Интернет, компьютеры, софт и прочий Hi-Tech. Xml разметка
Языки разметки. XML и альтернативные форматы
XML – одна из самых широко используемых в современном интернете технологий работы с данными. Однако в чём именно она заключается, в состоянии сказать лишь немногие пользователи Глобальной сети. Давайте попробуем вместе разобраться в XML и альтернативных ему форматах.

Что такое XML?
XML – это eXtensible Markup Language, что в переводе значит «расширенный язык разметки». Фактически, это способ записи данных в структурированном виде, который будет читаем для пользователя, но при этом удобен для обработки программному обеспечению. Вот пример данных в виде XML:
<?xml version="1.0" encoding="UTF-8"?> <Recipe name="хлеб" prep_time="5 мин" cook_time="3 час"> <title>Хлеб</title> <ingredient amount="3" unit="стакан">Мука</ingredient> <ingredient amount="0.25" unit="грамм">Дрожжи</ingredient> <ingredient amount="1.5" unit="стакан">Тёплая вода</ingredient> <ingredient amount="1" unit="чайная ложка">Соль</ingredient> <Instructions> <step>Смешать все ингредиенты и тщательно замесить.</step> <step>Закрыть тканью и оставить на один час в тёплом помещении.</step> <step>Замесить ещё раз, положить на противень и поставить в духовку.</step> </Instructions> </Recipe>Содержимое XML-документа можно представить в виде древовидной структуры данных. При этом стандарт XML требует, чтобы у этого дерева был «ствол» ‑ корневой элемент, который будет содержать внутри себя все остальные, и такой корневой элемент должен быть единственным. Как и в HTML-разметке, специальные символы (амперсанд «&», знаки неравенства, кавычки и апостроф) должны быть записаны в виде специальных символьных комбинаций, которые называются предопределёнными сущностями. Аналогично можно вставлять ссылки на сущности – это символическая замена какой-либо сущности (то есть комбинации символов) выражением вида «&имя_сущности;» (без кавычек в документе). При этом ссылка может быть на предопределённую сущность или на какую-то сущность, хранящуюся в DTD-документе.
Что такое DTD?
Здесь мы видим следующую картину: корневой элемент – это list, а элементы, содержащиеся внутри него – это item. Значок «*» означает, что этих элементов может быть любое число, от 0 до практически бесконечности. Каждый элемент item содержит в себе элементы par1 и par2, причём значок вопроса означает, что присутствие par2 не является обязательным.
В последнее время формат описания структуры DTD всё больше меняется на XML Schema. Оба эти формата описывают, какие элементы должен содержать в себе XML-документ, какими атрибутами могут обладать эти самые элементы и какого типа должны быть значения атрибутов и элементов. Синтаксисы DTD и Schema существенно отличаются. С помощью Schema то же самое можно записать следующим образом:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="list" type="List"/> <xs:complexType name="List"> <xs:sequence> <xs:element name="par1" type="xs:string"/> <xs:element name="par2" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:schema>
JSON – первая альтернатива XML
Несмотря на то, что XML – очень распространённый способ записи данных, он не является единственным и неповторимым в своём роде. Одна из альтернативных текстовых форм записи данных называется JSON. Расшифровывается эта аббревиатура как JavaScript Object Notation – что-то вроде «запись объектов с помощью JavaScript». Стоит отметить, что для пользователя этот формат, на мой взгляд, удобнее, чем XML. Для того, чтобы это утверждение не выглядело голословным, приведу пример данных в JSON-представлении:
var earth = { "planet" : { "name" : "earth", "type" : "small", "info": [ "Earth is a small planet, third from the sun", "Surface coverage of water is roughly two-thirds", "Exhibits a remarkable diversity of climates and landscapes" ] } };Пользователю гораздо проще, как говорится, отделить зёрна от плевел, чем в случае с XML, поскольку нет открывающих и закрывающих тегов. Это, кстати, приводит и к тому, что на больших объёмах данных экономится память, которую эти теги занимают. Программистам будет приятно узнать, что JSON лучше, чем XML, подходит и для использования в AJAX. Основное его преимущество – в простоте обработки JSON-данных на стороне клиента.
Вторая альтернатива: YAML
YAML – это рекурсивная аббревиатура, которая расшифровывается как «YAML Ain't Markup Language» (по-русски это будет звучать как «YAML не является языком разметки»). Чем он при этом является, правда, его создатели уточнять не берутся, но, пожалуй, определение «язык разметки» будет всё-таки довольно подходящим. Чем YAML отличается от XML? Компактностью представления данных и удобством их редактирования для человека. Вот как выглядят данные, записанные с помощью YAML:
--- - - PRIVMSG - newUri - '^http://.*' - - PRIVMSG - deleteUri - ^delete.* - - PRIVMSG - randomUri - ^random.*YAML-разметка в больших документах больше подходит для их ручного редактирования, поскольку здесь теги не загромождают смысловую часть документа. Сейчас YAML применяется активно в некоторых инструментах программирования, но в целом эта технология ещё довольно молода, а потому не слишком распространена.

Зачем нужны XML, JSON, YAML?
XML и альтернативные форматы в последнее время начинают использоваться всё более активно по всему миру. И на то есть множество объективных причин. Одной из главных специалисты обычно называют доступность этих форматов для чтения как человеком, так и компьютером. Сейчас в мире существует великое множество инструментов для работы с XML, которые могут применять как программисты, так и конечные пользователи программного обеспечения.
Также большим плюсом XML и прочих подобных форматов является то, что они позволяют описывать данные практически любой структуры и сложности, поскольку данные представляются в древовидной форме. К тому же, поскольку любые данные в них – это просто текст, то и работать с ними можно как с текстом: кодировать, набирать XML-документы в блокноте, а в случае потери части данных остальные будут по-прежнему читабельны. Кроме того, текст можно использовать на любой платформе.
Что касается XML, то очень широкое применение этот стандарт нашёл во Всемирной паутине. На базе XML разработана технология XSL, с помощью которой XML-документы преобразуются специальным образом, в соответствии со стандартами и правилами, в HTML-документы, которые уже можно отображать в браузере. Хотя на самом деле суть технологии XSL значительно шире, и её можно применять для преобразования XML-документа в практически любой формат. JSON и YAML используются пока что реже, но у этих технологий большой потенциал, связанный с развитием Web 2.0, и в интернете можно найти всё больше мест, где они также применяются.
www.kv.by
IT Notes: Структура XML-документа
XML-документ состоит из деклараций, элементов, комментариев, специальных символов и директив.
1. Элементы и атрибуты
XML — это теговый язык разметки документов. Иными словами, любой документ на языке XML представляет собой набор элементов, причем начало и конец каждого элемента обозначается специальными пометками, называемыми тегами. То есть, как и HTML, язык XML для описания данных использует тэги. Но, в отличие от HTML, XML позволяет использовать неограниченный набор пар тэгов, каждая из которых представляет не то, как заключенные в нее данные должны выглядеть, а то, что они означают.
Элемент состоит из трех частей: начального тега, содержимого и конечного тега. Тег — это текст, заключенный в угловые скобки "<" и ">". Конечный тег имеет то же имя, что начальный тег, но начинается с косой черты "/". Пример XML-элемента:
<author>Сергей Довлатов</author>Имена элементов зависят от регистра, т. е. <author>, <Author> и <AUTHOR> — это имена различных элементов. Наличие закрывающего тега всегда обязательно. Если тег является пустым, т. е. не имеет содержимого и закрывающего тега, то он имеет специальную форму:
<элемент/>Любой элемент может иметь атрибуты, содержащие дополнительную информацию об элементе. Атрибуты всегда включаются в начальный тег элемента и имеют вид:
имя_атрибута="значение_атрибута"Аттрибут обязан иметь значение, которое всегда должно быть заключено в одинарные или двойные кавычки. Имена атрибутов также зависят от регистра. Пример элемента, имеющего атрибут:
<author country="USA">Сергей Довлатов</author>Элементы должны либо следовать друг за другом, либо быть вложены один в другой:
<books> <book isbn="5887821192"> <title>Часть речи</title> <author>Бродский, Иосиф</author> <present/> </book> <book isbn="0345374827"> <title>Марш одиноких</title> <author>Довлатов, Сергей</author> <present/> </book></books>Здесь элемент books (книги) содержит два вложенных элемента book (книга), которые, в свою очередь, имеют атрибут isbn и содержат три последовательных элемента: title (название), author (автор) и present (есть в наличии), причем последний пуст, т. к. в данном случае соответствует логическому флажку.
Из приведенного описания видно, что синтаксис XML напоминает синтаксис HTML (что естественно, т. к. оба они являются диалектами одного языка SGML), но требования к оформлению правильных XML-документов выше. Еще одним очень важным отличием XML от HTML является то, что содержимое элементов, т. е. все, что содержится между начальным и конечным тегами, считается данными. Это означает, что XML не игнорирует символы пробела и разрыва строк, как это делает HTML.
2. Пролог и директивы
Любой XML-документ состоит из пролога и корневого элемента, например:
<?xml version="1.0"?><books> <book isbn="0345374827"> <title>Марш одиноких</title> <author>Довлатов, Сергей</author> <present/> </book></books>В этом примере пролог сводится к единственной директиве (первая строка документа), указывающей версию XML. За ней следует XML-элемент с уникальным именем, который содержит в себе все остальные элементы и называется корневым. Директива (processing instruction) — это выражение, заключенное в специальные теги "<?" и "?>", которое содержит указания программе, обрабатывающей XML-документ.
Стандарт XML резервирует только одну директиву <?xml version="1.0"?>, указывающую на версию языка XML, которой соответствует данный документ (второй версии XML пока нет). В действительности, эта директива несколько богаче и в самом общем виде выглядит так:
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>Здесь атрибут encoding задает кодировку символов документа. По умолчанию считается, что XML-документы должны создаваться в формате UTF-8 или UTF-16. Если же используется какая-либо другая кодировка символов, то ее название должно быть указано в данном атрибуте, как показано в примере. Атрибут standalone говорит о том, содержит ли данный документ внешние разделы. Значение yes означает, что таких разделов нет, значение no — что они есть.
В общем случае, пролог может содержать также декларации типа документа.
3. Комментарии
XML-документы могут содержать комментарии, которые игнорируются приложением, обрабатывающим документ. Комментарии строятся по тем же правилам, что и в HTML:
- начинайте комментарий с символов "<!--",
- завершайте комментарий символами "-->",
- не используйте внутри комментария символов "--".
Пример комментариев:
<!-- это комментарий --><!-- а вот еще комментарий, занимающий более одной строки -->4. Имена и данные
Все имена элементов, атрибутов и разделов должны начинаться с буквы Unicode и состоять из букв, цифр, символов точки (.), подчеркивания (_) и дефиса (-). Единственное ограничение состоит в том, что они не должны начинаться с комбинации букв xml в любом регистре; подобные имена зарезервированы для будущих расширений языка. Существенно, что стандарт допускает использование в именах не только английских букв, но и любых других, хотя существующие XML-процессоры часто ограничены теми системами кодировок, которые в них заложены создателями. Поэтому мы в своих примерах пишем имена по-английски.
Данные, т. е. содержимое элементов и значения атрибутов, могут состоять из любых символов, кроме перечисленных в следующем разделе.
5. Специальные символы
Ряд символов в языке XML зарезервирован и должен представляться специальным образом:
левая угловая скобка ("<") | < |
правая угловая скобка (">") | > |
амперсант ("&") | & |
двойная кавычка (") в значениях атрибутов | " |
одинарная кавычка (') в значениях атрибутов | ' |
При желании можно пользоваться числовой кодировкой символов в стандарте Unicode. При этом символ может быть задан своим десятичным кодом (&#код;) или шестнадцатеричным кодом (&#xкод;). Например © представляет символ авторского права ©, а А – русскую букву А. Как мы увидим в дальнейшем, XML гораздо богаче, чем HTML, в использовании подобных конструкций, поскольку позволяет осуществлять подстановку в текст документов любых символьных выражений.
6. Секции CDATA
Еще одним способом включения в содержимое XML-элементов недопустимых символов является использование т. н. секций CDATA (сокр. от Character DATA, т. е. символьные данные). Допустим, что мы хотим сделать содержимым элемента layout фрагмент HTML-текста, например:
<layout> <h2>Заголовок</h2></layout>Подобная конструкция неверна, т. к. HTML-тег h2 будет в данном случае воспринят как тег XML. Для того, чтобы все содержимое элемента layout воспринималось как данные, мы должны заключить его в секцию CDATA:
<layout> <![CDATA[<h2>Заголовок</h2>]]></layout>Как мы видим из этого примера, секция CDATA заключается в ограничители <![CDATA[ и ]]>. Все внутри этой секции считается символьными данными; в частности, секции CDATA не могут вкладываться друг в друга.
Разделы и их декларации
1. Разделы XML-документа
Физически XML-документ может состоять из несколько разделов (entities). При этом корневой элемент документа также является разделом, который называется разделом документа, хотя он никак специально не оформлен. Все разделы имеют содержимое; все они, кроме раздела документа и внешней DTD, имеют имя.
С точки зрения синтаксического разбора документа разделы подразделяются на анализируемые и неанализируемые. Неанализируемый раздел (unparsed entity) — это ресурс, содержимое которого XML-процессор воспринимает как внешние данные без их синтаксического анализа (например, текст, не являющийся XML-документом). Неанализируемые разделы всегда имеют нотацию, указывающую на их формат. Анализируемые разделы (parsed entities) предназначены для текстовой подстановки: всякий раз, когда XML-процессор встречает в документе имя такого раздела, он заменяет его на содержимое этого раздела.
2. Внутренние разделы
Декларации разделов подразделяются на внутренние и внешние. Декларация внутреннего раздела выглядит так:
<!ENTITY имя значение>Она включает в себя содержимое объекта (параметр значение) и используется для подстановки этого значения вместо имени раздела. Мы можем, например, ввести в пример с книгами атрибут жанр и использовать для задания жанра внутренние разделы:
<!DOCTYPE spec [ <!ENTITY pr "проза"> <!ENTITY po "поэзия">]><books> <book genre="&po;"> <title>Часть речи</title> <author>Бродский, Иосиф</author> </book> <book genre="≺"> <title>Марш одиноких</title> <author>Довлатов, Сергей</author> </book></books>Из этого примера видно, что ссылка на раздел (entity reference) выглядит точно так же, как ссылка на специальный символ, т. е. имеет вид &имя;. На самом деле, специальные символы — это точно такие же ссылки, но соответствующие разделы заданы неявно во внутренней декларации языка XML. Подобные текстовые подстановки удобны для задания сокращений, позволяющих уменьшить объем документа, и для введения обозначений для часто изменяемых полей документа. Так, например, мы можем вынести во внутренний раздел дату очередной ревизии публикации и затем изменять только значение этого раздела.
3. Внешние разделы
Существуют два варианта деклараций внешнего раздела:
<!ENTITY имя SYSTEM URI [NDATA нотация]?><!ENTITY имя PUBLIC строка? URI [NDATA нотация]?>Первый вариант называется системным разделом, второй — публичным разделом. Они оба связывают имя раздела с внешним ресурсом, заданным своим URI, который должен иметь кодированную форму и не содержать закладок. URI внешнего ресурса называется системным идентификатором раздела. Использование внешнего ресурса зависит от нескольких факторов:
- Если декларация содержит параметр NDATA, задающий нотацию раздела, то раздел является неанализируемым.
- Если параметр NDATA не задан, то раздел анализируемый, и соответствующий ресурс должен быть XML-документом. Это означает, что вместо ссылки на раздел в текст документа будет включаться текст соответствующего ресурса.
- Публичный раздел может содержать строку, задающую публичный идентификатор раздела. XML-процессор может использовать этот идентификатор для генерации альтернативного URI данного раздела. Если ему это не удалось, то он должен использовать системный идентификатор для загрузки содержимого раздела.
Примеры деклараций внешних ресурсов:
<!-- неанализируемый ресурс: GIF-образ --><!ENTITY photo SYSTEM "images/photo.gif" NDATA gif><!-- системный анализируемый ресурс --><!ENTITY hatch SYSTEM "http://www.textuality.com/boilerplate/hatch.xml"><!-- публичный анализируемый ресурс --><!ENTITY hatch PUBLIC "-//Textuality//TEXT Standard hatch boilerplate//EN" "http://www.textuality.com/boilerplate/hatch.xml">Внешний анализируемый раздел должен начинаться с директивы <?xml …?>, которая может не содержать номера версии, но обязана содержать кодировку символов. Эта директива не входит в состав подставляемого текста.
kavayii.blogspot.com
Полезности для вебмастеров и не только — xBB.uz
31.01.2015: Пессимизация. Что это такое и как избежать?
28.01.2015: 5 инструментов продвижения, которые больше не работают
26.01.2015: Простой способ прогнозировать посещаемость сайта
23.01.2015: Что такое верстка сайта и ее виды
21.01.2015: Объем контента сайта и его влияние на позиции в поисковой выдаче
Для вебмастеров
Пессимизация. Что это такое и как избежать? 31.01.2015 Одним из популярных способов продвижения является оптимизация текстового контента под поисковые системы. Это объясняется достаточно высокой эффективностью и относительной простотой. Но часто случается, что веб-мастера чрезмерно увлекаются оптимизацией текстов. Как результат, можно наблюдать переспам ключевых слов или другие злоупотребления. За такие проступки поисковые системы предусматривают наказание, именно оно имеет название пессимизация. 5 инструментов продвижения, которые больше не работают 28.01.2015 Поисковая оптимизация динамично развивается и при ее проведении нужно быть очень аккуратным. Те инструменты, которые недавно работали и давали результаты, могут оказаться бесполезными и вредными. Бывает и наоборот, когда методы, за которые можно было получить наказание от поисковых систем, начинают эффективно работать. Соответственно, оптимизатор должен всегда находиться в курсе тенденций и понимать, какие способы продвижения можно использовать. Простой способ прогнозировать посещаемость сайта 26.01.2015 Узнать будущую посещаемость сайта легко. Но зачем это делать? Если вы собираетесь использовать сайт как рекламную площадку, то еще до того, как приступать к его созданию, вам необходимо понять, сколько людей будут заходить на сайт в будущем. Вы оцениваете видимость сайта и потенциальный трафик по каждому из интересующих вас запросов, и на основании полученной информации создаете семантическое ядро. Это научный подход, который приносит результаты.Для программистов
Программируем на R: как перестать бояться и начать считать 28.11.2014 Возможно, вас заинтересовала проблема глобального потепления, и нужно сравнить погодные показатели с архивными данными времен вашего детства. Калькулятором тут не обойтись. Да и такие программы для обработки электронных таблиц, как Microsoft Excel или Open Calc, пригодны только для простых вычислений. Придется изучать специализированный статистический софт. В этой статье мы расскажем об одном из популярнейших решений — языке программирования R. Smart Install Maker. Создаем установщик 23.11.2014 Появляется все больше инди-разработчиков, которые создают собственное программное обеспечение для компьютеров. Однако, чтобы продукт выглядел качественным, необходимо продумать все до мелочей, в том числе и систему установки программы. Тратить время на написание собственных инсталляторов никто не хочет, поэтому на рынке появляется все больше специализированных утилит, которые все сделают за вас. Они дают целевому пользователю то, что ему необходимо. Функции в языке программирования C++ 18.11.2014 Функцией называют обособленный модуль программы, внутри которого производятся некоторые вычисления и преобразования. Помимо непосредственных вычислений внутри данного модуля могут создаваться и удаляться переменные. Теперь расскажем о том, из каких основных частей состоит функция в C++. Самая первая часть — это тип возвращаемого значения. Он показывает, что будет передавать функция в основную программу после своих внутренних преобразований...Для других IT-специалистов
Роль дизайна в разработке пользовательских интерфейсов 23.11.2014 Разработка программного обеспечения — сложный, трудоемкий процесс, требующий привлечения экспертов разного профиля. Команда опытных программистов способна создать систему, удовлетворяющую любым техническим заданиям заказчика. Однако зачастую вне зоны внимания остается существенный вопрос: а насколько привлекательна разработанная система для пользователя? К сожалению, на сегодняшний день разработчики не всегда готовы дать внятный ответ на этот вопрос. Аренда программного обеспечения 13.11.2014 В последнее время на рынке IT-услуг все большую популярность набирает услуга аренды серверных мощностей с размещенным на них программным обеспечением. Суть услуги состоит в том, что заказчику предоставляется доступ к необходимому программному обеспечению по модели «бизнес-приложения» в аренду. Базы пользователей располагаются на серверах в специально оборудованном дата-центре. Пользователи работают в программе через удаленный рабочий стол. Машина трехмерного поиска 09.11.2014 Поисковые машины, без которых немыслим современный интернет, еще довольно ограничены. Можно искать слова, изображения, а в последние годы и мелодии (по фрагменту, проигранному перед микрофоном). Но как найти, например, аромат яблока? Технологии цифровой обработки запахов пока не очень развиты. Однако есть прогресс в другом направлении — стал возможен поиск 3D-объектов. И судя по растущему количеству 3D-принтеров, это будет востребованный сервис.Для других пользователей ПК и Интернет
YouTube и раритетные видеозаписи. Часть 2 19.01.2015 У скачанного файла *.MP4 напрочь отсутствует звук. Это просто кусок видеопотока, совершенно не проиндексированный, с некорректным заголовком. В Ubuntu воспроизвести его может лишь Gnome MPlayer, да и то без перемотки, без задействования пауз, строго подряд и непрерывно. Из всех бесплатных редакторов, доступных для Ubuntu Linux, переварить такое видео согласился лишь OpenShot. Импортировал и разместил на TimeLine (в области монтажа) без проблем. YouTube и раритетные видеозаписи 17.01.2015 В давние времена много чего записывалось на древние видеокассеты (VHS), большие плоские коробки с рулоном плёнки внутри. Затем контент оцифровывался и попадал на сервис YouTube, ставший для меломанов одним из основных источников добычи старых видеоклипов и концертов. Но пришла беда. Теперь почти все средства скачивания предлагают для загрузки лишь «360p». Этого разрешения хватит для просмотра разве что на маленьком экране телефона в четыре дюйма. Биржи контента. Ситуация к началу 2015 г. Обзор и тенденции. Часть 2 14.01.2015 Требования к качеству статей неуклонно растут. Хозяева бирж приспосабливаются к этому по-разному. Кто-то хитрит и придирается к чему может. Кто-то снижает уникальность из-за одного единственного технического термина в статье. А кто-то, не в силах придумать благовидные способы, просто блокирует и грабит пользователей. Во-вторых, биржи контента всё больше ориентируются на выполнение заданий, а продажа готовых статей становится второстепенной.Для мобильных пользователей
Обзор смартфона Lenovo S580 26.11.2014 В этой статье подробно рассмотрен очередной смартфон Lenovo. Одним из направлений компании является выпуск смартфонов в доступном ценовом сегменте и с достойными характеристиками. Такой моделью и является S580. Качественный дисплей, хорошая камера, нестандартные 8 Гб памяти и производительный процессор обрекают этот смартфон на успех. В ближайшие месяцы он станет хитом продаж. Рассмотрим его внешний вид, функционал, характеристики, время работы. Firefox OS глазами пользователя. Часть 2 22.11.2014 К данному моменту Firefox OS вполне стабильна (по-настоящему) и вполне пригодна для использования теми, кому от смартфона нужны лишь базовые умения. Звонить умеет, Wi-Fi работает, смотреть видео и фотографии можно. Однако о покупке телефона с Firefox OS лучше не думать до тех пор, пока в местных магазинах не начнёт рябить в глазах от таких аппаратов. Ведь тогда и хороший выбор приложений появится, и дизайнеров Mozilla отыщет и на работу примет. Firefox OS глазами пользователя 22.11.2014 Мировосприятие многих сторонников Open Source основано на перманентном ожидания новинок. Когда-нибудь что-то разработают, выпустят, допилят, обвешают плюшками — реальность состоит лишь из надежд на счастливое будущее в заоблачных далях. Мы же в эти самые дали слегка заглянем и посмотрим на Firefox OS глазами ординарного пользователя. После чего, возможно, какие-то надежды развеются и растают, однако истина дороже. Рассматривать будем релиз 2.0.Все публикации >>>
Последние комментарииВсе комментарии >>>
xbb.uz
Разметка (layout) | Русская документация Android
Разметка(layout)
Разметка описывает визуальную структуру пользовательского интерфейса, к примеру, для явлений и виджетов. Создать разметку можно двумя способами:
- Описать в XML. Android предоставляет простой набор XML элементов, соответствующих подклассам View.
- Создать элементы интерфейса в коде во время выполнения программы. Вы можете создавать визуальные элементы типа View и ViewGroup и управлять их свойствами программным способом.
Android позволяет гибко использовать эти методы отдельно друг от друга или одновременно для управления пользовательским интерфейсом приложения. Например, вы можете описать элементы экрана в XML, а затем во время выполнения изменить свойства этих объектов.
- Плагин ADT для Eclipse поддерживает предпросмотр XML разметки.
- Попробуйте также утилиту Hierarchy Viewer для отладки разметки.
- Инструмент layoutopt позволяет проводить быстрый анализ разметки и иерархии для поиска неэффективных решений и других проблем.
Преимущество разметки в XML заключается в том, что она позволяет лучшим образом отделить внешний вид интерфейса от кода его поведения. Интерфейс хранится отдельно от кода, что позволяет модифицировать и адаптировать его без необходимости менять код и перекомпилировать его. Например, вы может создать XML разметку для различных экранов или различных языков. Кроме того, описание разметки в XML легче воспринимается визуально и облегчает отладку. Данный урок рассказывает о создании разметки в XML. Если вас интересует создание разметки программным путем, обратитесь к описанию классов View и ViewGroup.
В общем, XML теги для объявления элементов интерфейса следуют структуре и наименованию классов и методов, так названия элементов соответствуют наименованиям классов, а названия атрибутов совпадают с соответствующими методами. В действительности, соответствие зачастую насколько прямое, что вы можете легко догадаться, что атрибут соответствует методу класса и какой класс соответствует заданному XML элементу. Те не менее, обратите внимание, что не все названия идентичны, в некоторых случаях есть небольшие различия. Например, элемент EditText имеет атрибут text, который соответствует методу EditText.setText().
Создание XML
Используя XML теги, вы можете быстро проектировать пользовательский интерфейс, также как вы создаете web-страницы, применяя HTML - с помощью серии вложенных элементов.
Каждый файл разметки должен включать только один корневой элемент, который является объектом типа View или ViewGroup. Остальные элементы должны быть дочерними по отношению к нему, вы можете создавать иерархию групп и элементов при описании разметки. Например, следующая XML разметка использует вертикальную линейную разметку LinearLayout, в которой размещена кнопка (Button) и текстовая строка (TextView):
[crayon-589755754faaa516186313/]Сохраните файл разметки с разрешением .xml в директории res/layout/ вашего проекта. Подробная информация о синтаксисе XML разметки содержится в разделе Ресурс разметки.
Загрузка XML ресурса
При компиляции приложения, каждый XML файл разметки компилируется в ресурс типа View. Вы должны загрузить ресурс разметки в методе обратного вызова Activity.onCreate(). Это делается с помощью метода setContentView(), в который передается в виде аргумента ссылка на ресурс в следующем виде: R.layout.имя_файла_разметки. Например, если XML разметка хранится в файле main_layout.xml, ее можно загрузить следующим образом:
[crayon-589755754fabd202091340/]Метод onCreate() вызывается системой Android при запуске явления. Подробнее о жизненном цикле явлений рассказано в разделе Явления.
Атрибуты
Каждый объект типа View и ViewGroup поддерживает собственный набор XML атрибутов. Некоторые атрибуты специфичны для объектов типа View (например, TextView поддерживает атрибут textSize), но эти атрибуты также наследуются другими объектами, расширяющими данный класс. Некоторые атрибуты являются общими для всех объектов View, поскольку они наследуются от корневого базового класса View (например атрибут id). А так же существуют другие атрибуты, которые считаются "параметрами разметки" и описывают компоновку и ориентацию View объектов, как это определено в родительском контейнере типа ViewGroup.
ID
Любой объект типа View может иметь уникальный целочисленный идентификатор, ассоциированный с ним. При компиляции приложения, данный идентификатор ссылается на целое число, но как правило идентификатор назначается в XML файле в виде строки с помощью атрибута id. Это общий для всех объектов атрибут, который имеет следующий синтаксис:
[crayon-589755754fac5377940426/]Символ собачка "@" указывает XML парсеру, что перед ним идентификатор ресурса. Символ плюс "+" указывает, что данный ресурс новый и для него должен быть добавлен объект в файле R.java. Android предоставляет ряд встроенных ресурсов. При ссылке на них не нужно указывать знак "+", но необходимо добавлять название пакета android:
[crayon-589755754facb220003087/]Добавляя название пакета android, мы таким образом ссылаемся на ресурсы класса android.R, а не на локальный класс ресурсов.
Чтобы создать визуальный компонент и ссылаться на него из приложения, проделайте следующее:
Опишите компонент в файле разметки и присвойте ему уникальный идентификатор:
[crayon-589755754fad1360314089/]-
Затем создайте экземпляр объекта нужного типа и установите для него разметку следующим образом:
[crayon-589755754fad7992639026/]
Указание идентификаторов важно при использовании относительной разметки (RelativeLayout). В относительной разметке, объекты могут указывать где они располагаются относительно соседей, ссылаясь на них с помощью идентификаторов.
ID не обязательно должен быть уникальным для всего дерево, но должен быть уникальным в пределах части дерева, в котором вы ищите объект (часто поиск происходит по всему дереву, поэтому лучше взять за правило назначать полностью уникальные идентификаторы для всех элементов проекта).
Параметры разметки
XML атрибуты разметки с именем layout_что-нибудь описывают параметры разметки, подходящие для контейнера ViewGroup, в котором располагается элемент View.
Каждый класс ViewGroup имеет внутренний класс ViewGroup.LayoutParams. Этот подкласс включает типы свойств, которые объявляют размер и позицию для каждого дочернего элемента группы. Как видно на рисунке 1, родительский контейнер указывает свойства разметки для каждого дочернего элемента (включая дочернюю подгруппу).
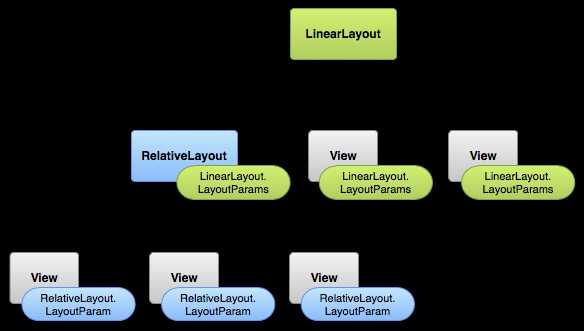
Рисунок 1. представление иерархии визуальных компонентов со свойствами разметки.
Помните, что каждый подкласс LayoutParams имеет свой собственный синтаксис для установки значений. Каждый дочерний элемент должен указывать параметры LayoutParams, который предоставляет его родительский элемент, хотя он может также определять различные параметры разметки для своих собственных дочерних элементов.
Все контейнеры включают ширину и высоту (layout_width и layout_height), и каждый элемент view должен их объявлять. Многие классы LayoutParams также включают необязательные параметры отступов и бордюров.
Вы можете указать ширину и высоту с помощью конкретных цифр, однако чаще всего вы будете использовать следующие ключевые слова:
- wrap_content сообщает, что должен быть установлен размер, которого достаточно, чтобы уместить содержимое компонента.
- match_parent(до API 8 fill_parent) сообщает, что компонент должен занять все доступное пространство родителя.
В общем, указывать ширину с помощью абсолютных единиц, вроде пикселей, не рекомендуется. Вместо этого используйте относительные единицы, такие как dp, wrap_content или match_parent. Это гарантирует, что приложение будет правильно отображаться на экранах различных размеров. Принятые типы измерений описаны в разделе Ресурсы.
Позиция разметки
Геометрически визуальный компонент это прямоугольник. Он имеет местоположение, заданное с помощью пары координат слева-сверху, а также размер, заданный как высота и ширина. Единица измерения положения и размера - пиксель.
Можно получить положение элемента с помощью двух методов getLeft() и getTop(). Первый возвращает координату X, второй Y, относительно родительского контейнера.
Кроме того, есть несколько удобных методов, позволяющих избежать ненужных вычислений - getRight() и getBottom(), которые возвращают, соответственно, координату правой и нижней стороны прямоугольника, представляющего компонент. Например getRight() вернет результат, аналогичный следующему выражение: getLeft() + getWidth().
Размер, поля и отступы
Размер задается с помощью пары ширина и высота. На самом деле компонент имеет две пары ширины и высоты.
Первая пара, известная как измеренная ширина и измеренная высота. Она показывает, как много элемент хочет занять места в его родительском контейнере. Получить измеренные размеры можно с помощью методов getMeasuredWidth() и getMeasuredHeight().
Вторая пара, известная как просто ширина и высота, или иногда нарисованная ширина и нарисованная высота. Она показывает актуальный размер элемента на экране. Это значение может отличаться от измеренного, хотя и не всегда. Может быть получена с помощью методов getWidth() и getHeight().
Для измеренной величины элемента принимается во внимание его поля. Поля задаются в пикселях для левой, верхней, правой и нижней части компонента. Поля могут использоваться для сдвига содержимого на определенное количество пикселей. Например, левое поле равное 2 позволяет сдвинуть содержимое элемента на два пикселя вправо (отодвинуть от левой границы элемента на 2 пикселя). Поля могут быть установлены с помощью метода setPadding(int, int, int, int) и получены с помощью методов getPaddingLeft(), getPaddingTop(), getPaddingRight() и getPaddingBottom().
Несмотря на то, что компоненты могут иметь поля, не существует какой-либо поддержки отступов. Однако, ViewGroup предоставляет такую поддержку. За подробной информацией обратитесь к документации по классам ViewGroup и ViewGroup.MarginLayoutParams.
Подробнее об измерениях смотрите в разделе Другие типы ресурсов.
Популярные контейнеры разметки
Каждый подкласс ViewGroup предоставляет уникальный способ отображения его дочерних элементов. Ниже представлены наиболее часто используемые виды разметки.
Примечание: хотя вы можете вкладывать контейнеры друг в друга, вы должны стремиться делать как можно меньше вложений. Это ускорит отрисовку макета и сделает приложение более производительным.
Линейная разметка (LinearLayout)
Группа для организации элементов по вертикали или горизонтали. Создает полосу прокрутки, если элементы не умещаются.
WebView
Показывает web-страницы.
Создание разметки с использованием адаптера
Для динамично изменяющегося содержимого вы можете использовать контейнер, который является подклассом AdapterView, позволяющий создавать элементы во время выполнения. Подкласс AdapterView использует адаптер (Adapter) для связи данных с макетом. Adapter представляет из себя прослойку между источником данных и разметкой типа AdapterView - адаптер получает данные из источника и преобразует каждую запись в визуальный компонент, который может быть добавлен в разметку.
Вот два наиболее популярных типа разметки для работы с адаптером:
ListView
Прокручиваемый список элементов.
GridView
Прокручиваемая сетка (таблица) элементов.
Заполнение контейнера с помощью адаптера
Вы можете заполнить контейнер подкласса AdapterView, такой как ListView или GridView, связав экземпляр AdapterView с объектом Adapter, который получает данные из внешнего источника и создает элемент View для их отображения.
Android предоставляет различные подклассы Adapter, которые удобны для получения различного вида данных. Вот два наиболее популярных из них:
ArrayAdapterИспользуется в случае, если данные хранятся в массиве. По умолчанию ArrayAdapter создает визуальные компоненты для каждого элемента массива, вызывая метод toString() и размещая результат в TextView.
Например, если у вас есть массив строк, который вы хотите отобразить в ListView, создайте экземпляр ArrayAdapter с помощью конструктора, указав в нем разметку для каждой строки и сам строковый массив:
[crayon-589755754faf6545531175/]Конструктор принимает следующие аргументы:
- Context приложения.
- Разметку, которая содержит TextView для строк массива.
- Строковый массив.
Затем просто вызовите метод setAdapter() для вашего ListView:
[crayon-589755754fafd441316560/]Для настройки внешнего вида каждого пункта, вы можете переопределить метод toString() для объекта вашего массива. Вы также можете создать любой другой визуальный компонент для каждого пункта (например ImageView для картинок), расширив класс ArrayAdapter и переопределив метод getView(), чтобы он возвращал нужный тип компонента.
SimpleCursorAdapterДанный адаптер используется когда данные должны быть получены из курсора (Cursor). При использовании SimpleCursorAdapter вы должны указать разметку, которая будет использоваться для каждой строки курсора, а каждый столбец курсора должен быть вставлен в соответствующий элемент разметки. Например, если вы хотите создать список людей с их номерами телефонов, вы можете выполнить запрос, который вернет объект типа Cursor, включающий строки для каждого из людей и столбцы имени и номера телефона. Затем создается строковый массив, который определяет какие столбцы курсора вы хотите отобразить в разметке, и какие визуальные компоненты разметки использовать для каждого из столбцов:
[crayon-589755754fb05468444115/]При создании экземпляра SimpleCursorAdapter, передайте макет, который будет использоваться для каждой строки объекта Cursor, а также два массива, указывающих соответствие столбцов визуальным элементам:
[crayon-589755754fb0b695902845/]Если в ходе выполнения приложения исходные данные, которые считывает адаптер, изменяются, вы должны вызвать метод notifyDataSetChanged(). Это позволит визуальным компонентам обновить себя.
Обработка нажатий
Вы можете обрабатывать нажатия на каждый пункт AdapterView, реализовав интерфейс AdapterView.OnItemClickListener. Например:
[crayon-589755754fb11651571836/]easyandroid.ru
НОУ ИНТУИТ | Лекция | Языки разметки. Введение в XML
Аннотация: Рассматривается основные понятия языков разметки. История их развития. Более подробно рассматриваются основные особенности языка разметки XML.
Язык разметки (markup languages) - это набор специальных инструкций, называемых тэгами, предназначенных для формирования в документах какой-либо структуры и определения отношений между различными элементами этой структуры. Другими словами разметка показывает, какая часть документа является заголовком, какая подзаголовком, что следует считать именем автора и т. д. Разметка разделяется на стилистическую разметку, структурную и семантическую.
Стилистическая разметка
Стилистическая разметка отвечает за внешний вид документа. Например, в HTML к данному типу разметки относятся такие теги как <I> </I> (курсив), <B> </B> (жирный), <U> </U> (подчеркивание), <S> </S> (перечеркнутый текст) и т.д.
Структурная разметка
Структурная разметка задает структуру документа. В HTML за данный тип разметки отвечают, например, теги <P> </P> (параграф), <H?> </H?> (заглавие), <DIV> </DIV> (секция) и т.д.
Семантическая разметка
Семантическая разметка информирует о содержании данных. Примерами данного типа разметки являются теги <TITLE> </TITLE> (имя документа), <CODE> </CODE> (код, используется для листингов кода), <VAR> </VAR> (переменная), <ADDRESS> </ADDRESS> (адрес автора).
Основными понятиями любого языка разметки являются теги, элементы и атрибуты.
Тэги и элементы.
Значения понятий тэги и элементы часто путают.
Тэги, или, как их еще называют, управляющие дескрипторы, служат в качестве инструкций для программы, производящей показ содержимого документа на стороне клиента как поступить с содержимым тега. Для того чтобы выделить тег относительно основного содержимого документа используются угловые скобки: тег начинается со знака "меньше" (<) и завершается знаком "больше" (>), внутри которых помещаются название инструкций и их параметры. Например, в языке HTML тег <I> указывает на то, что следующий за ним текст должен быть выведен курсивом.
Элемент - это тэги в совокупности с их содержанием. Следующая конструкция является примером элемента:
<I> Это текст выделен курсивом </I>.
Элемент состоит из открывающего тега (в нашем примере это тег <I> ), содержимого тега (в примере это текст "Это текст, выделен курсивом") и закрывающего тега( </I> ), правда иногда в HTML, закрывающий тег можно опустить.
Атрибуты
Для того чтобы при определении элемента задать какие-либо параметры, уточняющие характеристики данного элемента используются атрибуты.
Атрибуты состоят из пары "название" = "значение", которую можно задавать при определении элемента в начальном тэге. Слева и справа от символа равенства можно оставлять пробелы. Значение атрибута указывается в виде строки, заключенной в одинарные или двойные кавычки.
Любой тэг может иметь атрибут, если этот атрибут определен.
В случае использования атрибута элемент принимает следующую форму:
<имя_тега атрибут = "значение"> содержимое тега </имя_тега>
Пример:
<p ALIGN="CENTER"> текст выравнивается по центру </p>
В одном открывающемся теге может содержаться несколько атрибутов, например:
<FONT SIZE = 7 color = "RED"> Указан размер и цвет текста </FONT>
История развития языков разметки.
Понятие гипертекста было введено В.Бушем в 1945 году а, начиная с 60-х годов, стали появляться первые приложения, использующие гипертекстовые данные. Однако основное развитие данная технология получила, когда возникла реальная необходимость в механизме объединения множества информационных ресурсов, обеспечения возможности создания, просмотра нелинейного текста.
В 1986 году ISO был утвержден универсальный стандартизированный язык разметки (Standardized Generalized Markup Language). Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тэгов, их атрибуты и внутреннюю структуру документа. Таким образом имеется возможность создавать свои собственные тэги, связанные с содержанием документа. Теперь становится очевидно, что такие документы трудно интерпретировать без определения языка разметки, которое хранится в определении типа документа ( DTD - Document Type Definition). В DTD сгруппированы все правила языка в стандарте SGML. Другими словами в DTD описывается связь тегов между собой и правила их применения. Причем для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Таким образом, только при помощи DTD можно проверить правильность использования тегов а, следовательно, его нужно посылать вместе с SGML-документом или включать в документ.
В то время кроме SGML существовали еще несколько конкурирующих между собой подобных языков, однако популярность (HTML, который является одним из его потомков) дала SGML неоспоримое преимущество перед своими собратьями.
С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но из-за своей сложности, SGML использовался, в основном, для описания синтаксиса других языков, и немногие приложения работали с SGML -документами напрямую. SGML обычно применяется лишь в крупных проектах, например, для создания единой системы документооборота крупной фирмы.
Язык разметки HTML гораздо более простой и удобный, чем SGML, его инструкции в первую очередь предназначены для управления процессом вывода содержимого документа на экране. Язык HTML как способ разметки технических документов был создан Тимом Бернерсом-Ли (Tim Berners-Lee) в 1991 году специально для научного сообщества. Первоначально он был всего лишь одним из SGML -приложений.
Не смотря на то, что единственное, что умеет HTML - классифицировать части документа и обеспечивать его правильное отображение в браузере, он является самым популярным языком разметки. Это связано с тем, что HTML достаточно легок для изучения. Все, что от вас требуется, - изучить команды HTML. DTD для HTML хранится в браузере. К тому же надо заметить, что HTML спроектирован для работы на самых разных платформах. Но у него есть ряд существенных ограничений:
- HTML имеет фиксированный набор тэгов, и данный набор нельзя расширить или изменить;
- теги языка HTML показывают только как должны быть представлены данные, то есть внешний вид документа. HTML не несет информации о значении содержания, заключенного в тэгах, структуре документа.
В 1996 общественной организацией World Wide Web Consortium ( W3C ) началась разработка XML (Extensible Markup Language) который стал золотой срединой между языками SGML и HTML. Язык XML позволяет разработчику создавать свои собственные теги, но в отличие от SGML он достаточно прост.
На основе языка XML был создан язык разметки для беспроводных устройств WML. Данный язык позволяет описать пользовательский интерфейс на устройствах с ограниченными возможностями представления данных, например, мобильных телефонах.
Все представленное множество языков разметки удобно для наглядности представить в виде следующего "генеалогического дерева" языков разметки:
www.intuit.ru
НОУ ИНТУИТ | Лекция | Языки разметки. Введение в XML
Аннотация: Рассматривается основные понятия языков разметки. История их развития. Более подробно рассматриваются основные особенности языка разметки XML.
Язык разметки (markup languages) - это набор специальных инструкций, называемых тэгами, предназначенных для формирования в документах какой-либо структуры и определения отношений между различными элементами этой структуры. Другими словами разметка показывает, какая часть документа является заголовком, какая подзаголовком, что следует считать именем автора и т. д. Разметка разделяется на стилистическую разметку, структурную и семантическую.
Стилистическая разметка
Стилистическая разметка отвечает за внешний вид документа. Например, в HTML к данному типу разметки относятся такие теги как <I> </I> (курсив), <B> </B> (жирный), <U> </U> (подчеркивание), <S> </S> (перечеркнутый текст) и т.д.
Структурная разметка
Структурная разметка задает структуру документа. В HTML за данный тип разметки отвечают, например, теги <P> </P> (параграф), <H?> </H?> (заглавие), <DIV> </DIV> (секция) и т.д.
Семантическая разметка
Семантическая разметка информирует о содержании данных. Примерами данного типа разметки являются теги <TITLE> </TITLE> (имя документа), <CODE> </CODE> (код, используется для листингов кода), <VAR> </VAR> (переменная), <ADDRESS> </ADDRESS> (адрес автора).
Основными понятиями любого языка разметки являются теги, элементы и атрибуты.
Тэги и элементы.
Значения понятий тэги и элементы часто путают.
Тэги, или, как их еще называют, управляющие дескрипторы, служат в качестве инструкций для программы, производящей показ содержимого документа на стороне клиента как поступить с содержимым тега. Для того чтобы выделить тег относительно основного содержимого документа используются угловые скобки: тег начинается со знака "меньше" (<) и завершается знаком "больше" (>), внутри которых помещаются название инструкций и их параметры. Например, в языке HTML тег <I> указывает на то, что следующий за ним текст должен быть выведен курсивом.
Элемент - это тэги в совокупности с их содержанием. Следующая конструкция является примером элемента:
<I> Это текст выделен курсивом </I>.
Элемент состоит из открывающего тега (в нашем примере это тег <I> ), содержимого тега (в примере это текст "Это текст, выделен курсивом") и закрывающего тега( </I> ), правда иногда в HTML, закрывающий тег можно опустить.
Атрибуты
Для того чтобы при определении элемента задать какие-либо параметры, уточняющие характеристики данного элемента используются атрибуты.
Атрибуты состоят из пары "название" = "значение", которую можно задавать при определении элемента в начальном тэге. Слева и справа от символа равенства можно оставлять пробелы. Значение атрибута указывается в виде строки, заключенной в одинарные или двойные кавычки.
Любой тэг может иметь атрибут, если этот атрибут определен.
В случае использования атрибута элемент принимает следующую форму:
<имя_тега атрибут = "значение"> содержимое тега </имя_тега>
Пример:
<p ALIGN="CENTER"> текст выравнивается по центру </p>
В одном открывающемся теге может содержаться несколько атрибутов, например:
<FONT SIZE = 7 color = "RED"> Указан размер и цвет текста </FONT>
История развития языков разметки.
Понятие гипертекста было введено В.Бушем в 1945 году а, начиная с 60-х годов, стали появляться первые приложения, использующие гипертекстовые данные. Однако основное развитие данная технология получила, когда возникла реальная необходимость в механизме объединения множества информационных ресурсов, обеспечения возможности создания, просмотра нелинейного текста.
В 1986 году ISO был утвержден универсальный стандартизированный язык разметки (Standardized Generalized Markup Language). Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тэгов, их атрибуты и внутреннюю структуру документа. Таким образом имеется возможность создавать свои собственные тэги, связанные с содержанием документа. Теперь становится очевидно, что такие документы трудно интерпретировать без определения языка разметки, которое хранится в определении типа документа ( DTD - Document Type Definition). В DTD сгруппированы все правила языка в стандарте SGML. Другими словами в DTD описывается связь тегов между собой и правила их применения. Причем для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Таким образом, только при помощи DTD можно проверить правильность использования тегов а, следовательно, его нужно посылать вместе с SGML-документом или включать в документ.
В то время кроме SGML существовали еще несколько конкурирующих между собой подобных языков, однако популярность (HTML, который является одним из его потомков) дала SGML неоспоримое преимущество перед своими собратьями.
С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но из-за своей сложности, SGML использовался, в основном, для описания синтаксиса других языков, и немногие приложения работали с SGML -документами напрямую. SGML обычно применяется лишь в крупных проектах, например, для создания единой системы документооборота крупной фирмы.
Язык разметки HTML гораздо более простой и удобный, чем SGML, его инструкции в первую очередь предназначены для управления процессом вывода содержимого документа на экране. Язык HTML как способ разметки технических документов был создан Тимом Бернерсом-Ли (Tim Berners-Lee) в 1991 году специально для научного сообщества. Первоначально он был всего лишь одним из SGML -приложений.
Не смотря на то, что единственное, что умеет HTML - классифицировать части документа и обеспечивать его правильное отображение в браузере, он является самым популярным языком разметки. Это связано с тем, что HTML достаточно легок для изучения. Все, что от вас требуется, - изучить команды HTML. DTD для HTML хранится в браузере. К тому же надо заметить, что HTML спроектирован для работы на самых разных платформах. Но у него есть ряд существенных ограничений:
- HTML имеет фиксированный набор тэгов, и данный набор нельзя расширить или изменить;
- теги языка HTML показывают только как должны быть представлены данные, то есть внешний вид документа. HTML не несет информации о значении содержания, заключенного в тэгах, структуре документа.
В 1996 общественной организацией World Wide Web Consortium ( W3C ) началась разработка XML (Extensible Markup Language) который стал золотой срединой между языками SGML и HTML. Язык XML позволяет разработчику создавать свои собственные теги, но в отличие от SGML он достаточно прост.
На основе языка XML был создан язык разметки для беспроводных устройств WML. Данный язык позволяет описать пользовательский интерфейс на устройствах с ограниченными возможностями представления данных, например, мобильных телефонах.
Все представленное множество языков разметки удобно для наглядности представить в виде следующего "генеалогического дерева" языков разметки:
www.intuit.ru
Расширяемый язык разметки XML. Синтаксис. Понятия правильно оформленного и действительного документов.
⇐ ПредыдущаяСтр 2 из 8Следующая ⇒XML, или eXtensible Markup Language - язык разметки, который позволяет вам создавать свои собственные теги. Он разработан консорциумом World Wide Web Consortium для того, чтобы обойти ограничения HTML - языка разметки, лежащего в основе всех WEB страниц. Подобно HTML, XML основывается на SGML - Standard Generalized Markup Language
Спецификация XML требует, чтобы программа-анализатор XML отклонял любой XML документ, не соответствующий этим основным правилам.
Существуют два уровня правильности XML документов. XML документ может быть:
• Правильно построенный (Well-formed). Документ следует правилам, определенным в спецификации XML, но не имеет ассоциированного с ним определения типа документа.
• Действительным (Valid). Документ следует правилам, определенным в спецификации XML, а так же с документом ассоциировано Определение типа документа и документ соответствует этому определению.
Взаимоотношение понятий действительности и правильности построения, в каком порядке XML анализатор выполняет проверку XML кода.
1. XML документ загружается и выполняется проверка на соответствие спецификациям XML. Если проверка не прошла, документ признается недействительным и неправильно построенным. Если проверка прошла успешно, документ признается правильно построенным и анализатор приступает к проверке на действительность.
2. Выполняется проверка на соответствие DTD. Если проверка не прошла документ признается недействительным (но правильно построенным!). Если проверка прошла успешно, документ признается действительным (а значит и правильно построенным).
Таким образом, понятие действительность включает в себя понятие правильного построения. Действительность является более строгим понятием.
Корневой элемент
Весь XML документ должен содержаться в одном элементе. Этот элемент называется корневым и содержит в себе весь текст и все другие элементы документа. В следующем примере (Пример 3.4, «Well-formed документ») весь XML документ содержится внутри элемента greeting. Обратите внимание, что документ имеет комментарий, который находится вне корневого элемента и это вполне допустимо.
<?xml version="1.0"?>
<!-- A well-formed document -->
<greeting>
Hello, World!
</greeting>
Пример 3.4. Well-formed документ
А в следующем примере (Пример 3.5, «Не Well-formed документ») документ не имеет единственного корневого элемента
<?xml version="1.0"?>
<!-- A well-formed document -->
<greeting>
Hello, World!
</greeting>
<greeting>
Hola, el Mundo!
</greeting>
Пример 3.5. Не Well-formed документ
Анализатор XML отклонит такой документ, независимо от содержащейся в нем информации.
Элементы не могут пересекаться
Элементы не могут пересекаться. В примере 3.6 показан неправильный XML документ.
<!-- NOT legal XML markup -->
<p>
<b>I <i>really
love</b> &xml;.</i>
</p>
Пример 3.6. Пересекающиеся элементы
Если вы начали элемент i внутри элемента b, то и закончить его вы должны здесь-же. В примере 3.7 показана исправленная версия этого документа.
<!-- Legal XML markup -->
<p>
<b>I <i>really
love</i></b>
<i>XML.</i>
</p>
Пример 3.7. Исправление пересекающихся элементов
Анализатор XML примет только второй вариант. Анализатор HTML в большинстве браузеров примет оба.
Закрывающие теги обязательны
Вы не можете оставлять элементы незакрытыми! В примере 3.8 разметка неверна, т.к. у элементов p нет закрывающих тегов (</p>). Это допустимо в HTML и иногда в SGML, но анализатор XML отклонит такой документ.
<!-- NOT legal XML markup -->
<p>Yada yada yada...
<p>Yada yada yada...
<p>...
Пример 3.8. Элемент не закрыт
Если элемент не содержит никакой разметки внутри, он называется пустым. В html примерами таких элементов могут быть элементы br и img. В XML, чтобы указать пустой элемент, вы должны поместить слэш (/) в конце открывающего тега. В примере 3.9) два элемента br и два элемента img значат для XML анализатора одно и то же.
<!-- Два эквивалентных элемента br -->
<br></br>
<br />
<!-- Два эквивалентных элемента img -->
<img src="../img/c.gif"></img>
<img src="../img/c.gif" />
Пример 3.9. Пустые элементы
Имена элементов чувствительны к регистру
Имена элементов чувствительны к регистру. В HTML теги h2 и h2 значат одно и то же. Но в XML это не так! Если вы попытаетесь закрыть элемент h2 тегом </h2>, то получите ошибку. В ( примере 3.10) верхний заголовок неправильный, а нижний правильный.
<!-- NOT legal XML markup -->
<h2>Elements are
case sensitive</h2>
<!-- legal XML markup -->
<h2>Elements are
case sensitive</h2>
Пример 3.10. XML чувствителен к регистру
Атрибуты должны быть заключены в кавычки
В XML есть два правила для атрибутов
• Атрибуты должны иметь значения
• Эти значения должны быть заключены в кавычки
Сравните два примера ниже (Пример 3.11, «Атрибуты»). Верхний правилен в HTML, но неправилен в XML. Нижний правилен и в HTML и в XML.
<!-- NOT legal XML markup -->
<ol compact>
<!-- legal XML markup -->
<ol compact="yes">
Пример 3.11. Атрибуты
2. Язык преобразования XML документов - XSLT. Назначение, общая структура и основные понятия. Основные управляющие операторы.
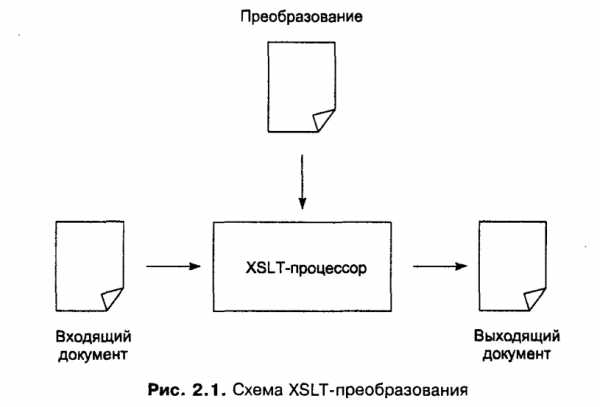
XSLT (Extensible Stylesheet Language Transformations) — часть спецификации XSL, задающая язык преобразований XML-документов. Спецификация XSLT является рекомендацией W3C.
XSLT имеет множество различных применений, в основном в области web-программирования и генерации отчётов. Одной из задач, решаемых языком XSLT, является отделение данных от их представления, как часть общей парадигмы MVC (англ. Model-view-controller). Другой стандартной задачей является преобразование XML-документов из одной XML-схемы в другую.
Консорциум W3 определяет три составные части языка XSL (англ. eXtensible Stylesheet Language — Расширяемый Язык Стилей): XSLT, XPath (язык путей и выражений, используемый в XSLT для доступа к отдельным частям XML-документа) и XSL-FO (англ. eXtensible Markup Language Formatting Objects — язык разметки типографских макетов и иных предпечатных материалов.
Пример
| Исходный XML-документ: <?xml version="1.0"?> <persons> <person username="MP123456"> <name>Иван</name> <surname>Иванов</surname> </person> <person username="PK123456"> <name>Пётр</name> <surname>Петров</surname> </person> </persons> | Результирующий XML-документ: <?xml version="1.0" encoding="UTF-8"?> <transform> <record> <username>MP123456</username> <fullname>Иван Иванов</fullname> </record> <record> <username>PK123456</username> <fullname>Пётр Петров</fullname> </record> </transform> |
| Таблица XSLT-стилей (преобразования): <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="xml" indent="yes"/> <xsl:template match="/"> <transform> <xsl:apply-templates/> </transform> </xsl:template> <xsl:template match="person"> <record> <username> <xsl:value-of select="@username" /> </username> <fullname> <xsl:value-of select="name" /><xsl:text> </xsl:text><xsl:value-of select="surname" /> </fullname> </record> </xsl:template> </xsl:stylesheet> |
| Схема | Структура |
 | <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:import href="..."/> <xsl:include href="..."/> <xsl:strip-space elements="..."/> <xsl:preserve-space elements="..."/> <xsl:output method="..."/> <xsl:key name="..." match="..." use="..."/> <xsl:decimal-format name="..."/> <xsl:namespace-alias stylesheet-prefix="..." result-prefix="..."/> <xsl:attribute-set name="..."> ... </xsl:attribute-set> <xsl:variable name="...">...</xsl:variable> <xsl:param name="...">...</xsl:param> <xsl:template match="..."> ... </xsl:template> <xsl:template name="..."> ... </xsl:template> </xsl:stylesheet> |
Основные управляющие операторы – непонятно что это в своей сути.
Преобразование, выраженное через XSLT, описывает правила преобразования исходного дерева документа в конечное дерево. Преобразование строится путем сопоставления образцов и шаблонов. Образец сравнивается с элементами исходного дерева, а шаблон используется для создания частей конечного дерева. Конечное дерево отделено от исходного дерева. Структура конечного дерева может полностью отличаться от структуры исходного дерева. В ходе построения конечного дерева элементы исходного дерева могут подвергаться фильтрации и переупорядочению, также может добавлена новая структура.
Преобразование, выраженное через XSLT, называется стилем (stylesheet). Так сделано потому, что в случае, когда XSLT приводится к словарю форматирования XSL, данное преобразование выполняет функции стиля.
Стиль содержит набор правил шаблона. Правило шаблона состоит из двух частей: это образец, который сопоставляется с узлами в исходном дереве, и шаблон, который может быть обработан для формирования фрагмента в конечном дереве. Такая схема позволяет использовать один стиль для большого класса документов, имеющих одинаковую структуру исходного дерева.
Чтобы получить фрагмент в конечном дереве, шаблон обрабатывается для определенного элемента в исходном документе. Шаблон может содержать элементы, определяющие фиксированную структуру конечного элемента. Шаблон может также содержать элементы из пространства имен XSLT, дающие инструкции по созданию фрагментов конечного дерева. При обработке шаблона каждая инструкция обрабатывается и заменяется на полученный фрагмент конечного дерева. Инструкции могут находить в исходном дереве и обрабатывать элементы-потомки. При обработке элемента-потомка в конечном дереве создается фрагмент путем нахождения соответствующего правила шаблона и обработки его шаблона. Заметим, что элементы обрабатываются только если они были выбраны в ходе выполнения инструкции. Конечное дерево строится после нахождения правила шаблона для корневого узла и обработки в нем шаблона.
В ходе поиска соответствующего правила шаблона может выясниться, что данному элементу соответствует не одно, а сразу несколько правил. Однако использоваться будет только одно правило шаблона.
Шаблон даже сам по себе наделен значительной мощностью: он может создавать структуры произвольной сложности, извлекать строковые значения из любых мест исходного дерева, создавать структуры, повторяющие появление элементов в исходном дереве. Для простых преобразований, когда структура конечного дерева не связана со структурой исходного дерева, стиль часто образуется одним шаблоном, который используется как шаблон для всего конечного дерева.
Если обрабатывается шаблон, то это всегда делается отталкиваясь от текущего узла и текущего набора узлов. Текущий узел всегда является членом текущего набора узлов. В XSLT многие операции привязаны к текущему узлу. И лишь несколько инструкций меняют текущий набор узлов или текущий узел (см. [5 Правила шаблона] и [8 Повторение]). При обработке любой из этих инструкций текущий набор узлов заменяется новым набором узлов, а каждый член этого нового набора по очереди становится текущим узлом. После того как обработка инструкции завершена, текущий узел и текущий набор узлов становится такими, каким они были до обработки этой инструкции.
Для выбора элементов для обработки, обработки при условии и генерации текста XSLT использует язык выражений, сформулированный в [XPath].
Традиционные императивные языки программирования очень плохо подходят для обработки древовидно структурированных данных. Программы, действия в которых непременно выполняются последовательно одно за другим, в общем случае не могут эффективно (с точки зрения компактности и понятности кода) обработать сложные иерархические структуры.Билет3
Структура XML документов. Определение типа документа (DTD)
Зачем может понадобиться определение структуры документа? Это может быть полезно при обмене XML документами между различными организациями или даже разными подразделениями одной организации. Наличие определения структуры позволит гарантировать (проверять) правильность получаемых и отдаваемых документов. Определение структуры документа может понадобиться разработчикам программного обеспечения. Например, разработчики СУБД могут формально определить допустимые структуры документов, которые разработчики сервера приложений могут отправлять в СУБД. Это позволит формально проверять корректность работы сервера приложений с СУБД, не обращаясь к разработчикам СУБД для тестирования. Ну и т.д.
Далее мы познакомимся с двумя способами определить структуру документа
Первый способ - использовать определение типа документа (Document Type Definition - DTD). DTD определяет элементы, которые можно использовать в XML документе; их содержимое; порядок, в котором они могут появляться в документе и другие детали структуры документа. Синтаксис DTD является частью спецификации XML.
Другой способ - использовать схемы. Схемы позволяют определять все то, что и DTD, а кроме этого еще и типы данных, более сложные структуры данных, чем в DTD. Существует несколько языков описания схем. Наиболее распространенные из них W3C XML Schema и RELAX NG. Мы будем изучать язык RELAX NG как более простой.
DTD позволяет нам определять базовую структуру XML документа. Давайте внимательно рассмотрим DTD (Пример 3.16, «DTD»), который определяет структуру XML документа, приведенного в первой части лекции (Пример 3.2, «Пример XML»).
<address>
<name>
<title>Mrs.</title>
<first-name>
Mary
</first-name>
<last-name>
McGoon
</last-name>
</name>
<street>
1401 Main Street
</street>
<city>Anytown</city>
<state>NC</state>
<postal-code>
</postal-code>
</address>
Пример 3.2. Пример XML
<!-- address.dtd -->
<!ELEMENT address (name, street, city, state, postal-code)>
<!ELEMENT name (title? first-name, last-name)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT first-name (#PCDATA)>
<!ELEMENT last-name (#PCDATA)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT postal-code (#PCDATA)>
Пример 3.16. DTD
:• Элемент address содержит name, street, city, state и postal-code. Все эти элементы должны быть обязательно, и именно в этом порядке.
• Элемент name содержит опциональный (об опциональности говорит символ ?) элемент title, за которым следуют элементы first-name и last-name.
• Все остальные элементы содержат внутри себя текст (об этом говорит #PCDATA; вы не можете включать другие элементы в такой элемент).
Синтаксис DTD очень прост, но с его помощью легко описывать, какие элементы могут появляться в XML документе. С другой стороны, синтаксис DTD отличается от синтаксиса XML
Символы в DTD
Для указания того, как часто в XML документе могут использоваться те или иные элементы, используются специальные символы. Вот несколько примеров.
• В записи <!ELEMENT address (name, city, state)> элемент address должен содержать элементы name, city, state именно в этом порядке. Все они обязательны. Запятая определяет последовательность символов.
• Запись <!ELEMENT name (title?, first-name, last-name)> означает, что элемент name содержит опциональный элемент title, за которым следуют обязательные элементы first-name и last-name. Символ ? означает, что элемент может появиться один раз или не появиться вообще.
• Запись <!ELEMENT addressbook (address+)> означает, что элемент addressbook содержит один или более элементов address. Символ + означает, что элемент должен встречаться как минимум один раз, но может и больше.
• Запись <!ELEMENT private-addresses (address*)> означает, что private-addresses может содержать ноль или более элементов address. Звездочка означает, что элемент может встречаться любое количество раз, в том числе и ноль.
• Запись <!ELEMENT name (title?, first-name, (middle-initial | middle-name)?, last-name)> означает, что элемент name содержит опциональный элемент title, за которым следует first-name. Далее возможны варианты: либо middle-initial, либо middle-name, но только что-нибудь одно. В конце обязательно присутствует элемент last-name. Вертикальная черта указывает на варианты. Может встретиться только один элемент из всех, разделенных вертикальной чертой. Обратите также внимание на то, как используются скобки для группировки элементов.
• Запись <!ELEMENT name ((title?, first-name, last-name) | (surname, mothers-name, given-name))> говорит о том, что элемент name может содержать одну из двух последовательностей: опциональный title, first-name и last-name; или surname, mothers-name, given-name.
Определение атрибутов
Очень глубоко в технологию DTD в этом курсе мы погружаться не будем, но некоторые основные вопросы затронем. Один из таких наиболее простых но важных вопросов - определение атрибутов. Для любого элемента можно определить:
• Какие атрибуты в нем могут быть
• Какие атрибуты обязательны
• Какие значения по умолчанию принимают атрибуты
• Список всех возможных значений для атрибута
Представьте, что вы хотите изменить DTD так,чтобы у элемента city был атрибут state (Пример 3.17, «Определение атрибута»).
<!ELEMENT city (#PCDATA)>
<!ATTLIST city state CDATA #REQUIRED>
Пример 3.17. Определение атрибута
Элемент city объявлен так же, как и раньше, но теперь для него добавлена инструкция ATTLIST, в которой определяется, что у элемента city есть атрибут state. Ключевое слово CDATA говорит анализатору, что атрибут state содержит внутри себя текст, а ключевое слово $REQUIRED говорит, что это обязательный атрибут. Если бы вы хотели указать, что атрибут необязательный, тогда вам необходимо использовать вместо #REQUIRED ключевое слово #IMPLIED (Пример 3.18, «Определение необязательного атрибута»).
<!ELEMENT city (#PCDATA)>
<!ATTLIST city state CDATA #IMPLIED>
Пример 3.18. Определение необязательного атрибута
В предыдущих примерах мы определяли только один атрибут. Чтобы определить несколько атрибутов, просто перечислите их в директиве ATTLIST (Пример 3.19, «Определение нескольких атрибутов»).
<!ELEMENT city (#PCDATA)>
<!ATTLIST city state CDATA #IMPLIED
postal-code CDATA #REQUIRED>
Пример 3.19. Определение нескольких атрибутов
И последнее, о чем мы упомянем в контексте DTD, это указание допустимых значений атрибута. Вы можете указать список значений, и анализатор будет контролировать, что атрибут принимает значения только из заданного списка значений. Кроме того, можно задать и значение по умолчанию (Пример 3.20, «Список допустимых значений атрибута, значение по умолчанию»).
<!ELEMENT city (#PCDATA)>
<!ATTLIST city state CDATA (AZ|CA|NV|OR|UT|WA) "CA">
Пример 3.20. Список допустимых значений атрибута, значение по умолчанию
2. Язык преобразования XML документов - XSLT. Назначение, общая структура и основные понятия. Шаблоны как функции.
Определение правил шаблона
Рекомендуемые страницы:
lektsia.com
- Firefox не отвечает почему
- Раскладка клавиатуры ноутбука hp
- Медиаплеер как настроить

- Как в неро скопировать диск на компьютер
- Раздел диска
- Флешку видит но не открывает и не форматирует что делать
- Камера не работает windows 10
- Почему не скачивается музыка с интернета на компьютер

- Sql server 2018 на windows server 2018
- Системный блок что входит в него

- Проверить компьютер доктор веб
