Рекурсивный запрос SQL в качестве подзапроса. Рекурсивные sql запросы
Рекурсивные SQL запросы / деревья
Рекурсивные SQL запросы
Рекурсивны SQL запросы являются одним из способов решения проблемы дерева и других проблем, требующих рекурсивную обработку. Они были добавлены в стандарт SQL 99. До этого они уже существовали в Oracle. Несмотря на то, что стандарт вышел так давно, реализации запоздали. Например, в MS SQL они появились только в 2005-ом сервере.
Рекурсивные запросы используют довольно редко, прежде всего, из-за их сложного и непонятного синтаксиса:
with [recursive] <имя_алиаса_запроса> [ (<список столбцов>) ]as (<запрос>) <основной запрос>
В MS SQL нет ключевого слова recursive, а в остальном все тоже самое. Такой синтаксис поддерживается в DB2, Sybase iAnywhere, MS SQL и во всех базах данных, которые поддерживают стандарт SQL 99.
Проще разобрать на примере. Предположим, есть таблица:
create table tree_sample ( id integer not null primary key, id_parent integer foreign key references tree_sample (id), nm varchar(31) )
id – идентификаторid_parent – ссылка на родительnm – название.
Для вывода дерева:
with recursive tree (nm, id, level, pathstr)as (select nm, id, 0, cast('' as text) from tree_sample where id_parent is null union all select tree_sample.nm, tree_sample.id, t.level + 1, tree.pathstr + tree_sample.nm from tree_sample inner join tree on tree.id = tree_sample.id_parent) select id, space( level ) + nm as nm from tree order by pathstr
Этот пример выведет дерево по таблице с отступами. Первый запрос из tree_sample этот запрос выдаст все корни дерева. Второй запрос соединяет между собой таблицу tree_sample и tree, которая определяется этим же запросом. Этот запрос дополняет таблицу узлами дерева.
Сначала выполняется первый запрос. Потом к его результатам добавляются результаты второго запроса, где данные таблица tree – это результат первого запроса. Затем снова выполняется второй запрос, но данные таблицы tree – это уже результат предыдущего выполнения второго запроса. И так далее. На самом деле база данных работает не совсем так, но результат будет таким же, как результат работы описанного алгоритма.
После этого данные этой таблицы можно использовать в основном запросе как обычно.
Хочу заметить, что я не говорю о применимости конкретно этого примера, а лишь пишу его для демонстрации возможностей рекурсивных запросов. Этот запрос реально будет работать достаточно медленно из-за order by.
webhamster.ru
средства формулировки аналитических и рекурсивных запросов
В этой лекции мы завершаем обсуждение средств выборки данных языка SQL коротким описанием сравнительно недавно появившихся в языке SQL средств формулировки аналитических и рекурсивных запросов.
Введение
Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются "трудными" для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки (OLAP). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING, позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций. Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
studfiles.net
sql - Рекурсивный запрос SQL в качестве подзапроса
Я работаю с базой данных SQL здесь, которая содержит таблицу CONTACT где я храню данные, связанные с контактом, а также его источник, чтобы я мог отслеживать, откуда он пришел. Одно конкретное поле в таблице CONTACT называется CONTACT_SOURCE а другое поле CONTACT_SOURCE_CONTACT_ID является самосоединением к этой же таблице на CONTACT_ID. То, что я пытаюсь сделать, - это отобразить данные CONTACT включая, где он появился, когда я присоединяюсь к другим таблицам в моей базе данных, например, QUOTE, ORDER и т.д.
Однако, вместо стандартного SELF-JOIN, я пытаюсь решить здесь рекурсивный сценарий. Например, мое поле CONTACT_SOURCE_CONTACT_ID - это место, где я храню CONTACT_ID другого контакта в той же самой таблице CONTACT которая устно передала этот контакт в мою компанию. То, что я пытаюсь сделать здесь, рекурсивно отслеживает контакт, используя это поле CONTACT_SOURCE_CONTACT_ID чтобы отображать в качестве источника источник этого контакта, который передал их мне. Например, если Джон нашел меня в социальных сетях и сказал Анне, которая затем сказала Бобу, что он отправил цитату, я хочу связать Боба с Джоном (через Энн) и, следовательно, показать Социальные СМИ в качестве своего источника и, следовательно, источник цитата.
Я создал пример SQL Fiddle, который демонстрирует это с использованием тестовых данных, а также рекурсивный SQL-запрос, который я создал для этого, и он отлично работает!
Все это имеет смысл, но мне просто интересно, если я делаю это правильно, и если это эффективно, когда я использую этот рекурсивный запрос в качестве подзапроса. Должен ли я иметь ссылку на поле QUOTE_CONTACT_ID в рекурсивном запросе? Я чувствую, что я проверяю все рекурсивные отношения во всей CONTACT таблице CONTACT а не только записи CONTACT возвращенные в результате SELECT * FROM dbo_QUOTE INNER JOIN dbo_CONTACT ON CONTACT_ID = QUOTE_CONTACT_ID. Скажем, у меня 2000 записей QUOTE но 12 000 записей CONTACT. Когда я просто хочу видеть записи QUOTE мне нужен только рекурсивный запрос для записей CONTACT, имеющих соответствующую запись в таблице QUOTE.
Имеет ли это смысл? Заранее благодарим за любые советы или советы!
qaru.site
- Разделы ubuntu
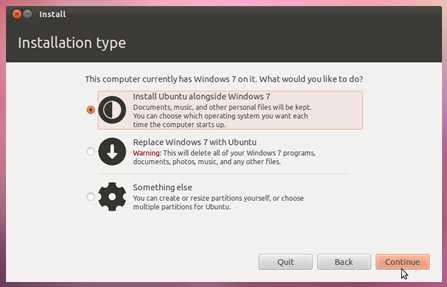
- Как подключить hdmi к компьютеру

- Что такое папка в информатике

- Как переводится вай фай

- Оперативная память это что

- Устройство pci

- Скрипты в командной строке windows
- Как открыть веб камеру на виндовс 10

- Как в одноклассниках подарить ок другу
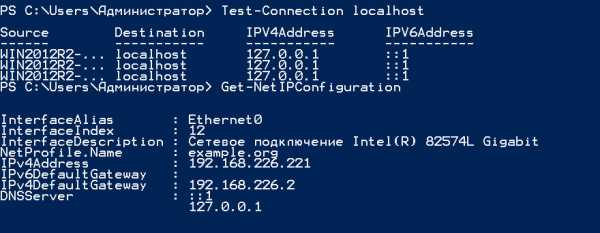
- Управление компьютером через командную строку
- Захват видео с ютуба