+ (объединение строк) (Transact-SQL). Работа со строками sql
Использование символьных, строковых функций и функций работы с датой в SQL
Функции, которые мы обсудим в этой части обычно используют встроенные PL/SQL код, сгруппированный в пакеты и поставляемый Oracle. Некоторые обрабатывают численные, символьные значения и значения даты, другие преобразуют данные в различные типы данных. Функции могут использовать вложенные вызовы и некоторые функции предназначены для работы со значением NULL. Функции условия CASE и DECODE позволяют отображать различный результат в зависимости от значений данных, что предоставляет возможность ветвления в контексте SQL запроса
Функции разделены на две большие группы: те, которые рассчитывают значения для каждой строки, и те, которые выполняют один рассчёт для всех строк. Мы рассмотрим функции конвертации, функции для работы с символьными данными, числовыми данными и данными типа дата.
Определение функции
Функция – это программа, которая может принимать (но необязательно) входные параметры, выполнять какие-либо операции и возвращать значение-литерал. Функция возвращает только одно значение за вызов.
Три важных компонента формируют базис определения функции. Первый – это список входных параметров. Он определяет ноль или более параметров, которые могут передаваться функции для обработки. Эти параметры, или аргументы, могут быть необязательными (иметь значение по умолчанию) и быть разными типами данных. Второй компонент – это тип данных вовзращаемого результата. После выполнения, только одно значение предопределенного типа данных возвращается функцией. Третий компонент инкапсулирует детали обработки выполняемой функцией и содержит программный код, который работает с входными параметрами, производит вычисления и возвращает значение.
Функция часто описывается как чёрный ящик, который берёт входные данные, делает что-то и возвращает результат. Вместо того, чтобы фокусироваться на деталях реализации функций, более полезно разобраться какой функционал предоставляют встроенные функции.
Вызовы функций могут быть вложенными, к примеру, как F1(x, y, F2(a, b), z), где функция F2 принимает два входных параметра и возвращает третий из четырёх параметров для функции F1. Функции могут работать с любыми типами данных: наиболее часто используемые это символьные и числовые данные, а также данные типа дата. Этими параметрами функции могут быть столбцами или выражениями.
Как пример можно рассмотреть функцию, которая рассчитывает возраст человека. Функция AGE принимает только один параметр, день рождения. Результат возвращаемый функцией AGE это число отображающее возраст человека. Расчёты черного ящика влючают в себя получение разницы в годах между текущей датой и днём рождения, переданным в качестве входного параметра.
Типы функций
Функции можно глобально разделить на две категории: обрабатывающие строку (строчные функции) и обрабатывающие набор строк (функции группировки). Это выделение очень важно для понимания контекста где используются различные функции.
Строчные функции
Доступны несколько видов строчных функций, включая функции работы со строками, функции работы с числами, датами, функции преобразования типа и общие функции. Эти функции обрабатывают одну строку из набора в момент времени. Если запрос выбирает десять строк, функция будет выполняться десять раз, по одному разу для каждой строки с возможным использованием значений столбцов строк как входных параметров функции.
Следующий запрос выбирает два столбца из таблицы REGIONS и выражение использующее функцию LENGTH и столбец REGION_NAME
select region_id, region_name, length(region_name) from regions;
Длина значения столбца REGION_NAME рассчитывается для каждой из четырёх строк в таблице REGIONS; функция выполняется четыре раза, возвращая каждый раз значение-литерал.
Строчные функции работают работают с данными элементами строки для выборки и форматирования их перед отображением. Входными значениями строчной функции может быть определенная пользователем константа или литерал, данные столбца, переменные или выражения, возможно использующие другифе вложенные строчные функции и т.д. Вложенные вызовы часто используемая техника. Функции могут возвращать значение типа данных, отличного от типа данных входных параметров. Прерыдущий запрос показывает, как функция LENGTH принимает входным значением строку и возвращает число.
Помимо использования функций в разделе SELECT строчные функции можно использовать в разделах WHERE и ORDER BY.
Функции, работающие с набором данных
Как можно догадаться из названия, эти функции оперируют больше чем одной строкой. Типичным использованием мультристрочной-функции является расчёт суммы или среднего значения какого-либо числового столбца или подсчёт количества строк в результате. Таким функции называются иногда функциями группировки, и мы рассмотрим их в следующей главе.
Использование функций, изменяющих регистр
Данные в таблицах могут заполняться из различных источников: программ, криптов и так далее. Не стоит полагаться что символьные данные будут вводиться в заранее определенном регистре. Строчные функции, изменяющие регистр предназначены для двух важных задач. Их можно использовать, во-первых, для изменения регистра данных при сохранении или выводе информации, либо в условиях WHERE для более гибкого поиска. Гораздо легче искать строку используя фиксированный регистр, вместро проверки всех комбинаций верхнего и нижнего регистра. Помните, что вызов функций не изменяет данные, которые хранятся в таблице. Они преобразуют данные результата запроса.
Входными параметрами могут быть символьные литералы, столбцы символьного типа данных, символьные выражения или числа и даты (которые неявно будут преобразованы в строки).
Функция LOWER
Функция LOWER заменяет все символы прописного регистра на эквивалентные символы строчного регистра. Синтакис функции LOWER(string). Рассмотрим пример запроса использующего эти функции
select lower(100+100), lower(‘SQL’), lower(sysdate) from dual
Преположим что текущая дата 17 декабря 2015 года. Результатом запроса будут строки ‘200’, ‘sql’ и ‘17-dec-2015’. Численное выражение и дата неявно преобразуются в строку перед вызовом функции LOWER.
В следующем примере функция LOWER используется для поиска строк где буквы ‘U’ и ‘R’ в любом регистре идут друг за другом
select first_name, last_name, lower(last_name) from employees
where lower(last_name) like ‘%ur%’;
Можно написать аналогичный запрос без использования функции LOWER. Например так
select first_name, last_name from employees
where last_name like ‘%ur%’ or last_name like ‘%UR%’
or last_name like ‘%uR%’ or last_name like ‘%Ur%’
Функция UPPER
Функция UPPER логическая противоположность функции LOWER и заменяет все строчные символы на их прописные эквиваленты. Синтаксис функции – UPPER(string). Рассмотрим пример
select * from countries where upper(country_name) like ‘%U%S%A%’;
Этот запрос выбирает строки из таблцы COUNTRIES где COUNTRY_NAME содержит буквы ‘U’, ‘S’, ‘A’ в любом регистре в этом порядке.
Функция INITCAP
Функция INITCAP часто используется для отображения данных. Первые символы каждого слова в строке преобразуются к верхнему регистру, все остальные символы преобразуются в строчные эквиваленты. Под словом подразумевается набор символов не содержащих пробелов и спецсимволов. Пробел, символ подчеркивания а также спецсимволы такие как знак процента, восклицательные знак, знак доллара расцениваются как разделители. Функция INITCAP принимает один параметр и синтаксис INITCAP(string). Следующий пример показывает пример использования функции INITCAP
select initcap(‘init cap or init_cap or init%cap’) from dual
Результатом этого запроса будет строка Init Cap Or Init_Cap Or Init%Cap
Использование функций работы со строками
Функции работы со строками одна из самых мощных возможностей, предоставляемых Oracle. Они очень полезны и понятны практически без детальных объяснений и очень часто используются разными программистами при обработке данных. Часто используются вложенные вызовы этих функций. Оператор конкатенации может использоваться вместо функции CONCAT. Функции LENGTH, INSTR, SUBSTR и REPLACE могут дополнять друг друга, так же как RPAD, LPAD и TRIM.
Функция CONCAT
Функция CONCAT объединяет два литерала, столбца или выражения для составление одного большого выражения. У функции CONCAT два входных параметра. Синтаксис функции CONCAT(string1, string2) где string1 и string2 могут быть литералом, столбцом или выражением результат которого символьный литерал. Следующий пример показывает использование функции CONCAT
select concat(‘Today is:’,SYSDATE) from dual
Второй параметр функции это функция SYSDATE, которая возвращает текущее системное время. Значение преобразуется в строку и к ней присоединяется первый параметр. Если текущая системная дата 17 Декабря 2015 года, то запрос вернёт строку ‘Today is:17-DEC-2015’.
Рассмотрим как использовать функция для объединения трех элементов. Так как функция CONCAT может принимать только два входных параметра, то можно объединить только два элемента. В таком случае можно использовать вызов функции как параметр другово вызова функции. Тогда запрос будет выглядеть так
select concat(‘Outer1 ‘, concat(‘Inner1′,’ Inner2′)) from dual;
У первой функции два параметра: первый параметр это литерал ‘Outer1 ‘, а второй параметра это вложенная функция CONCAT. Вторая функция принимает два параметра: литерал ‘Inner1’ и литерал ‘ Inner2’. Результатом выполнения этого запроса будет строка ‘Outer1 Inner1 Inner 2’. Вложенные функции расмотрим чуть позже.
Функция LENGTH
Функция LENGTH возвращает число символов которые составляют строку. Пробелы, табуляция и специальные символы учитываются функцией LENGTH. У функции один параметра и синтаксис LENGTH(string). Рассмотрим запрос
select * from countries where length(country_name) > 10;
Функция LENGTH используется для выбора тех стран у которых длина названия больше чем десять символов.
Функции RPAD и LPAD
Функции RPAD и LPAD возвращают строку фиксированной длины и при необходимости дополняют исходное значение определенным набором символов слева или справа. Символами используемые для добавления могут быть литерал, значение столбца, выражение, пробел (значение по умолчанию), табуляция и спец символы. Функции LPAD и RPAD принимают три входных параметра и синтаксис LPAD(s, n, p) и RPAD(s, n, p) где s – значение строки для обработки, n – количество символов результата и p – символы для добавления. Если используется LPAD, то символы p добавляются слева до достижения длины n. Если RPAD – то справа. Обратите внимание что если длина s больше чем длина n – то результатом будет первые n символов значения s. Рассмотрим запросы на рисунке 10-1
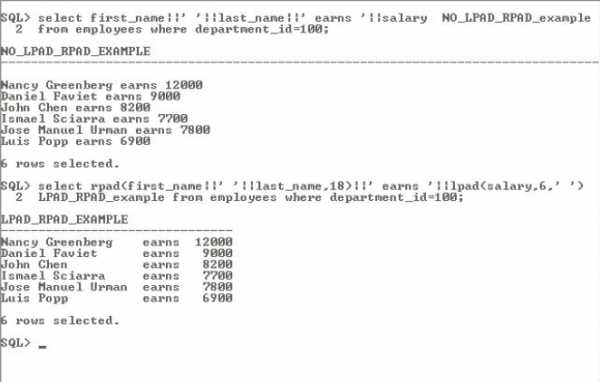
Рисунок 10-1 – Использование функций RPAD и LPAD
Первый запрос не изменяет данные и результат не очень читабельный по сравнению с результатом второго запроса. RPAD используется для добавления пробелов там где необходимо для first_name и last_name чтобы все значения были фиксированной длины в 18 символов, и LPAD используется для добавления пробелов в начало значения salary до достижения длины 6 символов.
Функция TRIM
Функция TRIM убирает символы и начала или окончания строки чтобы сделать её потенцильно короче. Функция принимает обязательный параметр и необязательный. Синтаксис функции TRIM([trailing|leading|both] trimstring from string). Параметр входная строка (s) обязательный. Следующие пункты перечисляют параметры
- TRIM(s) убираются пробелы в начале в к конце строки
- TRIM(trailing trimstring from s) убирает символы trimgstring в конце строки
- TRIM(leading trimstring from s) убирает символы trimgstring в начале строки
- TRIM(both trimstring from s) OR TRIM(trimstring from s) убирают все символы trimstring в начале и в конце строки
Запрос
select trim(both ‘*’ from ‘****Hidden****’),
trim(leading ‘*’ from ‘****Hidden****’),
trim(trailing ‘*’ from ‘****Hidden****’) from dual;
Вернёт “Hidden”, “Hidden****”, и “****Hidden”. Обратите внимание что, указав всего один символ, все символы убираются если они последовательно повторяются.
Функция INSTR
Функция INSTR ищет подстроку в строке. Возвращается число, обозначающее позицию откуда n-ное вхождение начинается, начиная с позиции поиска, относительно начала строки. Если подстрока не найдена в строке – возвращается 0.
У функции INSTR два параметра обязательных и два параметра необязательных. Синтаксис функции INSTR(source string, search string, [search start position], [n occurrence]). Значение по умолчанию для search start position=1 или другими словами начало строки source string. Значение по умолчанию для n occurrence=1 или первое вхождение. Рассмотрим несколько примеров
Query 1: select instr(‘1#3#5#7#9#’, ‘#’) from dual;
Query 2: select instr(‘1#3#5#7#9#’, ‘#’ ,5) from dual;
Query 3: select instr(‘1#3#5#7#9#’, ‘#’, 3, 4) from dual;
Первый запрос ищет первое вхождение хеш-тега в строке и возвращает значение 2. Второй запрос ищет хеш-тег в строке начиная с пятого символа и находит первое вхождение с 6 символа. Третий запрос ищет четвертое вхождение хеш-тега начиная с третьего символа и находит его в позиции 10.
Функция SUBSTR
Функция SUBSTR возвращает подстроку определённой длины из исходной строки начиная с определённой позиции. Если начальная позиция больше чем длина исходной строки – возвращается значение NULL. Если длины исходной строки недостаточно для получения значения необходимой длины начиная с определённой позиции, то возвращается часть строки с исходного символа до конца строки.
У функции SUBSTR три параметра, первые два обязательны и синтаксис SUBSTR(source string, start position, [number of characters]). Значение по умолчанию для characters to extract = разница между длиной source string и start position. Рассмотрим следующие примеры
Query 1: select substr(‘1#3#5#7#9#’, 5) from dual;
Query 2: select substr(‘1#3#5#7#9#’, 5, 3) from dual;
Query 3: select substr(‘1#3#5#7#9#’, -3, 2) from dual;
Запрос 1 возвращает подстроку начиная с позиции 5. Так как третий параметр не указан, количество символов равно длине исходной строки минус начальная позиция и будет равно шести. Первый запрос вернёт подстроку ‘5#7#9#’. Запрос два возвращает три символа начиная с пятого символа и строка результат будет ‘5#7’. Запрос три начинается с позиции минус три. Отрицательная начальная позиции говорит Oracle о том, что начальная позиция рассчитывается от конца строки. Таким образом начальная позиция будет длина строки минус три и равна 8. Третий параметр равен двум и возвращается значение ‘#9’.
Функция REPLACE
Функция REPLACE заменяет все вхождения искомого элемента на значение строки для подстановки. Если длина заменяемого элемента не равна длине элемента, на который происходит замена, длина получаемой строки будет отличной от исходной строки. Если искомая подстрока не найдена, строка возвращается без изменений. Доступно три параметра, два первых обязательные и синтаксис вызова REPLACE(source string, search element, [replace element]). Если явно не указать параметр replace element, то из исходной строки удаляются все вхождения search element. Другими словами, replace element равно пустой строке. Если все символы исходной строки заменяются пустым replace element возвращается NULL. Рассмотрим несколько запросов
Query 1: select replace(‘1#3#5#7#9#’,’#’,’->’) from dual
Query 2: select replace(‘1#3#5#7#9#’,’#’) from dual
Query 3: select replace(‘#’,’#’) from dual
Хеш в первом запрос обозначает символ для поиска и строка для замены ‘->’. Хеш появляется в строке пять раз и заменяется, получаем итоговую строку ‘1->3->5->7->9->’. Запрос 2 не указывает явно строку для замены. Значением по умолчанию является пустая строка и результатом будет ‘13579’. Запрос номер три вернёт NULL.
Использование численных функций
В Oracle доступно множество встроенных функций для работы с числами. Существенной разницой между численными функция и другими является то, что эти функции принимают параметрами только числа и возвращают только числа. Oracle предоставляет численные функции для работы с тригонометрическими, экспоненциальными и логарифмическими выражениями и со многими другими. Мы сфокусируемся на простых численных строчных функциях: ROUND, TRUNC и MOD.
Функция ROUND
Функция ROUND округляет число в зависимости от необходимой точности. Возвращаемое значение округляется либо в большую, либо в меньшую сторону, в зависимости от значения последней цифры в необходимом разряде. Если значение точности n, то цифра, которая будет округляться будет на позиции n после запятой, а значение будет зависеть от цифры на позиции (n+1). Если значение точности отрицательное, то все цифры после разряда n слева от запятой будут 0, а значение n будет зависеть от n+1. Если значение цифры от которой зависит округление больше или равно 5, то округление происходит в большую сторону, иначе в меньшую.
Функция ROUND принимает два входных параметра и синтаксис ROUND(source number, decimal precision). Source number может быть любым числом. Параметр decimal precision определяет необходимую точность и необязателен. Если этот параметр не указан, значение по умолчанию будет 0, что обозначает необходимость округления до ближайшего целого числа.
Рассмотрим таблицу 10-1 для числа 1601.916. Отрицательные значения точности находятся слева от точки (целая часть), когда положительные считаются вправо от точки (дробная часть).
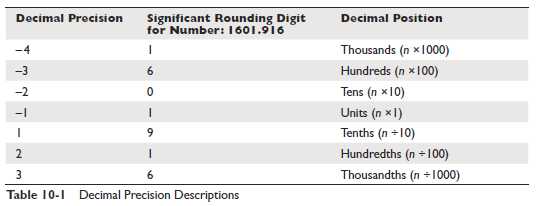
Если значение точности единица, значение округляется до десятка. Если два, то значение округляется до второго порядка и т.д. Следующие запросы отображают использование этой функции
Query 1: select round(1601.916, 1) from dual;
Query 2: select round(1601.916, 2) from dual;
Query 3: select round(1601.916, -3) from dual;
Query 4: select round(1601.916) from dual;
Первый запрос использует параметр точности равные единице, что означает что число будет округлено до ближайшей десятой. Так как значение сотой части равно единице (меньше чем 5), то происходит округление в меньшую сторону и возвращается значение 1601.9. Точность второго запроса равна двойке, таким образом значение окружается до сотой. Так как значение тысячной части равно 6 (что больше 5), то значение сотой части округляется вверх и возвращается значение 1601.92. Значение параметра точности в третьем запросе равно минус трём. Так как значение отрицательное, это значит, что округление будет происходить, основываясь на значении третьей позиции слева от точки, во втором разряде (сотни), и значение 6. Так как 6 больше пяти, то происходит округление вверх и возвращается значение 2000. Запрос 4 вызывает функцию без параметра точности. Это означает что число округляется до ближайшего целого. Так как десятая часть равна 9, то значение округляется в большую сторону и возвращется значение 1602.
Численная функция TRUNC
Функия TRUNC сокращает значение числа основываясь на значение параметра точности. Сокращение отличается от округления тем, что при сокращении лишняя часть просто отрезается и не происходит никаких изменений остальных цифр числа. Если значение точности отрицательное, то входное значение сокращается на позиции слева от запятой. Синтаксис функции TRUNC(source number, decimal precision). Параметром source number может быть любое число и этот параметр обязателен. Параметр decimal precision определяет позицию округления и не обязателен, значением по умолчанию будет ноль, что означает сокращение до целого числа.
Если значение decimal precision равно одному, то число сокращается до десятых, если два, то до сотых и так далее. Рассмотрим несколько примеров использования этой функции
Query 1: select trunc(1601.916, 1) from dual;
Query 2: select trunc(1601.916, 2) from dual;
Query 3: select trunc(1601.916, -3) from dual;
Query 4: select trunc(1601.916) from dual;
В запросе 1 используется точность равная единице, что значит сокращение значения до десятых и возвращается значение 1601.9. Точность во втором запросе равна двум, исходное значение сокращается до сотых и возвращается значение 1601.91. Обратите внимание что получаемое значение будет отличаться от значения, возвращаемого функцией ROUND с такими же параметрами, так как при вызове ROUND произойдёт округление в большую сторону (6 больше 5). В запросе номер три используется отрицательное число как значение параметра точности. Позиция три слева от запятой означает что сокращение будет до третьего разряда (сокращаются сотни) как показано в таблице 10-1 и возвращаемое значение будет 1000. И наконец в четвертом запросе явно неуказано значение точности и сокращается дробная часть исходного числа. Результатом будет 1601.
Функция MOD
Функция MOD возвращает остаток от деления. Два числа, делимое (число которое делится) и делитель (число на которое делится) определяются как параметры и вычисляется операция деления. Если делимое делится на делитель нацело, то возвращается ноль, так как нет остатка. Если делитель ноль, то не происходит ошибки деления на ноль, а возвращается делимое. Если делитель больше чем делимое, возвращается делимое.
У функции MOD два входные параметра и синтаксис MOD(dividend, divisor). Параметры dividend и divisor могут быть численными литералами, столбцами или выражениями и могут быть положительными или отрицательными. Следующие примеры показывают использование этой функции
Query 1: select mod(6, 2) from dual
Query 2: select mod(5, 3) from dual
Query 3: select mod(7, 35) from dual
Query 4: select mod(5.2, 3) from dual
В запросе один 6 делится на два нацело без остатка и возвращается 0. В запросе два 5 делится на 3, целая часть будет 1 и возвращается остаток 2. В запросе номер три семь делится на 35. Так как делитель больше чем делимое – возвращается делимое, т.е. целая часть 0. Запрос четыре использует дробное число как делимое. Целой частью будет один и остаток будет 2.2.
Tip
Любое чётное число делится на два без остатка, любое нечётное число при делении на два вернёт остаток 1. Поэтому функцию MOD часто используют чтобы отличать чётные и нечётные числа.
Работа с датами
Функции работы с датами предлагают удобный способ решать задачи, связанные с датами без необходимости учитывать высокосные года, сколько дней в конкретном месяце. Вначале рассмотрим, как хранятся данные типа дата и форматирование даты, а также функцию SYSDATE. Затем рассмотрим функции ADD_MONTHS, MONTHS_BETWEEN, LAST_DAT, NEXT_DAY, ROUND и TRUNC.
Хранение даты в базе данных
База данных хранит данные как число, которое способно поддерживать расчёт века, года, месяца и дня, а также информации о времени, такой как час, минута и секунда. Когда происходит запрос к данным, на число накладывается определённое форматирование (маска), и по умолчанию маска отображает день, три первых буквы названия месяца и две цифры, отображающие год.
Функция SYSDATE
Функция SYSDATE не использует входные параметры и возвращает текущее время и дату установленную на сервере БД. По умолчанию функция SYSDATE возвращает дату в формате DD-MON-RR и отображает дату на сервере. Если сервер установлен в другом часовом поясе чем машина клиента, то время и дата, возвращаемые SYSDATE могут отличаться от локальных значений на клиентсой машине. Можно выполнить такой запрос для отображения системной даты на сервере
select sysdate from dual
Арифметика над датами
Следуещее уравнение отображает важный принцип при работе с датами
Date1 – Date2 = Num1
Дата может вычитаться из другой даты. Разница между двуми датами понимается как количество дней между ними. Любое число, включая дробные, может быть добавлено или вычтено из даты. В этом контексте число представляет собой количество дней. Сумма или разница между число и датой – это всегда дата. Этот принцип подразумевает что сложение, умножение или деление двух дат невозможен.
Функция MONTHS_BETWEEN
Функция MONTHS_BETWEEN возвращает количество месяцев между двумя обязательными входными параметрами. Синтаксис функции MONTHS_BETWEEN(date1, date2). Функция рассчитывает разницу между date1 и date2. Если date1 меньше чем date2, то возвращается отрицательное число. Возвращаемое значение может состоять из целой части, отражающей количество месяцев между двумя датами, и дробной части, отражающей сколько дней и часов осталось (основываясь на месяце равном 31 дню) после вычета целого количества месяцев. Целое число вовзращается если день сравниваемых месяцев одинаковый или последний день соответствующего месяца.
Следующие примеры используют функию MONTHS_BETWEEN
Query 1: select months_between(sysdate, sysdate-31) from dual;
Query 2: select months_between(’29-mar-2008′, ’28-feb-2008′) from dual;
Query 3: select months_between(’29-mar-2008′, ’28-feb-2008′) * 31 from dual;
Преположим что текущая дата 16 Апреля 2009. Запрос один вернёт один как количество месяцев между 16 апреля 2009 и 16 марта 2009. Запрос два неявно конвертирует литералы в даты используя формат DD-MON-YYYY. Так как часть о времени опущена Oracle установит значение времени 00.00.00 для обеих дат. Фукнция вернёт значение примерно равное 1.03225806. Целая часть результата обозначает что между датами один месяц. Между 28 февраля и 28 марта ровно один месяц. Тогда дробная часть должна показывать ровно один день. Результат включает в себя часы минуты и секунды, но в нашем случае временная составляющая дат одинаковая. Умножение 0.03225806 на 31 вернёт 1, так как дробная часть, возвращаемая MONTHS_BETWEEN, рассчитывается, допуская что месяц равен ровно 31 дню. Поэтому запрос номер три вернёт значение 32.
Exam tip
Популярной ошибкой является допущение что возвращаемый тип данных функции зависит от типа функции (функции работы с датой должны возвращать дату, функции обработки строк – строку). Это верное только для численных функций. Символьные функции и функции работы с датами могут возвращать значение любого типа данных. Например, INSTR явлется символьной функцией, а MONTS_BETWEEN функцией работы с датой, но обе они возвращают результатом число. Также часто ошибочно рассуждают что разница между датами – это дата, когда фактически это число.
Функция ADD_MONTHS
Функция ADD_MONTHS возвращает дату, полученную путём добавления определённого количества месяцев к исходной дате. У этой функции два обязательных параметра и синтаксис ADD_MONTHS(start date, number of months). Значение параметра number of months может быть отрицательным, тогда исходное значение будет уменьшаться на это количество месяцев и дробным, но учитываться будет только целая часть. Следующие три запроса показывают использование функции ADD_MONTHS
Query 1: select add_months(’07-APR-2009′, 1) from dual;
Query 2: select add_months(’31-DEC-2008′, 2.5) from dual;
Query 3: select add_months(’07-APR-2009′, -12) from dual;
Результатом первого запроса буде 7 мая 2009, так как день остаётся одинаковым если это возможно и месяц увеличивается на один. Во втором запросе число месяцев дробное, что игнорируется, то есть этот запроса равен ADD_MONTHS(’31-DEC-2008’,2). Добавление двух месяцев должно вернуть 31-FEB-2009, но такой даты не существует, поэтому возвращается последний день месяца. В последнем примере используется отрицательное число для параметра кол-во месяцев и возвращается дата 07-APR-2008 что на двенадцать месяцев раньше, чем исходное значение.
Функция NEXT_DAY
Функция NEXT_DATE возвращает следующий ближайший заданный день недели после исходной даты. У этой функции два обязательных параметра и синтаксис NEXT_DAY(start date, day of the week). Функция выичсляет значение, когда заданный day of the week наступит после start date. Параметр day of the week может быть задан как числом, так и строкой. Допустимые значения определяются параметром NLS_DATE_LANGUAGE и по умолчанию используются три первые буквы названия дня недели в любом регистре (SUN, mon etc) или целые числа где 1 равно воскресенью, 2 – понедельник и так далее. Также имена дней недели могут быть более чем три символа; например, воскресенье можно указать как sun, sund, Sunday. Рассмотрим несколько запросов
Query 1: select next_day(’01-JAN-2009′, ‘tue’) from dual;
Query 2: select next_day(’01-JAN-2009′, ‘WEDNE’) from dual;
Query 3: select next_day(’01-JAN-2009′, 5) from dual;
1 января 2009 года это четверг. Следущий вторник будет через 5 дней, 6 января 2009 года. Второй запрос вернёт 7 января 2009 – следующая среда после 1 января. Третий запрос использует число как параметр и если у вас установлены Американские значения, то пятый день — это четверг. Следующий четверг после 1 января ровно через неделю – 8 января 2009 года.
Функция LAST_DAY
Функция LAST_DAY возвращает дату последнего дня месяца исходной даты. Эта функция требует один обязательные параметр и синтаксис LAST_DAY(start date). Функция выбирает месяц исходной даты и затем расчитывает последний день месяца. Следующий запрос вернёт 31 января 2009 года
select last_day(’01-JAN-2009′) from dual;
Функция ROUND для работы с датами
Функция ROUND округляет значение даты до заданной точности даты. Возвращаемое значение округляется либо к большему, либо r меньшему значению в зависимости от значения округляемого элемента. Эта функция требует один обязательный параметр и допускает один необязательные и синтаксис функции ROUND(source date, [date precision forma]). Параметром source data может быть любой элемент типа данных дата. Параметр date precision format определяет уровень округления и значение по умолчанию – день. Параметром date precision format может быть век (CC) год YYYY квартал Q месяц M неделя W день DD час HH минута MI.
Округления до века эквивалентно добавление единицы к текущему веку. Округление до месяца будет в большую сторону если день больше 16 иначе будет округление до первого дня месяца. Если месяц от одного до шести округление будет до начала текущего года, иначе вернётся дата начала следующего года. Рассмотрим запрос
Предположим, что этот запрос был выполнен 17 апреля 2009 года в 00:05. Вначале происходит округление текущей даты до дня (параметр точности явно неуказан). Так как время 00:05 то день не округляется в большую сторону.Так как 1 апреля 2009 года это среда, то второй столбец вернёт среду той недели, в которую входит исходная дата. Первая среда недели, в которую входит 19 апреля – это 15 апреля 2009 года. Третий столбец оругляет месяц до следующего (так как 17 больше 16) и возвращает 01 мая 2009. Поледний столбец округляет дату до года и возвращает 1 явнваря 2009 года, так как апрель это 4ый месяц.
Функция TRUNC при работе с датами
Функция TRUNC сокращает дату основываясь на параметре точности. У этой функции один параметр обязательный и один нет и синтаксис вызова TRUNC(source date, [date precision format]). Параметром source date может быть любая валидная дата. Параметр date precision format определяет уровень сокращения даты и необязателен, значение по умолчанию – сокращение до дня. Это значит что все значения времени обнуляются – 00 часов 00 минут 00 секунд. Сокращение до месяца вернёт дату равную первому дню месяца исходной даты. Сокращение до года – вернёт первый день года исходной даты. Рассмотрим запрос, использующий функцию с разными параметрами
Этот запрос выполнятся 17 апреля в 00:05. Первый столбец сокращает системную дату до дня, время преобразуется из 00:05 в 00:00 (параметр точности явно неуказан, используется значение по умолчанию) и возвращается текущий день. Второй столбец сокращает дату до такого же дня недели, который был первого числа месяца (среда) и возвращает среду текущей недели – 15 апреля. Третий столбец сокращает дату до месяца и возвращает первый день месяца – 1 апреля. Четвертый столбец сокращает дату до года и возвращает первый день года.
oracledb.ru
Функция языка SQL SUBSTRING
Функция SUBSTRING в SQL-запросах чаще всего используется при работе с текстовыми данными - она отвечает за "обрезку" передаваемой в неё строки.
Синтаксис
Как и в большинстве языков программирования, включая ORACLE и MS SQL, SUBSTRING включает в себя три параметра. Первым аргументом функции является сама входная строка - её можно как явно прописать, так и получить в результате выполнения некоторого запроса. Далее следуют два числовых параметра - стартовый символ, с которого и произойдет обрез, и непосредственно длина - число символов, которые требуется считать, начиная со стартовой позиции.
Структура запроса на языке SQL выглядит следующим образом :
SUBSTRING( "некоторая строка", 1, 3)
Результатом выполнения данного запроса будет строка "еко" - в SQL функция SUBSTRING определяет элементы, начиная с нулевого, которым, в данном примере, является буква "н". Стоит отметить, что при указании отрицательной длины СУБД выдаст ошибку, а при выборе значения, превышающего разницу между номером последнего символа и стартовым номером, результатом запроса будет цепочка символом от указанной позиции до конца строки.
Пример
В языках SQL SUBSTRING редко используют для выполнения простых запросов - в основном функция применяется как часть сложного алгоритма. Тем не менее, существуют и достаточно простые задачи с её участием. Так, например, если требуется создать категорию пользователей, аналогичную первой букве их фамилии, то SUBSTRING позволит обойтись без вспомогательного разбиения строки.
SELECT Addres, SUBSTRING(LastName, 1, 1) AS FirstChar FROM Clients
Таким образом, можно создать упрощённый телефонный справочник, где для получения всего списка пользователей, чьи фамилии начинаются на определённую букву, будет достаточно сделать выборку по полю FirstChar.
Более реалистичным примером является создание готового сокращённого варианта имени пользователя - то есть в качестве результата запроса должна вернуться фамилия с инициалом клиента.
SELECT LastName & ' ' & SUBSTRING(FirstName, 1, 1) & '.' AS Initial FROM Clients
Стоит отметить, что SQL SUBSTRING одинаково успешно работает как с текстовыми полями, так и с числовыми.
fb.ru
Глава 6. Работа со строками
6
Данная глава посвящена работе со строками в SQL. Не надо забывать, что SQL разработан не для того, чтобы выполнять сложные операции над строками, поэтому подчас решение этих задач в SQL может пока! заться (и покажется) весьма громоздким и утомительным. Несмотря на ограниченность SQL в этом вопросе, есть несколько очень полезных встроенных функций, предоставляемых разными СУБД, и я попытал! ся творчески подойти к их использованию. Данная глава, в частности, прекрасно иллюстрирует послание, которое я пытался передать во вве! дении: SQL бывает хорош, плох и просто кошмарен. Надеюсь, из этой главы вы вынесете лучшее понимание того, что возможно и невозмож! но сделать со строками в SQL. Во многих случаях простота синтакси! ческого разбора и преобразования строк просто поразительна, тогда как иногда SQL!запросы, которые приходится создавать для выполне! ния той или иной задачи, приводят в ужас.
Особенно важен первый рецепт, поскольку он используется в несколь! ких последующих решениях. Возможность посимвольного обхода стро! ки пригодится во многих случаях. К сожалению, в SQL реализовать это не просто. Поскольку в SQL нет циклов (за исключением Oracle опера! тора MODEL), для обхода строки цикл приходится имитировать. Я на! зываю эту операцию «проход строки» или «проход по строке», ее тех! ника описывается в самом первом рецепте. Это фундаментальная опе! рация синтаксического разбора строк при использовании SQL. Она упо! минается и используется практически во всех рецептах данной главы. Настоятельно рекомендую досконально разобраться в этом вопросе.
Проход строки | 135 |
Проход строки
Задача
Требуется обойти строку и возвратить каждый ее символ в отдельной строке таблицы, но в SQL нет операции цикла.1 Например, значение столбца ENAME (KING) таблицы EMP необходимо представить в виде четырех строк таблицы по одному символу слова «KING» в каждой.
Решение
Чтобы получить количество строк, необходимое для вывода каждого символа в отдельной строке, используем декартово произведение. За! тем с помощью встроенной функции СУБД для синтаксического разбо! ра извлекаем интересующие нас символы (пользователи SQL Server будут работать с функцией SUBSTRING, а не SUBSTR2):
1 select substr(e.ename,iter.pos,1) as C
2 from (select ename from emp where ename = 'KING') e,
3(select id as pos from t10) iter
4 where iter.pos <= length(e.ename)
C
K I N G
Обсуждение
Основная идея перебора символов строки – осуществить объединение с таблицей, имеющей достаточно строк, чтобы обеспечить необходи! мое число итераций. В данном примере используется таблица Т10, со! держащая 10 строк (и один столбец, ID, в котором располагаются зна! чения от 1 до 10). В результате этого запроса может быть возвращено максимум 10 строк.
В следующем примере показано декартово произведение представле! ний E и ITER (т. е. декартово произведение заданного имени и 10 строк таблицы Т10) без синтаксического разбора ENAME:
select ename, iter.pos
from (select ename from emp where ename = 'KING') e, (select id as pos from t10) iter
1Большинство СУБД поддерживают процедурные расширения, в которых есть циклы. – Примеч. науч. ред.
2Кроме того, в SQL Server используется функция LEN вместо LENGTH. –
Примеч. науч. ред.
136 | Глава 6. Работа со строками |
ENAME | POS |
| |
KING | 1 |
KING | 2 |
KING | 3 |
KING | 4 |
KING | 5 |
KING | 6 |
KING | 7 |
KING | 8 |
KING | 9 |
KING | 10 |
Кардинальность вложенного запроса Е равна 1, а вложенного запроса ITER – 10. Таким образом, в результате декартова произведения полу! чаем 10 строк. Формирование такого произведения – первый шаг при имитации цикла в SQL.
Обычно таблицу Т10 называют сводной таблицей.
Для выхода из цикла после возвращения четырех строк в решении ис! пользуется предикат WHERE. Чтобы результирующее множество со! держало столько же строк, сколько символов в имени, WHERE накла! дывает условие ITER.POS <= LENGTH(E.ENAME):
select ename, iter.pos
from (select ename from emp where ename = 'KING') e,
| (select id as pos from t10) iter |
where iter.pos <= length(e.ename) | |
ENAME | POS |
| |
KING | 1 |
KING | 2 |
KING | 3 |
KING | 4 |
Теперь, когда количество строк соответствует количеству символов E.ENAME, ITER.POS можно использовать как параметр SUBSTR, что позволит перебирать символы строки имени. Каждое последующее значение ITER.POS больше предыдущего на единицу, таким образом, можно сделать, чтобы каждая последующая строка возвращала оче! редной символ E.ENAME. Таков принцип работы примера решения.
В строке может выводиться разное количество символов в зависимости от поставленной задачи. Следующий запрос является примером обхода E.ENAME и вывода разных частей (более одного символа) строки:
select substr(e.ename,iter.pos) a, substr(e.ename,length(e.ename) iter.pos+1) b
Как вставить кавычки в строковые литералы | 137 |
from (select ename from emp where ename = 'KING') e, (select id pos from t10) iter
where iter.pos <= length(e.ename)
A B
KING G
ING NG NG ING
GKING
Чаще всего в рецептах данной главы используются сценарии обхода всей строки и вывода каждого ее символа в отдельной строке таблицы или обхода строки таким образом, чтобы число сгенерированных строк таблицы отражало количество символов или разделителей в строке.
Как вставить кавычки в строковые литералы
Задача
Требуется вставить кавычки в строковые литералы. Хотелось бы с по! мощью SQL получить результат, подобный приведенному ниже:
QMARKS
g'day mate beavers' teeth
'
Решение
Следующие три выражения SELECT представляют разные способы создания кавычек: как в середине строки, так и отдельных:
1 | select 'g''day mate' qmarks | from t1 | union all | |
2 | select 'beavers'' teeth' | from | t1 | union all |
3 | select '''' | from | t1 |
|
Обсуждение
Работая с кавычками, обычно удобно рассматривать их как скобки. Ес! ли есть открывающая скобка, всегда должна быть соответствующая ей закрывающая скобка. То же самое и с кавычками. Необходимо пом! нить, что число кавычек в любой строке должно быть четным. Чтобы вставить в строку одну кавычку, мы должны использовать две кавычки:
select 'apples core', 'apple''s core',
case when '' is null then 0 else 1 end from t1
'APPLESCORE | 'APPLE''SCOR | CASEWHEN''ISNULLTHEN0ELSE1END |
|
|
|
apples core | apple's core | 0 |
138 | Глава 6. Работа со строками |
Далее представлено решение, разобранное по элементам. Имеются две внешние кавычки, определяющие строковый литерал, и в строковом литерале есть еще две кавычки, вместе представляющие всего одну ка! вычку строки, которую, фактически, мы и получаем:
select '''' as quote from t1
Q
'
При работе с кавычками необходимо помнить, что строковый литерал, состоящий только из двух кавычек, без символов между ними, соот! ветствует пустой строке.
Как подсчитать, сколько раз символ встречается в строке
Задача
Требуется подсчитать, сколько раз символ или подстрока встречаются в заданной строке. Рассмотрим следующую строку:
10,CLARK,MANAGER
Необходимо определить количество запятых в строке.
Решение
Чтобы определить количество запятых в строке, вычтем ее длину без запятых из исходной длины. Каждая СУБД предоставляет функции для получения длины строки и удаления из нее символов. В большин! стве случаев это функции LENGTH (длина) и REPLACE (заменить) со! ответственно (пользователям SQL Server вместо LENGTH предлагает! ся встроенная функция LEN):
1 select (length('10,CLARK,MANAGER')
2length(replace('10,CLARK,MANAGER',',','')))/length(',')
4from t1
Обсуждение
Мы получили решение, используя простое вычитание. В результате вызова функции LENGTH в строке 1 получаем исходный размер стро! ки, а вызов LENGTH в строке 2 возвращает размер строки без запя! тых, которые были удалены функцией REPLACE.
Вычитая одну длину из другой, получаем разницу в символах, кото! рая соответствует количеству запятых в строке. Последней операцией является деление на длину строки поиска. Эта операция необходима, если длина искомой строки более 1 символа. В следующем примере
studfiles.net
+ (объединение строк) (Transact-SQL) | Microsoft Docs
- 03/07/2014
- Время чтения: 3 мин
В этой статье
Оператор в строковом выражении, объединяющий две или более символьных или двоичных строки, два или более столбцов или несколько строк и имен столбцов в одно выражение (строковый оператор).
Cинтаксические обозначения в Transact-SQL
Синтаксис
expression + expressionАргументы
expressionЛюбое действительное выражение любого типа данных в категории символьных и двоичных данных, за исключением типов данных image, ntext или text. Оба выражения должны быть одного типа данных, либо должна иметься возможность неявного преобразования типа данных одного выражения в тип данных другого выражения.
При сцеплении двоичных строк с любыми символами между двоичными строками необходимо использовать явное преобразование в символьные данные. В следующем примере показано, когда с двоичным объединением необходимо использовать функции CONVERT или CAST, а когда они могут не применяться.
DECLARE @mybin1 varbinary(5), @mybin2 varbinary(5) SET @mybin1 = 0xFF SET @mybin2 = 0xA5 -- No CONVERT or CAST function is required because this example -- concatenates two binary strings. SELECT @mybin1 + @mybin2 -- A CONVERT or CAST function is required because this example -- concatenates two binary strings plus a space. SELECT CONVERT(varchar(5), @mybin1) + ' ' + CONVERT(varchar(5), @mybin2) -- Here is the same conversion using CAST. SELECT CAST(@mybin1 AS varchar(5)) + ' ' + CAST(@mybin2 AS varchar(5))
Типы результата
Возвращает тип данных аргумента с самым высоким приоритетом. Дополнительные сведения см. в разделе Приоритет типов данных (Transact-SQL).
Замечания
При работе с пустыми строками нулевой длины оператор + (объединение строк) ведет себя иначе, чем при работе со значениями NULL или с неизвестными значениями. Символьная строка символа нулевой длины может быть указана в виде двух одинарных кавычек без каких-либо символов между ними. Двоичная строка нулевой длины может быть указана как 0x без указания каких-либо байтовых значений в шестнадцатеричной константе. При сцеплении строки нулевой длины всегда сцепляются две указанные строки. При работе со строками со значением NULL результат объединения зависит от настроек сеанса. При присоединении нулевого значения к известному значению результатом будет неизвестное значение, объединение строк с нулевым значением также дает нулевое значение, как и в арифметических действиях с нулевыми значениями. Однако можно изменить данное поведение, поменяв настройку CONCAT_NULL_YIELDS_NULL для текущего сеанса. Дополнительные сведения см. в разделе SET CONCAT_NULL_YIELDS_NULL (Transact-SQL).
Если результат объединения строк превышает предел в 8 000 байт, то он усекается. Однако усечения не произойдет, если хотя бы одна из сцепляемых строк принадлежит к типу больших значений.
Примеры
А.Использование объединения строк
В следующем примере создается единственный столбец с заголовком Name из нескольких символьных столбцов, где за фамилией лица следуют запятая, один пробел и имя того же лица. Результирующий набор сортируется в алфавитном порядке по возрастанию, сначала по фамилии, а затем по имени.
USE AdventureWorks2012; GO SELECT (LastName + ', ' + FirstName) AS Name FROM Person.Person ORDER BY LastName ASC, FirstName ASC;Б.Объединение числовых типов данных и дат
Следующий пример использует функцию CONVERT для объединения типов данных numeric и date.
USE AdventureWorks2012; GO SELECT 'The order is due on ' + CONVERT(varchar(12), DueDate, 101) FROM Sales.SalesOrderHeader WHERE SalesOrderID = 50001; GOНиже приводится результирующий набор.
------------------------------------------------
The order is due on 04/23/2007
(1 row(s) affected)
В.Использование объединения нескольких строк
Следующий пример сцепляет несколько строк в одну длинную строку для отображения фамилии и первой буквы инициалов вице-президентов в Компания Adventure Works Cycles. После фамилии ставится запятая, а после первой буквы инициалов — точка.
USE AdventureWorks2012; GO SELECT (LastName + ',' + SPACE(1) + SUBSTRING(FirstName, 1, 1) + '.') AS Name, e.JobTitle FROM Person.Person AS p JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID WHERE e.JobTitle LIKE 'Vice%' ORDER BY LastName ASC; GOНиже приводится результирующий набор.
Name Title
------------- ---------------
Duffy, T. Vice President of Engineering
Hamilton, J. Vice President of Production
Welcker, B. Vice President of Sales
(3 row(s) affected)
См. также
Справочник
ALTER DATABASE (Transact-SQL)
Функции CAST и CONVERT (Transact-SQL)
Типы данных (Transact-SQL)
Выражения (Transact-SQL)
Встроенные функции (Transact-SQL)
Операторы (Transact-SQL)
SELECT (Transact-SQL)
Инструкции SET (Transact-SQL)
+= (объединение строк) (Transact-SQL)
Основные понятия
Преобразование типов данных (компонент Database Engine)
msdn.microsoft.com