Индексирование в базах данных. Индексы в базах данных
Типы индексов, виды индексов, или какие вообще бывают индексы?
Типы индексов, виды индексов, или какие вообще бывают индексы?
// Август 2nd, 2012 // MySQL, Веб-разработка
После прочтения многочисленной литературы по СУБД, некоторого опыта работы с MongoDB и листанию статей по базам данных у меня созрело желание сделать cheatsheet по индексам применительно к БД. А индексирование — достаточно интересный раздел теории баз данных, а главное — нужный в практике. Вообще-то говоря, золотое правило индексирования — иметь индекс под каждый запрос.
По порядку сортировки
- Упорядоченные — индексы, в которых элементы поля(столбца) упорядочены.
- Возрастающие
- Убывающие
- Неупорядоченные — индексы, в которых элементы неупорядочены.
По источнику данных
- Индексы по представлению (view).
- Индексы по выражениям — например в PostgreSQL.
По воздействию на источник данных
- Некластерный индекс — наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки. Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя: информацию об идентификационном номере файла, в котором хранится строка; идентификационный номер страницы соответствующих данных; номер искомой строки на соответствующей странице; содержимое столбца.
- Кластерный индекс — Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту. Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными.
По структуре
- B*-деревья
- B+-деревья
- B-деревья
- Хеши.

По количественному составу
- Простой индекс (индекс с одним ключом) — строится по одному полю.Составной (многоключевой, композитный) индекс — строится по нескольким полям. Важен порядок следования полей (например в MongoDB).Индекс с включенными столбцами — Некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые.
- Главный индекс (индекс по первичному ключу) — это тот индексный ключ, под управлением которого в данный момент находится таблица. Таблица не может быть отсортирована по нескольким индексным ключам одновременно. Хотя, если одна и та же таблица открыта одновременно в нескольких рабочих областях, то у каждой копии таблицы может быть назначен свой главный индекс.
По характеристике содержимого
- Уникальный индекс — состоит из множества уникальных значений поля.Плотный индекс (NoSQL) — индекс, при котором, каждом документе в индексируемой коллекции соответствует запись в индексе, даже если в документе нет индексируемого поля.
- Разреженный индекс (NoSQL) — тот, в котором представлены только те документы, для которых индексируемый ключ имеет какое-то определённое значение (существует).
- Пространственный индекс — оптимизирован для описания географического местоположения. Представляет из себя многоключевой индекс состоящий из широты и долготы.
- Составной пространственный индекс — индекс, включающий в себя кроме широты и долготы ещё какие-либо мета-данные (например теги). Но географические координаты должны стоять на первом месте.
- Полнотекстовый (инвертированный) индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются. При наличии такого индекса достаточно осуществить поиск нужных слов в нём и тогда сразу же будет получен список документов, в которых они встречаются.
- Хэш-индексы — предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей.Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий.
- Битовый индекс (bitmap index) — метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
- Обратный индекс (reverse index) — это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.
- Функциональный (function-based) индекс (индекс по вычисляемому полю) — индекс, ключи которого хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
- Первичный индекс — уникальный индекс по полю первичного ключа.
- Вторичный индекс — индекс по другим полям (кроме поля первичного ключа).
- XML-индекс — вырезанное материализованное представление больших двоичных XML-объектов (BLOB) в столбце с типом данных xml.
По механизму обновления
- Полностью перестраиваемый — при добавлении элемента заново перестраивается весь индекс.
- Пополняемый (балансируемый) — при добавлении элементов индекс перестраивается частично (например одна из ветви) и периодически балансируется.
По покрытию индексируемого содержимого
- Полностью покрывающий (полный) индекс — покрывает всё содержимое индексируемого объекта.
- Частичный (partial) индекс — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
- Инкрементный (Delta) индекс — индексируется малая часть данных(дельта), как правило, по истечении определённого времени. Используется при интенсивной записи. Например, полный индекс перестраивается раз в сутки, а дельта-индекс строится каждый час. По сути это частичный индекс по временной метке.
- Real-time индекс — особый вид delta индекса в Sphinx, характеризующийся высокой скоростью построения. Предназначен для часто-меняющихся данных.
Индексы в кластерных системах
- Глобальный индекс — индекс по всему содержимому всех shard’ов (секций).
- Сегментный индекс — глобальный индекс по полю-сегментируемому ключу (shard key). Используется для быстрого определения сегмента(shard’а), на котором хранятся данные в процессе маршрутизации запроса в кластере БД.
- Локальный индекс — индекс по содержимому только одного shard’а.
Если есть неточности, коррективы — пишите в комменты. Надеюсь кому-то будет полезным эта «шпаргалка».
Ссылки
http://ru.wikipedia.org/wiki/Индекс_(базы_данных)http://habrahabr.ru/post/102785/http://www.sql.ru/articles/mssql/03013101indexes.shtml#16_3http://msdn.microsoft.com/ru-ru/library/ms175049(v=sql.90).aspx
Спасибо!
Если вам помогла статья, или вы хотите поддержать мои исследования и блог - вот лучший способ сделать это:tokarchuk.ru
Лекция №8- Индексирование в базах данных
Индекс- структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей.
Индекс в базе данных аналогичен предметному указателю в книге. Это — вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они могут существенным образом повысить ее производительность. Как и в случае с предметным указателем книги, читатель может найти определение интересующего его понятия, просмотрев всю книгу, но это потребует слишком много времени. А предметный указатель, ключевые слова в котором расположены в алфавитном порядке, позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, — индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
Файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
Индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.
Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей.
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом. Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основу поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
первичная область хранения;
отдельный индекс или несколько индексов;
область переполнения.
Обычно большая часть первичного индекса может храниться в оперативной памяти, что позволяет обрабатывать его намного быстрее. Для ускорения поиска могут применяться специальные методы доступа, например метод бинарного поиска. Основным недостатком использования первичного индекса (как и при работе с любым другим отсортированным файлом) является необходимость соблюдения последовательности сортировки при вставке и удалении записей. Эти проблемы усложняются тем, что требуется поддерживать порядок сортировки как в файле данных, так и в индексном файле. В подобном случае может использоваться метод, заключающийся в применении области переполнения и цепочки связанных указателей, аналогично методу, используемому для разрешения конфликтов в хешированных файлах.
studfiles.net
Индексирование в базах данных
Ключ для таблицы определяется с целью автоматической сортировки записей, контроля отсутствия повторяющихся значений, которые находятся в ключевых полях записей, и ускорения выполнения поисковых операций таблице. В СУБД для выполнения этих функций применяется индексирование.
Термины «индекс» и «ключ» тесно связаны между собой.
Определение 1
Индексом является средство ускорения поиска записей в таблице и других операций, связанных с поиском: модификации, извлечения, сортировки и т.д.
Индекс выступает в роли оглавления таблицы и просматривается до обращения к записям таблицы. В отдельных системах (к примеру, Paradox) индексы помещаются в индексные файлы, которые сохраняются отдельно от файлов табличных.
Организация физического доступа к данным зависит от:
- типа содержимого поля ключа записей индексного файла;
- вида ссылок, которые используются на запись основной таблицы;
- метода поиска необходимых записей.
Поле ключа индексного файла может содержать свертку ключа (хэш-код) или значения ключевых полей таблицы, которая индексируется. Преимуществом хранения хэш-кода, а не значения, является постоянная и достаточно маленькая длина свертки (например, 4 байта), которая не зависит от длины начального значения ключевого поля. Это достаточно эффективно влияет на скорость выполнения поисковых операций.
Недостаток хеширования – это обязательное выполнение операции свертки, на которую уходит некоторое время, а также возможность возникновения коллизий (при свертке разных значений можно получить одинаковый хэш-код).
При создании ссылки на запись таблицы возможно использование 3 типов адресов: символического (идентификатора), относительного и абсолютного (действительного).
В практической деятельности зачастую используют 2 поисковых метода: бинарный (базируется на делении поискового интервала пополам) и последовательный.
Одноуровневая схема индексирования таблиц
Индексный файл при одноуровневой схеме хранит короткие записи, имеющие 2 поля: поле адреса начала блока и поле содержимого старшего ключа (хэш-кода ключа) данного блока (рисунок 1).
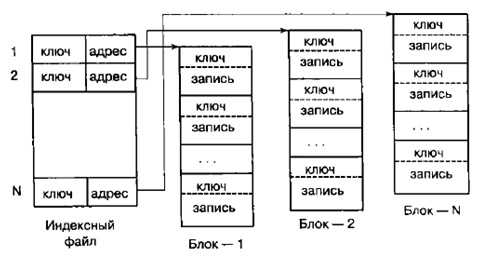
Записи каждого блока располагаются по возрастанию значения ключа или свертки. Ключ последней записи каждого блока является его старшим ключом.
Основной недостаток одноуровневой схемы состоит в хранении ключей (сверток) записей вместе с записями, что приводит к возрастанию поискового времени записей.
Двухуровневая схема индексирования таблиц
Более рациональной является двухуровневая схема, в которой ключи (свертки) записей отделяются от содержимого записей (рисунок 2).

Индекс основной таблицы в данной схеме разнесен по нескольким файлам: один файл главного индекса и множество файлов с блоками ключей.
Виды индексов
При создании индекса для таблицы базы данных пользователем указывается поле таблицы, для которого требуется индексация. Во многих СУБД ключевые поля таблицы обычно индексируются автоматически.
Индексы, которые создаются пользователем для неключевых полей, называются вторичными (или пользовательскими) индексами. Индексные файлы, которые создаются для поддержания вторичных индексов, называют файлами вторичных индексов.
Некоторые СУБД (к примеру, Access), индексы на первичные и вторичные не делят.
Замечание 1
Главной причиной увеличения скорости выполнения разных операций в индексированных таблицах является выполнение основной части работы не с таблицами, а с небольшими индексными файлами.
spravochnick.ru
Индекс (базы данных) - Википедия
Материал из Википедии — свободной энциклопедии
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 8 января 2017; проверки требуют 2 правки. Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 8 января 2017; проверки требуют 2 правки. У этого термина существуют и другие значения, см. Индекс.Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Некоторые СУБД расширяют возможности индексов введением возможности создания индексов по столбцам представлений[1] или индексов по выражениям.[2] Например, индекс может быть создан по выражению upper(last_name) и соответственно будет хранить ссылки, ключом к которым будет значение поля last_name в верхнем регистре. Кроме того, индексы могут быть объявлены как уникальные и как неуникальные. Уникальный индекс реализует ограничение целостности на таблице, исключая возможность вставки повторяющихся значений.
Архитектура[ | ]
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочены по значению ключа этого индекса. Если в таблице нет кластерного индекса, таблица называется кучей[3]. Некластерный индекс, созданный для такой таблицы, содержит только указатели на записи таблицы. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами. Наиболее часто употребимы B*-деревья, B+-деревья, B-деревья и хеши.
Последовательность столбцов в составном индексе[ | ]
Последовательность, в которой столбцы представлены в составном индексе, достаточно важна. Дело в том, что получить набор данных по запросу, затрагивающему только первый из проиндексированных столбцов, можно. Однако в большинстве СУБД невозможно или неэффективно получение данных только по второму и далее проиндексированным столбцам (без ограничений на первый столбец).
Например, представим себе телефонный справочник, отсортированный вначале по городу, затем по фамилии, и затем по имени. Если вы знаете город, вы можете легко найти все телефоны этого города. Однако в таком справочнике будет весьма трудоёмко найти все телефоны, записанные на определённую фамилию — для этого необходимо посмотреть в секцию каждого города и поискать там нужную фамилию. Некоторые СУБД выполняют эту работу, остальные же просто не используют такой индекс.
Производительность[ | ]
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того, индексы занимают дополнительный объем памяти, поэтому п
encyclopaedia.bid
- Как найти все фото на компьютере windows 10

- Windows 10 подтверждение удаления файлов
- Если не открывается флешка на компьютере что делать
- Скорость 2 интернета

- Группа вай фай состав

- Как обновить mikrotik
- Stop 0x00000016 windows 7

- Команды linux терминал

- Как на windows 7 перевести на русский язык
- Поиск в эксель сочетание клавиш

- Windows 7 iis установка