Пример Unpivot / Pivot SQL-Server. Пример unpivot sql
PIVOT и UNPIVOT в Transact-SQL – описание и примеры использования операторов | Info-Comp.ru
Сегодня мы поговорим о таких операторах Transact-SQL как PIVOT и UNPIVOT, узнаем, для чего они нужны, рассмотрим синтаксис написания запросов, и, конечно же, разберем примеры использования их на практике.
В Transact-SQL для написания перекрестных запросов или кросс табличных выражений существует специальный оператор, я бы сказал даже целая конструкция под названием PIVOT, которая имеет достаточно специфический синтаксис, также существует оператор, который делает и обратное действие он называется как не странно UNPIVOT. Эти операторы мы сейчас подробно рассмотрим, и для начала давайте я расскажу, как будет выглядеть данная статья.
Сначала мы поговорим об операторе PIVOT, узнаем, что он делает, для чего он нужен, где он может пригодиться, рассмотрим синтаксис и разберем пример, а затем мы перейдем к оператору UNPIVOT.
Примечание! Все примеры мы будем рассматривать в СУБД MS SQL Server 2014 Express с использованием Management Studio.
Оператор PIVOT
PIVOT – это оператор Transact-SQL, который поворачивает результирующий набор данных, т.е. происходит транспонирование таблицы, при этом используются агрегатные функции, и данные соответственно группируются. Другими словами, значения, которые расположены по вертикали, мы выстраиваем по горизонтали.
Данный оператор может потребоваться тогда, когда необходимо, например, предоставить какой либо отчет в наглядной форме по годам, допустим для бухгалтеров и экономистов, так как именно они любят представления данных в таком виде. Также он может пригодиться и просто для преставления какой-либо статистики, но в любом случае из собственного опыта могу сказать, что оператор PIVOT будет требоваться достаточно редко, но когда он потребуется он будет просто незаменим и очень полезен, поэтому Вы должны знать, как и когда его можно использовать.
Результат, который мы получим при использовании оператора PIVOT, можно также получить и с использованием известной конструкции select…case, а до появления MS SQL сервера 2005 только с использованием этой конструкции, как Вы правильно поняли, оператор PIVOT можно использовать, только начиная с 2005 sql сервера.
У данного оператора очень специфический, непривычный и некоторые даже скажут сложный синтаксис, как для написания, так и для простого понимания.
Синтаксис оператора PIVOT
SELECT столбец для группировки, [значения по горизонтали],…
FROM таблица или подзапрос
PIVOT(агрегатная функция
FOR столбец, содержащий значения, которые станут именами столбцов
IN ([значения по горизонтали],…)
)AS псевдоним таблицы (обязательно)
в случае необходимости ORDER BY;
Вот такой вот синтаксис, помимо всего прочего значения, которые будут выступать в качестве названия колонок по горизонтали, необходимо писать вручную, т.е. мы должны знать их заранее, другими словами, динамический запрос построить, не получиться. На самом деле можно, с помощью динамического формирования строки запроса, а потом исполнение этой строки через специальную команду EXECUTE, но как говорится это уже совсем другая история (для начинающих рекомендую прочитать наш справочник по Transact-SQL).
Пример использования оператора PIVOT
С теорией я думаю достаточно, поэтому давайте переходить к практике, тем более что на примерах лучше понять, как же работает этот оператор.
И для начала давайте разберем исходные данные.
Допустим, у нас есть таблица вот с такой структурой:
CREATE TABLE [dbo].[test_table_pivot]( [fio] [varchar](50) NULL, [god] [int] NULL, [summa] [float] NULL ) ON [PRIMARY] GOГде, fio - это ФИО сотрудника, god – год, в котором он получал премию, summa - соответственно сумма премии, вот такой незамысловатый пример, так как в плоскости времени наглядней видна работа оператора PIVOT.
И в данной таблице у нас есть тестовые данные, для просмотра этих данных напишем простой запрос на выборку, т.е. select
SELECT * FROM dbo.test_table_pivot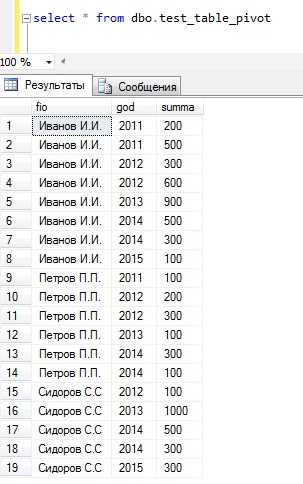
А теперь представим, что нам необходимо сделать отчет, скажем для начальника, о размере премии, которую получал каждый сотрудник за год, в течение нескольких лет.
Самым простым способом будет конечно просто использовать конструкцию GROUP BY, например
SELECT fio, god, sum(summa) AS summa FROM dbo.test_table_pivot GROUP BY fio, god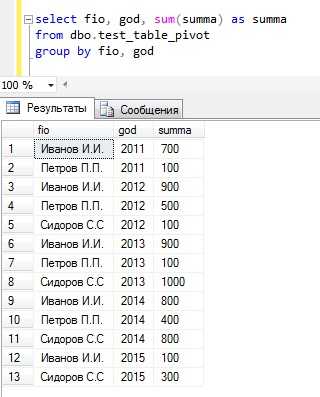
На что нам начальник скажет, что это такое? ничего не понятно? не наглядно? Улучшить ситуацию можно, добавив еще и сортировку ORDER BY, допустим сначала по фамилии, а затем по году
SELECT fio, god, sum(summa) as summa FROM dbo.test_table_pivot GROUP BY fio, god ORDER BY fio, godно это все равно не то. А вот если мы будем использовать оператор PIVOT, например вот таким образом
SELECT fio, [2011], [2012], [2013], [2014], [2015] FROM dbo.test_table_pivot PIVOT (SUM(summa)for god in ([2011],[2012],[2013],[2014],[2015]) ) AS test_pivotто у нас получится вот такой результат
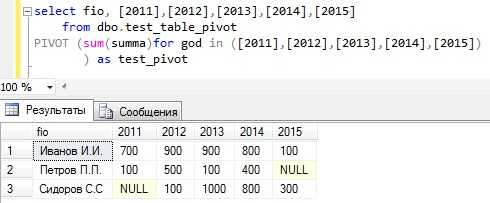
Я думаю, Вы согласитесь, что так намного наглядней и понятней.
Здесь у нас:
- fio - столбец, по которому мы будем осуществлять группировку;
- [2011],[2012],[2013],[2014],[2015] - названия наших столбцов по горизонтали, ими выступают значения из колонки god;
- sum(summa) - агрегатная функция по столбцу summa;
- for god in ([2011],[2012],[2013],[2014],[2015]) - тут мы указываем колонку, в которой содержатся значения, которые будут выступать в качестве названия наших результирующих столбцов, по факту в скобках мы указываем то же самое, что и чуть выше в select;
- as test_pivot - это обязательный псевдоним, не забывайте его указывать, иначе будет ошибка.
Переходим к UNPIVOT.
Оператор UNPIVOT
UNPIVOT – это оператор Transact-SQL, который выполняет действия, обратные PIVOT. Сразу скажу, что да он разворачивает таблицу в обратную сторону, но в отличие от оператора PIVOT он ничего не агрегирует и уж тем более не раз агрегирует.
UNPIVOT требуется еще реже, чем PIVOT, но о нем также необходимо знать.
Здесь я думаю, давайте сразу перейдем к рассмотрению примера.
Пример использования UNPIVOT
Допустим, таблица имеет следующую структуру:
CREATE TABLE [dbo].[test_table_unpivot]( [fio] [varchar](50) NULL, [number1] [int] NULL, [number2] [int] NULL, [number3] [int] NULL, [number4] [int] NULL, [number5] [int] NULL, ) ON [PRIMARY] GOГде, fio - ФИО сотрудника, а number1, number2… и так далее это какие-то номера этого сотрудника:)
Данные будут, например, такие:
И допустим, нам необходимо развернуть эту таблицу, для этого мы будем использовать оператор UNPIVOT, а запрос будет выглядеть следующим образом:
SELECT fio, column_name, number FROM dbo.test_table_unpivot UNPIVOT( number for column_name in ( [number1],[number2],[number3],[number4],[number5] ) )AS test_unpivot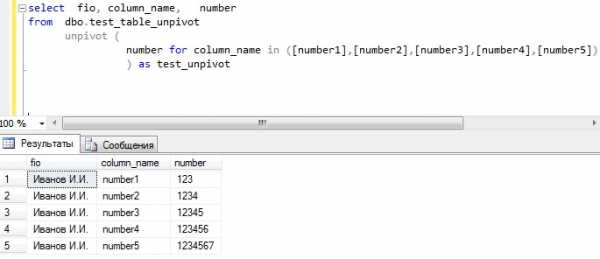
Где,
- fio – столбец с ФИО, он в принципе не изменился;
- column_name – псевдоним столбца, который будет содержать названия наших колонок;
- number – псевдоним для значений из столбцов number1, number2…
Заметка! Начинающим программистам рекомендую почитать мою книгу «Путь программиста T-SQL. Самоучитель по языку Transact-SQL», в ней я подробно, с большим количеством примеров, рассказываю про другие возможности языка Transact-SQL.
На этом все, удачи!
Похожие статьи:
info-comp.ru
UNPIVOT / Хабр
За время моей работы, я сталкивался с широким кругом задач. Одни задачи требовали монотонной работы, другие сводились к чистому креативу.Оптимизация – это, в первую очередь, поиск оптимального плана запроса. Однако, что делать в ситуации, когда стандартная конструкция языка выдает план, который очень далек от оптимального?
С такого рода проблемой я столкнулся, когда применял конструкцию UNPIVOT для преобразования столбцов в строки.
Путем небольшого сравнительного анализа, для UNPIVOT была найдена более эффективная альтернатива. Чтобы задача не казалось абстрактной, предположим, что в нашем распоряжении таблица, содержащая информацию о количестве медалей среди пользователей.
IF OBJECT_ID('dbo.UserBadges', 'U') IS NOT NULL DROP TABLE dbo.UserBadges GO CREATE TABLE dbo.UserBadges ( UserID INT , Gold SMALLINT NOT NULL , Silver SMALLINT NOT NULL , Bronze SMALLINT NOT NULL , CONSTRAINT PK_UserBadges PRIMARY KEY (UserID) ) INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze) VALUES (1, 5, 3, 1), (2, 0, 8, 1), (3, 2, 4, 11) Взяв за основу эту таблицу, приведем различные методы преобразования столбцов в строки, а также планы их выполнения.
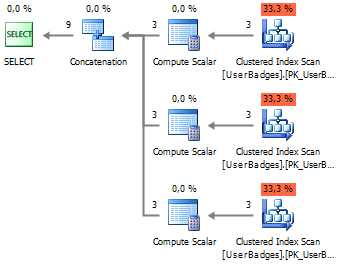
1. UNION ALL
В свое время, SQL Server 2000 не предоставлял эффективного способа преобразовывать столбцы в строки. Вследствие чего широко практиковалась практика многократной выборки из одной и той же таблицы, но с разным набором столбцов, объединенных через конструкцию UNION ALL:SELECT UserID, BadgeCount = Gold, BadgeType = 'Gold' FROM dbo.UserBadges UNION ALL SELECT UserID, Silver, 'Silver' FROM dbo.UserBadges UNION ALL SELECT UserID, Bronze, 'Bronze' FROM dbo.UserBadges Огромным минус этого подхода — повторные чтения данных, которые существенно снижали эффективность при выполнения такого запроса. Если взглянуть на план выполнения, то в этом можно легко убедится:
2. UNPIVOT
С релизом SQL Server 2005, стало возможным использовать новую конструкцию языка T-SQL – UNPIVOT.Применяя UNPIVOT предыдущий запрос можно упростить до:
SELECT UserID, BadgeCount, BadgeType FROM dbo.UserBadges UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt При выполнении мы получим следующий план:3. VALUES
Начиная с SQL Server 2008 стало возможным использовать конструкцию VALUES не только для создания многострочных INSERT запросов, но и внутри блока FROM.4. Dynamic SQL
Применяя динамический SQL, есть возможность создать «универсальный» запрос для любой таблицы. Главное условие при этом — столбцы, которые не входят в состав первичного ключа, должны иметь совместимые между собой типы данных.Узнать список таких столбцов можно следующим запросом:
SELECT c.name FROM sys.columns c WITH(NOLOCK) LEFT JOIN ( SELECT i.[object_id], i.column_id FROM sys.index_columns i WITH(NOLOCK) WHERE i.index_id = 1 ) i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id WHERE c.[object_id] = OBJECT_ID('dbo.UserBadges', 'U') AND i.[object_id] IS NULL Если посмотреть на план запроса, можно заметить, что соединение с sys.index_columns является достаточно затратной:Чтобы избавится от этого соединения можно воспользоваться функцией INDEX_COL. В результате итоговый вариант запроса примет следующий вид:

5. XML
Более элегантно реализовать динамический UNPIVOT возможно, если использовать следующий трюк с XML:SELECT p.UserID , BadgeCount = t.c.value('.', 'INT') , BadgeType = t.c.value('local-name(.)', 'VARCHAR(10)') FROM ( SELECT UserID , [XML] = ( SELECT Gold, Silver, Bronze FOR XML RAW('t'), TYPE ) FROM dbo.UserBadges ) p CROSS APPLY p.[XML].nodes('t/@*') t(c) В котором для каждой строки формируется XML вида:<t Column1="Value1" Column2="Value2" Column3="Value3" ... /> После чего парсится имя каждого атрибута и его значения.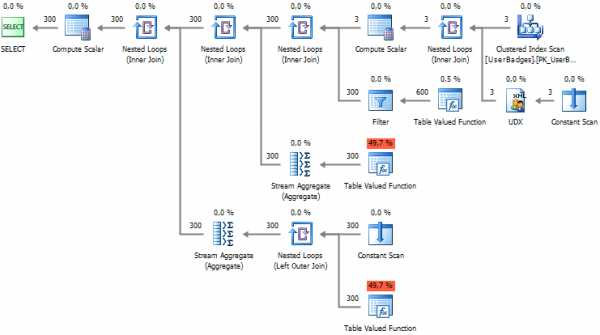
Теперь сравним полученные результаты:
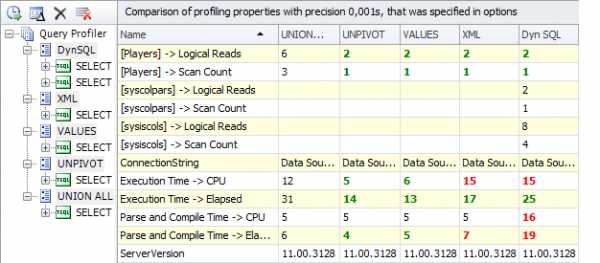
Кардинальной разницы в скорости выполнения между UNPIVOT и VALUES не наблюдается. Это утверждение верно, если речь идет о простом преобразовании столбцов в строки.
Усложним задачу и рассмотрим другой вариант, где по каждому пользователю необходимо узнать тип медалей, которых у него больше всего.
Попробуем решить задачу применяя конструкцию UNPIVOT:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM dbo.UserBadges b2 UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt WHERE UserID = b.UserID ORDER BY BadgeCount DESC ) FROM dbo.UserBadges b На плане выполнения видно, что проблема наблюдается в повторном чтении данных и сортировке, которая необходима для упорядочивания данных: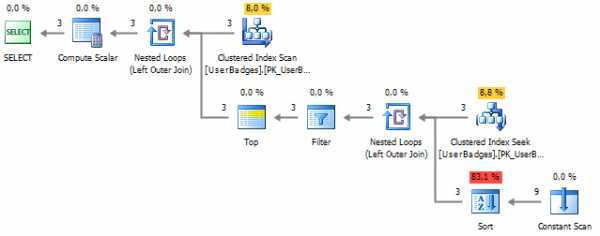
Избавится от повторного чтения достаточно легко, если вспомнить, что в подзапросе допускается использовать столбцы из внешнего блока:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM (SELECT t = 1) t UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt ORDER BY BadgeCount DESC ) FROM dbo.UserBadges Повторные чтения ушли, но операция сортировки никуда не делась:Посмотрим как ведет себя конструкция VALUES в данной задаче:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) ORDER BY BadgeCount DESC ) FROM dbo.UserBadges План ожидаемо упростился, но сортировка по-прежнему присутствует в плане:Попробуем обойти сортировку используя аггрегирующую функцию:
SELECT UserID , BadgeType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) WHERE BadgeCount = ( SELECT MAX(Value) FROM ( VALUES (Gold), (Silver), (Bronze) ) t(Value) ) ) FROM dbo.UserBadges Мы избавились от сортировки: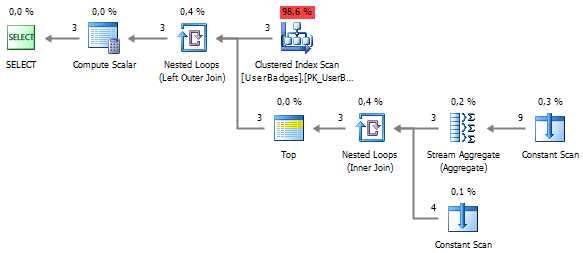
Небольшие итоги:
В ситуации, когда необходимо произвести простое преобразование столбцов в строки, то наиболее предпочтительно использовать конструкции UNPIVOT или VALUES.
Если после преобразования, полученные данные планируется использовать в операциях агрегирования или сортировки, то более предпочтительно использовать именно конструкцию VALUES, которая, в большинстве случаев, позволяет получать более эффективные планы выполнения.
Если число столбцов в таблицы переменчиво, рекомендуется использовать XML, который в отличии от динамического SQL можно использовать внутри табличных функций.
P.S. Чтобы адаптировать, часть примеров под особенности SQL Server 2005, конструкцию с применением VALUES:
SELECT * FROM ( VALUES (1, 'a'), (2, 'b') ) t(id, value) необходимо заменить на комбинацию SELECT UNION ALL SELECT:SELECT id = 1, value = 'a' UNION ALL SELECT 2, 'b' UPDATE 16/10/2013: Как ведут себя UNPIVOT и VALUES на больших объемах данных?За основу взята таблица со следующей структурой (всего 25 столбцов).
CREATE TABLE [dbo].[WorkOutFactors] ( WorkOutID BIGINT NOT NULL PRIMARY KEY, NightHours INT NOT NULL, EveningHours INT NOT NULL, HolidayHours INT NOT NULL, ... ) Данная таблица содержит ~186000 строк. С холодного старта на локальном SQL Server 2012 SP1, операция преобразования строк в столбцы дала следующие результаты.План выполнения UNPIVOT:
План выполнения VALUES:
В сравнении видно, что VALUES выполняется быстрее (на 3 секунды), но требует больших ресурсов CPU:
От себя добавлю, что в каждой конкретной ситуации разница в производительности будет различаться.
habr.com
sql - Пример Unpivot/Pivot SQL-Server
Я делаю заявку на управление бронированием гостиниц, и мне нужно показать уровень оплаты за месяц в год. Я сделал запрос, который разрешает проблему, но я хочу представить ее в другом формате.
Мой текущий запрос возвращает следующую таблицу (2x12):
January|February|March|April| ..... and so on 20 15 18 20 ..... and so onИ я хочу что-то вроде этого (12x2):
January|20 February|15 March|18 ... |...Это мой запрос:
Select SUM(CASE WHEN datename(month, [CheckIn]) = 'January' or datename(month, [CheckOut]) = 'January' THEN 1 ELSE 0 END) January, SUM(CASE WHEN datename(month, [CheckIn]) = 'February' or datename(month, [CheckOut]) = 'February' THEN 1 ELSE 0 END) February, SUM(CASE WHEN datename(month, [CheckIn]) = 'March' or datename(month, [CheckOut]) = 'March' THEN 1 ELSE 0 END) March, SUM(CASE WHEN datename(month, [CheckIn]) = 'April' or datename(month, [CheckOut]) = 'April' THEN 1 ELSE 0 END) April, SUM(CASE WHEN datename(month, [CheckIn]) = 'May' or datename(month, [CheckOut]) = 'May' THEN 1 ELSE 0 END) May, SUM(CASE WHEN datename(month, [CheckIn]) = 'June' or datename(month, [CheckOut]) = 'June' THEN 1 ELSE 0 END) June, SUM(CASE WHEN datename(month, [CheckIn]) = 'July' or datename(month, [CheckOut]) = 'July' THEN 1 ELSE 0 END) July, SUM(CASE WHEN datename(month, [CheckIn]) = 'August' or datename(month, [CheckOut]) = 'August' THEN 1 ELSE 0 END) August, SUM(CASE WHEN datename(month, [CheckIn]) = 'September' or datename(month, [CheckOut]) = 'September' THEN 1 ELSE 0 END) September, SUM(CASE WHEN datename(month, [CheckIn]) = 'October' or datename(month, [CheckOut]) = 'October' THEN 1 ELSE 0 END) October, SUM(CASE WHEN datename(month, [CheckIn]) = 'November' or datename(month, [CheckOut]) = 'November' THEN 1 ELSE 0 END) November, SUM(CASE WHEN datename(month, [CheckIn]) = 'December' or datename(month, [CheckOut]) = 'December' THEN 1 ELSE 0 END) December FROM {Booking} INNER JOIN {Status} ON {Booking}.[StatusId] = {Status}.[Id] WHERE {Booking}.[CheckIn] >= @BeginDate AND {Booking}.[CheckOut] <= @EndDate AND {Status}.[Label] <> 'Canceled'Любая помощь будет оценена, я застрял, и theres не так много информации в Интернете, спасибо!
qaru.site
Операторы PIVOT и UNPIVOT
Pivot и unpivot являются нестандартными реляционными операторами, которые поддерживаются Transact-SQL. Вы можете их использовать для манипулирования выражением табличного значения в другой таблице, pivot преобразует такое значение, возвращая уникальные значения одного столбца этого выражения в виде множества столбцов, и выполняет агрегирование любых остальных значений столбца, которые нужны в результирующем выводе.
В примере 24.24 показано, как работает pivot.
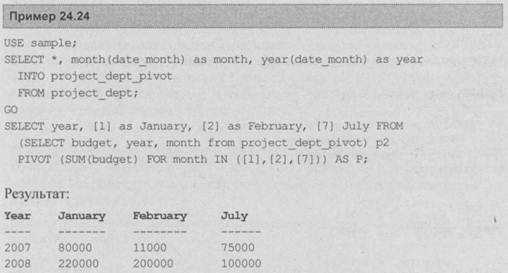
В первой части примера 24.24 создается новая таблица, project_dept_pivot, которая будет использована для демонстрации того, как работает оператор pivot. Эта таблица идентична таблице projectdept (введенной в примере 24.1), за исключением двух дополнительных столбцов: month и year. Столбец month таблицы projectdeptpivot содержит годы 2007 и 2008, которые появляются в столбце date_month таблицы projectdept. Также столбцы month таблицы project_dept_pivot (January, February и July) содержат итоговые значения бюджетов, соответствующие этим месяцам в таблице projectdept.
Второй оператор select содержит внутренний запрос, который встроен в предложение from внешнего запроса. Предложение pivot является частью внутреннего запроса. Оно начинается с задания агрегатной функции sum (суммы бюджетов). Вторая часть задает основной столбец (month) и значения этого столбца, которые будут использоваться в качестве заголовков столбца (в примере 24.24 это первый, второй и седьмой месяц года). Значение конкретного столбца в строке вычисляется с использованием заданной агрегатной функции над строками, которые соответствуют заголовку столбца.
Оператор unpivot выполняет реверсирование операции pivot путем циклического сдвига столбцов в строках. В примере 24.25 показано использование этого оператора.
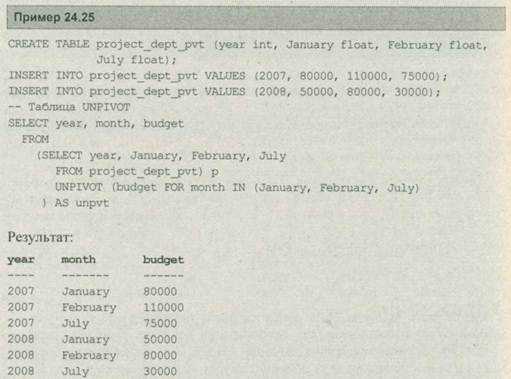
В примере 24.25 используется таблица project_dept_part для демонстрации реляционного оператора unpivot. Первыми входными данными unpivot является имя столбца (budget), который содержит нормализованные значения.
После этого опция for применяется для определения имени целевого столбца (month). Под конец в качестве части опции in указываются выбранные значения целевого столбца.
serversql.ru
sql - Синтаксис SQL Query & unpivot
Вам не нужно использовать UNPIVOT для этого запроса. UNPIVOT используется для преобразования нескольких столбцов в несколько строк. Вам нужно всего лишь применить функцию PIVOT, чтобы превратить ваши элементы в столбцы.
Сначала я предложил бы использовать функцию windowing, такую как row_number() чтобы создать новые заголовки столбцов, а затем применить функцию PIVOT:
select id, name, Item1, Item2, Item3 from ( select members.id, members.name, items.name as item, 'item'+ cast(row_number() over(partition by members.id order by members.id) as varchar(10)) col from members Left Join member_permission On memberID = members.id Left Join items On items.id = member_permission.itemID ) d pivot ( max(item) for col in (Item1, Item2, Item3) ) piv;См. SQL Fiddle with Demo. Тогда, если у вас есть неизвестное количество значений, ваш запрос должен будет использовать динамический SQL:
DECLARE @cols AS NVARCHAR(MAX), @query AS NVARCHAR(MAX) select @cols = STUFF((SELECT ',' + QUOTENAME('item'+cast(seq as varchar(10))) from ( select row_number() over(partition by memberid order by memberid) seq from member_permission ) d group by seq order by seq FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') ,1,1,'') set @query = N'SELECT id, name, ' + @cols + N' from ( select members.id, members.name, items.name as item, ''item''+ cast(row_number() over(partition by members.id order by members.id) as varchar(10)) col from members Left Join member_permission On memberID = members.id Left Join items On items.id = member_permission.itemID ) x pivot ( max(item) for col in (' + @cols + N') ) p ' execute sp_executesql @query;См. SQL Fiddle with Demo
qaru.site
Пример Unpivot / Pivot SQL-Server MS SQL Server
Я делаю заявку на управление бронированием гостиниц, и мне нужно показать уровень оплаты за месяц в год. Я сделал запрос, который разрешает проблему, но я хочу представить ее в другом формате.
Мой текущий запрос возвращает следующую таблицу (2×12):
January|February|March|April| ..... and so on 20 15 18 20 ..... and so onИ я хочу что-то вроде этого (12×2):
January|20 February|15 March|18 ... |...Это мой запрос:
Select SUM(CASE WHEN datename(month, [CheckIn]) = 'January' or datename(month, [CheckOut]) = 'January' THEN 1 ELSE 0 END) January, SUM(CASE WHEN datename(month, [CheckIn]) = 'February' or datename(month, [CheckOut]) = 'February' THEN 1 ELSE 0 END) February, SUM(CASE WHEN datename(month, [CheckIn]) = 'March' or datename(month, [CheckOut]) = 'March' THEN 1 ELSE 0 END) March, SUM(CASE WHEN datename(month, [CheckIn]) = 'April' or datename(month, [CheckOut]) = 'April' THEN 1 ELSE 0 END) April, SUM(CASE WHEN datename(month, [CheckIn]) = 'May' or datename(month, [CheckOut]) = 'May' THEN 1 ELSE 0 END) May, SUM(CASE WHEN datename(month, [CheckIn]) = 'June' or datename(month, [CheckOut]) = 'June' THEN 1 ELSE 0 END) June, SUM(CASE WHEN datename(month, [CheckIn]) = 'July' or datename(month, [CheckOut]) = 'July' THEN 1 ELSE 0 END) July, SUM(CASE WHEN datename(month, [CheckIn]) = 'August' or datename(month, [CheckOut]) = 'August' THEN 1 ELSE 0 END) August, SUM(CASE WHEN datename(month, [CheckIn]) = 'September' or datename(month, [CheckOut]) = 'September' THEN 1 ELSE 0 END) September, SUM(CASE WHEN datename(month, [CheckIn]) = 'October' or datename(month, [CheckOut]) = 'October' THEN 1 ELSE 0 END) October, SUM(CASE WHEN datename(month, [CheckIn]) = 'November' or datename(month, [CheckOut]) = 'November' THEN 1 ELSE 0 END) November, SUM(CASE WHEN datename(month, [CheckIn]) = 'December' or datename(month, [CheckOut]) = 'December' THEN 1 ELSE 0 END) December FROM {Booking} INNER JOIN {Status} ON {Booking}.[StatusId] = {Status}.[Id] WHERE {Booking}.[CheckIn] >= @BeginDate AND {Booking}.[CheckOut] <= @EndDate AND {Status}.[Label] <> 'Canceled'Любая помощь будет оценена, я застрял, и theres не так много информации в Интернете, спасибо!
Solutions Collecting From Web of "Пример Unpivot / Pivot SQL-Server"
Похоже, вы пытаетесь сделать UNPIVOT :
SELECT Month, CheckIns FROM (Select SUM(CASE WHEN datename(month, [CheckIn]) = 'January' or datename(month, [CheckOut]) = 'January' THEN 1 ELSE 0 END) January, SUM(CASE WHEN datename(month, [CheckIn]) = 'February' or datename(month, [CheckOut]) = 'February' THEN 1 ELSE 0 END) February, SUM(CASE WHEN datename(month, [CheckIn]) = 'March' or datename(month, [CheckOut]) = 'March' THEN 1 ELSE 0 END) March, SUM(CASE WHEN datename(month, [CheckIn]) = 'April' or datename(month, [CheckOut]) = 'April' THEN 1 ELSE 0 END) April, SUM(CASE WHEN datename(month, [CheckIn]) = 'May' or datename(month, [CheckOut]) = 'May' THEN 1 ELSE 0 END) May, SUM(CASE WHEN datename(month, [CheckIn]) = 'June' or datename(month, [CheckOut]) = 'June' THEN 1 ELSE 0 END) June, SUM(CASE WHEN datename(month, [CheckIn]) = 'July' or datename(month, [CheckOut]) = 'July' THEN 1 ELSE 0 END) July, SUM(CASE WHEN datename(month, [CheckIn]) = 'August' or datename(month, [CheckOut]) = 'August' THEN 1 ELSE 0 END) August, SUM(CASE WHEN datename(month, [CheckIn]) = 'September' or datename(month, [CheckOut]) = 'September' THEN 1 ELSE 0 END) September, SUM(CASE WHEN datename(month, [CheckIn]) = 'October' or datename(month, [CheckOut]) = 'October' THEN 1 ELSE 0 END) October, SUM(CASE WHEN datename(month, [CheckIn]) = 'November' or datename(month, [CheckOut]) = 'November' THEN 1 ELSE 0 END) November, SUM(CASE WHEN datename(month, [CheckIn]) = 'December' or datename(month, [CheckOut]) = 'December' THEN 1 ELSE 0 END) December FROM {Booking} INNER JOIN {Status} ON {Booking}.[StatusId] = {Status}.[Id] WHERE {Booking}.[CheckIn] >= @BeginDate AND {Booking}.[CheckOut] <= @EndDate AND {Status}.[Label] <> 'Canceled' ) monthTotals UNPIVOT (CheckIns FOR Month IN (January, February, March, April, May, June, July, August, September, October, November, December) ) AS upvtВот упрощенная SQLFiddle этого
И вот страница документа на PIVOT и UNPIVOT
Вы можете сделать свои заявления о случаях немного короче / проще, чтобы их было легче читать. MONTH () – это более простая функция чтения, и избавление от else будет означать, что она просто возвращает нуль, который SUM () обрабатывает как 0
SELECT [Month], CheckIns FROM ( Select SUM(CASE WHEN MONTH([CheckIn]) = 01 or MONTH([CheckOut]) = 01 THEN 1 END) January, SUM(CASE WHEN MONTH([CheckIn]) = 02 or MONTH([CheckOut]) = 02 THEN 1 END) February, SUM(CASE WHEN MONTH([CheckIn]) = 03 or MONTH([CheckOut]) = 03 THEN 1 END) March, SUM(CASE WHEN MONTH([CheckIn]) = 04 or MONTH([CheckOut]) = 04 THEN 1 END) April, SUM(CASE WHEN MONTH([CheckIn]) = 05 or MONTH([CheckOut]) = 05 THEN 1 END) May, SUM(CASE WHEN MONTH([CheckIn]) = 06 or MONTH([CheckOut]) = 06 THEN 1 END) June, SUM(CASE WHEN MONTH([CheckIn]) = 07 or MONTH([CheckOut]) = 07 THEN 1 END) July, SUM(CASE WHEN MONTH([CheckIn]) = 08 or MONTH([CheckOut]) = 08 THEN 1 END) August, SUM(CASE WHEN MONTH([CheckIn]) = 09 or MONTH([CheckOut]) = 09 THEN 1 END) September, SUM(CASE WHEN MONTH([CheckIn]) = 10 or MONTH([CheckOut]) = 10 THEN 1 END) October, SUM(CASE WHEN MONTH([CheckIn]) = 11 or MONTH([CheckOut]) = 11 THEN 1 END) November, SUM(CASE WHEN MONTH([CheckIn]) = 12 or MONTH([CheckOut]) = 12 THEN 1 END) December FROM [Booking] INNER JOIN {Status} ON {Booking}.[StatusId] = {Status}.[Id] WHERE {Booking}.[CheckIn] >= @BeginDate AND {Booking}.[CheckOut] <= @EndDate AND {Status}.[Label] <> 'Canceled' ) MONTHTotals UNPIVOT ( CheckIns FOR [Month] IN (January, February, March, April, May, June, July, August, September, October, November, December) ) AS upvtsqlserver.bilee.com