Как описать взаимодействие между веб-сервером и веб-клиентом? Взаимодействие сервера и клиента
О модели взаимодействия клиент-сервер простыми словами. Архитектура «клиент-сервер» с примерами
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем рубрику Сервера и протоколы. В этой записи мы поговорим о том, как работают приложения и сайты в сети Интернет, да и вообще в любой компьютерной сети. В основе работы приложения лежит так называемая модель взаимодействия клиент-сервер, которая позволяет разделять функционал и вычислительную нагрузку между клиентскими приложениями (заказчиками услуг) и серверными приложениями (поставщиками услуг).
Модель взаимодействия клиент-сервер. Архитектура «клиент-сервер».
Итак, небольшая аннотация к записи: сначала мы разберемся с концепцией взаимодействия клиент сервер. Затем поговорим о том зачем вообще веб-мастеру нужно понимать модель клиент-сервер. Далее мы посмотрим на архитектуру приложений, которые работают по принципу клиент-сервер и в завершении рассмотрим преимущества и недостатки данной модели.
Концепция взаимодействия клиент-сервер
Содержание статьи:
Миллионы людей каждый день выходят в сеть Интернет, чтобы почитать новости, пообщаться с друзьями, получить полезную информацию, совершить покупку или оплатить счет. Но большая часть рядовых пользователей даже не догадывается о том, как и с помощью чего они всё это делают, да на самом деле большинству людей это и не нужно, главное, чтобы они получали услугу вовремя и качественно.
Здесь мы разберемся с концепцией, которая позволяет нам выполнять все эти действия в сети Интернет. Данная концепция получила название «клиент-сервер». Как понятно из названия, в данной концепции участвуют две стороны: клиент и сервер. Здесь всё как в жизни: клиент – это заказчик той или иной услуги, а сервер – поставщик услуг. Клиент и сервер физически представляют собой программы, например, типичным клиентом является браузер. В качестве сервера можно привести следующие примеры: все HTTP сервера (в частности Apache), MySQL сервер, локальный веб-сервер AMPPS или готовая сборка Denwer (последних два примера – это не проста сервера, а целый набор серверов).
Клиент и сервер взаимодействую друг с другом в сети Интернет или в любой другой компьютерной сети при помощи различных сетевых протоколов, например, IP протокол, HTTP протокол, FTP и другие. Протоколов на самом деле очень много и каждый протокол позволяет оказывать ту или иную услугу. Например, при помощи HTTP протокола браузер отправляет специальное HTTP сообщение, в котором указано какую информацию и в каком виде он хочет получить от сервера, сервер, получив такое сообщение, отсылает браузеру в ответ похожее по структуре сообщение (или несколько сообщений), в котором содержится нужная информация, обычно это HTML документ.
Сообщения, которые посылают клиенты получили названия HTTP запросы. Запросы имеют специальные методы, которые говорят серверу о том, как обрабатывать сообщение. А сообщения, которые посылает сервер получили название HTTP ответы, они содержат помимо полезной информации еще и специальные коды состояния, которые позволяют браузеру узнать то, как сервер понял его запрос.
Сейчас мы схематично описали, как взаимодействуют клиент и сервер на седьмом уровне модели OSI, но, на самом деле это взаимодействие происходит на всех семи уровнях. Когда клиент отправляет запрос, сообщение упаковывается, можно представить, что сообщение заворачивается в семь оберток (хотя их может быть намного больше или же меньше), а когда сообщение получает сервер, он начинает эти обертки разворачивать.
Также стоит заметить, что в основе взаимодействия клиент-сервер лежит принцип того, что такое взаимодействие начинает клиент, сервер лишь отвечает клиенту и сообщает о том может ли он предоставить услугу клиенту и если может, то на каких условиях. Клиентское программное обеспечение и серверное программное обеспечение обычно установлено на разных машинах, но также они могут работать и на одном компьютере.
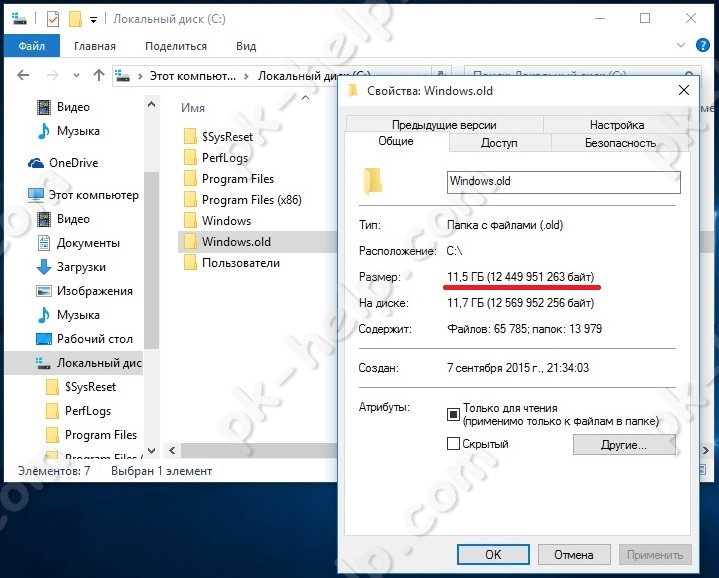
Данная концепция взаимодействия была разработана в первую очередь для того, чтобы разделить нагрузку между участниками процесса обмена информацией, а также для того, чтобы разделить программный код поставщика и заказчика. Ниже вы можете увидеть упрощенную схему взаимодействия клиент-сервер.
Простая схема взаимодействия клиент-сервер
Мы видим, что к одному серверу может обращаться сразу несколько клиентов (действительно, на одном сайте может находиться несколько посетителей). Также стоит заметить, что количество клиентов, которые могут одновременно взаимодействовать с сервером зависит от мощности сервера и от того, что хочет получить клиент от сервера.
Многие сетевые протоколы построены на архитектуре клиент-сервер, поэтому в их основе обычно лежат одинаковые или схожие принципы взаимодействия, а разницу мы видим лишь в деталях, которые обусловлены особенностями и спецификой области, для которой разрабатывался тот или иной сетевой протокол.
Почему веб-мастеру нужно понимать модель взаимодействия клиент-сервер
Давайте теперь ответим на вопрос: «зачем веб-мастеру или веб-разработчику понимать концепцию взаимодействия клиент-сервер?». Ответ, естественно, очевиден. Чтобы что-то делать своими руками нужно понимать, как это работает. Чтобы сделать сайт и, чтобы он правильно работал в сети Интернет или хотя бы просто работал, нам нужно понимать, как работает сеть Интернет.
Мы уже упоминали, что большая часть сетевых протоколов имеют архитектуру клиент-сервер. Например, веб-мастеру или веб-разработчику будут интересны протоколы седьмого и шестого уровня эталонной модели. Сетевым администраторам важно понимать, как происходит взаимодействие на уровнях с пятого по второй. Для инженеров связи наибольший интерес представляют протоколы с четвертого по первый уровень модели OSI.
Поэтому если вы действительно хотите быть профессионалом в сфере web, то сперва вам необходимо понимать, как происходит взаимодействии в сети (именно на седьмом уровне), а уже потом начинать изучать инструменты, которые позволят создавать сайты.
Архитектура «клиент-сервер»
Архитектура клиент-сервер определяет лишь общие принципы взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
Существует два вида архитектуры взаимодействия клиент-сервер: первый получил название двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер (иногда его называют трехуровневая архитектура или трехзвенная архитектура, но это частный случай).
Принцип работы двухуровневой архитектуры взаимодействия клиент-сервер заключается в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рисунке ниже.
Двухуровневая модель взаимодействия клиент-сервер
Здесь четко видно, что есть клиент (1-ый уровень), который позволяет человеку сделать запрос, и есть сервер, который обрабатывает запрос клиента.
Если говорить про многоуровневую архитектуру взаимодействия клиент-сервер, то в качестве примера можно привести любую современную СУБД (за исключением, наверное, библиотеки SQLite, которая в принципе не использует концепцию клиент-сервер). Суть многоуровневой архитектуры заключается в том, что запрос клиента обрабатывается сразу несколькими серверами. Такой подход позволяет значительно снизить нагрузку на сервер из-за того, что происходит распределение операций, но в то же самое время данный подход не такой надежный, как двухзвенная архитектура. На рисунке ниже вы можете увидеть пример многоуровневой архитектуры клиент-сервер.
Многоуровневая архитектура взаимодействия клиент-сервер
Типичный пример трехуровневой модели клиент-сервер. Если говорить в контексте систем управления базами данных, то первый уровень – это клиент, который позволяет нам писать различные SQL запросы к базе данных. Второй уровень – это движок СУБД, который интерпретирует запросы и реализует взаимодействие между клиентом и файловой системой, а третий уровень – это хранилище данных.
Если мы посмотрим на данную архитектуру с позиции сайта. То первый уровень можно считать браузером, с помощью которого посетитель заходит на сайт, второй уровень – это связка Apache + PHP, а третий уровень – это база данных. Если уж говорить совсем просто, то PHP больше ничего и не делает, кроме как, гоняет строки и базы данных на экран и обратно в базу данных.
Преимущества и недостатки архитектуры клиент-сервер
Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен. Если мы говорим про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать (в качестве частного случая можно привести пример: мощности сервера не всегда хватает, чтобы удовлетворит запросы клиентов, если вы хоть раз работали с биллинговыми системами, то понимаете о чем я: время ожидания ответа от сервера может быть очень большим).
В качестве заключения нам стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.
zametkinapolyah.ru
Взаимодействие клиента и сервера
Ежедневно мы используем сетевые службы и сеть Интернет для обмена данными и выполнения типичных задач обработки информации.

Мы редко задумываемся над тем, что прием электронной почты, ввод информации в блог или совершение покупок через электронные магазины возможны благодаря работе серверов, клиентских программ и сетевых устройств. В большинстве наиболее популярных интернет-приложений происходят сложные взаимодействия между различными серверами и клиентами.
Под термином "сервер" понимается узловая машина, на которой выполняется прикладное программное обеспечение, предоставляющее информацию или службы для других узлов, подключенных к сети. Типичным примером такой прикладной программы является веб-сервер.
К сети Интернет подключены миллионы серверов, предоставляющих такие услуги, как веб-службы, электронная почта, финансовые операции, загрузка музыкальных файлов и т.п. Для обеспечения надежного функционирования всех этих сложных взаимодействий необходимо правильно подобрать необходимые стандарты связи и протоколы.

Для передачи запроса веб-странице и ее просмотра пользователь обращается к устройству, на котором запущено программное обеспечение веб-клиента. Под термином "клиент" понимается имя, присвоенное прикладной программе, которая используется для получения доступа к информации, хранящейся на сервере. Типичным примером клиентского приложения является веб-обозреватель.

Главной особенностью клиент-серверных систем является отправка клиентом запроса на сервер, который, отвечая на запрос, выполняет ту или иную функцию, например, передачу клиенту запрашиваемой информации. Типичным примером клиент-серверной системы является комплекс веб-обозревателя и веб-сервера.
Далее: Беспроводные технологии и устройства
osnovy-setei.ru
Что такое взаимодействие Клиент-Сервер? | Info-Comp.ru
Сегодня речь пойдет о так называемом взаимодействии Клиент-Сервер, так как практически все программное обеспечение построено на данном принципе. А как Вы помните, что у нас сайт для начинающих программистов и понимание данного взаимодействия обязательно для новичка в программирование. Поэтому в данном материале мы рассмотрим, что это такое и для чего это нужно.
Как я уже сказал, если Вы хотите стать программистом то Вы должны понимать принцип данного взаимодействия, потому что хотите Вы или нет, Вам придется столкнуться с этим, так как это встречается практически везде, например все сайты в Интернете построены на этом, все программы которые используют базу данных, сюда также можно и отнести и автоматическое обновление программ, и многое другое.
Теперь поговорим подробней. Что такое взаимодействие Клиент-сервер? Это взаимодействие двух программных продуктов между собой, один из которых выступает в качестве сервера, а другой соответственно в качестве клиента. Клиент посылает запрос, а сервер отвечает ему. А что такое клиент и что такое сервер? Спросите Вы. Клиент это программная оболочка, с которой взаимодействует пользователь. А сервер это та часть программного обеспечения, которая выполняет все основные функции (хранит данные, выполняет расчеты). Другими словами, пользователь видит программу, которая, допустим, работает с какими-то данными, которые хранятся в базе данных, тем самым он видит всего лишь интерфейс этой программы, а все самое основное выполняет сервер, и процесс когда пользователь оперирует данными через интерфейс программы, при котором клиентская часть взаимодействует с серверной, и называется Клиент-Сервер. В качестве клиента не обязательно должен выступать интерфейс, который видит пользователь, в некоторых случаях в качестве клиента может выступать и просто программа или скрипт, например, данные на сайте хранятся в базе данных, соответственно скрипты, которые будут обращаться к базе данных и будут являться клиентом в данном случае, хотя и сами эти скрипты являются сервером для клиентской часть сайта (интерфейса).
А для чего это нужно?
Это лучше объяснить на примере.
Допустим, Вы написали программу, которая умеет работать с некими данными и установили ее пользователю, все замечательно работает, пока другой пользователь не скажет, а я хочу такую же программу, но чтобы данные у нас были одни, и при редактировании одним пользователем другой мог увидеть это изменение. И для этого Вам необходимо сделать какую-то базу данных доступ, к которой можно получить через интерфейс Вашей программы, причем данная база должна располагаться на отдельном сервере, для того чтобы все пользователи могли получить к ней доступ, конечно, которым Вы разрешите.
И тем самым всем пользователям, которым нужна эта программа, Вы устанавливаете только клиентскую часть и настраиваете взаимодействие с сервером. В данном случае подразумевается, что Вы на сервере установите СУБД (Система управления базами данных).

Где под клиентом понимается клиентская часть приложения, которая взаимодействует с серверной частью приложения по средствам сети.
Другой пример.
Все сайты в Интернете располагаются где-то на серверах (хостинге), а Вы соответственно хотите получить доступ к ним и для этого используете браузер и в данном случае браузер и есть клиент, а файлы на хостинге сервер. Если разбирать отдельно взятый сайт, то здесь также присутствует данное взаимодействие, к примеру, в браузере Вы видите всего лишь интерфейс приложения и при любых Ваших действиях на этом сайте данный интерфейс будет отправлять запрос серверу который выполнит все что Вы запросили и пришлет ответ, а клиент в свою очередь отобразит этот ответ, для того чтобы пользователь смог увидеть его.
Другими словами принцип клиент-сервер основан на том, что клиент отправляет запрос серверу, а сервер отвечает ему. И данные запрос-ответы могут выглядеть по-разному, могут использоваться разные протоколы, такие как tcp/ip, http, rdp и много других.
Теперь надеюсь, стало понятно, что такое Клиент-сервер, теперь давайте немного поговорим о том, как лучше реализовывать данное взаимодействие.
Как уже говорилось выше, если Вы захотели хранить данные в базе данных то лучше всего использовать СУБД, такие как MSSql, MySQL, Oracle, PostgreSQL так как данные СУБД предоставляют огромные возможности для серверной разработки. Так как, когда Вы будете разрабатывать программное обеспечение по такому принципу, Вам лучше всего четко разграничить клиент и сервер, т.е. клиент выполняет только роль интерфейса, из которого можно будет посылать запросы серверу на запуск процедур или функций, а соответственно сервер будет выполнять эти процедуры и функции и посылать результат их выполнения клиенту, предварительно, конечно же, Вы должны будете написать эти самые процедуры и функции, что и позволяют делать данные СУБД. Этим Вы упростите разработку и увеличите производительность Вашего программного обеспечения. Поэтому запомните клиент, во всех случаях, при взаимодействии Клиент-Сервер должен выполнять только лишь функцию интерфейса, и не нужно на него возлагать какие-то там другие задачи (обработка данных и другое), все, что можно перенести на сервер переносите, а пользователю предоставьте всего лишь интерфейс.
В связи с этим пришло время поговорить о преимуществах данной технологии:
- Низкие требования к компьютерам клиента, так как вся нагрузка должна возлагаться на сервер и серверную часть приложения, в некоторых случаях можно значительно сэкономить затраты на приобретение вычислительной техники в организациях;
- Многопользовательский режим. Ресурсами сервера могут пользоваться неограниченное число пользователей, при том что данные располагаются в одном месте;
- Целостность данных. Вывести из строя компьютер клиента гораздо проще, и чаще встречается, чем компьютер, который выполняет роль сервера. Как Вы знаете, проблемы с компьютерами у пользователей встречаются достаточно часто, так как они сами их себе и создают.
- Внесение изменений. Проще внести изменения один раз в серверной части, чем вносить их на каждом клиенте.
Есть также пару недостатков:
- Для быстродействия требуется приобрести достаточно мощный сервер, но как было уже сказано выше, это может и окупится, за счет компьютеров пользователей;
- Выход из строя серверной части прекратит работу всех клиентов, в связи с этим возникает необходимость постоянного мониторинга серверной части.
Перед тем как заняться разработкой приложения Вы должны знать, на чем Вы это будете реализовывать, так как существуют разные технологии и языки, например, при взаимодействии с СУБД Вам придется изучить SQL, хотя бы основы SQL, но лучше, если Вы будете знать, как написать функцию или процедуру, так как без этого Вам не обойтись, ну если конечно не разделить обязанности между программистами, например, один специалист разрабатывает серверную часть, а другой клиентскую, так, кстати, все и делают, потому что сами понимаете, что все знать просто невозможно.
Или на примере сайта в Интернете, существуют как серверные языки программирования, например PHP так и клиентские, например JavaScript, поэтому, если Вы решили сами создать нормальный сайт в Интернете, то учтите, что Вам придется с этим столкнуться и проще говоря, Вы должны будете стать Web-мастером который должен знать ой как много:).
Подведем итог.
Как Вы уже поняли, что взаимодействие Клиент-Сервер используется практически везде, и можно сказать, сеть построена, для того чтобы пользователь, по средствам программного обеспечения, мог взаимодействовать с другими пользователями или удаленными ресурсами, так как все что Вы запрашиваете или отправляете по сети основано на взаимодействие запрос-ответ. Поэтому начинающий программист должен понимать данное взаимодействие и в последствие реализовывать его.
Похожие статьи:
info-comp.ru
Клиент-серверная архитектура: особенности взаимодействия
Компьютеры, программы и периферийные устройства являются неравноправными составляющими информационной сети. Одни владеют каким-то ресурсом, поэтому называются серверами, другие обращаются к этим ресурсам и называются клиентами. Рассмотрим, как же они взаимодействуют между собой и что собой представляет клиент-серверная архитектура.
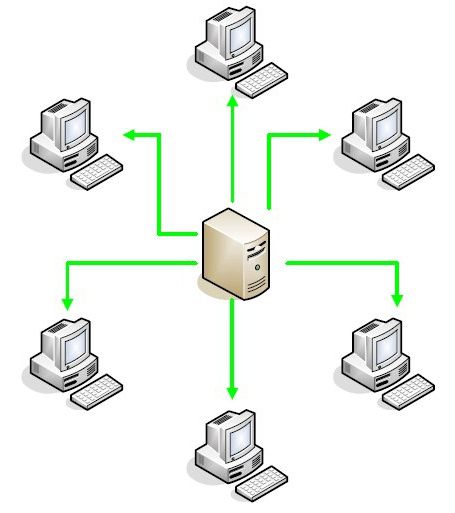 Клиент-серверная архитектура
Клиент-серверная архитектура
Архитектура «Клиент-Сервер» представляет собой взаимодействие структурных компонентов в сети на основе определенных принципов организации данной сети, где структурными компонентами являются сервер и узлы-поставщики определенных специализированных функций (сервисов), а также клиенты, которые пользуются данным сервисом. Специфические функции принято делить на три группы на основе решения определенных задач:
- функции ввода и представления данных предназначены для взаимодействия пользователя с системой;
- прикладные функции - для каждой предметной области имеется собственный набор;
- функции управления ресурсами предназначены для управления файловой системой, различными базами данных и прочими компонентами.
Автономная система, например, компьютер без сетевого подключения, представляет компоненты представления, прикладного назначения и управления на различных уровнях. Такого рода уровнями считаются операционная система, прикладное и служебное программное обеспечение, различные утилиты. Точно так же и в сети представлены все вышеуказанные компоненты. Главное – правильно обеспечить сетевое взаимодействие между этими составляющими.
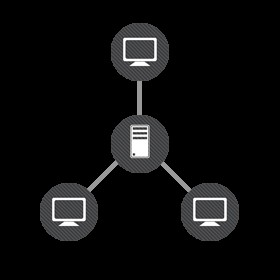 Принцип работы клиент-серверной архитектуры
Принцип работы клиент-серверной архитектуры
Клиент-серверная архитектура наиболее часто используется для создания корпоративных баз данных, в которых информация не только хранится, но и периодически поддается обработке различными методами. Именно база данных является главным элементом любой корпоративной информационной системы, а на сервере располагается ядро этой базы. Так, на сервере происходят наиболее сложные операции, касающиеся ввода, хранения, обработки и модификации данных. Когда пользователь (клиент) обращается к базе данных (серверу), происходит обработка запроса: непосредственно обращение к базе данных и возврат ответа (результата обработки). Результат обработки – это сообщение сети об успешном проведении операции или ошибке. Серверные компьютеры могут обрабатывать одновременно обращение нескольких клиентов к одному и тому же файлу. Такая работа и передача данных по сети позволяет ускорить работу используемых приложений.
 Клиент-серверная архитектура: применение технологии
Клиент-серверная архитектура: применение технологии
Данная архитектура используется для доступа к различным ресурсам с использованием сетевых технологий: Web-серверы, серверы приложений, серверы баз данных, почтовые серверы, файрволы, прокси-серверы. Разработка клиент-серверных приложений позволяет повысить безопасность, надежность и производительность используемых приложений и сети в целом. Наиболее часто клиент-серверные приложения используются для автоматизации бизнеса.
23 Сентября, 2013
fb.ru
http - Как описать взаимодействие между веб-сервером и веб-клиентом?
1. Установление соединения
Наиболее распространенным способом взаимодействия веб-серверов и клиентов является соединение, которое следует за Протоколом управления передачей или TCP. В принципе, при использовании TCP соединение устанавливается между клиентскими и серверными машинами посредством серии проверок "назад-вперед". Как только соединение будет установлено и открыто, данные могут быть отправлены между клиентом и сервером. Это соединение также можно назвать Session.
Существует также UDP или Протокол пользовательских дейтаграмм, который имеет несколько иной способ общения и поставляется со своим набором плюсов и минусов. Я считаю, что в последнее время некоторые браузеры, возможно, начали использовать комбинацию из двух, чтобы получить наилучшие результаты.
Здесь еще нужно сказать тонну, но если вы не собираетесь писать браузер (или стать хакером), это не должно слишком сильно зависеть от вас.
2. Отправка пакетов
Как только соединение клиент-сервер будет установлено, пакеты данных могут быть отправлены между ними. Пакеты TCP содержат различные биты информации, которые помогают в обмене данными между двумя портами. Для веб-программистов наиболее важной частью пакета будет раздел, который включает HTTP-запрос.
HTTP, Протокол передачи гипертекста - это еще один протокол, который описывает, как должна выглядеть макияж/формат этих сообщений клиент-сервер.
Самый простой пример соответствующей части пакета, отправленного клиентом на сервер, выглядит следующим образом:
GET /index.html HTTP/1.1 Host: www.example.comПервая строка здесь называется Response line. GET описывает метод, который будет использоваться (другие включают POST, HEAD, PUT, DELETE и т.д.) /index.html описывает запрашиваемый ресурс. Наконец, HTTP/1.11 описывает используемый протокол.
Вторая строка в этом случае является единственным header field в запросе, и в этом случае это поле HOST, которое является своего рода псевдонимом для IP-адреса сервера, данным DNS.
[Поскольку вы упомянули это, разница между запросом GET и запросом POST просто заключается в том, что в запросе GET параметры (например: данные формы) включены как часть Response line, тогда как в запросе POST параметры будут включены как часть Message Body (см. ниже).]
3. Прием пакетов
В зависимости от запроса, отправленного на сервер, сервер поцарапает его голову, подумает о том, что вы попросили, и ответьте соответствующим образом (иначе, как вы его программируете).
Вот пример отправки пакета ответа с сервера:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8 ... <html> <head> <title>A response from a server</title> </head> <body> <h2>Hello World!</h2> </body> </html>Первая строка здесь - это Status Line, которая включает в себя числовой код вместе с кратким текстовым описанием. 200 OK, очевидно, означает успех. Например, большинство людей также знакомы с 404 Not Found.
Вторая строка - первая из Response Header Fields. Другие добавленные поля включают date, Content-Length и другие полезные метаданные.
Ниже заголовков и нужной пустой строки, наконец, (необязательно) Message Body. Конечно, это, как правило, самая захватывающая часть ответа, так как она будет содержать такие вещи, как HTML для наших браузеров, для отображения для нас данных JSON или почти все, что вы можете закодировать в инструкции return.
4. AJAX, асинхронный JavaScript и XML
Исходя из всего этого, AJAX достаточно прост для понимания. Фактически, отправленные и полученные пакеты могут выглядеть идентичными запросам non-ajax.
Единственное различие заключается в том, как и когда браузер решает отправить пакет запроса. Обычно при обновлении страницы браузер отправляет запрос на сервер. Однако при выдаче запроса AJAX программист просто сообщает браузеру отправить пакет на сервер NOW, а не на обновление страницы.
Однако, учитывая характер запросов AJAX, обычно Message Body не будет содержать весь HTML-документ, но будет запрашивать меньшие, более конкретные биты данных, такие как запрос из базы данных.
Тогда ваш JavaScript, который вызывает Ajax, также может действовать исходя из ответа. Любой метод JavaScript доступен, поскольку вызов Ajax - это еще одна функция JavaScript. Таким образом, вы можете делать что-то вроде innerHTML для добавления/замены содержимого на вашей странице с помощью HTML, возвращаемого вызовом Ajax. В качестве альтернативы, вы также можете сделать что-то вроде вызова Ajax, который просто должен вернуть True или False, а затем вы можете вызвать некоторую функцию JavaScript с инструкцией if else. Как вы можете надеяться, Ajax не имеет никакого отношения к HTML для одного слова, это просто функция JavaScript, которая делает запрос с сервера и возвращает ответ, каким бы он ни был.
5. Cookies
Протокол HTTP - это пример протокола бездействия. В основном это означает, что каждая пара Request и Response (как мы описали) обрабатывается независимо от других запросов и ответов. Таким образом, серверу не нужно отслеживать всех тысяч пользователей, которые в настоящее время требуют внимания. Вместо этого он может просто отвечать на каждый запрос индивидуально.
Однако иногда мы хотим, чтобы сервер помнил нас. Как это было бы неприятно, если бы каждый раз, когда я осматривал свой Gmail, мне приходилось регистрироваться снова, потому что сервер забыл обо мне?
Чтобы решить эту проблему, сервер может отправить Cookies, который будет храниться на клиентской машине. Сервер может отправить ответ, который сообщает клиенту о сохранении файла cookie и о том, что именно он должен содержать. Клиентский браузер отвечает за сохранение этих файлов cookie в клиентской системе, поэтому расположение этих файлов cookie будет зависеть от вашего браузера и ОС. Важно понимать, что это всего лишь небольшие файлы, хранящиеся на клиентской машине, которые на самом деле доступны для чтения и записи любому, кто знает, как их найти и понять. Как вы можете себе представить, это создает несколько различных потенциальных угроз безопасности. Одним из решений является шифрование данных, хранящихся внутри этих файлов cookie, чтобы злоумышленник не смог воспользоваться предоставленной вами информацией. (Поскольку ваш браузер устанавливает эти файлы cookie, обычно в вашем браузере есть параметр, который вы можете изменить, чтобы принять, отклонить или, возможно, установить новое местоположение для файлов cookie.
Таким образом, когда клиент делает запрос с сервера, он может включать Cookie в один из Request Header Fields, который будет сообщать серверу: "Привет, я являюсь аутентифицированным пользователем, меня зовут Боб, и я был только в середине написания чрезвычайно увлекательного сообщения в блоге до того, как мой ноутбук умер" или "У меня есть три дизайнерских костюма, выбранных в моей корзине покупок, но я все еще планирую искать ваш сайт завтра на четвертый", например.
6. Локальное хранилище
HTML5 представил Локальное хранилище как более безопасную альтернативу Cookies. В отличие от файлов cookie, данные локального хранилища фактически не отправляются на сервер. Вместо этого браузер сам отслеживает состояние.
Эта альтернатива также позволяет хранить гораздо большие объемы данных, так как нет необходимости передавать ее через Интернет между клиентом и сервером.
7. Продолжайте исследовать
Это должно осветить основы и дать довольно четкую картину того, что происходит между клиентами и серверами. В каждом из этих пунктов есть еще что-то, и вы можете найти много информации с простым поиском Google.
qaru.site
Взаимодействие Клиент-Сервер | Уроки и примеры программирования
6. Взаимодействие Клиент-Сервер
Этот мир - клиент-серверный, машыл. Практически всё в сети происходит по клиент-серверной логике. Возьмём хоть Telnet. При подключении к удалённому узлу на 23 порт телнетом, программа на этом хосте (так называемый telnetd, сервер telnet) как бы просыпается, возвращается к жизни. Она обрабатывает входящее telnet-соединение, обрабатывает введённые вами логин и пароль, и т.д.

В этой диаграмме показан обмен данными между клиентом и сервером. Обратим внимание, что клиент-серверная пара может "разговаривать" через SOCK_STREAM, SOCK_DGRAM, да и как угодно иначе - до тех пор, пока они говорят "на одном языке", то есть на одинаковом протоколе.
Некоторые хорошие примеры пар клиент-сервер: telnet/telnetd, FTP/FTPd, Firefox/Apache. Каждый раз, используя фтп, на другой стороне провода вы общаетесь с FTPD-сервером.
Обычно на машине запускается только один экземпляр сервера, который обрабатывает несколько клиентов, используя fork(). Основная процедура: сервер ждёт соединения, accetp() его и fork() - рождает дочерний процесс для обработки каждого соединения. Именно так и будет работать наш простой сервер из следующего раздела.
Простой TCP-сервер
Всё, что делает этот сервер - шлёт строку "Hello, World!n" через потоковое соединение. Всё, что вам нужно сделать для проверки этого сервера - запустить его в одном окне, а в другом запустить telnet и зайти на порт своего сервера:
telnet localhost 3490
Код сервера:
/*** server.c -- a stream socket server demo*/#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <errno.h>#include <string.h>#include <sys/types.h>#include <sys/socket.h>#include <netinet/in.h>#include <netdb.h>#include <arpa/inet.h>#include <sys/wait.h>#include <signal.h>
#define PORT "3490" // порт, на который будут приходить соединения
#define BACKLOG 10 // как много может быть ожидающих соединений
void sigchld_handler(int s){ while(waitpid(-1, NULL, WNOHANG) > 0);}
// получаем адрес сокета, ipv4 или ipv6:void *get_in_addr(struct sockaddr *sa){ if (sa->sa_family == AF_INET) { return &(((struct sockaddr_in*)sa)->sin_addr); }
return &(((struct sockaddr_in6*)sa)->sin6_addr);}
int main(void){ int sockfd, new_fd; // слушаем на sock_fd, новые соединения - на new_fd struct addrinfo hints, *servinfo, *p; struct sockaddr_storage their_addr; // информация об адресе клиента socklen_t sin_size; struct sigaction sa; int yes=1; char s[INET6_ADDRSTRLEN]; int rv;
memset(&hints, 0, sizeof hints); hints.ai_family = AF_UNSPEC; hints.ai_socktype = SOCK_STREAM; hints.ai_flags = AI_PASSIVE; // use my IP
if ((rv = getaddrinfo(NULL, PORT, &hints, &servinfo)) != 0) { fprintf(stderr, "getaddrinfo: %sn", gai_strerror(rv)); return 1; }
// цикл через все результаты, чтобы забиндиться на первом возможном for(p = servinfo; p != NULL; p = p->ai_next) { if ((sockfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) == -1) { perror("server: socket"); continue; }
if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(int)) == -1) { perror("setsockopt"); exit(1); }
if (bind(sockfd, p->ai_addr, p->ai_addrlen) == -1) { close(sockfd); perror("server: bind"); continue; }
break; }
if (p == NULL) { fprintf(stderr, "server: failed to bindn"); return 2; }
freeaddrinfo(servinfo); // всё, что можно, с этой структурой мы сделали
if (listen(sockfd, BACKLOG) == -1) { perror("listen"); exit(1); }
sa.sa_handler = sigchld_handler; // обрабатываем мёртвые процессы sigemptyset(&sa.sa_mask); sa.sa_flags = SA_RESTART; if (sigaction(SIGCHLD, &sa, NULL) == -1) { perror("sigaction"); exit(1); }
printf("server: waiting for connections...n");
while(1) { // главный цикл accept() sin_size = sizeof their_addr; new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size); if (new_fd == -1) { perror("accept"); continue; }
inet_ntop(their_addr.ss_family, get_in_addr((struct sockaddr *)&their_addr), s, sizeof s); printf("server: got connection from %sn", s);
if (!fork()) { // тут начинается дочерний процесс close(sockfd); // дочернему процессу не нужен слушающий сокет if (send(new_fd, "Hello, world!", 13, 0) == -1) perror("send"); close(new_fd); exit(0); } close(new_fd); // а этот сокет больше не нужен родителю }
return 0;}
Весь код содержится в одной большой функции main() для большей синтаксической ясности. Если вам это кажется неудобным, разбейте код на функции поменьше.
(Новая функция - sigaction() - отвечает за подчисткой зомби-процессов, которые возникают после того, как дочерний (fork()) процесс завершает работу. Если вы сделаете много зомби и не подчистите их, это не лучшим образом скажется на работе ОС).
Вы можете получить данные с сервера, используя написанный клиент, в следующем разделе.
Простой TCP-клиент
Эта штука ещё проще, чем сервер. Всё, что делает клиент - конектится к хосту, который вы укажете в командной строке, и к порту 3490. И примет строку, которую отошлёт сервер.
Код клиента:
/*** client.c -- a stream socket client demo*/#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <errno.h>#include <string.h>#include <netdb.h>#include <sys/types.h>#include <netinet/in.h>#include <sys/socket.h>
#include <arpa/inet.h>
#define PORT "3490" // Порт, к которому подключается клиент
#define MAXDATASIZE 100 // максимальное число байт, принимаемых за один раз
// получение структуры sockaddr, IPv4 или IPv6:void *get_in_addr(struct sockaddr *sa){ if (sa->sa_family == AF_INET) { return &(((struct sockaddr_in*)sa)->sin_addr); }
return &(((struct sockaddr_in6*)sa)->sin6_addr);}
int main(int argc, char *argv[]){ int sockfd, numbytes; char buf[MAXDATASIZE]; struct addrinfo hints, *servinfo, *p; int rv; char s[INET6_ADDRSTRLEN];
if (argc != 2) { fprintf(stderr,"usage: client hostnamen"); exit(1); }
memset(&hints, 0, sizeof hints); hints.ai_family = AF_UNSPEC; hints.ai_socktype = SOCK_STREAM;
if ((rv = getaddrinfo(argv[1], PORT, &hints, &servinfo)) != 0) { fprintf(stderr, "getaddrinfo: %sn", gai_strerror(rv)); return 1; }
// Проходим через все результаты и соединяемся к первому возможному for(p = servinfo; p != NULL; p = p->ai_next) { if ((sockfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) == -1) { perror("client: socket"); continue; }
if (connect(sockfd, p->ai_addr, p->ai_addrlen) == -1) { close(sockfd); perror("client: connect"); continue; }
break; }
if (p == NULL) { fprintf(stderr, "client: failed to connectn"); return 2; }
inet_ntop(p->ai_family, get_in_addr((struct sockaddr *)p->ai_addr), s, sizeof s); printf("client: connecting to %sn", s);
freeaddrinfo(servinfo); // эта структура больше не нужна
if ((numbytes = recv(sockfd, buf, MAXDATASIZE-1, 0)) == -1) { perror("recv"); exit(1); }
buf[numbytes] = '
masandilov.ru
Взаимодействие типа клиент/сервер
⇐ ПредыдущаяСтр 5 из 12Следующая ⇒Как и в других сетевых приложениях, в программах просмотра Web применяется модель взаимодействия типа клиент/сервер. После получения URL документа браузер становится клиентом, который обращается с запросом на получение документа к серверу, работающему на компьютере, указанном в URL. Затем браузер отображает документ для пользователя.
В отличие от сетевых приложений, в которых предусмотрено постоянное соединение между клиентом и сервером, при взаимодействии между Web – браузером и сервером соединение создается лишь на короткое время. Браузер устанавливает соединение, отправляет запрос и получает либо затребованный элемент данных, либо сообщение, что такого элемента не существует. Сразу после передачи документа или изображения соединение закрывается; клиент не остается подключенным к серверу.
Быстрое прекращение соединений вполне себя оправдывает в большинстве случаев, поскольку просмотр Web не характеризуется высокой степенью локализации связей. Пользователь может обратиться к Web-странице на одном компьютере, а затем немедленно проследовать по ссылке к Web-странице на другом компьютере. Однако слишком быстрое прекращение соединения может привести к ненужным издержкам в тех случаях, если браузер должен неоднократно обращаться к одному и тому же серверу для получения большого числа документов.
Передача документов Web и протокол HTTP
При взаимодействии браузера с Web-сервером эти две программы выполняют протокол HTTP (HyperText Transfer Protocol – протокол передачи гипертекста). Назначение протокола HTTP состоит в том, что он позволяет браузеру запросить конкретный элемент данных, который затем отправляет ему сервер. Однако на практике с применением протокола HTTP связано много сложностей, поскольку сервер вместе с каждой передачей отправляет дополнительную информацию состояния, а браузер, согласно этому протоколу, может не только запрашивать, но и передавать информацию.
Запросы HTTP передаются в виде текста в кодировке ASCII. Протокол HTTP поддерживает четыре основных операции, которые могут быть указаны браузером при выполнении запроса:
• Операция GET позволяет запросить конкретный элемент данных с сервера. Сервер возвращает заголовок, за которым следует информация состояния, пустая строка и затребованный элемент данных.
• Операция HEAD позволяет запросить информацию о состоянии некоторого элемента. Сервер возвращает информацию состояния, не передавая копию самого элемента.
• Операция POST служит для передачи данных на сервер. Сервер добавляет переданные данные к указанному элементу (например, добавляет сообщение к списку сообщений).
• Операция PUT также позволяет передать данные на сервер. Однако сервер использует эти данные для замены указанного элемента.
При вводе пользователем URL или выборе ссылки браузер формирует запрос HTTP. В том или ином случае браузер передает запрос GET, в котором указан определенный элемент данных, и сервер возвращает запрашиваемый элемент. Запрос GET имеет следующую форму:.
GET item version CRLF
Здесь item обозначает URL затребованного элемента, version указывает версию HTTP (обычно 1.0 или 1.1), a CRLF обозначает символы CR (сокращение от carriage return — возврат каретки) и LF (сокращение от linefeed — перевод строки) кодировки ASCII.
Каждый ответ от сервера начинается с заголовка в кодировке ASCII. Первая строка заголовка содержит код состояния, который сообщает браузеру, успешно ли обработан сервером запрос. Если запрос был сформирован неправильно или затребованный в нем элемент недоступен, то код состояния позволяет выявить эту проблему. Например, сервер возвращает широко известный код состояния 404, если затребованный элемент не удалось найти. Успешно выполнив запрос, сервер возвращает код состояния 200; дополнительные строки заголовка предоставляют более полную информацию об элементе данных, такую как его длина, время последнего изменения и тип информационного наполнения. Пример заголовка HTTP приведен ниже.
НТТР/1.0 200 ОК
Date: Mon, 30 Oct 2000 01:22:22 GMT
Server: Apache/1.2.5
Last-Modified: Sat, 28 Oct 2000 01:03:37 GMT
ETag: "130fe-81-3883bbe9"
Content-Length: .129
Accept-Ranges: bytes
Connection: close,
Content-Type: text/plain
Код состояния 200 в первой строке указывает, что сервер успешно выполнил запрос; остальные строки содержат дополнительную информацию о затребованном элементе данных.
Архитектура программного обеспечения браузера
Программы Web-браузеров имеют более сложную структуру по сравнению с Web-серверами. Сервер постоянно выполняет одну и ту же несложную задачу: ожидает, пока какой-либо браузер не откроет соединение и не затребует страницу. Затем сервер передает копию затребованного элемента данных, закрывает соединение и ожидает следующего запроса на установление соединения. Основную часть операции по обеспечению доступа к документу и его отображению выполняет браузер. В связи с этим браузер содержит несколько крупных программных компонентов, которые тесно взаимодействуют друг с другом, создавая впечатление бесперебойно функционирующей службы. В частности, браузер включает целый ряд клиентов, широкий перечень интерпретаторов, а также контроллер, который управляет этими программными компонентами. Контроллер образует центральную часть браузера. Он интерпретирует и щелчки мышью, и ввод с клавиатуры, а также вызывает другие компоненты для выполнения операций, указанных пользователем. Например, при вводе пользователем URL или щелчке на гипертекстовой ссылке контроллер вызывает клиентскую программу для выборки затребованного документа с удаленного сервера, на котором он находится, а затем вызывает интерпретатор для отображения документа на экране пользователя.
Браузер должен содержать интерпретатор HTML для отображения документов. Другие интерпретаторы являются необязательными. На вход интерпретатора HTML поступает документ, который соответствует синтаксическим правилам HTML; на выход интерпретатора поступает отформатированная версия документа, предназначенная для отображения на экране пользователя. Интерпретатор выполняет компоновку, преобразуя спецификацию HTML в команды, подходящие для аппаратного обеспечения дисплея, за которым работает пользователь. Например, встретив в документе тег заголовка раздела, интерпретатор изменяет размер текста, который служит для изображения заголовка раздела. Встретив тег разрыва строки, интерпретатор открывает новую строку вывода.
Одна из наиболее важных функций интерпретатора HTML относится к выбираемым элементам. Интерпретатор должен хранить информацию о том, как связаны между собой позиции на экране и элементы документа HTML, относящиеся к каждому анкеру. При выборе пользователем любого элемента с помощью мыши браузер сравнивает информацию о текущей позиции курсора и хранимую информацию о положении анкеров, определяя, был ли пользователем выбран анкер.
Кроме клиента HTTP и интерпретатора HTML, браузер может включать компоненты, позволяющие выполнять дополнительные задачи. Например, многие браузеры включают клиент FTP, который применяется для доступа к службе передачи файлов. Некоторые браузеры содержат также программное обеспечение клиента электронной почты, позволяющее передавать и принимать сообщения по электронной почте.
Кэширование в Web-браузерах
Взаимодействие между клиентом и сервером при просмотре Web отличается от взаимодействия во многих клиент-серверных приложениях. На это есть две причины. Во-первых, поскольку пользователи обычно просматривают Web-страницы, находящиеся за пределами их организации, то Web-браузеры обращаются к страницам на удаленных компьютерах чаще, чем к локальным страницам. Во-вторых, поскольку пользователи не выполняют повторный поиск одной и той же информации, они, как правило, не повторяют доступ к одним и тем же ресурсам.
Таким образом, просмотр Web имеет другой характер локализации связей по сравнению с другими приложениями, поэтому для оптимизации производительности браузеров используются не такие методы, как в других приложениях. В частности, ни браузеры, ни Web-серверы не оптимизированы с учетом физической локализации связей. Кроме того, в браузерах применяются совершенно иные методы оптимизации с учетом временной локализации связей.
Как и в других приложениях, в браузерах для ускорения доступа к документа применяется кэш. Браузер помещает копию каждого полученного элемента данных в кэш на локальный диск. При выборе пользователем элемента, прежде чем обратиться за свежей копией этого элемента, браузер проверяет кэш на диске. Если кэш содержит нужный элемент, браузер получает его копию из кэша и обращается к серверу-источнику (т.е. к серверу, на котором находится просматриваемая страница), если элемент данных, принадлежащий к странице, не может быть найден в кэше.
Хранение элементов данных в кэше позволяет резко повысить производительность, поскольку браузер может считывать их с диска, не ожидая передачи этих элементов по сети. Кэширование является особенно важным при просмотре больших страниц или при использовании низкоскоростных сетевых соединений.
Несмотря на значительное повышение скорости, хранение элементов данных в кэше в течение продолжительного времени не всегда оправдано. Во-первых, кэш может занимать огромные объемы дискового пространства. Во-вторых, повышение производительности происходит, только если пользователь снова возвращается к просмотру того же элемента данных. К сожалению, пользователи часто просматривают ресурсы Web только в поисках конкретной информации; найдя необходимую информацию, пользователи прекращают просмотр. В подобных ситуациях кэширование снижает производительность, поскольку браузер расходует дополнительное время для записи на диск ненужной информации.
Для того чтобы пользователи могли управлять использованием браузером кэша, в большинстве браузеров предусмотрены средства, которые дают возможность пользователю изменять правила работы с кэшем. Пользователь может установить лимит времени для кэширования, и браузер будет удалять элементы данных из кэша по истечении установленного времени. Браузеры обычно сопровождают кэш на протяжении конкретного сеанса. Пользователь, который не желает оставлять элементы в кэше от одного сеанса к другому, может установить лимит времени хранения элементов данных в кэше равным нулю. В подобных случаях браузер очищает весь кэш после завершения сеанса работы пользователя.
Читайте также:
lektsia.com
- Как удалить историю в браузере эксплорер

- Есть ли wi fi

- Vba создать новую книгу excel

- Обновить internet explorer до 11

- Pci express что такое

- Как увеличить работоспособность процессора

- Как нанести термопасту на видеокарту

- Windows 7 пропали все значки с рабочего стола

- Приложение для чистки компьютера от мусора

- Отличие windows server 2018 r2 datacenter от enterprise

- Удалить папку windows old