Micrsoft SQL Server для 1С. Sql server для чего нужен
Для чего нужен сервер SQL?
Для чего нужен сервер SQL? Прежде всего, для сжатия данных. Подобный сервер позволит вам сэкономить место на диске.
Одна из очевидных причин пользы сервера SQL - экономия затрат. Это может показаться странным, ведь все мы можем купить вместительный жесткий диск менее чем за $ 100. Впрочем, такие винчестеры не помогут вам, если речь идет о системах с высокой производительностью. И потом, вряд ли в обычной практике вы встретите одну копию данных - их, по крайней мере, две. В-третьих, как насчет резервного копирования? Объем информации с течением времени также в разы умножает затраты.
Вторая причина - цена работы с данными. Любое проявление активности по отношению к большой базе данных занимает много времени в плане создания резервной копии, или восстановления информации. Точно так же для осуществления команд DBCC, восстановления индексов и массового импорта/экспорта. Естественно, если мы могли бы уменьшить размер данных, все действия с ними можно было бы реализовать быстрее. И, еще лучше, если эти действия не будут влиять на вашу систему. Любопытный нюанс также состоит в том, что если информация сжимается, ее резервная копия будет также намного меньше.
Третья причина заключается в памяти. Разве мы не хотим располагать существенным объемом памяти на серверах? Что, если вы могли бы сжимать данные на 50%, а потом увеличивать память на 100% (т.е. позволяя вместить двойной размер данных). Разве это не фантастика?
И это еще не все плюсы от серверов SQL - sql сервер для 1с может прекрасно связываться с огромными базами данных. С помощью подобного сервера можно получать ответы на важные вопросы за несколько секунд. SQL применяется для формирования баз данных, а также для безопасного управления ими. Помимо этого - для поиска, обновлений и обмена информацией с клиентами. В практике применения SQL могут быть предусмотрены разные точки зрения структуры и информационной базы для потребностей разных клиентов. SQL также применяется в трехуровневой архитектуре в Сети. Она включает в себя базу данных, клиент, серверную программу.
Кроме того, не один, а сразу несколько пользователей способны получать доступ к базе при одновременном ее использовании.
Известно также, что серверы SQL используются большими и маленькими компаниями - это общепризнанная и распространенная практика. А для корпоративных клиентов - это и вовсе идеальное предложение для базы данных.
inkorr.com
SQL Server для 1С Бухгалтерии
Почему 1C “тормозит” или что такое SQL сервер?
ВведениеДанная статья поможет понять многим из разработчиков и пользователей, нужен ли им SQL-продукт или нет. И для чего собственно он нужен.
Итак, первое, что необходимо знать, понять и запомнить: SQL-системы не ускоряют выполнения выборок и печать отчетов. Если Вы рассчитываете, что после установки 1C-Торговли на SQL, Скорость работы системы врзрастет в разы, Вы глубоко заблуждаетесь. Быстрее она работать не станет. В связи с этим говорить о том, что “…SQL-Торговля - это тормозная система…” абсолютно не имеют смысла.
Теория
Несколько лет назад одно компьютерное издание провело сравнительный анализ (в частности и быстродействия) систем управления базами данных ( сокращенно СУБД), построенных на основе обычных файл серверов и с использованием клиент-серверных (SQL) систем. Естественно, условия испытаний по возможности были нивелированы, т.е. применялись одинаковые объемы баз данных, одинаковые их структуры, один и тот же компьютер в качестве сервера, одинаковое количество рабочих станций и т.д.
Если мне не изменяет память, из клиент-серверных систем были испытаны Oracle, Interbase, Informix, Gupta и самый дешевый в то время Watcom SQL Server. Во всех случаях, средняя скорость выполнения запросов в SQL-системах была ниже, чем у файл-серверной системы (сейчас об этом эффекте можно прочесть в любой серьезной книге по SQL ). Испытатели не были удивлены полученным эффектом, поскольку были людьми грамотными и понимали причину такого поведения SQL-систем при заданных условиях эксперимента. Ведь задачей эксперимента было сравнение быстродействия двух видов систем и поэтому были выбраны условия, позволяющие произвести это сравнение.
В частности для тестов использовались базы данных объемом 1.5 - 2 Гигабайта. Ведь если бы исследователи взялись проводить испытания, используя базы данных на порядок большего размера, то им просто не с чем было бы сравнивать SQL-варианты, поскольку обычная файл-серверная система на таких объемах информации просто заткнулась бы. Вот в этом то и состоит основное отличие и достоинство клиент-серверных систем: они будут работать со вполне приемлемой скоростью с базами данных такого объема, с которыми файл-серверная система работать просто не сможет (”не сможет” в том смысле, что ее функциональность, в том числе и быстродействие, станут неприемлемы для коммерческих приложений).
Сетевой вариант 1С программы, файл-серверная база SQL
Рассмотрим обычный сетевой вариант реализации Торговли 1С. Она работает на файл-серверном принципе, это значит что обработка данных производится вычислительными мощностями данной рабочей станции, а сервер является ничем ином как дисковое устройство с хранящимся на нем файлом базы данных. Объясню, что при выполнении задачи, например формирование отчета, фрагмент базы данных (из которого будут отбираться данные для этого отчета) по сети передается на рабочую станцию (запросившую формирование отчета) и обрабатывается непосредственно процессором этой рабочей станции.
Быстродействие такой системы напрямую зависит от скорости жесткого диска диска сервера, скорости передачи данных по сети (канал локальной сети 10 или 100 мегабит), тактовой частоты процессора рабочей станции, размера кеша данного процессора, объема оперативной памяти, в общем всех "железных" факторов от которых зависит производительность компьютера. Центральный процессор сервера в таком случае, играет уже роль второстепенную и просто обеспечивает передачу потока данных с диска в сетевой канал и обратно. Суть в том что, практически вся база данных перегоняется по сети на рабочую станцию где она и обрабатывается.
Если несколько пользователей запускают одновременно выполняют формирование отчетов, эти компьютеры начинают качать базу к себе через сеть, и сервер не успевает всем одновременно предоставить быструю передачу данных, это и становиться причиной притормаживания работы всей 1с системы в целом. Менее емкие операции, как например ввод нового документа, или просто просмотр ранее созданных документов, то объем передаваемых от сервера данных значительно ниже, хотя в реальности ввод нового документа сопровождается поиском клиента в справочнике, вычислением задолженности клиента и прочее, что также вызывает повышение передаваемого трафика от сервера к клиенту. Следует помнить о необходимости синхронизации доступа рабочих станций к данным.
Поскольку обработка данных ведется на уровне рабочих станций, а файл-сервер просто играет роль разделяемого дискового устройства, задачи синхронизации решаются в таких системах с помощью организации различных файлов блокировок хранящихся на диске файл-сервера, в эти файлы каждая рабочая станция записывает свои логи, информацию о данных, которые она получает, передает и изменяет в данный момент, при попытке считать данные проверяет не заняты ли эти данные другим запросом в данный момент. Несмотря на ряд недостатков, зависающие блокировки при аварийном выключении рабочих станций, возникновение тормозов в работе всей системы при изменении большого количества записей, этот способ вполне работоспособен.
Скорость работы системы файл-серверной базы, напрямую зависит от обрабатываемой базы данных. Заметное снижение скорости работы начинает проявляться, когда размер базы данных достигает 300 - 500 Мб, а за отметкой 1 Гигабайт работать уже практически невозможно. Цифры взяты приблизительные, и зависят от производительности рабочих станций, используемого программного обеспечения и формата базы данных. К примеру, при использовании формата таблиц базы данных Paradox замедление работы наступает значительно позже, чем при использовании формата DBase. Когда эти тормоза уже мешают нормально работать, пользователи системы идут на различные хитрости: закрывают старую базу и открывают новую каждый квартал, пытаются удалить старые данные (почистить базу) и прочее. Однако любой бухгалтер скажет Вам, что данные нужны ему не за квартал, а минимум за год и предпочтительно в динамике, а не в виде отдельных кусков. Ведь долги клиентов иногда тянутся годами.
Временным решением проблемы в такой ситуации может быть увеличение пропускной способности сети за счет установки 1 гигабитной сети вместо 100 мегабитной и интеллектуальных маршрутизаторов вместо тупых хабов. Однако, маршрутизаторы чрезвычайно дороги, а гигабитная сеть даст повышение пропускной способности лишь в 2.5 - 3 раза (а не в 10 раз, как этого бы хотелось). Да смысла увеличивать пропускную способность сети нет, когда жесткий диск сервера работает на пределе своей производительности?
Через пол-года Ваша база данных вырастет еще на 300-500Мб и система опять начнет задыхаться, пустив по ветру все вложенные в модернизацию денежки. Не следует забывать и еще об одной значительной детали. Это регулярное архивирование базы данных. Знаете ли вы, что за время пока будет архивироваться база данных объемом 1 - 1.5 Гб, пообедать, посмотреть кино и поругаться с начальником. А архивация должна производиться ежедневно. При этом во время архивирования базы, ни один из пользователей работать в программе не сможет. Как тут быть? Можно настроить резервирование по расписанию, средствами WIndows, или установить программу, которая будет делать архив по ночам, когда сервер простаивает, и в базе никто не работает. К примеру есть хорошая бесплатная программа архивации Cobian Backup.
Серверный вариант 1С базы (с использованием СУБД)
Теперь рассмотрим принцип работы с базой данных на SQL. Так называемую клиент-серверная систему. Если кто-то жалуется о том, что у него тормозит SQL, спросите какой у него сервер. Если он ответит, что-то вроде: Pentium 4.. то можете смело сказать ему, что он … мало знает о том как надо готовить SQL сервер...
Серверы для SQL-систем должны иметь высокие показатели производительности, и отказоустойчивотси. Pentium Core2Duo 2х ядерный, частотой от 2,5 Гигагерц, 4Гб ОЗУ, RAID массивом минимум из 2х жестких дисков SATA2 - это пожалуй минимум, на котором может НОРМАЛЬНО функционировать программное обеспечение MS SQL Server на 10-15 подключенных клиентов (пользователей базы данных).
При этом, сеть с пропускной способностью 100Мбит даже не обязательна. Дело в том, что при работе с SQL-сервером рабочая станция не качает базу данных к себе по сети. Она просто передает по сети компактный запрос на сервер, который выполняет заданную выборку, и передает результат запроса обратно на рабочую станцию. Таким образом, трафик по сети значительно ниже чем в случае файл-серверной базой.
Конечно, если при разработке клиентской части программного обеспечения будет допущена ошибка и будет сформирован запрос, результатом выполнения которого является вся база данных или большая ее часть, то вся информация будет качаться на рабочую станцию, создавшая такой запрос. Но это уже по большей части лежит на совести разработчиков прикладных задач, это применительно к программам 1С - и на совести тех, кто занимается настройками (и на совести разработчиков из “1С” - в части запрещения оптимизации таких запросов).
Схема работы SQL серверной связки 1С
Теперь рассмотрим, что происходит с сервером в SQL системе. Север сам обрабатывает полученный запрос, и легко представить себе, что если с SQL-системой работают 10 пользователей, то для сервера это практически то же самое, как если бы на нем были одновременно запущены 10 экземпляров программы, с которой работают пользователи (например 10 локальных копий 1С-Торговли). Попробуйте запустить локально на каком-нибудь Pentium 4 десять экземпляров 1C-Торговли и выполнить одновременно 10 отчетов об остатках на складе. Представив это, возможный результат Вы поймете, что всякие разговоры о тормозах SQL-системы без обсуждения параметров сервера не имеют никакого смысла.
SQL-системы очень требовательны к ресурсам процессора, и сервера в целом, то есть нужен очень мощный и многоядерный процессор, достаточно высокий обьем оперативной памяти (по сравнению с другими серверами, или рабочими станциями, где можно отделаться 1-2 гигбайтами). В идеале для таких систем следует использовать компьютеры с RISC процессорами в многопроцессорном варианте (например как в продукции SUN Microsystems). SQL - системы имеют существенное преимущество: даже при использовании сервера стоимостью 4 - 5 тыс. $ будут работать вполне приемлемо, с позволяя добиться хорошей скорости при работе с базами данных такого объема, который обычная файл-серверная система просто перестанут работать.
Причем, на SQL варианте, объем БД может достигать в несколько десятков ГИГАБАЙТ. А скорость доступа к данным останется на прежнем уровне, ведь - они расположены, на диске сервера и не требуют передачи по сети для последующей обработки. Все запросы поступают к серверу, так что кроме обычного файлового кэширования есть огромные возможности по оптимизации выполнения запросов, их распараллеливанию. Все эти эти возможности изначально заложены в программном обеспечении пакета MS SQL Server, фирмой 1С разработан сервер предприятия, который работает в связке с СУБД MS SQL.
Также возможно применение различных ухищрений, например в виде серверов-репликаторов (для разделения групп пользователей на тех, кто пользуется только отчетами, т.е работает в режиме “только чтение”, и тех, кто активно изменяет документы) или разделение баз данных по разным дисковым массивам. При перегрузке дисковой системы она легко модернизируется, например с помощью RAID-массива (не забывайте однако, что SQL-система - это вообще иная ценовая категория как в отношении программного обеспечения, так и по стоимости серверного железа)
Преимущества SQL базы данных для 1С
В первую очередь использование SQL системы снижает нагрузку на локальную сеть. Вообще, SQL-система предоставляет значительные возможности в плане оптимизации аппаратной части и тонкой настройки программной части для увеличения производительности. Поэтому говорить о том что SQL-система тормозит, имеет смысл только тогда, когда эти возможности исчерпаны, а такого в принципе не может быть... О том как рабоатет сервер 1с на СУБД SQL можно проситать в этой статье.
До сих пор мы говорили о принципиальных различиях файл-серверных систем от клиент-серверных. Теперь немного о дополнительных преимуществах клиент-сервера.Надежность SQL варианта баз данных.
Клиент-серверные системы имеют встроенный механизм работы с транзакциями, в том числе и их отката. В файл-серверных версиях программ 1С также имеется механизм работы с транзакциями, однако способ реализации их принципиально отличается. В файл-серверных версиях механизм транзакций представляет собой ни что иное, как просто блокировку всей базы данных до завершения выполнения критических по времени операции, запрошенной одной из рабочих станций. Откат возможен только при сохранении работоспособности рабочей станции, запросившей эту транзакцию.
В клиент-серверной системе этот механизм (который реализуется программным обеспечением SQL-сервера - в нашем случае MS SQL Server 2005) значительно более сложен. Он позволяет получить “слепок” базы данных на момент начала транзакции без блокировки базы данных. И слепков таких может достаточно большое количество: для каждой рабочей станции - он будет свой. И в случае “зависания” рабочей станции, открывшей транзакцию, она (транзакция) может быть просто откачена (т.е. база данных будет восстановлена в том виде, в каком она была до начала инициации транзакции). Откат осуществляется либо по запросу рабочей станции (при сохранении ее работоспособности), либо при перезагрузке рабочей станции, либо администратором SQL сервера.
Таким образом, выход из строя рабочей станции не столь опасен для целостности всей базы данных. Кроме того, SQL-система записывает так называемый журнал транзакций. По сути база данных хранится в виде ее начального содержимого и ее модификаций записанных в журнал транзакций. Такой способ хранения позволяет производить архивирование базы данных во время работы всей системы: просто состояние базы данных фиксируется на момент начала архивирования, отсекаются незавершенные транзакции, а основная база и часть журнала транзакций, содержащая завершенные транзакции записываются в архив. Процесс архивирования легко поддается автоматизации, т.е. присутствие оператора необязательно - SQL-сервер имеет встроенные средства для этого.Защита базы данных
В общем-то защищенность данных в значительной мере зависит от прикладной задачи, 1С Торговли или 1С Бухгалтерии, однако по сравнению с обычным вариантом, в котором любой начинающий хакер спокойно может срубить пароль, в клиент-серверном варианте защита данных опирается на средства, предоставляемые администрированием SQL сервера, что гораздо более надежно.Гибкость применения СУБД
Системы на основе SQL-сервера позволяют выстраивать сложные сетевые конфигурации со многими десятками и даже сотнями пользователей. При этом разработчику предоставляются широкие возможности по оптимизации системы, ее разделению по группам сложности и способам доступа. Серверы-репликаторы, например, дают прекрасный механизм для организации системы учета в крупной организации с разветвленной системой удаленных офисов, складов и т.п. При этом, работа на такой системе может вестись в реальном режиме времени, без перерывов для переноса и синхронизации данных - достаточно лишь организовать постоянные каналы связи 32-128 Кбит, что вполне осуществимо на наших телефонных линиях и не слишком дорого (конечно, в масштабе крупной компании).
Теперь о недостатках. А их у SQL-систем много, крупных и мелких - тех же самых, которые присущи и файл-серверным системам. Однако есть два и весьма существенных.
Главный недостаток наглядно виден из прайса фирмы “1С” - это цена. Цена не только программного обеспечения, но и цена железа на котором оно может достойно функционировать и цена обслуживания. Ну, что же делать - SQL это продукт высоких технологий, но отличное решение для бизнеса, когда торговля, или производство напрямую зависят от всех расчетов бухгалтерии и финансовых операций. А продукт высоких технологий всегда на порядок выше, и эксплуатироваться должен грамотным, обученным персоналом, поэтому даже системный администратор, способный грамотно работать с SQL-системой обойдется дороже, чем аналогичный специалист для обычной файл-серверной системы.
Подведем некоторые итоги
Не ждите, что SQL-система будут работать быстрее. Она позволяет работать в том случае, когда файл-серверный вариант уже не тянет из за возросшего числа пользователей, или обьема базы данных. Однако и обойдется это ускорение Вам не дешево.
Вот, пожалуй, и все, в кратце касаемо различия файловой бызы данных и серверной, на основе SQL. Надеемся, что эта статья помогла Вам понять зачем нужен SQL для 1С, и хоть немного сориентироваться в вопросе, что такое SQL и зачем он нужен.
Теги материала: SQL сервер для 1С,что такое SQL сервер,1С сервер, SQL сервер, 1С медленно работает, 1С тормозит, 1С зависает ,SQL для 1С
www.compline-ufa.ru
Для чего нужен sql server?
Майкрософт SQL Server – это своеобразная система управления в сфере баз данных. Система обеспечивает сетевой многопользовательский доступ и использует язык запросов T-SQL.
Цена SQL server 2008 никого не смутит. Она берет свою историю с тысяча девятьсот восемьдесят девятого года. Самая первая версия – Sybase. В прошлой версии двух тысячи пятого года включили поддержку CLR. Она дала возможность писать процедуры с применением специальных языков, которые поддерживала платформа Net.Популярен Sql Server во многих предприятиях. Кстати, большинство компаний предпочитают использовать версию двух тысячного года. Некоторые DBA говорят, что лучше ее Майкрософт не смогла сделать. Это был намек на Management Studio и на его стоимость. Sql Server 2008 появился в августе 2008 года. Дело в том, что это интеллектуальная, надежная и эффективная платформа по управлению данными. Она готова к работе в требовательных, ответственных бизнес-приложениях, также помогает сократить затраты на обслуживание уже существующих систем, разработку свежих приложений и предоставляет широкие возможности BI для каждого сотрудника вашей компании. Надо давать вашим самым важным бизнес-приложениям защищенную, масштабируемую, надежную платформу. Сделайте процесс разработки специальных приложений для баз данных быстрым, простым. Сократите затраты на инфраструктуре серверов. Откройте возможности бизнес-анализа для подразделений, сотрудников вашей компании. Стоимость Sql Server 2008 доступна. Так как эта система дает возможность клиентам поддерживать, создавать важные среды и обеспечивать дополнительную уверенность, эффективность мгновенно, без какой-либо дополнительной, долгой настройки. Улучшенные, новые инструменты способны обеспечить качественно новый анализ данных, причем на всех уровнях предприятия. Технологии всегда готовы к работе с облачными решениями позволяет клиентам подготовиться к будущему развитию. На сегодняшний день организации становятся максимально динамичными. Это связано с быстро меняющимися условиями ведения бизнеса. Активно проходит процесс децентрализации принятия решений. Стремление максимально повысить продуктивность принятия решений предприятий, организаций обращаются за помощью к технологиям распределенной специальной обработки информации. Данные технологии позволяют размещать таким образом данные, что пользователям не составляет труда отыскать необходимую информацию. Цену SQL Server 2008 можно увидеть в интернете или специализированном магазине.
Дата публикации: 18.06.2013, 15:41
www.epica.com.ru
7 вещей, которые разработчик должен знать о SQL Server / Хабр
Привет. Я бывший разработчик, ставший администратором баз данных, и ниже написал о том, что, в своё время, хотел бы услышать сам.7. Производительность скалярных UDF оставляет желать лучшего
Хорошие разработчики любят повторно использовать код, помещая его в функции и вызывая эти функции из разных мест. Это отлично работает на уровне приложения, но на уровне баз данных может привести к огромным проблемам с производительностью.Посмотрите этот пост о принудительном использовании параллелизма – в частности, список того, что приводит к генерации «однопоточного» плана выполнения запроса. Скорее всего, использование скалярных UDF (прим. переводчика: а для серверов младше 2008 R2 и не только скалярных) приведёт к тому, что ваш запрос будет выполняться в одном потоке (*грустно вздыхает*). Если вы хотите, чтобы ваш код использовался повторно, подумайте о хранимых процедурах и представлениях. (На самом деле, они могут привнести свои проблемы с производительностью, но я просто хочу направить вас на правильный путь как можно быстрее, а UDF, увы, таковым не является).
6. «WITH (NOLOCK)» не означает, что блокировок не будет вообще
На одном из этапов своей карьеры разработчика вы можете начать использовать хинт WITH (NOLOCK) повсеместно, поскольку с ним ваши запросы выполняются быстрее. Это не всегда плохо, но может сопровождаться неожиданными побочными эффектами, про которые Kendra Little рассказывала вот в этом видео. Я же сфокусируюсь только на одном из них.Когда ваш запрос обращается к какой-либо таблице, даже с хинтом NOLOCK, вы накладываете блокировку стабилизации схемы (schema stability lock, Sch-S). Никто не сможет изменить эту таблицу или её индексы до тех пор, пока ваш запрос не завершится. Это не кажется серьёзной проблемой до тех пор, пока вам не понадобится удалить индекс, но вы не сможете этого сделать, поскольку люди постоянно работают с этой таблицей, находясь в полной уверенности, что не создают никаких проблем, поскольку они используют хинт WITH (NOLOCK).
Здесь нет «серебряной пули», но начните читать об уровнях изоляции SQL Server — я полагаю, что уровень изоляции READ COMMITTED SNAPSHOT будет наилучшим выбором для вашего приложения. Вы будете получать целостные данные с меньшим количеством проблем с блокировками.
5. Используйте три строки соединения в своём приложении
Я знаю, что сейчас у вас только один SQL Server, но поверьте мне, оно стоит того. Создайте три строки соединения, которые сейчас будут ссылаться только на один сервер, но потом, когда вы задумаетесь о масштабировании, у вас будет возможность использовать разные сервера «для обслуживания» каждой из этих строк.- Строка соединения для записи и чтения «в реальном времени» — это та строка соединения, которую вы используете сейчас и думаете, что все данные должны приходить именно отсюда. Вы можете оставить весь свой код таким, какой он есть сейчас, но когда будете что-то дописывать, или изменять текущий, подумайте о том, чтобы изменить в запросах строку соединения на одну из представленных ниже.
- Строка соединения для получения «относительно свежих» данных, возрастом 5-15 минут – для данных которые могут быть слегка устаревшими, но всё равно сегодняшними.
- Строка соединения для «вчерашних» данных – для отчётов и построения трендов. Например, в онлайн-магазине, с этой строкой соединения вы можете вытягивать пользовательские обзоры к товарам, а самих пользователей предупреждать, что их обзоры будут опубликованы на следующий день.
4. Используйте промежуточную БД
Вероятно, вы используете БД для выполнения каких-то второстепенных задач – вычисления, сортировка, загрузка и т.д. Если вдруг эти данные пропадут, вы вряд ли сильно расстроитесь, но вот структура таблиц – это, конечно, другое дело. Сейчас вы делаете всё в «основной базе данных» вашего приложения.Создайте отдельную базу данных, назовите её MyAppTemp, и делайте всё в ней! Поставьте ей простую модель восстановления и просто создавайте резервную копию раз в день. Не заморачивайтесь с высокой доступностью или аварийным восстановлением этой БД.
Использование такой техники имеет кучу плюсов. Она минимизирует количество изменений в основной БД, а значит резервные копии журнала транзакций и дифференциальные бэкапы будут делаться быстрее. Если вы используете log shipping, по-настоящему важные данные будут копироваться быстрее. Вы даже можете хранить эту БД отдельно от других баз, например на недорогом, но шустром SSD-диске, оставив основную систему хранения данных для критически важных в продакшене данных.
3. «Вчерашние» статьи и книги могут перестать быть актуальными сегодня.
SQL Server вышел уже больше десяти лет назад и за эти годы в нём произошло множество изменений. К сожалению, старые материалы не всегда обновляются, чтобы описать «сегодняшние» изменения. Даже свежие материалы из проверенных источников могут быть неправильными – вот, например, критика методики Microsoft по повышению производительности SQL Server. Microsoft Certified Master Jonathan Kehayias нашёл множество по-настоящему плохих советов в документе Microsoft.Когда вы слышите что-то, что звучит как хороший совет, я предлагаю вам использовать стратегию, обратную стратегии доктора Фила. Доктор Фил говорит, что вы должны «проникнуться» любой идеей на протяжении 15 минут. Вместо этого, попробуйте возненавидеть её – постарайтесь опровергнуть то, что вы прочитали перед тем как применять это в продакшене. Даже если совет чертовски хорош, он может быть не очень-то и полезным на вашей системе. (Да, это относится и к моим советам).
2. Избегайте использования ORDER BY; сортируйте данные в приложении
На сортировку результатов вашего запроса, SQL Server тратит процессорное время. SQL Server Enterprise Edition стоит порядка 7000$ за одно ядро – не за процессор, а за само ядро. Двухсокетный, шестиядерный сервер обойдётся примерно в 84000$ — и это только цена лицензий, не считая железа. Вы можете купить чертовски много серверов приложений (даже с 256 ГБ оперативки на каждом) за $84k.Как можно быстрее отдавайте полученные результаты запросов своему приложению и там сортируйте. Вероятно, ваш сервер приложений спроектирован таким образом, что сможет распределить нагрузку процессора по разным узлам, в то время как ваш сервер баз данных так не может.
UPD. Я получил множество комментариев о том, что приложение нуждается, например, только в десяти строках, вместо десяти миллионов строк, возвращаемых запросом. Да, конечно, если вы пишете TOP 10, вам нужна сортировка, но как на счёт того, чтобы переписать запрос так, чтобы он не возвращал кучу ненужных данных? Если же данных так много, что серверу приложений приходится тратить слишком много ресурсов на сортировку – так ведь и SQL Server выполняет ту же самую работу. Мы поговорим о том как находить такие запросы на вебинаре, ссылка на который есть в конце поста. Кроме того, помните, что я сказал «Избегайте использования ORDER BY», а не «Никогда не используйте ORDER BY». Я точно так же использую эту инструкцию – но, если я могу избежать этого на очень дорогом уровне баз данных, я стараюсь это сделать. Вот что означает «избегать».
(А это часть, в которой фанаты MySQL и PostgreSQL рассказывают о том как снизить стоимость лицензий, используя СУБД с открытым исходным кодом). (А в этой части вы ждёте, что я им остроумно отвечу, но я не буду этого делать. Если вы разрабатываете новое приложение и задумались о выборе БД, прочтите мой ответ на StackOverflow о том какая БД выдержит наибольшую нагрузку.)
1. У SQL Server есть встроенные инструменты для поиска узких мест, не влияющие на производительность
Динамические административные представления SQL Server (DMV) могут показать вам все места, пагубно влияющие на производительность, т.е.:- какие запросы генерируют наибольшую нагрузку на вашем сервере
- какие индексы просто занимают место и замедляют операции вставки/удаления/обновления
- какие узкие места есть на вашем сервере (CPU, диск, сеть, блокировки и т.д.)?
Примечание переводчика: любые предложения и замечания по переводу и стилистике, как обычно, приветствуются.
habr.com
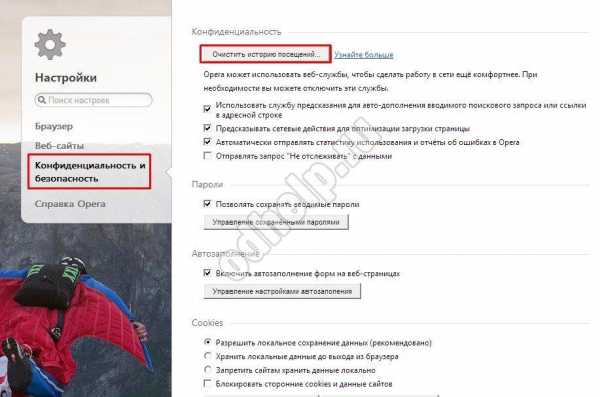
- Как удалить ume браузер
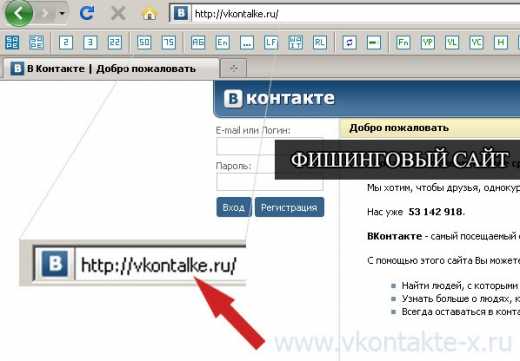
- Создать фишинговый сайт
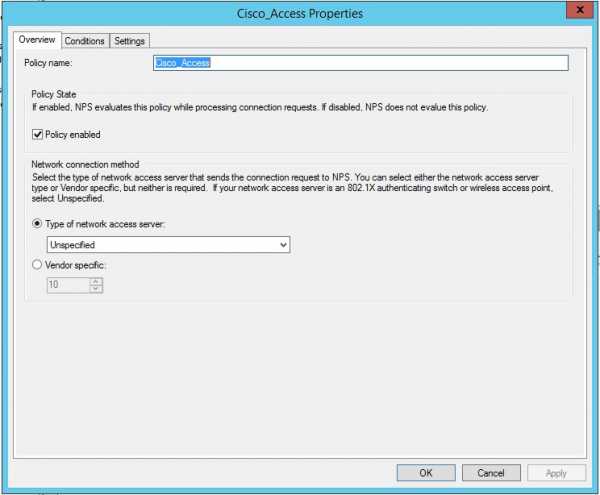
- Настройка radius windows server 2018 r2
- Mint linux установка программ
- Кеш очистка
- Как на рабочем столе отобразить языковую панель

- Не удается найти файл сценария c windows run vbs
- Проверка интернет соединения на стабильность
- Разбиение диска на разделы windows xp
- Сканирование онлайн документов

- Почему картинки не открываются на компьютере