Создание таблицы SQL из соединения данных. Создание таблицы sql из таблицы
Таблицы в SQL
1) Создание структуры таблицыCREATE [{GLOBAL|LOCAL} TEMPORARY]TABLE [LIKE []]|( [])|[AS [WITH [NO] DATA]]Примечание:В SQL Server перед именем временной таблицы ставится символ @@|@.
2) Опции копированияПри копировании (LIKE) таблицы из уже имеющейся могут быть включены опции копирования, подразумевающие следующую конструкцию:{INCLUDING|EXCLUDING}{IDENTITY|DEFAULTS|GENERATED}Примечания:INCLUDING|EXCLUDING – добавить/удалить ограничения столбца.IDENTITY|DEFAULTS|GENERATED – включить соответствующие свойства столбца.
3) Определение столбца{|[()]}[][DEFAULT ]
4) Ограничения столбца[CONSTRAINT ]NOT NULL|PRIMARY KEY|UNIQUE|REFERENCES [()][]| CHECK [[NOT] DEFERRABLE][INITIALLY IMMEDIATE|DEFERRED]
5) Ссылочная спецификацияСсылочная спецификация (или декларативная целостность) отвечает за действия, выполняющиеся при попытке изменить значения родительского ключа, и подразумевает следующую конструкцию:[MATCH FULL|PARTIAL] [ON UPDATE|DELETE{CASCADE|SET NULL| SET DEFAULT|NO ACTION}]
6) Изменение структуры таблицыALTER TABLE {ADD [COLUMN] }|{ALTER [COLUMN] SET DEFAULT| DROP DEFAULT}|{DROP [COLUMN] CASCADE|RESTRICT}|{ADD }
7) Удаление таблицыDROP TABLE CASCADE|RESTRICTПримечание:RESTRICT – запрещает удалять таблицу, если на неё имеется ссылка в других объектах базы данных.CASCADE – удаляются и все другие объекты, ссылающиеся на данную таблицу.
8) Ключевые словаa) NOT NULLТребуется обязательного указания данных в столбце в операторах INSERT и UPDATE.
b) PRIMARY KEYУказывается при объявлении столбца или таблицы и требует уникальных значений в соответствующих столбцах, запрещая в них NULL – значения.Ограничение на столбец отличается от аналогичного ограничения на таблицу отсутствием списка столбцов.
c) UNIQUEУказывается при объявлении столбца или таблицы и требует уникальных значений в соответствующих столбцах, но NULL-значения в них разрешены и все строки с NULL-значениями считаются уникальными.
Ограничения на столбец отличается от аналогичного ограничения на таблицу отсутствием списка столбцов. Для двух или более столбцов запрещается повтор комбинаций значений. Вместе с ограничением NOT NULL определяет потенциальный ключ (CANDIDATE KET).Для неидентифицируемой связи с NULLS ALLOWED PARENT KEY объявляется без NOT NULL. Тогда допустимы NULL-значения.
d) FOREIGN KEYТребует совпадения значений внешнего ключа подчиненной таблицы соответствующим значениям PARENT KEY, в качестве которого указывают PRIMARY KEY или UNIQUE (возможно с NOT NULL) главной таблицы.Допускает NULL-значения, если ссылается на UNIQUE.Имена столбцов могут не совпадать с именами столбцов PARENT KEY, но должны быть совместимы.
e) REFERENCESВ подчиненной таблице при объявлении столбца или таблицы ссылается на PRIMARY KEY или UNIQUE (возможно с NOT NULL) главной таблицы.Для PRIMARY KEY столбцы главной таблицы можно не указывать.В операторе INSERT требует совпадения значений подчиненной таблицы значениям PARENT KEY главной таблицы.В операторе DELETE запрещает удаление из главной таблицы, если есть ссылочные записи в подчиненной.
f) CHECKВключает логическое выражение (предикат) для проверки значения в операторе INSERT. Причем предикат проверки таблицы может ссылаться на несколько таблиц, а предикат проверки столбца – несколько столбцов.В обоих случаях возможны ложные отклонения условия, если предикат включает подзапрос.
g) MATCH FULL|PARTIALОпределяет полное/частичное совпадение значений PRIMARY KEY и FOREIGN KEY. Фактически уточняется способ обработки NULL-значений в составе внешнего ключа. MARCH PARTIAL допускает NULL значения. Более того, возможны ситуации, когда одна строка из подчиненной таблицы может соответствовать нескольким строкам из главной таблицы (неуникальное совпадение), а одна строка в главной таблице может иметь несколько уникальных и несколько неуникальных строк в подчиненной таблице.
Уникальные и неуникальные строки по-разному исполняются в ссылочных спецификациях (ON DELETE|UPDATE). Игнорируется, если установлено ограничение NOT NULL.
h) CASCADE|NO ACTIONCASCADE – обеспечивает выполнение таких же изменений в FK, какие были сделаны в PK, но только в уникально совпадающих строках, т.е. когда установлено MATCH PARTIAL.NO ACTION – не устанавливает автоматического изменения внешнего ключа.
i) SET NULL|DEFAULTSET NULL – обеспечивает установку всех значений внешнего ключа в совпадающих строках равным NULL, но только в уникально совпадающих строках, т.е. когда установлено MATCH PARTIAL.
SET DEFAULT – обеспечивает установку всех значений внешнего ключа в совпадающих строках равными значениям по умолчанию, но только в уникально совпадающих строках, т.е. когда установлено MATCH PARTIAL.
9) Примеры объявления таблиц
a) CREATE TABLE SalesPeople(SNum Integer, SName Char(10), City Char(10), Comm Decimal)
b) CREATE TABLE SalesPeople(SNum Integer NOT NULL UNIQUE, SName Char(10) NOT NULL, City Char(10) DEFAULT ‘New York’, Comm Decimal CHECK (Comm
all4study.ru
sql - Создание таблицы SQL из соединения данных
Прежде чем я изложу вопрос, прочитает информацию о моих данных:
Table Name: dbo.DecodedCSVMessages_Staging Columns: MMSI, Message_ID, Time, Vessel_Name, Ship_Type, IMO, Dimension_to_Bow, Dimension_to_stern, Dimension_to_port, Dimension_to_starboard, Draught, Longitude, LatitudeМне нужно создать новую таблицу. Вот что мне нужно в таблице:
Меня интересуют все эти данные, , но мне нужны только идентификаторы сообщений 1 или 3. ** Проблема в том, что Message_IDs 1 и 3 ** не хватает: (что доступно только с Message_ID 5.)
Для Message_IDs 1 и 3 эти столбцы помечены как NULL. Все, что у них есть, это
Longitude, Latitude, Time, MMSI(которые отмечены как NULL для Message_ID, равным 5)
MMSI является первичным ключом в этом экземпляре. Message_IDs 1, 3 и 5 будут иметь номера MMSI, которые представляют данный корабль. Эти MMSI хотя и повторяются, поскольку каждое судно отправляет несколько сообщений типа 1, 3 и 5. Так что скажем, у нас есть MMSI 210293000, этот номер будет рядом с несколькими Message_ID разных типов. Так что мне нужно сделать, это захватить все Message_ID, которые являются 1 и 3, и добавить информацию из идентификаторов Message_ID, которые от 5 до 1 и 3. Таким образом, столбцы больше не являются NULL.
И последнее, но не менее важное: мне нужно выбрать только Message_ID 1s и 3s, которые относятся к следующему:
Where Latitude > 55 and Latitude <85 and Longitude > 50 and Longitude < 141;Пример того, как выглядят несколько столбцов:
MMSI/ Message_ID /Time/Ship_type/Vessel_Name/Latitude/Longitude 21029300, 3, 2012-06-01, NULL, NULL, 56.528003, 85.233443 21029300, 5, 2012-07-01, 70, RIO_CUBAL, NULL, NULL 2109300, 1, 2012-08-01, NULL, NULL, 57.432345, 131.123343 2109300, 1, 2012-09-01, NULL, NULL, 62.432345, 121.123343 2109300, 1, 2012-09-02, NULL, NULL, 65.432345, 140.123343 21029300, 5, 2012-08-01, 70, RIO_CUBAL, NULL, NULLСпасибо!
qaru.site
Создание таблицы из SQL-запроса Безопасный SQL
Это одна неприятная проблема, и я не могу понять, как ее решить. Я использую Microsoft SQL Server 2008.
Итак, у меня есть две таблицы, и мне нужно обновить их оба. У них общий ключ, например id. Я хочу обновить Table1 некоторыми материалами, а затем обновить строки Table2 которые были соответственно изменены в Table1 .
Проблема в том, что я не совсем знаю, какие строки были изменены, потому что я произвольно ORDER BY NEWID() их с помощью ORDER BY NEWID() поэтому я, вероятно, не могу использовать JOIN на Table2 каким-либо образом. Я пытаюсь сохранить необходимые данные, которые были изменены в моем запросе для Table1 и передать их в Table2
Это то, что я пытаюсь сделать
CREATE TABLE IDS (id int not null, secondid int) SELECT [Table1].[id], [Table1].[secondid] INTO IDS FROM ( UPDATE [Table1] SET [secondid]=100 FROM [Table1] t WHERE t.[id] IN (SELECT TOP 100 PERCENT t.[id] FROM [Table1] WHERE (SOME_CONDITION) ORDER BY NEWID() ) ) UPDATE [Table2] SET some_column=i.secondid FROM [Table2] JOIN IDS i ON i.id = [Table2].[id]Но я получаю
Неверный синтаксис рядом с ключевым словом «ОБНОВЛЕНИЕ».
Поэтому возникает вопрос: как я могу решить синтаксическую ошибку или это лучший способ сделать это?
Примечание: запрос, заключенный между круглыми скобками первого FROM хорошо работал перед этим новым требованием, поэтому я сомневаюсь, что там есть проблема. Или, может быть?
EDIT : изменение второго UPDATE как предлагалось skk, все же приводит к той же ошибке (точно в строке ниже, содержащей UPDATE ):
UPDATE [Table2] SET some_column=i.secondid FROM [Task] JOIN IDS i on i.[id]=[Table2].[id] WHERE i.id=some_value
Solutions Collecting From Web of "Создание таблицы из SQL-запроса"
Он жалуется, потому что вы не сглаживаете производную таблицу, используемую в первом запросе, непосредственно перед UPDATE [Table2] .
Если вы добавите псевдоним, вы получите другую ошибку:
Вложенные инструкции INSERT, UPDATE, DELETE или MERGE должны иметь предложение OUTPUT.
Это вернулось к ответу @Adam Wenger.
Не уверен, что я полностью понимаю, что вы пытаетесь сделать, но выполнит следующий sql (после замены SOME_CONDITION ):
CREATE TABLE IDS (id int not null, secondid int) UPDATE t SET [secondid] = 100 OUTPUT inserted.[id], inserted.[secondid] into [IDS] FROM [Table1] t WHERE t.[Id] IN ( SELECT TOP 100 PERCENT t.[id] from [Table1] WHERE (SOME_CONDITION) ORDER BY NEWID() ) UPDATE [Table2] SET some_column = i.secondid FROM [Table2] JOIN IDS i ON i.id = [Table2].[id]Вместо того, чтобы вручную создавать новую таблицу, SQL-сервер имеет предложение OUTPUT , чтобы помочь с этим
Синтаксис обновления следующий.
UPDATE TableName SET ColumnName = Value WHERE {Condition}РЕДАКТИРОВАТЬ:
Вы меняете код следующим образом и повторите попытку
UPDATE [Table2] SET some_column=IDS.secondid WHERE IDS.[id] = [Table2].[id] and IDS.id=some_valuesql.fliplinux.com
sql - создание таблицы SQL из пользовательского типа
Я создал пользовательский тип, подобный этому
CREATE TYPE [dbo].[MyType] AS TABLE( [Template] [varchar](50) NOT NULL, [Cust_Name] [varchar](50) NOT NULL, [Invoice_No] [int] NOT NULL, [InvoiceDate] [date] NOT NULL, Sr_No int, CurrencyCode varchar(50), Amount money, [Subject] varchar(MAX), Reference varchar(MAX), CustAddress1 varchar(MAX), CustAddress2 varchar(MAX), CustAddress3 varchar(MAX), CustAddress4 varchar(MAX), CustAddress5 varchar(MAX), CustAddress6 varchar(MAX), CustomerTelephone varchar(MAX), Emailto varchar(50), EmailCC varchar(50), BankName varchar(MAX), AccountTitle varchar(MAX), AccountNo varchar(50), CurrencyCode1 varchar(50), BankAddress1 varchar(MAX), BankAddress2 varchar(MAX), BankAddress3 varchar(MAX), BankAddress4 varchar(MAX), SwiftCode varchar(50), ContactName1 varchar(50), ContactEmail1 varchar(MAX), ContactTel1 varchar(50), ContactName2 varchar(50), ContactEmail2 varchar(MAX), ContactTel2 varchar(50), ContactName3 varchar(50), ContactEmail3 varchar(MAX), ContactTel3 varchar(50) ) GOПараметр @tblInvoice не может быть объявлен READONLY, поскольку он не является табличным значением. Параметр
И когда я удалил READONLY из декларации, я получил следующую ошибку
Параметр @tblInvoice имеет недопустимый тип данных
Я не могу определить, что случилось.
qaru.site
Создание таблицы SQL из соединения данных Безопасный SQL
Прежде чем я изложу вопрос, вот информация о моих данных:
Table Name: dbo.DecodedCSVMessages_Staging Columns: MMSI, Message_ID, Time, Vessel_Name, Ship_Type, IMO, Dimension_to_Bow, Dimension_to_stern, Dimension_to_port, Dimension_to_starboard, Draught, Longitude, LatitudeМне нужно создать новую таблицу. Вот что мне нужно в таблице:
Меня интересуют все эти данные, но мне нужны только идентификаторы Message_ID, которые являются 1 или 3. ** Проблема в том, что 1 и 3 ** Message_ID не имеют : (который доступен только с Message_ID с параметрами 5)
Vessel_Name, Ship_Type, IMO, Dimension_to_Bow, Dimension_to_stern, Dimension_to_port, Dimension_to_starboard, DraughtДля Message_ID 1 и 3 эти столбцы помечены как NULL. Все, что у них есть, это
Longitude, Latitude, Time, MMSI(которые обозначены как NULL для равенства Message_ID 5 )
MMSI является основным ключом в этом случае. 1, 3 и 5 Message_ID будут иметь номера MMSI, которые представляют данный корабль. Эти MMSI, однако, повторяются, поскольку каждое судно отправляет несколько сообщений типа 1, 3 и 5. Так что скажем, у нас есть MMSI 210293000, этот номер будет рядом с несколькими типами Message_ID. Так что мне нужно сделать, это захватить все Message_ID, которые являются 1 и 3, и добавить информацию из Message_ID, которая равна 5 для 1 и 3. Таким образом, столбцы больше не являются NULL.
И последнее, но не менее важное: я должен выбрать только Message_ID 1 и 3, которые относятся к следующему:
Where Latitude > 55 and Latitude <85 and Longitude > 50 and Longitude < 141;Пример того, как выглядят несколько столбцов:
MMSI/ Message_ID /Time/Ship_type/Vessel_Name/Latitude/Longitude 21029300, 3, 2012-06-01, NULL, NULL, 56.528003, 85.233443 21029300, 5, 2012-07-01, 70, RIO_CUBAL, NULL, NULL 2109300, 1, 2012-08-01, NULL, NULL, 57.432345, 131.123343 2109300, 1, 2012-09-01, NULL, NULL, 62.432345, 121.123343 2109300, 1, 2012-09-02, NULL, NULL, 65.432345, 140.123343 21029300, 5, 2012-08-01, 70, RIO_CUBAL, NULL, NULLКонечный результат будет следующим:
21029300, 3, 2012-06-01, 70, RIO_CUBAL, 56.528003, 85.233443 2109300, 1, 2012-08-01, 70, RIO_CUBAL, 57.432345, 131.123343 2109300, 1, 2012-09-01, 70, RIO_CUBAL, 62.432345, 121.123343 2109300, 1, 2012-09-02, 70, RIO_CUBAL, 65.432345, 140.123343Благодаря!
Solutions Collecting From Web of "Создание таблицы SQL из соединения данных"
В одной транзакции создайте новую таблицу, используйте INSERT INTO ... SELECT ... для переноса данных из DecodedCSVMessages_Staging в новую таблицу, затем DELETE FROM ... для удаления старых данных из DecodedCSVMessages_Staging .
Принимая во внимание всю информацию из раздела комментариев (особенно об одноразовой ноте), вы можете попробовать следующую инструкцию SQL. Это, однако, будет работать только в том случае, если соответствующие данные «типа 5» действительно соответствуют вашим требованиям!
SELECT Messages.MMSI ,Messages.Message_ID ,Messages.TIME ,Type5Messages.Vessel_Name ,Type5Messages.Ship_Type ,Type5Messages.IMO ,Type5Messages.Dimension_to_Bow ,Type5Messages.Dimension_to_stern ,Type5Messages.Dimension_to_port ,Type5Messages.Dimension_to_starboard ,Type5Messages.Draught ,Messages.Longitude ,Messages.Latitude INTO [DataBaseName].[dbo].[YourNewTableName] FROM dbo.DecodedCSVMessages_Staging Messages LEFT OUTER JOIN ( SELECT DISTINCT MMSI ,Vessel_Name ,Ship_Type ,IMO ,Dimension_to_Bow ,Dimension_to_stern ,Dimension_to_port ,Dimension_to_starboard FROM dbo.DecodedCSVMessages_Staging WHERE Messages.Message_ID = 5 ) Type5Messages ON Messages.MMSI = Type5Messages.MMSI WHERE Messages.Message_ID IN (1,3) AND Messages.Latitude > 55 AND Messages.Latitude < 85 AND Messages.Longitude > 50 AND Messages.Longitude < 141;В этом выражении вы выбираете все строки типа «1» и «тип 3» и объединяете их со всеми строками типа 5, которые имеют одинаковое значение MMSI . Если информация «Тип 5» является последовательной в отношении выбранных столбцов, для каждой строки «тип 5» будет только одна запись, поэтому каждая строка «тип 1» и «тип 3» появится только один раз. Тем не менее, вам обязательно нужно провести некоторое тестирование. INTO [DataBaseName].[dbo].[YourNewTableName] (которую вы должны настроить для именования) создает новую таблицу (если вы выберете имя, которое еще не было использовано) с типами данных и вставками исходной таблицы выбранные строки. Возможно, вам захочется изменить эту таблицу позже, если вам нужны индексы, ключи, отношения или что-то еще.
Вы можете выбрать сообщения типа 1 и типа 3 с добавлением информации из соединения к первой соответствующей записи типа 5 в ваших данных. (Если нет соответствующей записи типа 5, вы получите нули для этих полей.) Попробуйте следующее:
SELECT DISTINCT M13.MMSI, M13.Message_ID, M13.Time, M13.Latitude, M13.Longitude, M5.Vessel_Name, M5.Ship_Type, M5.IMO, M5.Dimension_to_Bow M5.Dimension_to_stern, M5.Dimension_to_port, M5.Dimension_to_starboard, M5.Draught FROM dbo.DecodedCSVMessages_Staging M13 JOIN ( SELECT MMSI, Time, Vessel_Name, Ship_Type, IMO, Dimension_to_Bow Dimension_to_stern, Dimension_to_port, Dimension_to_starboard, Draught FROM dbo.DecodedCSVMessages_Staging WHERE Message_ID = 5 ORDER BY Time ) M5 ON M5.MMSI = M13.MMSI WHERE M13.Message_ID IN (1, 3) AND M13.Latitude > 55 AND M13.Latitude < 85 AND M13.Longitude > 50 AND M13.Longitude < 141 ORDER BY M13.TimeЕсли это вернет нужные данные, создайте новую таблицу и вставьте записи, используя INSERT INTO NewTable SELECT .
Помните, что MMSI не является первичным ключом, как в старой таблице, так и в новой таблице. Первичные ключи (PK) должны быть уникальными, и в этом случае у вас есть несколько записей для каждого MMSI.
Когда вы создаете новую таблицу, вы должны добавить целое поле IDENTITY, чтобы оно имело PK. Это поле IDENTITY не включено в инструкцию insert, но оно автоматически заполняется инкрементирующим целым числом. Таким образом, каждая запись получает уникальный ПК, что очень желательно.
EDITED использовать DISTINCT для внешнего запроса.
sql.fliplinux.com
- Как в windows media player 11 включить общий доступ к файлам
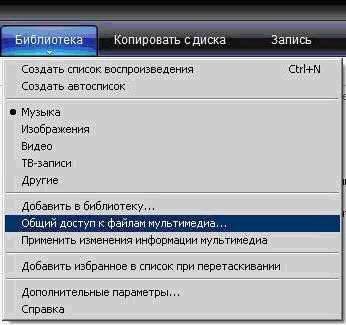
- Набрать голосом текст

- Язык html для чайников

- Ubuntu сервер
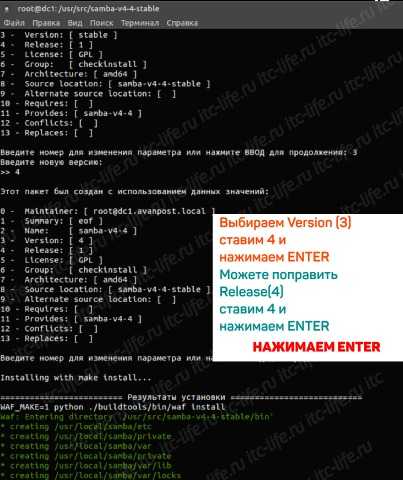
- На ноутбуке не открывается флешка

- Windows variables windows 7 где находится
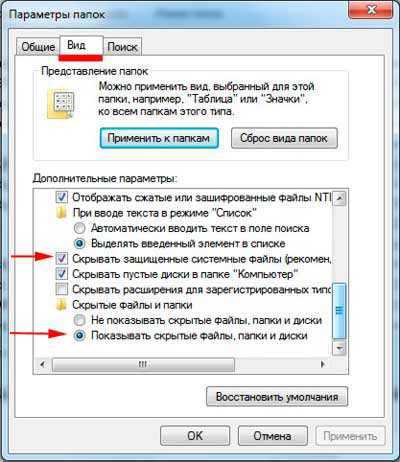
- Кто изобрел wifi

- Как нажать решетку на ноутбуке

- Вк вход взлом

- Windows server 2018 установка и настройка
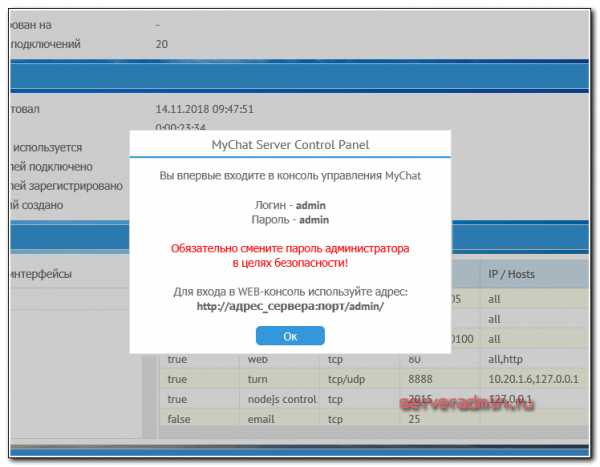
- Почему пропадает сигнал вай фай
