Оптимизация производительности в СУБД Microsoft SQL server. Какой из методов встроенного sql правильный
Оптимизация производительности в СУБД Microsoft SQL server
Цель данной работы состоит в описании методов настройки сервера таким образом, чтобы добиться максимальной производительности СУБД MS SQL Server с сохранением уже имеющегося функционала.
Введение
Настройка SQL-кода с точки зрения оптимизации производительности на практике начинается уже после того, как основной функционал БД разработан, и большая часть логических ошибок устранена. Пользователей (в широком смысле этого слова) устраивает, что делает приложение. Они хотят, чтобы то же самое делалось быстрее.
Как правило, молодые специалисты достаточно хорошо знают стандарты языка SQL и теорию реляционных баз данных. Они умеют проектировать хорошо нормализованные базы данных и строить достаточно сложные многотабличные запросы, возвращающие правильные результаты. К сожалению, на практике эти запросы работают непозволительно долго для системы on-line на больших таблицах (десятки и сотни тысяч строк) и/или в условиях работы большого числа (десятков и сотен) пользователей, выполняющих однотипные операции.
Цель данной работы состоит в описании методов настройки сервера таким образом, чтобы добиться максимальной производительности СУБД MS SQL Server с сохранением уже имеющегося функционала.
«Самый важный момент, о котором необходимо помнить при настройке производительности, состоит в том, что вам никогда не удастся познать всю подноготную данного вопроса. Если вы являетесь среднестатистическим разработчиком SQL Server, тогда хорошо, если вам известно хотя бы 20% всей информации. К счастью, к этой теме, несомненно, применим принцип “20/80” (знание 20% теории позволяет решить 80% практических вопросов)» [2].
Данная работа может быть интересна преподавателям курсов изучения многопользовательских SQL-ориентированных СУБД, а также администраторам и разработчикам баз данных (особенно на этапе сопровождения продукта).
Задача оптимизации производительности в MS SQL Server
Теоретически разработчик принимается за настройку производительности SQL-кода:
- При разработке функционала БД, который априорно определен как «жизненно важный» и при этом достаточно сложный (потенциально «тяжелым» для СУБД). К сожалению, после внедрения не так уж редко выясняется, что:
- «жизненно важный» код на самом деле не такой уж «жизненно важный», выполняется не так часто, как предполагалось, и пользователи вполне готовы подождать результата лишнюю секунду/минуту. Тем временем другие пользователи при выполнении совершенно других операций постоянно жалуются, что «все работает медленно или не работает вообще».
- запросы, выполняющиеся за миллисекунды на таблицах с десятками и сотнями записей, работают недопустимо долго (десятки минут), когда число записей достигают миллиона-другого...
- Нагрузочное тестирование показало недостаточную производительность с точки зрения некоторых заранее выбранных количественных показателей. Однако, принимая решения на этом этапе, следует учитывать, что:
- возможно, выбранные показатели на самом деле не являются адекватными показателями производительности системы;
- скорость выполнения многотабличного запроса зависит не столько от абсолютного размера используемых в нем таблиц, сколько от отношения их размеров, а также от конкретных данных, прогнозировать и генерировать которые на этапе тестирования порой слишком сложно, слишком долго, слишком дорого или вообще невозможно.
- Система уже внедрена и работает, с точки зрения конечного пользователя, недостаточно быстро.
На практике по-настоящему серьезные проблемы возникают именно на последней стадии, когда разработчик может получить максимум информации о том, что действительно нуждается в оптимизации, и минимум времени для того, чтобы эту настройку выполнить.
Собственно настройку SQL можно условно разделить на следующие этапы:
- Идентификация и анализ запросов, которые являются причинами недостаточно высокой производительности;
- Составление оптимального плана выполнения для запросов, определенных на предыдущем этапе;
- Внесение изменений в запрос или структуру базы данных так, чтобы получить оптимальный план выполнения.
Мониторинг производительности в MS SQL Server
Перед тем, как приступать к настройке, необходимо выяснить, что именно в такой настройке нуждается. На что тратятся ресурсы сервера? Какие хранимые процедуры нужно оптимизировать в первую очередь? Врачи говорят, что гораздо проще лечить конкретный орган, чем человека в целом. Проводя аналогию, администратору приходится иметь дело с работой сервера как единым процессом.
Этот этап, как правило, является наиболее трудоемким при решении проблем связанных с производительностью. Он практически не поддается формализации. Иногда на решение задачи диагностики уходят дни или даже недели, тогда как собственно разработка и реализация необходимых изменений в коде может занять всего несколько минут.
SQL Server предоставляет набор разнообразных средств для предупреждения, обнаружения и оценки быстродействия медленно выполняющихся запросов. Возможности этих средств варьируются от пассивных (выполняется измерение реальной производительности, позволяющее следить, что и с какой скоростью выполняется) до более активных (позволяющих создать «регулятор» запросов, который будет автоматически уничтожать запросы, работающие дольше установленного вами времени).
Мы рассмотрим некоторые из них.
Трассировка выполнения процессов
Инструмент SQL Server Profiler по праву называют «спасательным средством» администратора и специалиста по сопровождению. Невозможно оценить исключительную важность этого инструментального средства при решении проблем быстродействия и не только. Именно SQL Server Profiler позволяет составить представление, что же «на самом деле» происходит на сервере. Однако настраивать трассировку следует так, чтобы она возвращала только необходимый минимум сведений. Нужно помнить о том, что SQL Server Profiler также необходимо пространство для аудита системы, и поэтому у системы могут появиться дополнительные накладные расходы, независимо от того, откуда был запущен SQL Server Profiler. Чем больше будет объем трассировочных сведений, тем больше увеличится нагрузка на систему.
В результате работы с SQL Server Profiler может быть составлен «черный список» запросов, выполняющихся недопустимо долго. Поскольку следует учитывать, что один и тот же параметризованный запрос может запускаться с разными параметрами, гораздо проще анализировать трассировки, представляющие собой вызовы хранимых процедур (и это нужно иметь в виду при разработке архитектуры БД!). Трассировку удобно сохранить в виде таблицы, которую затем можно обработать с помощью агрегатных запросов, с целью поставить в соответствие каждой процедуре количественное значение некоторого критерия, выбранного для сравнения процедур с точки зрения даваемой ими нагрузки на сервер. Такими критериями могут быть:
- Максимальное зафиксированное время выполнения процедуры (самый «неудачный» с точки зрения производительности запуск).
- Суммарное время выполнения всех вызовов процедуры.
- Среднее время выполнения процедуры (суммарное время выполнения всех вызовов процедуры, отнесенное к числу вызовов).
Оперативный мониторинг процессов, занимающих ресурсы сервера
Нагрузка на сервер, как правило, является непостоянной в течение дня. Если с помощью SQL Server Profiler удалось обнаружить, что процедуры выполняются существенно дольше «среднестатистического» времени, или (что вероятнее) пользователи жалуются, что «два часа назад все работало нормально, а сейчас очень медленно», возникает необходимость оперативно выяснить, какие процессы занимают ресурсы сервера именно сейчас, а также какие именно ресурсы являются конфликтными.
- Процессорное время (в этом случае нагрузка сервера максимальна, остальные процедуры выполняются, но медленнее обычного, так как на их «долю» ресурсов остается недостаточно).
- Таблица/страница/строка, заблокированная в рамках транзакции (в этом случае процессы, обратившиеся конфликтным ресурсам, стоят в очереди и ожидают освобождения; загрузка сервера при этом может быть обычной или даже меньше обычного).
SQL Server имеет встроенное средство для мониторинга процессов. На рис. 1 показан монитор активности от SQL Server 2005 [5].
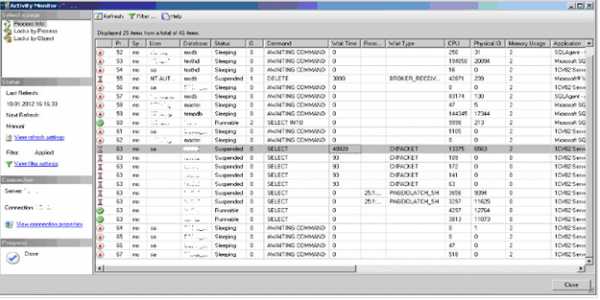 Рисунок 1. Мониторинг процессов.
Рисунок 1. Мониторинг процессов.К сожалению, администратору этот инструмент зачастую недоступен: в «час пик», если в базе работают сотни пользователей, на сбор данных с его помощью требуются десятки минут, что, разумеется, недопустимо. Тем же недостатком в различной степени страдают разнообразные системные хранимые процедуры служебной базы данных master.
В этом случае, как правило, используются самостоятельно разработанные запросы к системным таблицам master.dbo.sysprocess и master.dbo.syslocks, названия которых говорят сами за себя. Ниже (рис.2) приведен пример запроса, используемого одним из авторов при сопровождении БД именно в таких целях.
Наконец, можно узнать последнюю SQL-команду, которую отдал серверу интересующий нас процесс по его уникальному номеру spid с помощью специальной процедуры DBCC INPUTBUFFER (Spid).
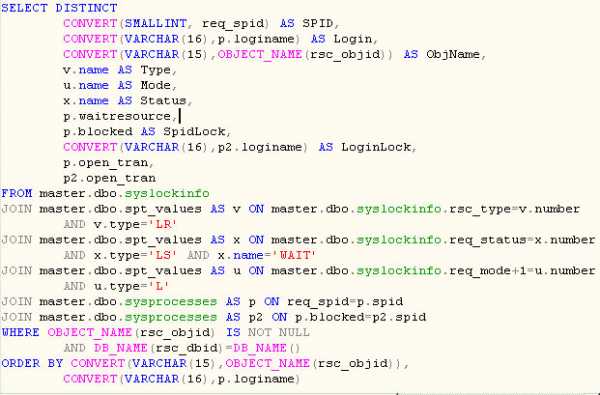 Рисунок 2. Запрос для просмотра текущих процессов, ожидающих заблокированный ресурс.
Рисунок 2. Запрос для просмотра текущих процессов, ожидающих заблокированный ресурс.Оптимизация SQL-кода
Так или иначе, разработчик получает список хранимых процедур, нуждающихся в оптимизации, и примеры их вызовов, выполняющиеся недостаточно быстро. Также он знает (или хотя бы предполагает, что знает) причину «медленной» работы:
- Ожидание ресурса, заблокированного в рамках транзакции, запущенной другим процессом;
- Неоптимальный план выполнения хранимой процедуры.
Работа по устранению каждой из этих причин имеет свою специфику.
Минимизация блокировок в системе
Задача минимизации блокировок в системе сложна в первую очередь потому, что приходится рассматривать различные сочетания вызовов процедур, выполняемых параллельно.
В реальной базе данных блокировки неизбежны. Рассмотрим базу данных торговой компании, реализующую учет товара на складе. Если несколько менеджеров параллельно запускают транзакции, которые в том числе бронируют для клиента товар А, блокировок и ожидания ресурсов не избежать: несколько процессов действительно должны последовательно изменить одну и ту же строку.
Поэтому, выясняя, подлежит ли блокировка устранению, рекомендуется ответить на следующие вопросы:
- Может ли объект блокировки (как правило, это таблица) быть конфликтным ресурсом? В каждой базе данных есть таблицы, по которым блокировки не должны возникать никогда.
- Какая часть таблицы (таблица/страница/строка) является конфликтным ресурсом? За очень редким исключением справедливо утверждение: «право на существование» имеет только блокировка по значению первичного ключа.
- Какие две параллельно выполняющиеся процедуры привели к возникновению блокировки? Имеют ли они общий конфликтный ресурс исходя из их функционального назначения?
- Если блокировка подлежит устранению – кто «виноват» в ее возникновении: процесс, неправильно заблокировавший ресурс, или процесс, неправильно к ресурсу обратившийся?
При написании запросов на изменение и удаление строк в таблице (операторы UPDATE и DELETE) в рамках транзакции следует помнить: эти операции должны выполняться только по первичному ключу! В противном случае сервер заблокирует таблицу целиком.
При написании запросов на выборку следует учитывать назначение полей таблицы, к которым выполняется обращение, а также назначение самого запроса. Возможно, что логика работы приложения допускает построение этого запроса с опциями, разрешающими чтение неподтвержденных данных (NOLOCK) или только незаблокированных строк (READPAST). Например, директор торговой сети периодически формирует и просматривает отчет о выполнении менеджерами планов по валовой прибыли за текущий месяц. При этом менеджеры активно совершают сделки, на сервере постоянно открыто несколько транзакций, проводящих или удаляющих соответствующие документы. Директору вовсе не нужно дожидаться, пока ему отдадут все ресурсы в монопольный доступ. Незавершенные транзакции можно просто не учитывать – они не могут серьезно изменить картину в целом.
Если процессы, вызывающие блокировку, обращаются к одной и той же строке, но к разным полям, то имеет смысл разбить таблицу на несколько, связанных друг с другом по схеме «один к одному».
Для исключения взаимоблокировок следует неукоснительно соблюдать один и тот же порядок опроса конфликтных ресурсов, при этом, по возможности, занимать ресурс, являющийся наиболее часто используемым, как можно ближе к концу транзакции.
Во время транзакции не должно осуществляться никакого интерактивного общения с пользователем (запрос параметров и т.п.), если есть хоть малейшая возможность этого избежать.
Транзакции должны быть настолько короткими, насколько это возможно для обеспечения целостности данных. Точно также уровень изоляции транзакции должен быть наименьшим из возможных.
Выбор индекса
Индексы являются очень мощным средством увеличения производительности сервера.
Разработчики склонны к крайностям при работе с индексами: либо не использовать их вовсе, либо создавать «на все случаи жизни».
Индексы должны создаваться для столбцов, которые будут часто использоваться в параметре WHERE либо, в меньшей степени, в параметре ORDER BY.
Однако, чем больше индексов в таблице, тем медленнее будут производиться операции вставки. С технической точки зрения каждый дополнительный индекс сказывается и на обновлении существующей информации, но в этом случае проблема не является столь глобальной, поскольку изменениям должны будут подвергнуться только те индексы, для которых модифицируемый столбец выступает в качестве части ключа.
Таким образом, если база данных организована так, что большая часть времени посвящена выполнению операторов SELECT, а изменения вносятся сравнительно редко, то чем больше индексов, тем лучше. В противном случае нужно ограничиться индексами только для наиболее часто используемых столбцов. Большую помощь в их определении может оказать мастер настройки индексов – специальный инструмент MS SQL Server, предназначенный для исследования рабочей нагрузки и поиска оптимального варианта внесения изменений в индексы.
Стратегическая денормализация
Иногда следование стандартным и, казалось бы, универсальным правилам, может навредить. На вопрос, в чем мы выигрываем, нормализуя базу данных, 90% вчерашних студентов бойко отвечают: «Обеспечивается целостность, устраняется избыточность и повышается быстродействие». При этом следующий вопрос о том, в чем же мы при этом проигрываем, приводит большинство в тупик. Далеко не все отдают себе отчет, что в хорошо нормализованной базе данных производительность повышается только при выполнении простых операций изменения данных, тогда как производительность запросов на выборку (а также в некоторых сложных случаях использования операторов DELETE, UPDATE и INSERT... SELECT) в лучшем случае не хуже, чем в слабо нормализованной базе данных. Часто добавление в таблицу всего лишь одного столбца может устранить необходимость в сложных объединениях, либо даже позволяет отказаться от объединений, включающих несколько таблиц, за счет чего время выполнения запроса уменьшается с нескольких минут до нескольких секунд.
Конечно, подобно большинству рассмотренных вопросов, данный вопрос имеет и оборотную сторону. Все имеющиеся в БД случаи денормализации существенно затрудняют жизнь разработчикам. Вначале требуется четко определить, чего именно планируется достичь, проверить, принесет ли денормализация желаемый эффект, а также оценить последствия возможного нарушения целостности данных (это особенно важно, если БД сопровождают несколько разработчиков). Если есть хоть малейшие сомнения – следует вернуться к стандартному способу работы с данными.
Правильная организация хранимых процедур
Реализация множественных решений
Примером может послужить поисковый запрос, допускающий множество параметров, но не требующий наличия всех. Вполне можно написать собственную хранимую процедуру, чтобы она просто запускала единственный запрос, независимо от того, сколько в действительности было задано параметров – достаточно универсальный подход. С точки зрения разработки – это громадная экономия времени, однако, если взглянуть на вещи с точки зрения оптимального быстродействия, такой подход убийственен. Более чем вероятно, что каждый раз при запуске вашей хранимой процедуры, сервер будет обращаться к нескольким абсолютно не нужным таблицам!
В такой ситуации можно поступить следующим образом: добавить в код несколько выражений IF . . . ELSE для проверки условий. Это уже может дать заметный эффект. Однако есть еще одна тонкость. Запуская такую процедуру с некоторым фиксированным набором параметров и исключая из недостижимых при данном вызове блоков IF . . . ELSE запросы на выборку, можно обнаружить, что время выполнения увеличивается иногда на порядок! Казалось бы, в чем причина? Ведь исключенные запросы все равно не запускались! К сожалению, SQL Server при составлении плана выполнения хранимой процедуры «не знает», что наши условия взаимоисключающие. Он исходит из худшего случая – что все операторы SELECT (а также INSERT, UPDATE и DELETE) будут выполняться последовательно. Алгоритмические конструкции (IF … ELSE, WHILE, GOTO) игнорируются. Поэтому с точки зрения быстродействия желательно, чтобы внутри блоков IF . . . ELSE помещались не запросы, а вызовы хранимых процедур, в каждой из которых содержится запрос для работы с каждым определенным набором параметров (вызов вложенной хранимой процедуры также игнорируется при составлении плана).
Данная проблема возникает во множестве написанных сценариев. Разработчики – тоже люди, и, как правило, они привыкли иметь дело с объектно-ориентированными языками и развитыми технологиями повторного использования кода. Можно представить, как они отнесутся (и относятся!) к идее написать кучу практически идентичных запросов, чтобы в зависимости от заданных параметров учесть все возможные нюансы применения. Однако этот случай, когда результат, достигаемый таким «возмутительным» образом, говорит сам за себя, и его невозможно достичь никаким другим способом. «По этому поводу я хочу сказать, что в любой работе случаются рутинные моменты, а иначе все давно уже стали бы разработчиками программного обеспечения. Иногда вам стоит, скрипнув зубами, все же проделать эту работу ради получения конечного результата» [2].
Минимальное использование курсоров и циклов
Программисты, работавшие на языках программирования высокого уровня, иногда широко используют курсоры. К сожалению, в среде SQL Server справедливо утверждение: все, что работает с использованием курсора, работает крайне медленно.
На самом деле многое, что, казалось бы, требует применения курсоров, может быть выполнено при помощи набора операций. Иногда искомое решение гораздо менее очевидно, чем цикл, но, как правило, оно вполне осуществимо. Ключевой момент здесь состоит в том, что, избавляясь от курсоров, где это только возможно, вы обеспечиваете грандиозный прирост производительности и одновременно упрощаете программный код [2].
Хорошей альтернативой курсорам с точки зрения производительности являются временные таблицы и табличные переменные. Начальный запрос создает рабочий набор данных. Затем запускается другой процесс, который и производит обработку этих данных.
На практике нужно помнить – операторы INSERT, UPDATE и DELETE – циклы сами по себе, и именно для выполнения таких и только таких циклов разрабатывался SQL Server. Один запрос на UPDATE (даже многотабличный, с вложенными JOIN), модифицирующий сразу 1000 строк выполняется в разы быстрее 1000 запросов, модифицирующих по одной строке.
Для выполнения рекурсивных запросов совсем отказаться от циклов невозможно. В этом случае рекомендуется использовать CTE (common table expression – общие табличные приложения), доступные, начиная с SQL Server 2005.
Заключение
В данной работе были рассмотрены цели и этапы настройки производительности СУБД MS SQL. Представлен обзор основных встроенных в СУБД инструментов мониторинга процессов. Собраны и систематизированы наиболее универсальные приемы оптимизации SQL-кода таким образом, чтобы можно было достичь максимальной производительности в условиях коммерческой базы данных.
novainfo.ru
Постраничная (пакетная, paging) выборка в MS SQL Server
От редактора. Данная версия статьи частично устарела, смотрите новый вариант с учетом изменений в SQL Server 2012
Материал этой статьи послужил основой для одной из глав книги "СУБД для программиста. Базы данных изнутри".
* * *
На дворе 2008 год, а разработчики MS SQL Server до сих пор не реализовали встроенную возможность ограничивать в запросах результирующую выборку номерами строк. Например, "выбрать заказы данного клиента, начиная с 10000-й строки и по 12000-ю". Нечто вроде простого и понятного:
SELECT O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code ORDER BY O.qty_date ASC LIMIT 10000, 12000Введенные в 2005-й версии функции ранжирования и в частности row_number() несколько скрасили серые будни рядовых разработчиков, но по сути проблему так и не решили. Дело в том, что конструкция LIMIT работает на уровне ядра СУБД, а функция row_number() - на пользовательском. Соответственно, скорость выполнения отличается принципиально, что особенно заметно на больших таблицах.
В данном обзоре я опишу различные методы решения задачи постраничной выборки (paging, пакетная выборка) на примере таблиц заказов и клиентов. Для тестов использовался MS SQL Server 2005 Service Pack 2 (9.00.3054.00) на рабочей станции с 2 Гб оперативной памяти (512 доступно под MS SQL) с двуядерным процессором Intel 1,8 ГГц.
Необходимо выбрать заказы всех итальянских клиентов (код страны "IT") пачками по 100 тысяч записей в каждом. Например, пакет с 400001-й строки и по 500000-ю - это четвертый пакет в серии. Заказов, соответствующим заданному критерию, в таблице порядка 800 тысяч. Всего же в таблице содержится примерно 4 млн 300 тыс. записей. Большим такое число не назовешь, но оно уже способно неплохо загрузить наш сервер для выявления оптимальных способов решения задачи.
Задача теста - выявить временные показатели выполения различных способов решения нашей задачи. Каждый способ выполняется в 4-х сериях тестов:
- Серия 1: с составным ключом из символьных (nvarchar) полей, SQL Server перезапускаем только в начале серии
- Серия 2: с составным ключом из символьных (nvarchar) полей, SQL Server перезапускаем перед каждым тестом серии
- Серия 3: с простым целочисленным ключом, SQL Server перезапускаем только в начале серии
- Серия 4: с простым целочисленным ключом, SQL Server перезапускаем перед каждым тестом серии
Перезапуск сервера производи для исключения влияния кэширования результатов предыдущих серий или отдельных тестов на последующие. После перезапуска всякий раз выполняем для "разогрева" - частичной загрузки данных в кэш и приближения к реальным условиям, следующий запрос:
SELECT count(*) FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT'Структура таблиц
Таблица заказов имеет простой целочисленный ключ, добавленный специально для тестов, и составной ключ из символьных полей. С небольшими упрощениями структура выглядит следующим образом.
CREATE TABLE dbo.customers ( customer_code nvarchar(15) NOT NULL, country_code nchar(2) NOT NULL, name nvarchar(255) NOT NULL, street_address nvarchar(100) NULL, city nvarchar(40) NULL, postal_code nvarchar(15) NULL, CONSTRAINT PK_CUSTOMERS PRIMARY KEY NONCLUSTERED (customer_code ASC) ) GO CREATE INDEX IX1_COUNTRY_CODE ON dbo.customers (country_code ASC) GO CREATE TABLE dbo.orders ( product_code nvarchar(18) NOT NULL, customer_code nvarchar(15) NOT NULL, order_type nvarchar(4) NOT NULL, qty_date datetime NOT NULL, qty int NOT NULL, order_id int NOT NULL, CONSTRAINT PK_ORDERS PRIMARY KEY NONCLUSTERED(order_id ASC), CONSTRAINT FK1_ORDERS_CUSTOMERS FOREIGN KEY(customer_code) REFERENCES dbo.customers (customer_code) ) GO CREATE UNIQUE INDEX AK1_ORDERS ON orders( product_code ASC, customer_code ASC, order_type ASC, qty_date ASC) GOДля каждого метода в качестве входных параметров мы определим два входых параметра: начальное смещение (@offset - заданный номер начальной строки выборки) и размер пакета (@batch_size - требуемое количество строк в выборке, начиная с заданной). Пример объявления и инициализации параметров перед выборкой:
DECLARE @offset int, @batch_size int; SELECT @offset = 1, @batch_size = 100;"Классический" способ с использованием стандартного SQL
У данного способа, видимо, есть только одно достоинство: запрос выполняется практически на любой СУБД. Принцип основан на соединении таблицы на саму себя (self join), что с миллионами записей более чем накладно. На таблицах же с несколькими тысячами/десятками тысяч записей способ вполне работоспособен. Так как окончания выполнения запроса на тестовом массиве данных я не дождался, то привожу только текст запроса без внесения результатов в сводную таблицу.
SELECT O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' AND (SELECT count(*) FROM orders O1 INNER JOIN customers C1 ON O1.customer_code = C1.customer_code WHERE C1.country_code = 'IT' AND O1.product_code <= O.product_code AND O1.customer_code <= O.customer_code AND O1.order_type <= O.order_type AND O1.qty_date <= O.qty_date ) BETWEEN @offset AND @offset + @batch_size - 1 ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASCВ первом запросе номера строк не выводятся. Для случая с простым ключом "order_id" этот недостаток легко исправить:
SELECT num, O.* FROM orders O INNER JOIN (SELECT count(*) AS num, O2.order_id FROM orders O1 INNER JOIN customers C1 ON O1.customer_code = C1.customer_code INNER JOIN orders O2 ON O1.order_id <= O2.order_id INNER JOIN customers C2 ON O2.customer_code = C2.customer_code AND C1.country_code = C2.country_code AND C1.country_code = 'IT' GROUP BY O2.order_id HAVING count(*) BETWEEN @offset AND @offset + @batch_size - 1 ) AS OO ON O.order_id = OO.order_id ORDER BY OO.num ASCИспользование функции row_number()
Пример использования функции имеется в документации к MS SQL Server (Books online), наш запрос выглядит похоже.
WITH ordered_orders AS ( SELECT O.*, row_number() OVER( ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC ) AS row_num FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' ) SELECT * FROM ordered_orders WHERE row_num BETWEEN 400001 AND 500000Использование временной таблицы
Заносим промежуточный результат (только ключевые поля) во временную таблицу с пронумерованными строками, отсекая по верхней границе, затем выбираем из нее нужный диапазон, соединяя с основной таблицей.
Не забудьте увеличить размер системной базы tempdb. Для данного примера она составила 1,5 Гбайта. В отсутствии верхнего предела для временных данных и заключается основной недостаток метода: чем больше исходная таблица и чем дальше от начального значения мы запрашиваем очередной пакет, тем больше потребуется заливать данных во временную таблицу. Конечно, дисковое пространство нынче большое и дешевое, но все таки винчестер не резиновый, да и скорость с ростом числа загружаемых во временную таблицу строк будет падать.
DECLARE @offset int, @batch_size int; SELECT @offset = 400001, @batch_size = 100000; CREATE TABLE #orders( row_num int identity(1, 1) NOT NULL, product_code nvarchar(18) NOT NULL, customer_code nvarchar(15) NOT NULL, order_type nvarchar(4) NOT NULL, qty_date datetime NOT NULL ); INSERT INTO #orders (product_code, customer_code, order_type, qty_date) SELECT TOP (@offset + @batch_size) O.product_code, O.customer_code, O.order_type, O.qty_date FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC; SELECT O.* FROM #orders T INNER JOIN orders O ON T.product_code = O.product_code AND T.customer_code = O.customer_code AND T.order_type = O.order_type AND T.qty_date = O.qty_date WHERE T.row_num BETWEEN @offset and @offset + @batch_size - 1; DROP TABLE #orders;Использование инструкции TOP
Принцип основан на отсечении нужного числа записей в двух запросах с противоположным порядком следования записей. По сути здесь нет отличий от способа со временной таблицей, кроме того, что она используется неявно. Однако, сравнив результаты, мы видим, что на небольших пакетах (100 записей) SQL Server манипулирует примежуточными выборками менее эффективно, чем в способе с явным использованием временных таблиц.
DECLARE @offset int, @batch_size int; SELECT @offset = 400001, @batch_size = 100000; SELECT TOP (@batch_size) * FROM (SELECT TOP (@offset + @batch_size) O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' ORDER BY O.product_code DESC, O.customer_code DESC, O.order_type DESC, O.qty_date DESC ) AS T1 ORDER BY product_code ASC, customer_code ASC, order_type ASC, qty_date ASCИспользование серверного курсора
Данный способ является не вполне документированным, так как функции работы с серверными курсорами не описаны в SQL Server Books Online, хотя они активно используются разработчиками Microsoft. Поэтому имеется весьма небольшой риск несовместимости с будущими версиями. Неофициальные описания функций можно найти, например, по ссылке.
DECLARE @handle int, @rows int; EXEC sp_cursoropen @handle OUT, 'SELECT O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = ''IT'' ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC', 1, -- Keyset-driven cursor 1, -- Read-only @rows OUT SELECT @rows; -- Contains total rows count EXEC sp_cursorfetch @handle, 16, -- Absolute row index 400001, -- Fetch from row 100000 -- Rows count to fetch EXEC sp_cursorclose @handle;Использование SET ROWCOUNT
Хотя способ использует стандартную настройку SET ROWCOUNT, но инициализация переменной в запросе, возвращающем более дной строки, его последним значением недокументирована. Во-вторых, как подтвердил эксперимент, данный метод не работает на составных ключах. Тем не менее, в случае простого ключа способ показал неплохие результаты.
DECLARE @order_id int; SET ROWCOUNT @offset; SELECT @order_id = O.order_id FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' ORDER BY O.order_id ASC; SET ROWCOUNT @batch_size; SELECT O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code WHERE C.country_code = 'IT' AND O.order_id >= @order_id ORDER BY O.order_id ASC; SET ROWCOUNT 0;Сводная таблица результатов выглядит следующим образом.
| Номер первой записи (смещение) | Размер пакета | Время выполнения, сек | |||||||||||||||||
| Row_number | Rowcount | Server cursor | Temp table | TOP | |||||||||||||||
| 1 | 2 | 3 | 4 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | ||
| 1 | 100 | 5 | 5 | 5 | 5 | 7 | 6 | 94 | 88 | 86 | 87 | 2 | 2 | 6 | 5 | 5 | 6 | 5 | 5 |
| 1000 | 100 | 24 | 29 | 24 | 30 | 26 | 51 | 36 | 90 | 34 | 87 | 1 | 3 | 24 | 58 | 25 | 32 | 24 | 32 |
| 10000 | 100 | 79 | 108 | 78 | 107 | 80 | 81 | 36 | 88 | 33 | 87 | 2 | 3 | 78 | 78 | 79 | 81 | 78 | 80 |
| 100000 | 100 | 246 | 358 | 234 | 343 | 240 | 78 | 36 | 88 | 30 | 87 | 13 | 28 | 240 | 79 | 250 | 82 | 236 | 81 |
| 200000 | 100 | 48 | 394 | 30 | 368 | 31 | 80 | 36 | 88 | 25 | 86 | 17 | 29 | 34 | 82 | 46 | 83 | 35 | 82 |
| 300000 | 100 | 47 | 405 | 20 | 379 | 21 | 78 | 32 | 88 | 24 | 87 | 21 | 13 | 25 | 80 | 49 | 84 | 24 | 82 |
| 400000 | 100 | 59 | 426 | 24 | 386 | 25 | 80 | 31 | 88 | 21 | 86 | 27 | 30 | 29 | 81 | 68 | 84 | 29 | 83 |
| 700000 | 100 | 88 | 450 | 45 | 399 | 36 | 81 | 27 | 89 | 18 | 88 | 42 | 19 | 46 | 87 | 107 | 88 | 47 | 85 |
| 400001 | 100000 | 434 | 443 | 395 | 394 | 98 | 94 | 123 | 102 | 102 | 103 | 106 | 125 | 97 | 98 | 96 | 98 | 95 | 95 |
| 500001 | 100000 | 125 | 468 | 40 | 399 | 17 | 94 | 50 | 102 | 45 | 102 | 59 | 125 | 21 | 100 | 47 | 97 | 43 | 96 |
| 600001 | 100000 | 104 | 468 | 44 | 406 | 16 | 94 | 49 | 102 | 45 | 102 | 63 | 116 | 26 | 100 | 45 | 100 | 43 | 97 |
| 700001 | 100000 | 122 | 473 | 67 | 411 | 12 | 91 | 46 | 101 | 39 | 98 | 61 | 127 | 18 | 99 | 41 | 100 | 37 | 97 |
Номера столбцов означают:(1) - использование составного ключа "product_code, customer_code, order_type, qty_date", перезапуск сервера перед каждой новой серией тестов(2) - то же что и (1), но с перезапуском сервера перед каждым новым тестом(3) - использование суррогатного ключа "order_id", перезапуск сервера перед каждой новой серией тестов(4) - то же что и (3), но с перезапуском сервера перед каждым новым тестом
Результаты в графике:
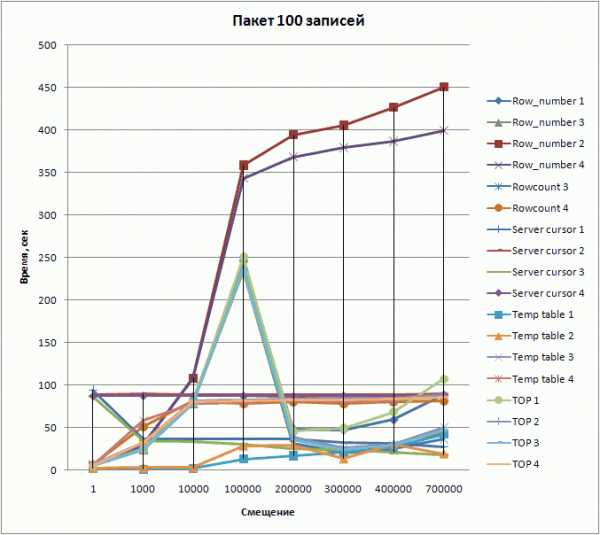
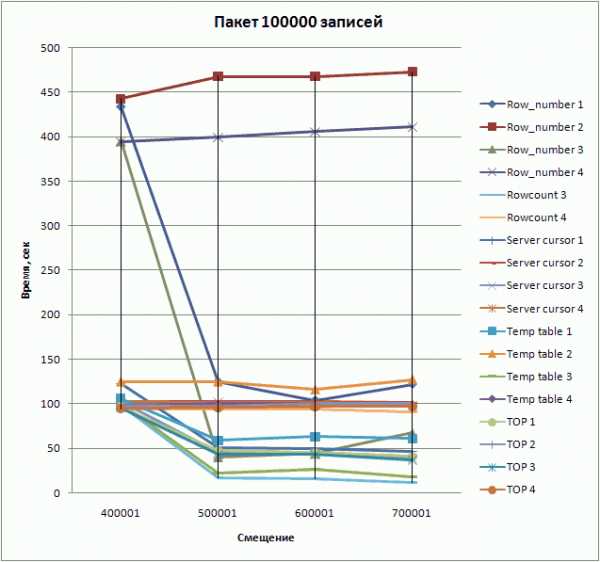
К сожалению, появившаяся в SQL Server 2005 новая функция ранжирования row_number() показала в целом плохие результаты в тестах по сравнению с другими методами. Наиболее быстрым оказался метод с установкой ROWCOUNT, но неприменим на составных ключах. У остальных способов есть свои достоинства и недостатки, их и необходимо учесть при выборе. Наиболее универсальным методом, одновременно показывающим приемлемую скорость выборки, является использование серверного курсора: он использует ваш исходный запрос в чистом виде без необходимости добавлять к нему условий ограничения диапазона выборки, что является очень важным при работе с возвращающими результат хранимыми функциями и процедурами или проекциями (view). Например, использование функции в способе с TOP зачастую приводит к удвоению времени выборки. И, будем надеяться, что в новых версиях разработчики Microsoft все-таки реализуют на уровне ядра конструкцию LIMIT.
www.arbinada.com
optimization - Каковы наилучшие методы оптимизации производительности SQL Server?
Применить правильную индексацию в столбцах таблицы в базе данных
- Убедитесь, что в каждой таблице базы данных есть первичный ключ.
Это обеспечит, чтобы каждая таблица создавала кластерный индекс (и, следовательно, соответствующие страницы таблицы физически сортируются на диске в соответствии с полем первичного ключа). Таким образом, любая операция извлечения данных из таблицы с использованием первичного ключа или любая операция сортировки в поле первичного ключа или любой диапазон значений первичного ключа, указанных в предложении where, будут очень быстро извлекать данные из таблицы.
-
Создайте некластеризованные индексы в столбцах
Часто используется в критериях поиска.
Используется для соединения с другими таблицами.
Используется как поля внешнего ключа.
Высокая избирательность (столбец, который возвращает низкий процент (0-5%) строк из общего количества строк на определенное значение).
Используется в предложении ORDER BY.
Не используйте "SELECT *" в SQL-запросе
Необязательные столбцы могут быть извлечены, что добавит затраты на время поиска данных. Механизм базы данных не может использовать преимущество "Covered Index" и, следовательно, запрос выполняется медленно.
Пример:
SELECT Cash, Age, Amount FROM Investments;Вместо:
SELECT * FROM Investments;Попытайтесь избежать предложения HAVING в операторах Select
Предложение HAVING используется для фильтрации строк после выбора всех строк и используется как фильтр. Старайтесь не использовать предложение HAVING для любых других целей.
Пример:
SELECT Name, count (Name) FROM Investments WHERE Name!= ‘Test’ AND Name!= ‘Value’ GROUP BY Name;Вместо:
SELECT Name, count (Name) FROM Investments GROUP BY Name HAVING Name!= ‘Test’ AND Name!= ‘Value’ ;Попробуйте минимизировать количество блоков вспомогательных запросов в запросе
Иногда у нас может быть несколько подзапросов в нашем основном запросе. Мы должны попытаться свести к минимуму количество блоков вспомогательных запросов в нашем запросе.
Пример:
SELECT Amount FROM Investments WHERE (Cash, Fixed) = (SELECT MAX (Cash), MAX (Fixed) FROM Retirements) AND Goal = 1;Вместо:
SELECT Amount FROM Investments WHERE Cash = (SELECT MAX (Cash) FROM Retirements) AND Fixed = (SELECT MAX (Fixed) FROM Retirements) AND Goal = 1;Избегайте ненужных столбцов в списке SELECT и ненужных таблиц в условиях соединения
Выбор ненужных столбцов в запросе Select добавляет служебные данные к фактическому запросу, особенно если ненужные столбцы имеют типы LOB. Включение ненужных таблиц в условия соединения заставляет механизм базы данных извлекать и извлекать ненужные данные и увеличивает время выполнения запроса.
Не используйте агрегат COUNT() в подзапросе, чтобы выполнить проверку существования
Когда вы используете COUNT(), SQL Server не знает, что вы делаете проверку существования. Он подсчитывает все соответствующие значения, либо путем сканирования таблицы, либо путем сканирования самого маленького некластеризованного индекса. Когда вы используете EXISTS, SQL Server знает, что вы выполняете проверку существования. Когда он находит первое совпадающее значение, он возвращает TRUE и перестает смотреть.
Попробуйте избежать соединения между двумя типами столбцов
При объединении двух столбцов разных типов данных один из столбцов должен быть преобразован в тип другого. Столбец, тип которого ниже, тот, который преобразован. Если вы присоединяетесь к таблицам с несовместимыми типами, один из них может использовать индекс, но оптимизатор запросов не может выбрать индекс для столбца, который он преобразует.
Попробуйте не использовать COUNT (*) для получения количества записей в таблице
Чтобы получить общее количество строк в таблице, мы обычно используем следующий оператор Select:
SELECT COUNT(*) FROM [dbo].[PercentageForGoal]Этот запрос выполнит полное сканирование таблицы, чтобы получить количество строк. Следующий запрос не требует полного сканирования таблицы. (Обратите внимание, что это может не дать вам 100% отличных результатов всегда, но это удобно, только если вам не нужен идеальный счет.)
SELECT rows FROM sysindexes WHERE id = OBJECT_ID('[dbo].[PercentageForGoal]') AND indid< 2Попробуйте использовать операторы типа EXISTS, IN и JOINS соответственно в вашем запросе
- Обычно IN имеет наименьшую производительность.
- IN эффективен, только когда большинство критериев фильтра для выбора помещаются в подзапрос инструкции SQL.
- EXISTS эффективен, когда большинство критериев фильтра для выбора находится в основном запросе оператора SQL.
Попробуйте избежать динамического SQL
Если это действительно необходимо, старайтесь избегать использования динамического SQL, потому что: Динамический SQL трудно отлаживать и устранять неполадки. Если пользователь предоставляет вход для динамического SQL, тогда есть вероятность атаки SQL-инъекций.
Старайтесь избегать использования временных таблиц
Если это действительно необходимо, старайтесь избегать использования временных таблиц. Скорее используйте переменные таблицы. В 99% случаев переменные таблицы хранятся в памяти, следовательно, это намного быстрее. Временные таблицы находятся в базе данных TempDb. Таким образом, работа на временных таблицах требует взаимодействия между базами данных и, следовательно, будет медленнее.
Вместо поиска LIKE используйте полнотекстовый поиск для поиска текстовых данных
Полнотекстовые поисковые запросы всегда превосходят LIKE-запросы. Полнотекстовый поиск позволит вам реализовать сложные критерии поиска, которые не могут быть реализованы с помощью поиска LIKE, например, поиск по одному слову или фразе (и, возможно, ранжирование набора результатов), поиск по слову или фразе, близкой к другой слово или фразу, или поиск синонимов формы определенного слова. Реализация полнотекстового поиска проще реализовать, чем поиск LIKE (особенно в случае сложных требований к поиску).
Попробуйте использовать UNION для реализации операции "ИЛИ"
Не пытайтесь использовать "ИЛИ" в запросе. Вместо этого используйте "UNION", чтобы объединить результирующий набор из двух выделенных запросов. Это улучшит производительность запросов. Лучше использовать UNION ALL, если не требуется выдающийся результат. UNION ALL быстрее, чем UNION, поскольку ему не нужно сортировать результирующий набор, чтобы узнать отличительные значения.
Реализовать ленивую стратегию загрузки для больших объектов
Храните столбцы большого объекта (например, VARCHAR (MAX), изображение, текст и т.д.) в другой таблице, чем основная таблица, и поместите ссылку на большой объект в основной таблице. Извлеките все основные данные таблицы в запросе, и если требуется большой объект для загрузки, извлеките большие данные объекта из таблицы больших объектов только тогда, когда это необходимо.
Внедрить следующие рекомендации в пользовательских функциях
Не вызывать функции повторно в своих хранимых процедурах, триггерах, функциях и партиях. Например, вам может потребоваться длина строковой переменной во многих местах вашей процедуры, но не называть функцию LEN всякий раз, когда это необходимо; вместо этого вызовите функцию LEN один раз и сохраните результат в переменной для последующего использования.
Внедрить следующие рекомендации в триггерах
- Старайтесь избегать использования триггеров. Запуск триггера и выполнение инициирующего события - дорогостоящий процесс.
- Никогда не используйте триггеры, которые могут быть реализованы с использованием ограничений.
- Не используйте один и тот же триггер для различных событий запуска (Insert, Update и Delete).
- Не используйте транзакционный код внутри триггера. Триггер всегда работает внутри транзакционной области кода, запускающего триггер.
qaru.site
Поиск узких мест ввода-вывода для MS SQL Server
Проблема
Суть проблематики данной статьи — регулярное замедление в работе баз данных SQL Server. После статей, посвящённых анализу использования памяти и CPU, мы хотели бы продолжить исследование причины замедления путём анализа узких мест ввода-вывода.
Решение
Подсистема ввода-вывода — ключевой фактор производительности SQL Server, поскольку страницы базы данных постоянно перемещаются с диска в буферный пул или обратно. Помимо этого существенный трафик ввода-вывода генерируют журналы транзакций и системная база данных tempDB. Учитывая эти факторы, Вы должны быть уверены, что используемая подсистема ввода-вывода работает стабильно, иначе проблемы в работе этой подсистемы приведут к увеличению времени отклика запросов и частым тайм-аутам. В этой статье я опишу несколько способов поиска узких мест ввода-вывода, используя для этого встроенные инструменты, и представлю некоторые идеи, связанные с конфигурацией дисков.
Performance Monitor
Чтобы определить загрузку подсистемы ввода-вывода, можно воспользоваться системной утилитой Performance Monitor. Перечисленные ниже счётчики производительности могут оказаться полезны для этих целей:
PhysicalDisk Object: Avg. Disk Queue Length. Этот счетчик показывает среднее число запросов чтения и записи, которые были поставлены в очередь для указанного физического диска. Чем выше это число, тем большее дисковых операций ожидает ввода-вывода. Если это значение во время пиковой нагрузки на SQL Server частенько превышает двойку, следует задуматься о необходимости принятия адекватных мер. Если используется несколько дисков, показания счётчика нужно разделить на число дисков в массиве и убедиться, не превышает ли результирующее значение число 2. Например, у Вас есть 4 диска и длина очереди диска 10, искомая глубина очереди находится следующим образом: 10/4 = 2,5, это и будет значением, которое нужно анализировать, а не 10.
Avg. Disk Sec/Read и Avg. Disk Sec/Write показывают среднее время чтения и записи данных на диск. Хорошо, если это значение не превышает 10 ms, но все еще приемлемо, если значение меньше 20 ms. Значения, превышающие этот порог, требуют исследования возможностей оптимизации.
Physical Disk: %Disk Time
- — время, которое диск был занят обслуживанием запросов записи или чтения. Это значение должно быть ниже 50%.
Disk Reads/Sec и Disk Writes/Sec — показатель уровня загруженности диска операциями чтения — записи. Значение должно быть меньше 85% от пропускной способности диска, поскольку при превышении этого порога время доступа увеличивается по экспоненте.Пропускную способность диска можно определить постепенно увеличивая нагрузку на систему. Одним из способов определения пропускной способности дисковой подсистемы является использование специализированной утилиты SQLIO. Она позволяет определить ту точку, где пропускная способность перестаёт расти при дальнейшем увеличении нагрузки.
При выборе конфигураций RAID можно использовать следующие формулы вычисления числа операций ввода-вывода (I/Os), приходящихся на один диск:
Raid 0: I/O на диск = (чтений + записей) / число дисков массиваRaid 1: I/O на диск = [чтений + (записей *2)] / 2Raid 5: I/O на диск = [чтений + (записей *4)] / число дисков массиваRaid 10: I/O на диск = [чтений + (записей *2)] / число дисков массива
Вот пример вычисления количества операций ввода-вывода на диск для RAID 1 на основе значений счетчиков:
Disk Reads/sec = 90Disk Writes/sec = 75Формула для ввода-вывода на RAID-1 массив является [чтений + (записей*2)] / 2 или [90 + (75*2)] / 2 = 120 I/Os на диск.
Динамические административные представления
Есть полезные динамические административные представления (DMV), с помощью которых можно выявить узкие места ввода-вывода.Специальный тип ожидания краткой блокировки для операции ввода-вывода (I/O latch) имеет место тогда, когда задача переходит в состояние ожидания завершения кратковременной блокировки буфера, находящегося в состоянии обслуживания запроса ввода-вывода. В зависимости от типа запроса, это приводит к появлению ожиданий с именами PAGEIOLATCH_EX или PAGEIOLATCH_SH. Длительные ожидания могут указывать на проблемы с дисковой подсистемой. Чтобы посмотреть статистику таких ожиданий можно использовать системное представление sys.dm_os_wait_stats. Для того, что бы определить наличие проблем ввода-вывода, нужно посмотреть значения waiting_task_counts и wait_time_ms при нормальной рабочей нагрузке SQL Server и сравнить их со значениями, полученными при ухудшении производительности.
select * from sys.dm_os_wait_stats where wait_type like 'PAGEIOLATCH%' ORDER BY wait_type asc
select * from sys.dm_os_wait_stats where wait_type like 'PAGEIOLATCH%' ORDER BY wait_type asc |
Ожидания запросов ввода-вывода можно посмотреть с помощью соответствующих DMV и эту информацию можно использовать для определения того, какой именно диск является узким местом.
select db_name(database_id), file_id, io_stall, io_pending_ms_ticks, scheduler_address from sys.dm_io_virtual_file_stats (NULL, NULL) iovfs, sys.dm_io_pending_io_requests as iopior where iovfs.file_handle = iopior.io_handle
select db_name(database_id), file_id, io_stall, io_pending_ms_ticks, scheduler_address from sys.dm_io_virtual_file_stats (NULL, NULL) iovfs, sys.dm_io_pending_io_requests as iopior where iovfs.file_handle = iopior.io_handle |
Дисковая фрагментация
Я рекомендую регулярно проверять уровень фрагментации и конфигурацию дисков, используемых экземпляром SQL Server.Фрагментация файлов на разделе NTFS может стать причиной существенной потери производительности. Диски должны регулярно дефрагментироваться. Исследование показывают, что в некоторых случаях диски, подключаемые из сетей SAN, менее производительны, если их файлы дефрагментированы, т.е. эти СХД оптимизированы под случайный ввод-вывод. Прежде чем устранять файловую фрагментацию, стоит выяснить, как она сказывается на производительности работы SAN.Фрагментация индексов также может стать причиной повышения нагрузки ввода-вывода на NTFS, но на это влияют уже другие условия, отличные от тех, что существенны для SAN, оптимизированных для случайного доступа.
Конфигурация дисков / Best Practices
Как правило, для повышения производительности, файлы журналов кладут на отдельные физические диски, а файлы данных размещают на других физических дисках. Ввод-вывод для высоко нагруженных файлов данных (включая tempDB) носит случайный характер. Ввод-вывод для файла журнала транзакций носит последовательный характер, кроме случаев отката транзакций.Встроенные в шасси сервера (локальные) диски можно использовать только для файлов журнала транзакций, потому что они хорошо ведут себя при последовательном вводе-выводе, а при случайном вводе-выводе ведут себя плохо.Файлы данных и журналов должны размещаться на разных дисковых массивах, у которых используются разные наборы физических дисков. В большинстве случаев, когда решение должно укладываться в не большой бюджет, я рекомендую размещать файл журнала транзакций на массиве RAID1, собранном из локальных дисков. Файлы данных БД лучше разместить на внешней системе хранения в сети SAN, так, чтобы к используемым для данных физическим дискам доступ получал только SQL Server, что позволит контролировать обслуживание его запросов и получать достоверные отчёты загрузки дисковой подсистемы. От подключения дисковых подсистем напрямую к серверу лучше отказаться.Кэширование записи должно быть включено везде, где только это возможно, и вы должны удостовериться, что кэш защищен от перебоев в питании и других возможных отказов (независимая батарея подпитки кэша на контроллере).Во избежание появления узких мест ввода-вывода для OLTP систем, лучше не смешивать нагрузки, характерные для OLTP и OLAP. Кроме того, удостоверьтесь, что серверный код оптимизирован и, где это необходимо, созданы индексы, которые тоже позволяют избавиться от ненужного ввода-вывода.
Автор: Ирина Наумова
Вконтакте
Google+
sqlcom.ru
Постраничная (пакетная, paging) выборка в MS SQL Server 2012
Материал этой статьи послужил основой для одной из глав книги "СУБД для программиста. Базы данных изнутри".
* * *
Хорошая новость: в SQL Server 2012, наконец, появилась возможность ограничивать выборку номером строки и размером пакета на уровне запроса. Точнее, на уровне инструкции ORDER BY. Означает ли это, что все ранее известные способы постраничной выборки станут ненужными? Ответить на этот вопрос нам помогут испытания.
По сравнению с предыдущими тестами SQL Server 2005, мы несколько упростим условия и автоматизируем процесс.
Исходные данные
Структура таблиц "customers" и "sales" для теста остается без особых изменений, используем целочисленные ключи и кластеры. Заполнение таблиц производится SQL-скриптом. Общее число продаж ограничено 10 миллионами при количестве клиентов в 10 тысяч. Используя генератор случайных значений, получаем равномерное распределение количества продаж по странам (скрипты для создания БД и вставки тестовых данных).
| country_code | sales_count |
| ES | 1424420 |
| FR | 1434608 |
| GE | 1391128 |
| IT | 1443384 |
| NL | 1414063 |
| RU | 1441266 |
| UK | 1451131 |
Запросы
Сценарий всех запросов заключается в выборке пакета из 100 записей, начиная с заданной, из массива продаж по выбранной стране. Сам запрос оформлен в виде проекции (view) "test_sales_data". Эта проекция используется в запросах производящих собственно пакетирование разными методами и оформленных в виде хранимых процедур (см. скрипт создания).
Сигнатура процедур одинакова (N - порядковый номер метода):
CREATE PROCEDURE dbo.test_paging_mN @offset int, @page_size int AS BEGIN ... реализация метода пакетирования ... ENDНиже приводим код реализации методов.
Метод 1: встроенный механизм ORDER BY в SQL Server 2012
SELECT * FROM dbo.test_sales_data ORDER BY id_product, id_customer, sale_date OFFSET @offset - 1 ROW FETCH NEXT @page_size ROWS ONLYМетод 2: функция ранжирования
WITH ordered_sales AS ( SELECT *, row_number() OVER( ORDER BY id_product, id_customer, sale_date) AS row_num FROM dbo.test_sales_data ) SELECT * FROM ordered_sales WHERE row_num BETWEEN @offset AND @offset + @page_size - 1;Метод 3: временная таблица
SELECT * INTO #s FROM dbo.test_sales_data WHERE 1 = 0; ALTER TABLE #s ADD row_num INT NOT NULL IDENTITY(1, 1) PRIMARY KEY; INSERT INTO #s SELECT TOP (@offset + @page_size - 1) * FROM dbo.test_sales_data ORDER BY id_product, id_customer, sale_date; SELECT * FROM #s WHERE row_num BETWEEN @offset and @offset + @page_size - 1;Метод 4: использование SELECT TOP
SELECT * FROM ( SELECT TOP (@page_size) * FROM (SELECT TOP (@offset + @page_size - 1) * FROM dbo.test_sales_data ORDER BY id_product ASC, id_customer ASC, sale_date ASC ) t1 ORDER BY id_product DESC, id_customer DESC, sale_date DESC ) t2 ORDER BY id_product, id_customer, sale_dateМетод 5: серверный курсор
Документация по API курсоров в MSDN.
DECLARE @handle int, @rows int; EXEC sp_cursoropen @handle OUT, 'SELECT * FROM dbo.test_sales_data ORDER BY id_product, id_customer, sale_date', 1, -- 0x0001 - Keyset-driven cursor 1, -- Read-only @rows OUT; -- Contains total rows count EXEC sp_cursorfetch @handle, 16, -- Absolute row index @offset, -- Fetch from row @page_size -- Rows count to fetch EXEC sp_cursorclose @handle;Результаты
Запуск тестов лучше делать из командной строки, чтобы не грузить SSMS десятками приходящих результатов выборок. Например так:
set SQL_BIN_HOME=C:\Program Files\Microsoft SQL Server\110\Tools\Binn "%SQL_BIN_HOME%\sqlcmd.exe" -S .\SQL2012 -d test_paging -E -i SQLServerPaging2_04_Test.sql -o Test.logПосле окончания тестов (в зависимости от мощности компьютера они длятся несколько десятков минут), запустите скрипт для получения результатов. Первая таблица дает значения времени выполнения "холодных" запросов (при очищенном кэше), вторая - среднее время из трех попыток при наличии данных и скомпилированного запроса в кэше.
На моем относительно слабом компьютере с одним медленным диском получились следующие данные и соответствующие им графики.
Таблица 1. Выборка "холодным" запросом, миллисекунды
| 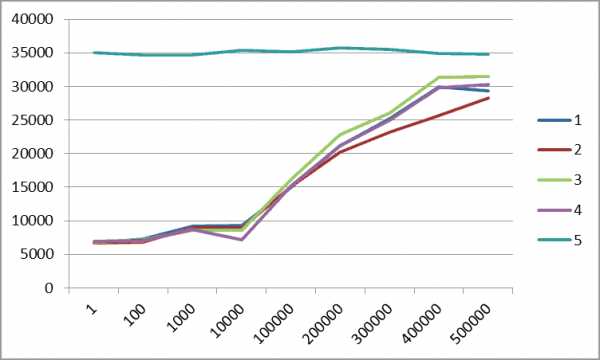 |
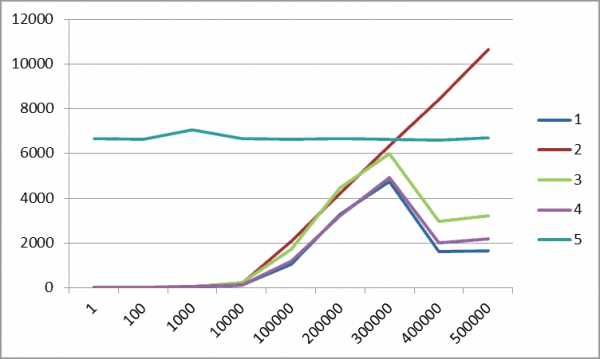
Таблица 2. Выборка "горячим" запросом, среднее время 3 попыток, миллисекунды
|  |
Выводы
Введенный в версии SQL Server 2012 метод пакетирования записей ORDER BY OFFSET ожидаемо показывает хорошие результаты, так как выполняется не на пользовательском уровне, а на уровне ядра СУБД. Использование этого способа можно рекомендовать всем разработчикам.
Тем не менее, метод "серверный курсор" по-прежнему показывает стабильное время выполнения, практически не растущее с объемом выборки. Этот метод остается важным для пакетирования обработки больших объемов данных, например, для вычислений по исходной таблице со многими миллионами (миллиардами) пачками, например, по несколько сотен тысяч.
Отдельный совет веб-программистам. Максимально ограничивайте возвращаемую веб-серверу выборку, чтобы не заниматься, как в тесте, пакетированием полутора миллионов записей. Нормальная ситуация, когда в ответ на запрос пользователю возвращается несколько десятков или сотен записей. Если запрос возвращает больше, выдавайте пользователю только TOP NNN записей и подсказку о необходимости ограничить запрос. И тогда вам в обычной ситуации не понадобится ни сверхмощный сервер, ни распределение нагрузки по СУБД-серверам.
www.arbinada.com
Как обеспечить производительность баз данных Microsoft SQL Server, размещаемых в облаке / Блог компании Техносерв / Хабрахабр
Источник
Всем привет! Сегодня хотим поговорить об облачных базах данных, а точнее о тех проактивных и разовых мероприятиях, которые непосредственно обеспечивают их производительность.
Облачные базы данных давно решили вопрос быстрого прироста мощностей и запуска новых баз данных, и сегодня стали практически насущной потребностью компаний любого размера, благодаря переносу задач по администрированию и мониторингу на сторону провайдера.
Мы проделали большую работу, запуская и оптимизируя свою новую услугу облачной базы данных на собственной платформе Техносерв Cloud и, конечно же, столкнулись с рядом проблем и выработали свои подходы к их решению. Сейчас, когда сервис протестирован и работает, мы хотим поделиться с вами своим опытом – уверены, что прочитав этот материал, вы сможете избежать повторения чужих ошибок или откроете для себя что-то новое.
Сегодня бизнесу приходится иметь дело с постоянно растущими объемами данных, поэтому возникла потребность каким-то образом облегчить задачу управления всеми этими огромными информационными массивами. Выход был найден благодаря внедрению платформ облачных вычислений и созданию облачных баз данных.
Согласно расчетам, объемы как структурированных, так и неструктурированных данных возрастают в среднем на 60% в год. До сих пор местом хранения всей этой информации служили традиционные базы данных, но этого оказалось недостаточно, и тогда на помощь пришли облачные технологии. Они избавили пользователей от необходимости выделять под базы данных собственные вычислительные мощности, возложив эту обязанность на провайдеров облачных сервисов. Такой подход оказался чрезвычайно продуктивным в плане повышения производительности и доступности баз данных, а также улучшения их масштабируемости.
В нашей статье мы решили сделать небольшой обзор наиболее оптимальных настроек и механизмов обеспечения производительности баз данных MS SQL Server. Данный список ни в коем случае не является исчерпывающим, поскольку рекомендации разработчиков и «лучшие отраслевые практики» корректируются со временем. Отследить все эти изменения и грамотно реализовать их может только команда профессиональных DBA (администраторов баз данных). Именно таким штатом специалистов располагает поставщик услуг облачных баз данных и, с большей вероятностью, наличием подобной команды не может похвастать большинство заказчиков.
Для обеспечения высокой доступности и высокой производительности БД MS SQL Server, размещаемых в облаке, в соответствии с рекомендациями Microsoft и лучшими практиками, мы проводим нижеследующие мероприятия.
Примечание: Хотя основная часть рекомендаций является общими, их применение на каждом конкретном сервере зависит от очень многих факторов. Поэтому ниже даются ссылки на соответствующие документы Microsoft c более детальной информацией.

Устанавливаем на все MS SQL серверы последние Service Packs / Cumulative Updates / Security Updates:
С 2016 года схема обновлений для Microsoft SQL Server была упрощена — теперь обновления выходят регулярно.
Общая последовательность установки обновлений приведена ниже (все обновления перед установкой на Производственных серверах — первоначально тестируем в Тестовом окружении):
• Устанавливаем последний пакет обновления Service Pack (SP). • Устанавливаем последнее кумулятивное обновление для Service Pack — Cumulative Update (CU). • В случае выхода Security Updates – также их устанавливаем. • В случае проблем ищем и применяем Critical On-Demand (COD) — фикс для их устранения.
Примечание: Хотя Microsoft рекомендует устанавливать последние CU как только они выходят, зачастую большинство компаний устанавливают только последний SP, а CU ставят только в случае, если в состав CU входит фикс для имеющейся на сервере проблемы. Мы согласуем данный процесс с закачиком в соответствии с его внутренними инструкциями, но всегда предлагаем вначале рассмотреть официальные рекомендации Microsoft.
Настраиваем оптимальные параметры использования памяти MS SQL Server и оптимальные параметры MaxDOP:
По умолчанию, MS SQL Server может динамически изменять требования к памяти на основе доступности системных ресурсов. По умолчанию параметр min server memory имеет значение 0, а параметр max server memory — значение 2 147 483 647 MБ. О выборе оптимальных параметров использования памяти MS SQL Server можно прочитать здесь.
Если MS SQL Server работает на многопроцессорном компьютере, он определяет оптимальную степень параллелизма, то есть количество процессоров, задействованных для выполнения одной инструкции, для каждого из планов параллельного выполнения. Для ограничения количества процессоров в плане параллельного выполнения может быть использован параметр max degree of parallelism. О выборе оптимальных параметров MaxDOP можно прочитать здесь.
Используем при необходимости trace flags:
Флаги трассировки в MS SQL Server являются своеобразными «переключателями» поведения сервера с заданного по умолчанию на другое. Информацию о флагах трассировки можно найти здесь.
Оптимизируем настройки базы “TempDB” и других системных баз:
В MS SQL Server входят следующие системные базы данных:
• “master” — в этой БД хранятся все данные системного уровня для экземпляра MS SQL Server; • “msdb” — используется агентом MS SQL Server для планирования предупреждений и задач; • “model” — используется в качестве шаблона для всех баз данных, создаваемых в экземпляре MS SQL Server. Изменение размера, параметров сортировки, модели восстановления и других параметров базы данных model приводит к изменению соответствующих параметров всех баз данных, создаваемых после изменения; • “Resource” — база данных только для чтения. Содержит системные объекты, которые входят в состав MS SQL Server. Системные объекты физически хранятся в базе данных Resource, но логически отображаются в схеме sys любой базы данных; • “TempDB” — рабочее пространство для временных объектов или взаимодействия результирующих наборов.
Рекомендациия для настройки оптимальной производительности базы данных “TempDB” можно найти здесь.
Корректно настраиваем параметры дефолтных расположений дата-файлов/лог-файлов:
Когда новая БД создается в MS SQL Server без явного указания расположения для дата-файла/ов и лог-файла, то MS SQL Server создает эти файлы в дефолтном расположении. Данное дефолтное расположение настраивается при установке MS SQL Server. О настройки параметров дефолтных расположений дата-файлов/лог-файлов можно прочитать здесь.
Используем оптимальные настройки дисковой подсистемы (быстрые накопители SSD, отформатированные с размером кластера 64К):
MS SQL Server имеет свои особенности хранения данных. В связи с этим подготовка дисковой подсистемы как на физическом, так и на логическом уровнях, учитывающие эти особенности, будет оказывать серьезное влияние на производительность. Подробнее об этом можно узнать здесь.
Настраиваем “Мгновенную инициализацию файлов базы данных”:
В MS SQL Server файлы данных могут быть инициализированы мгновенно. Мгновенная инициализация файлов освобождает место на диске, не заполняя пространство нулями. Вместо этого содержимое диска перезаписывается, поскольку в файлы записываются новые данные. Файлы журналов не могут быть инициализированы мгновенно. Подробности – здесь.
Используем разные сетевые интерфейсы для “пользовательской” и для “системной” нагрузок:
Наши сервера имеют несколько сетевых интерфейсов и каждый отдельно взятый интерфейс можно использовать под какую-то выделенную задачу, например, под трафик периодического резервного копирования. Такая конфигурация имеет свои плюсы, например, позволяет максимально жестко разграничить использование интерфейсов под особенности разных задач.

Источник
Проверяем, чтобы параметры “Auto Shrink” и “Auto Close” были выключены:
“Auto Shrink” (Автоматическое сжатие) указывает, что MS SQL Server будет периодически сжимать файлы базы данных (более подробно здесь). “Auto Close” (Автоматическое закрытие) указывает, что база данных будет закрыта после освобождения всех ее ресурсов и отсоединения всех пользователей (более подробно здесь).
Проверяем, чтобы параметры “Auto Create Statistics” и “Auto Update Statistics” были включены:
Если включен параметр “Auto Create Statistics” (Автоматическое создание статистики), то оптимизатор запросов в случае необходимости создает статистику по отдельным столбцам в предикате запроса, чтобы улучшить оценку количества элементов для плана запроса (более подробно здесь).
Если включен параметр “Auto Update Statistics” (Автоматическое обновление статистики), то оптимизатор запросов определяет, когда статистика может оказаться устаревшей, и обновляет ее, если она используется в запросе (более подробно здесь).
Используем при необходимости “Read Committed Snapshot Isolation”:
Термин “Snapshot” («Моментальный снимок») отражает тот факт, что все запросы в транзакции обнаруживают одинаковую версию, или моментальный снимок базы данных, который соответствует состоянию базы данных в момент начала транзакции. Транзакция моментального снимка не требует блокировок базовых строк или страниц данных, что позволяет выполнять другую транзакцию без ее блокировки предыдущей незавершенной транзакцией. Транзакции, изменяющие данные, не блокируют транзакции, в которых происходит чтение данных, а транзакции, считывающие данные, не блокируют транзакции, в которых происходит запись данных, что обычно также наблюдается при использовании уровня изоляции “Read Committed”, заданного по умолчанию в MS SQL Server. Применение такого подхода, предусматривающего отказ от блокировок, способствует значительному снижению вероятности взаимоблокировок в сложных транзакциях.
Включение параметра “Read Committed Snapshot Isolation” обеспечивает доступ к версиям строк из под дефолтного уровня изоляции “Read Committed”. Если параметр “Read Committed Snapshot Isolation” установлен в значение OFF, то для получения доступа к версиям строк потребуется явно задавать уровень изоляции моментального снимка для каждого сеанса (более подробно здесь).
Проверяем, чтобы параметр “Page Verify” была выставлена в “CHECKSUM”:
Если для параметра базы данных “Page Verify” указано значение “CHECKSUM”, то MS SQL Server рассчитывает контрольную сумму для содержимого страницы в целом и сохраняет значение в заголовке страницы при записи страницы на диск. При считывании страницы с диска контрольная сумма вычисляется повторно и сравнивается со значением из заголовка. Это помогает обеспечить высокий уровень целостности данных в файлах (более подробно здесь).
Дата-файл/ы и лог-файл БД размещаем на отдельных физических дисках:
Размещение файлов данных и файлов журнала на одном устройстве может привести к состязанию, что вызовет снижение производительности. Размещение файлов на разных дисках позволяет выполнять операции ввода-вывода для файлов данных и файлов журнала параллельно (более подробно здесь).
Создаем только один лог-файл БД:
Лог-файл используется MS SQL Server последовательно, а не параллельно, и нет никакого выигрыша по производительности иметь несколько лог-файлов (более подробно здесь).
Не допускаем появления фрагментации “Виртуального лог-файла (VLF)” БД:
Лог-файл БД внутренне разделен на разделы, именуемые виртуальными лог-файлами (Virtual Log Files – VLF), и чем выше фрагментация в лог-файле, тем больше число VLF. После того, как число VLF в лог-файле превысит 200, может ухудшиться производительность связанных с лог-файлом операций, таких как чтение лог-файла (скажем, для транзакционной репликации/отката), резервное копирование лог-файла и т.п. (более подробно здесь).
Выбираем корректные начальные размеры дата-файла/ов и лог-файла БД:
При создании базы данных файлы данных следует делать как можно большего размера, в соответствии с наибольшим предполагаемым объемом данных в базе данных. Например, если мы знаем, что сейчас у нас данных будет 50 ГБ, а через полгода добавится еще 50 ГБ, то начальный размер дата-файла лучше сразу сделать равным 100 ГБ (более подробно здесь).
Выбираем корректные параметры “Авто-роста” для дата-файла/ов и лог-файла БД:
Не рекомендуется использовать “Авто-рост” в процентах, так как, если размер файлов БД большой, то сам процесс увеличения базы может вызвать существенное снижение производительности, поэтому более предпочтительным является увеличение базы на фиксированный размер в МБ (более подробно здесь).
Постоянно отслеживаем размеры дата-файла/ов и лог-файла БД и при необходимости проактивно их увеличиваем во время минимальной нагрузки БД:
В производственной системе функцию “Авто-роста” следует использовать только как средство увеличения размера файлов в чрезвычайных обстоятельствах. Не рекомендуется использовать ее для повседневного управления ростом файлов данных БД. Для наблюдения за размерами файлов и их заблаговременного увеличения обычно используют оповещения или программы мониторинга. Это позволяет избежать фрагментации и перенести выполнение этих операций по обслуживанию на часы, когда нагрузка минимальна (более подробно здесь).

Источник
Выполняем проверку целостности данных БД:
Проверяем логическую и физическую целостность всех объектов в базе данных путем выполнения следующих операций (более подробно здесь):
• выполнение инструкции DBCC CHECKALLOC для базы данных; • выполнение инструкции DBCC CHECKTABLE для каждой таблицы и каждого представления в базе данных; • выполнение инструкции DBCC CHECKCATALOG для базы данных; • проверка содержимого каждого индексированного представления в базе данных; • проверка согласованности между файлами и директориями файловой системы и метаданными таблицы на уровне ссылок при хранении данных varbinary(max) в файловой системе с помощью FILESTREAM; • проверка данных компонента Service Broker в базе данных.
Выполняем кастомный index rebuild/reorganize в зависимости от фрагментации индексов:
MS SQL Server автоматически поддерживает состояние индексов при выполнении операций вставки, обновления или удаления в отношении базовых данных. Со временем эти изменения могут привести к тому, что данные в индексе окажутся разбросанными по базе данных (фрагментированными). Фрагментация имеет место в тех случаях, когда в индексах содержатся страницы, для которых логический порядок, основанный на значении ключа, не совпадает с физическим порядком в файле данных. Значительно фрагментированные индексы могут серьезно снижать производительность запросов и служить причиной замедления откликов приложения. Можно устранить фрагментацию путем реорганизации или перестроения индекса (более подробно здесь).
Обновляем статистику:
По умолчанию оптимизатор запросов обновляет статистику по мере необходимости для усовершенствования плана запроса. Обновление статистики гарантирует, что запросы будут компилироваться с актуальной статистикой. Однако обновление статистики вызывает перекомпиляцию запросов. Рекомендуется не обновлять статистику слишком часто, поскольку необходимо найти баланс между выигрышем в производительности за счет усовершенствованных планов запросов и потерей времени на перекомпиляцию запросов. Критерии выбора компромиссного решения зависят от приложения (более подробно здесь).
Не используем никакие “плохие” практики, например, такие как “регулярное сжатие”:
Данные, перемещаемые в процессе сжатия файла, могут быть разбросаны по любым доступным местам в файле. Это вызывает фрагментацию индекса и может увеличить время выполнения запросов, выполняющих поиск в диапазоне индекса (более подробно здесь).
При необходимости организовываем регулярную очистку БД от “старых” данных:
Зачастую компании должны хранить данные в течение какого-то времени, чтобы соответствовать требованиям действующего законодательства и своим внутренним требованиям. После того как данные становятся не нужны – обычно рекомендуется их удалять, что позволяет повысить производительность MS SQL Server и дает возможность более точно предсказывать возможный рост требований к серверному оборудованию (более подробно здесь).

Источник
Определяем лучшую стратегию бэкапирования БД в соответствии с требованиями заказчика по RTO/RPO и лучшими мировыми практиками:
MS SQL Server обеспечивает необходимую защиту важных данных, которые хранятся в базах данных. Чтобы минимизировать риск необратимой потери данных, необходимо регулярно создавать резервные копии баз данных, в которых будут сохраняться производимые изменения данных. Хорошо продуманная стратегия резервного копирования и восстановления защищает базы от потери данных при повреждениях, происходящих из-за различных сбоев (более подробно здесь).
Выполняем регулярное тестовое восстановление бэкапов БД:
Можно сказать, что стратегия восстановления отсутствует, пока резервные копии не протестированы. Очень важно полностью протестировать стратегию резервного копирования для каждой базы данных, восстанавливая копию базы данных в тестовую систему. Необходимо протестировать восстановление каждого типа резервной копии, которую планируется использовать (более подробно здесь).
Always On Failover Cluster Instances:
Экземпляры отказоустойчивой кластеризации AlwaysOn используют функциональные возможности отказоустойчивой кластеризации Windows Server (WSFC) для обеспечения высокого уровня доступности локальных ресурсов за счет избыточности на уровне экземпляра сервера — экземпляра отказоустойчивого кластера (FCI). Экземпляр отказоустойчивого кластера (FCI) является единственным экземпляром MS SQL Server, установленным на всех узлах отказоустойчивой кластеризации Windows Server (WSFC) и, возможно, в нескольких подсетях. Экземпляр отказоустойчивого кластера выглядит в сети как экземпляр MS SQL Server, запущенный на одном компьютере, но экземпляр отказоустойчивого кластера обеспечивает отработку отказа с переходом одного узла WSFC на другой узел, если текущий узел становится недоступным (более подробно здесь).
Always On availability groups:
Группы доступности AlwaysOn — это решение высокой доступности и аварийного восстановления, являющееся альтернативой зеркальному отображению баз данных (“database mirroring”). Группа доступности поддерживает отказоустойчивую среду для набора пользовательских баз данных, известных как базы данных доступности, которые совместно выполняют переход на другой ресурс. Группа доступности поддерживает набор первичных баз данных для чтения/записи и от одного до восьми наборов соответствующих вторичных баз данных. Кроме того, вторичные базы можно сделать доступными только для чтения и/или для некоторых операций резервного копирования (более подробно здесь).
Database mirroring:
Зеркальное отображение базы данных — это решение, нацеленное на повышение доступности базы данных MS SQL Server. Зеркальное отображение каждой базы данных осуществляется отдельно и работает только с теми базами данных, которые используют модель полного восстановления (более подробно здесь).
Log shipping:
MS SQL Server позволяет автоматически отправлять резервные копии журналов транзакций из базы данных-источника экземпляра сервера-источника в одну или более баз данных-получателей других экземпляров сервера-получателя. Резервные копии журналов транзакций применяются к каждой из баз данных-получателей индивидуально (более подробно здесь).
Мониторинг сервера относится к категории жизненно важных мероприятий. Эффективное наблюдение подразумевает регулярное создание моментальных снимков текущей производительности для обнаружения процессов, вызывающих неполадки, и постоянный сбор данных для отслеживания тенденций роста или изменения производительности.

Источник
Постоянная оценка производительности базы данных помогает добиться оптимальной производительности путем минимизации времени ответа и максимального увеличения пропускной способности. Приблизительный сетевой трафик, дисковый ввод-вывод и загрузка ЦП — ключевые факторы, влияющие на производительность. Следует тщательно проанализировать требования приложения, понять логическую и физическую структуру данных, оценить использование базы данных и добиться компромисса между такими конфликтующими нагрузками, как оперативная обработка транзакций (OLTP) и поддержка решений (более подробно здесь).
habr.com
- Abbyy finereader 12

- Как восстановить страницу в контакте если ее вскрыли

- Как подключить сетевой адаптер windows 7 на ноутбуке

- Hkcu что это
- Рабочее окружение

- Как восстановить страницу в одноклассниках если заблокировали
- Как ноутбук подключить к телевизору через провод

- Авторизация на php и регистрация
- Как сделать скриншот без программы

- Не отвечает компьютер

- Закрыть доступ к сайтам