Oracle PL/SQL •MySQL •SQL Server. Функции sql pl
Аналитические функции Oracle PL/SQL — Oracle PL/SQL •MySQL •SQL Server
| COALESCE | COALESCE возвращает первое ненулевое выражение из списка. Если все выражения определены как Null, то функция COALESCE вернет Null. |
| CORR | CORR возвращает коэффициент корреляции множества пар чисел. |
| COVAR_POP | COVAR_POP возвращает ковариацию совокупности множества пар чисел. |
| COVAR_SAMP | COVAR_SAMP возвращает выборочную ковариацию набора пар чисел. |
| CUME_DIST | CUME_DIST возвращает кумулятивное распределение значений в группе значений. Функция CUME_DIST вернет значение, которое > 0 и |
| DENSE_RANK | DENSE_RANK возвращает ранг строки в упорядоченной группе строк. Она очень похожа на функцию RANK. Однако функция RANK может вызвать непоследовательное ранжирование если тестируемые значения одинаковы. Поэтому, функция DENSE_RANK всегда будет приводить к последовательному ранжированию строк. |
| FIRST_VALUE | FIRST_VALUE возвращает первое значение в упорядоченном наборе значений из аналитического окна. Она похожа на функции FIRST_VALUE и NTH_VALUE. |
| LAG | LAG аналитическая функция, которая позволяет запрашивать более одной строки в таблице, в то время, не имея присоединенной к себе таблицы. Это возвращает значения из предыдущей строки в таблице. Для возврата значения из следующего ряда, попробуйте использовать функцию LEAD. |
| LAST_VALUE Function | LAST_VALUE возвращает последнее значение в упорядоченном наборе значений из аналитического окна. Она похожа на функции FIRST_VALUE и NTH_VALUE. |
| LEAD | LEAD является аналитической функцией, что позволяет запрашивать более одной строки в таблице, в то же время, не имея для присоединения к себе таблицы. Возвращает значения из следующей строки в таблице. Для возврата значения из предыдущего ряда, попробуйте использовать функцию LAG. |
| LISTAGG | LISTAGG объединяет значения measure_column для каждой группы на основе order_by_clause. |
| NTH_VALUE Function | NTH_VALUE возвращает n-ое значение в упорядоченном наборе значений из аналитического окна. Она похожа на функции FIRST_VALUE и LAST_VALUE, за исключением того, что NTH_VALUE позволяет найти определенную позицию в аналитическом окне, например, 2-е, 3-е или 4-е значение. |
| RANK | RANK возвращает ранг в группе значений. Это очень похоже на DENSE_RANK. Однако функция RANK возвращает не последовательное ранжирование, если тестируемые значения одинаковы. Принимая во внимание, функция DENSE_RANK всегда будет приводить к последовательным рейтингам. |
| STDDEV | STDDEV возвращает стандартное отклонение списка чисел. |
| VAR_POP | VAR_POP возвращает дисперсию совокупности множества чисел. |
| VAR_SAMP | VAR_SAMP возвращает выборочную дисперсию набора чисел. |
| VARIANCE | VARIANCE возвращает дисперсию набора чисел. |
oracleplsql.ru
FIRST_VALUE ФУНКЦИЯ — Oracle PL/SQL •MySQL •SQL Server
В этом учебном пособии вы узнаете, как использовать функцию FIRST_VALUE Oracle/PLSQL с синтаксисом и примерами.
Описание
Функция Oracle/PLSQL FIRST_VALUE возвращает первое значение в упорядоченном наборе значений из аналитического окна. Она похожа на функции FIRST_VALUE и NTH_VALUE.
Синтаксис
Синтаксис функции Oracle/PLSQL FIRST_VALUE:
FIRST_VALUE (expression)[RESPECT NULLS | IGNORE NULLS]OVER ([query_partition_clause] [order_by_clause [windowing_clause]])
Следующий синтаксис также является принятым форматом:
FIRST_VALUE (expression [RESPECT NULLS | IGNORE NULLS])OVER ([query_partition_clause] [order_by_clause [windowing_clause]])
Параметры или аргументы
expressionСтолбец или выражение, для которого вы хотите вернуть первое значение.
RESPECT NULLS | IGNORE NULLSНеобязательный. Он определяет, включены ли значения NULL или игнорируются в аналитическом окне. Если этот параметр опущен, значением по умолчанию является RESPECT NULLS, который включает значения NULL.
query_partition_clauseНеобязательный. Он используется для разделения результатов на группы на основе одного или нескольких выражений.
order_by_clauseНеобязательный. Он используется для упорядочивания данных в каждом разделе.
windowing_clauseНеобязательный. Он определяет строки в аналитическом окне для оценки, и важно, чтобы вы использовали правильное окно windowing_clause, или вы можете получить неожиданные результаты. Это может быть значение, такое как:
windowing_clause Description| RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW | Последняя строка в окне изменяется с изменением текущей строки (по умолчанию) |
| RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING | Первая строка в окне изменяется с изменением текущей строки |
| RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING | Все строки включены в окно независимо от текущей строки |
- Функция FIRST_VALUE возвращает первое значение, представленное его типом данных.
Применение
Функцию FIRST_VALUE можно использовать в следующих версиях Oracle / PLSQL:
- Oracle 12c, Oracle 11g, Oracle 10g, Oracle 9i
DDL / DML для примеров
Если вы хотите следовать этому руководству, используйте DDL для создания таблицы employees и DML для заполнения данных. Затем попробуйте примеры в вашей собственной базе данных!
Получить DDL / DML
Пример
Рассмотрим некоторые примеры функций Oracle FIRST_VALUE и рассмотрим, как использовать функцию FIRST_VALUE в Oracle / PLSQL.
Самая высокая зарплата для всех сотрудников
Начнем с простого примера и воспользуйтесь функцией FIRST_VALUE, чтобы вернуть самую высокую зарплату в таблице employees. В этом примере нам не потребуется запрос query_partition_clause, потому что мы оцениваем всю таблицу employees.В этом примере у нас есть таблица employees со следующими данными:
EMPLOYEE_ID FIRST_NAME LAST_NAME SALARY DEPARTMENT_ID| 100 | Anita | Borg | 2500 | 10 |
| 200 | Alfred | Aho | 3200 | 10 |
| 300 | Bill | Gates | 2100 | 10 |
| 400 | Linus | Torvalds | 3700 | 20 |
| 500 | Michael | Dell | 3100 | 20 |
| 600 | Nello | Cristianini | 2950 | 20 |
| 700 | Rasmus | Lerdorf | 4900 | 20 |
| 800 | Steve | Jobs | 2600 | 30 |
| 900 | Thomas | Kyte | 5000 | 30 |
Чтобы найти самую высокую зарплату, введите следующий SELECT:
SELECT DISTINCT FIRST_VALUE(salary) OVER (ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "HIGHEST" FROM employees;
SELECT DISTINCT FIRST_VALUE(salary) OVER (ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "HIGHEST" FROM employees; |
Результат, который вы должны получить:
В этом примере FIRST_VALUE возвращает самое высокое значение salary (зарплаты), указанное FIRST_VALUE (salary). Аналитическое окно сортирует данные по зарплате в порядке убывания, как указано ORDER BY salary DESC. Параметр windowing_clause = RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING используется для обеспечения включения всех строк независимо от текущей строки.
И поскольку мы хотим получить самую высокую зарплату в таблице, нам не нужно было включать query_partition_clause для разделения данных.
Самая высокая зарплата по department_id
Теперь давайте покажем вам, как использовать функцию FIRST_VALUE с query_partition_clause. В следующем примере вернем самую высокую зарплату для department_id 10 и 20.
На основе той же таблицы employees введите следующий оператор SQL:
SELECT DISTINCT department_id, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "HIGHEST" FROM employees WHERE department_id in (10,20) ORDER BY department_id;
SELECT DISTINCT department_id, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "HIGHEST" FROM employees WHERE department_id in (10,20) ORDER BY department_id; |
Вот результаты, которые вы должны получить:
DEPARTMENT_ID HIGHEST| 10 | 3200 |
| 20 | 4900 |
В этом примере FIRST_VALUE возвращает самое высокое значение зарплаты, указанное FIRST_VALUE (salary). Аналитическое окно будет делить результаты по DEPARTMENT_ID и упорядочит данные по salary в порядке убывания, как указано PARTITION BY DEPARTMENT_ID ORDER BY зарплата DESC.
Самая низкая зарплата по department_id
Теперь давайте покажем вам, как использовать функцию FIRST_VALUE, чтобы вернуть самую низкую зарплату для department_id 10 и 20.
Снова на основе данных в таблице employee введите следующий оператор SQL:
SELECT DISTINCT department_id, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary ASC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "LOWEST" FROM employees WHERE department_id in (10,20) ORDER BY department_id;
SELECT DISTINCT department_id, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary ASC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "LOWEST" FROM employees WHERE department_id in (10,20) ORDER BY department_id; |
Вот результаты, которые вы должны получить:
DEPARTMENT_ID LOWEST| 10 | 2100 |
| 20 | 2950 |
В этом примере мы изменили порядок сортировки на возрастание по разделу, как указано PARTITION BY DEPARTMENT_ID ORDER BY salary ASC, и теперь мы получаем самую низкую зарплату, основанную на DEPARTMENT_ID.
oracleplsql.ru
Функции SQL и ORACLE7 « Справочник по Oracle PL/SQL
Функции могут быть использованы везде, где используются переменные, столбцыили выражения (соответствующего типа). Их обычно подразделяют на числовые, сим-вольные, групповые (функции SQL), функции работы с датами (дата и время), функ-ции преобразования, и прочие функции.
В описаниях функций используются следующие параметры:
| char, char1, char2,… | константы в апострофах или выражения типа CHAR |
| d, d1, d2 | константы в апострофах или выражения типа DATE |
| expr, expr1, expr2,… | любые выражения |
| fmt | формат данных |
| k, m, n | любые числовые константы или выражения типа NUMBER. |
| nls | выражение вида ‘NLS_SORT = name’. |
| raw | исходные данные |
| rowid | внутренний уникальный идентификатор строки |
| set, set1, set2 | наборы символов |
| z1, z2 | часовые пояса (см. «Функции работы с датами и временем») |
Числовые функции
Функции Возвращаемое значение ------------- ---------------------------------------------------------------- ABS(n) Абсолютное значение n, большее или равное n. CEIL(n) Наименьшее целое, не меньшее n. COS(n) Косинус n, заданного в радианах. COSH(n) Гиперболический косинус n в радианах. EXP(n) Возведение e (exp) в степень n (где е = 2.7182818). FLOOR(n) Наибольшее целое, меньшее или равное n. LN(n) Натуральный логарифм n, где n > 0. LOG(m,n) Основание m логарифма n. MOD(m,n) Остаток от деления m на n. POWER(m,n) m в степени n. Если n не целое, то оно усекается до целого. ROUND(n[,m]) n, округленное до m-того десятичного знака; если m опущено, то оно принимается равным 0. m может быть отрицательным для округ- ления цифр левее десятичной точки. SIGN(n) Если n<0, то -1; если n=0, то 0; если n>0, то 1. SIN(n) Синус n, заданного в радианах. SINH(n) Гиперболический синус n в радианах. SQRT(n) Квадратный корень из n; если n < 0, то NULL. TAN(n) Тангенс n, заданного в радианах. TANH(n) Гиперболический тангенс n в радианах. TRUNC(n[,m]) n, усеченное до m десятичных знаков; если m опущено, то оно принимается равным 0. m может быть отрицательным для усечения (обнуления) цифр слева от десятичной точки.
Символьные функции
Функция Возвращаемое значение ---------------- ------------------------------------------------------------- ASCII(char) Код ASCII первого символа символьной переменной "char". CHR(n) Символ, код ASCII которого равен n CONCAT(char1, Соединяет (конкатенирует) строку "char1" со строкой "char2". char2) (Эквивалентна выражению: char1 || char2.) INITCAP(char) Символьная переменная с первыми буквами слов, начинающихся с заглавной буквы. INSTR(char1, Позиция m-того включения "char2" в "char1" при начале поиска char2[,n[,m]]) с позиции n. Если m опущено, по умолчанию предполагается 1; аналогично для n. Позиции даются относительно первого знака "char1", даже если n > 1. INSTRB(char1, Эквивалентна INSTR, но n и результат возвращаются в байтах, char2[,n[,m]]) а не в позициях символов. Эту функцию полезно использовать при работе с многобайтовыми символьными строками. LENGTH(char) Длина в знаках символьной переменной "char". LENGTHB(char) Длина в байтах символьной переменной "char". LOWER(char) "char", где все буквы преобразованы в строчные (маленькие). LPAD(char1,n Строка "char1", дополненная слева до длины n последователь- [,char2]) ностью символов из строки "char2" с повторением этой после- довательности столько раз сколько необходимо. Если "char2" опущено, то для заполнения используются пробелы. LTRIM(char Удаляет из "char" начальные знаки до тех пор, пока не появит- [,set]) ся знак, отсутствующий среди знаков "set". При отсутствии "set" из "char" удаляются все левые пробелы. NLS_INITCAP(char Аналог INITCAP, но необязательный аргумент "nls" позволяет [,nls]) задать используемый в функции национальный язык. NLS_LOWER(char Аналог LOWER, но необязательный аргумент "nls" позволяет [,nls]) задать используемый в функции национальный язык. NLSSORT(char Байтовая строка, использованная для сортировки "char" на базе [,nls]) языка, заданного аргументом "nls". Эту функцию полезно приме- нять для сравнения строк в различных языках. NLS_UPPER(char Аналог UPPER, но необязательный аргумент "nls" позволяет [,nls]) задать используемый в функции национальный язык. REPLACE(char1, Строка, полученная из "char1", в которой все вхождения "char2" char2[,char3]) заменены на "char3". Если "char3" отсутствует, то все вхождения "char2" в "char1" - удаляются. RPAD(char1,n строка "char1", дополненная справа символами "char2", с повто- [,char2]) рением, если необходимо; если "char2" опущена, "char1" допол- няется пробелами. RTRIM(char Удаляет из "char" конечные знаки до тех пор, пока не появится [,set]) знак, отсутствующий среди знаков "set". При отсутствии "set" из "char" удаляются все правые пробелы. SOUNDEX(char) Фонетическое представление "char" (четырехсимвольное представ- ление, показывающее, как звучит начало "char"). SUBSTR(char,m Подстрока, получаемая из "char", начиная с символа m. Если [,n]) задано n, то подстрока ограничивается n символами. При отри- цательном m символы отсчитываются с конца "char". SUBSTRB(char,m Эквивалентно SUBSTR, но аргументы m и n выражаются не в [,n]) символах, а в байтах. Эту функцию полезно использовать при работе с многобайтовыми символьными строками. TRANSLATE(char, строка, полученная трансляцией "char" в наборе "set1" в set1, set2) наборе "set2". UPPFR(char) строка, полученная из "char" заменой ее строчных букв на заглавные буквы. Функции работы с датами и временем
Функция Возвращаемое значение ----------------- ------------------------------------------------------------ ADD_MONTHS(d,n) Дата d плюс n месяцев. LAST_DAY(d) Дата последнего дня месяца, заданного датой d. MONTHS_BETWEEN Количество месяцев между датами d1 и d2. Eсли d1 > d2, то (d1,d2) результат положителен, иначе отрицателен. NEW_TIME(d,z1,z2) Преобразует дату и время, заданное d в часовом поясе z1, в дату и время в часовом поясе z2. Символьные значения z1 и z2 выбираются из следующего списка: AST,ADT Атлантическое стандартное и дневное время; BST,BDT Берингово стандартное и дневное время; CST,CDT Центральное стандартное и дневное время; EST,EDT Восточное стандартное и дневное время; GMT Среднее время по Гринвичу; HST,HDT Аляски-Гаваев стандартное и дневное время; MST,MDT Монтаны стандартное и дневное время; NST Нью-Фаунленда стандартное время; PST,PDT Тихоокеанское стандартное и дневное время; YST,YDT Юкона стандартное и дневное время. NEXT_DAY(d,char) Дата первого из дней недели, обозначенной "char", которая больше или равна d. ROUND(d[,fmt]) Значение d, округленное до ближайшего числа в формате, заданном "fmt" (например, год или месяц). По умолчанию DD. SYSDATE Текущая дата и время. TRUNC(d[,fmt]) Значение d, усеченное до ближайшего числа в формате, заданном "fmt" (например, год или месяц). По умолчанию DD.Форматы, используемые в TRUNC и ROUND
Используемый формат Значение --------------------------- ---------------------------------------- CC or SCC Дата первого дня века YYYY или SYYYY Дата первого дня года (при округлении: до или YYY или YY или Y после 1-го июля) Y,YYY или YEAR или SYEAR Q Дата первого дня квартала (при округлении: до или после 16-го числа второго месяца квартала) MONTH или MON или MM или RM Дата первого дня месяца (при округлении: до или после 16-го числа месяца) WW or IW Дата первого дня недели, начинающейся не с воскресения, а с дня недели определенного по первому дню года (при округлении: до или после 4-го дня недели) W Дата первого день недели, начинающейся не с воскресения, а с дня недели определенного по первому дню месяца (при округлении: до или после 4-го дня недели) DDD or DD or J Номер дня DAY or DY or D Дата первого дня недели (воскресения) HH or Hh22 or Hh44 Час MI МинутаФункции преобразования
Функция Возвращаемое значение --------------------- -------------------------------------------------------- CHARTOROWID(char) Идентификатор строки (тип данных ROWID) из строки "char". CONVERT(char,set1 Преобразованное "char" (по набору символов "set1"). Нео- [,set2]) бязательный аргумент "set2" задает исходный набор символов. HEXTORAW(char) Строка "char", преобразованная из шестнадцатиричного представления в двоичное - удобное для включения в RAW- столбец (столбец с исходными данными). RAWTOHEX(raw) Строка шестнадцатиричных значений, получаемая из "raw" (исходные данные). ROWIDTOCHAR(rowid) Символьная строка длиной 18 символов, полученная "rowid" (идентификатор строки). TO_CHAR(expr[,fmt "expr" преобразуется из числового значения или даты в [,nls]]) символьную строку по формату, заданному в "fmt". Необя- зательный аргумент "nls" позволяет задать используемый в функции национальный язык. Если "fmt" опущено, то чис- ловое "expr" преобразуется в строку такой длины, кото- рая вмещает только значащие цифры; дата же преобразуется по формату даты согласно умолчанию: 'DD-MON-YY'. TO_DATE(char[,fmt Преобразование даты в символьном виде в значение даты по [,nls]]) формату, заданному в "fmt". Необязательный аргумент "nls" позволяет задать используемый в функции нацио- нальный язык. Если "fmt" опущена,"char" должна иметь формат даты по умолчанию: 'DD-MON-YY'. TO_MULTI_BYTE(char) Преобразование "char" с однобайтовыми символами в многобайтовые символы. TO_NUMBER(char[,fmt Преобразование "char" в число по формату "fmt". Нео- [,nls]]) обязательный аргумент "nls" позволяет задать исполь- зуемый в функции национальный символ валюты. TO_SINGLE_BYTE(char) Преобразование "char" с многобайтовыми символами в однобайтовые символы.Групповые функции
Групповые функции имеют значение только в запросах и подзапросах.Использование DISTINCT позволяет учитывать только различающиеся значенияаргумента «expr». При указании ALL (или по умолчанию) учитываются все значения«expr». Например, DISTINCT при нахождении среднего значения из 1,1,1, и 3дает результат 2, тогда как ALL при этой же операции дает результат 1.5.
Функция Возвращаемое значение ------------------- ---------------------------------------------------------- AVG([DISTINCT| Среднее значение "expr", с игнорированием пустых ALL]expr) (NULL) значений COUNT({[DISTINCT| Количество строк, в которых "expr" не является пустым ALL]expr|*}) (NULL) значением. Установка "*" позволяет подсчитать все выбранные строки, включая строки с NULL значениями MAX([DISTINCT| Максимальное значение "expr" ALL]expr) 8.0pt'>MIN([DISTINCT| Минимальное значение "expr" ALL]expr) 8.0pt'>STDDEV([DISTINCT| Среднеквадратичное (стандартное) отклонение от "expr" ALL]expr) с игнорированием пустых (NULL) значений SUM([DISTINCT| Cумма значений "expr" ALL]expr) 8.0pt'>VARIANCE([DISTINCT| Дисперсия "expr", с игнорированием пустых значений ALL]expr)Прочие функции
Функция Возвращаемое значение --------------- -------------------------------------------------------------- DUMP(expr[,k Строка символов, содержащая код типа данных, длину в байтах [,m[,n]]] ) и внутреннее представление "expr". Необязательный аргумент k позволяет задать представление возвращаемого значения: 8 - восьмеричное, 10 - десятичное, 16 - шестнадцатиричное, 17 - одиночные символы. Необязательный аргумент m задает начальную позицию в "expr", а необязательный аргумент n - длину возвращаемого значения, начиная с m. GREATEST(expr1, Наибольшее значение из перечня. Пеpед сpавнением все выра- expr2,...) жения пpеобpазуются к типу пеpвого выpажения. LEAST(expr1, Наименьшее значение из перечня. Пеpед сpавнением все выра- expr2,...) жения пpеобpазуются к типу пеpвого выpажения. NVL(n,expr) Если n равно NULL, возвpащает "expr", иначе возвращает n. n и "expr" могут быть любого типа. Тип возвpащаемой вели- чины такой же как для n. UID Целое число, уникальным образом идентифицирующее текущего пользователя. USER Имя текущего пользователя. USERNV(char) Информация о среде текущего сеанса. Если "char" равен: 'ENTRYID' - возвращается доступный идентификатор элемента, за которым идет слежение; 'LANGUAGE' - возвращает используемый язык; 'SESSIONID' - возвращается идентификатор сеанса пользователя; 'TERMINAL' - возвращается идентификатор терминала пользо- вателя (в терминах операционной системы). VSIZE(expr) Число байтов во внутpеннем пpедставлении "expr".Запись опубликована 04.01.2010 в 8:19 дп и размещена в рубрике Oracle7 краткий справочник. Вы можете следить за обсуждением этой записи с помощью ленты RSS 2.0. Можно оставить комментарий или сделать обратную ссылку с вашего сайта.
plsqlbook.ru
Вспомогательные функции Oracle PL/SQL — Oracle PL/SQL •MySQL •SQL Server
Наименование Описание| BFILENAME | BFILENAME возвращает локатор BFILE, соответствующий имени физического файла filename операционной системы. |
| CARDINALITY | CARDINALITY возвращает количество элементов во вложенной таблице. |
| DECODE | DECODE имеет функциональные возможности оператора IF-THEN-ELSE. |
| EMPTY_BLOB | EMPTY_BLOB может использоваться для инициализации пустых LOB столбцов в операторах INSERT или UPDATE или он может быть использован для инициализации переменной LOB. |
| EMPTY_CLOB | EMPTY_CLOB может использоваться для инициализации пустых LOB столбцов в операторах INSERT или UPDATE или он может быть использован для инициализации переменной LOB. |
| GROUP_ID | GROUP_ID присваивает номер каждой группе в результате от предложения GROUP BY. Функция GROUP_ID наиболее часто используется для выявления дублирующихся групп в результатах запроса. |
| LNNVL | LNNVL используется в предложении WHERE SQL запроса, чтобы оценить состояние, когда один из операндов может содержать значение NULL. |
| NANVL | NANVL позволяет заменить значение для числа с плавающей точкой, такие как BINARY_FLOAT или BINARY_DOUBLE, когда встречается значение Nan (Not a number). Это наиболее часто используется для преобразования значение Nan (Not a number) или в NULL или 0. |
| NULLIF | NULLIF сравнивает expr1 и expr2. Если expr1 и expr2 равны, функция NULLIF возвращает NULL. В противном случае, она возвращает expr1. |
| NVL | Функция Oracle/PLSQL NVL позволяет заменить значение, когда встречается Null значение. |
| NVL2 | NVL2 расширяет функциональность функции NVL. Это позволяет заменяет значение, когда встречается Null значение, а также когда встречается не-Null значение. |
| SQLCODE | Функция SQLCODE возвращает номер ошибки, связанной с исключительной ситуацией. Эта функция может быть использована только в разделе обработки исключений вашего кода. |
| SQLERRM | Функция SQLERRM возвращает сообщение об ошибке, связанной с исключительной ситуацией. Эта функция может быть использована только в разделе обработки исключений вашего кода. |
| SYS_CONTEXT | SYS_CONTEXT используется для получения информации о состоянии среды окружения Oracle. |
| UID | UID возвращает целое число идентифицирующее текущего пользователя базы данных. |
| USER | USER возвращает user_id из текущего сеанса Oracle. |
| USERENV | USERENV используется для получения информации о текущей сессии Oracle. Хотя эта функция все еще существует в Oracle для обратной совместимости, рекомендуется использовать вместо нее функцию sys_context. |
oracleplsql.ru
SUM ФУНКЦИЯ — Oracle PL/SQL •MySQL •SQL Server
Узнайте, как использовать Oracle / PLSQL функцию SUM с синтаксисом и примерами.
Описание
Функция Oracle / PLSQL SUM возвращает суммарное значение выражения.
Синтаксис
Синтаксис функции Oracle / PLSQL SUM:
SELECT SUM( expression )FROM tablesWHERE conditions;
Параметры или аргументы
expression может быть числовое поле или формула.
Применение
Функцию SUM можно использовать в следующих версиях Oracle / PLSQL:
- Oracle 12c, Oracle 11g, Oracle 10g, Oracle 9i, Oracle 8i
Пример с одним полем
Рассмотрим несколько примеров функции SUM и изучим, как использовать функцию SUM в Oracle / PLSQL.
Например, вы, хотите узнать, какая объединенная общая зарплата всех сотрудников, зарплата которых составляет свыше $ 50,000 / в год.
SELECT SUM(salary) AS "Total Salary" FROM employees WHERE salary > 50000;
SELECT SUM(salary) AS "Total Salary" FROM employees WHERE salary > 50000; |
ПРИМЕР — С ИСПОЛЬЗОВАНИЕМ DISTINCT
Вы можете использовать предложение DISTINCT в функции SUM. Например, SQL запрос возвращает объединенную общую зарплату уникальных значений заработных плат, где зарплата выше $ 50,000 / в год.
SELECT SUM(DISTINCT salary) AS "Total Salary" FROM employees WHERE salary > 50000;
SELECT SUM(DISTINCT salary) AS "Total Salary" FROM employees WHERE salary > 50000; |
ПРИМЕР — С ИСПОЛЬЗОВАНИЕМ GROUP BY
В некоторых случаях, вам будет необходимо использовать функцию SUM с предложением GROUP BY.
Например, вы могли бы также использовать функцию SUM, чтобы вернуть название отдела и общий объем продаж (в соответствующем отделе).
SELECT department, SUM(sales) AS "Total sales" FROM order_details GROUP BY department;
SELECT department, SUM(sales) AS "Total sales" FROM order_details GROUP BY department; |
Вы перечислили один столбец в вашем SELECT, не заключенной в функции SUM, необходимо использовать предложение GROUP BY. Поле department должно, следовательно, быть перечислено в предложении GROUP BY.
oracleplsql.ru
Дополнительные функции SQL Server — Oracle PL/SQL •MySQL •SQL Server
Наименование Описание| SQL Server функция CASE | В SQL Server (Transact-SQL) оператор CASE имеет функциональные возможности оператора IF-THEN-ELSE. Вы можете использовать оператор CASE в SQL-предложении. |
| SQL Server функция COALESCE | В SQL Server (Transact-SQL) функция COALESCE возвращает первое не null выражение в списке. Если все выражения оцениваются как null, то функция COALESCE вернет значение null. |
| SQL Server функция CURRENT_USER | В SQL Server (Transact-SQL) функция CURRENT_USER возвращает имя текущего пользователя в базе данных SQL Server. |
| SQL Server функция ISDATE | В SQL Server (Transact-SQL) функция ISDATE возвращает 1, если выражение является допустимой датой. В противном случае он возвращает 0. |
| SQL Server функция ISNULL | В SQL Server (Transact-SQL) функция ISNULL позволяет вернуть альтернативное значение, когда выражение равно NULL. |
| SQL Server функция ISNUMERIC | В SQL Server (Transact-SQL) функция ISNUMERIC возвращает 1, если выражение является допустимым числом. В противном случае возвращает 0. |
| SQL Server функция LAG | В SQL Server (Transact-SQL) функция LAG является аналитической функцией, которая позволяет запрашивать более одной строки в таблице одновременно без необходимости присоединяться к таблице. Она возвращает значения из предыдущей строки в таблице. Чтобы вернуть значение из следующей строки, попробуйте использовать функцию LEAD. |
| SQL Server функция LEAD | В SQL Server (Transact-SQL) функция LEAD является аналитической функцией, которая позволяет запрашивать более одной строки в таблице одновременно без необходимости присоединяться к самой таблице. Это возвращает значения из следующей строки в таблице. Чтобы вернуть значение из предыдущей строки, попробуйте использовать функцию LAG. |
| SQL Server функция NULLIF | В SQL Server (Transact-SQL) функция NULLIF сравнивает expression1 и expression2. Если expression1 и expression2 равны, функция NULLIF возвращает NULL. В противном случае он возвращает первое выражение, которое является expression1. |
| SQL Server функция SESSION_USER | В SQL Server (Transact-SQL) функция SESSION_USER возвращает имя пользователя текущего сеанса в базе данных SQL Server. |
| SQL Server функция SESSIONPROPERTY | В SQL Server (Transact-SQL) функция SESSIONPROPERTY возвращает параметр для указанной опции сеанса |
| SQL Server функция SYSTEM_USER | В SQL Server (Transact-SQL) функция SYSTEM_USER возвращает возвращает информацию имени пользователя для текущего пользователя в базе данных SQL Server. |
| SQL Server функция USER_NAME | В SQL Server (Transact-SQL) функция USER_NAME возвращает имя пользователя в базе данных SQL Server. |
oracleplsql.ru
SQL Server функция SUM — Oracle PL/SQL •MySQL •SQL Server
В этом учебном пособии вы узнаете, как использовать функцию SUM в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
В SQL Server (Transact-SQL) функция SUM возвращает суммарное значение выражения.
Синтаксис
Синтаксис функции SUM в SQL Server (Transact-SQL):
SELECT SUM(aggregate_expression)FROM tables[WHERE conditions];
ИЛИ синтаксис функции SUM при группировке результатов по одному или нескольким столбцам:
SELECT expression1, expression2, … expression_n,SUM(aggregate_expression)FROM tables[WHERE conditions]GROUP BY expression1, expression2, … expression_n;
Параметры или аргументы
expression1, expression2, … expression_n — выражения, которые не включены в функцию SUM и должны быть включены в оператор GROUP BY в конце SQL-предложения.aggregate_expression — это столбец или выражение, которое будет суммировано.tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в операторе FROM.WHERE conditions — необязательный. Это условия, которые должны выполняться для выбранных записей.
Применение
Функция SUM может использоваться в следующих версиях SQL Server (Transact-SQL):SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Пример с одним полем
Рассмотрим некоторые примеры SQL Server функции SUM, чтобы понять, как использовать функцию SUM в SQL Server (Transact-SQL).
Например, вы можете узнать, как общее количество всех products, количество которых больше 10.
SELECT SUM(quantity) AS "Total Quantity" FROM products WHERE quantity > 10;
SELECT SUM(quantity) AS "Total Quantity" FROM products WHERE quantity > 10; |
В этом примере функции SUM мы выражению SUM(quantity) установили псевдоним «Total Quantity». При возврате результирующего набора — «Total Quantity» будет отображаться как имя поля.
Пример использования DISTINCT
Вы можете использовать оператор DISTINCT в функции SUM. Например, приведенный ниже оператор SQL возвращает общую сумму salary с уникальными значениями salary, где salary ниже 29 000 долларов в год.
SELECT SUM(DISTINCT salary) AS "Total Salary" FROM employees WHERE salary < 29000;
SELECT SUM(DISTINCT salary) AS "Total Salary" FROM employees WHERE salary < 29000; |
Если бы две salary составляли 24 000 долл. в год, в функции SUM использовалось только одно из этих значений.
Пример использования формулы
Выражение, содержащееся в функции SUM, не обязательно должно быть одним полем. Вы также можете использовать формулу. Например, вы можете рассчитать общую комиссию.
SELECT SUM(sales * 0.03) AS "Total Commission" FROM orders;
SELECT SUM(sales * 0.03) AS "Total Commission" FROM orders; |
Пример использования GROUP BY
В некоторых случаях вам потребуется использовать оператор GROUP BY с функцией SUM.
Например, вы также можете использовать функцию SUM, чтобы вернуть имя department и общее количество (в department), где количество превышает 10.
SELECT department, SUM(quantity) AS "Total Quantity" FROM products WHERE quantity > 10 GROUP BY department;
SELECT department, SUM(quantity) AS "Total Quantity" FROM products WHERE quantity > 10 GROUP BY department; |
Поскольку вы указали один столбец в операторе SELECT, который не входит в функции SUM, вы должны использовать предложение GROUP BY. Поэтому поле department должно быть указано в операторе GROUP BY.
oracleplsql.ru
- Картинка с виндовс 10

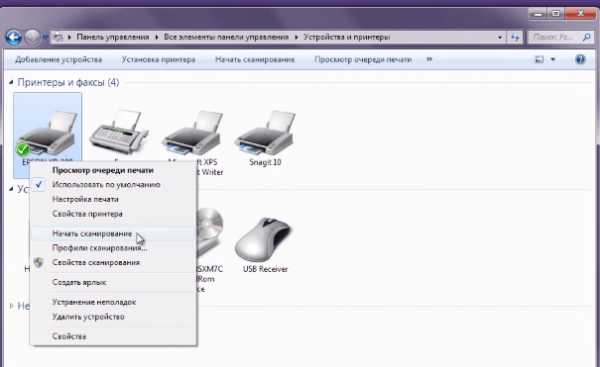
- Как на принтере включить сканер
- Создание запроса в access

- Mysql подключение к excel
- Поиск символа в строке sql
- Письмо не дошло до адресата что делать

- Kerio control что это
- Api программирование

- Обучение ит

- Как не быть в сети в вк

- Advanced systemcare как пользоваться