формула для вычисленного столбца на основе столбца другой таблицы. Вычисляемый столбец sql
sql - Как создать вычисляемый столбец в таблице SQL Server 2008
Мне действительно нужен вычисленный столбец таблицы с простой суммой.
См. ниже:
SELECT key3 ,SUM(UTOTALWBUD) FROM CONTACT1 INNER JOIN CONTACT2 ON CONTACT1.ACCOUNTNO = CONTACT2.ACCOUNTNO WHERE KEY1 = 'Client' GROUP BY KEY3Я попытался создать вычисляемый столбец, добавив следующий
ALTER TABLE ManagerTaLog ADD WeeklyBudget as ( SELECT key3 ,SUM(UTOTALWBUD) FROM CONTACT1 JOIN CONTACT2 ON CONTACT1.ACCOUNTNO = CONTACT2.ACCOUNTNO WHERE KEY1 = 'Client' GROUP BY KEY3)Я получил сообщение об ошибке:
Msg 1046, уровень 15, состояние 1, строка 4 Подзапросы в этом контексте не допускаются. Разрешены только скалярные выражения.
Пожалуйста, сообщите, что я могу с этим сделать.
Большое спасибо
Часть 2
Я создал функцию; однако, я получаю нулевые значения, пожалуйста, сообщите.
CREATE FUNCTION [dbo].[SumIt](@Key3 varchar) RETURNS TABLE AS RETURN ( SELECT SUM(UTOTALWBUD) FROM CONTACT1 JOIN CONTACT2 ON CONTACT1.ACCOUNTNO = CONTACT2.ACCOUNTNO JOIN Phone_List ON CONTACT1.KEY3 = Phone_List.[Manager ] WHERE KEY1 = 'Client' AND Phone_List.[Manager ] = @Key3 GROUP BY [Manager ] ) END GOОпределения таблиц
CREATE TABLE [dbo].[CONTACT1]( [ACCOUNTNO] [varchar](20) NOT NULL, [COMPANY] [varchar](40) NULL, [CONTACT] [varchar](40) NULL, [LASTNAME] [varchar](15) NULL, [DEPARTMENT] [varchar](35) NULL, [TITLE] [varchar](35) NULL, [SECR] [varchar](20) NULL, [PHONE1] [varchar](25) NOT NULL, [PHONE2] [varchar](25) NULL, [PHONE3] [varchar](25) NULL, [FAX] [varchar](25) NULL, [EXT1] [varchar](6) NULL, [EXT2] [varchar](6) NULL, [EXT3] [varchar](6) NULL, [EXT4] [varchar](6) NULL, [ADDRESS1] [varchar](40) NULL, [ADDRESS2] [varchar](40) NULL, [ADDRESS3] [varchar](40) NULL, [CITY] [varchar](30) NULL, [STATE] [varchar](20) NULL, [ZIP] [varchar](10) NOT NULL, [COUNTRY] [varchar](20) NULL, [DEAR] [varchar](20) NULL, [SOURCE] [varchar](20) NULL, [KEY1] [varchar](20) NULL, [KEY2] [varchar](20) NULL, [KEY3] [varchar](20) NULL, [KEY4] [varchar](20) NULL, [KEY5] [varchar](20) NULL, [STATUS] [varchar](3) NOT NULL, [NOTES] [text] NULL, [MERGECODES] [varchar](20) NULL, [CREATEBY] [varchar](8) NULL, [CREATEON] [datetime] NULL, [CREATEAT] [varchar](5) NULL, [OWNER] [varchar](8) NOT NULL, [LASTUSER] [varchar](8) NULL, [LASTDATE] [datetime] NULL, [LASTTIME] [varchar](5) NULL, [U_COMPANY] [varchar](40) NOT NULL, [U_CONTACT] [varchar](40) NOT NULL, [U_LASTNAME] [varchar](15) NOT NULL, [U_CITY] [varchar](30) NOT NULL, [U_STATE] [varchar](20) NOT NULL, [U_COUNTRY] [varchar](20) NOT NULL, [U_KEY1] [varchar](20) NOT NULL, [U_KEY2] [varchar](20) NOT NULL, [U_KEY3] [varchar](20) NOT NULL, [U_KEY4] [varchar](20) NOT NULL, [U_KEY5] [varchar](20) NOT NULL, [recid] [varchar](15) NOT NULL ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO CREATE TABLE [dbo].[Phone_List]( [Manager ] [nvarchar](255) NULL, [SalesCode] [nvarchar](255) NULL, [Email] [nvarchar](255) NULL, [PayrollCode] [nvarchar](255) NULL, [Mobile] [nvarchar](255) NULL, [FName] [nchar](20) NULL, [idd] [tinyint] NULL, [OD] [varchar](20) NULL, [WeeklyBudget] AS ([dbo].[SumIt]([manager])) ) ON [PRIMARY]sql - Как создать столбец, вычисляемый из другого столбца?
Для решения этой проблемы необходимо использовать вычисляемый столбец. Что-то с определением, подобным этому:
Исходное выражение, взятое из и дополнительной информации, доступной по адресу BlackWasp.
Вычисленный столбец вычисляется из выражения, которое может использовать другое столбцы в одной таблице. Выражение может быть неукомплектованным столбцом имя, константу, функцию и любую комбинацию из них, связанных одного или нескольких операторов. Выражение не может быть подзапросом.
Если не указано иное, вычисленные столбцы являются виртуальными столбцами, которые физически не хранятся в таблице. Их значения пересчитываются каждый раз, когда они ссылаются на запрос. Механизм Database Engine использует ключевое слово PERSISTED в операторах CREATE TABLE и ALTER TABLE для физического хранения вычисляемых столбцов в таблице. Их значения обновляется, когда изменяются любые столбцы, которые являются частью их расчета. От маркировка вычисленного столбца как PERSISTED, вы можете создать индекс на вычисленный столбец, который является детерминированным, но не точным. Дополнительно, если вычисленный столбец ссылается на функцию CLR, механизм Database Engine не может проверить, действительно ли функция детерминирована. В этом case, вычисляемый столбец должен быть PERSISTED, чтобы индексы могли быть созданный на нем. Дополнительные сведения см. В разделе Создание индексов на вычисленном Столбцы.
Вычисляемые столбцы могут использоваться в избранных списках, предложения WHERE, ORDER BY или любые другие местоположения, в которых регулярные выражения могут быть с последующими исключениями:
Вычисляемые столбцы, используемые как ограничения CHECK, FOREIGN KEY или NOT NULL, должны быть отмечены Сохранялось. Вычисленный столбец может использоваться как ключевой столбец в индексе или как часть любого PRIMARY KEY или UNIQUE, если значение вычисленного столбца определяется детерминированное выражение и тип данных результата разрешены в индексе столбцы.
Например, если таблица имеет целые столбцы a и b, вычисленный столбец a + b может быть индексированный, но вычисляемый столбец a + DATEPART (dd, GETDATE()) не может быть проиндексирован, поскольку значение может меняться > в последующих вызовах.
Вычисленный столбец не может быть объектом инструкции INSERT или UPDATE.
Механизм базы данных автоматически определяет недействительность вычисляемые столбцы на основе используемых выражений. Результат большинства выражения считаются нулевыми, даже если только неизменяемые столбцы присутствуют, потому что возможные потоки или переливы будут нулевые результаты. Используйте функцию COLUMNPROPERTY с помощью AllowsNull свойство исследует значение nullability любого вычисленного столбец в таблице. Выражение, которое является нулевым, можно превратить в неизменяемый, указав ISNULL (check_expression, constant), где константа является ненулевым значением, заменяемым любым нулевым результатом.
qaru.site
Как изменить этот вычисленный столбец в SQL Server 2008? Безопасный SQL
Если вы пытаетесь изменить существующий столбец, вы не можете использовать ADD. Вместо этого попробуйте следующее:
alter table tbPedidos alter column restricoes as (cast (case when restricaoLicenca = 1 или restricaoLote = 1 или restricaoValor = 1, затем 1 else 0 end как бит))
EDIT: Вышеуказанное неверно . При изменении вычисленного столбца единственное, что вы можете сделать, это сбросить его и повторно добавить.
Что-то вроде этого:
ALTER TABLE dbo.MyTable DROP COLUMN OldComputedColumn ALTER TABLE dbo.MyTable ADD OldComputedColumn AS OtherColumn + 10Источник
Это одна из тех ситуаций, когда проще и быстрее просто использовать функцию диаграммы SQL Server Management Studio.
- Создайте новую диаграмму, добавьте таблицу и выберите отображение столбца формулы в виде таблицы диаграммы.
- Измените формулу столбцов на пустую строку ('') или что-то такое же безобидное (возможно, так, чтобы вы не изменяли тип данных столбца).
- Сохраните диаграмму (которая должна сохранить таблицу).
- Измените свою функцию.
- Верните функцию обратно в формулу для этого столбца.
- Сохраните еще раз.
Выполнение этого способа в SSMS сохранит упорядочение столбцов в вашей таблице, что простое drop...add не гарантирует. Это может быть важно для некоторых.
Как правильно утверждает Майкл Тодд в своем ответе
При изменении вычисленного столбца единственное, что вы можете сделать, это сбросить его и повторно добавить.
Просто нужно было сделать это сам, хотя я хотел сохранить существующие данные (как Management Studio делает, когда вы выполняете эту задачу через дизайнера).
Мое решение состояло в том, чтобы хранить данные во временной таблице, а затем обновлять таблицу с сохраненными значениями после того, как я сбросил и воссоздал вычисленный столбец.
SELECT IDKey, Value INTO #Temp FROM MyTable ALTER TABLE MyTable DROP COLUMN Value ALTER TABLE MyTable ADD Value nvarchar(max) NULL UPDATE MyTable SET Value = #Temp.Value FROM MyTable INNER JOIN #Temp ON #Temp.IDKey= MyTable.IDkeysql.fliplinux.com
sql-server - Автоматический вычисляемый столбец SQL Server
Я хочу изменить таблицу и добавить столбец, который является суммой двух других столбцов, и этот столбец автоматически вычисляется при добавлении новых данных.
Вместо того, чтобы добавлять этот столбец в таблицу, я бы рекомендовал использовать View для вычисления дополнительного столбца и прочитать его.
Вот учебник о том, как создавать представления здесь:
http://odetocode.com/Articles/299.aspx
Ваш запрос будет выглядеть примерно так:
SELECT ColumnA, ColumnB, (ColumnA+ColumnB) as ColumnC FROM [TableName] ответ дан Curt 14 марта '12 в 12:37 источник поделитьсяСинтаксис для спецификации вычисляемого столбца следующий:
column-name AS formulaЕсли значения столбцов должны быть сохранены в базе данных, ключевое слово PERSISTED должно быть добавлено к синтаксису, как показано ниже:
column-name AS formula PERSISTEDВы не упомянули пример, но если вы хотите добавить столбец "sumOfAAndB" для вычисления суммы A и B, ваш синтаксис выглядит так:
ALTER TABLE tblExample ADD sumOfAAndB AS A + BНадеюсь, это поможет.
ответ дан ExternalUse 14 марта '12 в 12:43 источник поделитьсяКак создать вычисляемый столбец при создании новой таблицы:
CREATE TABLE PRODUCT ( WORKORDERID INT NULL, ORDERQTY INT NULL, [ORDERVOL] AS CAST ( CASE WHEN ORDERQTY < 10 THEN 'SINGLE DIGIT' WHEN ORDERQTY >=10 AND ORDERQTY < 100 THEN 'DOUBLE DIGIT' WHEN ORDERQTY >=100 AND ORDERQTY < 1000 THEN 'THREE DIGIT' ELSE 'SUPER LARGE' END AS NVARCHAR(100) ) ) INSERT INTO PRODUCT VALUES (1,1),(2,-1),(3,11) SELECT * FROM PRODUCT ответ дан Manish D 15 марта '18 в 13:08 источник поделитьсянапример
CREATE TABLE T1 ( a INT, b INT, operator CHAR, c AS CASE operator WHEN '+' THEN a+b WHEN '-' THEN a-b ELSE a*b END PERSISTED ) ;Разумеется, см. Документы SQL, предполагающие, что вы используете SQL Server.
ответ дан Phil 14 марта '12 в 12:40 источник поделитьсяUPDATE table_name SET total = mark1+mark2+mark3;
сначала подумайте, что вы можете вставить все данные в таблицу, а затем вы можете обновить таблицу, как эта форма.
//Я надеюсь, что это поможет вам
источник поделитьсяДругие вопросы по метке sql-server
формула для вычисленного столбца на основе столбца другой таблицы Безопасный SQL
Для этого вы можете создать определенную пользователем функцию:
CREATE FUNCTION dbo.GetValue(INT @ncode, INT @recid) RETURNS INT AS SELECT @recid * nvalue FROM c_const WHERE code = @ncodeа затем используйте это для определения вычисленного столбца:
ALTER TABLE dbo.YourTable ADD NewColumnName AS dbo.GetValue(ncodeValue, recIdValue)Это больше похоже на работу для представлений (индексированные представления, если вам нужен быстрый поиск в вычисленном столбце):
CREATE VIEW AnyView WITH SCHEMABINDING AS SELECT a.rec_id, a.s_id, a.n_code, a.rec_id * c.nvalue AS foo FROM AnyTable a INNER JOIN C_Const c ON c.code = a.n_codeЭто имеет незначительное отличие от версии подзапроса в том, что он будет возвращать несколько записей вместо создания ошибки, если для объединения есть несколько результатов. Но это легко решить с помощью UNIQUE ограничения на c_const.code (я подозреваю, что это уже PRIMARY KEY ).
Это также намного легче понять кому-то, чем версия подзапроса.
Вы можете сделать это с помощью подзапроса и UDF, как показала marc_s, но это, скорее всего, будет очень неэффективно по сравнению с простым JOIN , поскольку скалярный UDF нужно будет вычислять по строкам.
Я сравнил план запроса вида с вычисленным столбцом, вызывающим UDF, который использует тот же запрос, что и представление, и был действительно удивлен, обнаружив, что стоимость вычисляемого столбца была намного меньше (8% против 92%). Я использую SQL Server 2016. Кто-нибудь знает, почему это было бы?
Я понял, что вычисляемый столбец будет по существу запрашивать представление для каждой строки родительской таблицы и будет намного медленнее. Я не работаю с таблицей с большим количеством данных, поэтому просто сравниваю планы запросов, а не фактическое время выполнения.
sql.fliplinux.com
Преобразование вычисленного столбца в обычный столбец MS SQL Server
-- Create a new Column (unpersisted): ALTER TABLE MyTable ADD newColumn DatatypeOfPersistedColumn GO UPDATE myTable SET newColumn = PersistedColumn GO -- Delete the persisted column ALTER TABLE MyTable DROP COLUMN PersistedColumn GO -- Rename new column to old name EXEC sp_rename 'MyTable.newColumn', 'PersistedColumn', 'COLUMN' GO -- Create a new Column (unpersisted): ALTER TABLE MyTable ADD newColumn DatatypeOfPersistedColumn UPDATE myTable SET newColumn = PersistedColumn -- Delete the persisted column ALTER TABLE MyTable DROP COLUMN PersistedColumn -- Rename the new column to the old name EXEC sp_rename 'MyTable.newColumn', 'PersistedColumn', 'COLUMN'Предполагая, что причина преобразования вычисленного столбца в «реальный» столбец состоит в том, что вы хотите сохранить существующие значения / функциональность, но добавьте возможность переопределить его по желанию, вы можете добавить новый столбец (для заполнения только там, где существующее производное значение должно быть переопределено) и изменить определение вычисленного столбца как COALESCE(NewColumn, Old Calculation Definition ) .
Просто удалите формулу из «Расчетных характеристик столбцов» в режиме отображения таблицы в SSMS. Значения будут оставаться в столбце, как есть.
Решение @Mitch Wheat отлично работает. Однако иногда это вызывает ошибку с «Недопустимое имя столбца: newColumn», потому что таблица не была обновлена до того, как она попытается запустить обновление.
Чтобы исправить это, добавьте инструкцию GO, чтобы разделить их на несколько партий:
-- Create a new Column (unpersisted): ALTER TABLE MyTable ADD newColumn DatatypeOfPersistedColumn GO UPDATE myTable SET newColumn = PersistedColumn -- Delete the persisted column ALTER TABLE MyTable DROP COLUMN PersistedColumn -- Rename new column to old name EXEC sp_rename 'MyTable.newColumn', 'PersistedColumn', 'COLUMN'sqlserver.bilee.com
sql - Вычисленный столбец SQL Server замедляет производительность при использовании простого оператора select
Фон:
Ранее моя компания использовала пользовательскую функцию для html кодирования некоторых данных в предложении where хранимой процедуры. Пример ниже:
DECLARE @LName --HTML encoded last name as input parameter from user SELECT * FROM (SELECT LName FROM SomeView xtra WHERE (( @LName <> '' AND dbo.EncodingFunction(dbo.DecodingFunction(xtra.LName)) = @LName) OR @Lname=''))Я упростил это ради ясности.
Проблема заключается в том, что когда хранимая процедура с этим запросом вызывалась 45 раз подряд, средняя производительность на столе с 62 000 записей составляла около 85 секунд. Когда я удалил UDF, производительность увеличилась чуть более 1 секунды, чтобы запустить sproc 45 раз.
Итак, мы консультировались и принимали решение о решении, которое включало вычисляемый столбец в таблице, к которому обращался вид, SomeView. Вычисленный столбец был записан в определение таблицы следующим образом:
[LNameComputedColumn] AS (dbo.EncodingFunction(dbo.DecodingFunction([LName])))Затем я запускал процесс, который обновлял таблицу и автоматически заполнял этот вычисленный столбец для всех 62 000 записей. Затем я изменил запрос хранимой процедуры на следующее:
DECLARE @LName --HTML encoded last name as input parameter from user SELECT * FROM (SELECT LNameComputedColumn FROM SomeView xtra WHERE (( @LName <> '' AND xtra.LNameComputedColumn=@LName) OR @Lname='')Когда я запустил эту хранимую процедуру, среднее время выполнения для 45 исполнений увеличилось примерно до 90 секунд. Мое изменение действительно сделало проблему хуже!
Что я делаю неправильно? Есть ли способ повысить производительность?
В качестве побочного примечания мы в настоящее время используем SQL Server 2000 и вскоре планируем перейти на 2008 R2, но весь код должен работать в SQL Server 2000.
qaru.site
- Возможности рабочего стола windows server 2018 r2

- Что лучше zte blade v7 lite или zte blade v7

- Svchost exe netsvcs грузит память windows 7
- Как улучшить производительность компьютера для игр

- Почему пропадает интернет на ноутбуке через wifi
- Не работает windows media center на windows 7

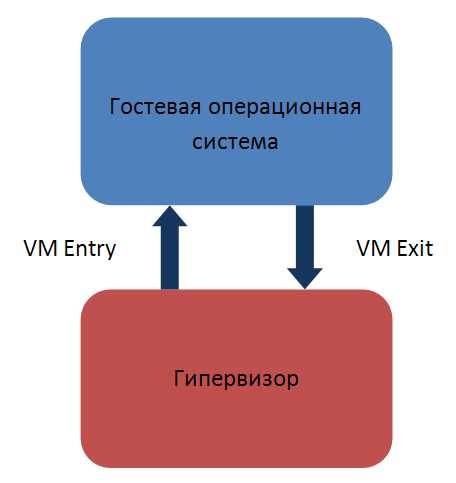
- Какой выбрать гипервизор
- Как на компьютере восстановить удаленные программы на компьютере

- Как точно измерить скорость интернета

- Как удалить system volume information

- Как на компьютере заблокировать доступ к социальным сетям