Как пронумеровать строки в результате SQL-запроса? Пронумеровать строки в sql
Как пронумеровать строки в результате SQL-запроса?
G.A.SH. Например делаем запросSELECT Name, Price FROM ProductКоторый возвращает намNotebook 1000Printer 500…Как получить результат с номерами строк1 Notebook 10002 Printer 500n…
SETdream В Postgresql можно так
CREATE SEQUENCE serial START 1;
select nextval('serial'), title from page;
Это так к примеру.
intlex Напрямую вроде никак, только через процедуру или запрос с обращением к генератору (последний придется обнулять перед самой выборкой)
Гость В приведенном примере проще добавить в таблицу Product номер записи (с авто-инкрементом, если нужно).
Можно сгенерировать порядковый номер на стандартном SQL с помощью подзапросов или представлений, если в таблице присутствует уникальное поле, по которому можно сортировать записи. Но для больших выборок это может оказаться неэффективным - O(n^2).
В большинстве практических случаев самый эффективный способ - добавить номер на стадии обработки результата (на PHP или C или на чем там программа написана).
Гость Легко делается при помощи переменных, вариант для MySQL выглядит примерно так:set @cnt=0;SELECT @cnt:=@cnt+1 as cnt, Name, Price FROM Product
ValWлучший ответ Если СУБД MSSQL, то там вообще нет такого понятия, как номер строки, но суррогатный номер все-таки можно ввести, используя конструкцию "ROW_NUMBER() OVER(ORDER BY":
select ROW_NUMBER() OVER(ORDER BY Name), Name, Price, FROM Product
только использовать его нужно осторожно, так как Этот номер не будет точно идентифицировать запись, а будет только указывать номер записи в КАЖДЫЙ МОМЕНТ выполнения запроса.то есть в случае, если между моментами выполнения двух запросов в таблице появится запись, которая "сдвинет" весь набор по установленной сортировке (в нашем случае сортировка по полю Name), то записи как бы "перенумеруются":-)
mysqlru.com
sql - Как пронумеровать строки, с итогом в конце?
Мой текущий sql:
select s.dcid, substr(s.lastfirst,0,3), to_char(a.att_date, 'mm/dd/yyyy'), a.periodid, p.name, a.attendance_codeid, ac.att_code, count(*) from students s join attendance a on s.id = a.studentid join period p on a.periodid = p.id join attendance_code ac on a.attendance_codeid = ac.id WHERE ac.att_code IS NOT NULL AND s.schoolid = 109 AND s.enroll_status = 0 AND s.student_number = 100887 AND a.att_date >= to_date('08/15/2013', 'mm/dd/yyyy') group by s.dcid, s.lastfirst, to_char(a.att_date, 'mm/dd/yyyy'), a.periodid, p.name, a.attendance_codeid, ac.att_code Выход: 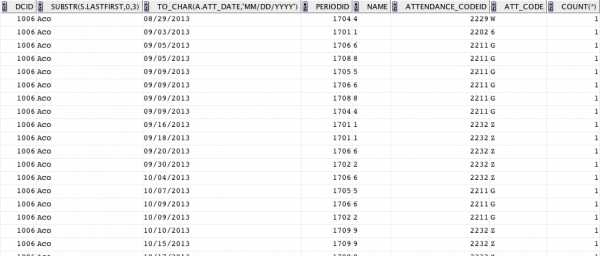
Я хотел бы получить вывод, чтобы последовательно записывать каждую запись, где находится столбец count (*), начиная с 1 в каждой новой группе, и помещать общее число в нижней части группы, но я не уверен, как это сделать, Я пробовал свертывание в разных частях группы по выражению, но он заканчивается, давая промежуточные итоги для дат, периодов и т.д. Мне нужно, чтобы он был ТОЛЬКО для ученика (либо s.dcid, либо s.lastfirst)
[Дополнительная информация по запросу...]
Я надеюсь получить отчет, в котором мои конечные пользователи могут искать студентов, которые имеют определенное количество записей посещаемости в диапазоне дат. Например, если конечный пользователь хочет найти студентов, у которых есть 20 отсутствий между 10/1/2013 и 10/31/2013, где att_code является одним из A, C, E, G... и т.д. После запуска отчета, Я хочу показать им дату отсутствия, а код, который использовался как визуальная проверка, что найденные записи действительно соответствуют их критериям поиска.
Результат должен выглядеть как текущий вывод, за исключением столбца COUNT (*), в котором я сейчас завис. Мне нравится, как row_number последовательно записывает каждую запись, но то, что я все еще ищу, - это то, как сбрасывать последовательную нумерацию, когда изменяется группа (ученика).
Например...
DCID S.LASTFIRST A.ATT_DATE PERIODID NAME ATT_CODE COUNT(or # or Num...) 1006 Aco 08/29/2013 1704 4 W 1 1006 Aco 09/03/2013 1701 1 6 2 1006 Aco 09/05/2013 1706 6 G 3 ... 1006 Aco 10/04/2013 1706 6 z 20 2543 Bro 08/29/2013 1704 4 W 1 2543 Bro 09/03/2013 1701 1 6 2 2543 Bro 09/05/2013 1706 6 G 3 ... 2543 Bro 10/04/2013 1706 6 z 20 3121 Com 08/29/2013 1704 4 W 1 3121 Com 09/03/2013 1701 1 6 2 3121 Com 09/05/2013 1706 6 G 3 ... 3121 Com 10/04/2013 1706 6 z 20Конечно, в этом примере я сокращаю вывод, заменяя номера строк 4-19 в каждой из трех групп "...". Я не хочу буквально выводить это.
qaru.site
TSQL-Tasks: Нумерация строк таблицы
Думаю всем программистам баз данных известна группа задач, в которых при определенных условиях требуется запросом получить набор всех записей некоторой таблицы, вместе со столбом, содержащим номер строки. То есть, чтобы в выходном наборе строки были пронумерованы последовательными числами, начиная с 1.Итак, что же известно и методах решения таких задач. Начиная с MS SQL Server 2005, довольно легко, используя функцию ранжирования row_number, решить задачу о нумерации всех строк любой таблицы. Благодаря этой новинке от Microsoft, можно не создавать для нумерации временные таблицы с identity-полями, не мучиться с курсорами, в общем, в реальном программировании задача стала простой. Но что если программиста попросили решить задачу с помощью голого select-а (то есть без всяких вспомогательных объектов, вроде временных таблиц или циклов), да еще и при помощи средств MS SQL Server 2000.Не стоит теряться. Тут все зависит от того, есть ли у таблицы один или несколько столбцов, которые дают уникальность строк этой таблицы. Предположим, что такая уникальность есть. Я бы не хотел рассматривать случай, когда в таблице есть одно поле дающее уникальность, поскольку в такой постановке описание решения уже дано на многих уважаемых и известных форумах. Поэтому давайте сперва рассмотрим случай, когда таблица имеет два поля, по которым имеется уникальность строк, а затем посмотрим, что можно сделать, если уникальность по строкам отсутствует.Итак, сформулируем точное условие задачи.Дана таблица dbo.Customers: create table dbo.Customers Name nvarchar ( 100 ) not null, SurName nvarchar ( 100 ) not null, constraint PK_Customers_Name_SurName primary key clustered ( Name asc, SurName asc )Вставим в нее несколько записей:
insert into dbo.Customers ( Name, SurName ) ( N'Сергей', N'Петров' ), ( N'Сергей', N'Иванов' ), ( N'Андрей', N'Петров' )Заметим, что в таблице нет уникальности ни по имени, ни по фамилии. Есть уникальность по двум этим столбцам.
Напишем и выполним такой запрос:
select custGreater.Name, custGreater.SurName, case when min ( custLess.Name ) is null then 1 else 1 + count (*) end as Number dbo.Customers custGreater left outer join dbo.Customers custLess on custGreater.Name > custLess.Name or custGreater.Name = custLess.Name and custGreater.SurName > custLess.SurNamegroup by custGreater.Name, custGreater.SurName
Давайте немного обсудим полученное решение. Здесь происходит левое соединение двух экземпляров таблицы. Но при этом в условии соединения используется не предикат равенства, а условие на то, что кортеж из двух элементов (имя и фамилия) левой таблицы больше по лексикографическому порядку кортежа таблицы справа. С помощью оператора group by и функции count происходит подсчет для каждой пары таблицы слева числа пар таблицы справа, меньших чем пара левой таблицы. Если пара левой таблицы является минимальной, то для нее есть только одна пустая запись от таблицы справа, что проверяется выражением case when.
Подобным образом задачу можно было бы решить через связанный подзапрос:
select cust.Name, cust.SurName, select count (*) + 1 from dbo.Customers where cust.Name > Name or ( cust.Name = Name and cust.SurName > SurName )А что если в таблице есть идентичные строки, то есть нет уникальности даже по всем наборам столбцам. У меня сложилось впечатление, что в этом случае, решения одним запросом средствами MS SQL Server 2000 нет. Сделаем тогда одно естественное допущение: предположим, что число дублей ограничено некоторым известным числом. То есть, например, если в описанной выше таблице есть строка ( 'Андрей', 'Петров' ), то существует еще не более чем, скажем 2 точно таких же строки. В этом случае задачу решить можно. Итак, будем предполагать, что общее число одинаковых строк не больше чем 3 для любой строки. Наполним заново таблицу dbo.Customers:
alter table dbo.Customers drop constraint PK_Customers_Name_SurName insert into dbo.Customers ( Name, SurName ) ( N'Андрей', N'Иванов' ), ( N'Сергей', N'Иванов' ), ( N'Сергей', N'Иванов' ), ( N'Сергей', N'Петров' ), ( N'Сергей', N'Петров' ), ( N'Сергей', N'Петров' )Перед началом решения немного обсудим общую идею. У нас нет столбцов, по которым была бы уникальность. Так давайте создадим их. В этом поможет исходное допущение и оператор cross join:
select Cust.Name, Cust.SurName, Cust.Number Number1, PrmData.Number Number2
select Name, SurName, count (*) as Number from dbo.Customers group by Name, SurName cross join select 1 as Number union all select 2 union all select 3where PrmData.Number <= Cust.Number
Видно, что получен набор записей, в котором последние 2 столбца дают уникальность. Теперь можно свести задачу к предыдущей (хотя общий запрос теперь выглядит громоздким):
select dataNum.Name, dataNum.SurName, select count (*) + 1 fromselect Cust.Name, Cust.SurName, Cust.Number Number1,
PrmData.Number Number2 from ( select Name, SurName, count (*) as Number from dbo.Customers group by Name, SurName ) Cust cross join ( select 1 as Number union all select 2 union all select 3 ) PrmData where PrmData.Number <= Cust.Number ) data where Number1 < dataNum.Number1 or ( Number1 = dataNum.Number1 and Number2 < dataNum.Number2 ) select data.Name, data.SurName, data.Number1, data.Number2select Cust.Name, Cust.SurName, Cust.Number Number1,
PrmData.Number Number2 from ( select Name, SurName, count (*) as Number from dbo.Customers group by Name, SurName ) Cust cross join ( select 1 as Number union all select 2 union all select 3 ) PrmData where PrmData.Number <= Cust.Numbertsql-tasks.blogspot.com
пронумеровать строки ms sql 2000
Вопрос: пронумеровать строки ms sql 2000
Прошу помочь с нумерацией строк с запросе. ms sql 2000.Всё должно быть решено с помощью одного запроса, использовать системные таблицы нельзя.Вот исходные данные и мое решение. Как добавить нумерацию по каждому фио 1,2,3 (добавить в мое решение ещё один столбец с нумерацией по каждому фио)?Если можно, не использовать в запросе order by.
DECLARE @T table ( fio varchar(100) ,a varchar(100) ,p smalldatetime ) INSERT INTO @T(fio, a, p) VALUES ('Иванов', 'работал', '2016-01-01 00:00:00.000'), ('Иванов', 'работал', '2016-02-01 00:00:00.000'), ('Иванов', 'уволен', '2016-03-01 00:00:00.000'), ('Иванов', 'работал', '2016-04-01 00:00:00.000'), ('Иванов', 'работал', '2016-02-01 00:00:00.000'), ('Иванов', 'работал', '2016-04-01 00:00:00.000'), ('Иванов', 'уволен', '2016-05-01 00:00:00.000'), ('Иванов', 'работал', '2016-06-01 00:00:00.000'), ('Петров', 'работал', '2016-01-01 00:00:00.000'), ('Петров', 'работал', '2016-02-01 00:00:00.000'), ('Петров', 'уволен', '2016-03-01 00:00:00.000'), ('Петров', 'работал', '2016-04-01 00:00:00.000'), ('Петров', 'уволен', '2016-05-01 00:00:00.000'), ('Петров', 'работал', '2016-06-01 00:00:00.000') SELECT fio, MIN(date1) as date1, date2 FROM ( SELECT t1.fio, t2.p as date1, MIN(t1.p) as date2 FROM (SELECT fio, p FROM @t t1 WHERE a = 'уволен') t1 INNER JOIN @T t2 ON t1.fio = t2.fio and t1.p > t2.p and t2.a = 'работал' GROUP BY t1.fio, t2.p ) ttt GROUP BY ttt.fio, ttt.date2 UNION ALL SELECT t3.fio, t3.p, NULL FROM @T t3 INNER JOIN (SELECT fio, MAX(p) as p FROM @t t1 WHERE a = 'уволен' GROUP BY fio) t4 ON t3.fio = t4.fio and t3.p > t4.p ORDER BY fio, date1 Решение нужно для ms sql 2000 (не обращайте внимание что уменя временная таблица в примере, это тест).Пока не разобрался с примерамиМожет подскажите готовое решение. Всё в одном запросе.
forundex.ru
Функции ранжирования и нумерации в Transact-SQL - ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же как и функции ранжирования или их также называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функция и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Ранжирующие функции в T-SQL
Ранжирующие функции - это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.
Примечание! Для детального изучения языка T-SQL, рекомендую почитать книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю основы программирования на языке T-SQL.
Исходные данные для примеров
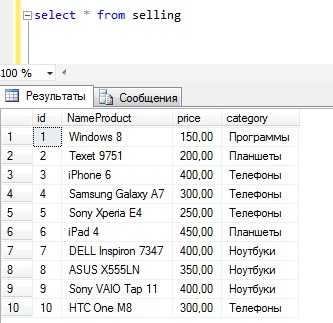
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
CREATE TABLE [dbo].[selling]( [id] [int] IDENTITY(1,1) NOT NULL, [NameProduct] [varchar](50) NOT NULL, [price] [money] NOT NULL, [category] [varchar](50) NOT NULL ) ON [PRIMARY] GOЗаполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
Синтаксис
ROW_NUMBER () OVER ([PARTITION BY столбы группировки] ORDER BY столбец сортировки)
где, partition by - это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Пример без группировки с сортировкой по цене
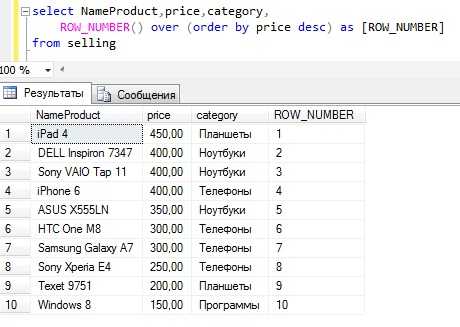
Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM sellingПример с группировкой по категории и с сортировкой по цене
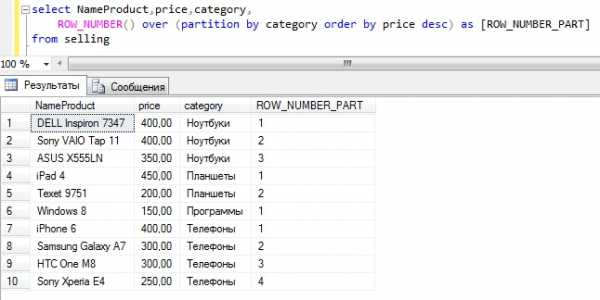
Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART] FROM sellingКак видите, здесь уже нумерация идет в каждой категории.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
Пример без группировки с сортировкой по цене и отличие от row_number()
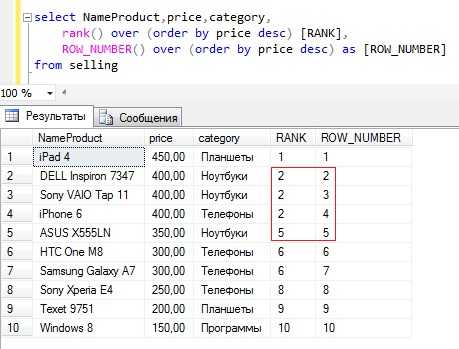
Текст запроса
SELECT NameProduct, price, category, rank() over (order by price desc) [RANK], ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM sellingПример с группировкой по категории и с сортировкой по цене и отличие от row_number()
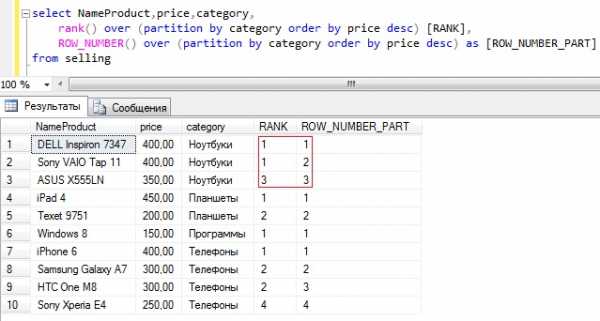
Текст запроса
SELECT NameProduct, price, category, rank() over (partition by category order by price desc) [RANK], ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART] FROM sellingDENSE_RANK
DENSE_RANK - ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
Пример без группировки с сортировкой по цене и отличие от rank() и row_number()
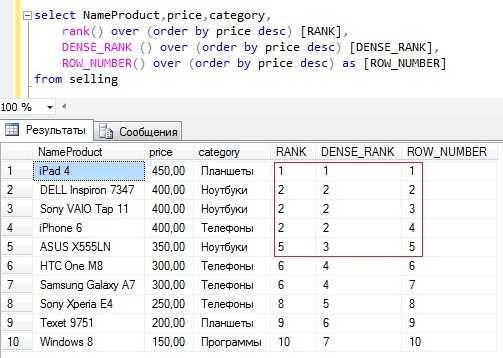
Текст запроса
SELECT NameProduct, price, category, rank() over (order by price desc) [RANK], DENSE_RANK () over (order by price desc) [DENSE_RANK], ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM sellingNTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример

Текст запроса
SELECT NameProduct, price, category, NTILE(3)over (order by price desc) [NTILE] FROM sellingВ заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
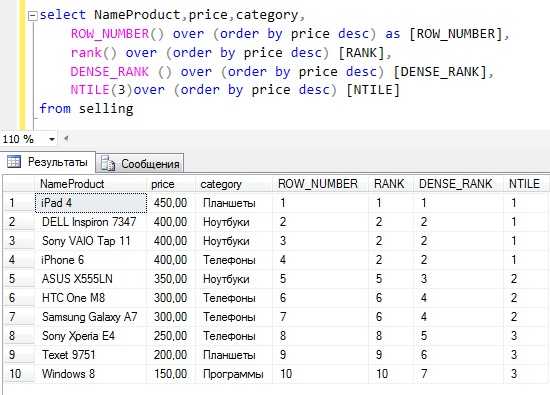
Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (order by price desc) as [ROW_NUMBER], rank() over (order by price desc) [RANK], DENSE_RANK () over (order by price desc) [DENSE_RANK], NTILE(3)over (order by price desc) [NTILE] FROM sellingНа этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
Похожие статьи:
info-comp.ru
Нумерация строк
Вопрос: И еще раз про нумерацию строк в запросе.
Здесь читалQ7
Сделал у себя:
SELECT (Select Sum(1) From Главная AS p Where p.[Внутренний код студента]<=p1.[Внутренний код студента]) AS Номер, p1.[Внутренний код студента], p1.[Код специальности], [Сертификат 1-ый предмет]+[Сертификат 2-ой предмет]+[Сертификат 3-ий предмет]+[Балл аттестата] AS сумм, p1.[Сертификат 1-ый предмет], p1.[Сертификат 2-ой предмет], p1.Ф, Специальности.[План приема бюджет] FROM Специальности INNER JOIN Главная as p1 ON Специальности.[Общий код специальности] = p1.[Код специальности] ORDER BY p1.[Внутренний код студента];Все работает нормально.Но мне нужна порядковая нумерация для другой сортировки, а не по уникальному полю [Внутренний код студента]
SELECT (Select Sum(1) From Главная AS p Where p.[Внутренний код студента]<=p1.[Внутренний код студента]) AS Номер, p1.[Код специальности], [Сертификат 1-ый предмет]+[Сертификат 2-ой предмет]+[Сертификат 3-ий предмет]+[Балл аттестата] AS сумм, p1.[Сертификат 1-ый предмет], p1.[Сертификат 2-ой предмет], p1.[Внутренний код студента], p1.Ф, Специальности.[План приема бюджет] FROM Специальности INNER JOIN Главная AS p1 ON Специальности.[Общий код специальности] = p1.[Код специальности] ORDER BY p1.[Код специальности], [Сертификат 1-ый предмет]+[Сертификат 2-ой предмет]+[Сертификат 3-ий предмет]+[Балл аттестата] DESC , p1.[Сертификат 1-ый предмет] DESC , p1.[Внутренний код студента];И все - порядковая нумерация пропадает((.
Полагаю, что вот здесь надо что-то менять
Where p.[Внутренний код студента]<=p1.[Внутренний код студента] но что и как? Ответ: sdku| forestry96,стесняюсь спросить-а зачем в запросе нумеровать записи? Создайте отчет(его можно сделать намного красивше запроса)-нумерация записей в нем-элементарно |
Спасибо за совет познавательный - буду мучить.
forundex.ru
Эмуляция функции row_number() в MySQL
В этой статье я расскажу вам, как пронумеровать строки результата запроса, возвращаемого MySQL.
Функция row_number() – это функция ранжирования, возвращающая порядковый номер строки, начиная с 1 для первой строки. Номер строки часто бывает нужен при генерации отчётов. Эта функция реализована в MS SQL и в Oracle. В MySQL подобная функция отсутствует, но её несложно реализовать за счёт глобальных переменных.
Нумерация строк
Чтобы пронумеровать строки, мы должны объявить переменную запроса. Продемонстрируем этот подход на примере простой таблицы, содержащей список работников предприятия (employees). Следующий запрос выбирает 5 работников из таблицы, присваивая им номера по порядку, начиная с 1:
SET @row_number = 0; SELECT (@row_number:=@row_number + 1) AS num, firstName, lastName FROM employees LIMIT 5;В выше приведённом запросе мы:
- Определили переменную row_number и инициализировали её нулевым значением;
- Увеличивали её значение на 1 при каждой итерации запроса.
Другая техника, позволяющая достичь того же результата, заключается в создании вместо глобальной переменной производной таблицы и перекрёстном объединении этих двух таблиц. Пример такого запроса:
SELECT (@row_number:=@row_number + 1) AS num, firstName, lastName FROM employees,(SELECT @row_number:=0) AS t LIMIT 5;Обратите внимание на то, что для соблюдения правил синтаксиса у производной таблицы должен быть псевдоним.
Возобновление нумерации в группах
Как нам задать отдельную нумерацию для каждой группы строк, объединённых выражением ORDER BY или GROUP BY? Например, как имитировать следующий запрос:
SELECT customerNumber, paymentDate, amount FROM payments ORDER BY customerNumber;Нам нужно сформировать список платежей, в котором каждому платежу будет соответствовать определённый порядковый номер. Для того чтобы получить требуемый результат, нам понадобятся две переменные: одна – с порядковым номером строки, другая – для хранения идентификатора клиента из предыдущей строки, чтобы сравнить его с текущим. Наш запрос будет выглядеть так:
SELECT @row_number:=CASE WHEN @customer_no = customerNumber THEN @row_number + 1 ELSE 1 END AS num, @customer_no:=customerNumber as CustomerNumber, paymentDate, amount FROM payments ORDER BY customerNumber;Мы использовали оператор CASE для вычисления условия: если номер клиента остаётся прежним, мы увеличиваем номер строки на 1, в противном случае мы устанавливаем номер строки равным 1. Результат будет тем же, что и на выше приведённом скриншоте.
Теперь добьёмся того же результата, используя технику производной таблицы и перекрёстного запроса:
SELECT @row_number:=CASE WHEN @customer_no = customerNumber THEN @row_number + 1 ELSE 1 END AS num, @customer_no:=customerNumber as CustomerNumber, paymentDate, amount FROM payments,(SELECT @customer_no:=0,@row_number:=0) as t ORDER BY customerNumber;Итак, мы научились эмулировать нумерацию строк запроса в MySQL.
Перевод статьи «MySQL row_number Emulation» был подготовлен дружной командой проекта Сайтостроение от А до Я.
www.internet-technologies.ru
- Создать файл в командной строке windows
- Написать макрос

- Что такое роутер и зачем он нужен для чайников

- Проверка антивируса на вирусы

- Sql добавление в таблицу столбца

- Ноут не работает без зарядки

- Браузеры по популярности

- Почему компьютер пищит

- Онлайн сканирование компьютера на вирусы бесплатно доктор веб
- Что есть интересного в телеграмм

- Как на компьютере поменять
