Языки запросов для XML-данных. Запросы xml
Запросы к XML-столбцам—Справка | ArcGIS Desktop
В таблицах GDB_Items и GDB_ItemRelationships есть несколько XML-столбцов, содержащих сведения о схеме и отношениях элементов. В частности, вам обязательно придется обращаться к столбцу Определение (Definition) в таблице GDB_Items, когда понадобится получить сведения о базе геоданных. Тип содержащегося в нем XML-документа зависит от типа элементов. Например, определение класса пространственных объектов содержит сведения о полях таблицы, используемом домене, подтипах, пространственной привязке, сведения о роли набора классов объектов и другие сведения.
Проще всего работать со значениями XML-столбца, когда документ полностью извлечен из базы данных и сохранен локально. Для этого XML-документ необходимо сохранить в виде файла и использовать для просмотра XML-вьюер или текстовый вьюер. Для программистов, работающих с Java, C++ или C#, будет удобнее просматривать документ в Document Object Model (DOM). Разработчики, использующие SQL, могут использовать XML-функции для извлечения отдельных значений из определений элементов с помощью выражений XPath (язык запросов для работы с XML-документами).
Примечание:
В разных СУБД подписи и поведение XML-функций могут существенно отличаться.
Простым примером определения элемента является интервальный домен. Ниже приведен XML-документ с типовым определением интервального домена.
<? xml version = "1.0" encoding="utf-8"?> <GPRangeDomain2 xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xmlns:xs = "http://www.w3.org/2001/XMLSchema" xmlns:typens = "http://www.esri.com/schemas/ArcGIS/10.0" xsi:type = "typens:GPRangeDomain2"> <DomainName>Angle</DomainName> <FieldType>esriFieldTypeInteger</FieldType> <MergePolicy>esriMPTDefaultValue</MergePolicy> <SplitPolicy>esriSPTDuplicate</SplitPolicy> <Description>Valid rotation angles</Description> <Owner>harley</Owner> <MaxValue xsi:type = "xs:int">359</MaxValue> <MinValue xsi:type = "xs:int">0</MinValue> </GPRangeDomain2>В принципе, в домене диапазона двумя важнейшими значениями являются минимальное и максимальное значение. Эти элементы представлены выражениями XPath /GPRangeDomain2/MinValue и /GPRangeDomain2/MaxValue, соответственно. Ниже приведен пример запроса SQL, извлекающего эти значения конкретного интервального домена.
В любом примере подобном вышеприведенному нетрудно найти выражения XPath для сведений, которые необходимо извлечь. Выражения XPath для более сложных решений см. в статье XML-схема базы геоданных (XML Schema of the Geodatabase), в частности в приложении для разработчиков. работающих с системными таблицами.
Запросы к другим XML-столбцам системных таблиц формируются так же, как и к столбцу Определение (Definition) таблицы GDB_Items. Учтите, что для столбца Документация (Documentation) не предусмотрено XML-схемы, определяемой базой геоданных. В столбце Документация (Documentation) содержатся метаданные, связанные с элементами базы геоданных. В разных организациях элементы метаданных, содержащиеся в этом столбце, будут отличаться, так как это зависит от стандартов метаданных и рабочих процессов, используемых для управления ими. XML-документ DTD с описанием структуры метаданных ArcGIS — ArcGISmetadatav1.dtd — предоставляется вместе с ArcGIS for Desktop и хранится во вложенной папке \Metadata\Translator\Rules в каталоге, где установлен ArcGIS.
Извлечение нескольких значений из XML-столбца
Довольно часто имеет смысл извлечь из одного XML-документа несколько значений сразу. В приведенном ниже примере используется значение определения: домен кодированных значений.
<? xml version = "1.0" encoding="utf-8"?> <GPCodedValueDomain2 xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xmlns:xs = "http://www.w3.org/2001/XMLSchema" xmlns:typens = "http://www.esri.com/schemas/ArcGIS/10.0" <DomainName>Material</DomainName> <FieldType>esriFieldTypeString</FieldType> <MergePolicy>esriMPTDefaultValue</MergePolicy> <SplitPolicy>esriSPTDuplicate</SplitPolicy> <Description>Valid pipe materials</Description> <Owner>aelflad</Owner> <CodedValues xsi:type= "typens:ArrayOfCodedValue"> <CodedValue xsi:type= "typens:CodedValue"> <Name>Cast iron</Name> <Code xsi:type= "xs:string">CI</Code> </CodedValue> <CodedValue xsi:type= "typens:CodedValue"> <Name>Ductile iron</Name> <Code xsi:type= "xs:string">DI</Code> </CodedValue> <CodedValue xsi:type= "typens:CodedValue"> <Name>PVC</Name> <Code xsi:type= "xs:string">PVC</Code> </CodedValue> <CodedValue xsi:type= "typens:CodedValue"> <Name>Asbestos concrete</Name> <Code xsi:type= "xs:string">AC</Code> </CodedValue> <CodedValue xsi:type= "typens:CodedValue"> <Name>Copper</Name> <Code xsi:type= "xs:string">COP</Code> </CodedValue> </CodedValues> </GPCodedValueDomain2>Сведения о системных таблицах и видах, используемых в Oracle, см. в разделе "XML в системных таблицах баз геоданных" документа Краткий обзор системных таблиц баз геоданных.
desktop.arcgis.com
Языки запросов для XML-данных | Открытые системы. СУБД
Однако большинство из них рассматривают XML лишь как технологию для электронной коммерции. Это, прежде всего связано с успешным применением XML именно в этой области. Однако пока за занавесом остается на менее важный аспект применения XML и связанные с этим перспективы — использование XML в качестве единого формата представления данных в Internet.
Перспективы использования XML в качестве единого формата представления данных в Internet вполне понятны — поиск во Всемирной Сети превратится из занятия для особо настойчивых advanced users в нормальную процедуру извлечения информации, когда на любой запрос пользователь будет получать точный, адекватный ответ за минимальное время.
Для решения этой задачи в глобальном масштабе необходимо создание по крайней мере двух основ — среды хранения и управления XML-документами (назовем ее XDBMS) и языка запросов, адекватно отвечающего модели XML и реализующего все необходимые механизмы для выборки, изменения, удаления и формирования ответа на запрос. Еще до появления самого XML в мировом научном сообществе велись работы по созданию систем управления полуструктурированными данными, примеры их хорошо известны [7]. Также в последнее время появилось много работ (в частности, внутри самого консорциума W3C) по созданию языков запросов и моделей данных для XML-документов, имеются также промышленные реализации. В данной статье проведен анализ предпосылок для создания языков запросов, возможностей основных стандартов и модели данных XML, существующих реализаций и некоторых перспектив создания единого языка запросов для XML-данных.
Запросы над XML данными
Прежде чем уходить в глубины и истоки появления различных стандартов и языков запросов, ответим на вполне очевидный вопрос — зачем все это, нельзя ли использовать старый добрый SQL.
Почему не SQL
Реляционные системы управления базами данных являются сейчас стандартом де-факто для больших информационных систем. Однако сама реляционная концепция далеко не идеально подходит для хранения данных в формате XML. Хранение XML-документов не требует заранее заданной схемы, в этом смысле объекты XML самодостаточны, они содержат всю информацию, необходимую для построения запроса и обращения к отдельным элементам. Такой подход требует в итоге несколько больше места для хранения, однако позволяет добавлять и удалять элементы без какой-либо реструктуризации. В реляционной базе требуется по меньшей мере выполнение операции UPDATE SCHEMA ADD/DROP COLUMN, соответственно для возможности использования новых значений — перепрограммирование клиентских приложений.
Также имеется несколько существенных требований к системам хранения и управления XML документами, поддержка которых отсутствует в классической реляционной модели. Во-первых, по определению (требованию первой нормальной формы) столбцы должны иметь атомарные значения, что совсем не оптимально для XML данных. Таким образом, XML-объект хранится в нескольких отношениях и для извлечения данных требуется выполнение нескольких операций соединения, т.е. сравнения первичного и внешнего ключа, в то время как даже ссылки в XML документах — не более чем непосредственный указатель. Более того, для поддержания целостности всего объекта в реляционной схеме потребуется выполнение соответствующих триггеров.
Во-вторых, в отношениях строки не упорядочены, т.е. обращаться к строке можно только по содержанию, а не позиционно — не поддерживается иерархия. Конечно, в промышленных системах существуют методы поддержки иерархий в одной таблице (отношении), однако в итоге это все равно реализуется через обращение по значению.
Обобщим вышесказанные отличия модели данных XML от реляционной модели.
- Метаданные, такие как теги и имена атрибутов содержатся в самом документе (метаданные относительно структуры данных содержатся в отдельных системных таблицах).
- Документ имеет структуру типа дерево.
- Элементы документа могут быть вложенными и содержать атрибуты (столбцы должны иметь атомарные значения).
- Допускаются несколько элементов с идентичными тегами (не допускается несколько столбцов с одинаковыми названиями).
- Элементы образуют последовательности и имеют некоторую позицию (кортеж — множество атрибутов, т.е. неупорядоченный набор).
Переходя к языкам запросов, SQL реализует реляционную модель данных, ориентирован на выборку данных из нескольких нормализованных таблиц путем соединений. В случае XML речь идет скорее о выделении элементов в иерархической структуре одного (хотя и необязательно) документа. Тем самым выразительная мощь SQL оказывается бесполезной для XML, при этом никак не используется собственно модель данных XML документов. При рассмотрении существующих языков запросов станут более понятными семантические ограничения SQL.
XML Information Set и XML Namespaces
XML Information Set определяет абстрактное множество данных, описывающее информацию, доступную в правильно составленных (well-formed) XML документах. XML Infoset определен только для документов, удовлетворяющих спецификации Namespace. XML Infoset не определяет и не отдает предпочтение внешнему интерфейсу представления данных, будь то структура типа дерево или интерфейс на основе событий или запросов. Как только информация из Information Set становится доступна тем или иным образом приложению, требования спецификации XML Infoset считаются удовлетворенными.
Информационное множество содержит пятнадцать типов различных информационных элементов (information items), каждый из которых обладает свойствами. Среди информационных элементов следующие: документ, элемент, атрибут, инструкция обработки, DTD, начало и окончание секции CDATA, а также элемент литерного символа. Информационный элемент литерного символа определяется для каждого символа элемента документа и секции CDATA, а также для нормализованных значений атрибутов. Среди свойств информационных элементов находятся дети данного элемента (некоторые информационные элементы, например инструкции обработки, не имеют детей), т.е. тем самым информационное множество формирует целую ориентированную графовую структуру с выделенной вершиной (информационный элемент «документ»). Таким образом XML Information Set описывает множество информации (в нестрогом смысле), которую можно извлечь из XML документа, причем можно адресовать любой символ текстовых полей.
XML Namespaces — очень значимая спецификация, неразделимо связанная с самой спецификацией XML. XML Namespaces решает очень важную задачу унификации имен в XML документах и разделения имен между различными программными модулями (вместо многочисленных переопределений). Namespaces также призвана разрешить проблемы коллизий имен, так как в XML документах приветствуется использование human-readable тегов и очевидно, что в различных областях применения XML документов (и даже в рамках одной области) неминуемо возникнут одинаковые названия разных по смыслу сущностей.
Namespaces решает эти задачи путем сопоставления каждому имени уникального идентификатора ресурса (Unified Resource Identifier). Однако поскольку в URI могут использоваться символы, не допустимые в именах, вводится сокращенный префикс имени (namespace prefix), отображаемый на URI. Соотношение между префиксом и ссылкой URI описывается в самом документе на основе синтаксиса атрибутов.
XML Namespaces имеет самый высоких статус рекомендации W3C, поэтому все дальнейшие спецификации должны опираться на него.
Стандарты запросов
На самом деле стандарт, описывающий извлечение данных из XML документа, уже существует. Это рекомендация XPath, которую используют некоторые другие стандарты W3C (XSL, XPointer, XLink), а также практически все существующие языки запросов по XML данным как базовую технологию доступа к отдельным элементам документа. Как было сказано одним из членов W3C, «…трудно себе представить способ построения запроса к XML данным, который не основан на XPath».
Формально XPath определяется как язык для адресации (выделения) отдельных частей XML документа и изначальной областью его применения были процессоры XSLT и XPointer.
Синтаксис выражений на XPath предполагает деревянное представление структуры документа. Однако более того, в выражении запроса может участвовать полный адрес самого документа, т.е. в роли XML документа может выступать все дерево документов Web-сайта. Это дает возможность в рамках XPath адресовать все множество документов XML в Сети, поскольку XPath выражает единое согласованное представление документов и элементов на уровне Web-сайта и отдельного XML документа.
Итак, XPath рассматривает документ как структуру типа дерево, состоящую из узлов. Модель данных XPath содержит семь различных типов узлов (элементные, атрибутные, текстовые и т.д.), каждый имеет значение, содержащееся либо непосредственно в узле, либо вычисляемое по значению потомков. Некоторые типы узлов имеют имя. XPath полностью поддерживает Namespaces. Таким образом, имя узла моделируется как пара, состоящая из локального имени и, возможно, полного URI, называемого расширенным именем. XPath также поддерживает Infoset в том смысле, что модель данных Infoset имеет отображение в модель данных XPath.
На концептуальном уровне узел может быть как самостоятельной сущностью документ, любым документом или атрибутом, инструкцией обработки или комментарием. Сам документ содержит корень, содержащий список узлов, являющихся непосредственными потомками корня. В свою очередь эти узлы также могут содержать списки узлов и т.д. Такой универсальный подход делает XPath простым, но мощным средством обеспечения доступа к элементам XML документа (или же элементам XML-сайта). Заметим, что XPath описывает только логическую структуру документа, но не физический формат хранения.
В силу вложенной иерархической структуры XML документа и вероятных повторяющихся элементов механизм доступа к XML данным должен поддерживать иерархические отношения, отношения последовательности и позиционирования элементов. XPath располагает соответствующими спецификаторами, позволяющими выполнять переходы по этим отношениям. Их полный список, а также список всех функций приведен в [3]. XPath располагает набором функций, выполняющих проверку различных условий, сравнений и преобразований. В частности, XPath поддерживает четыре типа данных: список узлов, строковый, числовой и логический. Поскольку содержание XML документа по своей природе — литерные данные, XPath предоставляет функции преобразования типов данных. Для определения критериев выборки данных используются фильтры, семантически подобные выражению WHERE в SQL. Однако XPath предлагает лишь выбор и преобразование данных в рамках одного документа и не решает вопросы связи между документами и построения структуры ответа на запрос (напр. сортировка и группировка по значению).
Стандарт на языки запросов
Теперь обратимся к важному направлению работ W3C XML Activity, призванному служить базой для проектов, связанных с запросами над XML документами.
Целью XML Query Working Group является создание модели данных для XML документов, набора операторов запроса над документами и языка запроса на основе операторов. Модель данных будет основана на спецификации XML Infoset, и соответствовать Namespaces. Таким образом, в результате работы группы будет сформирован некоторый стандарт на язык запросов, правда, не рассматривающий такие важные моменты, как удаление и модификация данных. Также отдается на откуп промышленному производителю механизм индексирования и оптимизации запросов.
На сегодняшний день опубликован документ XML Query Requirements, имеющий статус working draft (промежуточный рабочий документ), в котором описываются цели, основные требования и сценарии использования модели данных и языка запросов для XML-документов.
Интересно, что в XML Query Requirements делаются ссылки на другие направления деятельности W3C и «выразительность, и поисковые возможности» XPath «будут взяты на рассмотрение» при формулировании алгебры и синтаксиса запросов. Тем самым деятельность XML Query Working Group не опирается на XPath как на один из основных стандартов.
Некоторые основные положения XML Query Requirements
Здесь отметим наиболее интересные положения, представленные в документе, специфичные для полуструктурированных данных. Многие требования, определенные в документе, вполне естественны для любого языка запросов.
Сразу же предполагается, что модель данных для XML-документов основана на деревянном представлении. Оператор запроса может быть построен как над одним документом, так и над фиксированной коллекцией документов, при этом для каждого документа может выбираться либо все дерево, либо поддерево, удовлетворяющее условиям запроса, определенным на структуре или содержанию документов. Результатом выполнения запроса также является дерево (т.е. новый документ), построенное согласно условиям выборки, определенным в запросе.
Основные требования:
- Язык запросов должен быть определен для конечных моделей данных. Поддержка бесконечных моделей приветствуется, но не обязательна.
- Язык предполагается быть декларативным (для систем управления полуструктурированными данными это означает наличие механизмов описания структуры данных, что реализуется в таких языках, как Lorel).
- Модель данных основана на информации, обеспечиваемой XML Processors и Schema Processors, соответственно, не должно быть информации, не определяемой этими процессорами. Согласно стандарту XML 1.0 или Namespaces Recommendation, конструкции модели данных запросов должны строится на основе элементов в XML Information Set. Т.е. модель данных должна представлять все элементы информации или же давать объяснения для всех пропущенных элементов.
- Должна существовать возможность осуществлять запросы над XML-документом даже если недоступна соответствующая схема документа (XML Schema или DTD).
- Модель данных должна поддерживать как внутренние ссылки, так и ссылки между документами.
- Язык запросов и модель данных должны поддерживать Namespaces.
- Язык запросов должен «уметь» комбинировать согласованную информацию отдельных частей документов или многих документов.
- Должна поддерживаться сортировка и агрегация.
Авторы проекта учли, что существенная часть XML-документов имеет гибкую структуру, в которой текст перемешан с элементами, а некоторые элементы могут вовсе отсутствовать. Структура таких документов может значительно отличаться от одного к другому. Поэтому способ выборки элементов в таких документах очень важен. Разработчикам языка настоятельно рекомендуется сохранять иерархию элементов в процессе выборки.
Языки запросов
Языки имеют различные цели создания, обладают разной выразительной мощностью, однако по оценкам исследователей [5,16], в каждом из них есть преимущества по выполнению тех или иных видов запросов.
Существует два основных подхода к языкам запросов для полуструктурированных данных и XML в частности: с точки зрения обработки документов и с точки зрения баз данных. Разные взгляды приводят к разным принципам построения запросов и разным функциональным возможностям (хотя, надо заметить, сообществом исследователей выдвигались единые требования к языкам запросов над XML данными [5,13] и разработчики стремятся обеспечить наиболее полную функциональность в новых версиях своих языковых подсистем).
Итак, два направления исследований имеют различные области приложений. Сообщество баз данных работает с позиций обработки запросов. Существует много типов систем: реляционные, иерархические, сетевые, дедуктивные, объектно-ориентированные, полуструктурированные и т.д., однако многие принципы общие для всех типов. Задачи этого сообщества ориентированы на большие репозитории данных, интеграцию из гетерогенных источников, экспорт данных из унаследованных систем и преобразование в общепринятые форматы обмена данными.
Сообщество исследователей в области обработки документов, с другой стороны, имеют дело с полнотекстовым поиском по большим массивам документов, запросами над структурированными документами, интеграцией полнотекстовых и структурных запросов и преобразованием документов для различного представления выходных форм.
Языки первого поколения
Lorel
Язык Lorel [4] изначально был спроектирован в Стандфордском университете в рамках проекта системы управления полуструктурированными данными Lorel, и затем был модифицирован для работы с XML. Это дружественный язык с большими возможностями, чем OQL, но более простым синтаксисом в стиле SQL. Основными преимуществами и новаторством Lorel являются широкое использование преобразования типов и мощный механизм построения пути запроса над нестрогой структурой данных, именуемый general path expression. Lorel реализует собственную модель данных [7], являющуюся расширением объектной модели данных (ODMG), с представлением в виде графа с узлами, соответствующими элементам данных XML. Lorel поддерживает все множественные операции, обеспечивает сортировку или сохранение порядка выбираемых данных в их представлении в исходных документах. Это один из немногих на сегодняшний день языков, разрешающих пользовательские типы данных и содержащий конструкции изменения и удаления данных.
Одной из наиболее сильных сторон языка Lorel являются богатые возможности навигации по «неопределенным» схемам с использованием шаблонов, причем шаблоны могут определяться как над отдельными значениями или именами ребер в графе модели, так и над путями (варианты имен ребер, обязательность/необязательность существования звена в пути, неопределенное число звеньев в пути и т.д.). Не вдаваясь в детали синтаксиса, приведем пример использования шаблонов в путях:
Guide.restaurant(.address)?.zipcode Guide.restaurant.#@P.comp%.name Guide.restaurant(.nearby)*{R}.nameПервое выражение определяет путь с необязательным ребром между zipcode и restaurant. Второе определяет все пути с неопределенным числом ребер с любыми названиями (символ #) между restaurant и ребром, начинающимся с подстроки comp. Переменная пути P связывается со всеми данными, удовлетворяющими критерию ?#?. Последнее выражение определяет все пути, проходящие через ребро restaurant, затем неопределенное число ребер nearby и заканчивающиеся ребром name. Объектная переменная R связывается с объектом непосредственно перед ребром name.
Основные свойства языка.
- Конструкции для создания нового элемента XML.
- Соединения (joins) как внутри одного документа так между несколькими документами.
- Множественные операции — объединение, пересечение, разность.
- Навешивание кванторов общности, существования и отрицания на предикаты.
- Поддержка всех основных видов агрегаций.
- Обработка вложенных подзапросов.
YATL
С развитием Web задача интеграции данных из гетерогенных источников и представление их в различных форматах стала одним из основных направлений деятельности сообщества баз данных. Один из наиболее распространенных подходов к решению этой проблемы — виртуальные хранилища данных, основанные на концепции посредников (mediator) и упаковщиков или оберток (wrapper) [6,7]. Для разработки архитектуры посредников и упаковщиков, в свою очередь, требуется решить задачу преобразования данных, на что направлены усилия многих исследователей в области баз данных.
В INRIA был спроектирован и разработан прототип системы с многообещающим названием YAT (Yet Another Tree-Based system), призванной служить основой для медиаторов и упаковщиков, т.е. для решения задачи преобразования данных [8]. YAT обеспечивает инструментарий для определения и внедрения преобразователей над разнородными источниками.
Подобно многим другим системам, YAT использует графовое представление данных для извлечения из гетерогенных источников, однако изначально определяется, что исходящие из вершин ребра упорядочены. Это оказывается особенно полезным при обработке упорядоченных коллекций, которые часто встречаются в форматах обмена данными и документах. Новаторством системы является возможность перерабатывать (уточнять) модель данных в любую другую графовую модель. Механизм преобразований заложен в язык системы YATL.
YATL (YAT Language) — основанный на механизме правил язык с мощными возможностями реструктуризации и шаблонами для создания и использования новых элементов. YATL поддерживает графический интерфейс, т.е. программисты не пишут непосредственно на YATL-программы, они генерируются автоматически по графической спецификации.
Как было сказано, YATL основан на правилах. Каждое правило определяет часть преобразования данных. Правило состоит из тела и заголовка. Тело содержит шаблоны, логические предикаты и внешние функции для фильтрации входных данных. Заголовок правила описывает, как данные будут представлены в выходной форме, т.е. саму реструктуризацию. Для данного DTD можно записать следующее правило, создающее объект «поставщик».
Отличием YATL от многих языков является управление не-множественными коллекциями (с повторяющимися элементами), а также синтаксические элементы для предотвращения зацикливаний в запросах, в случаях взаимного определения шаблонных переменных одной через другую. Например, на рисунке 1 шаблонная переменная Psup определяется через Pcar. Если задать при этом Pcar через Psup, то мы получим зацикливание. Синтаксический элемент & предотвращает подобные ситуации.
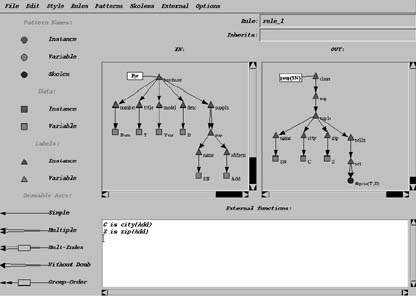 |
| Рис. 2. Представление правила с рис. 1 в графическом редакторе |
Основные свойства языка.
- Представление модели данных на различных уровнях абстракции (от общего к частному, рис. 3).
- Обработка данных из различных источников (даже в рамках одного правила), возможности разрешения коллизий.
- Обработка мультимножеств и списков на основе примитив группировки и упорядочивания.
- Настройка программ под входные данные, комбинирование программ.
Формальное описание языка можно найти в [9].
Прототип системы создан в Verso Database Group в INRIA. В качестве базового языка разработки использовался Objective CAML (также детище INRIA) и Java для создания графического интерфейса. Промышленная версия была установлена для реализации проекта OPAL.
XML-QL
Этот язык был спроектирован в AT&T Labs как язык запросов именно над XML данными для решения задач выборки, интеграции и преобразования данных (например, из одного DTD в другое). Поскольку эти задачи хорошо известны и на протяжении многих лет рассматриваются в сообществе баз данных, разработчики XML-QL выбрали именно этот подход к построению языка. В качестве основной прикладной задачи рассматривается электронный обмен данными.
XML-QL имеет SQL-подобный синтаксис с конструкциями CONSTRUCT-WHERE, где CONSTRUCT определяет структуру выходного XML-документа. В то же время существует возможность построения структуры по образу одного из входных документов.
В качестве модели данных используется графовое представление документов (XML Graph). Такой подход был выбран на основе опыта известных систем управления полуструктурированными данными. XML Graph состоит из графа с вершинами, каждой из которых сопоставлена уникальная строка — идентификатор объекта. Ребра графа помечены идентификаторами (тегами XML документа), узлы помечены множеством пар атрибут-значение, также и листовые вершины имеют значения. Также существует выделенная вершина — корень графа.
XML данные могут определять вложенные и циклические структуры, такие как деревья, направленные ациклические графы или же произвольные графы. Запросы над такими структурами часто влекут прохождение по частично определенным путям. Для таких операций часто используется техника регулярных выражений над путями (regular path expressions). В XML-QL регулярные выражения составляются на основе операций дизъюнкции (?|?), конкатенации (?.?) и звезды Клини (?*?). Также XML-QL поддерживает запросы с теговыми переменными, например:
WHERE 1995 Smith IN "www.a.b.c/bib.xml", $e IN {author, editor} CONSTRUCT SmithЗдесь p и e — теговые переменные, p определяет любой тег верхнего уровня, т.е. book или article для данного DTD, e определяет теги author и editor, согласно заданному ограничению.
Важной возможностью XML-QL является преобразование данных, например, из одного DTD в другое. Это обеспечивается конструкцией CONSTRUCT и функцией получения уникального идентификатора объекта для каждого уникального значения заданной комбинации ключей, например:
CONSTRUCT $fn $ln $tВ данном примере функция PersonID генерирует идентификатор для каждой различной пары значений переменных $fn и $ln. Если же запрос содержит новую информацию для существующей комбинации значений ключей, то она добавляется к элементу. Т.е. все одного автора будут группироваться в едином элементе .
Основные свойства XML-QL.
- Поддержка типов ID и IDREF — идентификация элементов и ссылки на объекты.
- Внешние и внутренние соединения.
- Группировка результатов запроса по значению элементов.
- Поддержка упорядоченности элементов на уровне модели данных.
В текущей версии XML-QL еще не реализованы такие важные возможности, как агрегации, регулярные выражения над строками, а также поддержка Namespaces, что необходимо для создания документов на основе различных схем данных. Однако авторы обещают реализовать эти и некоторые другие возможности в последующих версиях языка.
XQL
Концепция этого языка основана на преобразовании документов. Сам язык является естественным расширением шаблонного синтаксиса XSL и представляет собой нотацию для адресации отдельных элементов в документе и поиска узлов (документа) с соответствующими характеристиками. Авторы стремились создать простой и компактный язык, применимый, например, в URL строке.
В отличие от группы языков со стороны сообщества баз данных, XQL не поддерживает такие операции как группировку и реструктуризацию, поскольку результат запроса всегда является проекцией исходного документа. И именно поэтому автоматически сохраняется группировка, представленная в исходных данных. В текущей версии языка отсутствуют операторы сортировки. Это связано с тем, что сравнения строк производятся путем сравнения их представления в Unicode (унаследовано еще из XQL) и для сравнения строк разной длины приходится добавлять к более короткой нулевые символы в соответствующей последовательности Unicode.
Важным свойством является возможность обращаться к элементам в порядке их расположения в документе. Для этого используются индексы, которые могут содержать отдельные числа, интервалы значений или их комбинации:
document("www.bn.com/bib.xml") /bib/book { title | author[1 to 2] | author[3]->et-al { } }В XQL поддерживаются переменные значений, с помощью которых можно реализовать не только внутренние, но и внешние соединения:
document("www.bn.com/bib.xml")/bib -> books-with-prices { book->book-with-prices[$t:=title] { title | price -> price-bn | document("www.amazon.com/ reviews.xml")/reviews /entry[title=$t] { price -> price-amazon } } }При этом нет возможности использовать переменные в теговых конструкциях, т.е. структура адресуемого документа должна быть известна. Это, безусловно, существенно снижает выразительную мощность языка. Формально не поддерживаются регулярные выражения над путями, тем не менее, возможно обращение к непосредственным и произвольным потомкам в путях за счет использования операторов / и // соответственно, а также применение символа ?*? вместо имени тега, например:
Bookstore//book/*/excerpt//emphДанное выражение находит все элементы emph где-либо в потомках элемента excerpt, который является «внуком» элемента book и произвольным элементом между ними; book, в свою очередь, является каким-либо потомком Bookstore.
Различные ограничения и ветвления могут быть учтены в строке поиска за счет использования фильтров ?[ ]?, аналогичных SQL WHERE с семантикой ANY. Фильтр представляет подзапрос, приводимый к логическому выражению. Результатом запроса будут все элементы, удовлетворяющие логическому выражению в подзапросе. Приведенное ниже выражение означает «найти все названия тех книг, которые содержат по крайней мере один элемент excerpt»:
Book[excerpt]/titleXQL предлагает мощный механизм методов, расширяющий возможности обработки элементов как узлов дерева XML документа. Существуют методы для извлечения информации о типе, имени, значении узла, а также привязанной к нему текстовой информации; методы для получения информации о Namespaces, а также метод index(), определяющий позицию узла в данном контексте, т.е. среди данного набора узлов (см. пример). Полный список методов можно найти в работе [12].
Основные свойства языка.
- Полная поддержка Namespaces для элементов и атрибутов.
- Операторы сравнения и логические операторы.
- Ключевые слова, выражающие семантику кванторов общности и существования.
- Множественные операторы объединения и пересечения.
Языки второго поколения
Одним из таких языков, претендующих на оформление в виде стандарта W3C, является язык запросов Quilt [16, 17], предложенный специалистами из Software AG, IBM и INRIA. По оценке некоторых исследователей [1], этот язык очень близок к идеальному (и соответственно глобальному) языку запросов для XML-документов.
Quilt
Quilt возник как результат попыток ряда исследователей применить существующие языки, такие как XML-QL, XPath, XQL, YATL и XSQL, для различных типов запросов. Авторы проекта нашли, что каждый из языков предлагает мощные механизмы для решения одних типов задач и слишком громоздкие и сложные конструкции для других. Целью авторов проекта стало создание небольшого, но выразительного языка, обладающего преимуществами всех вышеперечисленных. Также некоторые идеи были заимствованы из стандартов SQL и OQL. Тем не менее, концептуальная целостность Quilt основана непосредственно на структуре XML.
Quilt способен выполнять запросы, основанные на структуре документа с ее сохранением или изменением; над плоскими структурами, такими как реляционные таблицы а также над связями типа и генерировать иерархии над реляционными данными, однако все типы данных должны быть представлены в виде XML и Quilt полагается исключительно на представление XML в своей модели данных.
Наибольшее влияние на Quilt оказали языки XML-QL и XQL-98. Авторы полагают, что концепция WHERE-CONSTRUCT, каркас запросов на XML-QL, обеспечивает очень мощный механизм, позволяющий соединять, группировать и преобразовывать данные, однако шаблоны для связывания переменных очень громоздки и избыточны. Кроме того, узким местом XML-QL является обработка иерархических структур и последовательностей с позиционным обращением к элементам. Эти недостатки XML-QL являются, наоборот, преимуществами XQL, обладающего мощным синтаксисом для навигации по иерархическим документам и выборки множества узлов, удовлетворяющих сложным условиям.
Подобно OQL, Quilt представляет собой функциональный язык, в котором запрос представляется как выражение. Quilt поддерживает несколько типов выражений, тем самым запрос может иметь различную форму. Различные типы выражений могут иметь вложенную структуру, т.е. подзапросы вполне естественны для Quilt. Основные формы выражений Quilt следующие:
- выражения путей;
- конструкторы элементов;
- выражения вида FOR-LET-WHERE-RETURN;
- выражения с операторами и функциями;
- условные выражения;
- квантифика
www.osp.ru
Получение и запрос XML-данных
В этом разделе описываются параметры запроса, которые необходимо указать для запроса XML-данных. Кроме того, в нем описаны компоненты экземпляров XML, нефиксируемых при сохранении экземпляров в базах данных.
SQL Server сохраняется содержимое экземпляра XML, но не сохраняются его аспекты, которые в модели XML-данных не рассматриваются как значительные. Это означает, что полученный экземпляр XML может отличаться от экземпляра, сохраненного на сервере, но при этом будет содержать те же самые данные.
XML-декларация
XML-декларация экземпляра не сохраняется при сохранении экземпляра в базе данных. Например:
CREATE TABLE T1 (Col1 int primary key, Col2 xml) GO INSERT INTO T1 values (1, '<?xml version="1.0" encoding="windows-1252" ?><doc></doc>') GO SELECT Col2 FROM T1Результат <doc/>.
XML-декларация, например <?xml version='1.0'?>, не сохраняется при сохранении XML-данных в экземпляре типа xml . Это сделано намеренно. XML-декларация () и ее атрибуты (version/encoding/stand-alone) будут утеряны после того, как данные преобразуются в тип xml. XML-декларация обрабатывается как директива для синтаксического анализатора XML. Все данные XML внутренне хранятся в кодировке UCS-2. Все другие инструкции по обработке (PI) в экземпляре XML сохраняются.
В этом разделе
Порядок атрибутов
Порядок атрибутов экземпляра XML не сохраняется. При запросе экземпляра XML, хранящегося в столбце типа xml , порядок атрибутов в результирующем XML может отличаться от порядка в исходном экземпляре XML.
В этом разделе
Кавычки вокруг значений атрибутов
Одинарные и двойные кавычки вокруг значений атрибутов не сохраняются. Значения атрибутов хранятся в базе данных в виде пар имени и значения. Кавычки не хранятся. При выполнении запроса XQuery к экземпляру XML результирующий XML сериализуется с использованием двойных кавычек вокруг значений атрибутов.
DECLARE @x xml SET @x = '<root a="1" />' SELECT @x GO DECLARE @x xml SET @x = '<root a=''1'' />' SELECT @x GOОба запроса вернут <root a="1" />.
В этом разделе
Префиксы пространства имен
Префиксы пространств имен не сохраняются. При выполнении запроса XQuery к столбцу типа xml для сериализации результирующего XML могут использоваться другие префиксы пространства имен.
DECLARE @x xml SET @x = '<ns1:root xmlns:ns1="abc" xmlns:ns2="abc"> <ns2:SomeElement/> </ns1:root>' SELECT @x SELECT @x.query('/*') GOПрефикс пространства имен в результате может быть другим. Например:
<p1:root xmlns:p1="abc"><p1:SomeElement/></p1:root>В этом разделе
При запросе столбцов или переменных с типом данных xml с помощью методов типа данных xml приведенные ниже параметры должны быть установлены следующим образом.
Параметры SETНеобходимые значения| ANSI_NULLS | ON |
| ANSI_PADDING | ON |
| ANSI_WARNINGS | ON |
| ARITHABORT | ON |
| CONCAT_NULL_YIELDS_NULL | ON |
| NUMERIC_ROUNDABORT | OFF |
| QUOTED_IDENTIFIER | ON |
Если эти параметры не установлены, как указано, запросы и методы изменения данных типа xml завершатся ошибкой.
В этом разделе
Создание экземпляров XML-данных
technet.microsoft.com
Получение и запрос данных XML
- 06/13/2017
- Время чтения: 4 мин
-
Соавторы
In this article
В этом разделе описываются параметры запроса, которые необходимо указать для запроса XML-данных.This topic describes the query options that you have to specify to query XML data. Кроме того, в нем описаны компоненты экземпляров XML, нефиксируемых при сохранении экземпляров в базах данных.It also describes the parts of XML instances that are not preserved when they are stored in databases.
Компоненты экземпляра XML, которые не сохраняютсяFeatures of an XML Instance That Are Not Preserved
SQL ServerSQL Server сохраняется содержимое экземпляра XML, но не сохраняются его аспекты, которые в модели XML-данных не рассматриваются как значительные. preserves the content of the XML instance, but does not preserve aspects of the XML instance that are not considered to be significant in the XML data model. Это означает, что полученный экземпляр XML может отличаться от экземпляра, сохраненного на сервере, но при этом будет содержать те же самые данные.This means that a retrieved XML instance might not be identical to the instance that was stored in the server, but will contain the same information.
XML-декларацияXML Declaration
XML-декларация экземпляра не сохраняется при сохранении экземпляра в базе данных.The XML declaration in an instance is not preserved when the instance is stored in the database. Пример:For example:
CREATE TABLE T1 (Col1 int primary key, Col2 xml) GO INSERT INTO T1 values (1, '<?xml version="1.0" encoding="windows-1252" ?><doc></doc>') GO SELECT Col2 FROM T1Результат <doc/>.The result is <doc/>.
XML-декларация, например <?xml version='1.0'?>, не сохраняется при сохранении XML-данных в экземпляре типа xml.The XML declaration, such as <?xml version='1.0'?>, is not preserved when storing XML data in an xml data type instance. Это сделано намеренно.This is by design. XML-узла (объявление) и ее атрибуты (версия/кодирование/stand-alone) будут утеряны, после преобразования в тип данных xml.The XML declaration () and its attributes (version/encoding/stand-alone) are lost after data is converted to type xml. XML-декларация обрабатывается как директива для синтаксического анализатора XML.The XML declaration is treated as a directive to the XML parser. Все данные XML внутренне хранятся в кодировке UCS-2.The XML data is stored internally as ucs-2. Все другие инструкции по обработке (PI) в экземпляре XML сохраняются.All other PIs in the XML instance are preserved.
Порядок атрибутовOrder of Attributes
Порядок атрибутов экземпляра XML не сохраняется.The order of attributes in an XML instance is not preserved. При запросе экземпляра XML, хранящегося в столбце типа xml, порядок атрибутов в результирующем XML может отличаться от порядка в исходном экземпляре XML.When you query the XML instance stored in the xml type column, the order of attributes in the resulting XML may be different from the original XML instance.
Кавычки вокруг значений атрибутовQuotation Marks Around Attribute Values
Одинарные и двойные кавычки вокруг значений атрибутов не сохраняются.Single quotation marks and double quotations marks around attribute values are not preserved. Значения атрибутов хранятся в базе данных в виде пар имени и значения.The attribute values are stored in the database as a name and value pair. Кавычки не хранятся.The quotation marks are not stored. При выполнении запроса XQuery к экземпляру XML результирующий XML сериализуется с использованием двойных кавычек вокруг значений атрибутов.When an XQuery is executed against an XML instance, the resulting XML is serialized with double quotation marks around the attribute values.
DECLARE @x xml -- Use double quotation marks. SET @x = '<root a="1" />' SELECT @x GO DECLARE @x xml -- Use single quotation marks. SET @x = '<root a=''1'' />' SELECT @x GOОба запроса вернут <root a="1" />.Both queries return = <root a="1" />.
Префиксы пространства именNamespace Prefixes
Префиксы пространств имен не сохраняются.Namespace prefixes are not preserved. При выполнении запроса XQuery к столбцу типа xml для сериализации результирующего XML могут использоваться другие префиксы пространства имен.When you specify XQuery against an xml type column, the serialized XML result may return different namespace prefixes.
DECLARE @x xml SET @x = '<ns1:root xmlns:ns1="abc" xmlns:ns2="abc"> <ns2:SomeElement/> </ns1:root>' SELECT @x SELECT @x.query('/*') GOПрефикс пространства имен в результате может быть другим.The namespace prefix in the result may be different. Пример:For example:
<p1:root xmlns:p1="abc"><p1:SomeElement/></p1:root>Задание обязательных параметров запросаSetting Required Query Options
При запросе xml столбцов или переменных с помощью типа xml методы типа данных, следующие параметры должны быть установлены следующим образом.When querying xml type columns or variables using xml data type methods, the following options must be set as shown.
Параметры SETSET Options Необходимые значенияRequired Values| ANSI_NULLSANSI_NULLS | ONON |
| ANSI_PADDINGANSI_PADDING | ONON |
| ANSI_WARNINGSANSI_WARNINGS | ONON |
| ARITHABORTARITHABORT | ONON |
| CONCAT_NULL_YIELDS_NULLCONCAT_NULL_YIELDS_NULL | ONON |
| NUMERIC_ROUNDABORTNUMERIC_ROUNDABORT | OFFOFF |
| QUOTED_IDENTIFIERQUOTED_IDENTIFIER | ONON |
Если параметры не заданы, как указано, запросы и изменения на xml методы типа данных не удастся.If the options are not set as shown, queries and modifications on xml data type methods will fail.
См. такжеSee Also
Создание экземпляров XML-данныхCreate Instances of XML Data
technet.microsoft.com
- Почему меня в скайпе не слышно на ноутбуке
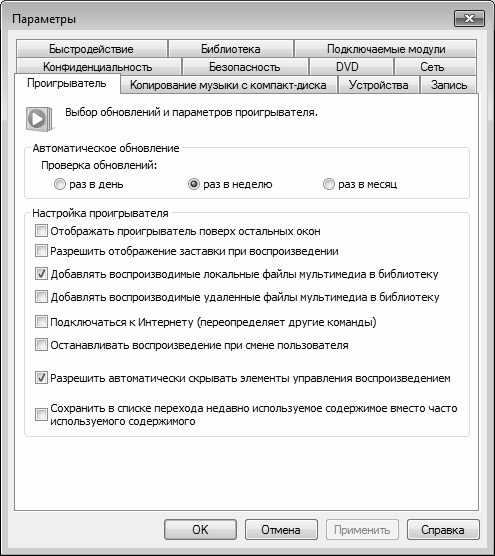
- Запускается виндовс медиаплеер на виндовс 7
- Профиль в интернете что это такое
- Hklm software что это

- Как проверить ноутбук на производительность

- Это приложение заблокировано в целях защиты windows 10 как исправить
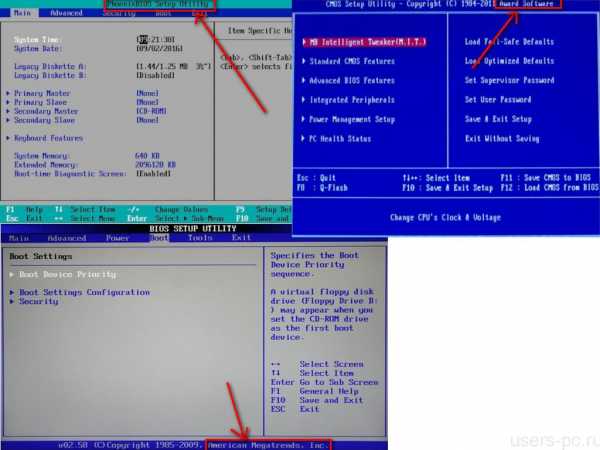
- Биос пищит 2 раза

- Чи компьютер

- Что делать если браузер не открывается на компьютере

- Активатор windows 7 service pack 1 64

- При загрузке компьютера звуковые сигналы