_pages + 1):
# Иначе проходим по каждом странице с данными, кликая на кнопку со следующим номером страницы
driver. find_element_by_xpath('//li[./a[@class="pagination__item-content" and text()="{}"]]'.format(page_num)).click()
time.sleep(0.2)
# и извлекаем данные с конкретной страницы
parse_page_data()
return data click()
# Выбор дня рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div//li[@data-option-array-index={}]'.format(birth_date.day)).click()
# Поиск выпадающего списка для указания дня месяца
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div/a').click()
# Выбор месяца рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div//li[@data-option-array-index={}]'.format(birth_date.month)).click()
# Ввод года рождения в виде строки
driver.find_element_by_xpath('//input[@placeholder="Год"]').send_keys(str(birth_date.year))
# Инициализация поиска
driver.find_element_by_xpath('//*[contains(., "Искать дело")]').click()
# Ожидание до 20 секунд до появления списка людей, данный список находится в контейнере с классом «probate-cases__result-list»
WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.
click()
# Выбор дня рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="День"]/following::div//li[@data-option-array-index={}]'.format(birth_date.day)).click()
# Поиск выпадающего списка для указания дня месяца
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div/a').click()
# Выбор месяца рождения из выпадающего списка
driver.find_element_by_xpath('//select[@data-placeholder="Месяц"]/following::div//li[@data-option-array-index={}]'.format(birth_date.month)).click()
# Ввод года рождения в виде строки
driver.find_element_by_xpath('//input[@placeholder="Год"]').send_keys(str(birth_date.year))
# Инициализация поиска
driver.find_element_by_xpath('//*[contains(., "Искать дело")]').click()
# Ожидание до 20 секунд до появления списка людей, данный список находится в контейнере с классом «probate-cases__result-list»
WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By. CLASS_NAME, "probate-cases__result-list")))
time.sleep(2)
# Ищем общее количество страниц с результатами
max_pages = 1
pages_counters = driver.find_elements_by_xpath('//a[@class="pagination__item-content"]')
if pages_counters:
max_pages = int(pages_counters[-1].text)
data = []
def parse_page_data():
# Извлекаем ссылки на все строки с данными по людям внутри нумерованного списка
lines = driver.find_elements_by_xpath('//ol[@class="probate-cases__result-list"]/li')
for line in lines:
name = ' '.join(map(lambda el: el[0].upper() + el[1:].lower(), line.find_element_by_xpath('.//h5').text.split()))
death_date = datetime.datetime.strptime(line.find_element_by_xpath('.//p').text.split(':')[-1].strip(), '%d.%m.%Y')
data.append((name, birth_date, death_date))
# Если всего одна страница с результатами
if max_pages == 1:
parse_page_data() # то парсим то что есть и на этом заканчиваем
else:
for page_num in range(1, max_pages + 1):
# Иначе проходим по каждом странице с данными, кликая на кнопку со следующим номером страницы
driver.
CLASS_NAME, "probate-cases__result-list")))
time.sleep(2)
# Ищем общее количество страниц с результатами
max_pages = 1
pages_counters = driver.find_elements_by_xpath('//a[@class="pagination__item-content"]')
if pages_counters:
max_pages = int(pages_counters[-1].text)
data = []
def parse_page_data():
# Извлекаем ссылки на все строки с данными по людям внутри нумерованного списка
lines = driver.find_elements_by_xpath('//ol[@class="probate-cases__result-list"]/li')
for line in lines:
name = ' '.join(map(lambda el: el[0].upper() + el[1:].lower(), line.find_element_by_xpath('.//h5').text.split()))
death_date = datetime.datetime.strptime(line.find_element_by_xpath('.//p').text.split(':')[-1].strip(), '%d.%m.%Y')
data.append((name, birth_date, death_date))
# Если всего одна страница с результатами
if max_pages == 1:
parse_page_data() # то парсим то что есть и на этом заканчиваем
else:
for page_num in range(1, max_pages + 1):
# Иначе проходим по каждом странице с данными, кликая на кнопку со следующим номером страницы
driver.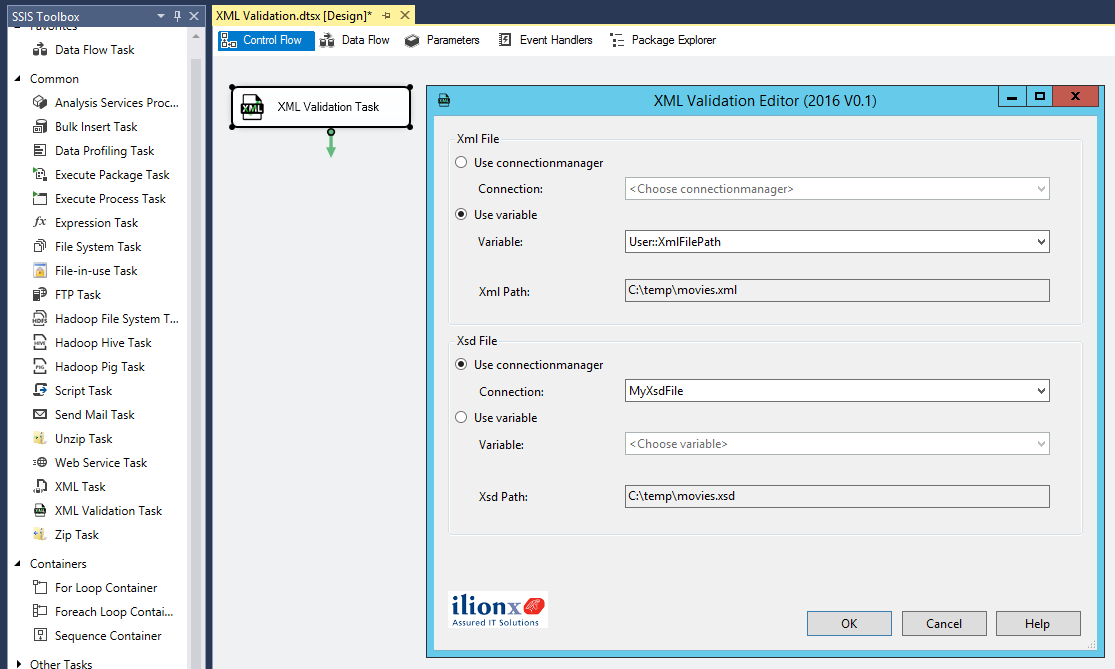 find_element_by_xpath('//li[./a[@class="pagination__item-content" and text()="{}"]]'.format(page_num)).click()
time.sleep(0.2)
# и извлекаем данные с конкретной страницы
parse_page_data()
return data
find_element_by_xpath('//li[./a[@class="pagination__item-content" and text()="{}"]]'.format(page_num)).click()
time.sleep(0.2)
# и извлекаем данные с конкретной страницы
parse_page_data()
return data
Осуществляем поиск, используя модуль multiprocessing, для ускорения сбора данных.
def parse_persons(persons_data_chunk, pool_num):
# Инициализируем браузер Chrome в режиме headless со стандартным разрешением (При меньшем разрешении расположение или классы DOM элементов на сайте notariat.ru может меняться)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=chrome_options)
driver.set_page_load_timeout(20)
data = []
print(pool_num, '')
# Производим поиск данных по каждому человеку из выделенной группы
for ind, (person_name, person_date) in enumerate(persons_data_chunk, start=1):
print('pool:', pool_num, ', person: ', ind, '/', len(persons_data_chunk))
try:
data. extend(find_persons(driver, person_name, person_date))
except Exception as e:
print(pool_num, 'failed to load', person_name, person_date, "error:", e)
traceback.print_exception(*sys.exc_info())
print(pool_num, 'done')
return data
def parse(people_data, parts=5):
p = mp.Pool(parts)
# Производим разбивку списка людей на обработку на несколько меньших списков для осуществления параллелизации сбора данных
people_in_chanks = np.array_split(people_data, parts if parts < len(people_data) else 1) or []
all_data = p.starmap(parse_persons, zip(people_in_chanks, range(parts)))
out = []
for el in all_data:
out.extend(el)
return out
parsed_data = parse(people_data) extend(find_persons(driver, person_name, person_date))
except Exception as e:
print(pool_num, 'failed to load', person_name, person_date, "error:", e)
traceback.print_exception(*sys.exc_info())
print(pool_num, 'done')
return data
def parse(people_data, parts=5):
p = mp.Pool(parts)
# Производим разбивку списка людей на обработку на несколько меньших списков для осуществления параллелизации сбора данных
people_in_chanks = np.array_split(people_data, parts if parts < len(people_data) else 1) or []
all_data = p.starmap(parse_persons, zip(people_in_chanks, range(parts)))
out = []
for el in all_data:
out.extend(el)
return out
parsed_data = parse(people_data)
extend(find_persons(driver, person_name, person_date))
except Exception as e:
print(pool_num, 'failed to load', person_name, person_date, "error:", e)
traceback.print_exception(*sys.exc_info())
print(pool_num, 'done')
return data
def parse(people_data, parts=5):
p = mp.Pool(parts)
# Производим разбивку списка людей на обработку на несколько меньших списков для осуществления параллелизации сбора данных
people_in_chanks = np.array_split(people_data, parts if parts < len(people_data) else 1) or []
all_data = p.starmap(parse_persons, zip(people_in_chanks, range(parts)))
out = []
for el in all_data:
out.extend(el)
return out
parsed_data = parse(people_data)И сохраняем результаты:
df = pd.DataFrame({
'ФИО': list(map(lambda el: el[0], parsed_data)),
"Дата рождения": list(map(lambda el: el[1], parsed_data)),
'Дата смерти': list(map(lambda el: el[2], parsed_data))
})
df.to_excel('results. xlsx', index=False) xlsx', index=False)
xlsx', index=False)
На рисунке ниже представлена страница поиска личных дел, на которой указываются ФИО, дата рождения, по которым в дальнейшем осуществляется поиск. После ввода ФИО и даты рождения алгоритм нажимает на кнопку искать дело, после чего анализирует полученные результаты.
На следующем рисунке видим список, парсингом элементов которого и занимается алгоритм.
На примере выше было показано, как можно использовать XPATH для сбора информации с веб-страниц. Но как уже было сказано, XPATH применим для обработки любых xml документов, являясь отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Зачастую читабельность кода влияет и на его качество, поэтому следует отказаться от регулярных выражений при парсинге, изучить XPATH и начать применять его в рабочем процессе. Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок, а также сократиться время отладки.
XML и XPath
XPath — это язык для поиска информации внутри XML документа.
Что такое XPath?
- XPath — специальный язык для определения частей XML документа
- XPath использует маршрутные выражения для навигации по XML документам
- XPath содержит библиотеку стандартных функций
- XPath — главный элемент в XSLT
- XPath также используется в XQuery, XPointer и XLink
Маршрутные выражения XPath
XPath использует маршрутные выражения для выбора узлов или узловых наборов в XML документе. Эти маршрутные выражения похожи на те выражения, которые можно увидеть при работе с традиционными файловыми системами.
В настоящее время выражения XPath можно использовать в JavaScript, Java, XML схемах, PHP, Python, C и C++, а также во множестве других языках программирования.
XPath используется в XSLT
XPath является главным составляющим элементом стандарта XSLT.
Знание XPath позволит в полной мере использовать все возможности XSL.
Пример XPath
Для демонстрации XPath будем использовать следующий XML документ:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49. 99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
 99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
| Выражение Xpath | Результат |
|---|---|
| /bookstore/book[1] | Выбирает первый элемент book, который является потомком элемента bookstore |
| /bookstore/book[last()] | Выбирает последний элемент book, который является потомком элемента bookstore |
| /bookstore/book[last()-1] | Выбирает предпоследний элемент book, который является потомком элемента bookstore |
| /bookstore/book[position()<3] | Выбирает первые два элемента book, которые являются потомками элемента bookstore |
| //title[@lang] | Выбирает все элементы title с атрибутом lang |
| //title[@lang=’en’] | Выбирает все элементы title с атрибутом lang, который имеет значение ‘en’ |
/bookstore/book[price>35. 00] 00] | Выбирает все элементы book, которые являются потомками элемента bookstore и которые содержать элемент price со значением больше 35.00 |
| /bookstore/book[price>35.00]/title | Выбирает все элементы title элементов book элементов bookstore, которые содержать элемент price со значением больше 35.00 |
Подробнее о XPath читайте в нашем Учебнике по XPath.
XML и XPath
❮ Предыдущий
Следующий ❯
|
Выражения пути XPath
XPath использует выражения пути для выбора узлов или наборов узлов в XML-документе. Эти пути
выражения очень похожи на выражения, которые вы видите, когда работаете с традиционной компьютерной файловой системой.
Выражения XPath могут использоваться в JavaScript, Java, XML-схеме, PHP, Python,
C и C++ и множество других языков.
XPath используется в XSLT
XPath является основным элементом стандарта XSLT.
Обладая знаниями XPath, вы сможете воспользоваться всеми преимуществами XSL.
Пример XPath
Мы будем использовать следующий документ XML:
<книжный магазин>
<год>2005
<год>2005
<год>2003
 Рэй
Рэй
<год>2003
В таблице ниже мы перечислили некоторые выражения XPath и результат выражений:
| Выражение XPath | Результат |
|---|---|
| /книжный магазин/книга[1] | Выбирает первый элемент book, который является дочерним элементом элемента bookstore |
| /книжный магазин/книга[последняя()] | Выбирает последний элемент книги, который является дочерним элементом элемента книжного магазина |
| /книжный магазин/книга[последний()-1] | Выбирает предпоследний элемент book, который является дочерним элементом элемента bookstore |
| /книжный магазин/книга[позиция()<3] | Выбирает первые два элемента book, которые являются дочерними элементами элемента bookstore |
| //название[@lang] | Выбирает все элементы заголовка, которые имеют атрибут с именем lang |
| //название[@lang=’ru’] | Выбирает все элементы заголовка, которые имеют атрибут «lang» со значением «en» |
/книжный магазин/книга[цена>35. 00] 00] | Выбирает все элементы книги элемента книжного магазина, у которых есть элемент цены со значением больше 35,00 |
| /книжный магазин/книга[цена>35.00]/название | Выбирает все элементы заголовка элементов книги элемента книжного магазина, у которых есть элемент цены со значением больше 35,00 |
Учебное пособие по XPath
Вы узнаете намного больше о XPath в нашем учебном пособии по XPath.
❮ Предыдущий
Далее ❯
НАБОР ЦВЕТА
Лучшие учебники
Учебное пособие по HTML
Учебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебное пособие по SQL
Учебное пособие по Python
Учебное пособие по W3.CSS
Учебное пособие по Bootstrap
Учебное пособие по PHP
Учебное пособие по Java
Учебное пособие по C++
Учебное пособие по jQuery
9000 3
Основные каталожные номера
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3. CSS
CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
ФОРУМ |
О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Copyright 1999-2023 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
| пакет xmlpath | |
| импорт ( | |
| «кодировка/xml» | |
| «ио» | |
| ) | |
| // Узел — это элемент дерева xml, который был скомпилирован в | |
| // обрабатываться через xml-пути. Узел может представлять: | |
| // | |
| // — Элемент в документе xml () | |
// — Атрибут элемента в xml документе (href=». ..») ..») | |
| // — Комментарий в xml документе () | |
| // — Инструкция по обработке в xml документе () | |
| // — Некоторый текст в XML-документе | |
| // | |
| тип Структура узла { | |
| вид узлаВид | |
| имя xml.Name | |
| строка атрибута | |
| текст []байт | |
| узлов []Узел | |
| позиция | |
| конец | |
| вверх *Узел | |
| вниз []*Узел | |
| } | |
| тип nodeKind int | |
| константа ( | |
| любой узел nodeKind = iota | |
| стартовый узел | |
| конечный узел | |
| attrNode | |
| текстовый узел | |
| комментарийУзел | |
| procInstNode | |
| ) | |
// Строка возвращает строковое значение узла. | |
| // | |
| // Строковое значение узла: | |
| // | |
| // — Для узлов элемента конкатенация всех текстовых узлов внутри элемента. | |
| // — Для текстовых узлов сам текст. | |
| // — Для узлов атрибута значение атрибута. | |
| // — Для узлов комментариев текст внутри разделителей комментариев. | |
| // — Для обработки узлов инструкций содержимое инструкции. | |
| // | |
| функция (узел *узел) String() строка { | |
, если node. kind == attrNode { kind == attrNode { | |
| вернуть node.attr | |
| } | |
| возвращаемая строка (node.Bytes()) | |
| } | |
| // Bytes возвращает строковое значение узла в виде среза байтов. | |
| // См. Node.String для описания строкового значения узла. | |
| функция (узел *Узел) Bytes() []byte { | |
| , если node.kind == attrNode { | |
| вернуть [] байт (node.attr) | |
| } | |
, если node. kind != startNode { kind != startNode { | |
| вернуть узел.текст | |
| } | |
| переменный текст [] байт | |
| для i := node.pos; я < узел.конец; я++ { | |
| , если node.nodes[i].kind == textNode { | |
| текст = добавить (текст, node.nodes[i].text…) | |
| } | |
| } | |
| текст возврата | |
| } | |
| // equals возвращает, равно ли строковое значение узла s, | |
// без выделения памяти. | |
| func (узел *узел) равно (s строка) bool { | |
| , если node.kind == attrNode { | |
| вернуть s == node.attr | |
| } | |
| , если node.kind != startNode { | |
| , если len(s) != len(node.text) { | |
| вернуть ложь | |
| } | |
| для я := диапазон с { | |
| , если s[i] != node.text[i] { | |
| вернуть ложь | |
| } | |
| } | |
| вернуть истину | |
| } | |
| си := 0 | |
для i := node. pos; я < узел.конец; я++ { pos; я < узел.конец; я++ { | |
| , если node.nodes[i].kind == textNode { | |
| для _, c := диапазон node.nodes[i].text { | |
| , если si > len(s) { | |
| вернуть ложь | |
| } | |
| , если s[si] != c { | |
| вернуть ложь | |
| } | |
| си++ | |
| } | |
| } | |
| } | |
| вернуть si == len(s) | |
| } | |
// Parse читает XML-документ из r, анализирует его и возвращает его корневой узел. | |
| func Parse(rio.Reader) (*Узел, ошибка) { | |
| возврат ParseDecoder(xml.NewDecoder(r)) | |
| } | |
| // ParseHTML читает HTML-подобный документ из r, анализирует его и возвращает | |
| // его корневой узел. | |
| func ParseHTML(rio.Reader) (*Узел, ошибка) { | |
| д := xml.NewDecoder(r) | |
| d.Strict = ложь | |
| d.AutoClose = xml.HTMLAutoClose | |
d. Entity = xml.HTMLEntity Entity = xml.HTMLEntity | |
| возврат ParseDecoder(d) | |
| } | |
| // ParseDecoder анализирует XML-документ, декодируемый с помощью d, и возвращает | |
| // его корневой узел. | |
| func ParseDecoder(d *xml.Decoder) (*Узел, ошибка) { | |
| вар узлов []Узел | |
| переменный текст [] байт | |
| // Корневой узел. | |
| узлов = добавить (узлы, узел {вид: startNode}) | |
| для { | |
т, ошибка := d. Token() Token() | |
| , если ошибка == io.EOF { | |
| перерыв | |
| } | |
| если ошибка != ноль { | |
| вернуть ноль, ошибка | |
| } | |
| переключатель t := t.(тип) { | |
| case xml.EndElement: | |
| узлов = добавить (узлы, узел { | |
| вид: endNode, | |
| }) | |
case xml. StartElement: StartElement: | |
| узлов = добавить (узлы, узел { | |
| вид: startNode, | |
| имя: t.Name, | |
| }) | |
| для _, атрибут := диапазон t.Attr { | |
| узлов = добавить (узлы, узел { | |
| вид: attrNode, | |
| имя: attr.Name, | |
| атрибут: значение атрибута, | |
| }) | |
| } | |
case xml.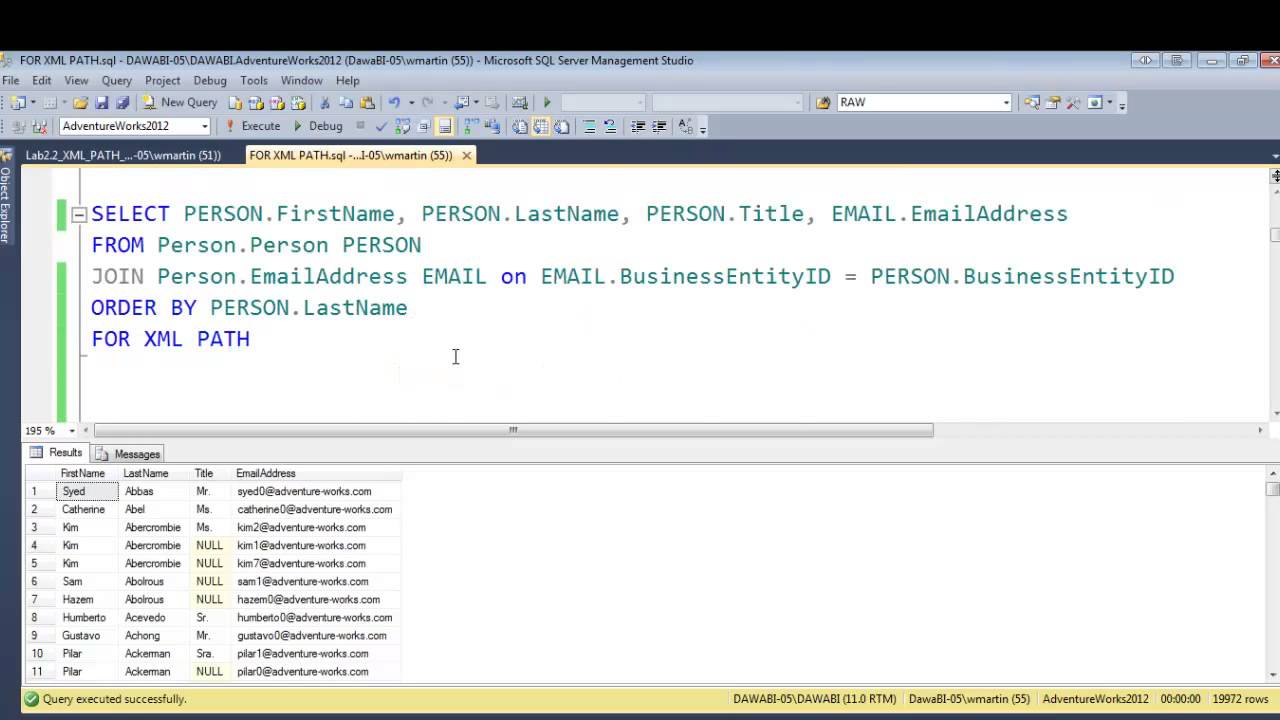 CharData: CharData: | |
| текст := длина (текст) | |
| текст = добавить (текст, т…) | |
| узлов = добавить (узлы, узел { | |
| вид: textNode, | |
| текст: текст[texti : texti+len(t)], | |
| }) | |
| case xml.Комментарий: | |
| текст := длина (текст) | |
| текст = добавить (текст, т…) | |
| узлов = добавить (узлы, узел { | |
| вид: комментарийУзел, | |
| текст: текст[texti : texti+len(t)], | |
| }) | |
case xml. ProcInst: ProcInst: | |
| текст := длина (текст) | |
| текст = добавить (текст, t.Inst…) | |
| узлов = добавить (узлы, узел { | |
| вид: procInstNode, | |
| имя: xml.Name{Local: t.Target}, | |
| текст: текст[texti : texti+len(t.Inst)], | |
| }) | |
| } | |
| } | |
// Закрыть корневой узел. | |
| узлов = добавить (узлы, узел {вид: endNode}) | |
| стек := make([]*Node, 0, len(nodes)) | |
| даунов := make([]*Node, len(nodes)) | |
| счетчик вниз := 0 | |
| для узлов pos := range { | |
| узлов переключения[pos].kind { | |
| case startNode, attrNode, textNode, commentNode, procInstNode: | |
| узел := &узлы[поз] | |
узел. узлы = узлы = | |
| узел.поз = поз | |
| , если длина (стек) > 0 { | |
| node.up = стек[len(стек)-1] | |
| } | |
| , если node.kind == startNode { | |
| стек = добавить (стек, узел) | |
| } еще { | |
| узел.конец = позиция + 1 | |
| } | |
| case endNode: | |
| узел := стек[len(стек)-1] | |
узел. конец = позиция конец = позиция | |
| стек = стек[:len(стек)-1] | |
| // Вычислить падения. Именно это и позволяет | |
| // использование фрагмента непрерывного предварительно выделенного блока. | |
| node.down = число падений[downCount:downCount] | |
| для i := node.pos + 1; я < узел.конец; я++ { | |
| , если узлы [i].up == узел { | |
| узлов переключения[i].kind { | |
| case startNode, textNode, commentNode, procInstNode: | |
node.
|
 go на мастере · masterzen/xmlpath · GitHub
go на мастере · masterzen/xmlpath · GitHub