Язык программирования R - Введение в R для программистов на C#. R язык программирования для начинающих
Хочу всё знать: язык R | GeekBrains
Полное погружение в Data Science.

Давайте немного поговорим о языке программирования под названием R. В последнее время вы могли у нас в блогах прочитать статьи о Big Data и Data Science, тех сферах, где просто необходимо под рукой иметь мощный язык для работы со статистикой и графиками. И R как раз из таких. Новичку в мире программирования буде достаточно непросто в это поверить, но сегодня R уже популярнее SQL, он активно используется в коммерческих организациях, исследовательских и университетах.
Не вникая в правила, синтаксис и конкретные области применения, просто давайте рассмотрим основные книги и ресурсы, которые помогут вам с нуля изучить R.
GeekBrains рекомендует
Что такое язык R, зачем он вам нужен и как его можно использовать с умом, можно узнать из прекрасного вебинара Руслана Купцова, который он провёл чуть меньше года назад в рамках GeekWeek-2015.
Книги
Теперь, когда в голове есть определённый порядок, можно приступать к чтению литературы, благо её более чем достаточно. Начнём с отечественных авторов:
«Статистический анализ и визуализация данных с помощью R», Мастицкий С.Э., Шитиков В.К.
«Наглядная статистика. Используем R!», А.Б. Шипунов, Е.М. Балдин и др.
Несмотря на то, что в эти книги имеют безусловную ценность для человека, изучающего язык R, они немного перегружены статистическими подходами. То есть если вы только учитесь в университете или недавно его окончили, то это проблем не вызовет. Однако если вам 13 или 35, то к статистическому анализу лучше подойти как раз сперва изучив язык.
Поэтому рассмотрим книги на английском языке, которые в этом помогут чуть лучше:
«Learning R», Richard Cotton
«Introduction to Data Science with R», Garrett Grolemund
«Introductory Statistics with R», Peter Dalgaard
Естественно, для языка, который существует уже более 20 лет, было написано и переведено на русский немало книг. Вот парочка:
«Анализ сетей (графов) в среде R», Дуглас Люк
«Введение в статистическое обучение с примерами на языке R», Джеймс Г., Уиттон Д., Хасти Т., Тибширани Р.
Как видно из названий этой литературы, здесь вновь язык R рассматривается в прямой связи со статистикой, но так как азам вы уже обучились, то эффект будет исключительно положительный.
Ну и подводя некий этой этому разделу, в последней ссылке вы найдёте список всей рекомендованной разработчиками R англоязычной литературы:
R-Project

Интернет-ресурсы
Любой человек, желающий изучить какой-либо язык программирования обязательно должен посетить в поисках знаний два ресурса: официальный сайт его разработчиков и самое крупное онлайн сообщество. Что ж. не будем делать исключение и для R:
Онлайн-сообщество.
Но опять проникшись заботой к тем, кто английский язык выучить ещё не успел, а вот изучить R ну очень хочет, упомянем несколько российских ресурсов:
Викиучебник;
Книги и статьи Евгения Балдина про R, статистику и не только;
Вот в общем и всё, если не считать разрозненных материалов блогеров. Впрочем, если вам известны российские сайты, где можно почитать много информации про R, обязательно оставляйте ссылки в комментариях.
А пока довершим картину небольшим списком англоязычных, но от этого не менее познавательных сайтов:
CRAN – собственно, место где можно загрузить к себе на компьютер среду разработки R. Кроме того мануалы, примеры и прочее полезное чтиво;
Quick-R – коротко и понятно про статистику, методы её обработки и язык R;
Burns-Stat – про R и про предшественника его S с огромным количеством примеров;
R for Data Science – ещё одна книга от Гаррета Гроулмунда (Garrett Grolemund), переведённая в формат онлайн учебника;
Awesome R – подборка лучшего кода с официального сайта, размещённая на нашем любимом GitHub;
Mran – язык R от Microsoft;
Tutorial R – ещё один ресурс с упорядоченной информацией с официального сайта.
geekbrains.ru
обзор, внешний вид, плюсы и минусы
автор: Samoedd Январь 8, 2016
 Статистический анализ является неотъемлемой частью научного исследования. Качественная обработка данных повышает шансы опубликовать статью в солидном журнале, и вывести исследования на международный уровень. Существует много программ, способных обеспечить качественный анализ, однако большинство из них платные, и зачастую лицензия стоит от нескольких сотен долларов и выше. Но сегодня мы поговорим о статистической среде, за которую не надо платить, а ее надежность и популярность конкурируют с лучшими коммерческими стат. пакетами: мы познакомимся с R!
Статистический анализ является неотъемлемой частью научного исследования. Качественная обработка данных повышает шансы опубликовать статью в солидном журнале, и вывести исследования на международный уровень. Существует много программ, способных обеспечить качественный анализ, однако большинство из них платные, и зачастую лицензия стоит от нескольких сотен долларов и выше. Но сегодня мы поговорим о статистической среде, за которую не надо платить, а ее надежность и популярность конкурируют с лучшими коммерческими стат. пакетами: мы познакомимся с R!
Что такое R?
Прежде чем дать четкое определение, следует отметить, что R - это нечто большее, чем просто программа: это и среда, и язык, и даже движение! Мы рассмотрим R с разных ракурсов.
R - это среда вычислений, разработанная учеными для обработки данных, математического моделирования и работы с графикой. R можно использовать как простой калькулятор, можно редактировать в нем таблицы с данными, можно проводить простые статистические анализы (например, t-тест, ANOVA или регрессионный анализ) и более сложные длительные вычисления, проверять гипотезы, строить векторные графики и карты. Это далеко не полный перечень того, что можно делать в этой среде. Стоит отметить, что она распространяется бесплатно и может быть установлена как на Windows, так и на операционные системы класса UNIX (Linux и MacOS X). Другими словами, R - это свободный и кроссплатформенный продукт.
R - это язык программирования, благодаря чему можно писать собственные программы (скрипты) при помощи управляющих конструкций, а также использовать и создавать специализированные расширения (пакеты). Пакет - это набор R функций, файлов со справочной информацией и примерами, собранных вместе в одном архиве. R пакеты играют важную роль, так как они используются как дополнительные расширения на базе R. Каждый пакет, как правило, посвящен конкретной теме, например: пакет 'ggplot2' используется для построения красивых векторных графиков определенного дизайна, а пакет 'qtl' идеально подходит для генетического картирования. Таких пакетов в библиотеке R насчитывается на данный момент более 7000! Все они проверены на предмет ошибок и находятся в открытом доступе.
 R - это сообщество/движение. Так как R - это бесплатный продукт с открытым кодом, то его разработкой, тестированием и отладкой занимается не отдельная компания с нанятым персоналом, а сами пользователи. За два десятилетия из ядра разработчиков и энтузиастов сформировалось огромное сообщество. По последним данным, более 2 млн человек так или иначе помогали развивать и продвигать R на добровольной основе, начиная от переводов документации, создания обучающих курсов и заканчивая разработкой новых приложений для науки и промышленности. В интернете существует огромное количество форумов, на которых можно найти ответы на большинство вопросов, связанных с R.
R - это сообщество/движение. Так как R - это бесплатный продукт с открытым кодом, то его разработкой, тестированием и отладкой занимается не отдельная компания с нанятым персоналом, а сами пользователи. За два десятилетия из ядра разработчиков и энтузиастов сформировалось огромное сообщество. По последним данным, более 2 млн человек так или иначе помогали развивать и продвигать R на добровольной основе, начиная от переводов документации, создания обучающих курсов и заканчивая разработкой новых приложений для науки и промышленности. В интернете существует огромное количество форумов, на которых можно найти ответы на большинство вопросов, связанных с R.
Как выглядит среда R?
Существует много "оболочек" для R, внешний вид и функциональность которых могут сильно отличаться. Но мы коротко рассмотрим лишь три наиболее популярных варианта: Rgui, Rstudio и R, запущенный в терминале Linux/UNIX в виде командной строки.
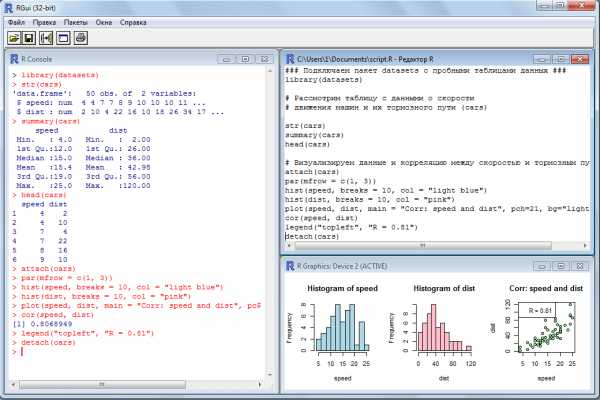
Rgui - это стандартный графический интерфейс (https://cran.r-project.org/), встроенный в R по умолчанию. Эта оболочка имеет вид командной строки в окне, называемым консолью. Командная строка работает по принципу "вопрос-ответ".
Например:> 2 + 2 * 2 # наш вопрос/запрос[1] 6 # ответ компьютера
Однако, для записи сложного алгоритма команд в Rgui существует дополнительное скриптовое окно, где пишется программа (скрипт). Третьим элементом данной оболочки является графический модуль, который появляется при необходимости отображения графиков.
На приведенном ниже рисунке, показана полная версия Rgui: консоль (слева), скриптовое окно и графический модуль (справа).
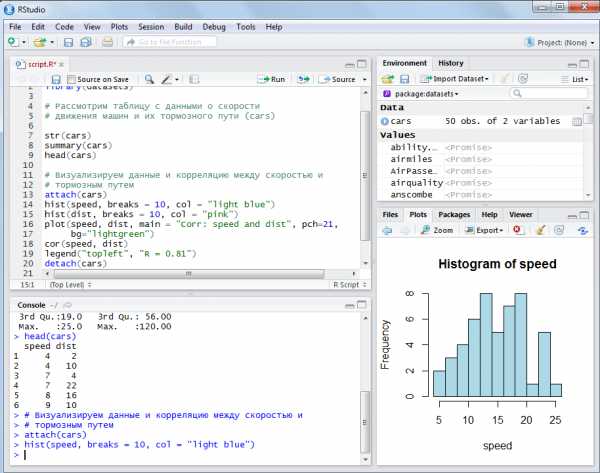
Rstudio - интегрированная среда разработки (IDE) (https://www.rstudio.com/). В отличие от Rgui, у данной оболочки есть заранее разделенные области и дополнительные модули (например, история команд, рабочая область). По мнению некоторых пользователей, Rstudio имеет более удобный интерфейс, упрощающий работу с R. Ряд особенностей, таких как цветовая подсветка и автоматическое завершение кода, удобная навигация по скрипту и другие, делают Rstudio привлекательной не только для новичков, но и для опытных программистов.
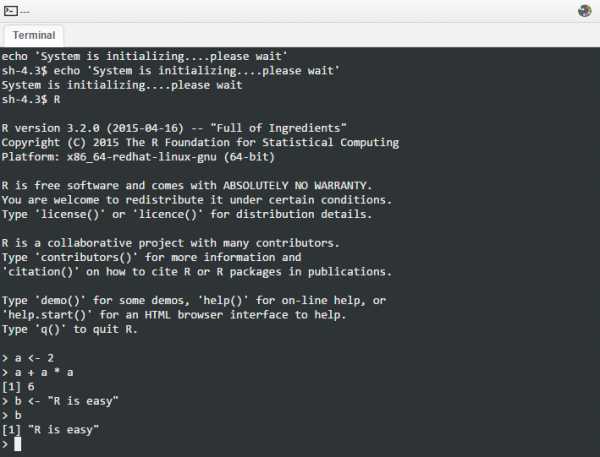
R в терминале Linux/UNIX. Данный вариант предпочтителен для анализа большого объема данных через сервер, суперкластер или суперкомпьютер. Большинство из них работают на операционных системах класса Linux/UNIX, доступ к которым осуществляется через терминал команд (например, bash). R в терминале представляет собой приложение, запущенное в виде командной строки (можете попрактиковаться здесь).
Язык R в мире статистических программ
На данный момент насчитываются десятки качественных статистических пакетов, среди которых явными лидерами являются SPSS, SAS и MatLab. Однако, в 2013 году, несмотря на высокую конкуренцию, R стал самым используемым программным продуктом для статистического анализа в научных публикациях (http://r4stats.com/articles/popularity/). Кроме того, в последнее десятилетие R становится все более востребованным и в бизнес-секторе: такие компании-гиганты, как Google, Facebook, Ford и New York Times активно используют его для сбора, анализа и визуализации данных (http://www.revolutionanalytics.com/companies-using-r). Для того чтобы понять причины растущей популярности языка R, обратим внимание на его общие черты и отличия от других статистических продуктов.
В целом большинство статистических инструментов можно разделить на три типа:
- программы с графическим интерфейсом, основанные на принципе "кликни здесь, тут и получи готовый результат";
- статистические языки программирования, в работе с которыми необходимы базовые навыки программирования;
- "смешанный", в которых есть и графический интерфейс (GUI), и возможность создания скриптов
samoedd.com
Мой опыт введения в R или «I Love R» / Хабр
Я — ученый [здесь про это подробнее]. «Пролетарий умственного труда». По образованию физик. Тружусь на ниве обработки медицинской и биологической информации 30+ лет. В R работаю ровно 10 лет, мигрировав на него после 15 лет плотного сотрудничества с Matlab. Первопричиной миграции на другую рабочую платформу послужила моя собственная физическая миграция на противоположный край Земли в Окланд, Новая Зеландия. Здесь жизнь с первых дней толкнула меня в объятия R, о чем мне еще не приходилось жалеть. " alt=«image»/>
В этом посте
" alt=«image»/>
В этом посте- Что такое R
- Откуда он взялся
- За что я его люблю
- Для чего и как я его использую (примеры)
- Мифы и правда
Что такое R
В первую очередь R это система для статистических и прочих научных расчетов, использующая язык программирования S.S — язык, написанный статистиками для статистиков. по определению автора Джона Чамберса. Язык с момента его появления был очень хорошо принят и протестирован поколениями весьма придирчивых пользователей-статистиков. Можно считать, что он достаточно широко известен и принят в мировом статистическом сообществе. На языке S реализованы и до сих пор эксплуатируются ряд критических эпидемиологических, экологических и финансовых моделей по всему миру и во многих отраслях. Как язык с точки зрения меня, как «пишущего пользователя», S представляет собой весьма приятную альтернативу языку SAS.
Из моего собственного опыта — Знакомство и первые уроки S я сам получил в начале 90-х от экспертов-статистиков ВОЗ, с которыми пересекался по научным исследованиям того времени.
По многим оценкам R (как по мне — так и не сильно преувеличенных) — один из самых успешных проектов опенсорса, распространяется свободно с десятков зеркал по всему миру по стандартам лицензий GNU. Авторы отвечают категорическим отказом на все предложения по коммерциализации проекта, хотя на сегодняшний день есть основание предполагать, что количество установленных копий R в мире превышает совокупное количество копий всех остальных систем статистического анализа.
С самого начала и по сию пору проект вызывает у меня глубочайшее уважение (на грани с восхищением) стабильностью, поддержкой пользователя, совместимостью кодов и пр., что я объединил бы в понятии культура. Впрочем, последнее предложение, скорее, для последующих подразделов.
Откуда взялся S и какое это имеет отношение к R
Несомненно, википедия даст вам много больше букв. Я лишь отмечу то, что считаю важным для понимания места S и R в этой жизни в этом мире.Лаборатории Белла (ака Bell Labs, AT&T Bell Labaratories) достаточно известны в истории науки и техники, и АйТи в частности. Статистические исследования там всегда были поставлены весьма серьезно и также серьезно поддерживались всеми доступными компьютерными средствами (читай — тоннами фортрановского и лисповского кода).
То, что потом стало языком S, возникло в 70-х по инициативе и под руководством Джона Чамберса (John Chambers), как набор скриптов, облегчающих «скармливание» данных фортрановскому коду. Т.е. во главу угла ставилась задача интерактивной манипуляции данными, компактность, приятность в написании и читаемость кода и получения приличного вывода на разнообразные устройства таблиц и графиков.
В синтаксисе языка предусмотрено построение практически сколь угодно сложных структур данных, средства для описания специфических статистических задач и объектов — стат. тестов, моделей и пр.
С 1984 года язык обрел имя, свою собственную «Библию» (издана книга Чамберса and Beckers: S: An Interactive Environment for Data Analysis and Graphics), стал по умолчанию содержать практически полный «джентельменский набор» статистика и «вероятностника» — распредления, генераторы случайных чисел, статистические тесты, многие стандартные статистические анализы, работы с матрицами и пр., не говоря уже о развитой системе научной графики. Самое главное — он стал доступен для пользователей по вему миру за весьма умеренную цену.
В 1988 (издана еще одна книга The New S Langugage) — модифицирован с применением ООП, все стало объектами с весьма разумными значениями по умолчанию, доступностью для модификации, элементами самодукоментирования и пр. и пр.
В это же время были лабораториями опубликованы исходники и «белл-лабовский» S стал бесплатным для студентов и для использования в научных целях. Это все как-то было связано с «раскулачиванием» AT&T, но меня уже эти подробности не сильно интересовали.
Существовали и, наверное, все еще существуют коммерческие реализация языка S. Я сталкивался с S-Plus и S2000. Они в разное время поддерживались разными компаниями, в основном, жили (живут?) за счет поддержки ранее созданных на S приложений. В этих пост-белловских версиях S появилась новая версия ООП-движка, но для чистого пользователя это прошло почти бескровно в плане совместимости исторического кода.
R — единственная некоммерческая полностью независимая (от исходной Белловской) реализация языка S.
И по редкому в наше время соглашению каким-то невообразимым для меня способом разработчики текущих версий коммерческого S и некоммерческого R поддерживают их практически полную совместимость и преемственность.
А теперь R
За любым значительным явлением в этой жизни стоит какая-то харизматическая личность. Впрочем, это может случиться и есть определение значительности явления.
В случае с R таких людей трое. Про Джона Чамберса я уже сказал.
Росс Ихака (Ross Ihaka) — студент, а потом научный сотрудник факультета статистики Оклендского университета темой своей диссертации (которая выполнялась в MIT, USA) выбрал исследование возможности построения виртуальной машины (VM) для статистических языков программирования. В качестве промежуточного языка был выбран Lisp (Common Lisp, CL) и на нем реализован прототип VM, «понимающий» небольшие подмножества из SAS и S. Дорабатывать диссертацию Росс вернулся в Окланд, где вскорости встретил Роберта Джентельменв и увлекся проектом R. Диссертацию Росс так и не защитил, но уже имеет ученую степень от нескольких университетов «по совокупности заслуг». В прошлом году ему было присвоено звание и он получил должность Associate Professor (доцент) в своем родном университете.
Роберт Джентелмен (Robert Gentleman) — еще один статистик со страстью к программированию, родом из Канады, будучи в Оклендском университете на стажировке (он тогда работал в Австралии), предложил Россу «написать какой-нибудь язычок». Согласно легенде, которую я сам слышал от этих «отцов-основателей» всего чуть ли не за месяц они в порыве безумного энтузиазма переписали на CL практически все команды S, включая мощную библиотеку линейного моделирования.
Вычислительным движком R, следуя традициям прототипа, была выбрана известная, общепризнанная и бесплатная библиотека BLAS, (с возможностью использования ATLAS и пр. с тем же интерфейсом). Пол Murrel, один из из ближайших друзей Росса и также сотрудник Окландского универа расстарался и написал (кажется, на С) с нуля графический движок, полностью воспроизводящий функциональность такового в S.
В результате получился бесплатный полнофункциональный пакетик, моментально получивший место в учебном процессе Окланлского университета, полностью соответствующий описаниям в очень подробных и качественных книгах Чамберса, которые по традиции издавались в мягких обложках и среднего качества печати, зато были дешевы и доступны. Несколько групп-активистов GNU-шного (например GIS) движения приняли R в качестве платформы для научных вычислений.
Но поистине широчайшую известность R приобрел в биоинформатике, когда один из «отцов» Роберт Джентельмен, вовлеченный в то время в работы фирмы Affimmetrix, продублировал всю функциональность коммерческого софта фирмы и запустил (ну не один, конечно) опенсорсный проект Bioconductor. В настоящее время Bioconductor является безусловным лидером биоинформатического опенсорса для всех "-омиксов" (genomics, proteomics, metabolomics etc.).
Единым языком интерфейса для сего буйства биоинформатических фантазий стал, естественно, R.
Круг замкнулся, когда вышедший на пенсию Чамберс, создатель языка S, вошел на правах полноправного члена в группу активных разработчиков R.
За что я его люблю (список)
- Интерактивность, «Программирование с данными» — мой любимый стиль работы
- Изящный (на любителя) язык — люблю списки, data frames, функциональное программирование и лямбда-функции (а-la)ю Свобода самовыражения: одну и ту же задачу можно решить десятью способами (смягчает ощущение рутины)
- «Трезво смотрит на этот мир» — редко «падает» или кого-нить «подвешивает», логичные операции с пропущенными данными, обработка ошибок во время выполнения (try-error), легкий обмен с системой на уровне стандартного I/O и пр.
- Полный набор готовых к употреблению статистических процедур
- Хорошо документирован и хорошо сопровождается — совместимость, преемственность и т.п.
- Собрал вокруг себя по-человечески приятное профессиональное сообщество (форумы, конференции пользователей и пр.)
- Хорошо докуметированный интерфейс для внешних библиотек и функций на чем угодно — Фортран, С, Java. Отсюда море хорошо документированных библиотек по всем аспектам статистики и обработки данных практически во всех сферах науки, но с основным упором на биоинформатику/биостатистику; все регулярно и корректно обновляется, если есть на то авторская воля
- Отсутствие обязательного GUI в «базовой комплектации» — Ну не «мышиный» я человек!
Для чего и как я его использую (примеры)
Начал писать в этот раздел, но остановился. Иначе я никогда бы не закончил. Ой, наверное, как нибудь потом.Мифы и правда
R медленный R — «тонкий», для вычислений использует blas/lapack/atlas библиотеки, попробуйте написать что-нибудь быстрее этих старых добры фортрановских (зачастую) «рабочих лошадок». Все критичные функции, как правило, используют векторные операции и реализованы на С. R нерационально использует вычислительные ресурсы, в частности — память Да, разработчики признают такой грех. Но рабочее время специалиста сейчас всяко дороже «железа». Выгрузите из современного рабочего компа игрушки и с большинством реальных наборов данных у вас с R проблем не будет.Бесплатный софт не может быть надежным Может: Fortran, Linux, C, Lisp, Java etc.Вместо Эпилога
Как сказано выше, пост ниже является фактически переводом моей презентации для достаточно специфичесуой целевой аудитории, и я вкратце опишу эту аудиторию.Многим «чистым» АйТи с такими людьми придется встретиться, поскольку производство продуктов питания по привлечению капитала и генерации прибылей уже давно соревнуется с нефтью и прочими энергоносителями. А емкость биоинформатического рынка при медицине и фармакологии ограничена, как ни крути.
Итак, моя аудитория — люди, с базовым образованием в генетике и селекции, ветеринарии, реже — биологии (преимущественно — молекулярной). Дядьки и тетки (последних больше), лет по 20-30-… программирующие (!) на FORTRANe или VB, лихо управляющиеся с excel-таблицами в 100к строк/столбцов и периодически «роняющие» своими задачами (и своим программированием) свой вычислительный линуксовый 500+ядерный кластер 12Тб общей памяти и время от времени требующие расширения дисковой памяти очередным десятком терабайт.
Методическая база — гремучая смесь древних как мир дисперсионных анализов со смешанными моделями, решаемыми никак иначе, как только методом максимального правдоподобия, «плавящие мозг» байесовские сети и т.п.
Данные — таблицы данных от единиц до десятков тысяч строк, включающие иногда 1-5 колонок с фенотипами, но все чаще — десятки или сотни «Ка» столбцов переменных, слабокореллирующих между собой и с фенотипами.
Ну да, еще у них есть «хорошая традиция» расматривать все в аспекте родственных связей (генетика, как-никак). Родственные связи традиционно представлены в виде матрицы «родственных связей» (pedigree) размерами, например 40 000 х 40 000 (это если 40 000 животных). Ну или (пока, к счастью, только в проекте) 20 000 000 х 20 000 000 — это чтобы «охватить» единой моделью все 20 млн. исторических животных, имеющихся в базе данных (DB2, если кому интересно, и даже Сobol еще «выпилили» не отовсюду...)
По столам, заваленным литературой по (одновременно) Fortran, Java, C#, Scalа, Octavia, Linux for Dummies можно узнать недавних выпускников-биоинформатиков. Но как-то быстро многие из них уходят из науки в «кодеры».
Впрочем, знаю и случай обратного движения. Так что R еще многим пригодится.
habr.com
Язык программирования R - Введение в R для программистов на C#
Джеймс Маккафри
Продукты и технологии:
R, C#, Visual Studio
В статье рассматриваются:
• пример проверки по хи-квадрату (chi-square test) с применением R;
• линейный регрессионный анализ;
• проверка по хи-квадрату независимости;
• графы в R;
• пример проверки по хи-квадрату на C# для сравнения.
Исходный код можно скачать по ссылке
Язык R используется специалистами по обработке и анализу данных и программистами для статистический вычислений. R является одной из самых быстро развивающихся технологий среди моих коллег, использующих C#. Отчасти это вызвано нарастающими объемами данных, собираемых программными системами, и потребностью в анализе этих данных. Знакомство с R может оказаться ценным пополнением в вашем арсенале технических навыков.
Язык R — это проект по лицензии GNU и бесплатное программное обеспечение. R произошел от языка S (сокращение от статистики), который был создан в Bell Laboratories в 1970-х годах. По R есть много великолепных онлайновых учебных пособий, но в большинстве из них предполагается, что вы — студент университета, изучающий статистику. Эта статья нацелена на то, чтобы помочь программистам на C# быстро освоить R.
Лучший способ понять, о чем эта статья, — взглянуть на пример сеанса работы с R на рис. 1. В примере сеанса демонстрируются две несвязанные между собой тематики. Первый набор команд показывает проверку по хи-квадрату (chi-square test), также называемую хи-квадратичной проверкой (chi-squared test), для равномерного распределения. Второй набор команд иллюстрирует пример линейной регрессии, которая, по моему мнению, является чем-то вроде «Hello World» в мире статистических вычислений.
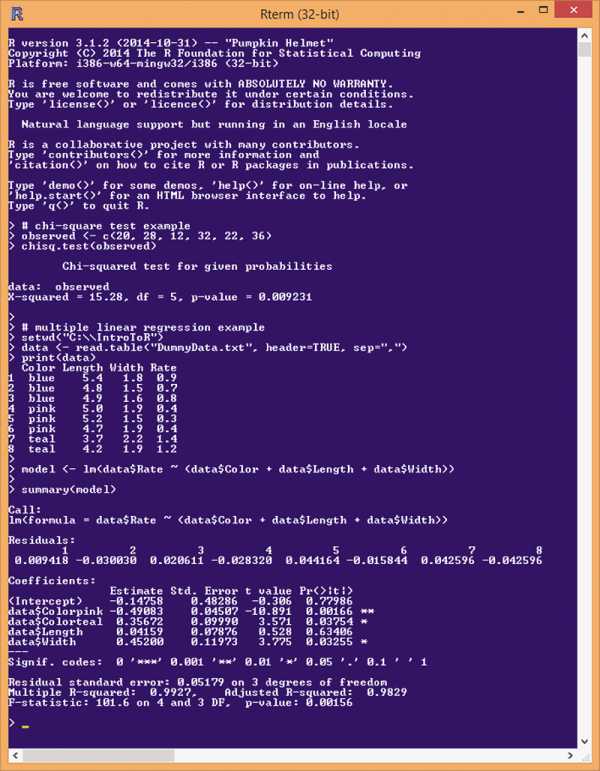 Рис. 1. Пример сеанса работы с R
Рис. 1. Пример сеанса работы с R
Веб-сайт R находится по адресу r-project.org. На этом сайте есть ссылки на несколько зеркальных сайтов, где можно скачать и установить R. Установка заключается в простом запуске самораспаковывающегося исполняемого файла. R официально поддерживается в Windows XP и более поздних версиях, а также на большинстве платформ, отличных от Windows. Я устанавливал R на компьютеры с Windows 7 и Windows 8 безо всяких проблем. По умолчанию процесс установки предоставляет как 32-, так и 64-разрядную версию.
В этой статье предполагается, что вы умеете программировать на C# хотя бы на среднем уровне (чтобы понять пояснения сходств и различий между C# и R), но ничего не знаете о R. Демонстрационная программа на C# представлена во всей ее полноте; кроме того, вы найдете весь исходный код в сопутствующем этой статье пакете кода.
Проверка по хи-квадрату с помощью R
Взгляните на рис. 1 и первым делом обратите внимание на то, что использование R весьма заметно отличается от использования C#. Хотя R позволяет писать скрипты, он чаще всего применяется в интерактивном режиме в командной оболочке. Первый пример R — это анализ того, является обычная шестигранная игральная кость правильной или нет. При многократных бросках правильная кость должна давать примерно одинаковое количество каждого из шести возможных результатов.
Строка приглашения R в командной оболочке помечается маркером >. Первое выражение, введенное на рис. 1, начинается с символа #, который отмечает комментарий.
Первая реальная команда в примере выглядит так:
> observed <- c(20, 28, 12, 32, 22, 36)Она создает вектор observed, использующий функцию c (сокращение от concatenate). Вектор хранит объекты одного и того же типа данных. Примерный эквивалент этого выражения на C# был бы таким:
var observed = new int[] { 20, 28, 12, 32, 22, 36 };Первое значение, 20, — число, указывающее, сколько раз встречалось одно очко, 28 — два очка и т. д. Сумма шести значений составляет 20 + 28 + . . + 36 = 150. От правильной игральной кости следовало бы ожидать приблизительно 150/6 = 25 раз для каждого из возможных результатов. Но наблюдаемое число выпадений трех очков (12) выглядит подозрительно малым.
После создания вектора проверка по хи-квадрату выполняется с помощью функции chisq.test:
В языке R при формировании имен переменных и функций вместо символа подчеркивания (_) часто используется точка (.) — такие имена легче читать. Результат вызова функции chisq.test выдает приличное количество текста:
Chi-squared test for given probabilities
data: observed X-squared = 15.28, df = 5, p-value = 0.009231В терминах C# большинство функций R возвращает структуру данных, которую можно игнорировать, но также содержит много выражений, эквивалентных Console.WriteLine, которые предоставляют вывод. Заметьте, что расшифровка смысла вывода R возлагается на вас. Далее в этой статье я покажу, как создать эквивалент проверки по хи-квадрату на чистом (без библиотек) C#.
В этом примере значение «X-squared», равное 15.28, является вычисленной статистикой хи-квадрата (греческая буква «chi» напоминает прописную «X»). Значение 0.0 указывает, что наблюдавшиеся значения точно соответствуют тому, что следовало бы ожидать, если игральная кость была правильной. Более высокие значения хи-квадрата информируют о растущей вероятности того, что наблюдаемые числа не могли бы выпасть случайно, будь эта игральная кость правильной. Значение df, равное 5, — это «число степеней свободы», которое на единицу меньше, чем число наблюдавшихся значений. В этом анализе df не слишком важно.
P-значение (0.009231) — это вероятность того, что наблюдаемые счетчики могли бы быть случайными, если бы игральная кость была правильной. Поскольку p-значение столь мало, менее 1%, вы должны считать, что наблюдаемые значения вряд ли выпадали случайно, а значит, у вас есть статистическое доказательство того, что данная игральная кость скорее всего имеет смещение центра тяжести.
Линейный регрессионный анализ с помощью R
Второй набор выражений на рис. 1 показывает пример линейной регрессии. Линейная регрессия — статистический метод, применяемый для описания взаимосвязи между числовой переменной (называемой в статистике зависимой переменной) и одной или более пояснительными переменными (explanatory variables) (называемыми в статистике независимыми переменными), которые могут быть либо числовыми, либо категориальными. При наличии только одной независимой пояснительной/прогностической переменной метод называют простой линейной регрессией. Когда имеются две или более независимых переменных, как в демонстрационном примере, метод называют множественной линейной регрессией (multiple linear regression).
Прежде чем заняться анализом линейной регрессии, я создал текстовый файл DummyData.txt с восемью элементами, разделенными запятыми, и поместил его в каталог C:\IntroToR. Вот содержимое этого файла:
Color,Length,Width,Rate blue, 5.4, 1.8, 0.9 blue, 4.8, 1.5, 0.7 blue, 4.9, 1.6, 0.8 pink, 5.0, 1.9, 0.4 pink, 5.2, 1.5, 0.3 pink, 4.7, 1.9, 0.4 teal, 3.7, 2.2, 1.4 teal, 4.2, 1.9, 1.2Предполагается, что этот файл представляет данные о цвете, длине и ширине лепестков и показателе роста цветков. Идея в том, чтобы прогнозировать значения Rate (последний столбец) на основе значений Color, Length и Width. После выражения с комментарием первые три команды R в анализе линейной регрессии выглядят следующим образом:
> setwd("C:\\IntroToR") > data <- read.table("DummyData.txt", header=TRUE, sep=",") > print(data)Первая команда устанавливает рабочий каталог, чтобы мне не приходилось указывать полный путь к файлу с исходными данными. Вместо привычного в C# символа (\\) я мог бы использовать символ (/), распространенный на платформах, отличных от Windows.
Вторая команда загружает данные в память в объект-таблицу с именем data. Заметьте, что R использует именованные параметры. Параметр header сообщает, является первая строка информацией о заголовке (TRUE, или T в сокращенной форме) или нет (FALSE, или F). R чувствителен к регистру букв, и для присваивания значений обычно можно использовать либо оператор <-, либо оператор =. Выбор является в основном делом личных предпочтений. Я использую <- для объектных присваиваний и = для присваивания значений параметрам.
Параметр sep (separator) указывает, как разделяются значения в каждой строке. Например, \t задавал бы разделение значений табуляторами, а (" ") — пробелами.
Функция print выводит таблицу данных в памяти. У этой функции много необязательных параметров. Заметьте, что вывод на рис. 1 отражает индексы элементов данных, начиная с 1. В случае индексов массивов, матриц и объектов R является языком, где отсчет ведется от 1, а не от 0, как в языке C#.
Анализ линейной регрессии выполняется следующими двумя командами R:
> model <- lm(data$Rate ~ (data$Color + data$Length + data$Width)) > summary(model)Первую команду можно интерпретировать как «Сохранить в объект с именем model результат функции анализа lm (линейная модель), где прогнозируемая зависимая переменная является столбцом Rate в объекте-таблице (data$Rate), а независимые переменные-предикторы представляют собой Color, Length и Width». Вторая команда означает: «Отображать только базовые результаты анализа, сохраненные в объекте с именем model».
Функция lm генерирует большое количество информации. Допустим, вы хотите предсказать значение Rate, когда входными значениями являются Color = pink, Length = 5.0 и Width = 1.9. (Заметьте, что это соответствует элементу данных [4] с реальным значением Rate, равным 0.4.) Для прогнозирования вы должны использовать значения в столбце Estimate:
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -0.14758 0.48286 -0.306 0.77986 data$Colorpink -0.49083 0.04507 -10.891 0.00166 ** data$Colorteal 0.35672 0.09990 3.571 0.03754 * data$Length 0.04159 0.07876 0.528 0.63406 data$Width 0.45200 0.11973 3.775 0.03255 *Если X представляет значения независимой переменной, а Y представляет прогнозируемый Rate, тогда:
X = (blue = NA, pink = 1, teal = 0, Length = 5.0, Width = 1.9) Y = -0.14758 + (-0.49083)(1) + (0.35672)(0) + (0.04159)(5.0) + (0.45200)(1.9) = -0.14758 + (-0.49083) + (0) + (0.20795) + (0.85880) = 0.42834Заметьте, что предсказанный Rate (0.43) довольно близок к реальному (0.40).
Если на словах, то, чтобы сделать прогноз на основе модели, вы вычисляете линейную сумму произведений значений Estimate и соответствующим им значений X. Значение Intercept является константой, не связанной ни с какой переменной. Когда вы имеете дело с категориальными пояснительными переменными, одно из значений отбрасывается (в данном случае — blue).
Информация в нижней части вывода сообщает, насколько хорошо независимые переменные Color, Length и Width поясняют зависимую переменную Rate:
Residual standard error: 0.05179 on 3 degrees of freedom Multiple R-squared: 0.9927, Adjusted R-squared: 0.9829 F-statistic: 101.6 on 4 and 3 DF, p-value: 0.00156Значение Multiple R-squared (коэффициент детерминации) (0.9927) — это процентная доля вариации зависимой переменной, поясняемая линейной комбинацией независимых переменных. Выражаясь несколько иначе, R-squared — это значение между 0 и 1, где более высокие значения свидетельствуют о более качественной модели прогнозирования. Здесь значение R-squared чрезвычайно высокое, указывая на то, что Color, Length и Width могут очень точно предсказывать Rate. F-statistic (статистика дисперсии) с учетом значения R-squared и p-value — другие критерии точности модели.
Один из моментов, демонстрируемых этим примером, заключается в том, что при программировании с применением R самая крупная проблема — понимание статистики, стоящей за языковыми функциями. Большинство людей осваивают R постепенно, добавляя в копилку своих знаний по одному методу единовременно — по мере необходимости найти ответ на некий специфический вопрос. Аналогией в C# могло бы послужить изучение различных объектов-наборов в пространстве имен Collections.Generic, таких как классы Hashtable и Queue. Большинство разработчиков изучают по одной структуре данных, не пытаясь сходу запомнить информацию обо всех классах до их использования в каком-либо проекте.
Другая проверка по хи-квадрату
Тип проверки по хи-квадрату на рис. 1 часто называют тестом на равномерное распределение, поскольку он проверяет, все ли наблюдаемые данные имеют равные счетчики, т. е. равномерно ли распределяются данные. Есть несколько других видов проверок по хи-квадрату, включая проверку независимости по хи-квадрату.
Допустим, есть группа из 100 людей и вас интересует, является ли пол (male, female) независимым от принадлежности к политической партии (Democrat, Republican, Other). Представьте, что ваши данные находятся в матрице сопряженности (contingency matrix), как показано в табл. 1. Из нее следует, что мужчины (males), возможно, чаще являются республиканцами (Rep), чем женщины (females).
Табл. 1. Матрица сопряженности
| Dem | Rep | Other | ||
| Male | 15 | 25 | 10 | 50 |
| Female | 30 | 15 | 5 | 50 |
| 45 | 40 | 15 | 100 |
Чтобы использовать R для проверки того, являются ли два фактора (пол и принадлежность к партии) статистически независимыми, вы должны сначала поместить данные в численную матрицу этой командой:
> cm <- matrix( c(15,30,25,15,10,5), nrow=2, ncol=3 )Обратите внимание, что в R матричные данные сохраняются по столбцам (сверху вниз и слева направо), а не по строкам (слева направо и сверху вниз), как в C#.
Команда проверки по хи-квадрату в R выглядит следующим образом:
Результат p-value после проверки — 0.01022, и это указывает на то, что при уровне значимости (significance level) в 5% два фактора не являются независимыми. Иначе говоря, между полом и партийной принадлежностью существует статистическая взаимосвязь.
В первом примере с игральной костью входной параметр был вектором, а во втором примере со связью между полом и партийной принадлежностью — матрицей. Функция chisq.test имеет всего семь параметров, из которых один обязательный (вектор или матрица), а последующие шесть являются необязательными именованными.
Подобно многим C#-методам в пространствах имен Microsoft .NET Framework большинство функций R имеет множество перегруженных версий. В C# перегрузка обычно реализуется использованием нескольких методов с одинаковыми именами, но с разными параметрами. Применение обобщений также представляет собой одну и форм перегрузки. В языке R перегрузка реализуется использованием одной функции с несколькими необязательными именованными параметрами.
Построение графиков с помощью R
Как программист на C#, когда я хочу построить график на основе выходных данных от какой-то программы, я обычно запускаю эту программу, копирую выходные данные, вставляю их в блокнот нажатием клавиш Ctrl+V для удаления управляющих символов, копирую эти данные, вставляю в Excel, а затем создаю график с помощью Excel. Довольно замысловато, но отлично работает в большинстве случаев.
Одна из сильных сторон системы R — ее способность генерировать графики. Взгляните на пример на рис. 2. Этот тип графика невозможно создать в Excel без установки какой-нибудь надстройки.
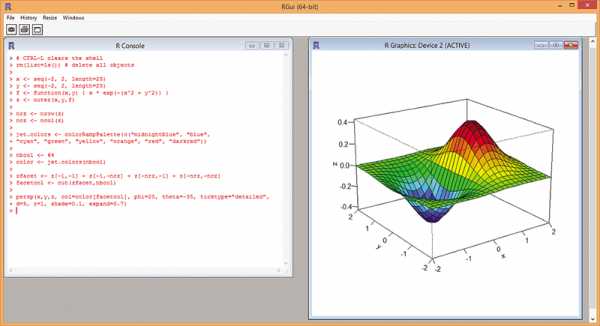 Рис. 2. Трехмерный график, созданный с использованием R
Рис. 2. Трехмерный график, созданный с использованием R
В дополнение к программе оболочки, показанной на рис. 1, R также имеет некое подобие GUI-интерфейса, RGui.exe, для использования при построении графиков (я называю этот интерфейс «полу-GUI»).
График на рис. 2 отражает функцию z = f(x,y) = x * e^(-(x^2 + y^2)). Вот как выглядят первые три команды R, генерирующие график:
> rm(list=ls()) > x <- seq(-2, 2, length=25) > y <- seq(-2, 2, length=25)Функция rm удаляет объект из текущего рабочего пространства в памяти. Использованная команда является магическим заклинанием R для удаления всех объектов. Вторая и третья команды создают векторы из 25 равноотстоящих значений — от –2 до +2 включительно. Вместо этого можно было бы использовать функцию c.
Следующие две команды:
> f <- function(x,y) { x * exp(-(x^2 + y^2)) } > z <- outer(x,y,f)Первая из них показывает, как определить функцию в R, используя ключевое слово function. Встроенная в R функция outer создает матрицу значений на основе векторов x и y и определения функции f. Результатом является матрица 25×25, где значение в каждой ячейке представляет собой значение функции f, которое соответствует x и y.
Еще две команды выглядят так:
> nrz <- nrow(z) > ncz <- ncol(z)Функции nrow и ncol возвращают количество строк или число столбцов в своем аргументе-матрице. Здесь оба значения будут по 25.
Следующая команда R использует функцию colorRampPalette для создания пользовательской палитры с цветовым градиентом, которой рисуется график:
msdn.microsoft.com
Необходимо ли вам изучать язык R?
Четыре серьезных довода в пользу того, чтобы опробовать эту платформу с открытым исходным кодом для анализа данных
Кэтрин ДелзеллОпубликовано 24.10.2014
Вы наверняка слышали о R. Возможно, вы читали соответствующую статью Сэма Сиверта (Sam Siewert) под названием Большие данные в облаке. Вы знаете, что R — это язык программирования и что он имеет определенное отношение к статистике, но подходит ли он вам?
Доводы в пользу R
R — язык, ориентированный на статистику. Его можно рассматривать в качестве конкурента для таких аналитических систем, как SAS Analytics, не говоря уже о таких более простых пакетах, как StatSoft STATISTICA или Minitab. Многие профессиональные статистики и методисты в правительственных организациях, в коммерческих компаниях и в фармацевтической отрасли решают свои задачи с помощью таких продуктов, как IBM SPSS или SAS, без написания какого-либо кода на языке R. Таким образом, в значительной степени решение об изучении и использовании R — это вопрос корпоративной культуры и профессиональных предпочтений применительно к рабочим инструментам. В своей статистической консультационной практике я использую несколько инструментов, однако большая часть того, что я делаю, сделана на R. Следующие примеры объясняют, почему дело обстоит именно таким образом.
- R — это мощный скриптовый язык. Недавно меня попросили проанализировать результаты одного масштабного исследования. Исследователи просмотрели 1600 научных работ и закодировали их содержимое по нескольким критериям — количество критериев было действительно большим, особенно с учетом множественных вариаций и ветвлений. После переноса в электронную таблицу Microsoft® Excel® эти данные содержали более 8000 столбцов, большинство из которых были пустыми. Исследователи хотели подсчитывать общие количества по различным категориям и под разными заголовками. R является мощным скриптовым языком и поддерживает Perl-подобные регулярные выражения для обработки текста. Для обработки неупорядоченных данных требуются возможности языка программирования; продукты SAS и SPSS имеют скриптовые языки для задач, для решения которых недостаточно ниспадающего меню, однако R был создан именно как язык программирования и поэтому является более подходящим инструментом для этой цели.
- R — лидер направления. Многие новые разработки в области статистики сначала появляются как пакеты для платформы R ("R-пакеты") и только потом приходят на коммерческие платформы. Недавно я получила данные медицинского исследования по повторным обращениям пациентов. По каждому пациенту в этих данных имелось количество элементов лечения, предложенных врачом, и количество элементов, которые реально запомнил пациент. Естественной моделью для этой ситуации является т. н. бета-биномиальное распределение. Оно известно с 1950-х годов, однако процедуры оценки, связывающие модель с интересующими нас ковариациями, появились лишь недавно. Такие данные обычно обрабатываются с помощью т.н. GEE-методов (Generalized Estimating Equations), однако эти методы являются асимптотическими и исходят из предположения, что выборка имеет большие размеры. Мне требовалась обобщенная линейная модель с бета-биномиальным распределением. Один из недавно появившихся R-пакетов осуществляет оценку согласно этой модели: пакет betabinom, автором которого является Бен Болкер (Ben Bolker). Инструмент SPSS не имеет таких возможностей.
- Интеграция со средствами публикации документов. R органично интегрируется с системами публикации документов, что позволяет встраивать статистические результаты и графику из среды R в документы публикационного качества. Эта возможность не нужна абсолютно всем, однако если вы хотите написать книгу о своем анализе данных или просто не любите копировать свои результаты в документы текстового процессора, то самый короткий и самый элегантный маршрут состоит в использовании R и LaTeX.
- Бесплатность Я — владелец небольшой компании, поэтому мне нравится, что R распространяется свободно. Даже для более крупного предприятия весьма неплохо, когда в случае привлечения нужного специалиста на временной основе оно способно немедленно предоставить такому специалисту рабочую станцию с передовым аналитическим программным обеспечением. При этом нет никакой необходимости волноваться о бюджете.
Что такое R и для чего он предназначен
140-символьное объяснение
R — это реализация языка S с открытым исходным кодом, представляющая собой среду программирования для анализа данных и для работы с графикой.
В качестве языка программирования R подобен многим другим языкам. Любой человек, который когда-либо писал программный код, найдет в R множество знакомых моментов. Отличительные особенности R лежат в статистической философии, которую он исповедует.
Статистическая революция: S и разведочный анализ данных
Компьютеры всегда были эффективным инструментом для вычислений — но лишь после того, как кто-то написал и отладил программу для выполнения нужного алгоритма. Однако в 1960-1970-х годах компьютеры были еще очень слабы в области отображения информации, особенно графической. Эти технические ограничения, наряду с тенденциями в статистической теории, привели к тому, что практика статистики, как и подготовка статистиков, ориентировались на построение моделей и на проверку гипотез. В этом мире исследователи предлагали гипотезы, тщательно продумывали эксперименты, настраивали модели и проводили испытания. Подобный подход реализован в программных средствах, подобных SPSS, которые базируются на электронных таблицах и управляются с помощью меню. Фактически первые версии программных продуктов SPSS и SAS Analytics состояли из подпрограмм, которые можно было вызвать из основной программы (на Fortran или на другом языке) с целью подгонки и проверки модели из имеющегося набора моделей.
В эту формализованную и перегруженную теорией среду Джон Тьюки (John Tukey) вбросил, как булыжник в стеклянную витрину, концепцию т. н. разведочного анализа данных (Exploratory Data Analysis, EDA). Сегодня трудно представить время, когда к анализу набора данных можно было приступать без использования ящичной диаграммы (box plot) для проверки на асимметрию и на выбросы или без проверки невязок линейной модели на нормальность с помощью квантильной диаграммы. Автором всех этих идей был Дж. Тьюки, и сегодня ни один вводный курс по статистике не обходится без них. Однако дело не всегда обстояло подобным образом.
Цитата из книги: Graphical Methods for Data Analysis (Графические методы анализа данных)
"В любом серьезном приложении на данные следует посмотреть несколькими способами, а затем построить несколько графиков и выполнить несколько исследований. Это позволит по результатам каждого очередного шага выбирать следующий шаг. Чтобы анализ данных был эффективным, он должен быть итеративным". — Джон Чамберс (John Chambers), см. раздел Ресурсы).
EDA — это в большей степени подход, чем теория. Для успешного применения этого подхода необходимо соблюдать следующие эмпирические правила.
- По возможности используйте графики для рассмотрения интересующих вас функций.
- Всегда выполняйте анализ инкрементным образом. Испытайте одну модель; исходя из полученных результатов, настройте следующую модель.
- Проверяйте допущения модели с помощью графиков. Обращайте внимание на выбросы, если они есть.
- Используйте робастные методы с целью нейтрализации отклонений от допущений распределения.
Подход Дж. Тьюки породил волну новых графических методов и робастных оценок. Кроме того, этот подход инициировал разработку новой программной среды, ориентированной на разведочные методы.
Джон Чамберс вместе со своими коллегами из компании Bell Laboratories создал язык S в качестве платформы для статистического анализа, особенно той его разновидности, которую исповедовал Дж. Тьюки. Первая версия языка S, предназначенная для внутреннего использования в компании Bell, была разработана еще в 1976 г., однако лишь в 1988 году этот язык приобрел свою нынешнюю форму. К этому времени язык был доступен и пользователям за пределами Bell. В каждом своем аспекте язык S соответствует "новой модели" анализа данных.
- S — это интерпретируемый язык, действующий в среде программирования. Синтаксис S во многом походит на синтаксис языка C, но без его сложностей. К примеру, S берет на себя заботу об управлении памятью и об объявлении переменных, поэтому у пользователя нет необходимости описывать и отлаживать подобные вещи. Более низкие накладные расходы на программирование позволяют быстро проводить несколько исследований с одним и тем же набором данных.
- С самого начала язык S допускал создание высокоуровневых графических артефактов и позволял добавлять опции к любому открытому графическому окну. Этот язык позволяет с легкостью выделить интересные места, запросить их значения, добавить сглаживющие кривые к точечной диаграмме и т.д.
- В 1992 г. в языке S была дополнительно реализована объектная ориентированность. В языке программирования объекты осуществляют структурирование данных и функций в соответствии с интуитивными представлениями пользователя. Человеческое мышление всегда является объектно-ориентированным, а статистические умозаключения – в особенности. Статистик работает с частотными таблицами, с временными рядами, с матрицами, с электронными таблицами, содержащими данные разных типов, с моделями и т.д. В каждом случае необработанные числа наделяются атрибутами и сопровождаются теми или иными ожиданиями. Например, временной ряд состоит из наблюдений и соответствующих моментов времени. Для каждого типа данных ожидаются стандартные статистические показатели и графики. В случае временных рядов можно сформировать график временного ряда и коррелограмму; для эмпирически подобранной модели можно графически изобразить приближения и остатки. Язык S позволяет создавать объекты для всех этих концепций; по мере необходимости вы сможете создавать новые классы объектов. Объекты облегчают переход от концептуализации проблемы к ее реализации в программном коде.
Язык с характером: S, S-Plus и проверка гипотез
В своем первоначальном виде язык S относился к EDA-методам Дж. Тьюки весьма серьезно – до такой степени, что на языке S было неудобно делать что-либо иное, помимо EDA. Это был язык с характером. Например, S имел ряд полезных внутренних функций, однако у него отсутствовали некоторые вполне очевидные возможности, наличия которых можно было бы ожидать у статистического программного обеспечения. Так, отсутствовала функция для выполнения t-теста для двух выборок и не поддерживалось настоящее тестирование для гипотез любого вида. Однако, несмотря на аргументацию Дж. Тьюки, тестирование гипотез зачастую бывает весьма полезным.
В 1988 г. компания из Сиэтла под названием Statistical Science приобрела лицензию на S и портировала улучшенную версию этого языка под названием S-Plus на платформу DOS, а затем и в среду Windows®. Обладая реальным представлением о том, что требуется ее клиентам, компания Statistical Science добавила в язык S-Plus функциональность классической статистики. Были добавлены функции для дисперсионного анализа (ANOVA), t-тест и другие модели. В соответствии с объектной ориентированностью языка S результат любой подобранной модели сам является объектом языка S. Вызовы соответствующей функции предоставляют приближения, остатки и p-значение при тестировании гипотезы. Объект модели может даже содержать промежуточные вычислительные шаги анализа, такие как QR-разложение матрицы плана (где Q – ортогональная матрица, а R — верхнетреугольная матрица).
Примерно в то же самое время, когда был выпущен язык S-Plus, Росс Айхэка (Ross Ihaka) и Роберт Джентлмен (Robert Gentleman) из Оклендского университета в Новой Зеландии решили попробовать свои силы в написании интерпретатора. В качестве своей модели они выбрали язык S. Проект конкретизировался и получил поддержку. Они дали своему проекту название R.
R — это реализация языка S с дополнительными моделями, разработанными в языке S-Plus. В некоторых случаях моделями в обоих языках занимались одни и те же люди. R — это проект с открытым исходным кодом, который доступен в соответствии с лицензией GNU. На этом фундаменте R продолжает развиваться, в значительной степени посредством добавления пакетов. R-пакет представляет собой коллекцию наборов данных, функций языка R, документации и динамически загружаемых элементов на языке C или Fortran. R-пакет может быть установлен как группа, которая будет доступна в рамках сеанса R. R-пакеты добавляют новую функциональность к языку R; посредством этих пакетов исследователи могут с легкостью обмениваться вычислительными методами со своими коллегами. Некоторые пакеты имеют ограниченную область применения, другие представляют целые области статистики, а некоторые отражают новейшие разработки. И действительно, многие новые разработки в области статистики сначала появляются как R-пакеты, и только потом реализуются в коммерческих программных продуктах.
В тот момент, когда я писала этот текст, на веб-сайте CRAN, с которого осуществляется загрузка R, количество R-пакетов составляло 4701. Из них шесть пакетов было добавлено только в один этот день. Платформа R имеет пакет для решения любой задачи - по крайней мере именно такое впечатление складывается.
Что происходит при использовании R
Прмечание: Эта статья не является обучающим руководством по R. Следующий пример – это не более чем попытка показать, как выглядит сеанс R.
Имеются двоичные дистрибутивы R для Windows, для Mac OS X и для нескольких вариантов Linux®. Кроме того, для тех, кому нравится компилировать самостоятельно, доступны и исходные коды.
В среде Windows® установщик добавляет пункт R в Меню Start (Пуск). Чтобы запустить R в среде Linux, откройте окно терминала и при появлении подсказки введите с клавиатуры букву R. Вы должны увидеть нечто похожее на рис.1 .
Рисунок 1. Рабочее пространство R
Введите команду в строке приглашения, и R отреагирует соответствующим образом.
В реальной ситуации на этом этапе вы, вероятно, ввели бы данные в объект R из внешнего файла данных. R способен читать данные в различных форматах; однако в этом примере я использую набор данных michelson из пакета MASS. Этот пакет сопровождает этапную книгу Венаблса (Venables) и Рипли (Ripley) под названием Modern Applied Statistics with S-Plus (Современная прикладная статистика с использованием S-Plus) (см. раздел Ресурсы). Набор данных michelson содержит результаты известных экспериментов Майкельсона–Морли по измерению скорости света.
Команды, показанные в листинге 1, загружают пакет MASS, получают данные из michelson и позволяют рассмотреть их. На рис.2 показаны эти команды с соответствующими ответами от R. Каждая строка содержит R-функцию с ее аргументами в квадратных скобках ([]).
Листинг 1. Старт сеанса R
2+2 # R может работать как калькулятор. R дает ответ "4" (правильный). library("MASS") # Загружает в память функции и наборы данных из # пакета MASS, который сопровождает книгу Modern Applied Statistics in S data(michelson) # Копирует набор данных michelson в рабочее пространство. ls() # Перечисляет содержимое рабочего пространства. В нем присутствуют данные #из набора michelson head(michelson) # Выводит на экран несколько первых строк этого набора данных. # Столбец Speed (скорость) содержит полученные Майкельсоном и Морли оценки # скорости света (менее 299000 км/с). # Майкельсон и Морли выполнили пять экспериментов по 20 прогонов в каждом. # Набор данных содержит индикаторные переменные для эксперимента и для прогона. help(michelson) # Вызывает экран справки, который описывает этот набор данных.Рисунок 2. Старт сеанса и ответы R
Теперь посмотрим на данные (листинг 2). Результаты показаны на рис.3.
Листинг 2. Ящичная диаграмма (box plot) на языке R
# Базовая ящичная диаграмма (boxplot) with(michelson, boxplot(Speed ~ Expt)) # Я могу добавить цвет и метки. Я также могу сохранить результаты в виде объекта. michelson.bp = with(michelson, boxplot(Speed ~ Expt, xlab="Experiment", las=1, ylab="Speed of Light - 299,000 m/s", main="Michelson-Morley Experiments", col="slateblue1")) # Текущая оценка скорости света в этом масштабе составляет 734,5 # Добавление горизонтальной линии с целью выделения этого значения. abline(h=734.5, lwd=2,col="purple") #Добавление современного значения скорости светаСкладывается впечатление, что Майкельсон и Морли систематически завышали оценку скорости света. Кроме того, в результатах экспериментов наблюдается некоторая неоднородность.
Рисунок 3. Представление в виде ящичной диаграммы
Если меня удовлетворяют мои исследования, я могу сохранить все свои команды в виде одной функции языка R (листинг 3).
Листинг 3. Простая функция на языке R
MyExample = function(){ library(MASS) data(michelson) michelson.bw = with(michelson, boxplot(Speed ~ Expt, xlab="Experiment", las=1, ylab="Speed of Light - 299,000 m/s", main="Michelsen-Morley Experiments", col="slateblue1")) abline(h=734.5, lwd=2,col="purple") }Этот простой пример иллюстрирует несколько важных особенностей языка R.
Нуждается ли R в мощных аппаратных средствах?
Я выполняла этот пример на нетбуке Acer под управлением Crunchbang Linux. R не требует мощного компьютера для проведения анализа малого и среднего масштаба. На протяжении 20 лет про R говорили, что это медленный язык, поскольку он является интерпретируемым, и что объем данных, которые он способен проанализировать, ограничен памятью компьютера. Все это соответствует действительности, однако для современных компьютеров это, как правило, некритично, при условии, что приложение не является действительно огромным (т.е. не относится к категории Больших данных).
- Сохранение результатов— Функция boxplot() помимо диаграммы возвращает несколько полезных статистических данных; их можно сохранить в объекте языка R посредством оператора присваивания (например, michelson.bp = ... ), а затем извлечь в случае необходимости. Результат любого оператора присваивания доступен на протяжении всей сессии R и может стать предметом последующего анализа. Функция boxplot возвращает матрицу статистических данных, использованных для построения ящичной диаграммы (медианы, квантили и т.д.), число элементов в каждой коробке и значения выбросов (показаны на рис. 3 как незаштрихованные круги). См. рис. 4.
Рисунок 4. Статистические данные из функции boxplot
- Язык формул— R (и S) — это компактный язык для представления статистических моделей. Код Speed ~ Expt в аргументе дает функции указание строить ящичную диаграмму значений Speed (скорость) для каждого уровня Expt (номер эксперимента). Если бы я хотела провести дисперсионный анализ для выявления существенных изменений значения Speed от эксперимента к эксперименту, я использовала бы ту же самую формулу: lm(Speed ~ Expt). Язык формул позволяет выражать широкое разнообразие статистических моделей, включая перекрестные и вложенные эффекты, а также постоянные и случайные факторы.
- Определяемые пользователем функции R— Это язык программирования.
R остается актуальным и в 21 веке
Разведочный подход Дж. Тьюки к анализу данных стал нормой для учебного процесса. Он преподается в учебных заведениях и применяется специалистами по статистике. Язык R поддерживает этот подход, и это одно из объяснений того, почему он до сих пор сохраняет популярность. Объектная ориентация также помогает языку R оставаться актуальным, поскольку для анализа новых источников данных требуются новые структуры данных. В настоящее время платформа InfoSphere® Streams поддерживает анализ на языке R для данных, отличных от тех, на которые ориентировался Джон Чамберс.
Инструментарий R-project Toolkit на платформе InfoSphere Streams
InfoSphere Streams — это передовая вычислительная платформа, которая предоставляет возможность быстро принимать, анализировать и сопоставлять информацию в приложениях, разработанных пользователями, по мере поступления информации из тысяч источников в реальном времени. Это решение способно обрабатывать данные с очень высокой пропускной способностью: до нескольких миллионов событий или сообщений в секунду. В состав этой платформы входит инструментарий R-project Toolkit. Узнайте больше и загрузите ознакомительную версию.
Язык R и платформа InfoSphere Streams
InfoSphere Streams — это вычислительная платформа и интегрированная среда разработки для анализа данных, которые с высокой скоростью поступают из тысяч источников. Содержимое этих потоков данных обычно является неструктурированным или структурированным частично. Цель анализа состоит в выявлении изменяющихся закономерностей в данных и в принятии решений непосредственно на основе быстро меняющихся событий. Язык программирования для платформы InfoSphere Streams под названием SPL организует данные посредством парадигмы, которая отражает динамичную природу данных, а также необходимость быстрого анализа и реагирования.
Мы далеко ушли от электронных таблиц и обычных плоских файлов классического статистического анализа, однако язык R способен адаптироваться. В версии 3.1 приложения на SPL способны передавать данные в R и таким образом задействовать обширную библиотеку R-пакетов. InfoSphere Streams поддерживает аналитику на R посредством создания соответствующих R-объектов для получения информации, содержащейся в кортежах SPL (базовая структура данных в языке SPL). Это позволяет передавать данные InfoSphere Streams в среду R для последующего анализа, а полученные результаты возвращать обратно в SPL.
Для каких случаев R не годится
Справедливости ради следует отметить, что некоторые вещи R делает не очень хорошо или вообще не делает. Кроме того, R не в одинаковой степени подходит каждому пользователю.
- R не является хранилищем данных. Самый легкий способ ввода данные в R состоит в том, чтобы ввести нужные данные в каком-либо другом месте, а затем импортировать их в среду R. В свое время имели место попытки добавить к среде R интерфейсную часть в виде электронной таблицы, однако они не завоевали популярности. Отсутствие функциональности электронной таблицы не только затрудняет ввод данных, но и осложняет визуальное рассмотрение данных в R (в отличие от SPSS или Excel).
- R осложняет решение обычных задач. К примеру, при проведении медицинских исследований первый этап обработки данных состоит в вычислении сводной статистики по всем переменным и в составлении перечня отсутствующих ответов и пропущенных данных. В SPSS этот процесс реализуется буквально тремя щелчками мыши, однако R не имеет встроенной функции для вычисления этой вполне очевидной информации и ее последующего отображения в табличной форме. Нужный код достаточно легко написать самому, однако иногда хочется, чтобы такие вещи можно было делать щелчком мыши.
- Процесс обучения языку R является нетривиальным. Новичок может открыть управляемую с помощью меню статистическую платформу и получить результат за всего за несколько минут. Не каждый хочет становиться программистом для того, чтобы быть аналитиком, а, возможно, не каждому это и нужно.
- R имеет открытый исходный код. Сообщество R является многочисленным, зрелым и активным; вне всякого сомнения, R входит в число наиболее успешных проектов с открытым исходным кодом. Как я уже говорила, реализация языка R имеет возраст более 20 лет, а реализация языка S — еще больше. Это проверенная концепция и испытанный продукт. Однако, как и для любого другого продукта с открытым исходным кодом, надежность зависит от прозрачности. Мы верим в программный код, поскольку мы сами способны проверять его и поскольку другие люди способны проверять его и сообщать о выявляемых при этом ошибках. Иная ситуация имеет место в корпоративном проекте, который берет на себя обязанности по тестированию и валидации своего программного продукта. При этом в случае редко используемых R-пакетов у нас нет достаточных оснований предполагать, что эти пакеты действительно обеспечивают получение корректных результатов.
Заключение
Необходимо ли вам изучать язык R? Вполне возможно, что нет; необходимо— это слишком сильное утверждение. Но является ли R ценным инструментом для анализа данных? Несомненно. Этот язык специально разработан таким образом, чтобы отражать способы мышления и работы статистиков. R закрепляет хорошие привычки и улучшает анализ. По-моему, это хороший инструмент для такой работы.
Ресурсы для скачивания
Похожие темы
- Оригинал статьи: Do I need to learn R?.
- The New S Language: A Programming Environment for Data Analysis and Graphics (R.A. Becker, John M. Chambers, A.R. Wilks; издательство Chapman & Hall, 1988). Эта основополагающая работа известна в кругах R и S как The Blue Book ("Синяя книга"). Книга содержит полное описание языка S и перечень всех его встроенных функций.
- Graphical Methods for Data Analysis (John M. Chambers, William S. Cleveland, Beat Kleiner, Paul A. Tukey; издательство Duxbury Press, 1983).
- Exploratory Data Analysis, (John Tukey) Обратите внимание, что Джон Тьюки (John Tukey) и Пол Тьюки (Paul Tukey) — это разные люди. В этой книге изложена концепция, которая была реализована в языке S.
- Modern Applied Statistics with S-Plus, (W.N. Venables, B.D. Ripley; издательство Springer-Verlag, 1997). Классическое введение в объектную ориентированность языка S-Plus (и языка R). Наборы данных и многие функции, использованные в этой книге, включены в пакет MASS языка R.
- R for Dummies (Joris Meys, Andrie de Vries; 2012). Доступное описание языка R для начинающих.
- R in a Nutshell (Joseph Adler; издательство O'Reilly, 2009). Фундаментальное введение в R для специалистов, осуществляющих стандартный статистический анализ наборов данных умеренного объема. Не охватывает большие данные.
- В издательстве Springer публикуется серия книг с оранжевыми обложками и заголовками типа Time Series Analysis in R и An Introduction to Applied Multivariate Analysis with R. These are a good introduction for the R user with a particular application Каждая из этих книг представляет собой хорошее введение для пользователей R, интересующихся определенной прикладной областью. В отличие от введений общего характера, книги этой серии в большей степени ориентированы на соответствующие пакеты для определенных предметных областей и в меньшей степени на базовые аспекты R.
- Многие "книги" по R в действительности являются работами по прикладной статистике с использованием R. Вероятно, самый сложный момент в использовании R — понимание статистических методов, реализованных в этом языке. В этой категории одной из моих любимых является книга Data Analysis and Graphics Using R — An Example-Based Approach (John Maindonald, John Braun; издательство Cambridge UP, 2010). Она охватывает множество полезных статистических методов и показывает, как использовать эти методы в R. Кроме того, к книге прилагается вспомогательный R-пакет с данными и функциями.
- The Art of R Programming, (Norman Matloff; издательство O'Reilly, 2011). Это не книга по статистике, а скорее одно из немногих учебных пособий, рассматривающих R именно как язык программирования. Она жизненно необходима вам, если вы планируете писать на R значительное количество программного кода, а не просто запускать пакеты.
- Если вы может позволить себе покупку лишь одной книги по R, то книга Data Mining with R, (Luis Torgo) не годится на эту роль. Однако если вы планируете иметь более одной книги, то эта книга послужит вам хорошим пособием промежуточного уровня. В этой книге, состоящей из трех различных примеров из области углубленного анализа данных, последовательно излагаются все этапы исследования, включая очистку данных и учет отсутствующих значений.
- Введение в InfoSphere Streams Превосходная вводная статья по платформе Streams.
- Overview of the R-project toolkit (Обзор инструментария R-project Toolkit) Описание Streams-инструментария для интеграции кода на языке R в приложения на языке SPL.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere Streams — высокопроизводительной вычислительной платформой IBM.
- Перечень продуктов по платформе InfoSphere Platform для проектов с интенсивным использованием информации.
- Новейшие видеоролики по большим данным для новичков и специалистов.
- Опробуйте InfoSphere Streams: загрузите пробную версию со сроком действия 90 суток или попробуйте его в облаке.
- Многие продукты IBM SPSS можно опробовать бесплатно.
- IBM SPSS Decision Management— автоматизация и оптимизация принятия транзакционных решений перед развертыванием
- SPSS Modeler— инструмент для углубленного анализа данных, помогающий пользователю создавать прогнозирующие модели быстро и интуитивным образом, без программирования
- SPSS Text Analytics for Surveys— применение мощных технологий обработки естественных языков, специально спроектированных для исследования текста.
- SPSS Visualization Designer— простое создание и совместное использование впечатляющей визуализации для улучшения обмена аналитическими результатами
- Загрузите R и документацию на сайте CRAN.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere BigInsights — аналитической платформой, основанной на программном обеспечении с открытым кодом Hadoop и расширяющей его возможности благодаря таким функциям, как Big SQL, анализ текста и BigSheets.
- Загрузите продукт InfoSphere BigInsights Quick Start Edition, который доступен как нативный установочный пакет или как VMware-образ.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere Streams — высокопроизводительной вычислительной платформой, которая предоставляет возможность быстро принимать, анализировать и сопоставлять информацию в приложениях, разработанных пользователями, по мере поступления информации из тысяч источников в реальном времени.
- Загрузите продукт InfoSphere Streams, который доступен как нативный установочный пакет или как VMware-образ.
- Оцените продукт InfoSphere Streams на платформе IBM SmartCloud Enterprise.
Подпишите меня на уведомления к комментариям
www.ibm.com
Шпаргалка по языку R / Хабр
Многие слышали про R — язык программирования и систему статистических вычислений. Язык весьма популярен за рубежом, а вот в России, к сожалению, на нём пишут относительно мало. Да и ресурсы на русском языке можно по пальцам пересчитать. Я считаю, что ситуацию нужно как-то исправлять. На официальном сайте есть такая замечательная штука, как R reference card. В базовых пакетах R содержится множество очень полезных функций, которые делают программирование действительно быстрым и лаконичным. Но новички, как правило, большую часть самых прекрасных функций не знают. Да и не откуда узнать — мануалы очень большие, мало кто их полностью читает. А вот R reference card позволяет совершить быстрое путешествие по основной функциональности и вынести для себя много полезного. Я решил перевести этот замечательный документ на русский язык. Но не просто перевести, а сделать его немного получше. Я чуток поменял структуризацию, для каждой функции поставил ссылку на документацию, убрал избыточные описания. Предлагаю вам ознакомиться с результатом. Готов к любым замечаниям и предложениям, чтобы сделать этот список ещё лучше. Надеюсь, что данный обзор R окажется полезным для многих людей, которые решили начать писать на этом прекрасном языке. Ещё мне хотелось бы сказать пару слов про пакеты. Пакетов в R очень много. Только в стандартном репозитории их 4300+. К сожалению, многие полезные пакеты малоизвестны, т.к. про них никто ничего не пишет. Нет, ну конечно есть мануалы. Но мануалы пригождаются большей частью тогда, когда ты уже используешь пакет, а тебе, к примеру, нужно уточнить какие-то нюансы в использовании функции или вроде того. А вот обзорное впечатление о пакете по мануалу получить не так просто. Кроме того, меня часто печалит, что в мануалах нет картинок. Чтобы толком понять, что рисует та или иная функция — нужно ручками запускать каждый пример. Поэтому в обозримом будущем я планирую составить популярные описания (с картинками и примерами) некоторых полезных пакетов. Обзоры будут выставляться тут. Начну с тех пакетов, которыми пользуюсь сам, но если у вас есть заявки на какие-то пакеты, полюбившиеся вам — то прошу в комментарии.habr.com
Язык программирования R для биржевого спекулянта
Эта статья посвящена азам работы с R. Если Вы уже знакомы с R она вряд ли Вам будет интересна, если же Вы смутно себе представляете, что это такое и хотите узнать побольше welcome. Итак, R это де-факто стандарт в области статистической обработки данных. Это одновременно язык программирования и программная среда вычислений с расширенными графическими возможностями. Для многих задач, этот инструмент успешно заменит Excel и Mathcad. И самое важное, R распространяется свободно и бесплатно.Установка R.
Установить R легко, идем на сайт разработчика, и далее по ссылкам Download R, выбираем ближайшее зеркало, качаем инсталятор, запускаем, проходите по стандартным шагам. Ставим. Всё.
Если у Вас доступ в интернет через HTTP прокси, то потребуется небольшая настройка. Следует добавить в переменные окружения адрес прокси:http_proxy = http://proxy.host:portНа Windows это можно сделать через Пуск > Панель управления > Система > Дополнительно > Переменные среды.
Мы поставили интерпретатор R и программное окружение. В принципе, этого достаточно для начала. Но если все же хочется еще иметь красивую среду разработки, добро пожаловать на RStudio все как обычно, качаем, ставим.
Какие модули нужны биржевому спекулянту
R сам по себе хорош, но куда интересней его использовать в связке с дополнительными модулями. А модулей там, великое множество, одни позволяют рисовать графики, другие скачивать данные, третьи открывают дополнительные аналитические возможности, четвертые позволяют интегрироваться со сторонними приложениями и языками программирования. Всего около 2100 модулей только в общем репозитории. Из этого разнообразия нам понадобиться лишь часть:
1) quantmod - это самое главное и основное, этот плагин позволяет получать котировки с Yahoo.Finance, Goolge.Finance и данные федерального резерва США. К сожалению, не работает с российскими площадками, но это мы исправим чуть позже. Кроме того, в нем есть средства построения, анализа и тестирования торговых моделей. Короче, запускаем R и набираем в консоли:
install.packages("quantmod") 2) zoo, xts, TTR - будут установленные вместе с quantmod. В принципе, можно поставить отдельно аналогичными командами. Это тоже незаменимые модули. zoo и xts предоставляют расширенные возможности для работы с временными рядами. TTR содержит огромное количество технических индикаторов.3) e1071 - библиотека для машинного обучения, включает в себя такие алгоритмы как преобразование фурье, наивный байесовский классификатор, кластеризация, svm и другие. Может пригодиться если Вы собираетесь привлекать один из этих алгоритмов для работы.
4) nnet - библиотека для работы с нейронными сетями. Аналогично e1071.
5) tseries - еще одна библиотека для анализа временных рядов.
Примеры использования
Строим котировки IBM
library(quantmod) getSymbols("IBM", from="2010-01-01") chartSeries(IBM) Если все установлено верно, должно получиться что-то подобное: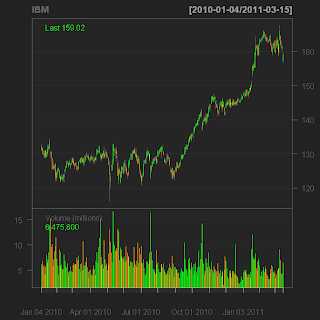 Добавить на графики MACD, RSI, EMA и другие технические индикаторы? Нет ничего проще:addMACD() addEMA(7) addRSI(n=14)
Добавить на графики MACD, RSI, EMA и другие технические индикаторы? Нет ничего проще:addMACD() addEMA(7) addRSI(n=14) 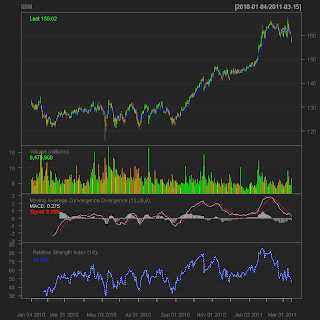 Полный список доступных индикаторов можно посмотреть тут.
Полный список доступных индикаторов можно посмотреть тут. Российский рынок, пишем велосипеды
Замечательно, что существует такой модуль quantmod, и все очень просто и красиво, но только на буржуйских рынках. К сожалению, в наших реалиях ему негде взять данные. Поэтому, мы напишем маленький велосипед, заодно разберемся с синтаксисом. Источником данных станет финам. На данном этапе мы напишем простой скрипт, позволяющий парсить файл вручную скачанный с финама. Он в любом случае нам пригодится, ведь не финамом единым жив человек. Итак, скрипт:
"parseQuotes" <- function(From) { require(xts) #загрузить модуль xts, он нам нужен fr <- read.csv(From, as.is = TRUE) #читаем данные из файла fr <- xts(as.matrix(fr[,(5:9)]), as.Date(strptime(fr[,3], "%Y%m%d"))) # функция strptime позволяет нам распарсить дату в заданном формате, в данном случае формат определяется выражением "%Y%m%d" # для интрадей данных последнюю строчку надо заменить на #fr<-xts(as.matrix(fr[,(4:9)]),as.POSIXct(strptime(paste(fr[,3],fr[,4]), "%Y%m%d %H%M%S"))) colnames(fr) <- c('Open','High','Low','Close','Volume') #присваивамем новые имена колонам для совместимости с xts return(fr) } Что здесь произошло? Мы создали функцию parseQuotes, которая берет в качестве параметров полный путь к файлу на диске, получает из него котировки и возвращает OHLC (Open-High-Low-Close) объект совместимый с quantmod.Важно! Формат записи в файл в финаме должен быть выбран такой: TICKER,PER,DATE,TIME,OPEN,HIGH,LOW,CLOSE,VOL. Все остальные значения по-умолчанию. Готово, теперь можно скачать, к примеру, данные по фьючерсу на индекс РТС и построить соответствующий график.
RTS <- parseQuotes("C:\\SPFB.RTS_070315_110315.txt") chartSeries(RTS)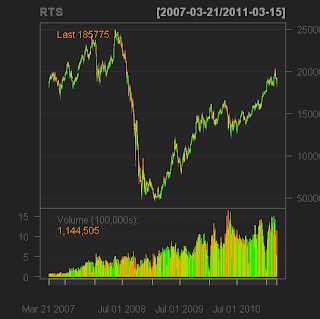 На этом, на сегодня всё. Продолжение следует...
На этом, на сегодня всё. Продолжение следует... www.algorithmist.ru
- Abbyy тест

- Windows 10 восстановление компьютера в исходное состояние
- Как открыть центр обновления windows 10
- Шпионаж компьютерный
- Дефрагментация диска на windows 7 что это такое

- Подключение компьютера через vga к телевизору

- Рабочий стол не отображается
- Автоматическое переключение языка на клавиатуре windows 7
- Как поставить на русский язык

- Mysql создание базы данных workbench
- Диск для записи