Операция MERGE в языке Transact-SQL – описание и примеры. Merge синтаксис oracle
Инструкция MERGE | sql-oracle.ru
Выполняется операция UPDATE, если строки существуют, и операция INSERT, если это новая строка:
исключает необходимость в отдельных обновлениях;
повышается производительность и простота использования;
удобна в приложениях хранилища данных.
Сервером Oracle поддерживается инструкция MERGE для операций INSERT, UPDATE и DELETE. Используя эту инструкцию, можно обновить, вставить или удалить строку по условию в таблице, таким образом исключая необходимость применения нескольких инструкций DML. Решение о выполнении обновления, вставки или удаления в целевой таблице основывается на условии в предложении ON.
Необходимо иметь объектные привилегии INSERT и UPDATE на целевую таблицу и объектную привилегию SELECT на исходную таблицу. Чтобы задать предложение DELETE для merge_update_clause, необходимо также обладать объектной привилегией DELETE на целевую таблицу.
Инструкция MERGE является детерминированной. Одну и ту же строку целевой таблицы невозможно обновить несколько раз в одной и той же инструкции MERGE.
Альтернативный подход состоит в использовании циклов PL/SQL и нескольких инструкций DML. Однако инструкцию MERGE удобно использовать и проще выразить в виде одиночной инструкции SQL.
Инструкция MERGE удобна в ряде приложений хранилища данных. Например, в приложении хранилища данных иногда возникает необходимость в работе с данными, поступающими из нескольких источников, часть из которых может быть дубликатами. Инструкция MERGE позволяет добавлять и изменять строки по определенному условию.
Синтаксис инструкции MERGE
Используя инструкцию MERGE, можно по определенному условию вставлять, обновлять и удалять строки в таблице.

Объединение строк
Используя инструкцию MERGE, можно обновлять существующие строки и вставлять новые строки по определенному условию. Применяя инструкцию MERGE, можно удалить устаревшие строки одновременно с обновлением строк в таблице. Чтобы сделать это, в синтаксис инструк- ции MERGE включите предложение DELETE со своим собственным предложением WHERE.
Элементы синтаксиса:
Предложение INTO - задает целевую таблицу, которая обновляется или в которую выполняется вставка.
Предложение USING - идентифицирует источник обновляемых или вставляемых данных; может быть таблицей, представлением или подзапросом.
Предложение ON - условие, по которому операция MERGE выполняет обновление или вставку.
WHEN MATCHED | WHEN NOT MATCHED - предписывает серверу, как реагировать на результаты условия объединения
Более подробно изложено в документации Oracle Database 11g SQL Reference (Справочник по SQL для базы данных Oracle 11g).
Далее: Функции TO_YMINTERVAL и TO_DSINTERVAL
sql-oracle.ru
DML-оператор MERGE (upsert) в Oracle SQL « Справочник по Oracle PL/SQL
Оператор MERGE — DML-оператор вставки (INSERT)/обновления (UPDATE)/удаления (DELETE, начиная с Oracle Database 10g) данных при слиянии таблиц. Kогда вы выполняете оператор MERGE, в сервере Oracle9i Database немедленно сработают триггеры BEFORE UPDATE и BEFORE INSERT (так как в этом операторе предложения WHEN MATCHED THEN UPDATE (когда совпадают, то обновить) и WHEN NOT MATCHED THEN INSERT (когда не совпадают, то вставить) являются обязательными). В сервере Oracle Database 10g будут срабатывать триггеры BEFORE UPDATE, INSERT и/или DELETE – в зависимости от указанных в операторе MERGE операций.Следующий пример произведет MERGE (слияние) данных из таблицы DEPT_ONLINE в таблицу DEPT:
При чем тут UPSERT
UPSERT является сходной операцией обновления существующих в таблице данных и вставке несуществующих, при срабатывании SQL%NOTFOUND в false в данном случае считаем, что update не произошел (операция MERGE появилась в спецификации языка SQL в 2003 году):
UPDATE my_table SET mast_id = :b1 WHERE ... IF SQL%NOTFOUND THEN INSERT INTO my_table VALUES .... END IF;Подробности:
Запись опубликована 08.01.2011 в 2:47 пп и размещена в рубрике Книга SQL. Вы можете следить за обсуждением этой записи с помощью ленты RSS 2.0. Можно оставить комментарий или сделать обратную ссылку с вашего сайта.
plsqlbook.ru
sql - Использование Oracle MERGE в одной таблице на основе условия
В вашем бизнес-правиле указано совпадение по DATE и TYPE. Таким образом, в коде есть две вещи:
- В предложении USING необходимо выбрать все критерии, необходимые для определения соответствия.
- предложение ON должно проверить все критерии, необходимые для определения соответствия.
Кроме того, если вам не нужно обновлять существующие записи, вы можете опустить ветвь WHEN MATCHED. Поэтому ваш оператор MERGE должен выглядеть примерно так:
merge into task using ( select date '2017-05-08' as dt, 'BATTLE' as typ from dual union all select date '2017-05-08' as dt, 'JUGGLE' as typ from dual union all select date '2017-05-08' as dt, 'PLOT' as typ from dual ) q on (task.task_date = q.dt and task.task_type = q.typ) when not matched then insert values (task_id_seq.nextval, q.dt, q.typ) /Демонстрация. Учитывая эту отправную точку...
SQL> select * from task; TASK_ID TASK_DATE TASK_TYPE ---------- ---------- ---------- 1 2017-05-06 CLEAN 2 2017-05-06 BATTLE 3 2017-05-06 JUGGLE 4 2017-05-07 JUGGLE 5 2017-05-07 CLEAN 6 2017-05-07 NAP 7 2017-05-08 BATTLE 7 rows selected. SQL>... выше MERGE должен вставить две строки (одна строка в источнике данных соответствует существующей строке).
Источник данных не совсем ясен. Поэтому в приведенном выше примере я сгенерировал набор задач с помощью DUAL. Если вы хотите создать новый набор задач на сегодняшний день из набора за вчерашнее предложение USING будет выглядеть так:
merge into task using ( select trunc(sysdate) as dt, task_type as typ from task where task_date = trunc(sysdate) - 1 ) q on (task.task_date = q.dt and task.task_type = q.typ) when not matched then insert values (task_id_seq.nextval, q.dt, q.typ) /qaru.site
Операция MERGE в языке Transact-SQL – описание и примеры | Info-Comp.ru
В языке Transact-SQL в одном ряду с такими операциями как INSERT (вставка), UPDATE (обновление), DELETE (удаление) стоит операция MERGE (слияние), которая в некоторых случаях может быть полезна, но некоторые почему-то о ней не знают и не пользуются ею, поэтому сегодня мы рассмотрим данную операцию и разберем примеры.
Начнем мы, конечно же, с небольшой теории.
Что такое MERGE в T-SQL?
MERGE – операция в языке T-SQL, при которой происходит обновление, вставка или удаление данных в таблице на основе результатов соединения с данными другой таблицы или SQL запроса. Другими словами, с помощью MERGE можно осуществить слияние двух таблиц, т.е. синхронизировать их.
В операции MERGE происходит объединение по ключевому полю или полям основной таблицы (в которой и будут происходить все изменения) с соответствующими полями другой таблицы или результата запроса. В итоге если условие, по которому происходит объединение, истина (WHEN MATCHED), то мы можем выполнить операции обновления или удаления, если условие не истина, т.е. отсутствуют данные (WHEN NOT MATCHED), то мы можем выполнить операцию вставки (INSERT добавление данных), также если в основной таблице присутствуют данные, которое отсутствуют в таблице (или результате запроса) источника (WHEN NOT MATCHED BY SOURCE), то мы можем выполнить обновление или удаление таких данных.
В дополнение к основным перечисленным выше условиям можно указывать «Дополнительные условия поиска», они указываются через ключевое слово AND.
Упрощённый синтаксис MERGE
MERGE <Основная таблица> USING <Таблица или запрос источника> ON <Условия объединения> [ WHEN MATCHED [ AND <Доп. условие> ] THEN <UPDATE или DELETE> [ WHEN NOT MATCHED [ AND Доп. условие> ] THEN <INSERT> ] [ WHEN NOT MATCHED BY SOURCE [ AND <Доп. условие> ] THEN <UPDATE или DELETE> ] [ ...n ] [ OUTPUT ] ;- В конце инструкции MERGE обязательно должна идти точка с запятой (;) иначе возникнет ошибка;
- Должно быть, по крайней мере, одно условие MATCHED;
- Операцию MERGE можно использовать совместно с CTE (обобщенным табличным выражением);
- В инструкции MERGE можно использовать ключевое слово OUTPUT, для того чтобы посмотреть какие изменения были внесены. Для идентификации операции здесь в OUTPUT можно использовать переменную $action;
- На все операции к основной таблице, которые предусмотрены в MERGE (удаления, вставки или обновления), действуют все ограничения, определенные для этой таблицы;
- Функция @@ROWCOUNT, если ее использовать после инструкции MERGE, будет возвращать общее количество вставленных, обновленных и удаленных строк;
- Для того чтобы использовать MERGE необходимо разрешение на INSERT, UPDATE или DELETE в основной таблице, и разрешение SELECT для таблицы источника;
- При использовании MERGE необходимо учитывать, что все триггеры AFTER на INSERT, UPDATE или DELETE, определенные для целевой таблицы, будут запускаться.
А теперь переходим к практике. И для начала давайте определимся с исходными данными.
Исходные данные для примеров операции MERGE
У меня в качестве SQL сервера будет выступать Microsoft SQL Server 2016 Express. На нем есть тестовая база данных, в которой я создаю тестовые таблицы, например, с товарами: TestTable – это у нас будет целевая таблица, т.е. та над которой мы будем производить все изменения, и TestTableDop – это таблица источник, т.е. данные в соответствии с чем, мы будем производить изменения.
Запрос для создания таблиц.
--Целевая таблица CREATE TABLE dbo.TestTable( ProductId INT NOT NULL, ProductName VARCHAR(50) NULL, Summa MONEY NULL, CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) ) --Таблица источник CREATE TABLE dbo.TestTableDop( ProductId INT NOT NULL, ProductName VARCHAR(50) NULL, Summa MONEY NULL, CONSTRAINT PK_TestTableDop PRIMARY KEY CLUSTERED (ProductId ASC) )Посмотрим на эти данные.
SELECT * FROM dbo.TestTable SELECT * FROM dbo.TestTableDop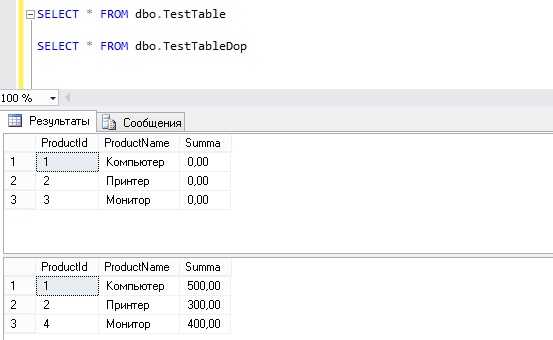
Видно, что в целевой таблице значение поля Summa = 0, а также есть несоответствие некоторых идентификаторов, т.е. у нас есть товары, которые есть в одной таблице, при этом они отсутствуют в другой.
Пример 1 – обновление и добавление данных с помощью MERGE
Это, наверное, классический вариант использования MERGE, когда мы по условию объединения обновляем данные, а если таких данных нет, то добавляем их. Для наглядности в конце инструкции MERGE я укажу ключевое слово OUTPUT, для того чтобы посмотреть какие именно изменения мы произвели, а также сделаю выборку итоговых данных.
MERGE dbo.TestTable AS T_Base --Целевая таблица USING dbo.TestTableDop AS T_Source --Таблица источник ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения WHEN MATCHED THEN --Если истина (UPDATE) UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa WHEN NOT MATCHED THEN --Если НЕ истина (INSERT) INSERT (ProductId, ProductName, Summa) VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa) --Посмотрим, что мы сделали OUTPUT $action AS [Операция], Inserted.ProductId, Inserted.ProductName AS ProductNameNEW, Inserted.Summa AS SummaNEW, Deleted.ProductName AS ProductNameOLD, Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой --Итоговый результат SELECT * FROM dbo.TestTable SELECT * FROM dbo.TestTableDop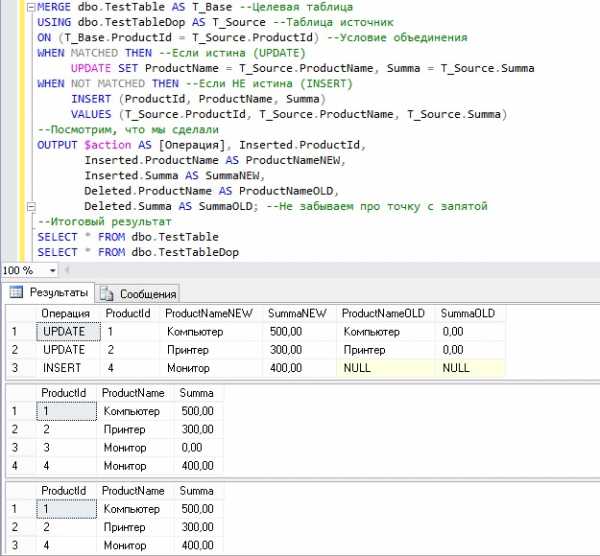
Мы видим, что у нас было две операции UPDATE и одна INSERT. Так оно и есть, две строки из таблицы TestTable соответствуют двум строкам в таблице TestTableDop, т.е. у них один и тот же ProductId, у данных строк в таблице TestTable мы обновили поля ProductName и Summa. При этом в таблице TestTableDop есть строка, которая отсутствует в TestTable, поэтому мы ее и добавили через INSERT.
Пример 2 – синхронизация таблиц с помощью MERGE
Теперь, допустим, нам нужно синхронизировать таблицу TestTable с таблицей TestTableDop, для этого мы добавим еще одно условие WHEN NOT MATCHED BY SOURCE, суть его в том, что мы удалим строки, которые есть в TestTable, но нет в TestTableDOP. Но для начала, для того чтобы у нас все три условия отработали (в частности WHEN NOT MATCHED) давайте в таблице TestTable удалим строку, которую мы добавили в предыдущем примере. Также здесь я в качестве источника укажу запрос, чтобы Вы видели, как можно использовать запросы в качестве источника.
--Удаление строки с ProductId = 4 --для того чтобы отработало условие WHEN NOT MATCHED DELETE dbo.TestTable WHERE ProductId = 4 --Запрос MERGE для синхронизации таблиц MERGE dbo.TestTable AS T_Base --Целевая таблица --Запрос в качестве источника USING (SELECT ProductId, ProductName, Summa FROM dbo.TestTableDop) AS T_Source (ProductId, ProductName, Summa) ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения WHEN MATCHED THEN --Если истина (UPDATE) UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa WHEN NOT MATCHED THEN --Если НЕ истина (INSERT) INSERT (ProductId, ProductName, Summa) VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa) --Удаляем строки, если их нет в TestTableDOP WHEN NOT MATCHED BY SOURCE THEN DELETE --Посмотрим, что мы сделали OUTPUT $action AS [Операция], Inserted.ProductId, Inserted.ProductName AS ProductNameNEW, Inserted.Summa AS SummaNEW,Deleted.ProductName AS ProductNameOLD, Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой --Итоговый результат SELECT * FROM dbo.TestTable SELECT * FROM dbo.TestTableDop
В итоге мы видим, что у нас таблицы содержат одинаковые данные. Для этого мы выполнили две операции UPDATE, одну INSERT и одну DELETE. При этом мы использовали всего одну инструкцию MERGE.
Пример 3 – операция MERGE с дополнительным условием
Сейчас давайте выполним запрос похожий на запрос, который мы использовали в примере 1, только добавим дополнительное условие на обновление данных, например, мы будем обновлять TestTable только в том случае, если поле Summa, в TestTableDop, содержит какие-нибудь данные (например, мы не хотим использовать некорректные значения для обновления). Для того чтобы было видно, как отработало это условие, давайте предварительно очистим у одной строки в таблице TestTableDop поле Summa (поставим NULL).
--Очищаем поле сумма у одной строки в TestTableDop UPDATE dbo. TestTableDop SET Summa = NULL WHERE ProductId = 2 --Запрос MERGE MERGE dbo.TestTable AS T_Base --Целевая таблица USING dbo.TestTableDop AS T_Source --Таблица источник ON (T_Base.ProductId = T_Source.ProductId) --Условие объединения --Если истина + доп. условие отработало (UPDATE) WHEN MATCHED AND T_Source.Summa IS NOT NULL THEN UPDATE SET ProductName = T_Source.ProductName, Summa = T_Source.Summa WHEN NOT MATCHED THEN --Если НЕ истина (INSERT) INSERT (ProductId, ProductName, Summa) VALUES (T_Source.ProductId, T_Source.ProductName, T_Source.Summa) --Посмотрим, что мы сделали OUTPUT $action AS [Операция], Inserted.ProductId, Inserted.ProductName AS ProductNameNEW, Inserted.Summa AS SummaNEW, Deleted.ProductName AS ProductNameOLD, Deleted.Summa AS SummaOLD; --Не забываем про точку с запятой --Итоговый результат SELECT * FROM dbo.TestTable SELECT * FROM dbo.TestTableDop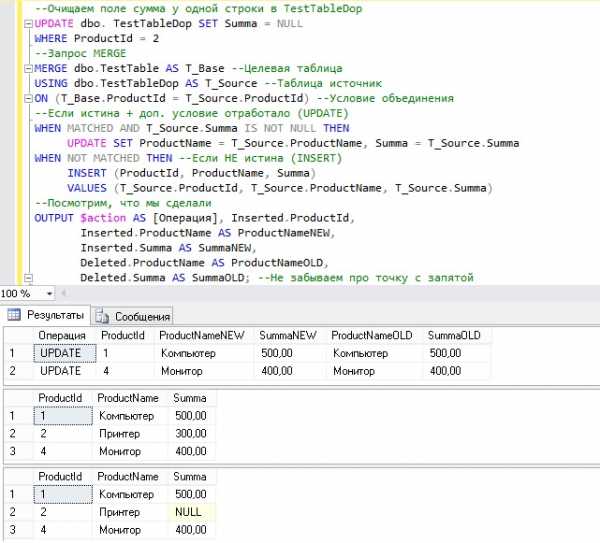
В итоге у меня обновилось всего две строки, притом, что все три строки успешно выполнили условие объединения, но одна строка не обновилась, так как сработало дополнительное условие Summa IS NOT NULL, потому что поле Summa у строки с ProductId = 2, в таблице TestTableDop, не содержит никаких данных, т.е. NULL.
Заметка! Начинающим программистам рекомендую почитать мою книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю про другие полезные возможности языка Transact-SQL.
На этом у меня все, удачи!
Похожие статьи:
info-comp.ru
Синтаксис MERGE
Вопрос: Merge дочек
Как можно сделать merge дочерних таблиц имея связь через родительские?Например есть таблицы create table p1 as select 1 id, 11 child_ref from dual union select 2 id, 22 child_ref from dual union select 3 id, 33 child_ref from dual ;/ create table p2 as select 1 id, 111 child_ref from dual union select 4 id, 444 child_ref from dual union select 3 id, 333 child_ref from dual ;/ create table c1 as select 1 id, 11 par_ref, 'A' key, 'AA' val from dual union select 2 id, 11 par_ref, 'B' key, 'AB' val from dual union select 3 id, 22 par_ref, 'C' key, 'AC' val from dual union select 4 id, 22 par_ref, 'D' key, 'AD' val from dual union select 5 id, 33 par_ref, 'E' key, 'AE' val from dual ;/ create table c2 as select 1 id, 111 par_ref, 'A' key, 'AA' val from dual union select 2 id, 111 par_ref, 'B' key, 'AF' val from dual union select 3 id, 444 par_ref, 'C' key, 'BC' val from dual union select 4 id, 444 par_ref, 'X' key, 'BD' val from dual union select 5 id, 333 par_ref, 'E' key, 'AG' val from dual ;/Нужно из с2 обновить в с1 записи 2, 5 и добавить записи 3,4сравнивая по
p1.id = p2.id and c1.key = c2.keyиспользую подзапрос или вьюхи, выходит
ORA-38106: MERGE not supported on join view or view with INSTEAD OF trigger. MERGE INTO ( select p1.id p_id, p1.child_ref , c1.id, c1.par_ref, c1.key, c1.val from p1, c1 where c1.par_ref = p1.child_ref ) D USING ( select p2.id p_id, p2.child_ref , c2.id, c2.par_ref, c2.key, c2.val from p2,c2 where c2.par_ref = p2.child_ref ) S ON (S.p_id = D.p_id and s.key = d.key) WHEN MATCHED THEN UPDATE SET S.val = D.val Ответ: merge into c1 using ( with pp1 as (select p1.id p_id, p1.child_ref , c1.id, c1.par_ref, c1.key, c1.val from p1, c1 where c1.par_ref = p1.child_ref) , pp2 as ( select p2.id p_id, p2.child_ref , c2.id, c2.par_ref, c2.key, c2.val from p2,c2 where c2.par_ref = p2.child_ref ) select pp2.*, pp1.par_ref c1_par_ref from pp2 left join pp1 on pp1.p_id = pp2.p_id and pp1.key = pp2.key ) c2 on (c1.par_ref = c2.c1_par_ref and c1.key = c2.key) when matched then update set c1.val = c2.val when not matched then insert values(c2.id, c2.child_ref, c2.key, c2.val )forundex.ru
Подсказки (Oracle Hints) | Oracle mechanics
Подсказки (Oracle Hints)
SQL Hints в документации Oracle
Ссылки
Oracle SQL Hints by Wei HuangOracle 12c new SQL Hints by Wei Huang
Замечания
QREF: SQL Statement HINTS [ID 29236.1]:
- «О синтаксисе: /*+ HINT HINT … */ в PL/SQL пробел между «+» и первой буквой подсказки имеет значение, в случае отсутствия пробела подсказка может быть игнорирована, т.е. /*+ ALL_ROWS */ правильное использование, а /*+ALL_ROWS */ — неправильное
- Подсказки всегда «форсируют» использование стоимостной оптимизации (cost based optimizer) — кроме подсказки RULE
- Если в запросе используются псевдонимы (table alias), в подсказках также должны использоваться псевдонимы вместо названий таблиц:
- В посказках не должно быть указания названия схемы:
- Некорректные подсказки (invalid hints) игнорируются без предупреждений… некорректность подсказки может быть неочевидна, например:
- указание подсказки FIRST_ROWS (для получения первых строк) для запроса с ORDER BY (поскольку данные должны быть отсортированы прежде, чем будут возвращены первые строки запроса, использование first_rows может не дать желаемого результата)
- указанные в подсказке операции с данными (access path) должны быть доступны Например: подсказка INDEXс указанием несуществующего индекса будет проигнорирована без сообщений об ошибках…»
Подсказка, указанная после некорректной (например, синтаксически) подсказки или текста в том же комментарии также может быть проигнорирована
Подсказки
— общие цели оптимизатора
/*+ RULE *//*+ ALL_ROWS *//*+ FIRST_ROWS *//*+ FIRST_ROWS(n) */
— порядок доступа
/*+ LEADING *//*+ ORDERED */
— методы
iusoltsev.wordpress.com
- Как установить на компьютер mozilla firefox
- Linux mint оптимизация

- Температура aida64
- Мониторинг действий пользователей за пк
- Почему на ноутбуке не открывается хром

- Что делать если шумит кулер на процессоре

- Как узнать кто взломал меня в вк

- Разница во временных зонах браузера и ip

- Как переустановить microsoft net framework

- Как включить windows
- Программирование на visual basic
