KOCHEROV.NET. Ms sql примеры join
MS SQL Server и T-SQL
OUTER JOIN
Последнее обновление: 20.07.2017
В предыдущей теме было рассмотрено внутреннее соединение таблиц. Но MS SQL Server также поддерживает внешнее соединение или outer join. В отличие от inner join внешнее соединение возвращает все строки одной или двух таблиц, которые участвуют в соединении.
Outer Join имеет следующий формальный синтаксис:
SELECT столбцы FROM таблица1 {LEFT|RIGHT|FULL} [OUTER] JOIN таблица2 ON условие1 [{LEFT|RIGHT|FULL} [OUTER] JOIN таблица3 ON условие2]...Перед оператором JOIN указывается одно из ключевых слов LEFT, RIGHT или FULL, которые определяют тип соединения:
LEFT: выборка будет содержать все строки из первой или левой таблицы
RIGHT: выборка будет содержать все строки из второй или правой таблицы
FULL: выборка будет содержать все строки из обоих таблиц
Также перед оператором JOIN может указываться ключевое слово OUTER, но его применение необязательно. Далее после JOIN указывается присоединяемая таблица, а затем идет условие соединения.
Например, соединим таблицы Orders и Customers:
SELECT FirstName, CreatedAt, ProductCount, Price, ProductId FROM Orders LEFT JOIN Customers ON Orders.CustomerId = Customers.IdТаблица Orders является первой или левой таблицей, а таблица Customers - правой таблицей. Поэтому, так как здесь используется выборка по левой таблице, то вначале будут выбираться все строки из Orders, а затем к ним по условию Orders.CustomerId = Customers.Id будут добавляться связанные строки из Customers.
По вышеприведенному результату может показаться, что левостороннее соединение аналогично INNER Join, но это не так. Inner Join объединяет строки из дух таблиц при соответствии условию. Если одна из таблиц содержит строки, которые не соответствуют этому условию, то данные строки не включаются в выходную выборку. Left Join выбирает все строки первой таблицы и затем присоединяет к ним строки правой таблицы. К примеру, возьмем таблицу Customers и добавим к покупателям информацию об их заказах:
Изменим в примере выше тип соединения на правостороннее:
SELECT FirstName, CreatedAt, ProductCount, Price, ProductId FROM Orders RIGHT JOIN Customers ON Orders.CustomerId = Customers.IdТеперь будут выбираться все строки из Customers, а к ним уже будет присоединяться связанные по условию строки из таблицы Orders:
Поскольку один из покупателей из таблицы Customers не имеет связанных заказов из Orders, то соответствующие столбцы, которые берутся из Orders, будут иметь значение NULL.
Используем левостороннее соединение для добавления к заказам информации о пользователях и товарах:
SELECT Customers.FirstName, Orders.CreatedAt, Products.ProductName, Products.Manufacturer FROM Orders LEFT JOIN Customers ON Orders.CustomerId = Customers.Id LEFT JOIN Products ON Orders.ProductId = Products.IdИли выберем всех пользователей из Customers, у которых нет заказов в таблице Orders:
SELECT FirstName FROM Customers LEFT JOIN Orders ON Customers.Id = Orders.CustomerId WHERE Orders.CustomerId IS NULLТакже можно комбинировать Inner Join и Outer Join:
SELECT Customers.FirstName, Orders.CreatedAt, Products.ProductName, Products.Manufacturer FROM Orders JOIN Products ON Orders.ProductId = Products.Id AND Products.Price < 45000 LEFT JOIN Customers ON Orders.CustomerId = Customers.Id ORDER BY Orders.CreatedAtВначале по условию к таблице Orders через Inner Join присоединяется связанная информация из Products, затем через Outer Join добавляется информация из таблицы Customers.
Cross Join
Cross Join или перекрестное соединение создает набор строк, где каждая строка из одной таблицы соединяется с каждой строкой из второй таблицы. Например, соединим таблицу заказов Orders и таблицу покупателей Customers:
SELECT * FROM Orders CROSS JOIN CustomersЕсли в таблице Orders 3 строки, а в таблице Customers то же три строки, то в результате перекрестного соединения создается 3 * 3 = 9 строк вне зависимости, связаны ли данные строки или нет.
При неявном перекрестном соединении можно опустить оператор CROSS JOIN и просто перечислить все получаемые таблицы:
SELECT * FROM Orders, Customersmetanit.com
SQL Full Join
FULL JOIN - возвращает строки, когда есть хоть одно совпадение в любой из таблиц.
Синтаксис SQL FULL JOIN
| 1 2 3 4 | SELECT column_name(s) FROM table_name1 FULL JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
Пример SQL FULL JOIN
Есть таблица "Persons":
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
Есть таблица "Orders":
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 1 |
| 4 | 24562 | 1 |
| 5 | 34764 | 15 |
Теперь мы хотим получить список всех людей и заказов.
Для этого используем такой запрос:
| 1 2 3 4 5 | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons FULL JOIN Orders ON Persons.P_Id=Orders.P_Id ORDER BY Persons.LastName |
Результат запроса:
| Hansen | Ola | 22456 |
| Hansen | Ola | 24562 |
| Pettersen | Kari | 77895 |
| Pettersen | Kari | 44678 |
| Svendson | Tove | |
| 34764 |
dimonchik.com
SQL Joins
SQL JOIN - используются для запроса данных из двух или нескольких таблиц связанных между собой ключами.
Ключом является столбец (или комбинация столбцов) с уникальным значением для каждой строки. Каждое значение первичного ключа должно быть уникальным в пределах таблицы. Цель состоит в том, чтобы связать данные всех таблиц вместе не повторяя все данные в каждой таблице.
Есть таблица "Persons":
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
Заметим, что столбец "P_Id" является первичным ключом в таблицы "Persons". Это означает - что никакие две строки могут иметь одинаковый "P_Id".
Есть таблица "Orders":
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 1 |
| 4 | 24562 | 1 |
| 5 | 34764 | 15 |
Заметим, что столбец "O_Id" является первичным ключом в таблицы "Orders" и что колонка "P_Id" относится к колонки "P_Id" в таблице "Persons".
Отметим, что связь между таблицами обеспечивается с помощью колонки "P_Id".
Различные SQL JOINs
Прежде чем приводить примеры, мы перечислим типы JOIN доступные к использованию и различия между ними.
- JOIN: Возвращает строки, когда есть хотя бы одно совпадение в обеих таблицах.
- LEFT JOIN: Возвращает строки из левой таблицы, даже если их нет правой таблице.
- RIGHT JOIN: Возвращает строки из правой таблицы, даже если их нет левой таблице.
- FULL JOIN: Возвращает строки, когда есть хоть одно совпадение в любой из таблиц.
dimonchik.com
Объяснение работы SQL JOIN на примере диаграмм Венна - Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Категории: Базы данных (mysql)
Использование синтаксиса SQL JOINS при работе с Базами данных достаточно популярно, без них не обходится любой серьезный SQL запрос. Я думал, что статья про SQL joins Ligaya Turmelle' великолепный примером для программистов-новчиков. Использование диаграмм Венна для объяснения их работы, вполне естественно и наглядно. Однако, комментируя ее статью, я обнаружил, что ее диаграммы Венна не вполне соответствовали синтаксису SQL join.
Я решил это разъяснить на примерах ниже. Предположим, что у нас есть две следующие таблицы. СлеваТаблица A, и таблица B справа. Поместим в каждой из них по 4 записи (строки).
id name id name -- ---- -- ---- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja
Давайте соединим эти таблицы с помощью SQL join по столбцу "name" несколькими способами и посмотрим как это будет выглядеть на диаграммах Венна.
|
SELECT * FROM TableA
INNER JOIN TableB
ON TableA.name = TableB.name
id name id name
-- ---- -- ----
1 Pirate 2 Pirate
3 Ninja 4 Ninja
Inner join (внутреннее присоединение) производит выбора только строк, которые есть и в таблице А и в таблице В.
|
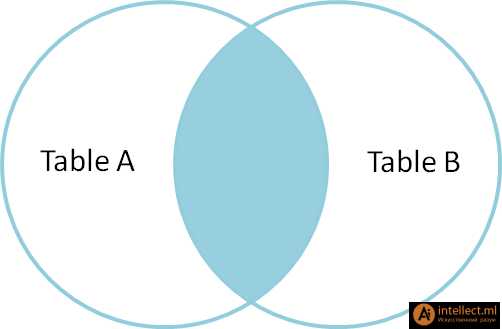 |
| SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name
id name id name
-- ---- -- ----
1 Pirate 2 Pirate
2 Monkey null null
3 Ninja 4 Ninja
4 Spaghetti null null
null null 1 Rutabaga
null null 3 Darth Vader
|
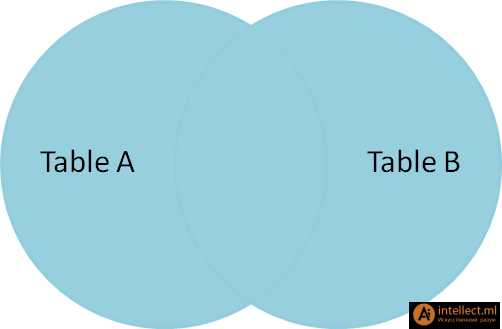 |
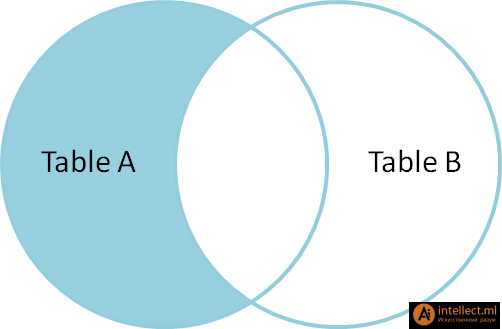
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name id name id name -- ---- -- ---- 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null Left outer join (левое внешнее соединение) производит выбор всех строк таблицы А с доступными строками таблицы В. Если строки таблицы В не найдены, то подставляется пустой результат (null).
|
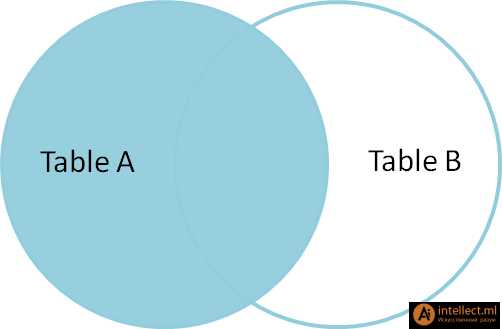 |
| SELECT * FROM TableA
LEFT OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableB.id IS null
id name id name
-- ---- -- ----
2 Monkey null null
4 Spaghetti null null
|
 |
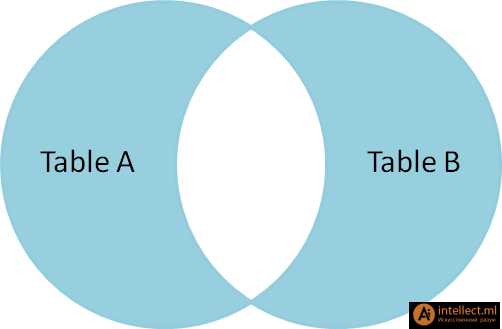
| SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableA.id IS null
OR TableB.id IS null
id name id name
-- ---- -- ----
2 Monkey null null
4 Spaghetti null null
null null 1 Rutabaga
null null 3 Darth Vader
Чтобы выбрать уникальные записи таблиц А и В, мы выполняем FULL OUTER JOIN, и затем исключаем записи, которые принадлежат и таблице А, и таблице Б с помощью условия WHERE. |
 |
Есть также декартовский соединение или CROSS JOIN, которое, насколько я могу сказать, не может быть выражено в диаграмме Венна:
SELECT * FROM TableA CROSS JOIN TableBОно соединяет "все со всеми", в результате мы получаем 4*4 = 16 строк, что намного больше, чем в оригинальных таблицах. Это очень опасно для таблиц, содержащих большое количество данных. То есть получаются ВСЕ возможные комбинации, включая все Null-null строчки.
выборка данных из верхней части матрицы (mysql выбрать уникальные пары)
SELECT fg.uid AS u1, fg2.uid as u2FROM data fg, data fg2 wherefg.uid!=fg2.uid and fg.uid <= fg2.uid
Категория: / Mine блог / PHP (LAMP)
Разберем пример. Имеем две таблицы: пользователи и отделы.U) users D) departmentsid name d_id id name-- ---- ---- -- ----1 Владимир 1 1 Сейлз2 Антон 2 2 Поддержка3 Александр 6 3 Финансы4 Борис 2 4 Логистика5 Юрий 4
SELECT u.id, u.name, d.name AS d_nameFROM users uINNER JOIN departments d ON u.d_id = d.id
Запрос вернет объединенные данные, которые пересекаются по условию, указанному в INNER JOIN ON <..>. В нашем случае условие <таблица_пользователей>.<идентификатор_отдела> должен совпадать с <таблица_отделов>.<идентификатор>
В результате отсутствуют:
- пользователь Александр (отдел 6 - не существует)- отдел Финансы (нет пользователей)
id name d_name-- -------- ---------1 Владимир Сейлз2 Антон Поддержка4 Борис Поддержка3 Юрий Логистика
рис. Inner join
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Выбираются только совпадающие данные из объединяемых таблиц. Чтобы получить данные, которые не подходят по условию, необходимо использовать
внешнее объединение - OUTER JOIN.
Такое объединение вернет данные из обеих таблиц совпадающими по одному из условий.
рис. Left join
Существует два типа внешнего объединения OUTER JOIN - LEFT OUTER JOIN и RIGHT OUTER JOIN.
Работают они одинаково, разница заключается в том что LEFT - указывает что "внешней" таблицей будет находящаяся слева (в нашем примере это таблица users). Ключевое слово OUTER можно опустить. Запись LEFT JOIN идентична LEFT OUTER JOIN.
SELECT u.id, u.name, d.name AS d_nameFROM users uLEFT OUTER JOIN departments d ON u.d_id = d.id
Получаем полный список пользователей и сопоставленные департаменты.
id name d_name-- -------- ---------1 Владимир Сейлз2 Антон Поддержка3 Александр NULL4 Борис Поддержка5 Юрий Логистика
Добавив условие
WHERE d.id IS NULL
в выборке останется только 3#Александр, так как у него не назначен департамент.
рис. Left outer join с фильтрацией по полю
RIGHT OUTER JOIN вернет полный список департаментов (правая таблица) и сопоставленных пользователей.
SELECT u.id, u.name, d.name AS d_nameFROM users uRIGHT OUTER JOIN departments d ON u.d_id = d.id
id name d_name-- -------- ---------1 Владимир Сейлз2 Антон Поддержка4 Борис ПоддержкаNULL NULL Финансы5 Юрий Логистика
Дополнительно можно отфильтровать данные, проверяя их на NULL.
SELECT d.id, d.nameFROM users uRIGHT OUTER JOIN departments d ON u.d_id = d.id WHERE u.id IS NULL
В нашем примере указав WHERE u.id IS null, мы выберем департаменты, в которых не числятся пользователи. (3#Финансы)
Все примеры вы можете протестировать здесь:
SQLFiddle
Self joins
Так называемая выборка с замыканием на себя (и совсем не closure). Нужна нам, если необходимо выбрать более одногозначения из таблицы для нескольких условий.
Имеем: набор фильтров для информации, значения которых сохраняются в табличке filts_data.Необходимо: фильтровать продукты по дате, артикулу и имеющимся фильтрам
CREATE TABLE filts_data( id serial NOT NULL, fid integer NOT NULL, -- product_item.id value integer NOT NULL, -- значение фильтра filts_items.id pid integer NOT NULL -- фильтр filts.id)
Есть таблица условных товаров product_item
CREATE TABLE product_item( id serial NOT NULL, section_id integer, date timestamp, art text, title text)
Пример: выбрать записи, добавленные после 17/01/2009 и с установленными фильтрами 3=14 и 4=15 и 6=19.Логика подскажет нам такой запрос (нерабочий):
SELECT p1.title FROM products_item p1 INNER JOIN filts_data p2 ON p1.id = p2.fid WHERE p1.date > '17.01.2009' AND (p2.pid = 3 AND p2.value = 14) AND (p2.pid = 4 AND p2.value = 15) AND (p2.pid = 6 AND p2.value = 19)
Этот запрос не найдет элементов в таблице.Перепишем запрос, используя join на себя:
SELECT p1.* FROM product_item p1 INNER JOIN filts_data p2 ON p1.id = p2.fid INNER JOIN filts_data p3 ON p1.id = p3.fid INNER JOIN filts_data p4 ON p1.id = p4.fid WHERE p1.date > '17.01.2009' AND (p2.pid = 3 AND p2.value = 14) AND (p3.pid = 4 AND p3.value = 15) AND (p4.pid = 6 AND p4.value = 19)
В этом случае мы получим записи, для которых установлены все три фильтра и дата добавления позднее заданной.
подитожим
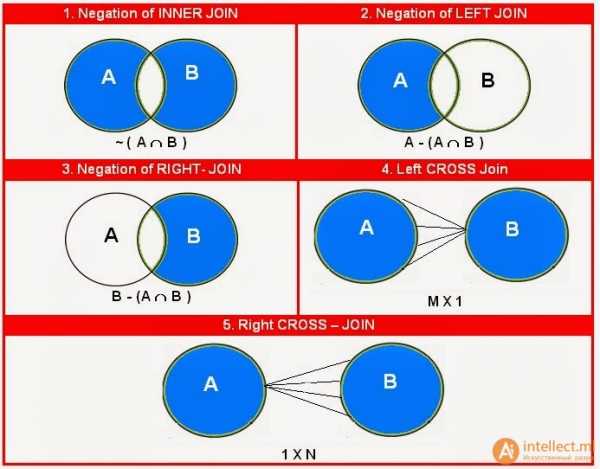
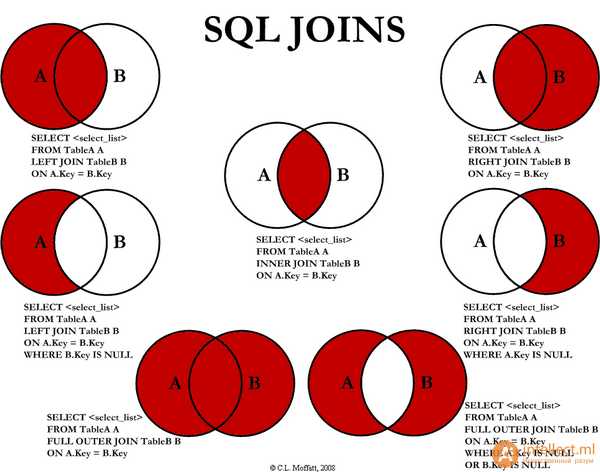
JOIN: возвращаются строки, когда есть хотя бы одно совпадение в обеих таблицах.LEFT JOIN: возвращаются все строки из левой таблицы, даже если нет совпадений в таблице справаRIGHT JOIN: возвращаются все строки из правой таблицы, даже если нет совпадений в таблице слеваFULL JOIN: возвращаются строки, когда есть совпадение в одной из таблицЕще есть CROSS JOIN - декартово произведение двух таблиц, но он используется крайне редко.
intellect.ml
SQL optimization. Join против In и Exists. Что использовать?
«Раньше было проще» — Подумал я, садясь за оптимизацию очередного запроса в SQL management studio. Когда я писал под MySQL, реально все было проще — или работает, или нет. Или тормозит или нет. Explain решал все мои проблемы, больше ничего не требовалось. Сейчас у меня есть мощная среда разработки, отладки и оптимизации запросов и процедур/функций, и все это нагромождение создает по-моему только больше проблем. А все почему? Потому что встроенный оптимизатор запросов — зло. Если в MySQL и PostgreSQL я напишу
select * from a, b, c where a.id = b.id, b.id = c.idи в каждой из табличек будет хотя бы по 5к строк — все зависнет. И слава богу! Потому что иначе в разработчике, в лучшем случае, вырабатывается ленность писать правильно, а в худшем он вообще не понимает что делает! Ведь этот же запрос в MSSQL пройдет аналогично
select * from a join b on a.id = b.id join c on b.id = c.idВстроенный оптимизатор причешет быдлозапрос и все будет окей.
Он так же сам решит, что лучше делать — exist или join и еще много чего. И все будет работать максимально оптимально.
Только есть одно НО. В один прекрасный момент оптимизатор споткнется о сложный запрос и спасует, и тогда вы получите большущую проблему. И получите вы ее, возможно, не сразу, а когда вес таблиц достигнет критической массы.
Так вот к сути статьи. exists и in — очень тяжелые операции. Фактически это отдельный подзапрос для каждой строчки результата. А если еще и присутствует вложенность, то это вообще туши свет. Все будет окей, когда возвращается 1, 10, 50 строк. Вы не почувствуете разницы, а возможно join будет даже медленнее. Но когда вытаскивается 500 — начнутся проблемы. 500 подзапросов в рамках одного запроса — это серьезно.
Пусть с точки зрения человеческого понимания in и exists лучше, но с точки зрения временных затрат для запросов, возвращающих 50+ строк — они не допустимы.
Нужно оговориться, что естественно, если где-то убывает — где-то должно прибывать. Да, join более ресурсоемок по памяти, ведь держать единовременно всю таблицу значений и оперировать ею — накладнее, чем дергать подзапросы для каждой строки, быстро освобождая память. Нужно смотреть конкретно по запросу и замерять — критично ли будет использование лишней памяти в угоду времени или нет.
Приведу примеры полных аналогий. Вообще говоря, я не встречал еще запросов такой степени сложности, которые не могли бы быть раскручены в каскад join’ов. Пусть на это уйдет день, но все можно раскрыть.
select * from a where a.id in (select id from b) select * from a where exists (select top 1 1 from b where b.id = a.id) select * from a join b on a.id = b.id select * from a where a.id not in (select id from b) select * from a where not exists (select top 1 1 from b where b.id = a.id) select * from a left join b on a.id = b.id where b.id is nullПовторюсь — данные примеры MSSQL оптимизатор оптимизирует под максимальную производительность и на таких простейших запросах тупняков не будет никогда.
Рассмотрим теперь пример реального запроса, который пришлось переписывать из-за того что на некоторых выборках он просто намертво зависал (структура очень упрощена и понятия заменены, не нужно пугаться некоей не оптимальности структуры бд).
Нужно вытащить все дубликаты «продуктов» в разных аккаунтах, ориентируясь на параметры продукта, его группы, и группы-родителя, если таковая есть.
select d.PRODUCT_ID from PRODUCT s, PRODUCT_GROUP sg left join M_PG_DEPENDENCY sd on (sg.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID), PRODUCT d, PRODUCT_GROUP dg left join M_PG_DEPENDENCY dd on (dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID) where s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID and d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME and s.PRODUCT_NAME=d.PRODUCT_NAME and s.PRODUCT_TYPE=d.PRODUCT_TYPE and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT and dg.PRODUCT_GROUP_IS_TMPL=0 and ( ( sd.M_PG_DEPENDENCY_CHILD_ID is null and dd.M_PG_DEPENDENCY_CHILD_ID is null ) or exists ( select 1 from PRODUCT_GROUP sg1, PRODUCT_GROUP dg1 where sd.M_PG_DEPENDENCY_PARENT_ID = sg1.PRODUCT_GROUP_ID and dd.M_PG_DEPENDENCY_PARENT_ID = dg1.PRODUCT_GROUP_ID and sg1.PRODUCT_GROUP_PERSPEC=dg1.PRODUCT_GROUP_PERSPEC and sg1.PRODUCT_GROUP_NAME=dg1.PRODUCT_GROUP_NAME and ) )Так вот это тот случай, когда оптимизатор спасовал. И для каждой строчки выполнялся тяжеленный exists, что убивало базу.
select d.PRODUCT_ID from PRODUCT s join PRODUCT d on s.PRODUCT_TYPE=d.PRODUCT_TYPE and s.PRODUCT_NAME=d.PRODUCT_NAME and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT join PRODUCT_GROUP sg on s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID join PRODUCT_GROUP dg on d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC left join M_PG_DEPENDENCY sd on sg.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID left join M_PG_DEPENDENCY dd on dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID left join PRODUCT_GROUP sgp on sgp.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_PARENT_ID left join PRODUCT_GROUP dgp on dgp.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_PARENT_ID and sgp.PRODUCT_GROUP_NAME = dgp.PRODUCT_GROUP_NAME and isnull(sgp.PRODUCT_GROUP_IS_TMPL, 0) = isnull(dgp.PRODUCT_GROUP_IS_TMPL, 0) where ( sd.M_PG_DEPENDENCY_CHILD_ID is null and dd.M_PG_DEPENDENCY_CHILD_ID is null ) or ( sgp.PRODUCT_GROUP_NAME is not null and dgp.PRODUCT_GROUP_NAME is not null ) goПосле данных преобразований производительность вьюхи увеличилась экспоненциально количеству найденных продуктов. Вернее сказать, время поиска оставалось практически независимым от числа совпадений и было всегда очень маленьким. Как и должно быть.
Это наглядный пример того, как доверие MSSQL оптимизатору может сыграть злую шутку. Не доверяйте ему, не ленитесь, join’те ручками, каждый раз думайте что лучше в данной ситуации — exists, in или join.
kocherov.net