Запрос MySQL SELECT. Описание, применение и функции. Синтаксис sql select
17) Основной синтаксис оператора select
Оператор SELECT – один из наиболее важных и самых распространенных операторов SQL. Он позволяет производить выборки данных из таблиц и преобразовывать к нужному виду полученные результаты.
Будучи очень мощным, он способен выполнять действия, эквивалентные операторам реляционной алгебры, причем в пределах единственной выполняемой команды. При его помощи можно реализовать сложные и громоздкие условия отбора данных из различных таблиц.
Оператор SELECT – средство, которое полностью абстрагировано от вопросов представления данных, что помогает сконцентрировать внимание на проблемах доступа к данным.
Операции над данными производятся в масштабе наборов данных, а не отдельных записей.
Основной синтаксис
SELECT [ALL | DISTINCT ]
{* | [имя_столбца [AS новое_имя]]} [,...n] FROM имя_таблицы [[AS] псевдоним] [,...n]
[WHERE <условие_поиска>]
[GROUP BY имя_столбца [,...n]]
[HAVING <критерии выбора групп>]
[ORDER BY имя_столбца [,...n]]
Оператор SELECT определяет поля (столбцы), которые будут входить в результат выполнения запроса.
В списке они разделяются запятыми и приводятся в такой очередности, в какой должны быть представлены в результате запроса.
Если используется имя поля, содержащее пробелы или разделители, его следует заключить в квадратные скобки.
Символом * можно выбрать все поля.
Если обрабатывается ряд таблиц, то (при наличии одноименных полей в разных таблицах) в списке полей используется полная спецификация поля, т.е. Имя_таблицы.Имя_поля.
Обработка элементов оператора SELECT выполняется в следующей последовательности:
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями;
GROUP BY – образуются группы строк , имеющих одно и то же значение в указанном столбце;
HAVING – фильтруются группы строк объекта в соответствии с указанным условием;
SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных;
ORDER BY – определяется упорядоченность результатов выполнения операторов.
Предложение FROM задает имена таблиц и представлений, которые содержат поля, перечисленные в операторе SELECT. Необязательный параметр псевдонима – это сокращение, устанавливаемое для имени таблицы.
Параметр WHERE определяет критерий отбора записей из входного набора. Но в таблице могут присутствовать повторяющиеся записи (дубликаты). Предикат ALL задает включение в выходной набор всех дубликатов, отобранных по критерию WHERE (это значение действует по умолчанию).
Предикат DISTINCT следует применять в тех случаях, когда требуется отбросить блоки данных, содержащие дублирующие записи в выбранных полях.
С помощью WHERE-параметра пользователь определяет, какие блоки данных из приведенных в списке FROM таблиц появятся в результате запроса.
За ключевым словом WHERE следует перечень условий поиска, определяющих те строки, которые должны быть выбраны при выполнении запроса.
Существует пять основных типов условий поиска (или предикатов):
1. Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления другого.
2. Диапазон: проверяется, попадает ли результат вычисления выражения в заданный диапазон значений.
3. Принадлежность множеству: проверяется, принадлежит ли результат вычислений выражения заданному множеству значений.
4. Соответствие шаблону: проверяется, отвечает ли некоторое строковое значение заданному шаблону.
5. Значение NULL: проверяется, содержит ли данный столбец определитель NULL (неизвестное значение).
В языке SQL можно использовать следующие операторы сравнения:
= – равенство;
< – меньше;
>– больше;
- <= – меньше или равно;
>= – больше или равно;
<>,!= – не равно.
Более сложные предикаты могут быть построены с помощью логических операторов AND, OR или NOT, а также скобок, используемых для определения порядка вычисления выражения. Вычисление выражения в условиях выполняется по следующим правилам:
Выражение вычисляется слева направо.
Первыми вычисляются подвыражения в скобках.
Операторы NOT выполняются до выполнения операторов AND и OR.
Операторы AND выполняются до выполнения операторов OR.
Для устранения любой возможной неоднозначности рекомендуется использовать скобки.
Оператор BETWEEN используется для поиска значения внутри некоторого интервала, определяемого своими минимальным и максимальным значениями. При этом указанные значения включаются в условие поиска.
При использовании отрицания NOT BETWEEN требуется, чтобы проверяемое значение лежало вне границ заданного диапазона.
NOT IN используется для отбора любых значений, кроме тех, которые указаны в представленном списке.
С помощью оператора LIKE можно выполнять сравнение выражения с заданным шаблоном, в котором допускается использование символов-заменителей:
Символ % – вместо этого символа может быть подставлено любое количество произвольных символов.
Символ _ заменяет один символ строки.
[] – вместо символа строки будет подставлен один из возможных символов, указанный в этих ограничителях.
[^] – вместо соответствующего символа строки будут подставлены все символы, кроме указанных в ограничителях.
Оператор IS NULL используется для сравнения текущего значения со значением NULL – специальным значением, указывающим на отсутствие любого значения.
IS NOT NULL используется для проверки присутствия значения в поле.
Параметр ORDER BY сортирует данные выходного набора в заданной последовательности.
Сортировка может выполняться по нескольким полям, в этом случае они перечисляются за ключевым словом ORDER BY через запятую.
Способ сортировки задается ключевым словом, указываемым в рамках параметра ORDER BY следом за названием поля, по которому выполняется сортировка.
По умолчанию реализуется сортировка по возрастанию. Явно она задается ключевым словом ASC. Для выполнения сортировки в обратной последовательности необходимо после имени поля, по которому она выполняется, указать ключевое слово DESC.
Построение вычисляемых полей
В общем случае для создания вычисляемого (производного) поля в списке SELECT следует указать некоторое выражение языка SQL.
В этих выражениях применяются арифметические операции сложения, вычитания, умножения и деления, а также встроенные функции языка SQL.
Можно указать имя любого столбца (поля) таблицы или запроса, но использовать имя столбца только той таблицы или запроса, которые указаны в списке предложения FROM соответствующей инструкции. При построении сложных выражений могут понадобиться скобки.
Стандарты SQL позволяют явным образом задавать имена столбцов результирующей таблицы, для чего применяется фраза AS.
Использование итоговых функций
С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить ряд обобщающих статистических сведений о множестве отобранных значений выходного набора.
Пользователю доступны следующие основные итоговые функции:
Count (Выражение) - определяет количество записей в выходном наборе SQL-запроса;
Min/Max (Выражение) - определяют наименьшее и наибольшее из множества значений в некотором поле запроса;
Avg (Выражение) - эта функция позволяет рассчитать среднее значение множества значений, хранящихся в определенном поле отобранных запросом записей.
Sum (Выражение) - вычисляет сумму множества значений, содержащихся в определенном поле отобранных запросом записей.
Чаще всего в качестве выражения выступают имена столбцов. Выражение может вычисляться и по значениям нескольких таблиц.
studfiles.net
SELECT SQL Server | Oracle PL/SQL •MySQL •SQL Server
В этом учебном пособии вы узнаете, как использовать оператор SELECT в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
Оператор SELECT SQL Server (Transact-SQL) используется для извлечения записей из одной или нескольких таблиц в базе данных SQL Server.
Синтаксис
В простейшей форме синтаксис оператора SELECT в SQL Server (Transact-SQL):
SELECT expressionsFROM tables[WHERE conditions];
Полный синтаксис оператора SELECT в SQL Server (Transact-SQL):
SELECT [ ALL | DISTINCT ][ TOP (top_value) [ PERCENT ] [ WITH TIES ] ]expressionsFROM tables[WHERE conditions][GROUP BY expressions][HAVING condition][ORDER BY expression [ ASC | DESC ]];
Параметры или аргументы
ALL — необязательный. Возвращает все соответствующие строки.DISTINCT — необязательный. Удаляет дубликаты из набора результатов. Подробнее об операторе DISTINCT …TOP (top_value) — необязательный. Если указано, то он вернет верхнее число строк в результирующем наборе на основе top_value. Например, TOP (10) вернет первые 10 строк из полного набора результатов.PERCENT — необязательный. Если указано, то верхние строки основаны на проценте от общего набора результатов (как указано в верхнем значении). Например, TOP (10) PERCENT вернет верхние 10% полного набора результатов.WITH TIES — необязательный. Если указано, то строки, привязанные на последнем месте в ограниченном результирующем наборе, возвращаются. Это может привести к возврату большего количества строк, чем позволяет параметр TOP.expressions — столбцы или вычисления, которые вы хотите получить. Используйте *, если вы хотите выбрать все столбцы.tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в предложении FROM.WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.GROUP BY expressions — необязательный. Он собирает данные по нескольким записям и группирует результаты по одному или нескольким столбцам.HAVING condition — необязательный. Он используется в сочетании с GROUP BY, чтобы ограничить группы возвращаемых строк только теми, чье условие TRUE.ORDER BY expression — необязательный. Он используется для сортировки записей в вашем результирующем наборе. ASC сортируется в порядке возрастания, а DESC — в порядке убывания.
Пример выборки всех полей из одной таблицы
Рассмотрим пример, как использовать SQL Server SELECT для выбора всех полей из таблицы.
SELECT * FROM inventory WHERE quantity > 5 ORDER BY inventory_id ASC;
SELECT * FROM inventory WHERE quantity > 5 ORDER BY inventory_id ASC; |
В этом примере SQL Server SELECT мы использовали *, чтобы указать, что мы хотим выбрать все поля из таблицы inventory, где quantity больше 5. Набор результатов сортируется по полю inventory_id в порядке возрастания.
Пример выборки отдельных полей из одной таблицы.
Вы также можете использовать оператор SELECT SQL Server для выбора отдельных полей из таблицы.Например:
SELECT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_id >= 250 AND inventory_type = 'Программное обеспечение' ORDER BY quantity DESC, inventory_id ASC;
SELECT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_id >= 250 AND inventory_type = 'Программное обеспечение' ORDER BY quantity DESC, inventory_id ASC; |
Этот пример SQL Server SELECT возвращает только данные inventory_id, inventory_type и quantity из таблицы inventory, где inventory_id больше или равно 250, а inventory_type — это ‘Программное обеспечение’. Результаты сортируются по quantity в порядке убывания, а затем inventory_id в порядке возрастания.
Пример выборки полей из нескольких таблиц.
Вы также можете использовать оператор SELECT SQL Server для извлечения полей из нескольких таблиц с помощью объединения (join).Например:
SELECT inventory.inventory_id, products.product_name, inventory.quantity FROM inventory INNER JOIN products ON inventory.product_id = products.product_id ORDER BY inventory_id;
SELECT inventory.inventory_id, products.product_name, inventory.quantity FROM inventory INNER JOIN products ON inventory.product_id = products.product_id ORDER BY inventory_id; |
Этот пример SQL Server SELECT объединяет вместе две таблицы, чтобы предоставить нам набор результатов, который отображает поля inventory_id, product_name и quantity, где значение product_id совпадает как в таблице inventory, так и в products. Результаты сортируются по inventory_id в порядке возрастания.
Пример использования ключевого слова TOP
Давайте посмотрим на пример SQL Server, где мы используем ключевое слово TOP в операторе SELECT.Например:
SELECT TOP(3) inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = 'Программное обеспечение' ORDER BY inventory_id ASC;
SELECT TOP(3) inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = 'Программное обеспечение' ORDER BY inventory_id ASC; |
Этот пример SQL Server SELECT выберет первые 3 записи из таблицы inventory, где inventory_type будет ‘Программное обеспечение’. Если в таблице inventory есть другие записи, которые имеют значение inventory_type ‘Программное обеспечение’, они не будут возвращаться оператором SELECT.
Пример использования ключевого слова TOP PERCENT
Рассмотрим пример SQL Server, в котором мы используем ключевое слово TOP PERCENT в операторе SELECT.Например:
SELECT TOP(10) PERCENT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = 'Программное обеспечение' ORDER BY inventory_id ASC;
SELECT TOP(10) PERCENT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = 'Программное обеспечение' ORDER BY inventory_id ASC; |
Этот пример SQL Server SELECT будет выбирать первые 10% записей из полного набора результатов. Таким образом, в этом примере оператор SELECT вернет 10% записей из таблицы inventory, где inventory_type — это ‘Программное обеспечение’. Остальные 90% набора результатов не будут возвращены оператором SELECT.
oracleplsql.ru
Синтаксис оператора SELECT - документация Mysql 4, 5 на русском языке
Используя ключевое слово AS, выражению в SELECT можно присвоить псевдоним. Псевдоним используется в качестве имени столбца в данном выражении и может применяться в ORDER BY или HAVING. Например:
mysql> SELECT CONCAT(last_name,', ',first_name) AS full_name FROM mytable ORDER BY full_name;Псевдонимы столбцов нельзя использовать в выражении WHERE, поскольку находящиеся в столбцах величины на момент выполнения WHERE могут быть еще не определены. Проблемы с alias.
Выражение FROM table_references задает таблицы, из которых надлежит извлекать строки. Если указано имя более чем одной таблицы, следует выполнить объединение. Информацию о синтаксисе объединения можно найти в разделе Синтаксис оператора JOIN. Для каждой заданной таблицы по желанию можно указать псевдоним.
table_name [[AS] alias] [[USE INDEX (key_list)] | [IGNORE INDEX (key_list)] | FORCE INDEX (key_list)]]В версии MySQL 3.23.12 можно указывать, какие именно индексы (ключи) MySQL должен применять для извлечения информации из таблицы. Это полезно, если оператор EXPLAIN (выводящий информацию о структуре и порядке выполнения запроса SELECT), показывает, что MySQL из списка возможных индексов выбрал неправильный. Если нужно. чтобы для поиска записи в таблице применялся только один из возможных индексов, следует задать значение этого индекса в USE INDEX (key_list). Альтернативное выражение IGNORE INDEX (key_list) запрещает использование в MySQL данного конкретного индекса.
В MySQL 4.0.9 можно также указывать FORCE INDEX. Это работает также, как и USE INDEX (key_list) но в дополнение дает понять серверу что полное сканирование таблицы будет ОЧЕНЬ дорогостоящей операцией. Другими словами, в этом случае сканирование таблицы будет использовано только тогда, когда не будет найдено другого способа использовать один из данных индексов для поиска записей в таблице.
Выражения USE/IGNORE KEY являются синонимами для USE/IGNORE INDEX.
Ссылки на таблицы могут даваться как tbl_name (в рамках текущей базы данных), или как dbname.tbl_name с тем, чтобы четко указать базу данных.
Ссылки на столбцы могут задаваться в виде col_name, tbl_name.col_name или db_name.tbl_name.col_name. В выражениях tbl_name или db_name.tbl_name нет необходимости указывать префикс для ссылок на столбцы в команде SELECT, если эти ссылки нельзя истолковать неоднозначно. Имена баз данных, таблиц, столбцов, индексы псевдонимы, где приведены примеры неоднозначных случаев, для которых требуются более четкие определения ссылок на столбцы.
Ссылку на таблицу можно заменить псевдонимом, используя tbl_name [AS] alias_name:
mysql> SELECT t1.name, t2.salary FROM employee AS t1, info AS t2 WHERE t1.name = t2.name; mysql> SELECT t1.name, t2.salary FROM employee t1, info t2 WHERE t1.name = t2.name;В выражениях ORDER BY и GROUP BY для ссылок на столбцы, выбранные для вывода информации, можно использовать либо имена столбцов, либо их псевдонимы, либо их позиции (местоположения). Нумерация позиций столбцов начинается с 1:
mysql> SELECT college, region, seed FROM tournament ORDER BY region, seed; mysql> SELECT college, region AS r, seed AS s FROM tournament ORDER BY r, s; mysql> SELECT college, region, seed FROM tournament ORDER BY 2, 3;Для того чтобы сортировка производилась в обратном порядке, в утверждении ORDER BY к имени заданного столбца, в котором производится сортировка, следует добавить ключевое слово DESC (убывающий). По умолчанию принята сортировка в возрастающем порядке, который можно задать явно при помощи ключевого слова ASC.
В выражении WHERE можно использовать любую из функций, которая поддерживается в MySQL. Функции, используемые в операторах SELECT и WHERE.
Выражение HAVING может ссылаться на любой столбец или псевдоним, упомянутый в выражении select_expression. HAVING отрабатывается последним, непосредственно перед отсылкой данных клиенту, и без какой бы то ни было оптимизации. Не используйте это выражение для определения того, что должно быть определено в WHERE. Например, нельзя задать следующий оператор:
mysql> SELECT col_name FROM tbl_name HAVING col_name > 0;Вместо этого следует задавать:
mysql> SELECT col_name FROM tbl_name WHERE col_name > 0;В версии MySQL 3.22.5 или более поздней можно также писать запросы, как показано ниже:
mysql> SELECT user,MAX(salary) FROM users GROUP BY user HAVING MAX(salary)>10;В более старых версиях MySQL вместо этого можно указывать:
mysql> SELECT user,MAX(salary) AS sum FROM users GROUP BY user HAVING sum>10;Параметры (опции) DISTINCT, DISTINCTROW и ALL указывают, должны ли возвращаться дублирующиеся записи. По умолчанию установлен параметр (ALL), т.е. возвращаются все встречающиеся строки. DISTINCT и DISTINCTROW являются синонимами и указывают, что дублирующиеся строки в результирующем наборе данных должны быть удалены.
Все параметры, начинающиеся с SQL_, STRAIGHT_JOIN и HIGH_PRIORITY, представляют собой расширение MySQL для ANSI SQL.
При указании параметра HIGH_PRIORITY содержащий его оператор SELECT будет иметь более высокий приоритет, чем команда обновления таблицы. Нужно только использовать этот параметр с запросами, которые должны выполняться очень быстро и сразу. Если таблица заблокирована для чтения, то запрос SELECT HIGH_PRIORITY будет выполняться даже при наличии команды обновления, ожидающей, пока таблица освободится.
Параметр SQL_BIG_RESULT можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результат будет содержать большое количество строк. Если указан этот параметр, MySQL при необходимости будет непосредственно использовать временные таблицы на диске, однако предпочтение будет отдаваться не созданию временной таблицы с ключом по элементам GROUP BY, а сортировке данных.
При указании параметра SQL_BUFFER_RESULT MySQL будет заносить результат во временную таблицу. Таким образом MySQL получает возможность раньше снять блокировку таблицы; это полезно также для случаев, когда для посылки результата клиенту требуется значительное время.
Параметр SQL_SMALL_RESULT является опцией, специфической для MySQL. Данный параметр можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результирующий набор данных будет небольшим. В этом случае MySQL для хранения результирующей таблицы вместо сортировки будет использовать быстрые временные таблицы. В версии MySQL 3.23 указывать данный параметр обычно нет необходимости.
Параметр SQL_CALC_FOUND_ROWS (MySQL 4.0.0 и более новый) возвращает количество строк, которые вернул бы оператор SELECT, если бы не был указан LIMIT. Искомое количество строк можно получить при помощи SELECT FOUND_ROWS(). Разные функции.
Заметьте, что в версиях MySQL до 4.1.0 это не работает с LIMIT 0, который оптимизирован для того, чтобы немедленно вернуть нулевой результат. Как MySQL оптимизирует LIMIT.
Параметр SQL_CACHE предписывает MySQL сохранять результат запроса в кэше запросов при использовании QUERY_CACHE_TYPE=2 (DEMAND). Кэш запросов в MySQL.
Параметр SQL_NO_CACHE запрещает MySQL хранить результат запроса в кэше запросов. Кэш запросов в MySQL.
При использовании выражения GROUP BY строки вывода будут сортироваться в соответствии с порядком, заданным в GROUP BY, - так, как если бы применялось выражение ORDER BY для всех полей, указанных в GROUP BY. В MySQL выражение GROUP BY расширено таким образом, что для него можно также указывать параметры ASC и DESC:
SELECT a,COUNT(b) FROM test_table GROUP BY a DESCРасширенный оператор GROUP BY в MySQL обеспечивает, в частности, возможность выбора полей, не упомянутых в выражении GROUP BY. Если ваш запрос не приносит ожидаемых результатов, прочтите, пожалуйста, описание GROUP BY. Функции, используемые в операторах GROUP BY.
При указании параметра STRAIGHT_JOIN оптимизатор будет объединять таблицы в том порядке, в котором они перечислены в выражении FROM. Применение данного параметра позволяет увеличить скорость выполнения запроса, если оптимизатор производит объединение таблиц неоптимальным образом. Синтаксис оператора EXPLAIN (получение информации о SELECT).
Выражение LIMIT может использоваться для ограничения количества строк, возвращенных командой SELECT. LIMIT принимает один или два числовых аргумента. Эти аргументы должны быть целочисленными константами. Если заданы два аргумента, то первый указывает на начало первой возвращаемой строки, а второй задает максимальное количество возвращаемых строк. При этом смещение начальной строки равно 0 (не 1):
Для совместимости с PostgreSQL MySQL также поддерживает синтаксис LIMIT # OFFSET #.
mysql> SELECT * FROM table LIMIT 5,10; # возвращает строки 6-15Для того, чтобы выбрать все строки с определенного смещения и до конца результата, вы можете использовать значение -1 в качестве второго параметра:
mysql> SELECT * FROM table LIMIT 95,-1; # Retrieve rows 96-last.Если задан один аргумент, то он показывает максимальное количество возвращаемых строк:
mysql> SELECT * FROM table LIMIT 5; # возвращает первых 5 строкДругими словами, LIMIT n эквивалентно LIMIT 0,n.
Оператор SELECT может быть представлен в форме SELECT ... INTO OUTFILE 'file_name'. Эта разновидность команды осуществляет запись выбранных строк в файл, указанный в file_name. Данный файл создается на сервере и до этого не должен существовать (таким образом, помимо прочего, предотвращается разрушение таблиц и файлов, таких как /etc/passwd). Для использования этой формы команды SELECT необходимы привилегии FILE. Форма SELECT ... INTO OUTFILE главным образом предназначена для выполнения очень быстрого дампа таблицы на серверном компьютере. Команду SELECT ... INTO OUTFILE нельзя применять, если необходимо создать результирующий файл на ином хосте, отличном от серверного. В таком случае для генерации нужного файла вместо этой команды следует использовать некоторую клиентскую программу наподобие mysqldump --tab или mysql -e "SELECT ..." > outfile. Команда SELECT ... INTO OUTFILE является дополнительной по отношению к LOAD DATA INFILE; синтаксис части export_options этой команды содержит те же выражения FIELDS и LINES, которые используются в команде LOAD DATA INFILE. Синтаксис оператора LOAD DATA INFILE. Следует учитывать, что в результирующем текстовом файле оператор ESCAPED BY экранирует только следующие символы:
-
Символ оператора ESCAPED BY
-
Первый символ оператора FIELDS TERMINATED BY
-
Первый символ оператора LINES TERMINATED BY
Помимо этого ASCII-символ 0 конвертируется в ESCAPED BY, за которым следует символ 0 (ASCII 48). Это делается потому, что необходимо экранировать любые символы операторов FIELDS TERMINATED BY, ESCAPED BY или LINES TERMINATED BY, чтобы иметь надежную возможность повторить чтение этого файла. ASCII 0 экранируется, чтобы облегчить просмотр файла с помощью программ вывода типа pager. Поскольку результирующий файл не должен удовлетворять синтаксису SQL, нет необходимости экранировать что-либо еще. Ниже приведен пример того, как получить файл в формате, который используется многими старыми программами.
SELECT a,b,a+b INTO OUTFILE "/tmp/result.text" FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\n" FROM test_table;Если вместо INTO OUTFILE использовать INTO DUMPFILE, то MySQL запишет в файл только одну строку без символов завершения столбцов или строк и без какого бы то ни было экранирования. Это полезно для хранения данных типа BLOB в файле.
Следует учитывать, что любой файл, созданный с помощью INTO OUTFILE и INTO DUMPFILE, будет доступен для записи всем пользователям! Причина этого заключается в следующем: сервер MySQL не может создавать файл, принадлежащий только какому-либо текущему пользователю (вы никогда не можете запустить mysqld от пользователя root), соответственно, файл должен быть доступен для записи всем пользователям.
При использовании FOR UPDATE с обработчиком таблиц, поддерживающим блокировку страниц/строк, выбранные строки будут заблокированы для записи.
mysqlru.com
Справочное руководство по MySQL. :: 6.4.1 Синтаксис оператора SELECT
Используя ключевое слово AS, выражению в SELECT можно присвоить псевдоним. Псевдоним используется в качестве имени столбца в данном выражении и может применяться в ORDER BY или HAVING. Например:
mysql> SELECT CONCAT(last_name,', ',first_name) AS full_name FROM mytable ORDER BY full_name;Псевдонимы столбцов нельзя использовать в выражении WHERE, поскольку находящиеся в столбцах величины на момент выполнения WHERE могут быть еще не определены. See Раздел A.5.4, «Проблемы с alias».
Выражение FROM table_references задает таблицы, из которых надлежит извлекать строки. Если указано имя более чем одной таблицы, следует выполнить объединение. Информацию о синтаксисе объединения можно найти в разделе Раздел 6.4.1.1, «Синтаксис оператора JOIN». Для каждой заданной таблицы по желанию можно указать псевдоним.
table_name [[AS] alias] [[USE INDEX (key_list)] | [IGNORE INDEX (key_list)] | FORCE INDEX (key_list)]]В версии MySQL 3.23.12 можно указывать, какие именно индексы (ключи) MySQL должен применять для извлечения информации из таблицы. Это полезно, если оператор EXPLAIN (выводящий информацию о структуре и порядке выполнения запроса SELECT), показывает, что MySQL из списка возможных индексов выбрал неправильный. Если нужно. чтобы для поиска записи в таблице применялся только один из возможных индексов, следует задать значение этого индекса в USE INDEX (key_list). Альтернативное выражение IGNORE INDEX (key_list) запрещает использование в MySQL данного конкретного индекса.
В MySQL 4.0.9 можно также указывать FORCE INDEX. Это работает также, как и USE INDEX (key_list) но в дополнение дает понять серверу что полное сканирование таблицы будет ОЧЕНЬ дорогостоящей операцией. Другими словами, в этом случае сканирование таблицы будет использовано только тогда, когда не будет найдено другого способа использовать один из данных индексов для поиска записей в таблице.
Выражения USE/IGNORE KEY являются синонимами для USE/IGNORE INDEX.
Ссылки на таблицы могут даваться как tbl_name (в рамках текущей базы данных), или как dbname.tbl_name с тем, чтобы четко указать базу данных.
Ссылки на столбцы могут задаваться в виде col_name, tbl_name.col_name или db_name.tbl_name.col_name. В выражениях tbl_name или db_name.tbl_name нет необходимости указывать префикс для ссылок на столбцы в команде SELECT, если эти ссылки нельзя истолковать неоднозначно. See Раздел 6.1.2, «Имена баз данных, таблиц, столбцов, индексы псевдонимы», где приведены примеры неоднозначных случаев, для которых требуются более четкие определения ссылок на столбцы.
Ссылку на таблицу можно заменить псевдонимом, используя tbl_name [AS] alias_name:
mysql> SELECT t1.name, t2.salary FROM employee AS t1, info AS t2 WHERE t1.name = t2.name; mysql> SELECT t1.name, t2.salary FROM employee t1, info t2 WHERE t1.name = t2.name;В выражениях ORDER BY и GROUP BY для ссылок на столбцы, выбранные для вывода информации, можно использовать либо имена столбцов, либо их псевдонимы, либо их позиции (местоположения). Нумерация позиций столбцов начинается с 1:
mysql> SELECT college, region, seed FROM tournament ORDER BY region, seed; mysql> SELECT college, region AS r, seed AS s FROM tournament ORDER BY r, s; mysql> SELECT college, region, seed FROM tournament ORDER BY 2, 3;Для того чтобы сортировка производилась в обратном порядке, в утверждении ORDER BY к имени заданного столбца, в котором производится сортировка, следует добавить ключевое слово DESC (убывающий). По умолчанию принята сортировка в возрастающем порядке, который можно задать явно при помощи ключевого слова ASC.
В выражении WHERE можно использовать любую из функций, которая поддерживается в MySQL. See Раздел 6.3, «Функции, используемые в операторах SELECT и WHERE».
Выражение HAVING может ссылаться на любой столбец или псевдоним, упомянутый в выражении select_expression. HAVING отрабатывается последним, непосредственно перед отсылкой данных клиенту, и без какой бы то ни было оптимизации. Не используйте это выражение для определения того, что должно быть определено в WHERE. Например, нельзя задать следующий оператор:
mysql> SELECT col_name FROM tbl_name HAVING col_name > 0;Вместо этого следует задавать:
mysql> SELECT col_name FROM tbl_name WHERE col_name > 0;В версии MySQL 3.22.5 или более поздней можно также писать запросы, как показано ниже:
mysql> SELECT user,MAX(salary) FROM users GROUP BY user HAVING MAX(salary)>10;В более старых версиях MySQL вместо этого можно указывать:
mysql> SELECT user,MAX(salary) AS sum FROM users GROUP BY user HAVING sum>10;Параметры (опции) DISTINCT, DISTINCTROW и ALL указывают, должны ли возвращаться дублирующиеся записи. По умолчанию установлен параметр (ALL), т.е. возвращаются все встречающиеся строки. DISTINCT и DISTINCTROW являются синонимами и указывают, что дублирующиеся строки в результирующем наборе данных должны быть удалены.
Все параметры, начинающиеся с SQL_, STRAIGHT_JOIN и HIGH_PRIORITY, представляют собой расширение MySQL для ANSI SQL.
При указании параметра HIGH_PRIORITY содержащий его оператор SELECT будет иметь более высокий приоритет, чем команда обновления таблицы. Нужно только использовать этот параметр с запросами, которые должны выполняться очень быстро и сразу. Если таблица заблокирована для чтения, то запрос SELECT HIGH_PRIORITY будет выполняться даже при наличии команды обновления, ожидающей, пока таблица освободится.
Параметр SQL_BIG_RESULT можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результат будет содержать большое количество строк. Если указан этот параметр, MySQL при необходимости будет непосредственно использовать временные таблицы на диске, однако предпочтение будет отдаваться не созданию временной таблицы с ключом по элементам GROUP BY, а сортировке данных.
При указании параметра SQL_BUFFER_RESULT MySQL будет заносить результат во временную таблицу. Таким образом MySQL получает возможность раньше снять блокировку таблицы; это полезно также для случаев, когда для посылки результата клиенту требуется значительное время.
Параметр SQL_SMALL_RESULT является опцией, специфической для MySQL. Данный параметр можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результирующий набор данных будет небольшим. В этом случае MySQL для хранения результирующей таблицы вместо сортировки будет использовать быстрые временные таблицы. В версии MySQL 3.23 указывать данный параметр обычно нет необходимости.
Параметр SQL_CALC_FOUND_ROWS (MySQL 4.0.0 и более новый) возвращает количество строк, которые вернул бы оператор SELECT, если бы не был указан LIMIT. Искомое количество строк можно получить при помощи SELECT FOUND_ROWS(). See Раздел 6.3.6.2, «Разные функции».
Заметьте, что в версиях MySQL до 4.1.0 это не работает с LIMIT 0, который оптимизирован для того, чтобы немедленно вернуть нулевой результат. See Раздел 5.2.8, «Как MySQL оптимизирует LIMIT».
Параметр SQL_CACHE предписывает MySQL сохранять результат запроса в кэше запросов при использовании QUERY_CACHE_TYPE=2 (DEMAND). See Раздел 6.9, «Кэш запросов в MySQL».
Параметр SQL_NO_CACHE запрещает MySQL хранить результат запроса в кэше запросов. See Раздел 6.9, «Кэш запросов в MySQL».
При использовании выражения GROUP BY строки вывода будут сортироваться в соответствии с порядком, заданным в GROUP BY, - так, как если бы применялось выражение ORDER BY для всех полей, указанных в GROUP BY. В MySQL выражение GROUP BY расширено таким образом, что для него можно также указывать параметры ASC и DESC:
SELECT a,COUNT(b) FROM test_table GROUP BY a DESCРасширенный оператор GROUP BY в MySQL обеспечивает, в частности, возможность выбора полей, не упомянутых в выражении GROUP BY. Если ваш запрос не приносит ожидаемых результатов, прочтите, пожалуйста, описание GROUP BY. See Раздел 6.3.7, «Функции, используемые в операторах GROUP BY».
При указании параметра STRAIGHT_JOIN оптимизатор будет объединять таблицы в том порядке, в котором они перечислены в выражении FROM. Применение данного параметра позволяет увеличить скорость выполнения запроса, если оптимизатор производит объединение таблиц неоптимальным образом. See Раздел 5.2.1, «Синтаксис оператора EXPLAIN (получение информации о SELECT)».
Выражение LIMIT может использоваться для ограничения количества строк, возвращенных командой SELECT. LIMIT принимает один или два числовых аргумента. Эти аргументы должны быть целочисленными константами. Если заданы два аргумента, то первый указывает на начало первой возвращаемой строки, а второй задает максимальное количество возвращаемых строк. При этом смещение начальной строки равно 0 (не 1):
Для совместимости с PostgreSQL MySQL также поддерживает синтаксис LIMIT # OFFSET #.
mysql> SELECT * FROM table LIMIT 5,10; # возвращает строки 6-15Для того, чтобы выбрать все строки с определенного смещения и до конца результата, вы можете использовать значение -1 в качестве второго параметра:
mysql> SELECT * FROM table LIMIT 95,-1; # Retrieve rows 96-last.Если задан один аргумент, то он показывает максимальное количество возвращаемых строк:
mysql> SELECT * FROM table LIMIT 5; # возвращает первых 5 строкДругими словами, LIMIT n эквивалентно LIMIT 0,n.
Оператор SELECT может быть представлен в форме SELECT ... INTO OUTFILE 'file_name'. Эта разновидность команды осуществляет запись выбранных строк в файл, указанный в file_name. Данный файл создается на сервере и до этого не должен существовать (таким образом, помимо прочего, предотвращается разрушение таблиц и файлов, таких как /etc/passwd). Для использования этой формы команды SELECT необходимы привилегии FILE. Форма SELECT ... INTO OUTFILE главным образом предназначена для выполнения очень быстрого дампа таблицы на серверном компьютере. Команду SELECT ... INTO OUTFILE нельзя применять, если необходимо создать результирующий файл на ином хосте, отличном от серверного. В таком случае для генерации нужного файла вместо этой команды следует использовать некоторую клиентскую программу наподобие mysqldump --tab или mysql -e "SELECT ..." > outfile. Команда SELECT ... INTO OUTFILE является дополнительной по отношению к LOAD DATA INFILE; синтаксис части export_options этой команды содержит те же выражения FIELDS и LINES, которые используются в команде LOAD DATA INFILE. See Раздел 6.4.9, «Синтаксис оператора LOAD DATA INFILE». Следует учитывать, что в результирующем текстовом файле оператор ESCAPED BY экранирует только следующие символы:
Символ оператора ESCAPED BY
Первый символ оператора FIELDS TERMINATED BY
Первый символ оператора LINES TERMINATED BY
Помимо этого ASCII-символ 0 конвертируется в ESCAPED BY, за которым следует символ '0' (ASCII 48). Это делается потому, что необходимо экранировать любые символы операторов FIELDS TERMINATED BY, ESCAPED BY или LINES TERMINATED BY, чтобы иметь надежную возможность повторить чтение этого файла. ASCII 0 экранируется, чтобы облегчить просмотр файла с помощью программ вывода типа pager. Поскольку результирующий файл не должен удовлетворять синтаксису SQL, нет необходимости экранировать что-либо еще. Ниже приведен пример того, как получить файл в формате, который используется многими старыми программами.
SELECT a,b,a+b INTO OUTFILE "/tmp/result.text" FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\n" FROM test_table;Если вместо INTO OUTFILE использовать INTO DUMPFILE, то MySQL запишет в файл только одну строку без символов завершения столбцов или строк и без какого бы то ни было экранирования. Это полезно для хранения данных типа BLOB в файле.
Следует учитывать, что любой файл, созданный с помощью INTO OUTFILE и INTO DUMPFILE, будет доступен для записи всем пользователям! Причина этого заключается в следующем: сервер MySQL не может создавать файл, принадлежащий только какому-либо текущему пользователю (вы никогда не можете запустить mysqld от пользователя root), соответственно, файл должен быть доступен для записи всем пользователям.
При использовании FOR UPDATE с обработчиком таблиц, поддерживающим блокировку страниц/строк, выбранные строки будут заблокированы для записи.
www.arininav.ru
Запрос MySQL SELECT. Описание, применение и функции
MySQL select самая востребованная конструкция языка SQL во всех его диалектах на всех вычислительных платформах и операционных системах. Умение правильно формулировать мысли на SQL упрощает мышление, придаёт ему системность и логичность.
MySQL select – это не обязательно реальный запрос. Это может быть вычисление арифметического выражения или формирование значения переменной. MySQL не ограничивает разработчика в том, как использовать конструкции языка SQL. Он предлагает только синтаксис и функционал.
Формальный синтаксис конструкции SELECT
Практически все источники о MySQL select декларируют официальный синтаксис. Принято все ключевые слова языка SQL писать заглавными буквами, но это не является общим правилом. Кому как нравится, но очень важно понимать: редко смесь строчных и прописных букв приводит к правильному результату.
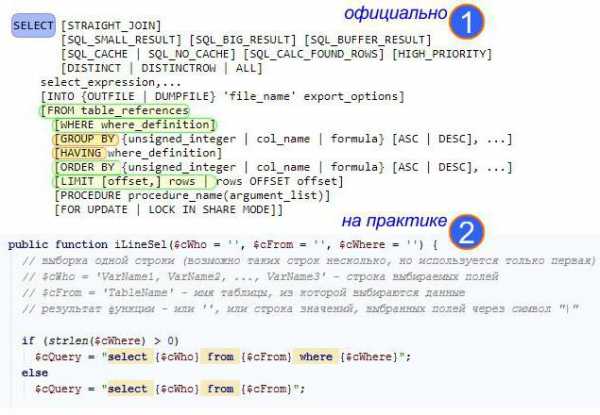
Чёткость и строгое соблюдение синтаксиса (1) – самое важное условие правильного, безопасного и надёжного программирования, стабильная работоспособность кода. В отношении MySQL, который допускает (2) использование букв любого регистра, важно понимать:
- select distinct `first_name` from `ex_workers` where `first_name` like '%иго%'"
- select distinct `first_name` from `ex_workers` where `First_name` like '%иго%'"
– это не одно и то же. Если писать ключевые слова можно так, как заблагорассудится, то вольности в изменении имен таблиц и переменных в одном запросе могут создать серьёзные проблемы.
Практичный синтаксис, простые таблицы
Вариант синтаксиса (2) – это реальная практика, которая оформляет любой запрос в виде процедуры, в которую поступает только:
- что нужно выбрать;
- откуда выбрать;
- на каком условии.
Результат процедуры (в данном случае: iLineSel) – обычный массив всех выбранных строк. Этот синтаксис – частность, но далеко не всегда нужны группировки, сортировки и сложные объединения по join.
Чем проще таблицы в базе данных, тем проще и быстрее работает MySQL query select. Чем чаще используется join, чем больше условий в одном запросе, тем хуже. Ситуация особенно усложняется, если запрос направлен на несколько больших таблиц.
Если запрос сформулирован правильно, MySQL select сработает как надо. Но сколько это займёт времени? Посетитель сайта может не дождаться результата. Нужно не только знать, что сказать, но и оценить,3 сколько времени займёт ответ!
Правильный запрос и учёт кодировки
Прежде чем сказать, что MySQL плох и обнаружен очередной баг, следует проверить формулировку запроса, правильность алгоритма и кодировку символов.

История и блестящая практика показывает, что MySQL в 99% случаев – это идеальный инструмент для успешной работы с информацией. Если что-то не даёт нужного результата, значит где-то допущена ошибка. Внимательно проверив содержание запроса, убедившись в том, что кодировка страницы правильная, можно попытаться переформулировать запрос.
При работе с MySQL никогда не следует забывать, что кодировка, локализация и условия хостинга могут быть разные. Хорошая практика: всегда проверять рабочую среду перед тем, как приступать к работе.
Простейшие конструкции SQL
Редко, когда разработчик решит использовать MySQL как арифмометр, но общая логика программирования соблюдена: PHP & MySQL select одинаково выполнят выражение:
Значение result будет 7. Приоритеты операций и логика операций языка MySQL выполнена по общим правилам программирования. Это касается и выражений, и условий.

В данном примере в секции 1 приведено арифметическое выражение в конструкции MySQL select, а в секции 2 три массива, из которых случайным образом построена таблица сотрудников компании:
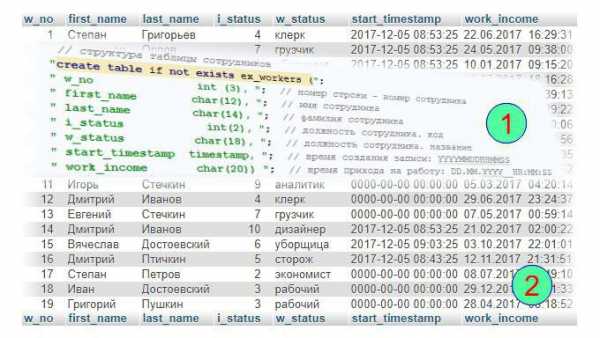
Имя, фамилия и должность сотрудника формировались случайным образом из массивов доступных имен, фамилий и должностей. Время принятия на работу и время прихода на работу умышленно записаны с ошибками:
- синтаксическими;
- смысловыми.
На данном наборе записей допустимы следующие простейшие запросы:
- select `first_name`, `last_name`, `w_status` from `ex_workers`;
- select distinct `w_status` from `ex_workers`;
- select distinct `start_timestamp` from `ex_workers` where `start_timestamp`!= '0000-00-00 00:00:00';
- select distinct `start_timestamp` from `ex_workers` where (`start_timestamp`!= '0000-00-00 00:00:00') and start_timestamp > '2017-12-05 09:00:00'.
Первый запрос формирует список всех сотрудников компании. Естественно, результат этого запроса будет содержать всё количество записей таблицы.
Второй запрос выбирает все действующие должности на предприятии, используя ключевое слово 'distinct', чтобы в выборке не было дубликатов.
Третий запрос выбирает все правильные даты о приёме на работу, то есть такие, которые содержат реальную информацию, а не нули.
Четвёртый запрос позволяет определить, что только две записи в таблице имеют смысл, то есть в них содержится информация, заполненная в рабочее время. Но в данном конкретном четвёртом запросе этот смысл не учитывает количества удовлетворяющих ему сотрудников: на самом деле правильных записей четыре.
Построение правильных запросов
Логика построения запросов развивается в процессе их разработки. Трудно сразу сформулировать правильное решение. В частности, таблица может содержать записи о сотрудниках, но если дата приёма на работу не верна, то, скорее всего, она была внесена некорректно.
Если дата приёма человека на работу – это ночное время, выходной день или, в общем случае, она была создана во внерабочее время, то она ошибочна или таблица была подвержена вирусной атаке.
На основании сказанного правильно было бы составить такой запрос:
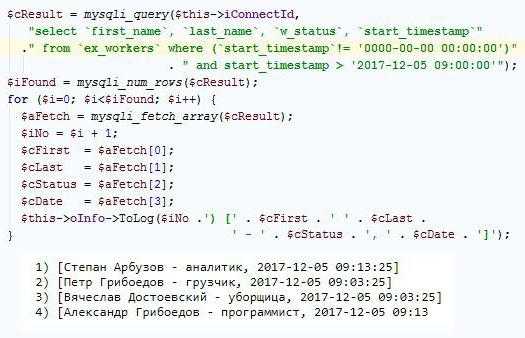
Этот запрос также не идеал, можно предусмотреть время обеда отдела кадров, время окончания рабочего дня. Но важна здесь вовсе не правильность запроса на выборку текущего состояния штатного расписания, а функционал его формирования.
В данном случае ошибки на этапе проектирования таблицы штатного расписания вынуждают разработчика составлять сложные и непонятные запросы.
В реальной практике крайне редко конструкция MySQL query select # from * where & будет содержать в позиции "#" должность, в позиции "*" только одну таблицу, а в условии "&" проверку рабочего времени. Всё это нонсенс, такого принципиально быть не должно. Все должности – это отдельная таблица, все записи всегда содержат правильную дату приёма на работу.
Правильная база данных, правильные запросы
Конструкция select может быть использована для определения используемой базы данных. В результате исполнения запроса MySQL "select database()" будет получено имя текущей базы данных.

Обычная практика – база данных проектируется таким образом, чтобы:
- обеспечить безопасное хранение и эффективное использование данных;
- сформировать систематизированное представление о структуре информации;
- обеспечить простой доступ к данным, универсальную конструкцию по всем запросам.
Это не единственные критерии, но даже их соблюдение позволит построить хорошее приложение, стабильно работающий веб-ресурс.
Хорошее правило: прежде чем начинать работу, проверить рабочую среду и состояние базы данных.
При использовании систем управления сайтами это важно. Например, можно очистить кэш или просмотреть, сколько пользователей уже работают с сайтом и перестроить запросы с целью их оптимизации. Интересным решением может быть динамика запроса, когда в MySQL select table – это переменная. В любом случае query – это строка символов. Но нет никакой причины делать эту строку статичной.
Если структура запроса формируется в процессе работы веб-ресурса, это позволяет динамично переключать таблицы. Например, посетители сайта начинают работу с одним комплектом таблиц базы данных, а после регистрации продолжают на другом. Динамика запроса позволяет оптимизировать работу сервера MySQL.
Запросы с сортировкой записей
Сортировка сортировке рознь, особенно, когда речь идёт о русском языке. Но иногда удобно использовать функционал языка PHP над MySQL select order by. Идеально, когда в результате запроса получается финальный результат, не требующий доработки конструкциями PHP, но обычно основная выборка сопровождается оформлением страницы, которое вынуждает разработчика уточнять содержимое управляющих элементов.

Например, выбрав штатное расписание, сайт должен предоставить администратору ресурса один функционал, работнику отдела кадров другой, а самому работнику третий. В первом случае, администратор анализирует и контролирует компанию в части ее социальной составляющей, во втором случае допускаются только операции изменения и добавления записей (сотрудников). В третьем случае сотрудник работает со своим планом: отмечает исполненное и планирует, что делать дальше.
Основной запрос требует адекватного исполнения вспомогательных запросов в контексте того, по какой причине он был исполнен.
Во всех случаях сортировка order by позволяет держать все записи в конкретном порядке. Это важно всегда, поскольку ускоряет процесс ориентации в сотрудниках, в задачах, в датах исполнения работ.
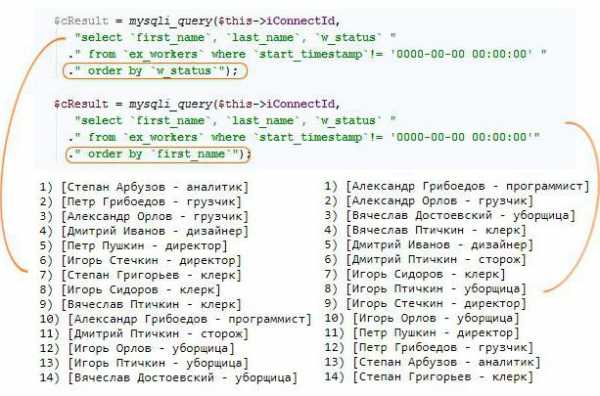
Обычно наименования должностей очень редко меняются, и их можно записать в сортированном порядке изначально. При изменении списка должностей можно однократно пересортировать его и внести изменения в штатное расписание, поскольку поменяется порядок ключей.

В этом контексте потребность сортировки остаётся только на тех таблицах, которые меняются динамически в процессе работы.
Запросы с группировкой записей
Группировка записей часто не менее важна, чем сортировка, но иногда это взаимоисключающие операции.
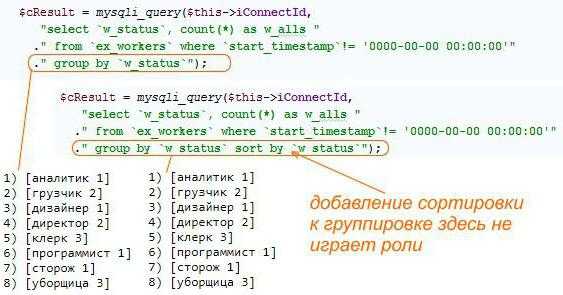
Группировку выгодно использовать для целей подсчёта записей, их систематизации, анализа. Например, можно использовать конструкцию group by для запросов типа MySQL select users, clients, visits, open pages. Это может работать в целях безопасности для предотвращения несанкционированного подключения или мониторинга рабочих процессов компании.
Условие запроса: идеально, когда его нет
Так уж сложилось, конструкция MySQL select & where – единое целое. Хотя при использовании различных вариантов объединения таблиц посредством join его вовсе может и не быть.
Но к тому, что where – неизменная составляющая всех MySQL select, начинающий разработчик начинает привыкать с самого начала. Примеры учат, нужно знать:
- что выбирается;
- из какой таблицы;
- по какому критерию.
Только после этого начинается обучение новобранца основам левого и правого объединения таблиц, логике мудрёного сленга: эта таблица сидит на вот этой, а данные выбирает вообще из третьего источника.
Практика – это всегда просто. Если база данных так построена, что без объединения (join) таблиц никак не получается составить запрос, то что-то в базе сделано не так. Если нужны условия за пределами task = 'value' или var > 0, то есть необходимы более сложные условные конструкции – это повод пересмотреть концепцию базы и логику необходимого спектра запросов к ней.
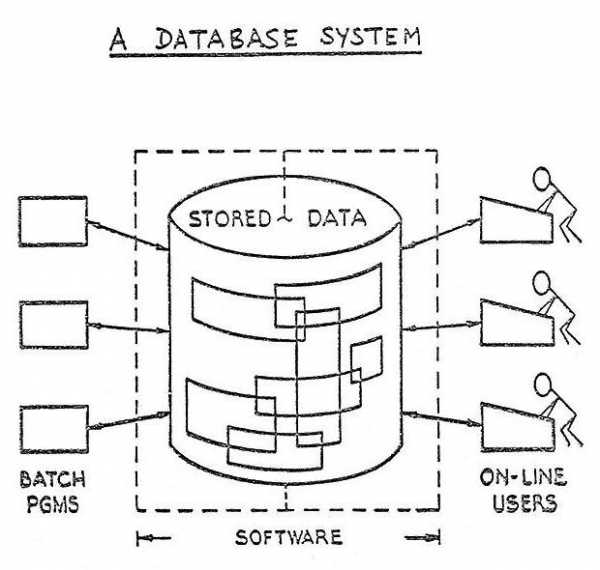
Нельзя рассматривать строительство базы данных вне запросов к ней. База данных – это информационная структура, забота которой отвечать на вопросы (запросы) максимально быстро и просто.
Объекты базы данных и запросы к ней
Реляционные отношения – это вполне конкретная структура базы данных и представление о запросах к ней. Если этот привычный концепт немного изменить: есть объекты (не таблицы) и есть методы объектов (свойства, а не запросы), то реляционные отношения и собственно запросы исчезают в телах объектов.

Так, штатное расписание – объект, взаимодействующий с объектами:
- сотрудник;
- должность;
- рабочее задание.
Сотрудник может быть директором, администратором, работником. Для штатного расписания это имеет значение, но в пределах соответствующего экземпляра объекта сотрудник. Аналогично, объект должность может быть совершенно любым. Но в выборке штатного расписания он будет строкой символов, а в контексте работы администратора он будет селектором для выборки нужной должности из числа доступных.

Строгое следование правилам синтаксиса MySQL select – хорошее правило: практично, безопасно, эффективно. Но если ограничиться его применением на уровне каждого объекта базы данных, а работать непосредственно с этими объектами по их методам (их правилам) эффективность повысится во много раз.
fb.ru
- Aida что такое
- Не показывает видео на компьютере
- Как настраивать роутер

- Что можно делать с помощью командной строки
- На ноутбуке отключается зарядка

- Как компьютер подключить к ноутбуку через hdmi

- С рабочего стола исчезли значки
- Приватный режим в explorer

- Как начать печатать текст на ноутбуке

- Не удалось восстановить систему windows 10
- Sql уменьшить размер базы
