Исправление ошибок сканирования в ABBYY Finereader. Как пользоваться файн ридером
Как это работает: FineReader
Хотя авансы, выданные искусственному интеллекту (ИИ) за последние 50 лет, ни на йоту не приблизили «умные» машины к когнитивным возможностям человека, полностью отрицать успехи в данном направлении было бы несправедливо. Наиболее очевидный и яркий пример — шахматы (не говоря уже о более простых играх). Компьютер пока не может имитировать наше мышление, но он вполне способен компенсировать данный пробел большим объемом специализированной памяти и скоростью перебора. Владимир Крамник охарактеризовал игру победившей его в 2006 г. программы Deep Fritz как «нечеловеческую» в том смысле, что она зачастую противоречила устоявшимся (человеческим) правилам стратегии и тактики.
А чуть более года назад очередное детище IBM, в свое время положившей начало триумфальным шахматным победам компьютеров (знаменитый Deep Blue), под названием Watson совершило новый прорыв, с большим отрывом победив сразу двух чемпионов популярной американской викторины Jeopardy. Показательно, однако, что хотя Watson самостоятельно озвучивал ответы, вопросы ему все же передавались в текстовом виде. Это говорит о том, что успехи во многих сферах приложения ИИ — распознавании речи и образов, машинном переводе — достаточно скромны, хотя это и не мешает нам уже сегодня применять их на практике. Наибольшие же успехи, пожалуй, демонстрируют системы оптического распознавания символов (OCR, Optical Character Recognition), с которыми наверняка так или иначе знакомы почти все пользователи ПК. Тем более, что российские разработки в данной области занимают достойное место в мире — я имею в виду ABBYY FineReader.
Немного истории
Текущая версия ABBYY FineReader имеет номер 11, т. е. приложение прошло достаточно долгий путь развития, и даже история этого процесса представляет определенный интерес. Не претендуя на исчерпывающую летопись, приведу лишь основные вехи за последнее десятилетие, в течение которого я более-менее следил за FineReader:
| Год | Версия | Главные особенности |
| 2003 | 7.0 | Прирост точности распознавания до 25%. Больше всего это отразилось на таблицах, особенно сложных, с окрашенными ячейками, скрытыми разделителями и пр. |
| 2005 | 8.0 | Дальнейшая оптимизация алгоритмов распознавания, в первую очередь направленная на работу не со сканами документов, а с цифровыми фотографиями. Для этого появились дополнительные функции подготовки оригиналов (устранение искажений, выравнивание строк и пр.). |
| 2007 | 9.0 | Появление технологии ADRT, которая учитывает логическую структуру всего обрабатываемого (многостраничного) документа и умеет выделять повторяющиеся элементы (колонтитулы), соединять «перетекающие» объекты (таблицы) и пр. |
| 2009 | 10.0 | Дальнейшее совершенствование ADRT и алгоритмов распознавания, повышение точности обработки оригиналов с низким разрешением до 30%. |
| 2011 | 11.0 | Основное внимание уделено скорости работы программы. «Второе пришествие» черно-белого режима, который на оригиналах хорошего качества дает дополнительное ускорение до 30%. |
Естественно, за это же время в FineReader расширялась поддержка форматов документов, совершенствовались встроенные инструменты и интерфейс, улучшалось воссоздание структуры оригиналов и т. п. Однако выделенные моменты непосредственно связаны с технологиями OCR и неплохо демонстрируют скачкообразный процесс развития, характерный для сложных наукоемких систем, когда после очередного «прорыва» следует некоторый период «затишья», необходимый для совершенствования новых алгоритмов. Они-то и представляют главную ценность любой OCR-программы, и поэтому сколько-нибудь подробная информация о них крайне редко доходит до пользователей. Однако компания ABBYY любезно согласилась приоткрыть завесу тайны, и сегодня мы имеем возможность заглянуть в святая святых FineReader.
Базовые принципы
Итак, поскольку OCR относится к области ИИ, вполне логично, что разработчики стремятся хоть в какой-то степени имитировать деятельность нашего мозга. Конечно, устройство нашей зрительной системы невероятно сложно, но базовые «крупноблочные» принципы ее функционирования достаточно изучены, обычно их выделяют три:
- Целостность (integrity) — объект рассматривается как совокупность своих частей и (для зрительных образов) пространственных отношений между ними. В свою очередь и части получают толкования только в составе всего объекта. Этот принцип помогает строить и уточнять гипотезы, быстро отсекая маловероятные.
- Целенаправленность (purposefulness) — поскольку любая интерпретация данных преследует определенную цель, то и распознавание представляет собой процесс выдвижения гипотез об объекте и целенаправленной их проверки. Система, действующая в соответствии с этим принципом, будет не только экономнее расходовать вычислительные мощности, но и реже ошибаться.
- Адаптивность (adaptability) — система сохраняет накопленную в процессе работы информацию и использует ее повторно, т. е. самообучается. Этот принцип позволяет создавать и накапливать новые знания и избегать повторного решения одних и тех же задач.
FineReader — единственная в мире OCR-система, которая действует в соответствии с вышеописанными принципами на всех этапах обработки документа. Соответствующая технология носит название IPA — по первым буквам английских терминов. К примеру, согласно принципу целостности, фрагмент изображения будет интерпретироваться как символ, только если в нем присутствуют все структурные части подобных объектов, причем находящиеся в определенных взаимоотношениях. Это помогает заменить перебор большого числа эталонов (в поисках более-менее подходящего) целенаправленной проверкой разумного количества гипотез, причем опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Однако принципы IPA применяются при анализе не только фрагментов, соответствующих (предположительно) отдельным символам, но и всего исходного изображения страницы. Большинство OCR-систем основываются на распознавании иерархической структуры документа, т. е. страница разбивается на основные структурные элементы, такие как таблицы, изображения, блоки текста, которые, в свою очередь, разделяются на другие характерные объекты — ячейки, абзацы — и так далее, вплоть до отдельных символов.
Такой анализ может проводиться двумя основными способами: сверху-вниз, т. е. от составных элементов к отдельным символам, или, наоборот, снизу-вверх. Чаще всего применяется один из них, но в ABBYY разработали специальный алгоритм MDA (multilevel document analysis, многоуровневый анализ документа), который сочетает оба. Вкратце он выглядит следующим образом: структура страницы анализируется методом сверху-вниз, а воссоздание электронного документа по окончании распознавания происходит снизу-вверх, однако на всех уровнях дополнительно действует механизм обратной связи. В результате резко снижается вероятность грубых ошибок, связанных с неверным распознаванием высокоуровневых объектов.
ADRT
Исторически OCR-системы развивались от распознавания отдельных символов. Эта задача и до сих пор является важнейшей и самой трудной, именно с ней связаны наиболее сложные алгоритмы. Однако вскоре стало понятно, что в ее решении может помочь более высокоуровневая информация (к примеру, о языке документа и правильности написания распознанных слов) — так появились контекстная и словарная проверки. Затем стремление сохранять форматирование и воссоздавать физическую структуру (т. е. взаимное расположение различных объектов) документа привело к необходимости подробного анализа целой страницы. Понятно, что это также заметно влияет на общее качество распознавания, поскольку помогает корректно обрабатывать многоколоночную верстку, таблицы и другие приемы «нелинейного» расположения текста.
Большинство современных OCR действуют именно на этих трех уровнях — символов, слов, страниц, — практикуя, как уже было сказано, подходы сверху-вниз или снизу-вверх. Однако ABBYY, в соответствии с принципами IPA, ввела в FineReader еще один уровень — всего многостраничного документа. Прежде всего это понадобилось для корректного воспроизведения логической структуры, которая в современных документах становится все сложнее. Но есть и дополнительные бонусы: повышение точности и ускорение обработки повторяющихся объектов, более корректная идентификация (а значит, и распознавание) «перетекающих» со страницы на страницу объектов.
Именно для этого и была разработана ADRT (Adaptive Document Recognition Technology) — технология анализа и синтеза документа на логическом уровне. В конечном итоге она помогает сделать результат работы FineReader максимально похожим на оригинал. Для этого анализируется изображение всего документа, а распознанные слова объединяются в группы (кластеры) в зависимости от начертания, окружения и местоположения на странице. Таким образом программа как бы видит «логику» разметки документа и в дальнейшем может унифицировать оформление результата.
Благодаря ADRT, FineReader, начиная с версии 9.0, научился обнаруживать, распознавать и воспроизводить следующие структурные части и элементы форматирования документа:
- основной текст;
- верхние и нижние колонтитулы;
- номера страниц;
- заголовки одного уровня;
- оглавление;
- текстовые вставки;
- подписи к рисункам;
- таблицы;
- сноски;
- зоны подписи/печати;
- шрифты и стили.
Процесс распознавания
В соответствии с алгоритмом MDA, собственно распознавание начинается сверху-вниз, с уровня страницы. Понятно, что чем больше неверных решений будет сделано на ранних этапах этого процесса, тем больше будет на следующих. Именно поэтому точность распознавания так сильно зависит от качества оригиналов, но и алгоритмы их предварительной обработки могут иметь существенное значение. Так, по мере роста популярности цветных документов в FineReader появилась процедура адаптивной бинаризации (adaptive binarization, AB). Если отсканировать сразу в черно-белом режиме документ, где присутствуют водяные знаки либо текст расположен на текстурной или цветной подложке, то на изображении неизменно появится «мусор», который затем будет довольно сложно отделить от «полезного» изображения (т. к. исходная информация о нем уже потеряна). Именно поэтому FineReader предпочитает работать с цветными или полутоновыми изображениями, самостоятельно преобразуя их в черно-белые (этот процесс и называется бинаризацией). Но и это не всё. Поскольку цвета текста и фона могут различаться в пределах страницы и даже отдельных строк, AB выделяет слова с более-менее одинаковыми характеристиками и подбирает для каждого оптимальные с точки зрения качества распознавания параметры бинаризации. Именно в этом и состоит адаптивность алгоритма, который, таким образом, является примером использования обратной связи в MDA. Понятно, что эффективность AB сильно зависит от оформления исходных документов — на тестовой базе ABBYY этот алгоритм обеспечил повышение точности распознавания на 14,5%.
Но наиболее интересное, конечно, начинается, когда процесс распознавания опускается на самые нижние уровни. Так называемая процедура линейного деления разбивает строки на слова, а слова на отдельные буквы; далее, в соответствии с принципом IPA, формирует набор гипотез (т. е. возможных вариантов того, что́ это за символ, на какие символы разбито слово и т. д.) и, снабдив каждую оценкой вероятности, передает на вход механизма распознавания символов. Последний состоит из ряда так называемых классификаторов, каждый из которых также формирует ряд гипотез, ранжированных по предполагаемой степени вероятности. Важнейшей характеристикой любого классификатора является среднее положение правильной гипотезы. Понятно, что чем выше она находится, тем меньше работы для последующих алгоритмов — к примеру, словарной проверки. Но для достаточно отлаженных классификаторов чаще всего оценивают такие характеристики, как точность распознавания по первым трем гипотезам или только по первой — т. е., грубо говоря, способность угадать верный ответ с трех или с одной попытки. ABBYY в своих системах применяет следующие типы классификаторов: растровый, признаковый, признаковый дифференциальный, контурный, структурный и структурный дифференциальный — которые сгруппированы на двух логических уровнях.
Принцип действия РК, или растрового классификатора, основан на попиксельном сравнении изображения символа с эталонами. Последние формируются в результате усреднения изображений из обучающей выборки и приводятся к некой стандартной форме; соответственно, для распознаваемого изображения также предварительно нормализуются размер, толщина элементов, наклон. Этот классификатор отличается простотой реализации, скоростью работы и устойчивостью к дефектам изображений, но обеспечивает сравнительно низкую точность и именно поэтому используется на первом этапе — для быстрого порождения списка гипотез.
Признаковый классификатор (ПК), как и следует из его названия, основывается на наличии в изображении признаков того или иного символа. Если всего таких признаков N, то каждую гипотезу можно представить точкой в N-мерном пространстве; соответственно, точность гипотезы будет оцениваться расстоянием от нее до точки, соответствующей эталону (который также нарабатывается на обучающей выборке). Понятно, что типы и количество признаков в значительной степени определяют качество распознавания, поэтому обычно их достаточно много. Этот классификатор также сравнительно быстр и прост, но не слишком устойчив к различным дефектам изображения. Кроме того, ПК оперирует не исходным изображением, а некой моделью, абстракцией, т. е. не учитывает часть информации: скажем, сам факт наличия каких-то важных элементов ничего не говорит об их взаимном расположении. По этой причине ПК используется не вместо, а вместе с РК.
Контурный классификатор (КК) представляет собой частный случай ПК и отличается тем, что анализирует контуры предполагаемого символа, выделенные из исходного изображения. В общем случае его точность ниже, чем у полновесного ПК.
Признаковый дифференциальный классификатор (ПДК) также похож на ПК, однако используется исключительно для различения похожих друг на друга объектов, таких как «m» и «rn». Соответственно, он анализирует только те области, где скрываются отличия, а на вход ему подаются не только исходные изображения, но и гипотезы, сформированные на ранних стадиях распознавания. Принцип его работы, однако, несколько отличается от ПК. На этапе обучения в N-мерном пространстве формируются два «облака» (групп точек) возможных значений для каждого из двух вариантов, затем строится гиперплоскость, отделяющая «облака» друг от друга и примерно равноудаленная от них. Результат распознавания зависит от того, в какое полупространство попадает точка, соответствующая исходному изображению.
Сам по себе ПДК не выдвигает гипотез, а лишь уточняет имеющиеся (список которых в общем случае сортируется пузырьковым методом), так что прямая оценка его эффективности не проводится, а косвенно ее приравнивают к характеристикам всего первого уровня OCR-распознавания. Однако понятно, что она зависит от корректности подобранных признаков и представительности выборки эталонов, обеспечение чего является достаточно трудоемкой задачей.
Структурно-дифференциальный классификатор (СДК) первоначально применялся для обработки рукописных текстов. Его задача состоит в различении таких похожих объектов, как «C» и «G». Таким образом, СДК основывается на признаках, характерных для каждой пары символов, процесс его обучения еще сложнее, чем у ПДК, а скорость работы ниже, чем у всех предыдущих классификаторов.
Структурный классификатор (СК) является предметом гордости компании ABBYY, первоначально он был разработан для распознавания так называемого рукопечатного текста, т. е. когда человек пишет «печатными» буквами, но впоследствии был применен и для печатного. Он используется на завершающих этапах распознавания и вступает в действие достаточно редко, а именно, только в том случае, когда до него доходят как минимум две гипотезы с достаточно высокими вероятностями.
Качественные характеристики всех классификаторов собраны в следующую таблицу. Они, впрочем, позволяют лишь оценить эффективность алгоритмов друг относительно друга, т. к. не являются абсолютными, а получены на основе обработки конкретной тестовой выборки. Может создаться впечатление, что на последних этапах распознавания борьба идет буквально за доли процента, но на самом деле каждый классификатор вносит существенную лепту в повышение точности распознавания — так, к примеру, СК снижает количество ошибок на ощутимые 20%.
| РК | ПК | КК | ПДК* | СДК** | СК** | |
| Точность по первым трем вариантам, % | 99,29 | 99,81 | 99,30 | 99,87 | 99,88 | — |
| Точность по первому варианту, % | 97,57 | 99,13 | 95,10 | 99,26 | 99,69 | 99,73 |
* оценка всего первого уровня OCR-алгоритма ABBYY** оценка для всего алгоритма после добавления соответствующего классификатора
Любопытно, однако, что, несмотря на довольно высокую точность, алгоритм собственно распознавания не принимает окончательного решения. В соответствии с принципом MDA, гипотезы выдвигаются на каждом логическом уровне, и число их может расти в геометрической прогрессии. Соответственно, последовательная проверка всех гипотез вряд ли окажется эффективной, и потому в OCR-системах ABBYY применяется метод структурирования гипотез, т. е. отнесения их к тем или иным моделям. Последних существует пара десятков, вот только несколько их типов: словарное слово, несловарное слово, арабские цифры, римские цифры, URL, регулярное выражение — а в каждый может входить множество конкретных моделей (к примеру, слово на одном из известных языков, латиницей, кириллицей и т. д.).
Все финальные действия выполняются уже именно с гипотезами, построенными по моделям. К примеру, контекстная проверка определит язык документа и сразу же существенно понизит вероятность моделей с использованием неправильных алфавитов, а словарная компенсирует погрешности при неуверенном распознавании некоторых символов: так, слово «turn» присутствует в словаре английского языка — в отличие от «tum» (во всяком случае, оно отсутствует среди популярных). Хотя приоритет словаря выше, чем у любого классификатора, он не обязательно является последней инстанцией, и в общем случае не останавливает дальнейшие проверки: во-первых, как говорилось выше, имеется модель несловарного слова, во-вторых, специальная организация словарей позволяет с высокой долей вероятности предположить, может ли какое-то неизвестное слово относиться к тому или иному языку. Тем не менее, словарная проверка (и полнота словарей) оказывает существенное влияние на результат распознавания, и в тестах самой ABBYY сокращает количество ошибок практически вдвое.
Не только OCR
Печатные документы — далеко не единственные, представляющие интерес с точки зрения их оцифровки и автоматической обработки. Довольно часто приходится работать с формами, т. е. документами с предопределенными и фиксированными полями, которые заполняются вручную, но сравнительно аккуратно (так называемыми рукопечатными символами) — примером могут служить различные анкеты. Технология их обработки имеет отдельное название — ICR (intelligent character recognition) — и достаточно существенно отличается от OCR. Так, поскольку в данном случае задача состоит не в воссоздании всего документа, а в извлечении из него конкретных данных, то она распадается на две основные подзадачи: нахождение нужных полей и собственно распознавание их содержимого.
Это достаточно специфическая область, и ABBYY предлагает для нее совершенно отдельный программный продукт ABBYY FlexiCapture. Он предназначен для создания автоматизированных и полуавтоматизированных систем, предполагает настройку на конкретные типы документов, для которых создаются специальные шаблоны, умеет интеллектуально находить на страницах различные поля и верифицировать данные в них и т. д. Однако в самой основе лежат алгоритмы распознавания символов, аналогичные тем, что применяются в FineReader, да и общая схема весьма похожа:
Впрочем, важное отличие все же имеется: структурный классификатор является обязательным участником процесса — это связано со спецификой рукопечатных символов. Кроме того, ICR предполагает большое число специфических дополнительных проверок: например, не является ли символ зачеркнутым, или действительно ли распознанные символы формируют дату.
www.ixbt.com
Abbyy finereader 12 как пользоваться — Как работать в FINE READER???? — 22 ответа
В разделе Компьютеры, Связь на вопрос Как работать в FINE READER???? заданный автором Марина лучший ответ это МОй совет:1. Сначала насканировать картинки с текстом в отдельную папку (картинки должны быть в оттенках серого с разрешением в 300 т/д).2. В Файнридере выбираешь язык распознаваемого текста, потом где первая кнопка (Сканировать и распознать... на ней спарва есть полоска со стрелочкой вниз) - Открыть и распознать - дальше открываешь папку с отсканированным текстом, "выделяешь все" и тыкаешь - Открыть.3. Ждешь пока распознает текст...4. Последней кнопкой в Файнридере жмешь - Сохранить результаты... и сохраняешь, куда надо...Типо все!Источник: собств. опыт.
Ответ от 22 ответа[гуру]Привет! Вот подборка тем с ответами на Ваш вопрос: Как работать в FINE READER????
Ответ от Зиг Фрид[гуру]Ищи версию 7 или уже наверное есть выше...На русском и справка работает...
Ответ от Невропатолог[мастер]Запускаешь прогу1 Сканиовать2 Распознать3 Конвертнутьтам прям на русском написано
Ответ от Вырост[гуру]очень просто. главное чтобы сканер работал - т.е. драйвера были и он реально сканировал. Все, запускаем файн ридер, там два режима работы - когда только нажали кнопочку что-то типа магикскан и она сама сканирует, распознает, сохраняет, только бумажки успевай вкладывать, либо самому сидеть и тупо давить на кнопки в верхней панели - сначала сканировать, затем распознать, редактировать, а затем экспортировать с какой-нить ворд. Все предельно просто.
Ответ от Особинка[активный]Это надо визуально показывать... при личном контакте. Так все равно не поймешь!!!
Ответ от Space connection[гуру]молча
Ответ от Force[гуру]Очень просто работать с программой FineReader. Например береш сканер открываеш FineReader на своем компе и в там тебе предложит программа сканировать ты выбераеш сканировать далее выбераеш разрешение а разрешение самой оптемальное разрешение это 600 потом сканировать после этого ты подгоняеш от сканированный фаил после этого импортируеш его в Word Вот и все.
Ответ от RON[гуру]У меня 8 версия, все прекрасно работает на русском, на главной панели четыре кнопки 1 Открыть 2 Распознать 3Проверить 4 Сохранить. Если скачаеш кряком поделюсь.
22oa.ru
ABBYY FineReader 11 приближает цифровую эру
Возможно, окончательная победа цифровых технологий уже не за горами, но сегодня мы все еще находимся в переходном периоде и вынуждены приводить разнородные потоки и источники информации к «общему знаменателю». Оцифровка печатных материалов (OCR, Optical Character Recognition), одна из наиболее типичных задач, хорошо знакома отечественным пользователям и на просторах СНГ однозначно ассоциируется с ABBYY FineReader. Популярность этого продукта вполне заслуженна, а компания-разработчик не почивает на лаврах и неутомимо отслеживает современные тенденции и развивает свое детище. Так, в девятой версии FineReader стал работать не с отдельными блоками или даже страницами, а с целыми документами (ADRT, Adaptive Document Recognition Technology), что позволило ему гораздо правильнее воссоздавать их структуру, включая такие элементы как таблицы, колонтитулы и пр. В десятой приоритет сместился в сторону качественной обработки изображений, полученных не со сканеров, а с цифровых фотокамер. Популярность последних продолжает расти, так, согласно информации ABBYY, фотокамеры для оцифровки печатной продукции (учебников и научной литературы, юридических и деловых документов, газет и журналов, анкет и пр.) применяют более 30% пользователей. Представленный в конце августа FineReader 11 также имеет немало полезных нововведений, хотя выделить главное направление довольно сложно. Скорее, в нынешней версии разработчики сосредоточились на совершенствовании накопленных технологий и, конечно, на повышении удобства работы.
Общая информация
На текущий момент доступны две редакции FineReader 11 — Professional и Corporate. Home пока осталась в 10-й версии. На сайте ABBYY есть довольно объемная таблица с описанием возможностей всех трех редакций, хотя проводить такое сравнение не совсем корректно — наверняка со временем появится и FineReader 11 Home Edition, который сократит отставание от старших собратьев. Однако принципиально картину это не изменит — функциональность редакции Home сильно урезана. Так, отсутствуют возможности обработки документов PDF, DjVu, XPS; распознавание штрихкодов; встроенный редактор; вывод во многие форматы; поддержка многоядерных процессоров и пр. Конечно, кому-то базовой функциональности будет достаточно, особенно для эпизодического применения, но в общем случае сниженная стоимость не компенсирует потери.
К примеру, последние версии FineReader характеризуются отличной, практически линейной масштабируемостью, т. е. на двух вычислительных ядрах программа будет работать почти вдвое быстрее чем на одном, на трех — втрое, на четырех — вчетверо и т. д. Заглянув в Task Manager после запуска редакции Professional или Corporate, вы увидите несколько процессов FineExec, ответственных за обработку изображений, — их будет два для двухъядерного процессора или на единицу меньше числа ядер, если последних больше двух (одно резервируется для интерфейса программы и других системных задач). А при обработке многостраничного документа будет отлично заметно, как одновременно распознаются несколько страниц. В общем, это весомый плюс, особенно при большой нагрузке.
Рис. 1. Каждому вычислительному ядру — свой рабочий процесс. За счет этого обеспечивается отличная масштабируемость и максимальная утилизация ресурсов.
Редакции Professional и Corporate похожи гораздо больше, в частности, в обеих присутствуют все важные новинки FineReader 11:
- программа стала более производительной: скорость обработки оригиналов на европейских языках увеличена до 25% (в зависимости от типов документов), на иероглифических — до 40%; новый черно-белый режим обещает дополнительное ускорение до 30% по сравнению с цветным;
- расширена поддержка выходных форматов, в число которых теперь попали не только DjVu и ODT (Writer из OpenOffice.org или LibreOffice), но и FB2 с ePub, так что теперь можно непосредственно в FineReader создавать цифровые книги;
- улучшены редактор стилей, документа и встроенный фоторедактор (добавились инструменты для исправления яркости, контрастности, шума, искажений), появилась возможность разбивать поток страниц на несколько документов.
Однако между ними также имеется существенная разница. Прежде всего, редакция Corporate предназначена для использования в организациях и, соответственно, обеспечивает гибкое управление лицензиями. Последние бывают двух основных типов: per-seat, закрепляемая за конкретным компьютером (т. е. по сути аналогичная персональной лицензии), и concurrent (распределенная), которую допускается использовать на любом компьютере. Распределенные лицензии позволяют установить FineReader Corporate на произвольном числе рабочих мест, при этом сервер лицензий будет автоматически выдавать имеющиеся лицензии при запуске клиентской программы и вновь забирать при завершении. Если корректно оценить потребность сотрудников в OCR (а большинство наверняка будет использовать FineReader лишь от случая к случаю), то комбинацией per-seat и concurrent лицензий можно добиться существенной экономии по сравнению с приобретением для всех персональных продуктов — даже при том, что корпоративные лицензии дороже: 4180-3200 р. за per-seat и 6260-5330 р. за concurrent (в зависимости от пакета лицензий) против 3590 р. за электронную поставку FineReader 11 Professional.
Разница в цене объясняется не только особенностями лицензирования. Редакция Corporate по сравнению с Professional также предлагает ряд полезных функций и дополнительных инструментов, в частности:
- возможность создавать пользовательские сценарии, аналогичные встроенным типовым задачам;
- режим совместной работы с одним документом, когда несколько пользователей могут параллельно выполнять различные действия;
- передачу документов на серверы SharePoint;
- режим Цензура, позволяющий в буквальном смысле вымарать лишнюю информацию, причем, в документах, которые поддерживают графический и текстовый слои, она будет удалена из обоих;
- программу ABBYY Hot Folder, обеспечивающую автоматическую обработку документов, поступающих в папку, почтовый ящик или на FTP-сервер;
- программу ABBYY Business Card Reader для преобразования визиток в электронные контакты.
Рис. 2. Редакция Corporate предлагает не только специфическое лицензирование, но и ряд дополнительных функций. К примеру только в ней можно создавать дополнительные сценарии работы (Мои задачи)
Системные требования и установка
По нынешним меркам системные требования FineReader 11 выглядят довольно скромно:
- операционная система Windows XP, Windows Server 2003 или более новая;
- процессор с частотой от 1 ГГц;
- объем оперативной памяти не менее 1 ГБ плюс по 512 МБ на каждое вычислительное ядро;
- 700 МБ дискового пространства непосредственно для установки и столько же для рабочих файлов.
Программа более чувствительна к производительности процессора, ресурсы которого обычно задействуются на все 100%, чем к объему оперативной памяти.
FineReader умеет напрямую работать со сканерами и МФУ, поддерживающими интерфейсы TWAIN или WIA. Изображения оригиналов можно также получать с помощью цифровых фотокамер, минимальным требованием является 2 Мп на лист формата A4, рекомендуется 5 Мп. Однако на деле более важно наличие автоматической или ручной фокусировки, никакие мегапиксели не помогут встроенным в телефон камерам с фиксированным фокусом. Естественно, съемку крайне желательно вести при хорошем освещении, с помощью штатива, отрегулировав баланс белого и т. д. Хотя встроенные в FineReader 11 инструменты способны скорректировать некоторые недочеты цифровых снимков, сильно рассчитывать на них не стоит.
Рис. 3. Развертывание FineReader 11 Corporate в сети следует начинать с сервера лицензий
Установка FineReader 11 довольно проста — настолько, что даже не описана в руководстве пользователя. Инсталляционная процедура запустится на языке, указанном в системных настройках, но на первом же экране можно выбрать нужную локализацию. Выборочная установка позволит отказаться от некоторых инструментов и функций, вроде ABBYY Screenshot Reader (для распознавания снимков экрана) и интеграции в сторонние приложения. Но все это относится к клиентской части, в основном, к редакции Professional. FineReader 11 Corporate в общем случае предполагает сетевое развертывание, описание которого приведено в руководстве администратора. С дистрибутивного диска вначале нужно установить сервер и менеджер лицензий. Последний представляет собой управляющую утилиту и также может размещаться на любой рабочей станции. Сервер лицензий на самом деле не требует серверной ОС, а учитывая минимальную вычислительную нагрузку, его вполне разумно установить в виртуальной машине. Принципиально только соединение с Интернетом, так как с помощью менеджера лицензий необходимо регистрировать и активировать имеющиеся лицензии.
Для установки FineReader 11 Corporate на рабочие станции есть несколько способов, самый простой (но не всегда самый эффективный) — формирование административного дистрибутива в папке общего доступа и запуск инсталляции на каждом рабочим месте. При этом все параметры сервера лицензий будут прописаны автоматически, так что никаких дополнительных действий не понадобится. При использовании per-seat лицензий FineReader 11 Corporate можно устанавливать и локально.
В дальнейшем менеджер лицензий позволяет объединять лицензии в пулы, закреплять за группами пользователей, принудительно назначать и забирать их и т. д. Но в простых вариантах (к примеру, только concurrent лицензии и одинаковые потребности у всех пользователей) в этом даже нет необходимости, все будет происходить автоматически.
Рис. 4. Менеджер лицензий позволяет контролировать использование лицензий и, при необходимости, управлять их распределением
Работа с FineReader 11
Несмотря на то, что за ABBYY FineReader стоит целая отрасль искусственного интеллекта и весьма изощренные алгоритмы, сама по себе программа достаточно проста и интуитивна. По сути она решает одну единственную задачу — распознавание текста, соответственно, в ней нет изобилия инструментов и сложных меню, хотя все необходимые опции и средства появляются при работе с конкретными объектами, будь то изображение, выделенный блок или распознанный текст. За последнее время интерфейс программы практически не менялся (никаких «лент») и это хорошо, так как пользователи предыдущих версий найдут привычные инструменты на своих местах. Работать с FineReader можно двумя основными способами: либо воспользоваться одним из типовых сценариев, к примеру, со сканера сразу в EPUB, либо проделать основные операции вручную. В любом случае обработка документов состоит из четырех основных этапов: получение изображения, его распознавание, проверка, сохранение результата, — и на каждом доступно некоторое количество опций и дополнительных возможностей, способных существенно повлиять на качество результата. С опытом каждый пользователь отработает собственный стиль взаимодействия с FineReader, но для начала вполне разумно полагаться на автоматические настройки, тем более, что программа оповестит о всех проблемах, скажем, о необходимости отсканировать с большим разрешением оригиналы, на которых имеется мелкий шрифт. Кроме того, в рабочем документе отмечаются все неуверенно распознанные символы, так что их можно будет быстро проверить, в том числе, в специальном окне с укрупненным фрагментом оригинала. В большинстве случаев FineReader и сам примет правильные решения, особенно если сомнения возникают в известных словах, в противном случае имеет смысл добавить слово в словарь и повторить распознавание. При возникновении большого количества ошибок следует обратить внимание на качество оригинала и его изображения — это самый важный фактор, нивелировать который в дальнейшем практически невозможно.
Рис. 5. Выбранный режим может сильно повлиять на результат, причем программа не восстанавливает стандартные настройки — перед сменой задания необходимо это делать самостоятельно
ABBYY FineReader 11 предлагает несколько режимов обработки, адаптированных к различным ситуациям. К примеру, в окне опций можно уточнить тип оригинала (факс, печатная машинка, авто) — после экспериментов с ними очень важно обратно выставить режим автовыбора. Здесь же задается основной режим обработки — цветной или черно-белый, более оперативно его можно выбрать, нажав на соответствующую кнопку в панели Страницы. Идея черно-белого режима состоит в ускорении обработки, а также в уменьшении объема изображений, получаемых при сканировании. Он пригоден в том случае, когда нет необходимости сохранять цветные элементы, а оригиналы достаточно качественны, прежде всего — контрастны.
Рис. 6. Программа сообщает обо всех затруднениях в своей работе и дает конкретные советы
Для сравнения доступных режимов обработки был проведен небольшой тест. В качестве оригинала был взят 10-страничный, отпечатанный на цветном принтере материал со сравнительно сложной версткой, но почти без иллюстраций. Такое задание можно считать достаточно типичным, так как главной задачей программ распознавания является именно извлечение текста. Затем в опциях FineReader 11 была отключена автоматическая обработка и сформированы три документа: один в черно-белом режиме и два в цветном, отсканированные в цвете и в оттенках серого. Сканирование выполнялось на МФУ с разрешением 300 dpi, что также является типичной ситуацией. Все прочие настройки FineReader 11 не менялись, в частности, использовался тщательный режим собственно распознавания. Серии операций по распознаванию проводились на компьютере с двухъядерным процессором, усредненные результаты можно видеть в следующей таблице:
Табл. Сравнение различных режимов обработки документа
| Показатели | черно-белый | серый | цветной |
| размер документа (МБ) | 1,5 | 49 | 301 |
| время работы — первый «холодный» прогон (с) | 01:05 | 01:30 | 01:45 |
| время работы — повторные прогоны (с) | 01:05 | 01:07 | 01:15 |
| кол-во неуверенно распознанных символов | 876 | 735 | 708 |
| средняя загрузка CPU (%) | 92 | 92 | 94 |
| CPU — процесс FineReader (%) | 27 | 25 | 28 |
| CPU — процесс FineExec #1 (%) | 40 | 65 | 57 |
| CPU — процесс FineExec #2 (%) | 60 | 51 | 47 |
| RAM — процесс FineReader — среднее/мин/макс (МБ) | 150/147/158 | 173/153/181 | 240/186/260 |
| RAM — процесс FineExec#1 — среднее/мин/макс (МБ) | 96/90/100 | 97/77/114 | 105/89/125 |
| RAM — процесс FineExec#2 — среднее/мин/макс (МБ) | 95/86/104 | 94/77/106 | 104/86/116 |
Очевидно, ускорение обработки в черно-белом режиме зависит от характера исходного документа и качества отпечатков. На самом деле экономия времени начнется еще на этапе сканирования, которое в цвете осуществляется намного дольше. Очень большая разница также наблюдается на первом «холодном» прогоне, что, вероятно, связано с размерами изображений. При повторных обработках скорости выравниваются, хотя разница все же присутствует, пусть и не такая большая, как обещано разработчиками. Естественно, в цветном режиме ABBYY FineReader требуется больше оперативной памяти, а вот процессор во всех случаях задействовался фактически одинаково — на 100% в процессе обработки, и несколько ниже при дополнительных операциях (сохранении и т. д.).
Рис. 7. Специальный режим проверки позволяет оперативно просмотреть все неуверенно распознанные символы и при необходимости внести коррективы или занести в словарь новые слова
Несмотря на достаточно высокое качество оригинала, в черно-белом режиме значительно большее число символов было распознано неуверенно. Однако, львиная доля их приходилась на фрагменты с изображениями. При этом на одной чисто текстовой странице лучшее качество распознавания оказалось именно в черно-белом режиме. Сканирование в оттенках серого считается ABBYY FineReader 11 оптимальным для OCR, с чем, пожалуй, можно согласиться, глядя на результаты теста. По физическим характеристикам, в том числе скорости, серый режим близок к черно-белому, а по качеству распознавания — к цветному. Справедливости ради, отметим, что результаты в черно-белом режиме было несложно значительно улучшить, предварительно разметив иллюстрации или добавив в словарь несколько часто встречающихся в документе аббревиатур (в них программа ошибалась наиболее часто). Тем не менее, цветной режим со сканированием в оттенках серого действительно выглядит не компромиссом, а оптимальным выбором.
Дополнительные возможности
Несмотря на прозрачность работы и наличие типовых сценариев, ABBYY FineReader 11 имеет в своем арсенале и достаточно тонкие инструменты, которые при умелом использовании существенно могут облегчить жизнь пользователям. К примеру, программу можно обучить для работы с декоративными шрифтами или специальными символами (вначале, конечно, следует убедиться, что она с ними не справляется). Хотя это довольно трудоемкий процесс, и применять его целесообразно только в исключительных случаях. Другим примером могут служить шаблоны областей для обработки однотипных документов. Достаточно проанализировать один образец, скорректировать его разметку, выделить нужные блоки и сохранить шаблон. В дальнейшем его можно будет применять к аналогичным документам, не повторяя рутинную работу. В полной мере возможности этой функции раскрываются при использовании вместе с Hot Folder для автоматической обработки документов.
Рис. 8. ABBYY Hot Folder позволяет настроить все параметры задания, чтобы в дальнейшем распознавание проходило в полностью автоматическом режиме
ABBYY Hot Folder, в свою очередь, является одним из дополнительных компонентов FineReader 11 (только редакции Corporate). Это специализированный планировщик, управляющий заданиями для автоматической обработки документов. По указанному расписанию он может проверять один из типов источников (папки, ftp-серверы, почтовые ящики, документы ABBYY FineReader, которые сами по себе также являются папками) и инициировать их обработку с предварительно настроенными параметрами. Типичное применение Hot Folder — централизованное распознавание документов, которые вводятся сотрудниками через сетевые МФУ. Как правило такие устройства умеют сохранять отсканированные изображения в папках общего доступа, за которыми как раз и будет следить Hot Folder.
Рис. 9. ABBYY Business Card Reader достаточно уверенно справляется с визитками, несмотря на разницу в их оформлении
Еще одним полезным дополнением FineReader 11 Corporate является ABBYY Business Card Reader — программа для распознавания визитных карточек. В ней все настройки и OCR-алгоритмы адаптированы для решения исключительно своей узкой задачи, пользователь может лишь скорректировать используемые языки. Разом можно сканировать несколько визиток, главное — одинаково их позиционировать в сканере. Для отличных результатов достаточно разрешения в 600 dpi, при этом не только корректно распознаются мелкие шрифты, но и достаточно уверенно идентифицируются различные поля: имя, фамилия, должность, телефоны, адреса и т. д. Ошибки случаются, в основном, в не совсем стандартных ситуациях, когда, к примеру, длинное название должности занимает сразу две строки. Экспортировать данные можно в файлы vCard или непосредственно в контакты Microsoft Outlook.
Рис. 10. ABBYY Screenshot Reader захватывает указанную часть экрана и распознает в ней текстовую информацию
Наконец, еще одно дополнение — ABBYY Screenshot Reader — присутствует в редакциях и Corporate, и Professional. Как и следует из названия, данная программа распознает информацию на экране компьютера (можно выделять окно или прямоугольную область). Таким образом, к примеру, можно быстро извлечь информацию о программной ошибке для поиска в базе знаний. Результат можно сохранять в файлах распространенных форматов или копировать в буфер обмена.
Резюме
ABBYY FineReader 11 сделал еще несколько шагов к тому, чтобы освободить пользователей от рутины и приблизить нашу жизнь к цифровому будущему. В программе внешняя простота сочетается с мощными алгоритмами, что позволяет даже неподготовленным пользователям добиваться хороших результатов. Все нововведения нынешней версии наверняка будут оценены по достоинству, начиная с повышенной производительности и заканчивая поддержкой популярных форматов электронных книг. Преимущества редакции Corporate также очевидны, хотя, с учетом более высокой стоимости лицензии, ее внедрение требует предварительной оценки реальной потребностей в OCR всех сотрудников.
www.ixbt.com
Что делать, если ABBYY FineReader не видит сканер
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ. Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст. Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и FB2, что полезно при создании электронных книг и документации для последующей печати.

Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений;
- доступ в интернет для активации.
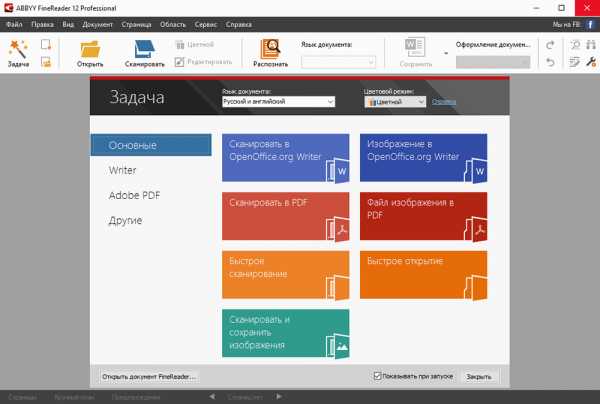
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Исправление ошибок
Есть ряд общих советов по исправлению некорректной работы:
- Обновите драйверы оборудования до последних версий с официального сайта производителя.
- Проверьте права текущего пользователя в системе, при необходимости повысьте уровень доступа.
- Иногда помогает установка более старой версии приложения, особенно если вы работаете на не новом оборудовании.
- Проверьте, видит ли сканер сама система. Если он не отображается в диспетчере устройств или показан с жёлтым восклицательным знаком, то проблема в оборудовании, а не программе. Обратитесь к инструкции или в техподдержку производителя.
- На официальном сайте ABBYY работает неплохая техническая поддержка https://www.abbyy.com/ru-ru/support. Вы можете задать вопрос, подробно описав конкретно свою проблему, и получить профессиональное решение из первых рук абсолютно бесплатно.

Устранение ошибки «Параметр задан неверно»
В последней версии ABBYY FineReader также может носить название «Ошибка инициализации источника». Инициализация – это процесс подключения и распознавания системой оборудования. 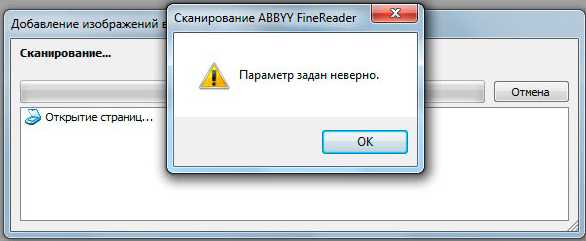
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:
- Перезапустите программу FineReader.
- Зайдите в меню «Инструменты», выберите «OCR-редактор».
- Нажмите «Инструменты», потом «Настройки».
- Включите раздел «Основные».
- Перейдите к «Выбор устройства для получения изображений», затем «Выберите устройство».
- Нажмите на выпадающий список доступных драйверов. Проверьте работоспособность сканирования поочерёдно с каждым из списка. В случае успеха с каким-то из них, используйте его в дальнейшем.
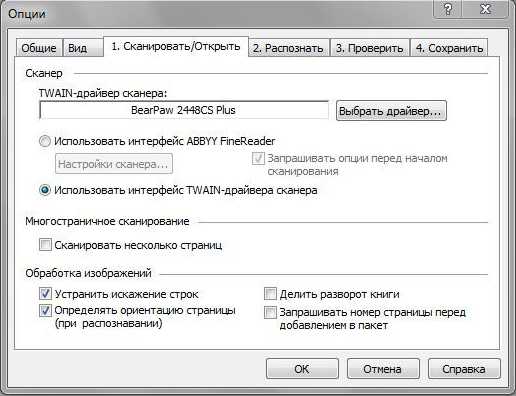
ВНИМАНИЕ. Возможна и такая ситуация, что ни с каким из доступных драйверов выполнить сканирование не получилось. Тогда нажмите «Использовать интерфейс сканера».
Если и это не помогло, вам понадобится утилита TWAIN_32 Twacker. Её можно скачать с официального сайта ABBYY по ссылке ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
После этого следуйте инструкции:
- Выйдите из Файн Ридер.
- Распакуйте архив twack_32.zip в любую папку.
- Дважды щёлкните по Twack_32.exe.
- После запуска программы зайдите в меню «File», затем «Acquire».
- Нажмите «Scan» в открывшемся диалоге.
- Если документ успешно отсканировался, откройте меню «File» и щёлкните «Select Source».
- Синим цветом окажется отображён драйвер, через который утилита успешно выполнила сканирование.
- Выберите этот же файл драйвера в файнридере.

Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Внутренняя программная ошибка
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:
- Добавьте Fine Reader в исключения антивирусного ПО.
- Перейдите в «Панель управления», «Установка и удаление программ».

- Найдите Fine Reader и нажмите «Изменить».
- Теперь выберите «Восстановить».
- Запустите программу и попробуйте отсканировать документ.
Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Таким образом решается проблема подключения программы Fine Reader к сканеру. Иногда причина в конфликте драйверов или несовместимости оборудования. А бывает, сбой сканирования возникает из-за внутренних программных ошибок. Если вы сталкивались с подобными проблемами в файнридере, оставляйте советы и способы решения в комментариях.
nastroyvse.ru
Руководство по пользованию программой для распознавания текстаABBYY FineReader
 ABBYY FineReader — это система оптического распознавания текстов (OCR — Optical Character Recognition). Она предназначена для конвертирования в редактируемые форматы отсканированных документов, PDF-документов и файлов изображений, включая цифровые фотографии. Преимущества программы ABBYY FineReaderСкорость и высокая точность распознавания
|
abbyy-fine-reader.narod.ru
Бесплатные аналоги FineReader

FineReader считается самой популярной и функциональной программой для распознавания текстов. Что же делать, если вам необходимо оцифровать текст, но нет возможности приобрести это программное обеспечение? На помощь придут бесплатные распознаватели текстов, о которых мы и поговорим в этой статье.
Читайте на нашем сайте: Как пользоваться FineReader
Бесплатные аналоги FineReader
CuneiForm
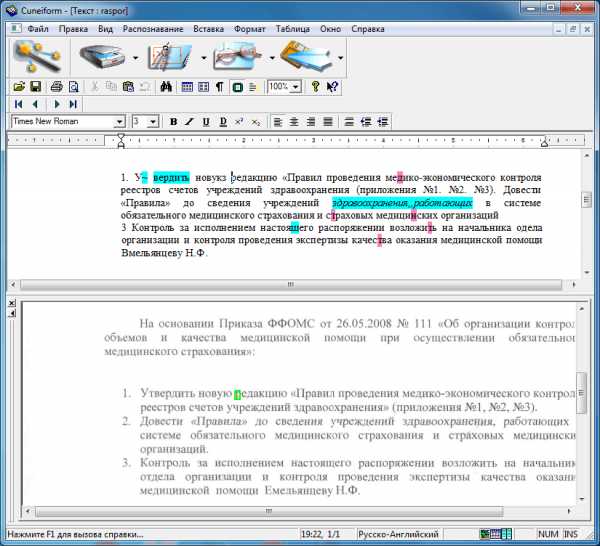 CuneiForm — достаточно функциональное бесплатное приложение, требующее установки на компьютер. Оно может похвастать взаимодействием со сканером, поддержкой большого количества языков. Программа подчеркнет ошибки в оцифрованном тексте и позволит редактировать текст в местах, которые не смогла распознать.
CuneiForm — достаточно функциональное бесплатное приложение, требующее установки на компьютер. Оно может похвастать взаимодействием со сканером, поддержкой большого количества языков. Программа подчеркнет ошибки в оцифрованном тексте и позволит редактировать текст в местах, которые не смогла распознать.
Скачать CuneiForm
Free Online OCR
Free Online OCR — бесплатный распознаватель текстов, представленный в онлайн формате. Он будет очень удобен для пользователей, которые редко пользуются оцифровкой текста. Разумеется им не нужно тратить время и деньги на покупку и установку специального софта. Чтобы воспользоваться этой программой, достаточно просто загрузить свой документ на главной странице. Free Online OCR поддерживает большинство растровых форматов, распознает более 70 языков, может работать как с целым документом, так и с его частями.
Готовый результат можно получить в форматах doc., txt. и pdf.

SimpleOCR
Бесплатная версия этой программы сильно ограничена в функциональности и может распознавать только тексты на английском и французском языках, оформленные стандартными шрифтами, размещенными в одну колонку. К достоинствам программы можно отнести то, что она подчеркивает слова, употребленные в тексте некорректно. Программа не является онлайн-приложением и требует установки на компьютер.
Полезная информация: Лучшие программы для распознавания текстов

img2txt
Это еще один бесплатный онлайн-сервис, преимущество которого заключается в том, что он работает с английским, русским и украинским языком. Он прост и удобен в использовании, однако имеет несколько ограничений — размер загружаемого изображения не должен превышать 4 Мб, а формат исходного файла должен быть только jpg, jpeg. или png. Впрочем, подавляющее большинство растровых файлов представлены именно этими расширениями.
Мы рассмотрели несколько бесплатных аналогов популярному FineReader. Надеемся, вы найдете в этом списке программу, которая поможет вам быстро оцифровать необходимые текстовые документы.
Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
Да Нетlumpics.ru
Настройка параметров распознавания. Режим распознавания
"Если настройки распознавания настроены правильно, то это дает возможность практически сразу же получить качественный документ, подходящий для последующего редактирования. Выбор пар-ров находится в зависимости от того, каким образом Вы собираетесь пользоваться распознанным документом. Необходимые нужно выбирать на закладке Распознать диалогового окна Опции. Обратите внимание: Распознавание страничек, добавленных в файл файн ридер, работает в автоматическом режиме с установленными параметрами программы. У вас есть возможность выполнить отключение автоматического анализа и распознавания добавленных изображений. Для этого в диалоговом окне Опции нужно перайти на закладку Сканировать/Открыть. Примечание. Во время изменения языка распознавания, выделения областей ручками, либо же изменения других параметров файн ридер, то процесс распознвания требуется запустить снова. скачать абби файн ридер с ключомФайн ридер: Режимы распознавания
Вы можете выбрать Быстрое распознавание и Тщательное распознавание. Режим Тщательное распознавание пригоден для того чтобы распознавать документы любой сложности. Примечание. В сравнении с Быстрым режимом, это режим нуждается в большем количестве времени, однако обеспечивает лучший уровень качества распознавания. Режим Быстрое распознавание советуется для того чтобы обрабатывать большие объемы документов с хорошим качеством печати и элементарным оформлением. Для того чтобы выбрать режим распознавания в «Режим распознавания» нужно выбрать одну из опций: Быстрое распознавание или Тщательное распознавание.Файн ридер: Параметры группы Обучение
Согласно стандартных настроек Распознавание с обучением отключено. Для того чтобы во время распознавания производить обучение файн ридер неизвестным символам, выберите опцию Распознавание с обучением. Распознавание с обучением применяется для того чтобы распознавать следующие тексты: Тексты с декоративными шрифтами и специальными символами. Тексты плохого качества, объем которых более ста страничек. В момент распознавания у вас есть возможность пользоваться встроенными эталонами или сотворить собственный эталон.Файн ридер: Пользовательские языки и эталоны
Вы можете сохранить настройки пользовательских языков и эталонов или загрузить настройки, которые были ранее сохранены. Для выполнения сохранения файлов эталонов и языков нужно кликнуть на Сохранить в файл… Далее указать наименование файла и кликните Сохранить. Для выполнения загрузки файлов эталонов и языков нужно кликнуть на загружать из файла… В открывшемся окне нужно выбрать документ формата FBT и кликните Открыть."
Верно установленные настройки распознавания помогут получить качественный документ, подходящий для последующего редактирования. Выбор пар-ров находится в зависимости от сложности и объема оригинала документа, а также от его применения.
Избрать необходимые настройки у вас есть возможность на закладке Распознавать диалогового окна Опции. Распознавание страничек, добавленных в файн ридер, работает в автоматическом режиме с текущими параметрами программы. У вас есть возможность выполнить отключение автоматического анализа и распознавания добавленных графических файлов на закладке Сканировать/Открыть диалогового окна Опции.
В файн ридер можно выбрать либо Тщательное распознавание, либо Быстрое распознавание.
Первый режим пригоден для распознавания любых документов, включая таблицы с цветными ячейками и таблицы без линий сетки. Этот режим занимает большое количество времени.
Второй же режим используется для того чтобы обрабатывать большие объемы документов с хорошим качеством печати и простым оформлением.
Файн ридер: Распознавание табличек
Вы можете выбрать требуемый для данного файла метод распознавания табличек.
Искать таблички с однозначно заданными разделителями. Данную опцию нужно включать, дабы в виде таблицы были распознаны лишь таблицы, которые имеют черные разделители.
Во всякой ячейке таблички не больше одной строчки текста. Данную опцию нужно включать, дабы в каждую ячейку таблицы в момент распознавания помещалось не более одной строки текста. В противном случае ячейки таблички обычно содержат несколько текстовых строк, другими словами они являются многострочными.
legkyyzarabotok.ucoz.ru
- Шумит системный блок

- Какой выбрать монитор
- Взлом сайта wordpress

- Как узнать свой ip компьютера

- Эксель макросы для чайников

- Что делать если не можешь удалить файл с компьютера

- Режим инкогнито в firefox

- Как в firefox удалить историю

- Моя страница вход код 992378

- Google chrome переустановить

- Удалить раздел восстановления