Анализ сетевых протоколов как метод оптимизации сети. Медленнее всего происходит чтение из локальной сети
Низкая скорость копирования по сети?
В последнее время стала активно ощущаться низкая скорость копирования файлов по сети. А сегодня это стало на пути мне и моим предпочтениям в музыке. Пришлось заняться.
Анамнез: Две машины находятся сети, на одной - наушники, на другой - музыкальный архив. Но сеть работает медленно, со скоростью ниже битрейта mp3, а слушать Глена Миллера с рывками - просто непристойно.
И что самое интересное - скорость копирования файлов в направлении Машина_2 -> Машина_1 - ~6 Mb/s. В обратном направлении всего - 10-20 Kb/s.
- Отключаем весь софт — ничего.
- Отключаем файрволы — ничего.
- Тасуем ip в подсетях и шлюзы — ничего.
- Отключаем QoS и смотрим службы — ничего.
- Несколько раз перезагружаемся :)
- Думаем над тем чтобы просто включить наушники в другую машину — не наш метод.
- Ищем в интернетах — ничего интересного.
Низкая скорость при копировании в сети осталась прежней.
Вывод один: в нашем случае проблема железная.
- Трогаем стопку свитчей и модемов — пшшш, горячие.
Дуем. Скорость та-же.
Смотрим Панель управления -> Система -> Железяки -> Сетевые платы. Вкладка Дополнительно... ммм... какие-то настройки ;)
Изменяем Connection Type -> 100 BaseTx Half Duplex. Перезагрузка — ничего.
Ну что-ж, пробуем лекарство "привод плохо пишет диски":
Изменяем Connection Type -> 10 BaseT Half Duplex — Чудо, скорость копирования по сети поднялась до ~1 Mb/s.
Вывод: как временное решение проблемы низкой скорости в сети помогло понижение скорости сети до 10 Мбит/cек. Умирающая сетевая карта или перебитый патчкорд на первой машине объяснил бы все кроме того факта что в одном из направлений сеть работала нормально.
Продолжение
В продолжение темы о том, почему медленно копируются файлы по сети, нужно отметить что гигабитные сети крайне капризны к качеству кабелей. Очень желательно выбирать FTP, а не UTP кабель. И опять-же 6й категории.
Поэтому перво-наперво сначала замените кабель на заведомо рабочий.
Высокая нагрузка сети
Отключите торрент-клиент и выключите на время эксперементов роутер (модем). Торренты гоняют по сети массу бесполезных пакетов, которые могут... и замедляют работу сети. И хотя в обычных приложениях их влияние слабо заметно, при использовании удаленного рабочего стола (rdp, radmin) можно почувствовать существенное замедление работы.
Использование сетевого диска
Хитрость вторая - использование сетевого диска. Как выяснилось опытным путем, при обращении к файлам, расположенным на сетевых дисках (например Z:\file) , скорость существенно выше, чем при помощи обращения к файлам через два слеша. (например \\computer\shared\file)
Для того чтобы подключить сетевой диск зайдите в Мой компьютер -> Сервис -> Подключить сетевой диск. Выберите произвольную букву диска и выберите расшаренную папку на другом компьютере.
Кроме того, из-за особенности настроек сетевых имен Windows, проблема может возникнуть из-за указания в пути к файлу имени компьютера в сети. Поэтому дабы избежать проблем на ровном месте, при подключении сетевых дисков используйте ip-адрес (например \\192.168.1.11\shared\file).
Похожие записи:
urths.com
Медленно работает сеть
Поиск по компьютерным статьям

Медленно работает сеть. Пожалуй каждый пользователь сталкивался с этой проблемой, что особенно остро проявляется в тех случаях, когда медленно работает сеть в течении долгого времени, то есть фактор является постоянным. Причин для этой проблемы достаточно много, причём все они довольно мало зависят от того, насколько большим быстродействием обладает ваш персональный компьютер.
Типичной причиной, по которой медленно работает сеть, является низкая пропускная способность точки доступа или оборудования (сетевая карта, Wi-Fi модем и т.д.). Решить эту проблему проще всего – необходимо лишь приобрести новое устройство. Однако, далеко не всегда дело скрывается в самом оборудовании, поскольку если на компьютере запускается большое количество программ, требующих изрядного быстродействия, то следовательно, существенно снижается скорость приёма и передачи информации. В этом случае, менять оборудование не стоит, а лучше всего воспользоваться специальными программами, помогающими очищать кэшированную информацию и тем самым снижать нагрузку на процессор и оперативную память устройства.
Проблемой, по которой медленно работает сеть, может также заключаться и в том, что локальная сеть имеет весьма большие объёмы, то есть количество компьютеров не совместима с быстродействием в передаче данных через сеть. Представить себе это весьма просто на примере того, что стоит взять обычную, являющуюся стандартную сетевую карту со скоростью передачи данных в 100 Мбит/с. Естественно, что если в сети будет находиться всего лишь 10 компьютеров, то средняя скорость сократится до 10 Мбит/с, но если компьютеров, предположим 200, что является достаточно обычным явлением в крупных компаниях и офисах, то вероятнее всего, вы заметите, что скорость обмена информации очень мала, так как будет составлять не более 512 Кбит/c. Для того, чтобы как-то устранить эту проблему, необходимо заменить оборудование сети на более производительное, например, установив беспроводную сеть, у которой скорость передачи данных может составлять до 400-600 Мбит/с, а это в 4-6 раз быстрее, чем в обычных проводных локальных сетях.

Помимо всего описанного выше, следует отметить, что довольно частым явлением являются локальные сети, в основе которые положена работа с сервером, специально выделенным для того, чтобы увеличить быстродействие сети и увеличить её пропускную способность. Нередко, такие серверы подвергаются чрезмерной нагрузке, что определённо влияет и на то, что медленно работает сеть. В этой ситуации следует позаботиться о проектирование локальной сети таким образом, чтобы она обеспечивала не только высокую скорость передачи данных и обмена информацией, но и работала бы стабильно со всеми компьютерами. Варианты для этого могут быть самыми различными, в том числе и включение в сеть дополнительных серверов, каждый из которых будет работать с отдельной группой компьютеров, но в тоже время оба сервера будут оставлять общую локальную сеть. Специалисты компьютерного сервисного центра «Хелп Юзер» готовы оказать вам любые услуги связанные с проектированием, разработкой, настройкой и оптимизацией работы компьютерных сетей – профессиональный подход к делу, даёт отличную гарантию того, что ваша компьютерная сеть будет работать стабильно и быстро.

Достаточно часто, причиной того, что медленно работает сеть, является наличие на компьютере или в локальной сети вируса, который может не только замедлять работу персональных компьютеров, но и вовсе запретить выход сеть. Сами по себе такие вирусные программы не являются вредоносными, но создают существенно неудобства для пользователей. Единственно правильным решением будет установка обновлённого антивирусного софта и проверка каждого компьютера в отдельности на наличие вредоносных объектов, причём сами компьютер потребуется отключить от сетевого доступа, чтобы вирус не смог после проверки проникнуть на другие устройства. Аналогичная ситуация возникает также и в случае неправильно установленных или вызывающих конфликт драйверов, что естественно может снизить скорость работ локальной сети и замедлить обмен данными и информацией. Использовать следует только официальные драйверы и программное обеспечение, но если с этим возникают какие-либо проблемы, то вам всегда готовы оказать квалифицированную помощь в сервисном компьютерном центре «ХелпЮзер».
Компания «Хелп Юзер» занимается ремонтом, восстановлением и настройкой персональных компьютеров и компьютерного оборудования уже более десяти лет, а это огромный опыт, который гарантирует весь необходимый профессиональный подход к решению задачи любой сложности.
Зачем мучиться?
И мы решим Ваши проблемы!Выезд осуществляется по Москве и ближайщему Подмосковью!Возможно, Вас также заинтересуют статьи:
все статьи
help-user.ru
Диагностика локальной сети - Секреты и советы - Интерактивные уроки
Очень часто под диагностикой локальной сети подразумевают тестирование только ее кабельной системы. Это не совсем верно. Кабельная система является одной из важнейших составляющих локальной сети, но далеко не единственной и не самой сложной с точки зрения диагностики. Помимо состояния кабельной системы на качество работы сети значительное влияние оказывает состояние активного оборудования (сетевых плат, концентраторов, коммутаторов), качество оборудования сервера и настройки сетевой операционной системы. Кроме того, функционирование сети существенно зависит от алгоритмов работы эксплуатируемого в ней прикладного программного обеспечения.Основных причин неудовлетворительной работы прикладного ПО в сети может быть несколько: повреждения кабельной системы, дефекты активного оборудования, перегруженность сетевых ресурсов (канала связи и сервера), ошибки самого прикладного ПО. Часто одни дефекты сети маскируют другие. Таким образом, чтобы достоверно определить, в чем причина неудовлетворительной работы прикладного ПО, локальную сеть требуется подвергнуть комплексной диагностике. Комплексная диагностика предполагает выполнение следующих работ (этапов).
1. Выявление дефектов физического уровня сети: кабельной системы, системы электропитания активного оборудования; наличия шума от внешних источников.
2. Измерение текущей загруженности канала связи сети и определение влияния величины загрузки канала связи на время реакции прикладного ПО.
3. Измерение числа коллизий в сети и выяснение причин их возникновения.
1. Измерение числа ошибок передачи данных на уровне канала связи и выяснение причин их возникновения.
1. Выявление дефектов архитектуры сети.
1. Измерение текущей загруженности сервера и определение влияния степени его загрузки на время реакции прикладного ПО.
1. Выявление дефектов прикладного ПО, следствием которых является неэффективное использование пропускной способности сервера и сети.
В рамках данной статьи мы рассмотрим первые четыре этапа комплексной диагностики локальной сети, а именно: диагностику канального уровня сети.
Мы не будем подробно описывать методику тестирования кабельной системы сети. Несмотря на важность этой проблемы, ее решение тривиально и однозначно: полноценно кабельная система может быть протестирована только специальным прибором - кабельным сканером. Другого способа не существует. Нет смысла заниматься трудоемкой процедурой выявления дефектов сети, если их можно локализовать одним нажатием клавиши AUTOTEST на кабельном сканере. При этом прибор выполнит полный комплекс тестов на соответствие кабельной системы сети выбранному стандарту.
Хотелось бы обратить ваше внимание на два момента, тем более что о них часто забывают при тестировании кабельной системы сети с помощью сканера.
Режим AUTOTEST не позволяет проверить уровень шума создаваемого внешним источником в кабеле. Это может быть шум от люминесцентной лампы, силовой электропроводки, сотового телефона, мощного копировального аппарата и др. Для определения уровня шума кабельные сканеры имеют, как правило, специальную функцию. Поскольку кабельная система сети полностью проверяется только на этапе ее инсталляции, а шум в кабеле может возникать непредсказуемо, нет полной гарантии того, что шум проявится именно в период полномасштабной проверки сети на этапе ее инсталляции.
При проверке сети кабельным сканером вместо активного оборудования к кабелю подключаются с одного конца - сканер, с другого - инжектор. После проверки кабеля сканер и инжектор отключаются, и подключается активное оборудование: сетевые платы, концентраторы, коммутаторы. При этом нет полной гарантии того, что контакт между активным оборудованием и кабелем будет столь же хорош, как между оборудованием сканера и кабелем. Мы неоднократно встречались со случаями, когда незначительный дефект вилки RJ-45 не проявлялся при тестировании кабельной системы сканером, но обнаруживался при диагностике сети анализатором протоколов.
В рамках предлагаемой методики мы не будем рассматривать ставшую хрестоматийной методику упреждающей диагностики сети (см. врезку "Методика упреждающей диагностики сети"). Не подвергая сомнению важность упреждающей диагностики, заметим только, что на практике она используется редко. Чаще всего (хоть это и неправильно) сеть анализируется только в периоды ее неудовлетворительной работы. В таких случаях локализовать и исправить имеющиеся дефекты сети требуется быстро. Предлагаемую нами методику следует рассматривать как частный случай методики упреждающей диагностики сети.
ОРГАНИЗАЦИЯ ПРОЦЕССА ДИАГНОСТИКИ СЕТИ
Любая методика тестирования сети существенно зависит от имеющихся в распоряжении системного администратора средств. По нашему мнению, в большинстве случаев необходимым и достаточным средством для обнаружения дефектов сети (кроме кабельного сканера) является анализатор сетевых протоколов. Он должен подключаться к тому домену сети (collision domain), где наблюдаются сбои, в максимальной близости к наиболее подозрительным станциям или серверу.
Если сеть имеет архитектуру с компактной магистралью (collapsed backbone) и в качестве магистрали используется коммутатор, то анализатор необходимо подключать к тем портам коммутатора, через которые проходит анализируемый трафик. Некоторые программы имеют специальные агенты или зонды (probes), устанавливаемые на компьютерах, подключенных к удаленным портам коммутатора. Обычно агенты (не путать с агентами SNMP) представляют собой сервис или задачу, работающую в фоновом режиме на компьютере пользователя. Как правило, агенты потребляют мало вычислительных ресурсов и не мешают работе пользователей, на компьютерах которых они установлены. Анализаторы и агенты могут быть подключены к коммутатору двумя способами.
При первом способе анализатор подключается к специальному порту (порту мониторинга или зеркальному порту) коммутатора, если таковой имеется, и на него по очереди направляется трафик со всех интересующих портов коммутатора.
Если в коммутаторе специальный порт отсутствует, то анализатор (или агент) следует подключать к портам интересующих доменов сети в максимальной близости к наиболее подозрительным станциям или серверу. Иногда это может потребовать использования дополнительного концентратора, данный способ предпочтительнее первого. Исключение составляет случай, когда один из портов коммутатора работает в полнодуплексном режиме. Если это так, то порт предварительно необходимо перевести в полудуплексный режим.
На рынке имеется множество разнообразных анализаторов протоколов - от чисто программных до программно-аппаратных. Несмотря на функциональную идентичность большинства анализаторов протоколов, каждый из них обладает теми или иными достоинствами и недостатками. В этой связи мы хотели бы обратить внимание на две важные функции, без которых эффективную диагностику сети провести будет затруднительно.
Во-первых, анализатор протоколов должен иметь встроенную функцию генерации трафика. Во-вторых, анализатор протоколов должен уметь "прореживать" принимаемые кадры, т. е. принимать не все кадры подряд, а, например, каждый пятый или каждый десятый с обязательной последующей аппроксимацией полученных результатов. Если эта функция отсутствует, то при сильной загруженности сети, какой бы производительностью ни обладал компьютер, на котором установлен анализатор, последний будет "зависать" и/или терять кадры. Это особенно важно при диагностике быстрых сетей типа Fast Ethernet и FDDI.
Предлагаемую методику мы будем иллюстрировать на примере использования чисто программного анализатора протоколов Observer компании Network Instruments, работающего в среде Windows 95 и Windows NT. С нашей точки зрения, этот продукт обладает всеми необходимыми функциями для эффективного проведения диагностики сетей.
Итак, предположим, что прикладное программное обеспечение в вашей сети Ethernet стало работать медленно, и вам необходимо оперативно локализовать и ликвидировать дефект.
Первый ЭТАП
Измерение утилизации сети и установление корреляции между замедлением работы сети и перегрузкой канала связи.
Утилизация канала связи сети - это процент времени, в течение которого канал связи передает сигналы, или иначе - доля пропускной способности канала связи, занимаемой кадрами, коллизиями и помехами. Параметр "Утилизация канала связи" характеризует величину загруженности сети.
Канал связи сети является общим сетевым ресурсом, поэтому его загруженность влияет на время реакции прикладного программного обеспечения. Первоочередная задача состоит в определении наличия взаимозависимости между плохой работой прикладного программного обеспечения и утилизацией канала связи сети.
Предположим, что анализатор протоколов установлен в том домене сети (collision domain), где прикладное ПО работает медленно. Средняя утилизация канала связи составляет 19%, пиковая доходит до 82%. Можно ли на основании этих данных сделать достоверный вывод о том, что причиной медленной работы программ в сети является перегруженность канала связи? Вряд ли.
Часто можно слышать о стандарте де-факто, в соответствии с которым для удовлетворительной работы сети Ethernet утилизация канала связи "в тренде" (усредненное значение за 15 минут) не должна превышать 20%, а "в пике" (усредненное значение за 1 минуту) - 35-40%. Приведенные значения объясняются тем, что в сети Ethernet при утилизации канала связи, превышающей 40%, существенно возрастает число коллизий и, соответственно, время реакции прикладного ПО. Несмотря на то что такие рассуждения в общем случае верны, безусловное следование подобным рекомендациям может привести к неправильному выводу о причинах медленной работы программ в сети. Они не учитывают особенности конкретной сети, а именно: тип прикладного ПО, протяженность домена сети, число одновременно работающих станций.
Чтобы определить, какова же максимально допустимая утилизация канала связи в вашем конкретном случае, мы рекомендуем следовать приведенным ниже правилам.
Правило # 1.1. Если в сети Ethernet в любой момент времени обмен данными происходит не более чем между двумя компьютерами, то любая сколь угодно высокая утилизация сети является допустимой.
Сеть Ethernet устроена таким образом, что если два компьютера одновременно конкурируют друг с другом за захват канала связи, то через некоторое время они синхронизируются друг с другом и начинают выходить в канал связи строго по очереди. В таком случае коллизий между ними практически не возникает.
Если рабочая станция и сервер обладают высокой производительностью, и между ними идет обмен большими порциями данных, то утилизация в канале связи может достигать 80-90% (особенно в пакетном режиме - burst mode). Это абсолютно не замедляет работу сети, а, наоборот, свидетельствует об эффективном использовании ее ресурсов прикладным ПО.
Таким образом, если в вашей сети утилизация канала связи высока, постарайтесь определить, сколько компьютеров одновременно ведут обмен данными. Это можно сделать, например, собрав и декодировав пакеты в интересующем канале в период его высокой утилизации.
Правило # 1.2. Высокая утилизация канала связи сети только в том случае замедляет работу конкретного прикладного ПО, когда именно канал связи является "узким местом" для работы данного конкретного ПО.
Кроме канала связи узкие места в системе могут возникнуть из-за недостаточной производительности или неправильных параметров настройки сервера, низкой производительности рабочих станций, неэффективных алгоритмов работы самого прикладного ПО.
В какой мере канал связи ответственнен за недостаточную производительность системы, можно выяснить следующим образом. Выбрав наиболее массовую операцию данного прикладного ПО (например, для банковского ПО такой операцией может быть ввод платежного поручения), вам следует определить, как утилизация канала связи влияет на время выполнения такой операции.
Проще всего это сделать, воспользовавшись функцией генерации трафика, имеющейся в ряде анализаторов протоколов (например, в Observer). С помощью этой функции интенсивность генерируемой нагрузки следует наращивать постепенно, и на ее фоне производить измерения времени выполнения операции. Фоновую нагрузку целесообразно увеличивать от 0 до 50-60% с шагом не более 10%.
Если время выполнения операции в широком интервале фоновых нагрузок не будет существенно изменяться, то узким местом системы является не канал связи. Если же время выполнения операции будет существенно меняться в зависимости от величины фоновой нагрузки (например, при 10% и 20% утилизации канала связи время выполнения операции будет значительно различаться), то именно канал связи, скорее всего, ответственнен за низкую производительность системы, и величина его загруженности критична для времени реакции прикладного ПО. Зная желаемое время реакции ПО, вы легко сможете определить, какой утилизации канала связи соответствует желаемое время реакции прикладного ПО.
В данном эксперименте фоновую нагрузку не следует задавать более 60-70%. Даже если канал связи не является узким местом, при таких нагрузках время выполнения операций может возрасти вследствие уменьшения эффективной пропускной способности сети.
Правило # 1.3. Максимально допустимая утилизация канала связи зависит от протяженности сети.
При увеличении протяженности домена сети допустимая утилизация уменьшается. Чем больше протяженность домена сети, тем позже будут обнаруживаться коллизии. Если протяженность домена сети мала, то коллизии будут выявлены станциями еще в начале кадра, в момент передачи преамбулы. Если протяженность сети велика, то коллизии будут обнаружены позже - в момент передачи самого кадра. В результате накладные расходы на передачу пакета (IP или IPX) возрастают. Чем позже выявлена коллизия, тем больше величина накладных расходов и большее время тратится на передачу пакета. В результате время реакции прикладного ПО, хотя и незначительно, но увеличивается.
Выводы. Если в результате проведения диагностики сети вы определили, что причина медленной работы прикладного ПО - в перегруженности канала связи, то архитектуру сети необходимо изменить. Число станций в перегруженных доменах сети следует уменьшить, а станции, создающие наибольшую нагрузку на сеть, подключить к выделенным портам коммутатора.
Второй ЭТАП
Измерение числа коллизий в сети.
Если две станции домена сети одновременно ведут передачу данных, то в домене возникает коллизия. Коллизии бывают трех типов: местные, удаленные, поздние.
Местная коллизия (local collision) - это коллизия, фиксируемая в домене, где подключено измерительное устройство, в пределах передачи преамбулы или первых 64 байт кадра, когда источник передачи находится в домене. Алгоритмы обнаружения местной коллизии для сети на основе витой пары (10BaseT) и коаксиального кабеля (10Base2) отличны друг от друга.
В сети 10Base2 передающая кадр станция определяет, что произошла локальная коллизия по изменению уровня напряжения в канале связи (по его удвоению). Обнаружив коллизию, передающая станция посылает в канал связи серию сигналов о заторе (jam), чтобы все остальные станции домена узнали, что произошла коллизия. Результатом этой серии сигналов оказывается появление в сети коротких, неправильно оформленных кадров длиной менее 64 байт с неверной контрольной последовательностью CRC. Такие кадры называются фрагментами (collision fragment или runt).
В сети 10BaseT станция определяет, что произошла локальная коллизия, если во время передачи кадра она обнаруживает активность на приемной паре (Rx).
Удаленная коллизия (remote collision) - это коллизия, которая возникает в другом физическом сегменте сети (т. е. за повторителем). Станция узнает, что произошла удаленная коллизия, если она получает неправильно оформленный короткий кадр с неверной контрольной последовательностью CRC, и при этом уровень напряжения в канале связи остается в установленных пределах (для сетей 10Base2). Для сетей 10BaseT/100BaseT показателем является отсутствие одновременной активности на приемной и передающей парах (Tx и Rx).
Поздняя коллизия (late collision) - это местная коллизия, которая фиксируется уже после того, как станция передала в канал связи первые 64 байт кадра. В сетях 10BaseT поздние коллизии часто фиксируются измерительными устройствами как ошибки CRC.
Если выявление локальных и удаленных коллизий, как правило, еще не свидетельствует о наличии в сети дефектов, то обнаружение поздних коллизий - это явное подтверждение наличия дефекта в домене. Чаще всего это связано с чрезмерной длиной линий связи или некачественным сетевым оборудованием.
Помимо высокого уровня утилизации канала связи коллизии в сети Ethernet могут быть вызваны дефектами кабельной системы и активного оборудования, а также наличием шумов.
Даже если канал связи не является узким местом системы, коллизии несущественно, но замедляют работу прикладного ПО. Причем основное замедление вызывается не столько самим фактом необходимости повторной передачи кадра, сколько тем, что каждый компьютер сети после возникновения коллизии должен выполнять алгоритм отката (backoff algorithm): до следующей попытки выхода в канал связи ему придется ждать случайный промежуток времени, пропорциональный числу предыдущих неудачных попыток.
В этой связи важно выяснить, какова причина коллизий - высокая утилизация сети или "скрытые" дефекты сети. Чтобы это определить, мы рекомендуем придерживаться следующих правил.
Правило # 2.1. Не все измерительные приборы правильно определяют общее число коллизий в сети.
Практически все чисто программные анализаторы протоколов фиксируют наличие коллизии только в том случае, если они обнаруживают в сети фрагмент, т. е. результат коллизии. При этом наиболее распространенный тип коллизий - происходящие в момент передачи преамбулы кадра (т. е. до начального ограничителя кадра (SFD)) - программные измерительные средства не обнаруживают, так уж устроен набор микросхем сетевых плат Ethernet. Наиболее точно коллизии обнаруживают аппаратные измерительные приборы, например LANMeter компании Fluke.
Правило # 2.2. Высокая утилизация канала связи не всегда сопровождается высоким уровнем коллизий.
Уровень коллизий будет низким, если в сети одновременно работает не более двух станций (см. Правило # 1.1) или если небольшое число станций одновременно ведут обмен длинными кадрами (что особенно характерно для пакетного режима). В этом случае до начала передачи кадра станции "видят" несущую в канале связи, и коллизии редки.
Правило # 2.3. Признаком наличия дефекта в сети служит такая ситуация, когда невысокая утилизация канала (менее 30%) сопровождается высоким уровнем коллизий (более 5%).
Если кабельная система предварительно была протестирована сканером, то наиболее вероятной причиной повышенного уровня коллизий является шум в линии связи, вызванный внешним источником, или дефектная сетевая плата, неправильно реализующая алгоритм доступа к среде передачи (CSMA/CD).
Компания Network Instruments в анализаторе протоколов Observer оригинально решила задачу выявления коллизий, вызванных дефектами сети. Встроенный в программу тест провоцирует возникновение коллизий: он посылает в канал связи серию пакетов с интенсивностью 100 пакетов в секунду и анализирует число возникших коллизий. При этом совмещенный график отображает зависимость числа коллизий в сети от утилизации канала связи.
Долю коллизий в общем числе кадров имеет смысл анализировать в момент активности подозрительных (медленно работающих) станций и только в случае, когда утилизация канала связи превышает 30%. Если из трех кадров один столкнулся с коллизией, то это еще не означает, что в сети есть дефект.
В анализаторе протоколов Observer график, показанный на Рисунке 3, меняет цвет в зависимости от числа коллизий и наблюдаемой при этом утилизации канала связи.
Правило # 2.4. При диагностике сети 10BaseT все коллизии должны фиксироваться как удаленные, если анализатор протоколов не создает трафика.
Если вы пассивно (без генерации трафика) наблюдаете за сетью 10BaseT и физический сегмент в месте подключения анализатора (измерительного прибора) исправен, то все коллизии должны фиксироваться как удаленные.
Если тем не менее вы видите именно локальные коллизии, то это может означать одно из трех: физический сегмент сети, куда подключен измерительный прибор, неисправен; порт концентратора или коммутатора, куда подключен измерительный прибор, имеет дефект, или измерительный прибор не умеет различать локальные и удаленные коллизии.
Правило # 2.5. Коллизии в сети могут быть следствием перегруженности входных буферов коммутатора.
Следует помнить, что коммутаторы при перегруженности входных буферов эмулируют коллизии, дабы "притормозить" рабочие станции сети. Этот механизм называется "управление потоком" (flow control).
Правило # 2.6. Причиной большого числа коллизий (и ошибок) в сети может быть неправильная организация заземления компьютеров, включенных в локальную сеть.
Если компьютеры, включенные в сеть не имеют общей точки заземления (зануления), то между корпусами компьютеров может возникать разность потенциалов. В персональных компьютерах "защитная" земля объединена с "информационной" землей. Поскольку компьютеры объединены каналом связи локальной сети, разность потенциалов между ними приводит к возникновению тока по каналу связи. Этот ток вызывает искажение информации и является причиной коллизий и ошибок в сети. Такой эффект получил название ground loop или inter ground noise.
Аналогичный эффект возникает в случае, когда сегмент коаксиального кабеля заземлен более чем в одной точке. Это часто случается, если Т-соединитель сетевой платы соприкасается с корпусом компьютера.
Обращаем ваше внимание на то, что установка источника бесперебойного питания не снимает описанных трудностей. Наиболее подробно данные проблемы и способы их решения рассматриваются в материалах компании APC (American Power Conversion) в "Руководстве по защите электропитания" (Power Protection Handbook).
При обнаружении большого числа коллизий и ошибок в сетях 10Base2 первое, что надо сделать, - проверить разность потенциалов между оплеткой коаксиального кабеля и корпусами компьютеров. Если ее величина для любого компьютера в сети составляет более одного вольта по переменному току, то в сети не все в порядке с топологией линий заземления компьютеров.
ТРЕТИЙ ЭТАП
Измерение числа ошибок на канальном уровне сети.
В сетях Ethernet наиболее распространенными являются следующие типы ошибок.
Короткий кадр - кадр длиной менее 64 байт (после 8-байтной преамбулы) с правильной контрольной последовательностью. Наиболее вероятная причина появления коротких кадров - неисправная сетевая плата или неправильно сконфигурированный или испорченный сетевой драйвер.
Последнее время мы наблюдаем большое число ошибок этого типа на относительно медленных компьютерах (486/SX), работающих под Windows 95 с сетевыми платами NE2000. Причина нам неизвестна.
Длинный кадр (long frame) - кадр длиннее 1518 байт. Длинный кадр может иметь правильную или неправильную контрольную последовательность. В последнем случае такие кадры обычно называют jabber. Фиксация длинных кадров с правильной контрольной последовательностью указывает чаще всего на некорректность работы сетевого драйвера; фиксация ошибок типа jabber - на неисправность активного оборудования или наличие внешних помех.
Ошибки контрольной последовательности (CRC error) - правильно оформленный кадр допустимой длины (от 64 до 1518 байт), но с неверной контрольной последовательностью (ошибка в поле CRC).
Ошибка выравнивания (alignment error) - кадр, содержащий число бит, не кратное числу байт.
Блики (ghosts) - последовательность сигналов, отличных по формату от кадров Ethernet, не содержащая разделителя (SFD) и длиной более 72 байт. Впервые данный термин был введен компанией Fluke с целью дифференциации различий между удаленными коллизиями и шумами в канале связи.
Блики являются наиболее коварной ошибкой, так как они не распознаются программными анализаторами протоколов по той же причине, что и коллизии на этапе передачи преамбулы. Выявить блики можно специальными приборами или с помощью метода стрессового тестирования сети (мы планируем рассказать об этом методе в последующих публикациях).
Рискуя навлечь на себя праведный гнев дистрибьюторов программ сетевого управления на основе SNMP, мы осмелимся тем не менее утверждать, что степень влияния ошибок канального уровня сети на время реакции прикладного ПО сильно преувеличена.
В соответствии с общепринятым стандартом де-факто число ошибок канального уровня не должно превышать 1% от общего числа переданных по сети кадров. Как показывает опыт, эта величина перекрывается только при наличии явных дефектов кабельной системы сети. При этом многие серьезные дефекты активного оборудования, вызывающие многочисленные сбои в работе сети, не проявляются на канальном уровне сети (см. Правило # 3.8).
Правило # 3.1. Прежде чем анализировать ошибки в сети, выясните, какие типы ошибок могут быть определены сетевой платой и драйвером платы на компьютере, где работает ваш программный анализатор протоколов.
Работа любого анализатора протоколов основана на том, что сетевая плата и драйвер переводятся в режим приема всех кадров сети (promiscuous mode). В этом режиме сетевая плата принимает все проходящие по сети кадры, а не только широковещательные и адресованные непосредственно к ней, как в обычном режиме. Анализатор протоколов всю информацию о событиях в сети получает именно от драйвера сетевой платы, работающей в режиме приема всех кадров.
Не все сетевые платы и сетевые драйверы предоставляют анализатору протоколов идентичную и полную информацию об ошибках в сети. Сетевые платы 3Com вообще никакой информации об ошибках не выдают. Если вы установите анализатор протоколов на такую плату, то значения на всех счетчиках ошибок будут нулевыми.
EtherExpress Pro компании Intel сообщают только об ошибках CRC и выравнивания. Сетевые платы компании SMC предоставляют информацию только о коротких кадрах. NE2000 выдают почти полную информацию, выявляя ошибки CRC, короткие кадры, ошибки выравнивания, коллизии.
Сетевые карты D-Link (например, DFE-500TX) и Kingstone (например, KNE 100TX) сообщают полную, а при наличии специального драйвера - даже расширенную, информацию об ошибках и коллизиях в сети.
Ряд разработчиков анализаторов протоколов предлагают свои драйверы для наиболее популярных сетевых плат.
Правило # 3.2. Обращайте внимание на "привязку" ошибок к конкретным MAC-адресам станций.
При анализе локальной сети вы, наверное, обращали внимание, что ошибки обычно "привязаны" к определенным МАС-адресам станций. Однако коллизии, произошедшие в адресной части кадра, блики, нераспознанные ситуации типа короткого кадра с нулевой длиной данных не могут быть "привязаны" к конкретным МАС-адресам.
Если в сети наблюдается много ошибок, которые не связаны с конкретными МАС-адресами, то их источником скорее всего является не активное оборудование. Вероятнее всего, такие ошибки - результат коллизий, дефектов кабельной системы сети или сильных внешних шумов. Они могут быть также вызваны низким качеством или перебоями питающего активное оборудование напряжения.
Если большинство ошибок привязаны к конкретным MAC-адресам станций, то постарайтесь выявить закономерность между местонахождением станций, передающих ошибочные кадры, расположением измерительного прибора (см. Правила # 3.3, # 3.4) и топологией сети.
Правило # 3.3. В пределах одного домена сети (collision domain) тип и число ошибок, фиксируемых анализатором протоколов, зависят от места подключения измерительного прибора.
Другими словами, в пределах сегмента коаксиального кабеля, концентратора или стека концентраторов картина статистики по каналу может зависеть от места подключения измерительного прибора.
Многим администраторам сетей данное утверждение может показаться абсурдным, так как оно противоречит принципам семиуровневой модели OSI. Впервые столкнувшись с этим явлением, мы также не поверили результату и решили, что измерительный прибор неисправен. Мы проверяли данный феномен с разными измерительными приборами, от чисто программных до программно-аппаратных. Результат был тот же.
Одна и та же помеха может вызвать фиксацию ошибки CRC, блика, удаленной коллизии или вообще не обнаруживаться в зависимости от взаимного расположения источника помех и измерительного прибора. Одна и та же коллизия может фиксироваться как удаленная или поздняя в зависимости от взаимного расположения конфликтующих станций и измерительного прибора. Кадр, содержащий ошибку CRC на одном концентраторе стека, может быть не зафиксирован на другом концентраторе того же самого стека.
Следствием приведенного эвристического правила является тот факт, что программы сетевого мониторинга на основе протокола SNMP не всегда адекватно отражают статистику ошибок в сети. Причина этого в том, что встроенный в активное оборудование агент SNMP всегда следит за состоянием сети только из одной точки. Так, если сеть представляет собой несколько стеков "неинтеллектуальных" концентраторов, подключенных к "интеллектуальному" коммутатору, то SNMP-агент коммутатора может иногда не видеть части ошибок в стеке концентраторов.
Подтверждение приведенного правила можно найти на серверах Web компаний Fluke (www.fluke.com) и Net3 Group (www.net3group.com).
Рекомендациям по разрешению описанного феномена посвящены Правила ## 3.4 и 3.5. Правило # 3.4. Для выявления ошибок на канальном уровне сети измерения необходимо проводить на фоне генерации анализатором протоколов собственного трафика.
Генерация трафика позволяет обострить имеющиеся проблемы и создает условия для их проявления. Трафик должен иметь невысокую интенсивность (не более 100 кадров/с) и способствовать образованию коллизий в сети, т. е. содержать короткие (<100 байт) кадры.
При выборе анализатора протоколов или другого диагностического средства внимание следует обратить прежде всего на то, чтобы выбранный инструмент имел встроенную функцию генерации трафика задаваемой интенсивности. Эта функция имеется, в частности, в анализаторах Observer компании Network Instruments и NetXray компании Cinco (ныне Network Associates).
Правило # 3.5. Если наблюдаемая статистика зависит от места подключения измерительного прибора, то источник ошибок, скорее всего, находится на физическом уровне данного домена сети (причина - дефекты кабельной системы или шум внешнего источника). В противном случае источник ошибок расположен на канальном уровне (или выше) или в другом, смежном, домене сети.
Правило # 3.6. Если доля ошибок CRC в общем числе ошибок велика, то следует определить длину кадров, содержащих данный тип ошибок.
Как мы уже отмечали, ошибки CRC могут возникать в результате коллизий, дефектов кабельной системы, внешнего источника шума, неисправных трансиверов. Еще одной возможной причиной появления ошибок CRC могут быть дефектные порты концентратора или коммутатора, которые добавляют в конец кадра несколько "пустых" байтов.
При большой доле ошибок CRC в общем числе ошибок целесообразно выяснить причину их появления. Для этого ошибочные кадры из серии надо сравнить с аналогичными хорошими кадрами из той же серии. Если ошибочные кадры будут существенно короче хороших, то это, скорее всего, результаты коллизий. Если ошибочные кадры будут практически такой же длины, то причиной искажения, вероятнее всего, является внешняя помеха. Если же испорченные кадры длиннее хороших, то причина кроется, вероятнее всего, в дефектном порту концентратора или коммутатора, которые добавляют в конец кадра "пустые" байты.
Сравнить длину ошибочных и правильных кадров проще всего посредством сбора в буфер анализатора серии кадров с ошибкой CRC.Правило # 3.8. Отсутствие ошибок на канальном уровне еще не гарантирует того, что информация в вашей сети не искажается.
В начале данного раздела уже упоминалось, что влияние ошибок канального уровня на работу сети сильно преувеличено. Следствием ошибок нижнего уровня является повторная передача кадров. Благодаря высокой скорости сети Ethernet (особенно Fast Ethernet) и высокой производительности современных компьютеров, ошибки нижнего уровня не оказывает существенного влияния на время реакции прикладного ПО.
Мы очень редко встречались со случаями, когда ликвидация только ошибок нижних (канального и физического) уровней сети позволяла существенно улучшить время реакции прикладного ПО. В основном проблемы были связаны с серьезными дефектами кабельной системы сети.
Значительно большее влияние на работу прикладного ПО в сети оказывают такие ошибки, как бесследное исчезновение или искажение информации в сетевых платах, маршрутизаторах или коммутаторах при полном отсутствии информации об ошибках нижних уровней. Мы употребляем слово "информация", так как в момент искажения данные еще не оформлены в виде кадра.
Причина таких дефектов в следующем. Информация искажается (или исчезает) "в недрах" активного оборудования - сетевой платы, маршрутизатора или коммутатора. При этом приемо-передающий блок этого оборудования вычисляет правильную контрольную последовательность (CRC) уже искаженной ранее информации, и корректно оформленный кадр передается по сети. Никаких ошибок в этом случае, естественно, не фиксируется. SNMP-агенты, встроенные в активное оборудование, здесь ничем помочь не могут.
Иногда кроме искажения наблюдается исчезновение информации. Чаще всего оно происходит на дешевых сетевых платах или на коммутаторах Ethernet-FDDI. Механизм исчезновения информации в последнем случае понятен. В ряде коммутаторов Ethernet-FDDI обратная связь быстрого порта с медленным (или наоборот) отсутствует, в результате другой порт не получает информации о перегруженности входных/выходных буферов быстрого (медленного) порта. В этом случае при интенсивном трафике информация на одном из портов может пропасть.
Опытный администратор сети может возразить, что кроме защиты информации на канальном уровне в протоколах IPX и TCP/IP возможна защита информации с помощью контрольной суммы.
В полной мере на защиту с помощью контрольной суммы можно полагаться, только если прикладное ПО в качестве транспортного протокола задействует TCP или UDP. Только при их использовании контрольной суммой защищается весь пакет. Если в качестве "транспорта" применяется IPX/SPX или непосредственно IP, то контрольной суммой защищается лишь заголовок пакета.
Даже при наличии защиты с помощью контрольной суммы описанное искажение или исчезновение информации вызывает существенное увеличение времени реакции прикладного ПО.
Если же защита не установлена, то поведение прикладного ПО может быть непредсказуемым.
Помимо замены (отключения) подозрительного оборудования выявить такие дефекты можно двумя способами.
Первый способ заключается в захвате, декодировании и анализе кадров от подозрительной станции, маршрутизатора или коммутатора. Признаком описанного дефекта служит повторная передача пакета IP или IPX, которой не предшествует ошибка нижнего уровня сети. Некоторые анализаторы протоколов и экспертные системы упрощают задач
profsoft.ucoz.ru
Повышаем скорость и качество работы сети, страдающей потерей пакетов / Хабр
Доброго времени суток. Решил поделиться с вами своим пониманием этого вопроса, и механизма его решения, используемого в устройствах WAN оптимизации Silver Peak.Итак, практическое большинство современных сетей, использует в своей основе пакетную передачу и протокол IP. Информация передается через сеть кусочками информации, и обычно размер этих кусочков варьируется от 1 байта до 1500 байт (Я имею ввиду полезную нагрузку). По пути через WAN сеть, такие пакеты могут пройти через великое множество маршрутизаторов и шлюзов. Некоторые из этих перевалочных пунктов вы можете увидеть при помощи утилиты Traceroute. Но это далеко не все реальные транзитные узлы, например вы не увидите здесь те узлы, через которые трафик прошел туннелированным (MPLS VPN, GRE и т.д.). При этом, с ненулевой долей вероятности, какой-нибудь из транзитных узлов будет в данный момент сильно загружен, и уничтожит ваш пакет, чтобы не допускать перегрузки сети. И чем больше таких транзитных узлов, тем больше вероятность потери пакета в сети. В качестве примера, приведу картинку, показывающую то, как может меняться процент потерянных пакетов, с течением времени, на одном и том же канале связи:

Теоретически, такое отбрасывание пакета, вещь вполне безопасная и нормальная – за целостность передачи данных следит специальный протокол TCP. Но как всегда, есть нюансы. Нюансы состоят в том, что протокол TCP, в случае потери пакета, должен будет послать его через сеть заново. Но для того, чтобы принять решение о перепосылке, нужно дождаться уведомления от приемной стороны, что очередной пакет не получен. И тут на первый план выходит такой параметр сети, как задержка сигнала. Чем она дольше, тем дольше передающая сторона будет в неведении, и тем медленнее будет происходить передача информации. Ниже приведены графики зависимости скорости передачи трафика от задержки в канале связи и процента потери пакетов. Из него видно, что на самом деле, основная потеря в скорости передачи в канале с типовой для WAN задержкой 50-100 миллисекунд, происходит при еще вполне, казалось бы, незначительном проценте потерь: 1-2%.

Если же говорить о приложениях, работающих через UDP, и ориентированных на работу в режиме реального времени, например телефония или видеоконференции, то в них не предусмотрен и не оправдан механизм повторной передачи. И если есть потери, то, как ни крути, вылезают артефакты в виде «кваканий», «заиканий», и рассыпающейся периодически картинке. Оказывается, на потерю пакетов можно посмотреть несколько по другим углом, и решить ее достаточно элегантным способом, как это сделали инженеры Silver Peak. Наверняка многие из вас слышали, про специальные методы кодирования, позволяющие выявлять ошибки, а некоторые из них даже исправлять ошибки в информации. Например, ECC коды и коды Рида-Соломона, впервые промышленно использованные еще в 70-х годах при появлении CD дисков. Общий смысл таких кодов, в том, что они вносят некоторую избыточность, причем избыточность эта, может адаптивно подстраиваться под текущие характеристики канала. Другим, более наглядным примером, может служить технология защиты информации на дисковых массивах RAID5, которая предусматривает один избыточный дисковый накопитель на каждые 3, 4, 5 и более дисков с данными. В случае пакетной передачи, аналогом дисков, является непосредственно пакет — на каждые N пакетов, создается один избыточный. Беда в том, что такие технологии, имеющее общее англоязычное название Forward Error Correction (FEC) применяются, обычно, только на физическом уровне канала передачи данных. И никоим образом не могут устранить потери информации, связанные с перегрузками в сети, динамическими перестроениями топологии и т.д. Инженеры Silver Peak реализовали технологию FEC на канальном уровне, так, что между любыми двумя устройствами Silver Peak, создается свой «туннель», в котором поддерживается и адаптивно подстраивается некоторое количество избыточных пакетов. Типовая топология канала связи с применением этого решения и технологии FEC, показана на следующей картинке:
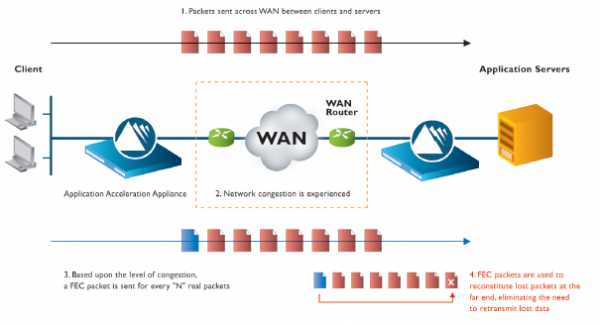
Из нее видно, как устройство не передающей стороне генерирует избыточный пакет, а устройство на приемной воссоздает на его основе, другой, потерянный пакет. Чтобы оценить эффективность применения FEC для устранения потерь пакетов, можно посмотреть на время передачи файла через сеть, с определенным процентом потери трафика. Из следующей картинки видно, что даже незначительный процент избыточности, позволяет в несколько раз повысить скорость передачи файла, а про заикания, и картины в стиле кубизма во время видеоконференции можно с облегчением забыть:

habr.com
Топ-7 команд по устранению неполадок сети
Подробности апреля 30, 2016 Просмотров: 12090Всякий раз, когда вы сталкиваетесь с проблемой с сетью, наиболее распространенным решением является, запустить программу диагностики, что позволит обнаружить и исправить ошибки. Тем не менее, наиболее часто встречающиеся сетевые проблемы могут быть решены с помощью простых команд, таких как ping, tracert, ipconfig, и др.
Знаете ли вы что?Команда "ipconfig" может быть использована, чтобы найти компьютер по IP-адресу как в Windows так и в Linux/Unix-машинах.
Все указанные ниже команды нужно вводить в командной строке. Чтобы открыть командную строку в Windows выполните любой из нижеследующих пунктов:
- Пуск -> Все программы -> Стандартные -> Командная строка.
- Пуск -> Выполнить и введите имя программы cmd.exe
- Нажать клавиши Win + R и ввести имя программы cmd.exe
Команда «ipconfig»

Любой человек с базовыми знаниями о работе сети знает про команду ipconfig. Эта команда дает информацию об IP-адресе компьютера, наряду с DNS, DHCP, шлюзом и маской подсети. IP-адрес необходим для выполнения дальнейших команд поиска неисправностей. Если эта команда возвращает по умолчанию шлюз 0.0.0.0, то у вас проблемы с маршрутизатором. Вы можете попробовать другой вариант этой команды, чтобы решить ваши проблемы с сетью. Очередное расширение этой команды - это команда ipconfig/flushdnsи. Она очищает кэш DNS при любом несанкционированном IP-адресе или техническом сбое.
Команда «ping»
Ping одна из самых важных команд, используемых в сети. Эта команда используется для проверки подключения между узлом и назначением. Главное преимущество использования этой команды, это выяснить проблемный участок в сети. Если вы проверите ping с любого компьютера в сети, вы получите статус маршрутизатора. Также вы получите четыре ответа на запрос проверки связи. Если Вы не получаете ответов, то это указывает на проблемы с сетевой картой.
«Ping» сайтов

Другим преимуществом, использования команды ping, является возможность проверки подключения к любому веб-сайту/интернету. Для того чтобы сделать это, вам нужно ввести имя веб-сайта после команды ping. Если вы получаете ответы от веб-сайта, то нет практически никакой проблемы. Но если вы не получите ответа, есть вероятность, что у вас неисправен кабель, DSL модем или ISP проблема подключения. Чтобы еще больше сузить вероятность и найти основную причину проблемы, введите ping 4.2.2.1. Если вы получите ответы в командной строке, но все равно не имеете доступ к веб-сайту, то у вас есть проблемы в конфигурации DNS.
Команда «tracert» (трассировка)

Команда tracert возвращает весь путь данных, который требуются, чтобы добраться до места назначения. Ответом будет список транзитных пунктов, через которые проходят данные, чтобы добраться до места назначения. Если вы внимательно присмотритесь, то увидите, что с каждым пунктом происходит изменение сети. Это означает, что каждая сеть передает данные в другую сеть, пока они не достигнут своего назначения. Однако, вы можете наблюдать звездочки в некоторых пунктах, эти звездочки представляет собой сеть, которая имеет проблемы.
Команда «nslookup»
Система доменных имен (DNS адреса), в основном, первопричина многих проблемы с сетью. DNS преобразует имена доменов (такие как juice-health.ru) в их IP-адреса. Эти IP-адреса необходимы для функционирования сетевых устройств для подключения к интернету или сети. В случае, если с этими адресами есть проблемы, функции всей сети затрудняются. Команда nslookup выдает список IP-адресов, связанных с доменным именем. Если Вы не можете получить любую информацию относительно IP-адреса, есть проблемы с DNS.
Команда «netstat»

В случае сетей, большое количество хостов подключены к одному маршрутизатору. Таким образом, возникает сложнейшая задача для проверки возможности подключения каждого узла в случае проблем с сетью. Однако, в то же время, важно, проверить, являются ли соединения (TCP, UDP порты) активными или нет. Команда Netstat возвращает список всех компьютеров, подключенных к маршрутизатору, а также их статус. Зная это состояние, вы будете знать номер порта (и IP-адрес) протокол TCP/udp соединения, который неисправен или находится в закрытом состоянии или состоянии ожидания.
Команда «arp»

Команда «arp» является внешней командой, которая используется для идентификации проблем, связанных с преобразованием IP в локальные сетевые адреса. Самой распространенной проблемой, которая может обнаружена в таблице «arp» - это совместное использование одного IP-адреса двумя системами. Два хоста (один из которых, безусловно, не тот) используют один и тот же IP-адрес, и шансы неправильного хоста, отвечающего на IP в этом случае бывают высоки. Это повлияет на всю вашу сеть. Вы должны проверить, наличие парных локальных сетей и правильность прописанных IP-адресов. Для этого вы должны составить список сетевых адресов каждого хоста. Сравнивая свой список и таблицу команды «arp», вы можете легко определить проблемный хост.
Читайте также
juice-health.ru
Анализ сетевых протоколов как метод оптимизации сети | Журнал сетевых решений/LAN
16.01.1999 Сергей Юдицкий, Владислав Борисенко, Олег Овчинников
Пользователей интересует прежде всего скорость и надежность сетевых приложений. Использование анализатора протоколов позволяет выяснить причину их неудовлетворительной работы.
Мы продолжаем серию публикаций, посвященных вопросам диагностики и тестирования локальных сетей. Предыдущие статьи (см. LAN №7-8, 9, 12) касались, в первую очередь, вопросов диагностики и тестирования сети на канальном и транспортном уровнях. В данной статье мы хотим уделить внимание задачам оптимизации работы сети, в частности локализации некоторых «скрытых дефектов» в архитектуре и эксплуатируемом прикладном ПО.
Сложность локализации «скрытых дефектов» в архитектуре сети и эксплуатируемом прикладном ПО заключается в том, что единственным симптомом их наличия является медленная или неустойчивая работа в сети прикладного ПО.
Причины медленной работы ПО
Без предварительной диагностики канального и транспортного уровней сети причину медленной работы ПО определить очень сложно. Это может быть как нехватка пропускной способности или неоптимальность архитектуры сети, так и недостатки самого ПО.
Очень часто клиенты жалуются на то, что прикладное ПО периодически работает медленно. При этом компания, которая устанавливала или разрабатывала данное ПО, считает, что причина в дефектах сети, так как «во всех остальных компаниях, где это ПО установлено, оно работает хорошо». Администратор сети в свою очередь утверждает, что все остальное эксплуатируемое ПО функционирует нормально, поэтому виновато, скорее всего, именно недавно установленное ПО.
Если вы хотите определить причины медленной работы ПО, то их выяснение целесообразно начать с проведения первичной диагностики сети. Первичная диагностика сети предполагает выполнение, как минимум, следующих работ.
- Диагностика кабельной системы с помощью кабельного сканера.
- Измерение утилизации канала связи и определения зависимости времени реакции прикладного ПО от утилизации канала связи.
- Измерение числа коллизий и ошибок на канальном уровне.
- Измерение доли широковещательного и группового трафика в общем трафике.
- Определение факта повторных передач пакетов на транспортном уровне сети, т. е. факта перегрузки сервера, коммутатора и других устройств.
Предположим, что после проведения первичной диагностики сети явных дефектов не обнаружено. Все параметры находятся, насколько можно судить, в допустимых пределах, а прикладное ПО тем не менее продолжает работать медленно или неустойчиво. В таких случаях причину медленной работы прикладного ПО следует искать в недостатках архитектуры сети или самого прикладного ПО.
Как показывает опыт диагностики сетей, не менее чем в 50% случаев одной из причин медленной или неустойчивой работы прикладного ПО в сети оказываются недостатки его самого, но наиболее типичным случаем является совокупное влияние дефектов прикладного ПО и дефектов сети. Дефекты сети провоцируют проявление недостатков ПО. Дефекты же прикладного ПО оказываются следствием того, что программисты часто не задумываются об оптимизации своих программ для работы в сети.
Дефекты прикладного ПО могут быть очень «коварны» и проявляться спустя длительное время после ввода ПО в эксплуатацию. К этому времени исходные тексты программ могут оказаться утеряны, или компания, установившая это ПО, может прекратить свое существование. Коварство заключается еще и в том, что недостатки могут заявить о себе только в определенных сетевых конфигурациях. Например, если сеть имеет большой запас пропускной способности, то дефект не проявляется. Однако незначительное изменение архитектуры или топологии сети может стать катализатором для его проявления.
Как писал классик: «Все счастливые семьи счастливы одинаково, каждая несчастливая семья несчастлива по-своему». Недостатки прикладного ПО могут быть самыми разнообразными. В применении к локальным сетям наиболее часто встречаются три вида недостатков прикладного ПО.
- Дефекты ПО, приводящие к неэффективному использованию пропускной способности сети.
- Дефекты ПО, связанные с неэффективным алгоритмом блокировки доступа к общим данным в сети.
- Дефекты ПО, вызывающие неоправданные сетевые операции и, как следствие, увеличивающие время реакции прикладного ПО.
Неэффективное использование пропускной способности
Дефекты ПО, следствием которых является неэффективное использование пропускной способности сети, наиболее распространены. Их суть заключается в том, что функционирование программы приводит к высокой утилизации канала связи, но при этом коэффициент полезного использования сети оказывается низок (т. е. высоки накладные расходы при передаче данных). Другими словами, служебная информация составляет значительную часть всей передаваемой информации. Косвенным признаком неэффективного использования пропускной способности сети прикладным ПО может служить заметная доля коротких кадров в сетевом трафике. Мы подробно обсуждали эту проблему во второй статье нашего цикла (LAN №9).
Рассмотрим пример неэффективного использования пропускной способности сети прикладным ПО, приведшего к замедлению работы пользователей других программ. Крупная коммерческая компания X обратилась к нам с просьбой выяснить причину периодического замедления работы пользователей в одном из сегментов сети - коллизионном домене А (см. Рисунок 1). Как выяснилось, компания X недавно провела модернизацию своей сети и установила на магистрали мощный коммутатор. Одно из подразделений компании традиционно использовало программу P для обработки информации, получаемой из удаленных офисов. Программа P работала с почтовым ящиком, расположенном на сервере Novell NetWare с именем FSNW06. Сам сервер находился в коллизионном домене A, а пользователи программы P - в доменах A и B. Получаемая с почтового сервера FSNW06 информация заносилась после обработки в базу данных на сервере рабочей группы FSNWA, находящемся в коллизионном домене A. Программа P была написана программистами компании X и использовалась в течение нескольких лет, причем никаких нареканий на ее работу не было.
После проведенной модернизации сети пользователи домена A стали жаловаться, что доступ к серверу FSNWA иногда осуществляется с большими задержками, вообще говоря, в непредсказуемые моменты времени.
Установив в коллизионном домене A анализатор протоколов Observer, мы провели первичную диагностику и выяснили следующее. Сервер FSNWA работает без перегрузки, следовательно, замедление не может происходить из-за недостаточной мощности сервера FSNWA (см. LAN №9). Число ошибок канального уровня близко к нулю, значит, замедление не может быть следствием повторных передач на транспортном уровне (см. LAN №7-8). Число широковещательных и групповых пакетов не превышает 3% от числа переданных кадров, поэтому замедление не может быть вызвано «широковещательным штормом».
Измерение степени загруженности домена A показало, что утилизация в течение рабочего дня периодически достигает 30%, однако число коллизий при этом не превышает 5% от числа переданных кадров. Как удалось выяснить, замедление происходит в моменты наибольшей утилизации канала связи (около 30%), но (и это важно!) высокая утилизация канала связи отнюдь не всегда сопровождается существенным замедлением работы пользователей домена A. Влияние утилизации канала связи на работу пользователей было проверено посредством создания с помощью генератора трафика пакетов Observer фоновой нагрузки, соответствующей уровню утилизации канала связи в 30%, и измерения времени реакции прикладного ПО на фоне этой нагрузки. Замедление работы пользователей наблюдалось, но оно было заметно меньше, чем в процессе эксплуатации сети.
Таким образом, достоверно установить причину замедления работы пользователей домена A можно было, только определив, что происходит в сети непосредственно в момент возникновения наибольших задержек. С этой целью мы настроили анализатор протоколов на циклическую запись трафика в буфер и останавливали запись в те моменты, когда наблюдалось наибольшее замедление работы пользователей. Выполнив подобную операцию несколько раз и проанализировав трафик в каждом случае, мы пришли к следующему выводу.
Наибольшее замедление работы пользователей, расположенных в домене A, происходит в те моменты времени, когда хотя бы один пользователь программы P из домена B производит обращение и/или считывание данных с почтового сервера FSNW06. Несколько меньшее замедление работы пользователей наблюдалось в те моменты времени, когда с программой P работал пользователь, расположенный в домене A.
И в том и в другом случае утилизация канала связи в домене A была близка к 30%. При этом замедление во втором случае приблизительно соответствовало задержке при создании фоновой нагрузки генератором трафика Observer.
Теоретически, на этом анализ работы сети можно было бы прекратить и рекомендовать администратору сети подключить сервер FSNW06 к выделенному порту коммутатора, но в результате остались бы невыясненными два вопроса. Почему утилизация канала связи близка к 30% при работе всего одного пользователя программы P? Почему замедление в работе пользователей домена A оказывается больше при обращении к серверу FSNW06 пользователей программы P из домена B, чем при обращении к серверу пользователя программы P из домена A, хотя утилизация канала связи в обоих случаях приблизительно одинакова?
Проанализировав трафик между пользователем программы P и почтовым сервером FSNW06, мы выяснили причину возникновения 30% утилизации канала. Анализ трафика (см. Рисунок 2) позволил определить следующее.
- Факт наличия входящего сообщения в почтовом ящике на сервере FSNW06 программа P определяет, считывая каждый раз его заголовок объемом 100 Кбайт.
- Чтение заголовка почтового ящика производится отдельными порциями данных по 1024 байт, при этом длина пакета равна 1081 байт (пакеты №№ 509-516), без использования блочной передачи данных (режим burst mode). В этом режиме заголовок почтового ящика мог бы быть прочитан всего за несколько обращений к серверу, а не за 100, как в данном случае.
- Несмотря на то что сообщения поступают в почтовый ящик с периодичностью, как правило, в несколько минут (они передаются из филиалов по модемной связи), задержка между циклами опроса почтового ящика программой не предусматривается. Пакет № 520 - окончание цикла опроса. Пакет № 521 - начало следующего цикла опроса. Как видно из Рисунка 2, задержка между этими пакетами составляет всего 0,003 секунды.
Ответ на вопрос о том, почему при обращении к серверу FSNW06 пользователей программы P из домена B наблюдается большее замедление в работе пользователей домена A, чем при обращении к серверу пользователя программы P из домена A, был получен путем сравнения соответствующего трафика.
Как выяснилось, магистральный коммутатор имеет следующую особенность: если в выходном буфере порта коммутатора (назовем его выходной порт) имеются данные на передачу, то при передаче данных в подключенный к порту домен сети коммутатор блокирует весь этот домен на время передачи данных. Блокировка осуществляется за счет того, что коммутатор не соблюдает паузы в 9,6 микросекунд перед передачей очередного кадра, как это предписывается стандартом CSMA/CD. Другими словами, выходной порт коммутатора ведет себя «более агрессивно», чем сетевые платы компьютеров в домене A (которые выдерживают паузу в 9,6 мкс). «Агрессивность» поведения коммутатора зависит от загруженности домена, куда подключен выходной порт. Чем выше утилизация, тем «агрессивней» ведет себя коммутатор. Строго говоря, эффект блокировки коммутатором домена сети не является дефектом коммутатора. Эта технология способствует предотвращению «заторов» в выходном буфере коммутатора (см. http://www.data.com/Lab_Tests).
Приведенный пример иллюстрирует то, как дефект прикладного ПО в сочетании со спецификой архитектуры сети может приводить к замедлению работы всех пользователей сети. Обращаем внимание читателя на то, что достоверно определить причину замедления работы пользователей домена A удалось только путем анализа пакетов сетевых протоколов.
Неэффективный алгоритм блокирования общих данных
При построении прикладного ПО на базе файловых (а не клиент-серверных) СУБД наиболее часто встречающиеся недостатки ПО являются следствием неэффективных алгоритмов блокирования общих данных разными станциями сети.
Заблокировав на длительный промежуток времени какой-то файл, одна рабочая станция может остановить работу всех остальных станций сети, также использующих данный файл для выполнения своих операций. Другими словами, для завершения своих операций все станции сети, за исключением одной, будут ждать, пока файл не будет освобожден. С этой целью они периодически будут обращаться на сервер, проверяя доступность заблокированного файла. Только после того, как файл будет освобожден, другие станции сети смогут продолжить выполнение своих операций. При этом уже другая станция может заблокировать общий файл и опять остановить работу всех остальных станций сети. Таким образом, станции сети работают фактически последовательно, а не параллельно.
Поскольку в период блокировки общего файла большинство станций не реагирует на нажатие клавиш, это создает полную иллюзию того, что причина зависания состоит в перегрузке или дефектах сети. Однако, измерив утилизацию канала связи или сервера в периоды зависания, вы можете убедиться, что утилизация этих ресурсов остается на низком уровне.
Очевидно, что при использовании файловых СУБД подобных зависаний невозможно избежать в принципе. Однако при соответствующей оптимизации алгоритма вероятность их возникновения можно свести к минимуму.
Особо мы хотели бы обратить внимание читателя на чувствительность файловых СУБД к ошибкам канального уровня сети. Если станция сети с неисправной или низкопроизводительной сетевой платой заблокирует общий файл, то, ввиду наличия проблем с доступом в сеть, она не будет освобождать его дольше, чем при использовании исправной платы.
Желающие познакомиться с этим типом недостатков ПО более подробно могут прочесть на сервере http://www.prolan.ru в разделе «Статьи и публикации» отчет компании «ПроЛАН» под названием «Некоторые особенности работы в сети прикладного ПО, реализованного с использованием файловой СУБД». Данный отчет посвящен рассмотрению результатов тестирования одного популярного программного продукта, в котором данный дефект имел место.
Неоправданные сетевые операции
Неоправданные сетевые операции - это, как правило, операции поиска информации на файловом сервере, выполняемые вследствие неэффективности алгоритма поиска, отсутствия однозначного пути к файлу или информации о типе файла. В каждом из этих случаев рабочая станция производит поиск информации во всех каталогах (подкаталогах) сервера, пока нужная информация не будет найдена. Подобный поиск создает неоправданный «паразитный» трафик в сети и увеличивает время выполнения задачи. В данной статье мы хотим привести пример для иллюстрации таких «паразитных» операций.
Администратор сети компании Y попросил нас определить причину медленной работы приложения S, время выполнения которого по сети составляло около 20 минут. Данное приложение было написано с использованием СУБД FoxPro и реализовано как набор модулей PRG для удобства внесения изменений.
Как и в приведенном выше примере, мы провели предварительную диагностику домена сети, где работает данное приложение. Никаких дефектов на канальном уровне сети, впрочем, как и перегруженности сервера, выявлено не было. После этого мы осуществили стандартную процедуру построения зависимости между временем выполнения задачи и утилизацией канала связи. Эта процедура предусматривает постепенное увеличение нагрузки в сети с помощью генератора трафика при одновременном измерении времени выполнения задачи (см. LAN №7-8). Эксперименты показали, что время выполнения задачи не зависит сколько-нибудь заметным образом от фоновой нагрузки в сети, и, следовательно, причину надо искать не в дефектах сети, а в алгоритмах работы самого прикладного ПО.
Установив анализатор протоколов Observer в домен сети, где работает данное приложение, и настроив входной фильтр для сбора пакетов на МАС-адрес станции одного из пользователей приложения S (IGOSHINA), мы записали в файл трафик, который приложение S генерировало при работе в сети. Фрагменты собранных пакетов при обмене между станцией IGOSHINA и сервером FSNW10 приведены на Рисунке 3.
Анализ трафика позволил установить причину медленной работы приложения S в сети. При запуске каждой очередной процедуры приложение S пыталось найти файл с исходным текстом модуля программы, в котором находится вызываемая процедура (в приведенном фрагменте это файл fgetdata.prg). Это делается в соответствии с алгоритмом функционирования самой СУБД FoxPro в целях проверки даты создания файла программы и наличия изменений в исходном тексте после последней компиляции. Программа ищет файл по всем известным ей каталогам, включая и каталоги на сервере. Если файл fgetdata.prg не обнаружен в одном каталоге, то поиск производится в следующем каталоге, и так до тех пор, пока файл не будет найден или не будут просмотрены все известные каталоги. Это хорошо видно в приведенных на Рисунке 3 фрагментах собранных пакетов.
- Пакет № 177. Станция IGOSHINA посылает серверу запрос на поиск файла fgetdata.prg (функция протокола NCP 57h, подфункция 14h). Имя файла можно видеть в нижней трети окна, где приводится содержимое пакета в шестнадцатеричном виде.
- Пакет № 178. Сервер FSNW10 отвечает, что запрашиваемый файл в текущем каталоге не найден (код завершения операции Constat=FF).
- Пакет № 179. Станция IGOSHINA посылает серверу запрос на информацию о следующем каталоге (функция протокола NCP 57h, подфункция 06h). Имя каталога можно увидеть из программы Observer при переходе на данный пакет в списке.
- Пакет № 180. Сервер FSNW10 отвечает, что запрос выполнен успешно.
- Пакет № 181. Станция IGOSHINA снова посылает серверу запрос на поиск файла fgetdata.prg.
- Пакет № 182. Сервер FSNW10 вновь отвечает, что запрашиваемый файл в текущем каталоге не найден.
И так до окончания процедуры поиска модуля fgetdata.prg.
В качестве решения проблемы было предложено поместить в каталог, из которого производится запуск приложения, пустые файлы с именами модулей программы с датой создания 01-01-1980. Поиск файлов (в частности, файла fgetdata.prg) был зафиксирован анализатором протоколов. Обнаружив этот файл и проверив, что дата компиляции старше, чем дата файла с исходным текстом, программа S переходит непосредственно к ее выполнению. После реализации этой рекомендации время выполнения программы S сократилось с 20 до 4 минут.
Недостатки архитектуры сети
В отличие от обрыва кабеля или выхода из строя сетевой платы недостатки архитектуры сети не столь заметны. Приведем один показательный пример.
В рамках проводимой нами кампании по экспресс-диагностике локальных сетей с использованием анализатора протоколов Observer нас пригласили «вылечить» сеть. Проблема состояла в том, что станции одного из сегментов сети 10Base2 не могли подключиться к серверу. Найти причину оказалось несложно: сетевая плата на сервере, подключенная к домену 10Base2, вышла из строя. Однако в процессе диагностики сети мы выяснили, что в этом домене сети отношение числа коллизий к числу успешно передаваемых кадров доходит до 300% при том, что утилизация домена не превышает 15%! Другими словами, только каждый четвертый кадр передается без коллизий. На наш вопрос, как сеть работала до того момента, когда сетевая плата на сервере вышла из строя, ответ был следующим: «Мы уже пять лет работаем в этой сети, и до сих пор все было нормально».
Оставим этот пример без комментариев. Напомним только фразу из монолога М. М. Жванецкого о том, что «отечественная обувь тоже хороша, если другой никогда не носили».
Кстати, в данном случае повышенное число коллизий было следствием неправильной топологии линий заземления компьютеров. Вероятнее всего, по этой же причине вышла из строя и сетевая плата на сервере.
Большинство проблем с архитектурой сетей оказываются следствием недостаточного внимания к вопросам оптимизации работы сети как системных интеграторов, так и администраторов сетей.
Часто системные интеграторы под задачей «создания сети» у клиента понимают исключительно объединение активного сетевого оборудования в единую систему таким образом, «чтобы все работало». Вопросы оптимизации архитектуры сети на этапе ее создания, как правило, не ставятся, так как системные интеграторы редко устанавливают прикладное ПО. Они считают, что это задача администратора сети.
Со своей стороны, большинство администраторов сетей под задачей «администрирования сети» понимают выполнение работ, связанных только с поддержкой пользователей сети (установка прикладного ПО, определение прав доступа пользователей к ресурсам сети, написание различных сценариев, организация сетевой печати и т. п.). При этом вопросы оптимизации работы сети остаются вне их профессиональных обязанностей. Многие из них, может быть, и хотели бы, в принципе, заняться этими вопросами, но у них либо не хватает на это времени, либо нет реального стимула. Зачем что-то оптимизировать, если и так все нормально работает (иногда как в приведенном выше примере)?
К наиболее типичным недостаткам архитектуры сети можно отнести следующие.
- Несбалансированность по пропускной способности различных компонентов сети, например сервера и коммутатора.
- Неоптимальный маршрут передачи сетевого трафика вследствие неправильной настройки параметров сетевой ОС или активного оборудования.
- Значительный процент широковещательных и групповых пакетов вследствие неоптимальной настройки параметров сетевой ОС или активного оборудования.
Вопросы несбалансированности по пропускной способности различных компонентов сети мы подробно рассмотрели во второй статье (см. LAN №9). За исключением недостаточной пропускной способности сетевых ресурсов (канала связи, коммутаторов, маршрутизаторов, сервера), все остальные недостатки архитектуры сети в той или иной степени являются следствием неправильной или неоптимальной настройки параметров активного оборудования и/или сетевой ОС.
Многих ошибок можно было бы избежать, внимательно прочитав инструкцию по эксплуатации оборудования. Однако, поскольку значительная часть активного сетевого оборудования работает по принципу Plug-n-Play, делается это далеко не всегда. Так, например, в инструкции по эксплуатации коммутатора Super Stack II Swich 1000 компании 3Com, как минимум, в двух местах написано, что режим коммутации Intelligent Flow Management нельзя использовать, если к порту коммутатора подключен концентратор. Тем не менее мы часто встречаемся с ситуациями, когда это требование не соблюдается. Сеть при этом работает плохо, но работает!
В данной статье мы хотели бы рассказать о некоторых любопытных, с нашей точки зрения, недостатках архитектуры сети, с которыми нам приходилось встречаться в процессе диагностики и тестирования сетей.
Неправильная настройка клиентов Novell NetWare
Компания Z обратилась к нам с просьбой выяснить причину неустойчивой работы в сети пользователя B, когда он связывается с удаленным компьютером A при помощи программы PCAnywhere (фрагмент схемы локальной сети компании Z приводится на Рисунке 4). Удаленный компьютер A находится в специальном помещении и подключен к производственному серверу через специальный служебный канал связи (не Ethernet). Через него пользователь B и управляет работой производственного сервера. Компьютер пользователя B и удаленный компьютер A находятся в разных доменах сети, но подключены к одному и тому же коммутатору. Неустойчивость работы проявляется в том, что в течение дня скорость работы пользователя B варьируется в широких пределах. Замедление наблюдается в непредсказуемые моменты времени.
Исследование доменов сети A и B на канальном уровне показало, что трафик в этих доменах очень низкий, а ошибки канального уровня отсутствуют. Из этого мы сделали вывод, что причину неустойчивой работы пользователя B следует искать в протоколах более высоких уровней. Это можно сделать только с использованием анализатора сетевых протоколов.
Установив анализатор протоколов Observer в том же домене сети, где находится пользователь B, мы записали в файл трафик между компьютером пользователя B и удаленным компьютером A. Фрагменты записанных пакетов приведены на Рисунке 5.
Анализ трафика показал, что компьютер пользователя B и удаленный компьютер A при работе программы PCAnywhere используют в качестве транспорта протокол IPX, но настроены на работу с разными типами кадров. В первом случае это формат кадров 802.3, что соответствует сети IPX 4DA13101. Во втором случае это формат кадров 802.2, что соответствует сети IPX 4DA12101. По этой причине маршрут обмена между станциями проходил не только между портами коммутатора (как предполагалось), но и через находящийся в сети маршрутизатор Cisco, который выполнял маршрутизацию пакетов с трансляцией протоколов в соответствующие типы кадров.
Очевидно, что подобное взаимодействие нельзя назвать эффективным. Объем сетевого трафика между компьютерами при такой их конфигурации удваивается. Скорость обмена между компьютерами зависит от загруженности как самого маршрутизатора, так и домена сети, к которому он подключен, не говоря уж о том, что пропускная способность самого маршрутизатора ниже пропускной способности коммутатора.
После настройки компьютеров на работу с одинаковыми типами кадров сети Ethernet скорость обмена между ними увеличилась и стабилизировалась.
Неправильная настройка алгоритма Spanning Tree
Сеть компании V, изображенная на Рисунке 6, строилась с учетом повышенных требований к отказоустойчивости. Магистраль создавалась на базе высокопроизводительных коммутаторов, связанных друг с другом сетью FDDI. В целях повышения отказоустойчивости каждый концентратор сети был подключен одновременно к двум центральным коммутаторам по 10BaseT. Серверы сети были распределены между двумя коммутаторами. При выходе из строя любого канала 10BaseT между этажным концентратором и центральным коммутатором (или слотом центрального коммутатора) сеть продолжала работать по резервному каналу.
Спустя некоторое время компания создала еще одно подразделение, деятельность которого требовала повышенной пропускной способности сети при работе с производственным сервером. Для этих целей вместо одного из концентраторов компанией был закуплен и установлен коммутатор для подключения производственного сервера по технологии Fast Ethernet и предоставления каждому пользователю данного подразделения канала на 10 Мбит/с. Вновь установленный коммутатор был подключен к центральным коммутаторам по той же схеме, что и работавший ранее концентратор.
Однако, вопреки ожиданиям пользователей, время реакции эксплуатируемого в сети прикладного ПО не уменьшилось, а увеличилось.
Гипотеза о причине проблемы была высказана практически сразу после того, как администратор сети изложил нам суть проблемы. По нашему предположению она заключалась в том, что после замены концентратора на коммутатор пути передачи данных в сети изменились в соответствии с алгоритмом Spanning Tree. Вновь установленный коммутатор был выбран в соответствии со значением своего MAC-адреса в качестве корневого коммутатора сети, и передача информации между центральными коммутаторами стала производиться не по кольцу FDDI со скоростью 100 Мбит/с, а через вновь установленный коммутатор со скоростью 10 Мбит/с. Анализ сетевого трафика в сети с помощью анализатора протоколов Observer полностью подтвердил эту гипотезу.
В соответствии с алгоритмом Spanning Tree, выбор корневого коммутатора осуществляется, исходя из комбинации постоянного параметра - MAC-адреса коммутатора и настраиваемого параметра - приоритета коммутатора. Нами было предложены два решения проблемы. Первое состояло в отключении поддержки алгоритма Spanning Tree на новом коммутаторе, а второе - в изменении значения приоритета вновь установленного коммутатора (Priority) для того, чтобы он не выбирался в качестве «корневого». Клиентом было выбрано второе решение, после чего время реакции прикладного ПО существенно снизилось.
Повышенное число широковещательных пакетов
Снижение числа широковещательных и групповых пакетов является важной задачей в больших распределенных сетях. Широковещательные пакеты предназначаются всем станциям в домене сети. В результате, при большом числе широковещательных пакетов, скорость работы всех пользователей домена сети снижается. Если число широковещательных пакетов превышает 8-10% от общего числа пакетов, то такой эффект называется «широковещательным штормом». Широковещательный шторм является следствием недостаточной продуманности архитектуры сети. Мы подробно писали об этой проблеме (см. LAN №9).
Заметим, что при проведении диагностики сети важно не только определить факт наличия в сети «широковещательного шторма», но и понять причину его возникновения. Широковещательный шторм почти всегда является следствием ошибок в настройке активного оборудования или сетевой ОС. На практике такие дефекты сложно локализовать без проведения детального анализа сетевых протоколов. Ниже мы рассмотрим несколько возможных причин широковещательного шторма на следующем примере.
В процессе обследования локальной сети компании W был выявлен значительный процент широковещательных пакетов в нескольких доменах сети. Их доля в общем трафике превышала пороговое значение 8%. Локальная сеть компании W представляет собой крупную распределенную сеть, построенную на базе сетевой ОС Novell NetWare 4.11. Большинство станций сети работает под управлением операционной системы Windows 95.
Установив в один из доменов сети анализатор протоколов Observer, мы записали в файл трафик в тот момент, когда в сети наблюдался широковещательный шторм. Анализ трафика позволил выявить несколько недостатков в архитектуре сети (см. Рисунок 7).
Каждый широковещательный пакет, переданный станцией, работающей под управлением Windows 95 (на рисунке - user), тиражировался всеми серверами в кадрах Ethernet другого формата. Кадр в формате 802.3 соответствует сети IPX 4DA13101, кадр в формате 802.2 - сети IPX 4DA12101. В результате количество широковещательных пакетов увеличилось почти на порядок. Причина такой ситуации является следствием активизации опции тиражирования пакетов NetBIOS через протокол IPX на серверах Novell NetWare.
В качестве решения этой проблемы нами было предложено удалить с тех рабочих станций, где они не нужны, клиентов для сети Microsoft и отключить на серверах Novell NetWare опцию тиражирования пакетов NetBIOS через протокол IPX. Для этого на сервере надо запустить утилиту SERVMAN и, выбрав в меню пункт «Server Parameters»->«Communication»->«IPX NetBIOS replication option», установить значение 0.
Еще один способ сокращения числа широковещательных пакетов в исследуемой сети заключался в следующем.
Для сетей Novell NetWare характерно большое число широковещательных пакетов SAP, рекламирующих различные сервисы сети. Сеть компании W территориально распределена по нескольким площадкам, причем они объединяются в единую корпоративную сеть с помощью маршрутизаторов. Очевидно, что часть рекламируемых сервисов одной площадки не представляет интереса для пользователей другой площадки. Это относится, прежде всего, к серверам печати, очередям заданий и т. п. Таким образом, большинство пакетов SAP, пересылаемых между удаленными площадками, представляют не что иное, как «паразитный» трафик. Как видно из Рисунка 8, декодированный пакет SAP содержит объявления об услугах серверов печати HP LaserJet/QUICK SILVER HEWLETT PACKARD (сервис 030Ch). Эти серверы находятся через три транзитных маршрутизатора от домена сети, где производился сбор пакетов (параметр HOPS=03). Условно говоря, маловероятно, чтобы пользователи, находящиеся в Москве, захотели печатать на принтере, установленном в Красноярске.
Использование механизма фильтрации на маршрутизаторах, связывающих между собой площадки сети компании W, позволило исключить передачу «ненужных» пакетов SAP, что привело к существенному сокращению числа широковещательных пакетов в сети. Но необходимо помнить, что перед установкой на маршрутизаторах механизма фильтрации пакетов SAP данную операцию требуется тщательно спланировать. В противном случае, пользователи могут не получить доступ к действительно нужным удаленным ресурсам корпоративной сети.
Сергей Семенович Юдицкий - генеральный директор ЗАО «ПроЛАН», Владислав Витальевич Борисенко - системный инженер ЗАО «ПроЛАН», Олег Игоревич Овчинников - эксперт ЗАО «ПроЛАН», с ними можно связаться по адресу: netproblems@testlab.ipv.rssi.ru или http://www.prolan.ru.Уважаемые читатели!
Нам очень хотелось бы знать, представляют ли для вас интерес подобные публикации? Достаточна ли для понимания детализация излагаемого материала?
Свои отзывы и вопросы вы можете направлять по адресу: netproblems@testlab.ipu.rssi.ru.
www.osp.ru
Почему тормозит сеть | Kickself.com

Почему медленно работает сеть?
Хааа, да что за тупой вопрос? Почему угодно. 100500+ причин. Но т.к. недавно столкнулся с одним интересным для себя малограмотного случаем, обязательно его тут отмечу. Итак, в упрощенном до безобразия виде дана такая вырезка из топология LAN организации:
Тут есть два больших коммутатора HP ProCurve 5412zl выполняющие роль корневых коммутаторов и выделенные на схеме красным. Через них, как положено, проходит львиная доля всего трафика ЛВС. Представлены здесь и два коммутатора 10.200.2.110 и 10.200.2.13, символизирующие собой свитчи уровня доступа, к которым подключены ПК пользователей, их IP телефоны и даже, по глупости, некоторые серверы. Синим цветом выделены аплинки, пропускная способность которых не меньше 1000Мбит/сек, красным же цветом отмечены тупые аплинки, работающие по какой-то причине на 10Мбит/сек.
Теперь о проблеме. Однажды случилось так, что голос людей в IP телефонах стал похож на голос Валли из одноименного мультфильма. Выяснилось, что неудачно собранный кластер терминальных серверов практически непрерывно генерировал в сеть до 10Мбит паразитного трафика (об этом, кста, детально написано здесь). Естественно, все устройства, согласовавшие с портами их свитчей скорость 10Мбит/сек (многие IP телефоны, некоторые ПК и т.п.) сильно пострадали, т.к. для их взаимодействия с миром в их сетевых портах совсем не осталось места.
Проблем с тупым терминальным кластером (ТК) быстро не решалась и поэтому телефоны, что давно следовало сделать, были вынесены в отдельный голосовой VLAN, куда, естественно, не проникал ненужный флуд от ТК. Таким образом возникшие проявления проблемы были устранены. То есть флуд в 10Мбит по прежнему никуда не делся, но все значимые устройства, ему подверженные и работающие на 10Мбит/сек были вынесены в отдельный VLAN, в то время как флуд остался в дефолтном первом VLANe.
Но дальше возникает такая вещь. Появляются странные задержки при обмене пакетами между хостами, подключенными в разных участках LAN. Смотрим на картинку. Например, обычный ICMP ping от Хоста 1 до Хоста 2 (оба находятся в VLAN 1) варьируется между 1 и 100+ msec, а некоторые пакеты вообще пропадают. Казалось бы, как так может быть, если это LAN, а не интернет и все линки от хоста 1 до хоста 2 имеют пропускную способность не меньше 1Гбит сек. При таких условиях ping должен стабильно летать туда-сюда за 1 мсек с оочень редкими девиациями от этой цифры. Даже если и благодаря флуду от ТК в сети постоянно висит паразитный фон в 10Мбмит/сек, это всего лишь 1% от пропускной способности канала между Хостом 1 и Хостом 2. В чем же проблема?
Как оказалось, проблема в некоторых хостах, которые по прежнему остались в первом VLANе и подключены в сеть аплинками с пропускной способностью 10Мбит/сек. Один такой хост и показан на картинке под именем Linux Router и воткнут прямо в порт I2 корневого коммутатора Core 1 и находится в VLAN 1. Хоть этот Linux Router и не лежит на пути трафика проходящего от хоста 1 до хоста 2, он еще как влияет на скорость прохождения этого трафика. Чтобы понять, почему это происходит, нужно посмотреть, например, на счетчики интерфейса J1 Core 1.
Core1# sh interfaces J1
Status and Counters — Port Counters for port J1
MAC Address : 0021f7-bc9c27Link Status : UpTotals (Since boot or last clear) :Bytes Rx : 812,984,141 Bytes Tx : 679,714,496Unicast Rx : 2,571,865,283 Unicast Tx : 3,329,931,025Bcast/Mcast Rx : 178,784,611 Bcast/Mcast Tx : 1,447,609,757Errors (Since boot or last clear) :FCS Rx : 0 Drops Tx : 0Alignment Rx : 0 Collisions Tx : 0Runts Rx : 0 Late Colln Tx : 0Giants Rx : 0 Excessive Colln : 0Total Rx Errors : 0 Deferred Tx : 0Others (Since boot or last clear) :Discard Rx : 10,086,697 Out Queue Len : 0Unknown Protos : 0Rates (5 minute weighted average) :Total Rx (Kbps) : 453,128 Total Tx (Kbps) : 449,464Unicast Rx (Pkts/sec) : 216,867 Unicast Tx (Pkts/sec) : 109,209B/Mcast Rx (Pkts/sec) : 256 B/Mcast Tx (Pkts/sec) : 107,624Utilization Rx : 04.53 % Utilization Tx : 04.49 %
Что тут видно? Видно, что счетчик Discard Rx имеет неплохое значение, которое постоянно увеличивается. Забитость интерфейса по счетчикам Utilization Rx, Tx, как писалось выше, ну уж совсем незначительна, т.е. с точки зрения загрузки порты почти спят. Из всего этого, после долгих раздумий, родилось предположение, что происходит все так (смотрим с позиции Core1):
1. На коммутатор Core1 в интерфейс J1, прилетает пакет (ну да, на деле этой фрейм, а не пакет, т.к. речь о L2, но не будем умничать), адресованный LinuxRouter, или, как в случае с бродкаст-флудом, о котором выше упомянуто, пакет/фрейм адресован всем в сети, в том числе и LinuxRouter. Коммутатор видит, что линк I2 до этого самого LinuxRouter уже забит донЕльзя и ставит этот пакет в очередь на интерфейсе, где получил его, т.е. на J1.
2. Таких пакетов прилетает великое множество и места в очереди J1 становится ну ооочень мало, а в некоторые моменты его нет вообще.
3. На Core 1 прилетает тот самый пакет от Хоста 1, адресованных Хосту 2. Пакет прилетает именно в тот момент, когда очередь интерфейса J1 забита на 100% и, как следствие, Core 1 его выбрасывает. А если место все же есть, то пакет в итоге долетает до Хоста 2, но с некоторой задержкой, в зависимости от того, сколько он простоял «в очереди» на Core 1. Вот и все.
В результате, из за одного тупого хоста, согласовавшего медленный линк с коммутатором уровня ядра, через который пролетает большая часть трафика LAN медленно работает вся сеть, т.к. очереди транзитных магистралей этого Core 1 напрочь забиты тем, чего ждет тот, кто в данном случае называется LinuxRouter. И большая пропускная способность всех аплинков между коммутаторами тут ну никак не помогает.
В моем случае вылечилось все выключением интерфейса I2 на Core 1. Это можно было сделать т.к. LinuxRouter уже давно никем не использовался и просто висел и работал как полуживой памятник.
Хотел еще привести те самые пинги с задержками до и после выключения I2 для большей наглядности, но, думаю, и так все понятно.
Не забывайте оставлять комментарии, если пост был вам полезен!
kickself.com
- Подтверждение входа в вк

- Как через командную строку очистить диск

- Pascal turbo команды

- Iis ftp настройка

- Монитор мигает черным
- Количество символов в поле sql

- Запись на cd r

- Как поменять вай фай пароль на виндовс 10

- Windows 10 как восстановить удаленные файлы с корзины

- 360 total security обзор

- Какие процессы в диспетчере задач можно отключить windows 10