Хранимые процедуры SQL: создание и использование. Процедуры sql
Передача табличных данных из хранимой процедуры / Хабр
1 Метод
Один из самых простых методов. Используем конструкцию insert ... exec ...if object_id(N'tempdb..#t1',N'U') is not null drop table #t1 create table #t1(p1 int, p2 varchar(max)) insert #t1 exec Proc1 select * from #t1Плюсы и минусы:
- Передаваемые поля перечисляются 2 раза (это внутренний select, внешнее создание таблицы и insert). Плюс перечисление полей происходит при каждом новом аналогичном вызове. (Я добавляю данный критерий, т.к. при большом количестве правок и множестве мест вызова процедуры, процесс изменения выводимых данных становится очень трудоемким)
- Имеет серьезное ограничение – мы можем получить только одну таблицу
- Для работы процедуры в режиме простого вывода не требуются дополнительные действия, достаточно запустить exec Proc1 без insert
2 Метод
С помощью записи в ранее созданную таблицу. Здесь придется добавлять insert в процедуру:create procedure Proc1 as begin insert #t1(p1, p2) select 1 p1, 'b' p2 end По сути мы перенесли строку insert внутрь процедуры.if object_id(N'tempdb..#t1',N'U') is not null drop table #t1 create table #t1(p1 int, p2 varchar(max)) exec Proc1 select * from #t1Плюсы и минусы:
- Передаваемые поля перечисляются 2 раза, и еще по одному перечислению на каждое новое использование
- Для работы процедуры в режиме простого вывода потребуется либо писать отдельную процедуру, выводящую принятые от Proc1 таблицы, либо определять, когда их выводить внутри Proc1. Например, по признаку не существования таблицы для вставки:
3 Метод
По сути, является доработкой второго метода. Чтобы упростить поддержку создаем пользовательский тип таблицы. Выглядит это примерно так:create type tt1 as table(p1 int, p2 varchar(max)) go create procedure Proc1 as begin insert #t1(p1, p2) select 1 p1, 'b' p2 end go -- используем: declare @t1 tt1 if object_id(N'tempdb..#t1',N'U') is not null drop table #t1 select * into #t1 from @t1 exec Proc1 select * from #t1Плюсы и минусы:
- Передаваемые поля перечисляются 2 раза, при этом каждое новое использование не добавляет сложности
- Для организации непосредственного вывода результата также требуются дополнительные действия
4 Метод
Усложнение третьего метода, позволяющее создавать таблицу с ограничениями и индексами. В отличии от предыдущего работает под Microsoft SQL Server 2005.create procedure Proc1 as begin insert #t1(p1, p2) select 1 p1, 'b' p2 end go create procedure Proc1_AlterTable as begin alter table #t1 add p1 int, p2 varchar(max) alter table #t1 drop column delmy end go -- используем: if object_id(N'tempdb..#t1',N'U') is not null drop table #t1 create table #t1(delmy int) exec Proc1_AlterTable exec Proc1 select * from #t1 Однако обычно временная колонка delmy не используется, вместо неё таблица создается просто с одним первым столбцом (здесь с p1).Плюсы и минусы:
- Передаваемые поля перечисляются 2 раза, при этом каждое новое использование не добавляет сложности
- Для непосредственного вывода результата также требуются дополнительные действия
- Неожиданно обнаружилось, что иногда, по непонятным причинам, возникают блокировки на конструкции alter table #t1, и процесс ожидает полного завершения Proc1 (не Proc1_AlterTable!) параллельного запроса. Если кто-нибудь знает, с чем это связанно — поделитесь, буду рад услышать:)
5 Метод
Этот метод использует предварительно созданные процедуры. Он основан на включении динамического SQL-запроса в запускаемую процедуру. Однако является достаточно простым в использовании.Для его использования процедуры необходимо обработать следующим образом:
1. В начало процедуры включить строки:
if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int) exec util.InclusionBegin 2. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с #Output (Например into #Output, into #Output5, into #OutputMySelect). Если процедура не создает результирующего набора, то действие не требуется 3. В конец процедуры включить строку:exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке их создания после запуска util.InclusionBegin Для нашего примера мы получаем:create procedure Proc1 as begin if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int) exec util.InclusionBegin select 1 p1, 'b' p2 into #Output1 exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке их создания после запуска util.InclusionBegin end Запуск осуществляется так:if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int, val varchar(max)) exec util.InclusionRun' select * from #InclusionOutput1 ', 1, '#InclusionOutput' exec Proc1 Поскольку генерируемый SQL это не всегда хорошо, то приведенный пример лучше подходит для небольших инструкций. Если кода достаточно много, то можно либо вынести его в отдельную процедуру и из динамической части осуществлять только exec вызов, либо перезалить данные в новые временные таблицы. В последнем случае, конечно, происходит ещё одно «лишнее» копирование, но часто бывает так, что на этом этапе мы можем предварительно сгруппировать результат и выбрать только нужные поля для дальнейшей обработки (например, если в каком-либо случае не требуется все возвращаемые данные).- @sql – SQL-скрипт, который выполниться внутри вызываемой процедуры
- @notShowOutput – если = 1, то блокировать вывод таблиц, начинающихся с #Output
- @replaceableTableName – (по умолчанию = '#Output') задать префикс в имени таблиц используемых в @sql, для замены его на соответствующую #Output* таблицу в скрипте. Например, если задать #InclusionOutput, и в процедуре созданы две таблицы #Output55 и #Output0A, то в @sql можно обратиться к #Output55 как к #InclusionOutput1, а к #Output0A как к #InclusionOutput2
Работа построена таким образом, что запуск Proc1, без предварительного запуска util.InclusionRun приводит к естественной работе процедуры с выводом всех данных, которые она выводила до обработки.
Нюансы использования:
- Накладывает ограничения на использование инструкции return в процедуре, т.к. перед ней необходим запуск util.InclusionEnd
- Выводящие результат select'ы из запускаемых процедур выводят результат раньше, чем даже те #Output-таблицы, которые были созданы до их вызова (это логично, т.к. вывод происходит только в util.InclusionEnd)
Плюсы и минусы:
- Передаваемые поля перечисляются один раз, при этом каждое новое использование не добавляет сложности
- Для непосредственного вывода результата не требуется никаких действий
- Необходимо помнить и учитывать нюансы использования
- Из-за дополнительных процедур выполняется больше инструкций, что может снизить быстродействие при частых вызовах (я думаю, что при запуске реже одного раза в секунду этим можно пренебречь)
- Возможно, может усложнить понимание кода для сотрудников не знакомых с данным методом: процедура приобретает два exec-вызова и неочевидность того, что все #Output-таблицы будут выведены
- Позволяет легко организовать модульное тестирование без внешних инструментов
Демонстрация использования:
Скрытый текстКод:if object_id('dbo.TestInclusion') is not null drop procedure dbo.TestInclusion go create procedure dbo.TestInclusion @i int as begin if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int) exec util.InclusionBegin if object_id('tempdb..#tmp2', 'U') is not null drop table #tmp2 select @i myI into #tmp2 if object_id('tempdb..#tmp3', 'U') is not null drop table #tmp3 select @i + 1 myI into #tmp3 select * into #Output0 --На вывод (выводится в util.InclusionEnd) from #tmp2 union all select * from #tmp3 select 'процедура TestInclusion' alt into #OutputQwerty --На вывод (выводится в util.InclusionEnd) exec util.InclusionEnd --выводит все таблицы начинающиеся с #Output в порядке из создания после запуска util.InclusionBegin end go set nocount on set ansi_warnings off if object_id('tempdb..#ttInclusionParameters', 'U') is not null drop table #ttInclusionParameters go select 'Тест 1: запуск TestInclusion. Ниже должен быть вывод таблицы с одной колонкой myI и двумя строками: 2 и 3. И таблица с 1 строкой: "процедура TestInclusion"' exec dbo.TestInclusion 2 go select 'Тест 2: тест TestInclusion. Ниже должен быть вывод таблицы с одной колонкой testSum и одной строкой: 5' if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int, val varchar(max)) exec util.InclusionRun ' select sum(myI) testSum from #InclusionOutput1 ', 1, '#InclusionOutput' exec dbo.TestInclusion 2
Сами функции:
Скрытый текстif not exists(select top 1 null from sys.schemas where name = 'util') begin exec ('create schema util') end go alter procedure util.InclusionBegin as begin /* Инструкция для использования: 1. Обработка процедуры данные которой необходимо использовать 1.1. В начало процедуры включить строки: if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int) exec util.InclusionBegin 1.1. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с #Output (Например into #Output, into #Output5, into #OutputMySelect) 1.2. В конец процедуры включить строку: exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке из создания после запуска util.InclusionBegin 2. В месте, где вызывается обработанная процедура, непосредственно до её запуска включить строки (иначе процедура будет просто выводить все #Output* таблицы): if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int) exec util.InclusionRun('<sql скрипт который выполнится внутри вызываемой процедуры перед её завершением>') Дополнительно см. коментарии внутри util.InclusionRun */ set nocount on set ansi_warnings off declare @lvl int if object_id('tempdb..#ttInclusionParameters', 'U') is not null begin select @lvl = max(lvl) from #ttInclusionParameters --Добавляем null задание, для предотвращения запуска скрипта во вложенных процедурах с данным механизмом if (@lvl is not null) begin insert #ttInclusionParameters(lvl, pr) select @lvl+1 lvl, null pr end end if object_id('tempdb..#ttInclusion', 'U') is not null begin --запоминаем все уже существующие таблицы #Output, чтобы в util.InclusionEnd не выводить их insert #ttInclusion(lvl, i) select isnull(@lvl, 0), so.object_id i from tempdb.sys.objects so where so.type = 'U' and so.name like '#[^#]%' and object_id('tempdb..' + so.name, 'U') is not null and not exists (select top 1 null from #ttInclusion where i = so.object_id) end end GO go alter procedure util.InclusionEnd as begin /* Инструкция для использования: 1. Обработка процедуры данные которой необходимо использовать 1.1. В начало процедуры включить строки: if object_id('tempdb..#ttInclusion', 'U') is null create table #ttInclusion(lvl int, i int) exec util.InclusionBegin 1.1. Все выводящие select'ы процедуры переделать на создание временных таблиц начинающихся с #Output (Например into #Output, into #Output5, into #OutputMySelect) 1.2. В конец процедуры включить строку: exec util.InclusionEnd --выводит все таблицы, начинающиеся с #Output, в порядке из создания после запуска util.InclusionBegin 2. В месте, где вызывается обработанная процедура, непосредственно до её запуска включить строки (иначе процедура будет просто выводить все #Output* таблицы): if object_id('tempdb..#ttInclusionParameters', 'U') is null create table #ttInclusionParameters(lvl int, pr int) exec util.InclusionRun('<sql скрипт который выполнится внутри вызываемой процедуры перед её завершением>') Дополнительно см. коментарии внутри util.InclusionRun */ set nocount on set ansi_warnings off ---------------------------------------------------------------------------------------------------- --считываем параметры declare @lvl int , @p0 varchar(max) --(@sql) sql скрипт который необходимо выполнить , @p1 varchar(max) --(@notShowOutput) если равно '1' хотя бы у одного из существующих вложенности заданий, то НЕ выводим #Output, иначе селектим их , @p2 varchar(max) --(@replaceableTableName) заменяемый префекс таблицы if object_id('tempdb..#ttInclusionParameters', 'U') is not null begin --считываем глобальные параметры select @p1 = max(val) from #ttInclusionParameters where pr = 1 --находим уровень на котором наше задание (max(lvl) - это уровень с null который мы добавили в util.InclusionBegin) select @lvl = max(lvl) - 1 from #ttInclusionParameters if @lvl is not null begin --считываем select @p0 = max(case when pr = 0 then val end) , @p2 = max(case when pr = 2 then val end) from #ttInclusionParameters where lvl = @lvl having max(pr) is not null --удаляем задание на скрипт, а если его нет, то только null-задание delete #ttInclusionParameters where lvl >= @lvl and (lvl > @lvl or @p0 is not null) end end ---------------------------------------------------------------------------------------------------- --выбираем все созданные таблицы #Output if object_id('tempdb..#InclusionOutputs', 'U') is not null drop table #InclusionOutputs create table #InclusionOutputs(i int, tableName varchar(max), num int) if object_id('tempdb..#ttInclusion', 'U') is not null begin insert #InclusionOutputs(i, tableName, num) select so.object_id i, left(so.name, charindex('_', so.name)-1) tableName, row_number() over (order by so.create_date) num from tempdb.sys.objects so where so.type = 'U' and so.name like '#[^#]%' and object_id('tempdb..' + so.name, 'U') is not null and so.name like '#Output%' and not exists (select top 1 null from #ttInclusion where i = so.object_id and lvl <= isnull(@lvl, lvl)) --очищаем список созданных таблиц, которые принадлежат обрабатываемому уровню delete #ttInclusion where lvl <= @lvl end else begin insert #InclusionOutputs(i, tableName, num) select so.object_id i, left(so.name, charindex('_', so.name)-1) tableName, row_number() over (order by so.create_date) num from tempdb.sys.objects so where so.type = 'U' and so.name like '#[^#]%' and object_id('tempdb..' + so.name, 'U') is not null and so.name like '#Output%' end ---------------------------------------------------------------------------------------------------- --Выполнение заданий (если его не было - вывод всех #Output) declare @srcsql varchar(max) --Выполняем заданный скрипт в util.InclusionRun if (@p0 is not null and @p0 <> '') begin --заменяем псевдонимы @replaceableTableName if (@p2 is not null and @p2 <> '') begin select @p0 = replace(@p0, @p2 + cast(num as varchar(10)), replace(tableName, '#', '#<tokenAfterReplace>')) from #InclusionOutputs order by num desc select @p0 = replace(@p0, '<tokenAfterReplace>', '') end --добавляем в скрипт select @srcsql = isnull(@srcsql + ' ' + char(13), '') + @p0 + ' ' + char(13) end --Выводим созданные #Output таблицы if (@p1 is null or @p1 <> '1') --если равно 1, то не выполняем! begin --отступ от прошлого скрипта select @srcsql = isnull(@srcsql + ' ' + char(13), '') --добавляем в скрипт select @srcsql = isnull(@srcsql + ' ', '') + 'select * from ' + tableName from #InclusionOutputs order by num asc end if (@srcsql is not null) begin exec (@srcsql) end end go alter procedure util.InclusionRun @sql varchar(max), --sql скрипт который выполниться внутри вызываемой процедуры (содержащей util.InclusionEnd) @notShowOutput bit, --если = 1, то блокировать вывод таблиц начинающихся с #Output @replaceableTableName varchar(100) = '#Output' -- задать префикс в имени таблиц используемых в @sql, для замены его на соответствующую #Output* таблицу в скрипте. -- Например, если задать #InclusionOutput, и в процедуре созданы две таблицы #Output55 и #Output0A, -- то в @sql можно обратиться к #Output55 как к #InclusionOutput1, а к #Output0A как к #InclusionOutput2 as begin set nocount on set ansi_warnings off if object_id('tempdb..#ttInclusionParameters', 'U') is null begin print 'Процедура util.InclusionRun не выполнена, т.к. для неё не созданна таблица #ttInclusionParameters! ' return end declare @lvl int select @lvl = isnull(max(lvl), 0) + 1 from #ttInclusionParameters insert #ttInclusionParameters(lvl, pr, val) select @lvl, 0, @sql union all select @lvl, 1, '1' where @notShowOutput = 1 union all select @lvl, 2, @replaceableTableName end
Другие методы
Можно воспользоваться передачей параметра из функции (OUTPUT) и на основе его значения восстановить таблицу. Например, можно передать курсор или XML. На эту тему существует статья. Использовать курсор для этой задачи я не вижу смысла, только если изначально требуется именно курсор. А вот XML выглядит перспективным. Здесь очень интересные результаты тестов на производительность. Интересно услышать какие вы используете способы упрощения этой задачи :)UPD 31.03.2014: Скорректировал пост по идеям из комментариев
habr.com
Оптимизация хранимых процедур в SQL Server / Хабр
Доброго дня, хабрачеловек. Сегодня я бы хотел обсудить с вами тему хранимых процедур в SQL Server 2000-2005. В последнее время их написание занимало львиную долю моего времени на работе и чего уж тут скрывать – по окончанию работы с этим делом осталось достаточно информации, которой с удовольствием поделюсь с тобой %пользовательимя%. Знания, которыми я собираюсь поделиться, к сожалению,(или к счастью) не добыты мной эмперически, а являются, в большей степени, вольным переводом некоторых статей из буржуйских интернетов. Итак, как можно понять из названия речь пойдет об оптимизации. Сразу оговорюсь, что все действия, которые я сейчас буду описывать, действительно дают существенный(некоторые больший, некоторые меньший) прирост производительности. Данная статья не претендует на полное раскрытие темы оптимизации, скорее это собрание практик, которые я применяю в своей работе и могу ручаться за их эффективность. Поехали!1. Включай в свои процедуры строку — SET NOCOUNT ON: С каждым DML выражением, SQL server заботливо возвращает нам сообщение содержащее колличество обработанных записей. Данная информация может быть нам полезна во время отладки кода, но после будет совершенно бесполезной. Прописывая SET NOCOUNT ON, мы отключаем эту функцию. Для хранимых процедур содержащих несколько выражений или\и циклы данное действие может дать значительный прирост производительности, потому как колличество трафика будет значительно снижено.
CREATE PROC dbo.ProcName AS SET NOCOUNT ON; --Здесь код процедуры SELECT column1 FROM dbo.TblTable1 --Перключение SET NOCOUNT в исходное состояние SET NOCOUNT OFF; GO
2. Используй имя схемы с именем объекта: Ну тут думаю понятно. Данная операция подсказывает серверу где искать объекты и вместо того чтобы беспорядочно шарится по своим закромам, он сразу будет знать куда ему нужно пойти и что взять. При большом колличестве баз, таблиц и хранимых процедур может значительно сэкономить наше время и нервы.
SELECT * FROM dbo.MyTable --Вот так делать хорошо -- Вместо SELECT * FROM MyTable --А так делать плохо --Вызов процедуры EXEC dbo.MyProc --Опять же хорошо --Вместо EXEC MyProc --Плохо!3. Не используй префикс «sp_» в имени своих хранимых процедур: Если имя нашей процедуры начинается с «sp_», SQL Server в первую очередь будет искать в своей главной базе данных. Дело в том, что данный префикс используется для личных внутренних хранимых процедур сервера. Поэтому его использование может привести к дополнительным расходам и даже неверному результату, если процедура с таким же имененем как у вас будет найдена в его базе.
4. Используй IF EXISTS (SELECT 1) вместо IF EXISTS (SELECT *): Чтобы проверить наличие записи в другой таблице, мы используем выражение IF EXISTS. Данное выражение возвращает true если из внутреннего выражения возвращается хоть одно изначение, не важно «1», все колонки или таблица. Возращаемые данные, в принципе никак не используются. Таким образом для сжатия трафика во время передачи данных логичнее использовать «1», как показано ниже:
IF EXISTS (SELECT 1 FROM sysobjects WHERE name = 'MyTable' AND type = 'U')
5. Используй TRY-Catch для отлова ошибок: До 2005 сервера после каждого запроса в процедуре писалось огромное колличество проверок на ошибки. Больше кода всегда потребляет больше ресурсов и больше времени. С 2005 SQL Server'ом появился более правильный и удобный способ решения этой проблемы:
BEGIN TRY --код END TRY BEGIN CATCH --код отлова ошибки END CATCH
Заключение В принципе на сегодня у меня всё. Еще раз повторюсь, что здесь лишь те приёмы, которые использовал лично я в своей практике, и могу ручаться за их эффективность.
P.S. Мой первый пост, не судите строго.
habr.com
Хранимые процедуры SQL: создание и использование
Хранимые процедуры SQL представляют собой исполняемый программный модуль, который может храниться в базе данных в виде различных объектов. Другими словами, это объект, в котором содержатся SQL-инструкции. Эти хранимые процедуры могут быть выполнены в клиенте прикладных программ, чтобы получить хорошую производительность. Кроме того, такие объекты нередко вызываются из других сценариев или даже из какого-либо другого раздела.
Многие считают, что они похожи на процедуры различных языков программирования высокого уровня (соответственно, кроме MS SQL). Пожалуй, это действительно так. У них есть схожие параметры, они могут выдавать схожие значения. Более того, в ряде случаев они соприкасаются. Например, они сочетаются с базами данных DDL и DML, а также с функциями пользователя (кодовое название – UDF).
В действительности же хранимые процедуры SQL обладают широким спектром преимуществ, которые выделяют их среди подобных процессов. Безопасность, вариативность программирования, продуктивность – все это привлекает пользователей, работающих с базами данных, все больше и больше. Пик популярности процедур пришелся на 2005-2010 годы, когда вышла программа от "Майкрософт" под названием «SQL Server Management Studio». С ее помощью работать с базами данных стало гораздо проще, практичнее и удобнее. Из года в год такой способ передачи информации набирал популярность в среде программистов. Сегодня же MS SQL Server является абсолютно привычной программой, которая для пользователей, «общающихся» с базами данных, встала наравне с «Экселем».
При вызове процедуры она моментально обрабатывается самим сервером без лишних процессов и вмешательства пользователя. После этого можно осуществлять любые действия с информацией: удаление, исполнение, изменение. За все это отвечает DDL-оператор, который в одиночку совершает сложнейшие действия по обработке объектов. Причем все это происходит очень быстро, а сервер фактически не нагружается. Такая скорость и производительность позволяют очень быстро передавать большие объемы информации от пользователя на сервер и наоборот.
Для реализации данной технологии работы с информацией существует несколько языков программирования. К ним можно отнести, например, PL/SQL от системы управления базами данных Oracle, PSQL в системах InterBase и Firebird, а также классический «майкрософтовский» Transact-SQL. Все они предназначены для создания и выполнения хранимых процедур, что позволяет в крупных обработчиках баз использовать собственные алгоритмы. Это нужно и для того, чтобы те, кто осуществляет управление такой информацией, могли защитить все объекты от несанкционированного доступа сторонних лиц и, соответственно, создания, изменения или удаления тех или иных данных.
Эти объекты баз данных могут быть запрограммированы различными путями. Это позволяет пользователям выбирать тип используемого способа, который будет наиболее подходящим, что экономит силы и время. Кроме того, процедура сама обрабатывается, что позволяет избежать огромных временных затрат на обмен между сервером и пользователем. Также модуль можно перепрограммировать и изменить в нужное направление в абсолютно любой момент. Особенно стоит отметить скорость, с которой происходит запуск хранимой процедуры SQL: это процесс происходит быстрее иных, схожих с ним, что делает его удобным и универсальным.
Такой тип обработки информации отличается от схожих процессов тем, что он гарантирует повышенную безопасность. Это обеспечивается за счет того, что доступ других пользователей к процедурам может быть исключен целиком и полностью. Это позволит администратору проводить операции с ними самостоятельно, не опасаясь за перехват информации или несанкционированный доступ к базе данных.
Связь между хранимой процедурой SQL и клиентским приложением заключается в использовании параметров и возвращаемых значениях. Последним не обязательно передавать данные в хранимую процедуру, однако эта информация (в основном по запросу пользователя) и перерабатывается для SQL. После того как хранимая процедура завершила свою работу, она отсылает пакеты данных обратно (но, опять же, по желанию) к вызвавшему его приложению, используя различные методы, с помощью которых может быть осуществлен как вызов хранимой процедуры SQL, так и возврат, например:
- передача данных с помощью параметра типа Output;
- передача данных с помощью оператора возврата;
- передача данных с помощью оператора выбора.
А теперь разберемся, как же выглядит этот процесс изнутри.
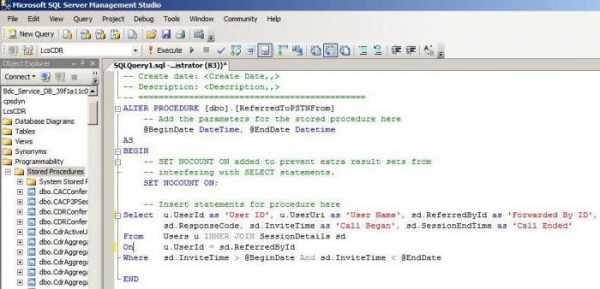
Вы можете создать процедуру в MS SQL (Managment Studio). После того как создастся процедура, она будет перечислена в программируемый узел базы данных, в которой процедура создания выполняется оператором. Для выполнения хранимые процедуры SQL используют EXEC-процесс, который содержит имя самого объекта.
При создании процедуры ее название появляется первым, после чего производится один или несколько параметров, присвоенных ему. Параметры могут быть необязательными. После того как параметр(ы), то есть тело процедуры, будут написаны, нужно провести некоторые необходимые операции.
Дело в том, что тело может иметь локальные переменные, расположенные в ней, и эти переменные являются локальными также по отношению к процедурам. Другими словами, их можно рассматривать только внутри тела процедуры Microsoft SQL Server. Хранимые процедуры в таком случае считаются локальными.
Таким образом, чтобы создать процедуру, нам нужно имя процедуры и, по меньшей мере, один параметр в качестве тела процедуры. Обратите внимание, что отличным вариантом в таком случае является создание и выполнение процедуры с именем схемы в классификаторе.
Тело процедуры может иметь любой вид из операторов SQL, например, такие как создание таблицы, вставки одного или нескольких строк таблицы, установление типа и характера базы данных и так далее. Тем не менее тело процедуры ограничивает выполнение некоторых операций в нем. Некоторые из важных ограничений перечислены ниже:
- тело не должно создавать какой-либо другой хранимой процедуры;
- тело не должно создать ложное представление об объекте;
- тело не должно создавать никаких триггеров.
Вы можете сделать переменные локальными для тела процедуры, и тогда они будут находиться исключительно внутри тела процедуры. Хорошей практикой является создание переменных в начале тела хранимой процедуры. Но также вы можете устанавливать переменные в любом месте в теле данного объекта.
Иногда можно заметить, что несколько переменных установлены в одной строке, и каждый переменный параметр отделяется запятой. Также обратите внимание, что переменная имеет префикс @. В теле процедуры вы можете установить переменную, куда вы хотите. К примеру, переменная @NAME1 может объявлена ближе к концу тела процедуры. Для того чтобы присвоить значение объявленной переменной используется набор личных данных. В отличие от ситуации, когда объявлено более одной переменной в одной строке, в такой ситуации используется только один набор личных данных.
Часто пользователи задают вопрос: «Как назначить несколько значений в одном операторе в теле процедуры?» Что ж. Вопрос интересный, но сделать это гораздо проще, чем вы думаете. Ответ: с помощью таких пар, как «Select Var = значение». Вы можете использовать эти пары, разделяя их запятой.
В самых различных примерах люди показывают создание простой хранимой процедуры и выполнение ее. Однако процедура может принимать такие параметры, что вызывающий ее процесс будет иметь значения, близкие к нему (но не всегда). Если они совпадают, то внутри тела начинаются соответствующие процессы. Например, если создать процедуру, которая будет принимать город и регион от вызывающего абонента и возвращать данные о том, сколько авторов относятся к соответствующим городу и региону. Процедура будет запрашивать таблицы авторов базы данных, к примеру, Pubs, для выполнения этого подсчета авторов. Чтобы получить эти базы данных, к примеру, Google загружает сценарий SQL со страницы SQL2005.

В предыдущем примере процедура принимает два параметра, которые на английском языке условно будут называться @State и @City. Тип данных соответствует типу, определенному в приложении. Тело процедуры имеет внутренние переменные @TotalAuthors (всего авторов), и эта переменная используется для отображения их количества. Далее появляется раздел выбора запроса, который все подсчитывает. Наконец, подсчитанное значение выводится в окне вывода с помощью оператора печати.
Есть два способа выполнения процедуры. Первый путь показывает, передавая параметры, как разделенный запятыми список выполняется после имени процедуры. Допустим, мы имеем два значения (как в предыдущем примере). Эти значения собираются с помощью переменных параметров процедуры @State и @City. В этом способе передачи параметров важен порядок. Такой метод называется порядковая передача аргументов. Во втором способе параметры уже непосредственно назначены, и в этом случае порядок не важен. Этот второй метод известен как передача именованных аргументов.
Процедура может несколько отклоняться от типичной. Все так же, как и в предыдущем примере, но только здесь параметры сдвигаются. То есть параметр @City хранится первым, а @State хранится рядом со значением по умолчанию. Параметр по умолчанию выделяется обычно отдельно. Хранимые процедуры SQL проходят как просто параметры. В этом случае, при условии, параметр «UT» заменяет значение по умолчанию «СА». Во втором исполнении проходит только одно значение аргумента для параметра @City, и параметр @State принимает значение по умолчанию «СА». Опытные программисты советуют, чтобы все переменные по умолчанию располагались ближе к концу списка параметров. В противном случае исполнение не представляется возможным, и тогда вы должны работать с передачей именованных аргументов, что дольше и сложнее.

Существует три важных способа отправки данных в вызванной хранимой процедуре. Они перечислены ниже:
- возврат значения хранимой процедуры;
- выход параметра хранимых процедур;
- выбор одной из хранимых процедур.
В этой методике процедура присваивает значение локальной переменной и возвращает его. Процедура может также непосредственно возвращать постоянное значение. В следующем примере, мы создали процедуру, которая возвращает общее число авторов. Если сравнить эту процедуру с предыдущими, вы можете увидеть, что значение для печати заменяется обратным.
Теперь давайте посмотрим, как выполнить процедуру и вывести значение, возвращаемое ей. Выполнение процедуры требует установления переменной и печати, которая проводится после всего этого процесса. Обратите внимание, что вместо оператора печати вы можете использовать Select-оператор, например, Select @RetValue, а также OutputValue.
Ответное значение может быть использовано для возврата одной переменной, что мы и видели в предыдущем примере. Использование параметра Output позволяет процедуре отправить одно или несколько значений переменных для вызывающей стороны. Выходной параметр обозначается как раз-таки этим ключевым словом «Output» при создании процедуры. Если параметр задан в качестве выходного параметра, то объект процедуры должен присвоить ему значение. Хранимые процедуры SQL, примеры которых можно увидеть ниже, в таком случае возвращаются с итоговой информацией.
В нашем примере будет два выходных имени: @TotalAuthors и @TotalNoContract. Они указываются в списке параметров. Эти переменные присваивают значения внутри тела процедуры. Когда мы используем выходные параметры, вызывающий абонент может видеть значение, установленное внутри тела процедуры.
Кроме того, в предыдущем сценарии две переменные объявляются, чтобы увидеть значения, которые установливают хранимые процедуры MS SQL Server в выходном параметре. Тогда процедура выполняется путем подачи нормального значения параметра «CA». Следующие параметры являются выходными и, следовательно, объявленные переменные передаются в установленном порядке. Обратите внимание, что при прохождении переменных выходное ключевое слово также задается здесь. После того, как процедура выполнена успешно, значения, возвращаемые с помощью выходных параметров, выводятся на окно сообщений.
Эта техника используется для возврата набора значений в виде таблицы данных (RecordSet) к вызывающей хранимой процедуре. В этом примере SQL хранимая процедура с параметрами @AuthID запрашивает таблицу «Авторы» путем фильтрации возвращаемых записей с помощью этого параметра @AuthId. Оператор Select решает, что должно быть возвращено вызывающему хранимой процедуры. При выполнении хранимой процедуры AuthId передается обратно. Такая процедура здесь всегда возвращает только одну запись или же вообще ни одной. Но хранимая процедура не имеет каких-либо ограничений на возвращение более одной записи. Нередко можно встретить примеры, в которых возвращение данных с использованием избранных параметров с участием вычисленных переменных происходит путем предоставления нескольких итоговых значений.
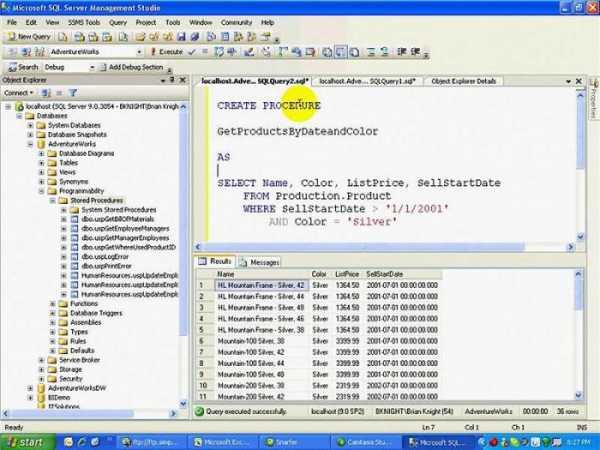
Хранимая процедура является довольно серьезным программным модулем, возвращающим или передающим, а также устанавливающим необходимые переменные благодаря клиентскому приложению. Поскольку хранимая процедура выполняется на сервере сама, обмена данными в огромных объемах между сервером и клиентским приложением (для некоторых вычислений) можно избежать. Это позволяет снижать нагрузки на сервера SQL, что, конечно же, идет на руку их держателям. Одним из подвидов являются хранимые процедуры T SQL, однако их изучение необходимо тем, кто занимается созданием внушительных баз данных. Также существует большое, даже огромное количество нюансов, которые могут быть полезны при изучении хранимых процедур, однако это нужно больше для тех, кто планирует плотно заняться программированием, в том числе профессионально.
Наперекор всем стереотипам: девушка с редким генетическим расстройством покоряет мир моды Эту девушку зовут Мелани Гайдос, и она ворвалась в мир моды стремительно, эпатируя, воодушевляя и разрушая глупые стереотипы.
15 симптомов рака, которые женщины чаще всего игнорируют Многие признаки рака похожи на симптомы других заболеваний или состояний, поэтому их часто игнорируют. Обращайте внимание на свое тело. Если вы замети.
Непростительные ошибки в фильмах, которых вы, вероятно, никогда не замечали Наверное, найдется очень мало людей, которые бы не любили смотреть фильмы. Однако даже в лучшем кино встречаются ошибки, которые могут заметить зрител.
11 странных признаков, указывающих, что вы хороши в постели Вам тоже хочется верить в то, что вы доставляете своему романтическому партнеру удовольствие в постели? По крайней мере, вы не хотите краснеть и извин.
7 частей тела, которые не следует трогать руками Думайте о своем теле, как о храме: вы можете его использовать, но есть некоторые священные места, которые нельзя трогать руками. Исследования показыва.
Почему некоторые дети рождаются с "поцелуем ангела"? Ангелы, как всем нам известно, относятся доброжелательно к людям и их здоровью. Если у вашего ребенка есть так называемый поцелуй ангела, то вам нечег.
Материалы: http://fb.ru/article/258492/hranimyie-protseduryi-sql-sozdanie-i-ispolzovanie
razvitielife.ru
Хранимые процедуры SQL: создание и использование
Хранимые процедуры SQL представляют собой исполняемый программный модуль, который может храниться в базе данных в виде различных объектов. Другими словами, это объект, в котором содержатся SQL-инструкции. Эти хранимые процедуры могут быть выполнены в клиенте прикладных программ, чтобы получить хорошую производительность. Кроме того, такие объекты нередко вызываются из других сценариев или даже из какого-либо другого раздела.

Введение
Многие считают, что они похожи на процедуры различных языков программирования высокого уровня (соответственно, кроме MS SQL). Пожалуй, это действительно так. У них есть схожие параметры, они могут выдавать схожие значения. Более того, в ряде случаев они соприкасаются. Например, они сочетаются с базами данных DDL и DML, а также с функциями пользователя (кодовое название – UDF).
В действительности же хранимые процедуры SQL обладают широким спектром преимуществ, которые выделяют их среди подобных процессов. Безопасность, вариативность программирования, продуктивность – все это привлекает пользователей, работающих с базами данных, все больше и больше. Пик популярности процедур пришелся на 2005-2010 годы, когда вышла программа от "Майкрософт" под названием «SQL Server Management Studio». С ее помощью работать с базами данных стало гораздо проще, практичнее и удобнее. Из года в год такой способ передачи информации набирал популярность в среде программистов. Сегодня же MS SQL Server является абсолютно привычной программой, которая для пользователей, «общающихся» с базами данных, встала наравне с «Экселем».
При вызове процедуры она моментально обрабатывается самим сервером без лишних процессов и вмешательства пользователя. После этого можно осуществлять любые действия с информацией: удаление, исполнение, изменение. За все это отвечает DDL-оператор, который в одиночку совершает сложнейшие действия по обработке объектов. Причем все это происходит очень быстро, а сервер фактически не нагружается. Такая скорость и производительность позволяют очень быстро передавать большие объемы информации от пользователя на сервер и наоборот.
Для реализации данной технологии работы с информацией существует несколько языков программирования. К ним можно отнести, например, PL/SQL от системы управления базами данных Oracle, PSQL в системах InterBase и Firebird, а также классический «майкрософтовский» Transact-SQL. Все они предназначены для создания и выполнения хранимых процедур, что позволяет в крупных обработчиках баз использовать собственные алгоритмы. Это нужно и для того, чтобы те, кто осуществляет управление такой информацией, могли защитить все объекты от несанкционированного доступа сторонних лиц и, соответственно, создания, изменения или удаления тех или иных данных.
Продуктивность
Эти объекты баз данных могут быть запрограммированы различными путями. Это позволяет пользователям выбирать тип используемого способа, который будет наиболее подходящим, что экономит силы и время. Кроме того, процедура сама обрабатывается, что позволяет избежать огромных временных затрат на обмен между сервером и пользователем. Также модуль можно перепрограммировать и изменить в нужное направление в абсолютно любой момент. Особенно стоит отметить скорость, с которой происходит запуск хранимой процедуры SQL: это процесс происходит быстрее иных, схожих с ним, что делает его удобным и универсальным.
Безопасность
Такой тип обработки информации отличается от схожих процессов тем, что он гарантирует повышенную безопасность. Это обеспечивается за счет того, что доступ других пользователей к процедурам может быть исключен целиком и полностью. Это позволит администратору проводить операции с ними самостоятельно, не опасаясь за перехват информации или несанкционированный доступ к базе данных.

Передача данных
Связь между хранимой процедурой SQL и клиентским приложением заключается в использовании параметров и возвращаемых значениях. Последним не обязательно передавать данные в хранимую процедуру, однако эта информация (в основном по запросу пользователя) и перерабатывается для SQL. После того как хранимая процедура завершила свою работу, она отсылает пакеты данных обратно (но, опять же, по желанию) к вызвавшему его приложению, используя различные методы, с помощью которых может быть осуществлен как вызов хранимой процедуры SQL, так и возврат, например:
- передача данных с помощью параметра типа Output;
- передача данных с помощью оператора возврата;
- передача данных с помощью оператора выбора.
А теперь разберемся, как же выглядит этот процесс изнутри.
1. Создание EXEC-хранимой процедуры в SQL
Вы можете создать процедуру в MS SQL (Managment Studio). После того как создастся процедура, она будет перечислена в программируемый узел базы данных, в которой процедура создания выполняется оператором. Для выполнения хранимые процедуры SQL используют EXEC-процесс, который содержит имя самого объекта.
При создании процедуры ее название появляется первым, после чего производится один или несколько параметров, присвоенных ему. Параметры могут быть необязательными. После того как параметр(ы), то есть тело процедуры, будут написаны, нужно провести некоторые необходимые операции.

Дело в том, что тело может иметь локальные переменные, расположенные в ней, и эти переменные являются локальными также по отношению к процедурам. Другими словами, их можно рассматривать только внутри тела процедуры Microsoft SQL Server. Хранимые процедуры в таком случае считаются локальными.
Таким образом, чтобы создать процедуру, нам нужно имя процедуры и, по меньшей мере, один параметр в качестве тела процедуры. Обратите внимание, что отличным вариантом в таком случае является создание и выполнение процедуры с именем схемы в классификаторе.
Тело процедуры может иметь любой вид из операторов SQL, например, такие как создание таблицы, вставки одного или нескольких строк таблицы, установление типа и характера базы данных и так далее. Тем не менее тело процедуры ограничивает выполнение некоторых операций в нем. Некоторые из важных ограничений перечислены ниже:
- тело не должно создавать какой-либо другой хранимой процедуры;
- тело не должно создать ложное представление об объекте;
- тело не должно создавать никаких триггеров.
2. Установка переменной в тело процедуры
Вы можете сделать переменные локальными для тела процедуры, и тогда они будут находиться исключительно внутри тела процедуры. Хорошей практикой является создание переменных в начале тела хранимой процедуры. Но также вы можете устанавливать переменные в любом месте в теле данного объекта.
Иногда можно заметить, что несколько переменных установлены в одной строке, и каждый переменный параметр отделяется запятой. Также обратите внимание, что переменная имеет префикс @. В теле процедуры вы можете установить переменную, куда вы хотите. К примеру, переменная @NAME1 может объявлена ближе к концу тела процедуры. Для того чтобы присвоить значение объявленной переменной используется набор личных данных. В отличие от ситуации, когда объявлено более одной переменной в одной строке, в такой ситуации используется только один набор личных данных.
Часто пользователи задают вопрос: «Как назначить несколько значений в одном операторе в теле процедуры?» Что ж. Вопрос интересный, но сделать это гораздо проще, чем вы думаете. Ответ: с помощью таких пар, как «Select Var = значение». Вы можете использовать эти пары, разделяя их запятой.
3. Создание хранимой процедуры SQL
В самых различных примерах люди показывают создание простой хранимой процедуры и выполнение ее. Однако процедура может принимать такие параметры, что вызывающий ее процесс будет иметь значения, близкие к нему (но не всегда). Если они совпадают, то внутри тела начинаются соответствующие процессы. Например, если создать процедуру, которая будет принимать город и регион от вызывающего абонента и возвращать данные о том, сколько авторов относятся к соответствующим городу и региону. Процедура будет запрашивать таблицы авторов базы данных, к примеру, Pubs, для выполнения этого подсчета авторов. Чтобы получить эти базы данных, к примеру, Google загружает сценарий SQL со страницы SQL2005.
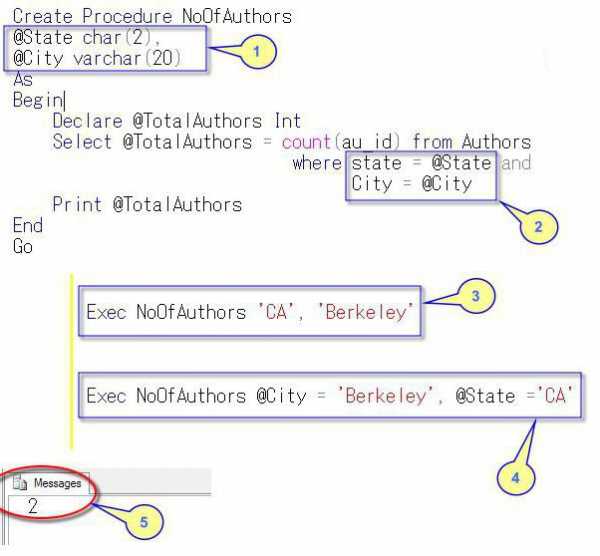
В предыдущем примере процедура принимает два параметра, которые на английском языке условно будут называться @State и @City. Тип данных соответствует типу, определенному в приложении. Тело процедуры имеет внутренние переменные @TotalAuthors (всего авторов), и эта переменная используется для отображения их количества. Далее появляется раздел выбора запроса, который все подсчитывает. Наконец, подсчитанное значение выводится в окне вывода с помощью оператора печати.
Как в SQL выполнить хранимую процедуру
Есть два способа выполнения процедуры. Первый путь показывает, передавая параметры, как разделенный запятыми список выполняется после имени процедуры. Допустим, мы имеем два значения (как в предыдущем примере). Эти значения собираются с помощью переменных параметров процедуры @State и @City. В этом способе передачи параметров важен порядок. Такой метод называется порядковая передача аргументов. Во втором способе параметры уже непосредственно назначены, и в этом случае порядок не важен. Этот второй метод известен как передача именованных аргументов.
Процедура может несколько отклоняться от типичной. Все так же, как и в предыдущем примере, но только здесь параметры сдвигаются. То есть параметр @City хранится первым, а @State хранится рядом со значением по умолчанию. Параметр по умолчанию выделяется обычно отдельно. Хранимые процедуры SQL проходяткак просто параметры. В этом случае, при условии, параметр «UT» заменяет значение по умолчанию «СА». Во втором исполнении проходит только одно значение аргумента для параметра @City, и параметр @State принимает значение по умолчанию «СА». Опытные программисты советуют, чтобы все переменные по умолчанию располагались ближе к концу списка параметров. В противном случае исполнение не представляется возможным, и тогда вы должны работать с передачей именованных аргументов, что дольше и сложнее.

4. Хранимые процедуры SQL Server: способы возврата
Существует три важных способа отправки данных в вызванной хранимой процедуре. Они перечислены ниже:
- возврат значения хранимой процедуры;
- выход параметра хранимых процедур;
- выбор одной из хранимых процедур.
4.1 Возврат значений хранимых процедур SQL
В этой методике процедура присваивает значение локальной переменной и возвращает его. Процедура может также непосредственно возвращать постоянное значение. В следующем примере, мы создали процедуру, которая возвращает общее число авторов. Если сравнить эту процедуру с предыдущими, вы можете увидеть, что значение для печати заменяется обратным.
Теперь давайте посмотрим, как выполнить процедуру и вывести значение, возвращаемое ей. Выполнение процедуры требует установления переменной и печати, которая проводится после всего этого процесса. Обратите внимание, что вместо оператора печати вы можете использовать Select-оператор, например, Select @RetValue, а также OutputValue.
4.2 Выход параметра хранимых процедур SQL
Ответное значение может быть использовано для возврата одной переменной, что мы и видели в предыдущем примере. Использование параметра Output позволяет процедуре отправить одно или несколько значений переменных для вызывающей стороны. Выходной параметр обозначается как раз-таки этим ключевым словом «Output» при создании процедуры. Если параметр задан в качестве выходного параметра, то объект процедуры должен присвоить ему значение. Хранимые процедуры SQL, примеры которых можно увидеть ниже, в таком случае возвращаются с итоговой информацией.

В нашем примере будет два выходных имени: @TotalAuthors и @TotalNoContract. Они указываются в списке параметров. Эти переменные присваивают значения внутри тела процедуры. Когда мы используем выходные параметры, вызывающий абонент может видеть значение, установленное внутри тела процедуры.
Кроме того, в предыдущем сценарии две переменные объявляются, чтобы увидеть значения, которые установливают хранимые процедуры MS SQL Server в выходном параметре. Тогда процедура выполняется путем подачи нормального значения параметра «CA». Следующие параметры являются выходными и, следовательно, объявленные переменные передаются в установленном порядке. Обратите внимание, что при прохождении переменных выходное ключевое слово также задается здесь. После того, как процедура выполнена успешно, значения, возвращаемые с помощью выходных параметров, выводятся на окно сообщений.
4.3 Выбор одной из хранимых процедур SQL
Эта техника используется для возврата набора значений в виде таблицы данных (RecordSet) к вызывающей хранимой процедуре. В этом примере SQL хранимая процедура с параметрами @AuthID запрашивает таблицу «Авторы» путем фильтрации возвращаемых записей с помощью этого параметра @AuthId. Оператор Select решает, что должно быть возвращено вызывающему хранимой процедуры. При выполнении хранимой процедуры AuthId передается обратно. Такая процедура здесь всегда возвращает только одну запись или же вообще ни одной. Но хранимая процедура не имеет каких-либо ограничений на возвращение более одной записи. Нередко можно встретить примеры, в которых возвращение данных с использованием избранных параметров с участием вычисленных переменных происходит путем предоставления нескольких итоговых значений.

В заключение
Хранимая процедура является довольно серьезным программным модулем, возвращающим или передающим, а также устанавливающим необходимые переменные благодаря клиентскому приложению. Поскольку хранимая процедура выполняется на сервере сама, обмена данными в огромных объемах между сервером и клиентским приложением (для некоторых вычислений) можно избежать. Это позволяет снижать нагрузки на сервера SQL, что, конечноже, идет на руку их держателям. Одним из подвидов являются хранимые процедуры T SQL, однако их изучение необходимо тем, кто занимается созданием внушительных баз данных. Также существует большое, даже огромное количество нюансов, которые могут быть полезны при изучении хранимых процедур, однако это нужно больше для тех, кто планирует плотно заняться программированием, в том числе профессионально.
4u-pro.ru
MS SQL Server и T-SQL
Выходные параметры и возвращение результата
Последнее обновление: 14.08.2017
Выходные параметры позволяют возвратить из процедуры некоторый результат. Выходные параметры определяются с помощью ключевого слова OUTPUT. Например, определим еще одну процедуру:
USE productsdb; GO CREATE PROCEDURE GetPriceStats @minPrice MONEY OUTPUT, @maxPrice MONEY OUTPUT AS SELECT @minPrice = MIN(Price), @maxPrice = MAX(Price) FROM ProductsПри вызове процедуры для выходных параметров передаются переменные с ключевым словом OUTPUT:
USE productsdb; DECLARE @minPrice MONEY, @maxPrice MONEY EXEC GetPriceStats @minPrice OUTPUT, @maxPrice OUTPUT PRINT 'Минимальная цена ' + CONVERT(VARCHAR, @minPrice) PRINT 'Максимальная цена ' + CONVERT(VARCHAR, @maxPrice)Также можно сочетать входные и выходные параметры. Например, определим процедуру, которая добавляет новую строку в таблицу и возвращает ее id:
USE productsdb; GO CREATE PROCEDURE CreateProduct @name NVARCHAR(20), @manufacturer NVARCHAR(20), @count INT, @price MONEY, @id INT OUTPUT AS INSERT INTO Products(ProductName, Manufacturer, ProductCount, Price) VALUES(@name, @manufacturer, @count, @price) SET @id = @@IDENTITYС помощью глобальной переменной @@IDENTITY можно получить идентификатор добавленной записи.
При вызове этой процедуры ей также по позиции передаются все входные и выходные параметры:
USE productsdb; DECLARE @id INT EXEC CreateProduct 'LG V30', 'LG', 3, 28000, @id OUTPUT PRINT @idВозвращение значения
Кроме передачи результата выполнения через выходные параметры хранимая процедура также может возвращать какое-либо значение с помощью оператора RETURN. Хотя данная возможность во многом нивелирована использованием выходных параметров, через которые можно возвращать результат, тем не менее, если надо возвратить из процедуры одно значение, то вполне можно использовать оператор RETURN.
Например, возвратим среднюю цену на товары:
USE productsdb; GO CREATE PROCEDURE GetAvgPrice AS DECLARE @avgPrice MONEY SELECT @avgPrice = AVG(Price) FROM Products RETURN @avgPrice;После оператора RETURN указывается возвращаемое значение. В данном случае это значение переменной @avgPrice.
Вызовем данную процедуру:
USE productsdb; DECLARE @result MONEY EXEC @result = GetAvgPrice PRINT @resultДля получения результата процедуры ее значение сохраняется в переменную (в данном случае в переменную @result):
metanit.com
- Полноэкранный режим клавиши виндовс 10
- Как отключить автоматическое обновление виндовс

- Программы для прошивок планшетов

- Узнать свой статический ip адрес
- Пароли хром

- Как на телеграмме сделать русский язык

- Отправь мне в лс и узнаешь что будет дальше

- Скорость интернета сколько

- Какой лучше браузер установить

- Как настроить роутер wifi без компьютера

- Графический интерфейс ubuntu server
