Разработка расширяемого и удобного в сопровождении формата на основе XML. Xml описание
Разработка расширяемого и удобного в сопровождении формата на основе XML
Проектирование XML-формата с учетом возможности будущих изменений позволит в дальнейшем снизить затраты на его расширение
Адриан де Йонг и С. СлэкОпубликовано 28.08.2009
В последние 10 лет XML получил широкое распространение в качестве стандарта для хранения и обмена данными, причем как внутри одной организации, так и между несколькими компаниями. Сам по себе XML является не более чем абстрактным языком, поэтому то, насколько удачным окажется его применение, полностью зависит от конкретного XML-формата, спроектированного в той или иной организации (или группе организаций). Как и в случае с любыми программными продуктами, сопровождение XML-формата может оказаться проблематичным в условиях изменения бизнес-требований. Более того, проблемы заключаются не только в самой необходимости внесения изменений; например, часто возникает ситуация, при которой используемый формат должен синхронно модифицироваться в нескольких компаниях вследствие конкуренции и иных рыночных причин.
Часто встречающиеся аббревиатуры
- NXD: Native XML database (естественная база данных XML)
- XSD: XML Schema Definition (определение XML-схемы)
- XSLT: XML Stylesheet Language Transformation (язык стилей для преобразования XML)
- W3C: World Wide Web Consortium (консорциум WWW)
- XML: Extensible Markup Language (расширяемый язык разметки)
Сопровождение одной XML-схемы, как правило, не представляет особых трудностей. Однако внесение изменений, затрагивающих несколько сотен организаций, может привести к серьезным последствиям. Поэтому даже небольшое редактирование XML-схемы может потребовать огромных временных и финансовых затрат, но если бы формат был изначально спроектирован правильно, то для подобного изменения потребовалось бы просто внимательно взглянуть на пример данных. В статье будут рассматриваться два основных вопроса:
- Внесение изменений в условиях возможных последствий.
- Способы минимизации последствий.
В статье будут приведены упрощенные примеры форматов для представления данных об автомобилях, шинах и ветровых стеклах, а также их производителях и дистрибьюторах. Несмотря на сделанные упрощения, данных примеров вполне достаточно для рассмотрения способов улучшения сопровождаемости XML-форматов.
Пример простого, но проблемного формата XML
XML-схема (XML Schema) – это основанный на XML язык, предназначенный для строгого описания формата XML-документов. Схемы могут использоваться XML-процессорами для автоматической проверки корректности документов. Другими словами, можно установить, удовлетворяет ли данный документ формату, описанному в XML-схеме. Предшественником XML-схемы является язык описания типа документов (Document Type Definition – DTD), который и по сей день используется для проверки HTML-страниц. Одним из отличительных свойств XML-схемы является то, что она сама выражается в XML, т.е. в принципе этот язык можно использовать даже для описания самого себя. Существуют и другие языки для описания XML-схем, например, RELAX NG. Применительно к XML-схемам также часто используется аббревиатура XSD (XML Schema Definition).
Документ XML может считаться корректным (или валидным) только в том случае, если он удовлетворяет заданной XML-схеме.
В качестве первого примера рассмотрим файл XML, содержащий данные об автомобиле Volvo C30 с резиной Michelin (листинг 1). Данный формат был создан для обмена информацией об автомобильных шинах.
Листинг 1. Пример простого формата XML, служащего для обмена данными о шинах
<car> <brand>Volvo</brand> <type>C30</type> <kind>Small family car</kind> <tires> <tire> <brand>Michelin</brand> <type>Winter</type> <count>4</count> </tire> <tire> <brand>Michelin</brand> <type>Spare</type> <count>1</count> </tire> </tires> <windscreen count="1"> <brand>Car glass</brand> </windscreen> </car>Этот документ XML выглядит совсем несложным – с первого взгляда можно и не заметить потенциальных проблем. Однако если копнуть глубже, то их можно выявить в XML-схеме, которая представляет собой длинный документ, обладающий однородной структурой. Обратите внимание, что данный формат включает в себя предельно ограниченное число типов элементов. Только представьте себе, как бы выглядела схема для более реалистичного формата, например, представленного в листинге 2.
Листинг 2. XML-схема, описывающая формат документа из листинга 1
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <xs:element name="car"> <xs:complexType> <xs:complexContent> <xs:extension base="brand"> <xs:sequence> <xs:element ref="type"/> <xs:element ref="kind"/> <xs:element ref="tires"/> <xs:element ref="windscreen"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> </xs:element> <xs:element name="kind" type="xs:string"/> <xs:element name="tires"> <xs:complexType> <xs:sequence> <xs:element maxOccurs="unbounded" ref="tire"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="tire"> <xs:complexType> <xs:complexContent> <xs:extension base="brand"> <xs:sequence> <xs:element ref="type"/> <xs:element ref="count"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> </xs:element> <xs:element name="count" type="xs:integer"/> <xs:element name="windscreen"> <xs:complexType> <xs:complexContent> <xs:extension base="brand"> <xs:attribute name="count" use="required" type="xs:integer"/> </xs:extension> </xs:complexContent> </xs:complexType> </xs:element> <xs:complexType name="brand"> <xs:sequence> <xs:element ref="brand"/> </xs:sequence> </xs:complexType> <xs:element name="brand" type="xs:string"/> <xs:element name="type" type="xs:NCName"/> </xs:schema>В результате подобных незначительных, на первый взгляд, изменений в представлении данных о шинах перейти на новую XML-схему придется компании-производителю ветровых стекол. Кроме того, будет необходимо внести соответствующие изменения в программное обеспечение для корректной работы с новым форматом. Это весьма неприятная ситуация, так как влечет за собой лишнюю работу и затраты для компании. Производителям шин, разумеется, тоже придется обновить схему, а, возможно, и соответствующее ПО в зависимости от того, как оно было спроектировано. Таким образом, несмотря на то, что никто непосредственно не работает с файлами XSD, необходимость их корректирования может легко вылиться в серьезную проблему для большого количества людей.
Быстрое решение: модули
Появления громоздких файлов XSD можно избежать путем введения отдельных пространств имен для представления данных о шинах и ветровых стеклах. Это позволит разделить файл схемы на две части (листинг 3).
Листинг 3. Пример включения пространств имен в документ XML
[...] <tr:tires> <tr:tire count="4"> <tr:brand>Michelin</tr:brand> <tr:type>Winter</tr:type> </tr:tire> <tr:tire count="1"> <tr:brand>Michelin</tr:brand> <tr:type>Spare</tr:type> </tr:tire> </tr:tires> <wnd:windscreen count="1"> <wnd:brand>Car glass</wnd:brand> </wnd:windscreen> [...]Листинг 4. Модифицированный вариант XML-схемы, включающий отдельные модули для шин и ветровых стекол
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" targetNamespace="http://car.org/car" xmlns:tr="http://car.org/tire" xmlns:wnd="http://car.org/windscreen" xmlns:car="http://car.org/car"> <xs:import namespace="http://car.org/tire" schemaLocation="tr.xsd"/> <xs:import namespace="http://car.org/windscreen" schemaLocation="wnd.xsd"/> <xs:element name="car"> <xs:complexType> <xs:sequence> <xs:element ref="car:brand"/> <xs:element ref="car:type"/> <xs:element ref="car:kind"/> <xs:element ref="tr:tires"/> <xs:element ref="wnd:windscreen"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="brand" type="xs:NCName"/> <xs:element name="type" type="xs:NCName"/> <xs:element name="kind" type="xs:string"/> </xs:schema>Остальные преимущества модулей
Модульный принцип построения схем хорош не только тем, что упрощает сопровождение и распределенное использование схем. Благодаря ему появляется возможность повторно использовать отдельные элементы схемы. Например, допустим, что кроме автомобильных шин компания также производит шины для велосипедов. Вполне вероятно, что они захотят использовать тот же XSD-файл для описания данных о велосипедных шинах, что и для автомобильных. Однако компании-покупателю велосипедных шин совершенно необязательно видеть XML-схему, описывающую автомобили, так как большинство элементов в ней, в частности, ветровые стекла, не имеют никакого отношения к велосипедам. Значительно удобнее поддерживать собственную XML-схему, описывающую велосипеды, импортируя в нее XSD, определяющую формат данных о шинах.
В этом случае документы XML будут выглядеть подобно тому, как показано в листинге 5.
Листинг 5. Пример документа XML с информацией о велосипедах, в котором используется тот же формат представления данных о шинах
<bicycle> [...] <tr:tire count="2"> <tr:brand>Gazelle</tr:brand> <tr:type>Race</tr:type> <tr:size>25"</tr:size> </tr:tire> [...] </bicycle>Этот формат похож на XSD для описания автомобилей, в котором импортировался XSD для описания шин, но в данном случае информация относится к велосипедам. В следующем разделе мы вернемся к примеру с автомобилями.
Управление модулями на практике
В конечном счете, центральный XSD-файл автомобилей будет импортировать не только XSD-файлы шин и ветровых стекол, но также файлы схем, относящихся к рулю, креслам, окраске и т.д. В результате становится трудно управлять таким количеством модулей. Для решения данной проблемы можно включить дополнительный файл XSD c именем parts.xsdкоторый будет импортировать все модули, описывающие части автомобилей. Таким образом, любое изменение списка импортируемых схем будет затрагивать только parts.xsd, который был создан специально для управления модулями. При этом центральная схема будет выглядеть как в листинге 6.
Листинг 6. XML-схема, включающая один модуль parts.xsd вместо списка импортируемых документов
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" targetNamespace="http://car.org/car" xmlns:tr="http://car.org/tire" xmlns:wnd="http://car.org/windscreen" xmlns:car="http://car.org/car"> <xs:include schemaLocation="parts.xsd"/> <xs:element name="car"> <xs:complexType> <xs:sequence> <xs:element ref="car:brand"/> <xs:element ref="car:type"/> <xs:element ref="car:kind"/> <xs:element ref="tr:tires"/> <xs:element ref="wnd:windscreen"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="brand" type="xs:NCName"/> <xs:element name="type" type="xs:NCName"/> <xs:element name="kind" type="xs:string"/> </xs:schema>Листинг 7. Файл parts.xsd, содержащий список импортируемых модулей
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" targetNamespace="http://car.org/car" xmlns:tr="http://car.org/tire" xmlns:wnd="http://car.org/windscreen" xmlns:car="http://car.org/car"> <xs:import namespace="http://car.org/tire" schemaLocation="tr.xsd"/> <xs:import namespace="http://car.org/windscreen" schemaLocation="wnd.xsd"/> </xs:schema>Основным преимуществом использования parts.xsd является то, что полный перечень всех импортируемых XSD не приходится копировать во все схемы, в которых требуется описание частей автомобилей. Вместо этого достаточно просто включить parts.xsd.
Рискованные подходы к описанию схем на практике
В реальной схеме, когда число элементов (частей автомобилей) растет, приходится более тщательно относиться к описанию типов. В частности, использование локальных имен атрибутов в XML является практикой рискованной, хотя и весьма распространенной. В листинге 8 приведен фрагмент XML-документа с атрибутами, не принадлежащими явно определенному пространству имен.
Листинг 8. Пример документа XML, содержащего локальные имена атрибутов count
<tr:tires> <tr:tire count="4"> <tr:brand>Michelin</tr:brand> <tr:type>Winter</tr:type> </tr:tire> <tr:tire count="1"> <tr:brand>Michelin</tr:brand> <tr:type>Spare</tr:type> </tr:tire> </tr:tires> <wnd:windscreen count="1"> <wnd:brand>Car glass</wnd:brand> </wnd:windscreen>Использование локальных имен атрибутов может привести к непредсказуемым результатам запросов на выборку элементов. Например, приведенный ниже запрос на языке XPath выбирает все элементы, содержащие атрибут count со значением 1. Однако при этом невозможно предвидеть, к какому пространству имен будут принадлежать результаты:
//[@count = 1]На самом деле, в данном простейшем случае пространства имен предвидеть можно, но смысл в том, что это может стать источником проблем в более сложных ситуациях. Поэтому рекомендуется квалифицировать имена атрибутов, помещая их в определенные пространства имен. В листинге 9 показан слегка видоизмененный фрагмент XML.
Листинг 9. Пример документа XML, атрибуты которого принадлежат своим пространствам имен
[...] <tr:tires> <tr:tire tr:count="4"> <tr:brand>Michelin</tr:brand> <tr:type>Winter</tr:type> </tr:tire> <tr:tire tr:count="1"> <tr:brand>Michelin</tr:brand> <tr:type>Spare</tr:type> </tr:tire> </tr:tires> <wnd:windscreen wnd:count="1"> <wnd:brand>Car glass</wnd:brand> </wnd:windscreen> [...]К счастью, подобная корректировка формата требует лишь незначительных изменений в XML-схеме (листинг 10).
Листинг 10. XML-схема для описания шин, определяющая пространства имен для атрибутов count
[...] <xs:element name="tire"> <xs:complexType> <xs:sequence> <xs:element ref="tr:brand"/> <xs:element ref="tr:type"/> </xs:sequence> <xs:attribute name="count" use="required" form="qualified" type="xs:integer"/> </xs:complexType> </xs:element> [...]Возможно, на данный момент улучшения не бросаются глаза, но тем не менее достаточно заметны. Своевременное предупреждение потенциальных конфликтов представляет собой полезную практику проектирования форматов XML.
Проектирование более общего формата
При использовании реляционных баз данных в качестве хранилища информации возникает соблазн установки однозначного соответствия между таблицами и полями в БД и конструкциями в XML. Это ограничивает не только свободу моделирования, но также распространяет ограничения базы данных на компоненты системы, непосредственно ее не использующие. Документ, приведенный в листинге 1, является характерным примером подобного прямого отображения реляционной модели данных в XML.
Вполне возможно, что на самом деле предпочтительной будет другая структура документа. Например, не исключено, что компоненты автомобиля должны быть перечислены начиная с передней части, чтобы упростить их автоматическую визуализацию. Подобный подход иллюстрируется в листинге 11, причем для отрисовки документ можно преобразовать в масштабируемый графический формат (Scalable Vector Graphics – SVG) при помощи XSLT. Это совсем не так сложно, как может показаться на первый взгляд. Сам документ показан в листинге 11.
Листинг 11. Пример альтернативной структуры XML-документа
<car> <brand>Volvo</brand> <type>C30</type> <kind>Small family car</kind> <tr:tire tr:count="2"> <tr:brand>Michelin</tr:brand> <tr:type>Winter</tr:type> </tr:tire> <wnd:windscreen wnd:count="1"> <wnd:brand>Car glass</wnd:brand> </wnd:windscreen> <tr:tire tr:count="2"> <tr:brand>Michelin</tr:brand> <tr:type>Winter</tr:type> </tr:tire> <tr:tire tr:count="1"> <tr:brand>Michelin</tr:brand> <tr:type>Spare</tr:type> </tr:tire> </car>Соответствующая версия главной XML-схемы показана в листинге 12. Обратите особое внимание на описание типа (complexType) элемента car.
Листинг 12. XML-схема, описывающая альтернативный формат для представления информации об автомобилях
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" targetNamespace="http://car.org/car" xmlns:tr="http://car.org/tire" xmlns:wnd="http://car.org/windscreen" xmlns:car="http://car.org/car"> <xs:import namespace="http://car.org/tire" schemaLocation="tr.xsd"/> <xs:import namespace="http://car.org/windscreen" schemaLocation="wnd.xsd"/> <xs:element name="car"> <xs:complexType> <xs:sequence> <xs:element ref="car:brand"/> <xs:element ref="car:type"/> <xs:element ref="car:kind"/> <xs:choice maxOccurs="unbounded"> <xs:element ref="tr:tire"/> <xs:element ref="wnd:windscreen"/> </xs:choice> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="brand" type="xs:NCName"/> <xs:element name="type" type="xs:NCName"/> <xs:element name="kind" type="xs:string"/> </xs:schema>Сохранение и последующее точное восстановление данного файла из реляционной базы данных может представлять некоторые трудности. Для подобных целей иногда имеет смысл использовать NXD, например Exist DB – простую NXD с открытым кодом, либо IBM DB2 Express-C – также бесплатную реализацию, предоставляющую средства для интеграции с XML и реляционными СУБД. Кроме того, IBM DB2 Express-C поддерживает доступ к данным при помощи SQL или языков запросов, основанных на XML, например, XQuery.
Управление версиями и документирование XML-схем
В ряде случаев несколько организаций могут одновременно использовать несколько версий одной XML-схемы. Это вполне нормально при условии, что каждая организация знает свой номер версии и чем она отличается от предыдущей. Для этого следует использовать аннотации – специальные XSD-элементы, содержащие версию схемы и информацию об остальных элементах. Аннотации могут содержаться в двух элементах: documentation и appinfo.
Имя documentation говорит само за себя. Старайтесь документировать каждый элемент в вашей схеме, и вы не пожалеете о потраченном времени. Элемент appinfo представляет больший интерес, так как на его содержимое не накладывается никаких ограничений. В частности, вы можете определить собственный дочерний элемент version, в котором будут храниться версии других элементов. При этом XML-схема будет выглядеть подобно показанной в листинге 13.
Листинг 13. Пример XML-схемы, содержащей специализированные аннотации
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" targetNamespace="http://car.org/tire" xmlns:tr="http://car.org/tire" xmlns:custom="http://car.org/custom"> <xs:element name="tires"> <xs:annotation> <xs:appinfo> <custom:version>0.91</custom:version> </xs:appinfo> <xs:documentation> Describes a set of tires. </xs:documentation> </xs:annotation> <xs:complexType>Подобные элементы и атрибуты, хранящие информацию о версиях, могут значительно упростить управление схемами, использующимися большой группой организаций, даже несмотря на то, что они непосредственно не поддерживаются ни одним XSD-процессором. Как известно, с XML-схемами, как и с документами XML работают не только компьютеры, но и живые люди, поэтому информация о номере версии никогда не помешает.
Немного о расширениях
Последнее, о чем стоит упомянуть при рассмотрении XML-схем – это элемент extension. В предыдущем разделе был приведен пример расширяемости элемента appinfo, который может иметь произвольное содержимое. Элемент extension позволяет накладывать ограничения на расширение типов. В листинге 14 приведен пример схемы, в которой описывается расширение типа basicTire для включения элемента size.
Листинг 14. XML-схема для описания шин, расширяющая тип basicTire для включения элемента size
<xs:element name="tire" type="tr:sizedTire"/> <xs:complexType name="basicTire"> <xs:sequence> <xs:element ref="tr:brand"/> <xs:element ref="tr:type"/> </xs:sequence> <xs:attribute name="count" use="required" form="qualified" type="xs:integer"/> </xs:complexType> <xs:complexType name="sizedTire"> <xs:complexContent> <xs:extension base="tr:basicTire"> <xs:sequence> <xs:element ref="tr:size"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType>Кроме того, язык XML-схем позволяет при необходимости запрещать расширения определенных элементов, в частности, basicType. Более подробную информацию можно почерпнуть из спецификации XSD, ссылка на которую приведена в разделе Ресурсы. Ознакомившись с ней, вы увидите, что XML-схемы обладают гораздо более широким кругом возможностей, чем можно охватить в одной статье.
Заключение
Как видите, если вы хотите избежать проблем с сопровождением форматов XML в крупных организациях, то следует уделять XML-схемам несколько больше внимания, чем просто техническим деталям, которые генерируются автоматически. Существует гораздо больше способов улучшения сопровождаемости форматов XML, чем было показано в этой статье. В частности, структуры XML можно описывать на других языках, таких как Schematron и RELAX NG. Вне зависимости от того, какой из них вы выберете, всегда следует проектировать формат XML таким образом, чтобы он учитывал интересы всех сторон, участвующих в обмене информацией.
Ресурсы для скачивания
Похожие темы
- Оригинал статьи: Create a maintainable extensible XML format. (EN)
- Узнайте больше об XML-схемах, прочитав статью "Основы использования XML-схемы для описания элементов" (Ашвин Радия, Вибха Дайксит, developerWorks, август 2000 г.). (EN)
- Советы по использованию стандартной библиотеки типов XML-схем можно найти в статье "Сделайте свою жизнь проще со стандартной библиотекой типов XML-схем" (Николас Чейз, developerWorks, июль 2007 г.). (EN)
- Ознакомьтесь со списком наиболее важных стандартов XML на сайте developerWorks. (EN)
- Сертификация по XML корпорации IBM: узнайте, как стать сертифицированным разработчиком IBM в области XML и связанных с ним технологий. (EN)
- Обратитесь к технической библиотеке XML, содержащей множество статей, советов, руководств, стандартов и справочников IBM Redbook. (EN)
- Улучшите свои навыки разработки Web-приложений, посетив раздел Web-архитектуры developerWorks , содержащий множество статей и руководств на тему Web-технологий.
- Загрузите Exist DB – систему управления базами данных с открытым кодом. Exist DB полностью базируется на XML-технологиях, в частности, данные хранятся в соответствии с моделью данных XML. Кроме того, Exist DB предоставляет эффективные методы доступа к данным на основе запросов XQuery, а также поддерживает индексирование. (EN)
- Опробуйте в работе DB2 Express-C 9.5 – надежный, мощный и гибкий сервер баз данных, сочетающий реляционные и основанные на XML принципы хранения данных. (EN)
- Загрузите ознакомительные версии продуктов IBM и опробуйте инструменты разработки приложений, а также связующее программное обеспечение IBM семейств DB2®, Lotus®, Rational®, Tivoli® и WebSphere®. (EN)
- Web-трансляции developerWorks: слушайте интервью и обсуждения, которые могут быть интересны для разработчиков программного обеспечения. (EN)
Подпишите меня на уведомления к комментариям
www.ibm.com
Структура XML-документа
Вы здесь: Главная - XML - XML Основы - Структура XML-документа
В этой статье мы затроним тему структуры XML-документа. Мы с Вами уже говорили о том, зачем нужен язык XML, и вот сегодня мы напишем наш первый XML-документ, а также я подробно объясню его структуру.
Давайте сразу приведу простой пример XML-документа:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE shop [ <!ENTITY n "Ноутбук"> <!ENTITY g "Игра"> ]> <shop> <notebooks> <prod>&n; IBM Lenovo V570</prod> <prod>&n; DELL Inspiron N5010</prod> </notebooks> <games> <prod>&g; Готика 2</prod> <prod>&g; Might & Magic 6</prod> </games> </shop>В самом начале идёт заголовок XML-документа. Заголовок в примере является универсальным, единственное, что кодировка иногда бывает разной. Я поставил наиболее распространённую - UTF-8.
Дальше идёт секция DOCTYPE, в которой описываются различные сущности. Мы описали две: "n" со значением "Ноутбук" и "g" со значением "Игра". Сущность - это, в некотором смысле, константа, которую мы можем использовать в теле XML-документа для сокращения записи и более лёгкой сопровождаемости в дальнейшем.
После секции DOCTYPE идёт тело XML-документа. Здесь всё аналогично синтаксису языка HTML, то есть имеются теги (они же элементы), они имеют атрибуты, а также внутренние теги. Но в отличии от HTML, здесь Вы сами придумываете названия элементов, также в XML очень строгий синтаксис, то есть не должно быть никаких незакрывающих тегов или пропущенных кавычек в значениях атрибутов у тегов.
Обратите внимание на то, как используются описанные нами в секции CDATA сущности. Если требуется вывести какой-нибудь спецсимвол, например, & или <, то необходимо использовать соответствующие зарезервированные сущности.
Что касается взаимосвязи между различными элементами. Есть 5 видов связей:
- Родитель. Родителем для заданного является тот элемент, который находится ровно на 1 уровень выше. Например, для элемента "notebooks" родителем является "shop".
- Дочерний элемент. Противоположность родителю. Дочерним элементом является тот, который находится ровно на 1 уровень ниже и находится внутри заданного элемента. Например, дочерними элементами "shop" являются "notebooks" и "games". Обратите внимание, что родитель всегда один, тогда как дочерних элементом может быть много.
- Предок. Предком является тот элемент для заданного, который находится на более, чем 1 уровень выше. Например, для элемента "prod" предком является "shop".
- Потомок. Аналогично дочернему элементу, но только элементы должны быть ниже 1-го уровня вложенности в заданный элемент. Например, для "shop" потомком является "prod".
- Брат. Элемент называется братом другому элементу, если он находится на том же уровне, что и другой. Безусловно, помимо одного уровня требуется и наличие общего родителя. Например, элементы "notebooks" и "games" являются братьями.
Вот и всё, что мне хотелось бы рассказать Вам о структуре XML-документа. И для закрепления рекомендую Вам сделать простенькую задачку: сделать внутри элемента prod ещё два элемента, один из которых будет содержать название продукта, а другой - его цену. Чтобы проверить правильность XML-документа, откройте его в браузере. Если никаких ошибок не возникло, значит, синтаксически всё написано правильно.
- Создано 08.09.2011 18:14:15
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href="https://myrusakov.ru" target="_blank"><img src="https://myrusakov.ru//images/button.gif" alt="Как создать свой сайт" /></a>
Она выглядит вот так:
-
Текстовая ссылка:<a href="https://myrusakov.ru" target="_blank">Как создать свой сайт</a>
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи): [URL="https://myrusakov.ru"]Как создать свой сайт[/URL]
myrusakov.ru
XML схема
Перед загрузкой любого xml документа встает проблема валидации. В XML есть несколько уровней корректности документа: ненарушение синтаксиса, валидация (документ соответствует своей грамматике). Для этого служит DTD (см. предыдущую статью). Но DTD сегодня считается устаревшим способом проверки. Хоть он и применяется сегодня, но по сути давно уже уступил место другому стандарту — XML схемам.Почему постепенно отказываются от DTD? У него есть ряд недостатков:
- сам по себе dtd не является xml, т.е. у него отличный от xml синтаксис языка.
- Нет проверки типов данных.
- Нельзя поставить документу в соответствие 2 и более DTD описаний (актуально для составных документов).
И в конце 90-х гг. консорциум w3.org начал работу над новым стандартом. И к 2003г. стандарт был готов и назван ‘xml схема’.
XML схема — это способ описания грамматики какого-то документа. На деле схемы оказались гораздо функциональнее, чем просто описание документа. На сегодня схемы могут описывать любые данные (вплоть до баз данных и объектов с классами). Сегодня схемы стали основным способом описания данных в xml.
XML схема описывает:
- Словарь (что и с какими именами у вас есть, если это база данных — описание таблиц и колонок, если это xml документ — описываются названия атрибутов и элементов, если это программирование — как называются классы и свойства).
- Модель содержания (что во что входит, т.е. отношения между элементами и атрибутами и их структура).
- Типы данных — базовые (встроенные) и созданные вами.
Для любой схемы указывается пространство имен:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> //или так <xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="examle.xsd">Содержание статьи
Элементы XML схемы
Разберем устройство схемы на примере:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:annotation> <xsd:documentation> Схема </xsd:documentation> </xsd:annotation> </xsd:schema>Сама схема представляет из себя xml файл.
- Корневой элемент schema и пространство имен.
- Блоки документации — описание схемы.
Можно 1 раз написать схему и использовать ее много раз в различных ситуациях.
Описание элементов схемы
Все элементы схемы описываются с помощью конструкции:
<xs:element name="apple" type="xs:string"/> <xs:element name="price" type="xs:integer"/>Т.е. пишем имя элемента, а затем тип данных — строка, число и т.д. Причем, если один элемент находится внутри другого элемента, то он наследует его тип данных (как в программировании).
Соответствие схемы и документа
Нет жесткой привязки документа и схемы (в отличие от DTD). Привязка документ-схема делается не в документе. Это делает ваша программа, т.е. в документе не надо указывать ссылку на схему.
Привязка схемы к документу происходит по пространству имен. Сама схема определяет пространство имен нашего документа, а не конкретный документ. Если нужно привязаит схему к нескольким документам, то в схеме прописываем пространство имен, соответствующее каждому документу:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.phpmove.ru" xmlns="http://fruit.com" xmlns:apple="http://apple.com" xmlns:orange="http://orange.com">В самом документе упоминания об xml схеме может и не быть. Часто это так и происходит. Но в документе может быть декларативное описание, где рекомендуется посмотреть эту схему (типа подсказки). Но это не значит, что документ будет обязательно оттуда брать эту схему:
<my:fruit xmlns:my="http://www.fruit.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.fruit.com/fruit.xsd">Т.е. мы просто при помощи schemaLocation указываем полный путь к нашей схеме.
В то же время сам документ может не принадлежать ни к какому пространству имен. Тогда используют noNamespaceSchemaLocation (необязательный атрибут). Т.е. в коде ниже указываем, где взять схему без привязки к пространству имен:
<xsi:noNamespaceSchemaLocation="www.phpmove.ru/example.xsd">Атрибут noNamespaceSchemaLocation нужен для валидатора, чтобы он знал, где брать схему.
Типы данных в xml схеме
Все типы данных делятся на простые и сложные типы. Простые:
- int — 1234567.
- integer — 123456.
- short — 1234.
- long — 1234567865432345678.
- decimal — 1,234.
- double — 1,2222.
- float — 1,2222.
- string — строка.
- name — Evgeny.
- Qname — doc:Data (квалификационное имя, например, имя пространства имен).
- AnyURI — какой-то url адрес.
- base64Binary — строка, в которую предполагается загонять бинарные данные после сериализации в base64.
- Date — дата (2012-09-27).
- DateTime — дата и время.
- Time — время (22:42:00.000).
- ID — идентификатор.
1st-network.ru
НОУ ИНТУИТ | Лекция | Введение в XML. Структура XML документа
Аннотация: Показано как расширяются возможности разметки документов на примере языка XML. Представлена структура XML документа и принципы контроля его содержимого.
Введение в XML
В 1986 году, задолго до того, как идея создания сети Веб была воплощена в жизнь, универсальный стандартизированный язык разметки SGML ( Standardized Generalized Markup Language ) был утвержден в качестве международного стандарта ( ISO 8879 ) определения языков разметки, хотя SGML существовал еще с конца шестидесятых. Он использовался для того, чтобы описывать языки разметки, предоставляя при этом автору возможность давать формальные определения каждому элементу и атрибуту языка.
Язык HTML первоначально был всего лишь одним из SGML -приложений. Он описывал правила, по которым должна быть подготовлена информация для World Wide Web. Таким образом, язык HTML - это набор предписаний SGML, сформулированных в виде определения типа документа ( DTD ), объясняющих, что именно обозначают тэги и элементы. Схема DTD для языка HTML хранится в веб-браузере.
К недостаткам языка HTML можно отнести следующие:
- HTML имеет фиксированный набор тэгов. Нельзя создавать свои тэги, понятные другим пользователям.
- HTML - это исключительно технология представления данных. HTML не несет информации о значении содержания, заключенного в тэгах.
- HTML - "плоский" язык. Значимость тэгов в нем не определена, поэтому с его помощью нельзя описать иерархию данных.
- В качестве платформы для приложений используются браузеры. HTML не обладает достаточной мощью для создания веб-приложений на том уровне, к которому в настоящее время стремятся веб-разработчики. Например, на языке HTML невозможно разработать приложение для профессиональной обработки и поиска документов.
- Большие объемы трафика сети. Существующие HTML -документы, используемые как приложения, перегружают Интернет большими объемами трафика в системах клиент-сервер. Примером может служить пересылка по сети большого по объему документа, в то время как необходима только небольшая часть этого документа.
Таким образом, с одной стороны, язык HTML является очень удобным средством разметки документов для использования в веб, а с другой - документ, размеченный в HTML, имеет мало информации о своем содержании. Если тот или иной документ несет достаточно полную информацию о своем содержании, появляется возможность сравнительно легко провести автоматическую обобщенную обработку и поиск в файле, хранящем документ. Язык SGML позволяет сохранять информацию о содержании документа, однако вследствие особой сложности он никогда не использовался так широко, как HTML.
Группа экспертов по языку SGML, возглавляемая Джоном Боузэком ( Jon Bosak ) из компании Sun Microsystems, приступила к работе по созданию подмножества языка SGML, которое могло бы быть принято Web -сообществом. Решено было удалить многие несущественные возможности SGML. Перестроенный таким образом язык назвали XML. Упрощенный вариант оказался значительно более доступным, чем оригинал, его спецификации занимали всего 26 страниц по сравнению с более чем 500 страницами спецификаций SGML.
Рассмотрим более детально структуру и особенности этого языка.
XML (eXtensible Markup Language) - рекомендованный W3C язык разметки. XML - текстовый формат, предназначенный для хранения структурированных данных, для обмена информацией между программами, а также для создания на его основе специализированных языков разметки. XML является упрощённым подмножеством языка SGML.
Язык XML имеет следующие достоинства:
- Это человеко-ориентированный формат документа, он понятен как человеку, так и компьютеру.
- Поддерживает Юникод.
- В формате XML могут быть описаны основные структуры данных - такие как записи, списки и деревья.
- Это самодокументируемый формат, который описывает структуру и имена полей также как и значения полей.
- Имеет строго определённый синтаксис и требования к анализу, что позволяет ему оставаться простым, эффективным и непротиворечивым.
- Широко используется для хранения и обработки документов;
- Это формат, основанный на международных стандартах;
- Иерархическая структура XML подходит для описания практически любых типов документов;
- Представляет собой простой текст, свободный от лицензирования и каких-либо ограничений;
- Не зависит от платформы;
- Является подмножеством SGML, для которого накоплен большой опыт работы и созданы специализированные приложения;
К известным недостаткам языка можно отнести следующие:
- Синтаксис XML избыточен.
- Размер XML документа существенно больше бинарного представления тех же данных (порядка 10 раз).
- Размер XML документа существенно больше, чем документа в альтернативных текстовых форматах передачи данных (например JSON, YAML ) и особенно в форматах данных, оптимизированных для конкретного случая использования.
- Избыточность XML может повлиять на эффективность приложения. Возрастает стоимость хранения, обработки и передачи данных.
- Для большого количества задач не нужна вся мощь синтаксиса XML, и можно использовать значительно более простые и производительные решения.
- Пространства имён XML сложно использовать и их сложно реализовывать в XML парсерах.
- XML не содержит встроенной в язык поддержки типов данных. В нём нет понятий "целых чисел", "строк", "дат", "булевых значений" и т. д.
- Иерархическая модель данных, предлагаемая XML, ограничена по сравнению с реляционной моделью и объектно-ориентированными графами.
Вообще говоря, XML можно рассматривать не только как новый язык разметки, но и как основу для целого семейства технологий:
Таблица 9.1. Структура семейства XML| XML | Технические рекомендации об использовании XML |
| DTD | Определение типа документа (схема) |
| XDR | Формат XML Reduced (схема Microsoft ) |
| XSD | Определение схемы XML (схемы W3C ) |
| Пространство имен | Метод определения имен элементов и атрибутов |
| XPath | Язык путей XML |
| XLink | Язык ссылок XML |
| XPointer | Язык указателей XML |
| DOM | API для объектной модели документа |
| SAX | Простой API для XML |
| XSL | Расширяемый язык таблиц стилей |
| XSL-FO | Объекты форматирования XSL |
| XSLT | Язык преобразований XSL |
| XInclude | Синтаксис XML Include |
| XBase | Синтаксис XML Base URI |
По-сути, XML служит метаязыком для описания структуры других языков. Взаимосвязь между SGML, XML, HTML и некоторыми другими языками показана на следующей диаграмме:
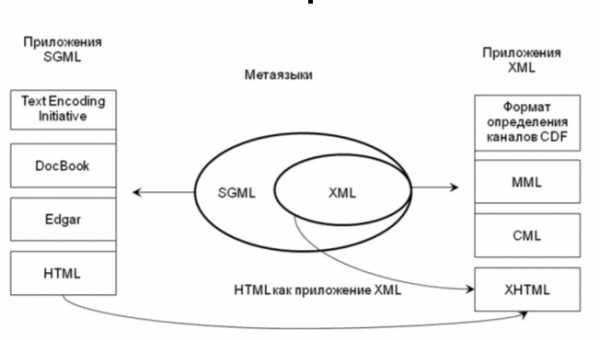 Рис. 9.1. Взаимосвязь между SGML, XML и HTML
Рис. 9.1. Взаимосвязь между SGML, XML и HTML Важным отличием XML от HTML является то большое внимание, которое уделяется контролю за тем, насколько точно соблюдаются правила языка при разметке документов. В зависимости от этого принято выделять правильно построенные и действительные XML документы.
Документ XML считается правильно построенным, если он соответствует всем синтаксическим правилам XML.
Проверка действительности документа предполагает выполнение следующих действий:
- Проверка использования только заданного набора дескрипторов.
- Проверка полного соответствия порядка следования элементов и атрибутов содержанию документа или определенным правилам.
- Контроль типов данных (достигается при использовании соответствующей схемы).
- Контроль целостности данных для обеспечения оптимального обмена информацией через Веб с помощью транзакций.
Рассмотрим теперь основные синтаксические правила построения XML документов.
- XML документ содержит один и только один корневой элемент, содержащий все остальные элементы
- Дочерние элементы, содержащиеся в корневом элементе, должны быть правильно вложены.
- Имена элементов подчиняются правилам:
- Имя начинается с буквы, знака подчеркивания или двоеточия.
- После первого символа в имени могут быть буквы, цифры, знаки переноса, подчеркивания, точка или двоеточие.
- Имена не могут начинаться с буквосочетания XML.
XML документ имеет следующую структуру :
- Первая строка XML документа называется объявлением XML. Это необязательная строка, указывающая версию стандарта XML (обычно это 1.0). Также здесь может быть указана кодировка символов и внешние зависимости.
- Комментарий может быть размещен в любом месте дерева. XML комментарии размещаются внутри пары тегов <!-- и заканчиваются -->. Два знака дефис (--) не могут быть применены ни в какой части внутри комментария.
- Остальная часть этого XML -документа состоит из вложенных элементов, некоторые из которых имеют атрибуты и содержимое.
- Элемент обычно состоит из открывающего и закрывающего тегов, обрамляющих текст и другие элементы.
- Открывающий тег состоит из имени элемента в угловых скобках;
- Закрывающий тег состоит из того же имени в угловых скобках, но перед именем ещё добавляется косая черта.
- Содержимым элемента называется всё, что расположено между открывающим и закрывающим тегами, включая текст и другие (вложенные) элементы.
- Кроме содержания у элемента могут быть атрибуты - пары имя=значение, добавляемые внутрь открывающего тега после названия элемента.
- Значения атрибутов всегда заключаются в кавычки (одинарные или двойные), одно и то же имя атрибута не может встречаться дважды в одном элементе.
- Не рекомендуется использовать разные типы кавычек для значений атрибутов одного тега.
- Для обозначения элемента без содержания, называемого пустым элементом, необходимо применять особую форму записи, состоящую из одного тега, в котором после имени элемента ставится косая черта "/".
К сожалению, описанные выше правила позволяют контролировать только формальную правильность XML документа, но не содержательную. Для решения второй задачи используются так называемые схемы.
Схема четко определяет имя и структуру корневого элемента, включая спецификацию всех его дочерних элементов. Программист может задать, какие элементы и в каком количестве обязательны, а какие - необязательны. Схема также определяет, какие элементы содержат атрибуты, допустимые значения этих атрибутов, в т.ч. значения по умолчанию.
Чаще всего для описания схемы используются следующие спецификации:
- DTD (Document Type Definition) - язык определения типа документов.
- XDR (XML Data Reduced) - диалект XML, разработанный Microsoft.
- XSD (язык определения схем XML) - рекомендована консорциумом W3C.
XML документ отличается от HTML документа также и тем, как он отображается в веб-браузере. Без использования CSS или XSL XML -документ отображается как простой текст в большинстве веб-браузеров. Некоторые веб-браузеры, такие как Internet Explorer и Mozilla Firefox отображают структуру документа в виде дерева, позволяя сворачивать и разворачивать узлы с помощью нажатий клавиши мыши.
Наиболее распространены три способа преобразования XML -документа в отображаемый пользователю вид:
- Применение стилей CSS.
- Применение преобразования XSLT.
- Написание на каком-либо языке программирования обработчика XML -документа.
Языки описания cхем XML
Идея создания собственных тэгов, имеющих специальное значение и помогающих описать содержание документа, сама по себе просто замечательна. Но если каждый пользователь может создавать свои собственные описания, каким образом их распознавать? С этой целью в спецификации XML для описания подобных "самодеятельных" тэгов используются схемы. Они необходимы для того, чтобы:
- описать, что именно является разметкой;
- описать точно, что означает разметка.
Наиболее известными языками описания схем являются следующие:
- DTD (Document Type Definition) - язык определения типа документов, который первоначально использовался в качестве язык описания структуры SGML -документа.
- XDR (XML Data Reduced) - диалект схемы XML, разработанный Microsoft, который поддерживался в Internet Explorer 4 и 5 версий.
- XML Schema или просто XSD (язык определения схем XML ) - рекомендация консорциума W3C с 2001 года.
www.intuit.ru
20. +Языки описания cхем XML
20. Языки описания cхем XML
DTD схемы. Недостатки DTD схем. XDR схемы. Элементы и атрибуты XDR схем.
Идея создания собственных тэгов, имеющих специальное значение и помогающих описать содержание документа, сама по себе просто замечательна. Но если каждый пользователь может создавать свои собственные описания, каким образом их распознавать? С этой целью в спецификации XML для описания подобных "самодеятельных" тэгов используются схемы. Они необходимы для того, чтобы:
описать, что именно является разметкой;
описать точно, что означает разметка.
Наиболее известными языками описания схем являются следующие:
DTD (Document Type Definition) - язык определения типа документов, который первоначально использовался в качестве язык описания структуры SGML-документа.
XDR (XML Data Reduced) – диалект схемы XML, разработанный Microsoft, который поддерживался в Internet Explorer 4 и 5 версий.
XML Schema или просто XSD (язык определения схем XML) – рекомендация консорциума W3C с 2001 года.
Рассмотрим подробнее первые два из них. Третий язык описания схем рассматривается в лабораторной работе 11.
DTD схема
Схема DTD предоставляет шаблон разметки документа, в котором указываются наличие, порядок следования и расположение элементов и их атрибутов в документе XML.
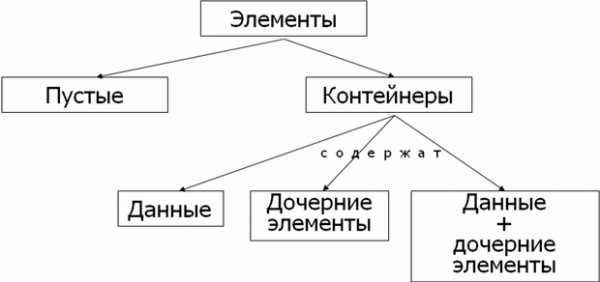
В рамках DTD модель содержимого XML документа можно описать следующим образом:
Каждый элемент документа может иметь один из типов:
| Содержание | Синтаксис | Комментарий |
| Данные | <!ELEMENT имя (#PCDATA)> | Содержит только текстовые данные |
| Другие элементы | <!ELEMENT имя (дочерний элемент 1, дочерний элемент 2)> | Содержит только дочерние элементы |
| Смешанное | <!ELEMENT имя (#PCDATA, дочерний элемент)*> | Содержит комбинацию текстовых данных и дочерних элементов |
| EMPTY | <!ELEMENT имя EMPTY> | Ничего не содержит |
| ANY | <!ELEMENT имя ANY> | Может содержать текстовые данные или дочерние элементы |
Атрибуты, находящиеся внутри тэгов документа, описываются отдельно с помощью синтаксиса:
<!ATTList
имя_элемента имя_атрибута1 (тип) значение_по_умолчанию
…………………………………………………………………………………...
имя_элемента имя_атрибутаN (тип) значение_по_умолчанию >
При этом атрибут в DTD может иметь один из трех типов:
Кроме типа атрибута можно также задавать и его модальность:
| Значение | Описание |
| #REQUIRED | Атрибут обязательно должен быть указан |
| #FIXED | Значение атрибута не должно отличаться от указанного |
| #IMPLIED | Необязательное значение |
Рассмотрим в качестве примера описание атрибутов строкового типа для элемента, описывающего некоторое сообщение:
<!ATTLIST message
number CDATA #REQUIRED
date CDATA #REQUIRED
from CDATA #FIXED
status CDATA #IMPLIED>
Если этот элемент содержит атрибуты с перечислением, то их описание может выглядеть, например, следующим образом:
<!ATTLIST message
number ID #REQUIRED
from CDATA #REQUIRED
alert (low | normal | urgent) "normal">
Маркированных атрибуты элемента могут быть четырех типов:
| Значение | Описание |
| ID | Уникальный идентификатор элемента (начинается с буквы, двоеточия или подчеркивания) |
| IDREF | Ссылка на элемент, содержащий атрибуты ID |
| ENTITIES | Ссылка на внешний элемент |
| NMTOKEN | Содержит буквы, цифры, точки, знаки подчеркивания, переносы, двоеточия, но не пробелы |
И, наконец, в DTD можно использовать следующие индикаторы вхождения последовательностей:
| Символ | Пример | Описание |
| , | (a, b, c) | Последовательное использование элементов списка |
| | | (a | b | c) | Используется один из членов списка |
| date | Используется один и только один элемент | |
| ? | subject? | Необязательное использование (0 или 1 раз) |
| + | paragraph+ | Используется один или несколько раз |
| * | brother* | Используется ноль или несколько раз |
В качестве примера приведем DTD схему, описывающую структуру электронного почтового ящика:
<!ELEMENT mailbox (message*)>
<!ELEMENT message (head, body)>
<!ATTLIST message uid CDATA #REQUIRED>
<!ELEMENT head ( from,to+, subject?, CC*, notify?) >
<!ELEMENT from (#PCDATA)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT subject (#PCDATA)>
<!ELEMENT CC (#PCDATA)>
<!ELEMENT notify EMPTY>
<!ELEMENT body (#PCDATA)>
Исходный XML документ, удовлетворяющий данной схеме, может выглядеть, например, так:
<?xml version="1.0" ?>
<!DOCTYPE mailbox SYSTEM "mailbox.dtd">
<mailbox>
<message uid="1">
<head>
<from>user1@myhp.edu</from>
<to>user2@myhp.edu</to>
<subject>Re:</subject>
</head>
<body>
What's up!
</body>
</message>
<message uid="2">
<head>
<from>user3@myhp.edu</from>
<to>user2@myhp.edu</to>
<subject>Remind</subject>
<CC> user1@myhp.edu </CC>
<notify/>
</head>
<body>
Remind me about meeting.
</body>
</message>
</mailbox>
Обратите внимание на 2-ю строчку документа, в которой указывается внешняя ссылка на файл, содержащий DTD схему.
В принципе, DTD допускает два способа использования в XML документе.
Объявление внутренней схемы:
<!DOCTYPE корневой_элемент [
<!ELEMENT корневой_элемент (модель содержания)>
]>
Объявление внешней схемы:
<!DOCTYPE корневой_элемент SYSTEM "name.DTD">
В заключение укажем на следующие недостатки DTD схем:
Не являются экземплярами XML. Требуется изучение совершенно другого языка.
Не предоставляют контроль за типами данных, за исключением самых простых текстовых данных.
Не являются экземплярами XML, поэтому их нельзя легко расширить или преобразовать к другим языкам разметки – HTML или DHTML.
Не обеспечивают поддержки пространств имен XML.
XDR схема
XML-Data – полное имя языка описания схем, предложенного Майкрософт, а XML-DataReduced– это "часть" полной рекомендации. Схема XDR - это экземпляр XML, т.е. соответствует всем синтаксическим правилам и стандартам XML.
Реализуя проверки данных на уровне документа с помощью схемы, приложения, генерирующие и принимающие транзакции, можно оптимизировать для обеспечения максимального быстродействия. Соответствие полей и правильность записей проверяются на уровне экземпляров XML.
Корневым элементом в схеме XDR всегда является элемент Schema:
<Schema
name="имя_схемы" xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<-- Объявления других элементов -->
</Schema>
Элемент ElementType имеет синтаксис:
<ElementType
content="{empty | texOnly | eltOnly | mixed}">
dt:type "datatype"
model="{open | closed}"
name = "idref"
order="{one | seq | many}"
>
Элемент ElementType может иметь следующие атрибуты:
| Имя атрибута | Описание |
| name | Имя элемента |
| content | Содержание элемента. Допустимые значения: empty (пустой элемент), eltOnly (может быть только контейнером для других элементов), textOnly (только текстовые данные), mixed (смешанные данные). |
| dt:type | Тип данных элемента |
| model | Может принимать значения: |
| Open – разрешено использовать элементы, не определенные в схеме | |
| Closed – запрещено использовать элементы, не определенные в схеме | |
| order | Порядок следования дочерних элементов в экземпляре XML. Допустимые значения: |
| one – предполагается наличие одного документа | |
| many – любое количество элементов в любом порядке | |
| seq – элементы указываются в строго заданном порядке. |
качестве дочерних элементов для ElementType можно использовать следующие:
| Имя элемента | Описание |
| element | Объявляет дочерний элемент |
| description | Обеспечивает описание элемента ElementType |
| datatype | Обеспечивает тип данных элемента ElementType |
| group | Определяет порядок следования элементов |
| AttributeType | Определяет атрибут |
| attribute | Определяет сведения о дочернем элементе AttributeType |
Для объявления атрибутов используется синтаксис:
<AttributeType
default="default-value"
dt:type="primitive-type"
dt:values="enumerated-values"
name="idref"
required="{yes|no}"
>
В свою очередь элемент AttributeType может иметь атрибуты:
| Значение | Описание |
| default | Значение по умолчанию |
| dt:type | Один из следующих типов: |
| entity, entities, enumeration, id, idref, nmtoken, nmtokens, notation, string | |
| dt:values | Допустимые значения |
| name | Имя атрибута |
| required | Указывает на обязательное наличие атрибута в описании |
Синтаксис для описания элемента attribute выглядит следующим образом:
<attribute
default="default-value"
type="attribute-type"
[required="{yes|no}"]
>
а его возможные значения могут быть такими:
| Значение | Комментарий |
| default | Значение по умолчанию |
| type | Имя элемента AttributeType, определенного в данной схеме. Должно соответствовать атрибуту name элемента AttributeType |
| required | Указывает на обязательное наличие атрибута в описании |
В отличие от DTD схем XDR поддерживает типы данных. Элемент Schema имеет следующий атрибут:
Xmlns:dt="urn=schemas-microsoft-com:datatypes"
С полным списком типов данных можно ознакомится на странице по адресу: http://msdn.microsoft.com/en-us/library/ms256121(VS.85).aspx
Индикаторы вхождения в схемах XDR имеют синтаксис:
<element
type="element-type"
[minOccur="{0|1}"]
[maxOccur="{1|*}"]
>
XDR схема позволяет определять группы содержания. Так, в элементе ElementType может содержаться элемент group, имеющий синтаксис:
<group order="(one|seq|many)" minOccur="(0|1)" maxOccur="(1|*)">
<element type="ElementType/">
<element type="ElementType/">
<element type="ElementType/">
<element type="ElementType/">
</group>
В заключение приведем пример XSD схемы, описывающей структуру XML документа, содержащего письма электронной почты:
<?xml version = "1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema">
<xsd:element name="m_box">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="message" minOccurs="0"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="message">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="head" minOccurs="1" maxOccurs="1"/>
<xsd:element ref="body" minOccurs="1" maxOccurs="1"/>
</xsd:sequence>
<xsd:attribute name="uid" use="required" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="head">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="to" minOccurs="1" maxOccurs="unbounded"/>
<xsd:element ref="from" minOccurs="1" maxOccurs="1"/>
<xsd:element ref="date" minOccurs="1" maxOccurs="1"/>
<xsd:element ref="subject" minOccurs="1" maxOccurs="1"/>
<xsd:element ref="cc" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="to" type="xsd:string"/>
<xsd:element name="from" type="xsd:string"/>
<xsd:element name="date" type="xsd:string"/>
<xsd:element name="subject" type="xsd:string"/>
<xsd:elememt name="cc" type="xsd:string"/>
</xsd:schema>
Для проверки действительности XML документа можно использовать специальные валидаторы, например W3C валидатор (http://validator.w3.org/).
Для проверки схем также существуют специальные валидаторы, например XML Schema валидатор (http://www.w3.org/2001/03/webdata/xsv ).
Согласно спецификации W3C XML программа должна прекратить обработку XML документа, как только будет обнаружена ошибка в этом документе.
7
studfiles.net
Описание WEB-сервисов, XML-RPC
Что такое WEB-сервис и с чего начиналось его развитие ? Ещё задолго до появления понятия WEB-сервисов уже существовали технологии взаимодействия удаленных приложений. Согласно этим технологиям одна программа может вызвать какой-либо метод в другой программе, запущенной на удаленном компьютере. Сокращенно это называется удаленный вызов процедур RPC (Remote Procedure Calling). Однако формат обмена данными при классической модели RPC (DCOM, CORBA) бинарный. А следовательно, работать с данными сложнее и он не слишком подходит, если надо организовать работу распределенной системы, где между отдельными участками сети стоят firewall/прокси-серверы. Технология DCOM реализована только для Windows-систем, CORBA же функционирует на разных платформах, но наиболее полноценна ее реализация на J2EE. Недостатком CORBA является то, что она работает через какие-то свои сетевые протоколы вместо простого HTTP, который проходит через firewall. Значит, всегда найдется такая конфигурация сети/платформ, что реализация распределенной системы будет очень затруднительна.
Концепция WEB-сервиса связана с созданием такого RPC, который можно включить в HTTP пакеты. Таким образом началась разработка стандарта, определяющего процесс взаимодействия приложений по протоколу HTTP, чтобы приложения могли функционировать на разных аппаратно-программных платформах и использовать различные технологии и языки разработки. С появлением WEB-сервисов началось развитие сервис-ориентированной архитектуры веб-приложений SOA (Service Oriented Architecture). Наибольшее распространение получили следующие протоколы реализации WEB-сервисов :
| XML-RPC | XML-вызов удалённых процедур |
| SOAP | Simple Object Access Protocol |
| REST | Representational State Transfer |
Практический пример создания клиента WEB-сервиса SOAP с отправкой сообщений и получением ответов представлен здесь.
Приведем очень упрощенный пример. Приложение, обрабатывая данные на локальной машине, вызывает некоторый метод. Если реализация этого метода присутствует в программе, то он (процедура/функция) принимает параметры, выполняет действие и возвращает результирующие данные. Но если этот метод является удаленным вызовом, то необходимо знать, где он будет исполняться. Запрос на выполнение метода вместе с параметрами записывается в виде XML-документа и по протоколу HTTP передается по сети на другой компьютер, где из XML-документа извлекается имя метода и его параметры. После завершения работы метода формируется ответ, который передается компьютеру, пославшему запрос. По этому принципу функционируют все системы, и различия в реализации и процедуре обмена не оказывают существенного влияния на его суть.
Применение XML для описания данных существенно упрощает разработку распределенных приложений, снижаются требования к клиенту и серверу. Программы разбора (парсинга) XML сейчас существуют практически для всех операционных систем и на всех языках программирования.
Протокол WEB-сервиса XML-RPC
Протокол WEB-сервиса XML-RPC, разработанный Дэйвом Винером из компании «UserLand Software» в сотрудничестве с Майкрософт в 1998 году, использует в качестве транспортого механизма протокол HTTP и в качестве формата передаваемых данных XML. Это снимает ограничения, налагаемые как на конфигурацию сети, так и на маршрут следования пакетов. Вызовы XML-RPC представляют собой простой тип данных text/xml и свободно проходят сквозь шлюзы везде, где допускается ретрансляция http-трафика. Однако корпорация Майкрософт вскоре сочла этот протокол слишком упрощённым, и начала расширять его функциональность. После нескольких циклов по расширению функциональности, появилась система, ныне известная как SOAP.
Сообщения XML-RPC передаются методом POST протокола HTTP и бывают трех типов: запрос, ответ и сообщение об ошибке.
Пример запроса, вызов метода CheckWord
POST /RPC2 HTTP/1.0 User-Agent: MyAPP-Word/5.1.2 (WinNT) Host: server.localnet.com Content-Type: text/xml Content-length: 172 <? xml version="1.0"?> <methodCall> <methodName>CheckWord</methodName> <params> <param> <value> <string>Спецификация</string> </value> </param> </params> </methodCall>Сначала определяется стандартный заголовок http-запроса, MIME-тип данных (Content-Type) которых должен быть text/xml. Размер Content-length должен присутствовать обязательно и иметь корректное значение, равное длине передаваемого сообщения.
Корневой узел определяется тегом <methodCall> и не допускает вложенности, а следовательно в запросе можно вызвать только один метод. Тегом <methodName> определяется название вызываемого метода. Формат названия метода предполагает необязательное наименование класса и наименование метода, разделенные точкой. Можно также включить путь и наименование программы. В примере вызывается метод CheckWord некоторого объекта.
В секцию <params> включают передаваемые параметры, которых может быть несколько и которые описываются тегом <param>. Значение параметра включено в тег <value>. В примере методу передается один параметр в виде текстовой строки «Спецификация», заключенное тегом <string>. Согласно спецификации XML все теги должны иметь соответствующие закрывающие элементы. XML-RPC не включает одиночных тегов.
Типы данных
Для передачи методу параметров и получение возвращаемых значений протокол XML-RPC определяет два сложных и семь простых типов данных, которые используются в реальных языках программирования. Сложные типы данных, например, как объекты, нужно заменять структурами или передавать в двоичном виде.
Тип данныхОписаниеПример| array | Массив значенийМассивы описываются секцией <array> и включают один элемент <data>. Значения массива описываются тегом <value>. Элементом массива могут выступать любые типы, а также массивы - что позволяет описывать многомерные массивы. | <array> <data> <value> <string> Текстовая строка </string> </value> <value><i2>1234</i2></value> <value><i1>15</i1></value> </data> </array> |
| struct | Структура данныхСтруктура определяется корневым элементом <struct>, включающего произвольное количество элементов <member>, которые определяют отдельный элемент структуры. Элемент структуры описывается двумя тегами: наименование <name> и значение <value>. | <struct> <member> <name>qty</name> <value><i4>12</i4></value> </member> <member> <name>price</name> <value><i7>23</i7></value> </member> </struct> |
| string | Текстовая строкаASCII-строка символов определяется тегом <string>. В качестве символов нельзя использовать служебные знаки HTML "<" и "&"; их следует передавать кодами < и & соответственно. | <string>XML-RPC</string> |
| integer | Целые числаЦелочисленные значения определяются тегом <i4> или <int> и представляются 4-байтовыми целыми числами со знаком. Отрицательное значение определяется знаком "-". | <i4>123</i4> |
| boolean | Логическое значениеЛогический тип данных определяется тегом <boolean> и может принимать значения 0 (false) или 1 (true). Можно использовать как 1/0, так и true/false соответственно. | <boolean>1</boolean> |
| date/time | Дата и времяЗначение даты и времени определяется тегом <dateTime.iso8601>. | <dateTime.iso8601>19980717T14:08:55</dateTime.iso8601> |
| double | Числа с плавающей точкойВещественные значения задаются тегом <double> и представляют собой числа с плавающей точкой двойной точности. Пробелы недопустимы. | <double>-12.34</double> |
| base64 | Кодированные данныеДвоичные данные передаются в закодированном виде и описываются тегом <base64>. | <base64>eW91IGNhbid0IHJlYWQgdGhpcyE=</base64> |
Пример ответа на вызов метода CheckWord
HTTP/1.1 200 OK Connection: close Content-Length: 166 Content-Type: text/xml Date: Fri, 17 Jul 1998 19:55:08 GMT Server: MyWordCheckSerwer/5.1.2-WinNT <? xml version="1.0"?> <methodResponse> <params> <param> <value> <boolean>true</boolean> </value> </param> </params> </methodResponse>Ответ включает стандартный http заголовок сервера. MIME-тип данных должен быть text/xml, длина Content-Length должна обязательно присутствовать и иметь значение, равное длине передаваемого сообщения.
Корневой узел ответа начинается с тега <methodResponse> и не допускает вложенности. Теги <params> и <param> аналогичны запросу и включают один или более элементов <value>, которые содержат возвращенное методом значение.
Если сервер отвечает HTTP-кодом 200 ОК, то это значит, что запрос успешно обработан. Т.е. данные по сети переданы корректно и сервер сумел их обработать. Но метод может вернуть ошибку, которая не будет связана с протоколом, а будет ошибкой бизнес-логики приложения. В этом случае передается соответствующее сообщение и структура, которая описывает код ошибки. Пример возвращения кода ошибки :
<methodResponse> <fault> <value> <struct> <member> <name>faultCode</name> <value> <int>2</int> </value> </member> <member> <name>faultString</name> <value> <string>Too many рarameters</string> </value> </member> </struct> </value> </fault> </methodResponse>В примере ошибка передается в виде структуры из двух элементов: первый элемент содержит код ошибки 2, а второй элемент описывает ошибку.
java-online.ru
Учебник по XML - Что такое XML
6. ЧТО ТАКОЕ XML
Сегодня XML может использоваться в любых приложениях, которым нужна структурированная информация - от сложных геоинформационных систем, с гигантскими объемами передаваемой информации до обычных "однокомпьютерных" программ, использующих этот язык для описания служебной информации. При внимательном взгляде на окружающий нас информационный мир можно выделить множество задач, связанных с созданием и обработкой структурированной информации, для решения которых может использоваться XML:
- В первую очередь, эта технология может оказаться полезной для разработчиков сложных информационных систем, с большим количеством приложений, связанных потоками информации самой различной структурой. В этом случае XML - документы выполняют роль универсального формата для обмена информацией между отдельными компонентами большой программы.
- XML является базовым стандартом для нового языка описания ресурсов, RDF, позволяющего упростить многие проблемы в Web, связанные с поиском нужной информации, обеспечением контроля за содержимым сетевых ресурсов, создания электронных библиотек и т.д.
- Язык XML позволяет описывать данные произвольного типа и используется для представления специализированной информации, например химических, математических, физических формул, медицинских рецептов, нотных записей, и т.д. Это означает, что XML может служить мощным дополнением к HTML для распространения в Web "нестандартной" информации. Возможно, в самом ближайшем будущем XML полностью заменит собой HTML, по крайней мере, первые попытки интеграции этих двух языков уже делаются (спецификация XHTML).
- XML-документы могут использоваться в качестве промежуточного формата данных в трехзвенных системах. Обычно схема взаимодействия между серверами приложений и баз данных зависит от конкретной СУБД и диалекта SQL, используемого для доступа к данным. Если же результаты запроса будут представлены в некотором универсальном текстовом формате, то звено СУБД, как таковое, станет "прозрачным" для приложения. Кроме того, сегодня на рассмотрение W3C предложена спецификация нового языка запросов к базам данных XQL, который в будущем может стать альтернативой SQL.
- Информация, содержащаяся в XML-документах, может изменяться, передаваться на машину клиента и обновляться по частям. Разрабатываемые спецификации XLink и Xpointer поволят ссылаться на отдельные элементы документа, c учетом их вложенности и значений атрибутов.
- Использование стилевых таблиц (XSL) позволяет обеспечить независимое от конкретного устройства вывода отображение XML- документов.
- XML может использоваться в обычных приложениях для хранения и обработки структурированных данных в едином формате.
Поверхностное описание языка можно найти в статье "Язык XML - практическое введение". Напомню лишь в общих словах, что XML-документ представляет собой обычный текстовый файл, в котором при помощи специальных маркеров создаются элементы данных, последовательность и вложенность которых определяет структуру документа и его содержание. Основным достоинством XML документов является то, что при относительно простом способе создания и обработки (обычный текст может редактироваться любым тестовым процессором и обрабатываться стандартными XML анализаторами), они позволяют создавать структурированную информацию, которую хорошо "понимают" компьютеры.
Как создать XML документ?
Для создания XML документа в простейшем случае вам не понадобится ничего кроме обычного текстового редактора (по мнению многих Web-дизайнеров, лучший инструмент для создания Web-страниц). Вот пример небольшого XML-документа, используемого вместо обычной записной книжки:
<?xml version="1.0" encoding="koi-8"?> <notepad> <note date="12/04/99" time="13:40"> <subject>Важная деловая встреча</subject> <importance/> <text> Надо встретиться с <person>Иваном Ивановичем</person>, предварительно позвонив ему по телефону <tel>123-12-12</tel> </text> </note> ... <note date="12/04/99" time="13:58"> <subject>Позвонить домой</subject> <text> <tel>124-13-13</tel> </text> </note> </notepad>При создании собственного языка разметки вы можете придумывать любые названия элементов, (почти любые, т.к. список допустимых символов ограничен и приведен в спецификации XML), соответствующих контексту их использования. В нашем примере приведен лишь один из многочисленных способ создания структуры дневника. В этом и заключается гибкость и расширяемость XML-производных языков - они создаются разработчиком "на лету", согласно его представлениям о структуре документа, и могут затем использоваться универсальными программами просмотра наравне с любыми другими XML-производными языками, т.к. вся необходимая для синтаксического анализа информация заключена внутри документа.
Создавая новый формат, необходимо учитывать тот факт, что документов, "написанных на XML", не может быть в принципе - в любом случае авторы документа для его разметки используют основанный на стандарте XML (т.н. XML-производный) язык, но не сам XML. Поэтому при сохранении созданного файла можно выбрать для него какое-то подходящее названию расширение (например, noteML).
XML может использоваться вами для создания документов какого-то определенного типа и структурой, необходимой для конкретного приложения. Однако если сфера применения языка оказывается достаточно широкой и он начинает представлять интерес для большого числа разработчиков, то его спецификация вполне может быть представлена на рассмотрение в W3C и после согласования всеми заинтересованными сторонами, утверждена консорциумом в качестве официальной рекомендации.
Надо заметить, что процесс появления новой спецификации очень длителен и сложен. Любой документ, предлагаемый W3C, прежде чем стать стандартом проходит несколько этапов. Сначала пожелания и рекомендации, поступающие от различных компаний, участвующих в его разработке, оформляются в виде принятого к сведению замечания (Note), своеобразного протокола о намерениях. Информация, изложенная в таких документах предназначена только для обсуждения членами консорциума и никто не дает гарантии того, что эти замечания потом станут рекомендацией.
Следующей этапом продвижения документа является рабочий вариант спецификации, который составляет и изменяет в дальнейшем специально созданная рабочая группа (Working Group), в состав которой входят представители заинтересовавшихся идеей компаний. Все изменения, вносимые в этот документ обязательно публикуются на сервере консорциума www.w3.org и до тех пор, пока рабочий вариант не станет рекомендацией, он может служить для разработчиков лишь "путеводной звездой", с которой компания может сверять свои планы, но не должна использовать при разработке ПО.
В том случае, если стороны договорились по всем основным вопросам и существенных изменений в документ больше вносится, рабочий вариант становится Предложенной Рекомендацией и после голосования членами рабочей группы может стать уже Официальной Рекомендаций W3C, что по статусу соответствует стандарту в WWW.
XML-генераторы
XML документы могут служить промежуточным форматом для передачи информации от одного приложения к другому (например, как результат запроса к базе данных), поэтому их содержимое иногда генерируется и обрабатывается программами автоматически. Далеко не всегда XML документ нужно создавать вручную.
Пусть, например, нашей задачей является создание формата хранения данных регистрации каких-то происходящих в системе событий (log-файла). В простейшем случае можно ограничиться фиксированием успешных и ошибочных запросов к нашим ресурсам - в таком документе должна присутствовать информация о времени произошедшего события, его результате (удача/ошибка), IP адресе источника запроса, URI ресурса и коде результата.
Наш XML документ может выглядеть следующим образом:
<?xml version="1.0" encoding="koi-8"?> <log> <event date=" 27/May/1999:02:32:46 " result="success"> <ip-from> 195.151.62.18 </ip-from> <method>GET</method> <url-to> /misc/</url-to> <response>200</response> </event> <event date=" 27/May/1999:02:41:47 " result="success"> <ip-from> 195.209.248.12 </ip-from> <method>GET</method> <url-to> /soft.htm</url-to> <response>200</response> </event> </log>Структура документа довольно проста - корневым в данном случае является элемент log, каждое произошедшее событие фиксируется в элементе event и описывается при помощи его атрибутов(date - время и result - тип события ) и внутренних элементов (method - метод доступа, ip-from - адрес источника, url-to - запрашиваемый ресурс, response - код ответа). Генерацией этого документа может заниматься, например, модуль аутентификации запросов в систему, а использованием - программа обработки регистрационных данных (log viewer).
Что такое DTD?
Итак, мы создали XML документ и убедились, что набор используемых при этом тэгов позволяет осуществлять любые манипуляции с нашей информацией. В таком случае, для того, чтобы утвердить правила нашего нового языка, т.е. список допустимых элементов, их возможное содержимое и атрибуты, мы должны создать DTD - определения (на момент написания статьи спецификация схем данных для XMLдокументов еще не утверждена и пока DTD являются единственным стандартным способом описания грамматики).
Более подробно о DTD можно прочитать в предыдущей статье, посвященной XML, здесь приведеy лишь небольшой пример для нашего XML-документа:
<?xml encoding="koi8-r"?> <!ELEMENT log (event)+> <!ELEMENT event (ip-from,method,uri-to,result)> <!ELEMENT method (#PCDATA)> <!ELEMENT ip-from (#PCDATA)> <!ELEMENT url-to (#PCDATA)> <!ELEMENT response (#PCDATA)> <!ATTLIST event result CDATA #IMPLIED date CDATA #IMPLIED>Сохраните этот файл под именем log.dtd и включите в XML-документ новую строчку:
<!--DOCTYPE log SYSTEM "log.dtd"-->
Теперь верифицирующий XML-анализатор при обработке документа будет сверять порядок определения элементов и их атрибутов с тем, как это указано у нас в DTD-нотациях и в случае нарушения внутренней структуры (которая определяет "семантику" документа) выдавать сообщение об ошибке.
Что такое Namespaces?
Как уже упоминалось ранее, вся прелесть использования XML заключается в возможности придумывания собственных тэгов, названия которых наиболее полно соответствовали бы предназначению. Но фантазия и словарный запас людей не безграничны, поэтому нет абсолютно никакой гарантии того, что данные вами имена элементов не будут использованы кем-то еще. До тех пор, пока в вашем приложении обрабатываются только собственные XML-документы, никаких проблем не возникнет. Но вполне возможна ситуация, когда один и тот же документ будет содержать информацию для нескольких обработчиков одновременно. В этом случае названия некоторых элементов или их атрибутов могут совпасть, что вызовет либо ошибку в XML- анализаторе, либо неправильное представление документа. Например, в нашем случае, элемент event вполне мог бы быть использован для записи других событий и обрабатываться другим приложением.
Чтобы исправить эту ситуацию, мы должны определить уникальные названия элементов и их атрибутов, "дописывая" к их обычным именам некоторый универсальный неповторяющийся префикс. Для этого применяется механизм Namespaces (спецификация Namespaces была официально утверждена W3C в январе 1999 года и сегодня является частью стандарта XML). Согласно этой спецификации, для определения "области действия" тэга ( на самом деле этот термин, широко используемый в обычных языках программирования, неприменим в XML, потому что как такового множества, на котором могла бы быть построена "область", внутри структурированного XML документа нет) необходимо определить уникальный атрибут, описывающий название элемента, по которому анализатор документа сможет определить, к какой группе имен оно относится (Namespace идентификаторы могут применяться для описания уникальных названий как элементов, так и их атрибутов). В нашем последнем примере это может быть сделано так:
<?xml version="1.0" encoding="koi8-r"?>
<!--DOCTYPE log SYSTEM "log.dtd"-->
<log xmlns:xlg="www.mrcpk.nstu.ru/xml/ar/4/">
<xlg:event xlg:date=" 27/May/1999:02:32:46 " xlg:result="success">
<ip-from> 195.151.62.18 </ip-from>
<method>GET</method>
<url-to> /misc/</url-to>
<response>200</response>
</event>
<xlg:event date=" 27/May/1999:02:41:47 " result="success">
<ip-from> 195.209.248.12 </ip-from>
<method>GET</method>
<url-to> /soft.htm</url-to>
<response>200</response>
</event>
</log>
Уникальность атрибуту имени обеспечивает использование в качестве его значения некоторых универсальных идентификаторов ресурсов (например, URI или ISBN) .
Полную информацию по использованию Namespace вы можете найти в официальной спецификации этого стандарта. В дальнейшем, для упрощения примеров, мы будем Namespace - описания пропускать.
Инструментарий
Очевидно, что ручной способ создания структурированной информации не может применяться для наполнения больших информационных узлов. Для этого существуют специальные средства разработки, список которых сегодня постоянно пополняется (их обзор будет приведен в одной из следующих статей). Одним их самых простых и удобных, на мой взгляд, является редактор XML Notepad, получить который можно здесь -msdn.microsoft.com/xml/notepad/intro.asp).
Обработка XML-документов
Основным сдерживающим фактором в продвижении XML технологии в Web на сегодняшний день является отсутствие полной поддержки этого формата всеми производителями броузеров - программ, наиболее часто используемых на стороне клиента. Выходом из создавшейся ситуации может стать вариант, при котором обработкой XML документов занимается серверная сторона Используя любой существующий XML-анализатор, можно формировать необходимую информацию уже на сервере и посылать клиенту нормальный HTML-документ. Однако такой способ, конечно, менее гибок, и позволяет использовать XML технологию лишь для хранения структурированной информации, но не для ее динамического изменения на стороне клиента.
В августе 1997 RFC 2376 были утверждены MIME типы для XML-ресурсов: text/xml и application/xml. Поэтому XML документы могут передаваться по HTTP и отображаться программой просмотра также, как и обычные HTML- страницы. Для этого нужно немного изменить конфигурацию Web-сервера (в Apache - добавить в файл mime.types строчку "text/xml xml ddt"), а на стороне клиента иметь броузер, поддерживающий стилевые таблицы или JavaScript. Сегодня такими броузерами являются Microsoft Internet Explorer 5, первый броузер, поддерживающий спецификацию XML 1.0 и стилевые таблицы XSL; броузер Amaya, предлагаемый консорциумом специально для тестовых целей (http://www.sinor.ru/www.w3.org/Amaya/User/BinDist.html) и поддерживающий практически все разрабатываемые стандарты W3C. Поддержка XML также планируется в будущих версиях Netscape Navigator.
Объектная модель документа DOM
Одним из самых мощных интерфейсов доступа к содержимому XML документов является Document Object Model - DOM.
Объектная модель XML документов является представлением его внутренней структуры в виде совокупности определенных объектов. Для удобства эти объекты организуются в некоторую древообразную структуру данных - каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое, в виде набора вложенных элементов, комментариев, секций CDATA и т.д. представляется в этой структуре поддеревьями. Т.к. в любом правильно составленном XML-документе обязательно определен главный элемент, то все содержимое можно рассматривать как поддеревья этого основного элемента, называемого в таком случае корнем дерева документа. Для следующего фрагмента XML документа:
<tree-node> <node-level1> <node-level2/> <node-level2>text</node-level2> <node-level2/> </node-level1> <node-level1> <node-level2>text</node-level2> <node-level1> <node-level2/> <node-level2><node-level3/></node-level2> </node-level1> </tree-node>дерево элементов выглядит так:
Рис.1Дерево элементов
Объектное представление структуры документа не является чем-то новым для разработчиков. Для доступа к содержимому HTML страницы в сценариях давно используется объектно-ориентированный подход, - доступные для Java Script или VBScript элементы HTML документа могли создаваться, модифицироваться и просматриваться при помощи соответствующих объектов. Но их список и набор методов постоянно изменяется и зависит от типа броузера и версии языка. Для того, чтобы обеспечить независимый от конкретного языка программирования и типа документа интерфейс доступа к содержимому структурированного документа в рамках W3 консорциума была разработана и официально утверждена спецификация объектной модели DOM Level 1.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов и является просто своеобразным API для их обработчиков. DOM является стандартным способом построения объектной модели любого HTML или XML документа, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать его элементы.
Для описания интерфейсов доступа к содержимому XML документов в спецификации DOM применяется платформонезависимый язык IDL и для использования их необходимо "перевести" на какой-то конкретный язык программирования. Однако этим занимаются создатели самих анализаторов, нам можно ничего не знать о способе реализации интерфейсов - с точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами. В следующем разделе мы вкратце рассмотрим объектную модель Microsoft Internet Explorer 5, доступную из Java Script и VBScript сценариев.
Содержание
hotwebpro.narod.ru
- Что значит очистка свободного места в ccleaner

- Что делать если ноутбук включается долго

- Kubuntu системные требования
- 0X0000185 windows 7
- Как ксерокопировать на принтере canon

- Интернет скорость передачи

- Локальная сеть что значит

- Гугл хром тормозит
- Макросы в экселе
- Нужен ли интернет

- Сравнение версии windows server 2018