Технический справочник (SQL Server Compact). Справочник sql
Справочник по операторам SQL-запросов
При создании отчетов Configuration Manager 2007 можно использовать много полезных инструкций Microsoft SQL Server, которые кратко описаны в этом разделе. Чтобы следить за ходом этого обсуждения, нужно иметь базовый уровень знаний инструкций запросов SQL и уметь писать запросы, такие как следующие:
SELECT Name, Comment, CollectionID
FROM v_Collection
WHERE Name LIKE 'All Windows%'
ORDER BY Name
Для получения сведений о том, как написать основные запросы, ищите раздел по основам составления запросов в электронной документации по Microsoft SQL Server 2005.
Статистические функции
Статистические функции (такие как SUM, AVG, COUNT, COUNT(*), MAX и MIN) генерируют итоговые значения в выходных наборах запроса. Статистическая функция (за исключением COUNT (*)) обрабатывает все выбранные значения в одном столбце, чтобы произвести одно значение результата. Статистические функции могут быть применены ко всем строками в представлении, к подмножеству представления, определенному предложением WHERE, или к одной или более группам строк в представлении. При применении статистической функции из каждого набора строк генерируется одно значение.
| Учтите, что значения NULL исключаются до вычисления результата статистической функции. Например, если есть 100 записей и для 8 из них есть значение NULL в столбце свойства, с которым производится вычисление, то результаты вычисления будут возвращены только для 92 записей. |
Пример использования статистической функции COUNT(*) отображен в следующем запросе (из встроенного отчета Подсчет клиентов для каждого сайта) и наборе результатов примера.
SELECT v_Site.SiteCode, v_Site.SiteName, v_Site.ReportingSiteCode,
Count(SMS_Installed_Sites0) AS 'Count'
FROM v_Site, v_RA_System_SMSInstalledSites InsSite
WHERE v_Site.SiteCode = InsSite.SMS_Installed_Sites0
GROUP BY SiteCode, SiteName, ReportingSiteCode
ORDER BY SiteCode
SiteCode SiteName ReportingSiteCode Количество
| ABC | Сайт ABC |
| 928 |
| 123 | Сайт 123 | ABC | 1010 |
Функции даты и времени
Многие встроенные отчеты используют функции даты и времени. Самые используемые общие функции — GETDATE, DATEADD, DATEDIFF и DATEPART.
GETDATE ()
Функция GETDATE выдает текущую дату и время во внутреннем формате SQL Server для значений datetime. GETDATE получает NULL параметр ().
В следующем примере результатами являются текущая системная дата и время:
SELECT GETDATE()
| 2005-05-29 10:10:03.001 |
DATEADD (datepart, number, date)
Функция DATEADD возвращает новое значение даты и времени datetime на основе добавления интервала к указанной дате.
Datepart — параметр, определяющий, в какую часть даты надо возвратить новое значение (например, год, месяц, день, час, минута и т.д), number — значение, используемое для увеличения datepart и date — начальная дата.
В следующем примере результатом является дата, спустя два дня после 29 мая 2005 г.:
SELECT DATEADD([day], 2, '2005-05-29 10:10:03.001')
(отсутствует имя столбца)
| 2005-05-31 10:10:03.001 |
DATEDIFF (datepart, startdate, enddate)
Функция DATEDIFF возвращает число пересеченных границ даты и времени между двумя указанными датами.
Datepart — параметр, определяющий, в какую часть даты надо возвратить новое значение (например, год, месяц, день, час, минута и т.д), startdate — начальная дата,enddate — конечная дата.
В следующем примере результатом является число минут между первой и второй датами:
SELECT DATEDIFF (minute, '2005-05-29 10:10:03.001',
'2005-06-12 09:28:11.111')
(отсутствует имя столбца)
| 20118 |
DATEPART (datepart, date)
Функция DATEPART возвращает целое число, представляющее указанную часть datepart из указанной даты.
Datepart — параметр, определяющий, в какую часть даты надо возвратить новое значение (например, год, месяц, день, час, минута и т.д), и date — указанная дата.
В следующем примере результатом является месяц в указанной дате:
SELECT DATEPART (month, '2005-05-29 10:10:03.001')
(отсутствует имя столбца)
| 5 |
Сочетание функций даты и времени
В отчетах Configuration Manager обычно используется сочетание функций даты и времени.
В следующем примере результатом являются текущие дата и время (2005-05-29 10:10:03.001 в этом примере) минус 100 дней:
SELECT DATEADD([day], - 100, GETDATE())
(отсутствует имя столбца)
2005-02-18 10:10:03.001 |
Пример запроса с использованием функций даты и времени
В следующем запросе результатом является общее число сообщений об изменении состояния за однодневный период. В этом запросе функции COUNT, GETDATE и DATEADD используются вместе с логическим оператором BETWEEN и предложениями GROUP BY и ORDER BY.
SELECT SiteCode, MessageID, COUNT(MessageID) AS [count],
GETDATE() AS [End Date]
FROM vStatusMessages
WHERE ([Time] BETWEEN DATEADD([day], -1, GETDATE()) AND GETDATE())
AND (MessageID BETWEEN '0' AND '10000')
GROUP BY SiteCode, MessageID
ORDER BY SiteCode, MessageID
Код сайта MessageID Количество Конечная дата
| ABC | 500 | 190 | 2005-05-29 10:10:03.001 |
| ABC | 501 | 130 | 2005-05-29 10:10:03.001 |
| ABC | 502 | 190 | 2005-05-29 10:10:03.001 |
| ABC | 1105 | 85 | 2005-05-29 10:10:03.001 |
| ABC | 1106 | 5 | 2005-05-29 10:10:03.001 |
| … | … | … | … |
СОЕДИНЕНИЯ
Чтобы создавать эффективные отчеты в Configuration Manager, необходимо знать, как соединить различные представления, чтобы получить ожидаемые данные. Есть три типа соединений: внутреннее, внешнее и перекрестное. Кроме того, есть три типа внешних соединений: левое, правое и полное. Самосоединение использует любое из вышеупомянутых соединений, но соединяет записи из одного и того же представления.
Внутренние соединения
При внутреннем соединении записи из двух представлений объединяются и добавляются к результатам запроса только в том случае, если значения соединяемых полей соответствуют определенным указанным критериям. При внутреннем соединении с использованием ResourceID для соединения представлений v_R_System и v_GS_WORKSTATION_STATUS результатом должен быть список всех систем с их датами последнего сканирования оборудования.
SELECT v_R_System.Netbios_Name0 AS MachineName,
v_GS_WORKSTATION_STATUS.LastHWScan AS [Last HW Scan]
FROM v_R_System INNER JOIN v_GS_WORKSTATION_STATUS
ON v_R_System.ResourceID = v_GS_WORKSTATION_STATUS.ResourceID
| Client1 | 2005-05-29 10:10:03.001 |
| Client3 | 2005-06-12 09:28:11.110 |
Внешние соединения
Внешнее соединение возвращает все строки из соединяемых представлений без учета соответствия строк между ними. Предложение ON дополняет данные, а не фильтрует их. Три типа внешних соединений (левое, правое и полное) указывают основной источник данных. Внешние соединения могут быть особенно полезными, когда в представлении есть значения NULL.
Левые внешние соединения
Когда используется левое внешнее соединение, чтобы объединить два представления, все строки в левом представлении включаются в результаты. В следующем запросе представления v_R_System и v_GS_WORKSTATION_STATUS соединяются с использованием левого внешнего соединения. Представление v_R_System указано в запросе при перечислении первым, что делает его левым представлением. Результат будет содержать список всех систем с их датами последнего сканирования оборудования. В отличие от внутреннего соединения, системы, на которых не было приведено сканирование оборудования, будут все же перечислены со значением NULL (как видно в наборе результата).
SELECT v_R_System.Netbios_Name0 AS MachineName,
v_GS_WORKSTATION_STATUS.LastHWScan AS [Last HW Scan]
FROM v_R_System LEFT OUTER JOIN v_GS_WORKSTATION_STATUS
ON v_R_System.ResourceID = v_GS_WORKSTATION_STATUS.ResourceID
| Client1 | 2005-05-29 10:10:03.001 |
| Client2 | NULL |
| Client3 | 2005-06-12 09:28:11.110 |
Правые внешние соединения
Правое внешнее соединение принципиально является таким же, как и левое внешнее соединение, за исключением того, что все строки из правого представления включаются в результаты.
Полное внешнее соединение
Полное внешнее соединение извлекает все строки из обоих соединяемых представлений. Оно возвращает все парные строки, где условие соединения выполнено (истина), плюс непарные строки из каждого представления, сцепленные со строками NULL из другого представления. Обычно нет потребности использовать этот тип внешнего соединения.
Перекрестное соединение
Перекрестное соединение возвращает произведение двух представлений, а не сумму. Каждая строка левого представления сопоставляется с каждой строкой правого представления. Получается набор всех возможных комбинаций строк без какой-либо фильтрации. Однако, если добавить предложение WHERE, перекрестное соединение будет функционировать как внутреннее соединение, используя условие для фильтрации и выбора из всех возможных комбинаций строк тех, которые требуются.
Самосоединение
Самосоединение использует любой из вышеупомянутых типов соединения, но является представлением, которое соединяется само с собой. В схемах базы данных самосоединение называется рефлексивной связью.
Ключевая фраза NOT IN
Вложенные запросы с ключевой фразой NOT IN очень полезны при поиске сведений о наборе данных, которые не отвечают определенным критериям. В следующем примере запрос возвращает имя NetBIOS всех компьютеров, на которых НЕ установлен Notepad.exe. Сначала нужно создать запрос, который может обнаружить все компьютеры с установленным выбранным файлом, как показано ниже:
SELECT DISTINCT v_R_System.Netbios_Name0
FROM v_R_System INNER JOIN v_GS_SoftwareFile
ON (v_GS_SoftwareFile.ResourceID = v_R_System.ResourceId)
WHERE v_GS_SoftwareFile.FileName = 'Notepad.exe'
После подтверждения, что первый запрос отображает все компьютеры, на которых установлен Notepad.exe, следующая инструкция вложенного запроса будет использовать ключевую фразу NOT IN, чтобы найти все имена компьютеров, на которых НЕ установлен файл Notepad.exe:
SELECT DISTINCT Netbios_Name0
FROM v_R_System
WHERE Netbios_Name0 NOT IN
(SELECT DISTINCT v_R_System.Netbios_Name0
FROM v_R_System INNER JOIN v_GS_SoftwareFile
ON (v_GS_SoftwareFile.ResourceID = v_R_System.ResourceId)
WHERE v_GS_SoftwareFile.FileName = 'Notepad.exe')
ORDER by Netbios_Name0
См. также
Дополнительные сведения см. на странице
.
Для обращений в группу разработчиков документации используйте адрес электронной почты
technet.microsoft.com
НОУ ИНТУИТ | Лекция | Справочник SQL
Оператор SELECT
Системы управления базами данных предоставляют для работы с информацией в базе данных язык структурированных запросов SQL. При использовании SQL всю работу выполняет система управления базой данных. Вместо программирования серверных сценариев для доступа к таблицам или для обслуживания данных в базе данных, можно передать эту работу СУБД. Сценарий просто создает запрос SQL для СУБД, которая самостоятельно выполняет задачу. Такой метод способствует использованию трехслойных, клиент-серверных систем, где доступ к данным и обработка базы данных локализованы на сервере базы данных.
Оператор SELECT
Наиболее часто используемым оператором SQL является оператор SELECT. Как предполагает его имя, этот оператор используется для выбора записей из таблицы базы данных. Выборка может охватывать всю таблицу со всеми полями, или она может быть ограничена определенными полями определенных записей, которые соответствуют заданным критериям поиска. При желании выбранные записи можно упорядочить или отсортировать по определенным полям. Группа выбранных записей сама становится множеством записей, которое можно обрабатывать таким же образом, как и при работе со всей таблицей.
Общий формат оператора SELECT показан ниже:
SELECT [TOP n | [PERCENT]] * | [DISTINCT] field1 [,field2]... FROM TableName WHERE criteria ORDER BY FieldName1 [ASC|DESC] [,FieldName2 [ASC|DESC] ]...За ключевым словом SELECT следует одна или две спецификации, определяющие поля данных, которые будут выбраны из таблицы. Звездочка (*) означает, что для каждой записи будут выбраны все поля. Иначе можно определить список имен полей, разделенных запятыми, и будут выбраны только эти поля данных. Предложение FROM определяет таблицу, из которой эти записи и поля будут выбраны.
Например, оператор
выбирает все записи из таблицы MyTable и включает все поля (*), которые составляют запись. Получаемое множество записей идентично тому, которое будет получено при открытии всей таблицы. В противоположность этому, оператор
SELECT LastName, FirstName FROM MyTableвыбирает все записи из таблицы, но предоставляет только поля с именами LastName и FirstName из всех полей записей. В этом случае получаемое множество записей содержит столько строк, сколько имеется записей в таблице, но только с двумя столбцами.
Ключевое слово DISTINCT
Некоторые поля таблицы, вполне вероятно, содержат не уникальные значения данных. То есть, одно и то же значение может появляться более чем в одной записи. Чтобы извлекать только уникальные значения из этих полей, надо перед именем поля поставить ключевое слово DISTINCT. Например, следующий оператор извлекает один столбец данных, содержащий только уникальные значения в поле с именем ItemType:
SELECT DISTINCT ItemType FROM ProductsПредложение WHERE
В обоих приведенных выше случаях из таблицы извлекаются все записи. Различаются только поля, которые составляют запись. Однако могут быть ситуации, когда не требуется извлекать все записи из таблицы. Может быть желательно выбрать только те записи, которые удовлетворяют определенному критерию. Для этих целей оператор SELECT предоставляет дополнительное предложение WHERE.
За ключевым словом WHERE следует один или несколько критериев выбора. Распространенный способ использования этого свойства состоит в проверке равенства, то есть поиска совпадающего значения в одном из полей записи. Например, если множество записей заказчиков обрабатывается на основе штата, в котором они расположены, то может быть желательно выбирать только те записи, где поле State содержит значение "GA". Для этого можно использовать оператор SQL,
SELECT * FROM Customers WHERE State='GA'а система управления базой данных предоставит только те записи, которые имеют совпадающий код штата. Фактически для определения критерия выбора можно выбрать любой из обычных операторов сравнения
| = | (равно) |
| <> | (не равно) |
| < | (меньше) |
| > | (больше) |
| <= | (меньше или равно) |
| => | (равно или больше) |
Кроме того, можно объединять критерии, используя логические операторы AND, OR и NOT для расширения или сокращения области выбора:
SELECT * FROM Customers WHERE State='GA' OR State='KY'Отметим в этих примерах, что значения критерия выбора заключаются в одиночные кавычки (апострофы). При любом поиске в текстовых полях базы данных значение критерия должно заключаться в одиночные кавычки ( WHERE State = 'GA' ). Если тестируется числовое поле, значение данных в кавычки не заключается ( WHERE Number > 10 ). Если тестируется поле даты/времени, то значение критерия окружается символами # (WHERE TheDate > #1/1/01#).
Предложение ORDER BY
Оператор SELECT может включать также предложение ORDER BY, чтобы организовать или отсортировать извлеченное из таблицы множество записей.
Предложение ORDER BY идентифицирует имена полей, по которым сортируются записи. Если используется более одного имени поля, то сортировка происходит в том порядке, в котором появляются разделенные запятыми имена. Первое поле становится основным полем сортировки, второе поле становится промежуточным полем сортировки, а третье поле — младшим полем сортировки. Поэтому можно упорядочить имена по фамилии, затем по имени, и затем по отчеству, применяя оператор SELECT следующего вида:
SELECT * FROM Customers ORDER By LastName,FirstName,MiddleInitialМожно также определить, будет ли упорядочивание происходить в возрастающей или убывающей последовательности, задавая ASC или DESC вслед за именем поля. По умолчанию используется возрастающий порядок ( ASC ), который можно не задавать.
SELECT * FROM Customers ORDER By LastName(DESC),FirstName(ASC),MiddleInitialПредложение WHERE и ORDER BY являются необязательными в операторе SELECT, но также могут появляться. Однако, если применются оба, предложение WHERE должно предшествовать предложению ORDER BY.
Предикат TOP n
Если поставить перед выбранным полем TOP n, то будет возвращено n записей, которые будут находиться вверху или внизу диапазона, определенного предложением ORDER BY. При упорядочивании по возрастанию ( DESC ) извлекается верхняя часть диапазона, при упорядочивании по убыванию ( ASC ) — нижняя часть диапазона.
SELECT TOP 10 ItemName, ItemPrice FROM Products ORDER BY ItemPrice ASCЭтот оператор выбирает 10 самых дешевых продуктов из таблицы. Можно использовать также зарезервированное слово PERCENT, чтобы возвращать определенный процент записей, которые попадают в верхнюю или нижнюю часть диапазона, определенного предложением ORDER BY.
Создание строк SQL
Иногда операторы SELECT могут стать достаточно сложными со всеми полями выбора, критериями выбора и предложениями упорядочивания. Поэтому часто удобно сначала создать оператор в переменной сценария, а затем выполнить оператор с помощью имени переменной.
SQLString = "SELECT * FROM Customers WHERE State='GA' ORDER BY LastName(DESC)"Здесь строка символов, составляющих оператор SELECT, присваивается переменной SQLString. Затем эта переменная используется для выполнения оператора SQL.
Если оператор SELECT является особенно длинным или сложным, то можно составить его по частям, соединяя отдельные строки:
SQLString = "SELECT * FROM Customers " SQLString &= "WHERE State='GA' OR State='KY' " SQLString &= "ORDER BY LastName(DESC), FirstName, MiddleInitial"или применив символ продолжения строки:
SQLString = "SELECT * FROM Customers " _ & "WHERE State='GA' OR State='KY' " _ & "ORDER BY LastName(DESC), FirstName, MiddleInitial"Здесь последующие предложения соединяются, чтобы создать строку SQL (не забывая добавлять необходимые пробелы для разделения предложений).
Апострофы в текстовых полях
Текстовые значения часто содержат апострофы, например, имена (O'Reilly), притяжательный падеж ( Bill's ), сокращения ( it's ) и тому подобное. Однако оператор SQL вида
SELECT * FROM Customers WHERE LastName = 'O'Reilly'будет вызывать ошибку, так как не разрешается кодировать апостроф внутри значения, которое само заключено в апострофы. Решение проблемы состоит в применении двойного апострофа ('') вместо любого одиночного апострофа внутри значения:
SELECT * FROM Customers WHERE LastName = 'O''Reilly'Интегрирование данных переменной
Обычно в операторах SQL используются порождаемые сценарием данные, а не строковые или числовые константы. В этом случае сценарий должен создать соответствующий оператор SELECT, соединяя фиксированную часть оператора SELECT с переменными данными:
SQLString = "SELECT * FROM Customers WHERE State = '$TheState'"Если переменная TheState имеет значение "GA", то SQLString будет содержать оператор SQL:
SQLString = "SELECT * FROM Customers WHERE State = 'GA'"Отметим, что апострофы, включенные в литеральные текстовые строки, окружают переменную, так что значение TheState равное "GA" интерпретируется как строка ( 'GA' ) в операторе SELECT.
При извлечении числовых данных апострофы не требуются:
SQLString = "SELECT * FROM Customers WHERE Age = $TheAge"Значение переменной TheAge добавляется в конце литеральной строки, создавая оператор SELECT следующего вида:
SQLString = "SELECT * FROM Customers WHERE Age = 30"При создании операторов, включающих дату, переменная должна быть заключена в специальные символы "#":
SQLString = "SELECT * FROM Orders WHERE OrderDate = #$TheDate#"Получающая строка в переменной SQLString представляет оператор SELECT следующего вида:
SQLString = "SELECT * FROM Orders WHERE OrderDate = #07/15/04#"Поэтому как общее правило, операторы SQL SELECT для трех типов данных имеют следующие общие конструкции:
SQLString = "SELECT * FROM Table WHERE StringField = '$StringVariable'" "SELECT * FROM Table WHERE NumericField = $NumericVariable "SELECT * FROM Table WHERE DateField = #$DateVariable#"www.intuit.ru
SQL. Справочник, 3-е издание – ScanLibs
История и реализации SQL
В начале 1970-х работы сотрудника IBM профессора Э. Ф. Кодда послужили основой при разработке продукта для работы с реляционными данными, получившего название SEQUEL (Structured English Query Language). SEQUEL позднее превратился в SQL (Structured Query Language).
IBM, равно как и другие производители СУБД, был очень заинтересован в стандартизации методов доступа и манипуляции данными в реляционных базах данных. Хотя в IBM была разработана теория реляционных баз данных, компания Oracle первой вывела технологию на рынок. Со временем SQL стал достаточно популярным, чтобы привлечь к себе внимание Американского национального института по стандартам (ANSI), выпустившего стандарты SQL в 1986, 1989, 1992, 1999, 2003 и 2006 годах. В этом издании используется стандарт 2003 года, так как стандарт SQL2006 описывает элементы SQL, не входящие в поле рассмотрения данной книги. (По существу, SQL2006 описывает использование XML в SQL.)
С 1986 года было создано много различных языков, позволявших программистам и разработчикам работать с реляционными данными. Но лишь немногие из них были столь же просты для изучения и стали настолько общеприняты, как SQL. Программисты и администраторы получили возможность изучения одного языка, который с небольшими поправками применим к широкому спектру платформ СУБД, приложений и продуктов.
В этом справочнике приводятся описания синтаксиса пяти реализаций SQL2003:
• Синтаксис по стандарту ANSI SQL
• MySQL версии 5.1
• Oracle Database llg
• PosgreSQL версии 8.3
• Microsoft SQL Server 2008
Реляционная модель и ANSI SQL
Реляционные системы управления базами данных, такие как описываемые в этой книге, являются двигателем множества информационных систем в мире, в особенности веб-приложений и распределенных клиент-серверных вычислительных систем. Реляционные СУБД позволяют множеству пользователей быстро и одновременно получать доступ, создавать, редактировать данные, не влияя на работу других пользователей. Реляционные СУБД позволяют разработчикам создавать полезные приложения для доступа к данным, а администраторам дают возможность развивать, защищать, оптимизировать информационные ресурсы.
Реляционная СУБД – это система, пользователи которой получают доступ к данным, представленным в виде набора связанных таблиц. Данные хранятся в таблицах, состоящих из строк и столбцов. Таблицы, хранящие независимые данные, могут быть связаны между собой, если в них есть столбцы, значения в которых уникально идентифицируют строки. Наборы таких столбцов называют ключами. Кодд впервые описал реляционную теорию в своей исторической работе «Реляционная модель данных для больших разделяемых банков данных», опубликованной в журнале Communications of the ACM (Association for Computing Machinery) в 1970 году. Согласно новой реляционной модели данных Кодда данные должны быть структурированными (в таблицы из строк и столбцов), управляемыми с помощью операторов, таких как выборка, проекция, объединение, и целостными в результате применения правил контроля целостности, таких как первичные и внешние ключи. Кодд также изложил правила, которые должны применяться при проектиров
scanlibs.com
Технический справочник (SQL Server Compact)
Раздел
Описание
| Справочник по пользовательскому интерфейсу (SQL Server Compact) | Содержит сведения о справке F1 по мастерам и средствам SQL Server Compact 4.0. |
| Справочник по SQL (SQL Server Compact) | Описывает синтаксис SQL, используемый в SQL Server Compact 4.0. |
| Справочник по поставщику OLE DB (SQL Server Compact) | Описывает интерфейсы, свойства и типы данных, зависящие от поставщика, а также отличия поставщика OLE DB для SQL Server Compact 4.0 от базовой спецификации OLE DB. |
| Справочник по собственному программированию (SQL Server Compact) | Содержит справочные сведения по программному доступу к SQL Server Compact 4.0 в собственных приложениях. |
| Библиотека классов SQL Server Compact 4.0 | Предоставляет сведения о пространстве имен System.Data.SqlServerCe, которое является поставщиком данных для SQL Server Compact. Пространство имен System.Data.SqlServerCe предоставляет программный доступ к базам данных SQL Server Compact из приложений рабочего стола. |
msdn.microsoft.com
Справочник по инструкциям SQL | SQL Программирование
Он представляет собой расположенный в алфавитном порядке перечень инструкций SQL с подробными объяснениями и примерами. Каждая инструкция или функция определяется как «поддерживаемая», «поддерживаемая с вариантами», «поддерживаемая с ограничениями» и «не поддерживаемая» каждым из пяти диалектов SQL: DB2, MySQL, Oracle, PostgreSQL, SQL Server. После краткого описания стандарта SQL 2003 коротко, но основательно, обсуждаются все реализации с приведением примеров. Если какая-то платформа не поддерживает данную команду, этот факт фиксируется в таблице, предваряющей описание команды, после чего описание команды для этой платформы не приводится. Также, каждая команда сравнивается со стандартом SQL 2003.
При изучении команды:
Здесь обсуждаются все свойства, общие для разных реализаций команды, а затем они сравниваются с соответствующей темой SQL 2003. Таким образом, подраздел, посвященный реализации команды на конкретной платформе, может не давать описания всех аспектов этой команды, поскольку некоторые детали попадают в раздел, относящийся к SQL 2003. Пожалуйста, обратите внимание, что если ключевое слово есть в синтаксисе, но отсутствует его описание, это означает, что мы решили не повторять описания, приведенного в разделе, относящемся к стандарту ANSI.
Если вы перейдете прямо к реализациям команд на платформе и не увидите обсуждение интересующего вас ключевого слова или предложения, это означает, что оно приведено в разделе SQL 2003, в подразделе, посвященном этой команде (это замечание применимо ко всем описанным платформам).
Источник
Похожие публикации
new-techs.ru
SQL. Справочник
В третьем издании книги "SQL. Справочник" описываются все операторы SQL согласно последнему стандарту ANSI SQL2003, а также особенности реализации этих операторов в наиболее популярных СУБД: Microsoft SQL Server 2008, Oracle 11g, MySQL 5.1 и PostgreSQL 8.3. Издание содержит описание реляционной модели данных, объяснение основных концепций реляционных СУБД, полное описание синтаксиса SQL, а также описание специфических функций, характерных для каждой СУБД.
Справочник подготовлен профессиональными администраторами и опытными разработчиками, использующими различные диалекты SQL для поддержки сложных корпоративных приложений. Основная задача издания - служить кроссплатформенным руководством для тех, кто, не будучи экспертами, занимается переносом кода (включая пользовательские приложения) между различными СУБД. Независимо от того, является ли читатель новичком в SQL или имеет значительный опыт его использования, он найдет много полезных советов и приемов в этой лаконичной и удобной для работы книге.
Отзывы читателей
Эта книга является справочником - она должна лежать у вас на столе рядом с компьютером после того, как вы изучили основы, но еще не запомнили всех деталей. Я обращаюсь к ней, когда у меня возникают вопросы.
Первый раз я открыл эту книгу, вообще не имея предварительного опыта работы в SQL (разве что знал, что это что-то для работы с базами данных), и за несколько дней узнал достаточно, чтобы приступить к работе. В этом мне очень помогло введение.
В книге замечательно то, что описываются четыре популярные реализации SQL в относительно беспристрастной и объективной манере. При необходимости перейти с одной СУБД на другую вам не придется искать новую книгу. (А иначе пришлось бы, потому что, как вы увидите, реализации очень сильно отличаются как друг от друга, так и от стандарта, который в книге тоже описан).
Книга не подойдет читателям, совершенно незнакомым с концепцией баз данных, но если вы не знаете SQL, то ничего страшного. Также вы не найдете здесь информации о планировании или организации базы данных - это книга о реализации. Поэтому в ней не рассматриваются вопросы о том, как распределить данные по таблицам, создавать или нет отдельную таблицу или базу данных и тому подобные. Вместо этого описывается синтаксис запросов, с помощью которых вы создаете базу данных и работаете с ней, с таблицами и данными в таблицах. Также описываются типы данных (так как они очень различаются в разных реализациях), типы таблиц и различные атрибуты (индексы и все такое прочее).
Ну и наконец, это не руководство по безопасности. В книгу входит информация о привилегиях и разрешениях, но только в терминах синтаксиса, а не стратегии.
- Натан Эди (Гэлион, Огайо)
До некоторой степени я согласен с теми, кто говорит, что это слишком тонкая книга, - ведь это справочник команд для четырех различных СУБД. Но ошибочно думать, что книга должна содержать полный набор документации. Нет, основное её предназначение - служить кроссплатформенным справочником для людей вроде меня, не являющихся экспертами, но занимающихся переносом кода (включая пользовательские приложения) между различными СУБД. Сорок страниц, посвященных оператору SELECT, из почти четырехсот, занятых описанием всех операторов, показывают, насколько эта команда важна на всех платформах.
Важное достоинство этой книги состоит в том, что она наконец уравнивает в правах PostgreSQL и MySQL, популярные СУБД с открытым кодом, и MS SQL Server и Oracle, которые получают большую прибыль от продажи первоклассной документации и руководств, тогда как первые бесплатно доступны в Интернете.
Поэтому, если вам нужна полная документация по вашей любимой СУБД, то идите и потратьте несколько сотен долларов. А если вам нужно иметь под рукой справочник с простыми объяснениями и сравнениями, представляющий четыре самые популярные на текущий момент СУБД, то купите этот справочник. Вы не будете разочарованы.
- Джей Джордж (Пало Альто, Калифорния)
Это справочник по синтаксису SQL, дающий бесценную информацию о переносимости всех типов операторов. К особым достоинствам книги можно отнести четыреста страниц справочной информации по операторам. Для каждого оператора приводится описание его синтаксиса и опций. Затем в деталях описывается поддержка оператора каждой платформой (MySQL, Oracle, PostgreSQL и SQL Server). Далее 120 страниц аналогичного описания по функциям SQL.
Это классическая книга издательства О'Reilly. Текст хорошо написан, а сама книга очень информативна и хорошо организована. В ней есть небольшое введение, но основной частью является справочник по операторам и функциям. Полезнее всего книга будет тем, у кого уже есть некоторое понимание SQL. Книга не предназначена для новичков.
Это идеальный настольный справочник, особенно для тех, кто работает над кроссплатформенными приложениями на SQL.
- Джек Херрингтон (Кремниевая долина, Калифорния)
Об авторах
Кевин Кляйн - директор деператмента SQL Server Solutions в компании Quest Software, занимающейся разработкой инструментов для управления базами данных и мониторинга приложений.
Дэниэл Кляйн - профессор и руководитель образовательной программы в университете Анкориджа, штат Аляска.
Брэнд Хант - директор по архитектуре и проектированию в Merril Lynch.
3-е издание
booksinfo.ru
- Защита сайта от взлома php
- Ноутбук не заряжается и не работает от сети

- Одинаковые ярлыки на рабочем столе windows 7 как восстановить

- Зарядка подключена не заряжается

- Использование даты в sql примеры

- Онлайн проверка на вирусы компьютер

- Одноклассники когда создали

- Как отключить тачпад на windows 10 на ноутбуке asus

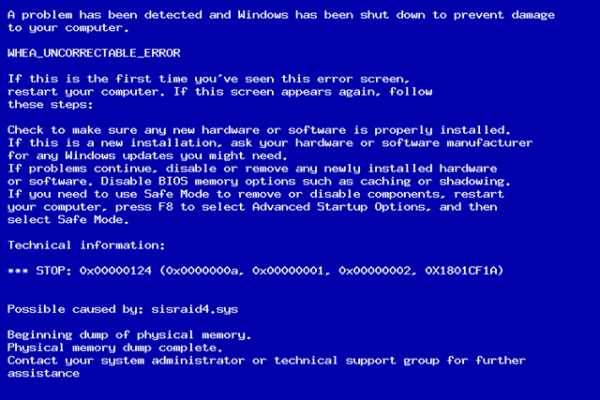
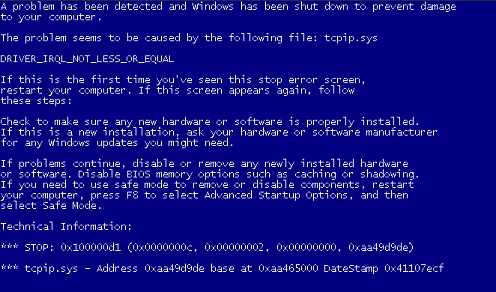
- Виндовс стоп код
- Как открыть ярлык lnk

- Синий экран смерти код ошибки 0x00000124 windows 7 как исправить