Многоядерность процессора или характеристика количества ядер. За счет чего увеличивается производительность процессора а значит и компьютера
61. Производительность процессора и методы ее увеличения
Производительность процессора можно увеличить за счет повышения плотности транзисторов — увеличения частоты такта.
Увеличение размера кэша также ведет к повышению производительности. Большую ставку производители делают на параллелизм вычислений.
Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD – расширения, Hyper Threading, многоядерность.В основном эти виды параллельной обработки интуитивно понятны, поэтому сделаем лишь небольшие пояснения. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть, пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Подобные аналогии можно найти и в жизни: если один солдат вскопает огород за 10 часов, то рота солдат из пятидесяти человек с такими же способностями, работая одновременно, справятся с той же работой за 12 минут (параллельная обработка данных), да еще и с песнями (параллельная обработка команд).
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций.
Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки.
Hyper Threading.Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств – это организация эффективной загрузки этих устройств. Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили – таки все ФИУ (очень похоже на многозадачность).
Многоядерность.Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т.е. разместить на одном кристалле несколько процессоров (Power4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру. При этом в кристалле интегрируются функции (например, интерфейсы сетевых и телекоммуникационных систем) для выполнения которых обычно используются наборы микросхем (процессорыMotorolaMPC8260,Power4).
Многоядерность - как способ увеличения производительности компьютера.
В идеальном варианте каждый поток инструкций утилизирует отведенное ему ядро процессора (и исполнительные блоки), что позволяет избежать конфликтных ситуаций и увеличить производительность процессора за счет параллельного выполнения потоков инструкций.
Говорить о том, что двухъядерные процессоры в два раза производительнее одноядерных, не приходится. Причина заключается в том, что для реализации параллельного выполнения двух потоков необходимо, чтобы эти потоки были полностью или частично независимы друг от друга, а кроме того, чтобы операционная система и само приложение поддерживали на программном уровне возможность распараллеливания задач. И в связи с этим стоит подчеркнуть, что сегодня далеко не все приложения удовлетворяют этим требованиям и потому не смогут получить выигрыша от использования двухъядерных процессоров. Должно пройти еще немало времени, чтобы написание параллельного кода приложений вошло в привычку у программистов, однако первый и самый важный камень в фундамент параллельных вычислений уже заложен. Впрочем, уже сегодня существует немало приложений, которые оптимизированы для выполнения в многопроцессорной среде, и такие приложения, несомненно, позволят использовать преимущества двухъядерного процессора.
studfiles.net
Увеличение производительности эвм, за счет чего?
А почему суперкомпьютеры считают так быстро? Вариантов ответа может быть несколько, среди которых два имеют явное преимущество: развитие элементной базы и использование новых решений в архитектуре компьютеров. Попробуем разобраться, какой из этих факторов оказывается решающим для достижения рекордной производительности. Обратимся к известным историческим фактам. На одном из первых компьютеров мира - EDSAC, появившемся в 1949 году в Кембридже и имевшем время такта 2 микросекунды (2*10-6 секунды), можно было выполнить 2*n арифметических операций за 18*n миллисекунд, то есть в среднем 100 арифметических операций в секунду. Сравним с одним вычислительным узлом современного суперкомпьютера Hewlett-Packard V2600: время такта приблизительно 1.8 наносекунды (1.8*10-9 секунд), а пиковая производительность около 77 миллиардов арифметических операций в секунду. Что же получается? Более чем за полвека производительность компьютеров выросла почти в 800 миллионов раз. При этом выигрыш в быстродействии, связанный с уменьшением времени такта с 2 микросекунд до 1.8 наносекунд, составляет лишь около 1000 раз. Откуда же взялось остальное? Ответ очевиден - использование новых решений в архитектуре компьютеров. Основное место среди них занимает принцип параллельной обработки команд и данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий.
Параллельные системы
Итак, пути повышения производительности ВС заложены в ее архитектуре. С одной стороны это совокупность процессоров, блоков памяти, устройств ввода/вывода ну и конечно способов их соединения, т.е. коммуникационной среды. С другой стороны, это собственно действия ВС по решению некоторой задачи, а это операции над командами и данными. Вот собственно и вся основная база для проведения параллельной обработки. Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD – расширения, Hyper Threading, многоядерность. В основном эти виды параллельной обработки интуитивно понятны, поэтому сделаем лишь небольшие пояснения. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть, пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Подобные аналогии можно найти и в жизни: если один солдат вскопает огород за 10 часов, то рота солдат из пятидесяти человек с такими же способностями, работая одновременно, справятся с той же работой за 12 минут (параллельная обработка данных), да еще и с песнями (параллельная обработка команд).
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций.
Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки.
Hyper Threading. Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств – это организация эффективной загрузки этих устройств. Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили – таки все ФИУ (очень похоже на многозадачность).
Многоядерность. Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т.е. разместить на одном кристалле несколько процессоров (Power 4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру. При этом в кристалле интегрируются функции (например, интерфейсы сетевых и телекоммуникационных систем) для выполнения которых обычно используются наборы микросхем (процессоры Motorola MPC8260, Power 4).
По каким же направлениям идет реализация высокопроизводительной вычислительной техники в настоящее время? Основных направлений четыре.
1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY куда входят, например, CRAY EL, CRAY J90, CRAY T90 (в марте 2000 года американская компания TERA перекупила подразделение CRAY у компании Silicon Graphics, Inc.).
2. Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п.
Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам.
3. Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
4. Кластерные системы. Последнее направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединим несколько узлов высокоскоростными каналами. Подобную архитектуру называют кластерной, и по такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие. Именно это направление является в настоящее время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности.
studfiles.net
Производительность процессора и характеристики его компонентов
Производительность процессора является интегральной характеристикой, которая зависит от показателей частоты процессора, его разрядности, а так же особенностей архитектуры (наличие кэш-памяти и др.). Производительность процессора нельзя вычислить. Она определяется в процессе тестирования, т.е. определения скорости выполнения процессором определенных операций в какой-либо программной среде.
Итак, рассмотрим ряд ключевых характеристик и компонентов процессора:
Тактовая частота
Принято считать, что чтобы правильно выбрать процессор нужно первым делом посмотреть на его главную характеристику – тактовую частоту, ее еще называют скорость. Как было сказано выше, от возможностей процессора зависит скорость работы всей Вашей системы (быстродействие). Тактовая частота задает ритм жизни компьютера. Чем выше тактовая частота, тем меньше длительность выполнения одной операции и тем выше производительность компьютера. Поэтому частота является главной характеристикой процессора.
Под тактом мы понимаем промежуток времени, в течение которого может быть выполнена элементарная операция. Тактовую частоту можно измерить и определить ее значение. Измеряется она в МегаГерцах (МГц) (MHz) или ГГц (GHz). Герц единица измерения, определяющая частоту какого-либо периодического процесса. Данная единица измерения имеет прямое соотношение с единицей времени, величиной в одну секунду. Иными словами, когда мы говорим 1 Гц - это означает одно исполнение какого-либо процесса за одну секунду (1 Гц = 1/с). Например, если мы имеем 10 Гц, то это означает, что мы имеем десять исполнений такого процесса за одну секунду. Приставка Мега увеличивает показатель базовой величины (Гц) в миллион раз (1 МГц - миллион тактов в секунду), а приставка Гига в миллиард (1 ГГц - миллиард тактов в секунду).
Ядро (совокупность технологических, физических и программных средств, лежащих в основе процессора)
Ядро - это главная часть центрального процессора (CPU). Именно эта часть определит большинство ключевых параметров Вашего CPU. Прежде всего - тип сокета, диапазон рабочих частот и частоту работы внутренней шины передачи данных (FSB).
Ядро процессора характеризуется следующими параметрами:
объем внутреннего кэша первого и второго уровня (см. далее),
технологический процесс (последовательная цепочка операций и соединений между элементами),
теплоотдача или тепловыделение (мощность, которую система охлаждения отводит, чтобы обеспечить нормальную работу процессора. Насколько велико значение этого параметра, настолько сильно Ваш процессор будет нагреваться. Следует обратить внимание, что некоторые производители процессоров по разному измеряют тепловыделение, поэтому сравнения стоит проводить в рамках одного производителя).
Прежде чем покупать CPU с тем или иным ядром, необходимо удостовериться, что ваша материнская плата сможет работать с таким процессором. В рамках одной линейки могут существовать CPU с разными ядрами. Например, в линейке Pentium IV присутствуют процессоры с ядрами Northwood, Prescott, Willamette.
Одно и то же ядро может лежать в основе разных моделей процессоров, отличающихся друг от друга по стоимости и уровню производительности. Если Вы сталкиваетесь с одинаковым названием ядра у разных моделей процессоров – это говорит об их принадлежности к одному поколению. Чаще всего они совместимы с одинаковыми моделями материнских плат.
Количество ядер
На протяжении десятилетий процессоры с одним ядром были единственной и безальтернативной реальностью в сегменте персональных компьютеров. Так было пока в 2005 году два микропроцессорных гиганта – Intel и AMD – дружно не выпустили свои первые двухъядерные процессоры. Эти продукты стали не просто очередными новинками от лидеров отрасли, но возвестили своим появлением о начале целой эры в развитии профессиональных технологий для персональных компьютеров. Со временем у них появлялось все больше преемников.
Справедливости ради скажем, что не взирая на глубоко укоренившуюся идею о полном несоответствии одного ядра современным реалиям, «старички-одноядернички» по-прежнему находят своего пользователя. Связано это с тем, что большинство программ еще не умеют использовать возможности многоядерных чипов. Вот несколько наименований одноядерных процессоров широко используемых и по сей день: AMD Athlon 64, AMD Sempron, Intel Celeron, Intel Core Solo, Intel Pentium 4.
Какие же реальные преимущества дает многоядерный процессор? Параллельная работа двух и более ядер при меньшей тактовой частоте обеспечивает бóльшую производительность. Работающая в текущий момент программа распределяет задачи по обработке данных на оба ядра. Это обеспечивает максимальный эффект, когда и операционная система, и прикладные программы работают в параллельном режиме, как, например, это часто бывает с приложениями для обработки графики. Многоядерность влияет также на одновременную работу стандартных приложений. Например, одно ядро процессора может отвечать за программу, работающую в фоновом режиме, в то время как антивирусная программа занимает ресурсы второго ядра.
Стоит, однако, оговориться, что управление параллельными задачами, тем не менее, требует времени и задействует другие ресурсы системы. А иногда даже для решения одной из задач приходится ждать результата выполнения другой. Поэтому на практике наличие 2-х ядерного процессора не означает производительность вычислений в два раза быстрее. Хотя прирост быстродействия и может оказаться весьма значительным, но в зависимости от типа приложения.
У игр, которые пока еще совсем не используют новую технологию, быстродействие увеличивается не более чем на 5% при одинаковой тактовой частоте. В большей степени игры получают пользу лишь от большого размера кэша процессора, установленного в Вашем компьютере. Пройдет еще некоторое время, пока появятся игры, которые на многоядерных процессорах будут работать заметно быстрее.
А вот оптимизированные под многоядерные процессоры программы для обработки музыки и видео будут работать уже на 50% быстрее. Увеличение скорости особенно заметно, если используемое приложение для работы по обработке и сжатию видео-файлов заточено под многоядерный процессор. Наличие 2-х и более ядер также повысит качество воспроизведения фильмов с высоким разрешением (Blu-ray, HD-DVD), т.к. при декомпрессии такого видео, содержащего большие объемы данных, процессор должен производить огромное количество вычислений.
Еще одно реальное преимущество многоядерного процессора – сниженное энергопотребление. Многоядерные чипы, в которых реализованы все современные технологии энергосбережения, быстрее обычных справляются с поставленными задачами и поэтому быстрее могут перейти в режим с меньшей тактовой частотой и, соответственно, с меньшим энергопотреблением. Особенно существенна эта деталь для ноутбука, чья автономная работа от аккумулятора в значительной степени продлевается.
В наше время среди моделей 2-х ядерных процессоров наиболее распространены AMD Athlon 64 х 2, Intel Core 2 Duo, Intel Pentium Dual Core, Intel Pentium D. Существуют также и 4-х ядерные процессоры для настольных компьютеров, как например Intel Core 2 Quad.
Однако чтобы воспользоваться всеми вышеописанными преимуществами многоядерного процессора, операционная система и приложения должны поддерживать именно многоядерный режим обработки. Современные операционные системы Windows, ориентированные на повышение производительности компьютера, самостоятельно распределяют программные задачи по разным ядрам процессора. Так, Windows XP перекладывает на второе ядро процессора фоновые задачи программ, специально разработанных для многоядерных процессоров (например, профессиональные приложения для обработки графики от Adobe). Windows Vista идет дальше, распределяя по ядрам задачи прикладных программ, изначально не предназначенных для использования на многоядерных чипах. Если Вы используете старые версии операционных систем – например, Windows 98 или Windows Me – то выгоды из использования многоядерных процессоров Вам не извлечь.
Кэш-память
Во всех современных процессорах имеется кэш (по-английски – cache) – массив сверхскоростной оперативной памяти, являющейся буфером между контроллером сравнительно медленной системной памяти и процессором. Кэш память процессора выполняет примерно ту же функцию, что и оперативная память. Только кэш - это память, встроенная в процессор. Кэш-память используется процессором для хранения информации, с которыми Ваш компьютер работает непосредственно в текущий момент, а также другие наиболее часто используемые данные. Благодаря работе кэш-памяти время очередного обращения к ним значительно сокращается. Тем самым заметно увеличивается общая производительность процессора.
В общем, можно выделить следующие задачи, которые выполняет кэш-память:
обеспечение быстрого доступа к интенсивно используемым данным;
согласование интерфейсов процессора и контроллера памяти;
упреждающая загрузка данных;
отложенная запись данных.
Предположим, Вы регулярно заходите на один и тот веб-сайт в интернете или каждый день запускаете любимую игру. Кэш-память Вашего процессора будет хранить основную массу изображений и видео-фрагментов, благодаря чему существенно уменьшается количество обращений процессора к чрезвычайно медленной (по сравнению со скоростью работы процессора) системной памяти.
Если емкость оперативной памяти на новых компьютерах от 1 Гб, то кэш у них около 2-8 Мб. Как видите, разница в объеме памяти ощутимая. Но даже этого объема вполне хватает, чтобы обеспечить нормальное быстродействие всей системы.
При этом в современных процессорах кэш давно не является единым массивом памяти, как раньше, а разделен на несколько уровней. Ранее были распространены процессоры с двумя уровнями кэш-памяти: L1 (первый уровень) и L2 (второй). Наиболее быстрый, но относительно небольшой по объему (обычно около 128 Кб) кэш первого уровня с которым работает ядро процессора, чаще всего делится на две половины – кэш инструкций и кэш данных. Кэш первого уровня намного меньше кэша второго уровня, он, т.к. используется исключительно для хранения инструкций. А вот второй уровень используется для хранения данных, поэтому он, как правило, гораздо больше по объему. Кэш второго уровня у большинства процессоров общий, т.е. смешанный, без разделения на кэш команд и кэш данных. Но не у всех, вот например в AMD Athlon 64 X 2 у каждого ядра по своему кэшу L2.
19 ноября 2007 года настал исторический момент. Компания AMD, после 18-ти месячного отставания от Intel с их весьма успешной линейкой Intel Core 2, представила долгожданный процессор AMD Phenom с четырьмя ядрами и тремя уровнями кэш-памяти. После этого большинство современных серверных процессоров, стали обзаводиться кэшем третьего уровня (L3). Кэш L3 обычно еще больше по размеру, хотя и несколько медленнее, чем L2 (за счет того, что шина между L2 и L3 более узкая, чем шина между L1 и L2), однако его скорость, в любом случае, несоизмеримо выше, чем скорость системной памяти.
Кэш бывает двух типов: эксклюзивный и не эксклюзивный. В первом случае информация в кэшах всех уровней четко разграничена – в каждом из них содержится исключительно оригинальная, тогда как в случае не эксклюзивного кэша информация может дублироваться на всех уровнях кэширования. Сегодня трудно сказать, какая из этих двух схем более правильная – и в той, и в другой имеются как минусы, так и плюсы. Эксклюзивная схема кэширования используется в процессорах AMD, тогда как не эксклюзивная – в процессорах Intel.
Разрядность
Другой характеристикой процессора, влияющей на его производительность, является разрядность. В общем случае производительность процессора тем выше, чем больше его разрядность. В настоящее время практически все программы рассчитаны на 32- и 64-разрядные процессоры.
32-разрядные процессоры обрабатывают 32 бита за один такт, а 64-разрядные вдвое больше данных, то есть 64 бита. Это преимущество особенно заметно при обработке больших объемов данных (например, при преобразовании фотографий). Но чтобы им воспользоваться, операционная система и приложения должны поддерживать именно 64-битный режим обработки. Под специально разработанными 64-битными версиями Windows XP и Windows Vista в зависимости от необходимости запускаются 32-битные и 64-битные программы. Но 64-битные приложения до сих пор достаточно редки: большинство программ, даже профессиональных, поддерживает лишь 32-битный режим.
При уточнении разрядности процессора и пишут, например, 32/20, что означает, что процессор имеет 32-разрядную шину данных и 20-разрядную шину адреса. Разрядность адресной шины определяет адресное пространство процессора, т.е. максимальный объем оперативной памяти, который может быть установлен в компьютере.
В первом отечественном персональном компьютере «Агат» (1985 г.) был установлен процессор, имевший разрядность 8/16, соответственно его адресное пространство составляло 64 Кб. Процессор Pentium II имел разрядность 64/32, т.е. его адресное пространство составляет 4 Гб. Все 32-разрядные приложения имеют адресное пространство процесса размером не более 4 ГБ
64-битный процессор позволил расширить адресуемое пространство оперативной памяти и избавиться от существующего ограничения в 4 Гб. В этом его существенное преимущество, которое позволяет компьютеру управлять бóльшей оперативной памятью. При наличии 64-битного чипа в настоящее время можно использовать до 32 Гб оперативной памяти. Но это отличие для большинства обычных пользователей мало актуально.
Сокет
Сокет (по-английски – Socket) - это гнездо (разъем) на материнской плате, в которое вставляется процессор. Каждому типу процессора соответствует свой тип сокета. Поэтому, при необходимости, через год-другой заменить процессор на более современный, почти всегда приходится менять и материнскую плату.
Наименование сокета как правило содержит в себе определенный номер, обозначающий число контактов у разъема. В последнее время наиболее используемы сокеты со следующими номерами: 478, 604, 754, 775, 939, 940.
Некоторым исключением из общего правила установки процессоров являлись варианты процессоров Pentium 2 и 3, которые сажались не в сокеты, а в узкие слоты, похожие на слоты под платы расширения на материнской плате. Однако подобная конструкция не прижилась.
Частота системной шины
Системная шина (по-английски – Front Side Bus, или FSB) – это магистраль, проходящая по материнской плате и соединяющая процессор с другими ключевыми компонентами системы, с которыми он обменивается данными и командами (например, контроллер-концентратор памяти).
Частота системной шины определяет скорость, с которой процессор взаимодействует с другими системными устройствами компьютера, получая от них необходимые данные и отправляя их в обратном направлении. Чем выше частота системной шины, тем больше общая производительность системы. Частота системной шины измеряется в ГГц или МГц.
Современные процессоры рассчитаны на работу с конкретным значением частоты FSB, в то время как материнские платы поддерживают несколько значений этой частоты.
Рабочая температура процессора.
Еще один параметр ЦП – допустимая максимальная температура поверхности процессора, при которой возможна нормальная работа (от 54.8 до 100 C). Температура процессора зависит от его загруженности и от качества теплоотвода. В холостом режиме и при нормальном охлаждении температура процессора находится в пределах 25-40C, при высокой загруженности она может достигать 60-65 градусов. При температуре, превышающей максимально допустимую производителем, нет гарантии, что процессор будет функционировать нормально. В таких случаях возможны ошибки в работе программ или зависание компьютера. Процессоры разных производителей нагреваются по-разному. Соответственно чем сильнее нагревается процессор, тем более мощный вентилятор для его охлаждения (кулер) следует покупать. Можно так же купить системнеый блок с дополнительными вентиляторами - это уменьшит температуру внутри ситемного блока.
Арифметико-логическое устройство и блок управления
Обязательными компонентами процессора является арифметико-логическое устройство и блок управления, или FPU (по-английски Floating Point Unit, устройство для выполнения операций с плавающей точкой). Особенно мощным этот блок представлен в линейках AMD. Эти параметры важны для игр и математических вычислений (то есть для программистов).
Арифметико-логическое устройство отвечает за выполнение арифметических и логических операций. Процессор компьютера предназначен для обработки информации и каждый процессор имеет определенный набор базовых операций (команд), например, одной из таких операций является операция сложения двоичных чисел.
Технически процессор реализуется на большой интегральной схеме, структура которой постоянно усложняется, и количество функциональных элементов (типа диод или транзистор) на ней постоянно возрастает (от 30 тысяч в процессоре 8086 до 5 миллионов в процессоре Pentium II и до 30 миллионов в Intel Core Duo). Блок управления координирует работу всех этих компонентов и выполнение процессов, происходящих в компьютере.
www.tehnopanda.ru
проблемы и решения / Хабрахабр
Компьютеры, даже персональные, становятся все сложнее. Не так уж давно в гудящем на столе ящике все было просто — чем больше частота, тем больше производительность. Теперь же системы стали многоядерными, многопроцессорными, в них появились специализированные ускорители, компьютеры все чаще объединяются в кластеры. Зачем? Как во всем этом многообразии разобраться? Что значит SIMD, SMP, GPGPU и другие страшные слова, которые встречаются все чаще? Каковы границы применимости существующих технологий повышения производительности?Введение
Откуда такие сложности?
Компьютерные мощности быстро растут и все время кажется, что все, существующей скорости хватит на все. Но нет — растущая производительность позволяет решать проблемы, к которым раньше нельзя было подступиться. Даже на бытовом уровне есть задачи, которые загрузят ваш компьютер надолго, например кодирование домашнего видео. В промышленности и науке таких задач еще больше: огромные базы данных, молекулярно-динамические расчеты, моделирование сложных механизмов — автомобилей, реактивных двигателей, все это требует возрастающей мощности вычислений. В предыдущие годы основной рост производительности обеспечивался достаточно просто, с помощью уменьшения размеров элементов микропроцессоров. При этом падало энергопотребление и росли частоты работы, компьютеры становились все быстрее, сохраняя, в общих чертах, свою архитектуру. Менялся техпроцесс производства микросхем и мегагерцы вырастали в гигагерцы, радуя пользователей возросшей производительностью, ведь если «мега» это миллион, то «гига» это уже миллиард операций в секунду. Но, как известно, рай бывает либо не навсегда, либо не для всех, и не так давно он в компьютерном мире закончился. Оказалось, частоту дальше повышать нельзя — растут токи утечки, процессоры перегреваются и обойти это не получается. Можно, конечно, развивать системы охлаждения, применять водные радиаторы или совсем уж жидким азотом охлаждать — но это не для каждого пользователя доступно, только для суперкомпьютеров или техноманьяков. Да и при любом охлаждении возможность роста была небольшой, где-то раза в два максимум, что для пользователей, привыкших к геометрической прогрессии, было неприемлемо. Казалось, что закон Мура, по которому число транзисторов и связанная с ним производительность компьютеров удваивалась каждые полтора-два года, перестанет действовать. Пришло время думать и экспериментировать, вспоминая все возможные способы увеличения скорости вычислений.Формула производительности
Возьмем самую общую формулу производительности:Видим, что производительность можно измерять в количестве выполняемых инструкций за секунду. Распишем процесс поподробнее, введем туда тактовую частоту:
Первая часть полученного произведения — количество инструкций, выполняемых за один такт (IPC, Instruction Per Clock), вторая — количество тактов процессора в единицу времени, тактовая частота. Таким образом, для увеличения производительности нужно или поднимать тактовую частоту или увеличивать количество инструкций, выполняемых за один такт. Т.к. рост частоты остановился, придется увеличивать количество исполняемых «за раз» инструкций.
Включаем параллельность
Как же увеличить количество инструкций, исполняемых за один такт? Очевидно, выполняя несколько инструкций за один раз, параллельно. Но как это сделать? Все сильно зависит от выполняемой программы. Если программа написана программистом как однопоточная, где все инструкции выполняются последовательно, друг за другом, то процессору (или компилятору) придется «думать за человека» и искать части программы, которые можно выполнить одновременно, распараллелить.Параллелизм на уровне инструкций
Возьмем простенькую программу:a = 1 b = 2 c = a + b Первые две инструкции вполне можно выполнять параллельно, только третья от них зависит. А значит — всю программу можно выполнить за два шага, а не за три.Процессор, который умеет сам определять независимые и непротиворечащие друг другу инструкции и параллельно их выполнять, называется суперскалярным. Очень многие современные процессоры, включая и последние x86 — суперскалярные процессоры, но есть и другой путь: упростить процессор и возложить поиск параллельности на компилятор. Процессор при этом выполняет команды «пачками», которые заготовил для него компилятор программы, в каждой такой «пачке» — набор инструкций, которые не зависят друг от друга и могут исполняться параллельно. Такая архитектура называется VLIW (very long instruction word — «очень длинная машинная команда»), её дальнейшее развитие получило имя EPIC (explicitly parallel instruction computing) — микропроцессорная архитектура с явным параллелизмом команд) Самые известные процессоры с такой архитектурой — Intel Itanium. Есть и третий вариант увеличения количества инструкций, выполняемых за один такт, это технология Hyper Threading В этой технологии суперскалярный процессор самостоятельно распараллеливает не команды одного потока, а команды нескольких (в современных процессорах — двух) параллельно запущенных потоков. Т.е. физически процессорное ядро одно, но простаивающие при выполнении одной задачи мощности процессора могут быть использованы для выполнения другой. Операционная система видит один процессор (или одно ядро процессора) с технологией Hyper Threading как два независимых процессора. Но на самом деле, конечно, Hyper Threading работает хуже, чем реальные два независимых процессора т.к. задачи на нем будут конкурировать за вычислительные мощности между собой.Технологии параллелизма на уровне инструкций активно развивались в 90е и первую половину 2000х годов, но в настоящее время их потенциал практически исчерпан. Можно переставлять местами команды, переименовывать регистры и использовать другие оптимизации, выделяя из последовательного кода параллельно исполняющиеся участки, но все равно зависимости и ветвления не дадут полностью автоматически распараллелить код. Параллелизм на уровне инструкций хорош тем, что не требует вмешательства человека — но этим он и плох: пока человек умнее микропроцессора, писать по-настоящему параллельный код придется ему.
Параллелизм на уровне данных
Векторные процессоры
Мы уже упоминали скалярность, но кроме скаляра есть и вектор, и кроме суперскалярных процессоров есть векторные. Векторные процессоры выполняют какую-то операцию над целыми массивами данных, векторами. В «чистом» виде векторные процессоры применялись в суперкомьютерах для научных вычислений в 80-е годы. По классификации Флинна, векторные процессоры относятся к SIMD — (single instruction, multiple data — одиночный поток команд, множественный поток данных). В настоящее время в процессорах x86 реализовано множество векторных расширений — это MMX, 3DNow!, SSE, SSE2 и др. Вот как, например, выглядит умножение четырех пар чисел одной командой с применением SSE:float a[4] = { 300.0, 4.0, 4.0, 12.0 }; float b[4] = { 1.5, 2.5, 3.5, 4.5 }; __asm { movups xmm0, a ; // поместить 4 переменные с плавающей точкой из a в регистр xmm0 movups xmm1, b ; // поместить 4 переменные с плавающей точкой из b в регистр xmm1 mulps xmm1, xmm0 ; // перемножить пакеты плавающих точек: xmm1=xmm1*xmm0 movups a, xmm1 ; // выгрузить результаты из регистра xmm1 по адресам a };
Таким образом, вместо четырех последовательных скалярных умножений мы сделали только одно — векторное. Векторные процессоры могут значительно ускорить вычисления над большими объемами данных, но сфера их применимости ограничена, далеко не везде применимы типовые операции над фиксированными массивами. Впрочем, гонка векторизации вычислений далеко не закончена — так в последних процессорах Intel появилось новое векторное расширение AVX (Advanced Vector Extension) Но гораздо интереснее сейчас выглядят
Графические процессоры
Теоретическая вычислительная мощность процессоров в современных видеокартах растет гораздо быстрее, чем в обычных процессорах (посмотрим знаменитую картинку от NVIDIA)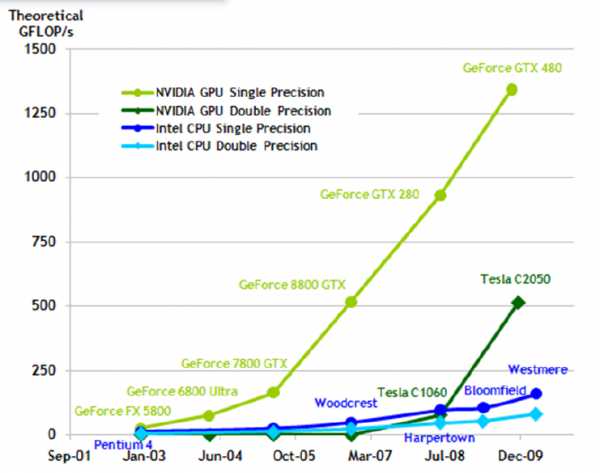 Не так давно эта мощность была приспособлена для универсальных высокопроизводительных вычислений с помощью CUDA/OpenCL. Архитектура графических процессоров (GPGPU, General Purpose computation on GPU – универсальные расчеты средствами видеокарты), близка к уже рассмотренной SIMD. Она называется SIMT — (single instruction, multiple threads, одна инструкция — множество потоков). Так же как в SIMD операции производятся с массивами данных, но степеней свободы гораздо больше — для каждой ячейки обрабатываемых данных работает отдельная нить команд. В результате 1) Параллельно могут выполняться сотни операций над сотнями ячеек данных. 2) В каждом потоке выполняется произвольная последовательность команд, она может обращаться к разным ячейкам. 3) Возможны ветвления. При этом, правда, параллельно могут выполняться только нити с одной и той же последовательностью операций.
Не так давно эта мощность была приспособлена для универсальных высокопроизводительных вычислений с помощью CUDA/OpenCL. Архитектура графических процессоров (GPGPU, General Purpose computation on GPU – универсальные расчеты средствами видеокарты), близка к уже рассмотренной SIMD. Она называется SIMT — (single instruction, multiple threads, одна инструкция — множество потоков). Так же как в SIMD операции производятся с массивами данных, но степеней свободы гораздо больше — для каждой ячейки обрабатываемых данных работает отдельная нить команд. В результате 1) Параллельно могут выполняться сотни операций над сотнями ячеек данных. 2) В каждом потоке выполняется произвольная последовательность команд, она может обращаться к разным ячейкам. 3) Возможны ветвления. При этом, правда, параллельно могут выполняться только нити с одной и той же последовательностью операций.GPGPU позволяют достичь на некоторых задачах впечатляющих результатов. но существуют и принципиальные ограничения, не позволяющие этой технологии стать универсальной палочкой-выручалочкой, а именно 1) Ускорить на GPU можно только хорошо параллелящийся по данным код. 2) GPU использует собственную память. Трансфер данных между памятью GPU и памятью компьютера довольно затратен. 3) Алгоритмы с большим количеством ветвлений работают на GPU неэффективно
Мультиархитектуры-
Итак, мы дошли до полностью параллельных архитектур — независимо параллельных и по командам, и по данным. В классификации Флинна это MIMD (Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных). Для использования всей мощности таких систем нужны многопоточные программы, их выполнение можно «разбросать» на несколько микропроцессоров и этим достичь увеличения производительности без роста частоты. Различные технологии многопоточности давно применялись в суперкомпьютерах, сейчас они «спустились с небес» к простым пользователям и многоядерный процессор уже скорее правило, чем исключение. Но многоядерность далеко не панацея.Суров закон, но это закон
Параллельность, это хороший способ обойти ограничение роста тактовой частоты, но у него есть собственные ограничения. Прежде всего, это закон Амдала, который гласитУскорение выполнения программы за счет распараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.Ускорение кода зависит от числа процессоров и параллельности кода согласно формуле
Действительно, с помощью параллельного выполнения мы можем ускорить время выполнения только параллельного кода. В любой же программе кроме параллельного кода есть и последовательные участки и ускорить их с помощью увеличения количества процессоров не получится, над ними будет работать только один процессор.
Например, если выполнение последовательного кода занимает всего 25% от времени выполнения всей программы, то ускорить эту программу более чем в 4 раза не получится никак.
Давайте построим график зависимости ускорения нашей программы от количества параллельно работающих вычислителей-процессоров. Подставив в формулу 1/4 последовательного кода и 3/4 параллельного, получим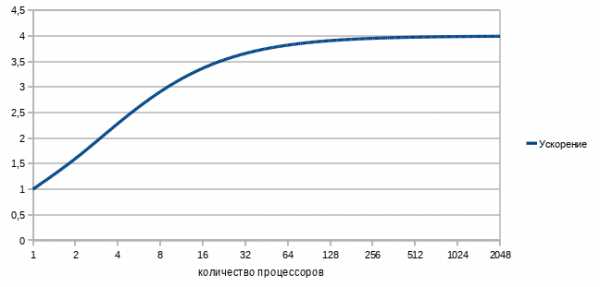
Грустно? Еще как. Самый быстрый в мире суперкомпьютер с тысячами процессоров и терабайтами памяти на нашей, вроде бы даже неплохо (75%!) параллелящейся задаче, меньше чем вдвое быстрее обычного настольного четырехядерника. Причем всё еще хуже, чем в этом идеальном случае. В реальном мире затраты обеспечение параллельности никогда не равны нулю и потому при добавлении все новых и новых процессоров производительность, начиная с некоторого момента, начнет падать. Но как же тогда используется мощь современных очень-очень многоядерных суперкомпьютеров? Во многих алгоритмах время исполнения параллельного кода сильно зависит от количества обрабатываемых данных, а время исполнения последовательного кода — нет. Чем больше данных требуется обработать, тем больше выигрыш от параллельности их обработки. Потому «загоняя» на суперкомп большие объемы данных получаем хорошее ускорение. Например перемножая матрицы 3*3 на суперкомпьютере мы вряд ли заметим разницу с обычным однопроцессорным вариантом, а вот умножение матриц, размером 1000*1000 уже будет вполне оправдано на многоядерной машине. Есть такой простой пример: 9 женщин за 1 месяц не могут родить одного ребенка. Параллельность здесь не работает. Но вот та же 81 женщина за 9 месяцев могут родить (берем максимальную эффективность!) 81 ребенка, т.е.получим максимальную теоретическую производительность от увеличения параллельности, 9 ребенков в месяц или, в среднем, тот же один ребенок в месяц на 9 женщин. Большим компьютерам — большие задачи!
Мультипроцессор
Мультипроцессор — это компьютерная система, которая содержит несколько процессоров и одно видимое для всех процессоров. адресное пространство. Мультипроцессоры отличаются по организации работы с памятью.Системы с общей памятью В таких системах множество процессоров (и процессорных кэшей) имеет доступ к одной и той же физической оперативной памяти. Такая модель часто называется симметричной мультипроцессорностью (SMP). Доступ к памяти при таком построении системы называется UMA (uniform memory access, равномерный доступ) т.к. любой процессор может обратиться к любой ячейке памяти и скорость этого обращения не зависит от адреса памяти. Однако каждый микропроцессор может использовать свой собственный кэш. Несколько подсистем кэш-памяти процессоров, как правило, подключены к общей памяти через шину
Несколько подсистем кэш-памяти процессоров, как правило, подключены к общей памяти через шинуПосмотрим на рисунок. Что у нас хорошего? Любой процессор обращается ко всей памяти и вся она работает одинаково. Программировать для таких систем проще, чем для любых других мультиархитектур. Плохо то, что все процессоры обращаются к памяти через шину, и с ростом числа вычислительных ядер пропускная способность этой шины быстро становится узким местом. Добавляет головной боли и проблема обеспечения когерентности кэшей.
Когерентность кэша Допустим, у нас есть многопроцессорный компьютер. Каждый процессор имеет свой кэш, ну, как на рисунке вверху. Пусть некоторую ячейку памяти читали несколько процессоров — и она попала к ним в кэши. Ничего страшного, пока это ячейка неизменна — из быстрых кэшей она читается и как-то используется в вычислениях. Если же в результате работы программы один из процессоров изменит эту ячейку памяти, чтоб не было рассогласования, чтоб все остальные процессоры «видели» это обновление придется изменять содержимое кэша всех процессоров и как-то тормозить их на время этого обновления. Хорошо если число ядер/процессоров 2, как в настольном компьютере, а если 8 или 16? И если все они обмениваются данными через одну шину? Потери в производительности могут быть очень значительные.Многоядерные процессоры Как бы снизить нагрузку на шину? Прежде всего можно перестать её использовать для обеспечения когерентности. Что для этого проще всего сделать? Да-да, использовать общий кэш. Так устроены большинство современных многоядерных процессоров.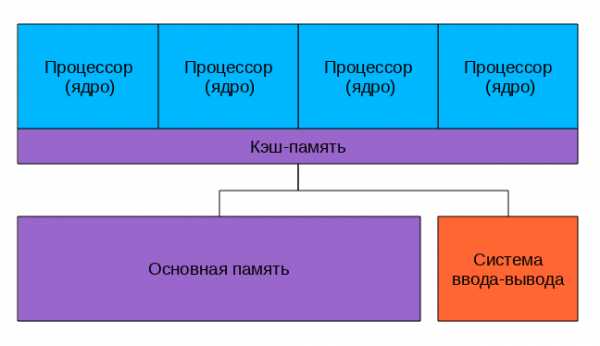 Посмотрим на картинку, найдем два отличия от предыдущей. Да, кэш теперь один на всех, соответственно, проблема когерентности не стоит. А еще круги превратились в прямоугольники, это символизирует тот факт, что все ядра и кэши находятся на одном кристалле. В реальной действительности картинка несколько сложнее, кэши бывают многоуровневыми, часть общие, часть нет, для связи между ними может использоваться специальная шина, но все настоящие многоядерные процессоры не используют внешнюю шину для обеспечения когерентности кэша, а значит — снижают нагрузку на нее. Многоядерные процессоры — один из основных способов повышения производительности современных компьютеров. Уже выпускаются 6 ядерные процессоры, в дальшейшем ядер будет еще больше… где пределы? Прежде всего «ядерность» процессоров ограничивается тепловыделением, чем больше транзисторов одновременно работают в одном кристалле, тем больше этот кристалл греется, тем сложнее его охлаждать. А второе большое ограничение — опять же пропускная способность внешней шины. Много ядер требуют много данных, чтоб их перемалывать, скорости шины перестает хватать, приходится отказываться от SMP в пользуNUMANUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — архитектура, в которой, при общем адресном пространстве, скорость доступа к памяти зависит от ее расположения Обычно у процессора есть " своя" память, обращение к которой быстрее и «чужая», доступ к которой медленнее. В современных системах это выглядит примерно так
Посмотрим на картинку, найдем два отличия от предыдущей. Да, кэш теперь один на всех, соответственно, проблема когерентности не стоит. А еще круги превратились в прямоугольники, это символизирует тот факт, что все ядра и кэши находятся на одном кристалле. В реальной действительности картинка несколько сложнее, кэши бывают многоуровневыми, часть общие, часть нет, для связи между ними может использоваться специальная шина, но все настоящие многоядерные процессоры не используют внешнюю шину для обеспечения когерентности кэша, а значит — снижают нагрузку на нее. Многоядерные процессоры — один из основных способов повышения производительности современных компьютеров. Уже выпускаются 6 ядерные процессоры, в дальшейшем ядер будет еще больше… где пределы? Прежде всего «ядерность» процессоров ограничивается тепловыделением, чем больше транзисторов одновременно работают в одном кристалле, тем больше этот кристалл греется, тем сложнее его охлаждать. А второе большое ограничение — опять же пропускная способность внешней шины. Много ядер требуют много данных, чтоб их перемалывать, скорости шины перестает хватать, приходится отказываться от SMP в пользуNUMANUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — архитектура, в которой, при общем адресном пространстве, скорость доступа к памяти зависит от ее расположения Обычно у процессора есть " своя" память, обращение к которой быстрее и «чужая», доступ к которой медленнее. В современных системах это выглядит примерно так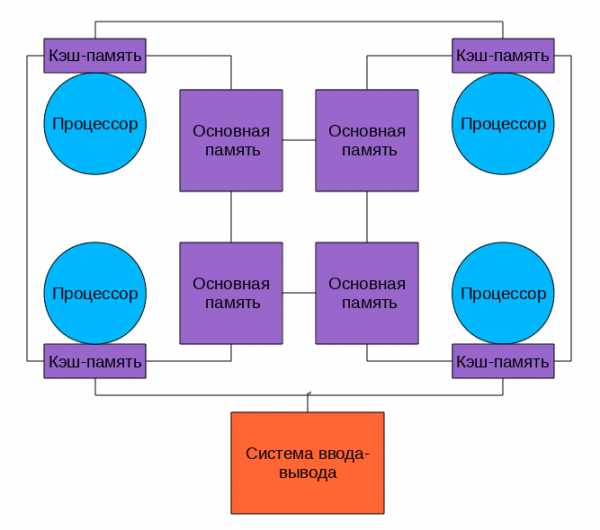
Процессоры соединены с памятью и друг с другом с помощью быстрой шины, в случае AMD это Hyper Transport, в случае последних процессоров Intel это QuickPath Interconnect Т.к. нет общей для всех шины то, при работе со «своей» памятью, она перестает быть узким местом системы. NUMA архитектура позволяет создавать достаточно производительные многопроцессорные системы, а учитывая многоядерность современных процессоров получим уже очень серьезную вычислительную мощность «в одном корпусе», ограниченную в основном сложностью обеспечения кэш-когерентности этой путаницы процессоров и памяти. Но если нам нужна еще большая мощность, придется объединять несколько мультипроцессоров в
Мультикомпьютер
Мультикомпьютер — вычислительная система без общей памяти, состоящая из большого числа взаимосвязанных компьютеров (узлов), у каждого из которых имеется собственная память. При работе над общей задаче узлы мультикомпьютера взаимодействуют через отправку друг другу сообщений. Современные мультикомпьютеры, построенные из множества типовых деталей, называют вычислительными кластерами. Большинство современных суперкомпьютеров построены по кластерной архитектуре, они объединяют множество вычислительных узлов с помощью быстрой сети (Gigabit Ethernet или InfiniBand) и позволяют достичь максимально возможной при современном развитии науки вычислительной мощности. Проблемы, ограничивающие их мощность, тоже немаленькие Это: 1) Программирование системы с параллельно работающими тысячами вычислительных процессоров 2) Гигантское энергопотребление 3) Сложность, приводящая к принципиальной ненадежности
Сводим все воедино
Ну вот, вкратце пробежались почти по всем технологиям и принципам построения мощных вычислительных систем. Теперь есть возможность представить себе строение современного суперкомпьютера. Это мультикомпьютер-кластер, каждый узел которого — NUMA или SMP система с несколькими процессорами, каждый из процессоров с несколькими ядрами, каждое ядро с возможностью суперскалярного внутреннего параллелизма и векторными расширениями. Вдобавок ко всему этому во многих суперкомпьютерах установлены GPGPU — ускорители. У всех этих технологий есть плюсы и ограничения, есть тонкости в применении. А теперь попробуйте эффективно загрузить-запрограммировать всё это великолепие! Задача нетривиальная… но очень интересная. Что-то будет дальше?Источники информации
Курс «Основы параллельных вычислений» Интернет-университета суперкомпьютерных технологийКлассификация Флинна на сайте parallels.ruMultiProcessors, their Memory organizations and Implementations by Intel & AMD Многоядерность, как способ увеличения производительности вычислительной системы Википедия и ИнтернетP.S. Текст родился как попытка самому разобраться и упорядочить в голове информацию о технологиях из области высокопроизводительных вычислений. Возможны неточности и ошибки, буду очень благодарен за замечания и комментарии.
habr.com
Оптимизация Windows — мифы и реальность (часть 2)
Что же такое оптимизация?
Прежде чем углубляться в рассуждения, определимся с терминами.
Толковый словарь дает следующие определения слова «оптимизация»:
- Оптимизация — нахождение наибольшего или наименьшего значения какой-либо функции.
- Оптимизация — выбор наилучшего (оптимального) варианта из множества возможных.
Первое определение сразу отбрасываем, поскольку речь идет не о математических функциях. На втором стоит остановиться подробнее. Вариантов изменения настроек ОС действительно множество, сценариев использования компьютеров тоже множество. Как определить, какой из вариантов настроек оптимален? И для чего он оптимален?
Еще один термин — скорость работы системы. Он также весьма многогранен.
С одной стороны, операционная система имеет множество функций, скорость выполнения которых может иметь весьма существенное значение, а может практически не оказывать влияния на другие процессы. Причем какая-то функция может быть важной для одного класса задач, но практически не влиять на работу задач другого класса, и наоборот. Например, скорость работы диспетчера памяти может заметно влиять на работу современных игр, но не сказываться на работе обозревателей интернета или архиватора. Скорость дисковых операций имеет большое значение при обработке видеофайлов или рисунков большого размера, но практически не влияет на набор и редактирование текста, фоновую проверку правописания в Word и на скорость пересчета таблиц Excel.
С другой стороны, собственно операционная система должна работать как можно более прозрачно и незаметно, оставляя как можно больше системных ресурсов прикладным программам, ради которых люди и прибегают к помощи компьютеров.
Проведем небольшой эксперимент: запустим какую-нибудь программу, активно использующую процессор, например архиватор, и посмотрим в диспетчере задач, какую часть процессорного времени она будет использовать (для чистоты эксперимента желательно взять компьютер с одним одноядерным процессором без гиперпоточности либо отключить гиперпоточность и многоядерность).
Скорее всего программа будет использовать 97-99 процентов вычислительной мощности процессора. На первый взгляд все нормально: на свои нужды Windows использует считанные единицы процентов или даже меньше одного процента.
Рис. 1. Запущен архиваторНемного усложним эксперимент и включим в диспетчере задач показ времени ядра.
Картина становится не такой радужной: оказывается, ядро системы работает и отнимает заметную долю ресурсов процессора — в данном случае около 10-20 процентов.
Рис. 2. Включаем показ времени ядраКазалось бы, вот он, резерв повышения производительности! Ведь очевидно, что, оптимизировав работу системы, можно увеличить скорость работы программы чуть ли не на те же самые 10-20 процентов! В идеале, конечно.
На самом деле этот вывод оказывается ложным. Та доля времени, которая отдается ядру, почти целиком используется опять же для нужд того самого архиватора, в частности на операции чтения с диска и записи на него, ведь эти операции выполняет не сама программа, а ОС по указаниям программы. Так что хоть в это «красное» время и исполняется код ядра системы, этот код обслуживает запросы архиватора.
Скорее всего, в этом месте у читателя сходу возникнет полувозражение-полувопрос. Но ведь в это время все же работает код ядра — наверняка можно оптимизировать его работу так, чтобы оно требовало меньше процессорного времени? Что-нибудь подкрутить, что-нибудь подстроить, что-то ненужное отключить?..
Увы, сколько-нибудь заметных улучшений добиться не удастся. Прежде всего потому, что львиная доля этого «красного» времени ядра уходит на работу с железом. Проверить это проще простого: возьмите носитель с невысокой скоростью обмена, скажем, переключив контроллер диска в режим PIO. Автор не рекомендует проводить такие эксперименты на основном жестком диске из-за возможности заметного снижения скорости работы. Поэтому для эксперимента был выбран контроллер PCMCIA с модулем флеш-памяти, работающий именно в режиме программного ввода-вывода.
Рис. 3. Тот же компьютер, те же данные, но очень медленный дискКак видим, доля времени ядра значительно увеличилась, соответственно, скорость работы архиватора сильно упала. Произошло это потому, что почти все ресурсы процессора тратятся на работу с медленным устройством.
Так что первоначальный вывод оказался правильным: на свои нужды ОС тратит лишь небольшую долю ресурсов современного компьютера. Впрочем, внимательный человек давно и сам мог бы сделать такой вывод, если бы вдумался в результаты сравнения производительности последних версий Windows — они различаются буквально на единицы процентов.
Есть ли в системе резервы для ускорения работы?
Каждый раз при выходе новой Windows можно услышать многочисленные возмущения очередными «свистелками» и «финтифлюшками», добавленными разработчиками. Априори подразумевается, что все эти изменения ухудшают работу системы.
Отчасти, конечно, это верно. Вопрос заключается только в том, насколько велико это ухудшение и ухудшение ли это вообще.
С одной стороны, на отображение улучшенных элементов интерфейса действительно тратится больше ресурсов процессора и памяти. Хотя и не всегда: например, включенный (в большинстве случаев) по умолчанию аэро-интерфейс в Висте и Windows 7 снижает нагрузку на процессор за счет переноса значительной части работы по формированию изображения на видеоадаптер. С другой стороны — и ресурсов этих стало гораздо больше, так что доля, «отъедаемая» ОС, практически не изменилась. С третьей… но об этом чуть позже.
Итак, ОС тратит на свои нужды некоторую долю ресурсов, в первую очередь это процессор и память. Обсуждение использования памяти в эту статью точно не влезет, так что отложим его на будущее и остановимся на процессоре. Как можно увидеть из приведенных выше рисунков, собственно ОС на свои собственные нужды в этом примере тратит единицы процентов.
Вернемся в прошлое. Незадолго до выхода Windows XP Майкл Фортин, долгое время руководивший в «Майкрософт» группой, отвечавшей за производительность системы, составил для бета-тестеров весьма любопытный документ о том, как его группа работала и какие результаты получила (выжимки из него можно найти в http://forum.ixbt.com/topic.cgi?id=67:1#22). Внутренняя оценка изменений производительности звучала так: «разница между Win2K и Windows XP временами мала, около одного процента, временами велика, 5-10 процентов или около того».
Из этого следует достаточно очевидный вывод, что сколько-нибудь заметного увеличения скорости работы при помощи твикинга и «оптимизаций» получить не удастся.
Предположим, что система отнимает на свои нужды пять процентов времени процессора (обычно эта величина все же меньше), значит, работающему в это время процессу достается 95%. Допустим, мы улучшим систему вдвое (конечно, это фантастика, но давайте все-таки предположим такую возможность), так что она отнимет только 2,5 процента времени ЦП, а приложению достанется уже 97,5 процента. Скорость работы приложения увеличится на (97,5−95)⁄95=2,6 процента, то есть прирост получится отнюдь не фантастическим и практически незаметным на глаз.
Так что утверждать, что какие-то мелкие изменения способны увеличить скорость работы на десятки процентов, может только весьма наивный или сверх меры оптимистичный человек.
Но ведь, опять же скажете вы, в интернете можно найти кучу советов по улучшению тех или иных характеристик — что они дают? Как вы, уже, наверное, поняли, у меня не возникло ни малейшего желания заниматься экспериментальным опровержением всех этих идей: пусть их доказывает тот, кто делает такие утверждения. Но вопрос Майклу Фортину я все же задал, ведь у его группы ресурсов намного больше, чем у любого человека. Ответ звучал так: «Я опросил часть нашей команды [напомню, она называется Windows performance team, то есть группа производительности Windows] и сам немного удивился. Оказалось, большинство из них обсуждало подобные рекомендации и коллективный вывод был таков: много шума из ничего. За одним-единственным исключением: совет удалять программы, которые не используются, — полезен».
Теперь о третьей стороне «свистелок»
Если нельзя добиться сколько-нибудь значительного прироста скорости работы ОС, то что же остается? Один из путей — увеличить производительность компьютера. Это самый надежный, самый дорогой, но не всегда эффективный метод. Помните старую шутку: замените в своем компьютере Pentium 100 на Pentium 200, и он начнет простаивать вдвое быстрее? Во многих случаях повышение скорости компьютера давно уже не увеличивает скорость выполнения работы человеком, сидящим за этим компьютером. Невозможно набрать текст в редакторе или ввести числа в электронную таблицу быстрее только из-за того, что в компьютере прибавилось оперативной памяти или у нового процессора выше частота.
Конечно, какие-то задачи могут эффективно использовать всё более мощные компьютеры, но отнюдь не все. И вот тут на первый план выходит совсем другой критерий — эффективность и производительность труда человека, сидящего за компьютером. И на взгляд автора, оптимизировать следует именно эту сторону, то есть не скорость работы компьютера, а скорость работы за компьютером. В конце концов, ведь компьютер для человека, а не наоборот.
Возьмем, к примеру, ту характеристику, которую можно реально улучшить некоторыми приемами: время загрузки. Если вы программист, пишете драйвер низкого уровня и при его отладке вам приходится перезагружаться каждые пять-десять минут — конечно, время загрузки для вас критично. Но для обычного пользователя, который загружает компьютер один раз в день, утром, этот параметр уже далеко не так важен. А если используется гибернация и компьютер перезагружается раз в пару недель, то время загрузки уже почти не имеет значения.
Проведем простенький расчет: допустим, вам удалось сократить время загрузки с одной минуты до 30 секунд. Казалось бы, результат весьма неплох. Но перед этим вы полдня провели, читая разные форумы, сравнивая и анализируя полученную информацию, решая, что именно следует предпринять. Итого для экономии 30 секунд на каждой перезагрузке потрачено 4 часа (14400 секунд). Нетрудно подсчитать, что эти затраты оправдаются через 480 перезагрузок, и только после этого (при загрузке раз в день — примерно через полтора года) вы начнете получать выгоду. Причем не исключено, что за эти полтора года вы купите новый компьютер или переустановите систему, и затраты на «оптимизацию» окажутся просто впустую потраченным временем. В лучшем случае вы получите косвенную выгоду за счет дополнительно приобретенных знаний, но право же, эти знания можно было приобрести и другим, более легким путем.
Но возможность увеличить скорость загрузки никто и не отрицал. А вот оценить полезный эффект от изменения настроек не удалось, насколько известно автору, еще никому. Впрочем, можно привести наглядный пример. Сравнительно недавно в форуме (и еще минимум в двух других) с целью «обсуждения системных служб Windows 7, их оптимизации и методов контроля изменения производительности (скорость загрузки ОС и т. д.) при оптимизации» была создана тема. И хотя участнику сразу говорили (на разных форумах), что проку от этого нет, он, однако, не поверил и решил перепроверить всё сам. В итоге появилась на свет статья, в которой человек после личной проверки пришел к тем же самым результатам. Остается надеяться, что гонорар за статью хотя бы частично окупил потраченное время.
И в заключение приведем несколько критериев, по которым можно определить качество работы составителей многочисленных советов по оптимизации.
Если вы видите совет установить некое значение в параметре SecondLevelDataCache, вспомните, что этот параметр перестал использоваться начиная с Win2000 SP1. Утверждения, что параметр DisablePagingExecutive увеличивает скорость работы системы, неверны: он увеличивает скорость отклика системы за счет некоторого снижения производительности в целом. Рекомендация установить число ядер в настройках Msconfig для ускорения загрузки в лучшем случае бесполезна, ведь система и так по умолчанию использует все ядра. Зато уже были примеры, когда человек, сменив двухъядерный процессор на четырехъядерный и забыв восстановить исходное значение настройки, недоумевал, куда же делись два добавленных ядра.
Заключение
Заниматься изучением и внедрением в жизнь различных советов по оптимизации Windows — значит в лучшем случае тратить время впустую, а в худшем — заботливо раскладывать на будущее грабли для себя, любимого.
Вместе с тем, изменение системы для своего удобства, комфорта, привычных условий работы — не только допустимо, но и рекомендуется. Ибо даже если какие-то рекомендации и будут иметь результатом небольшое снижение производительности системы в целом, это с лихвой компенсируется тем, что вы сами сможете сделать больше за тот же период времени.
www.ixbt.com
Многоядерность процессора или характеристика количества ядер
На первых порах развития процессоров, все старания по повышению производительности процессоров были направлены в сторону наращивания тактовой частоты, но с покорением новых вершин показателей частоты, наращивать её стало тяжелее, так как это сказывалось на увеличении TDP процессоров. Поэтому разработчики стали растить процессоры в ширину, а именно добавлять ядра, так и возникло понятие многоядерности.

Ещё буквально 6-7 лет назад, о многоядерности процессоров практически не было слышно. Нет, многоядерные процессоры от той же компании IBM существовали и ранее, но появление первого двухъядерного процессора для настольных компьютеров, состоялось лишь в 2005 году, и назывался данный процессор Pentium D. Также, в 2005 году был выпущен двухъядерник Opteron от AMD, но для серверных систем.
В данной статье, мы не будем подробно вникать в исторические факты, а будем обсуждать современные многоядерные процессоры как одну из характеристик CPU. А главное – нам нужно разобраться с тем, что же даёт эта многоядерность в плане производительности для процессора и для нас с вами.
Увеличение производительности за счёт многоядерности
Принцип увеличения производительности процессора за счёт нескольких ядер, заключается в разбиении выполнения потоков (различных задач) на несколько ядер. Обобщая, можно сказать, что практически каждый процесс, запущенный у вас в системе, имеет несколько потоков.
Сразу оговорюсь, что операционная система может виртуально создать для себя множество потоков и выполнять это все как бы одновременно, пусть даже физически процессор и одноядерный. Этот принцип реализует ту самую многозадачность Windows (к примеру, одновременное прослушивание музыки и набор текста).

Возьмём для примера антивирусную программу. Один поток у нас будет сканирование компьютера, другой – обновление антивирусной базы (мы всё очень упростили, дабы понять общую концепцию).
И рассмотрим, что же будет в двух разных случаях:
а) Процессор одноядерный. Так как два потока выполняются у нас одновременно, то нужно создать для пользователя (визуально) эту самую одновременность выполнения. Операционная система, делает хитро: происходит переключение между выполнением этих двух потоков (эти переключения мгновенны и время идет в миллисекундах). То есть, система немного «повыполняла» обновление, потом резко переключилась на сканирование, потом назад на обновление. Таким образом, для нас с вами создается впечатление одновременного выполнения этих двух задач. Но что же теряется? Конечно же, производительность. Поэтому давайте рассмотрим второй вариант.
б) Процессор многоядерный. В данном случае этого переключения не будет. Система четко будет посылать каждый поток на отдельное ядро, что в результате позволит нам избавиться от губительного для производительности переключения с потока на поток (идеализируем ситуацию). Два потока выполняются одновременно, в этом и заключается принцип многоядерности и многопоточности. В конечном итоге, мы намного быстрее выполним сканирование и обновление на многоядерном процессоре, нежели на одноядерном. Но тут есть загвоздочка – не все программы поддерживают многоядерность. Не каждая программа может быть оптимизирована таким образом. И все происходит далеко не так идеально, насколько мы описали. Но с каждым днём разработчики создают всё больше и больше программ, у которых прекрасно оптимизирован код, под выполнение на многоядерных процессорах.
Нужны ли многоядерные процессоры? Повседневная резонность
При выборе процессора для компьютера (а именно при размышлении о количестве ядер), следует определить основные виды задач, которые он будет выполнять.
Для улучшения знаний в сфере компьютерного железа, можете ознакомится с материалом про сокеты процессоров.
Точкой старта можно назвать двухъядерные процессоры, так как нет смысла возвращаться к одноядерным решениям. Но и двухъядерные процессоры бывают разные. Это может быть не «самый» свежий Celeron, а может быть Core i3 на Ivy Bridge, точно так же и у АМД – Sempron или Phenom II. Естественно, за счёт других показателей производительность у них будет очень отличаться, поэтому нужно смотреть на всё комплексно и сопоставлять многоядерность с другими характеристиками процессоров.
К примеру, у Core i3 на Ivy Bridge, в наличии имеется технология Hyper-Treading, что позволяет обрабатывать 4 потока одновременно (операционная система видит 4 логических ядра, вместо 2-ух физических). А тот же Celeron таким не похвастается.
Но вернемся непосредственно к размышлениям относительно требуемых задач. Если компьютер необходим для офисной работы и серфинга в интернете, то ему с головой хватит двухъядерного процессора.
Когда речь заходит об игровой производительности, то здесь, чтобы комфортно чувствовать себя в большинстве игр необходимо 4 ядра и более. Но тут всплывает та самая загвоздочка: далеко не все игры обладают оптимизированным кодом под 4-ех ядерные процессоры, а если и оптимизированы, то не так эффективно, как бы этого хотелось. Но, в принципе, для игр сейчас оптимальным решением является именно 4-ых ядерный процессор.

На сегодняшний день, те же 8-ми ядерные процессоры AMD, для игр избыточны, избыточно именно количество ядер, а вот производительность не дотягивает, но у них есть другие преимущества. Эти самые 8 ядер, очень сильно помогут в задачах, где необходима мощная работа с качественной многопоточной нагрузкой. К таковой можно отнести, например рендеринг (просчёт) видео, или же серверные вычисления. Поэтому для таких задач необходимы 6, 8 и более ядер. Да и в скором времени игры смогут качественно грузить 8 и больше ядер, так что в перспективе, всё очень радужно.
Не стоит забывать о том, что остается масса задач, создающих однопоточную нагрузку. И стоит задать себе вопрос: нужен мне этот 8-ми ядерник или нет?
Подводя небольшие итоги, еще раз отмечу, что преимущества многоядерности проявляются при «увесистой» вычислительной многопоточной работе. И если вы не играете в игры с заоблачными требованиями и не занимаетесь специфическими видами работ требующих хорошей вычислительной мощи, то тратиться на дорогие многоядерные процессоры, просто нет смысла (какой процессор лучше для игр?).
we-it.net
Способы повышения производительности процессора
⇐ ПредыдущаяСтр 10 из 27Следующая ⇒Повышение производительности вычислительной системы идет по двум направлениям. Первое – это повышение быстродействия самого процессора, второе – это повышение скорости доставки данных и команд процессору. Первое достигается за счет:
a) увеличением тактовой частоты;
b) расширение методов параллельной обработки данных;
c) совершенствование конвейеризации исполнения команд;
d) дублирование вычислительных средств процессора (переименование регистров);
e) предсказание переходов;
f) спекулятивное (опережающее) выполнение операций;
g) динамическое исполнение инструкций.
Второе достигается за счет:
a) иерархической организации памяти;
b) физического приближения буферной (кэш) памяти к вычислительному устройству процессора;
c) повышения тактовой частоты шины данных;
d) расширения разрядности шины данных;
e) совершенствование архитектуры (например, расслоение) основной памяти.
Аппаратура процессора ориентирована на естественный параллелизм вычислений целочисленных выражений и обработки данных в формате с плавающей точкой, привело к появлению процессоров с разнесенной архитектурой. Упрощенная структура такого процессора (рисунок 3.1), состоит из двух связанных подпроцессоров CPU и FPU, каждый из которых управляется собственным потоком команд.
CPU (Central Processing Unit) – предназначен для обработки целочисленных данных и управления всем вычислительным процессом. FPU (Floating Point Unit) – расширяет вычислительные возможности центрального процессора, выполняя арифметические операции над данными представленными в форме с плавающей точкой, вычисляя различные математические функции и т.д.
Всю работу по декодированию инструкций, вычислению адресов и доставке данных, осуществляет СРU. Оба процессора могут работать самостоятельно, выполняя вычисления параллельно. Разнесенная архитектура позволяет достигать при скалярной обработке производительности векторных процессоров, чему способствуют также предвыборка данных из памяти и конвейерная обработка данных в СРU.
Конвейеризация (pipelining) предполагает разбивку выполнения каждой инструкции на микрооперации. Каждая микрооперация выполняется отдельным блоком конвейера, причем этап исполнение команды выполняется отдельным конвейером, состоящим из 5÷20 ступеней, в зависимости от модели процессора. При выполнении, инструкция продвигается по конвейеру по мере освобождения последующих ступеней. Таким образом, на конвейере одновременно может обрабатываться несколько десятков последовательных инструкций, и производительность процессора можно оценивать темпом выхода выполненных инструкций со всех его конвейеров. Конвейер «классического» процессора Pentium имеет пять ступеней (рисунок 3.2) Конвейеры процессоров с суперконвейерной архитектурой (superpipelined) имеют большее число ступеней, что позволяет упростить каждую из них и, следовательно, сократить время пребывания в них инструкций.
Суперскалярный (superscalar) процессор имеет более одного (Pentium — два) конвейера, способных обрабатывать инструкции параллельно. Pentium является двухпотоковым процессором (имеет два конвейера), Pentium Pro, Pentium 4–мультипотоковые.
Рисунок 3.2 – Конвейер суперскалярнрго процессора
Переименование регистров (register renaming)
Применение этой технологии позволяет обойти архитектурное ограничение на возможность параллельного исполнения инструкций (доступно всего восемь общих регистров). Процессоры с переименованием регистров фактически имеют более восьми общих регистров, т.е. в процессоре дублируются технические ресурсы. При записи промежуточных результатов устанавливается соответствие логических имен и физических регистров.
Таким образом, одновременно могут исполняться несколько инструкций, ссылающихся на одно и то же логическое имя регистра, если, конечно, между ними нет фактических зависимостей по данным. К примеру, процессор Pentium 4 имеет 128 регистров общего назначения, которые могут иметь одинаковые логические, но разные физические имена. Процедура переименования регистров зависит от алгоритма функционирования процессора.
Продвижение данных (data forwarding) подразумевает начало исполнения инструкции до готовности всех операндов. При этом выполняются все возможные действия, и декодированная инструкция с одним операндом помещается в исполнительное устройство, где дожидается готовности второго операнда, выходящего с другого конвейера.
Предсказание переходов (branch prediction) позволяет продолжать выборку и декодирование потока инструкций после выборки инструкции ветвления (условного перехода), не дожидаясь проверки самого условия. Предсказание переходов направляет поток выборки и декодирования по одной из ветвей.
Статический метод предсказания работает считая, что переходы по одним условиям, вероятнее всего, произойдут, а по другим — нет.
Динамическое предсказание опирается на предысторию вычислительного процесса — для каждого конкретного случая перехода накапливается статистика поведения, и переход предсказывается, основываясь именно на ней.
Исполнение по предположению, называемое также спекулятивным (speculative execution), идет дальше — предсказанные после перехода инструкции не только декодируются, но и по возможности исполняются до проверки условия перехода. Если предсказание сбывается, то труд оказывается ненапрасным, если не сбывается — конвейер оказывается недогруженным и простаивает несколько тактов.
Динамическое исполнение (исполнение с изменением последовательности инструкций) свойственное RISC-архитектуре, теперь реализуется и для процессоров х86. При этом изменяется порядок внутренних манипуляций данными, а внешние (шинные) операции ввода/вывода и записи в память выполняются, конечно же, в порядке, предписанном программным кодом. Однако эта способность процессора в наибольшей степени может блокироваться несовершенством программного кода (особенно 16-битных приложений), если он генерируется без учета возможности изменения порядка.
Лекция 7
Рекомендуемые страницы:
lektsia.com
- Что в компьютере главное

- Как на компьютер записать музыку на
- На ноутбуке клавиша

- Программа для освобождения места на диске с
- Дом ру скорость измерить
- Что такое televerify

- Как проверить кэш на компьютере
- Клавиатура ноутбука тошиба назначение клавиш описание
- Функции командной строки

- Javascript плюсы и минусы
- Ошибка диска с как исправить