4. Создание базы данных средствами субд ms sql 2012. Создание бд sql
4. Создание базы данных средствами субд ms sql 2012
Заключительно частью моделирования информационной системы является создание реальной базы данных, опираясь на проведенное выше проектирование. Сюда входит выбор подходящей базы данных, ее развертывание и настройка, создание объектов структуры базы данных при помощи соответствующих средств, наполнение БД тестовым набором данных.
Для реализации реляционной базы данных предложенной структуры в данной курсовой работе выбрана СУБД MS SQL Server — один из лидеров современного рынка реляционных СУБД, распространяемая свободно для разработки или тестирования приложений и лицензируемой для промышленного использования. Преимуществами MS SQL являются:
— Высокая функциональность;
— Полная поддержка стандарта SQL и его расширения T-SQL;
— Широкая распространенность и доступность поддержки;
— Надёжность;
— Производительность.
— Наличие встроенных средств для работы и администрирования БД.
MS SQL является лидером современного рынка реляционных СУБД. Актуальной стабильной версией MS SQL на момент написания работы была версия 2012. Установка данной СУБД не представляет трудностей. Процесс установки сопровождается мастером, который запрашивает у пользователя необходимые данные и дальше самостоятельно устанавливает сервер БД, настраивает его на оптимальное быстродействие.
Для создания базы данных в СУБД MS SQL использовались запросы на стандартизированном языке SQL (англ. Structured Query Language, «Структурированный язык запросов»). В процессе создания базы данных для всех атрибутов реляционной были указаны подходящие типы данных. Названия сущностей и атрибутов были переведены на английский язык, ключевые поля сформированы с префикса «ID_» и суффикса, состоящего из имени связанной с ним таблицы. В таблице 8 показано соответствие названия сущности физической таблице в БД.
Таблица 8
Соответствие названия сущности физической таблице
| Сущность | Таблица |
| Страна | LAND |
| Город | CITY |
| Тур | TOUR |
| Отель | HOTEL |
| Виды транспорта | TOUR_TRANSPORT |
| Турист | TOURIST |
| Путевка | VOUCHER |
Физическая модель информационной системы в БД показана на рис. 5.
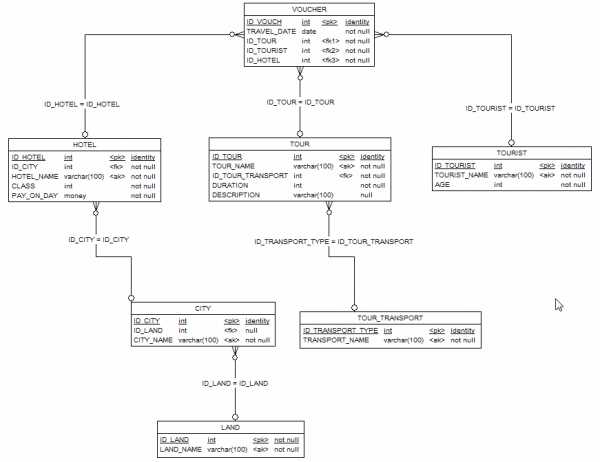
Рис. 5. Физическая модель информационной системы
Исходный код создания всех отношений базы данных представлен в Приложении к данной работе.
После создания базы данных её было наполнено пробным набором данных. Исходный код запросов на заполнение базы тестовым набором данных представлен в Приложении к данной работе.
Созданные на сервере таблицы базы данных показаны на рис. 6.
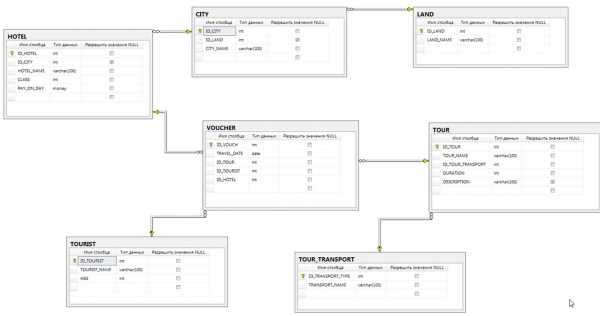
Рис. 6. Диаграмма данных сервера MS SQL
5. Разработка объектов базы данных, демонстрирующих логику предметной области
Для демонстрации работоспособности логики работы базы данных создадим в ней и продемонстрируем работу на тестовом наборе данных следующих объектов:
Запросы на базу данных.
Представляют собой базовое средство для получения информации из базы данных. Для написания запроса используется стандарт SQL. Для демонстрации напишем запрос, выводящий перечень туристов, отправившихся отдыхать в отель «San Simeon Apartments», фамилии туристов отсортируем по алфавиту. Запрос и результат его выполнения показан на рис. 7.
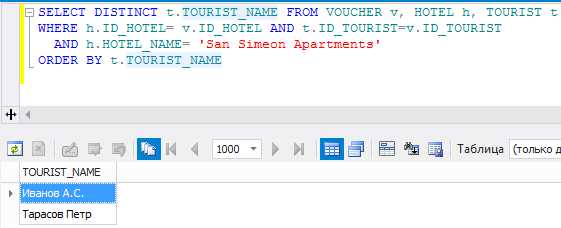
Рис. 7. Результат выполнения запроса
Представления— виртуальные объекты баз данных, отражающие данные в определенной форме из содержимого других объектов. Текст представления представляет собой SQL запрос на получения данных из одной или нескольких таблиц, других представлений, результатов выполнения процедур. Для демонстрации работы логики на тестовых данных, создадим представление, отображающую таблицу путевок и все расшифровывающую значения всех связанных, ключевых полей. Текст представления и результат его выполнения показан на рис. 8.
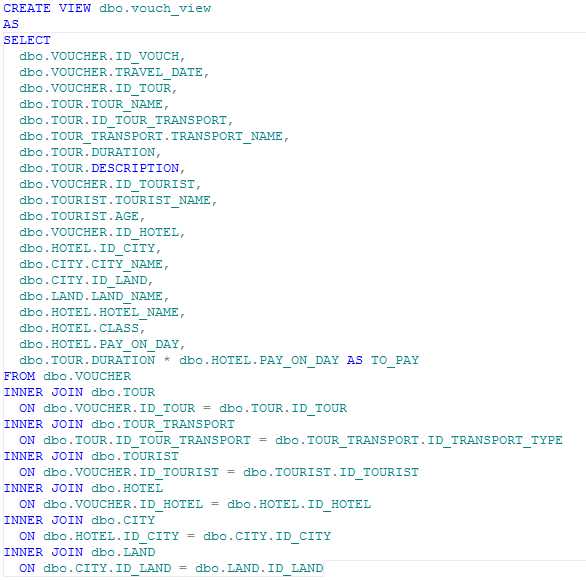
Рис. 8. Представление и результат его работы
Хранимые процедуры.Это объекты в базе данных, позволяющие хранить в ней наборы инструкций по обработке и изменению данных. Текст процедуры пишется на диалекте языка SQL для MS SQL Server, называемом Transacts SQL или сокращенно T-SQL. Для демонстрации напишем хранимую процедуру, позволяющую изменять на заданный процент стоимость проживания во всех отелях. Текст хранимой процедуры показан на рис. 9.
Рис. 9. Хранимая процедура
Триггеры.Это специальная хранимая процедура, которая вызывается не пользователем, а самим сервером БД в ответ на событие INSERT, DELETE, UPDATE на указанной таблице. Триггеры широко используются программистами для автоматизации контроля и изменений данных в БД. Как правило, триггер работает незаметно для пользователя БД и проявляет себя тогда, когда он вводит ошибочные с точки зрения программиста данные. Припустим, что туристическое агентство не работает с детьми младше 10 лет. Напишем триггер, который не позволит ввести возраст туриста меньше 10 лет. Текст триггера показан на рис. 10.
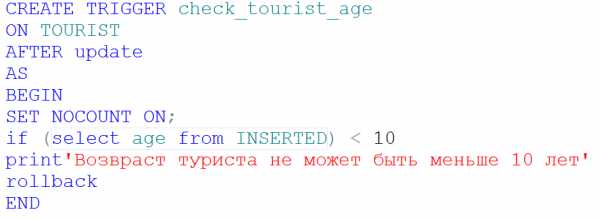
Рис. 10. Триггер, не позволяющий внести возраст туриста меньше 10 лет
studfiles.net
Создание базы данных с помощью программного SQL кода — МегаЛекции
Курсовой проект
по дисциплине «Базы данных»
Проектирование базы данных Агентство по трудоустройству
Выполнил Лян А.А
Студентка гр.2143\5
Руководитель Бураков П. В.
Доцент
Санкт-Петербург
1.Постановка задачи. 3
2. Информационно-логическая модель. 4
3. Физическая модель базы данных. 7
4. Создание базы данных в СУБД MS SQL Server 8
4.2 Создание базы данных с помощью программного SQL кода. 9
4.3 Создание диаграммы базы.. 12
5. Описание SQL запросов. 14
Постановка задачи
Выбранной предметной областью является агентство по трудоустройству , которое помогает найти людям работу .
Соискатель может ознакомиться с примерными видами услуг агентства, прежде чем что то выбрать . Этот заказ принимает и курирует менеджер. Заказ передается в вакансию непосредственно на выполнение. После выполнения проекта, менеджер предоставляет информацию, о существующих вариантах вакансий . Каждый работник специализируется на своей сфере.
Наиболее важными компонентами системы являются:
· соискатель;
· менеджер;
· Вакансия;
Основными процессами данной системы являются:
· ознакомление с услугами, предоставляемыми менеджером ;
· оформление документов;
· учет трудоустройства или не трудоустройства соискателя;
Итак, задачей является автоматизация работы пользователя по поиску, просмотру и редактированию информации о работниках, соискателях, вакансиях. Основной целью является предоставление клиенту, существующие вакансий, максимального удовлетворения желаний и потребностей соискателя.
Информационно-логическая модель
Для построения модели данных необходимо определить сущности и атрибуты, а так же связи между сущностями. То есть необходимо обозначить какая именно информация будет храниться в проектируемой базе данных.
Сущность – это то, о чем необходимо хранить информацию, что может быть однозначно идентифицировано.
Исходя из поставленной цели и задачи, можно выделить следующие объекты: менеджер, соискатель, предприятие, запись о трудоустроистве, вакансия . Далее следует определить взаимосвязи между ними. Обозначим взаимосвязь объектов в соответствии с поставленной задачей (см. Рис. 2.1).
Первой нужно выбрать сущность, в которой атрибут, определяющий связь, является первичным ключом. После определения связи связываемый атрибут другой сущности становится внешним ключом.
Затем следует определить свойства (атрибуты) каждой сущности (см. Таблица 2.1).
Рис 2.1 Логическая модель базы данных
Таблица 2.1
Сущность и их свойства
| Сущность | Атрибуты |
| Менеджер | УК менеджер Адрес Телефон ФИО Должность Возраст Пол |
| Соискатель | УК Соискателя Фамилия Имя Отчество Дата рождения Пол Стаж работы Диплом Образование |
| Вакансия | УК вакансий Минимальная заработная плата Образование Опыт работы Возраст Гражданство УК предприятия Должность |
| Предприятие | УК предприятие Название предприятия Адрес Лицензия Должность |
| Запись о трудоустройстве | УК записи трудоустройства УК вакансий УК соискателя |
Физическая модель базы данных
Следующим этапом проектирования базы данных является построение физической модели. Для ее создания необходимо определить типы данных для бедующих столбцов таблиц. Так же необходимо установить ограничения на каскадное обновление таблиц. Они будут определять характер поведения связанных полей (см.Рис 3.1)
Рис 3.1 Физическая модель базы данных
Создание базы данных в СУБД MS SQL Server
Создание файла базы данных
Рис. 4.1 Создание файла базы данных
Создание базы данных с помощью программного SQL кода
На языке SQL создание таблиц осуществляется с помощью оператора Create Table. Далее необходимо указать имя будущей таблицы, названия столбцов, их тип данных и возможность наличия значения null. Таким ключевым словом указывается столбец, который может содержать неопределенные значения. Столбцы первичных ключей обязательно имеют значения not null.
CREATE TABLE Menedzher (
Adres char(25) NULL,
UK_Menedzhera char(5) NOT NULL,
Telefon int NULL,
F_I_O char(25) NULL,
Dolzhnost char(50) NULL,
Vozrast char(5) NULL,
Pol char(2) NULL,
PRIMARY KEY NONCLUSTERED (UK_Menedzhera)
)
go
Для создания своей базы данных нужно скопировать код базы получившейся в программной среде ERWin в окно нового запроса New Query и запустить его.
Код схемы базы данных:
CREATE TABLE Predpriyatie (
Nazvanie_predpriyatiya char(30) NULL,
UK_Predpriyatiya char(5) NOT NULL,
Adres char(30) NULL,
Licenziya char(25) NULL,
PRIMARY KEY NONCLUSTERED (UK_Predpriyatiya)
)
go
CREATE TABLE Vakansiya (
Min_zar_plata money NULL,
UK_Vakansi char(5) NOT NULL,
Obrazovanie char(15) NULL,
Opit_raboti char(10) NULL,
Vozrast char(5) NULL,
Grazhdanstvo char(18) NULL,
UK_Predpriyatiya char(5) NULL,
Dolzhnost char(30) NULL,
PRIMARY KEY NONCLUSTERED (UK_Vakansi),
FOREIGN KEY (UK_Predpriyatiya)
REFERENCES Predpriyatie
)
go
CREATE TABLE Menedzher (
Adres char(25) NULL,
UK_Menedzhera char(5) NOT NULL,
Telefon int NULL,
F_I_O char(25) NULL,
Dolzhnost char(50) NULL,
Vozrast char(5) NULL,
Pol char(2) NULL,
PRIMARY KEY NONCLUSTERED (UK_Menedzhera)
)
go
CREATE TABLE Soiskatel (
F_I_O char(25) NULL,
UK_Soiskatel char(5) NOT NULL,
Data_rozhdeniya int NULL,
Pol char(2) NULL,
Stazh_raboti char(10) NULL,
Diplom char(35) NULL,
Obrazovanie char(15) NULL,
PRIMARY KEY NONCLUSTERED (UK_Soiskatel)
)
go
CREATE TABLE Zapis_o_trudoystroistve (
UK_Vakansi char(5) NULL,
UK_zapisi_trudystroistva char(5) NOT NULL,
UK_Soiskatel char(5) NULL,
UK_Menedzhera char(5) NULL,
PRIMARY KEY NONCLUSTERED (UK_zapisi_trudystroistva),
FOREIGN KEY (UK_Menedzhera)
REFERENCES Menedzher,
FOREIGN KEY (UK_Soiskatel)
FOREIGN KEY (UK_Vakansi)
REFERENCES Vakansiya
)
go
Создание диаграммы базы
В базе данных уже созданы таблицы и при помощи первичных и внешних ключей описаны отношения между этими таблицами. Для наглядного представления этой информации. Создадим диаграмму базы данных (см.Рис.4.3).
Для этого нужно выбрать команду New Database Diagram из контекстного меню Database Diagram (см.Рис.4.2) и в появившемся диалоговом окне добавим в диаграмму все столбцы .
Рис. 4.2. Создание новой диаграммы
Рис. 4.3 Диаграмма базы данных
Описание SQL запросов
Существуют четыре основных типа запросов данных в SQL, которые относятся к языку манипулирования данными:
INSERT – добавить строки в таблицу;
UPDATE – изменить строки в таблице;
DELETE – удалить строки в таблице;
SELECT – выбрать строки из таблиц;
Каждый из них имеет различные операторы и функции для произведения каких-то действий с данными.
Запрос INSERT
Что бы добавить строки в таблицу, для начала откроем SQL . Потом находим нашу базу данных. Найдя нашу базу, откроем контекстное меню и выбираем New Query (Рис 5.1).
Рис 5.1
В открывшемся окне вводим наш запрос INSERT.
insert into dbo.Menedzher
(Adres, UK_Menedzhera, Telefon, F_I_O)
values ('Gra 30 dom 3 kv 5', '01', '891145323', 'Лян Артём Андреевич').
После этого нажимаем EXECUTE ( рис 5.2).
Рис 5.2 Результат запроса INSERT
Запрос UPDATE
Для того что бы изменить строки в таблице не обходимо открыть New Query и появившемся окне вести запрос.
update dbo.Menedzher
Set Telefon = '891145323'
where Telefon = '892165356' ;
Результат (рис 5.3).
Рис 5.3 Результат запроса UPDATE
Запрос DELETE
Для того что бы удалить строки в таблице не обходимо открыть New Query и появившемся окне вести запрос (см. рис 5.4).
Рис 5.4 Результат запроса DELETE
Запрос SELECT
С помощью команды SELECT осуществляется выборка данных. По этой инструкции ядро базы данных возвращает данные из базы в виде набора записей. (см Рис. 5.5)
select F_I_O, Vozrast, Dolzhnost
from dbo.Menedzher
Предикат TOP
Возвращает определенное число записей, находящихся в начале или в конце диапазона, описанного с помощью предложения ORDER BY. Следующая инструкция SQL позволяет получить список 3 лучших менеджеров.
SELECT TOP 3
Имя, Фамилия, должность , возраст.
FROM Менеджер
Предикат ASC обеспечивает возврат последних значений. Значение, следующее после предиката TOP должно быть числовым значением типа Integer без знака.
Предикат TOP не влияет на возможность обновления запроса.( Рис.5.6)
Операция INNER JOIN
Объединяет записи из двух таблиц, если связующие столбцы этих таблиц содержат одинаковые значения.
Синтаксис
FROM таблица_1 INNER JOIN таблица_2 ON таблица_1.столбец_1 оператор таблица_2.столбец_2
Ниже перечислены аргументы операции INNER JOIN:
Элемент
Описание
таблица_1, таблица_2
Имена таблиц, записи которых подлежат объединению.
столбец_1, столбец_2
Имена объединяемых столбцов. Если эти столбцы не являются числовыми, то должны иметь одинаковый тип данных и содержать данные одного рода, однако столбцы могут иметь разные имена.
оператор
Любой оператор сравнения: "=", "<", ">", "<=", ">=" или "<>".
Дополнительные сведения
Операцию INNER JOIN можно использовать в любом предложении FROM. Это самые обычные типы связывания. Они объединяют записи двух таблиц, если связующие столбцы обеих таблиц содержат одинаковые значения.
Операцию INNER JOIN можно использовать с таблицами «Отделы» и «Сотрудники» для отбора всех сотрудников каждого отдела. Для отбора же всех отделов (в том числе тех, в которых нет ни одного сотрудника) или всех сотрудников (в том числе тех, кто не приписан ни к одному отделу) следует использовать операцию LEFT JOIN или RIGHT JOIN, которая создает внешнее объединение. Допускается объединение любых двух числовых столбцов подобных типов. Например, столбец счетчика можно объединить со столбцом типа «Длинное целое». Однако нельзя объединить типы столбцов Single и Double.
Следующая инструкция SQL объединяет таблицы «Типы» и «Товары» по столбцу «КодТипа»:
SELECT Категория, Марка
FROM Типы INNER JOIN Товары
ON Типы.КодТипа = Товары.КодТипа;
В предыдущем примере столбец «КодТипа» используется для объединения таблиц, однако оно не включается в результат выполнения запроса, поскольку не включено в инструкцию SELECT. Чтобы включить связующий столбец (в данном случае столбец Типы.КодТипа) в результат выполнения запроса, следует включить имя этого столбца в инструкцию SELECT.
Чтобы связать несколько предложений ON в инструкции JOIN, используйте следующий синтаксис.( Рис 5.7).
select Nazvanie_predpriyatiya, Dolzhnost
from dbo.Predpriyatie inner join dbo.Vakansiya
on dbo.Predpriyatie.UK_Predpriyatiya = dbo.Vakansiya.UK_Predpriyatiya
order by Nazvanie_predpriyatiya asc
Рис 5.7
Рекомендуемые страницы:
Воспользуйтесь поиском по сайту:
megalektsii.ru
Создание базы данных SQL Server на Visual Basic
Покажем, как можно создать базу данных SQL Server в среде Visual Studio. В этой простейшей базе данных будет всего одна таблица, содержащая сведения о телефонах ваших знакомых, т. е. в этой таблице будем иметь всего три колонки: Имя, Фамилия и Номер телефона.
Запускаем VB2010, заказываем новый проект шаблона Windows Forms Application, задаем имя — BD_sdf_2. Далее непосредственно создаем новую базу данных SQL Server. Для этого в пункте меню Project выбираем команду Add New Item (т. е. создать новый элемент) и в появившемся одноименном окне выбираем шаблон Local Database (локальная база данных), указываем имя файла (в поле Name) vic2.sdf и последовательно щелкаем на кнопках Add, Next, Finish.
Теперь добавляем таблицу в базу данных, для этого в пункте меню View выбираем команду Server Explorer (Обозреватель баз данных). В обозревателе баз данных развернем узел (щелкнем знак треугольника) vic2.sdf и выберем Tables (Таблицы). Щелкнем правой кнопкой мыши пункт Tables, а затем выберем пункт Create Table (Создать таблицу). Откроется окно New Table. Назовем новую таблицу (поле Name) БД телефонов. Заполним структуру таблицы.
Нажмем кнопку ОК, чтобы создать таблицу и закрыть окно New Table.
Чтобы исключить повторяющиеся записи (т. е. строки в таблице), следует назначить первичные ключи (или ключевые столбцы). Ключевым столбцом назначают столбец в таблице, который всегда содержит уникальные (неповторяющиеся в данной таблице) значения. Однако в нашей таблице могут быть люди с одинаковыми именами или одинаковыми фамилиями, т. е. в нашей таблице в качестве первичных ключей следует использовать одновременно два столбца: столбец Имя и столбец Фамилия. Представьте себе, что у нас уже есть сотни записей в таблице, и при попытке ввести вторую строку, содержащую то же самое значение, появляется сообщение об ошибке. Это очень технологично, удобно!
Чтобы добавить первичные ключи, в таблицу в Server Explorer развернем узел Tables, далее щелкнем правой кнопкой мыши на нашей только что созданной таблице и выберем пункт Edit Table Schema, затем для полей Имя и Фамилия укажем для параметра Allow Nulls значение No, т. е. обяжем нашего пользователя всегда заполнять эти поля (ячейки таблицы). Далее для параметра Unique (Являются ли эти поля уникальными?) ответим No, поскольку и имена, и фамилии повторяются. И, наконец, назначим колонки Имя и Фамилия первичными ключами (Primary Key — Yes). Нажмем кнопку OK для сохранения этих настроек и закрытия окна Edit Table — БД телефонов.
Теперь добавим данные в таблицу. Для этого в окне Server Explorer щелкнем правой кнопкой мыши на пункте БД телефонов и выберем команду Show Table Data. Откроется окно данных таблицы, но только пока пустое.
Далее заполняем данную таблицу. Для нашей демонстрационной цели введем пять строчек в данную таблицу. После ввода в меню File выберите команду Save All для сохранения проекта и базы данных. Теперь убедитесь, что в папке проекта появился файл Database1.sdf. Его можно открыть вне проекта с помощью Microsoft Visual Studio 2010 для редактирования базы данных.
about-windows.ru
НОУ ИНТУИТ | Лекция | Создание базы данных и проектирование таблиц
Аннотация: Определяется процесс создания базы данных. Описываются операторы создания, изменения базы данных. Рассматривается возможность указания имени файла или нескольких файлов для хранения данных, размеров и местоположения файлов. Анализируются операторы создания, изменения, удаления пользовательских таблиц. Приводится описание параметров для объявления столбцов таблицы. Дается понятие и характеристика индексов. Рассматриваются операторы создания и изменения индексов. Определяется роль индексов в повышении эффективности выполнения операторов SQL.
База данных
Создание базы данных
В различных СУБД процедура создания баз данных обычно закрепляется только за администратором баз данных. В однопользовательских системах принимаемая по умолчанию база данных может быть сформирована непосредственно в процессе установки и настройки самой СУБД. Стандарт SQL не определяет, как должны создаваться базы данных, поэтому в каждом из диалектов языка SQL обычно используется свой подход. В соответствии со стандартом SQL, таблицы и другие объекты базы данных существуют в некоторой среде. Помимо всего прочего, каждая среда состоит из одного или более каталогов, а каждый каталог – из набора схем. Схема представляет собой поименованную коллекцию объектов базы данных, некоторым образом связанных друг с другом (все объекты в базе данных должны быть описаны в той или иной схеме ). Объектами схемы могут быть таблицы, представления, домены, утверждения, сопоставления, толкования и наборы символов. Все они имеют одного и того же владельца и множество общих значений, принимаемых по умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора конкретного механизма создания и уничтожения каталогов, однако механизм создания и удаления схем регламентируется посредством операторов CREATE SCHEMA и DROP SCHEMA. В стандарте также указано, что в рамках оператора создания схемы должна существовать возможность определения диапазона привилегий, доступных пользователям создаваемой схемы. Однако конкретные способы определения подобных привилегий в разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в очень немногих СУБД. В других реализациях, например, в СУБД MS SQL Server, используется оператор CREATE DATABASE.
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных, а затем принадлежащий ей журнал транзакций. Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf. (для журнала транзакций ). В файле базы данных записываются сведения об основных объектах ( таблицах, индексах, представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE. Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::= CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ <определение_файла> [,...n] ] [,<определение_группы> [,...n] ] ] [ LOG ON {<определение_файла>[,...n] } ] [ FOR LOAD | FOR ATTACH ]Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf. В этом случае основная информация о базе данных располагается в первичном ( PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле. Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных.
Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакций генерируется на основе имени базы данных, и в конце к нему добавляются символы _log.
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
<определение_файла>::= ([ NAME=логическое_имя_файла,] FILENAME='физическое_имя_файла' [,SIZE=размер_файла ] [,MAXSIZE={max_размер_файла |UNLIMITED } ] [, FILEGROWTH=величина_прироста ] )[,...n]Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных. При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=FILEGROUP имя_группы_файлов <определение_файла>[,...n]Пример 3.1. Создать базу данных, причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE Archive ON PRIMARY ( NAME=Arch2, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch3, FILENAME=’c:\user\data\archdat2.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch4, FILENAME=’c:\user\data\archdat3.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) LOG ON (NAME=Archlog1, FILENAME=’c:\user\data\archlog1.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Archlog2, FILENAME=’c:\user\data\archlog2.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) Пример 3.1. Создание базы данных.Изменение базы данных
Большинство действий по изменению конфигурации базы данных выполняется с помощью следующей конструкции:
<изменение_базы_данных> ::= ALTER DATABASE имя_базы_данных { ADD FILE <определение_файла>[,...n] [TO FILEGROUP имя_группы_файлов ] | ADD LOG FILE <определение_файла>[,...n] | REMOVE FILE логическое_имя_файла | ADD FILEGROUP имя_группы_файлов | REMOVE FILEGROUP имя_группы_файлов | MODIFY FILE <определение_файла> | MODIFY FILEGROUP имя_группы_файлов <свойства_группы_файлов>}Как видно из синтаксиса, за один вызов команды может быть изменено не более одного параметра конфигурации базы данных. Если необходимо выполнить несколько изменений, придется разбить процесс на ряд отдельных шагов.
В базу данных можно добавить ( ADD ) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций.
Параметры файлов и групп файлов можно изменять ( MODIFY ).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE. Однако удаление файла возможно лишь при условии его освобождения от данных. В противном случае сервер не разрешит удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
DROP DATABASE имя_базы_данных [,...n]Удаляются все содержащиеся в базе данных объекты, а также файлы, в которых она размещается. Для исполнения операции удаления базы данных пользователь должен обладать соответствующими правами.
www.intuit.ru
- Пропала английская раскладка
- Оперативная система windows 10

- Как написать bat файл для запуска программы
- Зависает компьютер и отключается клавиатура и мышь

- Вставка в таблицу sql данных
- Не воспроизводит плеер видео

- Как удалять правильно
- Не видно языковую панель windows 7
- Ubuntu phpmyadmin не работает

- Термопаста для чего нужна

- Ip узнать адрес узнать другого
