Как уменьшить использование журнала транзакций при удалении из массивной таблицы в SQL Server? Как очистить журнал транзакций в sql 2018
MS SQL очистка журнала транзакций — Soft Setup
В MS SQL очистка журнала транзакций необходима в том случае, если настроена полная модель восстановления базы данных. Если журнал транзакций переполнился, то ваша база данных откажется работать и будет выдавать ошибку: «журнал транзакций для базы данных заполнен». Почему такое происходит и как этого избежать? Рассмотрим два решения, которые помогут быстро устранить ошибку и продолжить работу с базой.
Увеличиваем размер журнала транзакций.
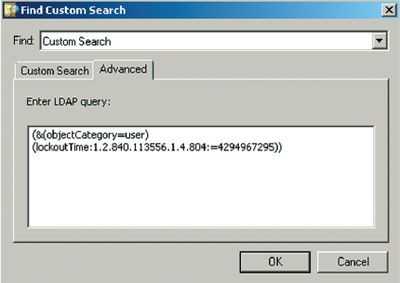
Запускаем SQL Server Management Studio, заходим в свойства базы и выбираем пункт [Файлы].
Для типа файла «Журнал» увеличиваем максимальный размера файла для авторасширения.
Сжимаем файл журнала транзакций.
Для сжатия журнала транзакций необходимо модель восстановления базы смнеить на простую, выполнить сжатие журнала, после чего модель восстановления переключить обратно на полную.
Запускаем SQL Server Management Studio, заходим в свойства базы и выбираем пункт [Параметры]. Модель восстановления выбираем «Простая» и нажимаем ОК.
Далее правой клавишей мышки по базе и выбираем из контекстного меню [Задачи] — [Сжать] — [Файлы]
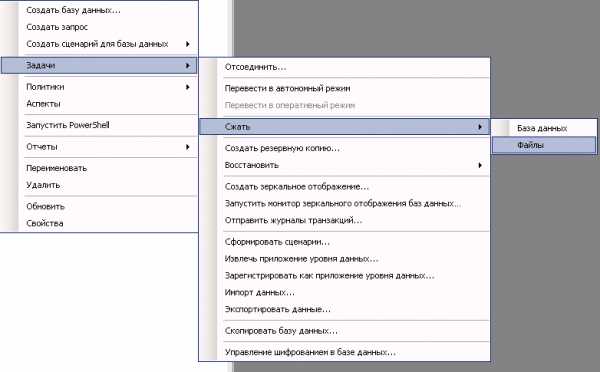
Тип сжатия: ЖурналОперация сжатия: Реорганизовать файлы, перед тем как освободить неиспользуемое местоИ указываем размер до которого необходимо сжать, например 0.
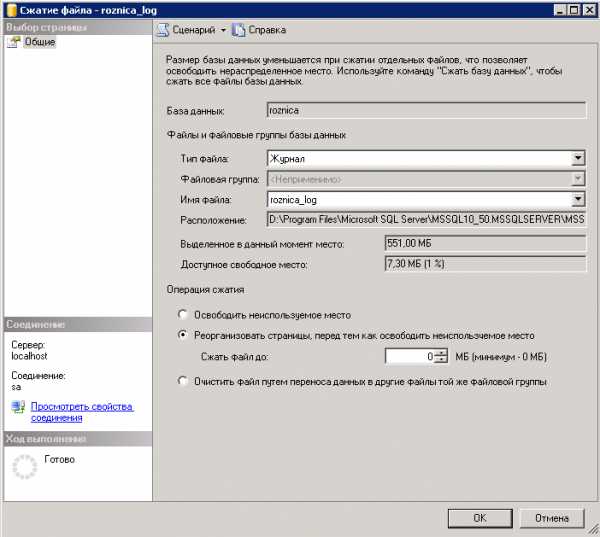
Теперь нужно вернуться в свойства базы к пункту [Параметры] и переключить модель восстановления на «Полная».
soft-setup.ru
Как уменьшить использование журнала транзакций при удалении из массивной таблицы в SQL Server?
Вместо подсчета количества строк все же удалить, вы должны либо использовать EXISTS (так как только он находит строку, он возвращает):
Или хитрее:
select top 1 * from sysobjects /* Force @@ROWCOUNT > 0 */ WHILE @@ROWCOUNT BEGIN DELETE TOP 10000 FROM BigTable FROM BigTable WHERE dtmtimestamp< DateAdd(month, -2,getdate()) CONTINUE ENDЕсли единственным поиском в таблице являются те, которые используются для фактических удалений.
Я также переместил логику даты, если столбец dtmtimestamp имеет полезный индекс.
Редактировать Конечно, как указывает Мартин, ни одно из этих протоколов использования журнала транзакций.
Стратегия ограничения удалений является разумной, чтобы остановить ужасающее использование журналов, но также необходимо иметь много резервных копий или обрезков журналов одновременно, чтобы разрешить повторное использование старого пространства журналов транзакций. В противном случае он все равно будет расти.
Если вы знаете, что резервное копирование журнала происходит, скажем, каждые пятнадцать минут, вы можете приостановить цикл каждые «n» итераций с задержкой WAITFOR, чтобы вы знали, что предыдущее использование журнала транзакций было скопировано/очищено. Что бы ни случилось, до тех пор, пока вы удаляете, а не усекаете, запись журнала для каждой удаленной строки по-прежнему будет занимать место в журнале или в резервной копии журнала.
Если вы можете использовать то, что обычно использует эту систему в автономном режиме, а объем строк, который вы хотите сохранить, значительно затмевается теми, которые вы хотите удалить, вы можете скопировать строки, чтобы сохранить их в другой таблице , удалить все внешние ключи, обрезать таблицу, скопировать сохраненные строки и перестроить внешние ключи. YMMV.
stackoverrun.com
Усечение журнала транзакций в MS SQL 2008
Итак, нам нужно усечь журнал транзакций в Microsoft SQL Server 2008. Привычная для администраторов предыдущих редакций опция "WITH TRUNCATE_ONLY" в директиве "BACKUP" больше не работает - она была изъята из SQL Server 2008.Итак, как же нам усечь файл транзакций?
1) Необходимо, чтобы тип резервного копирования базы данных был установлен в "Simple". Для этого:
1а) открываем SQL Management Studio, выбираем нашу базу данных, жмем на ней правой кнопкой мыши и выбираем "Properties" (Свойства).
1б) переходим на вкладку "Options" и меняем значение "Recovery model" на "Simple" (по-умолчанию стоит "Full").
2) Для усечения журнала транзакций выполняем T-SQL запрос:
2а) Жмем на "Database Engine Query" в SQL Management Studio (кнопка сверху).
2б) Вводим следующи запрос:
USE mydatabaseGODBCC SHRINKFILE (N'mydatabase_Log' , 1)GO
где вместо "mydatabase" подставьте имя своей базы данных, а вместо "mydatabase_Log" подставьте имя лог файла (журнала транзакций) для этой базы.
Имя лог файла можно узнать открыв Properties этой базы данных во вкладке "Files".
2в) Жмем на "Execute" - и вуаля - файл журнала транзакций усечен.
Что в остатке:
1) Файл журнала транзакций усечен и имеет небольшой размер.
2) Вам следует почитать про режимы "Recovery mode" - вот англоязычная ссылка на сайт Microsoft MSDN, где рассказывается - что Вы теряете и что приобретаете при применении типа "Simple":
http://msdn.microsoft.com/en-us/library/ms189275.aspx
От себя хочу сказать два слова (как я понял Microsoft):- Теряете: возможность восстановления базы данных из файла журнала транзакции в случае краха файла базы данных с точностью до последней незавершенной транзакции (по сути - до секунды/минуты).- Получаете: отсутствие непрерывно растущего файла журнала транзакций, который только растет, но не уменьшается, храня все и вся за все время жизни базы данных (как я понял)... Для базы, например, в 2Гб поитогу иметь журнал весом 10Гб, 20Гб, а то и 100Гб - ээээ... как бы не лучше ли почаще делать Full-backup Вашей базы?
Актуально для: MS SQL Server 2008
my-biz.com.ua
sql - Как уменьшить использование журнала транзакций при удалении из массивной таблицы в SQL Server?
Вместо того, чтобы подсчитывать количество строк, которые нужно удалить, вы должны либо использовать EXISTS (поэтому, как только он найдет строку, он возвращается):
WHILE EXISTS(SELECT * FROM BigTable WHERE DATEDIFF(month,dtmtimestamp, getdate()) > 2) BEGINИли sneakier:
select top 1 * from sysobjects /* Force @@ROWCOUNT > 0 */ WHILE @@ROWCOUNT BEGIN DELETE TOP 10000 FROM BigTable FROM BigTable WHERE dtmtimestamp< DateAdd(month, -2,getdate()) CONTINUE ENDЕсли единственным поиском в таблице являются те, которые используются для фактических удалений.
Я также перемещал логику даты, если столбец dtmtimestamp имеет полезный индекс.
Отредактируйте, конечно, как указывает Мартин, ни одно из этих сообщений об использовании журнала транзакций.
Стратегия ограничения удалений является разумной, чтобы остановить ужасающее использование журнала, но также необходимо иметь много резервных копий журнала или усечений, происходящих одновременно, чтобы разрешить повторное использование старого пространства журналов транзакций. В противном случае он по-прежнему будет расти.
Если вы знаете, что резервные копии журнала происходят, скажем, каждые пятнадцать минут, вы можете приостановить цикл каждые "n" итераций с задержкой WAITFOR, чтобы вы знали, что предыдущее использование журнала транзакций было скопировано/очищено. Что бы ни случилось, если вы удаляете, а не обрезаете, запись журнала для каждой удаленной строки по-прежнему будет занимать место в журнале или резервной копии журнала.
Если вы можете использовать все, что обычно используется в этой системе в автономном режиме, а объем строк, который вы хотите сохранить, значительно затмевается теми, которые нужно удалить, вы можете скопировать строки, чтобы сохранить их в другой таблице, удалить все внешние ключи, усечь таблицу, скопировать сохраненные строки и перестроить внешние ключи. YMMV.
qaru.site
Чтение журнала транзакций SQL Server
Журнал транзакций SQL Server содержит подробную информацию обо всех операциях, совершённых в базе данных. Этой информации достаточно, чтобы восстановить базу данных на определённый момент времени, повторно воспроизвести все операции над данными или отменить их. Но как просмотреть эту информацию, найти конкретную транзакцию в журнале, определить, что именно происходило в базе и откатить какие-нибудь изменения, например, восстановить случайно удалённые записи?
Разобраться в той информации, которая хранится в журнале транзакций или в резервной копии журнала транзакций не так просто.
Если открыть файл журнала транзакций *.LDF или файл резервной копии журнала *.TRN в любом двоичном редакторе, то информация, которую вы увидите, будет мало чем информативна. Ниже представлен фрагмент LDF-файла:
Функция fn_dbblog
fn_dblog – это недокументированная функция SQL Server, которая позволяет просматривать активную часть журнала транзакций в режиме реального времени.
Давайте посмотрим, как с ней работать:
- Выполните функцию fn_dblog Select * FROM sys.fn_dblog(NULL,NULL)
-
Из всего набора данных, который возвращает функция fn_dblog выведем только нужные транзакции.
-
Информация по вставленным или удалённым строкам храниться в столбцах – RowLog Contents 0, RowLog Contents 1, RowLog Contents 2, RowLog Contents 3, RowLog Contents 4, Description и Log Record
- Далее необходимо преобразовать двоичные данные в табличный вид с учётом типа данных столбцов таблицы. Следует отметить, что механизм преобразования различный для разных типов данных.
Функция возвращает 129 столбцов, поэтому желательно сузить результирующий набор по необходимым наборам полей и по возможности ограничить выборку только нужным типом транзакций
Например, выберем только транзакции на вставку строк в таблицу:
SELECT [Current LSN], Operation, Context, [Transaction ID], [Begin time] FROM sys.fn_dblog (NULL, NULL) WHERE operation IN ('LOP_INSERT_ROWS');Чтобы увидеть транзакции на удаление строк, выполните следующий скрипт:
SELECT [begin time], [rowlog contents 1], [Transaction Name], Operation FROM sys.fn_dblog (NULL, NULL) WHERE operation IN ('LOP_DELETE_ROWS');Для каждого типа транзакций используются разные столбцы, для того, чтобы получить нужную вам информацию вы должны точно знать какие столбцы используются для каких транзакций, а сделать это не просто, так, как официальной документации с описанием нет.
Вставленные и удаленные строки хранятся в шестнадцатеричных значениях. Для того, чтобы вытащить данные из этих значений вы должны знать формат хранения, понимать биты состояний, знать общее количество столбцов и так далее.
fn_dbLog замечательный бесплатный инструмент для чтения журнала транзакций, но эта функция имеет ряд ограничений – разобраться в данных достаточно сложно, т.к. среди прочей информации содержатся записи, связанные с системными таблицами, функция отображает только активную часть журнала и не отображает информацию по обновлению BLOB-значений.
Операция UPDATE при минимальном протоколировании журнала транзакций не содержит полное значение, которое было до и после изменений, а хранит только то, что изменилось (SQL Server может записать, что изменилось значение “G” на “D”, хотя в действительности изменилось слово “GLOAT” на “FLOAT”). В этом случаи вам потребуется вручную восстанавливать все промежуточные состояния записи на странице от первой её вставки до момента, который вас интересует.
При удалении BLOB-объектов сами объекты не записываются в журнал, а лишь фиксируется факт удаления. Для восстановления, удалённого BLOB-объекта вам необходимо найти в журнале пару для этого удаления, которой является ранее осуществлённая вставка, а она скорее всего уже не содержится в активной части журнала.
Функция fn_dump_dblog
fn_dump_dblog – это ещё одна недокументированная функция, которая позволяет просматривать журнал транзакций из резервной копии журнала транзакций, как сжатого, так и обычного.
- Ниже пример запуска функции fn_dump_dblog, обратите внимание, что необходимо указать все её 63 параметра
- Определить LSN (Log Sequence Number) для этой транзакции
- Преобразовать LSN в формат, который используется в конструкции WITH STOPBEFOREMARK = ‘<mark_name>’, например значение 00000070:00000011:0001 должно быть переведено в формат 112000000001700001
- Восстановите полную резервную копию БД и всю цепочку резервных копий журнала транзакций до нужной транзакции с помощью конструкции WITH STOPBEFOREMARK = ‘<mark_name>’ , где укажите идентификатор нужной транзакции. RESTORE LOG AdventureWorks2012 FROM DISK = N'E:\ApexSQL\backups\AW2012_05232013.trn' WITH STOPBEFOREMARK = 'lsn:112000000001700001', NORECOVERY;
Т.к. функция fn_dump_dblog возвращает так же, как и fn_dblog 129 столбцов, то желательно сократить этот набор полей
SELECT [Current LSN], Operation, Context, [Transaction ID], [transaction name], Description FROM fn_dump_dblog (NULL,NULL,N'DISK',1,N'E:\ApexSQL\backups\AdventureWorks2012_05222013.trn', DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT,DEFAULT, DEFAULT);Но вам потребуется опять расшифровать шестнадцатеричные значения, чтобы найти искомые записи
И вы опять получаете те же самые ограничения, что и при работе с функцией fn_dblog.
Для восстановления БД из копии журнала транзакций до определённого момента времени или до конкретной транзакции, вам необходимо:
DBCC PAGE
Ещё одна полезная команда DBCC PAGE, но также, как и две предыдущих функции –недокументированная. Она позволяет просматривать содержимое файлов MDF и LDF. Её синтаксис:
DBCC PAGE ( {'dbname' | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])Для просмотра содержимого первой страницы журнала транзакций БД AdventureWorks2012, необходимо выполнить:
SELECT FILE_ID ('AdventureWorks2012_Log') AS 'File ID' DBCC PAGE (AdventureWorks2012, 2, 0, 2)В качестве результата вы получите сообщение:
DBCC execution completed. If DBCC printed error messages, contact your system administrator.По умолчанию результат команды DBCC PAGE не выводится в SQL Server Management Studio и для её отображения первым шагом необходимо включить флаг трассировки 3604:
И теперь повторно выполните команду:
DBCC PAGE (AdventureWorks2012, 2, 0, 2)Вы увидите несколько ошибок и заголовок страницы, которые можно проигнорировать. Ниже вы получите шестнадцатеричное отображение LDF-файла:

Полученный результат ничем не отличается от того, который вы можете получить в любом hex-редакторе, а может быть даже и в менее наглядном виде. Главное отличие – это возможность просматривать файл в режиме реального времени, без отключения БД, но дружелюбным такой формат никак нельзя назвать.
Use ApexSQL Log
ApexSQL Log – это инструмент, который позволяет работать с журналом транзакций SQL Server в наглядном виде. Он позволяет просматривать текущий журнал транзакций в режиме реального времени, обращаться к резервным копиям журнала транзакций, как обычным, так и созданных в режиме компрессии. При этом приложение самостоятельно считывает данные из резервных копий БД, чтобы получить всю необходимую информацию для успешного восстановления. С помощью ApexSQL Log вы можете просматривать цепочки транзакций, которые произошли в вашей БД, даже те, которые были совершены до установки утилиты. В отличии от недокументированных и неподдерживаемых функций, рассмотренных выше, вы получите наглядную информацию о том, какие операции происходили над объектами, сможете увидеть старое и новое значение.
- Запустите ApexSQL Log
-
Подключитесь к базе данных, чей журнал транзакций вы хотите проанализировать
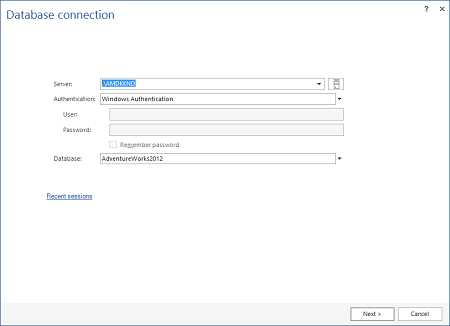
-
На шаге Select SQL logs to analyze, выберите записи, которые нужно прочитать. Убедитесь, что они образуют полную цепочку
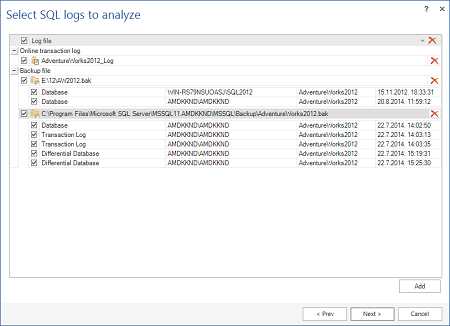
- Чтобы добавить резервные копии журнала транзакций и отдельные файлы LDF, используйте кнопку Add
-
Используйте фильтр на шаге Filter setup, чтобы уменьшить количество считываемых транзакций с помощью указания временного диапазона, типа операций, таблицы и другие фильтры
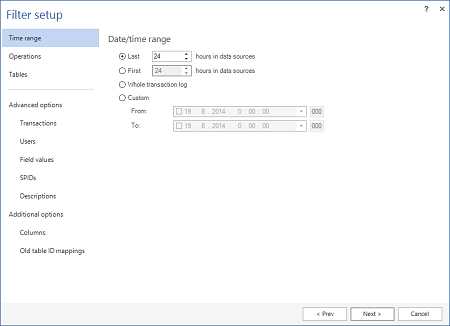
-
Нажмите Open
Полный результат можно будет увидеть в табличном виде
Вы сможете отследить, когда операция началась и когда закончилась, тип операции, схему и объект, над которым произошла операция, имя пользователя, совершившего эту операцию, а также имя компьютера и приложения из которого эта операция была совершена. Для операций обновления (UPDATE) вы сможете увидеть, как новое, так и старое значение.
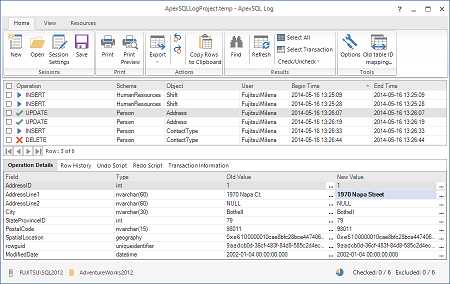
Чтобы избежать нечитаемых шестнадцатеричных значений, недокументированных функций, непонятного содержимого колонок, запросов со сложной конструкцией, сложных сценариев получения данных, неполных данных операций UPDATE, а также проблем с получением BLOB значений из журнала транзакций SQL Server, используйте программу ApexSQL Log. Она за вас выполнит все сложные операции и предоставит результат в читабельном виде. Кроме того, она позволит вам с помощью одного нажатия отменить или повторно выполнить нужную транзакцию.
Переводчик: Алексей Князев
November 20, 2015solutioncenter.apexsql.com
sql-server - Как уменьшить использование журнала транзакций SQL Server
У нас есть приложение, которое записывает журналы в таблицах Azure SQL. Структура таблицы следующая.
CREATE TABLE [dbo].[xyz_event_history] ( [event_history_id] [uniqueidentifier] NOT NULL, [event_date_time] [datetime] NOT NULL, [instance_id] [uniqueidentifier] NOT NULL, [scheduled_task_id] [int] NOT NULL, [scheduled_start_time] [datetime] NULL, [actual_start_time] [datetime] NULL, [actual_end_time] [datetime] NULL, [status] [int] NOT NULL, [log] [nvarchar](max) NULL, CONSTRAINT [PK__crg_scheduler_event_history] PRIMARY KEY NONCLUSTERED ( [event_history_id] ASC ) )Таблица хранится как кластеризованный индекс столбцом scheduled_task_id (не уникальным).
CREATE CLUSTERED INDEX [IDX__xyz_event_history__scheduled_task_id] ON [dbo].[xyz_event_history] ( [scheduled_task_id] ASC )event_history_id, сгенерированный приложением, является случайным (не последовательным) GUID. Приложение создает, обновляет и удаляет старые объекты из таблицы. Столбец log обычно содержит 2-10 КБ данных, но в некоторых случаях он может вырасти до 5-10 МБ. К элементам обычно обращаются PK (event_history_id), а наиболее частый порядок сортировки - event_date_time desc.
Проблема, которую мы видим после того, как мы снизили уровень производительности для Azure SQL до "S3" (100 DTU), пересекает ограничения скорости транзакций. Это можно четко увидеть в таблице sys.dm_exec_requests - будут записи с типом ожидания LOG_RATE_GOVERNOR (msdn).
Происходит, когда DB ожидает, что квота будет записываться в журнал.
Операции, которые я заметил, которые оказывают большое влияние на скорость регистрации, - это удаления из xyz_event_history и обновления в столбце log. Обновления сделаны следующим образом.
UPDATE xyz_event_history SET [log] = COALESCE([log], '') + @log_to_append WHERE event_history_id = @idМодель восстановления баз данных Azure SQL FULL и не может быть изменена.
Вот статистика физического индекса - есть много страниц, которые пересекаются с пределом 8K на строку.
TableName AllocUnitTp PgCt AvgPgSpcUsed RcdCt MinRcdSz MaxRcdSz xyz_event_history IN_ROW_DATA 4145 47.6372868791698 43771 102 7864 xyz_event_history IN_ROW_DATA 59 18.1995058067705 4145 11 19 xyz_event_history IN_ROW_DATA 4 3.75277983691623 59 11 19 xyz_event_history IN_ROW_DATA 1 0.914257474672597 4 11 19 xyz_event_history LOB_DATA 168191 97.592290585619 169479 38 8068 xyz_event_history IN_ROW_DATA 7062 3.65090190264393 43771 38 46 xyz_event_history IN_ROW_DATA 99 22.0080800593032 7062 23 23 xyz_event_history IN_ROW_DATA 1 30.5534964170991 99 23 23 xyz_event_history IN_ROW_DATA 2339 9.15620212503089 43771 16 38 xyz_event_history IN_ROW_DATA 96 8.70488015814184 2339 27 27 xyz_event_history IN_ROW_DATA 1 34.3711391153941 96 27 27 xyz_event_history IN_ROW_DATA 1054 26.5034840622683 43771 28 50 xyz_event_history IN_ROW_DATA 139 3.81632073140598 1054 39 39 xyz_event_history IN_ROW_DATA 1 70.3854707190511 139 39 39- Есть ли способ сократить использование журнала транзакций?
- Как SQL Server регистрирует транзакции, как в примере выше? Это просто "старое" плюс "новое" значение? (что, вероятно, сделало бы добавление небольших фрагментов данных, которые зачастую были бы весьма неэффективными с точки зрения размера журнала транзакций).
ОБНОВЛЕНИЕ (20 апреля): Я провел несколько экспериментов с предложениями в ответах и был впечатлен различием, которое делает INSERT вместо UPDATE.
В соответствии с следующей статьей msdn о внутренних журналах транзакций SQL Server (https://technet.microsoft.com/en-us/library/jj835093(v=sql.110).aspx):
Записи журнала для модификаций данных записывают либо логическую операцию или они записывают изображения до и после модифицированных данные. Перед изображением - копия данных до начала операции. выполнено; последующее изображение является копией данных после операции была выполнена.
Это автоматически делает сценарий с UPDATE ... SET X = X + 'more' крайне неэффективным с точки зрения использования журнала транзакций - для этого требуется "до захвата изображения".
Я создал простой тестовый набор, чтобы протестировать оригинальный способ добавления данных в столбец "log" в сравнении с тем, как мы просто вставляем новую часть данных в новую таблицу. Результаты, которые я получил довольно удивительно (не для меня, не слишком опытный парень SQL Server).
Тест прост: 5'000 раз добавить 1'024 символа длинной части журнала - всего 5 МБ текста в результате (не так уж плохо, как можно было бы подумать).
FULL recovery mode, SQL Server 2014, Windows 10, SSD UPDATE INSERT Duration 07:48 (!) 00:02 Data file grow ~8MB ~8MB Tran. Log grow ~218MB (!) 0MB (why?!) 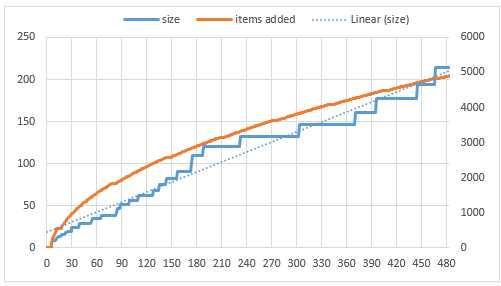
Всего 5000 обновлений, которые добавляют 1 Кбайт данных, могут отключать SQL Server в течение 8 минут (wow!). Я этого не ожидал!
Я думаю, что исходный вопрос разрешен на этом этапе, но следующие подняты:
- Почему транзакционный журнал растет, выглядит линейно (не квадратично, как мы можем ожидать, когда просто захватываем изображения "до" и "после" )? Из диаграммы видно, что количество элементов в секунду растет пропорционально на квадратный корень - это, как ожидалось, если накладные расходы растут линейно с количеством вставленных элементов.
- Почему в случае, если журнал транзакций вставки имеет тот же размер, что и перед любыми вставками? Я просмотрел журнал транзакций (с Dell Toad) для случая со вставками и выглядит как только последние 297 элементов находятся там - предположительно журнал транзакций был усечен, но почему, если он FULL режим восстановления?
ОБНОВЛЕНИЕ (21 апреля). DBCC LOGINFO вывод для случая с INSERT - до и после. Физический размер файла журнала соответствует выходу - ровно 1 048 576 байт на диске. Почему он выглядит, как журнал транзакций остается неподвижным?
RecoveryUnitId FileId FileSize StartOffset FSeqNo Status Parity CreateLSN 0 2 253952 8192 131161 0 64 0 0 2 253952 262144 131162 2 64 0 0 2 253952 516096 131159 0 128 0 0 2 278528 770048 131160 0 128 0 RecoveryUnitId FileId FileSize StartOffset FSeqNo Status Parity CreateLSN 0 2 253952 8192 131221 0 128 0 0 2 253952 262144 131222 0 128 0 0 2 253952 516096 131223 2 128 0 0 2 278528 770048 131224 2 128 0Для тех, кто заинтересован, я записал действия "sqlserv.exe", используя Process Monitor - я вижу, что файл перезаписывается снова и снова - похоже, что SQL Server обрабатывает старые записи журналов, поскольку по какой-то причине больше не требуется: https://dl.dropboxusercontent.com/u/1323651/stackoverflow-sql-server-transaction-log.pml.
ОБНОВЛЕНИЕ (24 апреля).Кажется, я наконец начал понимать, что там происходит, и хочу поделиться с вами. Вышеприведенное рассуждение верно в целом, но имеет серьезные оговорки, что также приводило к путанице в отношении странного использования журнала транзакций с помощью INSERT s.
База данных будет вести себя как в режиме восстановления SIMPLE до тех пор, пока не будет полностью заполнен выполняется резервное копирование (даже если оно находится в режиме восстановления FULL).
Мы можем рассматривать числа и диаграмму выше как действительные для режима восстановления SIMPLE, и мне нужно повторить измерение для реального FULL - они еще более поражают.
UPDATE INSERT Duration 13:20 (!) 00:02 Data file grow 8MB 11MB Tran. log grow 55.2GB (!) 14MB 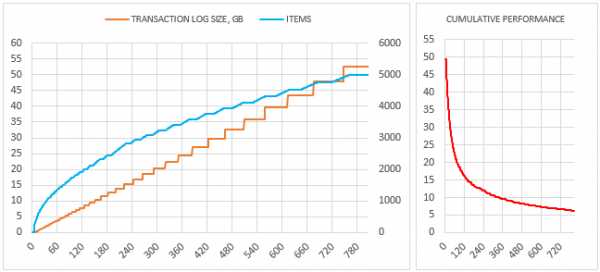
qaru.site