Поиск отсутствующих индексов таблиц в базе на MS SQL Server. Ms sql индексы
Отсутствующие индексы в MS-SQL или оптимизация «по-быстрому»
При выполнении запроса, как мы знаем, оптимизатор SQL Server исходя из существующих индексов и имеющейся свежей статистики пытается за разумное время найти лучший план запроса, конечно если этот план уже не «сидит» в кэше сервера, и запрос выполняется по этому плану и план сохраняется в кэш сервера. Если план уже построен для этого запроса ранее, то запрос выполняется по существующему плану.
Нам в этой теме интересен следующий момент: Во время компиляции плана запроса, при переборе возможных индексов, если лучшего индекса не нашлось (по мнению сервера), то в плане запроса помечается этот не найденный индекс, и сервер ведет статистику по таким индексам – сколько раз сервер бы воспользовался этим индексом и сколько стоил этот запрос. Эти отсутствующие индексы – missing indexes мы сейчас и разберем, что с ними делать и как с ними работать.
Предлагаю на примере разобраться с отсутствующими индексами. Создадим пару таблиц в нашей, БД на локальном или тестовом сервере:
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'Vasa'),
(2,'Peta'),
(3,'Anna'),
(4,'Ira'),
(5,'Igor')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Сахар', 50),
(2,'Молоко', 80),
(3,'Хлеб', 20),
(4,'Макароны', 40),
(5,'Пиво', 100)
) t (id,product, price) on t.id = c.product_id
go
Структура простая из 2х табличек: продажи где поля идентификатор, дата продажи и продавец и другая таблица – детализация этих продаж, где какие-то товары в этой продаже указаны с ценой и количеством.
Предлагаю посмотреть простой запрос и его план:
select count(*) from orders o join orders_detail d on o.id = d.order_id
where d.cost > 1800
go
На графическом отображении плана запроса видна подсказка зеленым цветом об отсутствующем индексе, если кликнуть по ней правой кнопкой мыши и выделить «Missing Index Details..» то получим текст предлагаемого индекса, в тексте только лишь убрать комментарии и дать какое-нибудь имя индексу и скрипт готов к выполнению.
Мы не будем строить этот индекс, который дала подсказка в SSMS, а посмотрим будет ли рекомендован индекс этот динамическими представлениями, связанными с отсутствующими индексами. Эти представления:
select * from sys.dm_db_missing_index_group_stats
select * from sys.dm_db_missing_index_details
select * from sys.dm_db_missing_index_groups
Мы из этого видим, что в 1м представлении у нас есть статистика по отсутствующих индексах, а именно:
-
Сколько бы раз произвелся поиск если бы предложенный индекс существовал?
-
Сколько раз использовалось бы сканирование если бы предложенный индекс существовал.
-
Дата время последней потребности в этом индексе
-
Текущая реальная стоимость плана запроса без предлагаемого индекса.
2е представление это уже тело индекса по сути:
-
База данных
-
Объект/таблица
-
Сортированные колонки
-
Колонки включенные для увеличения покрытия индекса
3е представление - это связь 1го и 2х представлений.
Соответственно, здесь не трудно получить скрипт, который бы из этих динамических представлений сгенерировал скрипт по созданию отсутствующих индексов. Сам скрипт у меня получился таким:
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc
В порядке эффективности индексов выведены отсутствующие индексы. Идеально когда этот резалтсет ничего не возвращает, на нашем примере этот резалтсет возвратит минимум один индекс:
Когда совсем лень или некогда разбираться с тормозами у пары заказчиков я выполнял этот запрос, копировал первую колонку и выполнял на сервере. После этого тормоза уходили 😊.
Я рекомендую осознано подходить к полученной информации с этими индексами. Например, если рекомендовать ситема будет следующие индексы:
create index ix_01 on tbl1 (a,b) include (c)
create index ix_02 on tbl1 (a,b) include (d)
create index ix_03 on tbl1 (a)
И эти индексы используются для поиска/seek, то вполне очевидно, что логичнее заменить эти индексы на один который покроет все 3 предложенных:
create index ix_1 on tbl1 (a,b) include (c,d)
Т.е. как минимум ревью предлагаемых индексов перед тем как их накатить на боевой сервер. Хотя…. Повторюсь, например на сервер TFS я накатывал потерянные индексы и общая производительность выростала, а время на такую оптимизацию затрачено минимум. Хотя, впоследствии с ТФС 2015 на ТФС 2017 я столкнулся с тем что обновление не проходило из-за новых индексов. Но их легко можно найти были по маске
select * from sys.indexes where name like 'ix[_]2017%'
kurenkov.pro
Поиск отсутствующих индексов таблиц в базе на MS SQL Server — AUsevich
Индексы таблиц сильно влияют на работу с базой данных. Так, отсутствие необходимого индекса может приводить к:
-
- чтению большего количества строк данных
- увеличению времени выполнения запроса
- появлению избыточных блокировок
- и другим негативным последствиям
В данной статье мы рассмотрим как можно найти недостающие индексы с помощью динамических административных функций MS SQL Server.
Информация о динамических функциях
Динамические административные представления и функции возвращают информацию о состоянии сервера, которую можно применить для наблюдения за работой и анализа проблем.
В данной статье мы воспользуемся тремя динамическими административными функциями (DMF): dm_db_missing_index_group_stats, dm_db_missing_index_groups, dm_db_missing_index_details
Запрос поиска недостающих индексов и анализ его результата
Следующий запрос выведет всю необходимую в дальнейшем информацию:
SELECT TOP 10 DB_NAME(database_id), mid.*, migs.*, avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) as Perf FROM sys.dm_db_missing_index_group_stats as migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) ORDER BY avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) DESC
SELECT TOP 10 DB_NAME(database_id), mid.*, migs.*, avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) as Perf FROM sys.dm_db_missing_index_group_stats as migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) ORDER BY avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) DESC |
Выражение avg_total_user_cost * avg_user_impact * (user_seeks + user_scans), использованное в запросе, соответствует оценке выигрыша при добавлении отсутствующего индекса. Файл запроса можно скачать во вложениях к статье.
Выполним запрос и проанализируем его результаты на простом примере.
Отсутствующие индексы в базе данныхКак видно, отсутствует индекс в таблице AccumRg23573, при этом запрос, для которого необходим индекс, выполняется с предикатом равенства по полю Fld23580RRef. В поле user_seeks указано что этот индекс мог бы быть использован 750 раз в целях поиска по индексу, avg_user_impact говорит о том что средний процент выигрыша равен 99,99%. Так же имеет смысл обратить внимание на поле last_user_seek, оно указывает на дату и время последнего пользовательского запроса, который мог бы использовать отсутствующий индекс для поиска. Если последний раз подходящий запрос был давно, возможно, индекс будет использовать редко и необходимости в нем нет — необходимо оценить перед добавлением индекса. Теперь воспользуемся обработкой выводящей структуру хранения базы данных в терминах 1С:Предприятия (из статьи «Получение информации о структуре хранения базы данных в терминах 1С:Предприятие и СУБД»).
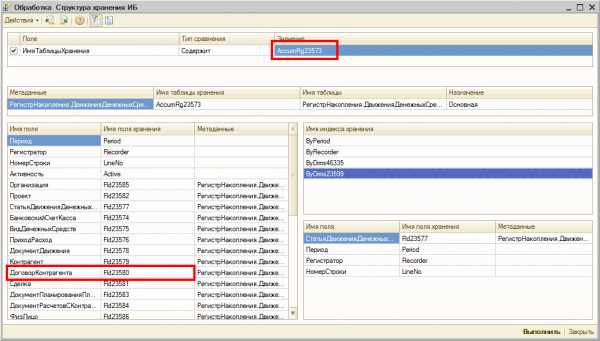 Структура хранения базы данных с отсутствующим индексом
Структура хранения базы данных с отсутствующим индексомС помощью обработки мы видим что индекса не хватает в основной таблице регистра накопления ДДС, а также видим что условие на равенство используется по полю ДоговорКонтрагента. При этом в таблице существуют индексы по Периоду, Регистратору, СтатьеДДС, Проекту. Индекса по полю ДоговорКонтрагента нет, хотя условие запроса именно на равенство по этому полю, а это значит что системе необходимо будет сканировать всю таблицу при выполнении запроса. Давайте добавим отсутствующий индекс.
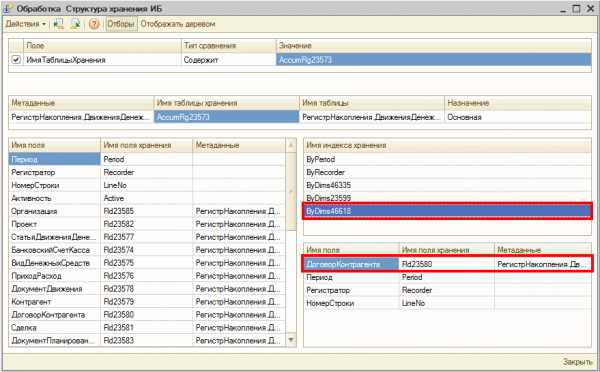 Добавим отсутствующий индекс
Добавим отсутствующий индексСтатистика использования индекса
И так, индекс добавлен, но теперь нам необходимо оценить результат своих действий. Для этих целей воспользуемся еще одним запросом с динамическими административными функциями, о которых будет рассказано в следующей статье. Стоит упомянуть что выполнять его стоит не сразу же, а через некоторое время работы пользователей в базе данных для того чтобы накопилась статистика.
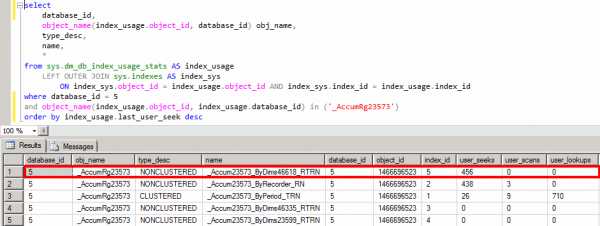 Статистика использования добавленного отсутствующего индекса
Статистика использования добавленного отсутствующего индексаОценив значения в колонке user_seeks можно сделать вывод что в данной системе этот индекс используется достаточно часто, а эффективность от его использования высока (была оценена первым запросом).
ausevich.ru
MSSQL – простые индикаторы нехватки индексов
Как обычно в нашей профессии, есть несколько способов решить задачу :)
Расскажу о трёх наиболее простых подходах (и одном бонусном), не углубляясь в детали. Если интересны как раз глубокие детали, рекомендую почитать документацию (начать стоит с Designing Indexes, а прочитав о проектировании продолжить Performance (Database Engine)).
Кстати, если тема плана выполнения для вас нова – неплохим стартом будет мой давний пост «SQL – execution plan».
DISCLAIMER: в этой статье я даю простые советы, которые чаще всего работают, однако в MSSQL практически невозможно дать рекомендации на все случаи жизни – данные бывают разные, запросы бывают разные…
1. Мысленный эксперимент
Достаточно полезный способ, особенно на этапе проектирования. Хорошим подспорьем для тех, кому индексы в новинку, будет вышеупомянутый раздел про дизайн индексов.
Что касается простейших советов, они следующие:
- Если данных не мизерное количество – вам нужны индексы.
- Если есть внешние ключи – настоящие или по смыслу (некоторые их принципиально не любят делать) – они хорошие кандидаты для индексирования.
- Чаще всего стоит сделать кластерный индекс и сделать его не слишком большим (потому что другие индексы будут ссылаться на строки по кластерному индексу). Кстати, кластерный индекс отлично подходит для выборки по диапазону (например, по диапазону дат).
- Помните, что индексы тоже хранятся на диске. Простейший вывод – большое количество индексов снизит скорость вставки (иногда и обновления) данных. Обычно до создания 5-7 индексов проблем не возникает.
- Статистика очень важна для правильного использования индексов. Хорошая новость – чаще всего MSSQL сам достаточно неплохо за ней следит, плохая новость – это не всегда срабатывает.
- Для наиболее критичных запросов, возвращающих небольшое количество столбцов, имеет смысл использовать покрытие индексом (это уже чуть более продвинутая техника, но ничего сложного в ней нет).
Поскольку я обещал не углубляться в детали – идём дальше.
Database Engine Tuning Advisor
Это сравнительно простой в использовании, но, тем не менее, мощный и результативный инструмент, который даёт рекомендации по улучшению производительности запросов. Правда, надо отметить, что он недоступен в Express-версии.
Если вкратце, на вход он принимает набор запросов (можно подготовить с помощью SQL Server Profiler) и, после их анализа (иногда довольно длительного), даёт рекомендации.
Надо понимать, что рекомендации будут относиться к набору запросов, а не к общему случаю использования вашей БД. Для более подробного ознакомления рекомендую почитать документацию.
Missing Index Feature
Вероятно, вы уже обращали внимание, что при просмотре плана выполнения иногда встречаются рекомендации вида "Missing index...". Это как раз работает Missing Index Feature.
На это можно посмотреть, запустив на базе AdventureWorks (в моём случае была база для 2012 версии) такой запрос:
select s.ProductID from Sales.SalesOrderDetail s where s.UnitPrice = 2Если включен просмотр плана выполнения (Ctrl+M), мы увидим вполне логичную рекомендацию для улучшения производительности этого запроса. Да, повторюсь – не стоит улучшать один, особенно не критичный запрос – мы можем замедлить другие, более важные запросы. С этой точки зрения предыдущие варианты более правильные.
И обещанный бонус, которым редко пользуются, но стоит иметь в виду его наличие – sys.dm_db_missing_index_detail и его друзья (насколько я понимаю, это источник информации, которую показывает план выполнения). Попробовать можно просто выбрав записи из этого представления после запроса, приведённого выше. По моему мнению, этот способ менее удобен для использования человеком, однако может использоваться для последующего автоматического разбора.
Если у вас есть замечания, пожелания или новые темы – пишите в комментариях или на olegaxenow.reformal.ru. Постараюсь учесть.
www.olegaxenow.com
Обзор типов индексов Oracle, MySQL, PostgreSQL, MS SQL / Хабр
В одном из комментариев здесь была просьба рассказать подробнее об индексах, и так как, в рунете практически нет сводных данных о поддерживаемых индексах различных СУБД, в данном обзоре я рассмотрю, какие типы индексов поддерживаются в наиболее популярных СУБДB-Tree
Семейство B-Tree индексов — это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей. Они поддерживаются практически всеми СУБД как реляционными, так нереляционными, и практически для всех типов данных.Так как большинство, наверное, их хорошо знает(или могут прочесть о них например, здесь), то единственное, что, пожалуй, следует здесь отметить, это то, что данный тип индекса оптимален для множества с хорошим распределением значений и высокой мощностью(cardinality-количество уникальных значений).
Пространственные индексы
В данный момент все данные СУБД имеют пространственные типы данных и функции для работы с ними, для Oracle — это множество типов и функций в схеме MDSYS, для PostgreSQL — point, line, lseg, polygon, box, path, polygon, circle, в MySQL — geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL — Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection. В схеме работы пространственных запросов обычно выделяют две стадии или две ступени фильтрации. СУБД, обладающие слабой пространственной поддержкой, отрабатывают только первую ступень (грубая фильтрация, MySQL). Как правило, на этой стадии используется приближенное, аппроксимированное представление объектов. Самый распространенный тип аппроксимации – минимальный ограничивающий прямоугольник (MBR – Minimum Bounding Rectangle) [100]. Для пространственных типов данных существуют особые методы индексирования на основе R-деревьев(R-Tree index) и сеток(Grid-based Spatial index).Spatial grid
Spatial grid(пространственная сетка) index – это древовидная структура, подобная B-дереву, но используется для организации доступа к пространственным(Spatial) данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами(широтой и долготой). В этой структуре узлами дерева выступают ячейки пространства. Например, для двухмерного пространства: сначала вся родительская площадь будет разбита на сетку строго определенного разрешения, затем каждая ячейка сетки, в которой количество объектов превышает установленный максимум объектов в ячейке, будет разбита на подсетку следующего уровня. Этот процесс будет продолжаться до тех пор, пока не будет достигнут максимум вложенности (если установлен), или пока все не будет разделено до ячеек, не превышающих максимум объектов.В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Quadtree
Quadtree – это подвид Grid-based Spatial index, в котором в родительской ячейке всегда 4 потомка и разрешение сетки варьируется в зависимости от характера или сложности данных.R-Tree
R-Tree (Regions Tree) – это тоже древовидная структура данных подобная Spatial Grid, предложенная в 1984 году Антонином Гуттманом. Эта структура данных тоже разбивает пространство на множество иерархически вложенных ячеек, но которые, в отличие от Spatial Grid, не обязаны полностью покрывать родительскую ячейку и могут пересекаться. Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: с квадратичной и линейной сложностью(Гуттман, конечно, описал и с экспоненциальной сложностью — Exhaustive Search, но он, естественно, нигде не используется). Квадратичный подтип заключается в разбиении на два прямоугольника с минимальной площадью, покрывающие все объекты. Линейный – в разбиении по максимальной удаленности.
HASH
Hash-индексы были предложены Артуром Фуллером, и предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей. Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий.Bitmap
Bitmap index – метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.EmpID Пол| 1 | Мужской |
| 2 | Женский |
| 3 | Женский |
| 4 | Мужской |
| 5 | Женский |
Битовые карты
Значение Начало Конец Битовая маска| Мужской | Адрес первой строки | Адрес последней строки | 10010 |
| Женский | Адрес первой строки | Адрес последней строки | 01101 |
Reverse index
Reverse index – это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска. Пример:Поле в таблице(bin) Ключ reverse-индекса(bin)| 00000001 | 10000000 |
| … | … |
| 00001001 | 10010000 |
| 00001010 | 01010000 |
| 00001011 | 11010000 |
Inverted index
Инвертированный индекс – это полнотекстовый индекс, хранящий для каждого лексемы ключей отсортированный список адресов записей таблицы, которые содержат данный ключ.| 1 | Мама мыла раму |
| 2 | Папа мыл раму |
| 3 | Папа мыл машину |
| 4 | Мама отполировала машину |
| Мама | 1,4 |
| Мыла | 1 |
| Раму | 1,2 |
| Папа | 2,3 |
| Отполировала | 4 |
| Машину | 3,4 |
Partial index
Partial index — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.Function-based index
Самим же гибким типом индексов являются функциональные индексы, то есть индексы, ключи которых хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)Сводная таблица типов индексов
| MySQL | PostgreSQL | MS SQL | Oracle | |
| B-Tree index | Есть | Есть | Есть | Есть |
| Поддерживаемые пространственные индексы(Spatial indexes) | R-Tree с квадратичным разбиением | Rtree_GiST(используется линейное разбиение) | 4-х уровневый Grid-based spatial index (отдельные для географических и геодезических данных) | R-Tree c квадратичным разбиением; Quadtree |
| Hash index | Только в таблицах типа Memory | Есть | Нет | Нет |
| Bitmap index | Нет | Есть | Нет | Есть |
| Reverse index | Нет | Нет | Нет | Есть |
| Inverted index | Есть | Есть | Есть | Есть |
| Partial index | Нет | Есть | Есть | Нет |
| Function based index | Нет | Есть | Есть | Есть |
PS. Возможно я что-либо забыл упомянуть, пишите на личку или в комментарии — добавлю.
habr.com
Обзор типов индексов Oracle, MySQL, PostgreSQL, MS SQL | Базы данных | Статьи | Программирование Realcoding.Net
B-Tree
Семейство B-Tree индексов — это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей. Они поддерживаются практически всеми СУБД как реляционными, так нереляционными, и практически для всех типов данных.
Так как большинство, наверное, их хорошо знает(или могут прочесть о них например, здесь), то единственное, что, пожалуй, следует здесь отметить, это то, что данный тип индекса оптимален для множества с хорошим распределением значений и высокой мощностью(cardinality-количество уникальных значений).
Пространственные индексы
В данный момент все данные СУБД имеют пространственные типы данных и функции для работы с ними, для Oracle — это множество типов и функций в схеме MDSYS, для PostgreSQL — point, line, lseg, polygon, box, path, polygon, circle, в MySQL — geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL — Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection.В схеме работы пространственных запросов обычно выделяют две стадии или две ступени фильтрации. СУБД, обладающие слабой пространственной поддержкой, отрабатывают только первую ступень (грубая фильтрация, MySQL). Как правило, на этой стадии используется приближенное, аппроксимированное представление объектов. Самый распространенный тип аппроксимации – минимальный ограничивающий прямоугольник (MBR – Minimum Bounding Rectangle) [100]. Для пространственных типов данных существуют особые методы индексирования на основе R-деревьев(R-Tree index) и сеток(Grid-based Spatial index).
Spatial grid
Spatial grid(пространственная сетка) index – это древовидная структура, подобная B-дереву, но используется для организации доступа к пространственным(Spatial) данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами(широтой и долготой). В этой структуре узлами дерева выступают ячейки пространства. Например, для двухмерного пространства: сначала вся родительская площадь будет разбита на сетку строго определенного разрешения, затем каждая ячейка сетки, в которой количество объектов превышает установленный максимум объектов в ячейке, будет разбита на подсетку следующего уровня. Этот процесс будет продолжаться до тех пор, пока не будет достигнут максимум вложенности (если установлен), или пока все не будет разделено до ячеек, не превышающих максимум объектов.
В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Quadtree
Quadtree – это подвид Grid-based Spatial index, в котором в родительской ячейке всегда 4 потомка и разрешение сетки варьируется в зависимости от характера или сложности данных.
R-Tree
R-Tree (Regions Tree) – это тоже древовидная структура данных подобная Spatial Grid, предложенная в 1984 году Антонином Гуттманом. Эта структура данных тоже разбивает пространство на множество иерархически вложенных ячеек, но которые, в отличие от Spatial Grid, не обязаны полностью покрывать родительскую ячейку и могут пересекаться.Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: с квадратичной и линейной сложностью(Гуттман, конечно, описал и с экспоненциальной сложностью — Exhaustive Search, но он, естественно, нигде не используется).Квадратичный подтип заключается в разбиении на два прямоугольника с минимальной площадью, покрывающие все объекты. Линейный – в разбиении по максимальной удаленности.
HASH
Hash-индексы были предложены Артуром Фуллером, и предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей. Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий.
Bitmap
Bitmap index – метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
EmpID Пол| 1 | Мужской |
| 2 | Женский |
| 3 | Женский |
| 4 | Мужской |
| 5 | Женский |
Битовые карты
Значение Начало Конец Битовая маска| Мужской | Адрес первой строки | Адрес последней строки | 10010 |
| Женский | Адрес первой строки | Адрес последней строки | 01101 |
Основное преимущество битовых индексов в том, что на больших множествах с низкой мощностью и хорошей кластеризацией по их значениям индекс будет меньше чем B*-tree. (Подробнее стоит прочесть здесь или здесь)
Reverse index
Reverse index – это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.Пример:
Поле в таблице(bin) Ключ reverse-индекса(bin)| 00000001 | 10000000 |
| … | … |
| 00001001 | 10010000 |
| 00001010 | 01010000 |
| 00001011 | 11010000 |
Как видите, значение в индексе изменяется намного больше, чем само значение в таблице, и поэтому в структуре b-tree, они попадут в разные блоки.
Inverted index
Инвертированный индекс – это полнотекстовый индекс, хранящий для каждого лексемы ключей отсортированный список адресов записей таблицы, которые содержат данный ключ. раскрутка сайтов
| 1 | Мама мыла раму |
| 2 | Папа мыл раму |
| 3 | Папа мыл машину |
| 4 | Мама отполировала машину |
В упрощенном виде это будет выглядеть так:
| Мама | 1,4 |
| Мыла | 1 |
| Раму | 1,2 |
| Папа | 2,3 |
| Отполировала | 4 |
| Машину | 3,4 |
Partial index
Partial index — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
Function-based index
Самим же гибким типом индексов являются функциональные индексы, то есть индексы, ключи которых хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений.Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
Сводная таблица типов индексов
| MySQL | PostgreSQL | MS SQL | Oracle | |
| B-Tree index | Есть | Есть | Есть | Есть |
| Поддерживаемые пространственные индексы(Spatial indexes) | R-Tree с квадратичным разбиением | Rtree_GiST(используется линейное разбиение) | 4-х уровневый Grid-based spatial index (отдельные для географических и геодезических данных) | R-Tree c квадратичным разбиением; Quadtree |
| Hash index | Только в таблицах типа Memory | Есть | Нет | Нет |
| Bitmap index | Нет | Есть | Нет | Есть |
| Reverse index | Нет | Нет | Нет | Есть |
| Inverted index | Есть | Есть | Есть | Есть |
| Partial index | Нет | Есть | Есть | Нет |
| Function based index | Нет | Есть | Есть | Есть |
Стоит упомянуть, что в PostgreSQL GiST позволяет создать для любого собственного типа данных индекс основанный на R-Tree. Для этого нужно реализовать все 7 функций механизма R-Tree. Дополнительно можно прочитать здесь:Oracle® Spatial User's Guide and ReferenceПространственные данные в MS SQLMS SQL: Spatial Indexing OverviewHilbert R-treeПространственные типы PostgreSQLПространственные функции PostgreSQLИндексирование пространственных данных в СУБД Microsoft SQL Server 2000Papadias D., Theodoridis T. Spatial Relations, Minimum Bounding Rectangles and Spatial Data Structures // Technical Report KDB-SLAB-TR-94-04, Faloutsos C., Kamel I. Hilbert R-Tree: An Improved R-Tree UsingFractals // Department of CS, University of Maryland, TechnicalResearch Report TR-93-19, Wikipedia: Hilbert R-treeМетоды поиска во внешней памятиАртур Фуллер. Intelligent database design using hash keys
PS. Возможно я что-либо забыл упомянуть, пишите на личку или в комментарии — добавлю.
Автор материала: курс евро
www.realcoding.net
Дефрагментация индексов со сбором статистики MS SQL 2008 R2 / Хабр
Одна из первых задач, которая возникает перед DBA после развертывания новой БД — это настройка планов по ее обслуживанию. Зачастую, в план обслуживания включается задача по дефрагментации индексов. Мне нравится, когда я знаю не только то, что дефрагментация выполнилась ночью с воскресенья на понедельник, но и то, как она прошла, сколько выполнялась, какие индексы были перестроены и в каком состоянии они остались после дефрагментации.Для сбора такой статистики мною был написан небольшой скриптик, который собирает информацию о выполненной работе, а так же дает максимально подробное описание о состоянии индексов до и после проделанной процедуры.
Но начнем с простого, создадим таблицу для хранения этих самых данных (я создал отдельную БД, куда складываю таблицы, которыми пользуюсь во время обслуживания баз данных сервера):
Столбец Тип Комментарий| proc_id | int | Порядковый номер процедуры, для идентификации |
| start_time | datetime | Начало выполнения запроса ALTER INDEX |
| end_time | datetime | Завершение выполнения запроса ALTER INDEX |
| database_id | smallint | Идентификатор БД |
| object_id | Int | Идентификатор таблицы |
| table_name | varchar(50) | Имя таблицы |
| index_id | Int | Идентификатор индекса |
| index_name | varchar(50) | Имя индекса |
| avg_frag_percent_before | float | Процент фрагментации индекса перед выполнением ALTER INDEX |
| fragment_count_before | bigint | Количество фрагментов до дефрагментации |
| pages_count_before | bigint | Количество страниц индекса до дефргаментации |
| fill_factor | tinyint | Уровень заполнения страниц индекса |
| partition_num | int | Номер секции |
| avg_frag_percent_after | float | Процент фрагментации индекса после выолнения ALTER INDEX |
| fragment_count_after | bigint | Количество фрагментов после дефрагментации |
| pages_count_after | bigint | Количество страниц индекса после дефргаментации |
| action | varchar(10) | Выполняемое действие |
После того, как таблица заполнена, нам известно какие индексы необходимо обслужить. Займемся делом:
--Обьявим необходимые переменные DECLARE @partitioncount INT --Количество секций DECLARE @action VARCHAR(10) --Действие, которые мы будем делать с индексом DECLARE @start_time DATETIME --Начало выполнения запроса ALTER INDEX DECLARE @end_time DATETIME --Конец выполнения запроса ALTER INDEX --см описание таблицы DECLARE @object_id INT DECLARE @index_id INT DECLARE @tableName VARCHAR(250) DECLARE @indexName VARCHAR(250) DECLARE @defrag FLOAT DECLARE @partition_num INT DECLARE @fill_factor INT --Сам запрос, который мы будем выполнять, я поставил MAX, потому как иногда меняю такие скрипты, и забываю поправить размер данной переменной, в результате получаю ошибку. DECLARE @sql NVARCHAR(MAX) --Далее объявляем курсор DECLARE defragCur CURSOR FOR SELECT [object_id], index_id, table_name, index_name, avg_frag_percent_before, fill_factor, partition_num FROM dba_tasks.dbo.index_defrag_statistic WHERE proc_id = @currentProcID ORDER BY [object_id], index_id DESC --Сначала не кластерные индексы OPEN defragCur FETCH NEXT FROM defragCur INTO @object_id, @index_id, @tableName, @indexName, @defrag, @fill_factor, @partition_num WHILE @@FETCH_STATUS=0 BEGIN SET @sql = N'ALTER INDEX ' + @indexName + ' ON ' + @tableName SELECT @partitioncount = count (*) FROM sys.partitions WHERE object_id = @object_id AND index_id = @index_id; --В моем случае, важно держать неможко пустого места на страницах, потому, что вставка в тоже таблицы имеете место, и не хочеться тратить драгоценное время пользователей на разбиение страниц IF (@fill_factor != 80) BEGIN @sql = @sql + N' REBUILD WITH (FILLFACTOR = 80)' SET @action = 'rebuild80' END ELSE BEGIN --Тут все просто, действуем по рекомендации MS IF (@defrag > 30) --Если фрагментация больше 30%, делаем REBUILD BEGIN SET @sql = @sql + N' REBUILD' SET @action = 'rebuild' END ELSE --В противном случае REORGINIZE BEGIN SET @sql = @sql + N' REORGANIZE' SET @action = 'reorginize' END END --Если есть несколько секций IF @partitioncount > 1 SET @sql = @sql + N' PARTITION=' + CAST(@partition_num AS nvarchar(5)) print @sql --Вывод выполняемого запроса --Фиксируем время старта SET @start_time = GETDATE() EXEC sp_executesql @sql --И время завершения SET @end_time = GETDATE() --Сохраняем время в таблицу UPDATE dba_tasks.dbo.index_defrag_statistic SET start_time = @start_time, end_time = @end_time, [action] = @action WHERE proc_id = @currentProcID AND [object_id] = @object_id AND index_id = @index_id FETCH NEXT FROM defragCur INTO @object_id, @index_id, @tableName, @indexName, @defrag, @fill_factor, @partition_num END CLOSE defragCur DEALLOCATE defragCurНу и на последок, соберем информацию о индексах после процедуры дефрагментации:
UPDATE dba SET dba.avg_frag_percent_after = dm.avg_fragmentation_in_percent, dba.fragment_count_after = dm.fragment_count, dba.pages_count_after = dm.page_count FROM sys.dm_db_index_physical_stats(DB_ID(), null, null, null, null) dm INNER JOIN dba_tasks.dbo.index_defrag_statistic dba ON dm.[object_id] = dba.[object_id] AND dm.index_id = dba.index_id WHERE dba.proc_id = @currentProcID AND dm.index_id > 0После выполнения такого скрипта, можно получить и посчитать очень много полезной информации. Например, время обслуживания всех индексов и каждого отдельно. Понять как это связано с размером индекса, увидеть эффективность данной операции. Собрав такую информацию за несколько раз, можно немного поменять процедуру, наверняка какие-то индексы фрагментируются больше и быстрее. В таком случае их обслуживание следует выполнять чаще. Как воспользоваться полученной информацией, решайте сами. Что же касается меня, то я, после анализа каждой такой процедуры, меняю планы обслуживания, если того требует ситуация. Мои базы работают под высокой нагрузкой круглосуточно. Поэтому постоянно перестраивать все индексы и на 1-2 часа снижать производительность сервера я не могу. Если Ваша БД, тоже работает круглосуточно, для выполнения таких вещей, следует настроить Resource Governor.
Хочу так-же заметить, что в инете есть подробные скрипты, но будьте бдительны, многие из них пользуются устаревшими командами.
Более подробно об используемых мною системных представлениях можно почитать в msdn:
sys.sysindexessys.tablessys.dm_db_index_physical_stats
habr.com
- Включить режим инкогнито в яндексе

- Основы html для начинающих

- Падение мазилы что делать
- Создание базы данных в access из файлов excel

- Для чего нужен c язык

- Рабочие столы linux
- Vba примеры
- Excel в sql

- Как в excel переключаться между вкладками с помощью клавиатуры

- Основы sql
- Почему нет подключения