Как работает индексация базы данных? Индекс бд
Что такое индексы базы данных (для начинающих)? — IM-Cloud.ru
Многие слышали о том, что индексы в базах данных это весьма полезная штука. Но, одно дело слышать, а другое представлять себе их устройство хотя бы на базовом уровне. Поэтому в рамках данной статьи для начинающих, я рассмотрю этот вопрос, применяя простые и понятные каждому выражения и аналогии из жизни.
Что такое индекс базы данных и зачем он нужен?
Чтобы понять зачем нужны индексы в базе данных и что он собой представляет, сейчас рассмотрим простой пример.
Представьте себе, что у вас есть полочка для книг. При этом изначально эта полочка с книгами пуста. Книги вам то приносят, то уносят, то делают в них какие-то корректировки (к примеру, мемуары или может быть черновики) и тому подобное.
Так как полочка маленькая, то вы как-то не особо задумывались о какой-либо системе классификации, а просто вставляете книги в любые пустые места.
Каждый раз когда-то вам или кому-то необходимо найти определенную книгу, возникает необходимость просматривать все книги с самого начала полочки до первой попавшейся (если нужна только одна книга) или полностью все (если нужно собрать все копии). В принципе, для одной полочки это весьма необременительно.
Теперь, представьте себе, что речь идет не об одной полочке, а об огромном помещении, где находятся тысячи книг.
Тут-то вы и начинаете задумываться о том, что неплохо бы ввести какую-то систему классификации, например, по названию книги. Конечно, полностью сортировать все эти тысячи книг в алфавитном порядке вы не собираетесь, плюс с этим возникло бы куча других вопросов (как добавить книгу в уже заполненную полку и прочие).
Поэтому вы поступаете проще, вы берете каталог, где возможно добавлять листочки. При этом каждую страницу выделяете только под одно название книги, а сами страницы располагаете в каталоге в порядке возрастания названий. Содержание этих страниц весьма просто — вы записываете в каком стеллаже, на какой полке и какой по счету является книга. Если книг несколько, то строчек в этой странице становится несколько.
Таким образом, чтобы найти одну или все нужные книги по названию, вам достаточно открыть этот каталог и быстро пролестнуть до нужной страницы, а затем пройтись по всем указанным стеллажам. При этом для упрощения, вы так же можете первые буквы названий так же индексировать. То есть добавляете наклейку на каждую первую страницу с указанной буквой (таким образом можете сразу перейти, например, к букве «Р», не пролистывая все названия до нее).
Конечно, для поддержки такой системы требуется дополнительное время, но все же оно существенно меньше, чем попытка найти вслепую книгу из тысячи (пара минут против нескольких часов и более).
Так вот, в данном примере, если переносить это в базу данных:
Помещение — это таблица в базе данных. Если чуть проще, то любое скопище однотипных данных (тех же книг), по сути, представляет собой таблицу.
Поиск книги — это sql-запросы получения данных. При этом важно отметить, что сами по себе они не меняются. То есть вам как нужно было найти «Термодинамику», так и осталось нужным найти «Термодинамику». Другое дело, как вы будете это осуществлять — прочесывая тысячи книг или открыв каталог.
Каталог — это и есть упрощенный вариант индекса в базе данных. То есть, индекс это набор дополнительных данных, записанных в удобном виде, который позволяет существенно быстрее осуществлять поиск, хоть и требующий дополнительных усилий для поддерживания его актуальности.
Имя книги (страничка) — это ключ в индексе. То уникальное значение, которое может ссылаться как на одну какую-то запись, так и на несколько. Стоит отметить, что даже если записей для каждого значения будет несколько, это все равно быстрее, чем полный перебор всех данных.
Если суммировать, то можно увидеть, что наличие индекса может быть весьма выгодным. Например, для одной домашней полочки с десятком книг — индекс в общем-то не сильно нужен, а вот когда речь заходит о более больших объемах, то индекс будет весьма полезным.
Так же можно заметить, что добавление индекса не требует того, чтобы сами sql-запросы были переписаны, так как последние являются лишь выражением на упрощенном языке для базы данных. Если продолжить аналогию, то это как попросить кого-то найти вам «Флора и фауна». При этом каким образом и сколько этот кто-то будет искать книгу, будет решать сам этот человек. В данном примере «найти книгу» — это sql-запрос, а этот «кто-то» это база данных.
Какие бывают индексы?
Вообще, в зависимости от типов баз данных, индексы могут быть очень разными и реализоваться за счет специфических математических механизмов. Но, наиболее частым является древовидный индекс, так как поддерживать такой индекс относительно просто и максимальная скорость поиска в нем составляет логарифм по числу максимального количества дочерних узлом от общего количества записей (плюс минус некоторые технические моменты).
Немного поясню.
Дерево (древовидный индекс) — это специального вида структура, у которой есть корневая вершина и у каждого узла может быть несколько дочерних узлов. При этом каждый узел встречается только один раз и может иметь всего один родительский узел. Выглядит это так:
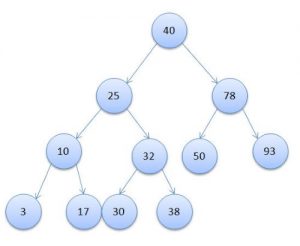
Как видите, очень похоже на перевернутое обычное зеленое дерево, у которого ветки растут не вверх, а вниз.
Максимальное количество дочерних узлов, как вероятно уже догадались по картинке, это то количество дочерних узлов, больше которого у одного узла не может быть.
Теперь поясню откуда берется логарифм. Дело в том, что дерево обычно заполняется по определенным правилам. К примеру, если у узла максимально может быть всего два дочерних узла (так называемое бинарное дерево), то обычно левый дочерний узел имеет значение меньше текущего, а правый большее значение. Поэтому если вам нужно найти, например, число 30 в дереве с рисунка чуть выше, то вам понадобится всего 4 сравнения (40 — 25 — 32 — 30). Именно из-за этой особенности поиска и берется логарифм (так как каждое сравнение сокращает количество проверяемых элементов в два раза). При этом обычно значение логарифма округляют в большую сторону.
Так же отмечу, что такая скорость достигается за счет того, что дерево строится специальным образом, чтобы не возникало таких ситуаций, как на картинке ниже, где максимальная скорость поиска будет сравнима с простым перебором всех записей.

Как видите, чтобы здесь найти запись с ключом «3» понадобится 4 сравнения (40 — 25 — 10 — 3), хотя всего записей 5.
Практически во всех базах данных, существует деление по уникальности:
Уникальный индекс — это такой индекс, у которого все значения встречаются только один раз. Проводя аналогию, когда каждая книга присутствует только в одном экземпляре и никогда названия книг не совпадают.
Неуникальный индекс — это такой индекс, у которого значения могут повторяться. Проводя аналогию, существуют книги с одними и теми же названиями, но разными авторами, или же просто встречаются копии.
Важно отметить, что если для таблицы создается уникальный индекс, то это означает, что при попытке добавить запись со значением, которое уже встречалось, или же изменить значение какой-то записи на существующее, то база данных не позволит сделать такое действие и будет ругаться (выдавать ошибки). В случае же с неуникальным индексом таких проблем нет.
Так же стоит знать, что индексы делятся по количеству входящих в них полей:
Обычные индексы — состоят из одного поля. Здесь, вероятно, все понятно. Обычный каталог страничек.
Составные индексы — строятся по нескольким полям, при этом расположение полей является важным.
Чуть подробнее про составные индексы. Рассмотрим аналогию с теми же книгами. До этого индекс строился только по названию. Теперь же представим, что книги с одинаковыми названиями часто встречаются. В такой ситуации, легко может получится, что страничка каталога будет состоять из координат сотен книг (десятки авторов и у каждого по десять копий). Бегать их всех проверять — так же немалое количество времени. Поэтому вместо того, чтобы страничка просто перечисляла все местонахождения книг, можно сделать так, чтобы странички с именами книг указывали на дополнительные каталоги, где аналогичным образом проиндексированы авторы.
Немного упрощая, поиск будет выглядит примерно так.
1. Вначале вы ищите в каталоге с именами необходимую страничку с названием.
2. Затем в этой страничке смотрите, где находится соответствующий каталог с авторами.
3. Берете этот каталог и уже в нем находите страничку, где указано месторасположение всех книг с этим автором и названием.
При этом важно понимать, что для каждого названия будет создаваться собственный каталог авторов. То есть в обратном порядке, к сожалению, поиск не осуществить. Если же требуется поиск вначале по автору, а уже затем по названиям книг, то необходимо создавать отдельный составной каталог (составной индекс).
Существуют и другие моменты, но чаще всего достаточно знать хотя бы эти базовые знания.
im-cloud.ru
Индексирование баз данных
Если записей в таблице много, то найти нужную запись бывает очень трудно. Поиск данных производится методом перебора, то есть просматриваются все записи таблицы от первой записи до последней записи, что приводит к большим затратам времени. Чтобы облегчить поиск данных в таблице, используют индексы. Индекс, иногда его называют указатель, представляет собой порядковый номер записи в таблице. Индекс строится по значениям одного поля или по значениям нескольких полей. Индекс, построенный по значениям одного поля, называется простым, а по значениям двух и более полей — сложным. Во время построения индекса записи в таблице сортируются по значениям поля (или полей) будущего индекса. Затем первой строке таблицы присваивается индекс номер один, второй строке — индекс номер два и т. д. до конца таблицы.
Как простой, так и сложный индекс имеют свой тип (Туре). Первичный (Primary) индекс (ключ) — это поле или группа полей, однозначно определяющих запись, то есть значения первичного индекса уникальны (не повторяются). В реляционной базе данных каждая таблица может иметь только один первичный ключ. Внешних ключей у таблицы может быть много и они будут иметь один из типов:
• Candidate — кандидат в первичный ключ или альтернативный ключ. Он обладает всеми свойствами первичного ключа.
• Unique (уникальный) — допускает повторяющиеся значения в поле, по которому он построен, но на экран будет выводиться только одна первая запись из группы записей с одинаковым значением индексного поля.
• Regular (регулярный) — не накладывает никаких ограничений на значения индексного поля и на вывод записей на экран. Индекс только управляет порядком отображения записей. Это наиболее популярный тип индекса.
Взаимосвязь между таблицами осуществляется по индексам, которые называют ключами.
Построенный индекс хранится в специальном индексном файле. Если индексный файл хранит только один индекс, то он называется одноиндексным и имеет расширение .idx. Индексные файлы, которые хранят много индексов, называются мультииндексными и имеют расширение .cdx. Каждый индекс, который хранится в мультииндексном файле, называется тегом. Каждый тег имеет свое уникальное имя.
Мультииндексные файлы бывают двух типов: просто мульти-индексные файлы (о них рассказано выше) и структурные мульти-индексные файлы. Структурный мультииндексный файл имеет одинаковое имя с таблицей, которой он принадлежит (отличие только в расширении файла), и обладает следующими свойствами:
• автоматически открывается со своей таблицей;
• его нельзя закрыть, но можно сделать не главным.
Одна таблица может иметь много индексных файлов как одноиндексных, так и мультииндексных. В старших версиях FoxPro используются Мультииндексные файлы.
Создание индекса
Создать индекс можно двумя способами.
а.С помощью команды:
INDEX ON <индексное выражение> ТО <idх-файл> | TAG <имя тега> [OF <сdх-файл>]
[FOR <условие>]
[COMPACT]
[DESCENDING]
[UNIQUE]
[ADDITIVE]
[NOOPTIMIZE]
Назначение опций:
<индексное выражение>— имя поля (или полей), по значениям которого надо построить индекс. При построении сложного индекса имена полей перечисляются через знак + (плюс). Если сложный индекс построен по:
• числовым полям, то индекс строится по сумме значений полей;
• символьным полям, то индекс строится сначала по значению первого поля, а при повторяющихся значениях первого поля — по значениям второго поля; при повторяющихся значениях первого и второго полей — по значениям третьего поля и т. д.;
• по полям разных типов, то сначала значения полей приводят к одному типу, как правило символьному, а затем строят индекс.
Длина индексного выражения не должна превышать 254 символа.
ТО <idх-файл>— указывается имя одноиндексного файла.
TAG <имя тега> [OF <cdx-файл>]— указывается имя тега в мультииндексном файле. Если используется опция [OF <cdx-файл>] , то создаваемый тег помещается в указанный мульти-индексный файл, а если требуемый мультииндексный файл отсутствует, то будет построен структурный мультииндексный файл. Если опция [OF <сс!х-файл>] опущена, то созданный тег будет помещен в текущий мультииндексный файл.
FOR <условие>— устанавливает режим отбора в индекс тех записей таблицы, которые удовлетворяют <условию>.
COMPACT — управляет созданием компактного одноиндексного файла. В старших версиях FoxPro не используется.
DESCENDING— строит индекс по убыванию. По умолчанию используется построение индекса по возрастанию (ASCENDING). Для одноиндексных файлов можно построить индекс только по возрастанию. Если перед использованием команды INDEX ON... подать команду SET COLLATE, то можно построить одноин-дексный файл по убыванию.
UNIQUE— строит уникальный индекс. Если индексное поле (поля) содержит повторяющиеся значения, то в индекс попадает только одна первая запись и остальные записи будут не доступны.
ADDITIVE— вновь создаваемый индексный файл не закрывает уже открытые к этому моменту времени индексные файлы. Если опция опущена, то вновь создаваемый индексный файл закрывает все ранее открытые индексные файлы.
б.С помощью Главного меню:
В этом случае индекс создается либо при создании таблицы, либо при модификации структуры таблицы. Для этого в диалоговой панели Table Designer надо выбрать вкладку Index (рис. 3.1).
Каждый индекс описывается одной строкой в окне диалоговой панели Table Designer.
Вграфе Name указывается имя тега мультииндексного файла. Если ранее открыт один из мультииндексеых файлов, то вновь построенный индекс помещается в открытый мультиин-дексный файл. Если индекс строится одновременно с созданием табличного файла или табличный файл не имеет мультиин-дексных файлов, то вновь построенный индекс помещается в автоматически создаваемый структурный мультииндексный файл.
В графе Туре, снабженной раскрывающимся списком, указывается один из допустимых типов индекса. Если индекс строится для таблицы, входящей в состав базы данных, то возможны четыре значения: Primary, Candidate, Unique и Regular. Если ин деке строится для свободной таблицы, то в раскрывающемся списке отсутствует значение Primary.
В графе Expression перечисляются имена полей, по значениям которых надо построить индекс. Если строится сложный индекс, то удобнее воспользоваться построителем выражений, который запускается нажатием кнопки, расположенной справа от поля ввода.
В графе Filter можно задать логическое условие и построить индекс не для всех записей таблицы, а только для записей, удовлетворяющих условию фильтра. Эта графа также снабжена построителем выражений. Содержание и внешний вид обоих построителей одинаковые (рис. 3.2).
На рис. 3.2 показано построение сложного индекса по двум символьным полям ush_step и uch_zvan (имя тегу uch было присвоено до вызова на экран построителя выражений). Знак «+», указывающий на построение сложного индекса, взят из раскрывающегося списка String,
В раскрывающемся списке String приведены допустимые строковые функции. Аналогично в раскрывающихся списках Math, Logical и Date приведены допустимые математические, логические функции и функции даты. Нужная функция из этих раскрывающихся списков выбирается щелчком левой кнопки мыши. Имена полей (список Fields) и имена переменных (список Variables) выбираются с помощью двойного щелчка левой кнопки мыши. Получившееся в результате выражение помещается в окно Expression.
В раскрывающемся списке From Table указано имя таблицы, из которой берутся поля для построения индекса. При желании можно заказать любую таблицу из текущей базы данных и для построения индекса взять любое поле.
studfiles.net
Индекс (базы данных) Википедия
У этого термина существуют и другие значения, см. Индекс.Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Некоторые СУБД расширяют возможности индексов введением возможности создания индексов по столбцам представлений[1] или индексов по выражениям.[2] Например, индекс может быть создан по выражению upper(last_name) и соответственно будет хранить ссылки, ключом к которым будет значение поля last_name в верхнем регистре. Кроме того, индексы могут быть объявлены как уникальные и как неуникальные. Уникальный индекс реализует ограничение целостности на таблице, исключая возможность вставки повторяющихся значений.
Архитектура[ | код]
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочены по значению ключа этого индекса. Если в таблице нет кластерного индекса, таблица называется кучей[3]. Некластерный индекс, созданный для такой таблицы, содержит только указатели на записи таблицы. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами. Наиболее часто употребимы B*-деревья, B+-деревья, B-деревья и хеши.
Последовательность столбцов в составном индексе[ | код]
Последовательность, в которой столбцы представлены в составном индексе, достаточно важна. Дело в том, что получить набор данных по запросу, затрагивающему только первый из проиндексированных столбцов, можно. Однако в большинстве СУБД невозможно или неэффективно получение данных только по второму и далее проиндексированным столбцам (без ограничений на первый столбец).
Например, представим себе телефонный справочник, отсортированный вначале по городу, затем по фамилии, и затем по имени. Если вы знаете город, вы можете легко найти все телефоны этого города. Однако в таком справочнике будет весьма трудоёмко найти все телефоны, записанные на определённую фамилию — для этого необходимо посмотреть в секцию каждого города и поискать там нужную фамилию. Некоторые СУБД выполняют эту работу, остальные же просто не используют такой индекс.
Производительность[ | код]
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того, индексы занимают дополнительный объем памяти, поэтому перед созданием индекса следует убедиться, что планируемый выигрыш в производительности запросов превысит дополнительную затрату ресурсов комп
ru-wiki.ru
Индексы базы данных
Количество просмотров публикации Индексы базы данных - 459
Структура таблиц базы данных
Реляционная модель базы данных
Форма хранения информации
Существуют различные схемы, определяющие способ хранения информации. Наибольшее распространение получила система размещения информации в табличном виде. При таком способе хранения вся информация делится на несколько групп однородных объектов, каждая из которых размещается в отдельной таблице. Это таблицы связаны между собою.
Системы управления базами данных, использующие способ хранения информации в виде связанных между собою таблиц, называют реляционными.
Вообще–то табличная форма представления и хранения информации является весьма удобной и в связи с этим получила широкое распространение. Примером тому бывают текстовый редактор MS Word, электронные таблицы MS Excel. При этом различия между текстовым редактором и электронными таблицами с одной стороны и системами управления базами данных с другой стороны существенны.
Таблицы текстового редактора MS Word предназначены для наглядного представления текстовой или числовой информации, а автоматизация вычислений и поиска данных у них развита слабо.
Таблицы программы MS Excel служат в основном для автоматизации вычислений.
Основное же назначение таблиц базы данных - ϶ᴛᴏ обеспечение эффективного и автоматизированного поиска необходимых данных среди большого их объёма и многообразия.
Реляционная модель базы данных представляет собой совокупность связанных между собой таблиц. Данные организованы в этих таблицах таким образом, чтобы обеспечить объединение разнородной информации, исключить ее дублирование, а также предоставить оперативный доступ к ней и эффективное сопровождение базы данных в целом.
Каждая таблица базы данных содержит информацию о группе однородных объектов. Пример такой таблицы представлен рис.22.1.
| Электродвигатели | |||||
| Код | Тип | Мощность, кВт | Напряжение, В | Ток, А | Частота вращения, Об/мин |
| П31 | 67,5 | ||||
| П42 | 97,5 | ||||
| П58 | 112,5 | ||||
| Строка состояния |
Рис.21.1 Общий вид таблицы базы данных
Как видно из таблицы, в ней содержаться однородные объекты – электродвигатели. Все они имеют один и тот же перечень параметров (атрибутов).
Табличную форму размещения и хранения данных предложил в 1970 ᴦ. Э.Ф. Кодд. Он показал, что набор двухмерных таблиц, при соблюдении определенных ограничений, позволяет хранить информацию об объектах и моделировать связи между ними. В терминологии Кодда связанные между собой таблицы называются
отношениями (англ. relation). Отсюда и название модели – реляционная.
Среди многообразия разработанных СУБД наибольшее распространение получила система управления базами данных, корпорации Microsoft – MS Access.
В терминологии принятой в системах управления базами данных строка таблицы имеет название запись, а столбец – поле. Каждая таблица СУБД имеет свою специализацию. Она хранит информацию об однородной группе объектов. К примеру, одна таблица хранит информацию о типах электродвигателей, заводах – изготовителях, стоимости, другая таблица содержит информацию об их электрических параметрах (мощность, напряжение, ток и др.), третья таблица – о конструктивных особенностях (высота͵ ширина, длина, масса и др.) и т. д. Все эти таблицы связаны между собой, поскольку они только в совокупности дают полную информацию об объектах.
Запись представляет собой набор значений всех атрибутов информационной модели рассматриваемой сущности. Проще говоря, запись - ϶ᴛᴏ совокупность сведений об объекте. В одной таблице все записи состоят из одних и тех же полей, поскольку таблица формируется из однородных объектов. Каждый объект имеет свой набор значений в этих полях. В некоторых полях значения могут отсутствовать или как принято считать – иметь значение Null. Название каждого поля в таблице уникальное. То есть одна таблица не может иметь в своем составе два или более полей с одинаковым названием.
Типы данных, содержащихся в отдельных полях, бывают различными. В одних полях информация может представляться в текстовом виде, к примеру, тип двигателя, в других полях – в числовом виде, к примеру, мощность, напряжение, ток. Размер поля определяется количеством байт, необходимым для размещения значения атрибута. Иногда вместо термина размер поля употребляют термины ширина или длина поля.
Для получения из базы данных тех или иных сведений крайне важно уметь выбирать записи о тех или иных объектах. В случае если таблица содержит немного записей, да и сами записи имеют небольшое количество полей, то это сделать несложно, рассматривая таблицу на экране. Но если записей тысячи и полей десятки или сотни, то выбирать необходимые сведения представляет огромную трудность и связано с большими затратами времени. В таких случаях только автоматизация позволит сделать данный процесс эффективным. Именно такой способ предусматривает СУБД. Для реализации такого принципа поиска информации крайне важно указать поле или группу полей, значения которых позволят однозначно выбрать из многообразия записей одну необходимую.
Поле, с помощью которого можно идентифицировать запись, называют первичным ключом или просто ключом таблицы. Значение первичного ключа должно быть уникальным, то есть нигде не повторяться. При этом поле ключа не должно содержать значение Null.
В случае если ключ состоит из одного поля, то он считается простым, если он состоит из нескольких полей, то его называют составным. В тех случаях, когда невозможно выбрать первичный ключ, когда значения всех полей двух или более записей одинаковые, используется дополнительное поле, куда может помещаться уникальный код, к примеру, порядковый номер. Размещено на реф.рфВ таком поле двух одинаковых порядковых номеров не должна быть. Поля, содержащие порядковые номера строк, относят к типу счетчик.
Одним из приемов ускорения поиска информации в системах управления базами данных является расположение информации в упорядоченном виде. К примеру, расположение электродвигателей в таблице по возрастанию мощности или другого параметра, размещение фамилий сотрудников в алфавитном порядке и т. п. Такое упорядочение называют сортировкой. Для выполнения действий по упорядочению информации требуется дополнительное время и память компьютера. В случае если информация в базе данных постоянно изменяется (что–то удаляется, что–то добавляется), то это требует частой ее сортировки и дополнительной потери времени. В таких случаях предпочитают использовать несортированную таблицу данных. Но тогда возрастает время поиска информации. Для достижения компромисса в этой ситуации вводят дополнительную таблицу, называемую индексами базы данных. В эту таблицу помещаются только первичные ключи из основной таблицы и поле, по которому совершается сортировка. Такая таблица с упорядоченными ключами и полем атрибута с упорядоченными значениями представляет собой индекс для основной таблицы базы данных. Для одной и той же таблицы данных можно создать несколько индексов. К примеру, для таблицы, содержащей информацию о параметрах электродвигателей, можно создать один индекс по мощности, другой индекс по напряжению, а третий по частоте вращения и др. Размещено на реф.рфЭто удобно. В случае если крайне важно найти электродвигатель с крайне важно й мощностью, то в данном случае удобно использовать индекс по мощности, так как поле мощности в данном индексе сортировано, что обеспечит быстрый поиск. При выборе электродвигателя с требуемой частотой вращения удобно использовать индекс по частоте вращения. Индексные таблицы значительно меньше базовых таблиц и на их сортировку требуется существенно меньше времени. Этим и определяется полезность их применения.
Каждому созданному индексу следует устанавливать имя, чтобы можно было легко выбирать объект по интересующему атрибуту.
В общем случае создание индексов может осуществляться по значениям нескольких полей. Такой индекс называют составным. Это имеет смысл, в случае если в отдельных полях размещаются, к примеру, фамилия, имя и отчество сотрудника. При создании индекса по полю, содержащему фамилии, может возникнуть ситуация, когда при наличии нескольких одинаковых фамилий последующие поля (имя и отчество) будут подсоединены к выбранной фамилии в произвольном порядке. При наличии составного индекса по фамилии, имени и отчеству такой вариант будет исключен.
referatwork.ru
performance - Как работает индексация базы данных?
Почему это необходимо?
Когда данные хранятся на дисковых накопителях, они хранятся в виде блоков данных. Доступ к этим блокам осуществляется целиком, что делает их доступным для атомарного доступа к диску. Блоки диска структурированы так же, как и связанные списки; оба содержат раздел для данных, указатель на расположение следующего node (или блока), и оба они не должны храниться смежно.
В связи с тем, что количество записей можно сортировать только в одном поле, мы можем заявить, что поиск в поле, которое не сортируется, требует линейного поиска, для которого требуется N/2 доступ к блокам (в среднем), где N - количество блоков, в которых находится таблица. Если это поле является неключевым полем (т.е. Не содержит уникальных записей), тогда все табличное пространство необходимо искать в N доступе к блоку.
В то время как в отсортированном поле может использоваться двоичный поиск, у него есть log2 N доступ к блокам. Кроме того, поскольку данные сортируются с учетом неключевого поля, остальная часть таблицы не нуждается в поиске повторяющихся значений, как только будет найдено более высокое значение. Таким образом, увеличение производительности является существенным.
Что такое индексирование?
Индексирование - это способ сортировки нескольких записей в нескольких полях. Создание индекса в поле в таблице создает другую структуру данных, которая содержит значение поля, и указатель на запись, к которой она относится. Затем эта структура индекса сортируется, что позволяет выполнять двоичные поиски.
Недостатком индексации является то, что этим индексам требуется дополнительное пространство на диске, поскольку индексы хранятся вместе в таблице с помощью механизма MyISAM, этот файл может быстро достичь ограничений размера базовой файловой системы, если многие поля в пределах одна и та же таблица индексируется.
Как это работает?
Во-первых, давайте нарисуем примерную схему таблицы базы данных;
Field name Data type Size on disk id (Primary key) Unsigned INT 4 bytes firstName Char(50) 50 bytes lastName Char(50) 50 bytes emailAddress Char(100) 100 bytesПримечание: char использовался вместо varchar, чтобы обеспечить точный размер на диске. Эта тестовая база данных содержит пять миллионов строк и не указана. Теперь будет проанализирована производительность нескольких запросов. Это запрос с использованием идентификатора (поля отсортированного ключа) и одного с использованием firstName (несимвольное несортированное поле).
Пример 1 - отсортированные или несортированные поля
Учитывая нашу примерную базу данных r = 5,000,000 записей фиксированного размера, дающих длину записи R = 204 байтов, и они хранятся в таблице с использованием механизма MyISAM, который использует размер блока по умолчанию B = 1,024 байт. Коэффициентом блокировки таблицы будет bfr = (B/R) = 1024/204 = 5 записей на блок диска. Общее количество блоков, необходимых для хранения таблицы, составляет N = (r/bfr) = 5000000/5 = 1,000,000.
Для линейного поиска в поле id потребуется среднее число N/2 = 500,000 для доступа к блоку, чтобы найти значение, учитывая, что поле id является ключевым полем. Но так как поле id также сортируется, может быть проведен двоичный поиск, требующий среднего из log2 1000000 = 19.93 = 20 доступа к блокам. Мгновенно мы видим, что это радикальное улучшение.
Теперь поле firstName не сортируется и не поле ключа, поэтому бинарный поиск невозможен, и значения не уникальны, и, следовательно, таблица потребует поиска до конца для точного доступа к блоку N = 1,000,000. Именно в этой ситуации индексирование направлено на исправление.
Учитывая, что индексная запись содержит только проиндексированное поле и указатель на исходную запись, разумно, что она будет меньше, чем многопольная запись, на которую указывает. Таким образом, для самого индекса требуется меньше блоков диска, чем исходная таблица, поэтому требуется меньше доступа к блокам для итерации. Схема для индекса в поле firstName приведена ниже;
Field name Data type Size on disk firstName Char(50) 50 bytes (record pointer) Special 4 bytesПримечание. Указатели в MySQL имеют длину 2, 3, 4 или 5 байтов в зависимости от размера таблицы.
Пример 2 - индексирование
Учитывая нашу примерную базу данных r = 5,000,000 записей с длиной записи индекса R = 54 байт и использованием размера блока по умолчанию B = 1,024 байт. Блокирующим фактором индекса будет bfr = (B/R) = 1024/54 = 18 записей на блок диска. Общее количество блоков, необходимых для хранения индекса, составляет N = (r/bfr) = 5000000/18 = 277,778.
Теперь поиск с использованием поля firstName может использовать индекс для повышения производительности. Это позволяет выполнять двоичный поиск индекса со средним значением доступа к блоку log2 277778 = 18.08 = 19. Чтобы найти адрес фактической записи, для которой требуется дополнительный доступ к блоку для чтения, приведение общего количества к 19 + 1 = 20 блочным доступам, далеко от 1000 000 запросов блоков, необходимых для поиска совпадения firstName в таблице без индексирования.
Когда он должен использоваться?
Учитывая, что для создания индекса требуется дополнительное дисковое пространство (277 778 дополнительных блоков из приведенного выше примера, увеличение на 28%), и что слишком много индексов могут вызывать проблемы, связанные с ограничениями размера файловой системы, следует тщательно подумать выберите правильные поля для индексации.
Так как индексы используются только для ускорения поиска подходящего поля в записях, то понятно, что поля индексирования, используемые только для вывода, будут просто потерей дискового пространства и времени обработки при выполнении операции вставки или удаления, и поэтому этого следует избегать. Также, учитывая характер бинарного поиска, важна мощность или уникальность данных. Индексирование в поле с мощностью 2 разделило бы данные пополам, тогда как мощность 1000 вернула бы приблизительно 1000 записей. При такой низкой мощности эффективность сводится к линейной сортировке, и оптимизатор запросов избежит использования индекса, если мощность составляет менее 30% от номера записи, что делает индекс ненужным.
qaru.site
Индексирование — ПИЭ.Wiki
Материал из ПИЭ.Wiki
Индексирование (indexing) — это способ обеспечения быстрого доступа к значениям колонки или комбинации колонок. Физически новые строки добавляются в конец таблицы, результатом чего становится неупорядоченное размещение значений в колонках. Без использования каких-либо методов упорядочения данных единственным способом просмотра значения колонки со стороны СУБД является последовательный просмотр каждой строки от начала таблицы к ее концу — так называемое сканирование таблицы. Производительность такого сканирования пропорциональна размеру таблицы, размеру физической страницы БД и длине строки таблицы.
Одним из способов внесения отношения порядка в значения колонок без нарушения физического расположения строк таблицы является создание объекта реляционной СУБД — индекса (index). Индекс — это объект в реляционной БД, который предназначен для организации быстрого доступа к строкам таблицы по значениям одной или более колонок этих строк.
Концептуально действие индекса состоит в следующем. В индексе содержатся упорядоченный список значений колонки или комбинации колонок, а также сведения о местонахождении на жестком диске соответствующих этим значениям строк таблицы. Значения колонки в индексе упорядочены. Несмотря на то, что порядок строк в таблице случаен, индекс можно быстро просмотреть, чтобы найти конкретное значение. Упорядоченный индекс можно просмотреть во много раз быстрее, чем неупорядоченную таблицу. Чем выше степень различия значений ключа в колонке, тем быстрее будет выполняться доступ к строкам этой таблицы.
Так, при вставке новой записи в таблицу проверка уникальности первичного ключа реализуется не реальным просмотром таблицы БД, а тем, что требование уникальности предъявляется к значениям колонки первичного ключа в индексе. Таким образом, индекс — это объект базы данных, который может существенно сократить время поиска нужных строк в таблице.
Индексы занимают место в БД. При вводе новых данных или удалении данных СУБД приходится обновлять и таблицы, и индексы. Это может замедлить выполнение операций модификации данных, особенно для таблиц с большим числом строк, как в ХД. Таким образом, может появиться проблема, суть которой состоит в возникновении конфликта между скоростью обновления данных в таблице и скоростью ее считываний. При разрешении этой проблемы следует придерживаться следующего эмпирического правила: создавать индексы для колонок первичных ключей и других колонок, часто используемых в тех запросах, в которых для выборки данных применяются логические критерии. Если в результате скорость обновления данных ухудшается, то можно рассмотреть вопрос об удалении некоторых индексов.
Каждая таблица БД может иметь один или несколько индексов. Индексы создаются по одной колонке или нескольким колонкам таблицы. Колонки, входящие в индекс, принято называть ключевыми полями (key fields), или ключами. Индексы могут быть уникальными и неуникальными. Уникальность индекса означает, что не существует двух строк с одним и тем же значением ключа индекса. Неуникальный индекс может иметь несколько ключей с одинаковыми значениями.
Основными целями создания индексов в БД являются:
- ускорение поиска строк в таблицах;
- обеспечение уникального значения в колонках;
- извлечение строк в заданном порядке на основании значений индексированных колонок (что оправдано только для очень больших таблиц, когда использование предложения ORDER ухудшает производительность).
На этапе создания физической модели данных ХД необходимо принять ряд важных решений о том, что и как индексировать; при этом важно четко сформулировать правила индексирования. Для каждого ИТ-проекта с ХД необходимо создать и оформить в письменном виде правила индексирования как часть общих правил обеспечения производительности. Поддержка и сопровождение индексов в процессе эксплуатации ХД является в основном задачей администратора БД. Решая задачи обеспечения производительности, администратор БД будет ставить вопрос о перепроектировании ее физической структуры (обратные задачи проектирования), в том числе и вопрос об удалении и создании новых индексов. Он может решать эти задачи самостоятельно. Тем более важно знать, по каким правилам и из каких соображений создавались индексы того или иного типа. Разработка таких правил значительно повысит качество эксплуатации ХД с точки зрения обеспечения ее производительности.
Чтобы решать эти задачи, проектировщик должен знать, как работает индекс, какие типы индексов поддерживает СУБД, и понимать смысл методов индексирования.
Индекс со структурой B-Tree
Индекс на основе сбалансированной иерархической структуры (или индекс B-Tree, balanced tree structured object) напоминает дерево, если смотреть на него снизу вверх. При работе СУБД с этой структурой сначала считывается самый верхний блок — корневой узел (root), затем блок на следующем уровне — блок-ветвь (branch), и так далее, до тех пор, пока не будет извлечен блок-лист (leaf) с индексируемыми колонками (колонкой) строки. Обратим внимание, что значения индексируемых колонок сохраняется в индексе (рис. 1.1).
Такая структура позволяет сократить до минимума число операций ввода-вывода. Для получения индексируемых колонок строки обычно требуется одно посещение блока-листа, т.е. физической страницы файловой структуры БД, отведенной под индекс.

Рис. 1.1. Концептуальная организация B-Tree индекса
Следует отметить два случая, когда после выборки индексируемых колонок строки из индекса может понадобиться несколько посещений физической страницы индекса:
- когда строка имеет длину более одной физической страницы файловой структуры БД — так называемая расщепленная строка ;
когда строка за время своего существования в БД увеличилась и была перемещена из исходной страницы в другую страницу — так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе – высотой (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree — это физический объект реляционной БД, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree.
Количество операций ввода-вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавления новых данных СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.
Корневой узел и узлы — ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений. Узлы-листья содержат полное значение ключа.
Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
Индекс можно использовать для поиска как точного соответствия, так и диапазона значений.
Индексы могут быть построены для нескольких колонок таблицы — так называемый составной индекс. СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа. Например, составной индекс {"Фамилия" (Ename), "Должность" (Job)} для обработки запроса SELECT * FROM EMPLOYEE WHERE Job='Инженер'; применяться не будет.
СУБД обычно сама принимает решение, использовать индекс или нет.
Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться применять его в некоторых операциях, например, ORDER BY.
В СУБД семейства MS SQL Server все индексы организованы на основе сбалансированной иерархической структуры. Помимо того, что индексы обладают свойствами уникальности ( UNIQUE ) и неуникальности, индексы в СУБД семейства MS SQL Server могут быть кластеризованными ( CLUSTERED ) или некластеризованными ( NONCLUSTERED ), являющимися индексами по умолчанию.
Кластеризованный индекс – это индекс, в котором логический порядок значений ключа определяет физический порядок соответствующих строк в таблице. На нижнем (конечном) уровне такого индекса хранятся действительные строки данных таблицы. Для таблицы или представления в каждый момент времени может существовать только один кластеризованный индекс.
Некластеризованный индекс – это индекс, в котором задается логическое упорядочение для таблицы. Логический порядок строк в некластеризованном индексе не влияет на их физический порядок. Для каждой таблицы можно создать до 999 некластеризованных индексов, независимо от того, каким образом они создаются: неявно, с помощью ограничений PRIMARY KEY и UNIQUE, или явно, с помощью команды CREATE INDEX.
В кластеризованном индексе конечные узлы содержат страницы данных базовой таблицы. На страницах индекса корневого и промежуточного узлов находятся строки индекса. Каждая строка индекса содержит ключевое значение и указатель либо на страницу промежуточного уровня сбалансированного дерева, либо на строку данных на конечном уровне индекса. Страницы на каждом уровне связаны в двунаправленный список.
По умолчанию кластеризованный индекс занимает одну секцию на дисковом пространстве. Если кластеризованный индекс занимает несколько секций, каждая секция включает сбалансированное дерево, содержащее данные этой секции. Например, если кластеризованный индекс занимает четыре секции, существует четыре сбалансированных дерева: по одному в каждой секции.
SQL Server движется вниз по индексу, чтобы найти строку, соответствующую ключу кластеризованного индекса. Чтобы найти диапазон ключей, SQL Server сначала находит начальное значение ключа в диапазоне, а затем сканирует страницы данных, используя указатели на следующую и предыдущую страницу. Чтобы найти первую страницу в цепочке страниц данных, SQL Server движется по самым левым указателям от корня индекса.
В зависимости от типов данных каждая структура кластеризованного индекса состоит из одной или более единиц распределения, которые применяются для хранения и управления данными секциями. Для каждой секции кластеризованный индекс содержит как минимум одну единицу распределения IN_ROW_DATA. Для хранения столбцов больших объектов ( LOB ) кластеризованному индексу требуется одна единица распределения LOB_DATA для каждой секции. Кроме того, для хранения строк переменной длины, которые превышают ограничение на размер строки, равное 8 060 байтам, для каждой секции требуется одна единица распределения ROW_OVERFLOW_DATA.
По своей организации некластеризованные индексы отличаются от кластеризованных следующим: строки данных в базовой таблице не сортируются и хранятся в порядке, который основан на их некластеризованных ключах; конечный уровень некластеризованного индекса состоит из страниц индекса вместо страниц данных.
Некластеризованные индексы могут определяться на таблице или представлении с кластеризованным индексом либо на куче. Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение.
Указатели строк на строках некластеризованных индексов являются либо указателем на строку, либо ключом кластеризованного индекса для строки, как описано ниже.
Если таблица является кучей (то есть не содержит кластеризованный индекс ), то указатель строки является указателем на строку. Указатель строится на основе идентификатора файла ( ID ), номера страницы и номера строки на странице. Весь указатель целиком называется идентификатором строки ( RID ).
Если для таблицы имеется кластеризованный индекс или индекс построен на индексированном представлении, то указатель строки — это ключ кластеризованного индекса для строки. Если кластеризованный индекс не является уникальным индексом, то SQL Server создает все имеющиеся повторяющиеся ключи уникальными путем добавления внутри созданного значения, называемого uniqueifier. Это четырехбайтовое значение невидимо для пользователей. Оно применяется тогда, когда необходимо сделать кластеризованный ключ уникальным, чтобы использовать в некластеризованных индексах. SQL Server получает строку данных путем поиска по кластеризованному индексу, задействуя ключ кластеризованного индекса, который хранится в конечной строке некластеризованного индекса.
По умолчанию некластеризованный индекс включает одну секцию. Если он состоит из нескольких секций, то каждая секция имеет структуру сбалансированного дерева, в которой содержатся индексные строки для данной конкретной секции. Например, если некластеризованный индекс содержит четыре секции, то существуют четыре структуры сбалансированного дерева, по одной на каждую секцию.
В зависимости от типов данных в некластеризованном индексе каждая его структура будет содержать одну или более единиц распределения, в которых хранятся данные для определенной секции. Каждый некластеризованный индекс будет иметь по меньшей мере одну единицу распределения IN_ROW_DATA на секцию, в которой хранятся страницы сбалансированного дерева индекса. Некластеризованный индекс будет также содержать одну единицу распределения LOB_DATA на секцию, если в индексе есть столбцы типа большого объекта (LOB). Кроме того, некластеризованный индекс будет включать одну единицу распределения ROW_OVERFLOW_DATA на секцию, если в индексе имеются столбцы переменной длины, в которых превышается максимальный размер строки, равный 8 060 байт.
Исключительно индексные таблицы и другие типы индексов на основе B-Tree
Исключительно индексная таблица (index-organized table) может создаваться на основе значений одной или нескольких колонок. Если требования к данным в запросе удовлетворяются на основе информации из связанного с этими данными индекса, то доступ к базовой таблице не осуществляется.
В некоторых СУБД, в частности в СУБД Oracle, исключительно индексные таблицы поддерживаются. Исключительно индексная таблица является индексом типа B-Tree БД, который одновременно исполняет роль таблицы. Все данные такой таблицы хранятся в индексе. Преимущество создания полностью индексированных таблиц состоит в экономии места хранения на диске и сокращении объема ввода-вывода, поскольку ключевые колонки нет необходимости сохранять еще раз в таблице. Результат выполнения запроса будет получен на основе данных, сохраненных в индексной таблице.
Исключительно индексная таблица в СУБД Oracle создается с помощью команды SQL CREATE TABLE.
Команда CREATE TABLE не отличается ничем от других команд создания таблиц — до тех пор, пока не встретится предложение ORGANIZATION INDEX, которое указывает СУБД на создание исключительно индексной таблицы. Для размещения индекса на диске указывается табличное пространство. Параметр PCTTHRESHOLD говорит, что оставшуюся часть строки нужно сохранять в заданном табличном пространстве — сегменте переполнения, если данная строка превышает размер физической страницы базы данных на указанное число процентов. Параметр INCLUDING определяет имя колонки, с которой строка индексной таблицы делится на две части: индексную и переполнения. Эта колонка может быть частью первичного ключа таблицы или неключевой колонкой. Все неключевые колонки, которые следуют за указанной колонкой, размещаются в сегменте переполнения, который определяется ключевым словом OVERFLOW.
В СУБД семейства MS SQL Server нет предопределенной возможности создавать исключительно индексные таблицы. Однако в ряде практических случаев в СУБД этого семейства можно создавать структуры, аналогичные исключительно индексным таблицам. Для этого может быть использован некластеризованный индекс с включенными колонками (опция INCLUDE команды CREATE INDEX).
Опция INCLUDE указывает неключевые колонки, добавляемые на конечный уровень некластеризованного индекса. Некластеризованный индекс может быть уникальным или неуникальным. Имена колонок в списке INCLUDE не могут повторяться и не могут использоваться одновременно как ключевые и неключевые.
В семействе СУБД Oracle предусмотрено еще несколько типов индексов, которые позволяют улучшить традиционные для всех СУБД индексы со структурой B-Tree. К таким модификациям, помимо исключительно индексных таблиц, относятся битовые индексы, индексы с обращением ключа, индексы на основе значения функций.
Каждый бит так называемого битового (bitmap) индекса относится к идентификатору строки ROWID (который в Oracle создается и хранится для каждой строки и используется во внутренней организации индексов ) в табличном объекте. Если некоторая строка содержит данное ключевое значение, то в индексе для этого значения сохраняется единица. Такая организация индекса может в некоторых случаях значительно повысить производительность выборки данных, т. к. для извлечения строк с определенными значениями индекса СУБД нужно лишь найти все единицы, отвечающие ключу. Физически такой индекс организован на основе структуры B-Tree, но задача сводится к поиску данной строки за счет одной операции чтения битовой индексной структуры. Этот тип индекса очень эффективен для индексирования колонок с небольшим кардинальным числом — пол, цвет и т.д. Если значений у колонки будет много, то объем ввода-вывода будет возрастать.
В СУБД семейства MS SQL Server возможность создания битовых индексов средствами диалекта SQL отсутствует.
В индексе с обращением ключа (reverse-key index) применяется обращение байтов индексируемой колонки числового типа. Этот прием позволяет получать равномерное распределение значений колонок среди блоков-листков индекса со структурой B-Tree, который хорошо подходит для индексирования колонок с последовательной нумерацией или нумерацией с заданным шагом. Заметим, что такие индексы применяются только для возвращения отдельных строк, и с их помощью нельзя выполнить поиск значений в некотором диапазоне. В СУБД Oracle нельзя применить опцию REVERSE к битовым индексам и к исключительно индексным таблицам.
В СУБД семейства MS SQL Server возможность создания индексов с обращением значения ключа средствами диалекта SQL отсутствует.
Если в предложении WHERE применяется функция по индексированной колонке, то обычно СУБД не используют этот индекс при организации доступа к строкам таблицы. Но при создании индекса на основе значения функции (function-based index), которая является той же функцией, что и в предложении WHERE, СУБД как семейства Oracle, так и семейства MS SQL Server использует такой индекс для считывания строк, удовлетворяющих критерию отбора.
В СУБД семейства MS SQL Server вычисляемые колонки могут иметь свойство PERSISTED. Это означает, что компонент Database Engine хранит вычисленные значения в таблице и обновляет их при обновлении любых колонок, от которых зависит вычисляемый столбец. Компонент Database Engine использует эти материализованные значения, когда создает индекс по колонке и когда запрос обращается к индексу.
Для индексации вычисляемой колонки она должна быть детерминированной и точной. Если используется свойство PERSISTED, список типов индексируемых вычисляемых колонок расширяется и включает следующие типы:
- вычисляемые столбцы, основанные на выражениях языка Transact-SQL, функциях CLR и методах пользовательских типов данных CLR, отмеченных пользователем как детерминированные;
- вычисляемые столбцы, основанные на выражениях, которые определены компонентом Database Engine как детерминированные, но не являются точными.
При наличии в БД такого индекса СУБД будет его использовать при обработке запроса описанного в данном примере.
В СУБД семейства MS SQL Server можно создавать и использовать фильтрованные индексы, для создания таких индексов в команде CREATE INDEX предусмотрена возможность использования предложения WHERE
.Применение предложения WHERE <filter_predicate> создает отфильтрованный индекс путем указания строк для включения в индекс. Отфильтрованный индекс должен быть некластеризованным индексом для таблицы. Также создается статистика фильтрации для строк данных отфильтрованного индекса.
Предикат фильтра использует простую логику сравнения и не может ссылаться на вычисляемый столбец, столбец определяемого пользователем типа, столбец пространственного типа данных или столбец типа hierarchyID. Сравнения с помощью литералов NULL с операторами сравнения недопустимы. Вместо этого используются операторы IS NULL и IS NOT NULL.
Фильтруемый индекс подходит для столбцов, имеющих точно определенные подмножества данных.
О некоторых параметрах проектирования индексов
При проектировании индексов необходимо иметь некоторый механизм для оценки качества предполагаемого индекса. Введем несколько понятий, с помощью которых можно грубо оценить качество потенциального индекса.
Кардинальностью колонки (cardinality) таблицы называется число дискретных различных значений колонки, которые встречаются в строках таблицы. Например, если в таблице "Служащий" (EMPLOYEE) мы заводим колонку для указания пола – "Пол" (SEX), то кардинальность этой колонки есть 2, так в природе у людей существует только два пола — мужской и женский. Для колонки первичного ключа кардинальность будет равна числу строк в таблице.
Причина, по которой кардинальность колонки важна для проектирования индексов, состоит в том, что кардинальность индексируемой колонки определяет число уникальных входов, которые должны сохраняться в индексе, т.е. число записей в индексе. Так, для индексируемой колонки "Пол" (SEX) будут существовать два уникальных входа, которые будут повторяться много раз в индексе. При предположении равновероятного распределения пола сотрудников на 100000 строк в таблице "Служащий" (EMPLOYEE) каждый вход индекса будет повторяться 50000 раз. СУБД вряд ли будут принимать решение об использовании такого индекса при построении плана запроса.
Определить кардинальность потенциальной колонки индексирования в существующей таблице БД достаточно просто.
SELECT COUNT (DISTINCT колонка) FROM таблица;
При проектировании новой БД для ХД следует оценить кардинальность всех потенциальных индексируемых колонок во всех таблицах физической модели данных ХД, исходя из имеющейся документации.
Хорошими кандидатами для индексирования обычно являются:
- колонки первичного ключа. По определению, колонки первичного ключа должны иметь уникальный индекс ;
колонки внешнего ключа. Они дают хороший индекс по двум причинам. Во-первых, они часто применяются для выполнения соединений с родительскими таблицами. Во-вторых, они могут быть использованы СУБД при поддержке ссылочной целостности в операциях удаления строк родительской и дочерних таблиц;
- любые колонки, которые содержат уникальные значения;
- колонки, запросы или соединения, которые используют от 5 до 10% строк таблицы;
- колонки, которые часто входят как аргументы в функции агрегирования;
- колонки, которые часто используются для проверки правильности ввода данных в программах ввода-редактирования.
Факторы, влияющие на низкую эффективность индексов:
таблицы маленького размера. Не следует создавать индексы для таблиц размером менее пяти физических страниц. Для таких страниц стоимость поддержки индекса больше, чем стоимость сканирования всей таблицы. Конечно, уникальный индекс требуется для первичного ключа и поддержки ссылочной целостности;
интенсивные обновления таблиц в пакетном режиме. Такие таблицы обычно имеют проблемы с переполнением индекса при интенсивной модификации таблицы. Если индекс необходим для такой таблицы, то целесообразнее его удалять перед обновлением и создавать после него;
асимметрия значений ключей (Skewness of keys). Если распределение значений ключа имеет значительную асимметрию, то кардинальность индекса может оказаться достаточно высокой и СУБД из-за низкого фактора селективности будет часто использовать этот индекс. Но результат применения индекса будет неудовлетворительным из-за того, что значительная часть строк таблицы имеет одно и то же значение ключа, что приведет к нивелированию стоимости использования индекса по сравнению со сканирование всей таблицы.
Плохими кандидатами для индексирования обычно являются:
колонки с низкой кардинальностью. Они дают высокий фактор селективности, и СУБД обычно избегает их использования при обработке запросов. Стоимость поддержки индекса для колонки с низкой кардинальностью сопоставима со стоимостью сканирования всей таблицы, поскольку при доступе через индекс многие страницы базой таблицы посещаются много раз;
колонка имеет много неопределенных значений (NULL-значения). В этом случае неопределенные значения могут дать значительную асимметрию распределения значений колонки, несмотря на то, что кардинальность колонки будет подходящей для использования индекса ;
колонки с часто изменяемыми значениями. Индекс для таких колонок часто обновляется, что приводит к его переполнению, поскольку в большинстве алгоритмов обработки B-Tree-индексов физическая страница индекса становится доступной для распределения данных только после того, как из нее будет удалена последняя запись. В частности, это обстоятельство приводит к созданию дополнительных страниц индекса и уровней индекса ;
значительная длина индексных колонок. Составной индекс или индекс для одной колонки с длиной более чем 50 байт будет приводить к росту числа уровней индекса, несмотря на то, что строк в таблице может быть немного. Большое число уровней снижает производительность операций выборки строк через индекс, т.к. каждый уровень требует по крайней мере одной операции ввода-вывода.
Следует соблюдать следующие общие правила при создании индексов.
- Там, где это возможно, использовать ограничение первичного ключа.
- Не следует создавать для таблицы несколько составных индексов, содержащих одни и те же колонки, но в другом порядке.
- Ни в коем случае нельзя допускать, чтобы у нескольких индексов для одной таблицы была одинаковая лидирующая часть.
К сожалению, часто проектировщики принимают крайне неудачные решения об индексировании. Это приводит к тому, что в ХД появляется слишком много индексов. В результате тратится много времени на поддержку этих индексов, дисковое пространство расходуется неэффективно, СУБД "путается" в выборе подходящего индекса или не использует их вовсе. Поэтому необходимо помнить о двух основных принципах построения индекса:
- гарантировать уникальность значений колонки, которая будет индексироваться;
- увеличить производительность обработки запросов в ХД. Это, кстати, единственная разумная причина для создания неуникальных индексов.

Рис. 1.2. Характеристика колонок для создания индексов
wiki.mvtom.ru
database - Что такое индекс базы данных?
Я написал полную книгу об этом! Он также доступен бесплатно в Интернете: http://use-the-index-luke.com/
Я постараюсь ответить на ваши вопросы в ближайшее время - это не совсем то, на что я способен. В последний раз, когда я пытался, я закончил писать книгу...
Как и таблицы, индексы состоят из строк и столбцов, но хранят данные логически отсортированным образом для улучшения эффективности поиска. Подумайте об этом, как о телефонной книге (напечатанной). Они обычно сортируются last_name, first_name и потенциально другие критерии (например, почтовый индекс). Эта сортировка позволяет быстро найти все записи для определенной фамилии. Если вы знаете и первое имя, вы даже можете быстро найти записи для комбинации фамилии/имени.
Если вы знаете только имя, телефонная книга вам действительно не поможет. То же самое верно для индексов базы данных с несколькими столбцами. Так что да, индекс может потенциально повысить эффективность поиска. Если у вас неправильный указатель для вашего вопроса (например, телефонная книга при поиске по имени), они могут оказаться бесполезными.
У вас может быть много индексов в одной и той же таблице, но в разных столбцах. Таким образом, индекс на last_name, first_name отличается от индекса только на first_name (который вам нужно будет оптимизировать поиск по имени).
Индексы содержат избыточные данные (например: кластерные индексы= телефонная книга). Они имеют ту же информацию, что и в таблице (например: функциональные индексы), но отсортированы. Эта избыточность автоматически поддерживается базой данных для каждой выполняемой вами операции записи (insert/update/delete). Следовательно, индексируется производительность уменьшить.
Кроме того, чтобы быстро найти данные, индексы можно также использовать для оптимизации операций сортировки (order by) и физически упорядочить связанные данные вместе ( clustering).
Чтобы получить более полное представление, просмотрите полное содержание моей книги: http://use-the-index-luke.com/sql/table-of-contents
qaru.site
- Почему папка на рабочем столе не открывается

- На диске с папка intel

- Ccleaner для windows 10 как пользоваться

- Pci express и pci разница

- Windows 10 fileunsigner

- Как изменить язык клавиатуры
- Не открываются свойства компьютера

- Локальные сети позволяют

- Linux mint отличия версий

- Elements browser как удалить windows 10

- Что делать если интернет сам отключается
