Должна ли каждая таблица пользователей иметь кластерный индекс? Кластерный индекс ms sql
Индексы в среде MS SQL Server Индекс
DROP INDEX имя_индекса
Индексы в среде MS SQL Server
Индекс представляет собой средство, помогающее ускорить поиск необходимых данных за счет физического или логического их упорядочивания. Индекс представляет собой набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом. Индексы - это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные. Они расположены в самой таблице и являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным наиболее оптимальным способом. В среде SQL Server реализованы эффективные алгоритмы поиска нужного значения в строго определенной последовательности данных. Ускорение поиска достигается именно за счет того, что данные представляются упорядоченными (хотя физически, в зависимости от типа индекса, они могут храниться в соответствии с очередностью их добавления в таблицу). К настоящему времени разработаны эффективные математические алгоритмы поиска данных в упорядоченной последовательности. Наиболее эффективной структурой для поиска данных в машинном представлении являются B-деревья – многоуровневая иерархическая структура с переменным количеством элементов в каждом узле.
Создание индекса
Если выборка данных из таблицы требует значительного времени, это означает, что для нее необходимо создать индекс. Индексы могут существенно повысить производительность выполнения операций поиска и выборки данных. При выборе столбца для индекса следует проанализировать, какие типы запросов чаще всего выполняются пользователями и какие столбцы являются ключевыми, т.е. задающими критерии выборки данных, например, порядок сортировки.
В среде SQL Server реализовано несколько типов индексов:
кластерные индексы;
некластерные индексы;
уникальные индексы.
Некластерный индекс
Некластерные индексы – наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
информацию об идентификационном номере файла, в котором хранится строка;
идентификационный номер страницы соответствующих данных;
номер искомой строки на соответствующей странице;
содержимое столбца.
В большинстве случаев следует ограничиваться 4-5 индексами.
Кластерный индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. В качестве такового следует выбирать наиболее часто используемые столбцы. При этом стоит следовать общим рекомендациям создания индексов и не индексировать слишком длинные столбцы.
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов рекомендуется по возможности свести к минимуму.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
Средства языка SQL предлагают несколько способов определения индекса:
автоматическое создание индекса при создании первичного ключа;
автоматическое создание индекса при определении ограничения целостности UNIQUE;
создание индекса с помощью команды CREATE INDEX.
Последняя команда имеет следующий формат:
<создание_индекса>::=
CREATE [ UNIQUE ]
[ CLUSTERED | NONCLUSTERED ]
INDEX имя_индекса ON имя_таблицы(имя_столбца
[ASC|DESC][,...n])
[WITH [PAD_INDEX]
[[,] FILLFACTOR=фактор_заполнения]
[[,] IGNORE_DUP_KEY]
[[,] DROP_EXISTING]
[[,] STATISTICS_NORECOMPUTE] ]
[ON имя_группы_файлов ]
Рассмотрим некоторые параметры приведенной команды.
Имя индекса должно быть уникальным в пределах таблицы, а сам индекс создается исключительно для таблицы текущей базы данных.
Параметр UNIQUE используется при необходимости ввода в определенное поле только уникальных значений. При указании этого ключевого слова будет создан уникальный индекс. В индексируемом столбце желательно запретить хранение значений NULL, чтобы избежать проблем, связанных с уникальностью значений. После того как для столбца появится уникальный индекс, сервер не разрешит выполнение команд INSERT и UPDATE, которые приведут к появлению дублирующих значений.
Параметр CLUSTERED использует возможность физического индексирования данных и позволяет произвести так называемое кластерное индексирование, в результате чего будут отсортированы данные в самой таблице согласно порядку этого индекса, а вся добавляемая информация станет приводить к изменению физического порядка данных. Кластерным может быть только один индекс в таблице.
Параметр NONCLUSTERED позволяет создавать некластерные индексы.
Параметр FILLFACTOR осуществляет настройку разбиения индекса на страницы и заметно оптимизирует работу SQL-сервера. Коэффициент FILLFACTOR определяет в процентном соотношении размер создаваемых индексных страниц. При этом имеется обратно пропорциональная зависимость частоты работы с таблицей и коэффициента FILLFACTOR.
Параметр PAD_INDEX определяет заполнение внутреннего пространства индекса и применяется совместно с FILLFACTOR.
Параметр DROP_EXISTING при использовании кластерного индекса определяет его повторное создание, что позволяет предотвратить нежелательное обновление кластерных индексов.
Параметр STATISTICS_NORECOMPUTE определяет функции автоматического обновления статистики для таблицы.
Параметр имя_группы_файлов позволяет осуществить выбор файловой группы, в которой будет находиться создаваемый индекс. Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Удаление индекса
Удаление индекса выполняется командой
DROP INDEX 'имя_индекса'[,...n]
Пример 3.5. Создать уникальный кластерный индекс для таблицы Клиент по столбцу Фамилия в первичной группе файлов.
CREATE UNIQUE CLUSTERED INDEX index_klient1
ON Клиент (Фамилия)
WITH DROP_EXISTING
ON PRIMARY
Пример 3.5. Создание уникального кластерного индекса. (, )
Пример 3.6. Создать уникальный некластерный индекс для таблицы Клиент по столбцам Фамилия и Имя в первичной группе файлов. Кроме того, элементы индекса будут упорядочены по убыванию. Также запретим автоматическое обновление статистики при изменении данных в таблице и установим фактор заполнения индексных страниц на уровне 30%.
CREATE UNIQUE NONCLUSTERED INDEX index_klient2
ON Клиент (Фамилия DESC,Имя DESC)
WITH FILLFACTOR=30,
STATISTICS_NORECOMPUTE
ON PRIMARY
Предложение SELECT
Оператор SELECT – один из наиболее важных и самых распространенных операторов SQL. Он позволяет производить выборки данных из таблиц и преобразовывать к нужному виду полученные результаты. Будучи очень мощным, он способен выполнять действия, эквивалентные операторам реляционной алгебры, причем в пределах единственной выполняемой команды. При его помощи можно реализовать сложные и громоздкие условия отбора данных из различных таблиц.
Оператор SELECT – средство, которое полностью абстрагировано от вопросов представления данных, что помогает сконцентрировать внимание на проблемах доступа к данным. Примеры его использования наглядно демонстрируют один из основополагающих принципов больших (промышленных) СУБД: средства хранения данных и доступа к ним отделены от средств представления данных. Операции над данными производятся в масштабе наборов данных, а не отдельных записей.
Оператор SELECT имеет следующий формат:
SELECT [ALL | DISTINCT ] {*|[имя_столбца
[AS новое_имя]]} [,...n]
FROM имя_таблицы [[AS] псевдоним] [,...n]
[WHERE <условие_поиска>]
[GROUP BY имя_столбца [,...n]]
[HAVING <критерии выбора групп>]
[ORDER BY имя_столбца [,...n]]
Оператор SELECT определяет поля (столбцы), которые будут входить в результат выполнения запроса. В списке они разделяются запятыми и приводятся в такой очередности, в какой должны быть представлены в результате запроса. Если используется имя поля, содержащее пробелы или разделители, его следует заключить в квадратные скобки. Символом * можно выбрать все поля, а вместо имени поля применить выражение из нескольких имен.
Если обрабатывается ряд таблиц, то (при наличии одноименных полей в разных таблицах) в списке полей используется полная спецификация поля, т.е. Имя_таблицы.Имя_поля.
Предложение FROM
Предложение FROM задает имена таблиц и просмотров, которые содержат поля, перечисленные в операторе SELECT. Необязательный параметр псевдонима – это сокращение, устанавливаемое для имени таблицы.
Обработка элементов оператора SELECT выполняется в следующей последовательности:
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями;
GROUP BY – образуются группы строк , имеющих одно и то же значение в указанном столбце;
HAVING – фильтруются группы строк объекта в соответствии с указанным условием;
SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных;
ORDER BY – определяется упорядоченность результатов выполнения операторов.
Порядок предложений и фраз в операторе SELECT не может быть изменен. Только два предложения SELECT и FROM являются обязательными, все остальные могут быть опущены. SELECT – закрытая операция: результат запроса к таблице представляет собой другую таблицу. Существует множество вариантов записи данного оператора, что иллюстрируется приведенными ниже примерами.
Пример 4.1. Составить список сведений о всех клиентах.
SELECT * FROM Клиент
Пример 4.1. Список сведений о всех клиентах. (, )
Параметр WHERE определяет критерий отбора записей из входного набора. Но в таблице могут присутствовать повторяющиеся записи (дубликаты). Предикат ALL задает включение в выходной набор всех дубликатов, отобранных по критерию WHERE. Нет необходимости указывать ALL явно, поскольку это значение действует по умолчанию.
Пример 4.2. Составить список всех фирм.
SELECT ALL Клиент.Фирма FROM Клиент
Или (что эквивалентно)
SELECT Клиент.Фирма FROM Клиент
Пример 4.2. Список всех фирм. (, )
Результат выполнения запроса может содержать дублирующиеся значения, поскольку в отличие от операций реляционной алгебры оператор SELECT не исключает повторяющихся значений при выполнении выборки данных.
Предикат DISTINCT следует применять в тех случаях, когда требуется отбросить блоки данных, содержащие дублирующие записи в выбранных полях. Значения для каждого из приведенных в инструкции SELECT полей должны быть уникальными, чтобы содержащая их запись смогла войти в выходной набор.
Причиной ограничения в применении DISTINCT является то обстоятельство, что его использование может резко замедлить выполнение запросов.
Откорректированный пример 4.2 выглядит следующим образом:
SELECT DISTINCT Клиент.Фирма
FROM Клиент
Предложение WHERE
С помощью WHERE-параметра пользователь определяет, какие блоки данных из приведенных в списке FROM таблиц появятся в результате запроса. За ключевым словом WHERE следует перечень условий поиска, определяющих те строки, которые должны быть выбраны при выполнении запроса. Существует пять основных типов условий поиска (или предикатов):
Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления другого.
Диапазон: проверяется, попадает ли результат вычисления выражения в заданный диапазон значений.
Принадлежность множеству: проверяется, принадлежит ли результат вычислений выражения заданному множеству значений.
Соответствие шаблону: проверяется, отвечает ли некоторое строковое значение заданному шаблону.
Значение NULL: проверяется, содержит ли данный столбец определитель NULL (неизвестное значение).
Сравнение
В языке SQL можно использовать следующие операторы сравнения: = – равенство; < – меньше; > – больше; <= – меньше или равно; >= – больше или равно; <> – не равно.
Пример 4.3. Показать все операции отпуска товаров объемом больше 20.
SELECT * FROM Сделка
WHERE Количество>20
Пример 4.3. Операции отпуска товаров объемом больше 20. (, )
Более сложные предикаты могут быть построены с помощью логических операторов AND, OR или NOT, а также скобок, используемых для определения порядка вычисления выражения. Вычисление выражения в условиях выполняется по следующим правилам:
Выражение вычисляется слева направо.
Первыми вычисляются подвыражения в скобках.
Операторы NOT выполняются до выполнения операторов AND и OR.
Операторы AND выполняются до выполнения операторов OR.
Для устранения любой возможной неоднозначности рекомендуется использовать скобки.
Пример 4.4. Вывести список товаров, цена которых больше или равна 100 и меньше или равна 150.
SELECT Название, Цена
FROM Товар
WHERE Цена>=100 And Цена<=150
Пример 4.4. Список товаров, цена которых больше или равна 100 и меньше или равна 150. (, )
Пример 4.5. Вывести список клиентов из Москвы или из Самары.
SELECT Фамилия, ГородКлиента
FROM Клиент
WHERE ГородКлиента="Москва" Or
ГородКлиента="Самара"
Пример 4.5. Список клиентов из Москвы или из Самары. (, )
Диапазон
Оператор BETWEEN используется для поиска значения внутри некоторого интервала, определяемого своими минимальным и максимальным значениями. При этом указанные значения включаются в условие поиска.
Пример 4.6. Вывести список товаров, цена которых лежит в диапазоне от 100 до 150 (запрос эквивалентен примеру 4.4).
SELECT Название, Цена
FROM Товар
WHERE Цена Between 100 And 150
Пример 4.6. Список товаров, цена которых лежит в диапазоне от 100 до 150. (, )
При использовании отрицания NOT BETWEEN требуется, чтобы проверяемое значение лежало вне границ заданного диапазона.
Пример 4.7. Вывести список товаров, цена которых не лежит в диапазоне от 100 до 150.
SELECT Товар.Название, Товар.Цена
FROM Товар
WHERE Товар.Цена Not Between 100 And 150
Или (что эквивалентно)
SELECT Товар.Название, Товар.Цена
FROM Товар
WHERE (Товар.Цена<100) OR (Товар.Цена>150)
Пример 4.7. Список товаров, цена которых не лежит в диапазоне от 100 до 150. (, )
Принадлежность множеству
Оператор IN используется для сравнения некоторого значения со списком заданных значений, при этом проверяется, соответствует ли результат вычисления выражения одному из значений в предоставленном списке. При помощи оператора IN может быть достигнут тот же результат, что и в случае применения оператора OR, однако оператор IN выполняется быстрее.
Пример 4.8. Вывести список клиентов из Москвы или из Самары (запрос эквивалентен примеру 4.5).
SELECT Фамилия, ГородКлиента
FROM Клиент
WHERE ГородКлиента in ("Москва", "Самара")
Пример 4.8. Список клиентов из Москвы или из Самары (, )
NOT IN используется для отбора любых значений, кроме тех, которые указаны в представленном списке.
Пример 4.9. Вывести список клиентов, проживающих не в Москве и не в Самаре.
SELECT Фамилия, ГородКлиента
FROM Клиент
WHERE ГородКлиента
Not in ("Москва","Самара")
Соответствие шаблону
С помощью оператора LIKE можно выполнять сравнение выражения с заданным шаблоном, в котором допускается использование символов-заменителей:
Символ % – вместо этого символа может быть подставлено любое количество произвольных символов.
Символ _ заменяет один символ строки.
[] – вместо символа строки будет подставлен один из возможных символов, указанный в этих ограничителях.
[^] – вместо соответствующего символа строки будут подставлены все символы, кроме указанных в ограничителях.
Пример 4.10. Найти клиентов, у которых в номере телефона вторая цифра – 4.
SELECT Клиент.Фамилия, Клиент.Телефон
FROM Клиент
WHERE Клиент.Телефон Like "_4%"
Пример 4.10. Выборка клиентов, у которых в номере телефона вторая цифра – 4. (, )
Пример 4.11. Найти клиентов, у которых в номере телефона вторая цифра – 2 или 4.
SELECT Клиент.Фамилия, Клиент.Телефон
FROM Клиент
WHERE Клиент.Телефон Like "_[24]%"
Пример 4.11. Выборка клиентов, у которых в номере телефона вторая цифра – 2 или 4. (, )
Пример 4.12. Найти клиентов, у которых в номере телефона вторая цифра 2, 3 или 4.
SELECT Клиент.Фамилия, Клиент.Телефон
FROM Клиент
WHERE Клиент.Телефон Like "_[2-4]%"
Пример 4.12. Выборка клиентов, у которых в номере телефона вторая цифра 2, 3 или 4. (, )
Пример 4.13. Найти клиентов, у которых в фамилии встречается слог "ро".
SELECT Клиент.Фамилия
FROM Клиент
WHERE Клиент.Фамилия Like "%ро%"
Пример 4.13. Выборка клиентов, у которых в фамилии встречается слог "ро". (, )
Значение NULL
Оператор IS NULL используется для сравнения текущего значения со значением NULL – специальным значением, указывающим на отсутствие любого значения. NULL – это не то же самое, что знак пробела (пробел – допустимый символ) или ноль (0 – допустимое число). NULL отличается и от строки нулевой длины (пустой строки).
Пример 4.14. Найти сотрудников, у которых нет телефона (поле Телефон не содержит никакого значения).
refdb.ru
22) Индексы в среде ms sql Server
Индекс представляет собой средство, помогающее ускорить поиск необходимых данных за счет физического или логического их упорядочивания.
Индекс представляет собой набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом.
Индексы это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные.
Расположенные в самой таблице, они являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным наиболее оптимальным способом.
В среде SQL Server реализованы эффективные алгоритмы поиска нужного значения в строго определенной последовательности данных.
Когда нужно создавать индексы
Если выборка данных из таблицы требует значительного времени, это означает, что для нее необходимо создать индекс.
Индексы могут существенно повысить производительность выполнения операций поиска и выборки данных.
При выборе столбца для индекса следует проанализировать, какие типы запросов чаще всего выполняются пользователями и какие столбцы являются ключевыми, т.е. задающими критерии выборки данных, например, порядок сортировки.
Типы индексов
При определении такого индекса в таблице физическое расположение данных перестраивается в соответствии со структурой индекса.
– наиболее типичные представители семейства индексов.
В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Кластерные индексы
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами.
При определении такого индекса в таблице физическое расположение данных перестраивается в соответствии со структурой индекса.
В таблице может быть определен только один кластерный индекс.
В качестве такового следует выбирать наиболее часто используемые столбцы. При этом стоит следовать общим рекомендациям создания индексов и не индексировать слишком длинные столбцы.
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов рекомендуется по возможности свести к минимуму.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс.
Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Некластерные индексы
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
•информацию об идентификационном номере файла, в котором хранится строка;
•идентификационный номер страницы соответствующих данных;
•номер искомой строки на соответствующей странице;
•содержимое столбца.
В большинстве случаев следует ограничиваться 4-5 индексами.
Создание индекса
Индекс создается в случаях:
•автоматическое создание индекса при создании первичного ключа;
•автоматическое создание индекса при определении ограничения целостности UNIQUE;
•создание индекса с помощью команды CREATE INDEX.
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ]
INDEX имя_индекса ON имя_таблицы(имя_столбца
[ASC|DESC][,...n])
[[,] DROP_EXISTING]
[ON имя_группы_файлов ]
Параметр UNIQUE используется при необходимости ввода в определенное поле только уникальных значений.
При указании этого ключевого слова будет создан уникальный индекс.
В индексируемом столбце желательно запретить хранение значений NULL, чтобы избежать проблем, связанных с уникальностью значений.
Параметр DROP_EXISTING при использовании кластерного индекса определяет его повторное создание, что позволяет предотвратить нежелательное обновление кластерных индексов.
Параметр STATISTICS_NORECOMPUTE определяет функции автоматического обновления статистики для таблицы.
Параметр имя_группы_файлов позволяет осуществить выбор файловой группы, в которой будет находиться создаваемый индекс.
Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Удаление индекса
DROP INDEX 'имя_индекса'[,...n]
studfiles.net
sql - SQL Server - Разделенные таблицы или кластерный индекс?
Предположим, что у вас есть одна массивная таблица с тремя столбцами, как показано ниже:
[id] INT NOT NULL, [date] SMALLDATETIME NOT NULL, [sales] FLOAT NULLТакже предположим, что вы ограничены одним физическим диском и одной файловой группой (PRIMARY). Вы ожидаете, что эта таблица проведет продажи для 10 000 000+ идентификаторов по 100 дат (легко 1B + записи).
Как и во многих сценариях хранилищ данных, данные, как правило, будут расти последовательно по дате (т.е. каждый раз, когда вы выполняете загрузку данных, вы будете вводить новые даты и, возможно, обновлять некоторые более поздние даты данных). В аналитических целях данные часто запрашиваются и агрегируются для случайного набора из ~ 10000 идентификаторов, которые будут указаны посредством соединения с другой таблицей. Часто эти запросы не указывают диапазоны дат или указывают очень широкие диапазоны дат, что приводит меня к моему вопросу: как лучше всего индексировать/разделять эту таблицу?
Я подумал об этом некоторое время, но застрял в противоречивых решениях:
Вариант №1:. Когда данные будут загружаться последовательно по дате, определите кластеризованный индекс (и первичный ключ) как [дата], [id]. Также создайте функцию/схему разделения "скользящего окна" в дате, что позволяет быстро перемещать новые данные в/из таблицы. Потенциально создайте некластеризованный индекс для id, чтобы помочь с запросом.
Ожидаемый результат №1:. Эта настройка будет очень быстрой для целей загрузки данных, но не оптимальная, когда дело доходит до аналитических просмотров, в худшем случае (без ограничений по датам, неудачным с запросом id), можно прочитать 100% страниц данных.
Вариант № 2:. Когда данные будут запрашиваться только для небольшого подмножества идентификаторов за раз, определите кластеризованный индекс (и первичный ключ) как [id], [date]. Не беспокойтесь, чтобы создать секционированную таблицу.
Ожидаемый результат №2: Ожидаемый огромный рост производительности, когда дело доходит до загрузки данных, поскольку мы не можем более быстро ограничивать дату. Ожидаемая огромная производительность, когда дело доходит до моих аналитических запросов, так как это минимизирует количество прочитанных страниц данных.
Вариант № 3: Кластеризованный (и первичный ключ) следующим образом: [id], [date]; Функция/схема разделения "скользящего окна" на дату.
Ожидаемый результат № 3: Не уверен, чего ожидать. Учитывая, что первый столбец в кластерном индексе имеет значение [id] и, следовательно, (я понимаю), данные упорядочены по идентификатору, я бы ожидал хорошей производительности из своих аналитических запросов. Однако данные разделяются по дате, что противоречит определению кластерного индекса (но все же выровнено, поскольку дата является частью индекса). Я не нашел много документации, которая говорит об этом сценарии, и какие, если таковые имеются, преимущества в производительности, которые я могу получить от этого, что подводит меня к моему окончательному вопросу о бонусе:
Если я создаю таблицу на одной файловой группе на одном диске с кластеризованным индексом в одном столбце, есть ли какая-либо польза (помимо переключения разделов при загрузке данных), которая возникает при определении раздела в том же столбце?
qaru.site
Индексы в среде MS SQL Server
Поиск ЛекцийИндекс представляет собой средство, помогающее ускорить поиск необходимых данных за счет физического или логического их упорядочивания. Индекс представляет собой набор ссылок, упорядоченных по определенному столбцу таблицы, который в данном случае будет называться индексированным столбцом. Индексы - это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные. Они расположены в самой таблице и являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным оптимальным способом. В среде SQL Server реализованы эффективные алгоритмы поиска нужного значения в строго определенной последовательности данных. Ускорение поиска достигается именно за счет того, что данные представляются упорядоченными (хотя физически, в зависимости от типа индекса, они могут храниться в соответствии с очередностью их добавления в таблицу ). К настоящему времени разработаны эффективные математические алгоритмы поиска данных в упорядоченной последовательности. Наиболее эффективной структурой для поиска данных в машинном представлении являются B-деревья – многоуровневая иерархическая структура с переменным количеством элементов в каждом узле.
Создание индекса
Если выборка данных из таблицы требует значительного времени, это означает, что для нее необходимо создать индекс. Индексы могут существенно повысить производительность выполнения операций поиска и выборки данных. При выборе столбца для индекса следует проанализировать, какие типы запросов чаще всего выполняются пользователями и какие столбцы являются ключевыми, т.е. задающими критерии выборки данных, например, порядок сортировки.
В среде SQL Server реализовано несколько типов индексов:
· кластерные индексы ;
· некластерные индексы ;
· уникальные индексы.
Некластерный индекс
Некластерные индексы – наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
· информацию об идентификационном номере файла, в котором хранится строка ;
· идентификационный номер страницы соответствующих данных;
· номер искомой строки на соответствующей странице;
· содержимое столбца.
В большинстве случаев следует ограничиваться 4-5 индексами.
Кластерный индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса . Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексовследующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. В качестве такового следует выбирать наиболее часто используемые столбцы. При этом стоит следовать общим рекомендациям создания индексов и не индексировать слишком длинные столбцы.
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов рекомендуется по возможности свести к минимуму.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа ( PRIMARY KEY ) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса . В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных встолбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
Средства языка SQL предлагают несколько способов определения индекса:
· автоматическое создание индекса при создании первичного ключа;
· автоматическое создание индекса при определении ограничения целостности UNIQUE ;
· создание индекса с помощью команды CREATE INDEX.
Последняя команда имеет следующий формат:
Рассмотрим некоторые параметры приведенной команды.
Имя индекса должно быть уникальным в пределах таблицы, а сам индекс создается исключительно для таблицы текущей базы данных.
Параметр UNIQUE используется при необходимости ввода в определенное поле только уникальных значений. При указании этого ключевого слова будет создан уникальный индекс. В индексируемом столбце желательно запретить хранение значений NULL, чтобы избежать проблем, связанных с уникальностью значений. После того как для столбца появится уникальный индекс, сервер не разрешит выполнение команд INSERT и UPDATE, которые приведут к появлению дублирующих значений.
Параметр CLUSTERED использует возможность физического индексирования данных и позволяет произвести так называемое кластерное индексирование, в результате чего будут отсортированы данные в самой таблице согласно порядку этого индекса, а вся добавляемая информация станет приводить к изменению физического порядка данных. Кластерным может быть только один индекс в таблице.
Параметр NONCLUSTERED позволяет создавать некластерные индексы.
Параметр FILLFACTOR осуществляет настройку разбиения индекса на страницы и заметно оптимизирует работу SQL-сервера. КоэффициентFILLFACTOR определяет в процентном соотношении размер создаваемых индексных страниц. При этом имеется обратно пропорциональная зависимость частоты работы с таблицей и коэффициента FILLFACTOR.
Параметр PAD_INDEX определяет заполнение внутреннего пространства индекса и применяется совместно с FILLFACTOR.
Параметр DROP_EXISTING при использовании кластерного индекса определяет его повторное создание, что позволяет предотвратить нежелательное обновление кластерных индексов.
Параметр STATISTICS_NORECOMPUTE определяет функции автоматического обновления статистики для таблицы.
Параметр имя_группы_файлов позволяет осуществить выбор файловой группы, в которой будет находиться создаваемый индекс. Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Удаление индекса
Удаление индекса выполняется командой
DROP INDEX 'имя_индекса'[,...n]Пример 3.5. Создать уникальный кластерный индекс для таблицы Клиент по столбцу Фамилия в первичной группе файлов.
Пример 3.6. Создать уникальный некластерный индекс для таблицы Клиент по столбцам Фамилия и Имя в первичной группе файлов. Кроме того, элементы индекса будут упорядочены по убыванию. Также запретим автоматическое обновление статистики при изменении данных в таблице и установим фактор заполнения индексных страниц на уровне 30%.
poisk-ru.ru
ВЛИЯНИЕ ИНДЕКСОВ НА ПРОИЗВОДИТЕЛЬНОСТЬ 1С:ПРЕДПРИЯТИЕ 8 | Gilev.ru
— Ну у вас и запросы! — сказала база данных и повисла…
Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server.Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.
Просто объекта «Индекс» в платформе 1С:Предприятие 8 нет.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
- Неявным образом индексы создаются с учетом типов полей ключа данных — набора полей, однозначно определяющих данные. Для объектных типов данных (Справочник, Документ, ПланСчетов и др.) — это «Ссылка»; для регистров, подчиненных регистратору (РегистрНакопления, РегистрБухгалтерии, РегистрСведений, подчиненный регистратору и др.) — «Регистратор»; для регистров сведений, неподчиненных регистратору — поля, соответствующие изменениям, входящим в основной отбор регистра; для констант — идентификатор объекта метаданных Константы.
- индексируются данные в «соответствии»
Явным способом включением свойства «Индексировать» реквизитов и измерений с значение «Индексировать» и «Индексировать с доп. Упорядочиванием». Вариант ««Индексировать с доп. Упорядочиванием»» включает обычно колонку «код» или «наименование» в индекс.
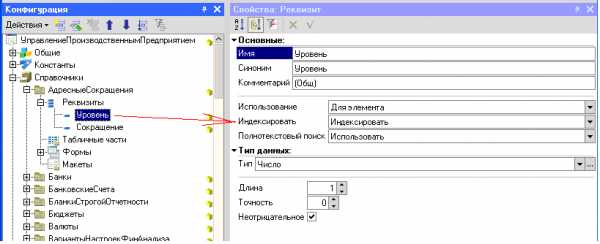
Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».

Можно указать индекс для таблицы значений и в запросах для временных таблиц.
ВЫБРАТЬКод,НаименованиеПОМЕСТИТЬ ВременнаяТаблицаИЗ Справочник.НоменклатураИНДЕКСИРОВАТЬ ПО Код
В любом случае, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти).
Физическая сущность индексов в MS SQL Server.
Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения.Когда вы хотите получить доступ к данным, SQL Server будет производить сканирование таблицы (table scan). SQL Server сканирует всю таблицу, что бы найти искомые записи.Отсюда становятся понятными базовые функции индексов:— увеличение скорости доступа к данным,— поддержка уникальности данных.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.В среде MS SQL Server реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Некластерный индекс
Некластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
- информацию об идентификационном номере файла, в котором хранится строка;
- идентификационный номер страницы соответствующих данных;
- номер искомой строки на соответствующей странице;
- содержимое столбца.
Некластерных индексов может быть несколько для одной таблицы.

Некластеризованный индекс по таблице, не имеющей кластеризованного индекса

Некластеризованный индекс по таблице, имеющей кластеризованный индекс
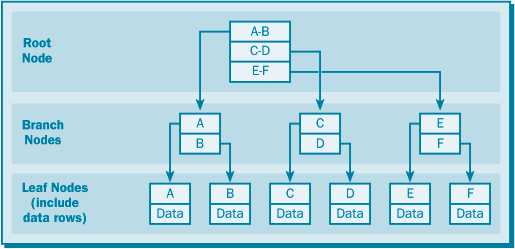
Кластерный (кластеризованный) индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.Естественно, в таблице может быть определен только один кластерный индекс. Кластерный индекс может включать несколько столбцов.Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
1С:Предприятие 8 активно использует кластерные уникальные индексы. Это означает, что можно получить ошибку не уникального индекса.
Если не уникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.«Рыба» скрипта для определения не уникальных записей:SELECT COUNT(*) Counter, <перечисление всех полей соответствующего индекса> from <имя таблицы>GROUP BY <перечисление всех полей соответствующего индекса>HAVING Counter > 1
Понятие первичного и внешнего ключа
Первичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку.
Внешний ключ (foreign key) . Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами. Внешний ключ в таблице может ссылаться и на саму эту таблицу. Такие внешние ключи, в основном, используются для хранения древовидной структуры данных в реляционной таблице. СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах.1С не использует внешние ключи. Ссылочная целостность обеспечивается логикой приложения.
Ограничения индексов
Индекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
В актуальных релизах платформы выполнена оптимизация данного случая и используется хэш по ключу полей, но это медленней «полноценных» индексов.
Статистика индексов
Microsoft SQL Server собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных.
При создании индекса оптимизатор запросов автоматически сохраняет данные статистики о проиндексированых столбцах.
Просмотр статистики — sp_helpstats.
Фрагментация индексов
Чрезмерная фрагментация создает проблемы для больших операций ввода-вывода. Фрагментация не должна превышать 25%. От снижения фрагментации индексов могут выиграть операции сканирования больших диапазонов данных. Для этого рекомендуется выполнять периодическую дефрагментацию индексов. Обратите внимание, что при дефрагментации индексов (по умолчанию) автоматически обновляется статистика.Смотреть степень фрагментированности индексов можно штатными средствами СУБД или в разрезе объектов метаданных можно например с помощью бесплатного онлайн-сервиса http://www.gilev.ru/sqlsize/
Оптимизация размещения индексов
При объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.
Подробное описание действий http://technet.microsoft.com/ru-ru/library/ms175905.aspxИспользование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.Для определения размеров можно использовать выше упомянутую обработку.
Влияние индексов на блокировки
Отсутствие необходимого индекса для запроса означает перебор всех записей таблицы, что в свою очередь приводит к избыточным блокировкам, т.е. блокируются лишние записи. Кроме того, чем дольше выполняется запрос из-за отсутствующих индексов, тем больше время удержания блокировок.Другая причина блокировок — малое количество записей в таблицах. В связи с этим SQL Server, при выборе плана выполнения запроса, не использует индексы, а обходит всю таблицу(Table Scan), блокируя целиком. Для того, чтобы избежать подобных блокировок, необходимо увеличить количество записей в таблицах до 1500-2000. В этом случае сканирование таблицы становится долее дорогостоящей операцией и SQL Server начинает использовать индексы. Конечно это можно сделать не всегда, ряд справочников как «Организации», «Склады», «Подразделения» и т.п. обычно имеют мало записей. В этих случаях индексирование не будет улучшать работу.
Эффективность индексов
Мы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы.
Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу.
Для того, что бы определить эффективность индекса, мы можем приблизительно оценить с помощью бесплатного онлайн-сервиса http://www.gilev.ru/querytj/ показывающий «план исполнения запроса» и используемые индексы.
www.gilev.ru
кластерный индекс MS SQL Server
Обработка очень большой таблицы в производительности SQL Server
У меня возникли проблемы с очень большой таблицей в моей базе данных. Прежде чем говорить о проблеме, давайте поговорим о том, чего я хочу достичь. У меня есть две исходные таблицы: Источник 1: SALES_MAN (ID_SMAN, SM_LATITUDE, SM_LONGITUDE) Источник 2: CLIENT (ID_CLIENT, CLATITUDE, CLONGITUDE) Цель: DISTANCE (ID_SMAN, ID_CLIENT, SM_LATITUDE, SM_LONGITUDE, CLATITUDE, CLONGITUDE, DISTANCE) Идея состоит в […]
Некластеризованный индекс и кластеризованный индекс в одном столбце
Я столкнулся с этим сообщением в Stackoverflow. В первом ответе упоминается что-то вроде кластерного индекса, который содержит все данные для таблицы, а индекс без кластеризации имеет только столбец + расположение кластерного индекса или строки, если он находится в куче (таблица без кластеризованного индекса). Как некластеризованный индекс может располагать кластеризованный индекс? Он содержит только значения столбцов, […]
Почему SQL Server использует некластеризованный индекс по кластерному ПК в операции «select *»?
У меня очень простая таблица, в которой хранятся названия для людей («Mr», «Mrs» и т. Д.). Вот краткий вариант того, что я делаю (используя временную таблицу в этом примере, но результаты те же): create table #titles ( t_id tinyint not null identity(1, 1), title varchar(20) not null, constraint pk_titles primary key clustered (t_id), constraint ux_titles […]
первичный ключ всегда индексируется в sql-сервере?
Вы можете создать кластерный индекс в столбце, отличном от столбца первичного ключа, если указано ограничение некластеризованного первичного ключа. http://msdn.microsoft.com/en-us/library/ms186342.aspx Итак, выше сказанное мне: я могу создать кластеризованный индекс в столбцах, отличных от первичного ключа. Я думаю, что это также означает, что первичный ключ должен быть либо некластеризованным первичным ключом, либо кластеризованным ключом. Возможно ли, что […]
Как выбрать кластерный индекс в SQL Server?
Обычно кластерный индекс создается в SQL Server Management Studio путем установки первичного ключа, однако мой недавний вопрос о кластерном индексе PK <-> ( значение основного ключа для Microsoft SQL Server 2008 ) показал, что нет необходимости устанавливать PK и кластерный индекс должен быть равен. Итак, как же нам выбрать кластеризованные индексы? Давайте рассмотрим следующий пример: […]
Куча SQL Server против кластерного индекса
Я использую SQL Server 2008. Я знаю, что таблица не имеет кластерного индекса, тогда она называется кучей, или же модель хранения называется кластеризованным индексом (B-Tree). Я хочу узнать больше о том, что именно означает хранилище кучи, как оно выглядит и организовано ли оно как структура данных «кучи» (например, минимальная куча, максимальная куча). Любые рекомендуемые показания? […]
Прежде всего, в Entity Framework, почему первичные ключи всегда хранятся как кластерные индексы?
Я больше узнаю об индексах в целом и о кластеризованных индексах в частности. В этой статье Маркус Винанд делает отличный пример для того, чтобы не использовать первичный ключ таблицы в качестве ключа кластеризации. Он подчеркивает, что индексирует только сканирование с использованием кластеризованных индексов и показывает, как вы можете использовать некластеризованные индексы для получения очень быстрых […]
sqlserver.bilee.com
Должна ли каждая таблица пользователей иметь кластерный индекс? MS SQL Server
Недавно я нашел пару таблиц в базе данных без определенных кластеризованных индексов. Но существуют некластеризованные индексы, поэтому они находятся в HEAP.
При анализе я обнаружил, что операторы select используют фильтр в столбцах, определенных в некластеризованных индексах.
Отсутствие кластеризованного индекса в этих таблицах влияет на производительность?
Трудно сказать это более кратко, чем SQL Server MVP Брэд МакГи :
Как правило, каждая таблица должна иметь кластеризованный индекс. Обычно, но не всегда, кластеризованный индекс должен находиться в столбце, который монотонно увеличивается – например, столбец идентификации или какой-либо другой столбец, где значение увеличивается, и является уникальным. Во многих случаях первичный ключ является идеальным столбцом для кластерного индекса.
BOL перекликается с этим чувством:
За некоторыми исключениями, каждая таблица должна иметь кластеризованный индекс.
Причин для этого много, и в основном это связано с тем, что кластеризованный индекс физически заказывает ваши данные на хранение .
-
Если ваш кластерный индекс находится на одном столбце, монотонно увеличивается, на вашем устройстве хранения встраиваются вложения, а разбиение страниц не произойдет.
-
Кластерные индексы эффективны для поиска определенной строки, когда индексированное значение уникально, например, общий шаблон выбора строки на основе первичного ключа.
-
Кластеризованный индекс часто позволяет эффективно запрашивать столбцы, которые часто ищут диапазоны значений ( between , > и т. Д.).
-
Кластеризация может ускорять запросы, когда данные обычно сортируются по определенному столбцу или столбцам.
-
Кластеризованный индекс может быть перестроен или реорганизован по требованию для управления фрагментацией таблицы.
-
Эти преимущества могут быть применены даже к представлениям .
Возможно, вам не нужен кластеризованный индекс:
-
Столбцы с частыми изменениями данных, поскольку SQL Server должен затем физически переупорядочить данные в хранилище.
-
Столбцы, которые уже охвачены другими индексами.
-
Широкие клавиши, так как кластеризованный индекс также используется в некластеризованных индексах.
-
GUID, которые больше тождеств, а также эффективные случайные значения (вряд ли будут отсортированы), хотя newsequentialid() может использоваться для смягчения физического переупорядочения во время вставок.
-
Редкая причина использования кучи (таблица без кластерного индекса) заключается в том, что данные всегда доступны через некластеризованные индексы, а идентификатор RID (идентификатор внутренней строки SQL Server), как известно, меньше кластерного индексного ключа.
Из-за этих и других соображений, таких как ваши конкретные рабочие нагрузки приложения, вы должны тщательно выбрать свои кластерные индексы, чтобы получить максимальную выгоду для своих запросов.
Также обратите внимание, что при создании первичного ключа в таблице в SQL Server он по умолчанию будет создавать уникальный кластеризованный индекс (если он еще не установлен). Это означает, что если вы найдете таблицу, которая не имеет кластерного индекса, но имеет первичный ключ (как и все таблицы), разработчик ранее принял решение создать его таким образом. Возможно, вам захочется иметь веские причины изменить это (из которого их, как мы видели, много. Добавление, изменение или удаление кластерного индекса требует перезаписи всей таблицы и любых некластеризованных индексов, поэтому это может занять некоторое время на большой таблице.
Да, вы должны иметь кластеризованный индекс в таблице. Таким образом, все некластеризованные индексы работают лучше.
Производительность – большая волосатая проблема. Убедитесь, что вы оптимизированы для правильной работы.
Бесплатный совет всегда стоит его цены, и нет никакой замены для фактических экспериментов.
Целью индекса является поиск совпадающих строк и получение данных при их обнаружении.
Некластеризованный индекс по вашим критериям поиска поможет найти строки, но для получения данных строки требуется дополнительная операция.
Если кластерный индекс отсутствует, SQL использует внутренний rowId для указания местоположения данных.
Однако, если в таблице есть кластеризованный индекс, этот rowId заменяется значениями данных в кластерном индексе.
Таким образом, шаг чтения данных строк не понадобится и будет покрываться значениями в индексе.
Даже если кластеризованный индекс не очень хорош в выборе избирательности, если эти ключи часто являются большинством или всеми запрошенными результатами – может быть полезно иметь их как лист некластеризованного индекса.
Да, каждая таблица должна иметь кластерный индекс. Кластерный индекс устанавливает физический порядок данных в таблице. Вы можете сравнить это с заказом музыки в магазине, по названию групп и или по желтым страницам, заказанным по фамилии. Поскольку это касается физического порядка, у вас может быть только один, он может состоять из многих столбцов, но вы можете иметь только один.
Лучше всего разместить кластеризованный индекс на столбцах, которые часто ищут диапазон значений. Пример – это диапазон дат. Кластеризованные индексы также эффективны для поиска определенной строки, когда индексированное значение уникально. Microsoft SQL поместит кластерные индексы в ограничение PRIMARY KEY автоматически, если не определены кластерные индексы.
Кластеризованные индексы не являются хорошим выбором для:
Колонны, которые часто меняются
- Это приводит к перемещению всей строки (поскольку SQL Server должен сохранять значения данных строки в физическом порядке). Это важное соображение в системах обработки больших объемов транзакций, где данные, как правило, нестабильны.
Широкие клавиши
- Значения ключа из кластерного индекса используются всеми некластеризованными индексами в качестве ключей поиска и поэтому сохраняются в каждой некластеризованной записи листа индекса.
Я бы не сказал: «Каждая таблица должна иметь кластерный индекс», я бы сказал: «Посмотрите внимательно на каждую таблицу и на то, как к ней обращаются, и попытайтесь определить кластеризованный индекс на ней, если это имеет смысл ». Это плюс, как Joker, у вас есть только один Joker за стол, но вам не нужно его использовать. Другие системы баз данных не имеют этого, по крайней мере в этой форме, BTW.
Включение кластеризованных индексов во всем мире без понимания того, что вы делаете, также может привести к гибели вашей производительности (в общем, производительность INSERT, поскольку кластеризованный индекс означает физический переупорядочивание на диске или, по крайней мере, это хороший способ понять это), например с первичными ключами GUID, как мы видим все больше и больше.
Итак, прочтите исключения и причины Тима Леннера.
Рассмотрите возможность использования clustered index столбцах, содержащих большое количество различных значений, чтобы избежать необходимости в SQL Server добавлять «уникализатор» для дублирования значений ключа
Недостаток : для обновления записей требуется больше времени, только если изменились поля в индексе кластеризации.
Избегайте конструкций индексов кластеров, где существует риск того, что многие параллельные вставки будут выполняться почти с одним и тем же значением индекса кластеризации
Поиски с некластеризованным индексом будут выглядеть медленнее, если кластерный индекс не создается правильно или он не включает все столбцы, необходимые для возврата данных обратно вызывающему приложению. В случае, если некластеризованный индекс не содержит всех необходимых данных, SQL Server перейдет к кластерному индексу, чтобы получить недостающие данные (через поиск), которые заставят запрос работать медленнее по мере выполнения поиска по строкам.
sqlserver.bilee.com
- Ок понял

- Мтс коннект что это такое и как пользоваться
- Ubuntu создать пользователя

- Основные команды windows

- Total commander синхронизация каталогов
- Создать базу данных sql server 2018

- Как сжать архив zip

- Профилактическое обслуживание компьютеров

- Неро как пользоваться

- Что значит код ошибки 0

- Как добавить устройство воспроизведения звука windows 10
