sql - Синтаксис сокращения строк Transact-SQL? Sql join синтаксис
JOIN Tables SQL Server | Oracle PL/SQL •MySQL •SQL Server
В этом учебном пособии вы узнаете, как использовать JOINS, как INNER, так и OUTER JOINS, в SQL Server (Transact-SQL) с синтаксисом, рисунками и примерами.
Описание
SQL Server (Transact-SQL) JOINS используются для извлечения данных из нескольких таблиц. JOIN SQL Server выполняется, когда две или более таблицы объединены в SQL-запрос.
Существует 4 разных типа соединений SQL Server:
Итак, обсудим синтаксис SQL Server JOIN, посмотрим на рисунки SQL Server JOINS и рассмотрим примеры JOIN для SQL Server.
INNER JOIN (простое соединение)
Скорее всего, вы уже писали запросы, в котором используется SQL INNER JOIN. Это наиболее распространенный тип соединения. SQL Server INNER JOINS возвращает все строки из нескольких таблиц, где выполняется условие объединения.
Синтаксис
Синтаксис INNER JOIN в SQL Server (Transact-SQL):
SELECT columnsFROM table1INNER JOIN table2ON table1.column = table2.column;
Рисунок
На этом рисунке SQL INNER JOIN возвращает затененную область: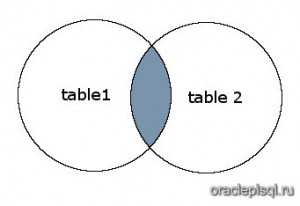 SQL Server INNER JOIN вернет записи, в которых пересекаются table1 и table2.
SQL Server INNER JOIN вернет записи, в которых пересекаются table1 и table2.
Пример
Ниже приведен пример INNER JOIN в SQL Server (Transact-SQL):
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Этот пример SQL Server INNER JOIN возвратит все строки из таблиц suppliers и orders, где в таблицах suppliers и orders будет указано соответствующее значение supplier_id.
Давайте рассмотрим некоторые данные, чтобы объяснить, как работает INNER JOINS:
У нас есть таблица, называемая suppliers с двумя полями (supplier_id и supplier_name), которая содержит следующие данные:
| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
Если мы выполним SQL Server оператор SELECT (который содержит INNER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Наш результирующий набор будет выглядеть следующим образом:
supplier_id name order_date| 10000 | IBM | 05.05.2015 |
| 10001 | Hewlett Packard | 08.02.2016 |
Строки для Microsoft и NVIDIA из таблицы suppliers будут опущены, так как значения supplier_id 10002 и 10003 не существует в обеих таблицах. Строка order_id 500127 из таблицы orders будет опущена, так как supplier_id 10004 не существует в таблице suppliers.
Старый Синтаксис
В качестве последнего примечания, стоит отметить, что приведенный выше пример SQL Server INNER JOIN можно переписать, используя старый неявный синтаксис следующим образом (но рекомендуется использовать синтаксис INNER JOIN):
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_dateFROM suppliers, ordersWHERE suppliers.supplier_id = orders.supplier_id;
LEFT OUTER JOIN
Другой тип соединения называется SQL Server LEFT OUTER JOIN. Этот тип соединения возвращает все строки из таблицы с левосторонним соединением, указанной в условии ON, и только те строки из другой таблицы, где объединенные поля равны (условие соединения выполнено).
Синтаксис
Синтаксис LEFT OUTER JOIN в SQL Server (Transact-SQL):
SELECT columnsFROM table1LEFT [OUTER] JOIN table2ON table1.column = table2.column;
В некоторых базах данных ключевые слова LEFT OUTER JOIN заменяются LEFT JOIN.РисунокНа этом рисунке, SQL Server LEFT OUTER JOIN возвращает затененную область:SQL Server LEFT OUTER JOIN вернет все записи из table1 и только те записи из table2, которые пересекаются с table1.
Пример
Ниже приведен пример LEFT OUTER JOIN в SQL Server (Transact-SQL):
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers LEFT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers LEFT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Этот пример LEFT OUTER JOIN возвращает все строки из таблиц suppliers и orders, где имеются соответствующие значение поля supplier_id в обоих таблицах.
Если значение supplier_id в таблице suppliers не существует в таблице orders, все поля в таблице orders будут отображаться как в наборе результатов.
Рассмотрим некоторые данные, чтобы понять, как работает INNER JOIN:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name) которая содержит следующие данные:
supplier_id supplier_name| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть еще одна таблица orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
order_id supplier_id order_date| 500125 | 10000 | 05.05.2015 |
| 500126 | 10001 | 08.02.2016 |
Если мы запустим оператор SELECT (который содержит LEFT OUTER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers LEFT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers LEFT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Результирующий набор будет выглядеть следующим образом:
supplier_id name order_date| 10000 | IBM | 05.05.2015 |
| 10001 | 08.02.2016 | |
| 10002 | Microsoft | null |
| 10003 | NVIDIA | null |
Строки для Microsoft и NVIDIA будут включены, так как был использован LEFT OUTER JOIN. Тем не менее, вы заметите, что поле order_date для этих записей содержит значение NULL.
RIGHT OUTER JOIN
Другой тип соединения называется SQL Server RIGHT OUTER JOIN. Этот тип соединения возвращает все строки из таблицы с правосторонним соединением, указанной в условии ON, и только те строки из другой таблицы, где объединенные поля равны (условие соединения выполнено).
Синтаксис
Синтаксис RIGHT OUTER JOIN в SQL Server (Transact-SQL):
SELECT columnsFROM table1RIGHT [OUTER] JOIN table2ON table1.column = table2.column;
В некоторых базах данных, RIGHT OUTER JOIN заменяется на RIGHT JOIN.
На этом рисунке, Oracle RIGHT OUTER JOIN возвращает затененную область:
Пример
Рассмотрим пример RIGHT OUTER JOIN SQL Server (Transact-SQL):
SELECT orders.order_id, orders.order_date, suppliers.supplier_name FROM suppliers RIGHT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT orders.order_id, orders.order_date, suppliers.supplier_name FROM suppliers RIGHT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Этот пример RIGHT OUTER JOIN возвращает все строки из таблицы orders и только те строки из таблицы suppliers, где объединяемые поля равны.
Если значение supplier_id в таблице orders не существует в таблице suppliers, все поля в таблице suppliers будут отображаться в результирующем наборе как NULL.
Рассмотрим некоторые данные, чтобы понять, как работает RIGHT OUTER JOIN:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name) которая содержит следующие данные:
supplier_id supplier_name| 10000 | Apple |
| 10001 |
У нас есть вторая таблица orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
order_id supplier_id order_date| 500125 | 10000 | 12.05.2016 |
| 500126 | 10001 | 14.05.2016 |
| 500127 | 10002 | 18.05.2016 |
Если мы запустим оператор SELECT (который содержит RIGHT OUTER JOIN) ниже:
SELECT orders.order_id, orders.order_date, suppliers.supplier_name FROM suppliers RIGHT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT orders.order_id, orders.order_date, suppliers.supplier_name FROM suppliers RIGHT OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Результирующий набор будет выглядеть следующим образом:
order_id order_date supplier_name| 500125 | 12.05.2016 | Apple |
| 500126 | 14.05.2016 | |
| 500127 | 18.05.2016 | null |
Строка для order_id 500127 будет включена, так как был использован RIGHT OUTER JOINS. Тем не менее, вы заметите, что поле supplier_name для этой записи содержит значение NULL.
FULL OUTER JOIN
Синтаксис
Синтаксис SQL Server FULL OUTER JOIN:
SELECT columnsROM table1FULL [OUTER] JOIN table2ON table1.column = table2.column;
В некоторых базах данных, FULL OUTER JOIN заменяются FULL JOIN.
На этом рисунке, FULL OUTER JOIN возвращает затененную область:
SQL Server FULL OUTER JOIN будет возвращать все записи из обеих таблиц table1 и table2.
Пример
Ниже приведен пример ПОЛНОГО ВНЕШНЕГО СОСТАВА в SQL Server (Transact-SQL):
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers FULL OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers FULL OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Этот пример FULL OUTER JOIN возвратит все строки из таблицы suppliers и все строки из таблицы orders и всякий раз, когда условие соединения не выполняется, то поля в результирующем наборе будут принимать значения NULL.
Если значение поля supplier_id в таблице suppliers не существует в таблице orders, то все поля в таблице orders будут отображаться в результирующем наборе как NULL. Если значение supplier_id в таблице orders не существует в таблице suppliers, то все поля в таблице suppliers будут отображаться результирующем наборе как NULL .
Рассмотрим некоторые данные, чтобы понять, как работает FULL OUTER JOIN:У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name). Она содержит следующие данные:
supplier_id supplier_name| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть вторая таблица orders с тремя полями (order_id, supplier_id и order_date), которая содержит следующие данные:
order_id supplier_id order_date| 500125 | 10000 | 12.05.2016 |
| 500126 | 10001 | 14.05.2016 |
| 500127 | 10004 | 18.05.2016 |
Если мы выполним оператор SELECT (который содержит FULL OUTER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers FULL OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers FULL OUTER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Результирующий набор будет выглядеть следующим образом:
supplier_id supplier_name order_date| 10000 | IBM | 12.05.2016 |
| 10001 | Hewlett Packard | 14.05.2016 |
| 10002 | Microsoft | null |
| 10003 | NVIDIA | null |
| null | null | 18.05.2016 |
Строки для Microsoft и NVIDIA будут включены, так как используется FULL OUTER JOIN. Тем не менее, вы заметите, что поле order_date для этих записей содержит значение NULL.
Строка для supplier_id 10004 также будет включена, так как используется FULL OUTER JOIN. Тем не менее, вы заметите, что supplier_id и поле supplier_name для этих записей содержат значение NULL.
oracleplsql.ru
sql - Синтаксис сокращения строк Transact-SQL?
The = * и * = не претендуют на текущие стандарты SQL, я считаю, что эти операторы будут устаревшими в ближайшее время, вы всегда должны использовать стандартный синтаксис соединения. Другие операторы, о которых вы говорите, сбивают с толку и должны уходить, я сжимаю, когда вижу их в объектах базы данных.
Если вы используете SQL Server, ни в коем случае не используйте этот синтаксис. Бывают случаи, когда неверные результаты возвращаются, поскольку иногда SQL-сервер правильно интерпретирует это как внешнее соединение, и иногда он интерпретирует этот синтаксис как перекрестное соединение. Поскольку результирующие множества этих двух радикально отличаются друг от друга, вы никогда не сможете полагаться на результаты использования этого синтаксиса. Кроме того, SQL Server 2008 является последней версией SQl Server, которая даже позволит использовать sysntax.
Я бы не использовал синтаксис * = или = (+), поскольку они не совместимы с другими СУБД или даже в случае MSSQL Server, совместимого с более поздними версиями, если вы не включите низкие уровни совместимости. Тогда действительно опасно, что в какой-то момент MS просто откажется от поддержки для него все вместе.
Потребовалось, чтобы я привык менять мои «старые» habbits. Я предпочел синтаксис * =, потому что его было меньше, чтобы набирать и приводить в порядок более простой поток равных объединений (которые совершенно все еще действительны и приемлемы)
Одно из моих возражений против перехода на использование JOINS - это все, что печаталось, и беспорядок, который я нашел в примерах запросов, используя их.
Некоторые трюки, которые я нашел, были просто форматированием и пониманием того, что действительно требуется. Использование «INNER» и «OUTER» полностью избыточно и не требуется. Также я использую скобки, чтобы разграничить конец предложения соединения и поместить каждое условие в свою собственную строку:
FROM blah b LEFT JOIN blah3 b2 ON (b.ID = b2.ID) LEFT JOIN blah4 b3 ON (b.ID = b3.ID) ...Некоторые сказали, что синтаксис ANSI JOIN сложнее испортить, потому что с равными объединениями легко пропустить параметр соединения ... На практике у меня было больше трудностей с забыванием сказать «ГДЕ», а интерпретатор все еще думает, что я определяя условия соединения, а не условия поиска, которые могут привести к разным результатам поиска / bizzare.
code-examples.net
variables - Синтаксис SQL - LEFT JOIN
Я новичок в stackoverflow, поэтому, пожалуйста, будьте осторожны. У меня серьезные проблемы с синтаксисом моего SQL. Суть в том, что я хочу скопировать из одной таблицы в другую без дубликатов. Я собирался сравнить два поля и только вставить, если есть NULL для поля1 в destinationTB.
Пожалуйста, знайте, что я новичок в операторах SQL, поэтому любые расширенные знания будут полезны... например, я могу использовать переменные. Я получил исходное выражение из исследования stackoverflow, но не смог его завершить.
Вот что у меня есть, и спасибо за помощь:
INSERT INTO destinationTB SELECT sourceTB.field1, destinationTB.field1 FROM sourceTB LEFT JOIN destinationTB ON sourceTB.field1 = destinationTB.field1 WHERE destinationTB.field1 IS NULL;----- ПЕРЕСМОТРЕННЫЙ ВОПРОС -----
Спасибо за советы! Я постараюсь пересмотреть вопрос (и будущие вопросы), чтобы быть более понятным, и мои извинения за неуклюжий запах "нового ребенка" в моем последнем вопросе.
Конечным результатом, который я ищу, является копирование из одной таблицы в другую без дубликатов. Есть две таблицы, с которыми я работаю. Первый - это destinationTB, который имеет четыре поля, только один из которых я хотел бы заполнить. Вторая таблица - sourceTB, которая имеет несколько полей, но только одна из которых мне нужна для получения информации. Мой план состоял в том, чтобы запустить INSERT в destinationTB. Поскольку первое значение не было там, оно должно отчитываться как NULL. После того, как первая вставка была выполнена, и строка все еще работала с теми же значениями, которые существовали в настоящее время, она больше не будет сообщать NULL и будет двигаться дальше, пока не найдет другое значение, которое не было в целевом ТБ.
В качестве примера позвольте взять телевизор. Существует несколько разных производителей телевизоров. В этом примере мы скажем, что у нас есть SHARP-32in, SHARP-45in и SHARP-60in. Я хочу, чтобы destinationTB имел только один экземпляр SHARP (хотя в sourceTB есть три экземпляра.Так что я пытался сравнить destinationTB.manufacturer с sourceTB.manufacturer, используя этот оператор JOIN. Когда я запускаю этот запрос, который я буду вставлять после этот параграф возвращает все три экземпляра, поэтому в конечном итоге я получаю три значения SHARP в моем целевом ТБ.
здесь мой последний, который я пробовал, основываясь на ваших предложениях:
INSERT INTO destnationTB (field1) SELECT sourceTB.field1 FROM sourceTB LEFT JOIN destinationTB ON sourceTB.field1 = destinationTB.field1 WHERE destinationTB.field1 IS NULL;qaru.site
sql - SQL - понимание синтаксиса JOIN, порядок
Порядок объединений, например проверьте этот ответ. Вы не можете получить доступ к псевдонимам таблицы, которые не были введены до состояния, например. вы не можете получить доступ к BRANCH в строке 5, потому что он вводится только в следующем соединении.
Код из MS Access вводит множество скобок для ограничения порядка объединения. Просто примените форматирование к нему и посмотрите на результат:
SELECT PUBLISHER.PUBLISHER_CODE, PUBLISHER.PUBLISHER_NAME, BOOK.TITLE, BOOK.TYPE, INVENTORY.BRANCH_NUM, BRANCH.BRANCH_NAME FROM PUBLISHER INNER JOIN ( BRANCH INNER JOIN ( BOOK INNER JOIN INVENTORY ON BOOK.BOOK_CODE = INVENTORY.BOOK_CODE ) ON BRANCH.BRANCH_NUM = INVENTORY.BRANCH_NUM ) ON PUBLISHER.PUBLISHER_CODE = BOOK.PUBLISHER_CODE WHERE ( ( (BOOK.TYPE)='FIC' ) AND ( (BRANCH.BRANCH_NAME)='Henry on the Hill' ) ) ORDER BY PUBLISHER.PUBLISHER_NAMEПосле удаления ненужных скобок это выглядит следующим образом:
SELECT PUBLISHER.PUBLISHER_CODE, PUBLISHER.PUBLISHER_NAME, BOOK.TITLE, BOOK.TYPE, INVENTORY.BRANCH_NUM, BRANCH.BRANCH_NAME FROM PUBLISHER INNER JOIN BRANCH INNER JOIN BOOK INNER JOIN INVENTORY ON BOOK.BOOK_CODE = INVENTORY.BOOK_CODE AND BRANCH.BRANCH_NUM = INVENTORY.BRANCH_NUM AND PUBLISHER.PUBLISHER_CODE = BOOK.PUBLISHER_CODE WHERE BOOK.TYPE='FIC' AND (BRANCH.BRANCH_NAME = 'Henry on the Hill') ORDER BY PUBLISHER.PUBLISHER_NAMEВыглядит лучше, но можно избежать проблем с упорядочением, просто преобразуя синтаксис ANSI в обычный запрос: ПРЕДУПРЕЖДЕНИЕ: синтаксические упражнения ANSI, пожалуйста, не читайте остальные ответы: -)
SELECT PUBLISHER.PUBLISHER_CODE, PUBLISHER.PUBLISHER_NAME, BOOK.TITLE, BOOK.TYPE, INVENTORY.BRANCH_NUM, BRANCH.BRANCH_NAME FROM PUBLISHER, BRANCH, BOOK, INVENTORY WHERE BOOK.TYPE='FIC' AND (BRANCH.BRANCH_NAME = 'Henry on the Hill') AND PUBLISHER.PUBLISHER_CODE = BOOK.PUBLISHER_CODE AND BOOK.BOOK_CODE = INVENTORY.BOOK_CODE AND BRANCH.BRANCH_NUM = INVENTORY.BRANCH_NUM ORDER BY PUBLISHER.PUBLISHER_NAMEПри этом варианте порядок условий не имеет значения и все условия, установленные для него, поэтому его можно реорганизовать в логическом порядке:
SELECT PUBLISHER.PUBLISHER_CODE, PUBLISHER.PUBLISHER_NAME, BOOK.TITLE, BOOK.TYPE, INVENTORY.BRANCH_NUM, BRANCH.BRANCH_NAME FROM BRANCH, INVENTORY, BOOK, PUBLISHER WHERE (BRANCH.BRANCH_NAME = 'Henry on the Hill') -- start from most restrictive -- condition (concrete branch) AND INVENTORY.BRANCH_NUM = BRANCH.BRANCH_NUM -- get all inventory from this branch AND BOOK.BOOK_CODE = INVENTORY.BOOK_CODE -- access book specification -- corresponding to inventory AND BOOK.TYPE = 'FIC' -- of specific type AND PUBLISHER.PUBLISHER_CODE = BOOK.PUBLISHER_CODE -- and finally find -- all publishers of that books ORDER BY PUBLISHER.PUBLISHER_NAMEТаким образом, в последнем варианте можно воспроизвести логику запроса в читаемом формате. Обратите внимание, что порядок таблиц в тексте запроса (по крайней мере, в Oracle, если вы не используете какие-либо специальные подсказки) не влияет на реальный план выполнения запросов, потому что оптимизатор меняет его на свой собственный по мере необходимости. Поэтому вариант ANSI в большинстве ситуаций просто вводит ограничения синтаксиса без реальной помощи.
qaru.site
sql - ANSI и не ANSI SQL JOIN синтаксис
В моем представлении предложение FROM - это то, где я решаю, какие столбцы мне нужны в строках для моего предложения SELECT. Здесь выражается бизнес-правило, которое выводит на ту же строку, значения, необходимые в вычислениях. Бизнес-правило может быть клиентом, у которого есть счета-фактуры, в результате чего строятся счета-фактуры, включая ответственность клиента. Это также могут быть места в том же почтовом индексе, что и клиенты, в результате чего список мест и клиентов, которые находятся близко друг к другу.
Здесь я определяю центричность строк в моем результирующем наборе. В конце концов, нам просто показана метафора списка в РСУБД, причем в каждом списке есть тема (сущность), и каждая строка является экземпляром объекта. Если понимать центричность строк, понимается объект набора результатов.
Предложение WHERE, которое концептуально выполняется после строк, определено в предложении from, отбирает строки, которые не требуются (или содержат строки, которые требуются) для предложения SELECT для работы.
Поскольку логика соединения может быть выражена как в предложении FROM, так и в предложении WHERE, а также потому, что существуют предложения для деления и преодоления сложной логики, я выбираю, чтобы поставить логику соединения, которая включает значения в столбцах в предложении FROM, потому что это по существу выражая бизнес-правило, которое поддерживается сопоставлением значений в столбцах.
то есть. Я не буду писать предложение WHERE следующим образом:
WHERE Column1 = Column2Я поставлю это в предложение FROM следующим образом:
ON Column1 = Column2Аналогично, если столбец следует сравнивать с внешними значениями (значениями, которые могут быть или не быть в столбце), например, сравнение почтового индекса с конкретным почтовым индексом, я поставлю это в предложение WHERE, потому что я в основном говорю Мне нужны только такие строки.
то есть. Я не буду писать предложение FROM следующим образом:
ON PostCode = '1234'Я поставлю это в предложение WHERE следующим образом:
WHERE PostCode = '1234'qaru.site
Синтаксис SQL Inner Join Безопасный SQL
два бита SQL ниже получают одинаковый результат
Я видел, как оба стиля используются в качестве стандарта в разных компаниях. Из того, что я видел, второй – это то, что большинство людей рекомендует в Интернете. Есть ли настоящая причина для этого, кроме стиля? Использует ли использование Inner Join иногда лучшую производительность?
Я заметил, что разработчики Ingres и Oracle склонны использовать первый стиль, тогда как пользователи Microsoft SQL Server имеют тенденцию использовать второе, но это может быть просто совпадение.
Спасибо за любую проницательность, я задавался вопросом об этом некоторое время.
Изменить: я изменил название из «SQL Inner Join to Cartesian Product», поскольку использовал неправильную терминологию. Спасибо за все ответы.
Оба запроса являются внутренними объединениями и эквивалентными. Первый – это более старый метод выполнения вещей, тогда как использование синтаксиса JOIN стало обычным явлением после введения стандарта SQL-92 (я считаю, что это в старых определениях, до этого не было особенно широко распространено до этого).
Использование синтаксиса JOIN настоятельно предпочтительнее, поскольку он отделяет логику соединения от логики фильтрации в предложении WHERE. Хотя синтаксис JOIN является действительно синтаксическим сахаром для внутренних объединений, его сила заключается в внешних соединениях, где старый синтаксис может создавать ситуации, когда невозможно однозначно описать объединение, и интерпретация зависит от реализации. [ВЛЕВО | RIGHT] JOIN избегает этих ошибок, и, следовательно, для согласованности использование предложения JOIN является предпочтительным при любых обстоятельствах.
Заметим, что ни один из этих двух примеров не является декартовыми произведениями. Для этого вы
SELECT c.name, o.product FROM customer c, order o WHERE o.value = 150или
SELECT c.name, o.product FROM customer c CROSS JOIN order o WHERE o.value = 150Чтобы ответить на часть вашего вопроса, я думаю, что ранние ошибки в синтаксисе JOIN … ON в Oracle обескуражили пользователей Oracle от этого синтаксиса. Я не думаю, что сейчас есть какие-то особые проблемы.
Они эквивалентны и должны быть проанализированы в одно и то же внутреннее представление для оптимизации.
Фактически эти примеры эквивалентны и не являются декартовым произведением. Декартовой продукт возвращается при объединении двух таблиц без указания условия объединения, например, в
select * from t1,t2В Википедии есть хорошее обсуждение этого вопроса.
Oracle опоздала на поддержку синтаксиса JOIN … ON (ANSI) (только до Oracle 9), поэтому разработчики Oracle часто не используют его.
Лично я предпочитаю использовать синтаксис ANSI, когда логически ясно, что одна таблица ведет запрос, а остальные – таблицы поиска. Когда таблицы «равны», я склонен использовать декартовой синтаксис.
Производительность не должна отличаться.
Синтаксис JOIN … ON … является более поздним дополнением к спецификациям ANSI и ISO для SQL. Синтаксис JOIN … ON … обычно предпочтительнее, поскольку он 1) перемещает критерии соединения из предложения WHERE, делая предложение WHERE только для фильтрации, и 2) делает его более очевидным, если вы создаете страшный декартово произведение, поскольку каждый JOIN должен сопровождаться по крайней мере одним предложением ON. Если все критерии соединения являются только ANDed в предложении WHERE, это не так очевидно, когда один или несколько из них отсутствуют.
Оба запроса выполняют внутреннее соединение, просто различный синтаксис.
sql.fliplinux.com
sql - SQL INNER JOIN над несколькими таблицами, равными синтаксису WHERE
У меня есть два запроса PostgreSQL, которые соединяют несколько таблиц:
Во-первых:
SELECT iradio.id, iradio.name, iradio.url, iradio.bandwidth, genre_trans.name FROM service_iradio_table AS iradio, genre_table AS genre, genre_name_table AS genre_name, genre_name_translation_table AS genre_trans, genre_mapping_table AS genre_mapping, language_code_table AS code WHERE iradio.id=genre_mapping.s_id AND genre_mapping.g_id=genre.id AND genre.id=genre_name.g_id AND genre_name.t_id=genre_trans.id AND genre_trans.code_id=code.id AND iradio.name='MyRadio' AND code.language_iso_code='ger'Во-вторых:
SELECT iradio.id, iradio.name, iradio.url, iradio.bandwidth, genre_trans.name FROM service_iradio_table AS iradio INNER JOIN genre_mapping_table AS genre_mapping ON iradio.id=genre_mapping.s_id INNER JOIN genre_table AS genre ON genre_mapping.g_id=genre.id INNER JOIN genre_name_table AS genre_name ON genre.id=genre_name.g_id INNER JOIN genre_name_translation_table AS genre_trans ON genre_name.t_id=genre_trans.id INNER JOIN language_code_table AS code ON genre_trans.code_id=code.id WHERE iradio.name='MyRadio' AND code.language_iso_code='ger'Итак, исходя из MySQL, я думал, что первый запрос должен быть медленнее второго из-за перекрестной ссылки на каждую таблицу.
Кажется, что в postgreSQL оба запроса являются внутренне одинаковыми. С ключевым словом "EXPLAIN" для двух запросов вывод одинаков.
Вопрос
Действительно ли это, что эти запросы "равны"? На самом деле это дизайн goog, чтобы так соединить таблицы?
В конце также эта попытка настройки производительности работает с тем же выходом с помощью "EXPLAIN":
SELECT iradio.id, iradio.name, iradio.url, iradio.bandwidth, genre_trans.name FROM service_iradio_table AS iradio INNER JOIN genre_mapping_table AS genre_mapping ON iradio.id=genre_mapping.s_id AND iradio.name='MyRadio', genre_table AS genre, genre_name_table AS genre_name, genre_name_translation_table AS genre_trans, language_code_table AS code WHERE genre_mapping.g_id=genre.id AND genre.id=genre_name.g_id AND genre_name.t_id=genre_trans.id AND genre_trans.code_id=code.id AND code.language_iso_code='ger'Все запросы обрабатываются в течение 2 мс.
qaru.site
- Восстановить меню пуск в windows 10
- Sql или

- Как не быть онлайн в вк с компьютера

- Bios flbk что это

- Структура html кода
- Логический диск и основной диск

- Функция сегодня эксель

- Windows 10 быстрее windows 7
- Маршрутизатор как включить

- Json это

- Локальная сеть примеры