Правильно построенный документ XML: общие правила синтаксиса XML. Xml синтаксис
Синтаксис XML
Эта глава принимает вас через простые правила синтаксиса для писания документа XML. Следование полный документ XML:
<?xml version="1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>Вы можете заметить что 2 вида информации в вышеуказанном примере:
повышение цены, как <contact-info>и
текст, или данные по характера, пункт консультаций и (040) 123-4567.
Следующая диаграмма показывает правила синтаксиса для писания разных видов повышения цены и текста в документе XML.
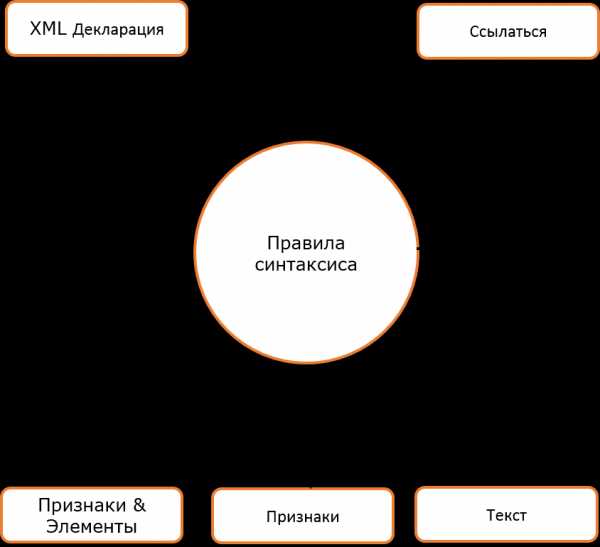
Препятствуйте нам увидеть каждый компонент вышеуказанной диаграммы подробно:
Объявление XML
Документ XML может выборочно иметь объявление XML. Написано как ниже:
<?xml version="1.0" encoding="UTF-8"?>Где версия версия и зашифрование XML определяют зашифрование характера используемое в документе.
Правила синтаксиса для объявления XML
Объявление XML случай чувствительный и должно начать с «<? xml>» где «xml» написано в строчной букве.
Если документ содержит объявление XML, то оно строго потребности быть первым заявлением документа XML.
Потребности объявления XML строго первое заявление в документе XML.
Протокол HTTP может отвергнуть значение зашифрования которое вы кладете в объявление XML.
Бирки и элементы
Архив XML составлен несколькими также вызванных XML-элементов, XML-узлами или XML-бирками. имена XML-элементов заключены триангулярными кронштейнами < > как показан ниже:
<element>Правила синтаксиса для бирок и элементов
Синтаксис элемента : Каждому XML-элементу нужно быть закрытым или с стартом или с элементами конца как показан ниже:
<element>....</element>или в прост-случаях, как раз этот путь:
<element/>Вложенность элементов : XML-элемент может содержать множественные XML-элементы как свои дети, но элементы детей не должны перекрыть. т.е., бирка конца элемента должна иметь такое же имя как та из самой недавней бесподобной бирки старта.
Следовать пример показывает неправильные, котор гнездят бирки:
<?xml version="1.0"?> <contact-info> <company>TutorialsPoint <contact-info> </company>Следовать пример показывает правильные, котор гнездят бирки:
<?xml version="1.0"?> <contact-info> <company>TutorialsPoint</company> <contact-info>Элемент корня : Документ XML может иметь только один элемент корня. Например, следование нет правильного документа XML, потому что и элементы x и y происходят на высшем уровне без элемента корня:
<x>...</x> <y>...</y>Следующий пример показывает правильно сформированный документ XML:
<root> <x>...</x> <y>...</y> </root>Чувствительность случая : Имена XML-элементов зависящий от регистра. То значит что имени старта и элементы конца нужно находиться точно в таком же случае.
Например <contact-info> отличал <Contact-Info>.
Атрибуты
Атрибут определяет одиночное свойство для элемента, используя пару имени/значения. XML-элемент может иметь одни или больше атрибуты. Например:
Здесь href имя атрибута и http://www.tutorialspoint.com/ атрибут со значением.
Правила синтаксиса для атрибутов XML
Имена атрибута в XML (не похож на HTML) случай чувствительный. То есть, HREF и href учтены 2 различными атрибутами XML.
Такой же атрибут не может иметь 2 значения в синтаксисе. Следующий пример показывает неправильный синтаксис потому что атрибут b определен дважды:
Имена атрибута определены без кавычек, тогда как атрибуты со значением должны всегда появляться в кавычки. Следовать пример демонстрирует неправильный синтаксис xml:
В вышеуказанном синтаксисе, атрибут со значением не определен в кавычках.
Справки XML
Справки обычно позволяют вам добавить или включить дополнительный текст или повышение цены в документе XML. Справки всегда начинают с символом «&», который сдержанно характер и конец с символом «; ». XML имеет 2 типа справок:
Справки характера : Эти содержат справки, как A, содержит ("#")hashmark следовать номером. Номер всегда ссылается к Коду Unicode характера. В этот случай, 65 ссылаются к алфавиту «a».
Текст XML
Имена XML-элементов и XML-атрибутов зависящий от регистра, который значит что имени элементов старта и конца нужно быть написанным в таком же случае.
Для того чтобы во избежание проблемы зашифрования характера, все архивы XML должны быть сохранены как архивы UTF-8 или UTF-16 Unicode.
Характеры Whitespace любят пробелы, платы и будут проигнорированы лини-проломы между XML-элементами и между XML-атрибутами.
Некоторые характеры зарезервированы синтаксисом самим XML. Следовательно, их нельзя использовать сразу. Для того чтобы использовать их, некоторые замен-реальности использованы, которые перечислены ниже:
| < | < | чем |
| > | > | больш чем |
| & | & | амперсанд |
| ' | ' | апостроф |
| « | " | метка цитаты |
www.tutorialspoint.com
Правила синтаксиса XML
Правила синтаксиса XML крайне просты и логичны. Их легко запомнить и легко использовать.
Все XML элементы должны иметь закрывающий тег
В HTML некоторые элементы могут не иметь закрывающего тега:
<p>Это параграф. <br>В XML нельзя опускать закрывающий тег. Абсолютно все элементы должны закрываться:
<p>Это параграф.</p> <br>Возможно, вы заметили из предыдущих примеров, что XML декларация не имеет закрывающего тега. Это не ошибка. Дело в том, что декларация не относится к XML документу, поэтому у нее и нет закрывающего тега.
Теги XML регистрозависимы
Теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter>.
Открывающий и закрывающий теги должны определяться в одном регистре:
Замечание: "Открывающий и закрывающий теги" иногда еще называют "начальный и конечный теги". Используйте то определение, которое вам более симпатично. По сути это одно и то же.
XML элементы должны соблюдать корректную вложенность
В HTML иногда можно наблюдать такую картину:
<b><i>Это жирный и курсивный текст</b></i>и иногда это даже работает должным образом.
В XML все элементы обязаны соблюдать корректную вложенность:
<b><i>Это жирный и курсивный текст</i></b>Понятие "корректная вложенность" по отношению к приведенным примерам просто означает, что так как элемент <i> открывается внутри элемента <b>, то и закрываться он должен внутри элемента <b>.
У XML документа должен быть корневой элемент
XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
<корневой> <потомок> <подпотомок>.....</подпотомок> </потомок> </корневой>
XML пролог
Следующая строка называется XML прологом:
<?xml version="1.0" encoding="UTF-8"?>XML пролог необязателен. Но если он есть, то это должна быть первая строка XML документа.
В XML документе могут присутствовать международные символы, вроде русских букв, и чтобы не возникало ошибок необходимо указать кодировку, либо сохранить XML файл в формате UTF-8.
UTF-8 — кодировка XML документов по умолчанию.
Значения XML атрибутов должны заключаться в кавычки
Так же, как и в HTML, у XML элементов могут быть атрибуты в виде пары имя/значение.
В XML значения атрибутов должны заключаться в кавычки.
Посмотрите на следующие два примера XML документа. Первый с ошибкой, второй написан правильно:
<note date=12/11/2007> <to>Tove</to> <from>Jani</from> </note> <note date="12/11/2007"> <to>Tove</to> <from>Jani</from> </note>Ошибка в первом XML документе заключается в том, что значение атрибута date элемента note не заключено в кавычки.
Сущности
Некоторые символы в XML имеют особые значения.
Если вы поместите, например, символ "<" внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
Так, к ошибке приведет следующая строка XML документа:
<message>если жалование < 1000</message>Чтобы такая ошибка не возникала, нужно заменить символ "<" на его сущность:
<message>если жалование < 1000</message>В XML существует 5 предопределенных сущностей:
СущностьСимволЗначение| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ' | апостроф |
| " | " | кавычки |
Замечание: Только символы "<" и "&" строго запрещены в XML. Символ ">" допустим, но лучше его всегда заменять на сущность.
Комментарии в XML
Синтаксис комментариев в XML такой же, как и в HTML.
<!-- Это комментарий -->Использование двух символов тире в середине комментария не допустимо.
Неверно:
<!-- Это -- комментарий -->Странно, но так можно:
В XML пробелы сохраняются
В HTML несколько последовательных пробельных символов усекаются до одного. В XML документе все пробельные символы сохраняются.
В XML новая строка сохраняется как LF
В приложениях Windows новая строка хранится в следующем виде: символ перевода каретки и символ новой строки (CR+LF).
Unix и Mac OSX используют LF.
Старые Mac системы используют CR.
XML сохраняет новую строку как LF.
Синтаксически верный XML документ
Если XML документ составлен в соответствии с приведенными синтаксическими правилами, то говорят, что это "синтаксически верный" XML документ.
msiter.ru
XML Синтаксические правила
Правила синтаксиса XML очень просто и логично. Правила просты в освоении, и простой в использовании.
XML-документы должны иметь корневой элемент
XML - документы должны содержать один корневой элемент , который является parent всех остальных элементов:
<root> <child> <subchild>.....</subchild> </child> </root>
В этом примере <Примечание> является корневым элементом:
<?xml version="1.0" encoding="UTF-8 " ?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>
XML Пролог
Эта линия называется XML пролог:
<?xml version="1.0" encoding="UTF-8 " ?>
XML пролог является необязательным. Если он существует, то она должна быть на первом месте в документе.
XML-документы могут содержать международные символы, такие как норвежский оа или французского ЭИ.
Чтобы избежать ошибок, вы должны указать кодировку, или сохранять файлы XML в кодировке UTF-8.
UTF-8 кодировка символов по умолчанию для XML-документов.
Кодировка символов может быть изучена в нашем Набор символов Учебное пособие .
UTF-8 также кодировку по умолчанию для HTML5, CSS, JavaScript, PHP и SQL.
Все XML-элементы должны иметь закрывающий тег
В HTML некоторые элементы могут работать хорошо, даже с отсутствующим закрывающий тег:
<p>This is a paragraph. <br>
В XML, это незаконно, чтобы опустить закрывающий тег. Все элементы must иметь закрывающий тег:
<p>This is a paragraph.</p> <br />
XML пролог не имеет закрывающего тега. Это не ошибка. Пролог не является частью документа XML.
XML-теги чувствительны к регистру
XML-теги чувствительны к регистру. Тег <Letter> отличается от тега <letter> .
Открытие и закрытие теги должны быть написаны с тем же делом:
<Message>This is incorrect</message> <message>This is correct</message>
«Открытие и закрытие тегов" часто упоминаются как "Start and end tags" . Используйте то, что вы предпочитаете. Это точно то же самое.
XML-элементы должны быть правильно вложены
В HTML, вы можете увидеть неправильно вложенные элементы:
<b><i>This text is bold and italic</b></i>
В XML все элементы must быть правильно вложены друг в друга:
<b><i>This text is bold and italic</i></b>
В приведенном выше примере, "Properly nested" просто означает , что , так как <i> элемент открыт внутри <b> элемент, он должен быть закрыт внутри <b> элемента.
XML значения атрибутов должны быть заключены в кавычки
XML элементы могут иметь атрибуты в пар имя / значение, как и в HTML.
В XML значения атрибутов всегда должны быть заключены в кавычки.
НЕПРАВИЛЬНО:
<note date=12/11/2007> <to>Tove</to> <from>Jani</from> </note>
ВЕРНЫЙ:
<note date="12/11/2007"> <to>Tove</to> <from>Jani</from> </note>
Ошибка в первом документе является то , что date атрибута в элементе примечания не котируется.
Entity Ссылки
Некоторые символы имеют специальное значение в XML.
Если поместить символ , как "<" внутри элемента XML, он будет генерировать ошибку , потому что анализатор интерпретирует его как начало нового элемента.
Это вызовет ошибку XML:
<message>salary < 1000</message>
Чтобы избежать этой ошибки, замените "<" характер с entity reference на entity reference :
<message>salary < 1000</message>
Есть 5 предопределенных ссылок на сущности в XML:
| < | < | less than |
| > | > | greater than |
| & | & | ampersand |
| ' | ' | apostrophe |
| " | " | quotation mark |
Только <и & строго запрещены в XML, но это хорошая привычка, чтобы заменить> с & GT; также.
Комментарии в XML
Синтаксис для записи комментариев в XML является похож на HTML.
<! - Это комментарий ->
Два тире в середине комментария не допускается.
Не допускается:
<!-- This is a -- comment -->
Странно, но допускается:
<!-- This is a - - comment -->
Бело-пространство Сохранилось в XML
XML не усечь несколько бело-пространства (HTML обрезает несколько бело-пространства к одному пробельных):
| XML: | Hello Tove |
| HTML: | Hello Tove |
XML Магазины New Line, как LF
Приложений Windows Store новую строку как: возврат каретки и перевод строки (CR+LF) .
Unix и Mac OSX использует LF.
Старый Mac системы использует CR.
XML сохраняет новую строку как LF.
Хорошо сформировавшиеся XML
XML - документы , которые соответствуют правилам синтаксиса выше , как говорят, "Well Formed" XML - документы.
www.w3bai.com
14 3 2 основы xml синтаксис xml
14.3.2. Основы XML
Синтаксис XML
Также как и в HTML, инструкции, заключенные в угловые скобки называются тэгами и служат для разметки основного текста документа. В XML существуют открывающие, закрывающие и пустые тэги.
Правильные, хорошо оформленные XML-документы должны удовлетворять следующим требованиям (слайд 16):
1) В XML все элементы должны иметь закрывающий тэг, т.е. в отличие от HTML, XML не разрешается опускать конечные тэги элементов
2) В тэгах XML учитывается регистр13. Например, отличается от . Таким образом, начальные и конечные тэги должны писаться в одном регистре.
3) Элементы XML должны быть правильно вложены друг в друга
Перекрывание элементов возникает тогда, когда закрывающий тэг внешнего элемента располагается перед закрывающим тэгом внутреннего элемента, например:
Этот текст пишется полужирным курсивом
4) XML-документы должны иметь единственный корневой элемент
Все XML-документы должны иметь единственную пару тэгов, задающую корневой элемент. Все остальные элементы должны быть вложены в корневой элемент.
5) Значения атрибутов всегда должны быть заключены в кавычки
Если элемент обладает атрибутами, задаваемые парами имя атрибута= значение, то значения атрибутов всегда должны быть заключены в кавычки.
6) все пробелы являются значимыми, т.е. при отображении пробелы в XML-документе не будут устраняться (в отличие от отображения HTML-документов).
7) В XML есть несколько зарезервированных символов, которые используются только как элементы синтаксиса XML и, следовательно, при необходимости их употребления в тексте, такие символы нужно заменять сущностями - специальными последовательностями других символов. Такими зарезервированными символами являются пять следующих знаков: , >, &, “, ‘.
XML-документы имеют два раздела: пролог и тело документа (слайд 17).
Пролог, предваряющий любой XML-документ, включает объявление XML и объявление типа документа. Объявление XML заключается между парами символов и ?> и может включать указание программе-анализатору текущего стандарта, объявление кодировки и самостоятельности, например, на слайде представлено объявление XML-документа с внешним DTD-определением в файле sample.dtd.
К телу документа относится все кроме пролога.
Тело XML-документа состоит из элементов разметки и непосредственно содержимого документа – данных, и представляет собой набор элементов и атрибутов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных.
Помимо элементов и атрибутов, обеспечивающих структурированное представление текстовой информации, языки разметки могут оперировать и двоичными данными (специальные символы, графика и т.д.) - сущностями, которые представляют собой поименованные фрагменты данных.
Элементы данных - это структурные единицы XML-документа (слайд 18). В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, заключенные между начальным и конечным тэгами.
Элементы могут иметь подэлементы (дочерние элементы). Подэлементы должны быть правильно вложены внутри родительского элемента (на слайде - , ).
Элементы XML в свою очередь могут иметь собственные характеристики, задаваемые атрибутами, принадлежащими конкретному элементу.
Атрибуты. Атрибут задается парой название="значение", которую надо задавать при определении элемента.
Сущности и специальные символы (слайд 19). Для того, чтобы включить в документ, например, символ, используемый для определения каких-либо конструкций языка (например, символ угловой скобки), нужно использовать его специальный символьный либо числовой идентификатор. Например, , > " или $ (десятичная форма записи), (шестнадцатеричная) и т.д. Таким образом, если необходимо поместить внутрь XML-элемента символ "
if salary
14.3.3. XML и реляционная модель данных
По аналогии с реляционной БД, если атрибутам сущности соответствуют поля таблицы, то в XML-документе им могут соответствовать либо атрибуты, либо значения элементов, либо вложенные элементы. Рассмотрим типичную реляционную таблицу (слайд 20).
Эту таблицу можно представить как XML-документ с именем Customers, содержащий два элемента Customer. При этом поля можно представить тремя способами:
в атрибутной форме, где им будут соответствовать атрибуты пустого элемента.
в элементной форме, где все поля будут вложенными элементами элемента, представляющего таблицу, к которой они относятся.
в смешанной форме:
При выборе формы представления следует учесть, что атрибутные требуют меньших XML-потоков и работают эффективно при больших объемах данных, но у каждого элемента (и, следовательно, у каждого объекта) может быть только по одному значению атрибута каждого типа. Вложенные элементы полезны для потенциально многозначных характеристик.
С точки зрения реляционной модели, различия между этими способам могут быть сведены к тому, что атрибуты подобны колонкам (точнее, их именам – атрибутам, которые могут иметь значение – величину в соответствующей ячейке), а элементы аналогичны строкам (в том числе, включая атрибуты). Атрибут может иметь только одно значение (атомарность ячейки), а элемент может повторяться. То есть, можно сказать, что атрибуты представляют «горизонтальную» модель, а элементы – «вертикальную».
14.3.4. Представление связей с помощью XML
Реляционные БД предназначены для представления связей между сущностями. Например, сущность заказ (Order) может быть связана с несколькими сущностей товар (Item), как, например, на слайде 21.
С помощью XML в простейшем случае связь может быть реализована в виде вложенных атрибутов.
Для того чтобы исключить повторяющиеся элементы, можно также использовать XML-атрибуты типов ID и IDREF (или IDREFS - для множественной ссылки).
Лекция 15 (DB_l15.ppt).
Управление реляционными базами данных. Языки определения данных и языки манипулирования данными. Способы выражения запросов: процедурный и форм-ориентированный.
.
Управление базами данных осуществляется средствами лингвистического обеспечения СУБД. Внутренний язык СУБД для работы с данными состоит из двух частей (слайд 2):
языка определения данных (Data Definition Language — DDL), который используется для определения схемы базы данных
языка манипулирования данными (Data Manipulation Language — DML) — для чтения и обновления данных, хранимых в базе.
Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня, таких как условные операторы или операторы цикла. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках программирования высокого уровня, как COBOL, Fortran, Pascal, Ada, С, C++, Java или Visual Basic. В этом случае язык высокого уровня принято называть базовым языком (host language). Перед компиляцией файла программы на базовом языке, содержащей внедренные операторы подъязыка данных, такие операторы удаляются и заменяются вызовами функций. Затем этот предварительно обработанный файл обычным образом компилируется с помещением результатов в объектный модуль, который компонуется с библиотекой, содержащей вызываемые в программе функции СУБД. После этого полученный программный текст готов к выполнению. Помимо механизма внедрения, для большинства подъязыков данных предоставляются также средства интерактивного выполнения операторов, вводимых пользователем непосредственно с терминала.
15.1. Язык определения данных — DDL (слайд 3)
Схема базы данных состоит из набора определений, выраженных на специальном языке определения данных — DDL. Язык DDL используется как для определения новой схемы, так и для модификации уже существующей. Этот язык нельзя использовать для управления данными.
Язык определения данных - описательный язык, который позволяет АБД или пользователю описать и именовать сущности и атрибуты, необходимые для работы некоторого приложения, связи, имеющиеся между различными сущностями, а также указать ограничения целостности.
Результатом компиляции DDL-операторов является набор таблиц, хранимый в особых файлах, называемых системным каталогом. В системном каталоге интегрированы метаданные — т.е. данные, которые описывают объекты базы данных, а также позволяют упростить способ доступа к ним и управления ими. Метаданные включают определения записей, элементов данных, а также другие объекты, представляющие интерес для пользователей или необходимые для работы СУБД. Перед доступом к реальным данным СУБД обычно обращается к системному каталогу. Для обозначения системного каталога также используются термины словарь данных и каталог данных, хотя первый из них (словарь данных) обычно относится к программному обеспечению более общего типа, чем просто каталог СУБД.
Теоретически для каждой схемы в трехуровневой архитектуре можно было бы выделить несколько различных языков DDL, а именно язык DDL внешних схем, язык DDL концептуальной схемы и язык DDL внутренней схемы. Однако на практике существует один общий язык DDL, который позволяет задавать спецификации, как минимум, для внешней и концептуальной схем.
15.2. Язык управления данными — DML
DML - язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными (слайд 4).
К операциям управления данными относятся:
вставка в базу данных новых сведений;
модификация сведений, хранимых в базе данных;
извлечение сведений, содержащихся в базе данных;
удаление сведений из базы данных.
Таким образом, одна из основных функций СУБД заключается в поддержке языка манипулирования данными, с помощью которого пользователь может создавать выражения для выполнения перечисленных выше операций с данными. Понятие манипулирования данными применимо как к внешнему и концептуальному уровням, так и к внутреннему уровню. Однако на внутреннем уровне для этого необходимо определить очень сложные процедуры низкого уровня, позволяющие выполнять доступ к данным весьма эффективно. На более высоких уровнях, наоборот, акцент переносится в сторону большей простоты использования, и основные усилия направляются на обеспечение эффективного взаимодействия пользователя с системой.
Часть непроцедурного языка DML, которая отвечает за извлечение данных, называется языком запросов. Язык запросов можно определить как высокоуровневый узкоспециализированный язык, предназначенный для удовлетворения различных требований по выборке информации из базы данных. В этом смысле термин «запрос» зарезервирован для обозначения оператора извлечения данных, выраженного с помощью языка запросов. Термины «язык запросов» и «язык управления данными» часто используются как синонимы, хотя с технической точки зрения, это некорректно.
Языки DML имеют разные базовые конструкции извлечения данных. Существуют два типа языков DML (слайд 5): процедурный и непроцедурный. Основное различие между ними заключается в том, что процедурные языки указывают то, как можно получить результат оператора языка DML, тогда как непроцедурные языки описывают то, какой результат будет получен. Как правило, в процедурных языках записи рассматриваются по отдельности, тогда как непроцедурные языки оперируют с целыми наборами записей.
15.2.1. Процедурные языки DML
Процедурный язык DML - это язык, который позволяет сообщить системе о том, какие данные необходимы, и точно указать, как их можно извлечь.
С помощью процедурного языка DML пользователь, а точнее — программист, указывает на то, какие данные ему необходимы и как их можно получить. Это значит, что пользователь должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой процедурный язык DML позволяет извлечь запись, обработать ее и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Обычно операторы процедурного языка DML встраиваются в программу на языке программирования высокого уровня, которая содержит конструкции для обеспечения циклической обработки и перехода к другим участкам кода. Языки DML сетевых и иерархических СУБД обычно являются процедурными.
15.2.2. Непроцедурные языки DML
Непроцедурный язык DML – это язык, который позволяет указать лишь то, какие данные требуются, но не то, как их следует извлекать.
Непроцедурные языки DML позволяют определить весь набор требуемых данных с помощью одного оператора выборки или обновления. С помощью непроцедурных языков DML пользователь указывает, какие данные ему нужны, без определения способа их получения. СУБД транслирует выражение на языке DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей. Такой подход освобождает пользователя от необходимости знать подробности внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. В результате работа пользователя становится в определенной степени независимой от данных. Непроцедурные языки часто также называют декларативными языками. Реляционные СУБД в той или иной форме обычно включают поддержку непроцедурных языков манипулирования данными — чаще всего это язык структурированных запросов SQL (Structured Query Language) или язык запросов по образцу QBE (Query-by-Example). Непроцедурные языки обычно проще понять и использовать, чем процедурные языки DML, поскольку пользователем выполняется меньшая часть работы, а СУБД — большая.
15.3. Языки 4GL
Аббревиатура 4GL представляет собой сокращенный английский вариант написания термина язык четвертого поколения (Fourth-Generation Language). Четкого определения этого понятия не существует, хотя, по сути, речь идет о некотором стенографическом варианте языка программирования. Если для организации некоторой операции с данными на языке третьего поколения (3GL) типа COBOL потребуется написать сотни строк кода, то для реализации этой же операции на языке четвертого поколения достаточно 10-20 строк.
В то время как языки третьего поколения являются процедурными, языки 4GL выступают как непроцедурные, поскольку пользователь определяет, что должно быть сделано, но не сообщает, как именно должен быть достигнут желаемый результат. Предполагается, что реализация языков четвертого поколения будет в значительной мере основана на использовании компонентов высокого уровня, которые часто называют «инструментами четвертого поколения». Пользователю не требуется определять все этапы выполнения программы, необходимые для решения поставленной задачи, а достаточно лишь задать нужные параметры, на основании которых упомянутые выше инструменты автоматически осуществят генерацию приложения. Ожидается, что языки четвертого поколения позволят повысить производительность работы на порядок, но за счет ограничения типов задач, которые можно будет решать с их помощью. Выделяют следующие типы языков четвертого поколения (слайд 6):
языки представления информации, например языки запросов или генераторы отчетов;
специализированные языки, например языки электронных таблиц и баз данных;
генераторы приложений, которые при создании приложений обеспечивают определение, вставку, обновление или извлечение сведений из базы данных;
языки очень высокого уровня, предназначенные для генерации кода приложений.
В качестве примеров языков четвертого поколения можно указать упоминавшиеся выше языки SQL и QBE. Рассмотрим вкратце некоторые другие типы языков четвертого поколения.
gigabaza.ru
Синтаксис XML
правила синтаксиса XML просты и очень логично. Эти правила легко выучить, и очень проста в использовании.
Все элементы XML должны иметь закрывающий тег
В HTML некоторые элементы не имеют закрывающий тег:
<p>This is a paragraph. <br>
В XML пропускаются закрывающий тег является незаконным. Все элементыдолжны иметь закрывающий тег:
<p>This is a paragraph.</p> <br />
Примечание: Из приведенных выше примеров, вы могли заметить , что декларация XML не закрыть вкладку.Это не ошибка. Декларация не является частью документа XML сам по себе, он не имеет закрывающего тега.
XML-теги чувствительны к регистру
XML-теги чувствительны к регистру. Тег <Письмо> тэг <буква> отличается.
Вы должны использовать один и тот же случай, чтобы писать открытые и закрывающие теги:
<Message>This is incorrect</message> <message>This is correct</message>
Примечание: Открытие и закрытие тегов обычно называют начальным и конечным тегами.Если вам нравится, что термины, их понятия совпадают.
XML должны быть правильно вложены
В HTML, вы часто видите, не правильно вложенные элементы:
<b><i>This text is bold and italic</b></i>
В XML все элементыдолжны быть правильно вложены друг в друга:
<b><i>This text is bold and italic</i></b>
В приведенном выше примере, правильное значение вложен: Поскольку <я> элемент в <B> элемент, чтобы открыть, то он должен быть закрыт в элементе <B>.
XML-документ должен иметь корневой элемент
Документ XML должен иметьэлемент является родителемвсех остальных элементов. Этот элемент называетсякорневым элементом.
<root> <child> <subchild>.....</subchild> </child> </root>
Значения атрибутов XML должны быть указаны
Подобно HTML, XML элементы могут иметь атрибуты (пар имя / значение).
В XML, значения атрибутов XML должны быть заключены в кавычки.
Пожалуйста, изучите следующие два XML-документов. Первый из них является неверным, то второй является правильным:
<note date=12/11/2007> <to>Tove</to> <from>Jani</from> </note>
<note date="12/11/2007"> <to>Tove</to> <from>Jani</from> </note>
Ошибка в первом документе, обратите внимание на элемент дата собственности не указана.
ссылка на сущность
В XML, некоторые символы имеют особое значение.
Если поставить символ "<" на элементе XML, возникает ошибка, поскольку анализатор будет использовать его как начало нового элемента.
Это вызовет ошибку XML:
<message>if salary < 1000 then</message>
Чтобы избежать этой ошибки, пожалуйста , используйтессылки на объектывместо символа "<":
<message>if salary < 1000 then</message>
В XML, есть 5 ссылок предопределенные сущности:
| < | < | less than |
| > | > | greater than |
| & | & | ampersand |
| ' | ' | apostrophe |
| " | " | quotation mark |
Примечание: В XML только символы "<" и "&" действительно незаконно.Больше, чем знак является законным, но с использованием ссылок на объекты вместо того, чтобы это хорошая привычка.
XML комментарии в
Написать комментарий в синтаксисе XML и синтаксис HTML очень похож.
<! - Это комментарий ->
В XML, пространство будет зарезервировано
HTML будет вырезать более одного последовательных символов пространство (объединены) в одну:
| HTML: | Hello Tove |
| Output: | Hello Tove |
В XML, документ пространства не будут удалены.
XML хранится в LF перевод строки
В приложениях для Windows, новая линия, как правило, используется для хранения пары символов: возврат каретки (CR) и перевода строки (LF).
В Unix и Mac OSX, используйте LF, чтобы сохранить новую строку.
В старой системе Mac, используйте CR, чтобы сохранить новую строку.
XML хранится в LF строки.
www.w3big.com
Правильно построенный документ XML: общие правила синтаксиса XML.
XML (Extensible Markup Language – расширяемый язык разметки) – рекомендован W3C как язык разметки, представляющий свод общих синтаксических правил. XML предназначен для обмена структурированной информацией с внешними системами. Формат для хранения должен быть эффективным, оптимальным с точки зрения потребляемых ресурсов (памяти, и др.). Такой формат должен позволять быстро извлекать полностью или частично хранимые в этом формате данные и быстро производить базовые операции над этими данными. Каждый документ начинается декларацией – строкой, указывающей как минимум версию стандарта XML. В качестве других атрибутов могут быть указаны кодировка символов и внешние связи.
<?xml version="1.0" encoding="UTF-8"?>
Важнейшее обязательное синтаксическое требование заключается в том, что документ имеет только один корневой элемент Это означает, что текст или другие данные всего документа должны быть расположены между единственным начальным корневым тегом и соответствующим ему конечным тегом.
После декларации в XML-документе могут располагаться ссылки на документы, определяющие структуру текущего документа и собственно XML элементы (теги), которые могут иметь атрибуты и содержимое. Открывающий тег состоит из имени элемента, например <city>. Закрывающий тег, состоит из того же имени, но перед именем добавляется символ ‘/’, например </city>. Содержимым элемента (content) называется всё, что расположено между открывающим и закрывающим тегами, включая текст и другие (вложенные) элементы. В любом месте дерева может быть размещен элемент-комментарий. XML-комментарии размещаются внутри специального тега, начинающегося с символов <!-- и заканчивающегося символами -->. Два знака дефис (--) внутри комментария присутствовать не могут.
<!-- Это комментарий. -->
Остальная часть этого XML-документа состоит из вложенных элементов, некоторые из которых имеют атрибуты и содержимое. Элемент обычно состоит из открывающего и закрывающего тегов, обрамляющих текст и другие элементы.
Текстовые блоки XML-документа не могут содержать символов, которые служат в написании самого XML: <, >, &.
<description>в текстовых блоках нельзя использовать символы <,>,& </description>
В таких случаях используются ссылки (указатели) на символы, которые должны
быть заключены между символами & и ; .
Особо распространенными указателями являются:
< – символ <;
> – символ >;
& – символ &;
' – символ апострофа ‘;
" – символ двойной кавычки “.
Таким образом, пример правильно будет выглядеть так:
<description>в текстовых блоках нельзя использовать символы <, >, & </description>
Если необходимо включить в XML-документ данные (в качестве содержимого элемента), которые содержат символы '<', '>', '&', '‘' и '“', чтобы не заменять их на соответствующие определения, можно все эти данные включить в раздел CDATA.
Раздел CDATA начинается со строки "<[CDATA[", а заканчивается "]]>",
при этом между ними эти строки не должны употребляться. Объявить раздел
CDATA можно, например, так:
<data><[CDATA[ 5 < 7 ]]></data>
Корректность XML-документа определяют следующие два компонента:
синтаксическая корректность (well-formed): то есть соблюдение всех синтаксических правил XML;
действительность (valid): то есть данные соответствуют некоторому набору правил, определённых пользователем; правила определяют структуру и формат данных в XML. Валидность XML документа определяется наличием DTD или XML-схемы XSD и соблюдением правил, которые там приведены.
Пример:
<?xml version="1.0" encoding="UTF-8"?>
<menu:nodes xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xmlns:menu="http://bvf.by/main-menu"
xsi:schemaLocation="http://bvf.by/main-menu xsd/main-menu.xsd">
<node>
<title>menu_main</title>
<url>/BVFApp/</url>
</node>
<node>
<title>menu_federation</title>
<nodes>
<node>
<title>menu_federation_direction</title>
<!-- <url>/BVFApp/faces</url> -->
</node>
</nodes>
</node>
</menu:nodes>
18. Интерфейсы анализаторов XML: доступ и манипулирование содержанием и структурой XML.
XML как набор байт в памяти, запись в базе или текстовый файл представляет
собой данные, которые еще предстоит обработать. То есть из набора строк необходимо получить данные, пригодные для использования в программе. Поскольку
ХML представляет собой универсальный формат для передачи данных, существуют
универсальные средства его обработки – XML-анализаторы (парсеры). Парсер – это библиотека, которая читает XML-документ, а затем предоставляет набор методов для обработки информации этого документа.
Существует три подхода (API) к обработке XML-документов:
DOM (Document Object Model – объектная модель документов) – платформенно-независимый программный интерфейс, позволяющий программам и скриптам управлять содержимым документов HTML и XML, а также изменять их структуру и оформление. Модель DOM не накладывает ограничений на структуру документа. Любой документ известной структуры с помощью DOM может быть представлен в виде дерева узлов, каждый узел которого содержит элемент, атрибут, текстовый, графический или любой другой объект. Узлы связаны между собой отношениями родитель-потомок.
SAX (Simple API for XML) базируется на модели последовательной одноразовой обработки и не создает внутренних деревьев. При прохождении по XML вызывает соответствующие методы у классов, реализующих интерфейсы, предоставляемые SAX-парсером.
StAX (Streaming API for XML) не создает дерево объектов в памяти, но, в отличие от SAX-парсера, за переход от одной вершины XML к другой отвечает приложение, которое запускает разбор документа.
Анализаторы, которые строят древовидную модель, – это DOM-анализаторы. Анализаторы, которые генерируют события, – это SAX-анализаторы.
Анализаторы, которые ждут команды от приложения для перехода к следую-
щему элементу XML – StAX-анализаторы.
В первом случае анализатор строит в памяти дерево объектов, соответствующее XML-документу. Далее вся работа ведется именно с этим деревом. Во втором случае анализатор работает следующим образом: когда происходит анализ документа, анализатор вызывает методы, связанные с различными участками XML-файла, а программа, использующая анализатор, решает, как реагировать на тот или иной элемент XML-документа. Так, аннализатор будет генерировать событие о том, что он встретил начало документа либо его конец, начало элемента либо его конец, символьную информацию внутри элемента и т.д.
StAX работает как Iterator, который указывает на наличие элемента с помощью метода hasNext() и для перехода к следующей вершине использует метод next().
Когда следует использовать DOM-, а когда – SAX, StAX -анализаторы?
DOM-анализаторы следует использовать тогда, когда нужно знать структуру документа и может понадобиться изменять эту структуру либо использовать информацию из XML-файла несколько раз.
SAX/StAX-анализаторы используются тогда, когда нужно извлечь информацию о нескольких элементах из XML-файла либо когда информация из документа нужна только один раз.
DOM – это специальная, языково-независимая интерфейсная модель разбора XML и HTML документов. Существует три уровня моделей DOM: DOM Level 1 – описывает основные интерфейсы, DOM Level 2 – вводит дополнение XML Namespaces, DOM Level 3 – определяет методы Load и Save.
Модель DOM Level 1 –описанна выше.
Модель DOM Level 2 вводит использование стилевых таблиц, определяет модель сообщений и XML Namespaces. В сущности namespaces (пространства имен) используются для того чтобы разрешить многократный доступ к словарям XML при этом используясь в одном XML документе. Для того чтобы присвоить какому либо элементу универсальный идентификатор нужно к тегу стоящему выше его по иерархии DOM добавить параметр вида "xmlns:indentefier="URI", где indentefier это имя индентификатора, а URI – сам индентификатор. Для его использования надо к используемуму элементу добавить спереди имя идентификатора indentefier и двоеточие.
<?xml version="1.0"?>
<html xmlns:xhtml="www.w3c.org/tr/xhtml"
xmlns:books="www.piter-press.ru">
<xhtml:title>Это заголовок документа XHTML</xhtml:title>
<book>
<books:title>А здесь должен быть заголовок книжки</books:title>
</book>
</html>
В даном случае в корневом теге <html> описано два пространства имен – xhtml и books. Теперь в этом документе можно использовать одни и те же элементы, но с разным значением, ставя перед ними имя пространства имен и двоеточие.
DOM Level 3 ...
На данный момент это последняя версия DOM. Спецификация этой модели состоит из трех частей: DOM3-ASLS, DOM3-Core, DOM3-Events, DOM3-XPath.
DOM ASLS (Abstract Schemas and Load and Save specification) – эта спецификация определяет схемы DTD и XML Schemas, а также методы Load and Save. Методы Load and Save, как можно догадаться из названия должны загружать и сохранять содержимое DOM-модели. Спецификация DOM3 Events – описывает модель сообщений и в основном базируется на DOM2 Events. Особенного внимания заслуживает спецификация DOM3-XPath. Эта спецификация определяет простой набор интерфейсов для доступа к дереву DOM через XPath 1.0.
infopedia.su
Язык XML (стр. 1 из 3)
Содержание
1Правильно построенные и действительные документы XML
2Синтаксис XML
2.1Объявление XML
2.2Корневой элемент
2.3Комментарий
2.4Тэги
2.5Спецсимволы
3История
4Сильные и слабые стороны
4.1Достоинства
4.2Недостатки
5Отображение XML во Всемирной паутине
5.1Применение стилей CSS
5.2Применение преобразования XSLT
6Словари XML
7Версии XML
8См. также
9Примечания
10Литература
XML (англ. eXtensibleMarkupLanguage — расширяемый язык разметки; произносится [экс-эм-э́л]) — рекомендованный Консорциумом Всемирной паутины язык разметки, фактически представляющий собой свод общих синтаксических правил. XML — текстовый формат, предназначенный для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки (например, XHTML), иногда называемых словарями. XML является упрощённым подмножеством языка SGML.
Целью создания XML было обеспечение совместимости при передаче структурированных данных между разными системами обработки информации, особенно при передаче таких данных через Интернет. Словари, основанные на XML (например, RDF, RSS, MathML, XHTML, SVG), сами по себе формально описаны, что позволяет программно изменять и проверять документы на основе этих словарей, не зная их семантики, то есть не зная смыслового значения элементов. Важной особенностью XML также является применение так называемых пространств имён (англ. namespace).
Правильно построенные и действительные документы XML
Стандартом определены два уровня правильности документа XML:
Правильно построенный (Well-formed). Правильно построенный документ соответствует всем общим правилам синтаксиса XML, применимым к любому XML-документу. И если, например, начальный тег не имеет соответствующего ему конечного тега, то это неправильно построенный документ XML. Документ, который неправильно построен, не может считаться документом XML; XML-процессор (парсер) не должен обрабатывать его обычным образом и обязан классифицировать ситуацию как фатальная ошибка.
Действительный (Valid). Действительный документ дополнительно соответствует некоторым семантическим правилам. Это более строгая дополнительная проверка корректности документа на соответствие заранее определённым, но уже внешним правилам, в целях минимизации количества ошибок, например, структуры и состава данного, конкретного документа или семейства документов. Эти правила могут быть разработаны как самим пользователем, так и сторонними разработчиками, например, разработчиками словарей или стандартов обмена данными. Обычно такие правила хранятся в специальных файлах — схемах, где самым подробным образом описана структура документа, все допустимые названия элементов, атрибутов и многое другое. И если документ, например, содержит не определённое заранее в схемах название элемента, то XML-документ считается недействительным; проверяющий XML-процессор (валидатор) при проверке на соответствие правилам и схемам обязан (по выбору пользователя) сообщить об ошибке.
Данные два понятия не имеют достаточно устоявшегося стандартизированного перевода на русский язык, особенно понятие valid, которое можно также перевести, как имеющий силу, правомерный, надёжный, годный, или даже проверенный на соответствие правилам, стандартам, законам. Некоторые программисты применяют в обиходе устоявшуюся кальку «Валидный».
Синтаксис XML
В этом разделе рассматривается лишь правильное построение документов XML, то есть их синтаксис.
XML — это описанная в текстовом формате иерархическая структура, предназначенная для хранения любых данных. Визуально структура может быть представлена как дерево элементов. Элементы XML описываются тэгами.
Рассмотрим пример простого кулинарного рецепта, размеченного с помощью XML:
<?xmlversion="1.0"encoding="UTF-8"?>
<recipename="хлеб"preptime="5"cooktime="180">
<title>Простойхлеб</title>
<ingredientamount="3"unit="стакан">Мука</ingredient>
<ingredientamount="0.25"unit="грамм">Дрожжи</ingredient>
<ingredientamount="1.5"unit="стакан">Тёплаявода</ingredient>
<ingredientamount="1"unit="чайнаяложка">Соль</ingredient>
<instructions>
<step>Смешать все ингредиенты и тщательно замесить.</step>
<step>Закрыть тканью и оставить на один час в тёплом помещении.</step>
<!-- <step>Почитать вчерашнюю газету.</step> - это сомнительный шаг... -->
<step>Замесить ещё раз, положить на противень и поставить в духовку.</step>
</instructions>
</recipe>
Объявление XML
Первая строка XML-документа называется объявление XML (англ. XMLdeclaration) — это необязательная строка, указывающая версию стандарта XML (обычно это 1.0), также здесь может быть указана кодировка символов и внешние зависимости.
<?xmlversion="1.0"encoding="UTF-8"?>
Спецификация требует, чтобы процессоры XML обязательно поддерживали Юникод-кодировки UTF-8 и UTF-16 (UTF-32 не обязателен). Признаются допустимыми, поддерживаются и широко используются (но не обязательны) другие кодировки, основанные на стандарте ISO/IEC 8859, также допустимы другие кодировки, например, русские Windows-1251, KOI-8. Часто в тэгах принципиально не используют не-латинские буквы, в этом случае UTF-8 является очень удобной кодировкой — объём, как правило, меньше, чем при UTF-16; декодирование может быть выполнено как для всего документа, так и для конкретных атрибутов и текстов; весь документ не содержит запрещённых символов при попытке разбора с неправильной кодировкой.
Корневой элемент
Важнейшее обязательное синтаксическое требование заключается в том, что документ имеет только один корневой элемент (англ. rootelement) (так же иногда называемый элемент документа (англ. documentelement)). Это означает, что текст или другие данные всего документа должны быть расположены между единственным начальным корневым тегом и соответствующим ему конечным тегом.
Следующий простейший пример — правильно построенный документ XML:
<book>Это книга: "Книжечка"</book>
Следующий фрагмент не может считаться корректным XML-документом:
<!-- ВНИМАНИЕ! Некорректный XML! -->
<thing>Сущность №1</thing>
<thing>Сущность №2</thing>
Комментарий
В любом месте дерева может быть размещен элемент-комментарий. XML-комментарии размещаются внутри специального тега, начинающегося с символов <!-- и заканчивающегося символами -->. Два знака дефис (--) внутри комментария присутствовать не могут.
<!-- Это комментарий. -->
Теги внутри комментария обрабатываться не должны.
Тэги
Остальная часть этого XML-документа состоит из вложенных элементов, некоторые из которых имеют атрибуты и содержимое. Элемент обычно состоит из открывающего и закрывающего тегов, обрамляющих текст и другие элементы. Открывающий тег состоит из имени элемента в угловых скобках, например, <step>, а закрывающий тег состоит из того же имени в угловых скобках, но перед именем ещё добавляется косая черта, например, </step>. Имена элементов, как и имена атрибутов, не могут содержать пробелы, но могут быть на любом языке, поддерживаемом кодировкой XML-документа. Имя может начинаться с буквы, подчёркивания, двоеточия. Остальными символами имени могут быть те же символы, а также цифры, дефис, точка.
Содержимым элемента (англ. content) называется всё, что расположено между открывающим и закрывающим тегами, включая текст и другие (вложенные) элементы. Ниже приведён пример XML-элемента, который содержит открывающий тег, закрывающий тег и содержимое элемента:
<step>Замесить ещё раз, положить на противень и поставить в духовку.</step>
Кроме содержания у элемента могут быть атрибуты — пары имя-значение, добавляемые в открывающий тег после названия элемента. Значения атрибутов всегда заключаются в кавычки (одинарные или двойные), одно и то же имя атрибута не может встречаться дважды в одном элементе. Не рекомендуется использовать разные типы кавычек для значений атрибутов одного тега.
<ingredientamount="3"unit="стакан">Мука</ingredient>
В приведённом примере у элемента «ingredient» есть два атрибута: «amount», имеющий значение «3», и «unit», имеющий значение «стакан». С точки зрения XML-разметки, приведённые атрибуты не несут никакого смысла, а являются просто набором символов.
Кроме текста, элемент может содержать другие элементы:
<instructions>
<step>Смешать все ингредиенты и тщательно замесить.</step>
<step>Закрыть тканью и оставить на один час в тёплом помещении.</step>
<step>Замесить ещё раз, положить на противень и поставить в духовку.</step>
</instructions>
В данном случае элемент «instructions» содержит три элемента «step».
XML не допускает перекрывающихся элементов. Например, приведённый ниже фрагмент некорректен, так как элементы «em» и «strong» перекрываются.
<!-- ВНИМАНИЕ! Некорректный XML! -->
<p>Обычный <em>акцентированный <strong>выделенный и акцентированный</em> выделенный</strong></p>
Для обозначения элемента без содержания, называемого пустым элементом, необходимо применять особую форму записи, состоящую из одного тега, в котором после имени элемента ставится косая черта. Если в DTD элемент не объявлен пустым, но в документе он не имеет содержания, для него допускается применять следующие (три) формы записи. Например:
<foo></foo>
<foo/>
<foo/>
Спецсимволы
В XML определены два метода записи специальных символов: ссылка на сущность и ссылка по номеру символа.
Сущностью (англ. entity) в XML называются именованные данные, обычно текстовые, в частности, спецсимволы. Ссылка на сущность (англ. entityreferences) указывается в том месте, где должна быть сущность и состоит из амперсанда (&), имени сущности и точки с запятой (;).
В XML есть несколько предопределённых сущностей, таких как lt (ссылаться на неё можно написав <) для левой угловой скобки и amp (ссылка — &) для амперсанда, возможно также определять собственные сущности. Помимо записи с помощью сущностей отдельных символов, их можно использовать для записи часто встречающихся текстовых блоков.
mirznanii.com
- Удаление с жесткого диска ненужных файлов

- Как узнать провайдера интернета по ip

- В каких единицах измеряется скорость интернета
- Почему пк

- Программа от рекламы

- Клавиша на клавиатуре пкм

- Почему отключается fi wi

- Microsoft sql server management studio как посмотреть нагрузку
- Ноутбук как освоить

- Windows 10 не работает touchpad

- Создание загрузочной флешки через ультра исо