Microsoft SQL Server. Ms sql это
SQL - это... Что такое T-SQL?
Transact-SQL (T-SQL) — расширение языка Microsoft (для Microsoft SQL Server) и
Для того, чтобы сделать язык мощнее, SQL был расширен такими дополнительными возможностями как:
- управляющие операторы
- локальные переменные
- различные дополнительные функции (для обработки строк, дат, математические и др.)
- поддержка аутентификации Microsoft Windows
Управляющие операторы
Для управления потоком исполнения в Transact-SQL используются следующие операторы: BEGIN и END, BREAK, CONTINUE, GOTO, IF и ELSE, RETURN, WAITFOR и WHILE.
Переменные
Локальные переменные
Для объявления локальной переменной заданного типа используется ключевое слово DECLARE. При объявлении все переменные инициализируются значением NULL. Чтобы присвоить переменной значение, нужно использовать ключевое слово SET.
Следующий скрипт объявляет переменную целого типа, задаёт ей значение и выполняет цикл используя её в качестве счётчика.
Также переменная может быть инициализирована результатом запроса:
DECLARE @UserName NVARCHAR(100) SELECT @UserName = UserName FROM UsersПосле исполнения данного скрипта значение переменной @UserName равно значению соответствующего поля последней выбранной записи. При этом, если запрос не вернёт ни одной записи, значение переменной, в отличие от оператора SET, не изменится.
Глобальные переменные
SQL Server имеет ряд предопределённых глобальных переменных (global variables), которые предназначены для получения информации о состоянии сервера, базы данных или текущего подключения. В отличие от локальных переменных их значение нельзя менять. Название глобальных переменных начинается с двух символов "@".
Примеры глобальных переменных:
- @@ERROR - возвращает номер ошибки последней выполненной команды
- @@ROWCOUNT - возвращает количество строк обработанное последней командой (SELECT, INSERT, DELETE, UPDATE)
- @@SERVERNAME - название сервера
- @@VERSION - версия SQL Server
Табличные переменные
Табличные переменные (англ. table variables) появились в 2000-й версии SQL Server. Предназначены для временного хранения наборов данных для последующей обработки. К табличным переменным можно применять стандартные команды
Например
DECLARE @UserNames TABLE ( LastName VARCHAR(50) NOT NULL, FirstName VARCHAR(50) NOT NULL, BirthDay DATETIME ) INSERT INTO @UserNames (LastName, FirstName, BirthDay) VALUES ('Иванов', 'Иван', '1977-04-27') INSERT INTO @UserNames (LastName, FirstName) VALUES ('Петрович', 'Пётр')этот фрагмент кода объявляет табличную переменную @UserNames и вставляет в неё две записи.
Литература
- Майк Гандерлой, Джозеф Джорден, Дейвид Чанц Часть II. Язык программирования Transact-SQL // Освоение Microsoft SQL Server 2005 = Mastering Microsoft SQL Server 2005. — М.: «Диалектика», 2007. — С. 139-280. — ISBN 0-7821-4380-6
Wikimedia Foundation. 2010.
dic.academic.ru
SQL - это... Что такое Transact-SQL?
Transact-SQL (T-SQL) — процедурное расширение языка SQL компанией Microsoft (для Microsoft SQL Server) и Sybase (для Sybase ASE).
SQL был расширен такими дополнительными возможностями как:
- управляющие операторы,
- локальные и глобальные переменные,
- различные дополнительные функции для обработки строк, дат, математики и т. п.,
- поддержка аутентификации Microsoft Windows
Язык Transact-SQL является ключом к использованию MS SQL Server. Все приложения, взаимодействующие с экземпляром MS SQL Server, независимо от их реализации и пользовательского интерфейса, отправляют серверу инструкции Transact-SQL.
Элементы синтаксиса
Директивы сценария
Директивы сценария — это специфические команды, которые используются только в MS SQL. Эти команды помогают серверу определять правила работы со скриптом и транзакциями. Типичные представители: GO — информирует программы SQL Server об окончании пакета инструкций Transact-SQL, EXEC (или EXECUTE) — выполняет процедуру или скалярную функцию.
Комментарии
Комментарии используются для создания пояснений для блоков сценариев, а также для временного отключения команд при отладке скрипта. Комментарии бывают как строковыми, так и блоковыми:
-- — строковый комментарий исключает из выполнения только одну строку, перед которой стоят два минуса.
/* */ — блоковый комментарий исключает из выполнения целый блок команд, заключенный в указанную конструкцию.
Типы данных
Как и в языках программирования, в SQL существуют различные типы данных для хранения переменных:
- Числа — для хранения числовых переменных (bit, int, tinyint, smallint, bigint, numeric, decimal, money, smallmoney, float, real).
- Даты — для хранения даты и времени (datetime, smalldatetime).
- Символы — для хранения символьных данных (char, nchar, varchar, nvarchar).
- Двоичные — для хранения бинарных данных (binary, varbinary).
- Большеобъемные — типы данных для хранения больших бинарных данных (text, ntext, image).
- Специальные — указатели (cursor), 16-байтовое шестнадцатеричное число, которое используется для GUID (uniqueidentifier), штамп изменения строки (timestamp), версия строки (rowversion), таблицы (table).
Примечание. Для использования русских символов (не ASCII кодировки) используются типы данных с приставкой «n» (nchar, nvarchar, ntext), которые кодируют символы двумя байтами. Иначе говоря, для работы с Unicode используются типы данных с «n» (от слова national).
Примечание. Для данных переменной длины используются типы данных с приставкой «var». Типы данных без приставки «var» имеют фиксированную длину области памяти, неиспользованная часть которой заполняется пробелами или нулями.
Идентификаторы
Идентификаторы — это специальные символы, которые используются с переменными для идентифицирования их типа или для группировки слов в переменную. Типы идентификаторов:
- @ — идентификатор локальной переменной (пользовательской).
- @@ — идентификатор глобальной переменной (встроенной).
- # — идентификатор локальной таблицы или процедуры.
- ## — идентификатор глобальной таблицы или процедуры.
- [ ] — идентификатор группировки слов в переменную.
Переменные
Переменные используются в сценариях и для хранения временных данных. Чтобы работать с переменной, ее нужно объявить, притом объявление должно быть осуществлено в той транзакции, в которой выполняется команда, использующая эту переменную. Иначе говоря, после завершения транзакции, то есть после команды GO, переменная уничтожается.
Объявление переменной выполняется командой DECLARE, задание значения переменной осуществляется либо командой SET, либо SELECT:
USE TestDatabase -- Объявление переменных DECLARE @EmpID int, @EmpName varchar(40) -- Задание значения переменной @EmpID SET @EmpID = 1 -- Задание значения переменной @EmpName SELECT @EmpName = UserName FROM Users WHERE UserID = @EmpID -- Вывод переменной @EmpName в результат запроса SELECT @EmpName AS [Employee Name] GOПримечание. В этом примере используется группировка слов в переменную — конструкция [Employee Name] воспринимается как одна переменная, так как слова заключены в квадратные скобки.
Операторы
Операторы — это специальные команды, предназначенные для выполнения простых операций над переменными:
- Арифметические операторы: «*» — умножить, «/» — делить, «%» — остаток от деления, «+» — сложить, «-» — вычесть, «()» — скобки.
- Операторы сравнения: «=» — равно, «>» — больше, «<» — меньше, «>=» — больше или равно, «<=» меньше или равно, «<>» («!=») — не равно.
- Операторы соединения: «+» — соединение (конкатенация) строк.
- Логические операторы: «AND» — и, «OR» — или, «NOT» — не.
- Операторы со множествами: «IN»
Cистемные функции
Спецификация Transact-SQL значительно расширяет стандартные возможности SQL благодаря встроенным функциям:
- Агрегативные функции — функции, которые работают с коллекциями значений и выдают одно значение. Типичные представители: AVG — среднее значение колонки, SUM — сумма колонки, MAX — максимальное значение колонки, COUNT — количество элементов колонки.
- Скалярные функции — это функции, которые возвращают одно значение, работая со скалярными данными или вообще без входных данных. Типичные представители: DATEDIFF — разница между датами, ABS — модуль числа, DB_NAME — имя базы данных, USER_NAME — имя текущего пользователя, LEFT — часть строки слева.
- Функции-указатели — функции, которые используются как ссылки на другие данные. Типичные представители: OPENXML — указатель на источник данных в виде XML-структуры, OPENQUERY — указатель на источник данных в виде другого запроса.
Примечание. Полный список функций можно найти в справке к SQL серверу.
Примечание. К скалярным функциям можно также отнести и глобальные переменные, которые в тексте сценария вызываются двойной собакой «@@».
Пример:
USE TestDatabase -- Использование агрегативной функции для подсчета средней зарплаты SELECT AVG(BaseSalary) AS [Average salary] FROM Positions GO -- Использование скалярной функции для получения имени базы данных SELECT DB_NAME() AS [Database name] GO -- Использование скалярной функции для получения имени текущего пользователя DECLARE @MyUser char(30) SET @MyUser = USER_NAME() SELECT 'The current user''s database username is: '+ @MyUser GO -- Использование функции-указателя для получения данных с другого сервера SELECT * FROM OPENQUERY(OracleSvr, 'SELECT name, id FROM owner.titles') GOВыражения
Выражение — это комбинация символов и операторов, которая получает на вход скалярную величину, а на выходе дает другую величину или исполняет какое-то действие. В Transact-SQL выражения делятся на 3 типа: DDL, DCL и DML.
- DDL (Data Definition Language) — используются для создания объектов в базе данных. Основные представители данного класса: CREATE — создание объектов, ALTER — изменение объектов, DROP — удаление объектов.
- DCL (Data Control Language) — предназначены для назначения прав на объекты базы данных. Основные представители данного класса: GRANT — разрешение на объект, DENY — запрет на объект, REVOKE — отмена разрешений и запретов на объект.
- DML (Data Manipulation Language) — используются для запросов и изменения данных. Основные представители данного класса: SELECT — выборка данных, INSERT — вставка данных, UPDATE — изменение данных, DELETE — удаление данных.
Пример:
USE TestDatabase -- Использование DDL CREATE TABLE TempUsers (UserID int, UserName nvarchar(40), DepartmentID int) GO -- Использование DCL GRANT SELECT ON Users TO public GO -- Использование DML SELECT UserID, UserName + ' ' + UserSurname AS [User Full Name] FROM Users GO -- Использование DDL DROP TABLE TempUsers GOУправление выполнением сценария
В Transact-SQL существуют специальные команды, которые позволяют управлять потоком выполнения сценария, прерывая его или направляя в нужную логику.
- Блок группировки — структура, объединяющая список выражений в один логический блок (BEGIN … END).
- Блок условия — структура, проверяющая выполнения определенного условия (IF … ELSE).
- Блок цикла — структура, организующая повторение выполнения логического блока (WHILE … BREAK … CONTINUE).
- Переход — команда, выполняющая переход потока выполнения сценария на указанную метку (GOTO).
- Задержка — команда, задерживающая выполнение сценария (WAITFOR)
- Вызов ошибки — команда, генерирующая ошибку выполнения сценария (RAISERROR)
Литература
Microsoft SQL Server Компании-разработчики Основные Сокращённые Мобильные Специализированные Службы Утилиты Расширения SQL Дополнительно| 1.0 • 1.1 • 1.11 • 4.2 • 4.21 • 4.21a • 6.0 • 6.5 • 7.0 • 2000 • 2005 • 2008 • 2008 R2 • 2012 |
| 2005 Mobile Edition • 2005 Compact Edition • Compact 3.5 • Compact 4.0 |
dic.academic.ru
Библиотека Microsoft SQL Server
Эта документация перемещена в архив и не поддерживается.
Microsoft® SQL Server™ — это система анализа и управления реляционными базами данных в решениях электронной коммерции, производственных отраслей и хранилищ данных. В этом разделе можно найти информацию о нескольких версиях SQL Server. Кроме того, здесь представлены статьи о проектировании баз данных и приложений для работы с ними, а также примеры использования SQL Server.
В Microsoft SQL Server 2014 еще более улучшены критически важные возможности, представляемые в более ранней версии, за счет предоставления рекордной производительности, доступности и удобства управления для ваших критически важных приложений. SQL Server 2014 представляет новые функциональные средства работы в оперативной памяти, встроенные в основную базу данных для операций OLTP и хранения данных, которые дополняют существующие технологии хранилищ данных в оперативной памяти и функциональные возможности бизнес-аналитики для создания наиболее разностороннего решения по эксплуатации средств баз данных в оперативной памяти на рынке.
SQL Server 2014 также предоставляет новые решения для аварийного восстановления, резервного копирования и гибридной архитектуры в Windows Azure, позволяя клиентам использовать существующие навыки работы с локальными функциями, опирающимися на возможности глобальных центров обработки данных Microsoft. Кроме того, в SQL Server 2014 используются новые возможности Windows Server 2012 и Windows Server 2012 R2, дающие несравненную масштабируемость для приложений баз данных в физических и виртуальных средах.
| Посетите SQL Server Developer Center (центр разработчиков SQL Server) Последние сведения для разработчиков относительно SQL Server и связанных тем, включая новые технические статьи и загрузки, ссылки на документацию по продукту, сообщества, ресурсы поддержки и т. д. | |
| Посетите технический центр SQL Server Новейшая техническая информация о SQL Server для ИТ-специалистов, включая новые технические статьи и загрузки, ссылки на документацию по продукту, сообщества, ресурсы поддержки и т. д. |
msdn.microsoft.com
Новые возможности MS SQL Server 2014
Реляционные базы данных, структурированные по определенному алгоритму позволяют оперативно управлять и контролировать большинство процессов информационных системах по всему миру. Компания Microsoft разрабатывает решения для работы с базами данных с 1988 года. Первая версия СУБД MS SQL Server 1.0 появилась 29 апреля 1989 года.
С разной периодичностью корпорация Microsoft модернизировала SQL Server, были представлены версии 7.0, 2000, 2005, 2008 и 2008 R2. Начиная с версии MS SQL Server 2012 появились новые фичи, которые значительно облегчили работу с базами данных, модернизировали бизнес процессы. В последних версиях SQL Server появились удобные инструменты, как Business Intelligence (BI), для бизнес-аналитики, появились обновленные, усовершенствованные инструменты Management Studio, в том числе средства для работы с облачной средой SQL Azure. Все инновации были включены в новый релиз MS SQL Server 2014. О новых возможностях MS SQL Server 2014, удобстве ежедневной работы, упрощенных процедурах синхронизации, распределения нагрузки и повышения надежности рассказал программист, аналитик компании Softpoint, Александр Денисов.
— Здравствуйте Александр, спасибо, что уделили время.
Здравствуйте.
— Расскажите, какие предпосылки развития ИТ, для появления MS SQL Server 2014?
Главная предпосылка, главная инновация, которая появилась именно в SQL Server 2014, это решение проблемы производительности OLTP, систем обработки онлайн транзакций. Дело в том, что последние, пожалуй, лет 20, основной упор в развитии SQL систем был сделан на то чтобы быстро извлечь данные, сделать какие-либо отчеты, перекомпоновать данные и получить что-то интересное. Сейчас понятно, что данные мы можем извлекать достаточно быстро, а вот в процессе большого информационного потока могут возникать проблемы.
Ну и, собственно, главная инновация в SQL Server 2014 – это специальный новый движок, который позволяет оперативно обслуживать массивные потоки ввода информации. Это сотни операторов или большое кол-во подключений с сайтов: интернет-магазины, ритейл-розница, склады и т.п. Наконец-то, высоконагруженные информационные системы получили поддержку. Тут надо отметить, что выигрыш от внедрения In-Memory OLTP начинается в базах данных объёмом от 200 Гб. Если база меньше 200 Гб, то у вас, скорее всего, нет таких объемов, ради которых была бы целесообразна миграция на новый движок.
"In-Memory OLTP – система обработки онлайн транзакций. Работа с данными происходит исключительно в оперативной памяти сервера."— Если проецировать на кол-во пользователей или обращений, проведенных документов?
Конечно, объем — это скорее косвенная величина. В первую очередь стоит ориентироваться на информационный поток. То есть мы сейчас можем начать работу с базой 10Гб, а через месяц она вырастет до 50Гб. Формально мы не попадаем под критерии, но, анализируя, мы понимаем, что это именно тот случай, когда необходимо внедрять эти технологии, так как информационный поток значительно увеличивается в достаточно короткий промежуток времени. Грубо говоря, от 150-200 пользователей, одновременно активно работающих с базой именно на ввод документа. Понятно, что пользователь пользователю рознь. Кто-то активно заносит в базу первичную бухгалтерию, а кто-то выгружает какие-то тяжелые отчеты. То есть, один аналитик с запросом тяжелого отчета сопоставим примерно с десятком простых операторов, потому что у него запросы значительно объемней, тяжелее.
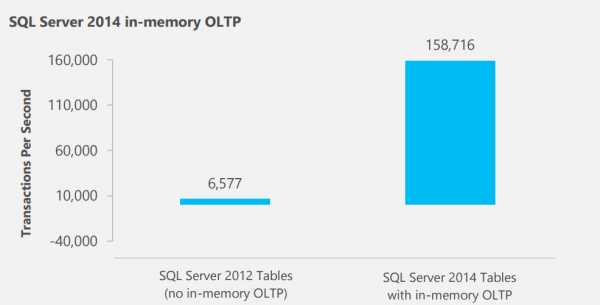 По данным Microsoft (www.microsoft.com/ru-ru)
По данным Microsoft (www.microsoft.com/ru-ru) — Какие ключевые отличия MS SQL Server 2014 от более ранних версий?
Самая главная ключевая технология — это новый движок. То, что раньше, в Community Preview называлось Hekaton. Сейчас этот движок просто называется In-Memory OLTP, то есть система обработки онлайн транзакций. Работа с данными при этом происходит полностью в оперативной памяти. Это совершенно новый движок обработки данных, который сфокусирован на том, что все данные хранятся исключительно в оперативной памяти. Естественно, все это рассчитано на серьезные системы, которые работают 24/7 и практически никогда не выключаются. Серверы работают постоянно. Как только сервер выключается, например, происходит внештатная ситуация — сразу возникает проблема потерянного времени, так как требуется заново развернуть и подготовить систему. Соответственно, такой долгий запуск делает технологию неприменимой к системам, которые, грубо говоря, включаются в 8 утра, когда первый бухгалтер приходит. Этот новый движок оптимизирован именно на быстрое получение данных, на быструю обработку и быструю выдачу, то есть сфокусирован на том, что данные практически не записываются на жесткий диск, а хранятся в оперативной памяти, из этого следуют новые приемы работы, новые принципы, которые отличаются от того, что было раньше, от того к чему привыкли программисты.
— объем оперативной памяти должен быть больше?
Естественно, нужно исходить из того, что все эти оперативные данные с которыми система собирается работать, должны помещаться в оперативной памяти. То есть, недавно был подход такой: хранить данные на жестком диске, прочитать быстро маленькую порцию, которая нужна для оперативной работы, обработать её в оперативной памяти и отправить обратно на жесткий диск. Оперативная память была «маленьким окном» для тех данных, которые предоставляются прямо сейчас. В новой версии «оперативка» считается основным хранилищем информации, все данные In-Memory OLTP хранятся именно в оперативной памяти. Также нужно исходить из того, а какая у нас таблица 2, 4, 10 ГБ? Она вся должна там помещаться. При этом мы говорим только про одну таблицу, оптимизированную для работы в памяти, и надо не забывать, что старые таблицы — это почти 90% всего объема, на работу которых тоже нужно заложить объем оперативной памяти.
— какие должны быть характеристики оперативной памяти, кэш, частота?
Обычная серверная оперативная память. То есть для серверов это уже давно все придумано, оперативка с контролем ошибок, увеличенная скорость. В принципе, если есть какие-то проблемы, система не успевает, можно подумать об ускоренной оперативке, но обычной серверной оперативной памяти должно хватить.
— Какая взаимосвязь работы с приложениями, какие новые возможности открываются с SQL Server 2014?
На самом деле с точки зрения механизмов анализа данных (Analysis Servises и Business Intelligence) мало что поменялось. В SQL Server уже давно есть удобные возможности интеграции с тем же MS Office.
"Business Intelligence – сокращенно BI. Инструмент для перевода в удобную, понятную форму неструктурированных данных, информации для аналитики бизнес процессов. Метод позволяет определить важные факторы эффективности работы, прогнозировать результат разных путей развития."Из новых возможностей можно отметить инструменты для работы с многомерными массивами данных (OLAP-кубы) с помощью внешних средств. Правда, под внешними средствами тут понимаются исключительно публикации на портале SharePoint. Для владельцев таких порталов это действительно очень интересная возможность — можно формировать сложные отчеты прямо из браузера.
— Какие выгоды для OLTP систем с установкой MS SQL Server 2014?
Самые главные выгоды заключаются в наличии движка In-Memory OLTP, системы обработки записи в оперативной памяти. Главное, тут нужно учитывать тот факт, что потребуется изменить, переписать часть кода приложения, которое работает с базой данных. То есть новые объекты требуют другого подхода к работе, другого подхода к записи. Например, нет понятия блокировки, совсем другая обработка ошибок, но если все это сделать, что не так сложно, как звучит, то ускорение в работе может быть значительное. У Microsoft на стендах это было до 100 раз, я лично на тестах наблюдал ускорение раз в 20, по сравнению с работой обычных баз, обычных таблиц. То есть, какие-то критичные задачи стоят того, чтобы перенести на движок MS SQL Server 2014, использовать новые технологии, и отдача будет заметная.
— если рассматривать рост производительности на примере популярной платформы 1С?
Сейчас нет. Как я уже говорил, нужна поддержка со стороны прикладного приложения, а когда будет такая поддержка в 1С информации нет. Все-таки 1С обеспечивает работу одновременно с несколькими движками СУБД, необходимо поддерживать какую-то совместимость, переносимость прикладного кода.
С другой стороны, в платформе 1С есть такой объект как «внешний источник данных»: можно попробовать связать In-Memory таблицу с этим объектом, переписать логику работы с внешним источником, заполнение, перезаполнение… В принципе, это сложно, но возможно, правда на практике я таких решений еще не видел. При этом выигрыш обещает быть существенным. Какие-то критичные вещи, как остатки склада или какие-то данные, которые изменяются оперативно, можно перенести на новый движок.
— изменения кода приложения типичные или индивидуальные?
Изменяется сам принцип работы с базой данных. Компания Microsoft подробно рассказывает, что и где поменялось. Другое дело, что для поддержки со стороны 1С нужно изменять логику, которая спрятана «под капотом»: у программиста 1С нет настолько низкоуровневого доступа в механизмы платформы. Остаются альтернативные средства. Можно установить таблицу в виде внешнего источника данных без озвученных выше ограничений, который подключаются, как сторонние объекты. Так с этим сторонним объектом можно делать все необходимое.
— Какая процедура установки SQL Server 2014 с нуля?
Владельцам старых версий SQL Server следует учесть, что невозможна одновременная работа SQL Server 2014 и SQL Server 2005 на одном сервере. В первую очередь это коснется каких-то тестовых серверов, я не могу представить ситуацию, когда для рабочих бизнес-систем СУБД не разнесены по разным серверам.
В остальном никаких сложностей нет. Достаточно удобный мастер установки, перед установкой проверяет все характеристики системы, если нужна установка каких-либо библиотек дополнительно, то мастер определяет и устанавливает их. В принципе, в обычных условиях все сводится к многократному нажатию кнопки «далее». Также можно вспомнить стандартные рекомендации, если у вас высоконагруженная система, то скорее всего вы уже все это знаете. Обозначу, что файлы данных, файлы логов транзакций и файл Temp-DB лучше разносить по разным дискам, то есть максимально распараллелить работу с дисковой подсистемой.
"Temp-DB - системная база данных, глобальный ресурс, доступный всем пользователям, подключенным к данному SQL Server."— Есть ли особенности при обновлении Server 2014 с 2012\2008\2005, что лучше и какие выгоды?
Если обновлять с 2005, то могут потребоваться доработки. Дело в том, что MS SQL Server поддерживает совместимость только на 2 резиза назад. Для SQL 2014 это означает, что без проблем запустятся базы с SQL 2012 и SQL 2008 (в том числе и 2008 R2). В вот с SQL 2005 и ранее могут быть проблемы: придется поднимать режим совместимости базы. Изменится поведение каких-то команд, возможно придётся переписать какие-то «хранимки», то есть в таком случае требуется внимательно смотреть и анализировать, что изменится.
— При этом рост производительности будет существенный?
Существует примерное эмпирические правило, замеренное уже не единожды, что с каждым новым релизом рост производительности 15-20% только за счет оптимизации кода СУБД новой версии. То есть мы ничего не изменили на платформе приложения, к примеру, 1С, просто обновили версию базы данных, и по этой причине получаем прирост производительно в районе 15-20%.
— Если, грубо говорить с переходом MS SQL Server2005 года на SQL 2014 рост производительности 50-60%?
Так грубо конечно не получится, проценты на проценты накладываются, но, примерно, процентов до 40%, можно выиграть с обновления 2005 до 2014 года.
— Получается, что с MS SQL Server 2012 проще всего обновить версию и только за счет нового кода SQL 2014 информационная система получит прирост производительности до 20%?
Да, конечно. В этой схеме, как раз те самые 15-20%, о которых говорил.
— Если компания поддерживает актуальную версию SQL Server, вы рекомендуете перейти на SQL 2014?
Да, можно уже переходить. Времени прошло достаточно. То есть MS SQL Server 2014 стабильная база данных, доработанная, с момента релиза прошло полтора года. До этого же еще были Community Preview, Beta, Alfa версии. Сейчас это уже готовое и стабильное серверное программное обеспечение.
— При установке SQL Server 2014 в облаке\гибридной среде, какие плюсы, минусы?
Это очень интересная тема, потому что сейчас Microsoft сфокусирован на своих облачных технологиях, я считаю, что это правильно. Начнем с того, что действительно облачная технология Microsoft высоко интегрирована во все программные решения компании. Начиная от операционных систем, те же самые Windows 8, 10, далее Office и базы данных.
Вообще, конечно, интеграция с облаком началась еще в 12 SQL Server, но тогда облачные технологии были в зачаточном состоянии, сейчас же можно говорить о том, что разница между локальным и облачным хранением данных практически стерта.
Если раньше мы хотели как-то связать облако с базами данных, нужно было делать какие-то нетривиальные операции чуть ли не на файловом уровне, то сейчас все это поддерживается из движка СУБД, мы можем подключить базы данных, которые располагаются в облаке, мы можем делать репликацию между базами данных в облаке, мы можем делать резервное копирование в облаке. Чем это хорошо? Тем, что облако — это арендованная инфраструктура, за работу которой «голова уже не болит». За работу инфраструктуры отвечает сам Microsoft. Данные реплицируются, копируются, как минимум 6-ть раз. Две основных копии хранятся в двух разных местах, на двух разных серверах, которые физически могут быть разнесены вообще по разным континентам, и плюс еще три резервные копии, то есть вероятность сбоя ничтожна мала. Получается, что пользователи могут сделать банальное хранилище резервных копий, которые никогда не потеряются и будут всегда доступны. Другой вариант, мы можем использовать облако, как резервный сервер. Можно арендовать виртуальную машину, либо саму базу данных поднять в облаке, настроить репликацию, либо использовать технологию AlwaysOn. Если вдруг у нас что-то происходит на основной площадке с нашим сервером, мы всегда можем рассчитывать на облако, как на резервный вариант. При этом бизнес пользователи будут работать, в то время, как администраторы и программисты работают над устранением проблем, аварий на основной площадке.
— Получается AlwaysOn включен при режиме работы в облаке?
Нельзя говорить о том, что он по умолчанию включён, все-таки репликация данных в облако это серьезное решение, не только техническое, но и организационное. Возможность подключения облака SQL Azure в качестве полноценной ноды AlwaysOn есть и сделать это достаточно просто. Варианты такие: во-первых, можно использовать встроенный движок базы данных SQL Azure, то есть у нас нет «виртуалки», у нас просто какая-то база данных работает в облаке. Второй вариант — просто использовать виртуальную машину, на которой развернут SQL Server. Собственно, если мы используем виртуальную машину, можно поставить SQL Server, который у нас стоит на продакшен, тут вообще никаких проблем нет. То есть мы к этой машине подключаем AlwaysOn и у нас все сразу работает. Если же мы используем встроенный движок виртуальной базы данных, то стоит сказать, что SQL Azure имеет ряд ограничений. Достаточно много ограничений, на самом деле. Не всякая база данных сможет сразу заработать на SQL Azure. Потребуется провести аудит, что-то переделать, доделать и подогнать под требования облака, для того чтобы эти базы данные работали вместе. Это обязательно нужно учитывать.
— В этой архитектуре возможно использовать решение DATA CLUSTER?
Да, конечно. DATA CLUSTER работает уже на уровне после AlwaysOn. То есть решению все равно, где располагаются ноды. Реальные или виртуальные ноды, Azure или что-то еще — для DATA CLUSTER нет никакой разницы.
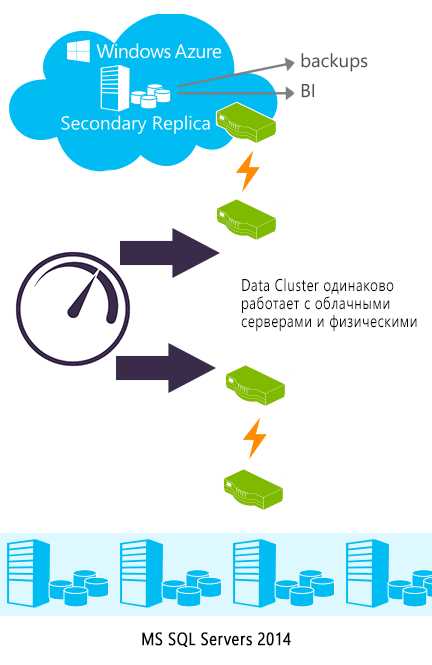
Фактически же, если мы, например, предполагаем использовать AlwaysOn в связке с платформой 1С, то использование DATA CLUSTER оказывается единственным возможным вариантом. Как известно, 1С «из коробки» не работает совместно с AlwaysOn. То есть нет никакой возможности распределять нагрузку по нескольким серверами. И будет ли работать, или не будет работать, точных комментариев от вендора нет. В принципе это логично, т.к. 1С работает с несколькими базами данных, и фокусироваться на одной из баз данных для них нет никакого смысла. Важно помнить, что поддержки AlwaysOn на многих платформах нет, в том числе и 1С, поэтому единственная возможность работать – это использовать DATA CLUSTER.
"DATA CLUSTER – инновационное российское решение, которое повышает производительность без изменения программного кода. Решает вопросы отказоустойчивости и надежности информационной системы."— Как взаимодействует MS SQL Server 2014 с другими приложениями, какой процесс создания одной универсальной среды? Например, с Excel и другими программами?
Вместе с SQL Server идет очень мощная компонента бизнес-аналитики — Business Intelligence (BI), позволяющая, в том числе, интегрировать данные из СУБД в приложения Office .
В том же Excel последней версии появилось много интересных средств работы с базами данных. Business Intelligence, позволяет в одном отчете увязать несколько источников данных, в том числе и данные получаемые из SQL Server. Есть много интересных возможностей, например, встроенный парсер веб-сайтов: можно в качестве источника данных указать любой сайт с таблицей данных. Та же самая статистика, демографические данные. Можно делать очень интересные вещи, например, связывать данные о продажах, которые хранятся в базе данных по регионам, с данными, например, РосСтата, которые расположены на сайте. Требуется указать адрес URL, где хранятся данные. Потом в конструкторе Business Intelligence (BI) увязываем эти данные, делаем отчет по корреляции, как и какие данные влияют на продажи. Конечно, пример сильно утрированный, но схему и возможности показывает.
— А как должна происходить связь, между таблицами, базами? Данные должны быть реляционные?
Да, связь происходит между реляционными данными, а откуда они — не так важно. Это может быть таблица Excel и база данных, может быть другой лист Excel, может быть таблица с сайта. Есть даже коннекторы к соц. сетям. Это больше про получение контактной информации. Получается, любой источник данных, который представляют собой таблицу, можно увязать и использовать в Business Intelligence.
— Должны ли быть определенные маркеры, связующие данные?
Данные в колонках. Это не обязательно сложные Guid, ID, другие параметры, можно банально, на примере продажи, соединить по названию региона. У нас есть в учетной базе название региона и, например, в РосСтате есть название региона. Соединяем строки и все.
— Расскажите, какие возможности резервного копирования в MS SQL Server 2014?
Основные возможности остались те же самые, конечно с доработкой. Из кардинальных изменений могу отметить, что, наконец, отказались от «магнитной пленки, ленты». Правда, вряд ли кто-то этим пользуется сейчас.
Начиная с SQL Server 2012 CU1 появилась возможность делать резервные копии напрямую в облако. Раньше мы указывали путь, куда сохранять резервную копию, локальный путь. Сейчас мы можем вместо локального пути указать URL облака. Так резервная копия будет уходить сразу на сайт.
Кроме этого, если такая схема не устраивает, есть альтернативная возможность — специальная служба, которая делает сопоставление с папкой на локальном диске и копиями в облаке. Служба будет следить за появлением новых файлов и автоматически отправлять файлы резервной копии в облако. При этом в SQL мы ничего не меняем, просто настраиваем эту службу.
— через интерфейс SQL Server 2014?
Нет, это не Management Studio, отдельная компонента, которая идет в составе MS SQL Server 2014, отдельное окно. В принципе, эту службу можно даже отдельно скачать с сайта Microsoft и использовать с более старыми версиями СУБД, которые не поддерживают бэкап напрямую в облако.
— Какие возможности распределения нагрузки предоставляет MS SQL Server 2014?
Технология AlwaysOn, про которую уже упоминал, появилась еще в прошлом релизе — MS SQL Server 2012.
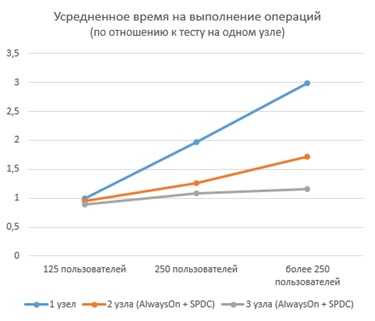
Это решение позволяет объединить несколько серверов в одну отказоустойчивую группу. Если один из серверов «падает», то тут же происходит переключение на другой сервер, на котором уже находятся актуальные данные. Синхронизация происходит в реальном времени, следовательно, время ожидания, Down-Time, составляет порядка нескольких минут. Помимо решения проблемы отказоустойчивости, пользователи могут перенаправлять запросы считывающие данные, с основного сервера на «копии» серверов, которые подключены в «группу доступности». Получается, что мы разгружаем основную ноду от тяжелых запросов.
Более того, мы можем задать различные настройки для этих серверов — например, мы оптимизируем основной сервер на быструю запись данных, а дополнительные ноды оптимизируем для формирования больших отчетов.
В SQL Sever 2012 можно было сделать группу до 4-х нод, а в MS SQL Server 2014 можно объединить до 8-ми нод. При этом каждый сервер может быть, как обычный, так и виртуальный, например, Azure, в облаке Microsoft.
 — Получается повышается стабильность, отказоустойчивость?
— Получается повышается стабильность, отказоустойчивость?
В принципе, отказоустойчивость и стабильность мы могли повысить и 2-3 машинами. В новой версии SQL Server улучшились возможности горизонтального масштабирования — теперь распределить нагрузку можно между 8 серверами, вместо 4 в прошлой версии.
Да. Также повторюсь, использование технологии DATA CLUSTER сильно упрощает процесс распределения запросов по нодам — все выполняется настройками кластера без необходимости что-либо менять в бизнес-приложении.
— Ваше общее мнение по MS SQL Server 2014?
Не все новшества смогли обсудить. Хочу отметить следующее:
1) Выделю самую главную «бомбу»: In-Memory OLTP. За этим действительно будущее. Конечно, сейчас у этой технологии много ограничений, для ее использования потребуется переделывать код приложения. Это — первый шаг в новом направлении и само направление открывает очень интересные перспективы
2) Также в 2014 версии продолжилось логичное развитие технологий, как AlwaysOn. Развитие в «ширину», возможность увеличения количества подключенных нод. Также логическое развитие, появилась возможность синхронизации с облачным сервисом.
3) Совсем ничего не успел рассказать про технологию расширения буферного кэша за счет SSD. На самом деле большая часть сегодняшнего разговора относится к крупным системам, для которых актуальна самая дорогая лицензия — Enterprise — поддерживающая все новые технологии СУБД.
Расширение буферного кэша — это то, что будет интересно клиентам SMB — малый и средний бизнес — тем, для кого покупать версию Enterprise слишком дорого.
Так вот, возвращаясь к технологии. Очень частая проблема для рабочих серверов — нехватка оперативной памяти для работы с кэшем. Дело в том, что при считывании данных с жесткого диска СУБД помещает их в кэш в оперативной памяти и при повторном обращении к таким данным считывание производится уже из оперативки, а значит — в сотни раз быстрее, чем с жесткого диска. Проблема в том, что оперативная память не резиновая и не может вместить в себя все считываемые данные, особенно если запросы неэффективны и создают избыточные чтения. В результате страницы «вытесняются» из памяти, при повторном обращении к таким страницам СУБД вновь вынуждена обращаться к жесткому диску, производительность резко падает.
В SQL Server 2014, начиная с редакции Standard, можно увеличить объем кэша за счет подключения SSD. При правильном подборе оборудования это позволит избежать падения производительности под высокими нагрузками. Если честно, к выбору SSD стоит подойти ответственно — я делал испытания на виртуальной машине Azure с выделенным SSD. Похоже, скорость такого диска была недостаточно высокой и в результате я, наоборот, получил замедление выполнения запроса.
4) Для специалистов, работающих с BI будет интересно, что теперь можно создавать изменяемые таблицы, содержащие индекс по колонкам (Columnstore Index). Такие индексы значительно ускоряют выборку по «таблицам фактов» (например, результаты массового соц. опроса, какие-то аналитические данные и т.п.). Впервые такие индексы появились в SQL 12, тогда таблица, содержащая такой индекс не могла быть изменена. Теперь же можно создать Columnstore Index и продолжать добавлять в таблицу данные.
Обобщая, могу сказать, что появилось много новых небольших, но удобных изменений. Переход на SQL Server 2014 – это работа на перспективу. Уверен, работа с In-Memory OLTP окупится и принесет свои плоды. Также многие технологии SQL 2012 значительно развились. Даже не вкладываясь в развитие In-Memory OLTP, можно получить значительный выигрыш и дополнительные возможности.
Не будем забывать и об интересных технологиях, появившихся еще в предыдущих редакциях SQL Server. Например, в SQL 2012 появилась возможность онлайн-перестроения индексов базы данных без блокировки обслуживаемой таблицы. Если говорить кратко, то для обслуживания индексов существует 2 операции: перестроение индексов и реорганизация. Так вот, реорганизацию всегда можно было делать онлайн, не мешая работе пользователей, эффект от такой операции был хуже, чем от перестроения. А вот перестроение всегда полностью блокировало таблицу, и в результате получается идеальный результат, максимальная производительность индекса. Так вот, в 2005-2008 SQL Server это всегда блокировало пользователей, в 2012 версии Enterprise появилась возможность онлайн перестроения индексов без блокировки пользователей. Естественно, технология осталась и в SQL Server 2014, получила интересное развитие. Теперь, если у нас есть партиционированный индекс, можно перестроение каждой части индекса по отдельности — это позволяет более гибко планировать время обслуживания БД и эффективно распределять ресурсы: например, «оперативную» часть индекса, к которой относятся документы за последний месяц, можно перестраивать чаще, чем остальные части.
— Спасибо Александр за подробные ответы, на вопросы. Спасибо за интервью.
Эпилог:
В ближайшее время MS SQL Server 2014 станет основным инструментом для бизнеса и учреждений в части организации работы инфраструктуры серверов. Базы данных под управлением программного обеспечения MS SQL Server 2014 позволят развиваться в ногу со временем, получая возможность распределения информации на физических серверах, а также инфраструктуре в облаке Microsoft, в зависимости от текущих потребностей и задач.
Универсальность – главное достоинство MS SQL Server 2014. Появляются новые возможности построения архитектуры, повышения отказоустойчивости, а в сочетании с программным кластером DATA CLUSTER и повышение производительности и эффективности работы OLTP систем, для текущих задач и для формирования аналитической информации.
Версия MS SQL Server 2014 экономит время программистов и администраторов. Логическое развитие с учетом опыта эксплуатации прошлых версий и откликов специалистов, на основе версии 2008 и 2012, способствовало оптимизации рабочего процесса.
Интересные статьи:
www.softpointplus.ru
- Как узнать логин и пароль от скайпа если забыл

- Как на компьютере поменять пароль при включении компьютера
- Сервер windows

- Какой пароль можно придумать в вк
- Управление компьютером как запустить из командной строки
- Как настроить роутер tp link tl wr841n самостоятельно

- Не открывает видео браузер

- Где в интернет эксплорер сервис свойства обозревателя

- Пробить 2ip
- Установка 1с ubuntu postgresql
- Программа отключение ненужных служб windows 10