SQL: вложенный SELECT с несколькими значениями в одном поле. Select с select sql
sql - SQL: вложенный SELECT с несколькими значениями в одном поле
В моей базе данных SQL 2005 у меня есть таблица со значениями, хранящимися как идентификаторы с отношениями к другим таблицам. Поэтому в моей таблице MyDBO.warranty я сохраняю product_id вместо product_name, чтобы сэкономить место. Имя_продукта хранится в MyDBO.products.
Когда отдел маркетинга извлекает демографическую информацию, запрос выбирает соответствующее имя для каждого идентификатора из связанных таблиц (сокращено для краткости):
SELECT w1.warranty_id AS "No.", w1.created AS "Register Date" w1.full_name AS "Name", w1.purchase_date AS "Purchased", ( SELECT p1.product_name FROM WarrDBO.products p1 WITH(NOLOCK) WHERE p1.product_id = i1.product_id ) AS "Product Purchased", i1.accessories FROM WarrDBO.warranty w1 LEFT OUTER JOIN WarrDBO.warranty_info i1 ON i1.warranty_id = w1.warranty_id ORDER BY w1.warranty_id ASCТеперь моя проблема в том, что столбец "аксессуары" в таблице warranty_info хранит несколько значений:
Мне нужно сделать что-то подобное с "Аксессуары", которое я сделал с "Продуктом", и вытащить имя_адреса из таблицы MyDBO.accessories, используя аксессуар_имя strong > . Я не уверен, с чего начать, потому что сначала мне нужно будет извлечь идентификаторы, а затем каким-то образом объединить несколько значений в строку. Таким образом, каждая строка будет иметь "имя_приложения1, имя_приложения2, имя_компьютера3":
No. Register Date Name Purchased Accessories --------------------------------------------------------------------- 1500 1/1/2008 Smith, John Some Product Case,Bag,Padding 1501 1/1/2008 Hancock, John Another Wrap,Label 1502 1/1/2008 Brown, James And Another Wrap,PaddingКак это сделать?
ИЗМЕНИТЬ → Проводка моего последнего кода:
Я создал эту функцию:
CREATE FUNCTION SQL_GTOInc.Split ( @delimited varchar(50), @delimiter varchar(1) ) RETURNS @t TABLE ( -- Id column can be commented out, not required for sql splitting string id INT identity(1,1), -- I use this column for numbering splitted parts val INT ) AS BEGIN declare @xml xml set @xml = N'<root><r>' + replace(@delimited,@delimiter,'</r><r>') + '</r></root>' insert into @t(val) select r.value('.','varchar(5)') as item from @xml.nodes('//root/r') as records(r) RETURN ENDqaru.site
html - помощь с синтаксисом select sql
Здесь он приходит, чтобы запутать свой день! (теперь должен быть мой дескриптор)
Я запутался и очень потерял.
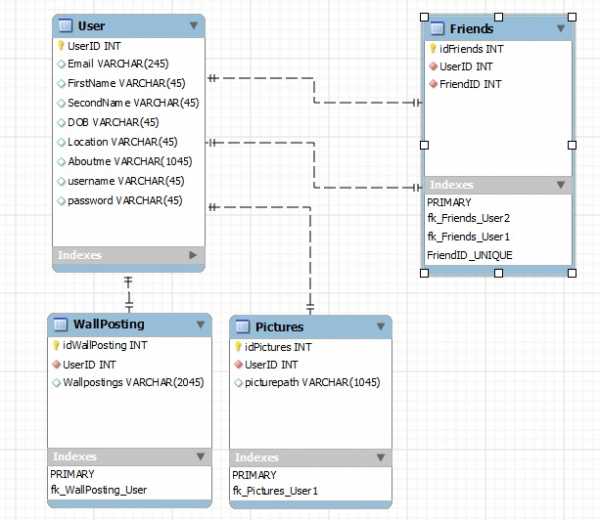
Мне нужно выяснить, как сделать оператор select для того, чтобы FriendID связывался с ним. UserID
Как вы можете видеть, FriendID относится к UserID моей таблицы User, поэтому, если FriendID = 2, то отобразите данные UserID 2.
Что я пытаюсь сделать, это если im UserID 1 Я хочу показать всех своих друзей, мой идентификатор пользователя задан сеансом,
Мне нужно выяснить, кто мои друзья. Выберите FriendID из freinds, где SessionID = UserID, а затем определите, кем является friendID, в таблице User и отобразите его имя, второе имя и его путь к картинке.
Очень запутанно...
Моя структура таблицы выглядит следующим образом:
Итак, чтобы подвести итог тому, что мне нужно в моей команде select:
Чтобы узнать, с кем я подружился (у текущей учетной записи UserID есть FriendID) Отобразить FirstName, SecondName, путь изображения другаID, связанный с его собственным UserID
Пример:
I (userID = 1) имеет FriendID 2 = UserID 2, поэтому выберите firstname, второе имя от пользователя, где UserID = 2
У меня могли бы быть проблемы с реляционной связью с моей структурой таблицы.
Я надеюсь, что вы поймете мое замешательство:
EDIT для тех, кто не видит изображения моего db
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL'; CREATE SCHEMA IF NOT EXISTS `gymwebsite2` DEFAULT CHARACTER SET latin1 COLLATE latin1_swedish_ci ; USE `gymwebsite2` ; -- ----------------------------------------------------- -- Table `gymwebsite2`.`User` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `gymwebsite2`.`User` ( `UserID` INT NOT NULL AUTO_INCREMENT , `Email` VARCHAR(245) NULL , `FirstName` VARCHAR(45) NULL , `SecondName` VARCHAR(45) NULL , `DOB` VARCHAR(45) NULL , `Location` VARCHAR(45) NULL , `Aboutme` VARCHAR(1045) NULL , `username` VARCHAR(45) NULL , `password` VARCHAR(45) NULL , PRIMARY KEY (`UserID`) ) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `gymwebsite2`.`WallPosting` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `gymwebsite2`.`WallPosting` ( `idWallPosting` INT NOT NULL AUTO_INCREMENT , `UserID` INT NOT NULL , `Wallpostings` VARCHAR(2045) NULL , PRIMARY KEY (`idWallPosting`) , INDEX `fk_WallPosting_User` (`UserID` ASC) , CONSTRAINT `fk_WallPosting_User` FOREIGN KEY (`UserID` ) REFERENCES `gymwebsite2`.`User` (`UserID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `gymwebsite2`.`Pictures` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `gymwebsite2`.`Pictures` ( `idPictures` INT NOT NULL AUTO_INCREMENT , `UserID` INT NOT NULL , `picturepath` VARCHAR(1045) NULL , PRIMARY KEY (`idPictures`) , INDEX `fk_Pictures_User1` (`UserID` ASC) , CONSTRAINT `fk_Pictures_User1` FOREIGN KEY (`UserID` ) REFERENCES `gymwebsite2`.`User` (`UserID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `gymwebsite2`.`Friends` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `gymwebsite2`.`Friends` ( `idFriends` INT NOT NULL AUTO_INCREMENT , `UserID` INT NOT NULL , `FriendID` INT NOT NULL , PRIMARY KEY (`idFriends`) , INDEX `fk_Friends_User2` (`FriendID` ASC) , INDEX `fk_Friends_User1` (`UserID` ASC) , UNIQUE INDEX `FriendID_UNIQUE` (`FriendID` ASC) , CONSTRAINT `fk_Friends_User2` FOREIGN KEY (`FriendID` ) REFERENCES `gymwebsite2`.`User` (`UserID` ) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_Friends_User1` FOREIGN KEY (`UserID` ) REFERENCES `gymwebsite2`.`User` (`UserID` ) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;sql - Система я SQL с SELECT DISTINCT
У меня есть SQL ниже, и он имеет неприемлемое время отклика.
Это используется с DECLARE, PREPARE, OPEN и FETCH в RPG-программе, где выбранные поля помещаются в переменные хоста, заполняются в массиве, а затем сортируются [по убыванию] для отображения подфайла.
2 используемые таблицы не имеют ключа (PF), и они соединены ниже, как показано в предложении WHERE.
Select DISTINCT B.Fld1, B.Fld2, B.Fld3, B.Fld4, A.Fld1, A.Fld2, A.Fld3, A.Fld4, A.Fld5, A.Fld6, A.Fld7, A.Fld8, A.Fld9 From TableA A, TableB B Where A.Fld2 = B.Fld5 And A.Fld1 = B.Fld6 || B.Fld7 And ((A.Fld7 BETWEEN <from-date> and <to-date>) Or (A.Fld5 BETWEEN <from-date> and <to-date>))Я также использовал 2 доступных LF с A.Fld2 и A.Fld1 в качестве ключей с небольшим улучшением.
Я чувствую, что рекурсивный SQL может сделать трюк, но мне не хватает опыта, чтобы выгнать его. У меня есть выборки из каждой таблицы, созданные и функционирующие по своему усмотрению. Я просто не знаю, как собрать их вместе в одного прекрасного зверя, чтобы получить желаемый результат.
Этот результат составляет примерно 10 000 строк за недельный период, и мне нужно увидеть 2 недели.
В TableA почти 6 000 000 записей и около 160 000 в TableB.
Сейчас логика
- Запустите простой SQL до того, как он выше.
- Курсор по записям и заполнение массива
- Запустите SQL выше.
- Курсор через записи и добавление к одному и тому же массиву
- Сортируйте массив и используйте его для заполнения подфайла.
В отладке я проверил, что SQL выше - это проблема.
По правде говоря, у меня есть 3 файла, которые, я считаю, могут быть объединены в 1 таблицу результатов для создания подфайла. Если я могу пройти мимо вышеприведенного запроса, то "я думаю, что могу обработать присоединение к другому файлу.
Я предполагаю, что есть кто-то, кто может "взломать это"! Я когда-то работал с ним!
Это не вопрос РПГ, вопрос о системе. Раньше я заложил некоторый SQL, как это в RPG. Проблема заключалась в том, что кто-то другой написал SQL. : (
qaru.site
sql - SQL-запрос с несколькими SELECT
У меня есть таблица для представления в моем приложении, и я хочу представить таблицу, в которой одна строка имеет значения, которые вычисляются следующим образом:
SELECT SUM (val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = ? AND rov.orbiting_group_indice_id = ?Для первой строки я хочу представить 4 значения, каждая из них будет выглядеть так:
SELECT SUM (val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = (1,2,3,4) AND rov.orbiting_group_indice_id = 1Где (1,2,3,4) - 4 разных оператора SELECT с (1,2,3,4) значениями соответственно. В следующей строке я изменю rov.orbiting_group_indice_id= 2 и захочу использовать те же значения rov.orbiting_group_type_id (1,2,3,4).
Я новичок в SQL, и я хочу спросить, как представить таблицу с этим valeus? Таким образом, это должно быть что-то вроде значения столбца1, значения столбца2, значения столбца3, значения столбца4.
Благодарю!
Обновлено: я хочу что-то вроде следующего:
SELECT (SELECT SUM(val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = 1 AND rov.orbiting_group_indice_id = 1) as colOne, (SELECT SUM(val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = 1 AND rov.orbiting_group_indice_id = 2) as colTwo, (SELECT SUM(val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = 1 AND rov.orbiting_group_indice_id = 3) as colThree, (SELECT SUM(val) FROM report_orbiting_vals rov WHERE rov.orbiting_group_type_id = 1 AND rov.orbiting_group_indice_id = 4) as colFourthК сожалению, выше код не работает, он вызывает ошибку, но я надеюсь, вы понимаете, что я хочу сейчас.
Обновлено (2):
Я попробовал 2 решения, приведенные ниже, первый:
Вывод:
Второе:
SELECT SUM(CASE WHEN rov.orbiting_group_type_id = 1 THEN val ELSE 0 END) as type1_sum, SUM(CASE WHEN rov.orbiting_group_type_id = 2 THEN val ELSE 0 END) as type2_sum, SUM(CASE WHEN rov.orbiting_group_type_id = 3 THEN val ELSE 0 END) as type3_sum, SUM(CASE WHEN rov.orbiting_group_type_id = 4 THEN val ELSE 0 END) as type4_sum FROM report_orbitings rov WHERE rov.orbiting_group_type_id in (1,2,3,4) AND rov.orbiting_group_indice_id = 1Вывод:
Чтобы быть ясным, я хочу признать, что у моей базы данных пока нет данных, просто структура. Тем не менее, я полагаю, что второй код работает, а первый нет, потому что он выводит [Null] вместо ничего. Почему в этих двух примерах есть разница? Он должен производить идентичный вывод.
qaru.site
sql - Переупорядочение строкового значения с помощью разделителей в запросе select sql
Проблема, которую вы представили, нелегко решить, ограничивая себя внутри оператора select. Хотя вы сказали, что этого не сделали, если бы вы знали, сколько "голов" будет в каждой строке, вы можете настроить один, сложный и очень длинный оператор select (с вашим "строковым значением с разделителями" Foobar):
SELECT x,y,z, SUBSTR(foobar, 1, INSTR(foobar, '~') - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^') + 1, INSTR(foobar, '~', INSTR(foobar, '^')) - INSTR(foobar, '^') - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 2) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) - INSTR(foobar, '^', 1, 2) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 3) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) - INSTR(foobar, '^', 1, 3) - 1) || ',' || SUBSTR(foobar, INSTR(foobar, '~') + 1, INSTR(foobar, '~', 1, 2) - INSTR(foobar, '~', 1, 1) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 1)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 1)) - INSTR(foobar, '^', 1, 1) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) - INSTR(foobar, '^', 1, 2) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) - INSTR(foobar, '^', 1, 3) - 1) FROM abcИ это получает только первые две "записи", однако он будет получать каждую "голову" независимо от длины, и ее можно расширить, чтобы включить больше записей, но это не сработало бы, если бы было только две записи, а оператор select был расширен для пяти записей, что нецелесообразно, поскольку вы сказали, что строка может иметь любое количество записей. Существует способ сделать это с помощью оператора CASE, но он очень длинный и очень сложный. Вот пример запроса, который может быть тем, что вы ищете:
SELECT x, y, z, CASE (LENGTH(SUBSTR(foobar, 1, INSTR(foobar, '^')))-LENGTH(REPLACE(SUBSTR(foobar, 1, INSTR(foobar, '^')), '~', '')) + 1) WHEN 1 THEN SUBSTR(foobar, 1, INSTR(foobar, '^') - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 1) + 1, INSTR(foobar, '^', 1, 2) - INSTR(foobar, '^', 1, 1) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 2) + 1, INSTR(foobar, '^', 1, 3) - INSTR(foobar, '^', 1, 2) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 3) + 1, LENGTH(foobar) - INSTR(foobar, '^', 1, 3)) WHEN 2 THEN SUBSTR(foobar, 1, INSTR(foobar, '~') - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^') + 1, INSTR(foobar, '~', INSTR(foobar, '^')) - INSTR(foobar, '^') - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 2) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) - INSTR(foobar, '^', 1, 2) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '^', 1, 3) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) - INSTR(foobar, '^', 1, 3) - 1) || ',' || SUBSTR(foobar, INSTR(foobar, '~') + 1, INSTR(foobar, '^', 1, 1) - INSTR(foobar, '~', 1, 1) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 1)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 1), 1) - INSTR(foobar, '^', 1, 1) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 2)) - INSTR(foobar, '^', 1, 2) - 1) || '-' || SUBSTR(foobar, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) + 1, INSTR(foobar, '~', INSTR(foobar, '^', 1, 3)) - INSTR(foobar, '^', 1, 3) - 1) ELSE 'Too many entries: ' || (LENGTH(SUBSTR(foobar, 1, INSTR(foobar, '^')))-LENGTH(REPLACE(SUBSTR(foobar, 1, INSTR(foobar, '^')), '~', '')) + 1) || ' entries given of 2 maximum' END AS SAMPLE_OUTPUT FROM abc;Вышеуказанный запрос (если он превышает его текущую емкость в две записи) организует ваши "голова". Он очень длинный и сложный, но если вы знаете, что длина каждой головки будет постоянной (например, всегда она имеет длину 4 на запись в "Head1"), тогда код может быть сокращен, с дополнительным преимуществом более быстрого выполнения, если значения жестко закодированы без INSTR. В приведенном ниже примере предполагается, что длина головы равна 4, 2, 3 и 2, как в ваших данных образца:
SELECT x, y, z, CASE (LENGTH(SUBSTR(foobar, 1, INSTR(foobar, '^')))-LENGTH(REPLACE(SUBSTR(foobar, 1, INSTR(foobar, '^')), '~', '')) + 1) WHEN 1 THEN REPLACE(foobar, '^', '-') WHEN 2 THEN SUBSTR(foobar, 1, 4) || '-' || SUBSTR(foobar, 11, 2) || '-' || SUBSTR(foobar, 17, 3) || '-' || SUBSTR(foobar, 25, 2) || ',' || SUBSTR(foobar, 6, 4) || '-' || SUBSTR(foobar, 14, 2) || '-' || SUBSTR(foobar, 21, 3) || '-' || SUBSTR(foobar, 28, 2) WHEN 3 THEN SUBSTR(foobar, 1, 4) || '-' || SUBSTR(foobar, 16, 2) || '-' || SUBSTR(foobar, 25, 3) || '-' || SUBSTR(foobar, 37, 2) || ',' || SUBSTR(foobar, 6, 4) || '-' || SUBSTR(foobar, 19, 2) || '-' || SUBSTR(foobar, 29, 3) || '-' || SUBSTR(foobar, 40, 2) || ',' || SUBSTR(foobar, 11, 4) || '-' || SUBSTR(foobar, 22, 2) || '-' || SUBSTR(foobar, 33, 3) || '-' || SUBSTR(foobar, 43, 2) ELSE 'Too many entries: ' || (LENGTH(SUBSTR(foobar, 1, INSTR(foobar, '^')))-LENGTH(REPLACE(SUBSTR(foobar, 1, INSTR(foobar, '^')), '~', '')) + 1) || ' entries given of 3 maximum' END AS SAMPLE_OUTPUT FROM abc;Последнее примечание: я рекомендую использовать псевдоним столбца для оператора case по причинам, которые становятся очень очевидными, если вы попытаетесь протестировать код без него.
qaru.site
SQL SELECT с несколькими таблицами и SUM Безопасный SQL
без большого количества деталей вы можете сделать что-то вроде этого:
SELECT s.source_id , s.location , s.source_name , s.source_description , s.source_date , s.price , sum(p.price) as SumProductPrice , sum(p.location) as SumProductLocation FROM source S JOIN product p on S.location = p.location WHERE p.quantity < 1 GROUP BY s.source_id, s.location, s.source_name , s.source_description, s.source_date, s.priceесли вы разместите более подробную информацию, тогда запрос можно будет точно настроить.
РЕДАКТИРОВАТЬ:
вы можете присоединиться к таблице продуктов во второй раз, чтобы получить общее количество для местоположения:
SELECT s.source_id , s.location , s.source_name , s.source_description , s.source_date , s.price , sum(p1.price) as SumProductPrice , p2.Total FROM source S JOIN product p1 on S.location = p1.location JOIN ( SELECT location, sum(price) as Total FROM product WHERE quantity < 1 GROUP BY location ) p2 on S.location = p2.location WHERE p1.quantity < 1 GROUP BY s.source_id, s.location, s.source_name , s.source_description, s.source_date, s.price, p2.TotalЯ не уверен, что полностью понимаю вашу структуру таблицы, но что-то вроде этого должно работать:
Select source.source_id, source.location, source.source_name, source.source_description, source.source_date, source.price, sum(production.location) from source, product where source.location = production.location and location < 0 group by source.source_id, source.location, source.source_name, source.source_description, source.source_date, source.priceИз того, что я собираю, вы хотите что-то вроде этого:
SELECT source.source_id, source.location, source.source_name, source.source_description, source.source_date, source.price, SUM(product.price) AS Price1, SUM(CASE WHEN product.quantity < 1 THEN product.price ELSE 0 END) AS Price2 FROM Source INNER JOIN Product ON Product.Location = Source.Location GROUP BY source.source_id, source.location, source.source_name, source.source_description, source.source_date, source.pricesql.fliplinux.com
SELECT COUNT с несколькими таблицами Безопасный SQL
У меня есть небольшая база данных MS Access, содержащая четыре таблицы и пытающаяся выполнить запрос SELECT COUNT, который включает в себя все таблицы. Любая помощь будет оценена.
Обзор базы данных:
TABLE COLUMNS Person Person_ID |.... Games Game_ID | Name |.... Played_Games Played_Games_ID | Game_ID |.... Participation Played_Games_ID | Person_ID |...Чтобы перечислить все игры и сколько раз каждую игру играют в общей сложности, я использую:
SELECT DISTINCT Games.Name, (SELECT COUNT(*) FROM Played_Games WHERE Played_Games.Game_ID = Games.Game_ID) AS TimesPlayed FROM Games ORDER BY Games.NameЭто отлично работает, но я также хотел бы перечислить, сколько раз каждую игру играют члены определенной группы лиц
Я сделал некоторый прогресс с кодом ниже (строка 4), но я все еще придерживаюсь одной небольшой проблемы:
Ссылка на Games.Game_ID в конце самых внутренних скобок больше не связана с текущим Game_ID, как в приведенном выше коде. Теперь это кажется неопределенным. Когда я запускаю это в MS Access Query Designer для тестирования, он запрашивает у меня значение для Games.Game_ID. Если я тогда наберу какой-то случайный Game_ID, код будет работать «отлично», но, как вы, вероятно, уже выяснили, значение TimesPlayedByGroupMembers будет таким же для каждой строки в наборе записей и будет истинно только для одного конкретного Game_ID, который я набрал
SELECT DISTINCT Games.Name, (SELECT COUNT(*) FROM Played_Games WHERE Played_Games.Game_ID = Games.Game_ID) AS TimesPlayed, (SELECT COUNT(*) FROM (SELECT DISTINCT Played_Games_ID FROM Participation WHERE Played_Games_ID IN (SELECT Played_Games_ID FROM Played_Games WHERE Game_ID = Games.Game_ID) AND Person_ID IN (26, 27, 28))) AS TimesPlayedByGroupMembers FROM Games ORDER BY Games.NameЯ попытаюсь объяснить, что мой код делает и / или должен делать изнутри
В самых внутренних скобках перечислены Played_Games_ID, которые связаны с текущей игрой, но это не работает, потому что Games.Game_ID не связан с текущим Game_ID
В средних скобках (в том числе выше) перечислены Played_Games_ID, которые включают текущую игру и одного или нескольких выбранных лиц. Приведенные здесь Person_ID являются всего лишь примером, и эта часть кода работает
Самые внешние скобки (включая все выше) подсчитывают, сколько раз каждую игру играет один или несколько выбранных лиц
Я действительно застрял в этом, поэтому любая помощь будет очень признательна
Спасибо за ваше время
Solutions Collecting From Web of "SQL: SELECT COUNT с несколькими таблицами"
Синтаксис моего доступа несколько ржавый, и я не уверен на 100% вашей структуры таблицы, но я думаю, что ниже будет работать.
SELECT Games.Name, TimesPlayed, TimesPlayedByGroupMembers FROM Games INNER JOIN ( SELECT Game_ID, COUNT(*) AS TimesPlayed, SUM(IIF(ISNULL(Participation.Played_Games_ID),0,1)) AS TimesPlayedByGroupMembers FROM Played_Games LEFT JOIN ( SELECT Played_games_ID FROM Participation WHERE Person_ID IN (1, 2) GROUP BY Played_games_ID ) AS Participation ON Participation.Played_Games_ID = Played_Games.Played_Games_ID GROUP BY Game_ID ) AS Played_Games ON Played_Games.Game_ID = Games.Game_ID ORDER BY Games.NameДОПОЛНЕНИЕ:
Чтобы получить игры, которые не были воспроизведены, чтобы показать как 0, используйте следующее:
SELECT Games.Name, IIF(ISNULL(TimesPlayed),0,TimesPlayed) AS TimesPlayed, IIF(ISNULL(TimesPlayedByGroupMembers),0,TimesPlayedByGroupMembers) AS TimesPlayedByGroupMembers FROM Games LEFT JOIN ( SELECT Game_ID, COUNT(*) AS TimesPlayed, SUM(IIF(ISNULL(Participation.Played_Games_ID),0,1)) AS TimesPlayedByGroupMembers FROM Played_Games LEFT JOIN ( SELECT Played_games_ID FROM Participation WHERE Person_ID IN (1, 2) GROUP BY Played_games_ID ) AS Participation ON Participation.Played_Games_ID = Played_Games.Played_Games_ID GROUP BY Game_ID ) AS Played_Games ON Played_Games.Game_ID = Games.Game_ID ORDER BY Games.NameВаш первый запрос обычно выполняется следующим образом:
SELECT Games.Name, COUNT(Played_Games.Game_ID) AS TimesPlayed FROM Games INNER JOIN Played_Games ON Played_Games.Game_ID = Games.Game_ID GROUP BY Games.Name ORDER BY Games.NameЭто может быть близко к тому, что вы делаете со своим вторым запросом:
SELECT Games.Name, COUNT(Participation.Played_Games_ID) AS TimesPlayedByGroupMembers FROM Games INNER JOIN Played_Games ON Played_Games.Game_ID = Games.Game_ID INNER JOIN Participation ON Participation.Played_Games_ID = Played_Games.Played_Games_ID WHERE Participation.Person_ID IN (26, 27, 28) GROUP BY Games.Name ORDER BY Games.Namesql.fliplinux.com